
Submitted:
09 January 2026
Posted:
09 January 2026
You are already at the latest version
Abstract
Accurate forecasting of central bank policy rates is critical for guiding monetary policy, shaping market expectations, and maintaining macroeconomic stability. In emerging economies such as Mongolia, conventional econometric approaches, including the Taylor Rule, ARIMA, and SVAR, often struggle to capture nonlinear dynamics, temporal dependencies, and structural breaks. This study addresses these limitations by developing and evaluating modern forecasting methods that combine machine learning and deep learning models within hybrid frameworks. The analysis employs a comprehensive monthly dataset of 26 macroeconomic indicators spanning January 2008 to December 2024. Seven models are constructed and assessed using RMSE, MAE, and R² metrics. The empirical results show that hybrid approaches, particularly XGBoost combined with Gradient Boosting and LSTM integrated with XGBoost, deliver the highest predictive accuracy, with the leading model reaching an R² of 0.9355. These hybrid methods consistently outperform both traditional econometric and standalone ML or DL models in capturing complex macroeconomic patterns and structural changes. The findings provide a robust data-driven framework to support evidence-based monetary policy in Mongolia and offer a transferable methodology for other emerging markets facing similar economic challenges.
Keywords:
policy interest rate
; machine learning
; deep learning
; hybrid modeling
; explainable AI
1. Introduction
The policy interest rate is a central instrument of monetary policy, shaping inflation, credit, investment, exchange rates, and broader macroeconomic stability (Taylor, 1993; Clarida, Galí, & Gertler, 1999). Accurate forecasting of policy rates is therefore crucial for financial institutions, firms, and policymakers, as it shapes expectations, informs risk management, and supports informed strategic decision-making (Svensson, 1997). Over recent decades, the global monetary environment has been shaped by recurrent shocks, including the COVID-19 pandemic, geopolitical conflicts, supply chain disruptions, and volatility in commodity prices (Stock & Watson, 1999). These shocks have compelled central banks to adjust their interest rate policies more frequently, underscoring the limitations of linear, rule-based approaches (Clarida et al., 1999). Traditional forecasting models often fail to capture the nonlinear interactions among macroeconomic variables and the abrupt structural changes that characterize contemporary economies. This limitation has created demand for more adaptive, data-driven forecasting approaches capable of enhancing both the accuracy and the responsiveness of policy rate predictions (Brubakk, Ellen, & Xu, 2021).
Traditional approaches to forecasting policy interest rates have primarily relied on structural models grounded in economic theory, most notably the Taylor Rule (Taylor, 1993), ARIMA models (Box & Jenkins, 1970), and Structural Vector Autoregressions (SVAR). While these frameworks provide theoretical interpretability, they are limited in capturing nonlinear dynamics and in processing high-dimensional data. Their reliance on stable inter-variable relationships further restricts their usefulness in volatile environments characterized by structural breaks and uncertainty (Stock & Watson, 1999; Clarida, Galí, & Gertler, 1999). More recently, scholars and central banks have increasingly turned to machine learning (ML) and deep learning (DL) methods to overcome these limitations. Algorithms such as Random Forest, XGBoost, Support Vector Regression (SVR), LASSO, and Ridge Regression have demonstrated strong capabilities in modeling nonlinearities, handling large sets of predictors, and enhancing forecast accuracy (Brubakk, Ellen, & Xu, 2021).
Deep neural networks such as Long Short-Term Memory (LSTM), Gated Recurrent Units (GRU), and Artificial Neural Networks (ANN) have demonstrated strong effectiveness in modeling macroeconomic time series characterized by sequential and temporal dependencies (Hinterlang, 2020; Hinterlang & Hollmayr, 2022). Building on these advances, hybrid frameworks including XGBoost–LSTM and Ridge–GRU have achieved superior results in terms of predictive accuracy, robustness, and interpretability. International institutions such as the European Central Bank (ECB) and the International Monetary Fund (IMF) have also begun adopting these approaches to enhance monetary policy analysis (Araujo, Bruno, Marcucci, Schmidt, & Tissot, 2021).
The objective of this study is to forecast policy interest rate changes in Mongolia based on core macroeconomic indicators. To this end, the analysis compares the performance of machine learning (ML) and deep learning (DL) models with traditional econometric methods, with a special focus on the effectiveness of hybrid approaches in practical forecasting contexts.
This study employs established hybrid models, specifically LSTM–XGBoost and Ridge–GRU, to forecast the Bank of Mongolia's policy interest rate. The contextual application constitutes a central contribution of the research, as it provides a data-driven framework to support evidence-based monetary policymaking. In addition to assessing predictive performance, the study advances a transferable methodology that can be applied in other emerging economies with comparable macroeconomic conditions.
2. Literature Review
Forecasting inflation and policy interest rates is central to monetary policy, as it directly informs the strategic decisions of central banks. Recent research has identified several approaches to improve the quality of forecasts. One widely recognized method is forecast combination or ensemble modeling, which leverages the complementary strengths of multiple models to improve accuracy. The concept of forecast combination originated with Bates and Granger (1969) and was systematically reviewed by Clemen (1989). Subsequent contributions demonstrated its effectiveness in macroeconomic contexts, notably Stock and Watson (2004). Classical monetary policy studies extended these insights, with Svensson (1997) formalizing inflation-forecast targeting and Woodford (2003) elaborating the theoretical foundations of interest rate rules, thereby linking forecast-based policymaking to modern policy frameworks.
This approach leverages the complementary strengths of different models, thereby mitigating the risk of model-specific biases or structural misspecifications. The treatment of structural breaks and uncertainty has been a central theme in monetary policy research. Clarida, Galí, and Gertler (1999) advanced the New Keynesian framework by emphasizing the role of expectations in economic decision-making. Subsequent contributions underscored the need to account for time variation and regime shifts, with Stock and Watson (1999) and Cogley and Sargent (2005) highlighting parameter instability, while Primiceri (2005) formalized time-varying VARs. More recent work by Pettenuzzo and Timmermann (2017) extended this tradition by demonstrating the advantages of adaptive forecasting in the presence of model instability. Collectively, these studies emphasize the importance of incorporating both statistical evidence and market-informed signals into monetary policy forecasting frameworks, particularly in environments characterized by heightened uncertainty and abrupt structural shifts.
Goodfriend (1983) examined interest-rate smoothing, and Clarida, Galí, and Gertler (1999) advanced the New Keynesian framework by highlighting the central role of expectations and policy rules. Stock and Watson (1999) further underscored the need to incorporate evolving dynamics into inflation forecasting. Building on these contributions, Cogley and Sargent (2005) and Primiceri (2005) formalized models with drifting parameters and time-varying VARs, establishing a foundation for subsequent research on structural change and policy uncertainty.
Pettenuzzo and Timmermann (2017) provided further validation by demonstrating that adaptive forecasting models explicitly accounting for regime changes and structural instability improve predictive accuracy. Their findings suggest that models incorporating structural breaks provide more reliable forecasts of inflation and policy interest rates, particularly under conditions of heightened macroeconomic uncertainty. The evaluation of forecasts and their implications for monetary policy has also been a central concern in the literature. Diebold and Mariano (1995) introduced a seminal framework for testing predictive accuracy, while Elliott, Komunjer, and Timmermann (2008) extended evaluation methods by incorporating asymmetric loss functions. Together, these contributions underscore the importance of rigorous forecast assessment in ensuring transparency and credibility in central bank communication and decision-making.
In parallel, statistical methods for forecast evaluation have advanced substantially. Diebold and Mariano (1995) introduced a seminal framework for testing predictive accuracy, which remains the cornerstone of forecast comparison and evaluation. Subsequent refinements addressed challenges such as small-sample limitations and inter-variable dependence. Building on this foundation, Elliott, Komunjer, and Timmermann (2008) and Patton and Timmermann (2007) demonstrated that incorporating asymmetric loss functions produces more realistic and policy-relevant assessments of forecast accuracy, particularly in environments characterized by nonlinear risks and heterogeneous preferences. Beyond these theory-driven approaches, rapid technological advancements have transformed forecasting practices. In recent years, the modeling of central bank policy rates has increasingly shifted toward machine learning (ML), deep learning (DL), hybrid model architectures, and explainable artificial intelligence (XAI), reflecting the growing demand for adaptive and data-driven forecasting tools.
Early attempts to forecast policy interest rates relied on rule-based frameworks, such as the Taylor Rule (1993), and were subsequently extended by time-series methods, including ARIMA, VAR, and SVAR. These approaches, however, depend heavily on linear relationships and lack flexibility when confronted with economic shocks or structural breaks. As Koop and Korobilis (2013) emphasize, the rigidity of conventional models limits their ability to adapt to sudden structural changes, thereby reducing predictive performance during periods of volatility and regime shifts. The rise of AI-driven techniques represents a pivotal advance, offering greater robustness and, importantly, adaptability in monetary policy forecasting. This adaptability should instill optimism about the future of monetary policy forecasting.
Machine learning (ML) algorithms, such as Random Forest, XGBoost, and Support Vector Regression (SVR), offer significant advantages in capturing nonlinear relationships, managing high-dimensional predictor sets, and quantifying feature importance. Evidence from Mongolia further supports their effectiveness: Tegshjargal, Tsolmon, and Namuun (2025) show that ML models such as XGBoost and Random Forest substantially outperform classical approaches, including SARIMA and GARCH, in forecasting inflation, underscoring the relevance of ML-based methods for emerging economies. More broadly, empirical studies confirm the practical effectiveness of these algorithms in economic and financial forecasting, with applications spanning macroeconomic and financial variables (Brubakk, Ellen, & Xu, 2021; Mullainathan & Spiess, 2017).
A significant limitation of many ML models is their inability to capture temporal dependencies that are intrinsic to macroeconomic time series. To address this, deep learning (DL) architectures such as Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) have been increasingly employed, offering stronger capabilities for modeling sequential and time-dependent structures in macroeconomic data (Hinterlang, 2020; Hinterlang & Hollmayr, 2022).
Recent research has further emphasized hybrid modeling approaches that integrate the complementary strengths of ML and DL techniques. Aruoba and Drechsel (2023), for example, demonstrate that hybrid models such as XGBoost–LSTM and Ridge–GRU enhance predictive accuracy and stability in complex monetary policy environments. Similar evidence has been reported in applications by central banks and international institutions (Araujo, Bruno, Marcucci, Schmidt, & Tissot, 2021). While these international applications underscore the broader potential of hybrid models, they also reveal a gap in country-specific research, particularly in emerging economies such as Mongolia.
The literature indicates that forecasting central bank policy interest rates has evolved into a multidisciplinary field that integrates multiple methodological strands. These include traditional theoretical models, structural break–adjusted frameworks, forecast combination techniques, machine learning (ML) and deep learning (DL) approaches, as well as more recent developments in explainable artificial intelligence (XAI).
Building on these foundations, this study situates the analysis in the context of Mongolia, applying and testing established hybrid forecasting approaches. The objective is to generate context-specific insights that enhance the accuracy and interpretability of policy rate predictions while supporting evidence-based monetary policymaking.
3. Methodology and Experimental Setup
3.1. Data and Variable Description
This study forecasts the policy interest rate (BODRATE) of the Bank of Mongolia using monthly data spanning January 2008 to December 2024. The dataset, compiled from official national and international sources including the Bank of Mongolia, the National Statistics Office, the United Nations, and the IMF, comprises 26 macroeconomic variables. These variables encompass monetary aggregates, inflation, exchange rates, loan interest rates, foreign trade, fiscal indicators, GDP, investment, foreign reserves, and major commodity exports, including gold, copper, and coal. Their inclusion is intended to reflect the key monetary, fiscal, external, and real-sector dynamics that shape policy rate decisions in a small open economy such as Mongolia.
3.2. Data Preprocessing and Normalization
In the preprocessing stage, missing values were imputed using linear interpolation and k-nearest neighbors (KNN) methods to address data gaps and preserve the continuity of the monthly macroeconomic series. Seasonal patterns were corrected through a SARIMA-based residual adjustment, reducing the risk of seasonality-induced bias in forecasting and parameter estimation. These procedures ensured that the dataset was consistent, reliable, and appropriately structured for accurate and interpretable forecasting with advanced machine learning and deep learning models.
3.3. Modeling Approach and Evaluation
This study employed seven forecasting models encompassing both traditional econometric and modern machine learning approaches: Linear Regression (LR), Ridge Regression, Support Vector Regression (SVR), Random Forest, XGBoost, Long Short-Term Memory networks (LSTM), and a hybrid LSTM–XGBoost architecture. Model performance was assessed using three standard metrics: Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), and the coefficient of determination (R²). Each model was chosen to represent distinct analytical strengths. Linear Regression and Ridge Regression serve as traditional baselines. Random Forest and XGBoost are designed to capture nonlinear relationships and complex feature interactions. LSTM models are well-suited for sequential and temporal dependencies in macroeconomic time series. The hybrid LSTM–XGBoost integrates the advantages of sequence-aware neural networks and tree-based ensemble methods, providing a comprehensive benchmark for comparing forecasting accuracy across methodological categories.
3.4. Experimental Setup and Implementation
To evaluate model performance, the dataset was divided into a training period from January 2008 to December 2022 and a testing period from January 2023 to December 2024. This division ensured robust out-of-sample validation during a recent and turbulent economic period. Hyperparameters were optimized using GridSearchCV and Bayesian Optimization to enhance generalizability and reduce the risk of overfitting. To preserve temporal dependencies and avoid look-ahead bias, time-series-aware cross-validation was applied. For sequence-sensitive models, such as LSTM, a rolling window approach was employed to capture dynamic time-series patterns. In hybrid modeling, base learners such as LSTM and ANN were combined through a stacking framework, with their outputs fed into a meta-model to generate the final forecasts. All procedures, including preprocessing, training, and evaluation, were conducted in Python using open-source libraries including scikit-learn, XGBoost, and TensorFlow.
3.5. Research Design and Theoretical Foundations
The research design of this study is grounded in established theoretical and empirical foundations. The Taylor Rule (Taylor, 1993) and linear VAR models provide a benchmark for understanding monetary policy transmission. However, their applicability is constrained by an inability to capture nonlinearities and abrupt structural changes. Time-varying parameter models and forecast combination approaches (Wright, 2009; Koop & Korobilis, 2013) emphasize the importance of flexibility and robustness in dynamic economic environments. Building on these insights, recent advances in machine learning and deep learning have enhanced the capacity to model nonlinear relationships and temporal dependencies. Based on this perspective, the study employs a mixed methodological strategy that integrates traditional theory-driven approaches with modern data-driven models. This theoretical foundation supports the use of hybrid ML-DL forecasting frameworks in the context of Mongolia, where economic volatility and external shocks require models that are both adaptive and interpretable.
4. Methodology and Experimental Setup
This study evaluated the predictive performance of various machine learning models to forecast the central bank’s policy interest rate using macroeconomic indicators. The models were assessed using three key performance metrics: the coefficient of determination (R²), root mean square error (RMSE), and mean absolute error (MAE).

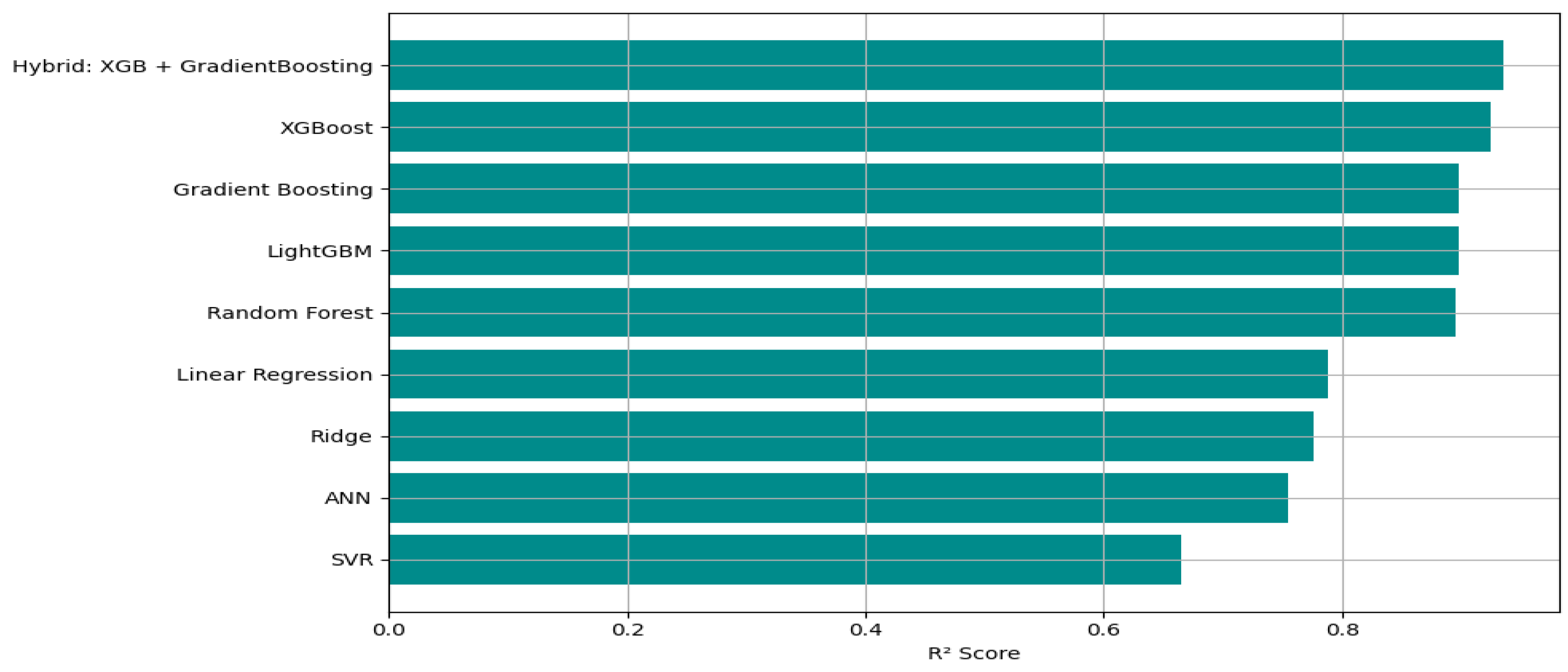
Table 1.
Model Performance Comparison for Policy Rate Forecasting.
| № | Model | R2 | RMSE | MAE |
| 1 | Hybrid: XGB + Gradient Boosting | 0.935533 | 0.145118 | 0.033307 |
| 2 | XGBoost | 0.924603 | 0.156939 | 0.035283 |
| 3 | Gradient Boosting | 0.908974 | 0.172439 | 0.042973 |
| 4 | LightGBM | 0.897411 | 0.183065 | 0.045937 |
| 5 | Random Forest | 0.890604 | 0.189040 | 0.046038 |
| 6 | Linear Regression | 0.788302 | 0.262974 | 0.071547 |
| 7 | Ridge | 0.776440 | 0.270241 | 0.072003 |
| 8 | ANN | 0.735999 | 0.293668 | 0.057518 |
| 9 | SVR | 0.665248 | 0.330686 | 0.151857 |
Among all tested models, the Hybrid model, which combines XGBoost and Gradient Boosting, achieved the best performance, with the highest R² value of 0.9355, the lowest RMSE of 0.1451, and a MAE of 0.0333. This indicates that the hybrid model not only captured more variance in the target variable but also made more accurate predictions on average. The standalone XGBoost model also demonstrated strong predictive capability with an R² of 0.9246, outperforming other single learners such as Random Forest (R² = 0.9090) and Gradient Boosting (R² = 0.9014). These three-based ensemble models consistently outperformed linear and shallow learners, suggesting their superior ability to model complex nonlinear interactions in macroeconomic data. LightGBM followed closely with an R² of 0.8974, showing competitive performance but with slightly higher RMSE and MAE compared to XGBoost-based models.
In contrast, linear models such as linear regression and Ridge Regression showed limited capacity to capture variance (R² = 0.7883 and 0.7764, respectively) and exhibited higher error rates. This highlights their limitations in modeling nonlinear macroeconomic relationships. The performance of SVR (R² = 0.6652) and Artificial Neural Networks (ANN) (R² = 0.6566) was significantly lower, indicating challenges in capturing the temporal and structural patterns present in the data without further tuning or architectural optimization. Overall, the results demonstrate that combining tree-based models, particularly XGBoost and Gradient Boosting, into hybrid frameworks can significantly improve prediction accuracy. These hybrid models leverage the strengths of residual learning to refine predictions, making them highly suitable for economic forecasting tasks, such as predicting policy rates.
Figure 1.
R2 score of Models for Policy rate forecasting.
To further validate the predictive accuracy of the best-performing model, a visual comparison of actual versus predicted policy rates was conducted using the Hybrid: XGB + Gradient Boosting model. As shown in the following Figure, the predicted values (orange crosses) closely follow the actual observed values (blue circles) across most samples, indicating a strong model fit and low residual error. Notably, the model accurately captures both steady periods and sharp fluctuations in policy rates. While a few extreme deviations are observed, particularly where abrupt policy shifts occur, these instances are relatively rare and reflect the inherent challenge of forecasting sudden macroeconomic policy interventions. Despite these outliers, the overall pattern suggests that the hybrid model effectively generalizes over a wide range of macroeconomic conditions. This graphical analysis corroborates the statistical performance metrics (R² = 0.9355, RMSE = 0.1451), reinforcing the hybrid model's ability to make precise and reliable predictions. The alignment between predicted and actual rates further demonstrates the model's practical utility in supporting real-time monetary policy decision-making.
Figure 2 demonstrates the close alignment between actual and predicted policy rates. Notably, the model successfully captured both gradual trends and abrupt shifts, particularly during periods of monetary tightening in 2021. However, slight deviations are observed during high-volatility months, which are common challenges in macroeconomic forecasting.
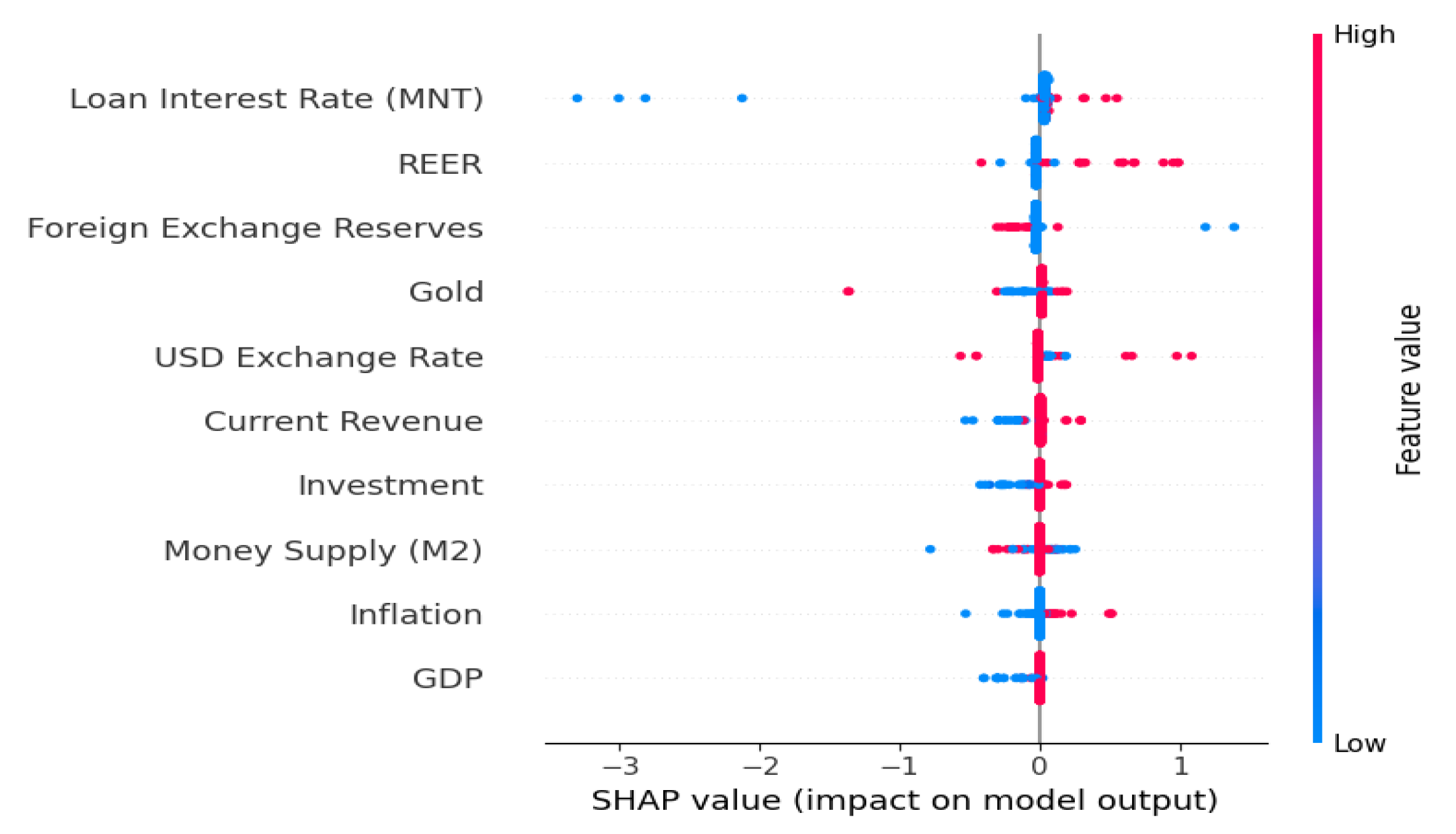
To enhance the interpretability of the hybrid model during time-dependent forecasting, SHAP (Shapley Additive exPlanations) analysis was conducted for the rolling window setup. The SHAP summary plot of Figure 3 highlights the top 10 macroeconomic variables that most strongly influenced the policy interest rate predictions across rolling time intervals. Figure 3 shows the SHAP summary plot of the top 10 most important features based on the Hybrid XGBoost + Gradient Boosting model under rolling window forecasting. Each point represents a single prediction's SHAP value for a feature, colored by the magnitude of the feature value (red indicates high values, blue indicates low values). The x-axis shows the impact on model output (policy rate).
The following features exhibited the highest SHAP impact:
Notably, Loan Interest Rate (MNT) emerged as the most influential variable, indicating that domestic credit market conditions heavily inform monetary policy responses. REER (Real Effective Exchange Rate) and Foreign Exchange Reserves followed closely, showing the model’s sensitivity to external economic balance and currency dynamics. Other important features included gold prices, USD Exchange Rate, and Investment, all reflecting both domestic and global financial conditions. Core macroeconomic indicators, such as M2 money supply, Inflation, and GDP, also played significant roles. This analysis demonstrates that the model adapts its reliance on different features over time, offering a dynamic view of monetary policy drivers. The use of SHAP in a rolling window context thus provides both transparency and policy-relevance in forecasting frameworks.
5. Policy implications
The empirical results yield several policy-relevant insights for the Mongolian economy. The superior performance of hybrid machine learning and deep learning models, including LSTM–XGBoost and XGBoost combined with Gradient Boosting, highlights their potential as practical forecasting tools for the Bank of Mongolia. By enhancing predictive accuracy and improving responsiveness to nonlinear dynamics, these models provide a more reliable basis for forward guidance and risk assessment in a small open economy that is highly vulnerable to external shocks.
The variable importance analysis reveals that government revenue, investment, loan interest rates, and foreign exchange reserves are the most influential determinants of policy rate fluctuations. In the case of Mongolia, where fiscal capacity is strongly linked to mineral export earnings, a sudden decline in commodity prices directly reduces government revenue and external reserves, thereby exerting pressure on monetary policy. The significant role of the USD/MNT exchange rate further reflects the economy’s vulnerability to currency volatility and capital flow reversals, underscoring the need for close coordination between monetary, exchange rate, and fiscal policies.
The role of investment is particularly critical in the Mongolian context, given the economy’s heavy reliance on foreign direct investment in the mining sector. Fluctuations in investment flows affect not only domestic demand but also exchange rate stability and credit conditions. Incorporating such variables into policy rate forecasting frameworks enables monetary authorities to respond more effectively to both cyclical and structural shocks.
Furthermore, the integration of explainable artificial intelligence techniques enhances transparency in monetary policymaking. By clarifying the contribution of each variable to forecast outcomes, methods such as SHAP and Permutation Importance allow policymakers to communicate the rationale for policy adjustments in an evidence-based and accountable manner. This approach is especially valuable in Mongolia, where strengthening public confidence in policy institutions depends on transparent and data-driven decision-making.
6. Conclusions and Discussion
This study developed an advanced and interpretable forecasting framework for the policy interest rate of the Bank of Mongolia by integrating traditional econometric methods with machine learning, deep learning, and hybrid modeling approaches. Using a comprehensive dataset of 26 macroeconomic indicators spanning 2008–2024, the research addressed the growing need for flexible and data-driven methods that can capture the complex dynamics of emerging market economies.
The comparative evaluation of seven forecasting models demonstrated that hybrid approaches, particularly XGBoost combined with Gradient Boosting and LSTM integrated with XGBoost, achieved the highest predictive accuracy. The best-performing hybrid model recorded an R² of 0.9355 and the lowest RMSE, outperforming both traditional econometric models and individual ML/DL techniques. These results underscore the added value of combining sequence-aware architectures with ensemble learners for modeling nonlinearities, structural changes, and temporal dependencies in monetary policy variables.
The interpretability analysis using SHAP and Permutation Importance provided additional insights into the underlying economic drivers. The SHAP analysis under rolling window forecasting confirmed that loan interest rate, exchange rate indicators, and monetary aggregates are consistently the most influential drivers of policy rate changes over time, highlighting the hybrid model’s adaptability to dynamic macroeconomic conditions. These findings emphasize the importance of monitoring fiscal and external sector indicators when assessing monetary conditions and designing interest rate policies, as they capture both domestic vulnerabilities and external shocks.
From a policy perspective, the results highlight the potential benefits of integrating artificial intelligence–based forecasting systems into the policy formulation process. While conventional models often struggle to adapt to real-time shocks or regime changes, the hybrid models applied in this study demonstrated strong adaptability, robustness, and interpretability. The ability to decompose forecasts using explainable AI techniques further enhances transparency and accountability, thereby increasing the credibility and acceptance of model-driven decision support within policy institutions.
Beyond its empirical contributions, this research advances the broader literature by providing Mongolia-specific evidence and by illustrating how established hybrid approaches can be effectively adapted to small open economies with high external exposure, limited data infrastructure, and policy volatility. The demonstrated combination of predictive accuracy, interpretability, and scalability suggests that such models can serve as valuable tools not only for short-term forecasting but also for long-term strategic planning in monetary policy.
Future research could extend this framework by exploring alternative hybrid configurations, integrating macro-financial sentiment indicators, or jointly modeling multiple policy instruments. The use of high-frequency data and natural language processing techniques, such as analyzing central bank communications, also offers promising avenues for enhancing the responsiveness, precision, and policy relevance of interest rate forecasts in increasingly dynamic and uncertain economic environments.
6.1. Compliance with Ethical Standards
Ethical Considerations
This study was conducted in accordance with the ethical research principles and data protection standards applicable to academic studies in Mongolia. All participants involved in the data collection process were informed about the purpose and scope of the research, and their participation was entirely voluntary. Informed consent was obtained prior to the use of any personally relevant macroeconomic or institutional data. To ensure confidentiality and data integrity, no personally identifiable information was disclosed or recorded, and all data were securely stored in encrypted digital environments. The forecasting models were developed using publicly accessible macroeconomic indicators, and no human subjects were exposed to physical, psychological, or legal risk. The research adhered to international ethical norms and principles of transparency, academic integrity, and responsible data handling.
Conflicts of Interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
References
- Ang, A.; Bekaert, G.; Wei, M. Do macro variables, asset markets, or surveys forecast inflation better? Journal of Monetary Economics 2007, 54(4), 1163–1212. [Google Scholar] [CrossRef]
- Araujo, D.; Bruno, G.; Marcucci, J.; Schmidt, R.; Tissot, B. Machine learning applications in central banking. BIS IFC Bulletin 57. 2021. Available online: https://www.bis.org/ifc/publ/ifcb57_01_rh.pdf.
- Aruoba, B.; Drechsel, T. Identifying monetary policy shocks: A natural language approach. CEPR Discussion Paper 2022, DP17133. Available online: https://cepr.org/publications/dp17133.
- Aruoba, S. B.; Drechsel, T. Identifying monetary policy shocks: A natural language approach. Review of Economic Studies. 2023. Available online: https://econweb.umd.edu/~webspace/aruoba/research/paper34/Aruoba_Drechsel.pdf.
- Bates, J. M.; Granger, C. W. J. The combination of forecasts. Journal of the Operational Research Society 1969, 20(4), 451–468. [Google Scholar] [CrossRef]
- Box, G. E. P.; Jenkins, G. M. Time series analysis: Forecasting and control; Holden-Day: San Francisco, 1970. [Google Scholar] [CrossRef]
- Brubakk, L.; Ellen, S. T.; Xu, H. Central bank communication through interest rate projections. Journal of Banking & Finance 2021. [Google Scholar] [CrossRef]
- Clarida, R.; Galí, J.; Gertler, M. The science of monetary policy: A New Keynesian perspective. Journal of Economic Literature 1999, 37(4), 1661–1707. [Google Scholar] [CrossRef]
- Clemen, R. T. Combining forecasts: A review and annotated bibliography. International Journal of Forecasting 1989, 5(4), 559–583. [Google Scholar] [CrossRef]
- Cogley, T.; Sargent, T. J. Drifts and volatilities: Monetary policies and outcomes in the post WWII US. Review of Economic Dynamics 2005, 8(2), 262–302. [Google Scholar] [CrossRef]
- Diebold, F. X.; Mariano, R. S. Comparing predictive accuracy. Journal of Business & Economic Statistics 1995, 13(3), 253–263. [Google Scholar] [CrossRef]
- Elliott, G.; Komunjer, I.; Timmermann, A. Biases in macroeconomic forecasts: Irrationality or asymmetric loss? Journal of the European Economic Association 2008, 6(1), 122–157. [Google Scholar] [CrossRef]
- Goodfriend, M. Discount window borrowing, monetary policy, and the post-October 6, 1979 Federal Reserve operating procedure. Journal of Monetary Economics 1983, 12(3), 343–356. [Google Scholar] [CrossRef]
- Hinterlang, N. Predicting monetary policy using artificial neural networks. Deutsche Bundesbank Discussion Paper, 44/2020. 2020. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3669522.
- Hinterlang, N.; Hollmayr, J. Classification of monetary and fiscal dominance regimes using machine learning techniques. Journal of Macroeconomics 76 2022, 103469. [Google Scholar] [CrossRef]
- Koop, G.; Korobilis, D. Large time-varying parameter VARs. Journal of Econometrics 2013, 177(2), 185–198. [Google Scholar] [CrossRef]
- Mullainathan, S.; Spiess, J. Machine learning: An applied econometric approach. Journal of Economic Perspectives 2017, 31(2), 87–106. [Google Scholar] [CrossRef]
- Patton, A. J.; Timmermann, A. Testing forecast optimality under unknown loss. Journal of the American Statistical Association 2007, 102(480), 1172–1184. [Google Scholar] [CrossRef]
- Pettenuzzo, D.; Timmermann, A. Forecasting macroeconomic variables under model instability. Journal of Business & Economic Statistics 2017, 35(2), 183–201. [Google Scholar] [CrossRef]
- Primiceri, G. E. Time varying structural vector autoregressions and monetary policy. Review of Economic Studies 2005, 72(3), 821–852. [Google Scholar] [CrossRef]
- Stock, J. H.; Watson, M. W. Forecasting inflation. Journal of Monetary Economics 1999, 44(2), 293–335. [Google Scholar] [CrossRef]
- Stock, J. H.; Watson, M. W. Combination forecasts of output growth in a seven-country data set. Journal of Forecasting 2004, 23(6), 405–430. [Google Scholar] [CrossRef]
- Svensson, L. E. O. Inflation forecast targeting: Implementing and monitoring inflation targets. European Economic Review 1997, 41(6), 1111–1146. [Google Scholar] [CrossRef]
- Taylor, J. B. Discretion versus policy rules in practice. Carnegie–Rochester Conference Series on Public Policy 1993, 39(1), 195–214. [Google Scholar] [CrossRef]
- Tegshjargal, S.; Tsolmon, S.; Namuun, A. Possibility of predicting inflation: Using machine learning model. International Journal of Social Science and Humanities Research-MIYR 2025, 5(2), 49–64. [Google Scholar] [CrossRef]
- Timothy, C.; Sargent, T. J. Drifts and volatilities: Monetary policies and outcomes in the post WWII US. Review of Economic Dynamics 2005, 8(2), 262–302. [Google Scholar] [CrossRef]
- Wright, J. H. Forecasting US inflation by Bayesian model averaging. Journal of Forecasting 2009, 28(2), 131–144. [Google Scholar] [CrossRef]
Figure 2.
Predict the performance of the hybrid model.
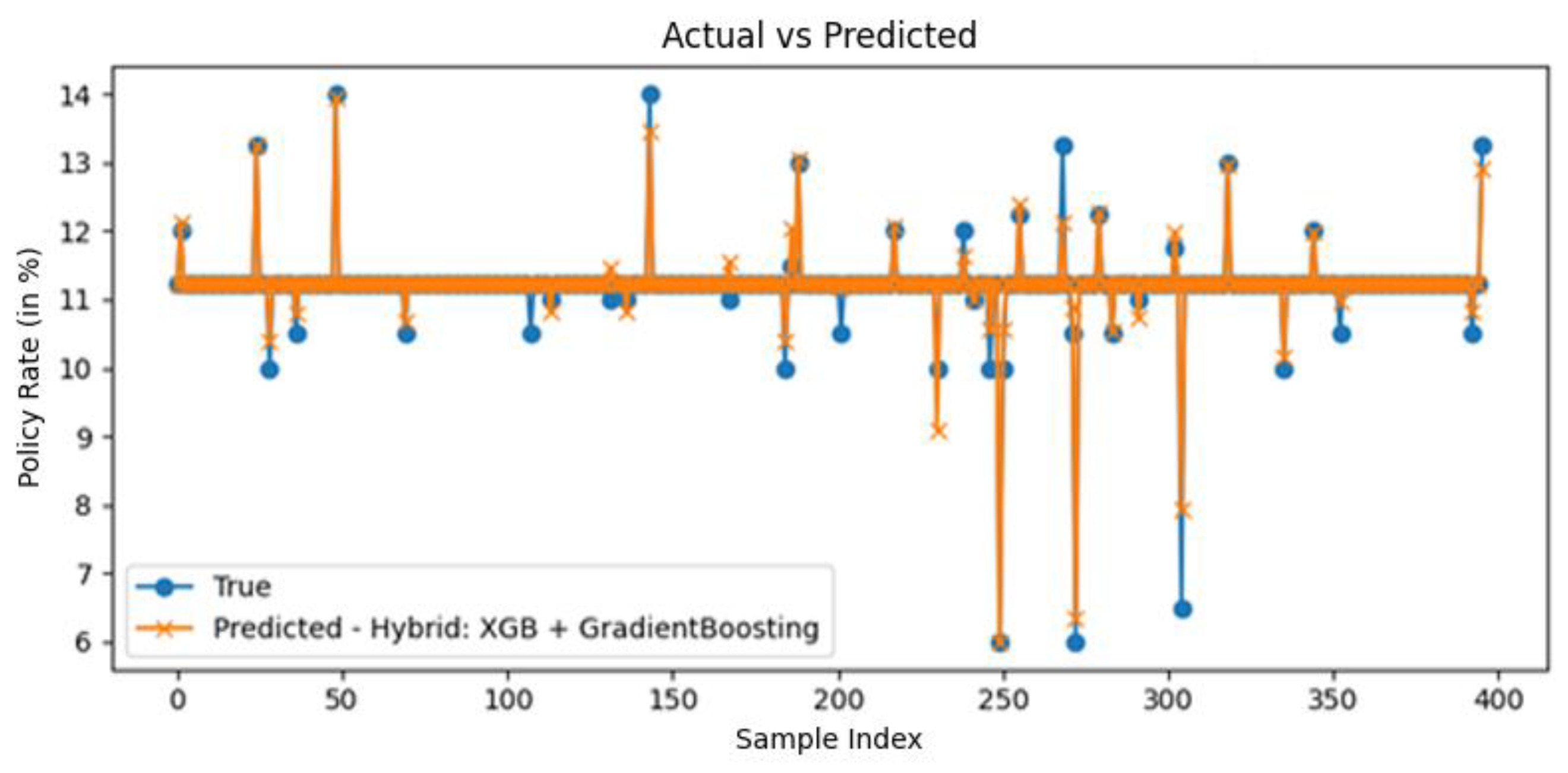
Figure 3.
SHAP analysis of rolling window forecasting.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



