
Submitted:
04 July 2025
Posted:
04 July 2025
You are already at the latest version
Abstract
Structural damage identification provides a theoretical foundation for the operational safety and preventive maintenance of in-service bridges. However, practical bridge health monitoring has the challenges in poor signal quality, difficulties in feature extraction, and insufficient damage classification accuracy. This study presents a bridge damage identification framework integrating time-varying filtering-based empirical mode decomposition (TVFEMD) with pre-trained convolutional neural networks (CNN). The proposed method enhances key frequency-domain features of signals and suppresses the interference of non-stationary noise on model training through adaptive denoising and time-frequency reconstruction. The TVFEMD was demonstrated in numerical simulation experiments have better performance than traditional EMD in terms of frequency separation and modal purity. Furthermore, the performance of three pre-trained CNN models were compared in damage classification tasks. The results indicate that the ResNet-50 has the best optimal performance compared to the other networks, particularly exhibiting better adaptability and recognition accuracy when processing TVFEMD-denoised signals. In addition, the principal component analysis visualization results demonstrate that the TVFEMD significantly improves the clustering and separability of feature data, providing clearer class boundaries and reducing feature overlap.
Keywords:
structural damage identification
; structural health monitoring
; time-frequency analysis
; signal processing
; convolutional neural network
1. Introduction
Bridges are an essential component of modern transportation infrastructure, supporting heavy traffic flows and maintaining transportation connections between cities and regions. Bridge damage often progresses gradually, with initial damage being difficult to detect promptly through traditional manual inspections [1,2,3,4]. The expansion and progression of damage can significantly compromise bridge safety, potentially leading to catastrophic consequences [5,6,7,8]. In recent years, with the rapid advancements in sensor technology, signal processing, and artificial intelligence, vibration-based bridge health monitoring (SHM) has emerged as a mainstream monitoring approach [9,10,11,12]. This method involves analyzing bridge vibration responses and employing algorithmic models to identify structural damage, thereby enabling real-time monitoring of bridge health conditions. However, in practical monitoring scenarios, vibration signals are frequently influenced by environmental noise, traffic interference, and temperature fluctuations [13,14,15], resulting in degraded signal quality and presenting significant challenges for damage detection. Consequently, improving signal effectiveness in noisy environments and accurately extracting damage features remain critical challenges in current bridge health monitoring technologies.
In bridge health monitoring, signal denoising technology is a critical step in improving the accuracy of damage identification [16,17]. Existing signal denoising techniques can be categorized into frequency-domain methods and time-domain methods. Frequency-domain methods convert time-domain signals into frequency-domain signals using techniques such as Fourier transforms, remove specific frequency components, and then convert the signal back to the time domain to achieve denoising, examples include band-pass filtering and low-pass filtering. These methods typically assume that low-frequency components are useful information and high-frequency components are noise; however, this assumption does not always hold true in practice, limiting their denoising effectiveness. In contrast, time-domain denoising methods directly remove noise from the signal time history or reconstruct the signal by extracting useful components through multi-scale analysis. Common time-domain methods include Empirical Mode Decomposition (EMD) [18], Ensemble Empirical Mode Decomposition (EEMD) [19], and Wavelet Transform (WT) [20,21]. For instance, Wang et al. [22] proposed a damage identification method based on time-varying modal wavelet transform and successfully applied it to the damage detection of cantilever beams and large bridges. However, the WT is sensitive to noise, which may affect identification accuracy. In comparison, the EMD is an adaptive signal decomposition technique, which handles nonlinear and non-stationary signals effectively [23]. Nevertheless, its recursive nature can lead to mode mixing, affecting the decomposition results.
The EMD and EEMD methods were subsequently developed to address these issues. For instance, Berrouche et al. [24] utilized EEMD to gear fault diagnosis and added white noise to reduce mode mixing. Although this method achieved good diagnostic results, the influence of noise was not completely eliminated. Most signal processing techniques based on decomposition, such as EMD and EEMD, face challenges such as mode mixing, endpoint effects, and waveform distortion [25], which may impact the extraction of damage features and identification accuracy. To overcome these limitations, the TVFEMD method was introduced integrating time-varying filters into the EMD process, enabling real-time filtering during signal decomposition and partially alleviating the aforementioned issues [26,27,28]. The effectiveness and reliability of TVFEMD in bridge measurement data have been validated, particularly in separating temperature effects, where TVFEMD significantly outperforms traditional EMD and EEMD methods [29].
In the fields of image and pattern recognition, deep learning models, particularly convolutional neural networks (CNNs), have achieved significant success [30,31]. However, for directly applied to bridge damage detection, the issues such as non-robust models, overfitting, and misclassification due to unreliable input signal quality are significant [32,33,34]. Therefore, it is essential to propose a new paradigm that integrates efficient signal reconstruction methods with deep feature extraction networks. Previous studies [35,36,37] have shown that combining VMD with shallow neural networks can enhance diagnostic performance, yet it still has limitations in removing high-frequency noise. In recent years, attention mechanisms, deep CNNs, and transfer learning techniques were introduced into the SHM domain [38,39]. However, most of these methods have overlooked the critical role of signal preprocessing at the input stage for deep models, resulting in significant performance fluctuations in complex signal-to-noise environments. Thus, it remains a pressing engineering challenge to integrate signal denoising with optimization of deep models to enhance their robustness and generalization capabilities effectively.
To the best of the authors’ knowledge, the TVFEMD method has been utilized in the fields of wind speed prediction and mechanical bearing fault diagnosis [40,41]. In practices, the TVFEMD has performance in removing non-stationary noise, which is better for feature extraction structural damage scenarios. In addition, the TVFEMD can perform processing of signals in both time and frequency domains through time-varying filtering, which provides better extracting features related to damage.
Therefore, this study develops a TVFEMD method integrating time-varying filters during the decomposition process to eliminate the need for forced upper and lower envelope symmetry. The challenging issues in traditional EMD, such as mode mixing and cumulative decomposition errors, were effectively addressed. After TVFEMD processing, the signals are encoded into two-dimensional images using MTF. The main innovations and contributions of this paper include: 1) proposing a signal denoising and feature extraction method based on TVFEMD, effectively suppressing complex noise and enhancing the prominence of damage features; 2) combining deep learning networks such as ResNet-50, EfficientNet-b0, and GoogLeNet to improve damage recognition accuracy and robustness while enhancing signal features; 3) verifying the advantages of the TVFEMD method in signal denoising and feature separation through PCA dimensionality reduction and visualization analysis. In the complex environment of actual engineering, this approach enhances the precision and stability of bridge damage detection.
The organization of the rest of the study is arranged as follows. Section 2 introduces the theoretical foundation of the TVFEMD method and presents the bridge damage detection framework combining TVFEMD with deep learning. Section 3 describes the experimental setup, scenario configuration, data collection, and signal processing. Section 4 discusses the findings, evaluating the effectiveness of this study by comparing different signal processing methods and deep learning models. Section 5 is the conclusion and future prospects.
2. Methodologies
2.1. Time-Varying Filtering-Based Empirical Mode Decomposition
The TVFEMD is used to separate the multi-scale information from bridge monitoring data. The process is shown as follows.
(1) Determine the instantaneous amplitude A(t) and instantaneous phase φ(t) of the signal x(t) to be decomposed by using:
(1)
(2)
where, the Hilbert transform of x(t) is denoted as .
(2) By calculating the local maxima and minima of the instantaneous amplitude A(t), the corresponding analytical signal is defined as:
(3)
where, z(t) is the complex form of the signal, and j is the imaginary unit.
(3) Obtain the curves of the minimum and maximum values of A(t), which are used to calculate β1(t) and β2(t). Based on this, the instantaneous mean a1(t) and instantaneous envelope a2(t) can be calculated as:
(4)
(4) Perform time-varying filter interpolation on A(tmax) and A(tmin) to obtain η1(t) and η2(t). The two IMF components φ1′(t) and φ2′(t) are then calculated by
(5)
(5) Compute the local cutoff frequency as:
(6)
(6) Use the time-variant filter to process the unfiltered signal and obtain the local mean. Calculate the signal h(t) and denote the final approximation result as m(t):
(7)
(7) Assess whether the threshold criterion is satisfied to determine the existence of a narrowband signal. If the criterion is met, the signal can be classified as a narrowband signal. Otherwise, update x(t) to x(t)-m(t) and repeat steps 1 to 6 until met the criterion:
(8)
where is the Loughlin instantaneous bandwidth, ξ is the bandwidth threshold, and φavg(t) is the weighted mean instantaneous frequency. Continuously updating x(t), if the signal satisfies θ(t)≤ξ, then x(t) is considered as the IMF component at this time. The Loughlin instantaneous bandwidth and weighted average instantaneous frequency are written by
(9)
(10)
2.2. Deep CNNs
With the rapid development of deep learning technology, CNNs have become core tools in signal processing and pattern recognition. In the field of bridge health monitoring and damage identification, CNNs have demonstrated exceptional performance. The GoogLeNet network [42] consists of 9 Inception modules connected in series, with each module comprising 1×1, 3×3, 5×5 convolutional kernels, and a 3×3 pooling layer, as shown in Figure 1(a). The Inception modules are capable of capturing features at different scales, enhancing the network ability to recognize various targets. Due to the introduction of the Inception structure, GoogLeNet has better performance compared to VGG and AlexNet in depth while having fewer parameters, resulting in lower memory and computational resource requirements. The overall structure of GoogLeNet is shown in Figure 1(b), which includes an input layer, a 7×7 convolutional layer, a 3×3 max pooling layer, two 3×3 convolutional layers, and nine Inception modules. These components are connected to a global average pooling layer, followed by a Dropout layer, a fully connected layer, a Softmax layer, and the final classification output layer.
Deep residual networks [43,44,45] address the issues of vanishing and exploding gradients in deep networks by introducing residual connections, enabling effective training of deep network models without compromising performance. The residual modules in the ResNet50 network use skip connections to directly pass the input to subsequent layers of the network, avoiding signal loss in deep networks. The structure of each residual block in ResNet50 is
(11)
where represents the feature maps obtained through convolution operations, written as:
(12)
where, W1 and W2 are the weights of the convolutional layers, and σ represents the Relu activation function.
To train the ResNet50 network, the cross-entropy loss function is typically used as the loss function, with the formula:
(13)
where, yi is the one-hot encoded true label, representing damage type i; P(i) is the predicted probability of damage type i output by the network.
Figure 2 shows the design of the ResNet50 network architecture. The residual network progressively extracts features through initial convolutional layers, pooling layers, and four residual modules (Block-1 to Block-4), and ultimately completes the classification task via a global average pooling layer (Avepool) and a fully connected layer (FC). To further enhance performance and training efficiency, ResNet leverages transfer learning strategies by utilizing models pretrained on the large-scale dataset ImageNet, transferring the learned general features to new tasks. The residual modules extract residual features from the input through convolutional layers and directly add these residuals to the input features via skip connections, generating the final output and ensuring effective transmission and reuse of features in deep networks.
EfficientNet achieves higher performance by balancing the width, the depth, and the resolution across three dimensions [46]. EfficientNet-b0 has fewer parameters and computational requirements but demonstrates outstanding performance in multiple image classification tasks. Its innovation lies in optimizing the network’s scale through a compound scaling strategy, which reduces computational overhead while maintaining accuracy. In damage recognition tasks, the efficiency of EfficientNet-b0 makes it an ideal choice [47], particularly in resource-constrained scenarios where it provides high performance, complementing transfer learning to achieve a balance between computational efficiency and model performance.
2.3Markov Transition Field for Encoding Time Series
The Markov transition field (MTF) is an image encoding method designed to capture the dynamic characteristics of time series signals. It transforms one-dimensional time series data into two-dimensional feature images with temporal correlations, thereby preserving the state transition relationships within the time series in a visual form.
For a vibration time series signal X={x1,x2,...,xn}, the signal is divided into Q quantile intervals based on its amplitude range. Each data point xi is assigned to the corresponding interval qj (where j∈[1,Q]). Based on the concept of a first-order Markov chain, the state transition probabilities between each pair of quantile intervals are written by:
(14)
(15)
where, wij represents the probability of transitioning to state qi at the current moment given that the previous moment was in state qj.
Since the Markov chain is memoryless, the transition probabilities depend only on the previous state, ignoring dependencies over longer time spans. To address this, the transition matrix W is extended to a matrix M that incorporates temporal position information, as shown in:
(16)
The elements of the MTF matrix are mapped to color pixels, forming a two-dimensional image with temporal correlations. The patterns in the image can reflect differences between healthy and damaged states.
2.4. A Bridge Damage Identification Framework Based on MTF
The bridge damage identification based on MTF is shown in Figure 3. In the first part, to remove noise from bridge monitoring acceleration signals, this paper adopts the TVFEMD method. This method decomposes the original signal into multiple Intrinsic Mode Functions (IMFs) and selects low-frequency components for signal reconstruction, thereby obtaining denoised signals that accurately reflect the bridge’s health condition.
In the second part, the reconstructed acceleration signals are converted into two-dimensional images using the MTF method. The MTF calculates the transfer probabilities between signal time sequences, mapping the signal’s temporal dependencies into image features, which facilitates subsequent deep learning model identification.
In the third part, three deep learning networks, including GoogLeNet, ResNet50, and EfficientNet-b0, were utilized to perform damage identification on the converted images. GoogLeNet provides basic convolutional feature extraction, ResNet50 addresses the vanishing gradient problem in deep networks through residual learning, and EfficientNet-b0 optimizes computational efficiency through compound scaling. Model performance is evaluated using metrics such as accuracy, recall, and F1 score.
This framework integrates TVFEMD signal processing, MTF image conversion, and deep learning to efficiently extract damage features from bridge monitoring data. By comparing the performance of different networks, the optimal model is selected, demonstrating strong practical application potential, particularly in SHM.
3. Case Study
3.1. Numerical Signal
Bridge monitoring data often comes with noise at different frequencies. Therefore, a simulated signal was constructed using two sine signals y1 and y2 with frequencies of 0.5 Hz and 2 Hz, respectively. A Gaussian white noise y3 with a signal-to-noise ratio of 10 dB. The signal parameters are: y1=3sin(2×0.5πt); y2=7sin(2×2πt). The sampling frequency is 100 Hz, and the duration is 10 s. The original signal and the signal after TVFEMD denoising are shown in Figure 4.
The numerical signal after VMD denoising and reconstruction is shown in Figure 5. To verify the effectiveness and superiority of the proposed method, both TVFEMD and VMD methods were used to decompose the simulated signal. The bandwidth threshold and B-spline order parameters for TVFEMD were set to 0.25 and 26, respectively [48].
Figure 6 shows the decomposition results of the two methods. It can be seen that both methods successfully extracted signals of different frequencies. The low-frequency components obtained by TVFEMD are smoother, while VMD exhibited mode mixing in the low-frequency components, where similar characteristics were distributed across different components at different time scales. Compared to VMD, TVFEMD can more precisely separate components with similar frequencies, especially in lower-order IMFs. This demonstrates TVFEMD’s advantages in maintaining modal purity and enhancing the interpretability of time-frequency features, which is crucial for subsequent structural damage assessment.
By performing a fast Fourier transform (FFT) on the IMF energy entropy increment, the true components were extracted, and spectral analysis was conducted. Figure 7 shows the effective component spectra under different methods. The results confirm that the signal frequencies are 0.5 Hz and 2.0 Hz, validating that the IMF energy entropy increment can accurately select these effective signals. The amplitudes of the simulated signals are 3 mm and 7 mm, and the effective signal amplitudes obtained using TVFEMD are more precise than those obtained using VMD. Additionally, compared to VMD, TVFEMD exhibits lower spectral energy in non-main frequency bands, indicating its superior ability to suppress frequency noise while retaining effective components.
3.2. The Old ADA Bridge
The Old ADA Bridge is located in Nara Prefecture, Japan, as shown in Figure 8. It is a simple-span steel truss bridge with a main span of 59.2 m and a bridge width of 3.6 m [49]. The bridge was demolished in 2012. Prior to its demolition, field vibration tests were conducted on the bridge under undamaged and four different damage conditions, with the specific damaged locations shown in Figure 10 [50]. The layout of the accelerometer measurement points is shown in Figure 9, with a sampling frequency of 200 Hz. It can be observed that 5 sensors were installed on one side of the damaged truss components, and 3 additional sensors were installed on the other side, providing sufficient information for bridge damage identification. This section investigates bridge damage identification using CNN under moving vehicle loading.
Under undamaged and four different damage conditions, 160 samples were collected for each condition, totaling 800 samples. The data were obtained from the vertical acceleration responses at eight measurement points on the deck of the Old ADA Bridge in Japan, acquired under vehicle excitation. The test details are shown in Table 1. During the testing process, the vibration responses of the deck under different damage conditions were recorded. The measured dataset was constructed using a sliding window method, with a sample size of 4500×2×10×8 for each damage condition. The dataset was divided into training, validation, and test sets in a 3:1:1 ratio. The training and validation sets were used to train the model, while the test set was used to evaluate the model’s performance in damage identification.
To improve signal quality and eliminate interference, appropriate signal processing techniques were applied to denoise and reconstruct the original data. Figure 11 shows a comparison of reconstructed signals under healthy and damage modes. The blue waveform represents the original signal, while the red waveform represents the reconstructed signal. It can be observed from the Figure 11 that the reconstructed signal retains the main features of the original waveform and reduces high-frequency noise components, thereby enhancing the signal-to-noise ratio. To analyze the intrinsic components of the signal, TVFEMD was employed for signal decomposition. Figure 12 presents the decomposition results for healthy and damage modes. The decomposed IMF are displayed in the form of three-dimensional surface plots. TVFEMD effectively decomposes the signal into multiple IMFs, capturing different oscillation patterns. The TVFEMD method can finely separate components with similar frequencies during the signal decomposition process.
4. Results and Discussion
4.1. Hyperparameter Settings and Training Processes
In this experiment, the hyperparameters for the bridge damage detection framework based on CNNs were set as follows: the initial learning rate was set to 0.0001, with a low learning rate chosen to avoid rapid convergence to a suboptimal solution during the early stages of training while ensuring training stability. The learning rate for the classifier was set to 0.001, the momentum coefficient for Stochastic Gradient Descent (SGD) was set to 0.9, the weight decay value was set to 0.01, and the number of training iterations was set to 150. The ResNet-50 architecture was developed using the PyTorch framework and trained and tested on a computer equipped with an Intel(R) Core i9-13700 CPU and an NVIDIA GeForce RTX 4070 GPU.
Figure 13 shows the variation of accuracy and loss of the original signal and the TVFEMD denoise-deconstructed signal during training. Figure 13 (a) and (b) represent the training accuracy and loss for the original signal, where blue circles indicate the training set and red circles indicate the validation set. It can be observed that the validation accuracy of the original signal gradually increases with the number of training epochs and stabilizes around the 60th epoch. However, the validation loss for the original signal remains at a high level throughout, and in the later stages of training, both the validation accuracy and loss exhibit significant fluctuations, indicating instability in the model’s generalization performance on the validation set and potential overfitting.
Figure 13 (c) and (d) shows the accuracy and loss for damage identification using the TVFEMD denoise-deconstructed signal. After TVFEMD processing, both the training and validation accuracy exhibit a smoother upward trend, with a more noticeable improvement in validation accuracy. The loss also shows lower fluctuations and gradually stabilizes and decreases, suggesting that TVFEMD effectively enhances the model’s stability and recognition accuracy after signal denoising and reconstruction. Compared to the original signal, the TVFEMD denoised and reconstructed signal demonstrates more stable and superior performance in terms of accuracy and loss, validating the effectiveness of TVFEMD in improving damage identification tasks.
4.2. Comparison of Different Signal Processing Methods
Figure 14 presents the confusion matrix for damage identification using ResNet-50, comparing the effects of different signal processing methods on the identification results. Specifically, Figure 14 corresponds to the following three signal processing methods: original signals without any processing; signals denoised and reconstructed using VMD; and signals denoised and reconstructed using TVFEMD. As shown in Figure 14, the damage identification results for original signals exhibit significant confusion among different categories, particularly between the INT and RCV categories, with a noticeable number of misclassifications by the classifier. Specifically, the RCV category in original signals is frequently misclassified as DMG1 and INT, indicating that unprocessed signals are significantly affected by noise interference, which impairs the accurate identification of damage patterns.
In contrast, signals processed with VMD demonstrate higher accuracy in damage identification. Notably, in the identification of the DMG1 category, the classifier can better distinguish among different damage states, with a marked reduction in misclassifications. However, signals processed with VMD still exhibit some misclassifications, particularly in the identification of the RCV category, where misclassification into other categories has not been eliminated. Signals processed with TVFEMD achieve the best recognition performance. Under this processing method, the misclassification rate in the confusion matrix is significantly reduced, with a substantial improvement in the identification accuracy of the RCV category. TVFEMD effectively removes noise from the signals, further enhancing the precision of damage identification and reducing confusion among different damage categories.
Figure 15 presents a feature distribution heatmap generated using the T-SNE method to visualize the effects of different signal decomposition approaches. Figure 15(a) shows the damage-sensitive features of the original signal, where the patterns are relatively complex, lacking clear separability, and the clustering boundaries are blurred. As seen in Figure 15(b), the VMD method effectively separates the signal features, though some areas remain somewhat mixed, failing to fully decouple different frequency components. The TVFEMD method achieves clearer separation of frequency components, resulting in purer signal modes and more pronounced clustering of damage features, as illustrated in Figure 15(c).
To further validate the effectiveness of the proposed method and understand its global features, Principal Component Analysis (PCA) was introduced for dimensionality reduction and visualization. By calculating the covariance matrix C of the data, the correlation between various features of the data was measured.
(17)
where, xi is the i-th sample, and each sample is a D-dimensional vector. By performing eigenvalue decomposition on C, the principal component θ is obtained.
Figure 16 shows the distribution of data processed by VMD and TVFEMD using PCA. Each solid circle represents a sample processed by TVFEMD, while each hollow circle represents data processed by VMD. As shown in the Figure 16, the data processed by TVFEMD is more concentrated across all categories (C1 to C5) and is clearly parallel to the baseline, indicating that TVFEMD effectively separates data from different categories and has better discriminability. On the other hand, the data processed by VMD is relatively more dispersed, especially between categories C2 and C5, suggesting that VMD has lower discriminability between certain categories. Through the dimensionality reduction and visualization of PCA, the advantages of TVFEMD in improving data separability and stability can be more intuitively observed, especially in high-dimensional data spaces.
4.3. Comparison of Different CNNs
Figure 17 presents a comparison of damage localization effects among three different networks when subjected to different signal processing methods. The comparison is evaluated using two metrics: accuracy and loss. As shown in Figure 17(a), the accuracy comparison reveals that signals processed by TVFEMD exhibit the best recognition performance across all network architectures. Specifically, the accuracy rates for TVFEMD-processed signals in ResNet-50, EfficientNet-b0, and GoogLeNet networks are 94 %, 93 %, and 90 %, respectively, which are significantly higher than those of the original signals. The accuracy of VMD denoising reconstructed signals also improves compared to the original signals, particularly in ResNet-50 and GoogLeNet architectures, reaching 90 % and 87 %, respectively. However, these results still fall short of those obtained from TVFEMD-processed signals. As seen in Figure 17(b), TVFEMD-processed signals demonstrate the lowest loss values across all network architectures. Signals reconstructed via VMD also show some improvement in loss values.
In addition to accuracy, recall and F1 score are commonly used as important metrics to evaluate the classification performance of each category [51]. To comprehensively assess the classification effectiveness of various models, this study also compares the performance of different pre-trained networks using recall and F1 score. Recall represents the ratio of correctly predicted positive samples to the actual positive samples:
(18)
where, TP denotes the number of samples correctly classified into the corresponding category, and FN denotes the number of samples that do not belong to the category but were incorrectly classified into it. The F1 score is the harmonic mean of precision and recall, taking into account both the accuracy and completeness of the classification model. Its value ranges from 0 to 1, with 1 indicating the best classification performance. When precision and recall differ significantly, the F1 score tends to shift toward the lower value. Its calculation formula is as follows:
(19)
where, TP is the number of true positive predictions, FP is the number of false positive predictions, and FN is the number of false negative predictions.
Figure 18 shows the impact of different signal processing methods on the classification performance of pre-trained networks, using Recall and F1 score as evaluation metrics. It comprehensively compares the performance of three typical deep neural networks—ResNet-50, EfficientNet-b0, and GoogLeNet—in damage identification tasks, presented in a radar chart format. The aim is to systematically evaluate the recognition capabilities of various models under different signal processing conditions, providing a reference for selecting a more optimal network structure in engineering applications. As shown in Figure 18, signals reconstructed after TVFEMD processing achieved the best classification performance across all network architectures, in terms of both recall and F1 score. Particularly in the identification of damage categories such as DMG1 and RCV, TVFEMD processing significantly improved recall and resulted in more stable and reliable classifier outputs. In comparison, while the VMD method improved noise interference in the original signals to some extent, its performance across most categories still fell short of TVFEMD. The original signals performed the worst across all evaluation metrics. In comparisons among different network architectures, the pre-trained ResNet-50 demonstrates the best overall performance across all three signal processing conditions, making it the preferred model for engineering applications. EfficientNet-b0 follows closely, while GoogLeNet shows relatively weaker performance in terms of recall and F1 score, indicating certain limitations in extracting complex damage features.
4.4. Feature Extraction Visualization
Figure 19 shows the distribution of high-dimensional features from three pre-trained networks after dimensionality reduction to a 3D space using PCA. PCA, including a linear dimensionality reduction tool, extracts the directions of maximum variance, thereby filtering out some noise, focusing on core information, and enabling the structural features of high-dimensional data to be presented in a 3D space. Figure 19 (a), (d), and (g) represent the feature points of the raw signal, which show a significantly mixed distribution across the three network architectures, with blurred boundaries between categories. This indicates that the raw input still carries a significant amount of noise, which affects the expression of high-level features. Figure 19 (b), (e), and (h) show that after VMD processing, the trend of feature aggregation is enhanced, noise interference is somewhat alleviated, and the spatial discriminability between categories is improved, particularly evident in EfficientNet-b0 and ResNet-50. This suggests that VMD is beneficial for denoising frequency band information. Figure 19 (c), (f), and (i) demonstrate that after TVFEMD processing, the feature point clouds exhibit the most distinct clustering effect across all networks, with clear boundaries between categories. This indicates that this method significantly improves feature separability by more effectively removing noise and reconstructing signal structures.
It can be seen from Figure 19 that the deep learning models with signal reconstruction demonstrate superior performance in feature extraction. Furthermore, by comparing network architectures, ResNet-50 exhibited the clearest feature distribution structure across all processing methods. After TVFEMD processing, category clustering has been further enhanced, which validates its efficient extraction and discrimination capabilities. The EfficientNet-b0 ranked second, while GoogLeNet demonstrated the weakest robustness to noise, with category boundaries remaining relatively blurred.
5. Conclusions
In practical bridge engineering, structural health monitoring has the challenges in low signal quality, difficulty in feature extraction, and insufficient accuracy in structural damage classification. This study proposed a damage identification framework that combines TVF-EMD with a pre-trained convolutional neural network. By enhancing signal feature separability and suppressing redundant noise, this method significantly improves classification performance and model stability. The main conclusions are summarized as follows:
(1) The TVFEMD method is introduced into deep learning-driven structural damage identification tasks, enabling adaptive denoising and time-frequency reconstruction of raw sensor signals. Compared with the traditional VMD method, the TVFEMD can effectively suppresses the interference of non-stationary noise in model training while preserving critical damage features.
(2) The ResNet-50 model has the strongest adaptability and highest recognition performance to features processed by TVF-EMD, compared with GoogLeNet and EfficientNet-b0 models. Therefore, ResNet-50 is more suitable for bridge damage identification tasks, offering better stability and engineering applicability.
(3) Under raw signal conditions, certain micro-damage categories are difficult to distinguish in the feature space. PCA provides interpretability for the deep network’s recognition mechanism, and the results show that TVF-EMD-processed data exhibits better clustering and clearer class boundaries in the feature space, effectively mitigating the issue of feature overlap in raw signals and providing more discriminative input.
This study provides a feasible and highly effective solution for deep learning-based structural damage identification tasks. However, challenges remain in practical engineering deployment, such as model light-weighting, real-time responsiveness, and cross-scenario adaptability. In further study, a lightweight TVF-EMD feature extraction mechanism will be developed for edge-side signal preprocessing. In addition, multi-source heterogeneous sensor data (e.g., strain, images, acoustic emissions) will be integrated to enhance the model performance.
Author Contributions
S. Z.: Writing - review and editing, Validation, Supervision, Resources, Project administration, Conceptualization. J. C.: Writing - original draft, Visualization, Software, Methodology, Investigation, Formal analysis, Data curation, Conceptualization. D. L.: Visualization, Formal analysis, Data curation. N. L.: Visualization, Formal analysis, Data curation, Funding acquisition. All authors have read and agreed to the published version of the manuscript.
Funding
This study is funded by the National Natural Science Foundation of China (grant number 51908068, 52178108, and 52408175), the Natural Science Foundation of Hunan Province (grant number 2024JJ5033).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be made available on request.
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Li, H.; Ren, L.; jia, Z.; Yi, T.; Li, D. State-of-the-art in structural health monitoring of large and complex civil infrastructures. J. Civ. Struct. Health. 2016, 6, 3–16. [Google Scholar] [CrossRef]
- Wang, L.; Dai, L.; Bian, H.; Ma, Y.; Zhang, J. Concrete cracking prediction under combined prestress and strand corrosion. Struct. Infrastruct. E. 2019, 15, 285–295. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, B.; Huang, Ke.; Wang, Lei. Probabilistic prediction and early warning for bridge bearing displacement using sparse variational gaussian process regression. Struct. Saf. 2025, 114, 102564. [Google Scholar] [CrossRef]
- Lu, N.; Wang, H.; Luo, Y.; Liu, X.; Liu, Y. Merging behaviour and fatigue life evaluation of multi-cracks in welds of OSDs. J. Constr. Steel. Res. 2025, 225, 109189. [Google Scholar] [CrossRef]
- Li, H.; Ou, J. The state of the art in structural health monitoring of cable-stayed bridges. J. Civ. Struct. Health. 2016, 6, 43–67. [Google Scholar] [CrossRef]
- Yuan, P.; Cai, Y.; Dong, B.; Wang, L. Topology optimization design for strengthening locally damaged structures: A non-gradient directed evolution method. Comput. Struct. 2024, 301, 107458. [Google Scholar] [CrossRef]
- Zhou, Y.; Shou, H.; Li, C.; Jiang, Y.; Tian, X. Punching shear behavior of ultra-high-performance fiber-reinforced concrete and normal strength concrete composite flat slabs. Eng. Struct. 2025, 322, 119123. [Google Scholar] [CrossRef]
- Ma, Y.; Peng, A.; Wang, L.; Dai, L.; Zhang, J. Structural performance degradation of cable-stayed bridges subjected to cable damage: Model test and theoretical prediction. Struct. Infrastruct. E. 2023, 19, 1173–1189. [Google Scholar] [CrossRef]
- Lu, N.; Zeng, W.; Cui, J.; Luo, Y.; Liu, X.; Liu, Y. An advanced computer vision method for noncontact vibration measurement of cables in cable-stayed bridges. Struct. Control. Hlth. 2025, 125404. [Google Scholar] [CrossRef]
- Hu, P.; Wang, S.; Han, Yan. ; Cai, C.; Zhang, Fei.; Yan, N. Mechanism analysis on wake-induced vibration of parallel hangers near a long-span suspension bridge tower. J. Wind. Eng. Ind. Aerod. 2023, 241, 105542. [Google Scholar] [CrossRef]
- Yan, W.; Yin, X.; Liu, Y.; Tuohuti, K.; Wu, L.; Liu, Y. Bridge damage detection based on vehicle scanning method and parallel convolutional neural network. Measurement 2025, 245, 116563. [Google Scholar] [CrossRef]
- Champneys, M.; Green, A.; Morales, A.; Silva, M.; Mascarenas, D. On the vulnerability of data-driven structural health monitoring models to adversarial attack. Struct. Health. Monit. 2021, 20, 1476–1493. [Google Scholar] [CrossRef]
- Lu, N.; Liu, J.; Wang, H.; Yuan, H.; Luo, Y. Stochastic propagation of fatigue cracks in welded joints of steel bridge decks under simulated traffic loading. Sensors 2023, 23(11), 5067. [Google Scholar] [CrossRef] [PubMed]
- Hu, P.; Yuan, B.; Han, Y.; Li, K.; Cai, C.; Chen, X. Numerical study on bifurcation characteristics of wind-induced vibration for an H-shaped section. Phys. Fluids. 2024, 36, 097156. [Google Scholar] [CrossRef]
- Yin, X.; Chen, X.; Yan, W.; Liu, Y.; Liu, Y. Bridge damping ratio identification based on function approximation-guided physics-informed neural networks. Structures, 2025, 74, 108540. [Google Scholar] [CrossRef]
- Su, Z.; Yu, J.; Xiao, X.; Wang, J.; Wang, X. Deep learning seismic damage assessment with embedded signal denoising considering three-dimensional time–frequency feature correlation. Eng. Struct. 2023, 286, 116148. [Google Scholar] [CrossRef]
- Dai, L.; Bian, H.; Wang, L.; Potier-Ferry, M.; Zhang, J. Prestress loss diagnostics in pretensioned concrete structures with corrosive cracking. J. Struct. Eng. 2020, 146, 04020013. [Google Scholar] [CrossRef]
- Wu, W.; Chen, C.; Jhou, J. A rapidly convergent empirical mode decomposition method for analyzing the environmental temperature effects on stay cable force. Comput-Aided. Civ. Inf. [CrossRef]
- Aied, H.; González, A.; Cantero, D. Identification of sudden stiffness changes in the acceleration response of a bridge to moving loads using ensemble empirical mode decomposition. Mech. Syst. Signal. PR. 2016, 66, 314–338. [Google Scholar] [CrossRef]
- Li, T.; Hou, R.; Zheng, K.; Zhang, Z.; Liu, B. Automated method for structural modal identification based on multivariate variational mode decomposition and its applications in damage characteristics of subway tunnels. Eng. Fail. Anal. 2024, 163, 108499. [Google Scholar] [CrossRef]
- Guo, J.; Zhen, D.; Li, H.; Shi, Z.; Gu, F.; Ball, A. Fault feature extraction for rolling element bearing diagnosis based on a multi-stage noise reduction method. Measurement 2019, 139, 226–235. [Google Scholar] [CrossRef]
- Wang, M.; Weng, S.; Yu, X.; Yan, J.; Yin, P. Structural damage identification based on time-varying modal mode shape of wavelet transformation. J. Vib. Shock. 2021, 40(16), 10–19. [Google Scholar]
- Wang, H.; Chen, S.; Zhai, W. Data-driven adaptive chirp mode decomposition with application to machine fault diagnosis under non-stationary conditions. Mech. Syst. Signal. PR. 2023, 188, 109997. [Google Scholar] [CrossRef]
- Berrouche, Y.; Vashishtha, G.; Chauhan, S.; Zimroz, R. Local damage detection in rolling element bearings based on a single ensemble empirical mode decomposition. Knowl-Based. Syst. 2024, 301, 112265. [Google Scholar] [CrossRef]
- Zare, M.; Nouri, N. End-effects mitigation in empirical mode decomposition using a new correlation-based expansion model. Mech. Syst. Signal. PR. 2023, 194, 110205. [Google Scholar] [CrossRef]
- Huang, T.; Wang, Y.; Shang, X. Time-varying modal identification of structures under seismic excitations using a novel time-frequency method. Soil. Dyn. Earthq. Eng. 2024, 178, 108501. [Google Scholar] [CrossRef]
- Zhang, S.; Xu, F.; Hu, M.; Zhang, L.; Liu, H.; Li, M. A novel denoising algorithm based on TVF-EMD and its application in fault classification of rotating machinery. Measurement 2021, 179, 109337. [Google Scholar] [CrossRef]
- Xin, J.; Zhou, C.; Jiang, Y. A signal recovery method for bridge monitoring system using TVFEMD and encoder-decoder aided LSTM. Measurement 2023, 214, 112797. [Google Scholar] [CrossRef]
- Li, S.; Xin, J.; Jiang, Y. Temperature-induced deflection separation based on bridge deflection data using the TVFEMD-PE-KLD method. J. Civ. Struct. Health. 2023, 13(2), 781–797. [Google Scholar] [CrossRef]
- Lin, Y.; Nie, Z.; Ma, H. Structural damage detection with automatic feature-extraction through deep learning. Comput-Aided. Civ. Inf. 1025. [Google Scholar] [CrossRef]
- Paymode, A.; Malode, V. Transfer learning for multi-crop leaf disease image classification using convolutional neural network VGG. Artificial Intelligence in Agriculture 2022, 6, 23–33. [Google Scholar] [CrossRef]
- Sun, L.; Shang, Z.; Xia, Y.; Bhowmick, S.; Nagarajaiah, S. Review of bridge structural health monitoring aided by big data and artificial intelligence: From condition assessment to damage detection. J. Struct. Eng. 2020, 146(5), 04020073. [Google Scholar] [CrossRef]
- Ma, Y.; Guo, Z.; Wang, L.; Zhang, J. Probabilistic life prediction for reinforced concrete structures subjected to seasonal corrosion-fatigue damage. J. Struct. Eng. 2020, 146(7), 04020117. [Google Scholar] [CrossRef]
- Xiao, J.; Peng, J.; Yang, Y.; Dong, Y.; Zhang, J. Comprehensive assessment of prestress loss in post-tensioned prestressed concrete structures exposed to wet-dry cycles in chloride environments. Eng. Struct. 2025, 328, 119691. [Google Scholar] [CrossRef]
- Peng, K.; Zhou, W.; Jiang, L.; Xiong, L.; Yu, J. VHXLA: A post-earthquake damage prediction method for high-speed railway track-bridge system using VMD and hybrid neural network. Eng. Struct. 2024, 298, 117048. [Google Scholar] [CrossRef]
- Wang, M.; Xiong, C.; Shang, Z. Predictive evaluation of dynamic responses and frequencies of bridge using optimized VMD and genetic algorithm-back propagation approach. J. Civ. Struct. Health. 2024, 15, 173–190. [Google Scholar] [CrossRef]
- Ding, Y.; Ye, X.; Guo, Y. A multistep direct and indirect strategy for predicting wind direction based on the EMD-LSTM model. Struct. Control. Hlth. 2023, 4950487. [Google Scholar] [CrossRef]
- Dizaji, M.; Mao, Z.; Haile, M. A hybrid-attention-ConvLSTM-based deep learning architecture to extract modal frequencies from limited data using transfer learning. Mech. Syst. Signal. PR. 2023, 187, 109949. [Google Scholar] [CrossRef]
- Liu, C.; Xu, X.; Wu, J.; Zhu, H.; Wang, C. Deep transfer learning-based damage detection of composite structures by fusing monitoring data with physical mechanism. Eng. Appl. Artif. Intel. 2023, 123, 106245. [Google Scholar] [CrossRef]
- Lu, N.; Liu, Z.; Cui, J.; Hu, L.; Xiao, X.; Liu, Y. Structural damage diagnosis of a cable-stayed bridge based on VGG-19 networks and markov transition field: Numerical and experimental study. Smart. Mater. Struct. 0250. [Google Scholar]
- Mao, M.; Xu, B.; Sun, Y.; Tan, K.; Wang, Y.; Zhou, C.; Yang, J. Application of FCEEMD-TSMFDE and adaptive CatBoost in fault diagnosis of complex variable condition bearings. Sci. Rep. 2024, 14(1), 1–30. [Google Scholar] [CrossRef]
- Teerakawanich, N.; Leelaruji, T.; Pichetjamroen, A. Short term prediction of sun coverage using optical flow with GoogLeNet. Energy. Rep. 2020, 6, 526–531. [Google Scholar] [CrossRef]
- Wang, R.; Chencho, A.; Li, J.; Li, L.; Hao, H.; Liu, W. Deep residual network framework for structural health monitoring. Struct. Control. Hlth. 2021, 20(4), 1443–1461. [Google Scholar] [CrossRef]
- Li, Y.; Bao, T.; Xu, B.; Shu, X.; Zhou, Y.; Du, Y.; Wang, K.; Zhang, K. A deep residual neural network framework with transfer learning for concrete dams patch-level crack classification and weakly-supervised localization. Measurement, 2022, 188, 110641. [Google Scholar] [CrossRef]
- Mao, Y.; Li, X.; Duan, M.; Feng, Y.; Wang, J.; Men, H.; Yang, H. A novel mooring system anomaly detection framework for SEMI based on improved residual network with attention mechanism and feature fusion. Reliab. Eng. Syst. Safe. 2024, 245, 109970. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. International conference on machine learning. PMLR 2019, 6105–6114. [Google Scholar]
- Wang, L.; Yi, S.; Yu, Y.; Gao, C.; Samali, B. Automated ultrasonic-based diagnosis of concrete compressive damage amidst temperature variations utilizing deep learning. Mech. Syst. Signal. PR. 2024, 221, 111719. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, Z.; Miao, Q.; Wang, L. An optimized time varying filtering based empirical mode decomposition method with grey wolf optimizer for machinery fault diagnosis. J. Sound. Vib. 2018, 418, 55–78. [Google Scholar] [CrossRef]
- Kim, C.; Zhang, F.; Chang, K.; McGetrick, P.; Goi, Y. Ambient and vehicle-induced vibration data of a steel truss bridge subject to artificial damage. J. Bridge. Eng. 2021, 26(7), 04721002. [Google Scholar] [CrossRef]
- Zhou, X.; Kim, C.; Zhang, F.; Chang, K. Vibration-based Bayesian model updating of an actual steel truss bridge subjected to incremental damage. Eng. Struct. 2022, 260, 114226. [Google Scholar] [CrossRef]
- Talaei, S.; Zhu, X.; Li, J.; Yu, Y.; Chan, T. Transfer learning based bridge damage detection: Leveraging time-frequency features. Structures 2023, 57, 105052. [Google Scholar] [CrossRef]
Figure 1.
GoogLeNet network model: (a) Inception-v1 architecture diagram (b) GoogLeNet network architecture.
Figure 1.
GoogLeNet network model: (a) Inception-v1 architecture diagram (b) GoogLeNet network architecture.
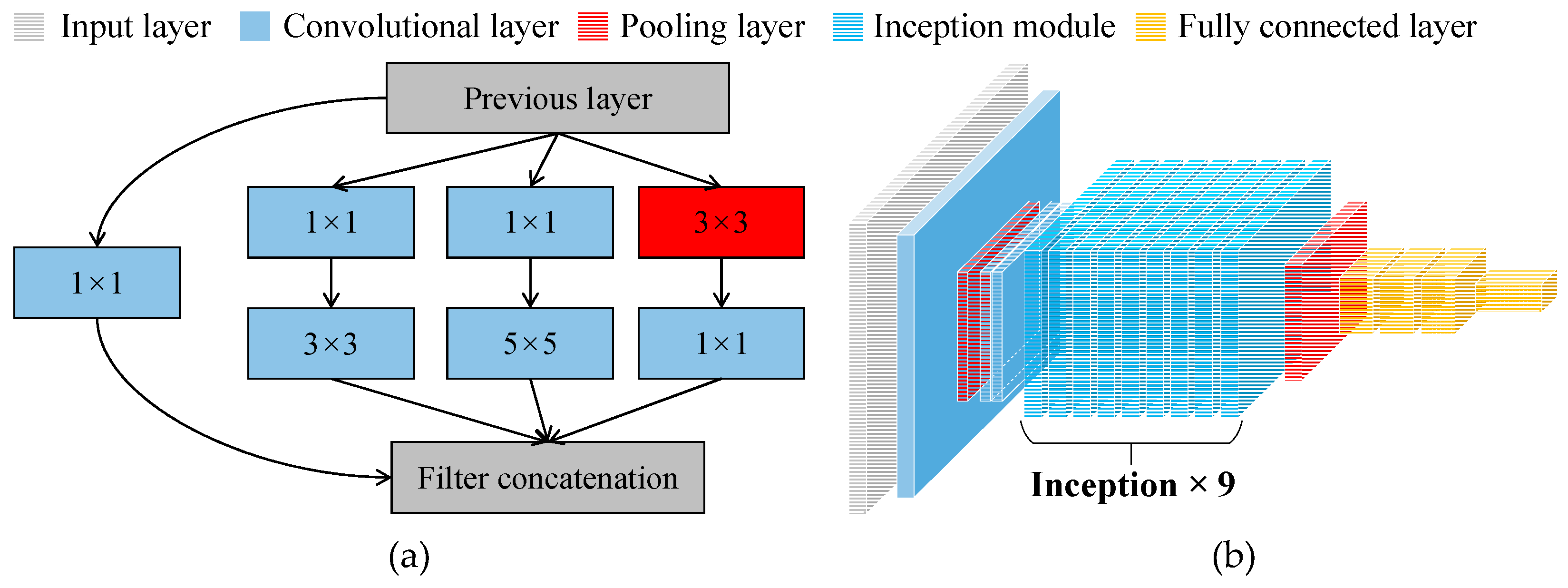
Figure 2.
ResNet50 network architecture and residual block design.
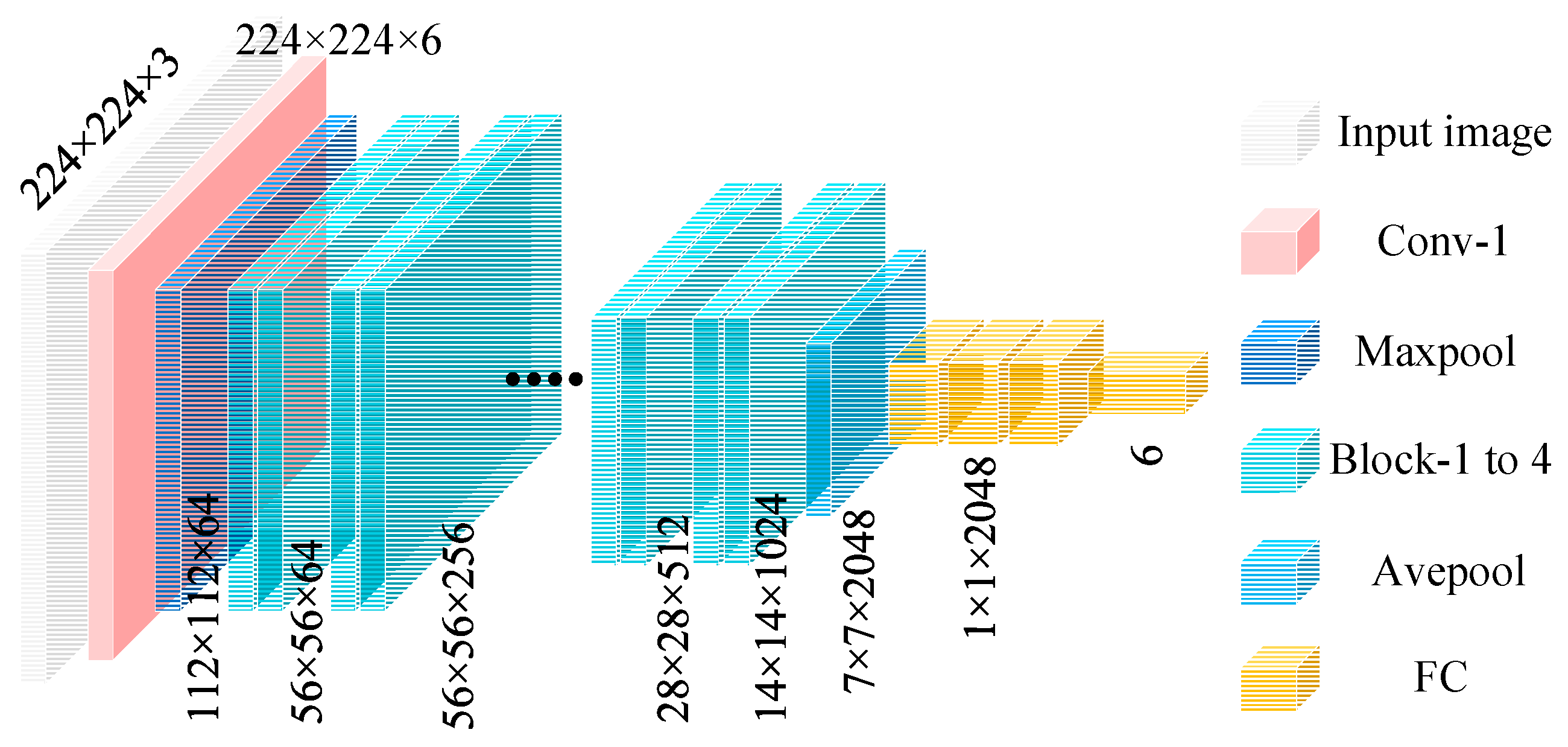
Figure 3.
Bridge damage identification framework based on MTF.

Figure 4.
Numerical signals before and after TVFEMD denoising and reconstruction: (a) Noisy signal; (b) Denoised signal.
Figure 4.
Numerical signals before and after TVFEMD denoising and reconstruction: (a) Noisy signal; (b) Denoised signal.
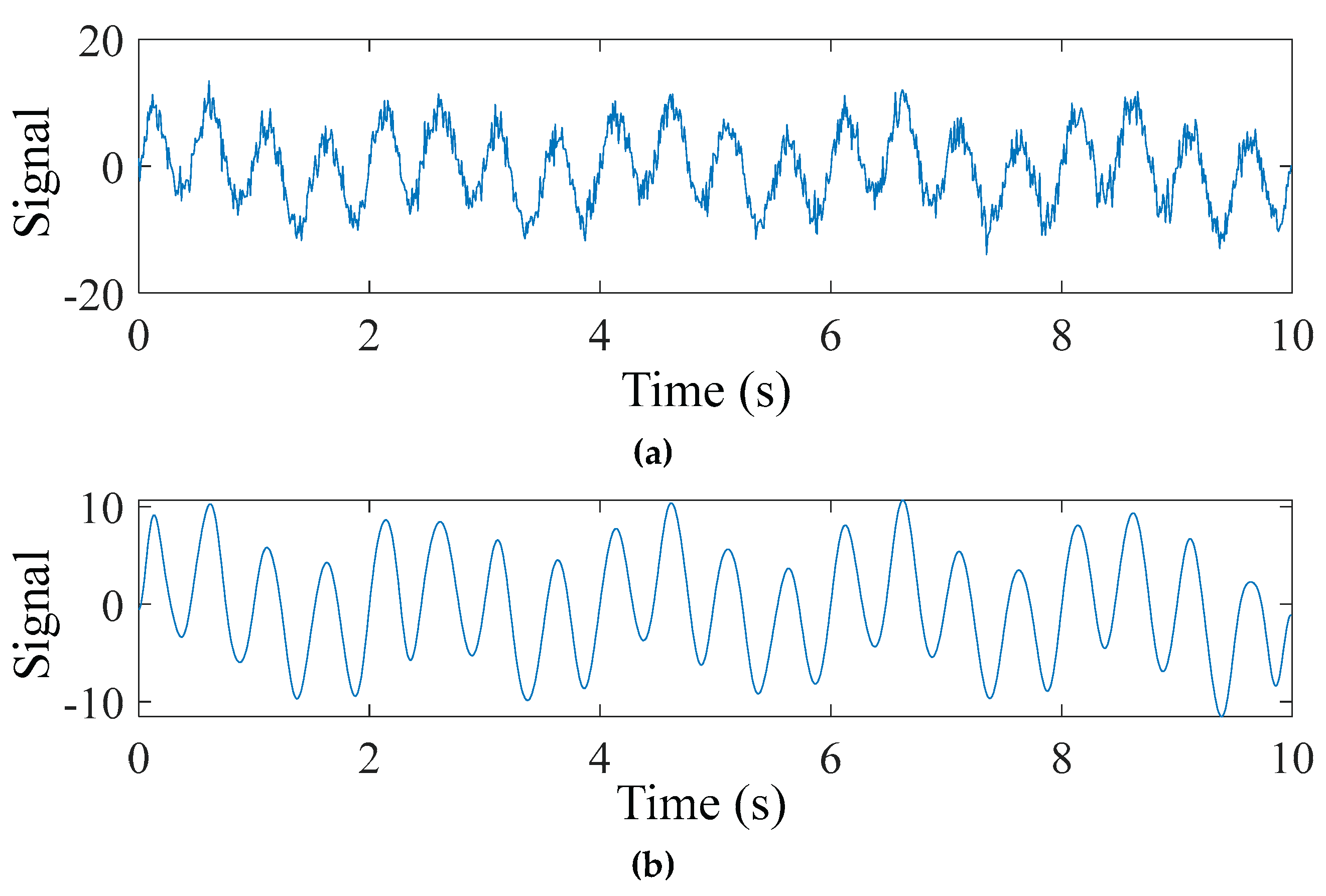
Figure 5.
Comparison of VMD denoising and reconstruction.
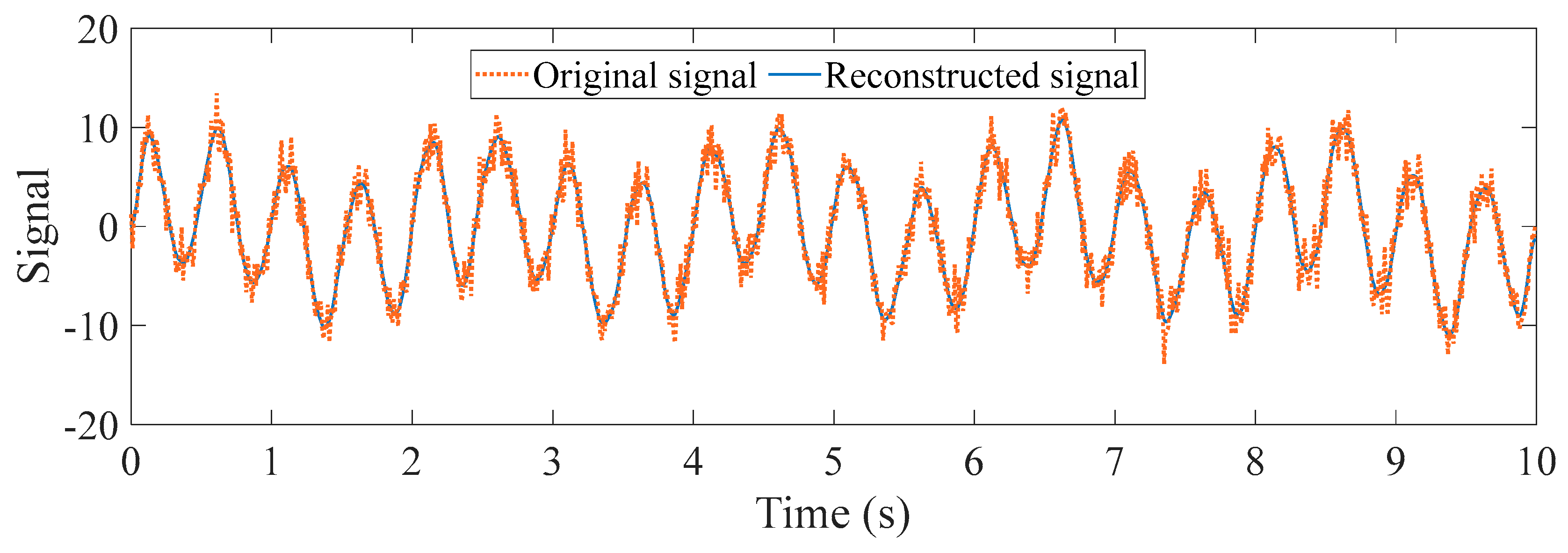
Figure 6.
Decomposition results of two methods: (a) TVFEM; (b) VMD.
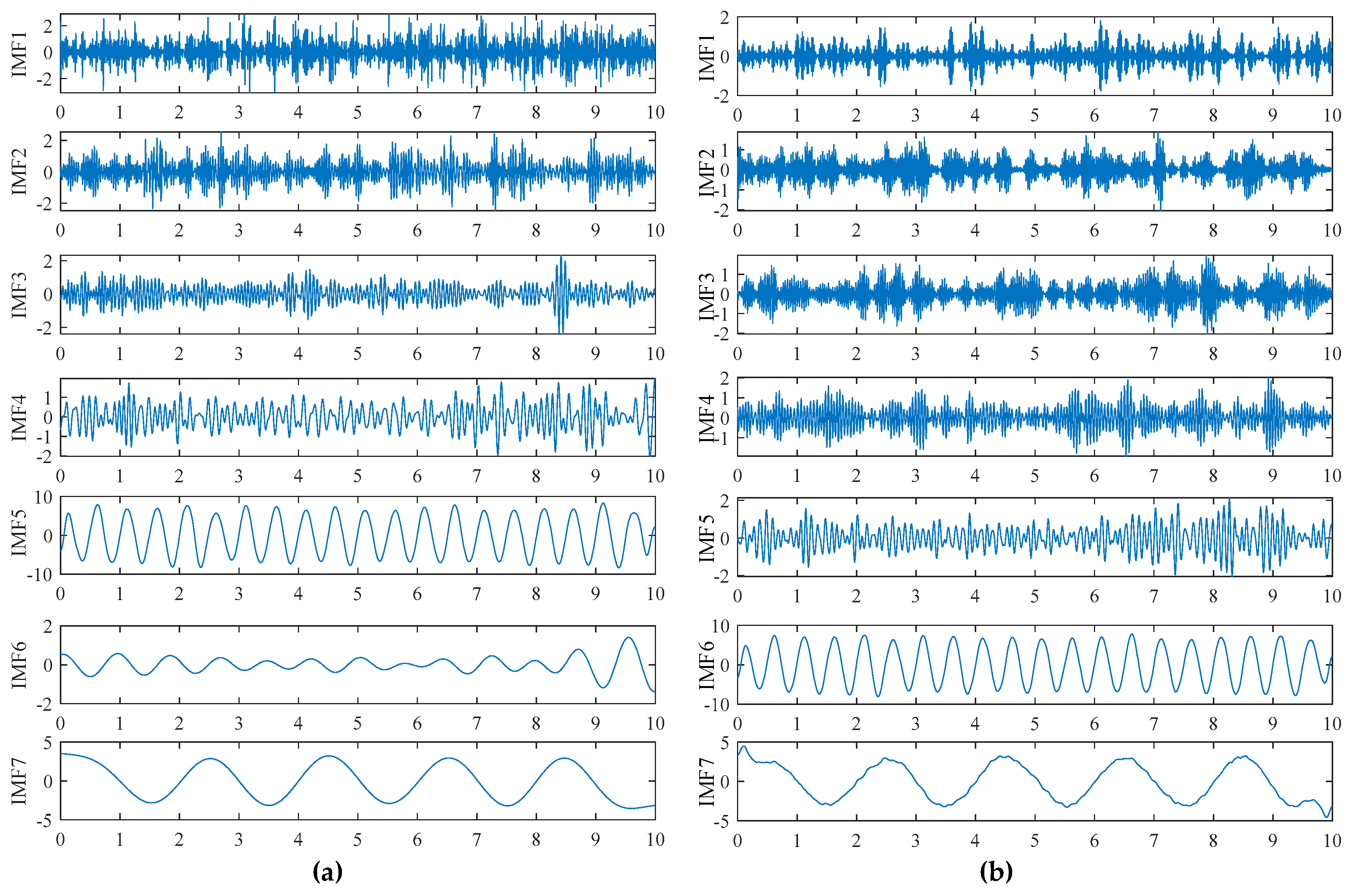
Figure 7.
Comparison of effective IMF component spectra under different methods: (a) IMF component spectrum using TVFEMD; (b) IMF component spectrum using VMD.
Figure 7.
Comparison of effective IMF component spectra under different methods: (a) IMF component spectrum using TVFEMD; (b) IMF component spectrum using VMD.
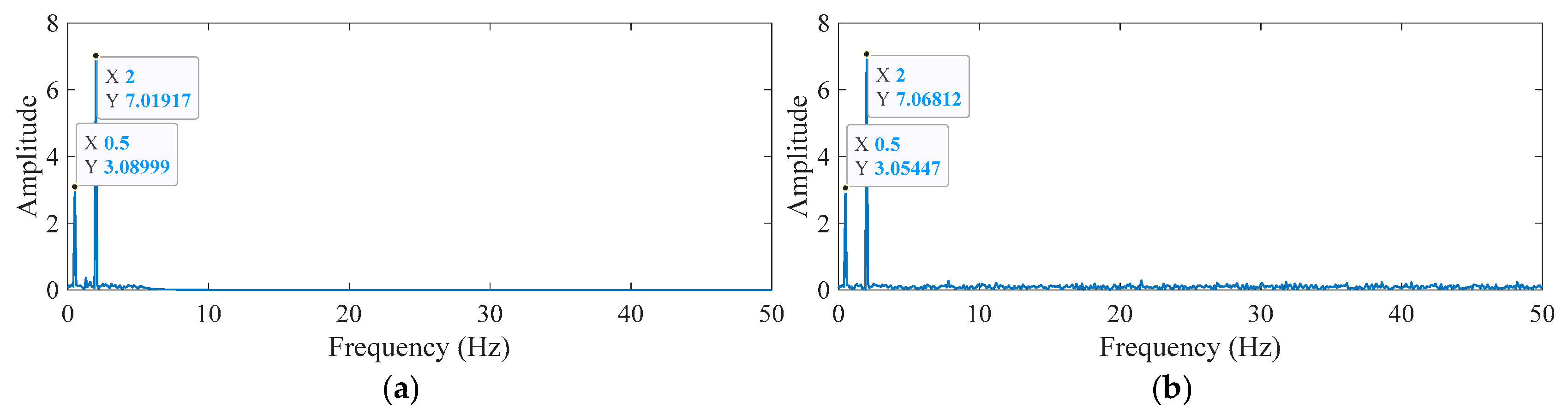
Figure 8.
Old ADA Bridge: (a) Elevation view; (b) Cross-sectional view.

Figure 9.
Layout of accelerometer sensors.
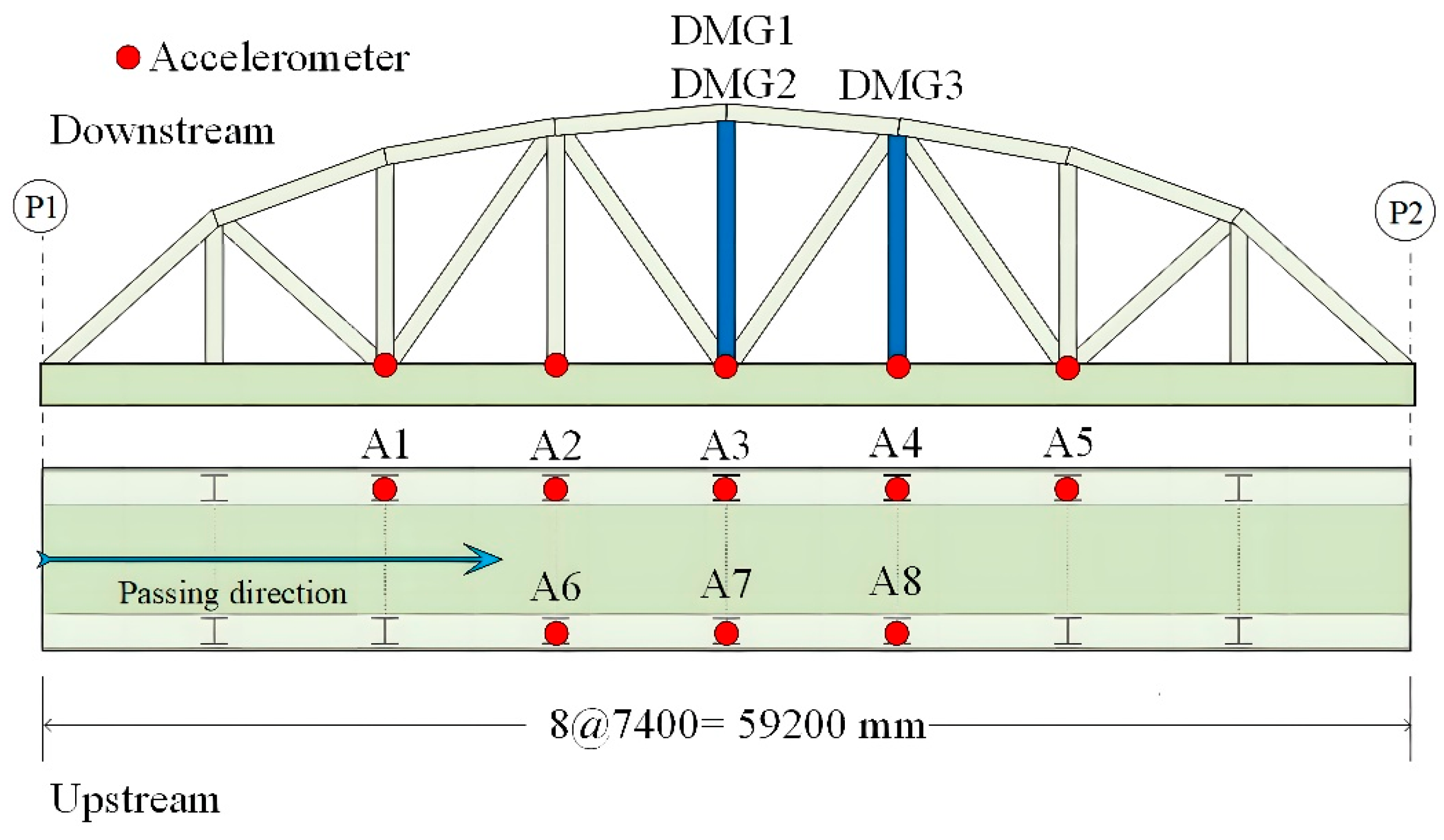
Figure 10.
Schematic diagram and photographs of damage modes for the Old ADA bridge: (a) Damage mode schematic diagram; (b) Photograph of damaged locations.
Figure 10.
Schematic diagram and photographs of damage modes for the Old ADA bridge: (a) Damage mode schematic diagram; (b) Photograph of damaged locations.

Figure 11.
Comparison of signals before and after TVFEMD processing: (a)INT; (b)DMG1.
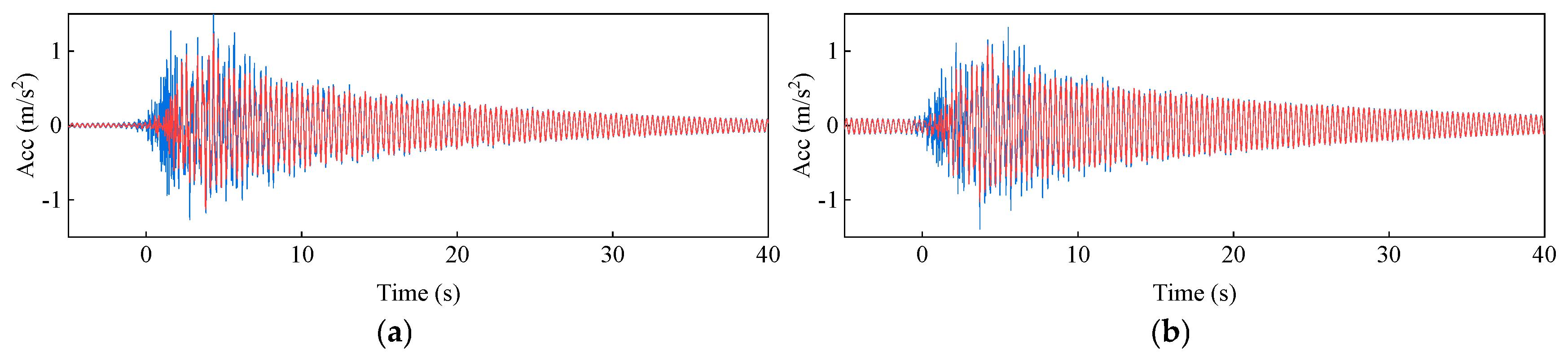
Figure 12.
Decomposition results of TVFEMD: (a)INT; (b)DMG1.
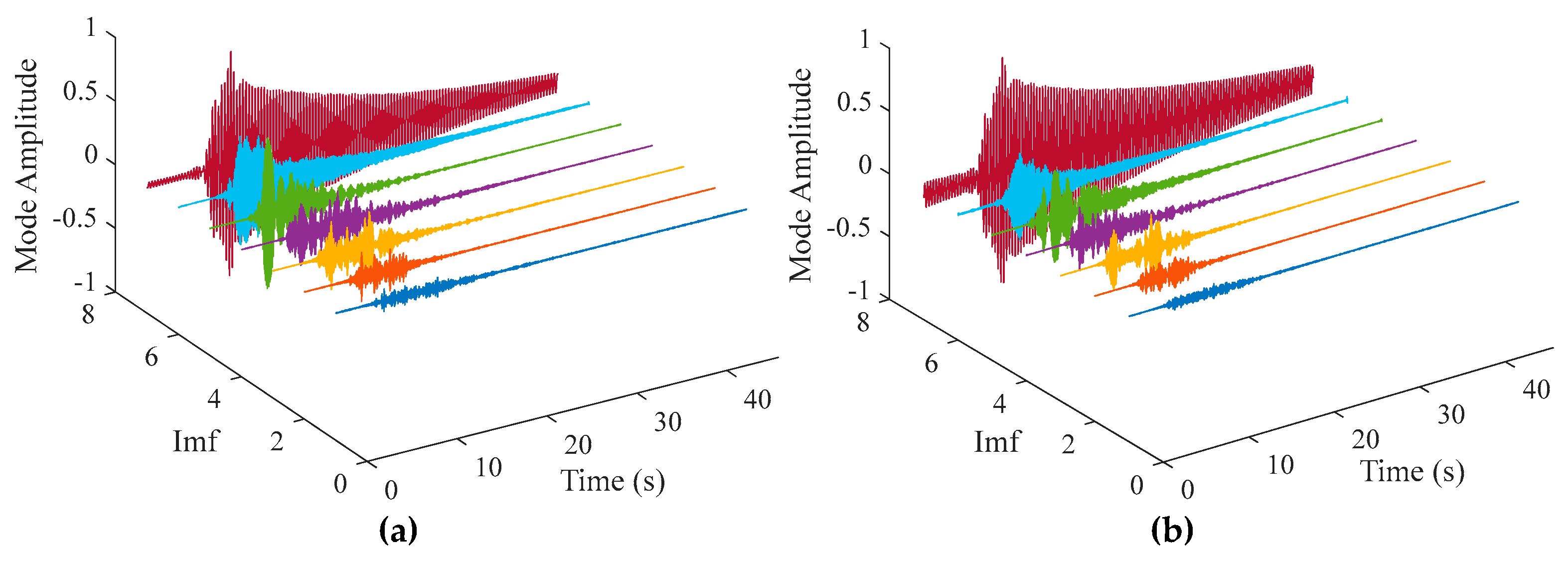
Figure 13.
Comparison of accuracy and loss: (a) Accuracy of the original signal; (b) Loss of the original signal; (c) Accuracy of TVFEMD reconstructed signal; (d) Loss of TVFEMD reconstructed signal.
Figure 13.
Comparison of accuracy and loss: (a) Accuracy of the original signal; (b) Loss of the original signal; (c) Accuracy of TVFEMD reconstructed signal; (d) Loss of TVFEMD reconstructed signal.
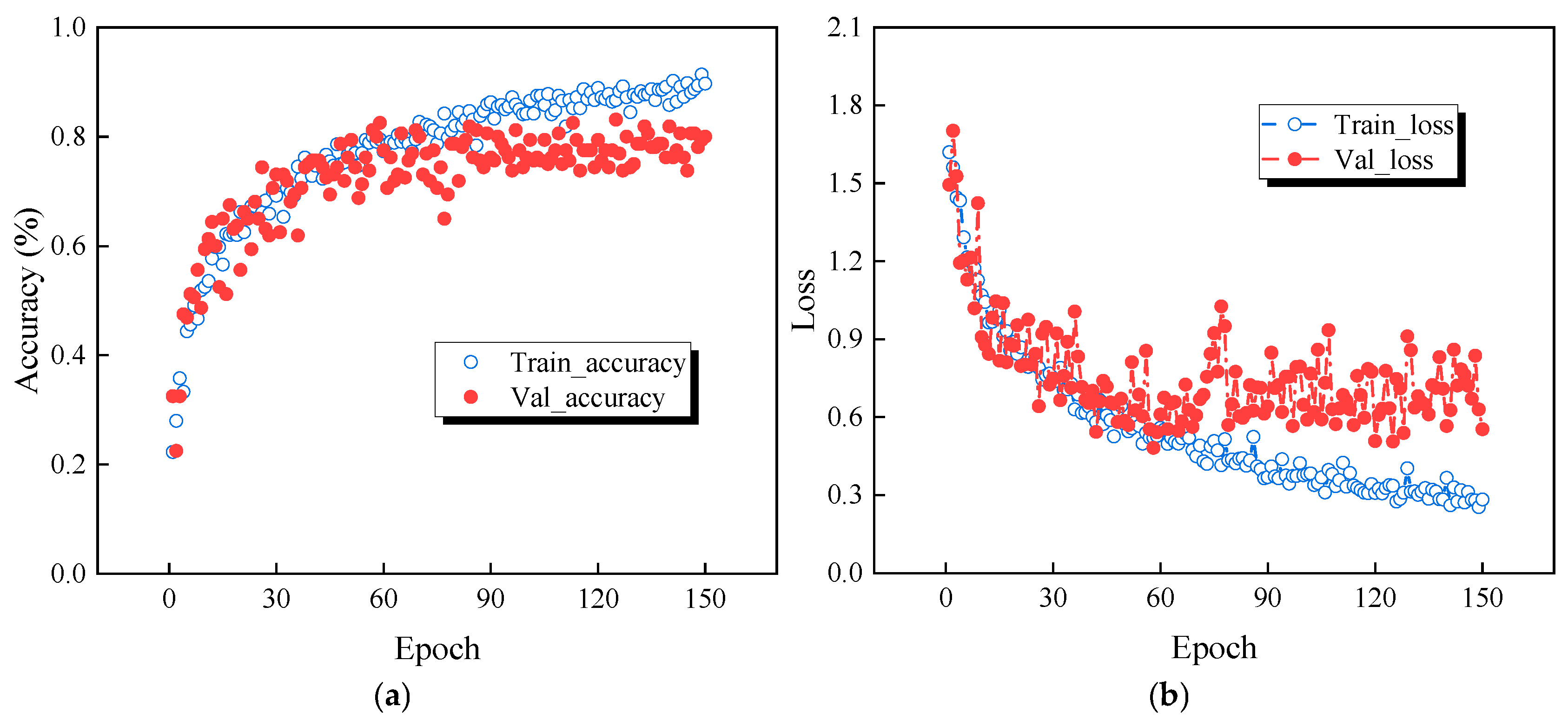
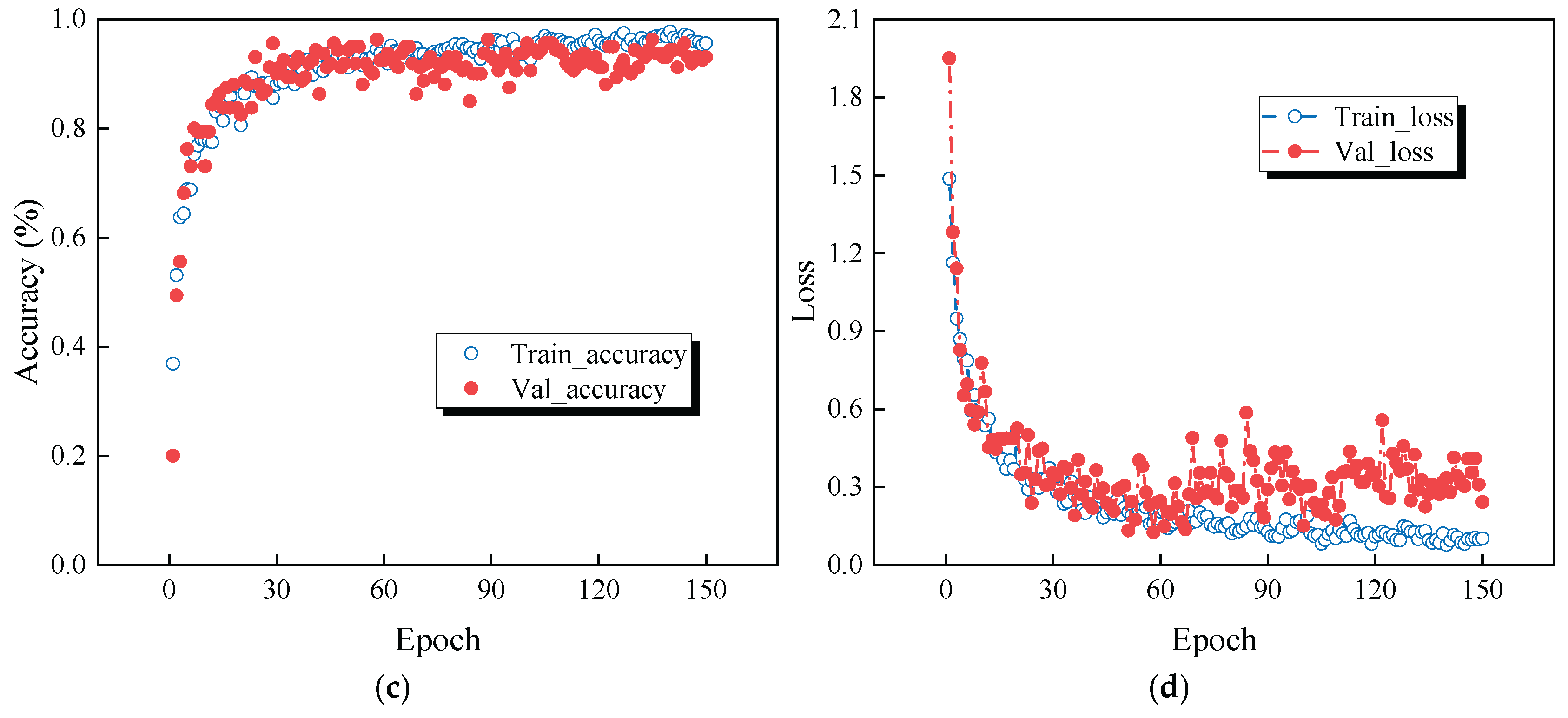
Figure 14.
Confusion matrix of different signal processing methods: (a) original; (b)VMD; (c)TVFEMD.
Figure 14.
Confusion matrix of different signal processing methods: (a) original; (b)VMD; (c)TVFEMD.
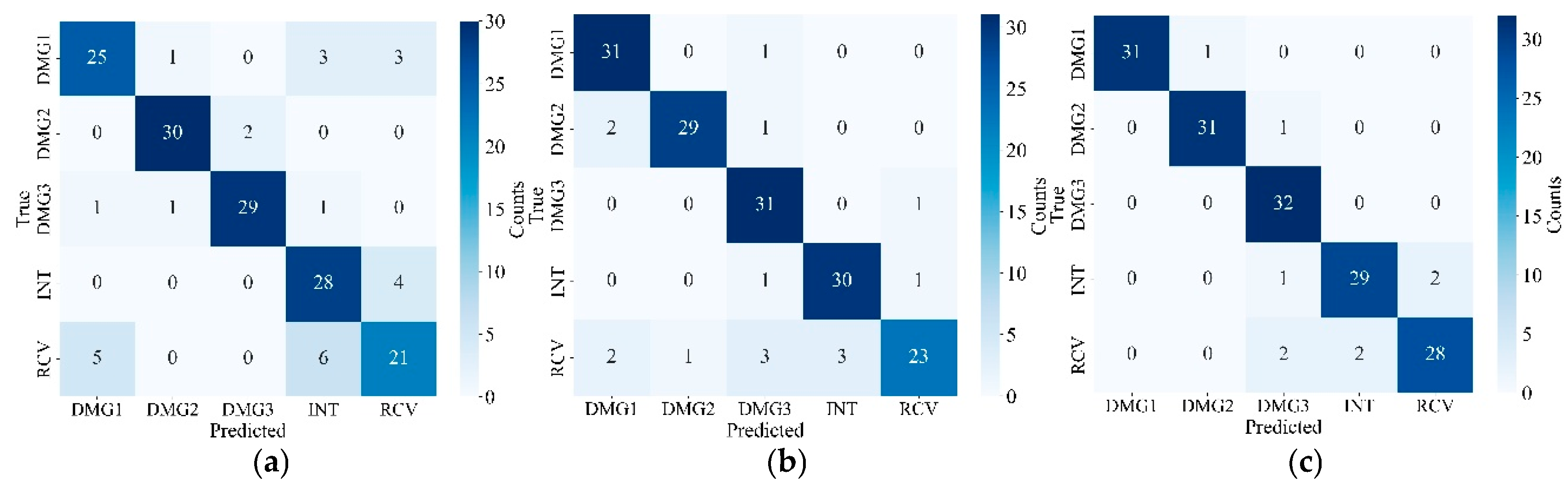
Figure 15.
T-SNE feature distribution heatmap: (a) original; (b)VMD; (c)TVFEMD.
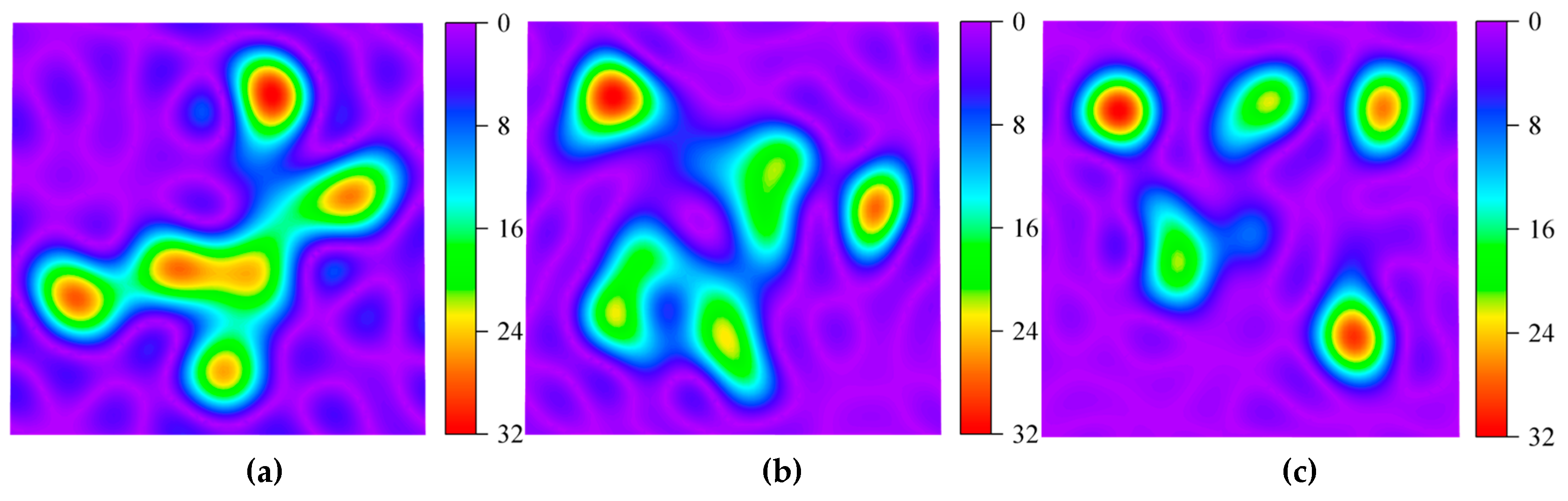
Figure 16.
PCA visualization using TVFEMD and VMD.
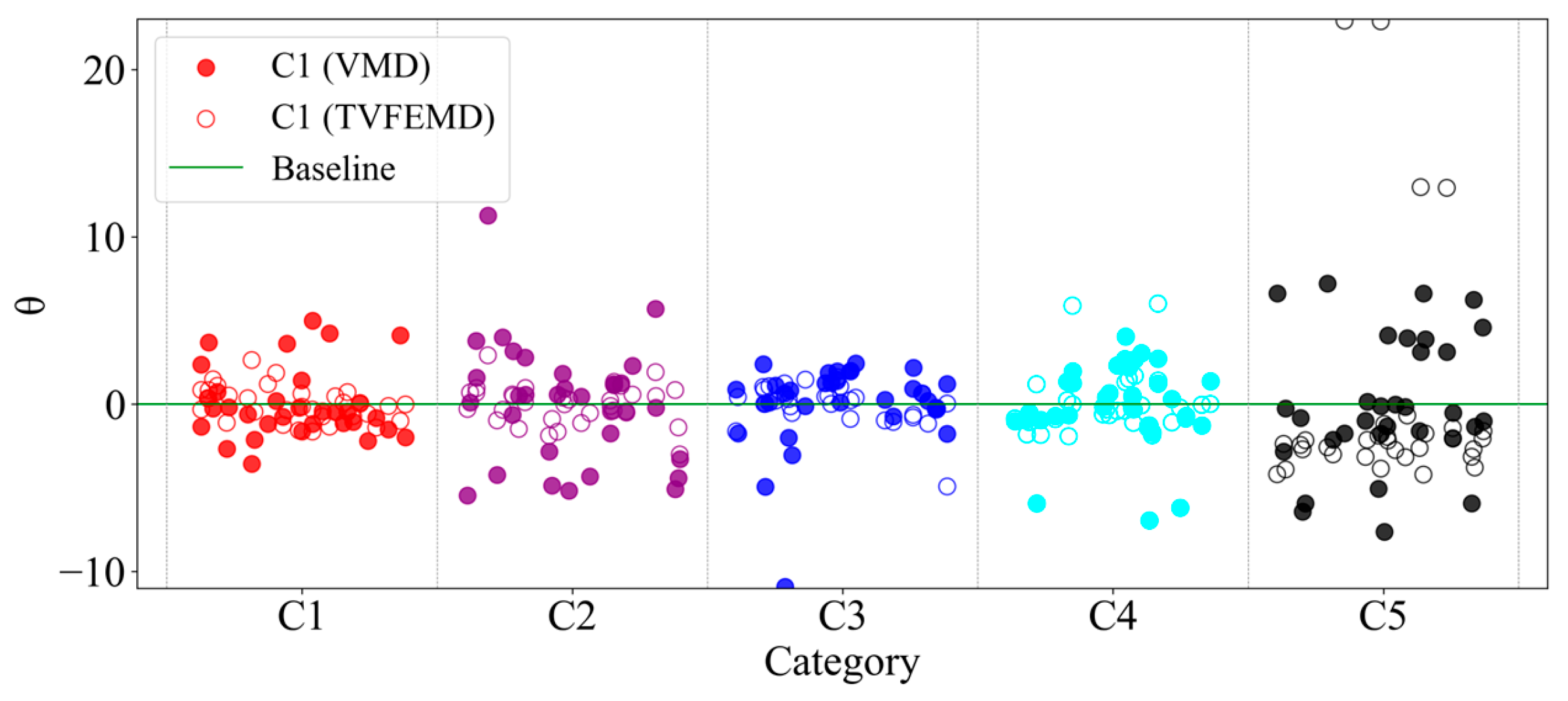
Figure 17.
Comparison of accuracy and loss among three networks.
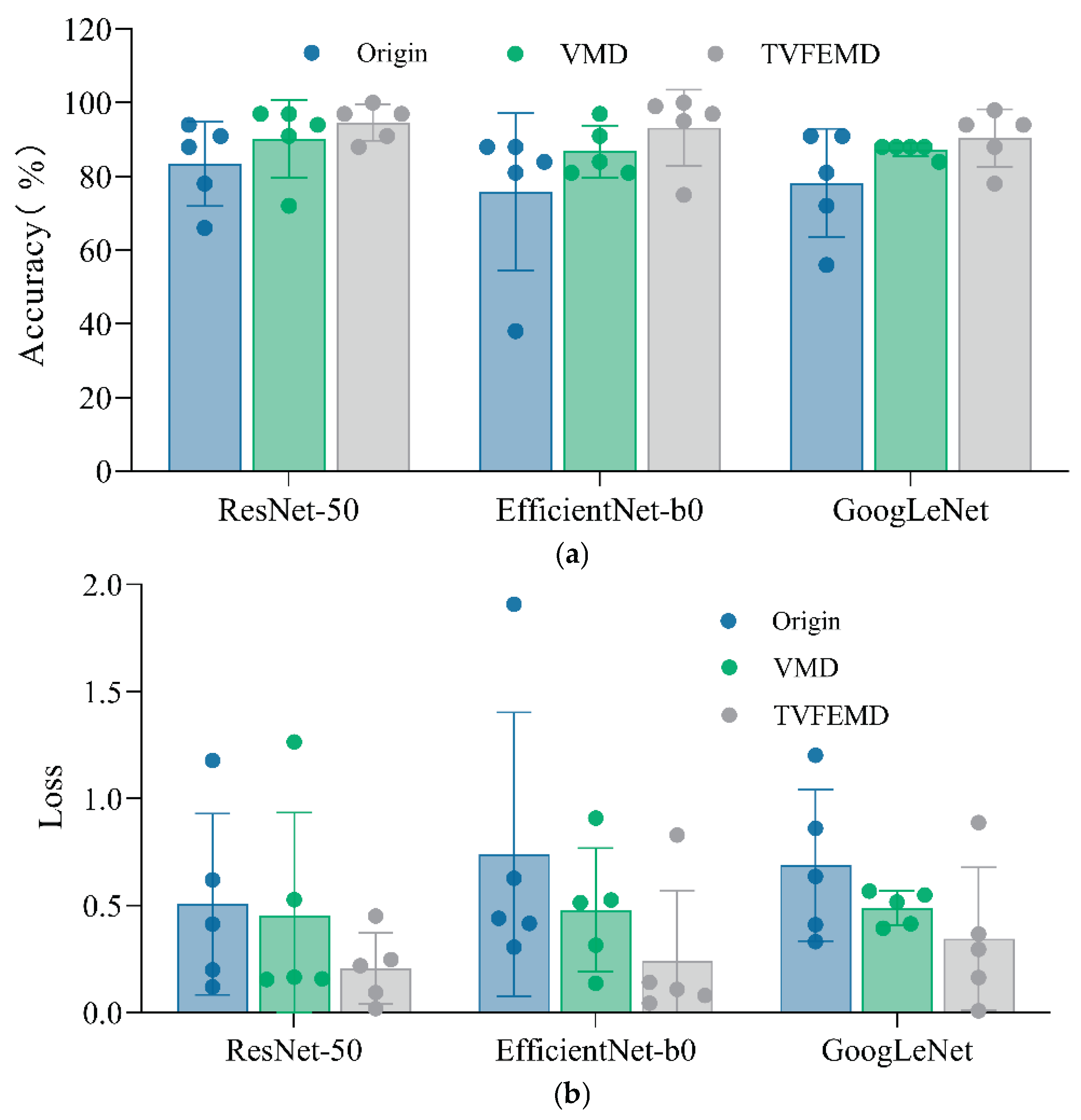
Figure 18.
Comparison of classification performance for different combinations of networks and denoising methods: (a) (a)ResNet-Recall; (b) Efficientnet-b0- Recall; (c) GoogLeNet- Recall; (d)ResNet- F1 score; (e) Efficientnet-b0- F1 score; (f) GoogLeNet- F1 score.
Figure 18.
Comparison of classification performance for different combinations of networks and denoising methods: (a) (a)ResNet-Recall; (b) Efficientnet-b0- Recall; (c) GoogLeNet- Recall; (d)ResNet- F1 score; (e) Efficientnet-b0- F1 score; (f) GoogLeNet- F1 score.
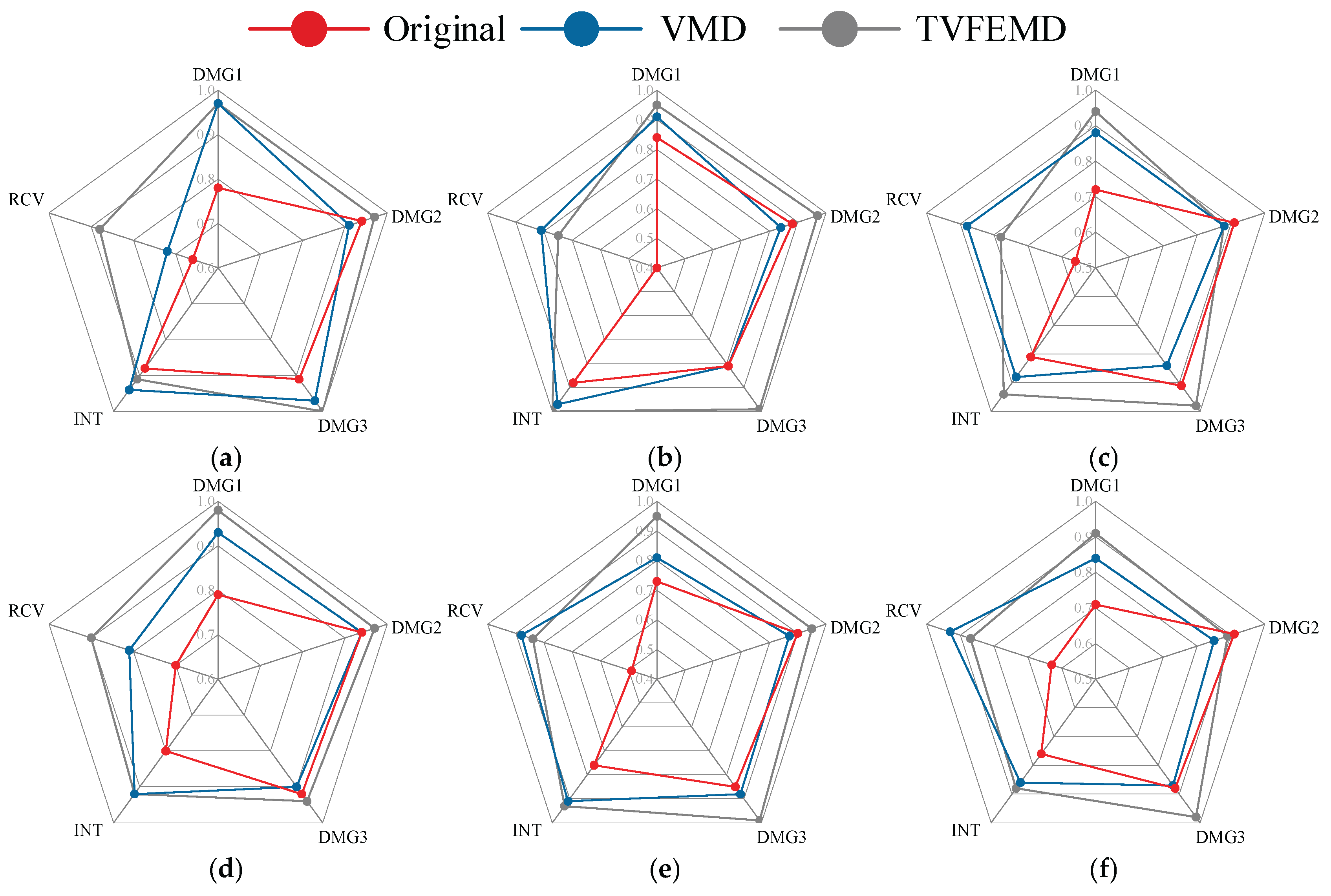
Figure 19.
Comparison of data feature distributions extracted by PCA: (a) GoogLeNet-original; (b) GoogLeNet-VMD; (c) GoogLeNet-TVFEMD; (d) Efficientnet-b0- original; (e) Efficientnet-b0-VMD; (f) Efficientnet-b0-TVFEMD; (g) ResNet50- original; (h) ResNet50-VMD; (i) ResNet50-TVFEMD.
Figure 19.
Comparison of data feature distributions extracted by PCA: (a) GoogLeNet-original; (b) GoogLeNet-VMD; (c) GoogLeNet-TVFEMD; (d) Efficientnet-b0- original; (e) Efficientnet-b0-VMD; (f) Efficientnet-b0-TVFEMD; (g) ResNet50- original; (h) ResNet50-VMD; (i) ResNet50-TVFEMD.
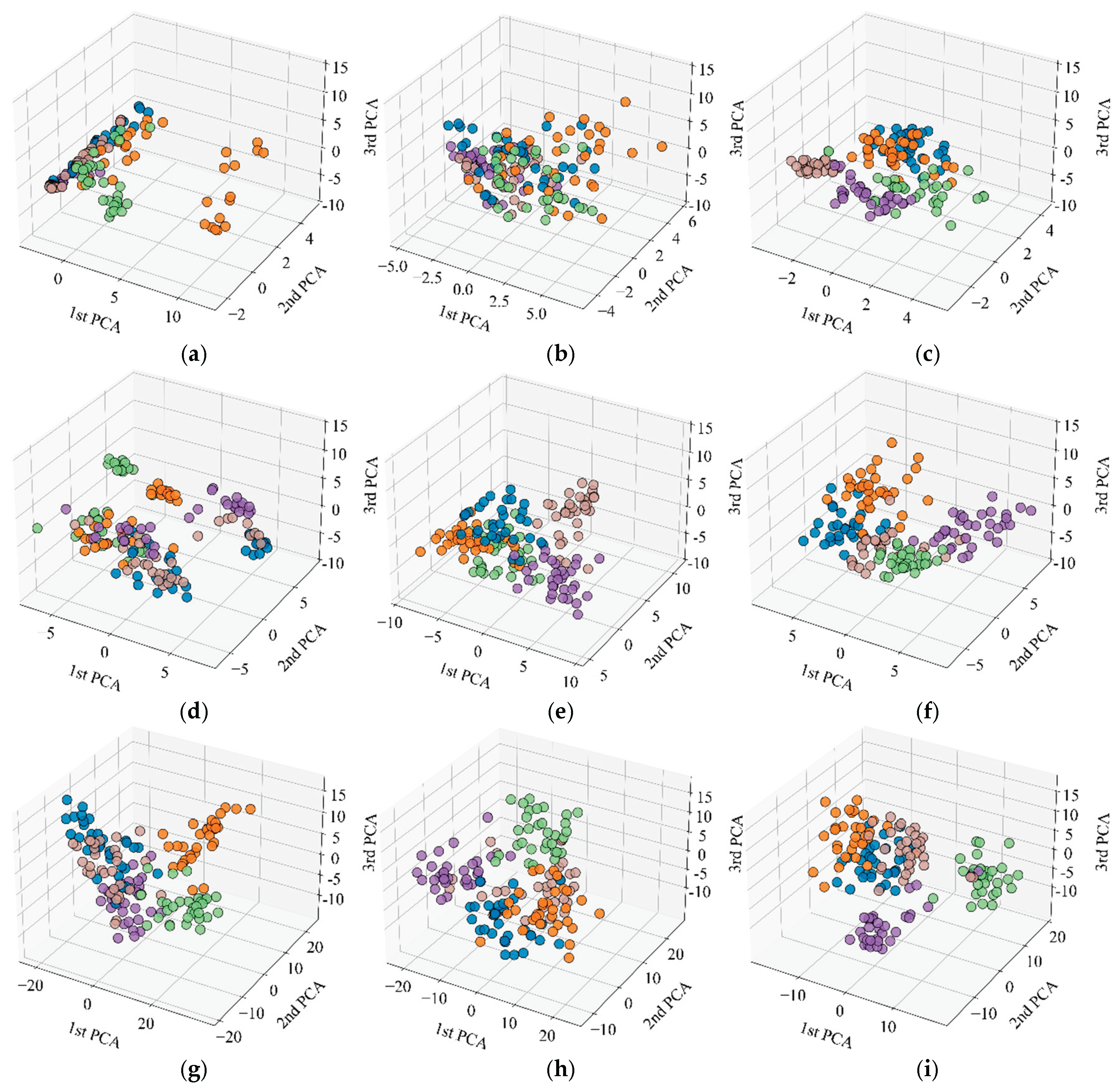

Table 1.
Damage modes of the old ADA bridge damage cases.
| Damage scenario | Description |
| INT | Full bridge intact |
| DMG1 | Half cut in a vertical member at midspan |
| DMG2 | Full cut in a vertical member at midspan |
| RCV | Recovery of the cut member at midspan |
| DMG3 | Full cut in a vertical member at 5/8th-span |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



