
Submitted:
19 September 2025
Posted:
22 September 2025
You are already at the latest version
Abstract
Information theory, originally rooted in thermodynamics, is utilized in scientometrics to quantify the diversity and heterogeneity of knowledge combinations. This study analyzes a large-scale journal citation network to introduce and empirically validate a fundamental principle of reference behavior, which we term "Mediating Similarity." We posit that a journal's reference distribution (the knowledge it cites) acts as a cognitive bridge between its own citation distribution (its identity in the scientific landscape) and the overall scientific content distribution (the broader knowledge environment). This phenomenon is captured by the Kullback-Leibler (KL) divergence inequality: the sum of the distances from a journal to its references and from its references to the global landscape is less than the direct distance from the journal to the global landscape. Our experimental findings provide robust, multi-level evidence for this principle. First, we demonstrate the universality of the phenomenon, showing that for all 19,129 journals in our dataset, the mediated KL divergence path is consistently shorter than the direct path. Second, we conducted two perturbation experiments on the top 500 journals ranked by the SJR indicator. Based on our finding that real references are mostly contained within the closest journals as measured by KL divergence, we created a high-relevance candidate pool for each journal, consisting of its real references plus twice the actual number of citations closest un-cited journals. In a global resampling test, we found that the actual reference portfolio exhibited a lower "cognitive energy" (sum of KL divergences) than 99% of 1,000 randomly assembled portfolios from the candidate pool averagely.This indicates that citation is a holistic process that selects for a synergistically optimal combination of references. In a local perturbation test where 10% of real references were swapped, the actual portfolio still outperformed the majority of 1,000 perturbed variations. This suggests that the real-world reference selection process, while driven by an optimization principle, operates as a robust "satisficing" strategy within the constraints of the scientific discovery process. Collectively, these findings reveal that reference behavior is a strategic process. Journals selectively curate references to construct an optimal cognitive path, efficiently shortening the distance between their field and the broader scientific environment.
Keywords:
reference behavior
; information theory
; Kullback-Leibler divergence
; scientometrics
; mediating similarity
1. Introduction
Information theory, originally rooted in thermodynamics, was later applied to measure uncertainty in information systems. In scientometrics, it’s utilized to quantify the diversity and heterogeneity of knowledge combinations. The field of scientometrics, which emerged in the mid-20th century with foundational works by Derek J. de Solla Price’s Little Science, Big Science [1] and Eugene Garfield’s pioneering efforts in citation analysis and the Science Citation Index [2,3], aims to study scientific practices and their effects through quantitative data. Early applications of information entropy in scientometrics, such as by [4], demonstrated its utility in measuring research institutions’ involvement in R&D and assessing the breadth and depth of national technology strategies. Since then, information entropy has become an indispensable tool for understanding the complex dynamics of scientific systems. Various entropy concepts and related information-theoretic measures have been extensively applied across diverse aspects of the science of science. Shannon entropy, as a fundamental measure of uncertainty [5], and Kullback-Leibler (KL) divergence [6], which quantifies the difference between two probability distributions, are particularly prominent.
Innovation emerges through the combinatorial process of exploring and integrating existing concepts. From a social network perspective, this process depends on the underlying structure of connections. Uzzi and Spiro [7] investigated creative idea genesis and found that groundbreaking achievements in creative industries arise from teams that bridge disparate knowledge clusters, characteristic of "small-world" networks. These networks combine dense local connectivity with long-range ties, facilitating both the development of existing ideas and the formation of novel combinations. Uzzi et al. [8] analyzed 17.9 million papers and found that while most scientific work builds on conventional knowledge combinations, high-impact studies are characterized by familiar conceptual foundations punctuated by novel, atypical combinations. This suggests breakthrough discoveries require balancing reinforced pathways of established knowledge with exploratory jumps to adjacent, less-traveled parts of the conceptual network. Iacopini et al. [9] model innovation as an "edge-reinforced random walk" where researchers’ attention moves between linked concepts. Innovation occurs when a new concept is visited for the first time, capturing the "adjacent possible" principle where discoveries emerge in the conceptual neighborhood of known ideas.
The evolution of scientific fields through novel idea combinations can be measured using information-theoretic tools like Kullback-Leibler (KL) divergence.Chen [10]applied KL divergence to analyze co-citation network dynamics, measuring year-over-year changes in betweenness centrality distributions for scientific articles. Higher KL divergence values, indicating substantial structural network changes, predicted which articles would later achieve high citation impact. This demonstrates KL divergence as an early indicator of transformative research. Similarly, Leydesdorff and de Nooy [11]utilized entropy statistics to map scientific "hot spots" by analyzing journal citation dynamics, identifying critical transitions and unexpected changes at both journal and citation levels. This approach is not limited to citation networks; modern analyses of dynamic networks, such as those in online political or public opinion discourse, similarly rely on information theory to quantify complexity, uncertainty, and influence [12,13].
Changes in reference patterns predict innovation. What factors influence changes in reference? Less is known about what guides reference behavior—how science navigates the vast knowledge landscape to select references. Recent work frames social power not only in terms of material and cultural resources but also as the ability to efficiently process information, which confers a competitive advantage [14]. Do journals also engage in a strategic selection of references to enhance their information-processing capacity, thereby boosting their potential for innovation and attracting greater attention? This paper introduces and empirically validates a phenomenon we term "Mediating Similarity." We propose that a journal’s reference list (the knowledge it cites) acts as a cognitive bridge between its own scientific identity (how it is cited by others) and the broader universe of scientific knowledge. Mathematically, this means the informational path from a journal’s ciatation distribution to the overall knowledge distribution is "shorter" when mediated by its reference distribution. This relationship is captured by the Kullback-Leibler (KL) divergence inequality: . Our analysis of a comprehensive journal citation network provides strong empirical support for this phenomenon through three key findings. First, the mediating effect is universal: the inequality holds for all 19,129 journals tested. Second, we demonstrate that this pattern reflects strategic optimization rather than random selection. Through perturbation experiments on the top 500 journals (ranked by SJR indicator), we show that actual reference portfolios consistently exhibit lower "cognitive energy" (sum of KL divergences) than randomly assembled alternatives from relevant candidate pools. When we created high-relevance candidate pools containing each journal’s real references plus twice the actual number of citations in closest un-cited journals as measured by KL divergence, actual reference selections outperformed 99% of 1,000 randomly sampled portfolios in global resampling tests averagely. Third, local perturbation experiments reveal that while citation follows optimization principles, it operates as a robust "satisficing" strategy. When 10% of real references were randomly swapped with alternatives from the candidate pool, actual portfolios still outperformed the majority of perturbed variations, suggesting that the selection process balances optimization with the practical constraints of scientific discovery.
Collectively, these results reveal that reference behavior is a strategic process whereby journals selectively curate references to construct optimal cognitive pathways, efficiently bridging the distance between a specialized scholarly journal and the broader scientific landscape. This finding advances our understanding of how scientific knowledge organizes itself and provides new insights into the fundamental mechanisms driving innovation through reference behavior.
2. Related Works
The view that scientific innovation is a combinatorial process has deep philosophical and economic roots. Physicist Max Planck argued that science is fundamentally a single, unbroken chain of knowledge—from physics through chemistry and biology to anthropology and the social sciences—whose apparent divisions are merely a product of limited human cognition [15]. Kuhn [16]further developed a holistic view, challenging the idea of simple, linear progress. He proposed that science is not an accumulation of isolated facts but a complex "constellation" of validated observations, conceptual frameworks, and procedural techniques. For Kuhn, true innovation involves rearranging this constellation or proposing a new configuration entirely—a process captured in his concept of the "paradigm shift." This combinatorial perspective is echoed in economics by Joseph Schumpeter, who defined innovation as the "new combination" of production factors to create novel products, methods, or markets [17]. If the process of innovation is one of constantly changing combinations, the challenge then becomes how to describe and quantify this fusion and transmutation. Here, information theory, with its capacity to measure complexity and uncertainty in complex systems, offers a powerful toolkit [5].
The application of entropy to measure the diversity of knowledge combinations is a central theme in the literature. Innovation is often conceptualized as a combinatorial process where novel ideas arise from new mixtures of existing knowledge [8]. Entropy-based metrics have proven effective at quantifying this diversity in several ways. They are used to measure citation diversity in papers and patents, where higher entropy values indicate engagement with a broader and more balanced range of literature and correlate positively with scientific disruptiveness [18]. This approach is fundamental to assessing interdisciplinarity, for which entropy can measure knowledge flows between research fields [19] , classify journals based on their disciplinary roles as knowledge importers or exporters [20,21], and evaluate the interdisciplinarity of journals by analyzing their cited and citing vectors [22]. More nuanced frameworks have even decomposed "diversity" into its constituent parts of variety, balance, and disparity for more granular analysis [23]. Addressing the computational challenges of these multi-component models, Qun and Menghui [24]proposed the Entropy of Degree Vectors Sum (EDVS). This method also incorporates variety, balance, and disparity but offers a more efficient approach that calculates diversity directly from observed data, avoiding the need for joint probability distributions and reducing computational complexity, which is particularly advantageous for large-scale network analysis. The concept of diversity also applies to an author’s portfolio, where a sequence of high-entropy exploration followed by low-entropy exploitation has been shown to precede creative "hot streaks" [25], and to predict an author’s future citations [26].
Beyond measuring the breadth of knowledge, information theory is used to analyze the heterogeneity and structural variation of knowledge combinations. This involves examining the unique, imbalanced, or evolving structures within scientific networks. Entropy has been applied to measure the temporal diversity of references, quantifying the imbalance in the age distribution of cited works; this revealed that citing older literature is positively associated with disruptive potential, even if it reduces short-term impact [27]. In network analysis, entropy is used to assess the diversity of institutional and departmental collaborations [28], investigate the complexity of co-authorship and co-word structures [29], and optimize the structure of research teams by balancing internal cohesion with external connectivity [30]. Furthermore, entropy-based models are used to detect relational patterns within citation networks [31], analyze the evolution of semantic networks by tracking changes in vocabulary [32], and perform structural analyses for community detection [33] and node importance ranking [34].
A critical application of these methods is in scientific trend identification and prediction. Chen [10] demonstrated that KL divergence can be used to quantify the year-over-year change in the betweenness centrality distribution of articles in a co-citation network; a higher divergence value, indicating significant structural variation, was found to be a robust predictor of future citation impact. Similarly, structural entropy has been used to identify emerging breakthrough topics by tracking temporal changes in knowledge networks [35], while Leydesdorff and de Nooy [11] utilized KL divergence to map scientific "hot spots" by identifying critical, non-linear transitions in journal-journal citation networks. These studies show that changes in citation patterns, viewed as combinations of reference knowledge, can predict innovation.
This raises a fundamental question: if certain patterns predict success, what underlying process drives the formation of these advantageous patterns? Albarracin et al. [14] offer a compelling perspective by reframing social power and influence through the lens of information processing. From this viewpoint, an agent’s power or competitive advantage stems not just from material resources, but from its ability to efficiently compute information, model its environment, and thereby expand its potential future actions. In complex social systems, this "possibilistic power" is amplified through mechanisms that enhance information-processing capacity, such as leveraging collective resources or offloading computational tasks. This creates a feedback loop where the ability to process information efficiently leads to greater influence, which in turn provides access to more information. When applied to the scientific ecosystem, this suggests that a journal’s innovative capacity and influence may be deeply tied to how strategically it processes the vast information landscape through its citation choices.
While a large body of work demonstrates how to identify and predict impactful patterns in science, the underlying factors that guide reference behavior remain less understood. The cognitive processes that lead scientists to select specific references from the vast landscape of knowledge are not fully explained by existing models. This paper addresses this gap by introducing and empirically validating the phenomenon of "Mediating Similarity." We propose that a journal’s reference list acts as a cognitive bridge between its own scientific identity and the broader universe of scientific knowledge. By showing that the informational path from a journal’s citation distribution to the overall knowledge distribution is consistently "shorter" when mediated by its reference distribution, this study aims to shed light on the cognitive underpinnings of reference behavior, suggesting that citation is a strategic process through which researchers select references to efficiently shorten the cognitive distance between their specialized work and the broader scientific landscape.
3. Methods
3.1. Data
The dataset was collected in February 2021 from the OpenAlex database [36]. As the successor to the Microsoft Academic Graph [37], OpenAlex indexes a comprehensive range of academic publications, making it a suitable choice for this analysis in terms of data scale and subject coverage. The dataset contains metadata for approximately 200 million academic articles. Using the citation information provided in these articles, a journal citation network was constructed, represented as a weighted directed graph with 99,152 nodes (journals) and 131,098,937 edges (citation relationships between journals). For the primary analysis, this study selected journals from the 2021 SCImago Journal Rank (SJR) list [38], which includes 27,339 journals. Of these, 19,129 were found in the OpenAlex database. These 19,129 journals were used to construct the citation network for our experiments.
3.2. Journal Citation Propensity Model
This paper employs a non-parametric statistical method to estimate a population distribution through a weighted combination of individual sample distributions. The weighting is designed to preserve the relative importance of each sample. Given a set D with n samples, , each sample is first represented as a vector . Each vector can be seen as a distribution with a magnitude, . The magnitude of each sample distribution vector, , is used as its weight in the estimation of the overall population distribution. This provides a natural way to represent the relative importance of each sample. The estimated population distribution, , is obtained by summing all individual sample distribution vectors: . This method is closely related to Kernel Density Estimation (KDE) [39]and Gaussian Mixture Models (GMM)[40]. Like KDE, it estimates the overall distribution by superimposing local distributions. However, unlike KDE which uses a uniform kernel function, our method allows each sample to have a unique distribution form and weight. Similar to GMM, our method uses a weighted sum of multiple distributions to represent a complex distribution. However, unlike GMM’s fixed number of components and explicit weights, the number of components in our method equals the number of samples, and the weights are implicitly defined by the vector magnitudes.
In the journal citation network, the degree vector of each journal can be considered a distribution with a magnitude, . This paper refers to as the Journal’s Citation Distribution. The sum of the degree vectors of all journals cited by a given journal is treated as a distribution estimated by the aforementioned non-parametric method. This paper refers to this as the Journal’s Reference Distribution. Existing research has shown that the complexity of this distribution can be measured to assess a journal’s diversity, a method known as Entropy of Degree Vectors Sum (EDVS)[24].
The Journal’s Citation Distribution () can be seen as a representation of an individual journal’s research content. The Journal’s Reference Distribution () represents the content of a journal’s references. The sum of the degree vectors of all journals in the citation network is considered to represent the content of the knowledge environment. This distribution transcends the scope of individual journals and disciplines, representing the overall attention distribution in science. The Overall Scientific Content Distribution () is thus a representation of the content of the knowledge environment. , and are shown as Equation (1).
Kullback-Leibler (KL) divergence, also known as relative entropy, is an asymmetric measure of the difference between two probability distributions, P and Q. It quantifies the extra average number of bits required to encode samples from a distribution P when using a code based on a distribution Q, representing uncertainty. We calculate the KL divergence of each journal’s Citation Distribution relative to the Overall Scientific Content Distribution, denoted as . This represents the uncertainty of a journal’s own research content relative to the knowledge environment. The KL divergence of each journal’s Citation Distribution relative to its Reference Distribution is denoted as . This represents the uncertainty of a journal’s own research content relative to its reference content. The KL divergence of each journal’s Reference Distribution relative to the Overall Scientific Content Distribution is denoted as . This represents the uncertainty of a journal’s reference content relative to the knowledge environment.
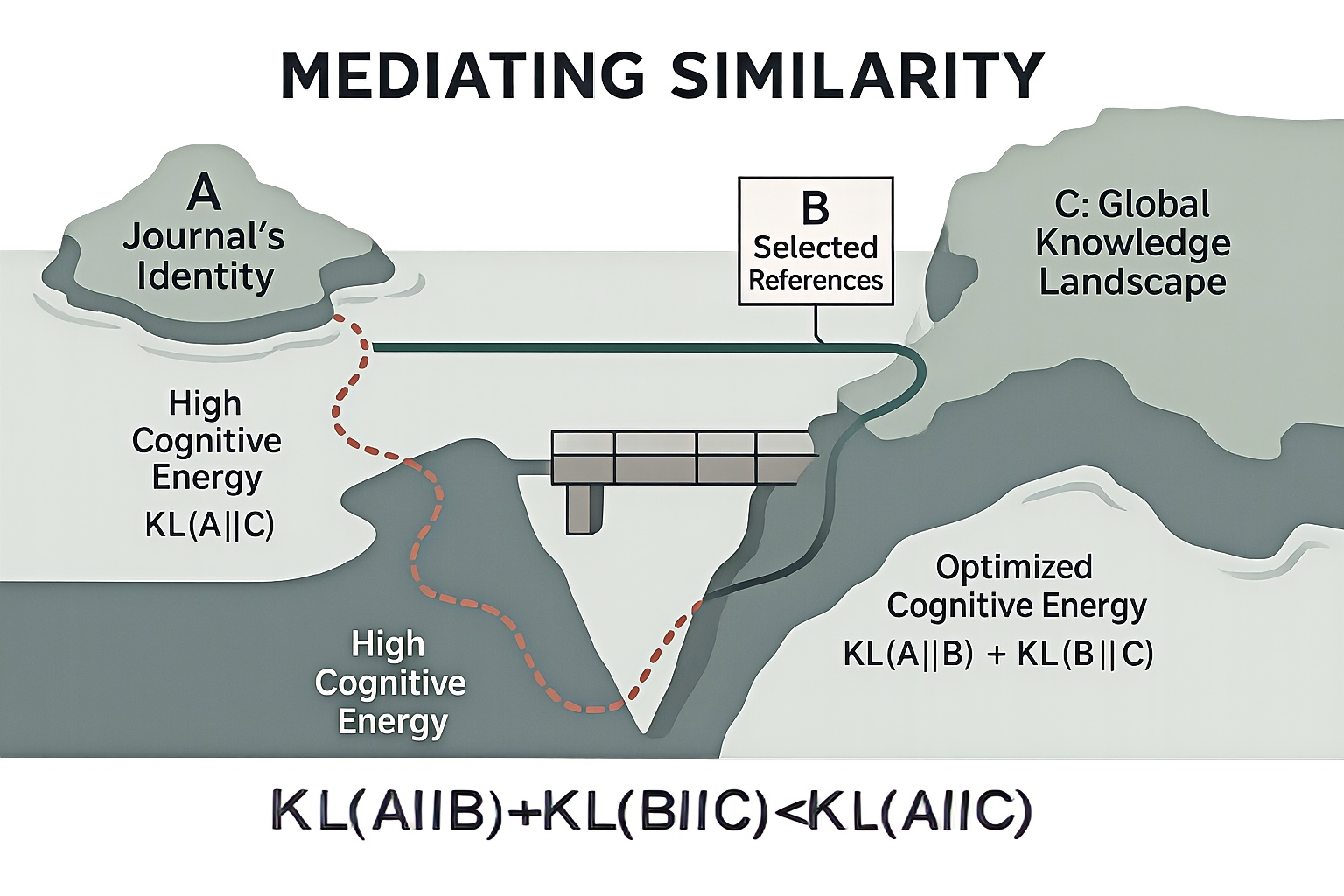
Physical systems tend toward a stable state of minimum energy. The origins of information theory are also closely related to thermodynamic entropy. This study views the citation selection behavior of journals as a process of spontaneously seeking the path of least "energy" consumption in an abstract "Cognitive Energy Landscape." By constructing and perturbing this energy landscape, we can verify whether citation selection follows a "minimum energy" principle. For any given journal i, the "cognitive energy" E after selecting a set of references as intermediaries is effectively. As shown in Equation (3) this energy function measures the "total cognitive cost" required to connect its own content with the knowledge environment by citing . And Mediating Similarity means that reference portfolio acts as a cognitive brigde to optimize the cognitive energy cost, shown in Figure 1.
4. Results
To test the phenomenon of mediating similarity in real journal citations, we selected the k journals closest to a target journal as the "most similar k’s Journal’s Reference Distribution" based on two distance metrics: KL divergence and Cosine similarity. We incrementally increased the value of k using a Fibonacci sequence to form different reference distributions. For each, we calculated the KL divergence between the Journal’s Citation Distribution and the most similark’s Journal’s Reference Distribution (most similar k’s ) and the KL divergence between the most similar k’s Journal’s Reference Distribution and the Overall Scientific Content Distribution (most similar k’s ). As shown in the Figure 2 and Figure 3, the sum of ( + ) for all journals under both distance metrics first decreases and then increases with k. This is because when k is small, is small but is large, whereas when k is large, is large but is small.
In Figure 2 and Figure 3, the value 80,939 represents the sum of for all journals. It is noteworthy that the sum based on Cosine similarity even exceeds this value, indicating that an improper citation strategy can increase cognitive energy consumption. The red dot in the figures represents the sum of ( + ) for all journals under their actual citation conditions. The x-coordinate, 976, is the median number of journals cited by all journals. This red dot lies below the fitted curve. Furthermore, upon examining each sample journal, the sum ( + ) for all 19,129 journals was less than their respective . The sum of ( + ) under real citation conditions for all journals was also smaller than the sum for a group of journals selected based on the two distance metrics with the same number as the real citation count. This shows that the actual Journal’s Reference Distribution serves effectively as an intermediary distribution between the Journal’s Citation Distribution and the Overall Scientific Content Distribution, efficiently shortening the cognitive distance.
The data reveals that a focal journal’s cited journals are concentrated within a range of three times its real reference number, among journals with the closest KL divergence. For example, if a target journal references 1,000 journals, these are almost entirely from the 3,000 journals closest to it in terms of KL divergence.

Table 1.
The percent of closet journals measured by KL in real reference journals.
| Within 1x the actual reference number | Within 2x | Within 3x | |
| proportion | 0.588 | 0.764 | 0.834 |
This study selected twice the actual reference number closest un-cited journals and the actual cited journals to form a sample pool of three times the real citation number for perturbation experiments. For each journal i, we calculated its "real cognitive energy" using its actual reference distribution . We then performed global and local "perturbations" on its reference list by randomly selecting journals from the candidate pool to test the constraints of the mediating similarity effect across different dimensions.
The experiment consisted of two parts. The first part was a global perturbation, where a number of journals equal to the real citation count were randomly drawn from the sample pool to form an experimental sample. This was repeated 1,000 times, and the energy consumed by these random combinations was compared with that of the real citation combination. The second part was a local perturbation, where the real citation combination was maintained, but 10% of its journals were replaced with journals drawn from the sample pool. This was also repeated 1,000 times and compared with the energy of the real citation combination.
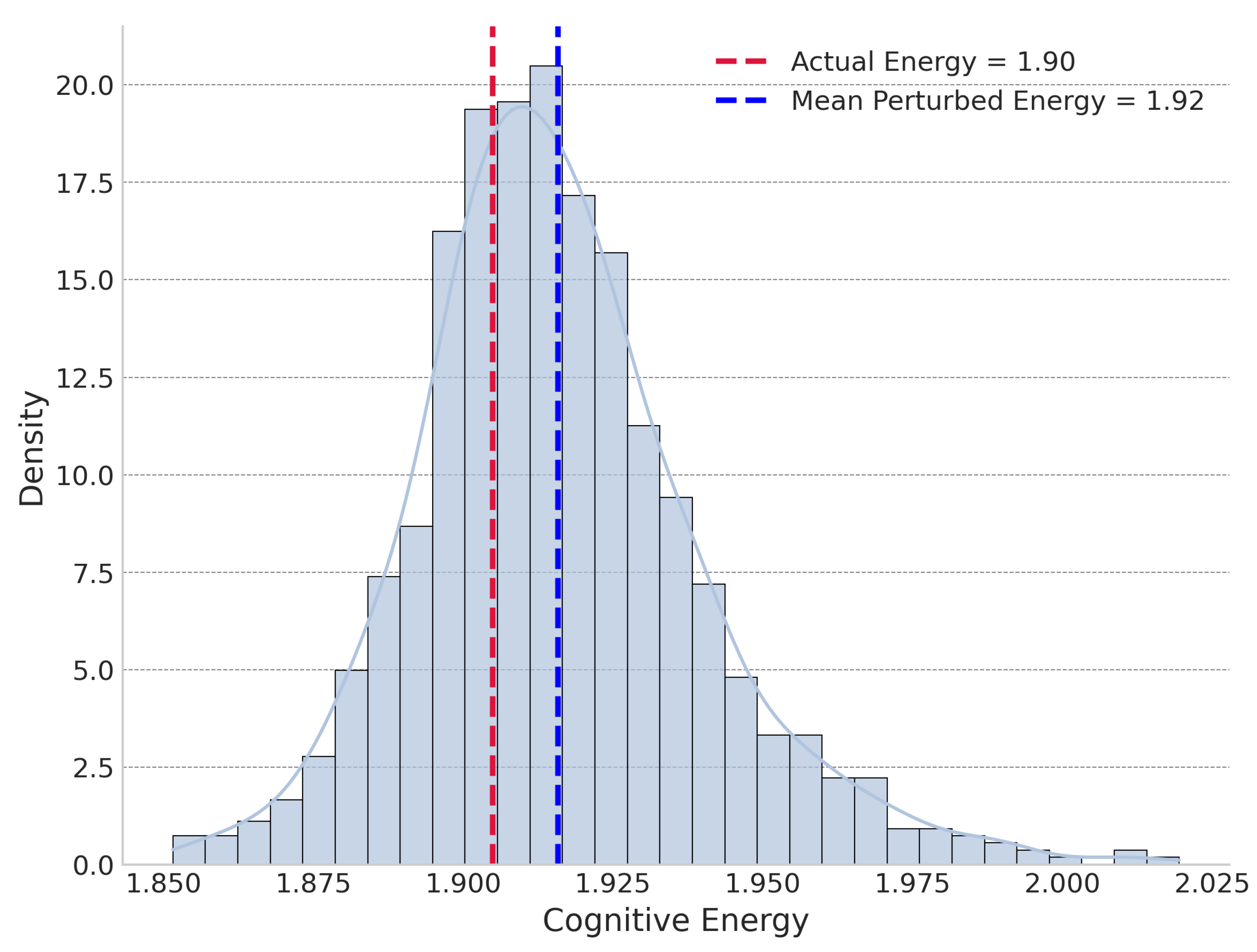
The experiment found that under global perturbation, In 500 sample journals, 403 sample journals’ was lower than all perturbed energies and the actual reference portfolio exhibited a lower "cognitive energy" (sum of KL divergences) than 99% of 1,000 randomly assembled portfolios from the candidate pool averagely. Figure 4 shows the distribution of percentile of global perturbation. Under local perturbation, was not always the lowest but was significantly lower than the mean of the locally perturbed energies, on average being lower than 77.25% of them. Figure 5 shows the distribution of percentile of global perturbation. We choose journal Cell as a case to demonstrate its and global and local perturbation energy distribution, shown in Figure 6 and Figure 7.
The global resampling experiment shows that, on a macro scale, a journal’s real citation portfolio is a highly optimized whole, whose synergistic effect far exceeds the simple sum of relevant literature. However, the local replacement experiment further reveals that this optimization is not without constraints in the real world. Although the real citation portfolio shows strong local stability and robustness, a small number of combinations with lower energy may theoretically exist. This suggests that the final citation choice is a result of a compromise between the theoretical drive for "minimum energy" and real-world constraints like path dependence and discovery costs, reflecting a pursuit of a "satisficing" rather than an absolute "optimal" solution in scientific practice.
Figure 8.
Duality of Global Optimization and Local Satisficing.
5. Discussion
This study introduced and validated the principle of "Mediating Similarity," demonstrating that a journal’s reference list acts as an optimized cognitive bridge between its unique scientific identity and the broader knowledge environment. Our findings confirm that this phenomenon is not an artifact but a fundamental and universal feature of reference behavior, holding true for all 19,129 journals analyzed. The core of our contribution, however, lies in elucidating the mechanisms that guide this behavior, which we explored through a series of perturbation experiments on 500 top-ranked journals. The results of these experiments reveal a dual-faceted selection process. The first, a global resampling experiment, showed that the actual reference portfolio exhibited a lower "cognitive energy" (sum of KL divergences) than 99% of 1,000 randomly assembled alternatives averagely, even when drawing from a highly relevant candidate pool. This strongly suggests that citation is a global synergistic optimization process, where the value lies not in selecting individually relevant papers but in curating a specific "combination" of references that is holistically optimal. The synergy of the chosen references collectively minimizes the cognitive distance to the wider scientific landscape far more effectively than any random assortment of individually similar works could. However, the second experiment, which involved a local 10% perturbation, provided a more nuanced picture. Here, the real reference portfolio, while still outperforming the vast majority of variations, was not always the absolute mathematical optimum. This finding points to citation as a locally stable strategy guided by the Satisficing Principle [41]. As Herbert Simon argued, agents in complex environments do not seek a perfect "optimizing" solution but rather a "satisficing" one that is "good enough" given real-world constraints. In scientific practice, these constraints include path dependence, the high cognitive cost of discovering every possible reference, and serendipity. Therefore, a journal’s reference list represents a highly effective and robust solution—a low point in the cognitive energy landscape—that is achievable within the practical limits of the scientific process. Taken together, these findings reframe reference behavior as a strategic navigation of this cognitive energy landscape. The "Mediating Similarity" principle can be understood as a force-like mechanism driving the self-organization of the scientific knowledge system, compelling journals to seek out the most efficient cognitive paths [41]. This advances our understanding beyond simply observing that citation patterns predict innovation to explaining the underlying cognitive strategy that shapes these influential patterns. By efficiently processing the information landscape through its reference choices, a journal enhances its innovative capacity and, consequently, its ability to attract future attention and influence.
6. Conclusion
This paper sought to uncover the principles that guide reference behavior in the vast landscape of scientific knowledge. We introduced and empirically validated the concept of "Mediating Similarity," a fundamental principle wherein journals strategically select references to create an optimal cognitive path between their own work and the broader scientific environment. Our analysis, supported by large-scale data and targeted perturbation experiments, demonstrates that this is a universal phenomenon driven by a dual process of global optimization and local satisficing. The findings show that a journal’s reference list is more than a collection of sources; it is a synergistically optimized portfolio that minimizes the "cognitive energy" required to connect a specialized field to the global knowledge base. While this selection process is guided by a powerful drive toward an optimal state, it is ultimately shaped by the practical constraints of scientific discovery, resulting in a robust and "good enough" solution. This study thus provides new insight into the self-organizing dynamics of science, framing reference not as a passive record of influence but as an active, strategic behavior fundamental to the advancement and integration of knowledge.
Data Availability Statement
Data available at: 10.5281/zenodo.16903123
References
- Derek J De Solla Price. Little science, big science. Columbia university press, 1963.
- Eugene Garfield. Citation indexes for science: A new dimension in documentation through association of ideas. Science 1955, 122, 108–111. [Google Scholar] [CrossRef]
- Eugene Garfield. Citation analysis as a tool in journal evaluation: Journals can be ranked by frequency and impact of citations for science policy studies. Science 1972, 178, 471–479. [Google Scholar] [CrossRef] [PubMed]
- Hariolf Grupp. The concept of entropy in scientometrics and innovation research: An indicator for institutional involvement in scientific and technological developments. Scientometrics 1990, 18, 219–239. [Google Scholar] [CrossRef]
- Claude E Shannon. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Solomon Kullback and Richard A Leibler. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Brian Uzzi and Jarrett Spiro. Collaboration and creativity: The small world problem. Am. J. Sociol. 2005, 111, 447–504. [Google Scholar] [CrossRef]
- Brian Uzzi, Satyam Mukherjee, Michael Stringer, and Ben Jones. Atypical combinations and scientific impact. Science 2013, 342, 468–472. [Google Scholar] [CrossRef]
- Iacopo Iacopini, Staša Milojević, and Vito Latora. Network dynamics of innovation processes. Phys. Rev. Lett. 2018, 120, 048301. [Google Scholar] [CrossRef]
- Chaomei Chen. Predictive effects of structural variation on citation counts. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 431–449. [Google Scholar]
- Loet Leydesdorff and Wouter de Nooy. Can “hot spots” in the sciences be mapped using the dynamics of aggregated journal–journal citation relations? J. Assoc. Inf. Sci. Technol. 2017, 68, 197–213. [Google Scholar] [CrossRef]
- Beril Bulat and Martin Hilbert. Quantifying bot impact: An information-theoretic analysis of complexity and uncertainty in online political communication dynamics. Entropy 2025, 27, 573. [Google Scholar] [CrossRef]
- Yan Zhuang, Weihua Li, and Yang Liu. Information and knowledge diffusion dynamics in complex networks with independent spreaders. Entropy 2025, 27, 234. [Google Scholar] [CrossRef]
- Mahault Albarracin, Sonia de Jager, and David Hyland. The physics and metaphysics of social powers: Bridging cognitive processing and social dynamics, a new perspective on power through active inference. Entropy 2025, 27, 522. [Google Scholar] [CrossRef]
- Brandon R Brown. Planck: Driven by vision, broken by war. Oxford University Press, 2015.
- Thomas S Kuhn. Historical structure of scientific discovery: To the historian discovery is seldom a unit event attributable to some particular man, time, and place. Science 1962, 136, 760–764. [Google Scholar] [CrossRef]
- Alin Croitoru. Schumpeter, ja, 1934 (2008), the theory of economic development: An inquiry into profits, capital, credit, interest and the business cycle. J. Comp. Res. Anthropol. Sociol. 2012, 3, 137–148. [Google Scholar]
- Michael Park, Erin Leahey, and Russell J Funk. Papers and patents are becoming less disruptive over time. Nature 2023, 613, 138–144. [Google Scholar] [CrossRef] [PubMed]
- Caroline S Wagner, J David Roessner, Kamau Bobb, Julie Thompson Klein, Kevin W Boyack, Joann Keyton, Ismael Rafols, and Katy Börner. Approaches to understanding and measuring interdisciplinary scientific research (idr): A review of the literature. J. Inf. 2011, 5, 14–26. [Google Scholar] [CrossRef]
- Jorge Mañana Rodríguez. Disciplinarity and interdisciplinarity in citation and reference dimensions: Knowledge importation and exportation taxonomy of journals. Scientometrics 2017, 110, 617–642. [Google Scholar] [CrossRef]
- Núria Bautista-Puig, Jorge Mañana-Rodríguez, and Antonio Eleazar Serrano-López. Role taxonomy of green and sustainable science and technology journals: Exportation, importation, specialization and interdisciplinarity. Scientometrics 2021, 126, 3871–3892. [Google Scholar] [CrossRef]
- Loet Leydesdorff and Ismael Rafols. Indicators of the interdisciplinarity of journals: Diversity, centrality, and citations. J. Inf. 2011, 5, 87–100. [Google Scholar] [CrossRef]
- Rüdiger Mutz. Diversity and interdisciplinarity: Should variety, balance and disparity be combined as a product or better as a sum? an information-theoretical and statistical estimation approach. Scientometrics 2022, 127, 7397–7414. [Google Scholar] [CrossRef]
- Zhao Qun and Yang Menghui. An efficient entropy of sum approach for measuring diversity and interdisciplinarity. J. Inf. 2023, 17, 101425. [Google Scholar] [CrossRef]
- Lu Liu, Nima Dehmamy, Jillian Chown, C Lee Giles, and Dashun Wang. Understanding the onset of hot streaks across artistic, cultural, and scientific careers. Nat. Commun. 2021, 12, 5392. [Google Scholar] [CrossRef]
- Harish S Bhat, Li-Hsuan Huang, Sebastian Rodriguez, Rick Dale, and Evan Heit. Citation prediction using diverse features. In 2015 IEEE International Conference on Data Mining Workshop (ICDMW), pages 589–596. IEEE, 2015.
- Alex J Yang. On the temporal diversity of knowledge in science. J. Inf. 2024, 18, 101594. [Google Scholar] [CrossRef]
- Lingyao Li, Ly Dinh, Songhua Hu, and Libby Hemphill. Academic collaboration on large language model studies increases overall but varies across disciplines. arXiv 2024, arXiv:2408.04163. [Google Scholar] [CrossRef]
- Shuto Miyashita and Shintaro Sengoku. Scientometrics for management of science: Collaboration and knowledge structures and complexities in an interdisciplinary research project. Scientometrics 2021, 126, 7419–7444. [Google Scholar] [CrossRef]
- Yves-Alexandre De Montjoye, Arkadiusz Stopczynski, Erez Shmueli, Alex Pentland, and Sune Lehmann. The strength of the strongest ties in collaborative problem solving. Sci. Rep. 2014, 4, 5277. [Google Scholar] [CrossRef]
- Riccardo Dainelli and Fabio Saracco. Bibliometric and social network analysis on the use of satellite imagery in agriculture: An entropy-based approach. Agronomy 2023, 13, 576. [Google Scholar] [CrossRef]
- Marcelo do Vale Cunha, Carlos Cesar Ribeiro Santos, Marcelo Albano Moret, and Hernane Borges de Barros Pereira. Shannon entropy in time-varying semantic networks of titles of scientific paper. Appl. Netw. Sci. 2020, 5, 53. [Google Scholar] [CrossRef]
- Yongli Li, Guijie Zhang, Yuqiang Feng, and Chong Wu. An entropy-based social network community detecting method and its application to scientometrics. Scientometrics 2015, 102, 1003–1017. [Google Scholar] [CrossRef]
- Shihu Liu and Haiyan Gao. The structure entropy-based node importance ranking method for graph data. Entropy 2023, 25, 941. [Google Scholar] [CrossRef]
- Haiyun Xu, Rui Luo, Jos Winnink, Chao Wang, and Ehsan Elahi. A methodology for identifying breakthrough topics using structural entropy. Inf. Process. Manag. 2022, 59, 102862. [Google Scholar] [CrossRef]
- Jason Priem, Heather Piwowar, and Richard Orr. Openalex: A fully-open index of scholarly works, authors, venues, institutions, and concepts. arXiv 2022, arXiv:2205.01833.
- Michael Färber. The microsoft academic knowledge graph: A linked data source with 8 billion triples of scholarly data. In The Semantic Web–ISWC 2019: 18th International Semantic Web Conference, Auckland, New Zealand, October 26–30, 2019, Proceedings, Part II 18, pages 113–129. Springer, 2019.
- Scimago journal & country rank. http://222.scimagojr.com/, 2024.
- Yen-Chi Chen. A tutorial on kernel density estimation and recent advances. Biostat. Epidemiol. 2017, 1, 161–187. [Google Scholar] [CrossRef]
- Douglas Reynolds. Gaussian mixture models. In Encyclopedia of biometrics, pages 827–832. Springer, 2015.
- Herbert A Simon. Satisficing. In The new Palgrave dictionary of economics, pages 11933–11935. Springer, 2018.
Figure 1.
Illustration of the Mediating Similarity principle.
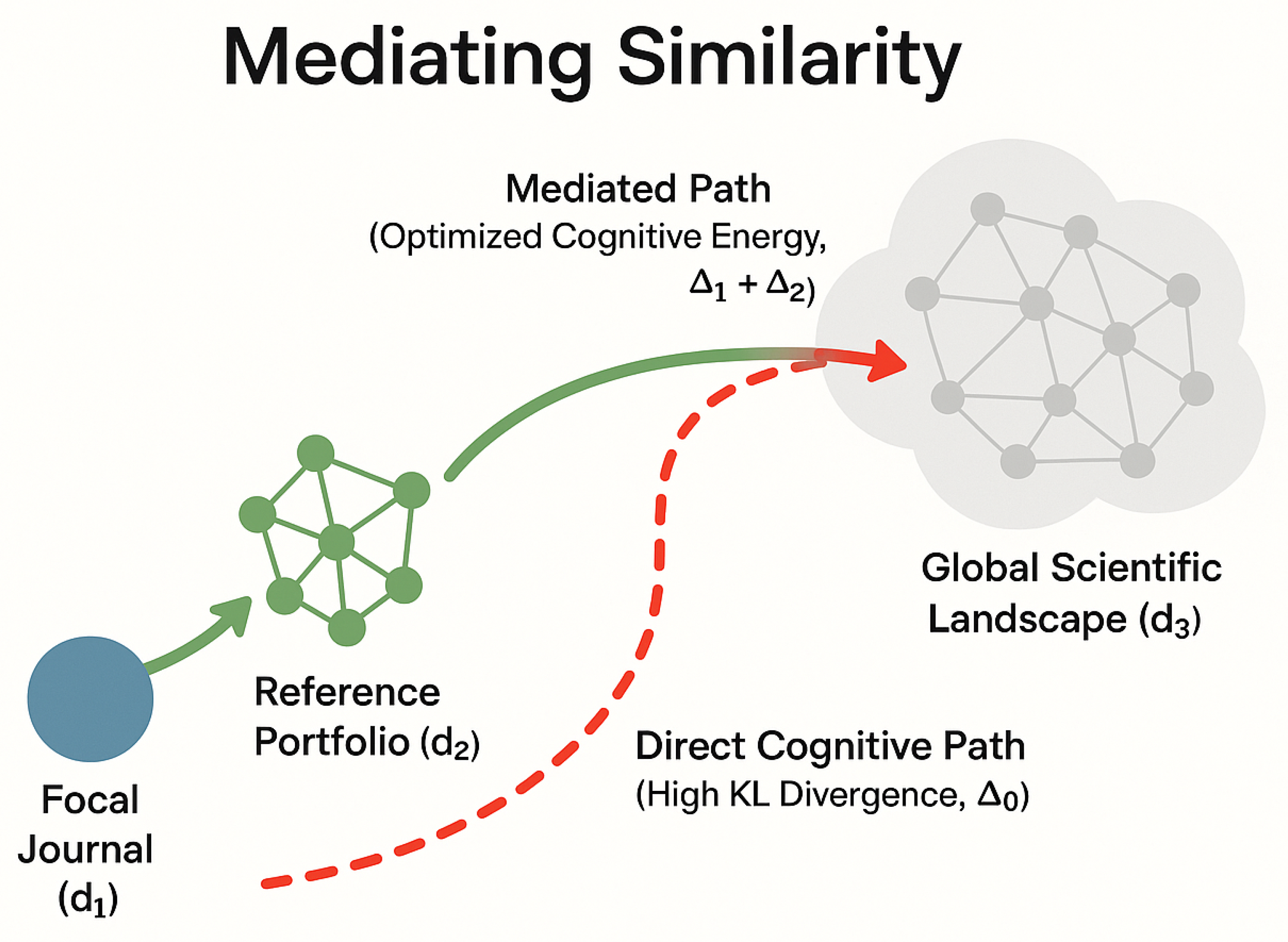
Figure 2.
Cognitive energy landscape vs closet journals reference set size measured by KL divergence.
Figure 2.
Cognitive energy landscape vs closet journals reference set size measured by KL divergence.
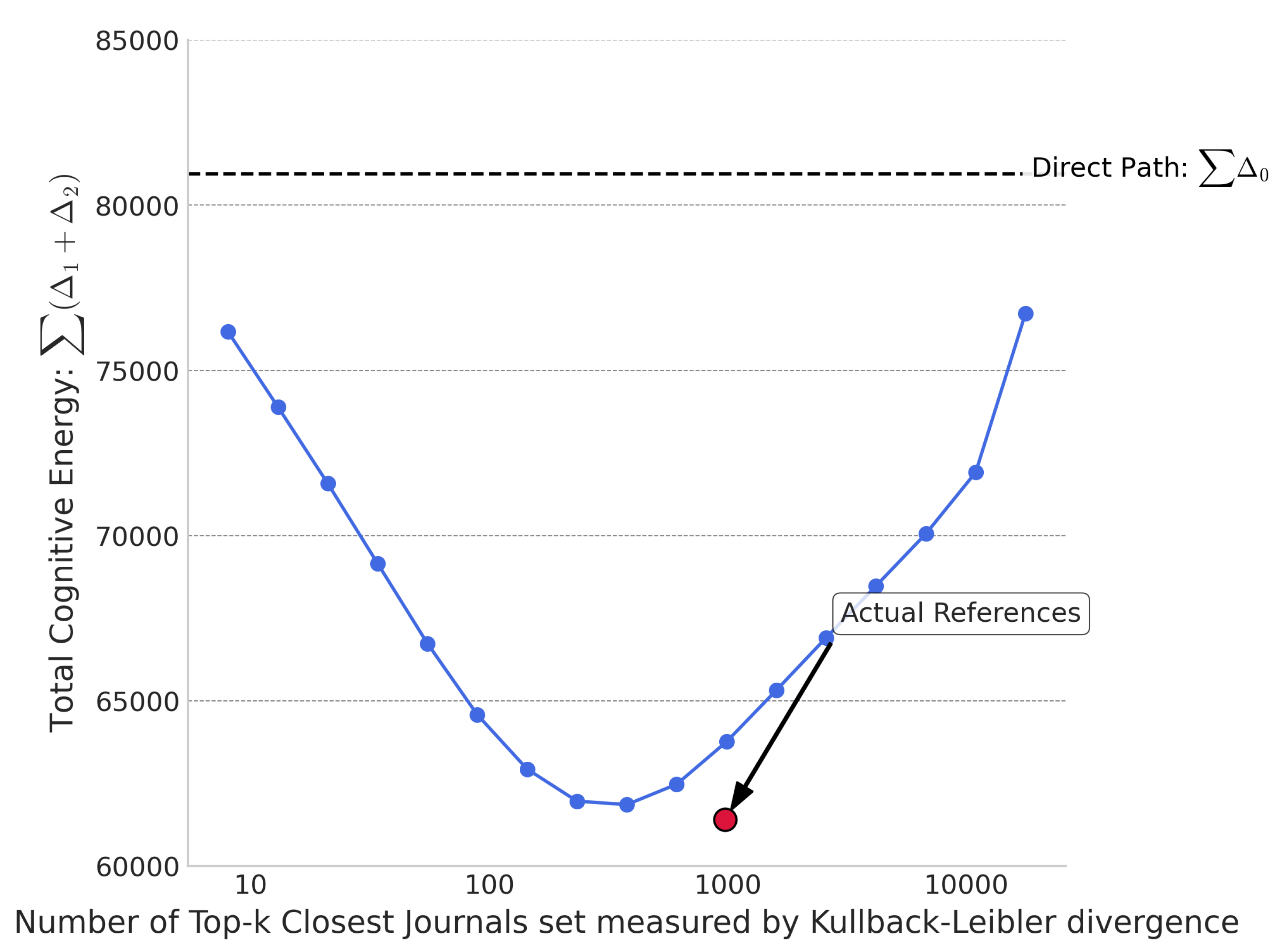
Figure 3.
Cognitive energy landscape vs closet journals reference set size measured by cosine similarity.
Figure 3.
Cognitive energy landscape vs closet journals reference set size measured by cosine similarity.
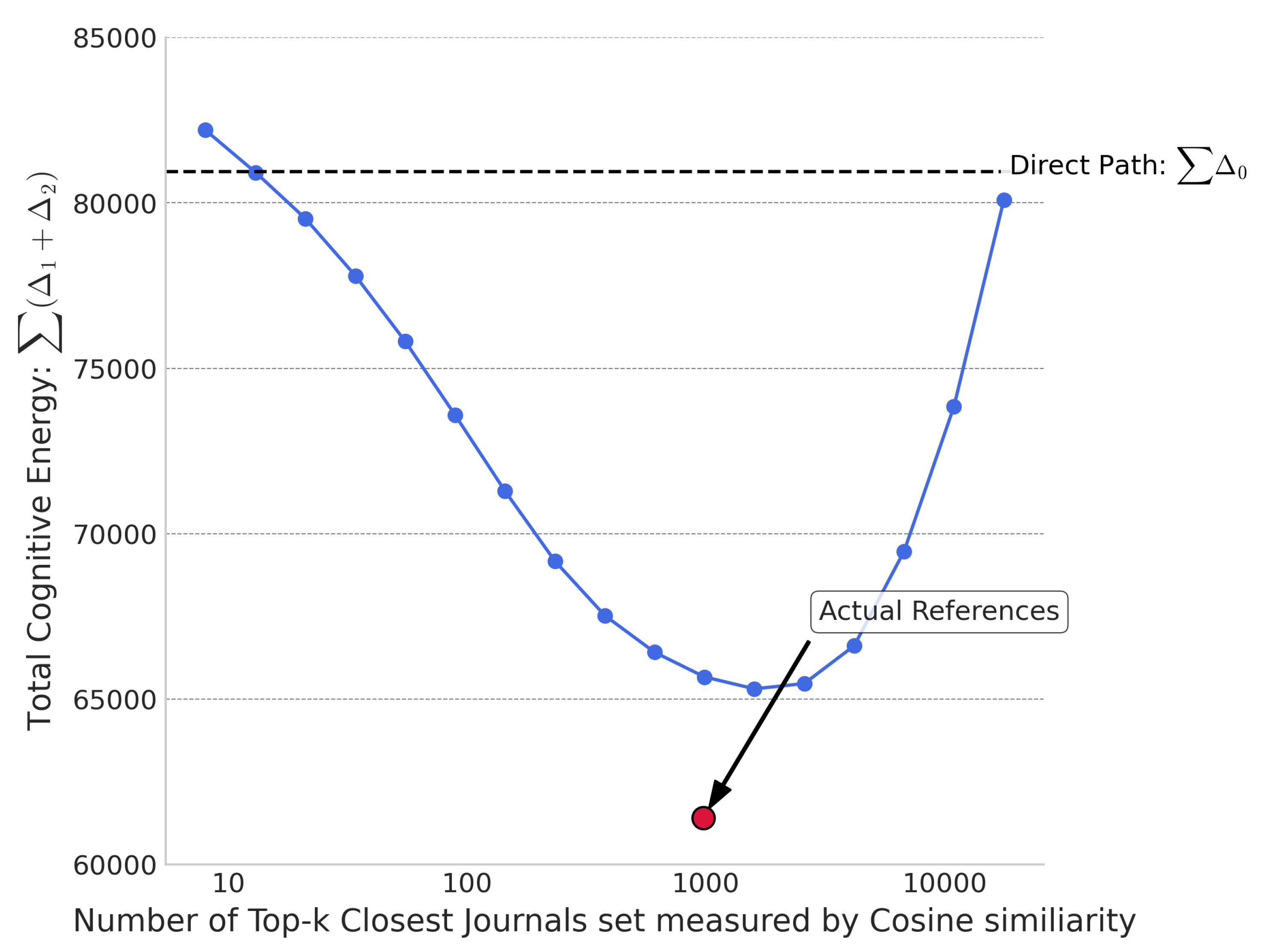
Figure 4.
Distribution of percentile for global perturbation.
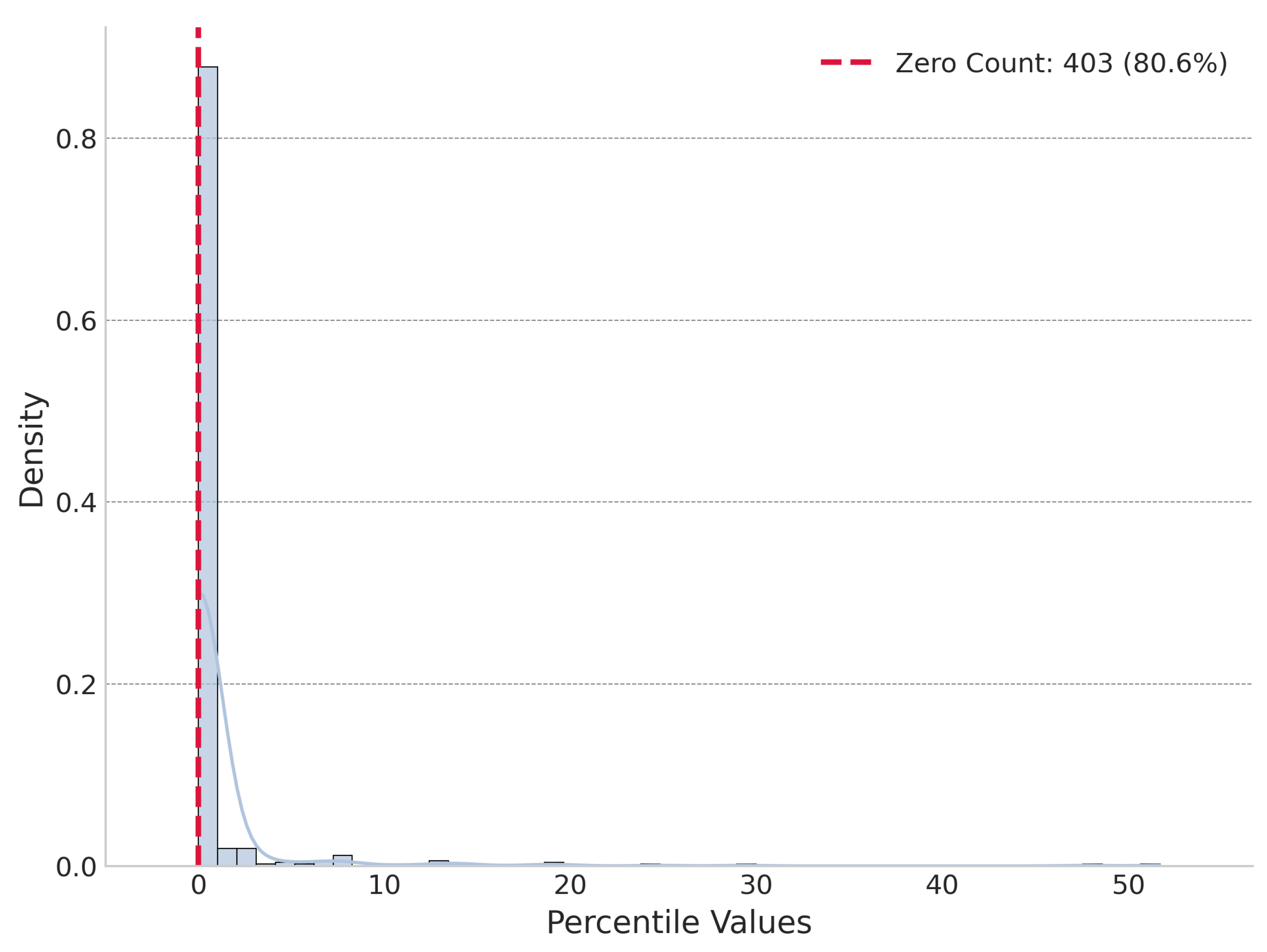
Figure 5.
Distribution of percentile for local perturbation.
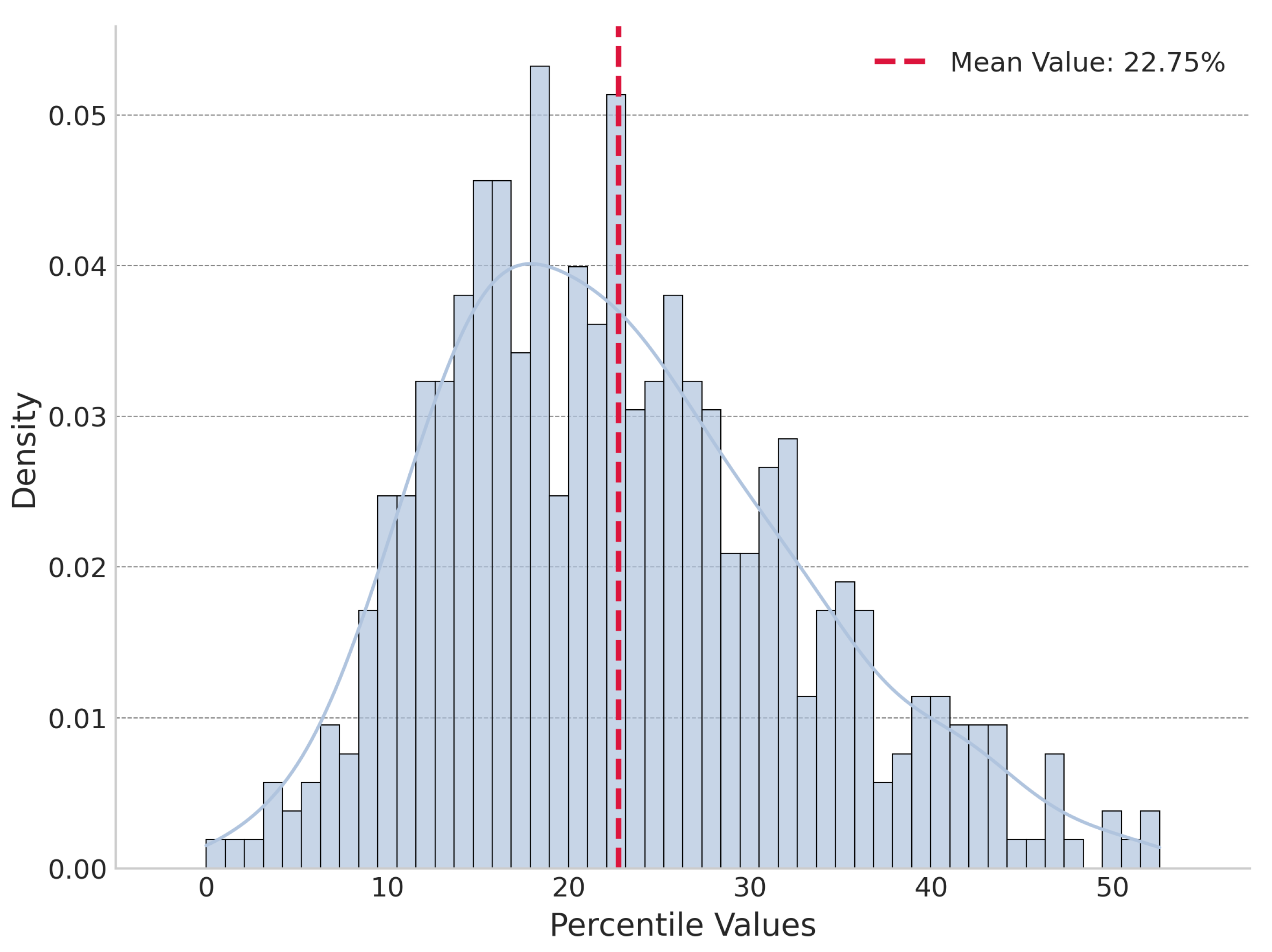
Figure 6.
Global perturbation cognitive energy distribution for Cell.
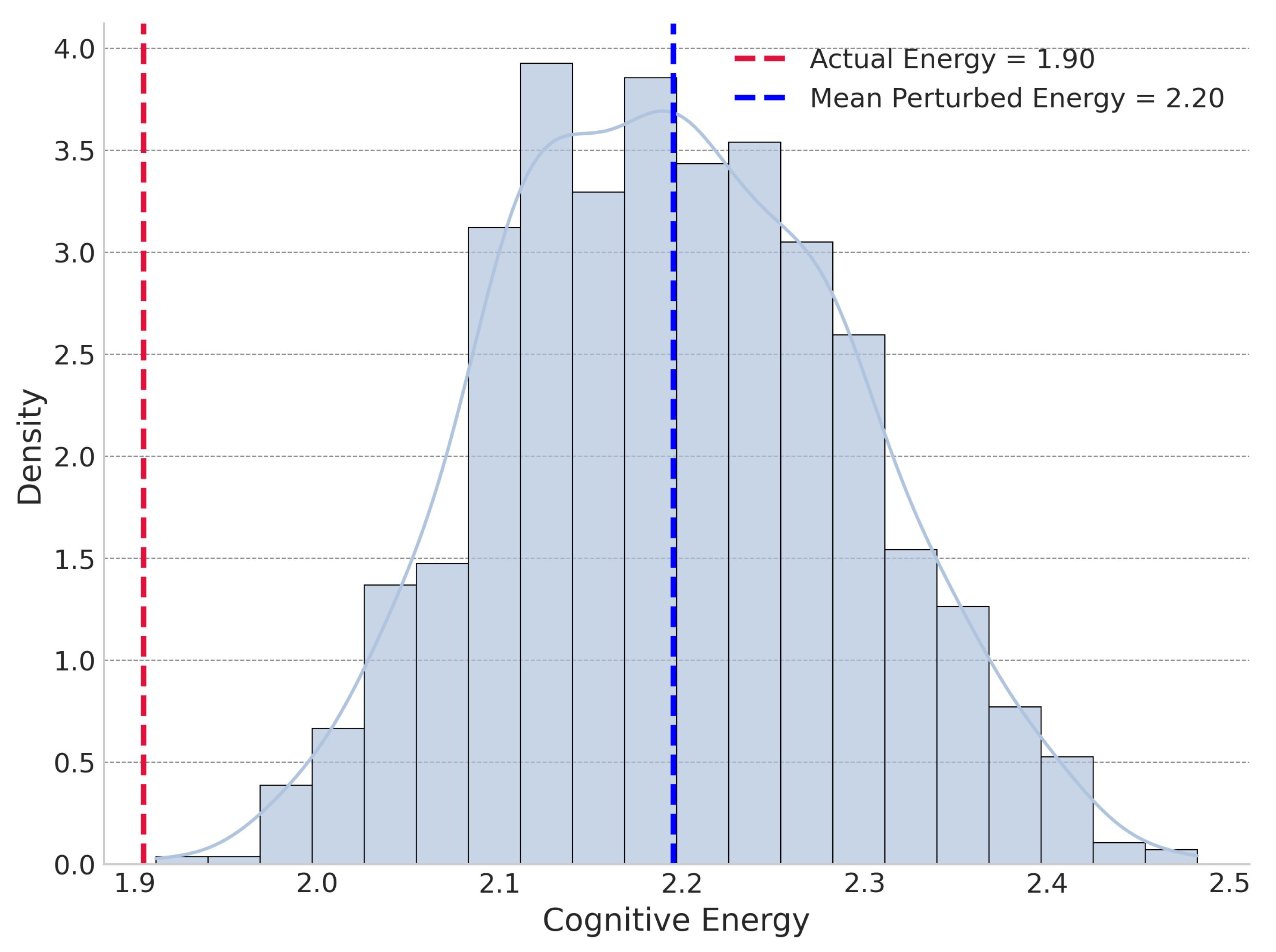
Figure 7.
Local perturbation cognitive energy distribution for Cell.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



