Submitted:
19 August 2025
Posted:
20 August 2025
You are already at the latest version
Abstract
Manipulator path and trajectory planning is a significant aspect of robotics that involves defining an optimal trajectory for the manipulator to move from a starting position to a target position while avoiding obstacles and minimizing latency factors such as time, energy, or jerk. This process typically involves algorithms that analyze the manipulator’s kinematic and dynamic constraints, including workspace object geometry and environmental obstacles, to generate a collision-free and efficient trajectory. Common techniques include sampling-based methods like Rapidly-exploring Random Trees (RRT) or Probabilistic Roadmaps (PRM), optimization-based approaches, and artificial potential fields that treat obstacles as repulsive forces and goals as attractive forces. Advanced path planning may also incorporate machine learning for adaptive navigation in dynamic environments. The goal is to ensure smooth, precise, and safe motion. Efficient path planning enhances performance, reduces wear and tear, and ensures operational reliability.
Keywords:
trajectory optimization
; federated learning (FL)
; distributed multi-robotic arms
; cooperative manipulation
; real-time planning
1. Introduction
1.1. Background
Robotic manipulators have become indispensable in modern industrial automation, performing complex tasks such as assembly, welding, and material handling with high precision. However, as industries increasingly adopt multi-robotic systems for collaborative operations, optimizing their trajectories in shared workspaces presents significant challenges.
1.2. Significance of This Problem
A critical limitation in multi-robotic systems is the need for centralized control, which often requires sharing raw sensor data among manipulators, raising concerns about data privacy and communication overhead. Federated Learning (FL) offers a promising solution by enabling decentralized model training, where manipulators collaboratively optimize trajectories without exchanging raw data [1]. Instead, local updates from reinforcement learning (RL) agents are aggregated into a global model, preserving privacy while improving adaptability [2].
1.3. Adopted Methods
Traditional trajectory planning methods, such as Rapidly-exploring Random Trees (RRT) and Probabilistic Roadmaps (PRM), focus on single-robot systems and often struggle with dynamic environments, real-time coordination, and computational efficiency when scaled to multiple robots [3]. Moreover, ensuring collision-free motion while maintaining synchronization and minimizing latency factors remains an open research problem.
1.4. Shortcomings of Existing Methods
However, implementing FL in multi-robotic trajectory optimization introduces challenges such as handling heterogeneous manipulator configurations, maintaining synchronization in dynamic environments, and balancing communication efficiency with real-time performance.
1.5. Optimization Contribution
This paper proposes a Federated Learning-based framework for distributed multi-robotic arm trajectory optimization, addressing these challenges through a hybrid approach combining FL with sampling-based motion planning. Our contributions include:
- A privacy-preserving FL architecture where robots train shared trajectory models locally and contribute only gradient updates, eliminating the need for raw data exchange.
- An adaptive RRT algorithm enhanced with pruning optimization to reduce computational overhead while ensuring collision-free paths in dynamic environments.
- Real-time synchronization via EtherCAT, ensuring precise coordination among manipulators with minimal latency [4].
- Integration of multi-sensor fusion such as vision, encoders, force feedback for robust object localization and trajectory adaptation.
Our experiments demonstrate that the proposed framework achieves superior trajectory efficiency, collision avoidance, and scalability compared to centralized and standalone RL approaches. Applications span industrial assembly lines, surgical robotics, and warehouse automation, where collaborative manipulation in constrained spaces is critical. The simulations have undergone significant revisions to improve clarity, technical depth, and organization. The algorithms were restructured to concisely present the core goal of optimizing multi-robotic arm trajectories using federated learning (FL) while preserving data privacy, along with key challenges like synchronization in dynamic environments and handling heterogeneous robot configurations. The introduction was substantially expanded to provide stronger motivation for the work, clearly outlining the limitations of existing centralized approaches and explaining how FL enables collaborative learning without raw data exchange [5]. A dedicated contributions subsection was added to highlight the paper’s novel elements, including the FL-based optimization framework, adaptive RRT algorithm with pruning optimization, and real-time synchronization through EtherCAT.
Technical sections were enhanced with deeper explanations of the federated learning architecture, particularly how local reinforcement learning updates are securely aggregated into a global model [6,7]. The trajectory optimization methodology now includes more detailed discussions of sampling-based techniques like RRT and PRM, with emphasis on the improved adaptive RRT algorithm that incorporates dynamic pruning to reduce computational overhead.
2. Synchronization of Multiple Manipulators
Synchronization of multiple manipulators is challenging task in bin picking. a perfect synchronization can assure accuracy. It’s quite difficult but precise coordination can enhance the working speed and work ability. This process involves a central controller to control and manage manipulator simultaneously through Ethercat [8,9,10]. Where precision also required to make sure exact positioning and multiple tasks can perform at same time by distributing approaches where individual controller can communicate in real time by Ethercat.
Adding encoder for the feedback to controller to assure the close loop communication. Multiple manipulators connected together symmetrically and performing action on same time required path planning and strong RRT algorithm. Central unit is responsible for decision making and precise control to avoid collision. When its shared space It also required the communication of multiple manipulators at the same time and advanced algorithm compute synchronization of RRT trajectories.
Figure 1.
Coordinated Control Synchronizing Multiple Manipulators Using (a) Controller (PID, MPC), (b) Feedback Controller for Stability, and (c) Visualization for Real-Time Monitoring. The system integrates (a) controllers (PID for precision, MPC for predictive optimization), (b) feedback controllers to correct deviations via encoder data, and (c) visualization tools RRT path plots, state trajectories to enhance operational transparency and debugging.
Figure 1.
Coordinated Control Synchronizing Multiple Manipulators Using (a) Controller (PID, MPC), (b) Feedback Controller for Stability, and (c) Visualization for Real-Time Monitoring. The system integrates (a) controllers (PID for precision, MPC for predictive optimization), (b) feedback controllers to correct deviations via encoder data, and (c) visualization tools RRT path plots, state trajectories to enhance operational transparency and debugging.
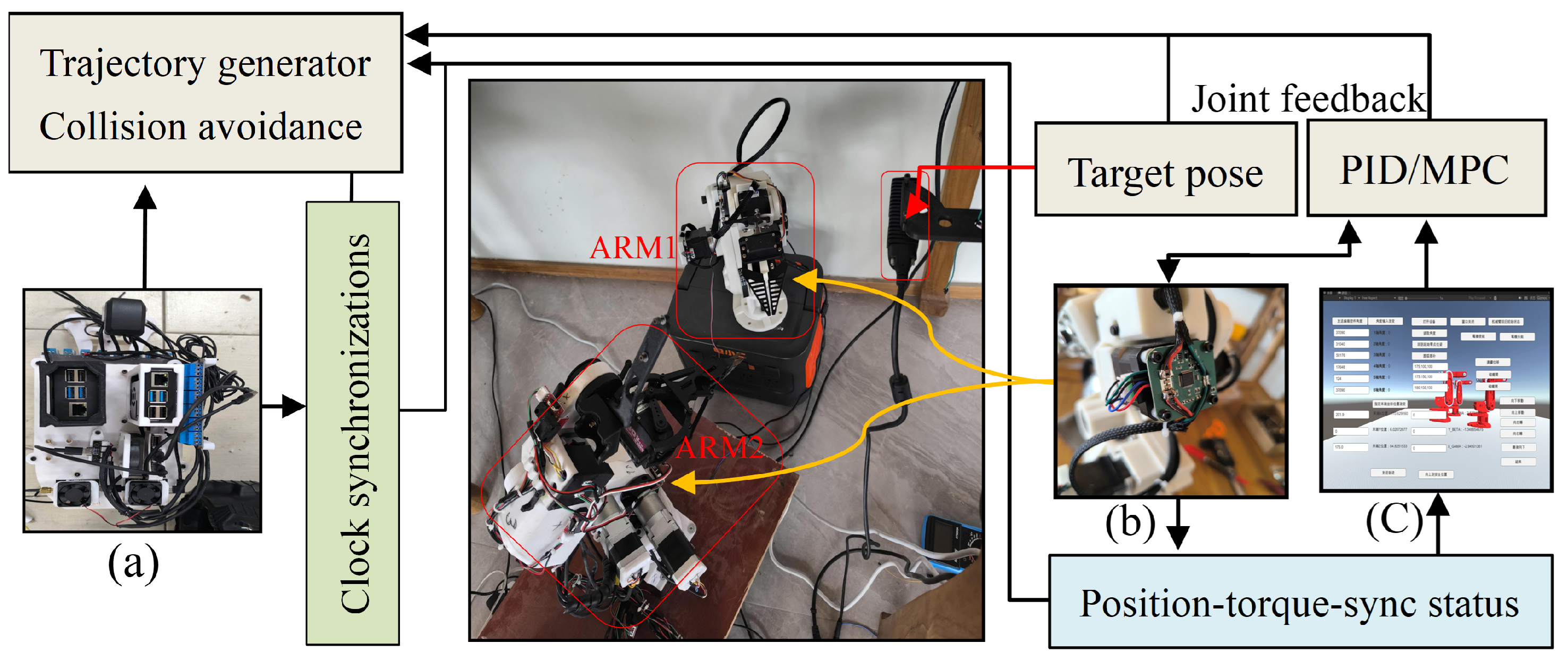
The equation describes how EtherCAT synchronizes the local clock of the i-slave device with the master’s reference clock. Here represents the synchronized time of the slave, while is the master’s reference time. The term corrects any initial time difference offset between the slave and master clocks, ensuring they start from a common baseline. Meanwhile accounts for the signal transmission delay as data travels from the master to the slave over the network.
2.1. Non-Repetitive Trajectories
Because the object location and size is different so need more calculations work to pick and place. When they must follow non-repeatable trajectory its more complex trajectory path, each manipulator required different sequence to perform task. Unlike repeatable trajectories non-repeatable trajectories required continues recalculations to perform collision free task [11]. Since the trajectory is not predefined task and motion planning RRT algorithm helps the control system to automatically choose minimum path to perform task.
The expression defines a vector-valued function as a polynomial in ¢ where each term consists of a time-dependent coefficient vector multiplied by . This allows to model dynamic, time-varying behaviors, such as trajectories or curves, where the coefficients themselves can change over time for greater flexibility.
The equations describe the motion of a point in 3D space over time ¢ Combines linear motion and oscillation Includes linear motion , oscillation and cubic growth Features a square root term , exponential decay and logarithmic growth . Together, they model complex motion with linear, oscillatory, and non-linear effects [12,13].
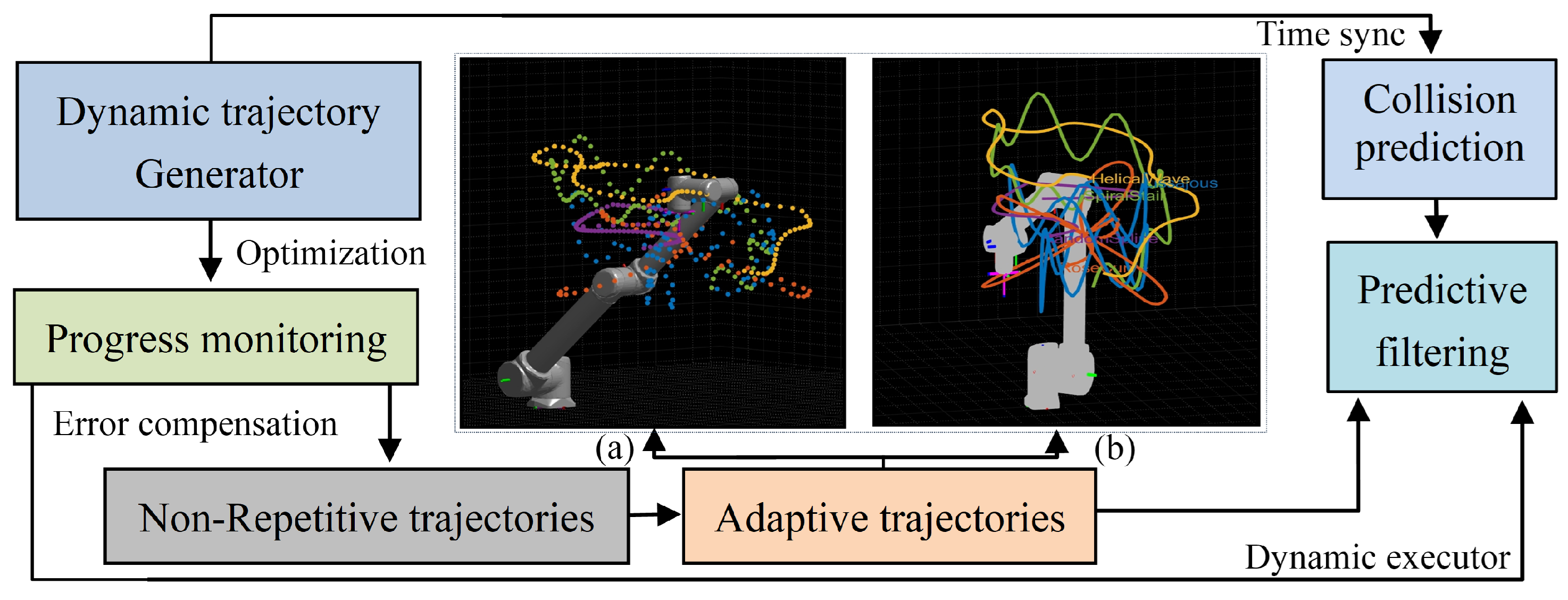
Figure 2.
Real-Time Optimization, Error Compensation, and Collision Prediction for Motion Systems—combining (a) intermittent/periodic control (irregular, cycle-skipping) for efficiency and (b) continuous control (smooth, unbroken cycles) for stability.
Figure 2.
Real-Time Optimization, Error Compensation, and Collision Prediction for Motion Systems—combining (a) intermittent/periodic control (irregular, cycle-skipping) for efficiency and (b) continuous control (smooth, unbroken cycles) for stability.
2.2. Repeatable Trajectories
Probabilistic Road map: Probabilistic Road map is referred to network of dots within occupied environment. This technique is used by manipulator where algorithm construct a graph in robotic configuration space. It consists two phases learning phase and query phase.
Learning phase: learning face creates random nodes in graph for collision free movement Query phase: this phase creates nearby paths for robot by connecting closest dots to each other These techniques will provide initial information about starting point to final point. As PRM relies on these nodes created randomly by algorithm and then connected together. Algorithm relies on sampling-based motion planner to constructing graph and connected random nodes. this can also include the analyzing obstacle in environment. Apart from usable space there is hurdles and obstacles in path. multiple planner Nodes connecting can be specified according to roots [14].
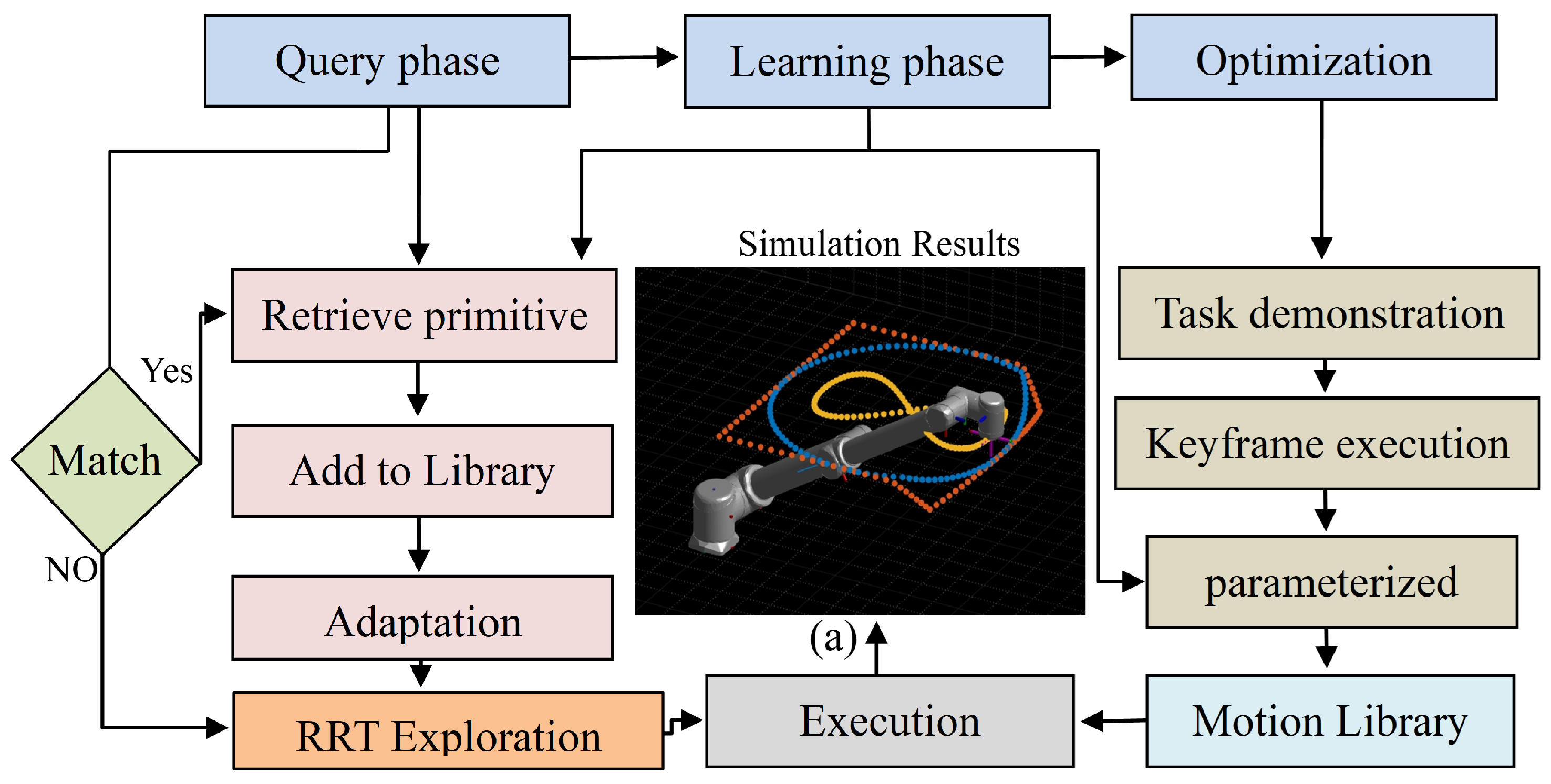
Figure 3.
Probabilistic Roadmaps (PRM) and Rapidly Exploring (RRT) for Repeatable Path Planning.(a)represents a unique one-time path without repetition.
Figure 3.
Probabilistic Roadmaps (PRM) and Rapidly Exploring (RRT) for Repeatable Path Planning.(a)represents a unique one-time path without repetition.
Once path building complete and the graph dots been created next process continues and can connect multiple dots together and same planner can use multiple times. This can save efforts and time. Rapidly Exploring Random trees: this technique is one of time query planner technique that use sampling-based motion planning algorithm to explore high dimensional spaces. RRT advancements a tree from starting configuration when graph been created start to end make it particularly effectively, RRT make it effective for real dynamic world. sometimes its bidirectional and if required to reuse need to make query plan again, if two different graphs created and at some point, they connect together.
The RRT algorithm expands a tree by generating new nodes from the nearest existing node moving a step size toward a random sample . Key conditions is randomly sampled is the tree’s closest node, the path must be collision-free, and the process stops when nears the goal within tolerance . This balances exploration and goal-directed growth for efficient path finding.
3. Actuation and Redundancy
Hardware very much relies on actuation where it converts energy to motions and often exploits to redundancy means having more degree of freedom that actually required this enhance flexibility and robustness robotic system being used has 2-4 robotic arm with 6DOF each.
Fully actuated: within working range within fully actuated condition manipulator all joints are fully actuated and has independently control over all the degree of freedom DOF in working process. Under actuated: in this condition robot don’t have degree of freedom instead of redundancy achieve by dynamic coupling fewer actuator then degree of freedom. conditions also apply.
For collision-free movement encoders and stop switches is used to stop over moving the manipulator. By this way end effector can be positioned to maximum reachable points[19]. In shared-space each manipulator moving in different position there is high chance to collide or hit with obstacles, system required high end safety to avoid collision. To avoid collision feedback required by master control to access full control to each manipulator.
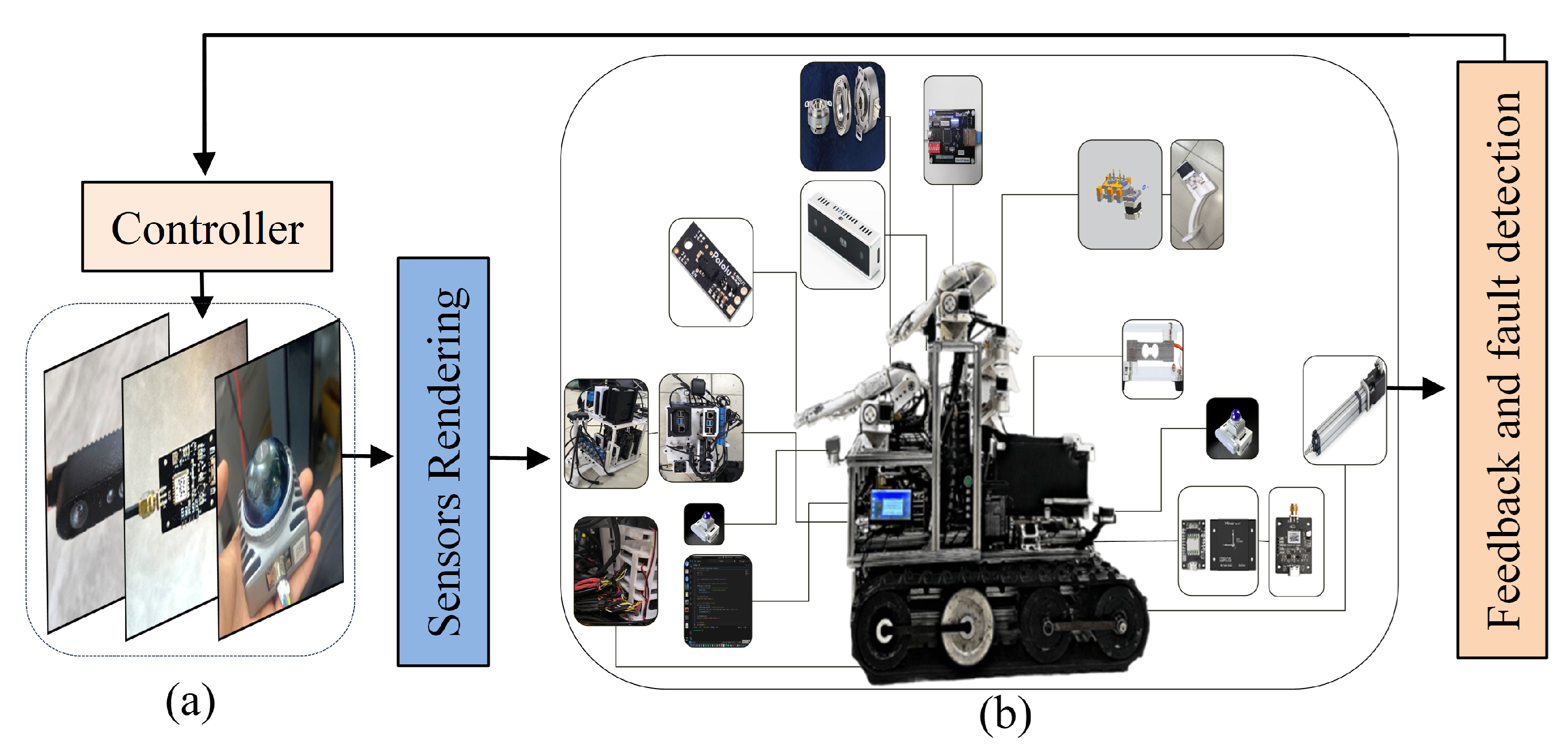
Figure 4.
Actuation and Redundancy in Robotic Systems Enhancing Performance and Control Strategies.(a)heterogeneous sensor fusion setup LiDAR/IMU/RGB-D.(b)Multi-sensor fusion system integrating LiDAR, IMU, and RGB-D data for unified perception and reporting.
Figure 4.
Actuation and Redundancy in Robotic Systems Enhancing Performance and Control Strategies.(a)heterogeneous sensor fusion setup LiDAR/IMU/RGB-D.(b)Multi-sensor fusion system integrating LiDAR, IMU, and RGB-D data for unified perception and reporting.
3.1. Manipulator Rendering
Dynamic environment is rendered with different sizes and shapes of geometries such as boxes or cylindrical shapes, process start with importing manipulator kinematics system use a technique called frugal that is provide initial information about the shape and size of geometry [15,16]. System sends signals and calculate the pose of arm to pick the geometry and perform next task. By using the Kalman filter State equation
The equation describes a discrete-time state-space model that describes how a system evolves from one time step to the next k. Here represents the current state vector (position, velocity) which depends on system Dynamics . The state transition matrix linearly transforms the previous state to predict the new state. Control Input . The matrix maps external control actions (motor commands) to their effect on the state. Process Noise . This term accounts for uncertainties or disturbances (assumed Gaussian, with zero mean and covariance) modeling unpredictable effects like friction or sensor errors. Measuring equation observation model:
The equation describes the measurement model in state estimation and filtering problems (Kalman filters). : The measurement vector at time step k representing observed data (sensor readings like position, velocity, or camera detections). : The observation matrix, which maps the true state to the expected measurement. It defines how the state variables relate to the sensor outputs. : The true state vector (manipulator poses, object position) being estimated. : The measurement noise, accounting for sensor inaccuracies. process noise (Gaussian with covariance
Figure 5.
Multi-modal Initialization and Multi-Sensor Fusion Architecture for Adaptive Trajectory Diversity.
Figure 5.
Multi-modal Initialization and Multi-Sensor Fusion Architecture for Adaptive Trajectory Diversity.
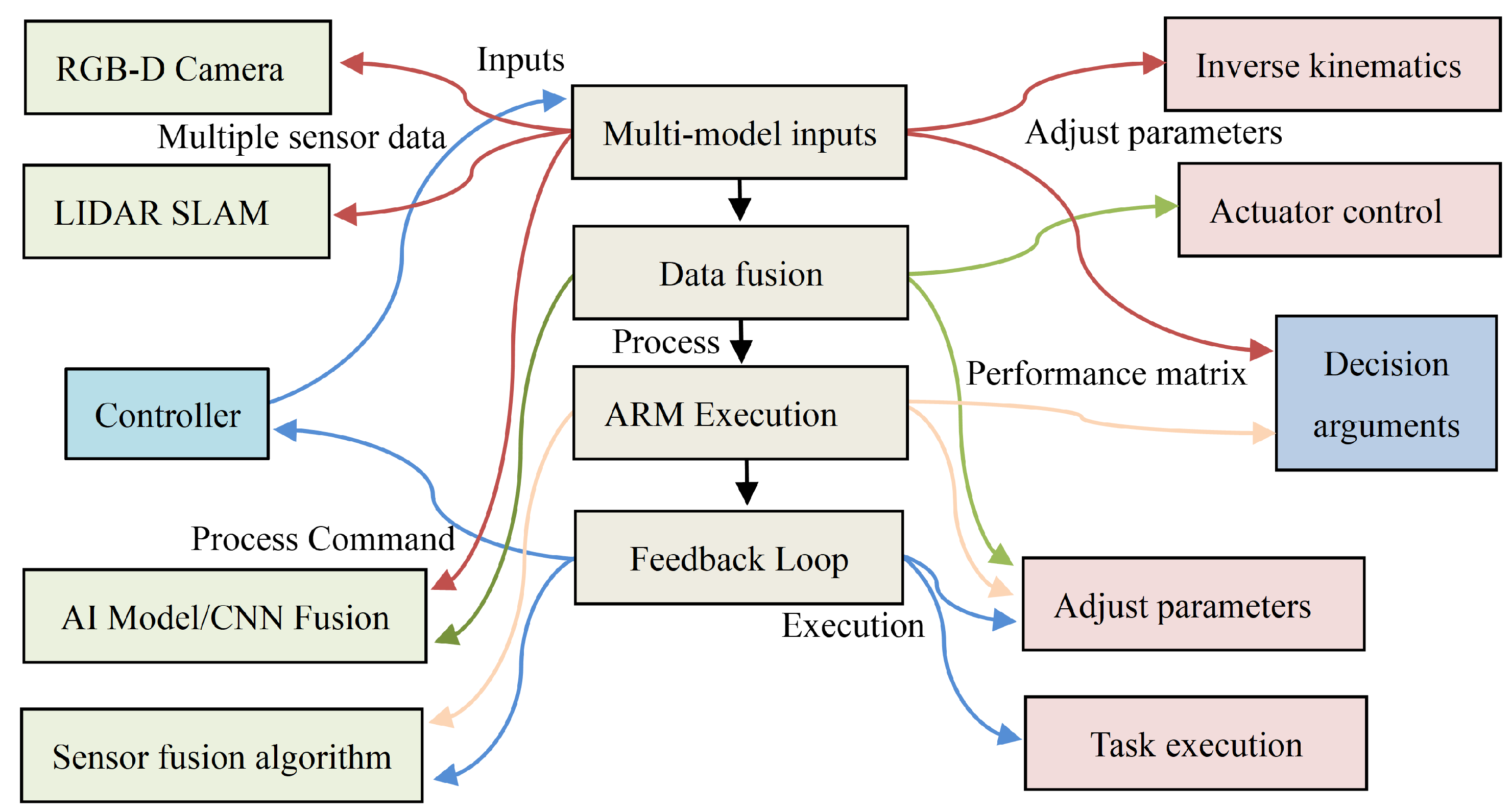
3.2. Multi-Modal Initialization
Control system align information from different sensors fusion and gathering data to a achieve a robust estimation shape of object size. Vision system provide orientation of object input can be given by pictures from different sizes after that system can analyze size of object by self and adjust gripper according to shape of object. additionally, pressure sensors also added to gripper for smooth gripping.
This equation defines multi-modal trajectory optimization for robotic arms. The optimal trajectory is chosen from candidates each generated by interpolating between sampled start and goal configurations. The selection minimizes a cost (path length) plus a collision penalty . This ensures safe, efficient motion in cluttered environments by evaluating multiple path options
- Trajectory generation:
- Configuration sampling:
- : Cost + safety trade-off
where is applied to penalize trajectories that collide with obstacles in the environment , and is a weighting factor. The control system integrates data from multiple sensors, fusing inputs from vision systems, LiDAR, and pressure sensors to create a robust estimation of an object’s size and shape.
3.3. Collision-Free Motion Planning
Multiple manipulators connected practically providing continuously feedback to master control to get exact positioning to improve coordination in complex dynamic environment, visual information can be process individually by each system and trajectory path can be determine by connectivity of multiple system [17].
3.4. Constrained Optimization for Each Manipulator
By using multiple constraints such as environmental constraints, these constraints execute complex task while staying in manipulators physical limits. task constraints and coordination constraints can get possible results by formulate motion planning and mathematically optimization of trajectories with explicit constraints. As manipulator perform different task by using diffident path trajectories.
4. Motion Variation
When multiple-manipulator work in shared space Object manipulation required shortest time as well as required collision free time to complete task in possible shortest time, where placing position is predefined but picking place is not predefined, system is required to recognized connection between each manipulator to perform task, adding encoder helps the manipulators for exact positioning and system can make a trajectory planning by collaboration of each manipulator, each manipulator control system is synchronized together and connected to master control.
Operating manipulators in share space required carefully synchronize in dynamic environment. create the path trajectories for separately to each manipulator this condition applies for multiple-manipulator at the same space and each manipulator required to work closely.
Equations describe the constraints for a multiple manipulators path planning problem. specifies the boundary conditions for each agent i: the initial position is set to the starting configuration and the final position must reach the goal configuration by time T. This ensures that each agent begins and ends its trajectory at predefined locations.
For every agent i, the area or volume occupied by the agent at any time t must not intersect with the combined areas or volumes occupied by all other agents at the same time. In other words, no two agents can occupy the same space simultaneously, ensuring safe and conflict-free paths.
5. System Structure and Updates in Design
Modern manipulator considering several factors sophisticated hierarchical new architecture design been added for both performance and adaptability. Consisting three layers: Physical layer: physical layer with modular interfaces to unified control connect such as Ethercat Coordination layer: coordination layer is responsible for handling real-time task distributions GPU-accelerated trajectory planning and collision-free motion planning. Cognitive layer: its human-robot interaction through machine learning models. with manipulator to enhance work efficiency Adopting a sudden new environment and making new trajectories is challenging task for control system. Essential details can be provided by sensor fusion and strategy based real time decision can be solve the removing error in trajectories.
5.1. Action-Space
Action space is defined by robot structure which allows each arm to work under working space and distance from object to gripper. Data integration can be best strategy to avoid collision between multiple-manipulators, this technique makes the pick and place process different in trajectories as well as in time so it will work one by one. Gripper designing varying size of object, opening/closing time can be adjusted by command. And position and pointing can be adjust according to position of object.
5.2. Motion Planning Failure
Motion planning failure occur if RRT algorithm fail to generate viable path for motion. different path trajectory required different path trajectory planning at the meantime some RRT trajectories can recover from prediction of previously used trajectories in real time. training data can be analyzing multiple time to determine whether mission can be successful or not.in real world environment scenario mission failure cannot be predicted in advanced yet to be perform task and analyze previous trajectories. this data can be used in variation in training data.
5.3. Rapidly-Exploring Random Tree
RPT expansion is use in the parabolicity compute sampling-based RRT method. It builds a search tree from a static beginning point and then gradually expands it using random sampling nodes to explore the whole environmental space until it reaches a target point. A continuous trajectory route between the starting and destination point is created by this technique. Adding the probabilistic computing and quick search capabilities of the RRT method are its main advantages. The term "completeness" describes the algorithm’s thorough coverage of the search space and connecting nodes through a process, where it allows for path planning between any two places by conducting an exhaustive and unhindered study of the full map region given enough time and iterations. Previous-recent sampling point, New Node, grows with radius r under collision detection circumstances. cost sums are computed sequentially from the starting coordinate point to the closest node and to the new node and every node in this dynamic environmental space is a subset of the new node. The new node’s parent is selected to be the node with the closest distance. if there are no barriers separating it from the closest node the new node is added to the tree structure. this iterative process keeps on until criteria are satisfied and workable solution is discovered.
5.4. Adaptive Pruning Optimization Strategy
With the addition of an adaptive pruning threshold and eliminate suboptimal nodes from motion. enhanced RRT algorithm integrates an adaptive pruning optimization technique that intelligently maintain computational efficiency without decreasing solution quality. Depending on real conditions the algorithm dynamically modifies this threshold encountered throughout the search process rather of relying just on the cost of the current best path to set pruning criteria [18]. In order to dynamically modify the lopping threshold, it also takes into account the features of obstacles avoidance in diverse contexts, including the numbers of obstacles the path’s complexity, and varied dimensions lowering the pruning threshold.
Figure 6.
Adaptive Pruning Metrics Error Reduction and Node Elimination.(a)representing data points or measurements in a process iteration count 10, an error value 0.035 rad.(b)error decreasing from 0.14 rad to 0.02 rad over 10 iterations, indicating improving system performance.
Figure 6.
Adaptive Pruning Metrics Error Reduction and Node Elimination.(a)representing data points or measurements in a process iteration count 10, an error value 0.035 rad.(b)error decreasing from 0.14 rad to 0.02 rad over 10 iterations, indicating improving system performance.
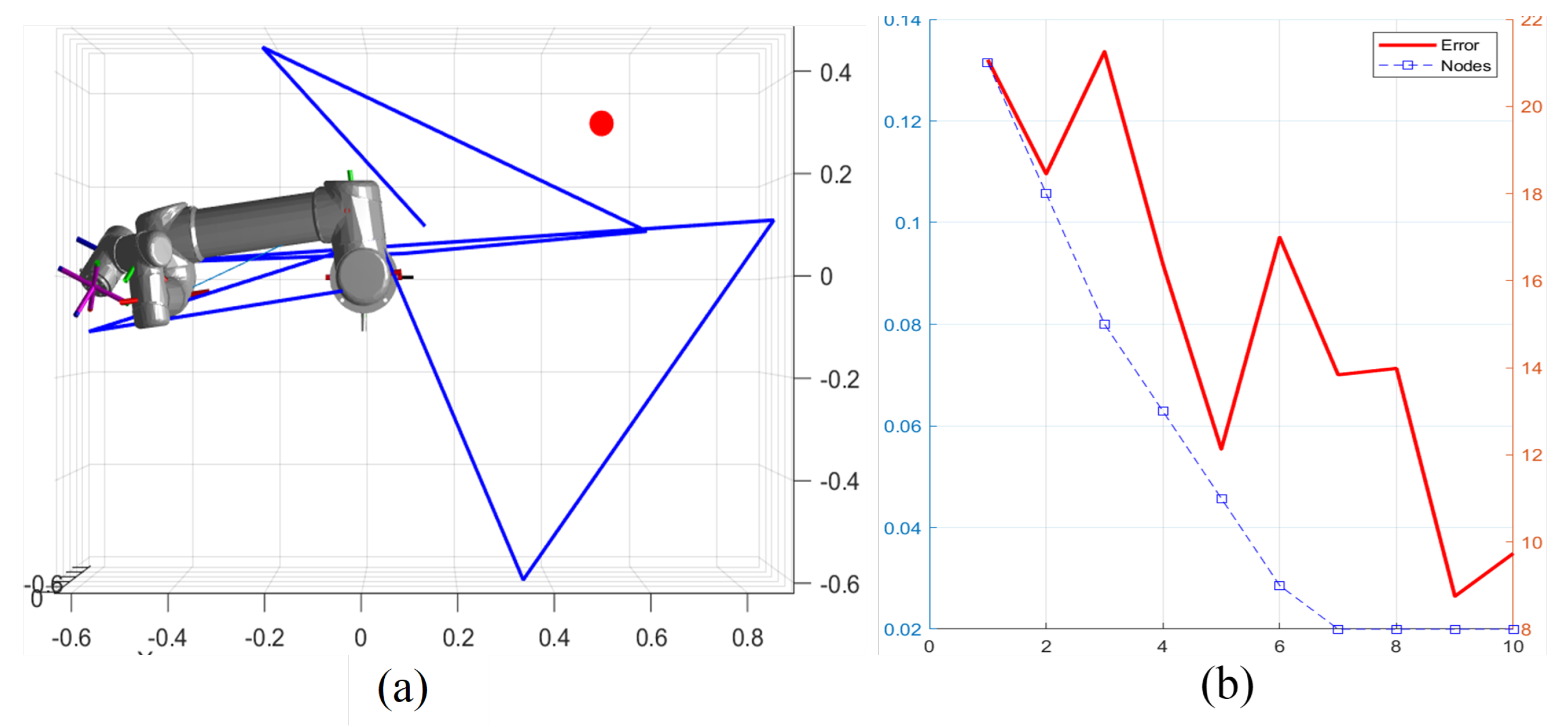
The optimization method in algorithm also incorporates a local path re-evaluation in mechanism. the optimization method can efficiently narrow the search space and By directly altering the tree structure boost the algorithm’s performance even further. The ongoing pruning and path optimization process can add enhanced RRT method can reduce the path length and increase path trajectory smoothness.
This equation optimizes robotic arm movements by minimizing tracking errors , control effort , and sudden joint changes over time. It ensures precise, energy-efficient, and smooth pruning motions. The integral balances these factors across the task duration, while missing constraints (like arm dynamics) would refine the system further.

Table 1.
Iteration Results Nodes, Error (rad), and Error Reduction
| Iteration | Nodes | Error (rad) | Error Reduction |
|---|---|---|---|
| 1 | 25 | 0.1700 | — |
| 2 | 18 | 0.1647 | 3.1% |
| 3 | 15 | 0.1382 | 16.1% |
| 4 | 13 | 0.0851 | 38.4% |
| 5 | 11 | 0.0791 | 7.0% |
| 6 | 9 | 0.0937 | 18.5% |
| 7 | 8 | 0.0332 | 64.6% |
| 8 | 8 | 0.0659 | 98.5% |
| 9 | 8 | 0.0380 | 42.3% |
| 10 | 8 | 0.0656 | 72.6% |
in order to preserve and maintain more possible route possibilities could be required to delay in pruning places with a lot of impediments to determine whether to keep or change the pathways in the current search tree.
6. Connectivity
Connecting refers to multiple-manipulator collision-free trajectory in controlled dynamic environment.it required multiple data for trajectories and path planning. Multi-layer trajectories required multiple RRT algorithms at back end, optimizing global planner and localization which is individually planner for each manipulator. connected multiple system to master control at the same time and continuous feedback to create collisions-free dynamic environment. A manipulator control system can connect to other system by physical interfaces which provided by system in use.
Figure 7.
Multi-Agent Robotic Coordination Real-Time Edge Processing & Cloud Analytics.
6.1. Motion-Planning in Joint Space
In shared space manipulator-system can connect to another manipulator-system by physical interface. trajectory planning and motion constraints in 3D visualization helps to avoid obstacle and also beneficial for system to locate exact position of object and update trajectory after every step. Path trajectory in a working space can divide according to available working space. RRT algorithm and motion constraints assist the motion planner to reduce complexity.
6.2. System-to-System Communication
Multiple system manipulation is challenging task for control system in shared working space. Mathematical algorithm for motion planning employs layered communication architecture for communication and self-decision making enables possibilities to communicate multiple manipulator-system with each other. Communication assist in coordination for planning, control and execution. Connected system with master control, system exchange related information with other system which can be processed and analyze or present and previous position of manipulator collectively information exchange creates close-loop communication between one system to another by sending request information and exchanging information. Master control-System inquiry about recent activities to other systems.
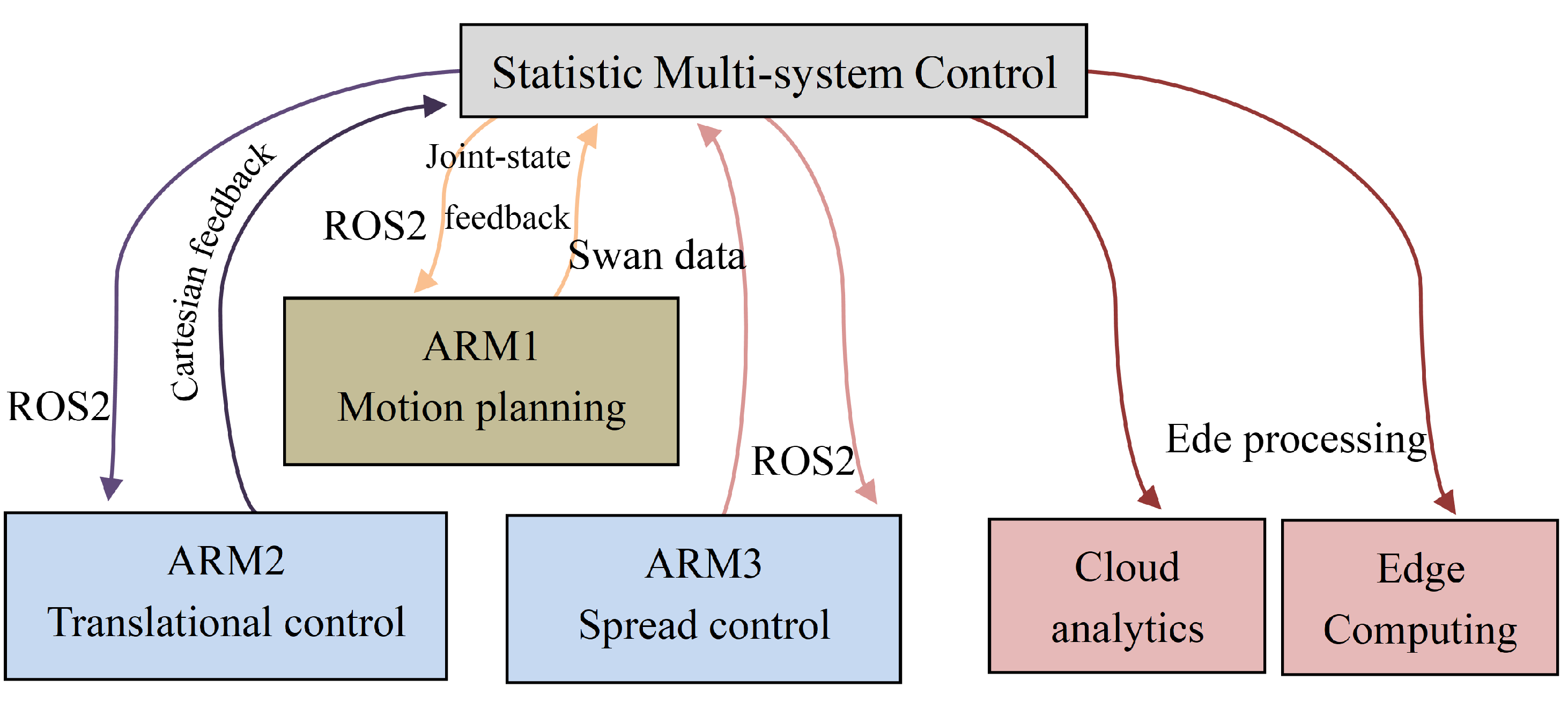
6.3. Statistic Multi System Control
This is a modern statistical technique that centralized control system, it is involving the global command to control each manipulator connected with master control. however, for clarification this refer to multi-control system, that provide a central command structure that can exceed to several numbers of control-system connected with each other by global command [19]. Control depends on communication range within range many systems can connect with each other.
6.4. Computational Limits
Manipulator motion planning confront fundamental computational limits that need to carefully scale with manipulator degree of freedom When numbers of systems connected with each other in dynamic control, computational limit become bottleneck for system to process to next step. System required complete structure which dot to dot connected with each other, path trajectory and planning will be analyzed individually but each system connected to master-control to get equally feedback to each manipulator. Adding Self decision-making possibilities required data provided by integration of sensors fusion data from each manipulator, localization required central control to be in action.
6.5. Translation Control
Translation control refer to end-factor of manipulator precisely transition control in cartesian moment and maintaining orientation stability. Let us consider we have distance target point —d as object functionality so each time lap the mean position incremental translation 1n( ) of the complying subset ( p n < N) calculated as root mean square •2 as given data:
This equation calculates the average incremental change by scaling the sum of individual terms by . It’s used in adaptive systems like robotics or machine learning to adjust parameters trajectories or weights based on collective feedback, where controls the adjustment rate and n normalizes the response.
6.6. Spread Control
Spread control responsible for managing multiple-manipulator degree of freedom. this technique optimize coverage while preventing collision. trajectory algorithm maximizes uniform spacing and minimize concentration. this technique helps in collision-free movement, optimal coverage and also load balancing.
This equation calculates control forces to maintain a robotic arm’s desired joint configuration . The stiffness term pushes joints toward their target positions, while the damping term ensures smooth, stable motion. Together, they enable the arm to preserve an optimal posture keeping joints spread for stability during tasks without abrupt movements. The gain matrices and determine the system’s responsiveness.
7. Distributed Optimization Algorithms
DOA refer to enabling multiple-systems to connect to each other and breakdown the algorithm to subparts. As using multiple optimization algorithms methods and getting multiple results here we distributed optimization algorithms into three general categories in this section: ADMM techniques: Such as DFO methods and sequential convex programming. These groups are categorized according to their suitability for multi-manipulator environmental scenarios and distributed via common junction procedures. Here, we provide a concise overview of each category by examine a representative distributed algorithm optimization. Following an analysis of each separable optimization problem, the following is discussed: Communication and computation: Multiple-manipulator trajectory planning systems require careful balancing of computational algorithm demands. in order to achieve best performance, solution, quality and latency constraints delay should no more then1s for low-level control to 10ms for high-level computational [20,21]. This interaction between communication and computation is a essential design consideration. using adaptive resolution mechanisms that dynamically transition between high-fidelity cloud plans and efficient edge fallbacks depending on network dynamics. robust architectures edge-cloud use hybridization to distribute processing across nodes. Master control handle raw sensor data and immediate control (sub-millisecond), edge nodes manage local planning (10-100ms), and cloud resources handle large scale computations such as policy learning (>100ms)
- Local Optimization : The term represents the gradient of robot i’s local objective function minimizing tracking error or energy consumption. The weight scales how aggressively the robot pursues this individual goal.
- Consensus Coordination : This term ensures alignment with neighboring robots by reducing differences between their states . The weight controls the strength of coordination, critical for tasks like collaborative lifting or formation control.
- Physical Control : Implied but not fully shown, the placeholder suggests additional physical constraints (joint limits, stability) are applied, scaled by . In practice, this might include terms like to maintain safe joint configurations.
7.1. DFO Method
We point out that when extending gradient descent to limited optimization a popular projection on gradient descent a common technique used, which entails projecting the iterates to the feasible set [22,23]. We discuss into more depth on the extensions of gradient descent techniques to limited optimization. These known as first-order techniques because they typically only need to compute the gradient, or the first derivative of the goal and constraint functions. When applying the unconstrained optimization variable is updated in the following way. DFO algorithms avoid this basic issue by permitting each manipulator to use only its local gradients and collaborating with its neighbor to reach a consent on a common solution.
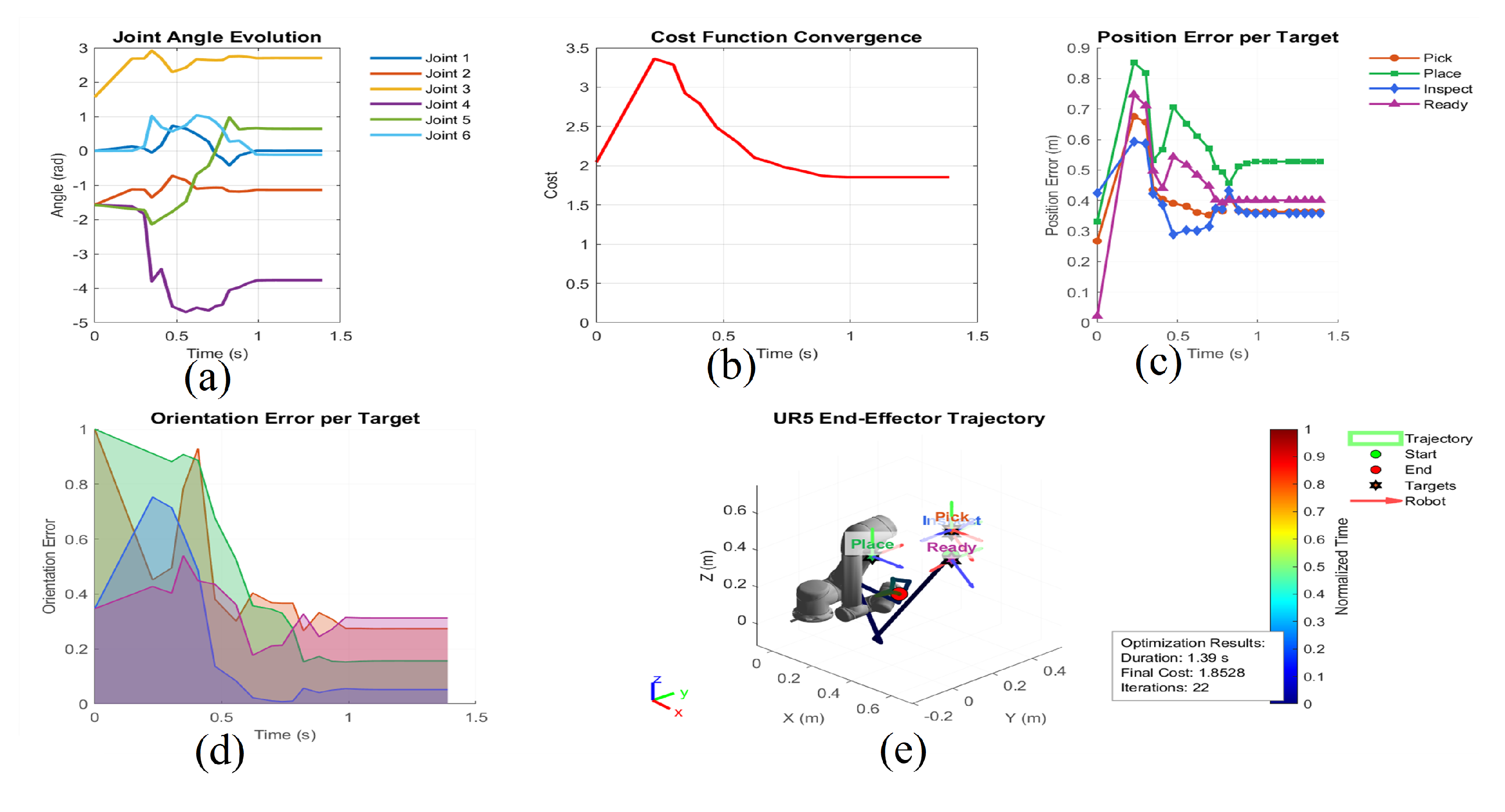
Figure 8.
Dynamic Task Allocation and Performance Metrics for Multi- Task Assessment, Environment Scalability and Adaptability Metrics for Multi-Manipulator Task Execution.(a) Joint Angle Evolution tracks angular displacement rad over time s, (A: 0.5 rad, B: 1.0 rad at distinct timesteps).(b)Cost Function Convergence plots optimization progress cost: 1.5 → 0.5 → 0.0 indicating error reduction.(c)Position Error per Target Measures positional deviation during tasks 0.8m → 0.1m, reflecting improving accuracy in phases like "Pick" or "Inspect".(d) Orientation Error per Target Orientation Error per Target improved precision 0.5s. (e) UR5 End-Effector Trajectory robotic arm’s end-effector ranges from 0m to 0.6m.
Figure 8.
Dynamic Task Allocation and Performance Metrics for Multi- Task Assessment, Environment Scalability and Adaptability Metrics for Multi-Manipulator Task Execution.(a) Joint Angle Evolution tracks angular displacement rad over time s, (A: 0.5 rad, B: 1.0 rad at distinct timesteps).(b)Cost Function Convergence plots optimization progress cost: 1.5 → 0.5 → 0.0 indicating error reduction.(c)Position Error per Target Measures positional deviation during tasks 0.8m → 0.1m, reflecting improving accuracy in phases like "Pick" or "Inspect".(d) Orientation Error per Target Orientation Error per Target improved precision 0.5s. (e) UR5 End-Effector Trajectory robotic arm’s end-effector ranges from 0m to 0.6m.
7.2. Sequential Convex Programming
Sequential Convex Programming (SCP) solving provides an iterative framework for Solving challenging non-convex motion planning and optimization issue by computing a series of iterates that indicate the resolution of a number of approximations of the original problem is known as sequential convex programming.
7.3. Multiple-Pose Distributed Optimization
A revolutionary method Multiple-pose distributed optimization which is a dynamically paradigm-shifting approach to selects the most efficient distributed formulation based on real-time system conditions for robotic coordination. This framework adaptively transition between three basic optimization poses. ADMM decomposition for loosely-coupled separatable issues and consensus approaches for tightly-coupled problems. federated averaging in dense networks, for star-topology systems with central coordination [24]. In order to automatically trigger pose transitions the system continuously monitors key metrics like network connectivity, problem separability, and residual convergence.
This equation describes the distributed optimization process for a robotic arm or multiple arms at each iteration . The goal is to find the optimal joint configuration that minimizes a local cost function (tracking error or energy consumption) while ensuring coordination with neighboring robots. The second term enforces consensus among robots by penalizing deviations from the average of their previous configurations , weighted by a penalty parameter . The Lagrange multipliers help balance the trade-off between local optimization and global agreement.
8. Multi-Manipulator Task Assessment
Multi-manipulator task assessment provides a comprehensive framework for estimating and optimizing of collaborative manipulator operations through real-time performance and minimize a trajectory cost and avoid colliding from starting point to desired state configuration. also included the monitoring and adaptive control inputs. The system continuously tracks key metrics such as desired reference trajectory including task completion time by using synchronized ROS2 clocks.
8.1. Flexible and Scalable Advances in Dynamic Task Allocation
Leverage adaptive algorithms to efficiently distribute workloads in real-time, ensuring optimal resource utilization. these modernizations enable seamless task reassignment and scalability, adapting to changing demands while maintaining system performance and reliability. At its core a classified architecture processes energy efficiency and workload balance, creating a multidimensional performance profile [25]. Through joint state data feature extraction pipelines that quantify trajectory smoothness, torque profiles, and completion ratios. For LSTMs temporal pattern analysis, we use to feed into machine learning models like random forests for failure prediction.
The variables and represent the positions of the i and j agents in the system, respectively. The tracking error term measures how far each agent is from its desired target position . The collision avoidance term ensures agents maintain a minimum safe distance by heavily penalizing proximity. enforces a lower bound on separation. The effort term quantifies the control input force or torque applied to the i agent, minimizing energy use. Together, these terms ensure precise, safe, and efficient multi-agent coordination.
8.2. Multi-Manipulator Collaborative Work
Multi-manipulator collaborative work including object identification, visual place recognition, depth estimation, 3D mapping, reinforcement learning, multi-manipulator learning involves applying deep learning techniques to estimate functions from data. in shared workspaces consent grasping that dynamically balances applied forces across end-effectors, and collision-aware path trajectory motion planning that integrates swarm potential fields for safe motion [26]..
At the algorithmic level, these systems leverage distributed task allocation through optimized assignment methods such as RRT algorithm, and modern implementations utilize quality-of-service-controlled communication architecture to synchronize state information at 100ms intervals while maintaining s-level hardware synchronization through Time-Sensitive Networking, with performance continuously monitored via metrics like force balance error (<0.15 target) and collision probability (<0.1%).
represents the object’s inertial properties in task space. acceleration vector of the system’s generalized coordinates. accounts for Coriolis and centrifugal effects due to rotational motion and handles gravitational forces. The right side of the equation sums the contributions from each robot, where transforms end-effector forces into equivalent joint torques.
9. Conclusion
This study presents a comprehensive framework for path planning and coordinated control of single and multiple robotic manipulators in dynamic, shared environments. By integrating sampling-based algorithms such as Rapidly exploring Random Trees (RRT) and Probabilistic Roadmaps (PRM), along with real-time synchronization via EtherCAT, the system achieves collision-free, adaptive motion trajectories for both repetitive and non-repetitive tasks. Advanced control architectures including PID, MPC, and adaptive pruning optimization—enhance the efficiency and safety of manipulation, particularly in complex scenarios requiring multi-arm cooperation. The implementation of feedback loops through encoders, Kalman filters, and multi-sensor fusion (vision, depth, force) significantly improves object recognition, pose estimation and trajectory adaptation. Moreover, the proposed multi-layered system architecture (physical, coordination, and cognitive layers) ensures robustness, scalability, and real-time responsiveness. Distributed optimization algorithms like ADMM and DFO, coupled with cloud-edge hybrid computing, enable high-performance multi-agent collaboration with minimized latency. Ultimately, this work provides a scalable and intelligent robotic control framework capable of dynamic task adaptation, efficient motion planning, and real-time coordination laying the foundation for future industrial and autonomous robotic systems that require precision, safety, and autonomy in cluttered or unpredictable environments.
Author Contributions
Fazal khan; conceived the study, developed the federated learning framework, implemented the software, conducted experiments on multiple robotic arms, and wrote the initial draft of the manuscript. Zhou meng ;supervised the research, provided critical feedback, secured funding, and contributed to revising and editing the manuscript. All authors reviewed and approved the final version of the paper.
Institutional Review Board Statement
This study was conducted in accordance with the research guidelines of Donghua University. Since the work involved simulated and laboratory-based experiments on robotic arms without human participation or sensitive data, formal ethics approval was not required. All procedures followed standard safety and operational protocols for robotic systems. The research adhered to the university’s policies on experimental integrity and data reproducibility. No conflicts of interest or risks were identified. Funding and resources were provided by Donghua University under its institutional research framework.
Acknowledgments
This research was supported by Donghua University. The authors gratefully acknowledge the technical and infrastructural support provided by the Mechatronics Lab at Donghua University, which was essential for conducting experimental work on multi-robot coordination and control. Special thanks to Dr. Zhou Meng for their expert guidance and for providing access to the advanced robotic testbeds, which were critical in validating the proposed framework. The lab’s high-precision motion-capture systems and collaborative robotics platforms enabled rigorous experimental testing and accurate data acquisition, significantly improving the reliability of this study.
References
- Zhang, W.; Yang, D.; Wu, W.; Peng, H.; Zhang, N.; Zhang, H.; Shen, X. Optimizing federated learning in distributed industrial IoT: A multi-agent approach. IEEE J. Sel. Areas Commun. 2021, 39, 3688–3703. [Google Scholar] [CrossRef]
- Zhang, S.Q.; Lin, J.; Zhang, Q. A Multi-Agent Reinforcement Learning Approach for Efficient Client Selection in Federated Learning. Proc. AAAI Conf. Artif. Intell. 2022, 36, 9091–9099. [Google Scholar] [CrossRef]
- Wu, N.; Jia, D.; Li, Z.; He, Z. Trajectory Planning of Robotic Arm Based on Particle Swarm Optimization Algorithm. Appl. Sci. 2024, 14, 8234. [Google Scholar] [CrossRef]
- Liu, W.; Huang, Z.; Qu, Y.; Chen, L. Path Planning for Robotic Arms Based on an Improved RRT Algorithm. Open J. Appl. Sci. 2024, 14. [Google Scholar] [CrossRef]
- Imakura, A.; Sakurai, T. FedDCL: A Federated Data Collaboration Learning as a Hybrid-Type Privacy-Preserving Framework Based on Federated Learning and Data Collaboration. arXiv 2024, arXiv:2409.18356. [Google Scholar]
- Wu, P.; Su, H.; Dong, H.; Liu, T.; Li, M.; Chen, Z. An obstacle avoidance method for robotic arm based on reinforcement learning. Ind. Robot 2025, 52, 9–17. [Google Scholar] [CrossRef]
- Cao, M.; Mao, H.; Tang, X.; et al. A novel RRT*-Connect algorithm for path planning on robotic arm collision avoidance. Sci. Rep. 2025, 15, 2836. [Google Scholar] [CrossRef]
- Le, Q.D.; Yang, E. Adaptive Fault-Tolerant Tracking Control for Multi-Joint Robot Manipulators via Neural Network-Based Synchronization. Sensors 2024, 24, 6837. [Google Scholar] [CrossRef]
- Yu, P.; Tan, N.; Gu, X. A Hybrid Neurodynamic Scheme for Bimanual Synchronized Tracking Control of Robotic Manipulators With Uncertain Kinematics. IEEE Trans. Ind. Inform. 2025, 21, 2967–2976. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, G.; Zhang, T.; Zhang, J.; Chen, R. Time-Synchronized Convergence Control for n-DOF Robotic Manipulators with System Uncertainties. Sensors 2024, 24, 5986. [Google Scholar] [CrossRef]
- Yu, C. Adaptive Iterative Learning Constrained Control for Linear Motor-Driven Gantry Stage with Fault-Tolerant Non-Repetitive Trajectory Tracking. Mathematics 2024, 12, 1673. [Google Scholar] [CrossRef]
- Widanage, K.N.D.; et al. Non-repetitive-path Iterative Learning and Control for Human-guided Robotic Operations on Unknown Surfaces. IEEE Trans. Robot.
- Wang, L.; Zhu, S.; Wei, M.; Wang, X.; Huangfu, Z.; Chen, Y. Iterative Learning Control with Adaptive Kalman Filtering for Trajectory Tracking in Non-Repetitive Time-Varying Systems. Axioms 2025, 14, 324. [Google Scholar] [CrossRef]
- Xie, S.; et al. Predictive Control for an Ankle Rehabilitation Robot Using Differential Evolution Optimization Algorithm-Based Fuzzy NARX Model. IEEE Trans. Neural Syst. Rehabil. Eng. 2025, 33, 1886–1895. [Google Scholar] [CrossRef]
- Tao, S.; Xiang, F.; Shukla, A.; et al. Maniskill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI. arXiv 2024, arXiv:2410.00425. [Google Scholar] [CrossRef]
- Wang, Y.; James, S.; Stathopoulou, E.K.; Beltrán-González, C.; Konishi, Y.; Del Bue, A. Autonomous 3-D Reconstruction, Mapping, and Exploration of Indoor Environments With a Robotic Arm. IEEE Robot. Autom. Lett. 2019, 4, 3340–3347. [Google Scholar] [CrossRef]
- Yang, F.; et al. A Collaborative Drone System with Robotic Arm Based on Lightweight Structure and Multimodal Control. Proc. 2024 4th Int. Conf. Robot. Autom. Intell. Control (ICRAIC) 2024, 375–381. [Google Scholar]
- Bi, A.; Zhang, C. Robot Arm Grasping based on Multi-threaded PPO Reinforcement Learning Algorithm. Proc. 2024 3rd Int. Conf. Artif. Intell. Hum.-Comput. Interact. Robot. (AIHCIR) 2024, 369–373. [Google Scholar]
- Shvalb, N.; Hacohen, S.; Medina, O. Statistical Robotics: Controlling Multi Robot Systems Using Statistical-Physics. IEEE Access 2024, 12, 134739–134753. [Google Scholar] [CrossRef]
- Soleimani Amiri, M.; Ramli, R. Intelligent Trajectory Tracking Behavior of a Multi-Joint Robotic Arm via Genetic-Swarm Optimization for the Inverse Kinematic Solution. Sensors 2021, 21, 3171. [Google Scholar] [CrossRef]
- Zhang, H.; Li, X.; Wang, L.; Liu, D.; Wang, S. Construction and Optimization of a Collaborative Harvesting System for Multiple Robotic Arms and an End-Picker in a Trellised Pear Orchard Environment. Agronomy 2024, 14, 80. [Google Scholar] [CrossRef]
- Desai, N.; Behara, G.; Deb, S.; Sen, D. A Genetic Algorithm Based Adaptive and Hybrid Pathfinding Algorithm to Enhance the Performance of Robotic Bin-Picking. Proc. 2024 IEEE 21st India Counc. Int. Conf. (INDICON) 2024, 1–7. [Google Scholar]
- Guo, P.; Luo, D.; Wu, Y.; et al. Coverage Planning for UVC Irradiation: Robot Surface Disinfection Based on Swarm Intelligence Algorithm. Sensors 2024, 24, 3418. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhou, X.; Liu, J.; et al. Instance-level 6D pose estimation based on multi-task parameter sharing for robotic grasping. Sci. Rep. 2024, 14, 7801. [Google Scholar] [CrossRef]
- Duan, S.; Jiang, Z.; Ren, Y.; Wei, H. Coordination of Multi-Robot Systems. Proc. 2022 Int. Conf. Electron. Devices Comput. Sci. (ICEDCS) 2022, 361–367. [Google Scholar]
- Ma, H.; Wei, X.; Wang, P.; Zhang, Y.; Cao, X.; Zhou, W. Multi-Arm Global Cooperative Coal Gangue Sorting Method Based on Improved Hungarian Algorithm. Sensors 2022, 22, 7987. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



