
Submitted:
01 December 2025
Posted:
02 December 2025
You are already at the latest version
Abstract
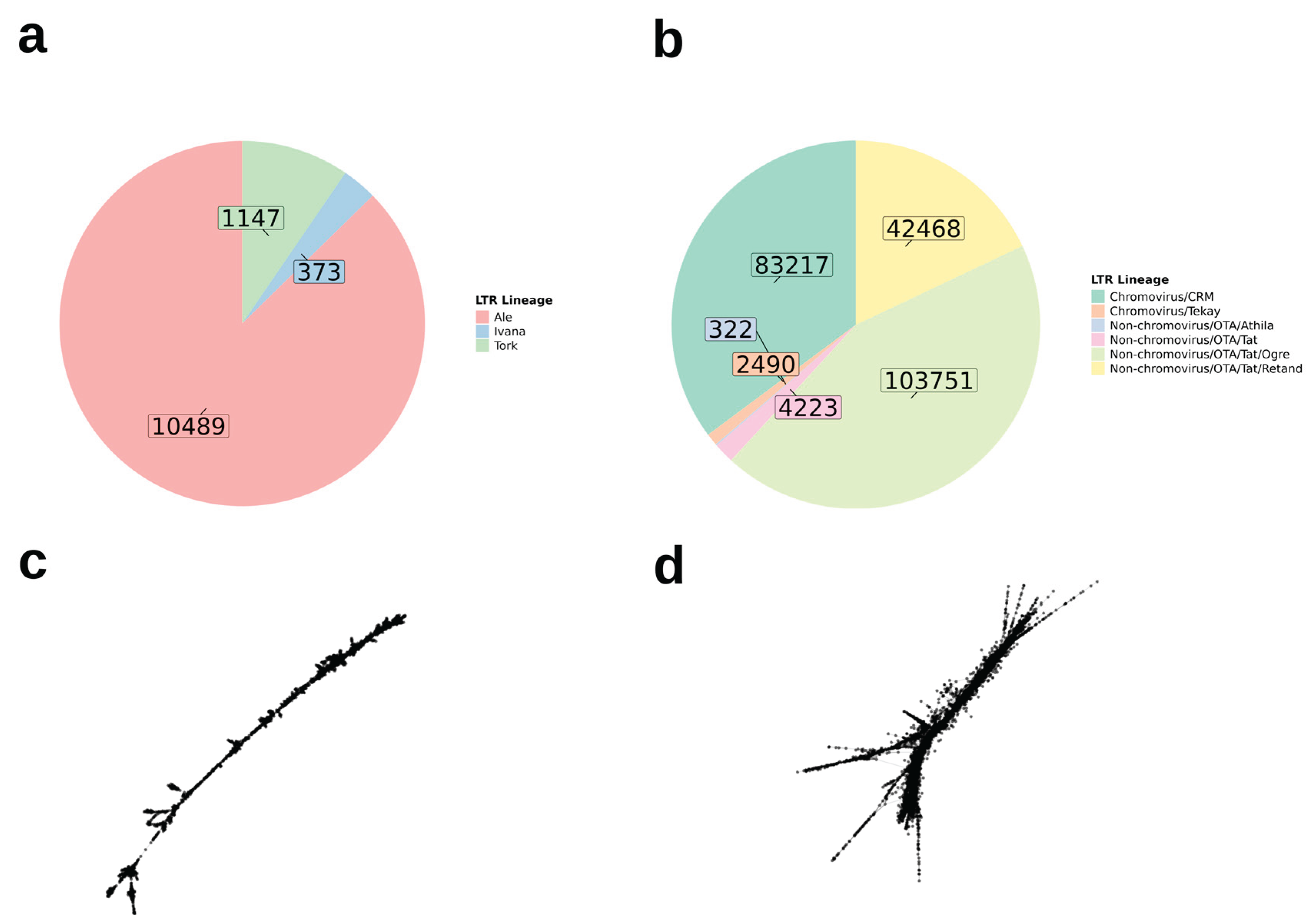
The repeatome is composed of satellite DNA (satDNA) and transposable elements (TEs), and variation in its composition is important for shaping genome architecture and driving evolutionary processes in plants. As no repeatome assessment exists for Epidendrum, the largest genus of Orchidaceae in the Neotropics, we aim to describe repetitive sequences across its species. We performed phylogenetic analyses based on plastid (matK and rbcL) and nuclear (ITS) markers using maximum likelihood and Bayesian inference methods, and characterized the repeatome of 34 species using the RepeatExplorer2 pipeline. Our results reveal substantial variation in satDNA content among species, with a total of 208 individually identified satDNAs, which were used to build a custom database for repeatome comparative analysis. We found that 73 satDNA clusters are shared among species, while only three are species-specific (CL359 and CL82 in E. rigidum, and CL430 in E. gasteriferum), supporting the library hypothesis. Regarding TEs, Class I elements were the most abundant repeats identified in Epidendrum, primarily long terminal repeat retrotransposons of the Ty3-gypsy superfamily. Elements of the Ty1-copia superfamily were the least abundant. Only two Class II TIR superfamilies were identified, namely EnSpm_CACTA and hAT. The heterogeneous distribution of satDNAs and TEs among closely related species suggests lineage-specific patterns of expansion and contraction, potentially influenced by evolutionary processes such as hybridization and environmental adaptation. Our findings represent the first comprehensive characterization of the repeatome in Epidendrum and provide a basis for future studies on the composition and cytogenomic variation within the mega-genus.
Keywords:
1. Introduction
2. Materials and Methods
2.1. Sequencing Data Collection
2.2. Phylogenetic Analysis
2.3. Preprocessing of Sequencing Reads
2.4. Individual Characterization of Epidendrum Species Repeatome Using RepeatExplorer2 and Construction of a Satellite DNA Database
2.5. Comparative Analysis of the Repeatome Composition in Epidendrum
3. Results
3.1. Phylogeny of Epidendrum
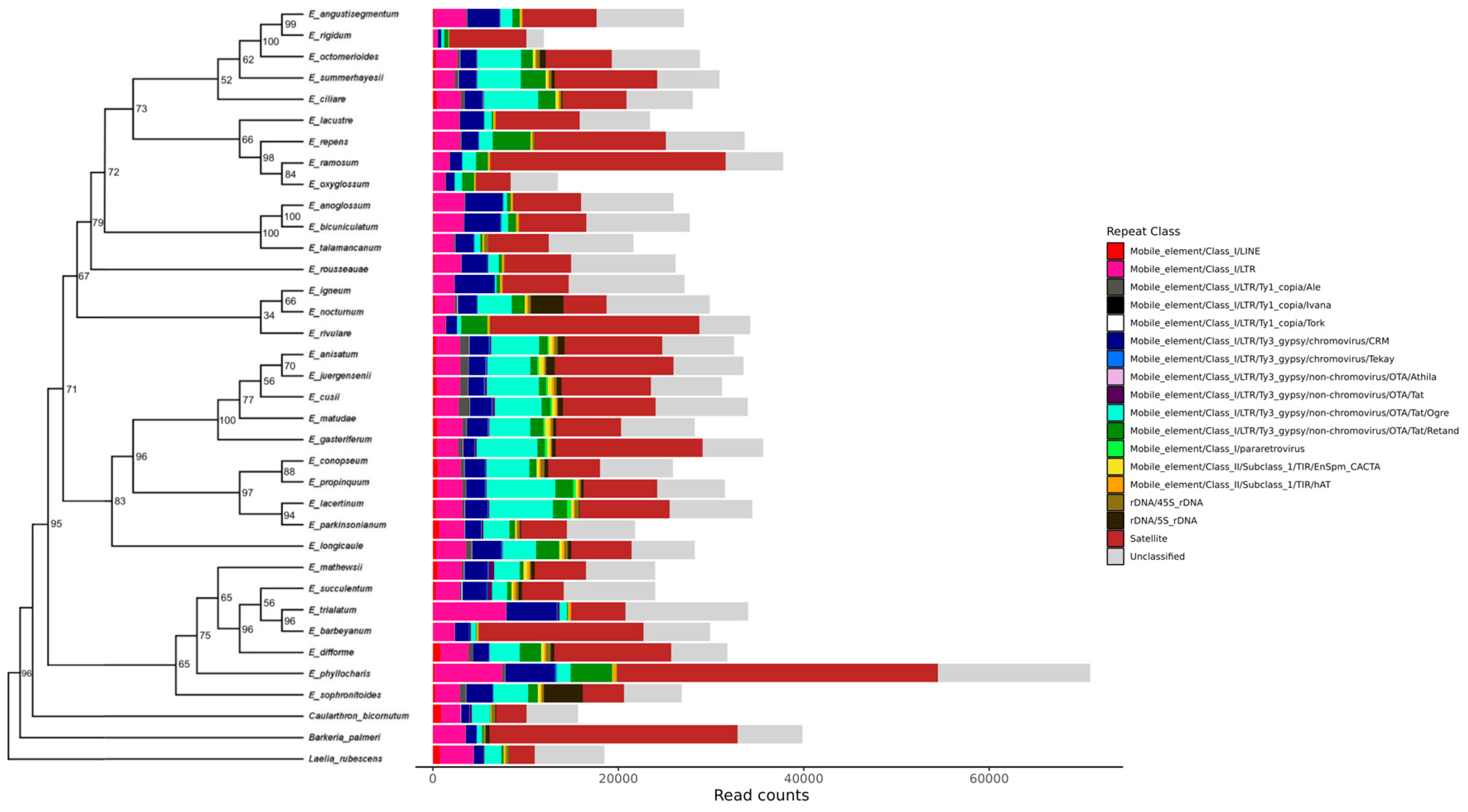
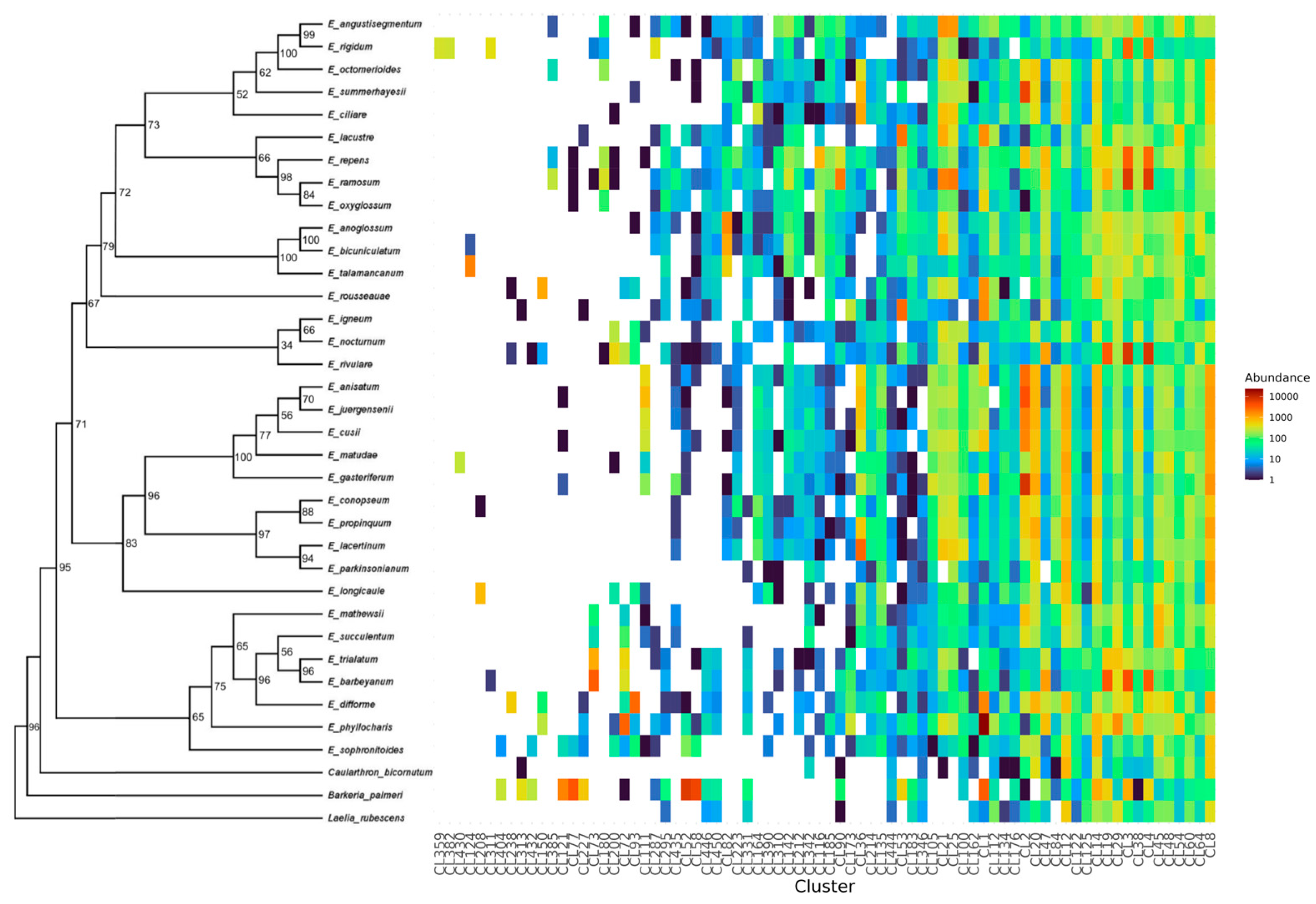
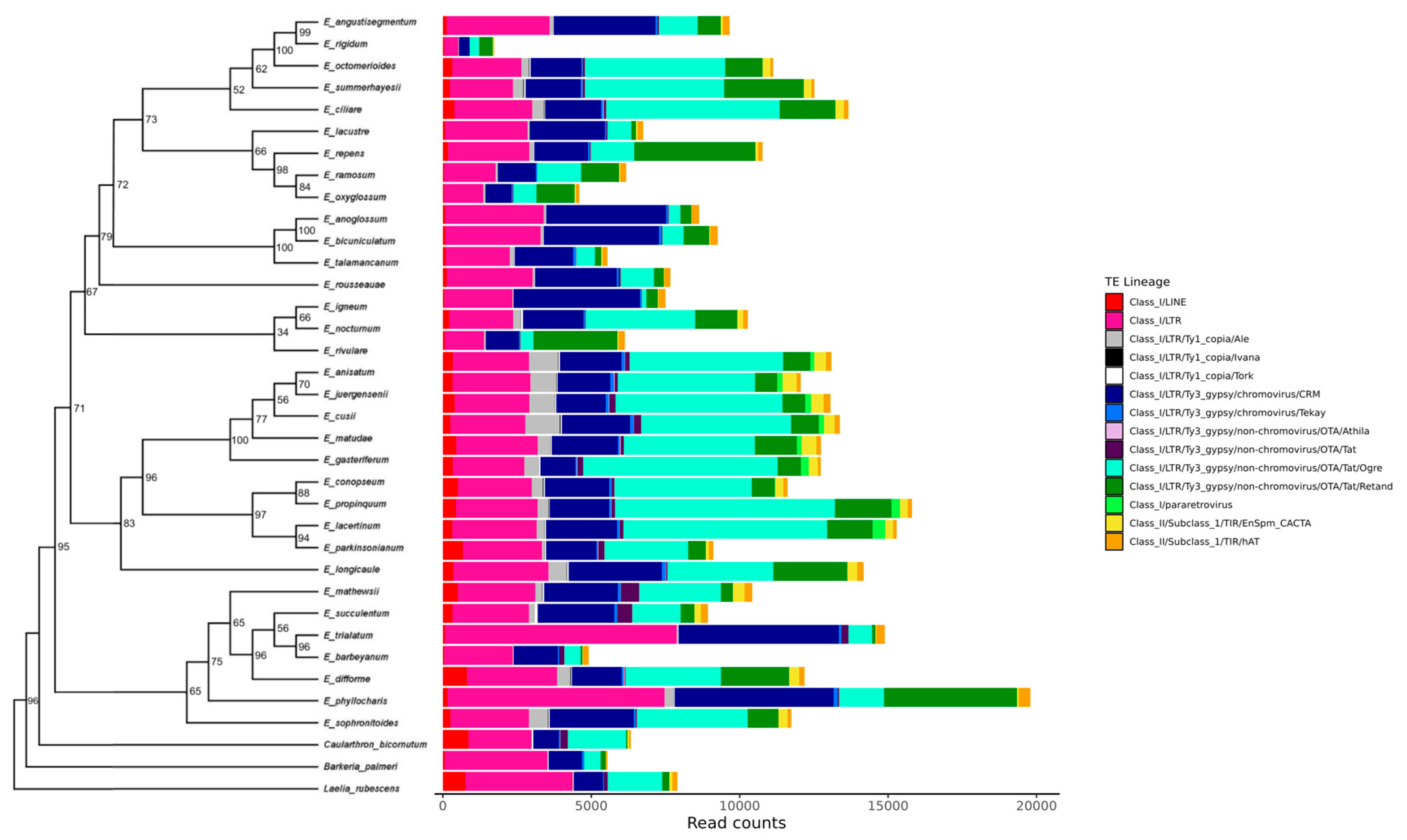
3.2. Individual and Comparative Analysis of Repeatome Composition in Epidendrum
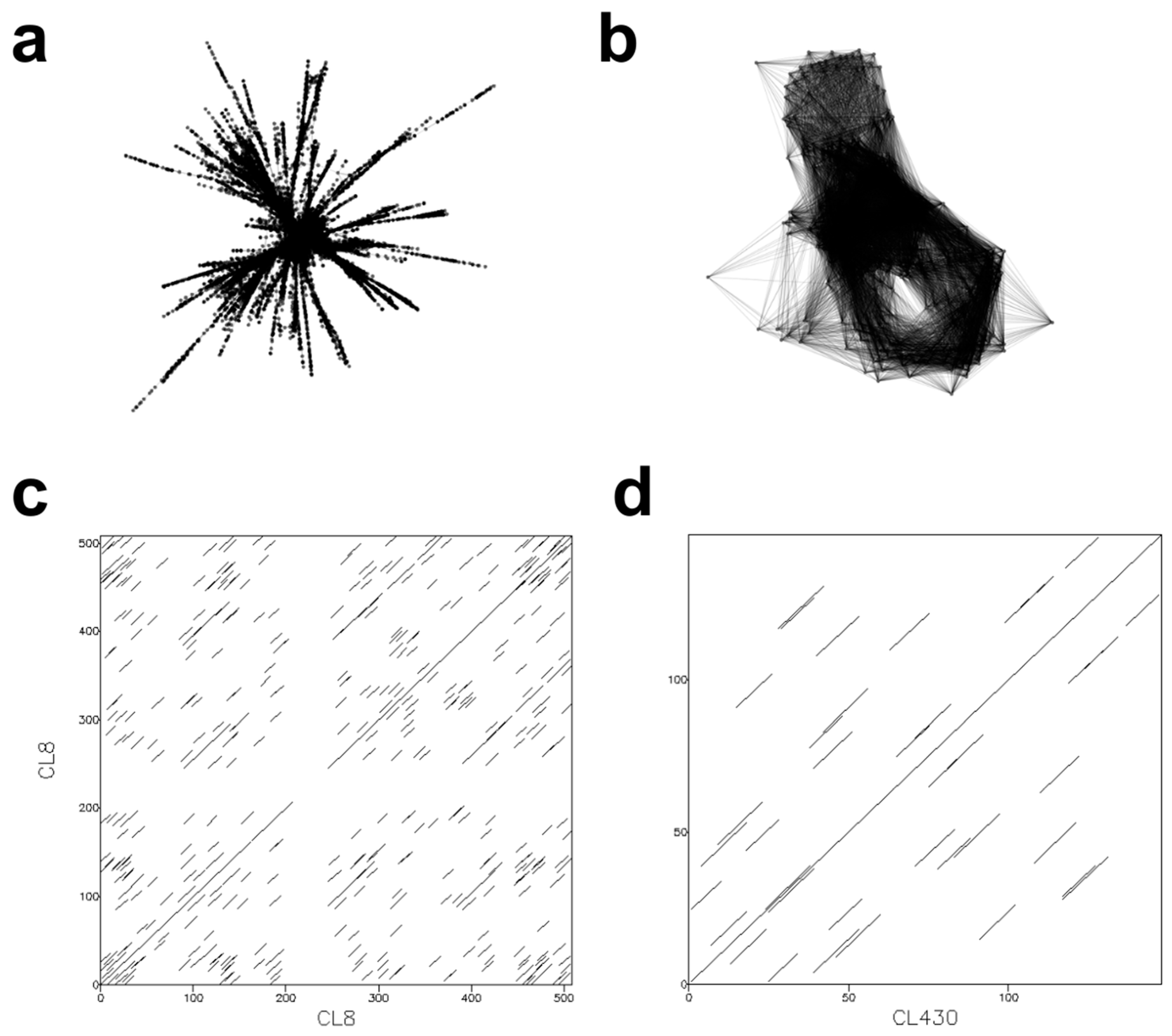
3.3. Characterization of Satellite DNA Composition in Epidendrum
3.4. Characterization of Transposable Element Composition in Epidendrum
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wendel, J.F.; Jackson, S.A.; Meyers, B.C.; Wing, R.A. Evolution of plant genome architecture. Genome Biol. 2016, 17, 1–14. [Google Scholar] [CrossRef]
- Mehrotra, S.; Goyal, V. Repetitive sequences in plant nuclear DNA: types, distribution, evolution and function. Genomics Proteomics Bioinformatics 2014, 12, 164–1711. [Google Scholar] [CrossRef]
- Todd, R.T.; Forche, A.; Selmecki, A. Ploidy variation in fungi: polyploidy, aneuploidy, and genome evolution. Microbiol. Spectr. 2017, 5, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Hannan, A.J. Tandem repeat polymorphisms. In Tandem Repeat Polymorphisms; Hannan, A.J., Ed.; Springer: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Kim, Y.B.; Oh, J.H.; McIver, L.J.; Rashkovetsky, E.; Michalak, K.; Garner, H.R.; Kang, L.; Nevo, E.; Korol, A.B.; Michalak, P. Divergence of Drosophila melanogaster repeatomes in response to a sharp microclimate contrast in Evolution Canyon, Israel. Proc. Natl. Acad. Sci. USA 2014, 111, 10630–10635. [Google Scholar] [CrossRef] [PubMed]
- Treangen, T.J.; Salzberg, S.L. Repetitive DNA and next-generation sequencing: Computational challenges and solutions. Nat. Rev. Genet. 2012, 13, 36–46. [Google Scholar] [CrossRef]
- Lee, S.I.; Kim, N.S. Transposable elements and genome size variations in plants. Genomics Inform. 2014, 12, 87–97. [Google Scholar] [CrossRef]
- Garrido-Ramos, M.A. Satellite DNA: An evolving topic. Genes 2017, 8, 1–41. [Google Scholar] [CrossRef]
- Wicker, T.; Sabot, F.; Hua-Van, A.; Bennetzen, J.L.; Capy, P.; Chalhoub, B.; Flavell, A.; Leroy, P.; Morgante, M.; Panaud, O.; Paux, E.; SanMiguel, P.; Schulman, A.H. A unified classification system for eukaryotic transposable elements. Nat. Rev. Genet. 2007, 8, 973–982. [Google Scholar] [CrossRef]
- Pulido, M.; Casacuberta, J.M. Transposable element evolution in plant genome ecosystems. Curr. Opin. Plant Biol. 2023, 75, 1–8. [Google Scholar] [CrossRef]
- Bourque, G.; Burns, K.H.; Gehring, M.; Gorbunova, V.; Seluanov, A.; Hammell, M.; Feschotte, C.; et al. Ten things you should know about transposable elements. Genome Biol. 2018, 19, 1–12. [Google Scholar] [CrossRef]
- Galindo-González, L.; Mhiri, C.; Deyholos, M.K.; Grandbastien, M.A. LTR-retrotransposons in plants: engines of evolution. Gene 2017, 26, 14–25. [Google Scholar] [CrossRef]
- Pellicer, J.; Hidalgo, O.; Dodsworth, S.; Leitch, I.J. Genome size diversity and its impact on the evolution of land plants. Genes 2018, 9, 1–14. [Google Scholar] [CrossRef]
- Neumann, P.; Novák, P.; Hoštáková, N.; Macas, J. Systematic survey of plant LTR-retrotransposons elucidates phylogenetic relationships of their polyprotein domains and provides a reference for element classification. Mobile DNA 2019, 10, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Wright, D.A.; Voytas, D.F. Athila4 of Arabidopsis and Calypso of soybean define a lineage of endogenous plant retroviruses. Genome Res. 2002, 12, 122–131. [Google Scholar] [CrossRef]
- Llorens, C.; Futami, R.; Covelli, L.; Domínguez-Escribá, L.; Viu, J.M.; Tamarit, D.; Aguilar-Rodríguez, J.; Vicente-Ripolles, M.; Fuster, G.; Bernet, G.P.; Maumus, F.; Munoz-Pomer, A.; Sempere, J.M.; Latorre, A.; Moya, A. The gypsy database (GyDB) of mobile genetic elements: Release 2.0. Nucleic Acids Res. 2011, 39, D70–D74. [Google Scholar] [CrossRef]
- Neumann, P.; Navrátilová, A.; Koblížková, A.; Kejnovský, E.; Hřibová, E.; Hobza, R.; Widmer, A.; Doležel, J.; Macas, J. Plant centromeric retrotransposons: A structural and cytogenetic perspective. Mobile DNA 2011, 2, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Macas, J.; Neumann, P. Ogre elements – a distinct group of plant Ty3/gypsy-like retrotransposons. Gene 2007, 390, 108–116. [Google Scholar] [CrossRef]
- Mascagni, F.; Vangelisti, A.; Giordani, T.; Cavallini, A.; Natali, L. A computational comparative study of the repetitive DNA in the genus Quercus L. Tree Genet. Genomes 2020, 16, 1–11. [Google Scholar] [CrossRef]
- Liu, P.; Cuerda-Gil, D.; Shahid, S.; Slotkin, R.K. The epigenetic control of the transposable element life cycle in plant genomes and beyond. Annu. Rev. Genet. 2022, 56, 63–87. [Google Scholar] [CrossRef]
- Meštrović, N.; Mravinac, B.; Pavlek, M.; Vojvoda-Zeljko, T.; Šatović, E.; Plohl, M. Structural and functional liaisons between transposable elements and satellite DNAs. Chromosome Res. 2015, 23, 583–596. [Google Scholar] [CrossRef]
- Amorim, I.C.; Sotero-Caio, C.G.; Costa, R.G.C.; Xavier, C.; de Moura, R.C. Comprehensive mapping of transposable elements reveals distinct patterns of element accumulation on chromosomes of wild beetles. Chromosome Res. 2021, 29, 203–218. [Google Scholar] [CrossRef]
- Plohl, M.; Meštrović, N.; Mravinac, B. Satellite DNA evolution. Repetitive DNA 2012, 7, 126–152. [Google Scholar] [CrossRef]
- Biscotti, M.A.; Olmo, E.; Heslop-Harrison, J.S. Repetitive DNA in eukaryotic genomes. Chromosome Res. 2015, 23, 415–420. [Google Scholar] [CrossRef] [PubMed]
- Satović, E.; Vojvoda Zeljko, T.; Luchetti, A.; Mantovani, B.; Plohl, M. Adjacent sequences disclose potential for intra-genomic dispersal of satellite DNA repeats and suggest a complex network with transposable elements. BMC Genomics 2016, 17, 1–12. [Google Scholar] [CrossRef]
- Silva, B.S.M.L.; Picorelli, A.C.R.; Kuhn, G.C.S. In silico identification and characterization of satellite DNAs in 23 Drosophila species from the Montium group. Genes 2023, 14, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Wlodzimierz, P.; Rabanal, F.A.; Burns, R.; Naish, M.; Primetis, E.; Scott, A.; Mandáková, T.; Gorringe, N.; Tock, A.J.; Holland, D.; Fritschi, K.; Habring, A.; Lanz, C.; Patel, C.; Schlegel, T.; Collenberg, M.; Mielke, M.; Nordborg, M.; Roux, F.; Henderson, I.R.; et al. Cycles of satellite and transposon evolution in Arabidopsis centromeres. Nature 2023, 618, 557–565. [Google Scholar] [CrossRef]
- Tunjić-Cvitanić, M.; García-Souto, D.; Pasantes, J.J.; Šatović-Vukšić, E. Dominance of transposable element-related satDNAs results in great complexity of “satDNA library” and invokes the extension towards “repetitive DNA library. ” Mar. Life Sci. Technol. 2024, 6, 236–251. [Google Scholar] [CrossRef] [PubMed]
- Macas, J.; Koblížková, A.; Navrátilová, A.; Neumann, P. Hypervariable 3′ UTR region of plant LTR-retrotransposons as a source of novel satellite repeats. Gene 2009, 448, 198–206. [Google Scholar] [CrossRef]
- Šatović-Vukšić, E.; Plohl, M. Satellite DNAs—From localized to highly dispersed genome components. Genes 2023, 14, 1–22. [Google Scholar] [CrossRef]
- Salser, W.; Bowen, S.; Browne, D.; El-Adli, F.; Fedoroff, N.; Fry, K.; Whitcome, P.; et al. Investigation of the organization of mammalian chromosomes at the DNA sequence level. Fed. Proc. 1976, 35, 23–35. [Google Scholar] [PubMed]
- Belyayev, A.; Jandová, M.; Josefiová, J.; Kalendar, R.; Mahelka, V.; Mandák, B.; Krak, K. The major satellite DNA families of the diploid Chenopodium album aggregate species: Arguments for and against the “library hypothesis. ” PLoS ONE 2020, 15, 1–14. [Google Scholar] [CrossRef]
- Palacios-Gimenez, O.M.; Milani, D.; Song, H.; Marti, D.A.; López-León, M.D.; Ruiz-Ruano, F.J.; Camacho, J.P.M.; Cabral-De-Mello, D.C.; O’Neill, R. Eight million years of satellite DNA evolution in grasshoppers of the genus Schistocerca illuminate the ins and outs of the library hypothesis. Genome Biol. Evol. 2020, 12, 88–102. [Google Scholar] [CrossRef]
- Kelly, L.J.; Renny-Byfield, S.; Pellicer, J.; Macas, J.; Novák, P.; Neumann, P.; Lysak, M.A.; Day, P.D.; Berger, M.; Fay, M.F.; Nichols, R.A.; Leitch, A.R.; Leitch, I.J. Analysis of the giant genomes of Fritillaria (Liliaceae) indicates that a lack of DNA removal characterizes extreme expansions in genome size. New Phytol. 2015, 208, 596–607. [Google Scholar] [CrossRef] [PubMed]
- McCann, J.; Macas, J.; Novák, P.; Stuessy, T.F.; Villaseñor, J.L.; Weiss-Schneeweiss, H. Differential genome size and repetitive DNA evolution in diploid species of Melampodium sect. Melampodium (Asteraceae). Front. Plant Sci. 2020, 11, 1–14. [Google Scholar] [CrossRef]
- Pellicer, J.; Fernández, P.; Fay, M.F.; Michálková, E.; Leitch, I.J. Genome size doubling arises from the differential repetitive DNA dynamics in the genus Heloniopsis (Melanthiaceae). Front. Genet. 2021, 12, 1–12. [Google Scholar] [CrossRef]
- Neumann, P.; Oliveira, L.; Čížková, J.; Jang, T.S.; Klemme, S.; Novák, P.; Stelmach, K.; Koblížková, A.; Doležel, J.; Macas, J. Impact of parasitic lifestyle and different types of centromere organization on chromosome and genome evolution in the plant genus Cuscuta. New Phytol. 2021, 229, 2365–2377. [Google Scholar] [CrossRef]
- Schmidt, N.; Sielemann, K.; Breitenbach, S.; Fuchs, J.; Pucker, B.; Weisshaar, B.; Holtgräwe, D.; Heitkam, T. Repeat turnover meets stable chromosomes: repetitive DNA sequences mark speciation and gene pool boundaries in sugar beet and wild beets. Plant J. 2024, 118, 171–190. [Google Scholar] [CrossRef]
- Pinheiro, F.; Cozzolino, S. Epidendrum (Orchidaceae) as a model system for ecological and evolutionary studies in the Neotropics. Taxon 2013, 62, 77–88. [Google Scholar] [CrossRef]
- Moraes, A.P.; Chinaglia, M.; Palma-Silva, C.; Pinheiro, F. Interploidy hybridization in sympatric zones: The formation of Epidendrum fulgens × E. puniceoluteum hybrids (Epidendroideae, Orchidaceae). Ecol. Evol. 2013, 3, 3824–3837. [Google Scholar] [CrossRef] [PubMed]
- Marques, I.; Draper, D.; Riofrío, L.; Naranjo, C. Multiple hybridization events, polyploidy and low postmating isolation entangle the evolution of neotropical species of Epidendrum (Orchidaceae). BMC Evol. Biol. 2014, 14, 1–14. [Google Scholar] [CrossRef]
- Karremans, A.P. With great biodiversity comes great responsibility: The underestimated diversity of Epidendrum (Orchidaceae). Harv. Pap. Bot. 2021, 26, 299–369. [Google Scholar] [CrossRef]
- Zhao, Z.; Zeng, M.Y.; Wu, Y.W.; Li, J.W.; Zhou, Z.; Liu, Z.J.; Li, M.H. Characterization and comparative analysis of the complete plastomes of five Epidendrum species. Int. J. Mol. Sci. 2023, 24, 1–14. [Google Scholar] [CrossRef]
- Nollet, F.; Medeiros Neto, E.; Cordeiro, J.M.; Buril, M.T.; Chase, M.W.; Felix, L.P. Chromosome numbers and heterochromatin variation in introgressed and non-introgressed populations of Epidendrum: Interspecific transfers of heterochromatin lead to divergent variable karyotypes. Bot. J. Linn. Soc. 2022, 199, 694–705. [Google Scholar] [CrossRef]
- Pinheiro, F.; Koehler, S.; Corrêa, A.M.; Salatino, M.L.F.; Salatino, A.; de Barros, F. Phylogenetic relationships and infrageneric classification of Epidendrum subgenus Amphiglottium. Plant Syst. Evol. 2009, 283, 165–177. [Google Scholar] [CrossRef]
- Felix, L.P.; Guerra, M. Variation in chromosome number and the basic number of subfamily Epidendroideae (Orchidaceae). Bot. J. Linn. Soc. 2010, 163, 234–278. [Google Scholar] [CrossRef]
- Trávníček, P.; Ponert, J.; Urfus, T.; Jersáková, J.; Vrána, J.; Hřibová, E.; Suda, J. Challenges of flow-cytometric estimation of nuclear genome size in orchids. Cytometry A 2015, 87, 958–966. [Google Scholar] [CrossRef]
- Assis, F. N. M. D. (2013). Mecanismos de evolução cariotípica em Epidendrum L. (Orchidaceae: Epidendroideae). Ph.D. Thesis, Federal University of Paraíba, Brazil, 2013. [Google Scholar]
- Cordeiro, J.M.; Chase, M.W.; Hágsater, E.; Almeida, E.M.; Costa, L.; Souza, G.; et al. Chromosome number, heterochromatin, and genome size support recent polyploid origin of the Epidendrum nocturnum group and reveal a new species. Botany 2022, 100, 409–421. [Google Scholar] [CrossRef]
- Cordeiro, J.M.P. Citotaxonomia do gênero neotropical Epidendrum L. (Laeliinae, Orchidaceae). Ph.D. Thesis, Universidade Federal da Paraíba, 2019. Available online at https://repositorio.ufpb. 1234. [Google Scholar]
- Novák, P.; Neumann, P.; Macas, J. Global analysis of repetitive DNA from unassembled sequence reads using RepeatExplorer2. Nat. Protoc. 2020, 15, 3745–3776. [Google Scholar] [CrossRef]
- Johnson, M.G.; Pokorny, L.; Dodsworth, S.; Botigué, L.R.; Cowan, R.S.; Devault, A.; Eiserhardt, W.L.; Epitawalage, N.; Forest, F.; Kim, J.T.; Leebens-Mack, J.H.; Leitch, I.J.; Maurin, O.; Soltis, D.E.; Soltis, P.S.; Wong, G.K.S.; Baker, W.J.; Wickett, N.J. A universal probe set for targeted sequencing of 353 nuclear genes from any flowering plant designed using k-Medoids clustering. Syst. Biol. 2019, 68, 594–606. [Google Scholar] [CrossRef]
- Costa, L.; Marques, A.; Buddenhagen, C.; Thomas, W.; Huettel, B.; Schubert, V.; Dodsworth, S.; Houben, A.; Souza, G.; Pedrosa-Harand, A. Aiming off the target: recycling target capture sequencing reads for investigating repetitive DNA. Ann. Bot. 2021, 128, 835–848. [Google Scholar] [CrossRef]
- Granados Mendoza, C.; Jost, M.; Hágsater, E.; Magallón, S.; van den Berg, C.; Lemmon, E.M.; Wanke, S.; et al. Target nuclear and off-target plastid hybrid enrichment data inform a range of evolutionary depths in the orchid genus Epidendrum. Front. Plant Sci. 2020, 10, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Kuraku, S.; Zmasek, C.M.; Nishimura, O.; Katoh, K. aLeaves facilitates on-demand exploration of metazoan gene family trees on MAFFT sequence alignment server with enhanced interactivity. Nucleic Acids Res. 2013, 41, W22–W28. [Google Scholar] [CrossRef] [PubMed]
- Katoh, K.; Rozewicki, J.; Yamada, K.D. MAFFT online service: multiple sequence alignment, interactive sequence choice and visualization. Brief. Bioinform. 2019, 20, 1160–1166. [Google Scholar] [CrossRef]
- Capella-Gutiérrez, S.; Silla-Martínez, J.M.; Gabaldón, T. trimAl: a tool for automated alignment trimming in large-scale phylogenetic analyses. Bioinformatics 2009, 25, 1972–1973. [Google Scholar] [CrossRef]
- Kalyaanamoorthy, S.; Minh, B.Q.; Wong, T.K.; Von Haeseler, A.; Jermiin, L.S. ModelFinder: fast model selection for accurate phylogenetic estimates. Nat. Methods 2017, 14, 587–589. [Google Scholar] [CrossRef]
- Schliep, K.P. phangorn: phylogenetic analysis in R. Bioinformatics 2011, 27, 592–593. [Google Scholar] [CrossRef]
- RStudio Team. RStudio: Integrated Development for R. RStudio, PBC, Boston, MA, 2020. http://www.rstudio.
- Trifinopoulos, J.; Nguyen, L.T.; von Haeseler, A.; Minh, B.Q. W-IQ-TREE: a fast online phylogenetic tool for maximum likelihood analysis. Nucleic Acids Res. 2016, 44, W232–W235. [Google Scholar] [CrossRef]
- Minh, B.Q.; Nguyen, M.A.T.; von Haeseler, A. Ultrafast approximation for phylogenetic bootstrap. Mol. Biol. Evol. 2013, 30, 1188–1195. [Google Scholar] [CrossRef]
- Ronquist, F.; Teslenko, M.; van der Mark, P.; Ayres, D.L.; Darling, A.; Höhna, S.; Huelsenbeck, J.P.; et al. MrBayes 3.2: efficient Bayesian phylogenetic inference and model choice across a large model space. Syst. Biol. 2012, 61, 539–542. [Google Scholar] [CrossRef]
- Cummings, M.P.; Handley, S.A.; Myers, D.S.; Reed, D.L.; Rokas, A.; Winka, K. Comparing bootstrap and posterior probability values in the four-taxon case. Syst. Biol. 2003, 52, 477–487. [Google Scholar] [CrossRef] [PubMed]
- Simmons, M.P.; Pickett, K.M.; Miya, M. How meaningful are Bayesian support values? Mol. Biol. Evol. 2004, 21, 188–199. [Google Scholar] [CrossRef]
- Baranow, P.; Rojek, J.; Dudek, M.; Szlachetko, D.; Bohdanowicz, J.; Kapusta, M.; Moraes, A.P.; et al. Chromosome number and genome size evolution in Brasolia and Sobralia (Sobralieae, Orchidaceae). Int. J. Mol. Sci. 2022, 23, 1–17. [Google Scholar] [CrossRef]
- Revell, L.J. phytools: an R package for phylogenetic comparative biology (and other things). Methods Ecol. Evol. 2012, 2, 217–223. [Google Scholar] [CrossRef]
- Andrews, S. FastQC: a quality control tool for high throughput sequence data. 2010. Available online at http://www.bioinformatics.babraham.ac.
- Novák, P.; Robledillo, L.Á.; Koblížková, A.; Vrbová, I.; Neumann, P.; Macas, J. TAREAN: A computational tool for identification and characterization of satellite DNA from unassembled short reads. Nucleic Acids Res. 2017, 45, 1–10. [Google Scholar] [CrossRef]
- Novák, P.; Neumann, P.; Macas, J. Graph-based clustering and characterization of repetitive sequences in next-generation sequencing data. BMC Bioinformatics 2010, 11, 1–12. [Google Scholar] [CrossRef]
- Madeira, F.; Madhusoodanan, N.; Lee, J.; Eusebi, A.; Niewielska, A.; Tivey, A.R.; Butcher, S.; et al. The EMBL-EBI Job Dispatcher sequence analysis tools framework in 2024. Nucleic Acids Res. 2024, 52, W521–W525. [Google Scholar] [CrossRef] [PubMed]
- Ibiapino, A.; Báez, M.; García, M.A.; Costea, M.; Stefanović, S.; Pedrosa-Harand, A. Karyotype asymmetry in Cuscuta L. subgenus Pachystigma reflects its repeat DNA composition. Chromosome Res. 2022, 30, 91–107. [Google Scholar] [CrossRef]
- Ruiz-Ruano, F.J.; López-León, M.D.; Cabrero, J.; Camacho, J.P.M. High-throughput analysis of the satellitome illuminates satellite DNA evolution. Sci. Rep. 2016, 6, 1–14. [Google Scholar] [CrossRef] [PubMed]
- GBIF.org. GBIF Occurrence Download; 05 September 2025. Available online at https://doi.org/10.15468/dl.5skaxx. 05 September.
- Ferree, P.M.; Prasad, S. How can satellite DNA divergence cause reproductive isolation? Let us count the chromosomal ways. Genet. Res. Int. 2012, 2012, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Thakur, J.; Packiaraj, J.; Henikoff, S. Sequence, chromatin and evolution of satellite DNA. Int. J. Mol. Sci. 2021, 22, 1–28. [Google Scholar] [CrossRef]
- De Lima, L.G.; Ruiz-Ruano, F.J. In-depth satellitome analyses of 37 Drosophila species illuminate repetitive DNA evolution in the Drosophila genus. Genome Biol. Evol. 2022, 14, 1–19. [Google Scholar] [CrossRef]
- Peona, V.; Kutschera, V.E.; Blom, M.P.K.; Irestedt, M.; Suh, A. Satellite DNA evolution in Corvoidea inferred from short and long reads. Mol. Ecol. 2023, 32, 1288–1305. [Google Scholar] [CrossRef]
- Kuo, Y.T.; Ishii, T.; Fuchs, J.; Hsieh, W.H.; Houben, A.; Lin, Y.R. The evolutionary dynamics of repetitive DNA and its impact on genome diversification in the genus Sorghum. Front. Plant Sci. 2021, 12, 1–16. [Google Scholar] [CrossRef]
- Costa, G.C.; Almeida, C. Identification of differential abundance of satellite DNA sequences in Asclepias (Apocynaceae): in-depth characterization of species-specific sequences. Plant Syst. Evol. 2022, 308, 1–7. [Google Scholar] [CrossRef]
- Han, Y.; Qin, S.; Wessler, S.R. Comparison of class 2 transposable elements at superfamily resolution reveals conserved and distinct features in cereal grass genomes. BMC Genom. 2013, 14, 1–10. [Google Scholar] [CrossRef] [PubMed]
- González, L.G.; Deyholos, M.K. Identification, characterization and distribution of transposable elements in the flax (Linum usitatissimum L.) genome. BMC Genom. 2012, 13, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Sader, M.; Vaio, M.; Cauz-Santos, L.A.; Dornelas, M.C.; Vieira, M.L.C.; Melo, N.; Pedrosa-Harand, A. Large vs small genomes in Passiflora: the influence of the mobilome and the satellitome. Planta 2021, 253, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Nascimento, J.; Sader, M.; Ribeiro, T.; Pedrosa-Harand, A. Influence of Ty3/gypsy and Ty1/copia LTR-retrotransposons on the large genomes of Alstroemeriaceae: genome landscape of Bomarea edulis (Tussac) Herb. Protoplasma 2025, 262, 881–894. [Google Scholar] [CrossRef]
- Kumar, A.; Bennetzen, J.L. Plant retrotransposons. Annu. Rev. Genet. 1999, 33, 479–532. [Google Scholar] [CrossRef]
- Kawakami, T.; Strakosh, S.C.; Zhen, Y.; Ungerer, M.C. Different scales of Ty1/copia-like retrotransposon proliferation in the genomes of three diploid hybrid sunflower species. Heredity 2010, 104, 341–350. [Google Scholar] [CrossRef]
- Huang, S.; Li, R.; Zhang, Z.; Li, L.; Gu, X.; Fan, W.; Lucas, W.J.; Wang, X.; Xie, B.; Ni, P.; Ren, Y.; Zhu, H.; Li, J.; Lin, K.; Jin, W.; Fei, Z.; Li, G.; Staub, J.; Kilian, A.; Li, S.; et al. The genome of the cucumber, Cucumis sativus L. Nat. Genet. 2009, 41, 1275–1281. [Google Scholar] [CrossRef]
- Arida, B.L.; Scopece, G.; Machado, R.M.; Moraes, A.P.; Forni-Martins, E.; Pinheiro, F. Reproductive barriers and fertility of two neotropical orchid species and their natural hybrid. Evol. Ecol. 2021, 35, 41–64. [Google Scholar] [CrossRef]
- McClintock, B. The significance of responses of the genome to challenge. Science 1984, 226, 792–801. [Google Scholar] [CrossRef]
- Chénais, B.; Caruso, A.; Hiard, S.; Casse, N. The impact of transposable elements on eukaryotic genomes: from genome size increase to genetic adaptation to stressful environments. Gene 2012, 509, 7–15. [Google Scholar] [CrossRef] [PubMed]
- De Storme, N.; Mason, A. Plant speciation through chromosome instability and ploidy change: cellular mechanisms, molecular factors and evolutionary relevance. Curr. Plant Biol. 2014, 1, 10–33. [Google Scholar] [CrossRef]
- Gantuz, M.; Morales, A.; Bertoldi, M.V.; Ibañez, V.N.; Duarte, P.F.; Marfil, C.F.; Masuelli, R.W. Hybridization and polyploidization effects on LTR-retrotransposon activation in potato genome. J. Plant Res. 2022, 135, 81–92. [Google Scholar] [CrossRef] [PubMed]
- Hlavatá, K.; Záveská, E.; Leong-Škorničková, J.; Pouch, M.; Poulsen, A.D.; Šída, O.; Fér, T.; et al. Ancient hybridization and repetitive element proliferation in the evolutionary history of the monocot genus Amomum (Zingiberaceae). Front. Plant Sci. 2024, 15, 1324358. [Google Scholar] [CrossRef]
- Hágsater, E.; Soto-Arenas, M.Á. L. In Genera Orchidacearum, 2nd ed.; Pridgeon, A.M., Cribb, P.J., Chase, M.W., Rasmussen, F.N., Eds.; Oxford University Press: Oxford, UK, 2005; Volume 4, pp. 236–251. [Google Scholar]
- Patwardhan, A.; Ray, S.; Roy, A. Molecular markers in phylogenetic studies: a review. J. Phylogenet. Evol. Biol. 2014, 2, 131. [Google Scholar] [CrossRef]
- Macías-Hernández, N.; Domènech, M.; Cardoso, P.; Emerson, B.; Borges, P.; Lozano-Fernandez, J.; Paulo, O.; Vieira, A.; Enguídanos, A.; Rigal, F.; Amorim, I.; Arnedo, M. Building a robust, densely-sampled spider tree of life for ecosystem research. Diversity 2020, 12, 1–23. [Google Scholar] [CrossRef]
- Luebert, F.; Scherson, R. Choice of molecular marker influences spatial patterns of phylogenetic diversity. Biol. Lett. 2024, 20, 1–6. [Google Scholar] [CrossRef]
- Castro, N.; Vilela, B.; Mata-Sucre, Y.; Marques, A.; Gagnon, E.; Lewis, G.P.; Souza, G.; et al. Repeatome evolution across space and time: Unravelling repeats dynamics in the plant genus Erythrostemon Klotzsch (Leguminosae Juss.). Mol. Ecol. 2024, e17510, 1–18. [Google Scholar] [CrossRef] [PubMed]

| NCBI ID | Species | Prefix |
|---|---|---|
| ERX7192163 | Epidendrum angustisegmentum (L.O.Williams) Hágsater | Eang |
| SRX7133951 | Epidendrum anisatum La Llave & Lex. | Eani |
| SRX22571358 | Epidendrum anoglossum Schltr. | Eano |
| SRX22571359 | Epidendrum barbeyanum Kraenzl. | Ebar |
| SRX22571360 | Epidendrum bicuniculatum Hágsater & E.Santiago | Ebic |
| SRX7133952 | Epidendrum ciliare L. | Ecil |
| SRX7133937 | Epidendrum conopseum R. Br | Econ |
| SRX7133953 | Epidendrum cusii Hágsater | Ecus |
| ERX7193246 | Epidendrum difforme Jacq. | Edif |
| SRX7133954 | Epidendrum gasteriferum Scheeren | Egas |
| SRX22571361 | Epidendrum igneum Hágsater | Eign |
| SRX7133955 | Epidendrum juergensenii Rchb.f. | Ejue |
| SRX7133935 | Epidendrum lacertinum Lindl. | Elac |
| SRX22571362 | Epidendrum lacustre Lindley | Elau |
| SRX7133936 | Epidendrum longicaule (L.O. Williams) L.O. Williams | Elon |
| SRX7133938 | Epidendrum matthewsii Rchb.f | Emah |
| SRX7133939 | Epidendrum matudae L.O.Williams | Emau |
| ERX7193247 | Epidendrum nocturnum Jacq. | Enoc |
| ERX7193201 | Epidendrum nora-mesae Hágsater & O.Pérez | Enor |
| SRX7133941 | Epidendrum octomerioides Schltr. | Eoct |
| SRX22544933 | Epidendrum oxyglossum Schltr. | Eoxy |
| SRX7133942 | Epidendrum parkinsonianum Hooker | Epar |
| SRX22571363 | Epidendrum phyllocharis Rchb.f. | Ephy |
| SRX7133943 | Epidendrum propinquum A. Rich. & Galeotti | Epro |
| ERX7193248 | Epidendrum ramosum Jacq. | Eram |
| ERX7193250 | Epidendrum repens Cogn. | Erep |
| ERX7193245 | Epidendrum rigidum Jacq. | Erig |
| ERX7193249 | Epidendrum rivulare Lindl. | Eriv |
| SRX22571365 | Epidendrum rousseauae Schltr. | Erou |
| SRX7133944 | Epidendrum sophronitoides F. Lehm. & Kraenzl. | Esop |
| SRX7133946 | Epidendrum succulentum Hágsater | Esuc |
| SRX7133947 | Epidendrum summerhayesii Hágsater | Esum |
| ERX7193031 | Epidendrum talamancanum (J.T.Atwood) Mora-Ret. & García Castro | Etal |
| SRX7133948 | Epidendrum trialatum Hágsater | Etri |
| Species | No. of shared satDNA clusters | Total satDNA abundance (%) | Total reads analysed in RE2 |
|---|---|---|---|
| E. angustisegmentum | 55 | 29.39 | 64,728 |
| E. anisatum | 50 | 32.38 | 65,012 |
| E. anoglossum | 54 | 28.06 | 64,350 |
| E. barbeyanum | 47 | 17.28 | 64,175 |
| E. bicuniculatum | 52 | 26.10 | 64,664 |
| E. ciliare | 48 | 24.54 | 64,766 |
| E. conopseum | 50 | 44.44 | 64,592 |
| E. cusii | 46 | 30.90 | 64,106 |
| E. difforme | 47 | 59.22 | 64,346 |
| E. gasteriferum | 47 | 24.82 | 64,446 |
| E. igneum | 47 | 26.15 | 64,690 |
| E. juergensenii | 45 | 38.17 | 65,008 |
| E. lacertinum | 47 | 25.20 | 64,416 |
| E. lacustre | 49 | 38.64 | 64,990 |
| E. longicaule | 37 | 22.69 | 64,640 |
| E. mathewsii | 44 | 22.98 | 64,566 |
| E. matudae | 50 | 29.41 | 65,036 |
| E. nocturnum | 48 | 15.56 | 65,484 |
| E. nora-mesae | 51 | 39.68 | 64,272 |
| E. octomerioides | 51 | 24.70 | 64,870 |
| E. oxyglossum | 53 | 27.53 | 35,926 |
| E. parkinsonianum | 47 | 28.17 | 65,092 |
| E. phyllocharis | 52 | 48.76 | 129,334 |
| E. propinquum | 47 | 21.64 | 64,664 |
| E. ramosum | 58 | 67.18 | 64,820 |
| E. repens | 56 | 41.89 | 64,834 |
| E. rigidum | 50 | 69.03 | 65,004 |
| E. rivulare | 54 | 65.81 | 65,026 |
| E. rousseauae | 49 | 27.29 | 65,378 |
| E. sophronitoides | 51 | 16.57 | 64,814 |
| E. succulentum | 42 | 23.07 | 64,600 |
| E. summerhayesii | 46 | 35.72 | 64,924 |
| E. talamancanum | 49 | 30.20 | 64,266 |
| E. trialatum | 43 | 18.75 | 64,452 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



