Submitted:
02 January 2026
Posted:
04 January 2026
You are already at the latest version
Abstract
This paper investigates a receiver-centric decoding framework for unit-rate transmission in which no redundancy is conveyed through the physical channel. Only k information bits are transmitted over an additive white Gaussian noise (AWGN) channel, while reliability is pursued by structured hypothesis testing and increased receiver-side computational complexity. The receiver embeds each candidate information hypothesis into a higher-dimensional (k, n) linear block code and evaluates all 2k hypotheses in parallel. For each hypothesis, a single message-passing iteration on the Tanner graph is employed as a soft refinement operator, and the final decision is obtained via an orthogonality-based constraint metric that measures the consistency of the refined estimate with the hypothesis-induced code structure. The parity-related terms used within this metric are not modeled as stochastic channel observations and do not introduce additional mutual information beyond the channel output; instead, they act as deterministic, hypothesis-conditioned constraint weights that control how strongly code consistency is enforced within the decision rule. The relationship between metric weighting, apparent horizontal shifts in bit-error-rate (BER) curves, and information-theoretic limits is explicitly clarified. Simulations for a short (8, 24) code demonstrate that near maximum-likelihood decision behavior can be approached by trading receiver complexity for reliability in a finite-hypothesis regime, without altering the physical channel model or violating established channel-capacity principles.
Keywords:
unit-rate transmission
; hypothesis testing
; parallel message passing
; constrained decoding
; LDPC-type Tanner graphs
; AWGN channel
1. Introduction
The era of channel coding began with linear block codes, in which codewords are represented as vectors in an n-dimensional space generated by a set of linearly independent rows of a generator matrix. Classical decoding methods for such codes, including syndrome-based lookup decoding and bounded-distance decoding, identify the most probable error pattern consistent with the received syndrome [1]. While these techniques are optimal for short block lengths, their computational complexity grows exponentially with code dimension or the number of parity constraints, which makes them impractical for moderate and long codes [2]. Maximum-likelihood (ML) decoding provides optimal error performance, but its complexity of is prohibitive for most real-time applications.
Iterative message-passing decoding, most notably belief propagation (BP) and the sum-product algorithm, offers a scalable alternative by performing probabilistic inference on the Tanner-graph representation of a code [3,4]. The computational complexity of message passing grows linearly with the number of graph edges, and when applied to sparse parity-check matrices, it enables decoding performance that approaches the Shannon limit [5]. These properties have established message-passing decoding as a core technique in modern communication systems.
Despite these advances, conventional coded systems rely on the transmission of redundancy, and the channel code rate is necessarily smaller than one. Improvements in minimum distance or iterative convergence typically require additional parity symbols, which reduce effective throughput. This paper examines a different operating regime: only the uncoded information bits are transmitted over the channel, while the receiver alone introduces code structure and performs decoding within an n-dimensional code space. From the channel perspective, the transmission operates at unit rate ().
Scope and interpretation. The proposed framework should be interpreted as constrained hypothesis testing rather than probabilistic inference under a modified channel model. The physical channel is unchanged: the only random observation is the channel output associated with the transmitted information symbols. Code structure is used at the receiver to restrict and score candidate hypotheses. In particular, the parity-related terms used within the decoder are deterministic, hypothesis-conditioned constraints and are not treated as additional channel observations or side information. Consequently, the method makes no claim of increasing channel capacity; instead, it explicitly trades receiver-side computational complexity against decision reliability in a finite-hypothesis regime.
The main contributions of this work are summarized as follows:
- A receiver-centric framework for unit-rate transmission is formulated as hypothesis-parallel, constrained decision-making in an n-dimensional code space.
- Message passing is employed as a one-shot soft refinement operator for each hypothesis, followed by an orthogonality-based constraint metric for final selection.
- The role of parity-related metric weighting is clarified: it controls constraint hardness and influences bit-error-rate (BER) curve presentation, without implying a physical signal-to-noise ratio (SNR) change or a capacity gain.
The rest of the paper is organized as follows. Section 2 introduces the system model and notation. Section 3 presents the receiver architecture, including hypothesis-conditioned constraint weighting and the selection rule. Section 4 clarifies the relationship to channel capacity and conditional entropy. Section 5 analyzes computational complexity. Section 6 reports simulation results. Section 7 concludes the paper.
2. System Model and Preliminaries
2.1. Linear Block Code Representation
We consider a binary linear block code of length n and dimension k, denoted as a code. The code can be specified by a generator matrix and a parity-check matrix such that
We focus on systematic generator matrices of the form
where is the identity matrix and P is a parity matrix. A corresponding systematic parity-check matrix is
The Tanner graph associated with H is a bipartite graph with variable nodes corresponding to codeword symbols and check nodes corresponding to parity constraints.
2.2. Channel Model and Information-Symbol LLRs
The transmitter sends k uncoded information bits
These bits are binary-phase shift-keying (BPSK) modulated as
and are transmitted over an additive white Gaussian noise (AWGN) channel:
No parity symbols are transmitted; the effective information rate over the physical channel is therefore .
At the receiver, log-likelihood ratios (LLRs) are computed for each received information symbol:
These k LLRs constitute the only probabilistic soft information derived from the physical channel.
2.3. Remark on Noise-Variance Bookkeeping
In traditional coded communication, all n symbols of a codeword are transmitted and independently corrupted by noise. The familiar relation
reflects that is spread across n channel uses. In the present unit-rate setting, only k channel uses occur, hence
is the relevant physical-noise relation for the transmitted information symbols. Any additional reliability parameters used inside the receiver act on the decision rule and are not part of the physical channel model.
3. Proposed Receiver and Hypothesis-Parallel Decoding
3.1. Receiver-Only Code Embedding
The receiver is equipped with a linear block code with known matrices and . All information hypotheses are considered,
and each hypothesis uniquely determines a candidate codeword
In particular, the parity pattern of is a deterministic function of the hypothesis .
3.2. Hypothesis-Conditioned Constraint Weighting
To enable message passing over the Tanner graph for each hypothesis, an n-dimensional initialization vector is formed. For the information positions, the initialization is given by the channel-derived LLRs . For the parity positions, the receiver introduces deterministic constraint weights that are conditioned on the hypothesis. These weights are not interpreted as channel observations. Instead, they control the hardness with which the parity consistency implied by is enforced within the decision rule.
For numerical convenience, a constraint-weight magnitude may be represented on an “LLR-like” scale. This is purely an internal parameter of the decoder metric and should not be interpreted as implying a reduced physical noise variance for untransmitted symbols.
3.3. Parallel Message Passing Across Hypotheses
For each hypothesis m, one iteration of message passing is executed on the Tanner graph with the above initialization. The goal of this single iteration is soft refinement of the hypothesis-conditioned estimate, not iterative convergence under a probabilistic channel model.
Let denote the refined soft estimate after the single message-passing step for hypothesis m.
3.4. Orthogonality-Based Constraint Metric and Selection Rule
Each refined estimate is scored by an orthogonality-based constraint metric defined with respect to the candidate codeword. Specifically, an energy functional is computed as
where denotes the complement (in the chosen bipolar or binary representation) of the i-th component of the hypothesis-induced codeword. The decoded hypothesis is
with the decoded information vector .
4. Relation to Channel Capacity and Conditional Entropy
This section clarifies why the proposed receiver-centric framework does not break established information-theoretic principles.
4.1. No Change to the Physical Channel or Mutual Information
The physical channel is the AWGN channel used to transmit the k information symbols. The only random observation available to the receiver is . The decoder does not obtain additional channel outputs, and it does not modify the channel law . Therefore, the mutual information between the transmitted information symbols and the channel output, , is unchanged by any internal decoder parameter.
It is important to mention that the observed reduction in the required for a given target BER does not indicate an increase in channel capacity. The physical channel remains unchanged, and the mutual information is fixed by the AWGN channel law. The improved performance reflects a reduction in the decoding gap to capacity achieved through a more powerful decision rule, rather than a shift of the capacity limit itself. In particular, the proposed receiver approaches ML decision behavior in a finite-hypothesis regime by enumerating and scoring all candidate information hypotheses under strong structural constraints. This improved hypothesis resolution is obtained at the expense of increased receiver-side computational complexity, which scales exponentially with the number of information bits k. Such a trade-off between complexity and reliability is fully consistent with information-theoretic principles and does not rely on transmitting additional redundancy or side information through the channel. Consequently, the apparent leftward shift of BER curves should be interpreted as a reduction of the decoder-induced performance gap to capacity, not as evidence of capacity enhancement, especially in short-block, unit-rate transmission scenarios.
4.2. Reliability via Constrained Hypothesis Testing and Complexity
The proposed method reduces decision uncertainty by restricting and scoring hypotheses using code-structure constraints. In information-theoretic terms, improved reliability corresponds to reducing the conditional uncertainty of the decision given the observation, i.e., reducing the effective ambiguity in through a more powerful decision rule (here, an explicit enumeration over a finite hypothesis set combined with constraint-based scoring). This reduction is achieved by computational complexity (scaling with for hypothesis enumeration) rather than by transmitting redundancy. No claim is made of exceeding capacity; rather, the framework highlights a complexity–reliability trade-off in a finite-hypothesis regime.
4.3. Interpretation of Metric Weighting and BER Presentation
The constraint-weight magnitude influences how strongly parity consistency is enforced inside the decision metric. Because is an internal metric parameter, varying can produce apparent horizontal displacements of BER curves when performance is plotted against . Such displacements reflect changes in the decision rule and metric scaling, not a physical reduction of channel noise. Any “compensation” applied in plots should therefore be interpreted as a plotting/normalization device to compare decision rules, not as a claim of physical equivalence between systems.
The magnitude of , causes a horizontal displacement of the BER curves when performance is plotted versus . This effect arises because representing the parity constraint on an LLR-like scale implicitly corresponds to assuming an effective noise variance for the parity positions, even though no physical channel observations exist for those symbols. To enable fair comparison across different values of , a deterministic horizontal normalization is applied. Under the standard AWGN LLR normalization with normalized constellation values, the corresponding horizontal offset is given by
This normalization compensates for the model-induced metric scaling only and does not represent a physical SNR gain or any change in the underlying channel conditions.
5. Complexity Considerations
A naive ML decoder over all hypotheses has complexity . A standard BP decoder for a length-n code, when all n symbols are transmitted, requires iterative processing with complexity on the order of
where I is the number of iterations and E is the number of edges in the Tanner graph.
In the proposed architecture, two observations alter the complexity profile. First, the number of hypotheses is fixed and small in the targeted regime (e.g., ). Second, each hypothesis requires only a single message-passing iteration. Thus, the total effort is dominated by
where denotes the cost of one BP iteration on the graph. For fixed k, complexity scales essentially linearly with n.
6. Simulation Setup and Illustrative Results
6.1. Code Family
We consider a family of codes with:
- fixed information dimension ;
- block length ;
- minimum distance ;
- systematic generator matrix of the form ;
- parity-check matrix constructed via a progressive edge-growth (PEG)-like procedure;
- sparse parity-check structure (low-density parity-check (LDPC) type), limited column and row weights;
- Tanner graph girth at least six (no four-cycles);
- no zero rows or zero columns in H.
These codes are generated using a PEG-style construction to ensure large girth and good graph connectivity [6].
6.2. Channel and Decoder Parameters
For each code and each SNR point, the simulation procedure is as follows:
- Random information vectors are generated.
- The bits are BPSK-modulated and transmitted over an AWGN channel with noise variancecorresponding to unit-rate transmission.
- LLRs for the information positions are computed from the received symbols.
- A hypothesis-conditioned constraint-weight magnitude is selected (varied from 25 to 100 in the reported experiments) to control the hardness of parity consistency in the internal decision metric. This parameter is not a channel observation and does not modify the physical noise model.
- Hypothesis-parallel message passing is executed over all hypotheses, with each hypothesis refined through a single BP iteration.
- The orthogonality-based constraint metric is computed for each candidate, and the hypothesis minimizing the metric is selected.
- BER is estimated over a large number of trials (e.g., 1000 packet errors per SNR point).
6.3. Results and Interpretations
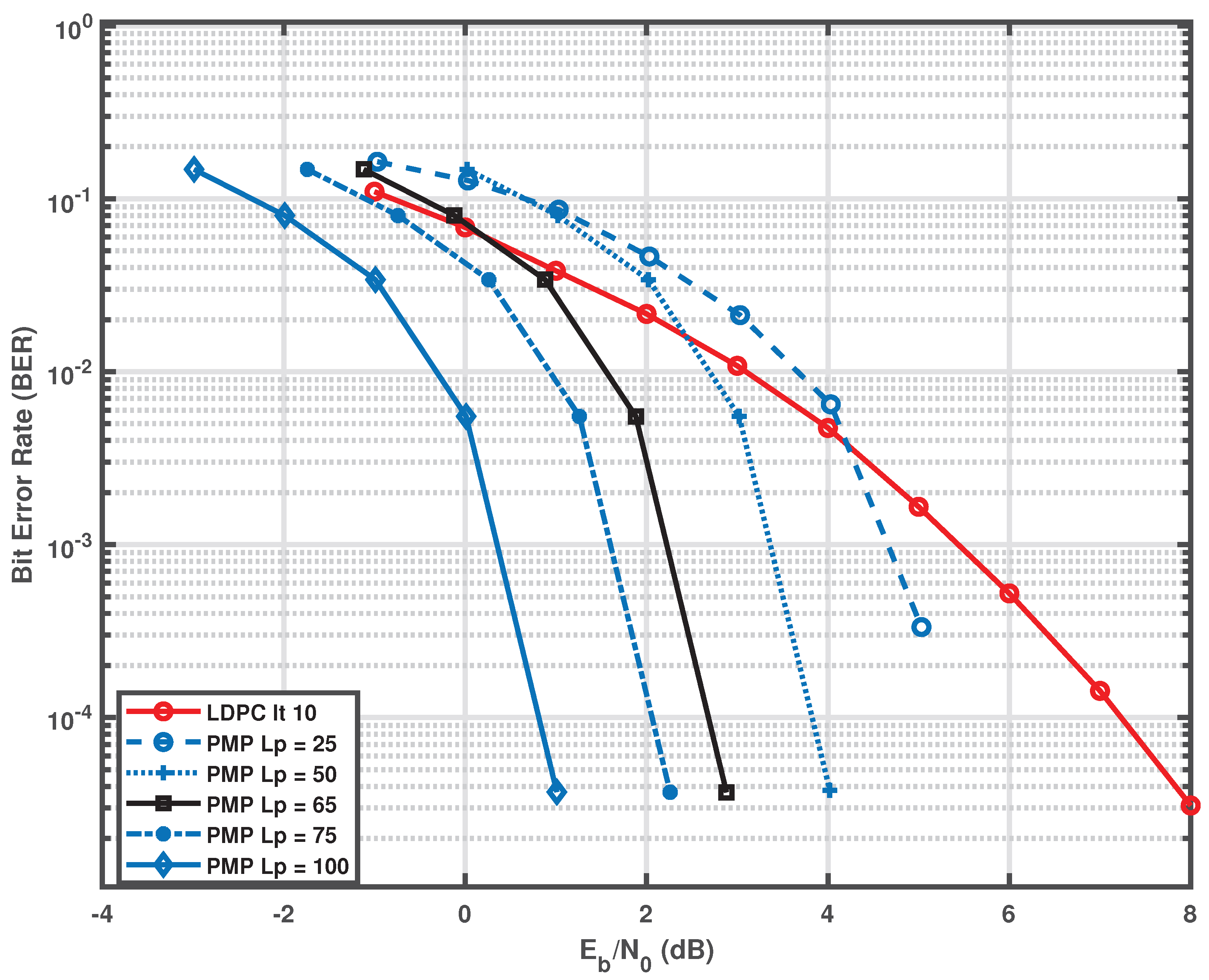
Figure 1 presents the BER performance of a conventional iterative LDPC decoder for the code and the proposed receiver for different values of the constraint-weight magnitude . The curves labeled LDPC correspond to the standard iterative LDPC decoder operated with its maximum allowed number of iterations. The curves labeled PMP correspond to the proposed hypothesis-parallel message-passing framework.
As increases, hypothesis discrimination becomes sharper, producing a steeper waterfall region. Because changes the internal metric scaling, BER curves may exhibit horizontal displacements when plotted versus . Such displacements reflect decision-rule parameterization rather than physical SNR changes; accordingly, any horizontal normalization applied to the plots should be interpreted as a comparison aid between decision rules, not as an attempt to claim physical equivalence.
It is observed that around (in the chosen parameterization), the proposed scheme approaches the performance of the conventional LDPC decoder, and for larger it can yield lower BER in the tested short-block regime. Beyond a certain , the curve shape saturates and further improvement requires increasing code length while keeping k fixed.
7. Conclusions
This paper investigated a receiver-centric framework for unit-rate transmission in which no redundancy is conveyed through the physical channel. By embedding each candidate information hypothesis into a higher-dimensional linear block code at the receiver and applying hypothesis-parallel message passing followed by an orthogonality-based constraint metric, reliable decisions can be approached in a finite-hypothesis regime.
The parity-related quantities used inside the decoder act as deterministic, hypothesis-conditioned constraint weights and are not interpreted as additional channel observations. Accordingly, the method does not alter the physical channel model, does not introduce additional mutual information beyond the channel output, and does not claim any channel-capacity gain. Instead, it highlights a complexity–reliability trade-off: improved decision performance is obtained by increased receiver-side computation and structured constraint enforcement.
Author Contributions
Conceptualization, A.M.; methodology, A.M.; software, A.M.; validation, A.M.; formal analysis, A.M.; investigation, A.M.; resources, A.M.; data curation, A.M.; writing—original draft preparation, A.M.; writing—review and editing, A.M.; visualization, A.M.; supervision, A.M.; project administration, A.M.; funding acquisition, A.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data sharing not applicable.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lin, S.; Costello, D.J. Error Control Coding: Fundamentals and Applications, 2nd ed.; Prentice Hall: Upper Saddle River, NJ, USA, 2004. [Google Scholar]
- Blahut, R.E. Theory and Practice of Error Control Codes; Addison-Wesley: Reading, MA, USA, 1983. [Google Scholar]
- Kschischang, F.R.; Frey, B.J.; Loeliger, H.-A. Factor graphs and the sum-product algorithm. IEEE Trans. Inf. Theory 2001, 47, 498–519. [Google Scholar] [CrossRef]
- Richardson, T.J.; Urbanke, R.L. Modern Coding Theory; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- MacKay, D.J.C.; Neal, R.M. Good codes based on very sparse matrices. In Cryptography and Coding; Springer: Berlin/Heidelberg, Germany, 1995; pp. 100–111.
- Hu, X.-Y.; Eleftheriou, E.; Arnold, D.-M. Regular and irregular progressive edge-growth Tanner graphs. IEEE Trans. Inf. Theory 2005, 51, 386–398. [Google Scholar] [CrossRef]
- Mirbadin, A.; Zaraki, A. Low–Complexity, Fast–Convergence Decoding in AWGN Channels: A Joint LLR Correction and Decoding Approach. Preprints 2025, 2025051199. [Google Scholar] [CrossRef]
- Mirbadin, A.; Zaraki, A. Partial Path Overlapping Mitigation: An Initial Stage for Joint Detection and Decoding in Multipath Channels Using the Sum–Product Algorithm. Appl. Sci. 2024, 14, 9175. [Google Scholar] [CrossRef]
Figure 1.
Performance comparison of the proposed hypothesis-parallel message-passing (PMP) decoder and a conventional iterative LDPC decoder for the code.
Figure 1.
Performance comparison of the proposed hypothesis-parallel message-passing (PMP) decoder and a conventional iterative LDPC decoder for the code.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



