
Submitted:
04 April 2025
Posted:
07 April 2025
You are already at the latest version
Abstract
Unsupervised anomaly detection algorithms have gained significant attention in the field of Mineral Prospectivity Mapping (MPM) due to their ability to reveal hidden mineralization zones by effectively modeling complex, nonlinear relationships between exploration data and mineral deposits. This study utilizes two tree-based anomaly detection algorithms namely Isolation Forest (IForest) and Extended Isolation Forest (EIF) to enhance MPM and exploration targeting. In accordance with the conceptual model of porphyry copper deposits, key evidence layers were generated, including fault density, multi-element geochemical signatures, proximity to various alteration types (phyllic, argillic, propylitic, and iron oxide), as well as proximity to intrusive rocks. These layers were integrated using IForest and EIF algorithms, and their results were subsequently compared with a geological map of the study area. The comparison revealed a high degree of overlap between identified anomalous zones and geological features such as andesitic rocks, tuffs, rhyolites, pyroclastics, and intrusions. Additionally, quantitative assessments through prediction-area plots validated the efficacy of both models in generating prospective targets. The results highlight the significant influence of hyperparameter tuning on the accuracy of prospectivity models. Furthermore, the study demonstrates that hyperparameter tuning is more intuitive and straightforward in IForest, as it provides a clear and distinct tuning pattern, whereas EIF lacks such clarity, complicating the optimization process.
Keywords:
Porphyry copper mineralization
; Mineral Prospectivity Mapping (MPM)
; Unsupervised anomaly detection algorithms
; Extended Isolation Forest (EIF)
; Isolation Forest (IForest)
; Geospatial Data Analysis
1. Introduction
In recent decades, mineral deposits with strong geochemical, geophysical, and geological footprints have been widely explored, extracted, and are close to depletion. Meanwhile, advancements in industry and technology have led to a substantial increase in the demand for mineral resources. As a result, it's become crucial to use more efficient and precise methods for identifying promising mineralization areas with minimal footprints in geochemical or geophysical data. Moreover, relying solely on a single type of exploration dataset might lead to missing some exploration targets due to limited coverage or incomplete datasets. Consequently, integrating multi-disciplinary spatial datasets through mineral prospectivity mapping (MPM) [1,2,3] framework can be an effective approach for identifying promising areas and enhancing the accuracy of discovering new mineralization zones [4,5,6]. MPM is a multi-stage analytical workflow [7,8] that integrates geo-exploration datasets to produce predictive models [9] and quantitatively assess the likelihood of mineralization within the study area [10,11]. This approach can be applied at various scales, from regional [12] to local [13], to identify areas with high mineralization potential [14]. MPM deals with multi-dimensional datasets that include various types of exploration data, including geological, geochemical, geophysical and remote sensing information [15,16,17,18]. Creating multi-disiplinary geospatial datasets leads to complex, high-dimensional, and non-linear exploratory data sets that are challenging to process and integrate effectively using classical methods [9,19].
Various mathematical approaches have been used to implement MPM, generally classified into three main categories: data-driven, knowledge-driven, and hybrid approaches [20,21]. Some studies have proposed data-driven machine learning (ML) and deep learning (DL) algorithms due to their ability to learn nonlinear features from complex geospatial datasets [3,14,22,23,24,25,26,27]. These algorithms are typically divided into supervised and unsupervised learning. Supervised algorithms use labeled data, which includes known deposit and non-deposit locations, to learn the appropriate features. With the help of these training points (labeled data), supervised algorithms extract the complex relationships between evidence layers and mineralized and non-mineralized locations and then apply them to identify high-potential areas [23]. The most widely used algorithms include support vector machine (SVM) [26,28], random forest (RF) [29,30,31], logistic regression [32], neural networks [33,34], and convolutional neural networks (CNN) [35,36,37]. Although these algorithms are highly effective at learning complex, non-linear relationships, the small number of positive training points (mineral deposits) and the lack of ground truth negative points (non-mineralized areas) pose challenges for supervised data-driven approaches. These limitations have restricted their application in the majority of MPM studies [15,38,39]. These approaches are effective when a significant amount of labeled data is available, such as in brownfield environments. However, since mineralization is a rare geological phenomenon [40], it inevitably leads to insufficient positive training samples (mineralization areas). In contrast, unsupervised learning algorithms detect patterns and structures within data without the need for labeled samples or prior knowledge [14]. The most commonly used unsupervised algorithms include various clustering algorithms (e.g., K-means [21], and SOM [33]) , restricted boltzmann machines (RBM) [41], isolation forest (IF) [16,42,43], one-class SVM (OC-SVM) [44], and deep autoencoders (AE)[15,22].
Among the unsupervised data-driven methods, the IF algorithm [45] is computationally efficient and highly suitable for analyzing high-dimensional datasets, which are common in MPM and geochemical studies [29,43,46]. Its ability to work without labeled data makes it a suitable tool for integrating exploratory layers and identifying high-potential areas. The IF algorithm was originally developed to detect anomalies in large and high-dimensional datasets [45]. It separates samples by building random binary trees and isolating samples by selecting random features and choosing a threshold limit between the maximum and minimum values of the selected feature. The anomaly score is determined by the path length required to isolate samples, where shorter paths indicate a higher anomaly likelihood. The key idea is that anomalies are rare and have distinct characteristics, so they are separated and isolated faster [47]. Several MPM and multivariate geochemical studies have proposed the IF algorithm to detect areas with high mineralization potential and to detect anomalous patterns in exploration datasets [16,29,42,48]. However, the IF algorithm often has biases in the anomaly score assignment due to its axis-parallel cuts, which may reduce its effectiveness in accurately detecting anomalies or patterns linked to mineralization in complex, high-dimensional geospatial datasets. To mitigate this issue, the extended isolation forest (EIF) [48] was developed by enhancing its capability to capture more subtle and complex anomalies through an improved splitting criterion i.e. non-axis-parallel cuts. The EIF reduces false positives by improving data splitting more accurately at the expense of a longer runtime [49]. Chenyi et al. (2023) conducted a comparative study on IF, EIF, and generalized IF for detecting multivariate geochemical anomalies [48]. Their results indicates that EIF is superior for identifying multivariate geochemical anomalies, particularly in complex geological settings, and it effectively detect mineralization-related anomalies.
In this study, the IF and EIF algorithms were employed to identify prospective areas and generate prospectivity models for porphyry copper mineralization in the 1:100,000 Jebal Barez geological sheet, situated within the Urumieh-Dokhtar metallogenic zone (UDMZ). To achieve this, seven evidence layers were generated based on the geological characteristics and the conceptual model of porphyry copper deposits. These layers include fault density, proximity to intrusive rocks, distances from argillic, phyllic, propylitic, and iron oxide alteration, and multi-element geochemical signatures. The optimal hyperparameter values for IF and EIF models were determined using the locations of known mineral deposits as ground truth points. The performance of the generated mineral potential models has been evaluated using the prediction-area (P-A) plot.
2. General Geological Setting of the Study Area
The closure of the Neo Tethyan Ocean, along with the prevailing collisional tectonics during the Tertiary period, resulted in the formation of a significant metallogenic belt known as the Cenozoic UDMZ [50]. Most porphyry copper deposits in Iran are located within this belt, particularly in the Kerman metallogenic arc [51,52,53,54]. The Kerman Cenozoic magmatic arc is characterized by calc-alkaline intrusive rocks, which have facilitated extensive hydrothermal copper mineralization. The Jebal Barez geological map at 1:100000 scale, covering approximately 2,500 Km2 (Figure 1), is situated in the Kerman Cenozoic magmatic arc [55]. This geological region is characterized by favorable tectonic conditions and extensive hydrothermal alterations, indicating significant mineralization potential.
The presence of both oxide and sulfide mineralization indicators further highlights the high potential for metal deposit exploration [56]. The youngest lithological units in this region are dacitic rocks, formed by volcanic and plutonic activities. The Jebal Barez massive, which intrudes Eocene pyroclastic rocks, is likely dated to the late Eocene epoch. A significant number of dykes composed of diabase, pyroxene-diabase, diorite-micro-granodiorite, and alkaline granite have intruded the pyroclastic series and intrusive masses. Dykes are predominantly found in the eastern and western sections of the region, while the oldest exposed rocks are primarily situated in the northern part of the geological sheet. These rocks consist of folded sequences, characterized by dark gray to brownish-green calcareous sandstones interspersed with layers of shale, green marl, and conglomerate. The conglomerate has well-rounded, medium-to-coarse-sized fragments of Cretaceous limestones.
3. Raw Data and Creation of Evidence Layers
3.1. Remote Sensing and Geochemical Data
In recent decades, the processing of satellite imagery through statistical and mathematical methods has captured the attention of exploration geologists in mineral exploration tasks, providing a cost-effective tool for identifying surface footprints associated with various mineral deposit types [57,58,59,60]. In this study, an ASTER image (AST_L1T_00308092003065547_20150430104234_118405) was utilized to identify and map the distribution of hydrothermal alteration zones as a key indicator for the exploration of hydrothermal deposits such as porphyry copper. The key characteristics of ASTER data are presented in Table 1.
In addition to satellite data, this study utilized 745 stream sediment samples collected by the Geological and Mineral Exploration Survey of Iran (GSI) to create a geochemical evidence layer. These samples were available for 20 elements (i.e., Zn, Pb, Ag, Cr, Ni, Bi, Sc, Cu, As, Sb, Cd, Co, Sn, Y, Ba, V, Sr, Hg, W, and Au). However, based on the conceptual model of porphyry copper deposits and previous studies [61,62], 8 elements were used for geochemical analysis. The locations of stream sediment samples are illustrated in Figure 2.
3.2. Geochemical Anomaly Evidence
One of the most significant layers in MPM is the evidence layer of multi-element geochemical anomalies [61,63,64]. The analysis of stream sediment geochemical data and the identification of anomalous samples is a widely used technique in regional-scale mineral exploration to locate mineral deposits [65,66,67,68]. In this research, data preparation and normalization were first performed to generate multi-element geochemical footprints. Then, factor analysis (FA) [69] as a multivariate statistics method was applied to the processing of the geochemical dataset, which includes the elements Au, Hg, Sb, As, Cu, Zn, Ag, and Pb. These elements were selected based on the conceptual model of the targeted mineral deposit type. According to this conceptual model (i.e, the mineral system of porphyry copper deposits) and previous studies, these elements were associated with such deposits and widely used for taget generation [61,62,70,71]. The correlation matrix (Pearson) of these elements was calculated (Table 2). In the next step, FA was implemented. As shown in Table 3, all three derived factors (i.e., Factor 1, Factor 2, and Factor 3) are associated with copper mineralization in the Jebal Barez region and can be considered representative and indicators of mineralization. Consequently, the results of all factors were utilized to construct the multi-element geochemical anomaly layer. To achieve this, the factor scores obtained from FA were transferred to fuzzy space using the logistic function of Equation 1. This function, known as the Geochemical Probability Index (GMPI) [62], is an appropriate method for fuzzy weighting and generating multi-element geochemical evidence layers. Several studies have demonstrated that utilizing the GMPI in MPM can enhance the prediction rates of the final prospectivity models [61,72,73,74].
After transferring the factor scores to fuzzy space, the fuzzy OR operator was utilized to combine the results of the three GMPI maps. Subsequently, a geochemical map associated with mineralization was generated. As shown in Figure 3, there is a significant spatial correlation between the known mineral deposits, intrusive rocks, and the anomalies identified in the produced map.
3.3. Distance-Based Generation of Evidence Layers for Hydrothermal Alterations
Hydrothermal fluids have an essential role in the formation of hydrothermal deposits such as porphyry copper. The movement and migration of these fluids lead to significant changes in the chemical composition and mineralogy of the surrounding rocks related to mineralization. Hydrothermal alterations surrounding porphyry copper deposits typically exhibit specific patterns and often encompass a larger surface area compared to the mineralization. Therefore, identifying zones with hydrothermal alteration is a fundamental aspect of the exploration of porphyry copper deposits on a regional scale [75,76]. The spectral characteristics of indicator minerals within these zones facilitate their identification through satellite image processing. As a result, hydrothermal alteration data can be utilized to generate remote sensing evidence layers for mineral potential modeling of porphyry copper deposits. In this study, hydrothermal alteration zones, including phyllic, argillic, propylitic, and iron oxide alterations were identified through the ASTER image processing using band ratio and spectral angle mapper techniques. Band ratios of 4/2, 5/6, 7/6, and 9/8 were used to map several alteration zones (i.e., iron oxide, argillic, phyllic, and propylitic) [75,76,77,78]. These ratios were selected based on the spectral deatures of the index minerals linked to each alteration and previous geological remote sensing studies. Also, the SAM method (along with USGS library) was utilized to selected endmember minerals (i.e., kaolinite, muscovite, and chlorite). The spectral absorption characteristics of these endmember minerals in the SWIR band of the ASTER image were applied as the spectral range to detect the alteration zones (i.e., argillic, phyllic, and propylitic). Subsequently, distance maps to these alteration zones were generated to create evidence layers. The values of these maps were then transformed to a 0-1 scale using the logistic function [79] defined in Equation 2 (Figure 4, Figure 5, Figure 6 and Figure 7). Notably, areas with higher values in these layers are predominantly associated with intrusive and igneous rocks, particularly within the faulted intrusive units located in the southern and southwestern parts of the region. This suggests that intrusive rocks and the intense activity of hydrothermal fluids in the Jebal Barez area have contributed to the development of extensive hydrothermal alteration zones.
Where denotes the slope of the logistic function, and is the inflection point of the logistic function. The values of and are derived from Equations 3 and 4, respectively.
3.4. Fault Density Evidence Layer
Various mineral deposits are correlated with specific geological structures, particularly faults and fractures [80,81]. Previous MPM studies have demonstrated the crucial role of faults in identifying prospective areas for intrusive-related deposits such as porphyry copper mineralization [61,82]. These faults, along with fractured and crushed zones, act as suitable conduits for the movement of hydrothermal and ore-bearing magmatic fluids, promoting the development of alteration zones linked to mineralization. As a result, areas with high fault density are considered favorable for porphyry copper exploration.
In this study, the faults from the Jebal Barez geological map (1:100,000 scale) were digitized. To create the fault density map, the total length of faults per pixel was calculated. Since the values of the fault density map were unbounded, a logistic function (Equation 2) was utilized to transform these values into fuzzy space (Figure 8).
3.5. Host Rock Evidence Layer
Porphyry copper deposits within the UDMZ show a strong spatial and genetic relationship with various intrusive rocks, including granite, granodiorite, monzonite, and quartz monzonite [74,83,84]. These rocks serve as proxy indicators of magmatic-related processes that contribute to the formation of ore-forming materials. The likelihood of porphyry copper deposits formation is higher in proximity to these rocks. Therefore, regions near intrusive rocks are considered to have higher exploration potential than more distant regions [74]. The majority of porphyry copper deposits, particularly the classic mineralization types found in the UDMZ, such as Sarcheshmeh and Sungun, exhibit a close association with intrusive rocks. This correlation has been confirmed through geological studies and various MPM investigations [11,53,83,85]. Thus, this study generated a distance map from intrusive rocks as a key evidence layer for modeling porphyry copper mineral potential. Euclidian distance from intusive rocks was calculated to generate this layer and its values were transformed into fuzzy space using a logistic function (Equation 2). As demonstrated in Figure 9, a significant number of known mineral deposits in the Jebal Barez region exhibit a strong spatial relationship with high values of this geological layer. Therefore, this layer is considered one of the most crucial layers in the prospectivity modeling of porphyry copper deposits.
4. Methodology
4.1. Predication-Area Plot
Evaluating the degree of importance and the prediction rates associated with the generated prospectivity models is essential in the MPM tasks. In this regard, the prediction-area (P-A) plot [86,87] can be utilized. This plot is based on ground truth positive samples (known mineral deposits) and is considered one of the most effective data-driven methods for the quantitative evaluation of prospectivity models. The accuracy of mineral potential models can be evaluated by analyzing the spatial relationship between the known mineral deposits and each of the generated model classes. This plot consists of two curves [87,88,89], and their intersection point indicates the prediction rate and accuracy of the prospectivity model. If the intersection point of a specific prospectivity model indicates a higher prediction rate (left axis) compared to the plots of other models, it implies that the former model has successfully identified a greater number of known mineral deposits within a smaller area (right axis). The normalized density of the MPM model, as a numerical assessment index, is derived based on the intersection of the prediction rate and occupied area curves. This index is obtained by calculating the ratio of the prediction rate to the occupied area at the intersection point (Equation 5). Finally, the weight of each prospectivity model is determined based on Equation 6.
In which refers to the normalized density, and and are the prediction rate and occupided area, respectively, obtained from the intersection point of the P-A plot.
This index can indicate the accuracy of the constructed model by utilizing ground truth labels. Considering the influence of various hyperparameters on the accuracy of machine learning algorithms, it can be used to determine the model's accuracy and evaluate the impact of different hyperparameters on the mineral prospectivity models produced. Ultimately, the best model can be selected based on the highest weight. Figure 10 demonstrates the methodology flowchart of this study.
4.2. Isolation Forest
The isolation forest (IF) algorithm depends on two key parameters: the number of isolation trees (t) and the maximum number of features (m). To train the model, one isolation tree (ITrees) is constructed as follows [45,90]:
A random sample is selected from the dataset which containing instances with features.
A feature () is selected from the randomly chosen subset of features , and a cut-point is randomly determined within its range.
The sample is divided into two sub-samples by splitting at the cut-point , forming left and right subtrees.
The process continues until each instance is isolated or the tree reaches predetermined height.
To form the IF, ITrees are generated. In the IF, The anomalous instances are identified by calculating the expected depth of an ITrees for given N training instances (Equation 7) for each instance, where anomalies typically have shorter path lengths in the trees. The expected depth for a data point and n instances is computed using Equation. 7, where and is Eular constant.
The formula for determining the detailed anomaly score is given by:
Where is the depth of the instance in the particular ITrees and is its average over all ITrees. Since, anomalies are isolated more quickly, they have shorter path lengths, resulting in score closer to 1.
4.3. Extended Isolation Forest
In the original IF algorithm, nodes are split along the vertical or horizontal axes. This approach introduces a bias because the split occurs only along the axes, which limit the flexibility of the model and can distort the anomaly score map. The extended isolation forest (EIF) [91] was developed to address this limitation by allowing splits in any direction, not just vertical or horizontal ones. While the scoring phase remains unchanged from IF, the training phase undergoes a significant modification. Instead of splitting nodes strictly along the axes, EIF selects both a random point and a random direction by considering a combination of all dimensions. This adjustment eliminates the bias introduce by the axis-parallel cuts in the original IF.
This adjustment in EIF corrects the biases inherent in the original IF, leading to more accurate anomaly detection. By splitting nodes along random directions, EIF creates more evenly distributed splits, which reduces the risk of generating biased anomaly scores. This results in more consistent anomaly scores and improves the overall reliability of the model, especially in complex datasets. Their comparative study highlights that EIF anomaly maps are more evenly distributed, which helps in better detecting anomalies without introducing the bias associated with axis-based divisions [49,91].
The EIF implementation has two key hyperparameters to configure, namely, "extension level" and the number of ITrees. The extension level is in range , where is the number of features in the dataset. A value of 0 corresponds to the original IF, where splits are axis-parallel cuts. As the extension level increase toward , allowing the to perform splits in various angle and the IF’s bias is reduced.
5. Algorithms Results
After constructing the evidence layers, the IF and EIF were employed for data integration, with considering to optimizing the key hyperparameters. For IF algorithm, two key hyperparameters, namely, "number of ITrees" and "maximum features" were optimized to maximize the performance of prospectivity model. The maximum features were adjusted from 1 to 7 (the maximum number of evidence layers), while number of ITrees was set to 600, 100, 1400, and 1800 (Table 4). For the EIF, the same number of ITrees was used, while the "Extension level" ranged from 1 to 6 (number of evidence layers minus one) (Table 4).
In total, 28 distinct models were generated using the IF algorithm, and each was evaluated based on the P-A plot. First, the 28 generated models were classified using the "natural break" method and P-A plots were plotted using the thresholds derived from this method. Subsequently, the weight of each model was computed, which uses the intersection point of the prediction rate and are curves. Figure 11 illustrates the impact of different values for the maximum features and number of ITrees on the weight obtained for each IF model. As can be observed, increasing the maximum features generally improves the performance of the IF model, regardless of the number ITrees used. For lower values of the maximum features (1 and 2), the models exhibited lower performance, with scores ranging between 0.49 and 0.66. This pattern contrasts with higher values of maximum features (4 to 7), where performance significantly improved and reached values between 0.71 and 0.85. For instance, models built with 1400 ITrees show a noticeable improvement in performance as the maximum features values increases. Specifically, as the maximum features value increased, the model performance improved gradually, from 0.53 (maximum features set to 1) to 0.85 (maximum features set to 7). This indicates that the model’s ability to capture important patterns improves with higher values for the maximum features.
Across all the 28 IF models generated, the model with a maximum features value of 7 and 1400 ITrees has the highest performance with a wight of 0.85. Consequently, this configuration was selected as the optimal hyperparameter value for IF MPM in the study. Figure 12 and Figure 13 respectively depict the P-A plot and the corresponding prospectivity model generated by this optimal configuration.
Figure 14 illustrates the performance of various EIF models based on the extension level and the number of ITrees. The performance of EIF models not follow consistent pattern when the extension is increased and the performance patterns show mixed relationship between the extension level and the number of ITrees.
The performance of EIF models fluctuates across different extension levels, which indicates that a higher extension level does not necessarily lead to better results (Figure 14). For example, while the EIF model with 1400 ITrees shows its highest performance at the lowest extension level of 1, the performance decreases across the subsequent levels, and never reaching that initial peak again. However, the EIF model with 600 ITrees peaks at extension levels 1 and 3. This pattern contrasts with the IFmodels, where performance increases more predictably with higher max features (Figure 11). The fluctuation in the performance of EIF models may be due to added complexity introduced by higher extension levels, which can make it harder for the model to isolate anomalies effectively. This result suggests that while both models rely on key hyperparameters to optimize performance, the relationship between these hyperparameters and model output is more straightforward and predictable in IF models, whereas EIF models require more careful tuning to avoid performance drops across different extension levels. Figure 15 and Figure 16 respectively depict the prospectivity model generated by the extension level value of 1 and 600 ITress and the corresponding P-A plot.
The prospectivity models generated by IF and EIF generally show similar patterns, but the EIF intensifies the high values regions more distinctly. In the EIF model (see Figure 16), the high potential areas (red) are more concentrated and have sharper boundaries, which makes anomalous areas more distinct. In contrast, the IF model (Figure 13) shows a more gradual transition, with smoother and less intense delineation of high-potential areas, resulting in a less distinct identification of anomalies.
The comparison of the prospectivity models generated by the two unsupervised tree-based algorithms, IF and EIF (Figure 13 and Figure 16), with the geological map of the study area (Figure 1) indicated that the identified anomalous zones by both methods are consistent with the andesitic units, tuffs, rhyolites, pyroclastic units, and intrusive rocks. Furthermore, these methods have suitably predicted many of the known mineral deposits in the region. Therefore, it can be inferred that both algorithms demonstrate a high level of effectiveness in identifying exploration targets associated with mineralization in the study area.
In Figures 11, and 14, we investigate the impact of key hyperparameters on the performance of the IF and EIF models. As illustrated in Figure 17, our comparative analysis specifically focuses on the average results across different number of ITrees, and assess the impact of this hyperparameters for both algorithms. The results indicate that the average performance remains relatively stable as the number of ITrees increases. This pattern is consistent for both the IF and EIF models and suggests that the average performance remains stable regardless of the number ITrees when averaged over multiple runs with different values for the other hyperparameter (i.e. max feature for IF and extension level for EIF). This stability indicates that increasing the number of ITrees may not contribute substantially to enhancing the models’ anomaly detection capabilities. These patterns also can be observed in Figure 11 and 14, as the models with higher number of ITrees necessity don't have higher performance. This indicates that both models reach a point where adding more trees does not contribute to better accuracy, particularly when considering averaged results.
As shown in Figure 17, the EIF model consistently outperforms the IF model in terms of average performance across all tested ITrees values and the average performance of EIF is always higher than that of the IF model, showing its enhanced capability for more reliable anomaly detection. Furthermore, the range of performance for the EIF model is considerably smaller compared to the IF model, indicating that EIF is less affected by changed in other hyperparameter values i.e. extension level. In contrast, the IF model shows a wider range of performance, Indicating higher sensitivity to max features hyperparameter and potential instability under certain hyperparameter configuration. This stability in the EIF model could be attributed to its unique mechanism of isolating anomalies using extended, multi-dimensional hyperplanes. Therefore, the comparative study demonstrates the superiority of the EIF model in terms of performance across varying hyperparameter settings. In this study, to identify prospecting zones linked to the porphyry copper mineralization and generate binary prospectivity models (Figure 18 and Figure 19), a percentile of 90% was used. Percentile 90% for IF and EIF prospectivity models were obtained at 0.68 and 0.69, respectively.
6. Discussion
In MPM studies, evidence layers are created based on the conceptual model of the sought mineralization and known mineral deposits in the study area. This leads to high values in each evidence layer typically having a strong spatial correlation with known deposits. Therefore, in exploratory datasets, other samples with high values can be associated with the target mineralization and identified as prospective areas [15,19]. As a result, unsupervised machine learning algorithms such as the IF, which identifies samples with high (anomalous) values, can be employed to generate mineral potential maps.
The IF and EIF algorithms are based on the assumption that datasets contain a limited number of anomalous samples whose values are significantly different from the background. These algorithms directly identify and isolate anomalous samples within the dataset. Due to their smaller numbers and different values for some features, anomalous samples are more easily isolated in ITrees compared to normal or background samples. Generally, they traverse shorter paths in each ITress than normal samples. The IF algorithm relies on randomness in selecting features (evidence layers) and thresholds within those features [48]. Thus, the "max features" hyperparameter, which determines the number of features to use during the construction of each ITrees, can significantly affect the final model. As demonstrated by the results of this study, the performance of the mineral potential model is highly sensitive to this hyperparameter. Specifically, increasing the number of features generally improves model performance (Figure 8). This suggests that incorporating all the evidence layers produced in this study can enhance the final model's effectiveness. In other words, setting the max features hyperparameter to 7 (equal to the number of evidence layers) allows the IF algorithm to simultaneously consider all evidence layers and their relationships for identifying anomalous regions, ultimately improving the model’s ability to detect high-potential areas. Conversely, when smaller values (1 to 3) are assigned to this hyperparameter, only a few layers are used to identify anomalies, resulting in reduced model performance. However, based on the performance of the EIF model with different hyperparameter values (Figure 11), it is difficult to make a general conclusion about the impact of its hyperparameters on the final model's performance.
7. Conclusion
Mineral prospectivity mapping (MPM) can be regarded as an anomaly detection process within the field of mineral exploration and exploration information system (EIS) frameworks, as mineralization is a relatively rare and spatially irregular geological phenomenon in the Earth's crust. In this context, unsupervised anomaly detection (UAD) algorithms based on machine learning are effective in identifying complex, non-linear patterns associated with high-potential mineralized zones. Moreover, they facilitate the extraction of exploration patterns from evidence layers, which are developed in alignment with the conceptual model of the mineral deposit type sought. This study highlights the performance of tree-based anomaly detection algorithms, namely and EIF in detecting irregular and subtle patterns associated with porphyry copper deposits. The results demonstrated that both algorithms provide effective support for unsupervised exploration targeting. The anomalous zones identified by these methods are spatially correlated with geological features, including andesites, tuffs, rhyolites, pyroclastics, and intrusive rocks. Furthermore, quantitative analysis using the prediction-area plot showed that IF and EIF exhibit strong performance in terms of prediction rate. Additionally, the results emphasize the significant impact of hyperparameter tuning in enhancing the accuracy of generated prospectivity models. IF demonstrated a more transparent and structured framework for hyperparameter optimization, while EIF lacked this level of clarity, making the optimization process more challenging.
Author Contributions
Conceptualization, M.S., S.A.A.S.M, and A.S. (Adel Shirazy); methodology, M.S. and S.A.A.S.M.; software, M.S. and S.A.A.S.M.; validation, M.S., S.A.A.S.M, R.D, A.S. (Adel Shirazy), A.S. (Aref Shirazy). and A.H.; formal analysis, M.S and A.H.; investigation, M.S., S.A.A.S.M., R.D., A.H., and A.S. (Adel Shirazy); data curation, M.S. and S.A.A.S.M.; writing—original draft preparation, M.S., S.A.A.S.M, and R.D.; writing—review and editing, M.S., S.A.A.S.M, A.S. (Adel Shirazy), A.S. (Aref Shirazy)., and A.H.; supervision, (Adel Shirazy), A.S. (Aref Shirazy)., and A.H; project administration, A.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable.
Acknowledgments
We would like to thank the Department of Mining Engineering, Amirkabir University of Technology (Tehran Polytechnic University), and the College of Engineering, University of Tehran.
Conflicts of Interest
The authors declare that there are no conflicts of interest.
References
- Yousefi, M. and E.J.M. Carranza. Geometric average of spatial evidence data layers: a GIS-based multi-criteria decision-making approach to mineral prospectivity mapping. Computers & Geosciences. 2015, 83, 72–79.
- Saremi, M., A. Maghsoudi, Z. Hoseinzade, and A.R. Mokhtari. Data-driven AHP: a novel method for porphyry copper prospectivity mapping in the Varzaghan District, NW Iran. Earth Science Informatics. 2024,1-16.
- Yin, B., R. Zuo, and S. Sun. Mineral prospectivity mapping using deep self-attention model. Natural Resources Research. 2023, 32, 37–56. [CrossRef]
- Bahrami, Y., H. Hasani, and A. Maghsoudi. Application of AHP-TOPSIS method to model copper mineral potencial in the Abhar 1: 100000 geological map, NW Iran. Researches in Earth Sciences. 2021, 12, 41–57. [CrossRef]
- Aali, A.A., A. Shirazy, A. Shirazi, A.B. Pour, A. Hezarkhani, A. Maghsoudi, M. Hashim, and S. Khakmardan. Fusion of remote sensing, magnetometric, and geological data to identify polymetallic mineral potential zones in Chakchak Region, Yazd, Iran. Remote Sensing. 2022, 14, 6018. [CrossRef]
- Shirazi, A., A. Hezarkhani, A. Beiranvand Pour, A. Shirazy, and M. Hashim. Neuro-Fuzzy-AHP (NFAHP) technique for copper exploration using Advanced Spaceborne Thermal Emission and Reflection Radiometer (ASTER) and geological datasets in the Sahlabad mining area, east Iran. Remote Sensing. 2022, 14, 5562.
- Bonham-Carter, G. Geographic information systems for geoscientists: modelling with GIS. 1994: Elsevier.
- Hoseinzade, Z., M. Shojaei, F. Khademi, A.R. Mokhtari, and M. Saremi. Integration of deep learning models for mineral prospectivity mapping: a novel Bayesian index approach to reducing uncertainty in exploration. Modeling Earth Systems and Environment. 2025, 11, 161. [CrossRef]
- Yousefi, M., E.J.M. Carranza, O.P. Kreuzer, V. Nykänen, J.M. Hronsky, and M.J. Mihalasky. Data analysis methods for prospectivity modelling as applied to mineral exploration targeting: State-of-the-art and outlook. Journal of Geochemical Exploration. 2021, 229, 106839. [CrossRef]
- Carranza, E.J.M. Geochemical anomaly and mineral prospectivity mapping in GIS. 2008: Elsevier.
- Saremi, M., A. Maghsoudi, R. Ghezelbash, M. Yousefi, and A. Hezarkhani. Targeting of porphyry copper mineralization using a continuous-based logistic function approach in the Varzaghan district, north of Urumieh-Dokhtar magmatic arc. Journal of Mining and Environment. 2024.
- Yousefi, M., V. Nykänen, J. Harris, J.M. Hronsky, O.P. Kreuzer, G. Bertrand, and M. Lindsay. Overcoming survival bias in targeting mineral deposits of the future: Towards null and negative tests of the exploration search space, accounting for lack of visibility. Ore Geology Reviews. 2024,106214.
- Abedi, M., S.B.M. Kashani, G.-H. Norouzi, and M. Yousefi. A deposit scale mineral prospectivity analysis: A comparison of various knowledge-driven approaches for porphyry copper targeting in Seridune, Iran. Journal of African Earth Sciences. 2017, 128, 127–146. [CrossRef]
- Yousefi, M. D. Lindsay, and O. Kreuzer. Mitigating uncertainties in mineral exploration targeting: Majority voting and confidence index approaches in the context of an exploration information system (EIS). Ore Geology Reviews. 2024,105930.
- Mirzabozorg, S.A.A.S. and M. Abedi. Recognition of mineralization-related anomaly patterns through an autoencoder neural network for mineral exploration targeting. Applied Geochemistry. 2023,105807.
- Saremi, M., S.M. Bagheri Ghadikolaei, S.A. Agha Seyyed Mirzabozorg, N.E. Hassan, Z. Hoseinzade, A. Maghsoudi, S. Rezania, H. Ranjbar, B. Zoheir, and A. Beiranvand Pour. Evaluation of Deep Isolation Forest (DIF) Algorithm for Mineral Prospectivity Mapping of Polymetallic Deposits. Minerals. 2024, 14, 1015.
- Abedi, M. and G.-H. Norouzi. Integration of various geophysical data with geological and geochemical data to determine additional drilling for copper exploration. Journal of Applied Geophysics. 2012, 83, 35–45. [CrossRef]
- Qaderi, S., A. Maghsoudi, A.B. Pour, A. Rajabi, and M. Yousefi. DCGAN-Based Feature Augmentation: A Novel Approach for Efficient Mineralization Prediction Through Data Generation. Minerals. 2025, 15, 71.
- Yousefi, M., O.P. Kreuzer, V. Nykänen, and J.M. Hronsky. Exploration information systems–A proposal for the future use of GIS in mineral exploration targeting. Ore Geology Reviews. 2019, 111, 103005. [CrossRef]
- Yousefi, M. and E.J.M. Carranza. Data-driven index overlay and Boolean logic mineral prospectivity modeling in greenfields exploration. Natural Resources Research. 2016, 25, 3–18. [CrossRef]
- Rezapour, M.J., M. Abedi, A. Bahroudi, and H. Rahimi. A clustering approach for mineral potential mapping: A deposit-scale porphyry copper exploration targeting. Geopersia. 2020, 10, 149–163.
- Xiong, Y., R. Zuo, and E.J.M. Carranza. Mapping mineral prospectivity through big data analytics and a deep learning algorithm. Ore Geology Reviews. 2018, 102, 811–817. [CrossRef]
- Chen, G., N. Huang, G. Wu, L. Luo, D. Wang, and Q. Cheng. Mineral prospectivity mapping based on wavelet neural network and Monte Carlo simulations in the Nanling W-Sn metallogenic province. Ore Geology Reviews. 2022, 143, 104765. [CrossRef]
- Li, S., J. Chen, and C. Liu. Overview on the development of intelligent methods for mineral resource prediction under the background of geological big data. Minerals. 2022, 12, 616.
- Lou, Y. and Y. Liu. Mineral prospectivity mapping of tungsten polymetallic deposits using machine learning algorithms and comparison of their performance in the Gannan region, China. Earth and Space Science. 2023, 10, e2022EA002596. [CrossRef]
- Abedi, M., G.-H. Norouzi, and A. Bahroudi. Support vector machine for multi-classification of mineral prospectivity areas. Computers & Geosciences. 2012, 46, 272–283.
- Shirazi, A., A. Shirazy, and A. Hezarkhani, An Artificial Intelligence (AI)-based Model for Optimal Exploratory Surveys. 2024: GRIN Verlag.
- Zuo, R. and E.J.M. Carranza. Support vector machine: A tool for mapping mineral prospectivity. Computers & Geosciences. 2011, 37, 1967–1975.
- Zhang, S., E.J.M. Carranza, K. Xiao, H. Wei, F. Yang, Z. Chen, N. Li, and J. Xiang. Mineral prospectivity mapping based on isolation forest and random forest: Implication for the existence of spatial signature of mineralization in outliers. Natural Resources Research. 2022, 31, 1981–1999. [CrossRef]
- Zhang, S., K. Xiao, E.J.M. Carranza, and F. Yang. Maximum entropy and random forest modeling of mineral potential: Analysis of gold prospectivity in the Hezuo–Meiwu district, west Qinling Orogen, China. Natural Resources Research. 2019, 28, 645–664. [CrossRef]
- Qaderi, S., A. Maghsoudi, A.B. Pour, and M. Yousefi. Geological Controlling Factors on Mississippi Valley-Type Pb-Zn Mineralization in Western Semnan, Iran. Minerals (2075-163X). 2024; 14(9).
- Carranza, E.j.m. and M. Hale. Logistic regression for geologically constrained mapping of gold potential, Baguio district, Philippines. Exploration and Mining Geology. 2001, 10, 165–175. [CrossRef]
- Rahimi, H., M. Abedi, M. Yousefi, A. Bahroudi, and G.-R. Elyasi. Supervised mineral exploration targeting and the challenges with the selection of deposit and non-deposit sites thereof. Applied Geochemistry. 2021, 128, 104940. [CrossRef]
- Rodriguez-Galiano, V., M. Sanchez-Castillo, M. Chica-Olmo, and M. Chica-Rivas. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geology Reviews. 2015, 71, 804–818. [CrossRef]
- Li, S., J. Chen, C. Liu, and Y. Wang. Mineral prospectivity prediction via convolutional neural networks based on geological big data. Journal of Earth Science. 2021, 32, 327–347. [CrossRef]
- Li, S., J. Chen, and J. Xiang. Applications of deep convolutional neural networks in prospecting prediction based on two-dimensional geological big data. Neural computing and applications. 2020, 32, 2037–2053. [CrossRef]
- Mirzabozorg, S.A.A.S. Abedi, and M. Yousefi. Enhancing training performance of convolutional neural network algorithm through an autoencoder-based unsupervised labeling framework for mineral exploration targeting. Geochemistry. 2024,126197.
- Zhang, S., E.J.M. Carranza, H. Wei, K. Xiao, F. Yang, J. Xiang, S. Zhang, and Y. Xu. Data-driven mineral prospectivity mapping by joint application of unsupervised convolutional auto-encoder network and supervised convolutional neural network. Natural Resources Research. 2021, 30, 1011–1031. [CrossRef]
- Zuo, R. and Z. Wang. Effects of random negative training samples on mineral prospectivity mapping. Natural Resources Research. 2020, 29, 3443–3455. [CrossRef]
- Cheng, Q. Mapping singularities with stream sediment geochemical data for prediction of undiscovered mineral deposits in Gejiu, Yunnan Province, China. Ore Geology Reviews. 2007, 32, 314–324. [Google Scholar] [CrossRef]
- Chen, Y. Mineral potential mapping with a restricted Boltzmann machine. Ore Geology Reviews. 2015, 71, 749–760. [Google Scholar] [CrossRef]
- Chen, Y. and W. Wu. Isolation forest as an alternative data-driven mineral prospectivity mapping method with a higher data-processing efficiency. Natural Resources Research. 2019, 28, 31–46. [CrossRef]
- Shahrestani, S., C. Conoscenti, and E.J.M. Carranza. Assessment of LUNAR, iForest, LOF, and LSCP methodologies in delineating geochemical anomalies for mineral exploration. Journal of Geochemical Exploration. 2025, 273, 107737. [CrossRef]
- Chen, Y. and W. Wu. Application of one-class support vector machine to quickly identify multivariate anomalies from geochemical exploration data. Geochemistry: Exploration, Environment, Analysis. 2017, 17, 231–238.
- Liu, F.T., K.M. Ting, and Z.-H. Zhou. Isolation forest. in 2008 eighth ieee international conference on data mining. 2008. IEEE.
- Liu, F.T., K.M. Ting, and Z.-H. Zhou. Isolation-based anomaly detection. ACM Transactions on Knowledge Discovery from Data (TKDD). 2012, 6, 1–39.
- Fadul, A.M.A. Anomaly Detection based on Isolation Forest and Local Outlier Factor. 2023, Africa University.
- ZHENG, C., Q. ZHAO, G. FAN, K. ZHAO, and T. PIAO. Comparative study on isolation forest, extended isolation forest and generalized isolation forest in detection of multivariate geochemical anomalies. Global Geology. 2023, 26, 167–176.
- Chabchoub, Y., M.U. Togbe, A. Boly, and R. Chiky. An in-depth study and improvement of Isolation Forest. IEEE Access. 2022, 10, 10219–10237. [CrossRef]
- Asadi, S., F. Moore, and A. Zarasvandi. Discriminating productive and barren porphyry copper deposits in the southeastern part of the central Iranian volcano-plutonic belt, Kerman region, Iran: a review. Earth-Science Reviews. 2014, 138, 25–46. [CrossRef]
- Sadigh, S., M. Mirmohammadi, O. Asghari, and A. Porwal. Spatial distribution of porphyry copper deposits in Kerman Belt, Iran. Ore Geology Reviews. 2023, 153, 105251. [CrossRef]
- Hezarkhani, A. and A.E. Williams-Jones. Controls of alteration and mineralization in the Sungun porphyry copper deposit, Iran; evidence from fluid inclusions and stable isotopes. Economic Geology. 1998, 93, 651–670. [CrossRef]
- Hezarkhani, A. Hydrothermal evolution of the Sar-Cheshmeh porphyry Cu–Mo deposit, Iran: evidence from fluid inclusions. Journal of Asian Earth Sciences. 2006, 28, 409–422. [Google Scholar] [CrossRef]
- Hezarkhani, A. Mineralogy and fluid inclusion investigations in the Reagan Porphyry System, Iran, the path to an uneconomic porphyry copper deposit. Journal of Asian Earth Sciences. 2006, 27, 598–612. [Google Scholar] [CrossRef]
- Honarmand, M., H. Ranjbar, and J. Shahabpour. Application of principal component analysis and spectral angle mapper in the mapping of hydrothermal alteration in the Jebal–Barez Area, Southeastern Iran. Resource Geology. 2012, 62, 119–139. [CrossRef]
- Fakhari, S., P. Afzal, and M. Lotfi. Delineation of hydrothermal alteration zones for porphyry systems utilizing ASTER data in Jebal-Barez area, SE Iran. Iranian Journal of Earth Sciences. 2019, 11, 80–92.
- Pour, A.B. and M. Hashim. The application of ASTER remote sensing data to porphyry copper and epithermal gold deposits. Ore geology reviews. 2012; 44,1-9.
- Hajaj, S., A. El Harti, A. Jellouli, A.B. Pour, S.M. Himyari, A. Hamzaoui, and M. Hashim. ASTER data processing and fusion for alteration minerals and silicification detection: Implications for cupriferous mineralization exploration in the western Anti-Atlas, Morocco. Artificial Intelligence in Geosciences. 2024, 5, 100077.
- Shirazi, A., A. Shirazy, and J. Karami. Remote sensing to identify copper alterations and promising regions, Sarbishe, South Khorasan, Iran. International Journal of Geology and Earth Sciences. International Journal of Geology and Earth Sciences. 2018, 4, 36–52.
- Shirazi, A., A. Hezarkhani, A. Shirazy, and I. Shahrood. Remote sensing studies for mapping of iron oxide regions, South of Kerman, Iran. International Journal of Science and Engineering Applications. 2018, 7, 45–51. [CrossRef]
- Saremi, M., S. Yousefi, and M. Yousefi. Combination of Geochemical and Structural Data to Determine Exploration Target of Copper Hydrothermal Deposits in Feizabad District. Journal of Mining and Environment. 2024, 15, 1089–1101.
- Yousefi, M., A. Kamkar-Rouhani, and E.J.M. Carranza. Geochemical mineralization probability index (GMPI): a new approach to generate enhanced stream sediment geochemical evidential map for increasing probability of success in mineral potential mapping. Journal of Geochemical Exploration. 2012, 115, 24–35. [CrossRef]
- Parsa, M., A. Maghsoudi, M. Yousefi, and M. Sadeghi. Recognition of significant multi-element geochemical signatures of porphyry Cu deposits in Noghdouz area, NW Iran. Journal of Geochemical Exploration. 2016, 165, 111–124. [CrossRef]
- Yousefi, M., A. Kamkar-Rouhani, and E.J.M. Carranza. Application of staged factor analysis and logistic function to create a fuzzy stream sediment geochemical evidence layer for mineral prospectivity mapping. Geochemistry: Exploration, Environment, Analysis. 2014, 14, 45–58.
- Ghasemzadeh, S., A. Maghsoudi, M. Yousefi, and M.J. Mihalasky. Information value-based geochemical anomaly modeling: A statistical index to generate enhanced geochemical signatures for mineral exploration targeting. Applied Geochemistry. 2022, 136, 105177. [CrossRef]
- Chen, J., M. Yousefi, Y. Zhao, C. Zhang, S. Zhang, Z. Mao, M. Peng, and R. Han. Modelling ore-forming processes through a cosine similarity measure: Improved targeting of porphyry copper deposits in the Manzhouli belt, China. Ore Geology Reviews. 2019, 107, 108–118. [CrossRef]
- Yilmaz, H., M. Yousefi, M. Parsa, F.N. Sonmez, and A. Maghsoodi. Singularity mapping of bulk leach extractable gold and− 80# stream sediment geochemical data in recognition of gold and base metal mineralization footprints in Biga Peninsula South, Turkey. Journal of African Earth Sciences. 2019, 153, 156–172.
- Shirazi, A., A. Hezarkhani, A. Shirazy, and A.B. Pour. Geochemical modeling of copper mineralization using geostatistical and machine learning algorithms in the Sahlabad area, Iran. Minerals. 2023, 13, 1133.
- Reimann, C., P. Filzmoser, and R.G. Garrett. Factor analysis applied to regional geochemical data: problems and possibilities. Applied geochemistry. 2002, 17, 185–206. [CrossRef]
- Hoseinzade, Z. and M.H. Bazobandi. Deep embedded clustering: Delineating multivariate geochemical anomalies in the Feizabad region. Geochemistry. 2024,126208.
- Yousefi, M., S. Barak, A. Salimi, and S. Yousefi. Should geochemical indicators be integrated to produce enhanced signatures of mineral deposits? A discussion with regard to exploration scale. Journal of Mining and Environment. 2023, 14, 1011–1018.
- Bahri, E., A. Alimoradi, and M. Yousefi. Mineral Potential Modeling of Porphyry Copper Deposits using Continuously-Weighted Spatial Evidence Layers and Union Score Integration Method. Journal of Mining and Environment. 2021, 12, 743–751.
- Afzal, P., M. Yusefi, M. Mirzaie, E. Ghadiri-Sufi, S. Ghasemzadeh, and L. Daneshvar Saein. Delineation of podiform-type chromite mineralization using geochemical mineralization prospectivity index and staged factor analysis in Balvard area (SE Iran). Journal of Mining and Environment. 2019, 10, 705–715.
- Yousefi, M. and E.J.M. Carranza. Fuzzification of continuous-value spatial evidence for mineral prospectivity mapping. Computers & Geosciences. 2015, 74, 97–109.
- Pour, A.B. and M. Hashim. Identification of hydrothermal alteration minerals for exploring of porphyry copper deposit using ASTER data, SE Iran. Journal of Asian Earth Sciences. 2011, 42, 1309–1323. [CrossRef]
- Pour, A.B. and M. Hashim. Identifying areas of high economic-potential copper mineralization using ASTER data in the Urumieh–Dokhtar Volcanic Belt, Iran. Advances in Space Research. 2012, 49, 753–769. [CrossRef]
- Beygi, S., I.V. Talovina, M. Tadayon, and A.B. Pour. Alteration and structural features mapping in Kacho-Mesqal zone, Central Iran using ASTER remote sensing data for porphyry copper exploration. International Journal of Image and Data Fusion. 2021, 12, 155–175. [CrossRef]
- Hewson, R., T. Cudahy, S. Mizuhiko, K. Ueda, and A. Mauger. Seamless geological map generation using ASTER in the Broken Hill-Curnamona province of Australia. Remote Sensing of Environment. 2005, 99, 159–172. [CrossRef]
- Yousefi, M. and V. Nykänen. Data-driven logistic-based weighting of geochemical and geological evidence layers in mineral prospectivity mapping. Journal of Geochemical Exploration. 2016, 164, 94–106. [CrossRef]
- Khalifani, F.M., A. Bahroudi, F. Aliyari, M. Abedi, M. Yousefi, and M. Mohammadpour. Generation of an efficient structural evidence layer for mineral exploration targeting. Journal of African Earth Sciences. 2019, 160, 103609. [CrossRef]
- Shirazi, A., A. Hezarkhani, and A.B. Pour. Fusion of lineament factor (Lf) map analysis and multifractal technique for massive sulfide copper exploration: The Sahlabad area, East Iran. Minerals. 2022, 12, 549.
- Yousefi, M. and J.M. Hronsky. Translation of the function of hydrothermal mineralization-related focused fluid flux into a mappable exploration criterion for mineral exploration targeting. Applied Geochemistry. 2023, 149, 105561. [CrossRef]
- Hezarkhani, A. Petrology of the intrusive rocks within the Sungun porphyry copper deposit, Azerbaijan, Iran. Journal of Asian Earth Sciences. 2006, 27, 326–340. [Google Scholar] [CrossRef]
- Ghasemzadeh, S., A. Maghsoudi, and M. Yousefi. Application of geometric average approach for Cu-porphyry prospectivity mapping in the Baft area, kerman. Scientific Quarterly Journal of Geosciences. 2019, 29, 231–130.
- Saremi, M., Z. Hoseinzade, S.A.A.S. Mirzabozorg, A.B. Pour, B. Zoheir, and A. Almasi. Integrated remote sensing and geochemical studies for enhanced prospectivity mapping of porphyry copper deposits: A case study from the Pariz district, Urmia-Dokhtar metallogenic belt, southern Iran. Remote Sensing Applications: Society and Environment. 2024, 36, 101343.
- Roshanravan, B., H. Aghajani, M. Yousefi, and O. Kreuzer. An improved prediction-area plot for prospectivity analysis of mineral deposits. Natural Resources Research. 2019, 28, 1089–1105. [CrossRef]
- Yousefi, M. and E.J.M. Carranza. Prediction–area (P–A) plot and C–A fractal analysis to classify and evaluate evidential maps for mineral prospectivity modeling. Computers & Geosciences. 2015, 79, 69–81.
- Hoseinzade, Z., A. Zavarei, and K. Shirani. Application of prediction–area plot in the assessment of MCDM methods through VIKOR, PROMETHEE II, and permutation. Natural Hazards. 2021, 109, 2489–2507. [CrossRef]
- Maryam, M., H. Zohre, and S. Kourosh. A comparison study on landslide prediction through FAHP and Dempster–Shafer methods and their evaluation by P–A plots. Environmental Earth Sciences. 2020; 79(3).
- Liao, L. and B. Luo. Entropy isolation forest based on dimension entropy for anomaly detection. in Computational Intelligence and Intelligent Systems: 10th International Symposium, ISICA 2018, Jiujiang, China, October 13–14, 2018, Revised Selected Papers 10. 2019. Springer.
- Hariri, S., M.C. Kind, and R.J. Brunner. Extended isolation forest. IEEE transactions on knowledge and data engineering. 2019, 33, 1479–1489.
Figure 1.
The geological map of the study region.
Figure 2.
the location of stream sediment samples collected in the study area.

Figure 3.
Multi-element geochemical map derived from the incorporation of the GMPI and OR operator.
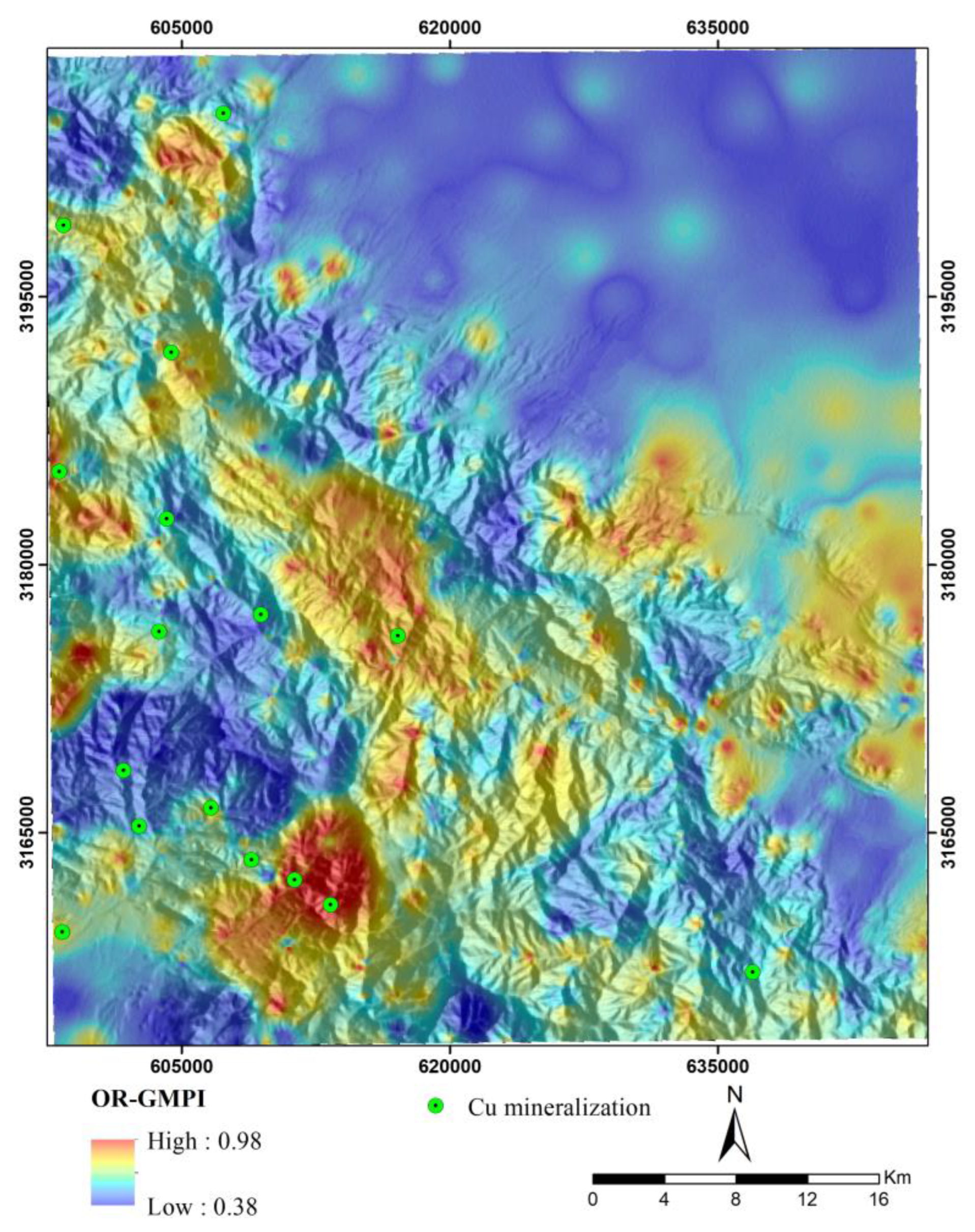
Figure 4.
Fuzzy maps of distance to argillic alteration.
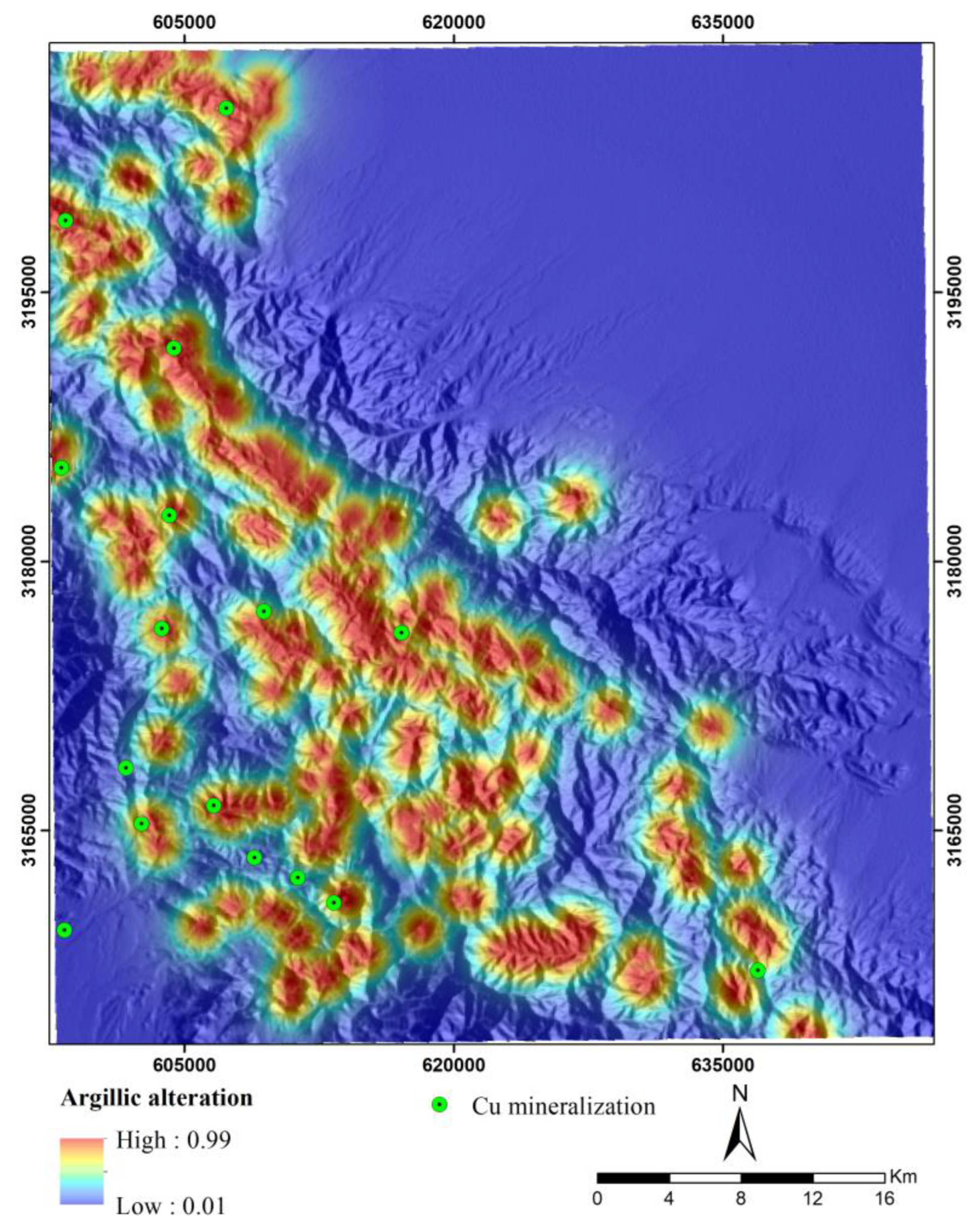
Figure 5.
Fuzzy maps of distance to phyllic alteration.
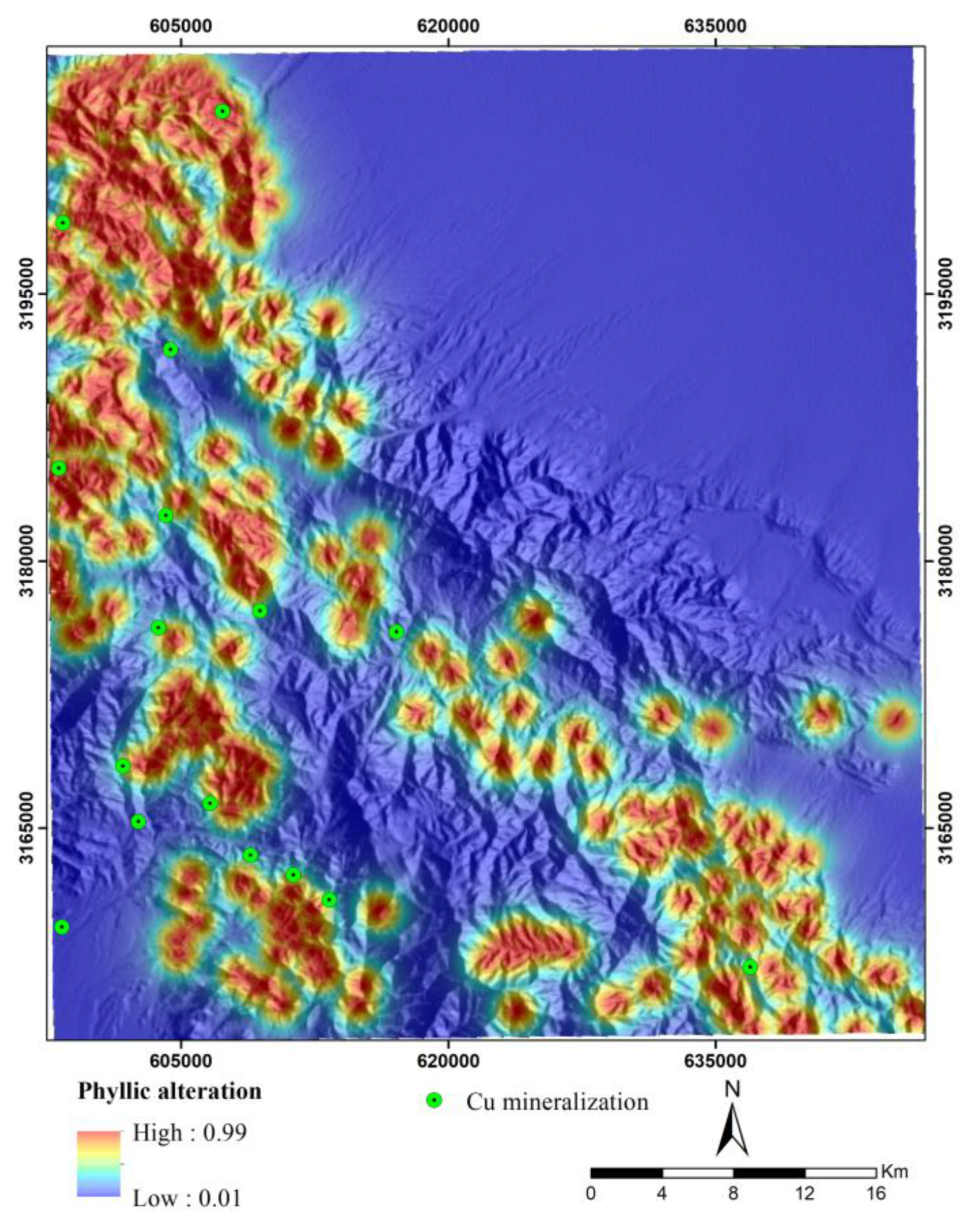
Figure 6.
Fuzzy maps of distance to propylitic alteration.
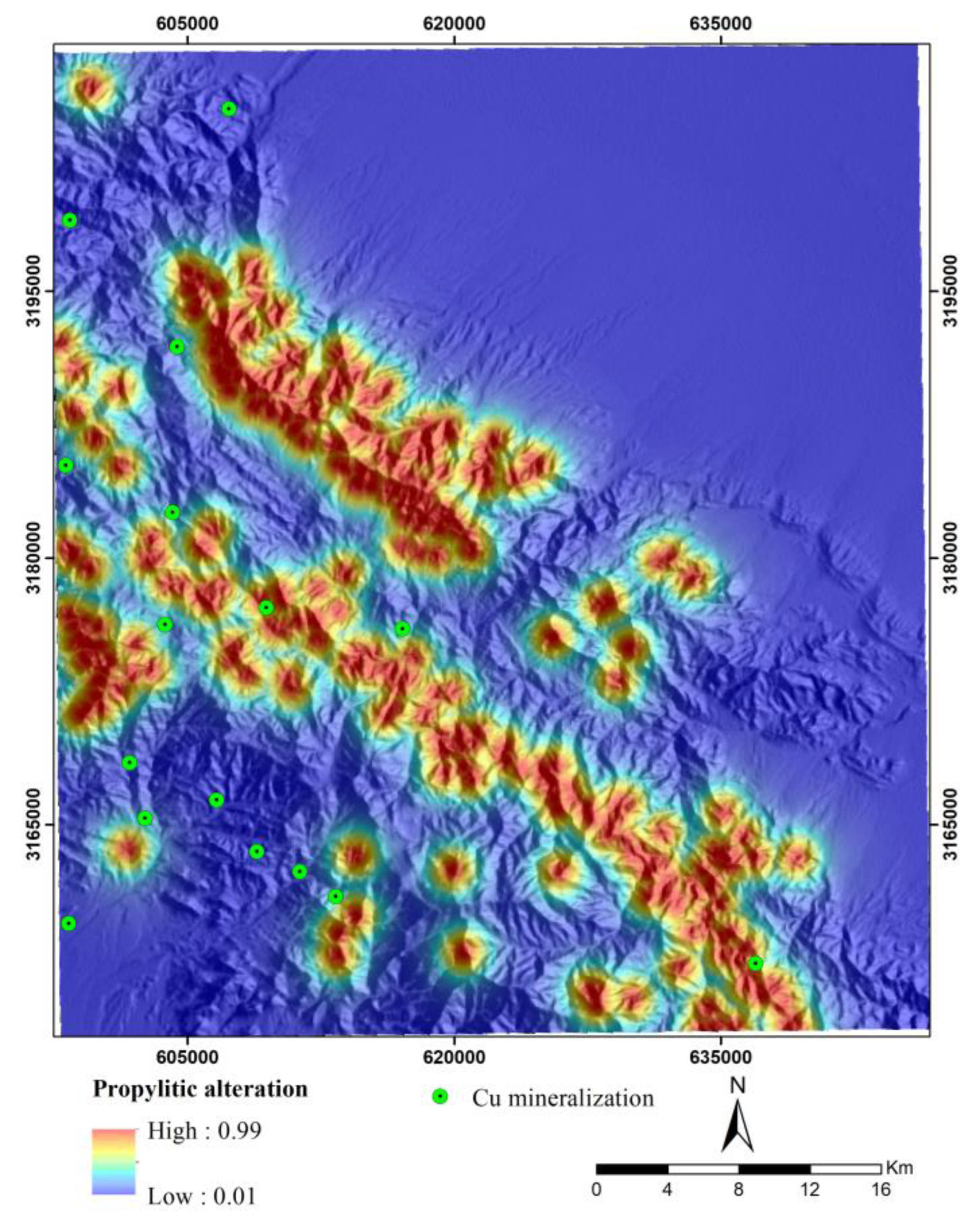
Figure 7.
Fuzzy maps of distance to iron oxide alteration.
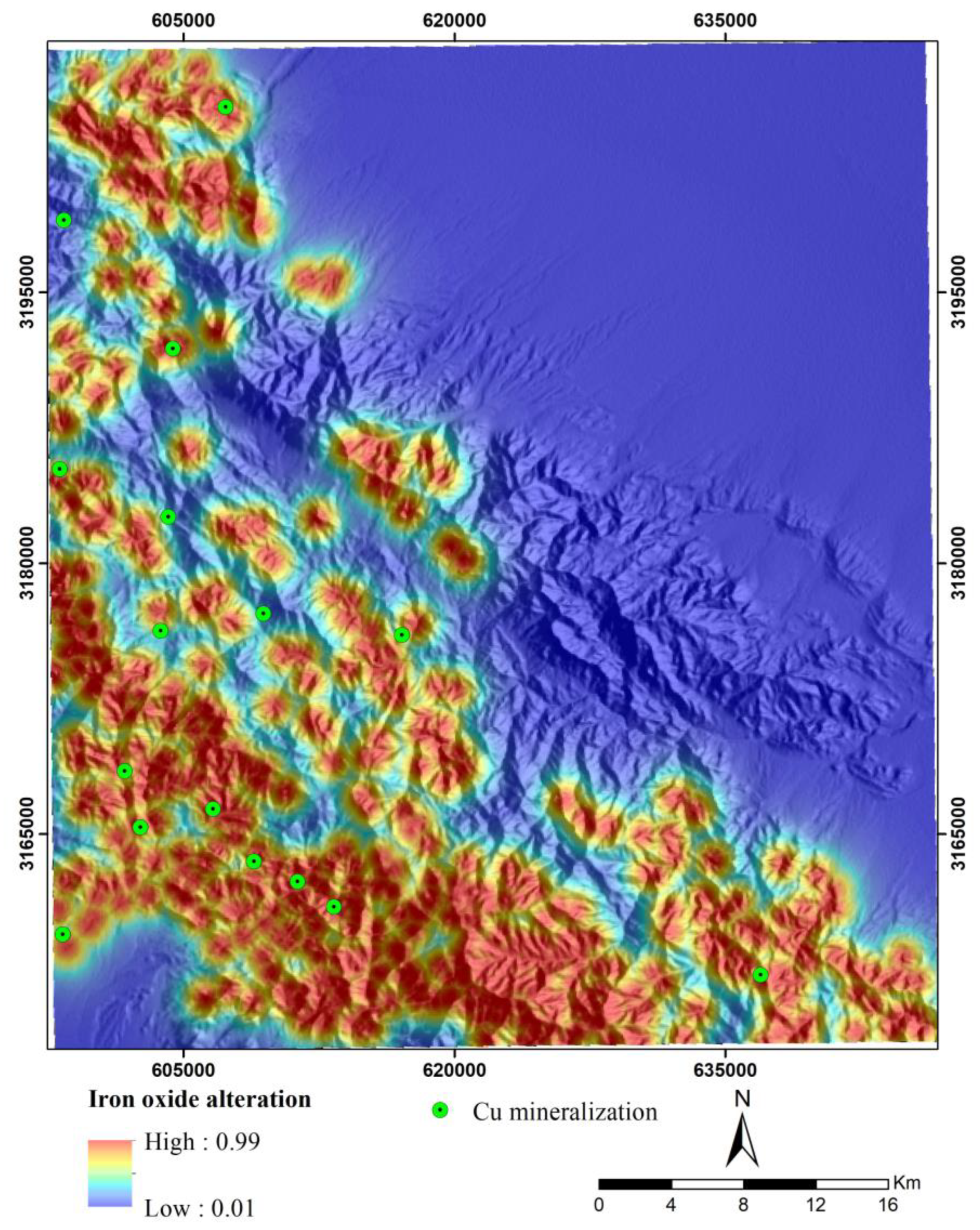
Figure 8.
Fuzzy fault density map of the Jebal Barez region.

Figure 9.
Fuzzified map of distance to intrusive rocks.
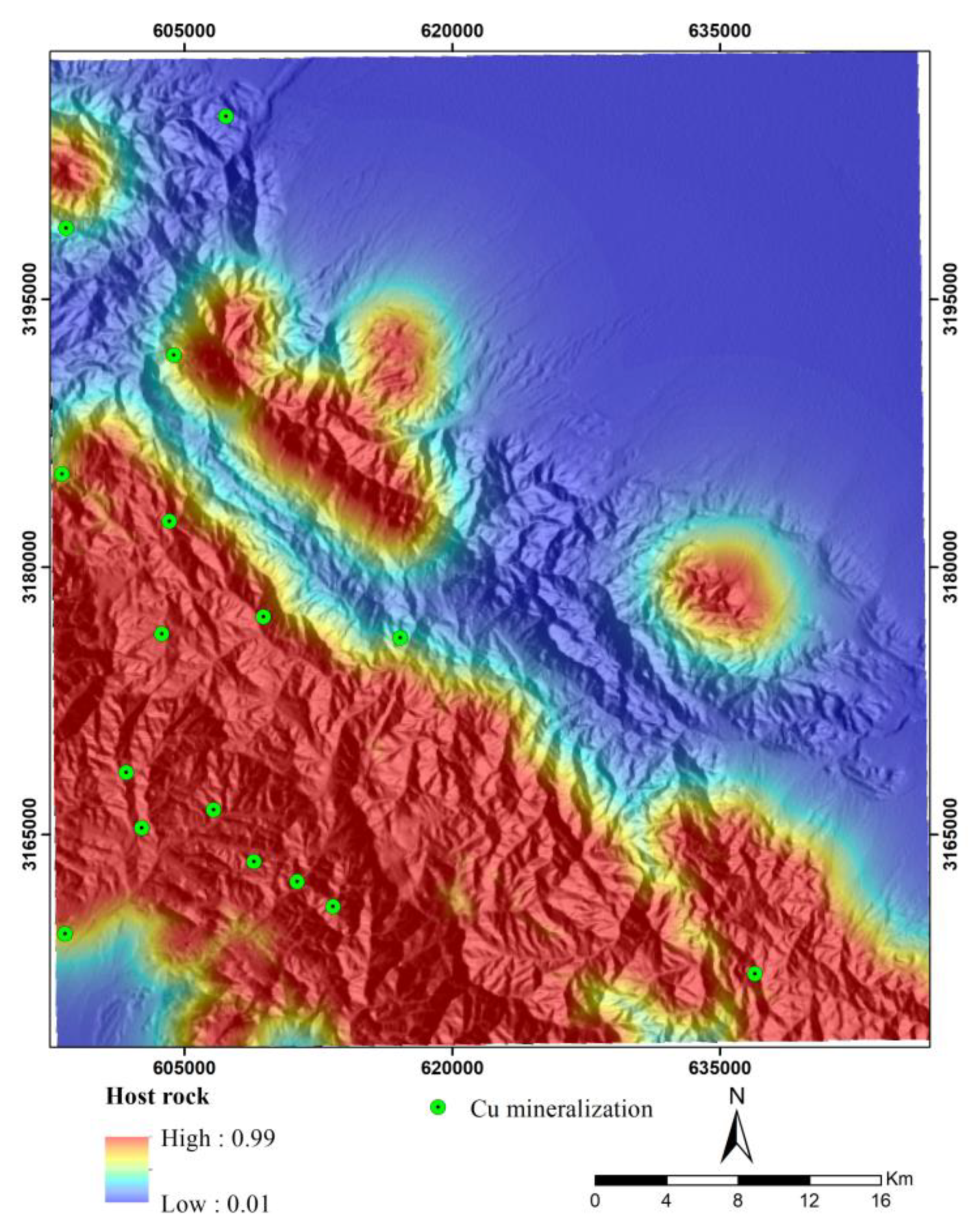
Figure 10.
Methodology workflow of this study.
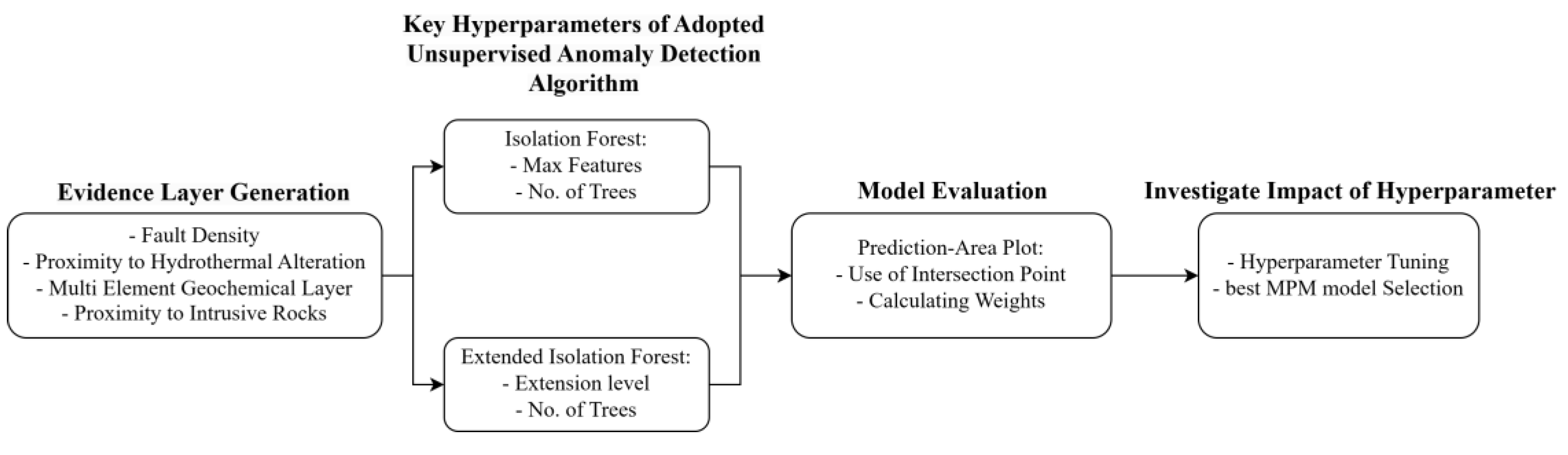
Figure 11.
The effect of two hyperparameters "maximum feature" and "number of ITrees" on the performance of the IF algorithm.
Figure 11.
The effect of two hyperparameters "maximum feature" and "number of ITrees" on the performance of the IF algorithm.
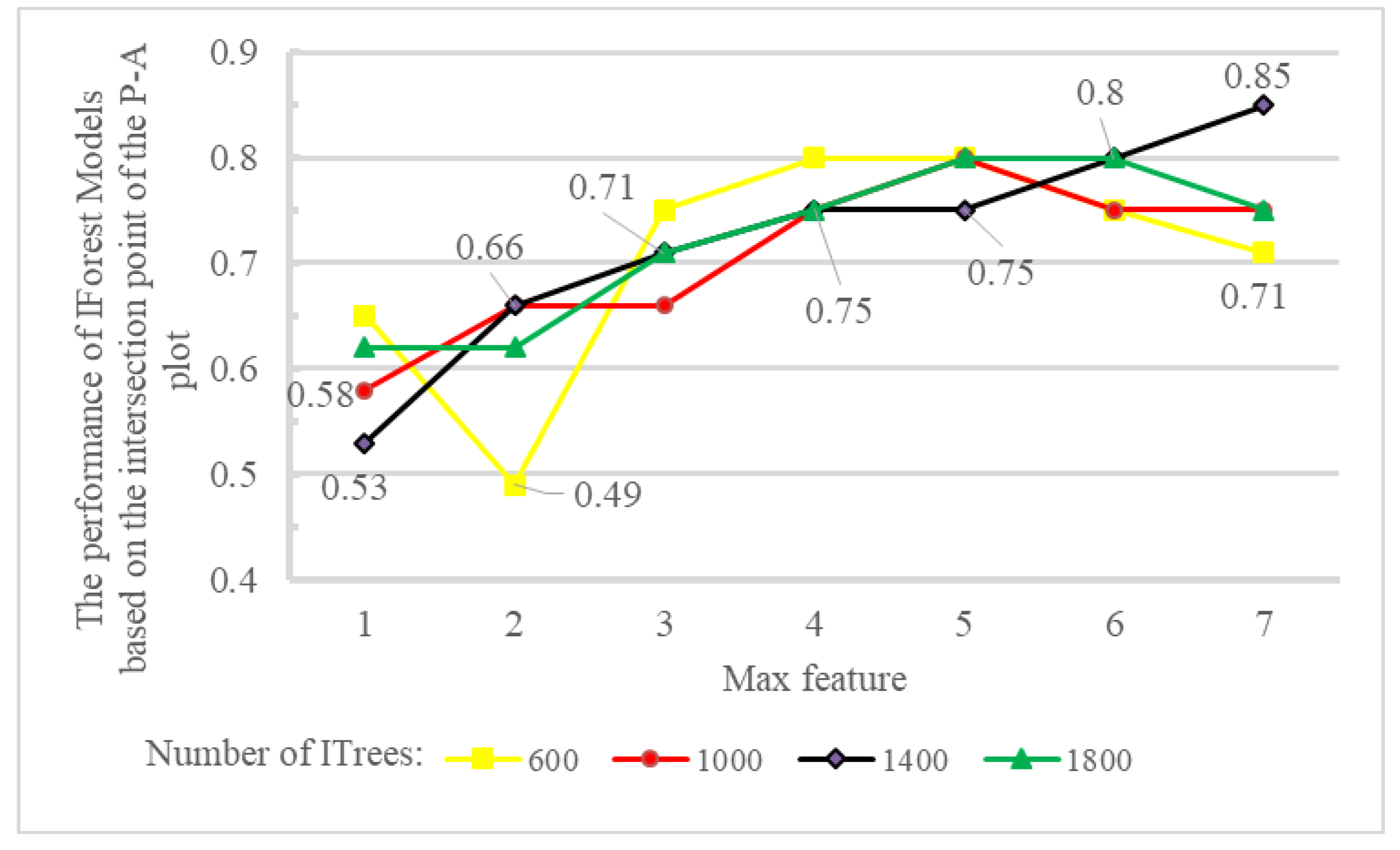
Figure 12.
P-A plot of the IF algorithm for optimal hyperparameters values.
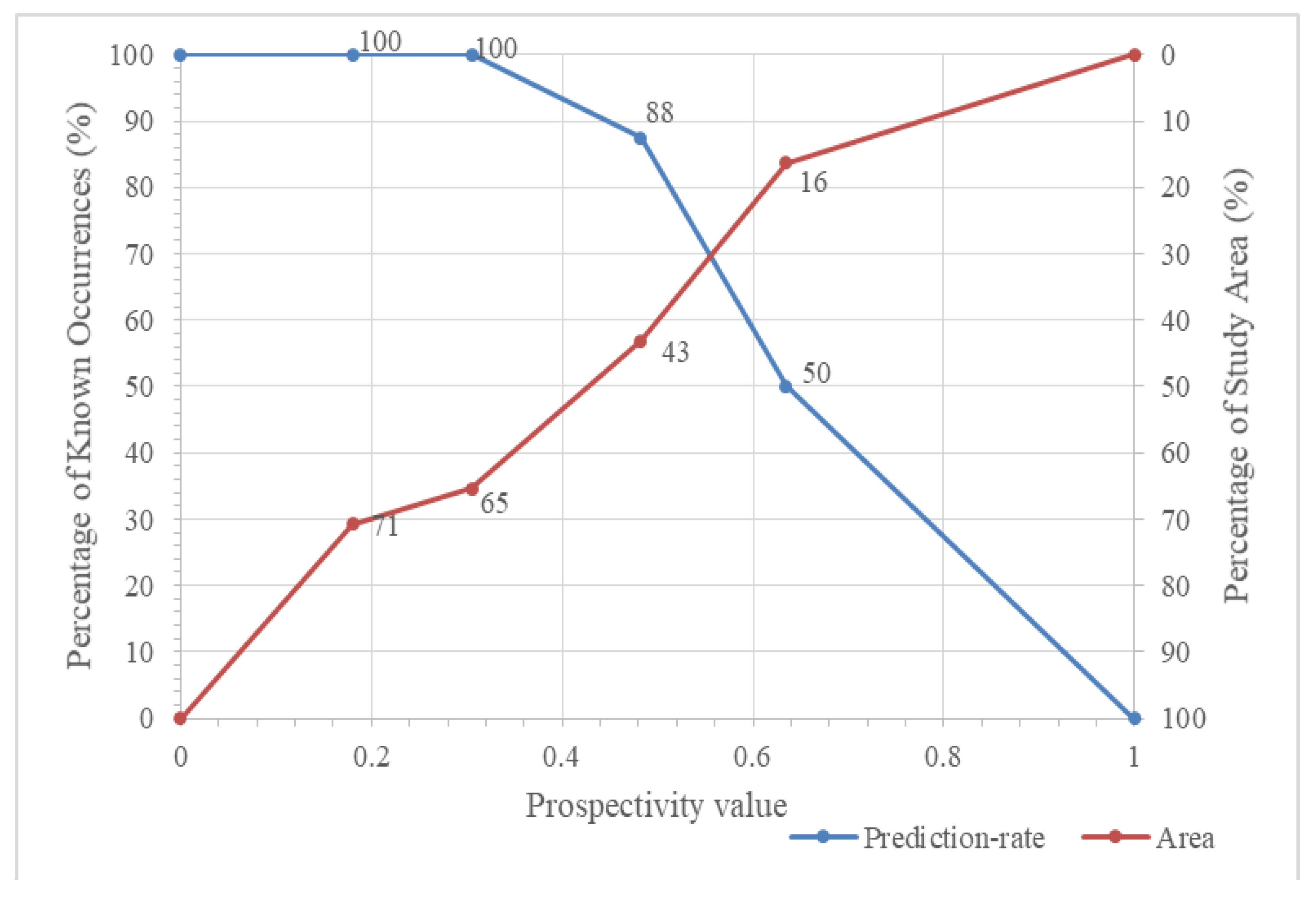
Figure 13.
prospectivity map of copper porphyry produced by the IF algorithm with 7 and 1400 for feature hyperparameters and number of ITrees, respectively.
Figure 13.
prospectivity map of copper porphyry produced by the IF algorithm with 7 and 1400 for feature hyperparameters and number of ITrees, respectively.
Figure 14.
The impact of two hyperparameters, "extension level" and "number of ITrees", on the overall performance of the EIF.
Figure 14.
The impact of two hyperparameters, "extension level" and "number of ITrees", on the overall performance of the EIF.
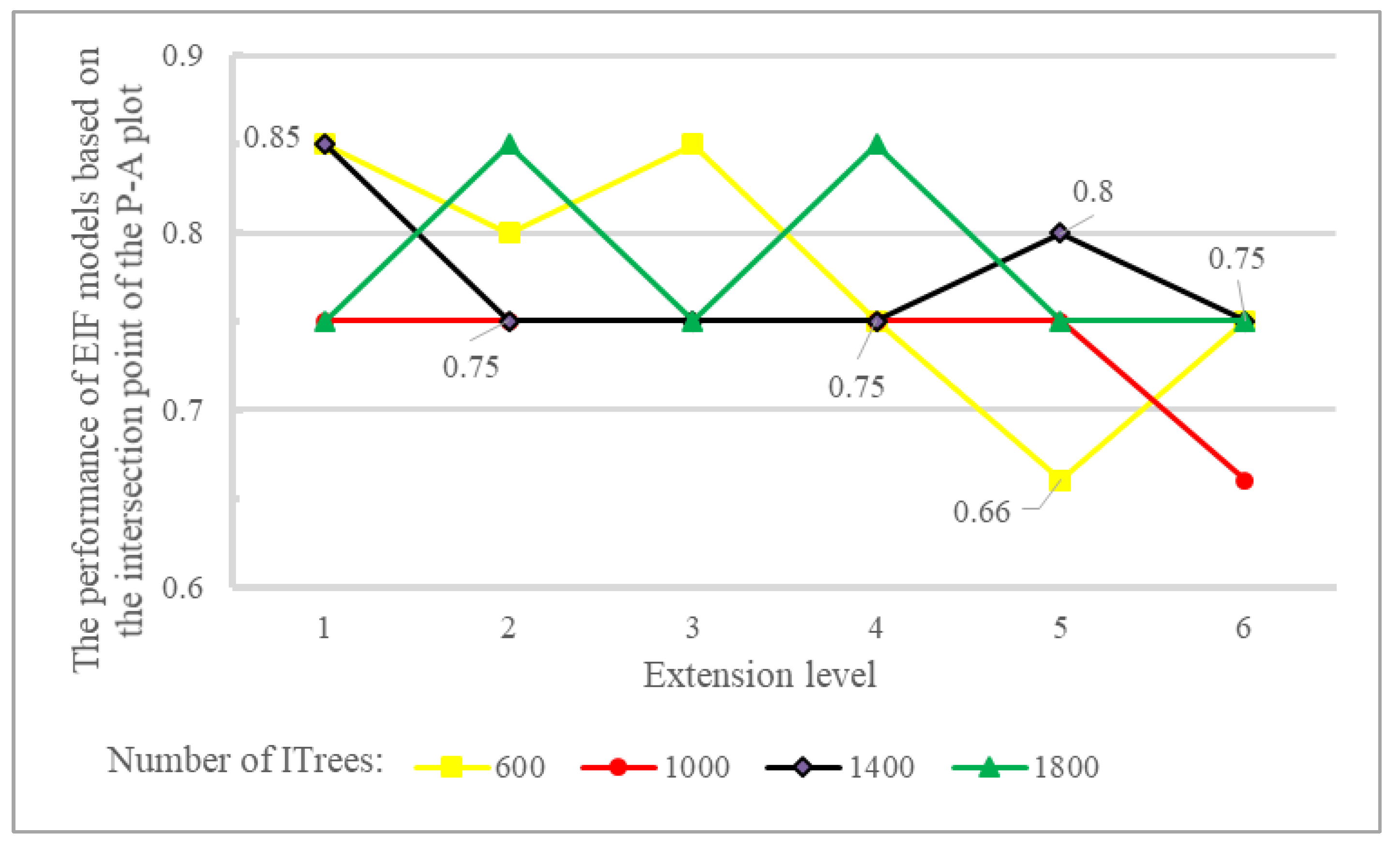
Figure 15.
P-A plot of the model generated by the EIF method.
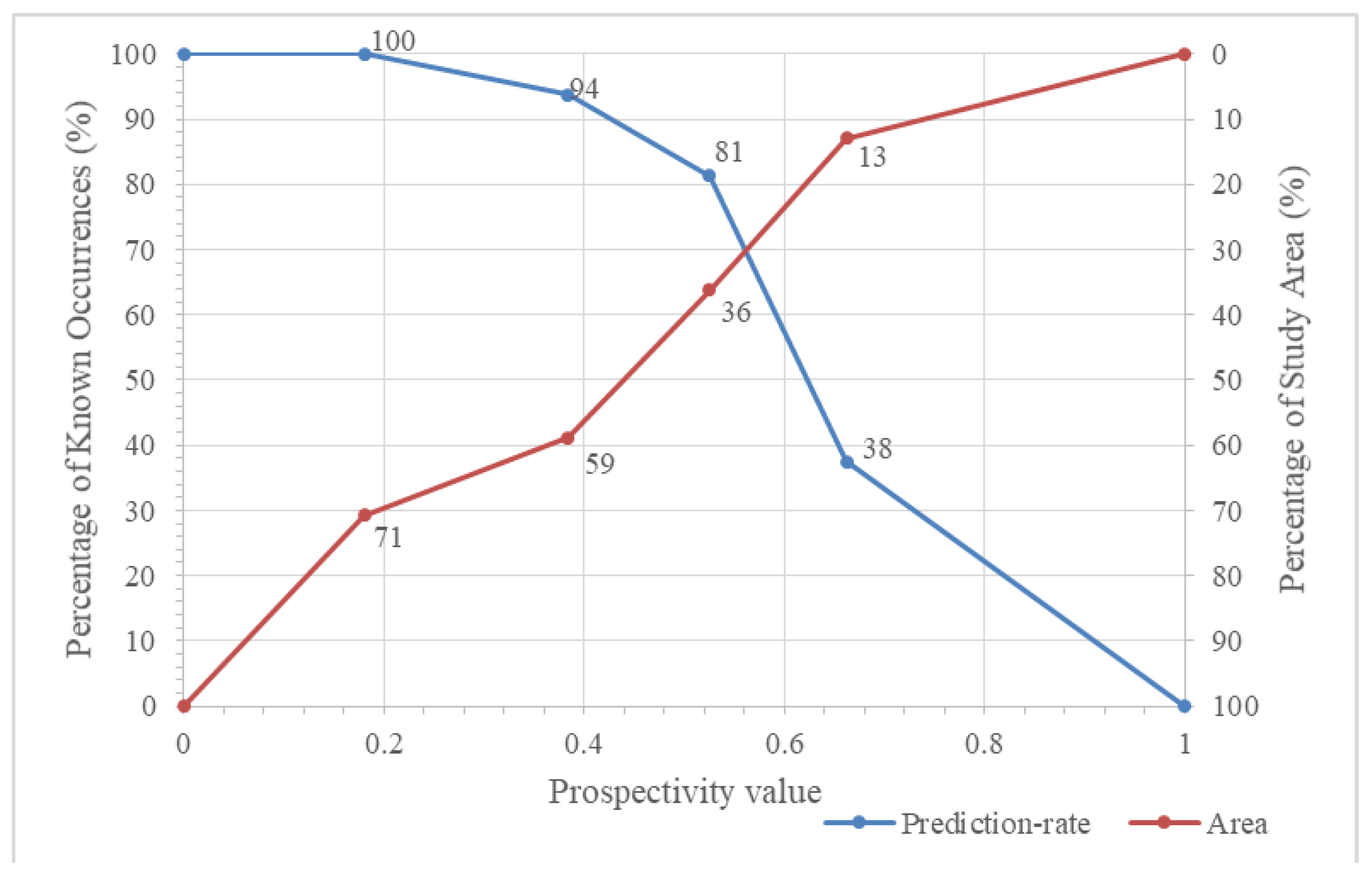
Figure 16.
Prospectivity model produced by optimal hyperparameters of EIF method.
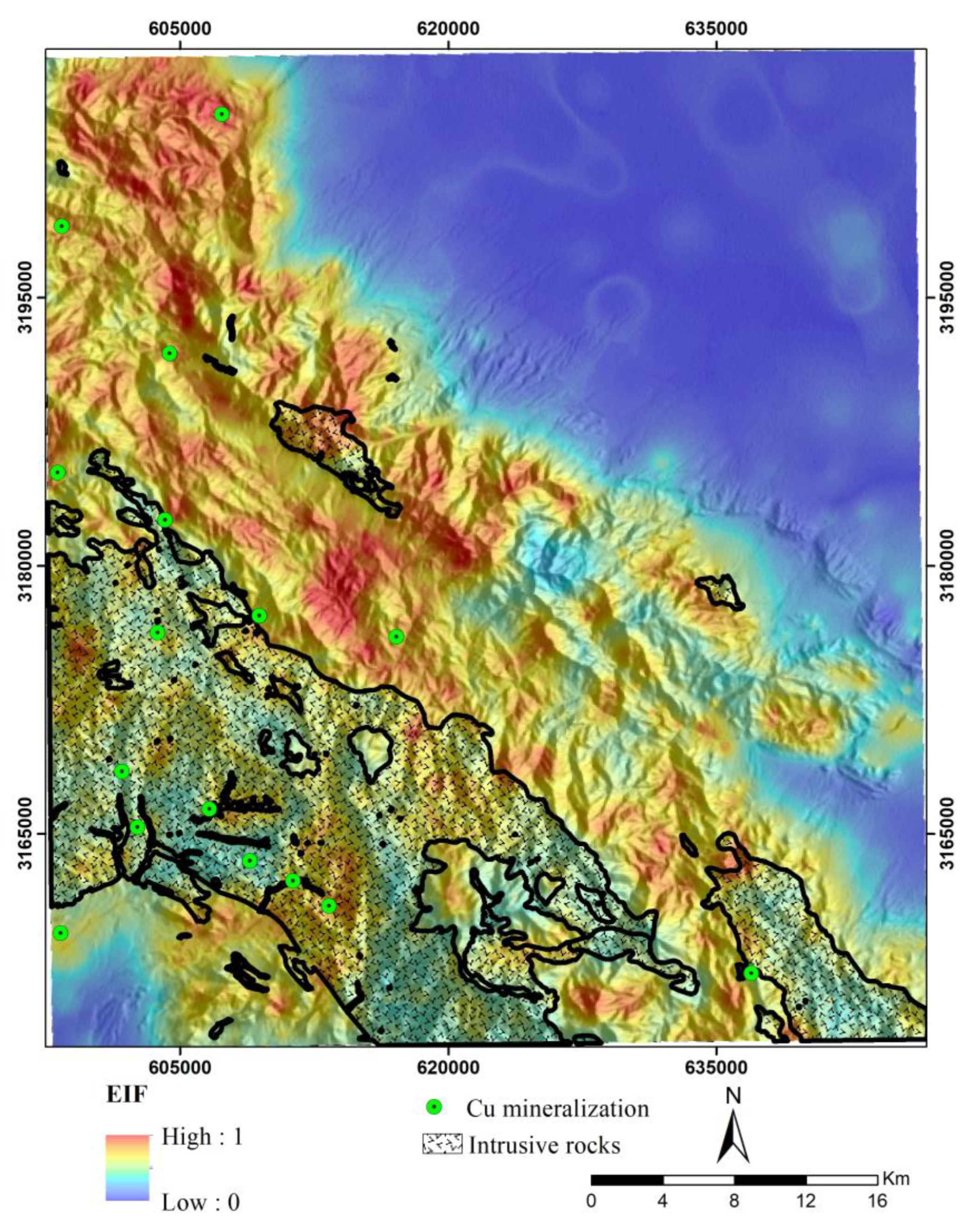
Figure 17.
Comparison of IF and EIF performance which shows average performance and variability across different numbers of ITrees.
Figure 17.
Comparison of IF and EIF performance which shows average performance and variability across different numbers of ITrees.
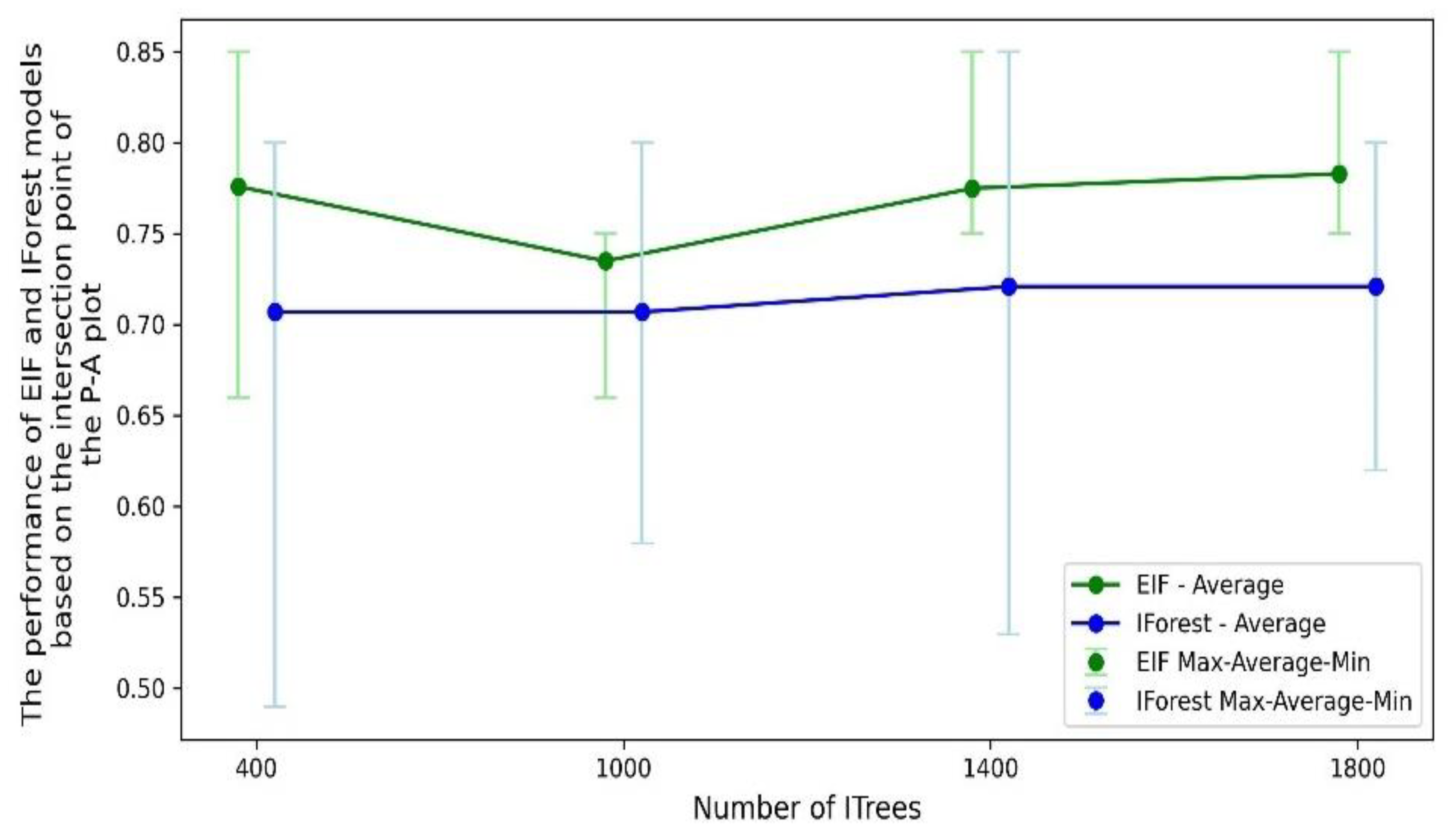
Figure 18.
IF binary prospectivity model in the study area.
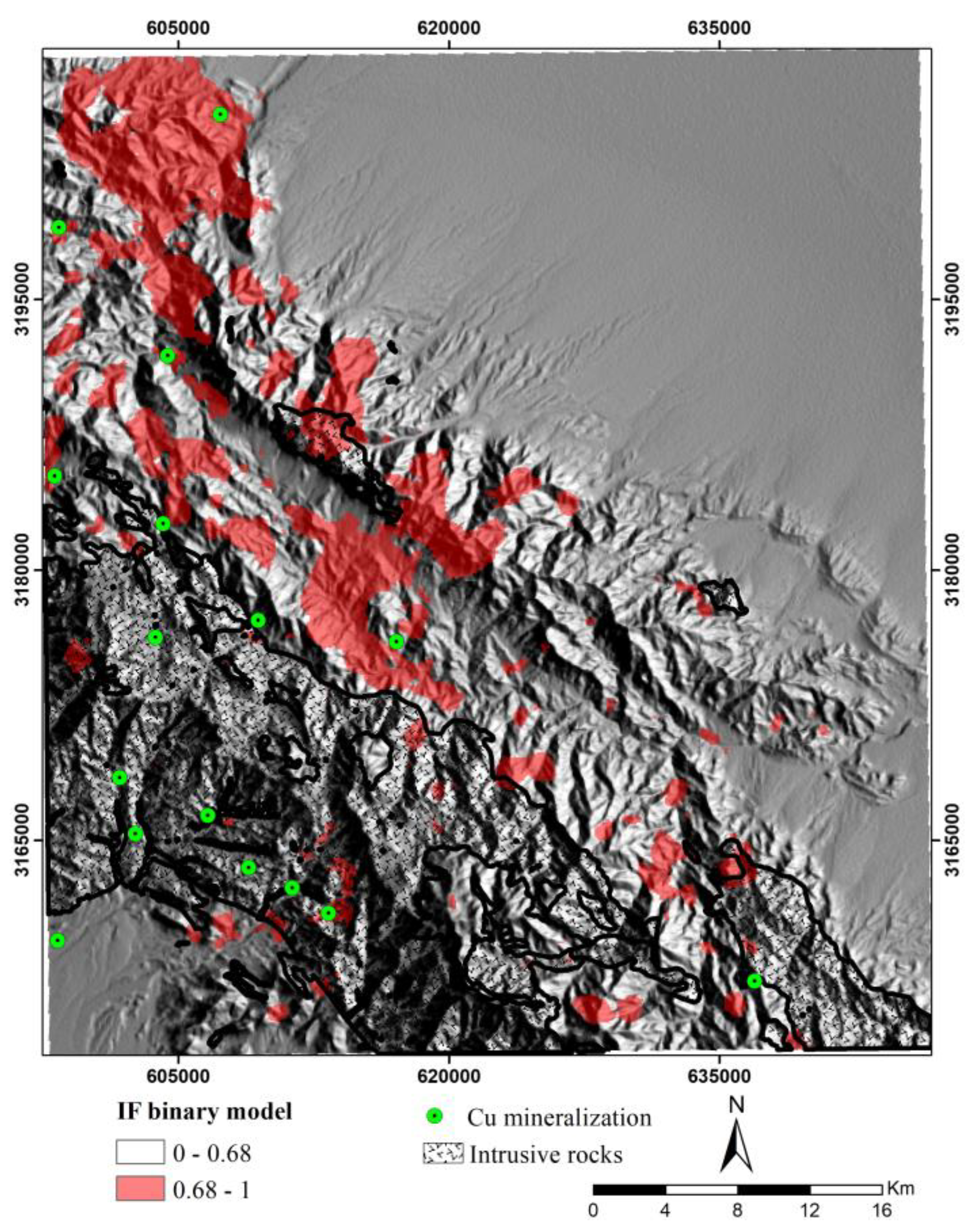
Figure 19.
EIF binary prospectivity model in the study area.
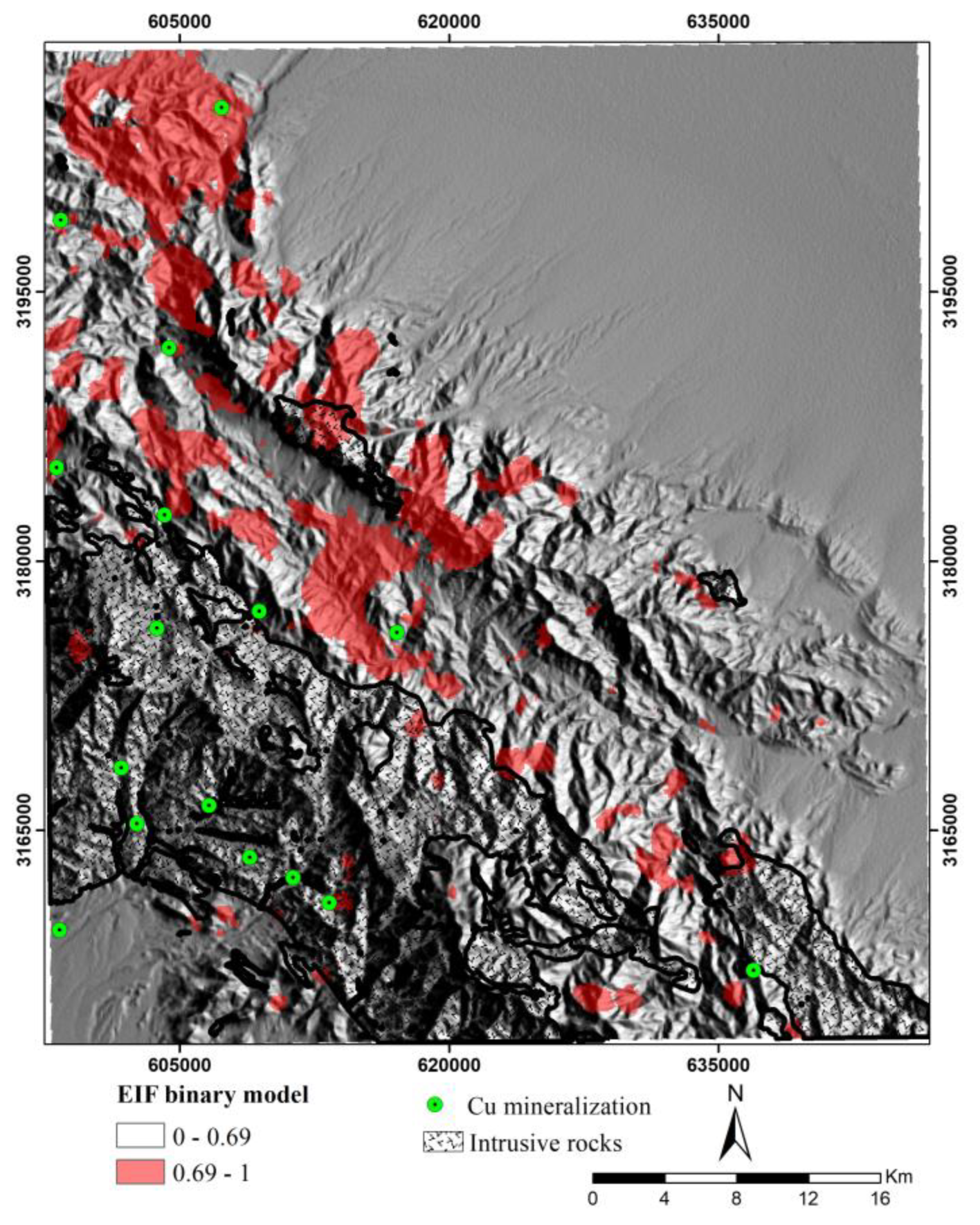

Table 1.
Key characteristics of ASTER data.
| Band | Spectral region | Wavelength(µm) | Resolution(m) |
|---|---|---|---|
| B1 | VNIR | 0.520-0.60 | 15 |
| B2 | 0.630-0.690 | ||
| B3N | 0.760-0.860 | ||
| B3B | 0.760-0.860 | ||
| B4 | SWIR | 1.600-1.700 | 30 |
| B5 | 2.145-2.185 | ||
| B6 | 2.185-2.225 | ||
| B7 | 2.235-2.285 | ||
| B8 | 2.295-2.365 | ||
| B9 | 2.360-2.430 | ||
| B10 | TIR | 8.125-8.475 | 90 |
| B11 | 8.475-8.825 | ||
| B12 | 8.925-9.275 | ||
| B13 | 10.250-10.950 | ||
| B14 | 10.950-11.650 |
Table 2.
Correlation matrix for 8 elements (Pearson).
| Elements | Zn | Pb | Ag | Cu | As | Sb | Hg | Au |
|---|---|---|---|---|---|---|---|---|
| Zn | 1 | -0.126 | -0.409 | -0.020 | -0.381 | 0.032 | -0.181 | 0.430 |
| Pb | -0.126 | 1 | 0.596 | -0.595 | -0.007 | -0.412 | -0.595 | -0.144 |
| Ag | -0.409 | 0.596 | 1 | -0.500 | 0.229 | -0.354 | -0.375 | -0.181 |
| Cu | -0.020 | -0.595 | -0.500 | 1 | -0.043 | 0.482 | 0.677 | 0.012 |
| As | -0.381 | -0.007 | 0.229 | -0.043 | 1 | 0.533 | -0.025 | -0.292 |
| Sb | 0.032 | -0.412 | -0.354 | 0.482 | 0.533 | 1 | 0.351 | -0.087 |
| Hg | -0.181 | -0.595 | -0.375 | 0.677 | -0.025 | 0.351 | 1 | 0.001 |
| Au | 0.430 | -0.144 | -0.181 | 0.012 | -0.292 | -0.087 | 0.001 | 1 |
Table 3.
Implementation of FA on geochemical data.
| Elements | Factor 1 | Factor 2 | Factor 3 |
|---|---|---|---|
| Au | 0.031 | 0.685 | -0.186 |
| Hg | 0.872 | -0.209 | -0.036 |
| Sb | 0.437 | 0.081 | 0.829 |
| As | -0.131 | -0.363 | 0.861 |
| Cu | 0.872 | -0.019 | 0.097 |
| Ag | -0.654 | -0.525 | -0.076 |
| Pb | -0.803 | -0.207 | -0.162 |
| Zn | -0.034 | 0.906 | -0.033 |
Table 4.
Important hyperparameters of IF and EIF and their corresponding values.
| Algorithm | Hyperparameter | Values | Total |
|---|---|---|---|
| IF | Number of ITress | [600,1000,1400,1800] | 28 |
| Max features | [1–7] | ||
| EIF | Number of ITress | [600,1000,1400,1800] | 24 |
| Extension level | [1–6] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



