Submitted:
10 February 2026
Posted:
11 February 2026
You are already at the latest version
Abstract
This study presents a novel data driven framework for developing airport-specific landing policies and procedures from historical successful landing data. The proposed process, termed the Airport Dependent Landing Procedure (ADLP), is motivated by the fact that airports rely on uniquely tailored approach charts reflecting local operational constraints and environmental conditions. While existing approach charts and landing procedures are primarily designed based on expert knowledge, safety margins, and regulatory conventions, the authors argue that data science and data mining techniques offer a complementary and empirically grounded methodology for extracting operationally meaningful structures directly from historical landing data. In this work, we construct a probabilistic three-dimensional environment from real-world aircraft approach trajectories, capturing spatiotemporal relationships under varying atmospheric conditions during approach. The proposed methodology integrates Adversarial Inverse Reinforcement Learning (AIRL) with Recurrent Proximal Policy Optimization (R-PPO) to establish a foundation for automated landing without pilot intervention. AIRL infers reward functions that are consistent with behaviors exhibited in prior successful landings. Subsequently, R-PPO is employed to learn control policies that satisfy safety constraints related to airspeed, sink rate, and runway alignment. Application of the proposed framework to real approach trajectories at Guam International Airport demonstrates the efficiency and effectiveness of the methodology.
Keywords:
adversarial inverse reinforcement Learning (AIRL)
; proximal policy optimization (PPO)
; aircraft
; imitation learning
; landing procedure
; data-driven framework
; aviation
1. Introduction
The landing phase remains one of the most demanding and safety-critical segments of all commercial flight operations. It requires precise, continuous management of descent rate, airspeed, lateral alignment as well as energy state amid variable wind conditions. Other parameters, such as traffic constraints and airport geographical constraints usually add to complexities involved. Despite significant advances in autopilot and flight-management systems, as well as "Instrument Landing Systems (ILS)", human pilots still bear primary responsibility for the final approach and landing, where even small deviations can lead to abortion of the process and execution of "go-arounds", or otherwise, runway excursions. On the other hand, with steadily increasing global air traffic and growing interest in higher levels of flight safety with even "single-pilot" operations as well as "crew-less" cargo aircraft—there is a pressing need for a sound a scientific approach to develop landing procedure and policies that could lead to control systems capable of replicating robust, expert-consistent landing performance directly from history of operational evidences at a given airport.
Traditional aircraft control-system design relies heavily on aircraft analytical dynamic models. The process continues with linearized equations of motion and gain-scheduled controllers tuned for different aircraft conditions. Surprisingly enough, such tradition completely ignores the geographical airport characteristics and solely concentrates on the aircraft and its dynamical characteristics. Not to mention that such labor-intensive approach would not even guarantee any safety measures and still calls for many hours of flight-testing with different weights in different atmospheric disturbances together with specifically tailored trainings at different airports. However, with new advances in Reinforcement learning (RL) techniques, we are at a turning point in the development of new class of control systems that have the ability to adjust themselves for different airport destinations. In this line of thought, in addition to the aircraft, the airport characteristics as well as its approach charts come into the process and play their roles from the beginning. Moreover, there are still no scientific process that any proposed approach chart for any airport is the best-one possible. In fact, as long as such approach charts seem doable for ordinary pilots, they are approved. In this mechanism, it is the novice pilot that has to learn how to land at a given airport and the burden is solely on the pilots to learn how to land at different airports. Nevertheless, the current work aims to enhance the situation and to lower pilot workload, while maintaining accepted level of safety. The idea is simple, with the help of data associated with successful previous landings, it is the aircraft that learns which trajectory to follow and how to land, not the pilot. Following sections descries the process.
2. Learning Mechanisms of Learning Capable Aircraft
In this work, we use Inverse Reinforcement Learning (IRL), and particularly its adversarial variant (AIRL), to address existing challenges to extract landing policies directly from previous successful landing data, instead of "Airport Approach Charts". The process recovers suitable reward functions directly from previous expert demonstrations, eliminating the need for manual reward manipulations. When combined with modern policy optimization methods, such as Proximal Policy Optimization (PPO), AIRL enables the training of policies that closely mimic previous experts' behavior. It has to be noted that unlike most prior works that rely on simulated environments for learning, we explicitly use actual aircraft trajectories so there are neither simplified dynamics involved nor any simplifications that might compromise the safety of the aircraft and its passengers.
The rest of the manuscript describes the framework of the so called "Policy Inference from Logged Operational Trajectories (PILOT)" in three sections, as the following:
- The first section describes how we can collect and prepare the relevant data for a specific flight case, such as ADS-B data during approach to a specific airport.
- The second section describes the learning process to form a robust, expert-consistent, 3D controller exclusively from real-world data associated with section (1)
- The third section, describes how the process could be fine-tuned for a specific airport, which in this study is International Airport (PGUM).
With proper data (For this work 1,039 successful approaches), we construct a probabilistic Markov Decision Process (MDP) that captures empirical spatiotemporal relationships in properly selected aircraft states. Different case-studies reveal that during approach phase of the flight, aircraft altitude, lateral deviation, and energy state are minimum necessary. Of course, other parameters could be added to the list, as needed. AIRL process is then applied to infer a reward function consistent with observed aircraft behavioral states, followed by recurrent PPO (R-PPO) training of an LSTM-based policy that aims to produce stable coherent command for the autopilot during approach.
In this approach, we are using all the data associated with "Successful flight conditions" we, obviously, expect to safety and realism to be naturally enforced in all critically selected states. The primary contributions of this work are:
- A new probabilistic model based on real-world data to extract policies without mathematical models.
- Extraction of applied reward functions directly from history of operation to feed into R-PPO, eliminating the need for trial-error in the process of reward adjustments.
- Provision of implicit robustness and stability based on experts in the field historical data.
- Provision of built-in validation process into the model with robustness to initial-state variations, and guarantees valid terminal conditions.
Based on the mentioned contributions, this work paves the way to develop a new class of control system that has the ability to mimic landing policies suitable for both manned and unmanned aircraft systems.
3. Literature Review
Adversarial Inverse Reinforcement Learning (AIRL) has become a central method for extracting reward functions from expert demonstrations using an adversarial discriminator–generator structure. The foundational work of Fu et al. [1] introduced AIRL as a robust alternative to traditional IRL, demonstrating improved reward transferability and policy generalization in continuous-control domains. This triggered a series of studies aimed at improving reward stability, scalability, and sample efficiency.
Several methodological extensions build on this foundation. Model-based variants such as MAIRL [2] introduced a self-attention dynamics model to reduce optimization variance, while option-based approaches such as oIRL [3] improved reward disentanglement through temporally extended actions. Off-policy AIRL [4] addressed the high sample cost of the original on-policy formulation, and generative extensions combining AIRL with DDPG [5] reduced training time through deterministic sampling. Hybrid AIRL (HAIRL) [6] incorporated curiosity-driven exploration to mitigate AIRL’s tendency toward premature exploration saturation.
A major application area for AIRL is sequential decision-making. In autonomous driving, several augmented AIRL frameworks [7,8,9] incorporated semantic features to improve learning stability and decision accuracy in interactive traffic settings, consistently outperforming GAIL and reinforcement-learning baselines. Beyond single-agent domains, multi-agent and adversarial extensions such as MA-AIRL [10] and I-IRL [11] expanded AIRL to strategy recovery in Markov games and adversarial environments. More recent work has addressed long-horizon challenges: hierarchical critics and subtask decompositions in H-AIRL [12] and SC-AIRL [13] improved credit assignment and exploration in complex robotic manipulation problems.
Overall, these studies highlight AIRL’s strengths in reward interpretability, robustness, and behavioral fidelity. However, the existing literature exhibits several limitations. AIRL research remains heavily dependent on simulated environments and rarely incorporates high-dimensional, physics-informed state representations.
Building on the advancements in Adversarial Inverse Reinforcement Learning (AIRL) for robust reward recovery from expert demonstrations, broader applications of Deep Reinforcement Learning (DRL) and Deep Imitation Learning (DIL) have extended these techniques to safety-critical domains.
Deep Reinforcement Learning (DRL) and Deep Imitation Learning (DIL) have emerged as leading paradigms for autonomous control in complex, safety-critical domains such as autonomous driving and mobile robotics [14,15,16,17]. These approaches have been successfully extended to Unmanned Aerial Vehicles (UAVs), enabling high-performance autonomous flight—including human-champion-level performance in real-world drone racing [18,19]. Notable applications include continuous-action obstacle avoidance [20], wind-aware navigation procedure optimization [14], and airport traffic management [21]. Algorithms such as Proximal Policy Optimization (PPO), Deep Deterministic Policy Gradient (DDPG), and modular or curriculum-based training have proven effective for motion planning and control in dynamic, uncertain environments [18,22,23].
Despite these advances, the “sim-to-real” gap remains a fundamental obstacle: most DRL methods perform well in simulation but degrade significantly in physical deployment due to unmodeled dynamics, sensor noise, and environmental variability [24,25]. Domain randomization and high-fidelity simulators offer partial solutions [24], yet direct learning from real-world data is increasingly recognized as a more robust path forward. Offline Reinforcement Learning, which trains solely on static datasets without online interaction, has gained prominence for applications where real-time exploration is expensive or hazardous [26].
A parallel challenge in applying RL to aircraft landing is the difficulty of manually designing reward functions that capture the subtle, multi-objective trade-offs expert pilots employ. Inverse Reinforcement Learning (IRL), particularly Adversarial IRL (AIRL), resolves this by inferring reward functions directly from expert demonstrations, thereby producing human-like policies without explicit reward engineering [27]. Combining AIRL with recurrent policy optimization (e.g., PPO with LSTM architectures) further supports stable, long-horizon decision-making required for extended flight segments.
Safety and certifiability are non-negotiable in aviation. Recent surveys stress the need for constrained learning, formal safety guarantees, and explicit enforcement of operational envelopes [20,28]. Terminal constraints on critical variables (airspeed, sink rate, alignment) and rigorous containment analysis within observed state distributions directly address these requirements.
The PILOT framework advances this body of work by learning robust, pilot-like landing policies exclusively from 1,039 real-world ADS-B approach trajectories collected at Antonio B. Won Pat International Airport (PGUM), Guam, across diverse meteorological conditions and aircraft types. By constructing an empirical probabilistic Markov Decision Process, employing AIRL to recover pilot-consistent rewards, and training a recurrent PPO policy with explicit safety constraints, PILOT eliminates both hand-crafted rewards and dependence on analytic flight-dynamics models. Validation demonstrates close statistical agreement with expert trajectories and physical plausibility up to the vicinity of the runway. This fully offline, data-anchored approach directly mitigates the sim-to-real gap and establishes the feasibility of deriving versatile, expert-level guidance for both manned and future unmanned aircraft using only operational surveillance data.
4. Dataset and Preprocessing
The flight dataset used in this study [29] focuses on approach and landing operations at Guam International Airport (PGUM). The details of the dataset are shown in Table 1. A total of 1,039 flight trajectories from 142 individual aircraft were collected, covering twelve major aircraft types, including the Airbus A321 and A330, as well as the Boeing 737, 757, 767, 777, and 787 series. All trajectories are related to the PGUM; therefore, the present study evaluates generalization across aircraft types within a single-airport operational context, not across airport geometries or procedures. These flights represent a diverse range of operational conditions and configurations typical of commercial approach procedures. The corresponding 2D and 3D views are shown in Figure 1.
Each trajectory contains 1-Hz measurements recorded during the terminal descent phase. All records were filtered to remove incomplete, duplicated, or physically inconsistent samples. Minor temporal gaps were filled using linear interpolation. The resulting dataset provides the foundation for constructing the probabilistic flight environment.
Meteorological variability during the 2025 data-collection period at Guam International Airport (PGUM) was characterized using routine aerodrome weather reports (METAR) [30]. METAR observations for PGUM were retrieved from the Iowa Environmental Mesonet (IEM) ASOS/AWOS/METAR archive using the asos.py interface [31]. The METAR wind fields (direction and speed) were used to compute the crosswind component relative to RWY 06L, and temperature/dew-point observations were used to compute relative humidity [30]. For visualization, months were grouped into a dry season (January-June) and a rainy season (July-December), consistent with climatological descriptions for Guam [32]. Figure 2 provides a compact summary for 2025, including monthly precipitation totals, the monthly distribution (P10 - P50 - P90) of the RWY 06L crosswind component, and monthly median relative humidity. The dashed 16 kt line in the crosswind panel denotes the FAA airport design allowable crosswind component used in runway wind coverage analyses, included here as a design reference rather than an aircraft operational landing limit [33].
5. State–Action–Environment Modeling
5.1. State Representation
The aircraft state is modeled using a nine-dimensional vector containing geometric, kinematic, and energetic quantities relevant to approach and landing:
These features represent distance and alignment relative to the runway, vertical profile, heading behavior, and total energy state. A detailed list of all variables, and their physical meaning is provided in Table 2.
5.2. Robust Normalization and Grid Construction
To ensure consistent scaling and avoid the influence of outliers, robust lower and upper bounds for each state variable were extracted directly from the flight dataset using quantile-based clipping. These bounds define the operational envelope used throughout the learning process.
A uniform discretization grid was then constructed: a single bin width per dimension was computed using the Freedman-Diaconis [34] rule and constrained within physically meaningful limits (e.g., minimum altitude resolution, maximum allowable slope step).
The bin width h is defined as:
where IQR(x) is the interquartile range of the data and n is the sample size. This rule provides a data-adaptive, outlier-robust discretization scale, ensuring the grid is neither too coarse nor too fine before applying domain-specific constraints.
These bin widths were held constant across the full domain and are summarized in Table 2.
This procedure yields a stable and interpretable partition of the continuous state space, forming the basis for constructing the empirical transition model and extracting expert demonstrations.
5.3. Demonstration Extraction
The flight dataset was split into training, validation, and test subsets. Each trajectory was converted into a sequence of expert demonstrations by labeling pilot control commands (actions) vertical (climb/level/descend) and lateral (left/straight/right) based on changes in altitude and heading rate. These labeled demonstrations serve as the supervisory signal for reward learning and policy optimization.
5.4. Action Space and Expert Labeling
The control space is discretized into nine primitive actions, representing the Cartesian combination of vertical and lateral intentions:
Actions are labeled from flight data by analyzing local altitude and heading changes. A dynamic vertical threshold
and a turn threshold, , were used to classify each time step into one of the nine action categories. This results in discrete state–action pairs suitable for transition modeling.
6. Training Methodology
6.1. Environment and Demonstration Preparation
The training environment is a data-derived Markov decision process formed from two empirical components: the transition kernel , obtained from state–action frequency counts, and the conditional feature statistics , which summarize the continuous flight variables associated with each discrete transition. States correspond to quantized combinations of flight parameters, and next state samples are drawn directly from observed transitions in the dataset. Expert demonstrations extracted from 1 Hz flight recordings provide sequences of 9-dimensional states and discrete pilot actions , formatted for the AIRL algorithm. The environment itself is reward-free; the learned reward is applied later through a wrapper that evaluates it online using the trained reward network.
6.2. Learning Framework and Model Architecture
The proposed model is trained using a unified two-stage learning framework that integrates Adversarial Inverse Reinforcement Learning (AIRL) for reward inference with a Recurrent Proximal Policy Optimization (R-PPO) agent for policy optimization. This architecture enables the system to first recover a latent reward function directly from expert flight demonstrations and subsequently learn a stable closed-loop control policy capable of reproducing pilot-like behavior across extended approach segments. In the first stage, AIRL is used to infer an intrinsic reward signal that best explains the demonstrated trajectories. AIRL formulates the problem as an adversarial game between a discriminator , which attempts to distinguish expert transitions from those generated by a provisional policy, and a generator that represents a PPO agent acting within a data-driven Markov decision process. Following the original AIRL formulation by [35], the discriminator models the density ratio between expert and policy-generated transitions via:
where is an energy-based reward-shaping function. The intrinsic reward is then recovered through the canonical AIRL transformation:
which yields a scalar reward consistent with maximum-entropy inverse reinforcement learning and is theoretically guaranteed to recover a reward that is invariant under potential-based shaping, thereby preserving the optimal policy [36]. The discriminator is implemented as a multilayer perceptron that receives the concatenated transition vector , normalized using running statistics to ensure numerical stability. The network consists of three fully connected layers with 256, 128, and 64 units with Leaky-ReLU nonlinearities, followed by a sigmoid output that provides the probability of a transition being expert-generated. During AIRL training, the discriminator and generator are optimized alternately: the discriminator is updated to improve its ability to classify transitions, while the PPO generator is updated to maximize the inferred reward function. We used discriminator indistinguishability (accuracy near 0.5) as a heuristic convergence signal, and additionally monitored policy performance metrics to avoid premature stopping due to discriminator underfitting. Figure 3 illustrates the AIRL stage.
After convergence of the AIRL stage, the learned reward function is fixed and used to train the final controller through Recurrent PPO. The policy network adopts an MlpLstm architecture composed of two 128-unit feed-forward layers followed by a 256-unit LSTM module. The actor head predicts logits over nine discrete control primitives representing vertical and lateral intent classes (climb/level/descend × left/straight/right) inferred from observed state changes., while the critic estimates the value function . The temporal recurrence in the LSTM enables the agent to integrate sequential information, capture flow-dependent structure in aircraft dynamics, and maintain stable control behavior throughout the approach path. Policy optimization follows the clipped surrogate objective introduced by [37],
where
is the probability ratio and denotes the advantage estimate.
Both AIRL and PPO are trained within a data-derived environment constructed from empirical flight trajectories. The continuous state space is discretized using a distribution-adaptive scheme. This rule provides a statistically robust, outlier-tolerant discretization that is subsequently constrained by flight dynamics specific limits such as minimum altitude resolution and maximum allowable slope variation. For each dimension in the state representation, empirical transition counts are accumulated to construct a tabular transition model , ensuring that the environment captures the stochastic variations present in expert behavior. During both AIRL and PPO training, the agent interacts exclusively with this data-driven MDP, guaranteeing that policy learning remains grounded in the distributional structure of real trajectories rather than relying on analytically simplified models.
This integrated framework allows the controller to learn from the implicit decision-making patterns encoded in pilot demonstrations, recover a reward function that reflects expert intent, and synthesize a recurrent policy that generalizes this behavior across the full landing approach envelope.
The principal hyperparameters used in both training stages are summarized in Table 3. The entire framework of this project is presented in Figure 4.
To promote stable learning, a curriculum mechanism controlled the initial-state distribution and success criteria. Early in training, episodes began close to touchdown (≤ 5 NM) with a wide heading tolerance ( ≤ 20°). As training progressed, the curriculum gradually extended the start distribution to full-approach distances (up to 15 NM) while tightening the success tolerance to 15° and eventually 10°.
This scheduling was implemented using a linear annealing function:
where and denote the near-start ratios at the beginning and end of training. This approach allows the policy to master the final approach region before confronting the full approach envelope.
7. Validation and Evaluation
We implement the proposed PILOT framework to learn a landing policy that replicates expert approach behavior. The policy is trained on recorded expert trajectories and evaluated using Monte Carlo rollouts initialized from randomly sampled start states drawn from the dataset. Each rollout is simulated until near touchdown or until a safety-constraint violation occurs. To enable point-wise comparison with expert behavior, all trajectories are re-parameterized by distance to the runway threshold D (ranging from 15 NM to 0 NM), allowing for a direct, point-by-point comparison with expert behavior. We report results from 500 agent rollouts and compare them against 1039 expert approaches. For each variable of interest, we compute the mean profile and the corresponding range across rollouts for both the agent and the expert, assessing agreement in terms of both central tendency and dispersion.
Computations were performed on a standard workstation (Intel Core i7 CPU, 16 GB RAM, single NVIDIA GPU), demonstrating that the PILOT framework can be trained reliably without the need for specialized hardware.
We validate the learned policy against expert trajectories using profile matching over distance and operational speed plausibility at landing. We report these comparisons for:
Vertical speed
This analysis tests whether the agent matches not only the average behavior but also the dispersion observed in real expert demonstrations. In Figure 5a, the agent’s mean altitude profile closely overlaps the expert’s mean from 15 NM to touchdown, with strong agreement also in the percentile bands. This indicates that the learned policy reliably reproduces the global descent geometry of the approach.
In Figure 5b-c, the agent generally follows the expert trend. Figure 5d shows that both the agent and expert maintain a broadly consistent descent rate on average. However, the agent exhibits larger short-range fluctuations at some distances.
Latitude and longitude comparisons (Figure 5e-f) show strong overlap between agent and expert means, with narrowing dispersion as . This is a positive result, suggesting that the policy is not only reproducing the vertical profile correctly but also aligning laterally.
In support of the landing-quality assessment, we verify that the learned policy produces physically plausible approach and touchdown speeds consistent with standard landing envelopes. Table 4 reports representative landing reference speeds (at MLW) and estimated stall speeds for the aircraft types present in the dataset. These values contextualize the touchdown-speed distributions observed in both expert trajectories and agent rollouts and provide a sanity check that the learned policy operates within expected landing-speed regimes. Table 4 also highlights that the expert demonstrations span a wider operating range across aircraft types.
(at MLW) and estimated stall speed for aircraft types in the dataset.
To complement the scalar profile comparisons in Figure 5; we provide Supplementary Animation S1 (Figure 6), a synchronized 3D replay of expert and agent approaches. The animation is included as a qualitative diagnostic to (i) reveal transient corrections and short-horizon deviations that may be partially obscured in percentile bands, and (ii) enable visual consistency checks between 3D path geometry and the corresponding scalar profiles (altitude, descent rate, and speed).
Overall, the combined evidence suggests that the learned policy captures key aspects of expert approach behavior while remaining within physically observed operating regimes. At the same time, residual mismatch in variables closely tied to touchdown quality indicates clear opportunities for improvement within the current data regime. Future work will focus on (i) improving representation and feature design for the approach phase (e.g., better normalization, distance-conditioned features, and more informative terminal descriptors) to reduce short-range oscillations and better match descent-rate behavior near the runway threshold, and (ii) extending the dataset with higher-fidelity near-ground measurements to explicitly model the flare phase, which is not reliably observable from the current ADS-B–based trajectories.
8. Discussion and Future Works
The results demonstrate that the PILOT framework effectively learns robust, pilot-consistent landing policies directly from operational ADS-B trajectories. Across 1,039 real-world approaches at Guam International Airport (PGUM), the learned policy reproduces vertical, lateral, and energy profiles of expert pilots with high fidelity while maintaining physically plausible terminal conditions. Mean profiles and variability ranges of key variables; including altitude, airspeed, glide slope, vertical speed, and lateral alignment; closely match expert demonstrations. These findings highlight the ability of data-driven methods to capture implicit pilot decision-making patterns without relying on analytic flight-dynamics models or hand-crafted reward functions. Future research will focus on enhancing state representation and feature engineering, including distance-conditioned features, improved normalization, and more informative terminal descriptors. Expanding the dataset to incorporate higher-fidelity near-ground measurements would allow more accurate modeling of flare and touchdown phases, which are currently underrepresented in ADS-B–based trajectories. The framework also provides a clear path to reducing human-imposed procedural constraints, particularly reliance on Minimum Descent Altitudes (MDA). By learning landing policies that respect safety limits and pilot-consistent behavior, the system can support continuous-descent operations and adaptive approach paths without strictly defined MDA restrictions, given proper real-time monitoring and safety verification. This represents a potential paradigm shift in approach design, enabling airport-specific landing procedures to evolve from historical operational evidence rather than prescriptive altitude minima. From a procedural standpoint, a data-driven framework can define conditional, probabilistic minima that reflect actual landing success statistics under well-characterized states of aircraft energy, alignment, and environmental conditions. While the study does not propose immediate replacement of certified minima, airport-specific, data-driven minima could be introduced incrementally as advisory or decision-support layers. Over time, these models may provide a basis for a gradual transition from conservative, rule-based minima toward adaptive minima grounded in operational performance, reducing unnecessary go-arounds, lowering pilot workload, and enabling more consistent approach outcomes—especially at airports with complex terrain or challenging meteorological conditions. Finally, extending this approach across multiple airports and aircraft types, combined with formal safety verification, could broaden applications for both manned and unmanned aircraft. Integration of probabilistic, data-driven policies with real-time sensor feedback offers a scalable, scientifically grounded alternative to chart-based approaches, paving the way for more automated, adaptive, and safer landing operations in diverse operational and meteorological environments.
References
References
- Fu, J.; Luo, K.; Levine, S. Learning robust rewards with adversarial inverse reinforcement learning. ArXiv Prepr. 2017. [Google Scholar]
- Sun, J.; Yu, L.; Dong, P.; Lu, B.; Zhou, B. Adversarial inverse reinforcement learning with self-attention dynamics model. IEEE Robot. Autom. Lett., 2021. [Google Scholar]
- Venuto, D.; Chakravorty, J.; Boussioux, L.; Wang, J.; McCracken, G.; Precup, D. OIRL: Robust adversarial inverse reinforcement learning with temporally extended actions. ArXiv Prepr., 2020. [Google Scholar]
- Arnob, S. Y. Off-policy adversarial inverse reinforcement learning. ArXiv Prepr., 2020. [Google Scholar]
- Zhan, M.; Fan, J.; Guo, J. Generative adversarial inverse reinforcement learning with deep deterministic policy gradient. IEEE Access, 2023. [Google Scholar]
- Yuan, M.; Pun, M.-O.; Chen, Y.; Cao, Q. Hybrid adversarial inverse reinforcement learning. ArXiv Prepr. 2021. [Google Scholar]
- Wang, P.; Liu, D.; Chen, J.; Chan, C.-Y. Adversarial inverse reinforcement learning for decision making in autonomous driving. ArXiv Prepr., 2019. [Google Scholar]
- Wang, P.; Liu, D.; Chen, J.; Han-han, L.; Chan, C.-Y. Human-like decision making for autonomous driving via adversarial inverse reinforcement learning. ArXiv Prepr., 2019. [Google Scholar]
- Wang, P.; Liu, D.; Chen, J.; Li, H.; Chan, C.-Y. Decision making for autonomous driving via augmented adversarial inverse reinforcement learning. ArXiv Prepr., 2019. [Google Scholar]
- Yu, L.; Song, J.; Ermon, S. Multi-agent adversarial inverse reinforcement learning. ArXiv Prepr. 2019. [Google Scholar]
- Pattanayak, K.; Krishnamurthy, V.; Berry, C. Inverse-inverse reinforcement learning: How to hide strategy from an adversarial inverse reinforcement learner. In Proceedings of the IEEE Conference on Decision and Control (CDC), 2022. [Google Scholar]
- Chen, J.; Lan, T.; Aggarwal, V. Hierarchical adversarial inverse reinforcement learning. In IEEE Trans. Neural Netw. Learn. Syst.; 2023. [Google Scholar]
- Xiang, G.; Li, S.; Shuang, F.; Gao, F.; Yuan, X. SC-AIRL: Share-critic in adversarial inverse reinforcement learning for long-horizon tasks. IEEE Robot. Autom. Lett., 2024. [Google Scholar]
- Zhu, L. DRL-RNP: Deep Reinforcement Learning-Based Optimized RNP Flight Procedure Execution. Sensors 2022, vol. 22(no. 17). [Google Scholar] [CrossRef] [PubMed]
- Sun, H; Zhang, W; Yu, R; Zhang, Y. “Motion planning for mobile robots—Focusing on deep reinforcement learning: A systematic review”. IEEE Access 2021, 9, 69061–81. [Google Scholar] [CrossRef]
- Richter, D. J.; Calix, R. A. QPlane: An Open-Source Reinforcement Learning Toolkit for Autonomous Fixed Wing Aircraft Simulation. In in Proceedings of the 12th ACM Multimedia Systems Conference, in MMSys ’21, New York, NY, USA, Sept. 2021; Association for Computing Machinery; pp. 261–266. [Google Scholar] [CrossRef]
- Wang, W.; Ma, J. A review: Applications of machine learning and deep learning in aerospace engineering and aero-engine engineering. Adv. Eng. Innov. 2024, vol. 6, 54–72. [Google Scholar] [CrossRef]
- Hu, Z. Deep Reinforcement Learning Approach with Multiple Experience Pools for UAV’s Autonomous Motion Planning in Complex Unknown Environments. Sensors 2020, vol. 20(no. 7). [Google Scholar] [CrossRef] [PubMed]
- Neto, E. C. P. Deep Learning in Air Traffic Management (ATM): A Survey on Applications, Opportunities, and Open Challenges. Aerospace 2023, vol. 10(no. 4). [Google Scholar] [CrossRef]
- Hu, J.; Yang, X.; Wang, W.; Wei, P.; Ying, L.; Liu, Y. Obstacle Avoidance for UAS in Continuous Action Space Using Deep Reinforcement Learning. IEEE Access 2022, vol. 10, 90623–90634. [Google Scholar] [CrossRef]
- Ali, H.; Pham, D.-T.; Alam, S.; Schultz, M. A Deep Reinforcement Learning Approach for Airport Departure Metering Under Spatial–Temporal Airside Interactions. IEEE Trans. Intell. Transp. Syst. 2022, vol. 23(no. 12), 23933–23950. [Google Scholar] [CrossRef]
- Choi, J. Modular Reinforcement Learning for Autonomous UAV Flight Control. Drones 2023, vol. 7(no. 7). [Google Scholar] [CrossRef]
- Chronis, C.; Anagnostopoulos, G.; Politi, E.; Dimitrakopoulos, G.; Varlamis, I. Dynamic Navigation in Unconstrained Environments Using Reinforcement Learning Algorithms. IEEE Access 2023, vol. 11, 117984–118001. [Google Scholar] [CrossRef]
- Wada, D.; Araujo-Estrada, S. A.; Windsor, S.; Wada, D.; Araujo-Estrada, S. A.; Windsor, S. Unmanned Aerial Vehicle Pitch Control under Delay Using Deep Reinforcement Learning with Continuous Action in Wind Tunnel Test. Aerospace 2021, vol. 8(no. 9). [Google Scholar] [CrossRef]
- Azar, A.T.; Koubaa, A.; Ali Mohamed, N.; Ibrahim, H.A.; Ibrahim, Z.F.; Kazim, M.; Ammar, A.; Benjdira, B.; Khamis, A.M.; Hameed, I.A.; Casalino, G. “Drone deep reinforcement learning: A review”. Electronics 2021, 10(9), 999. [Google Scholar] [CrossRef]
- Lou, J. Real-Time On-the-Fly Motion Planning for Urban Air Mobility via Updating Tree Data of Sampling-Based Algorithms Using Neural Network Inference. Aerospace 2024, vol. 11(no. 1). [Google Scholar] [CrossRef]
- Zhu, H. Inverse Reinforcement Learning-Based Fire-Control Command Calculation of an Unmanned Autonomous Helicopter Using Swarm Intelligence Demonstration. Aerospace 2023, vol. 10(no. 3). [Google Scholar] [CrossRef]
- Brunke, L.; Greeff, M.; Hall, A.W.; Yuan, Z.; Zhou, S.; Panerati, J.; Schoellig, A.P. Safe learning in robotics: From learning-based control to safe reinforcement learning. Annual Review of Control, Robotics, and Autonomous Systems 2022, 5(1), 411–444. [Google Scholar] [CrossRef]
- Alipour, E.; Malaek, S. “Learning Capable Aircraft (LCA): an Efficient Approach to Enhance Flight-Safety,” under review.
- WMO Codes Registry : wmdr/DataFormat/FM-15-metar. 05 Jan 2026. Available online: https://codes.wmo.int/wmdr/DataFormat/FM-15-metar.
- Iowa Environmental Mesonet. 05 Jan 2026. Available online: https://mesonet.agron.iastate.edu/cgi-bin/request/asos.py.
- Climate trends and projections for Guam | U.S. Geological Survey. 05 Jan 2026. Available online: https://www.usgs.gov/publications/climate-trends-and-projections-guam.
- Advisory Circular No.:150-5300-13A; Airport Design, Updates to the standards for Taxiway Fillet Design. FAA, 2014.
- Freedman, D.; Diaconis, P. On the histogram as a density estimator: L2 theory. Z. Für Wahrscheinlichkeitstheorie Verwandte Geb. 1981, vol. 57(no. 4), 453–476. [Google Scholar]
- Fu, J.; Luo, K.; Levine, S. Learning robust rewards with adversarial inverse reinforcement learning. In Proceedings of the 6th International Conference on Learning Representations (ICLR), 2018. [Google Scholar]
- Ng, Y.; Harada, D.; Russell, S. Policy Invariance under Reward Transformations: Theory and Application to Reward Shaping. In Proceedings of the 16th International Conference on Machine Learning (ICML), 1999; Morgan Kaufmann; pp. 278–287. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. ArXiv Prepr. ArXiv170706347, 2017. [Google Scholar]
- Aircraft Characteristics Database | Federal Aviation Administration. 31 Dec 2025. Available online: https://www.faa.gov/airports/engineering/aircraft_char_database.
- Use of Aircraft Approach Category During Instrument Approach Operations. FAA, 01/09/2023.
Figure 1.
Approaches to Guam Airport Located at 13.48° N, 144.80° E: (a) 2D view; (b) 3D view.
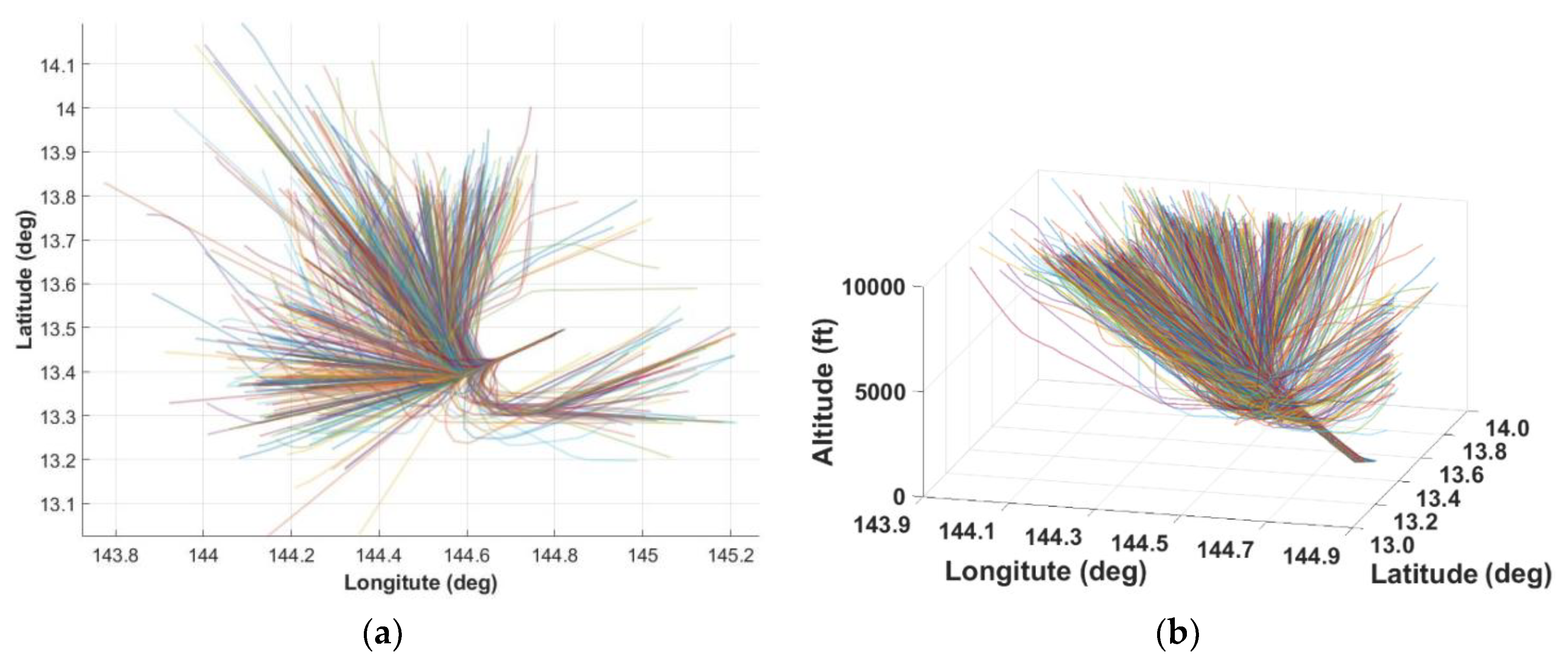
Figure 2.
PGUM meteorological summary for 2025 (RWY 06L). Monthly precipitation totals, RWY 06L crosswind component (P10 - P50 - P90), and monthly median relative humidity for PGUM in 2025, with dry (Jan-Jun) and rainy (Jul-Dec) seasons indicated.
Figure 2.
PGUM meteorological summary for 2025 (RWY 06L). Monthly precipitation totals, RWY 06L crosswind component (P10 - P50 - P90), and monthly median relative humidity for PGUM in 2025, with dry (Jan-Jun) and rainy (Jul-Dec) seasons indicated.
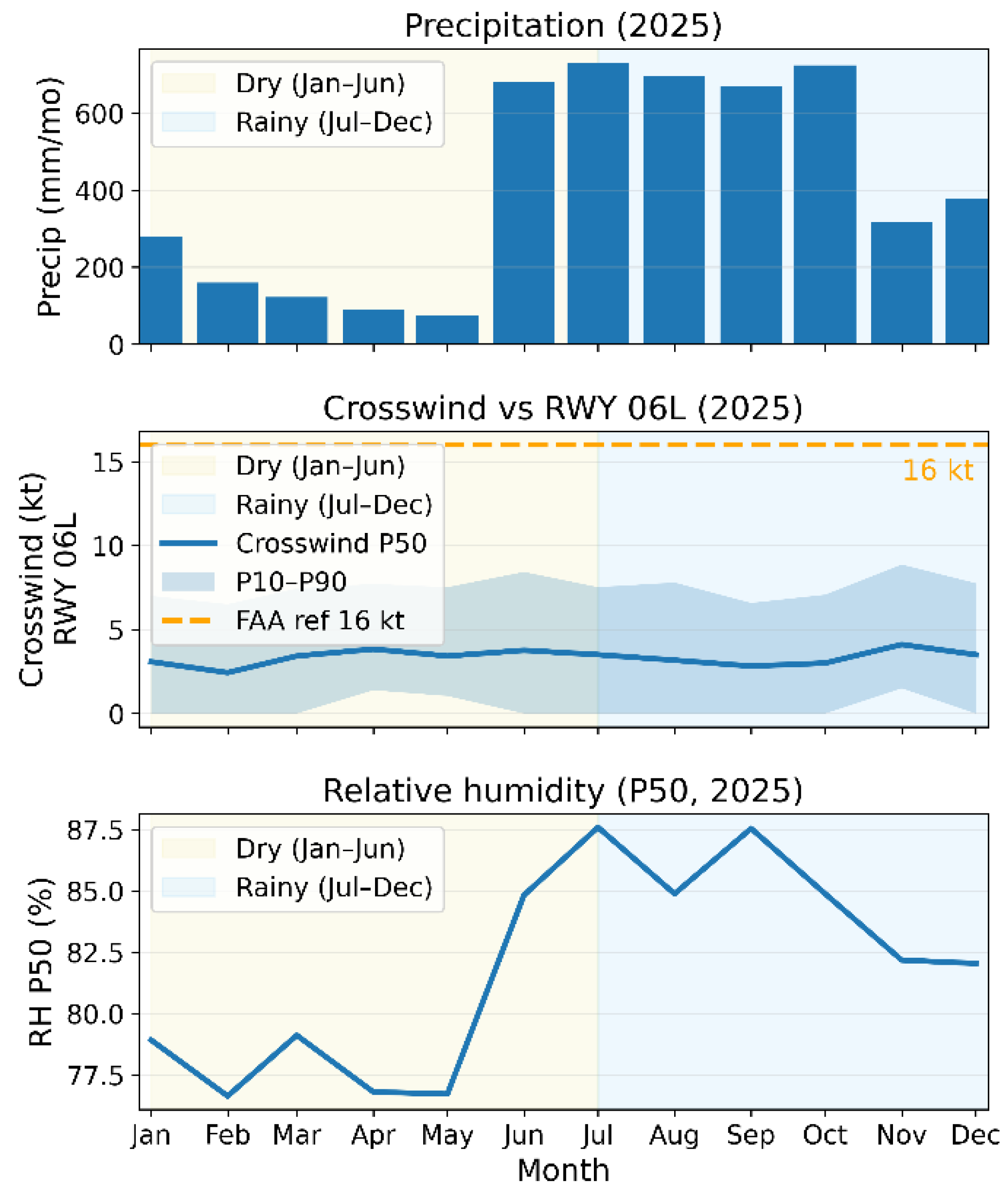
Figure 3.
AIRL Stage.
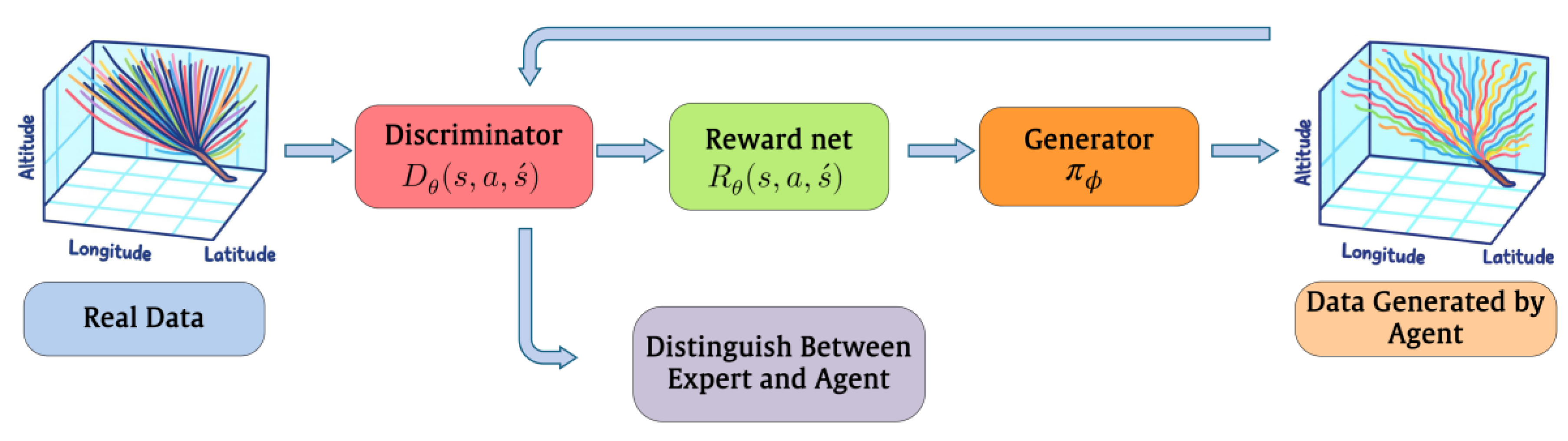
Figure 4.
PILOT (Policy Inference from Logged Operational Trajectories) framework for Robust Aircraft Approach Guidance.
Figure 4.
PILOT (Policy Inference from Logged Operational Trajectories) framework for Robust Aircraft Approach Guidance.
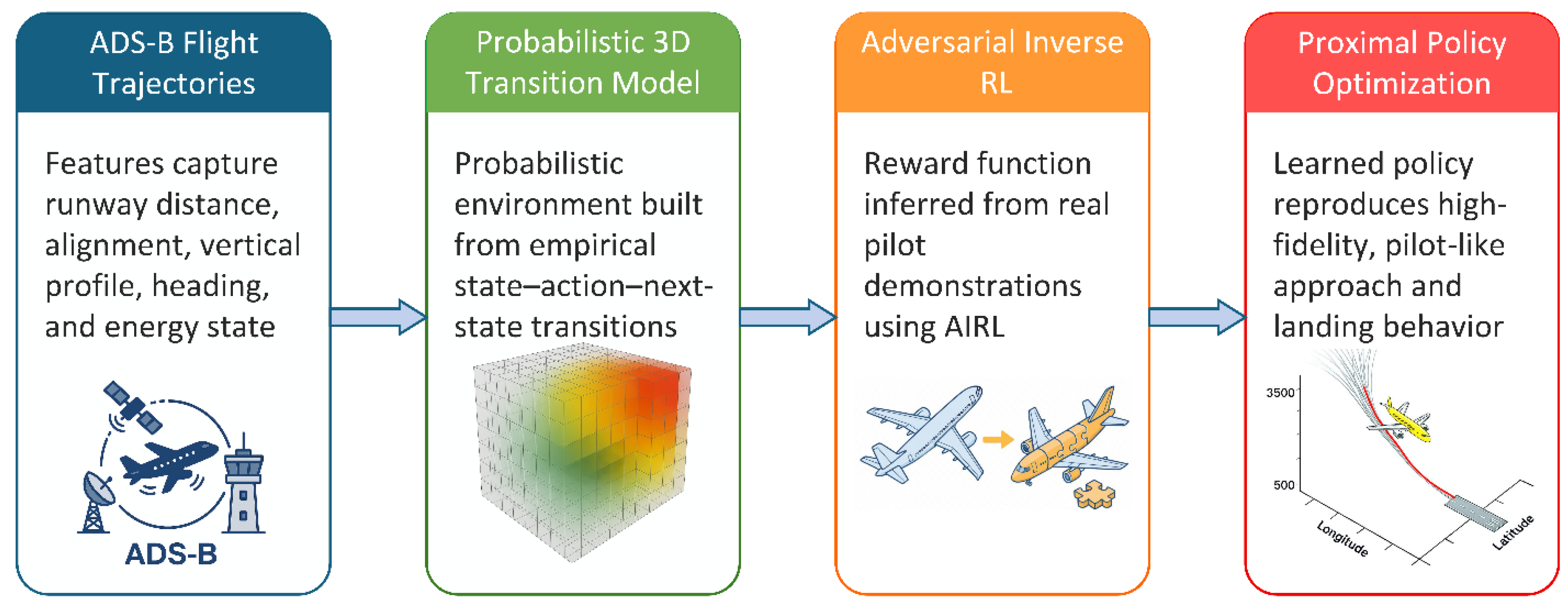
Figure 5.
Comparison of Agent and Expert approach profiles versus distance to runway threshold D (NM): (a) altitude (ft); (b) speed (Kt); (c) glide slope (ft/NM); and (d) vertical speed (fpm); (e) latitude (deg); (f) longitude (deg). Solid lines show the mean, and shaded bands indicate the range.
Figure 5.
Comparison of Agent and Expert approach profiles versus distance to runway threshold D (NM): (a) altitude (ft); (b) speed (Kt); (c) glide slope (ft/NM); and (d) vertical speed (fpm); (e) latitude (deg); (f) longitude (deg). Solid lines show the mean, and shaded bands indicate the range.
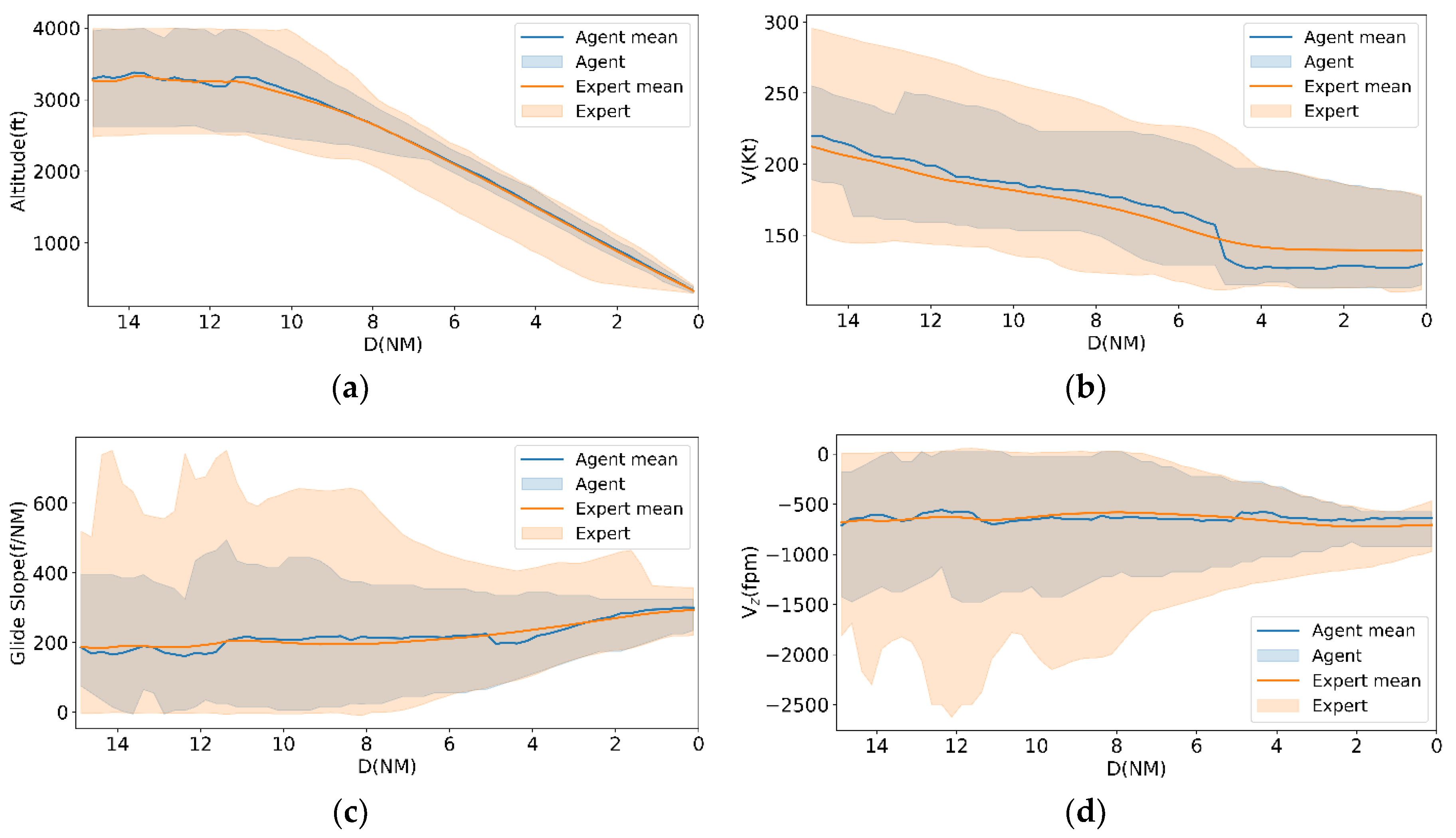
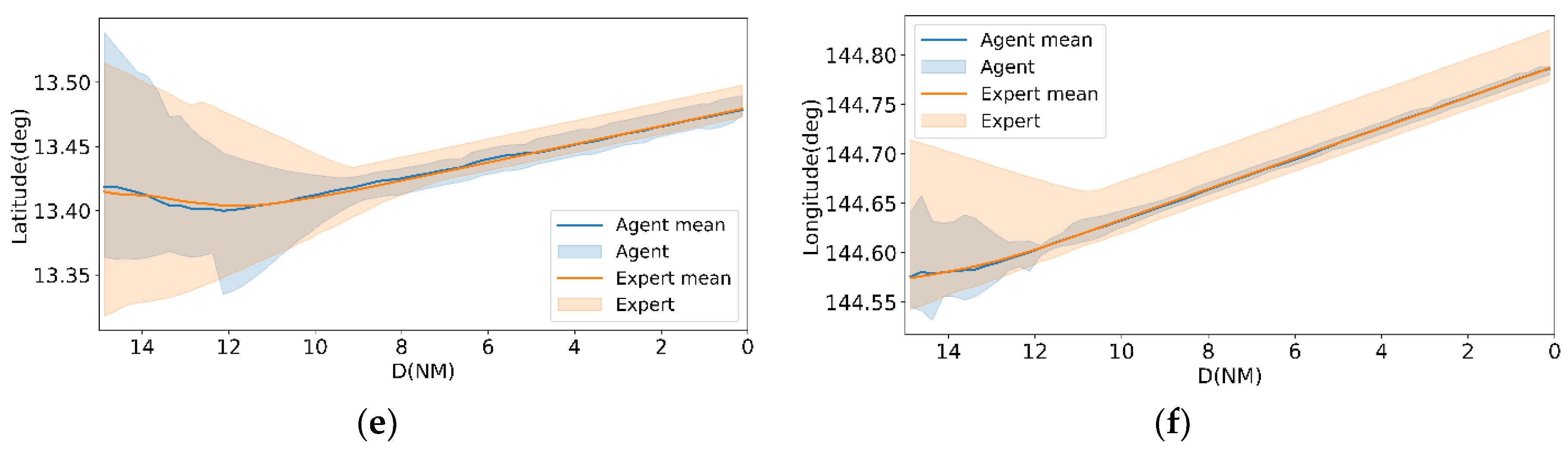
Figure 6.
Expert trajectories (gray) overlaid with randomly sampled trajectories generated by the learned policy (from Supplementary Animation S1).
Figure 6.
Expert trajectories (gray) overlaid with randomly sampled trajectories generated by the learned policy (from Supplementary Animation S1).
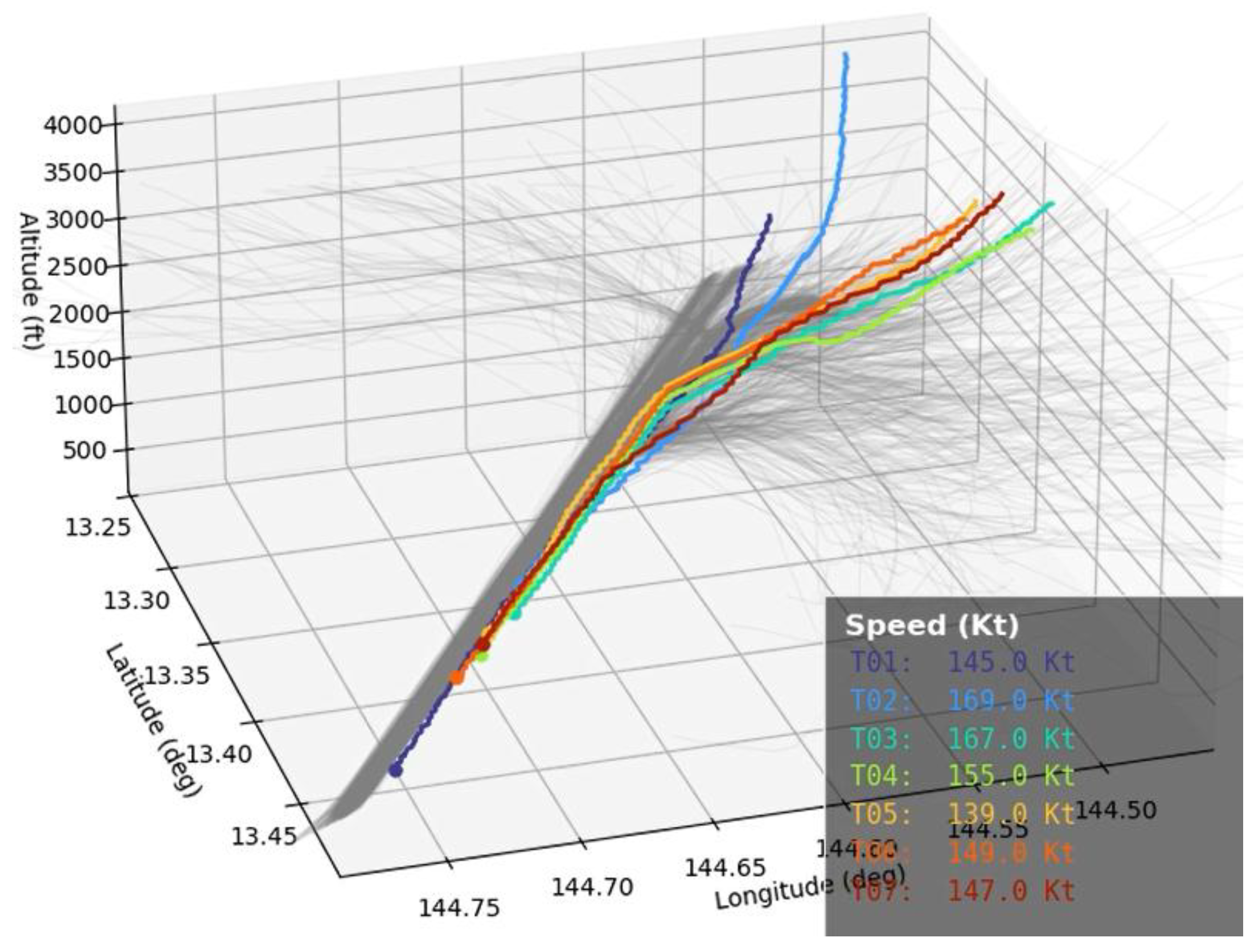

Table 1.
Flight Dataset Summary for Guam International Airport (PGUM).
| No. | Airplane Type | Number of Flights | Number of Airplanes of this Type |
|---|---|---|---|
| 1 | Airbus A321-271N (A21N) | 56 | 15 |
| 2 | Boeing 767-346-ER (B763) | 91 | 9 |
| 3 | Boeing 737-8K5 (B738) | 384 | 34 |
| 4 | Airbus A330-200 (A332) | 1 | 1 |
| 5 | Airbus A330-322 (A333) | 18 | 10 |
| 6 | Boeing 777-2B5-ER (B772) | 31 | 5 |
| 7 | Boeing 777-3B5 (B773) | 66 | 4 |
| 8 | Boeing 777-3B5-ER (B77W) | 91 | 33 |
| 9 | Boeing 787-9 Dreamliner (B789) | 22 | 8 |
| 10 | Boeing 757-230(PCF) (B752) | 64 | 3 |
| 11 | Airbus A321-231 (A321) | 109 | 19 |
| 12 | Boeing 737 MAX 8 (B38M) | 106 | 2 |
| Total | 1039 | 142 |
Table 2.
State variables and final discretization widths.
| Symbol | Description | Unit | BIN Width (h) |
|---|---|---|---|
| D | Distance to touchdown | NM | 0.05 |
| XTE | Cross-track error | NM | 0.015 |
| H | Altitude | ft | 5 |
| V | Airspeed | kt | 2 |
| Vertical speed | fpm | 50 | |
| G/S | Glide Slope | ft/NM | 10 |
| Heading error | deg | 1 | |
| Heading rate | deg/s | 0.1 | |
| ft | 70 |
Table 3.
Training configuration for AIRL and R-PPO stages.
| Parameter | AIRL (Reward Inference) | R-PPO (Policy Optimization) | Description |
|---|---|---|---|
| Learning rate | 3 × 10⁻⁴ | 3 × 10⁻⁴ | Adam optimizer learning rate |
| n _steps (per update) | 2048 | 2048 | Number of environment steps before each PPO update |
| Batch size | 64 | 64 | Minibatch size for gradient updates |
| PPO epochs | 5 | 10 | Gradient passes per batch |
| Discount factor (γ) | 0.995 | 0.99 | Temporal discounting constant |
| GAE λ | 0.97 | 0.95 | Generalized Advantage Estimation factor |
| Target KL | 0.02 | 0.03 | Early-stop threshold on policy KL (Kullback–Leibler divergence) |
| Entropy coefficient | 0.01 | 0.01 | Exploration regularization term |
| Max gradient norm | 0.5 | 0.5 | Gradient clipping threshold |
| Discriminator updates per round | 2 | — | AIRL discriminator optimization steps |
Table 4.
Representative landing reference speed
| No. | Airplane Type (ICAO Code) | @ MLW (kt IAS) [38] | |
|---|---|---|---|
| 1 | Airbus A321-271N (A21N) | 136 | 104.6 |
| 2 | Boeing 767-346-ER (B763) | 140 | 107.7 |
| 3 | Boeing 737-8K5 (B738) | 144 | 110.8 |
| 4 | Airbus A330-200 (A332) | 136 | 104.6 |
| 5 | Airbus A330-322 (A333) | 137 | 105.4 |
| 6 | Boeing 777-2B5-ER (B772) | 140 | 107.7 |
| 7 | Boeing 777-3B5 (B773) | 149 | 114.6 |
| 8 | Boeing 777-3B5-ER (B77W) | 149 | 114.6 |
| 9 | Boeing 787-9 Dreamliner (B789) | 144 | 110.8 |
| 10 | Boeing 757-230(PCF) (B752) | 137 | 105.4 |
| 11 | Airbus A321-231 (A321) | 142 | 109.2 |
| 12 | Boeing 737 MAX 8 (B38M) | 145 | 111.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



