1. Introduction
The increasing global demand for marine resource exploration and environmental protection has driven the widespread application of Autonomous Underwater Vehicles (AUV) in fields such as deep-sea exploration, seabed topographic mapping, environmental monitoring, and resource prospecting [
1]. However, the complexity and dynamic nature of the marine environment—characterized by variable ocean currents, dense moving obstacles (such as ice floes or marine organisms), and irregular three-dimensional terrains—poses significant challenges to AUV navigation. Consequently, achieving efficient and reliable 3D trajectory planning for AUV in dynamic and complex environments has become a crucial research topic in ocean engineering and intelligent control.
Existing studies show that AUV trajectory planning tasks encompass three major categories of algorithms: classical graph search algorithms, heuristic algorithms, and intelligent algorithms. Each category has its own strengths and limitations and is suitable for different environmental conditions and performance requirements based on the nature of the problem and the application scenario. Specifically, classical algorithms, such as A* [
2] and Dijkstra, are based on rigorous mathematical theory and are capable of finding optimal paths in known and stable static environments. These algorithms are computationally efficient and well-suited for trajectory planning problems. However, they struggle to handle dynamic obstacles, high-dimensional complex environments, and the computational burdens of large-scale problems [
3]. Heuristic algorithms, such as the Artificial Potential Field (APF) method and Rapidly-Exploring Random Trees (RRT), incorporate heuristic functions or random extension strategies. These methods exhibit good real-time responsiveness and flexibility in dynamic and complex environments, enabling rapid obstacle avoidance and efficient pathfinding. However, they are prone to local optima and heavily rely on parameter tuning, which limits their ability to guarantee globally optimal solutions [
4]. Intelligent algorithms, such as Deep Reinforcement Learning (DRL) [
5] and Genetic Algorithms (GA), mimic biological learning mechanisms and are well-suited for handling complex and dynamically changing environments. They exhibit strong adaptability and self-learning capabilities, especially for multi-objective optimization problems. Nevertheless, the training process for intelligent algorithms requires large amounts of data and computational resources, and their results often lack stability and convergence, particularly in highly uncertain environments [
6]. In practical applications, these three categories of algorithms have different applicability depending on the task characteristics and performance requirements: classical algorithms are suited for optimal pathfinding in known environments, heuristic algorithms are ideal for real-time reactions in dynamic environments, while intelligent algorithms excel at tackling highly uncertain, complex, and multi-objective dynamic tasks.
The APF method is a commonly used local planning approach, characterized by its simplicity, low computational complexity, and fast responsiveness, making it suitable for online planning. However, traditional APF methods may fail to generate feasible or optimal paths due to issues such as target inaccessibility and local optima. To address this, many researchers have analyzed and improved the APF method. One notable example is the work of Ge Shuzhi’s team at the National University of Singapore [
7,
8], which enhanced the repulsive potential field function to address issues such as local minima, unreachable targets, and the avoidance of moving threats. Despite these improvements, APF still lacks the concept of obstacle shapes (envelopes) and relies entirely on force field adjustments to generate paths. As a result, improper parameter tuning may cause AUVs to enter obstacles, leading to failures in obstacle avoidance. To overcome the limitations of APF, researchers proposed the stream function method based on the fundamental principles of potential fields [
9,
10]. This method provides advantages such as fast planning speed and smooth trajectories. However, the concept of stream functions becomes invalid when extended from two-dimensional to three-dimensional planning spaces, limiting this method to 2D trajectory planning.
To address this issue, researchers introduced a 3D trajectory planning method inspired by the "flowing water avoiding stones" principle [
11], which references the macroscopic behavior of natural water flow: water flows in a straight line in the absence of obstacles, while it smoothly bypasses obstacles and continues toward its target when obstructions are present. This method integrates trajectory planning with fluid computation by introducing the concept of three-dimensional obstacle envelopes. However, traditional flow-based methods still have significant limitations: (1) analytical methods can only handle spherical obstacles; (2) due to the need for computational fluid dynamics simulations, the computational cost is excessively high, restricting these methods to offline trajectory planning.
To address the limitations of traditional flow-based methods, the Interfered Fluid Dynamical System (IFDS) algorithm was first proposed [
12]. Based on analytical methods, IFDS avoids solving fluid equations with complex boundary conditions, making it suitable for handling complex terrains and various obstacle shapes. The planned routes not only retain the natural characteristics of flow-based methods but also feature simple environmental modeling and low computational cost, significantly expanding the applicability of flow-based methods. However, the streamline distribution generated by IFDS has certain limitations and is prone to local traps and stagnation points, which cannot be fundamentally resolved by auxiliary strategies alone [
13]. The root cause of these issues lies in the insufficiently objective and comprehensive definition of the perturbation matrix, which limits the spatial distribution of streamlines. To address this, the Improved Interfered Fluid Dynamical System (IIFDS) algorithm was proposed [
14]. By introducing a tangential matrix into the perturbation matrix, IIFDS effectively addresses these limitations. Compared to IFDS, IIFDS redefines the perturbation matrix by incorporating tangential velocity components into the perturbation flow, allowing it to point in any direction. By adjusting the repulsion response coefficients in the repulsion matrix and the tangential response coefficients and directional coefficients in the tangential matrix, IIFDS generates a variety of streamline shapes distributed throughout the planning space. These streamlines are then filtered to select paths that avoid local traps and stagnation points. However, some of these streamlines fail to meet AUV dynamics constraints or incur excessively high trajectory costs. Therefore, it is necessary to optimize the coefficients to select a trajectory that satisfies environmental and kinematic constraints while ensuring optimal performance under specific metrics or multiple objectives.
In recent years, new-generation artificial intelligence methods represented by DRL have been widely applied to the optimization and control of complex systems. These machine learning methods have several advantages [
15,
16,
17]: (1) they do not rely on environmental models or prior knowledge, and policies can be improved solely through interaction with the environment; (2) the deep neural networks used in DRL have powerful nonlinear approximation capabilities, making them effective for optimizing high-dimensional continuous state-action spaces, which is fundamental to 3D trajectory planning in complex dynamic environments; and (3) the policies obtained through DRL require only a forward pass during inference, making them highly suitable for decision-making tasks with high real-time requirements. Based on these advantages, some researchers have explored the application of DRL in planning. For example, [
18] proposed an end-to-end perception-planning-execution framework based on a two-layer deterministic policy gradient algorithm to address challenges related to training and learning in end-to-end control approaches. Similarly, [
19] proposed an online collision avoidance planning algorithm based on active sonar sensors for obstacle detection. While these methods achieve good planning results, three key issues warrant further investigation:
First, DRL, as a general decision-making framework, may struggle to simultaneously ensure safety and trajectory smoothness when addressing the specific problem of AUV 3D dynamic trajectory planning. Simulation results indicate that directly using DRL to generate control inputs for trajectory planning ensures fast and safe obstacle avoidance but often produces trajectories lacking smoothness, which hinders precise tracking by low-level controllers. Combining DRL with classical heuristic methods could leverage their respective strengths in optimization speed and trajectory quality, leading to improved planning results. However, designing a hybrid framework that effectively handles complex dynamic obstacles (e.g., 3D obstacles with varying sizes and trajectories) remains an open challenge.
Second, DRL-based trajectory planning methods require agents to interact with simulated task environments and update the weights of deep neural networks based on environmental feedback. The trained deep action networks are then deployed for online planning in real-world environments. Therefore, designing simulation environments tailored to the trajectory planning methods being used is essential for improving training efficiency and ensuring the policy’s generalization in complex obstacle scenarios. Unfortunately, existing studies lack targeted research on systematic modeling methods for training environments.
Finally, high-quality trajectories must consider multiple objectives simultaneously, such as obstacle avoidance effectiveness, target reachability, trajectory smoothness, energy consumption within acceptable ranges, and adherence to AUV dynamics and kinematics constraints. Most current studies focus on single-objective optimization, which does not align with the practical requirements of AUV trajectory planning.
Contributions of This Paper:
(1) A trajectory planning framework integrating PPO and IIFDS:
This paper designs a 3D dynamic trajectory planning framework for AUVs, integrating PPO with the IIFDS. In this framework, IIFDS serves as the planning layer, dynamically adjusting flow field parameters to generate obstacle-adaptive trajectories in dynamic environments. PPO acts as the learning and decision-making layer, optimizing flow field disturbance parameters and dynamically adjusting planning strategies, enabling efficient coordination between the two algorithms in dynamic obstacle environments.
(2) Key improvements to the PPO and IIFDS algorithms:
PPO algorithm improvement: For the trajectory planning task, a multi-objective dynamic reward function is designed, incorporating obstacle avoidance, target distance, trajectory smoothness, dynamic constraints, and energy consumption. This approach effectively addresses the sparse reward problem in traditional methods, significantly improving the algorithm's convergence and the practicality of trajectory planning.
IIFDS algorithm improvement: Task-specific dynamic and kinematic constraints for AUVs are introduced into the IIFDS planning layer. This ensures that the generated trajectories not only satisfy environmental constraints but are also executable, enhancing the reliability and applicability of the planning results in real-world scenarios.
(3) Construction of a dynamic and complex obstacle environment for model training and framework validation:
A diverse dynamic obstacle environment model is developed, capable of simulating various obstacle behaviors and complex scenarios. This environment supports interactions between the agent and the environment while dynamically generating training data of varying complexity. As a result, it improves training efficiency and enhances the framework's generalization performance in practical applications. During testing, the environment validates the framework's trajectory planning performance in high-density dynamic obstacle scenarios, including the generation of collision-free trajectories, trajectory smoothness, and energy efficiency.
2. A Three-Dimensional Dynamic Trajectory Planning Framework Based on PPO and IIFDS
To simplify the analysis in this paper, the following assumptions are made:
Assumption 1: All obstacles, including both static and dynamic obstacles, are approximated as standard convex polyhedrons, such as spheres, ellipsoids, and cylindrical shapes. The mathematical representation of an obstacle’s boundary can be defined as:
(1)
where represents an implicit expression for the boundary of an obstacle. A value of indicates that point lies exactly on the obstacle's surface, a value less than indicates that is inside the obstacle, and a value greater than indicates that is outside the obstacle. are the coordinates of point, while denote the coordinates of the obstacle's center in the three-dimensional space. control the extent of the obstacle along the ,,and directions (i.e., the size of the obstacle). control the curvature of the obstacle along each direction (i.e., the exponents of the shape parameters).
Assumption 2: The information on the target location and obstacle status at the current moment is available online. This information includes, but is not limited to, position and velocity.
2.1. Introduction to the Improved Interfered Fluid Dynamical System (IIFDS)
2.1.1. Initial Flow Field Velocity Model
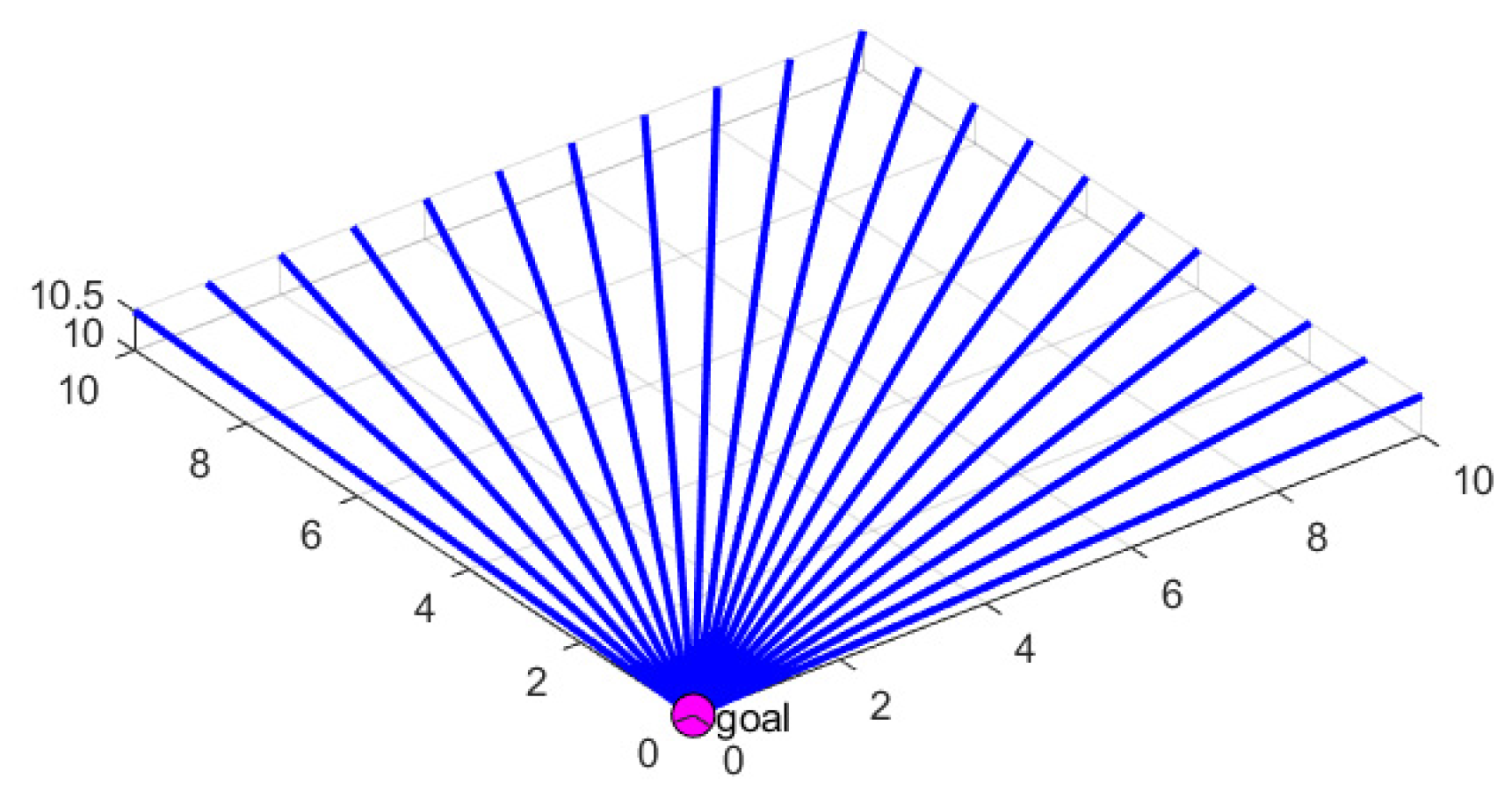
The IIFDS algorithm is based on mimicking the characteristics of natural fluid dynamics. Under conditions free from interference, the initial flow field streamlines are directed straight toward the target point. The model of the initial flow field is shown in
Figure 1.
In the initial flow field, the velocity vector of the fluid passing through each position , denoted as , can be expressed as:
(2)
where represents the velocity vector of the initial flow field at the current position of the AUV. is a virtual velocity constant, used to determine the intensity of the flow field. denotes the current position of the AUV, represents the target position, and denotes the Euclidean distance between the current position and the target point , which is given by:
(3)
2.1.2. Obstacle Influence Modeling
When obstacles exist in the environment, their influence on the predefined initial flow field changes the fluid's velocity direction, resulting in flow field distortion. The effect of obstacles on the initial flow field is modeled using an influence matrix, defined as:
. (4)
where represents the overall disturbance matrix, denotes the weight coefficient of the k-th obstacle, is the disturbance matrix of the k-th obstacle, and indicates the total number of obstacles.
The weight coefficient for each obstacle is defined as:
(5)
where represents the implicit equation of the obstacle's surface, defining whether is inside, on, or outside the obstacle.
The influence matrix of the k-th obstacle is defined based on repulsion and redirection effects as:
(6)
where denotes the 3×3 identity matrix, also referred to as the attraction matrix, which functions similarly to the attractive force in the artificial potential field method. represents the normal vector of the obstacle's surface, represents the tangential vector, and is the repulsion coefficient that controls the intensity of the obstacle's repulsive effect. A larger value enables the disturbed fluid to avoid obstacles in the environment earlier. denotes the tangential response coefficient, which regulates the intensity of tangential fluid flow. represents the distance from the obstacle's center to the current position, normalized by the obstacle's radius.
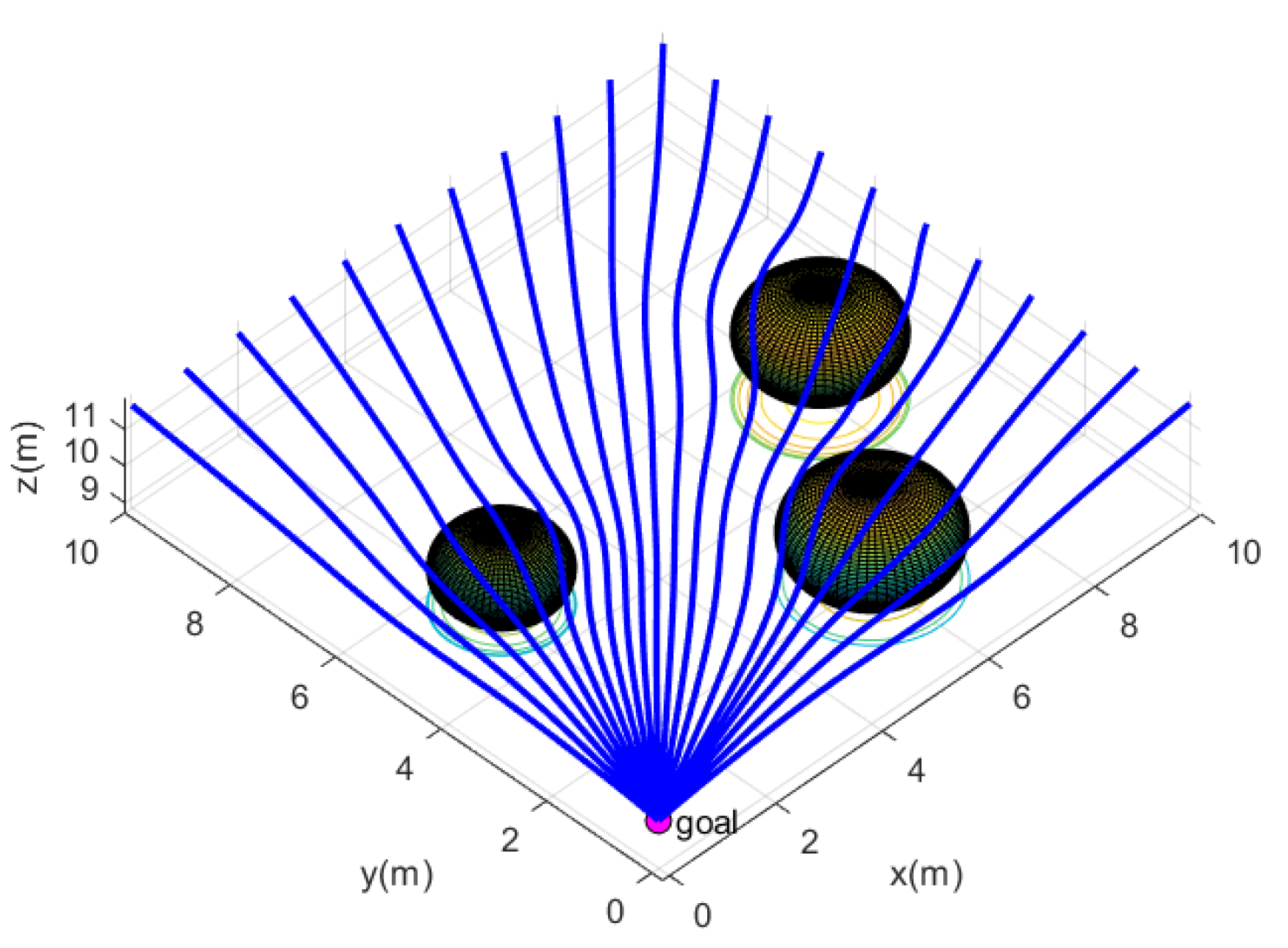
In a three-dimensional environment with obstacles, the presence of obstacles causes deviations in the original flow field paths, resulting in a disturbed flow field. This disturbed flow field is capable of avoiding obstacles while converging toward the target point. The disturbed flow field model is illustrated in
Figure 2.
2.1.3. Tangential Vector Modeling
In the practical application of the IIFDS algorithm, the flow lines generated for obstacle avoidance are often restricted to a single plane, which may result in trajectories becoming trapped in local minima or stagnating at certain points. To address this issue, the IIFDS algorithm introduces the concept of a tangential matrix, allowing flow lines to move in arbitrary directions around obstacles rather than being confined to a single plane. When approaching stagnation points, the IIFDS algorithm enhances the tangential matrix to provide tangential momentum along the obstacle surface, effectively preventing the AUV from lingering at stagnation points.
On the tangent plane defined by the normal vector , any tangential vector is generated as follows:
(7)
where represents the tangential vector in the local tangential coordinate system, determined based on the tangential angle . denotes the rotation matrix that transforms the local tangential basis vectors into the global coordinate system, defined as:
(8)
In this context, controls the rotational angle of the tangential direction, determining the specific direction for bypassing the obstacle.
2.1.4. Influence of Dynamic Obstacles
The velocity of dynamic obstacles affects the flow field through the following equation:
(9)
where represents the velocity influence of the dynamic obstacle at the current position. denotes the normalized distance between the current point and the obstacle. is the attenuation factor, which controls the influence range of the obstacle's velocity on the flow field. represents the velocity vector of the dynamic obstacle.
2.1.5. Comprehensive Velocity Calculation
The comprehensive velocity of the AUV is calculated using the following equation:
(10)
2.1.6. Trajectory Update
The next trajectory point is determined by integrating the velocity , according to the following equation:
(11)
where is the time step.
2.1.7. Heading and Pitch Angle Constraints
From the above derivation, it can be seen that traditional IIFDS does not explicitly consider the motion model and constraints of the AUV during trajectory planning. In 3D dynamic trajectory planning for AUVs, to ensure that the generated trajectory satisfies both the optimization objectives of flow-field perturbation and the motion capability constraints of the AUV itself, we introduce dynamics and kinematics constraints. These constraints primarily act on the updates of the heading angle and pitch angle, and by adjusting the next position, they ensure the physical feasibility of the trajectory.
Based on the current position of the AUV, , the position at the previous time step, , and the next position predicted by the flow field, , the heading angle and its variation are calculated as follows:
(12)
where denotes the heading angle from to , and represents the heading angle from to .
If , the heading angle is corrected as follows:
(13)
The correction logic for the pitch angle is analogous to that of the heading angle and is not repeated here. After completing the corrections for the heading and pitch angles, the previously planned position for the next time step is updated accordingly. The corrected position is given by:
(14)
where represents the next position of the AUV after incorporating the dynamics and kinematics constraints, and denotes the corrected pitch angle.
2.2. Introduction to the Improved PPO Algorithm
From Equation (6), it can be seen that the influence matrix is not only related to the position of the AUV and the implicit equation of the obstacle's surface but also to the repulsion coefficient ,tangential response coefficient , and directional coefficient of each obstacle. If these three parameters are fixed, the resulting trajectory may fail to meet the specific requirements of certain scenarios or obstacles, leading to suboptimal trajectory planning.
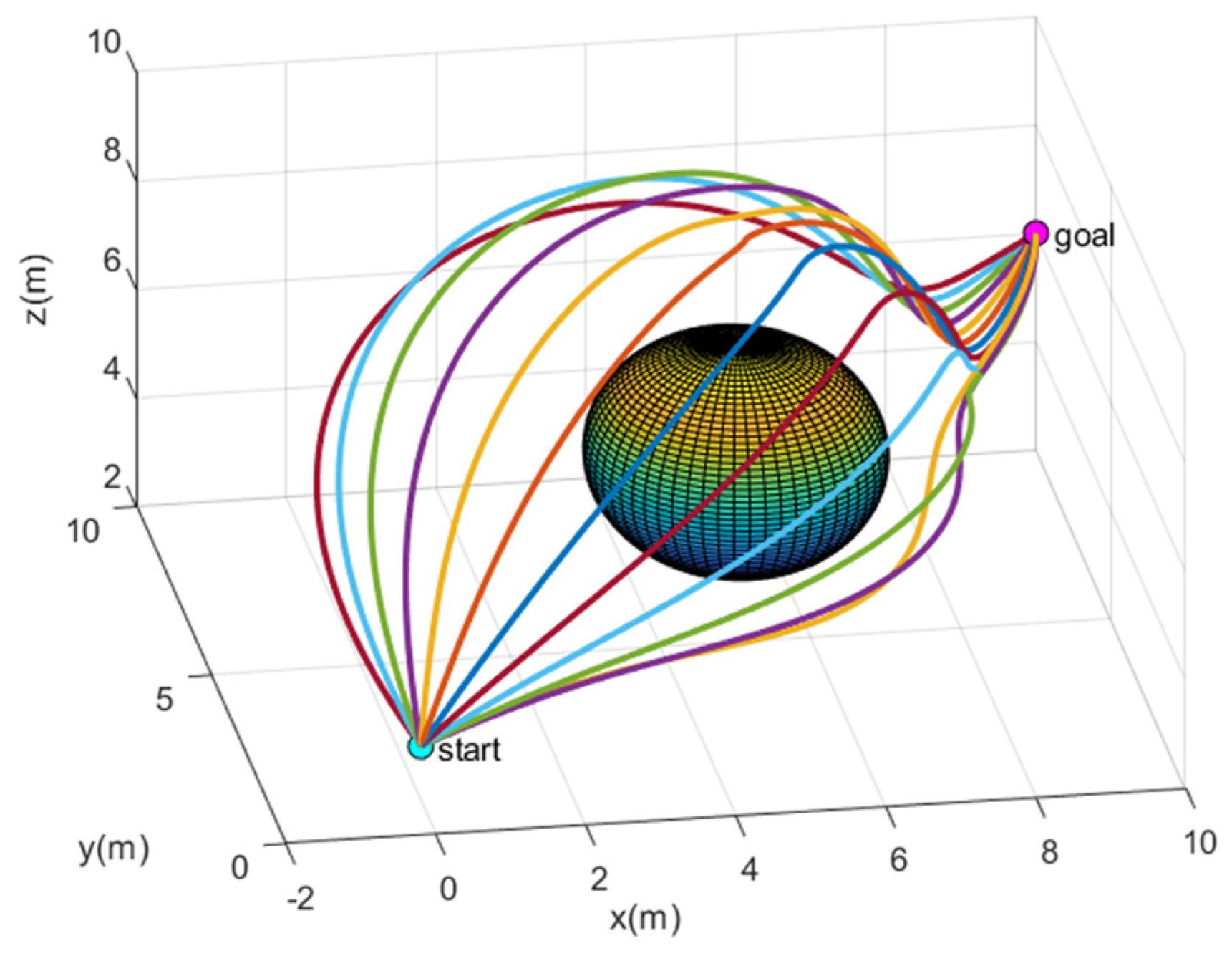
As shown in
Figure 3, the plotted trajectories represent different parameter combinations. The orange trajectory in the bottom-right corner corresponds to
,
, and
,From the bottom-left to the top-left corner, the coefficients increment by 0.2 for each trajectory. Different parameter combinations determine the shape and direction of the trajectories. In previous research [
20], receding horizon control (RHC) has been used to optimize these parameters online. However, the serial nature of RHC's solution mechanism is not well-suited to the robustness and real-time requirements of complex dynamic obstacle environments.
PPO is a policy-based deep reinforcement learning algorithm and an off-policy algorithm. With its advantages of high stability and strong real-time performance in complex dynamic environments, we choose the PPO algorithm to optimize the three parameters of the IIFDS algorithm: the repulsion coefficient , the tangential coefficient , and the directional coefficient . The PPO algorithm comprises five core components: environment, agent, state, reward function, and action. The following sections will provide detailed explanations of these five components.
In the 3D dynamic trajectory planning task, the environment is a three-dimensional space that contains multiple dynamic spherical obstacles with varying radii and trajectories. In this environment, it is possible to observe the instantaneous velocities of the dynamic obstacles at any given moment, the distance between the AUV and the surface of the obstacles, as well as the relative position of the AUV to the target point. This dynamic environment simulates various complex scenarios that the AUV might encounter during real-world navigation, providing a realistic basis for testing and validating the algorithm.
In the 3D dynamic trajectory planning task, the AUV is considered as the agent.
The state space represents the collection of environmental information perceived by the agent. It comprises three vectors: the vector pointing to the target point, the vector pointing to the surface of the nearest obstacle, and the velocity vector of the nearest obstacle.
In traditional deep reinforcement learning methods, the reward function in the PPO algorithm often suffers from the issue of sparse rewards, which makes the learning process less adaptive to specific tasks. This issue is particularly pronounced in the 3D dynamic trajectory planning task for AUVs, where traditional reward designs fail to effectively guide the AUV in performing fine-grained action control. To address this, the paper introduces an improved reward function aimed at providing more precise guidance for the dynamic trajectory planning of the AUV. This reward function comprises five main components: obstacle avoidance reward, target distance reward, trajectory smoothness reward, dynamics constraint reward, and energy consumption reward.
(1) Obstacle Avoidance Reward
The obstacle avoidance reward encourages the AUV to maintain a safe distance from obstacles while considering the velocity of the obstacles. The reward is calculated as follows:
(15)
where, represents the dynamic influence factor of the obstacle’s velocity on the reward. Faster obstacle velocities increase the dynamic impact factor, which amplifies the reward’s sensitivity to obstacle avoidance. is the distance between the AUV and the center of the obstacle. is the radius of the obstacle. is the threshold radius of the obstacle’s influence zone. is the velocity vector of the obstacle.
(2) Target Distance Reward
The target distance reward encourages the AUV to move closer to the target point, with the reward increasing as it approaches the target. The reward is calculated as follows:
(16)
where, represents the distance between the current position of the AUV and the target point. represents the total distance from the starting point to the target point.
is a small positive constant added to prevent logarithmic computation errors.
If the AUV is very close to the target (less than a specified threshold value), an additional bonus reward is given:
(17)
(3) Trajectory Smoothness Reward
The trajectory smoothness reward is designed to encourage the AUV to move along a smooth trajectory, avoiding abrupt changes in direction, velocity, or acceleration. The reward is defined as follows:
(18)
where, represents the angle between the current motion direction of the AUV and the direction toward the target. denotes the change in velocity between the current and previous time steps. represents the current acceleration of the AUV.and are weighting factors penalizing changes in velocity and acceleration, respectively.
(4) Kinematic Constraint Reward
The kinematic constraint reward ensures that the AUV's motion adheres to kinematic limits, avoiding excessive heading angles, pitch angles, and over-speeding behaviors. The reward is defined as:
(19)
where, represent the AUV's current heading and pitch angles. , represent the corrected heading and pitch angles. , denote the maximum allowable variations in heading and pitch angles. represents the current speed of the AUV, and represents the current acceleration of the AUV. , denote the maximum allowable speed and acceleration of the AUV. and are weighting factors penalizing excessive speed and acceleration, respectively.
(5) Energy Consumption Reward
This reward penalizes energy-inefficient behaviors and encourages the AUV to adopt energy-saving motion strategies. It is defined as:
(20)
where, represents the current speed of the AUV. is the weighting factor for the energy consumption penalty.
(6) Total Reward Function
By combining all the individual reward components, the total reward function is obtained, which comprehensively guides the AUV to accomplish its tasks while ensuring stable, safe, and efficient motion. The total reward is expressed as:
(21)
The trajectories generated by the IIFDS algorithm are determined by three parameters within the algorithm: the repulsion coefficient , the tangential coefficient , and the directional coefficient . Therefore, we select these three parameters as the action outputs of the improved PPO algorithm.
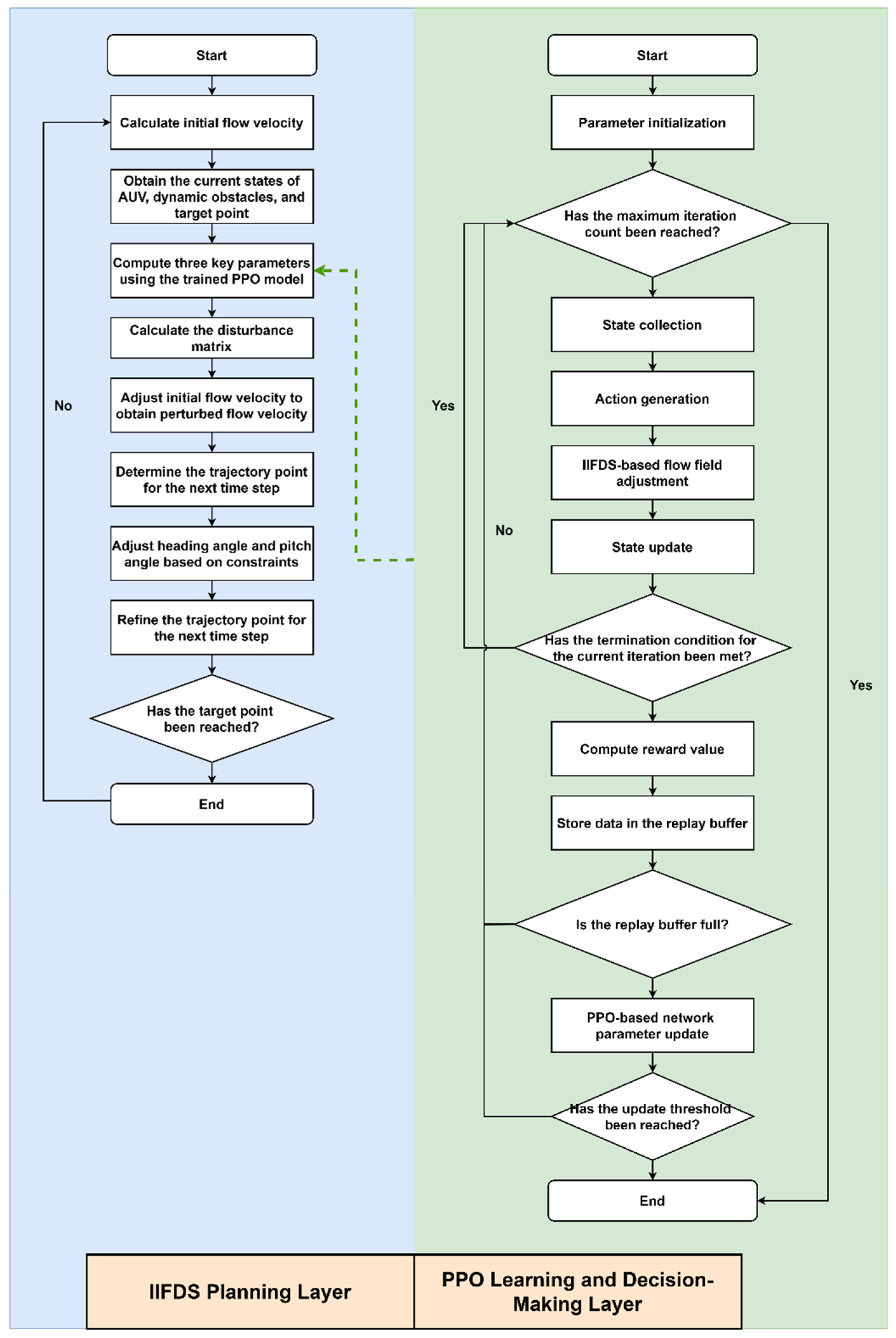
2.3. Optimization of IIFDS Parameters Using the Improved PPO
To enable trajectory planning for AUVs in complex dynamic three-dimensional environments, this paper proposes a trajectory planning framework based on the integration of PPO and IIFDS. In this framework, IIFDS serves as the planning layer, adjusting the flow field parameters dynamically to generate trajectories that adapt to moving obstacles. PPO acts as the learning and decision-making layer, optimizing the IIFDS flow field parameters, including the repulsion coefficient
, the tangential coefficient
, and the directional coefficient
. The detailed process of the integrated algorithm is shown in the flowchart in
Figure 4.
Initialization involves setting the IIFDS flow field parameters, constructing the AUV dynamics model and dynamic obstacle environment, and defining the start and target points. Simultaneously, the Actor-Critic network of the PPO algorithm is initialized, along with the replay buffer (size 4096). Multi-objective reward functions and related hyperparameters (discount factor, PPO clipping range, learning rate, etc.) are also configured.
Subsequently, the training loop is entered, which primarily includes the main loop and the PPO network update component.
The main loop constitutes the core part of the interaction between the AUV and the environment during training. The detailed steps of the main loop are as follows:
Step 1: State Collection
The AUV gathers environmental information through sensors to construct the current state, including the vector pointing to the target, , and the vector pointing to the surface of the nearest obstacle, , as well as the velocity vector of the nearest obstacle, . The current state vector is represented as:
(22)
Step 2: Action Generation
The action for the current state is generated through the Actor network of the PPO algorithm. First, the Actor network produces the parameters of a Gaussian distribution:
(23)
where represents the mean vector of the actions, and represents the standard deviation vector of the actions.
Subsequently, actions are sampled from the Gaussian distribution:
(24)
Step 3: Flow Field Adjustment and Trajectory Planning
The planning layer of the IIFDS algorithm adjusts the flow field dynamically based on the action . The repulsion intensity of the obstacle is modified through , the tangential effect range is adjusted through , and the flow field direction is altered via , enabling the AUV to avoid obstacles. The next trajectory point is planned using the following formula:
(25)
Subsequently, the AUV state is updated:
(26)
Step 4: Reward Calculation
Based on the current state , action , and the next state , the instantaneous reward is calculated as:
(27)
Step 5: Data Storage
The current state, action, reward, and next state are stored in the experience replay buffer:
(28)
Step 6: Termination Check for the Main Loop
The main loop ends when any of the following termination conditions are met: The AUV reaches the target point. The AUV collides with an obstacle. The number of steps executed by the AUV reaches the predefined maximum value.
If none of the termination conditions are met, the process continues from Step 1 to execute the next step. If the termination conditions are met, the current episode ends, and a new episode begins by reinitializing the environment (including start point, target point, and obstacle information). Once the experience replay buffer is full (set to a capacity of 4096 in this study), it triggers an update of the PPO network.
First, the Critic network parameters are optimized using the mean square error loss function:
(29)
where represents the instantaneous reward, represents the value function of the current state, and is the discount factor.
Next, the Actor network parameters are optimized using the objective function of PPO, which includes a clipping mechanism:
(30)
where represents the advantage function, balancing the action preference.
The training loop continues until the termination condition is met. The termination condition for the training loop is defined as follows: the variation in parameters of the PPO's Actor and Critic networks falls below the predefined threshold, and the training iteration reaches the preset value.
During the testing process, the initial velocity of the AUV is first calculated, and based on the current state information, the pre-trained Actor network of PPO generates the updated IIFDS flow field parameters. Next, through optimized computation, the disturbance matrix is determined, and the velocity of the initial flow field is corrected to obtain the resultant velocity, which determines the trajectory point at the next time step. Then, based on the dynamics and kinematics constraints, this trajectory point is further corrected to obtain the final adjusted trajectory point at the next time step. Finally, it is evaluated whether the adjusted trajectory point reaches the target location. If not, the loop continues.The above testing loop concludes when the target is reached, marking the end of the testing process.
3. Results
The framework for three-dimensional dynamic trajectory planning of AUV proposed in this paper is critical during the training phase. The most important aspect of training is the construction of a standardized simulated environment. Considering the uncertainty of dynamic obstacle motion in real-world tasks, the construction of the simulated environment introduces dynamic obstacles with varying motion speeds, radii, and trajectory changes. During training, each episode begins by randomly selecting an initial and a terminal point within the predefined range and then randomly selecting a dynamic obstacle from the set of predefined obstacles.
The main training settings are as follows: the maximum number of steps for AUV execution is set to 500; the learning rates of the Actor network and Critic network are both set to 0.0001; the replay buffer size is 4096; the batch size is 512; the number of repeated training steps is 8; and the GAE advantage estimation parameter is 0.98. The training results are shown in
Figure 5.
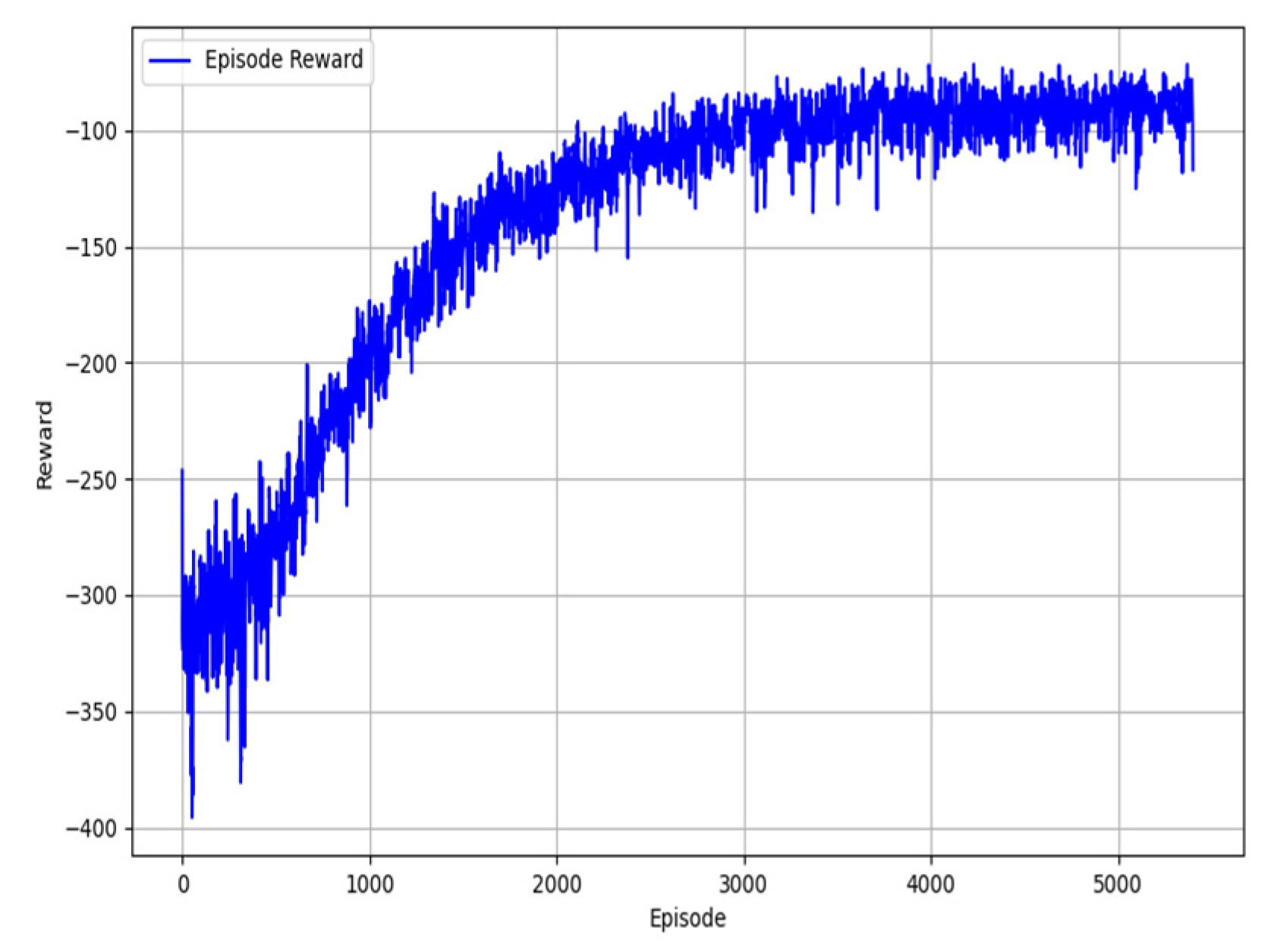
In
Figure 5, the reward curve of the PPO-IIFDS framework illustrates the gradual optimization process from the initial exploratory strategies to the final effective strategies, demonstrating strong adaptability and robustness. During the initial phase of training, the reward rises rapidly, indicating that the model establishes its fundamental trajectory planning capabilities through interaction with the environment. In the middle phase, the reward growth slows down while the fluctuation amplitude decreases, reflecting the gradual improvement in the model’s adaptability to random initialization and dynamic obstacle environments. In the later phase, the reward stabilizes, showing that the strategy has approached the globally optimal or near-optimal level, with minor fluctuations primarily caused by environmental randomness, exploratory actions, and multi-objective trade-offs. Statistical results further validate the high efficiency and robustness of the model, achieving high success rates (5361 successful tasks), low collision rates (39 failures), and near-zero superfluous stops. Overall, the reward's minor fluctuation demonstrates the rationality of the training process, reinforcing the model's ability to generalize in dynamic environments while confirming that the PPO-IIFDS framework effectively fulfills the task of three-dimensional dynamic trajectory planning.
3.1. Static Obstacle Environment Testing
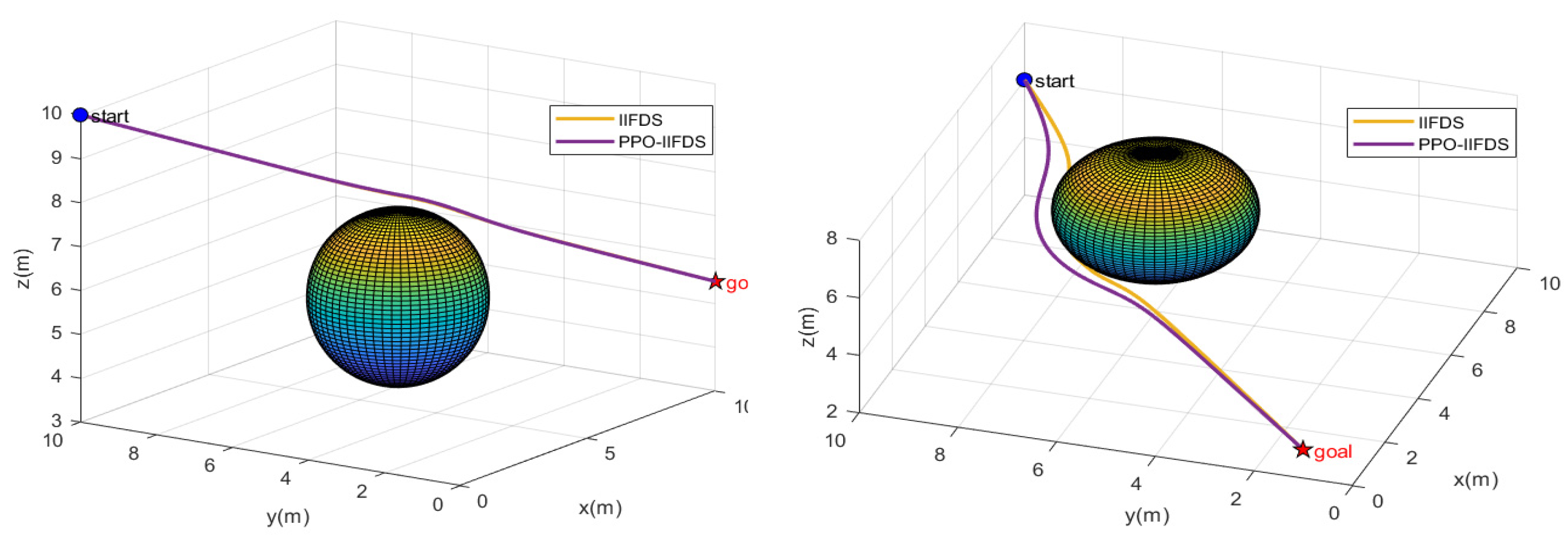
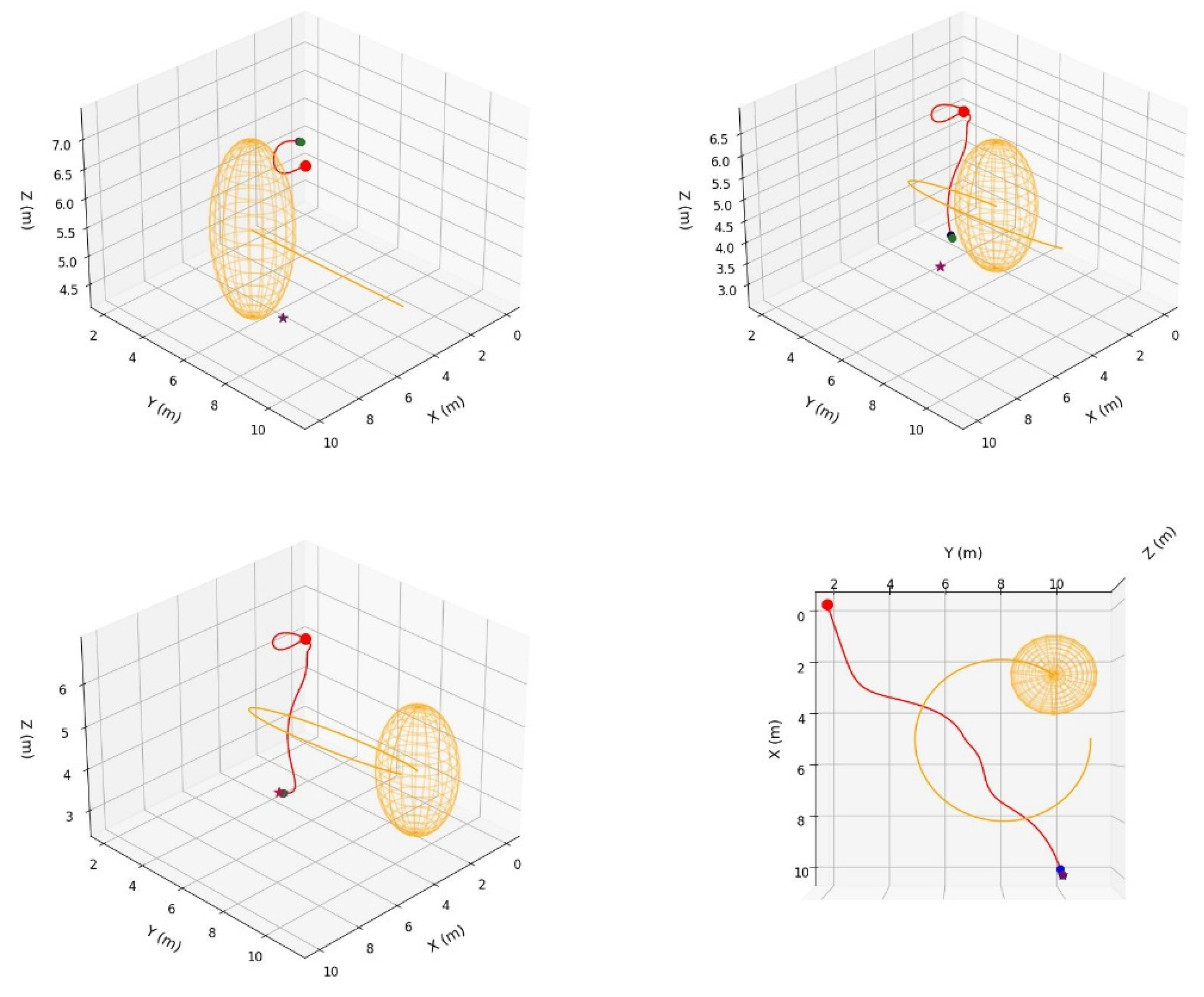
In a static environment, we conducted tests on the IIFDS algorithm and the PPO-IIFDS framework, as shown in
Figure 6. In the left panel of
Figure 6, the start point is [0,10,10], the endpoint is [10,0,5.5], and the center coordinates of the static obstacle are [5,5,5.5]. In the right panel of Figure 3.2, the start point is [10,10,6], the endpoint is [0,1,3], and the center coordinates of the static obstacle are [6,6,5.5]. The influence range of the static obstacle is uniformly set to 2, and the repulsion coefficient
, tangential response coefficient
, and directional coefficient
of the IIFDS algorithm are fixed at 0.2, 0.2, and 0.1, respectively.
As shown in
Figure 6, in static obstacle environments, the IIFDS algorithm with fixed parameters can plan relatively optimal paths in certain scenarios (as shown in the left panel). However, in other scenarios, it may result in paths passing too close to obstacles (as shown in the right panel). This is primarily because fixed parameters lack flexibility to adapt to different environmental features. In contrast, the PPO-IIFDS framework, through enhanced reinforcement learning, dynamically adjusts the repulsion coefficient
, tangential response coefficient
, and directional coefficient
, enabling it to generate more desirable trajectories in different scenarios. These trajectories effectively avoid obstacles while ensuring rationality and smoothness. Experimental results demonstrate that the PPO-IIFDS framework outperforms the traditional IIFDS algorithm in terms of robustness and adaptability. This advantage allows the PPO-IIFDS framework to better accommodate diverse environmental characteristics and plan more efficient and safer trajectories, verifying its superior performance and practical application potential in complex static obstacle environments.
3.2. Testing with Modified Reward Function
To compare with the results in
Figure 5, we conducted experiments where all settings remained the same except for the exclusion of certain reward components, including various initialization parameters and the training environment. Specifically, this test only included obstacle avoidance rewards and target distance rewards.
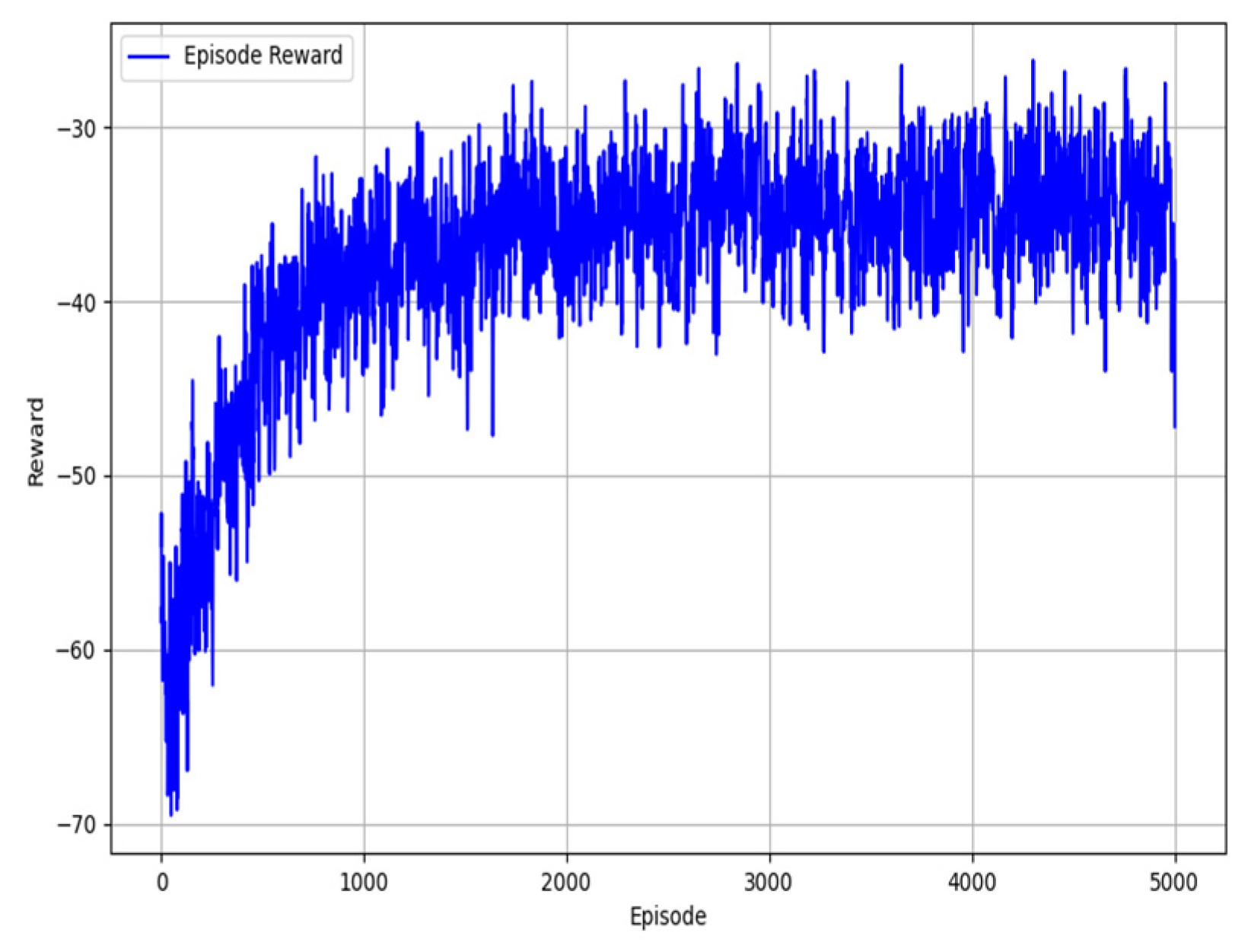
Figure 7 shows the reward changes during training under these conditions.
The reward variations in
Figure 7 indicate that the model's learning performance was lower than that in
Figure 5 when using only obstacle avoidance and target distance rewards.
From the reward curve in
Figure 7, it can be observed that although the reward values show an upward trend during the initial phase of training, reflecting the model's gradual learning of obstacle avoidance and moving toward the target, the growth rate of rewards slows significantly compared to
Figure 5. Moreover, the reward fluctuations in the later phase are larger and less stable. This suggests that relying solely on obstacle avoidance and target distance rewards makes the model more prone to falling into local optima, resulting in less smooth trajectories and behavior that may fail to meet dynamics and kinematics constraints.
Next, we tested the trained models in two scenarios. For the single dynamic obstacle environment test, we first analyzed the movement of the dynamic obstacle.
We set a reference position as follows:
(31)
The center position of the dynamic obstacle (obsCenter) changes over time. Its position in three-dimensional space is defined by the following equations:
(32)
(33)
(34)
The velocity vector of the dynamic obstacle is the derivative of its position with respect to time, calculated as follows:
(35)
(36)
(37)
Based on the above equations, the movement of the dynamic obstacle exhibits the following characteristics:
Spatial trajectory characteristics: The obstacle moves periodically along a circular trajectory in the x-y plane with a radius of 3, while simultaneously performing small amplitude oscillations (with an amplitude of 1) in the z-direction.
Velocity characteristics: The magnitude and direction of the obstacle's velocity vary over time, governed by the sinusoidal and cosinusoidal functions. The velocity magnitude is determined by the following equation:,and varies periodically with time.
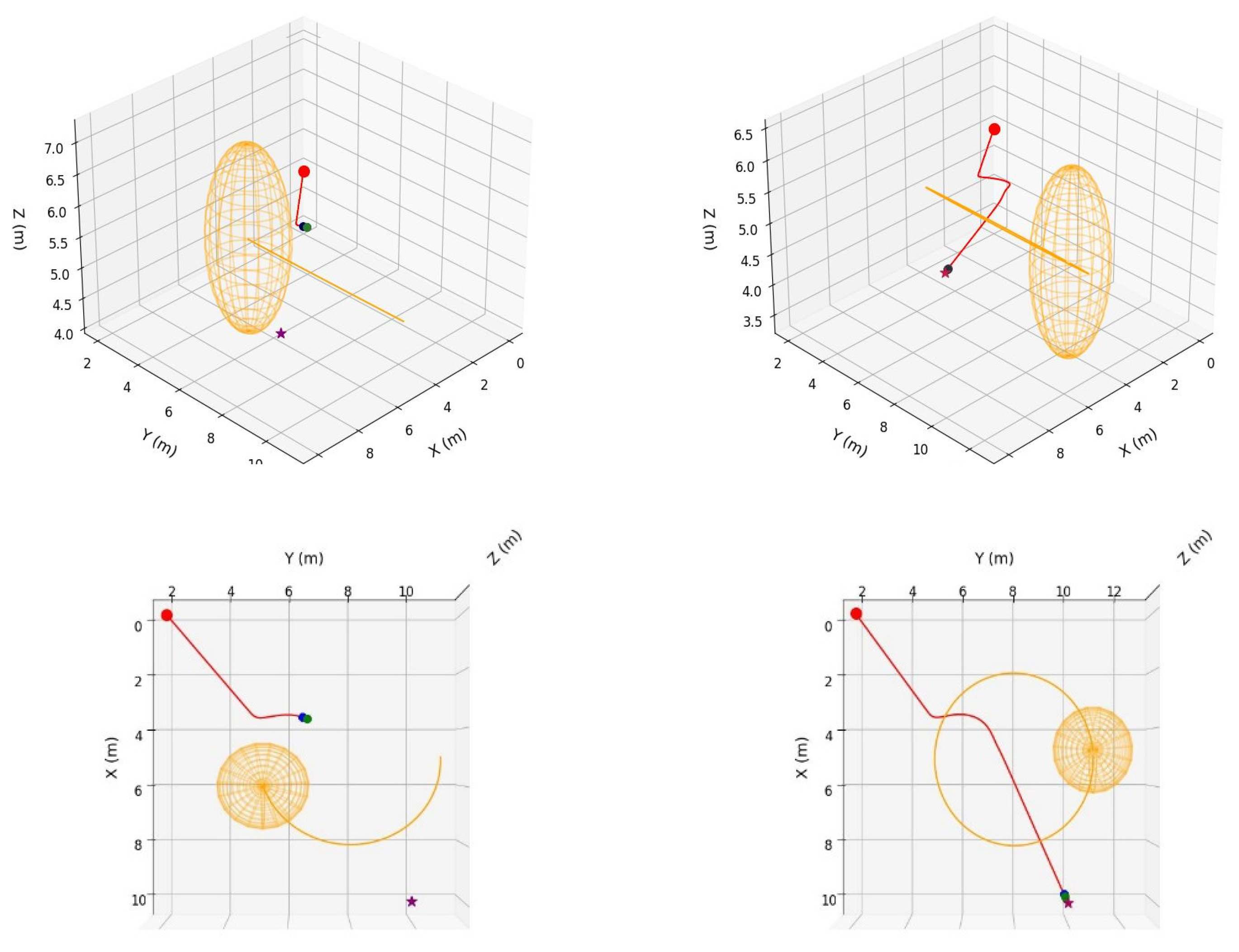
As shown in
Figure 8 and
Figure 9,
Figure 8 presents the trajectory of the trained model under the single dynamic obstacle environment using the framework proposed in this study.
Figure 9 shows the results when the trained model only uses obstacle avoidance and target distance rewards in the same environment. In the figures, the starting point is set to [0,2,5], and the target point is set to [10,10,5.5]. The blue circle represents the current position of the AUV, the green sphere represents the AUV's next position as calculated, the purple pentagram represents the target position, the yellow cuboid represents the dynamic obstacle, the red solid line represents the trajectory of the AUV, and the orange dashed line represents the trajectory of the dynamic obstacle.
Through
Figure 8 and
Figure 9, it is evident that the model trained in
Figure 9 lacks trajectory smoothness rewards, dynamics and kinematics constraint rewards, and energy efficiency rewards. As a result, the optimization process of the model primarily focuses on meeting the basic requirements of obstacle avoidance and reaching the target, while neglecting key indicators such as trajectory smoothness, physical constraints, and energy efficiency. In contrast, the comprehensive reward function design adopted in
Figure 8 incorporates trajectory smoothness and dynamics constraint rewards, effectively guiding the model to achieve obstacle avoidance and target-reaching tasks while further enhancing the trajectory's smoothness and adaptability to dynamic environments. At the same time, the inclusion of energy efficiency rewards facilitates more energy-efficient trajectory planning. Thus, the results of
Figure 8 and
Figure 9 further validate the comprehensiveness of the reward function design in the PPO-IIFDS framework. They also demonstrate that considering only a subset of reward terms significantly impacts the model's robustness and generalization ability. The comprehensive reward function design not only better aligns the model with multi-objective requirements but also improves the global optimization level of trajectory planning.
4. Discussion
The paper proposes a PPO-IIFDS framework for 3D dynamic trajectory planning of AUV. Experimental results show that the PPO-IIFDS framework exhibits significant advantages in complex and dynamic obstacle environments. During training, the multi-objective reward function effectively guides the algorithm to optimize collision avoidance, target proximity, trajectory smoothness, dynamics constraints, and energy efficiency. In comparison, models trained with partial reward terms exhibit reduced optimization performance and efficacy, further validating the importance of comprehensive reward function design.
In static and dynamic obstacle environments, the PPO-IIFDS framework consistently demonstrates superior trajectory planning. Compared to the traditional IIFDS algorithm, the PPO-IIFDS framework produces smoother and safer trajectories while exhibiting strong adaptability to dynamic environments. Unlike traditional methods, which are limited by fixed parameter settings, PPO-IIFDS leverages reinforcement learning to dynamically adjust parameters such as repulsion coefficients, tangential response coefficients, and directional coefficients. This adaptability enhances trajectory quality and computational balance, addressing the traditional IIFDS algorithm's limitations in handling diverse scenarios.
Despite the progress achieved in this research, several directions merit further exploration. The primary focus of future work lies in the following areas:
(1) Theoretically, other continuous deep reinforcement learning methods can also be applied to the framework presented in this paper. Therefore, future work could integrate more advanced reinforcement learning algorithms, such as SAC [
21] and TD3 [
22], with the improved interfered fluid dynamic system (IIFDS) and conduct comparative tests with the approach proposed in this study.
(2) The PPO-IIFDS trajectory planning framework proposed in this study demonstrates strong robustness and adaptability, suggesting its potential for expansion into more complex autonomous underwater vehicle (AUV) task scenarios. Furthermore, it is recommended to conduct corresponding hardware experiments in real underwater environments to verify the feasibility and effectiveness of the algorithm in real-world tasks.
(3) The trajectory planning in this study utilizes a simplified AUV kinematic model and constraints, without incorporating more complex nonlinear dynamic models and controller characteristics. This could lead to an increased collision risk during execution due to controller delays or tracking errors. Therefore, future research could integrate planning, control, and dynamic modeling within the PPO-IIFDS framework to form a closed-loop system. By considering AUV dynamics and controller response characteristics in the reward function design, the reliability and safety of trajectory planning execution can be further enhanced.