Submitted:
02 January 2026
Posted:
06 January 2026
You are already at the latest version
Abstract
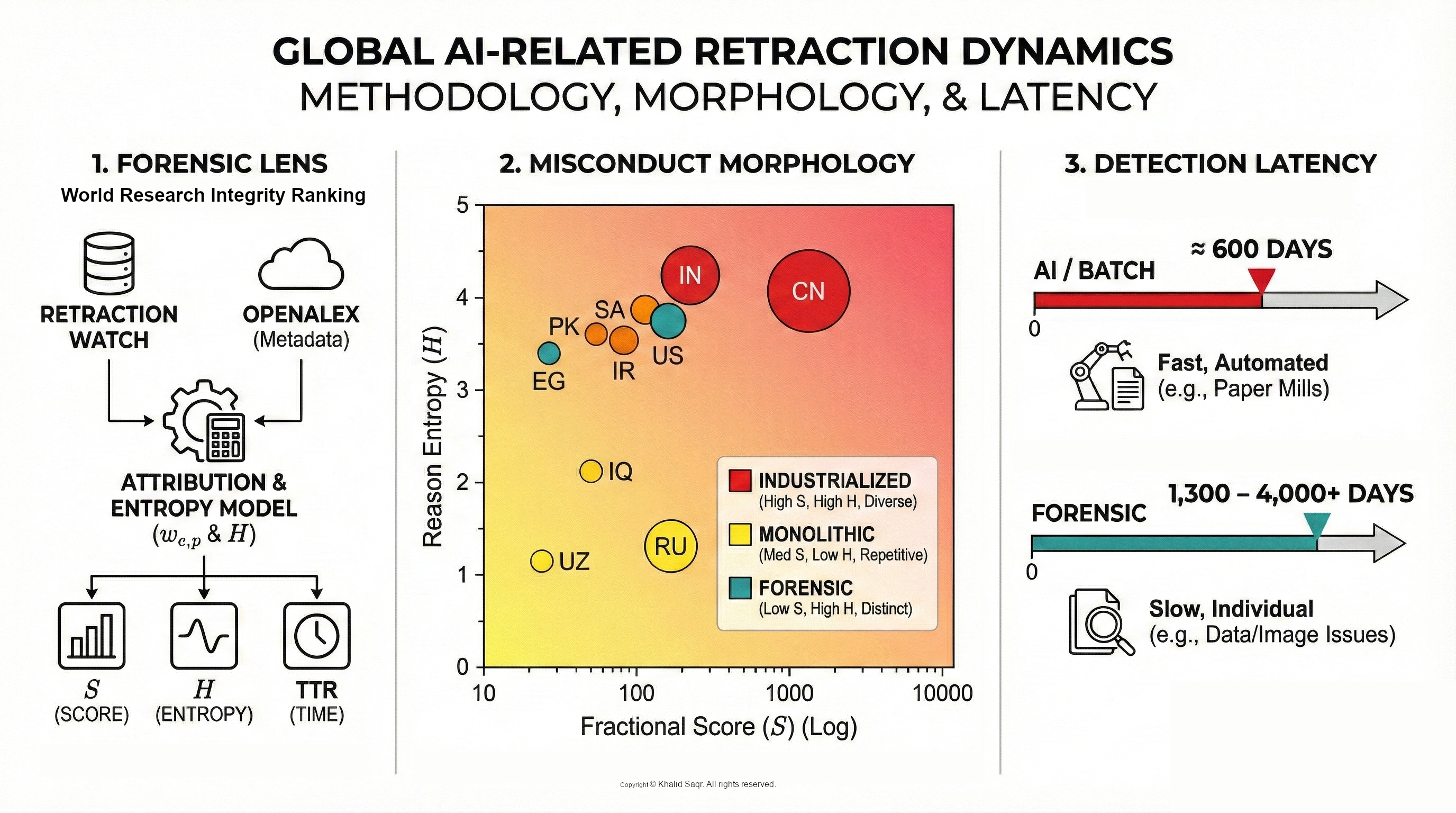
Research integrity is currently besieged by a surge in synthetic manuscripts. A forensic workflow is operationalized herein to isolate and quantify ``computer-aided'' misconduct within the global scholarly record. A corpus of \( N=3,974 \) retracted DOIs sourced from the Retraction Watch Database was analyzed, with records cross-linked to institutional metadata via the OpenAlex API. Through the application of fractional attribution modeling and the calculation of Shannon entropy (\( H \)) for retraction rationales, a distinct geographic schism in fraud typologies was identified. High-output hubs, specifically China and India, exhibit high reason entropy (\( H > 4.2 \)), where ``Computer-Aided Content'' frequently clusters with established ``Paper Mill'' signatures. These AI-driven retractions exhibit a compressed median Time-to-Retraction (TTR) of \( \sim \)600 days, nearly twice as fast as the \( 1,300 \)+ day latencies observed in the US and Japan---where retractions remain skewed toward complex image and data manipulation. The data suggests that while traditional fraud has not been replaced by generative AI, it has been effectively industrialized. It is concluded that current post-publication filters fail to keep pace with the near-zero marginal cost of synthetic content, necessitating a shift toward provenance-based verification.
Keywords:
Introduction
Methods
Mathematical Model and Variable Definitions
Analysis Logic, Code, and Data Pipeline
- (1)
- Temporal Filter: (aligned with the public release of ChatGPT).
- (2)
- Taxonomy Filter: The Reason field must contain the exact substring “Computer-Aided Content or Computer-Generated Content”.
Results
Institutional-Level Retraction Dynamics
Country-Level Retraction Dynamics
Discussion
Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Van Noorden, R. ChatGPT: five priorities for research. Nature 2023, 614(7947), 224–226. [Google Scholar] [CrossRef] [PubMed]
- Else, H. ’Paper-mill’ alarm software flags potentially fake papers. Nature 2022, 609(7929), 20–21. [Google Scholar] [CrossRef]
- Cabanac, G.; Labbé, C.; Magazinov, A. Tortured phrases: A dubious writing style emerging in science. arXiv 2021, arXiv:2107.06751. [Google Scholar] [CrossRef]
- Brainard, J. Fake scientific papers are alarmingly common. Science 2023, 380(6645), 567. [Google Scholar] [CrossRef]
- Stokel-Walker, C. ChatGPT listed as author on research papers: many scientists disapprove. Nature 2023, 613(7945), 620–621. [Google Scholar] [CrossRef] [PubMed]
- Thorp, H. H. ChatGPT is fun, but not an author. Science 2023, 379(6630), 313. [Google Scholar] [CrossRef] [PubMed]
- Conroy, G. How ChatGPT and other AI tools could disrupt scientific publishing. Nature 2023, 622(7982), 234–236. [Google Scholar] [CrossRef] [PubMed]
- Abalkina, A.; Aquarius, R.; Bik, E.; Bimler, D.; Bishop, D.; Byrne, J.; Cabanac, G.; Day, A.; Labbé, C.; Wise, N. ’Stamp out paper mills’ — science sleuths on how to fight fake research. Nature 2025, 637(8048), 1047–1050. [Google Scholar] [CrossRef] [PubMed]
- Kincaid, E. Wiley to stop using "Hindawi" name amid 18 million revenue decline. Retraction Watch. 2023. Available online: https://retractionwatch.com/2023/12/06/wiley-to-stop-using-hindawi-name-amid-18-million-revenue-decline/.
- Forbes Advisor. Surge In Academic Retractions Should Put U.S. Scholars On Notice. Forbes. 2024. Available online: https://www.forbes.com/sites/petersuciu/2024/02/01/surge-in-academic-retractions-should-put-us-scholars-on-notice/.
- Hvistendahl, M. China’s publication bazaar. Science 2013, 342(6162), 1035–1039. [Google Scholar] [CrossRef] [PubMed]
- Ordway, D.-M. Retraction Watch: Tracking retractions as a window into the scientific process. In Journal’s Resource; 2021. [Google Scholar]
- Priem, J.; Piwowar, H.; Orr, R. OpenAlex: A fully-open index of scholarly works, author, venues, institutions, and concepts. arXiv 2022, arXiv:2205.01833. [Google Scholar]
- Guerrero-Bote, V. P.; Chinchilla-Rodríguez, Z.; Mendoza, A.; de Moya-Anegón, F. Comparative analysis of the bibliographic data sources Dimensions and Scopus: An approach at the country and institutional level. Frontiers in Research Metrics and Analytics 2021, 5, 593494. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C. E. A mathematical theory of communication. The Bell System Technical Journal 1948, vol. 27(no. 3), 379–423. [Google Scholar] [CrossRef]
- Weber-Wulff, D.; Anohina-Naumeca, A.; Bjelobaba, S.; Foltýnek, T.; Guerrero-Dib, J.; Popoola, O.; Waddington, L. Testing of detection tools for AI-generated text. International Journal for Educational Integrity 2023, 19(1), 26. [Google Scholar] [CrossRef]
- Else, H. Abstracts written by ChatGPT fool scientists. Nature 2023, 613(7944), 423. [Google Scholar] [CrossRef] [PubMed]

| Rank | Institution | Score | TTR | Top Retraction Reasons |
|---|---|---|---|---|
| 1 | Vellore Inst. of Technology | 31.61 | 801.0 | Peer Review; Investigation by Journal/Publisher |
| 2 | Saveetha University | 31.34 | 632.0 | Computer-Aided Content or Computer-Generated Content; Referencing/Attributions |
| 3 | King Saud University | 29.51 | 630.5 | authorship/Affiliation; Investigation by Journal/Publisher |
| 4 | Sichuan Normal University | 28.00 | 1238.0 | Computer-Aided Content or Computer-Generated Content; authorship/Affiliation |
| 5 | Lovely Professional Univ. | 22.15 | 469.0 | Article Issues; Referencing/Attributions |
| 6 | Don State Technical Univ. | 21.33 | 490.0 | Article Issues; Referencing/Attributions |
| 7 | Institute of Engineering | 16.48 | 640.0 | Article Issues; Referencing/Attributions |
| 8 | Shandong First Med. Univ. | 16.48 | 574.5 | Computer-Aided Content or Computer-Generated Content; Data Issues |
| 9 | Menoufia University | 16.48 | 1497.0 | Referencing/Attributions; Investigation by Journal |
| 10 | National Inst. AIST | 16.42 | 4054.0 | Error in Image; Falsification/Fabrication of Image |
| Rank | Country | Score | TTR | H | Primary Retraction Reasons |
|---|---|---|---|---|---|
| 1 | China (CN) | 1351.54 | 850.0 | 4.22 | Computer-Aided Content or Computer-Generated Content; authorship/Affiliation |
| 2 | India (IN) | 359.29 | 651.0 | 4.29 | Article Issues; Referencing/Attributions |
| 3 | Russia (RU) | 190.80 | 490.0 | 1.33 | Article Issues; Referencing/Attributions |
| 4 | USA (US) | 134.98 | 1365.0 | 3.85 | Concerns/Issues about Data; Image Issues |
| 5 | Saudi Arabia (SA) | 122.60 | 743.0 | 3.91 | Referencing/Attributions; Investigation by Journal |
| 6 | Iran (IR) | 109.95 | 1132.0 | 3.65 | authorship/Affiliation; Investigation by Journal |
| 7 | Pakistan (PK) | 92.12 | 878.0 | 3.72 | Referencing/Attributions; Peer Review Issues |
| 8 | Iraq (IQ) | 88.77 | 640.0 | 2.10 | Article Issues; Referencing/Attributions |
| 9 | Egypt (EG) | 68.12 | 1122.0 | 3.44 | Referencing/Attributions; Investigation by Journal |
| 10 | Uzbekistan (UZ) | 55.89 | 490.0 | 1.15 | Article Issues; Referencing/Attributions |
| Jurisdiction | Morphology Type | H | Dominant Indicators |
|---|---|---|---|
| China (CN) | Industrialized / Generative | 4.22 | Computer-Aided Content; Paper Mill; Compromised Peer Review |
| India (IN) | Industrialized / Procedural | 4.29 | Article Issues; Referencing/Attributions; Peer Review |
| Russia (RU) | Monolithic / Citation | 1.33 | Concerns/Issues about Article; Referencing/Attributions |
| United States (US) | Substantive / Forensic | 5.04 | Concerns/Issues about Data; Image Issues; authorship |
| Saudi Arabia (SA) | Procedural / Citation | 4.77 | Referencing/Attributions; Investigation by Journal |
| Pakistan (PK) | Mixed / Procedural | 3.79 | Referencing/Attributions; Peer Review Issues |
| Cluster Type | Institution | Median TTR | Primary Retraction Driver |
|---|---|---|---|
| Fast / Batch | Uzbekistan (National) | 490 days | Article Issues; Referencing |
| Shandong First Med. Univ. | 574.5 days | Computer-Aided Content; Data Issues | |
| Saveetha University | 632.0 days | Computer-Aided Content; Paper Mill | |
| King Saud University | 630.5 days | authorship; Investigation by Journal | |
| Slow / Forensic | Vellore Inst. of Tech. | 801.0 days | Peer Review; Investigation |
| Menoufia University | 1,497.0 days | Referencing; Unreliable Results | |
| AIST (Japan) | 4,054.0 days | Image Falsification; Misconduct |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



