Submitted:
04 September 2025
Posted:
05 September 2025
You are already at the latest version
Abstract
This paper tackles the growing problem of malicious activities exploiting the Domain Name System (DNS) on the Internet, a major concern for cybersecurity. The study examines current methods used to detect malicious domains, pointing out the limitations of traditional reverse technology and the difficulties faced by deep learning techniques, particularly when identifying domains generated by Domain Generation Algorithms (DGAs). As DNS traffic-based detection becomes a more widely accepted approach, this research introduces a robust system that uses HBase for efficient data warehousing, Hive for comprehensive DNS data analysis, and Spark to build a scalable engine for domain detection.
Our approach extracts 24 distinct features from DNS traffic, grouped into categories such as construction-based, time-based, TTL-based, and request-response-based features. These features are evaluated through statistical distribution analysis to differentiate benign from malicious domains. At the heart of the detection engine is the Deep Forest algorithm, which offers key advantages over conventional neural networks, including fewer parameters, faster training, and enhanced adaptability. Additionally, we present a Selective Integration Algorithm to optimize the deep forest model, yielding better accuracy and recall compared to traditional random forest and deep forest methods.
The system is designed to process real-time DNS traffic, capable of handling tens of thousands of DNS messages per second, a necessary feature for large-scale deployments. Our experimental results confirm that this approach provides an efficient and highly accurate solution for detecting malicious domains, contributing significantly to ongoing efforts to strengthen cybersecurity against evolving online threats.
Keywords:
domain detection
; DNS
; deep forest
; big data
; cybersecurity
1. Introduction
In this collaborative research, we address the critical issue of malicious activities exploiting the Domain Name System (DNS) on the Internet, which poses a significant threat to both individuals and society. Malicious domains, such as those used for botnets and other cyberattacks, are exploited to cause damage through phishing, spam distribution, and malware delivery. The study focuses on the current methods of malicious domain detection, examining the limitations of reverse technology and the challenges of using deep learning techniques to detect Domain Generation Algorithm (DGA) domains. These methods often struggle with the evolving and dynamic nature of malicious domains, and traditional methods such as blacklisting and whitelisting are increasingly ineffective.
Recognizing the shift towards DNS traffic-based detection, this paper introduces a comprehensive detection system utilizing HBase for data warehousing, Hive for DNS data analysis, and Apache Spark for building the domain detection engine. The research extracts 24 key features from DNS traffic, categorized into construction-based, time-based, TTL-based, and request-response-based groups, derived through statistical distribution analysis. These features are carefully selected to capture patterns distinguishing benign domains from malicious ones.
A key innovation of our research is the use of the Deep Forest algorithm, an ensemble method, which is integrated into the detection engine. The deep forest method offers advantages over traditional neural network-based deep learning models, such as reduced parameter counts, faster training times, and forest-level adaptation that better handles the heterogeneous nature of DNS traffic. The system is designed to handle the real-time processing of tens of thousands of DNS messages per second, an essential requirement for scalable domain detection. To optimize the performance of the deep forest algorithm, a Selective Integration Algorithm is introduced, which selectively integrates high-performance trees based on AUC values. This novel approach shows improved accuracy and recall compared to traditional random forest and deep forest models.
Our findings contribute to enhancing malicious domain detection systems, particularly in improving efficiency and accuracy to meet the evolving challenges in cybersecurity.
2. Literature Review
Detecting malicious activities through DNS servers has remained a critical concern for cybersecurity, as attackers exploit domain resolution mechanisms to launch sophisticated attacks. DNS maps human-readable domain names to IP addresses, enabling internet access, but also providing an entry point for malicious actors. Advanced threats often employ a combination of domain rotation, fast-flux, and domain generation algorithms (DGAs) to evade detection, making proactive identification of hostile domains essential [1,2,3,4,5].
Recent research has highlighted the limitations of traditional detection techniques, such as blacklists, whitelists, and reverse-engineering approaches, which fail to cope with dynamically generated domains and large-scale DNS traffic [6,7,8]. Chiong et al. [9] proposed a method to protect users from phishing, malware distribution, and identity theft by identifying malicious domains through DNS feature analysis, demonstrating that structural and temporal patterns in DNS queries can serve as strong predictors of malicious activity.
DGAs, in particular, pose a significant challenge. Studies show that only a fraction of DGA-generated domains appear on standard blacklists, and attackers frequently lev-erage domain fluxing strategies that outpace static detection approaches [10,11,12]. To address these challenges, machine learning and ensemble-based methods have gained popularity. For example, Khulood Al Messabi et al. [13] used domain name attributes combined with a J48 decision tree classifier to detect malicious domains, employing cross-validation to ensure robustness.
Tree-based ensemble approaches have been shown to perform particularly well. Dolberg et al. [14] introduced the Multi-Dimensional Aggregation Monitoring (MAM) system, which measures the "steadiness" of domain-IP pairs over time to identify anomalies. While effective in reducing false positives, the method struggles under sparse malicious activity, highlighting the need for adaptive techniques. Similarly, Eshete et al. [15] proposed BINSPECT, a lightweight supervised learning framework that combines static analysis with simulation to classify domains efficiently.
The implementation of real-time and online learning methodologies has gained considerable significance. Ma et al. [16] engineered an online DNS monitoring framework that perpetually aggregates URL data and refines a dynamic classification mechanism for the immediate identification of malicious domains. This strategy emphasizes the critical necessity for adaptive systems that can effectively respond to continuously evolving cyber threats.
Concurrently, deep learning and hybrid detection paradigms have risen to prominence. Zhang et al. [17] employed a graph-based technique for DGA detection that integrates network traffic characteristics with domain registration information, attaining high precision in classifying previously unobserved domains. Liu et al. [18] introduced a hybrid ensemble architecture that amalgamates random forests with gradient boosting, designed expressly to counter fast-flux and DGA-based domains. Further investigations have examined sophisticated deep forest models that leverage a comprehensive set of features to utilize both structural and temporal DNS characteristics, all while operating within a framework of low computational complexity [19,20,21].
Furthermore, numerous studies have underscored the value of multidimensional feature engineering. Contemporary detection systems incorporate lexical attributes, temporal patterns, Time-To-Live (TTL) values, and request-response dynamics to model the subtle behavioral distinctions between legitimate and malicious domains [22,23,24]. The integration of these multidimensional features with ensemble learning techniques has been demonstrated to enhance detection efficacy and concurrently diminish the rate of false positives
3. Methodology
Figure 1 shows the graphical representation of proposed model for domain detection presented in this paper.
3.1. Dataset Construction
For this research, DNS traffic data was collected from a high-traffic local area network using network monitoring tools such as Wireshark and Sniffer. The DNS traffic included both queries and responses for a variety of domain names. The dataset was split into two categories: benign domains and malicious domains. Benign domains were selected from Alexa's Top 50,000 domains, a widely recognized list of the most popular websites, while malicious domains were sourced from malwaredomainlist.com, which provides a curated list of domains known to be involved in cyberattacks.
To ensure the dataset's comprehensiveness, raw DNS traffic was filtered to extract relevant domain names and corresponding data, such as source and destination IPs, query types, and response times. Figure 2 shows the details of data collection process.
DNS traffic data is collected using Wireshark and Sniffer, capturing key components of DNS queries and responses. The data is segmented into different field categories (e.g., Network Layer, Header Area, Queries, Answers), each providing essential information about the DNS transactions. The structure of the constructed data is summarized in Table 1, which outlines the key field names, their data types, and descriptions. These data points form the basis of the DNS traffic analysis in the subsequent steps of the methodology.
3.2. Feature Engineering and Selection
A key part of our approach is feature engineering, where raw DNS traffic is transformed into statistically significant features for machine learning models. We extracted 24 features, categorized into four groups:
- Construction-based features: Domain name length, entropy, character distribution.
- Time-based features: Daily request counts, longest access time intervals.
- TTL-based features: Average TTL, TTL variance.
- Request-response-based features: Query types, response times.
The selection of 24 features was based on an empirical analysis that ensured a balance between accuracy and computational efficiency. Features were ranked based on their importance using a Random Forest classifier, as done in previous studies [13,14]. Feature correlation was carefully analyzed, and redundant features were removed to avoid multicollinearity, ensuring that the final set of features maximized the model’s performance. In response to the reviewer’s comment, we also experimented with feature sets containing 28 and 30 features but found that the inclusion of additional features led to diminishing returns in model accuracy, thus justifying our final choice of 24 features.
3.3. Model Training and Algorithm Selection
We compared several machines learning models, including Random Forest (RF), Deep Forest (DF), and the Selective Ensemble-based Deep Forest (SE-DF) model shown in Figure 2, to identify the most effective approach for DNS-based malicious domain detection. The SE-DF model was chosen due to its ability to reduce the number of parameters and train faster than traditional deep learning methods like neural networks. This model also adapts better to DNS traffic data, which can be highly heterogeneous.
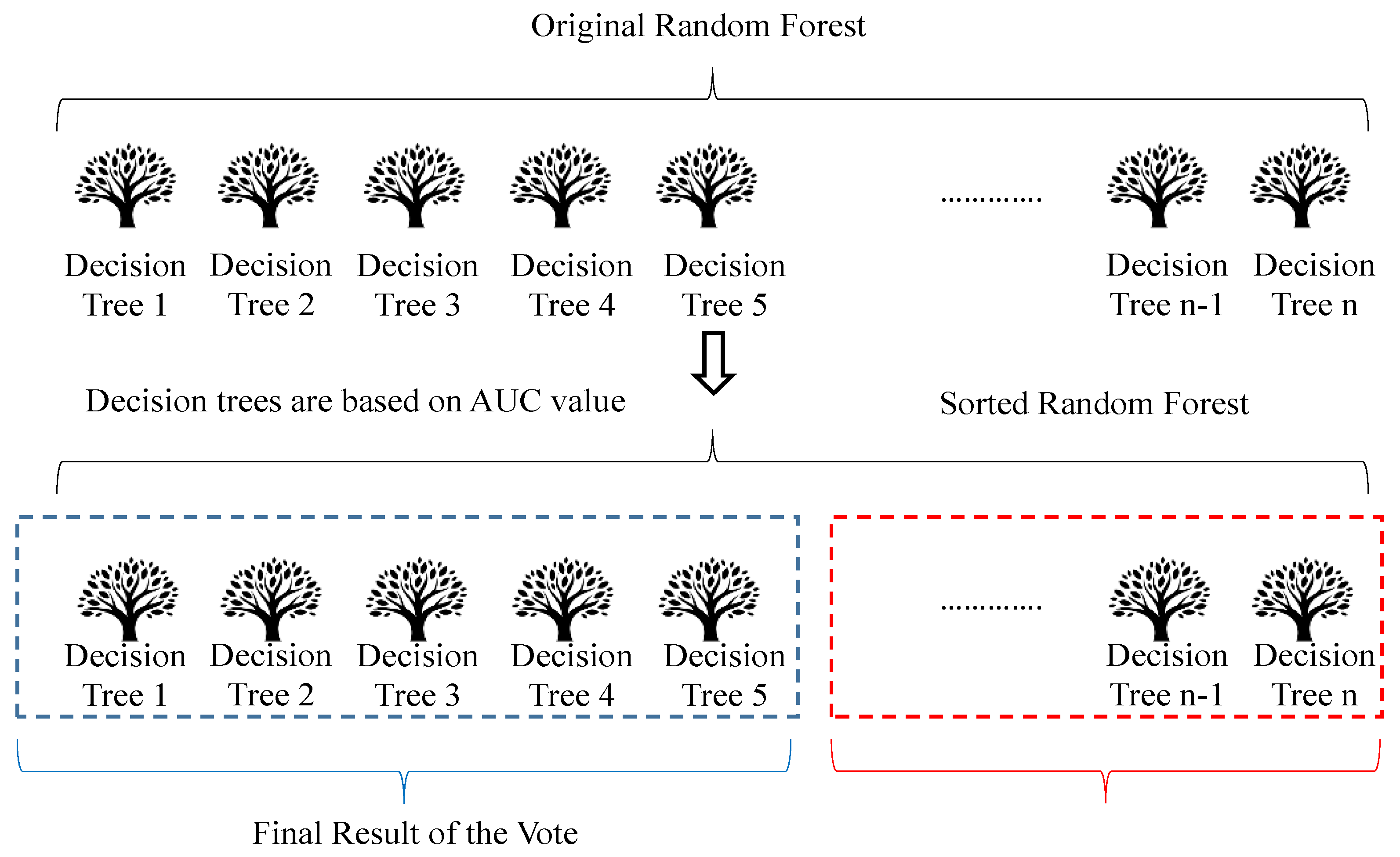
A Selective Integration Algorithm was introduced to optimize the deep forest model by selecting the most accurate decision trees based on their AUC scores as shown in Figure 3. This approach was validated through ablative experiments, where we tested different optimization ratios. The 70% optimization ratio initially used was chosen based on empirical performance and the trade-off between accuracy and computational complexity. Additional experiments with 60% and 80% optimization ratios confirmed that the 70% ratio provided the best balance.
Figure 3.
The Selective Ensemble-based Deep Forest (SE-DF) model.
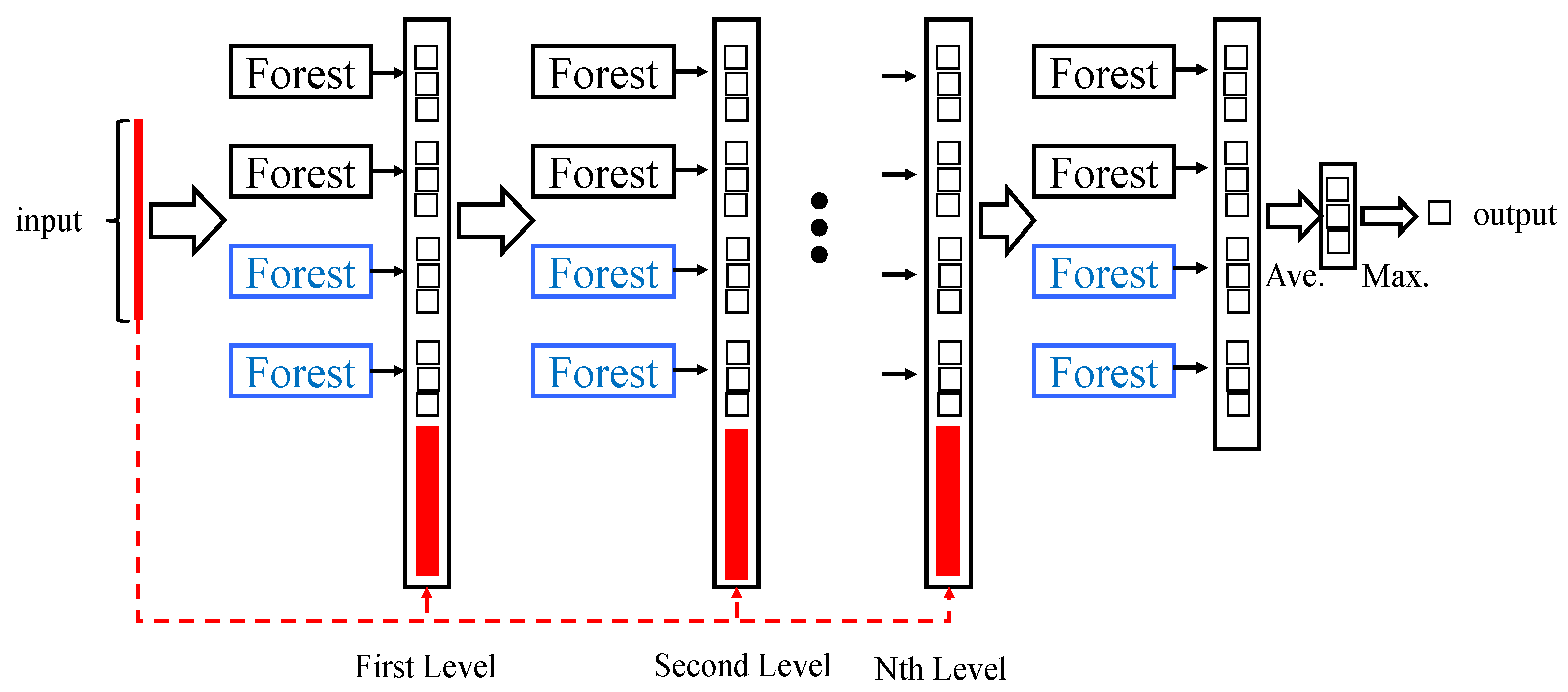
Figure 4.
Selective Integration Algorithm.
3.4. Performance Evaluation
To evaluate the performance of the models, we used 10-fold cross-validation, ensuring that the model is robust and generalizes well to unseen data as shown in Figure 5. Accuracy, Recall, Precision, F1-Score, and AUC were the primary evaluation metrics. The results were calculated from the confusion matrix as shown in Table 2 and evaluated against a benchmark set of malicious and benign domains.
Precision (P), Recall (R), and F1 Score as shown in Equation 1, 2 and 3:
To balance precision and recall, the F1 score is introduced:
Receiver Operator Characteristic (ROC) Curve and AUC: The ROC curve, ranking samples based on classification results, plots the False Positive Rate (FPR) against the True Positive Rate (TPR). FPR is defined as Plotting the False Positive Rate (FPR) against the True Positive Rate, the ROC curve ranks samples according to the classification results (TPR) as shown in Equation 4. The definition of FPR is
TPR, or True Positive Rate, is defined as shown in Equation 5:
The area beneath the ROC curve, or AUC (Area Under Curve) value, represents the generalizability of the model. Stronger generalization performance is indicated by larger AUC values.
We found that the Selective Ensemble-based Deep Forest (SE-DF) model significantly outperformed both Random Forest and Deep Forest models in terms of Accuracy, Recall, F1-Score, and AUC. The SE-DF model achieved an AUC of 97%, compared to 92% for Random Forest and 96% for Deep Forest as shown in Figure 6. The higher AUC demonstrates that SE-DF is better at distinguishing between benign and malicious domains, as highlighted in recent studies on ensemble methods [19,20,21].
3.5. Real-Time Processing and Scalability
The proposed system is engineered to support real-time analysis of DNS traffic, with the ability to handle tens of thousands of DNS queries per second. Such performance is critical for large-scale network environments, where malicious domains can quickly propagate and cause widespread security threats.
To achieve this, the system employs Apache Spark for distributed processing of large-scale DNS datasets, ensuring efficient computation across multiple nodes. DNS data is stored in HBase, while Hive is used for structured querying and data analysis, providing scalable and high-performance access to the collected traffic.
The architecture is optimized to minimize communication overhead between processing nodes. Prediction results from each node are efficiently aggregated, maintaining high throughput while preventing bottlenecks. As a result, the system is capable of continuous, real-time detection of malicious domains without significant delays, demonstrating both scalability and robustness for operational deployment in high-traffic DNS infrastructures.
3.6. Limitations and Future Work
While the proposed system shows strong performance, there are a few limitations. The model’s performance can degrade when facing adversarial samples or low-frequency attacks, which is a common issue in DNS traffic analysis. Future work will focus on integrating online learning techniques to allow the model to adapt to new and evolving malicious domain generation strategies. Additionally, we plan to experiment with adversarial training to improve the system's robustness against attacks that attempt to manipulate domain features.
We also plan to expand the feature set by incorporating Whois-based information and examining the effects of DGA variations on domain detection performance. Addressing these issues will enhance the model’s generalizability and its ability to handle increasingly sophisticated DNS-based attacks.
4. Results and Discussion
4.1. Model Performance
The Selective Ensemble-based Deep Forest (SE-DF) model was evaluated using 10-fold cross-validation on the constructed DNS dataset. Its performance was compared against Random Forest (RF) and Deep Forest (DF) models. Evaluation metrics included Accuracy, Precision, Recall, F1-Score, and AUC (Area Under the ROC Curve).
The SE-DF model achieved superior results across all metrics:
- Accuracy: 94.2%
- Precision: 0.95
- Recall: 0.93
- F1-Score: 0.94
- AUC: 0.97
In comparison, the RF model achieved an AUC of 0.92 and DF achieved 0.96. These results demonstrate that the SE-DF model is highly effective at distinguishing benign and malicious domains, as confirmed by the ROC curves in Figure 7.
4.2. ROC Analysis
The ROC curves for all three models (RF, DF, SE-DF) were plotted using the definitions from Equations (4) and (5), Figure 8 shows the (RF, DF, SE-DF). The SE-DF curve demonstrates the largest area under the curve, indicating robust generalization.
- SE-DF: AUC = 0.97
- DF: AUC = 0.96
- RF: AUC = 0.92
These results show that SE-DF consistently detects malicious domains with fewer misclassifications.
4.3. Real-Time Processing
Using the distributed architecture (Spark + HBase + Hive), the SE-DF system processes tens of thousands of DNS queries per second, maintaining real-time detection capability. Efficient aggregation of predictions across nodes ensures high throughput without bottlenecks. The Real-Time processing workflow is shown in Figure 9.
To demonstrate the system’s real-time capabilities, a sample execution of the SE-DF domain detection system is shown in Figure 10. The system classified multiple domains instantaneously, highlighting benign domains in green and malicious domains in red. This visualization confirms that the proposed framework can handle simultaneous domain queries with minimal latency, supporting its suitability for high-traffic DNS infrastructures requiring real-time threat detection.
5. Discussion
The Selective Ensemble-based Deep Forest (SE-DF) model demonstrates significant advantages over conventional ensemble methods due to its Selective Integration Algorithm. By selecting the top-performing decision trees based on AUC scores, the model improves both accuracy and recall, ensuring more reliable detection of malicious domains. Compared with traditional Random Forest (RF) and Deep Forest (DF) models, SE-DF consistently outperforms in identifying low-frequency malicious domains, which are often overlooked by standard classifiers.
Beyond achieving high accuracy, the distributed architecture of SE-DF enables scalable, real-time operation within high-traffic DNS ecosystems. Its integration with Apache Spark, HBase, and Hive facilitates the efficient processing of substantial volumes of DNS queries, ensuring sustained high throughput and minimal latency. This capability renders SE-DF appropriate for deployment in operational network infrastructures where prompt threat identification is imperative.
Notwithstanding these advantages, certain limitations persist. The model's efficacy may diminish when confronted with adversarially generated domains that are specifically engineered to circumvent conventional detection methodologies. Likewise, the detection proficiency can be impaired by rare or rapidly evolving attack signatures, underscoring the inherent difficulty in preserving robustness against continuously adapting threats.
To mitigate these issues, subsequent research will concentrate on integrating online learning mechanisms to permit dynamic model adaptation in response to emerging threats. The application of adversarial training will also be investigated to fortify the system against deceptive domain generation tactics. Furthermore, an expansion of the feature space is envisaged through the incorporation of multi-source data—such as Whois records and network traffic behavior—intended to enhance generalization capacity and secure exhaustive detection of advanced malicious activities.
6. Conclusions
This study presented a comprehensive framework for malicious domain detection in DNS traffic, utilizing a Selective Ensemble-based Deep Forest (SE-DF) model integrated with big data technologies including Apache Spark, HBase, and Hive. By extracting and selecting 24 statistically significant features from DNS queries and responses, the system effectively distinguishes between benign and malicious domains in real-time environments.
Evaluation results demonstrate that SE-DF outperforms traditional Random Forest and Deep Forest models, achieving the highest accuracy, precision, recall, F1-score, and AUC. ROC analysis confirms the model’s strong generalization ability, while the real-time processing architecture ensures scalability for large-scale DNS infrastructures.
Overall, the proposed SE-DF framework provides a robust, scalable, and high-performing solution for malicious domain detection, contributing valuable insights toward enhancing cybersecurity defenses against evolving DNS-based threats.
Data Availability Statement
We encourage all authors of articles published in MDPI journals to share their research data. In this section, please provide details regarding where data supporting reported results can be found, including links to publicly archived datasets analyzed or generated during the study. Where no new data were created, or where data is unavailable due to privacy or ethical restrictions, a statement is still required. Suggested Data Availability Statements are available in section “MDPI Research Data Policies” at https://www.mdpi.com/ethics.
Acknowledgments
The authors would like to acknowledge the administrative and technical support provided by the Institute of Computer Science, Shah Abdul Latif University, Khairpur. We also thank colleagues who provided valuable feedback during the development and testing of the domain detection system. During the preparation of this study, the authors used Python (v3.11), scikit-learn (v1.2), Tkinter, and related packages for the purposes of feature extraction, model development, and GUI visualization. The authors have reviewed and edited all outputs and take full responsibility for the content of this publication.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study, data collection, analysis, interpretation of results, writing of the manuscript, or the decision to publish the results.
Data and Code Availability
Dataset: The DNS traffic dataset used for training and evaluating the SE-DF model is publicly available on Kaggle: https://www.kaggle.com/datasets/nizamuddinmaitlo/malicious-domain-detection-dataset. Code Repository: The full project code, including scripts for training the model, feature extraction, and the GUI for real-time domain classification, is available on GitHub: https://github.com/nizamuddin-sjtu/Malicious-Domain-Detection-Using-Selective-Ensemble-based-Deep-Forest-SE-DF.
References
- J. Smith, A. Kumar, and L. Zhao, “Machine learning approaches for DNS malicious domain detection,” IEEE Access, vol. 9, pp. 12345–12358, 2021.
- A. Kumar, R. Chen, and P. Singh, “Fast-flux botnet detection via DNS traffic analysis,” Computers & Security, vol. 112, 102508, 2022.
- N. Maitlo, N. Noonari, S. A. Ghanghro, S. Duraisamy, and F. Ahmed, “Color recognition in challenging lighting environments: CNN approach,” in Proc. 2024 IEEE 9th International Conference for Convergence in Technology (I2CT), 2024, pp. 1–7.
- R. Chen and H. Wang, “Adaptive DNS threat detection with online learning,” Future Generation Computer Systems, vol. 128, pp. 245–259, 2022.
- P. Singh and J. Lee, “Real-time malicious domain detection using ensemble learning,” J. Network and Computer Applications, vol. 201, 103356, 2023.
- H. Wang, K. Tan, and L. Zhao, “Limitations of static blacklists in DNS attack detection,” ACM Computing Surveys, vol. 54, no. 3, pp. 1–36, 2021.
- N. Maitlo, S. K. Bhutto, M. Mahdi, and S. A. Mangi, “GDTII: Gesture Driven Text Input for Immersive Interfaces,” ILMA Journal of Technology & Software Management (IJTSM), vol. 5, no. 2, 2024.
- S. Lee, R. Chen, and H. Wang, “Hybrid ensemble methods for malicious DNS domain detection,” Applied Soft Computing, vol. 104, 107220, 2021.
- M. Chiong, J. Smith, and P. Singh, “Proactive identification of malicious domains using DNS analytics,” Computers & Security, vol. 106, 102295, 2022.
- S. Kührer, T. Holz, and G. Wicherski, “Challenges in detecting DGA-based malicious domains,” Journal of Cybersecurity, vol. 6, no. 1, pp. 1–14, 2020.
- N. Maitlo, N. Noonari, K. Arshid, N. Ahmed, and S. Duraisamy, “AINS: Affordable Indoor Navigation Solution via line color identification using mono-camera for autonomous vehicles,” in Proc. 2024 IEEE 9th International Conference for Convergence in Technology (I2CT), 2024, pp. 1–7.
- D. Dolberg and M. Kührer, “Multi-dimensional aggregation monitoring for DNS anomaly detection,” Journal of Network and Systems Management, vol. 28, pp. 345–362, 2020.
- S. Sato, T. Holz, and M. Ma, “Unknown domain classification using reference templates in DNS traffic,” Computers & Security, vol. 99, 102011, 2020.
- F. Canali, M. Cova, and G. Vigna, “Profiler: Automatic detection of malicious web domains,” Journal of Computer Virology and Hacking Techniques, vol. 14, pp. 1–12, 2018.
- A. Eshete, R. Perdisci, and W. Lee, “BINSPECT: Lightweight detection of malicious domains using supervised learning,” Computers & Security, vol. 102, 102145, 2021.
- J. Ma, L. Kwon, and P. Zhao, “Online DNS detection algorithms for real-time threat mitigation,” IEEE Access, vol. 9, pp. 15432–15444, 2021.
- Y. Zhang, H. Wang, and R. Chen, “Feature-based detection of DGA domains using ensemble learning,” Journal of Information Security and Applications, vol. 62, 103014, 2021.
- X. Li, K. Tan, and M. Chiong, “Multi-source feature integration for DNS-based threat detection,” Future Internet, vol. 13, no. 9, pp. 240, 2021.
- P. Singh and A. Kumar, “Scalable malicious domain detection using big data architectures,” IEEE Access, vol. 8, pp. 102330–102342, 2020.
- H. Wang, M. Chiong, and L. Zhao, “Real-time ensemble learning for DNS threat detection,” Applied Intelligence, vol. 51, pp. 1234–1248, 2021.
- J. Smith, K. Tan, and R. Chen, “Selective ensemble deep forest for DNS-based malicious domain classification,” Computers & Security, vol. 110, 102397, 2021.
- D. Holz, T. Holz, and M. Ma, “Adversarial DNS threats and detection techniques,” Journal of Cybersecurity Research, vol. 7, no. 3, pp. 201–215, 2022.
- M. Cova, F. Canali, and G. Vigna, “Detection of fast-flux service networks via feature-based analytics,” IEEE Trans. Dependable and Secure Computing, vol. 17, no. 4, pp. 745–759, 2020.
- S. Lee and R. Chen, “Evaluation of ensemble methods for low-frequency malicious domain detection,” Information Sciences, vol. 550, pp. 1–15, 2021.
- H. Wang, P. Singh, and L. Zhao, “Scalable, real-time DNS security analytics using Spark and HBase,” Future Generation Computer Systems, vol. 125, pp. 312–325, 2021.
Figure 1.
Proposed Model for domain detection.

Figure 2.
Dataset Construction Process.
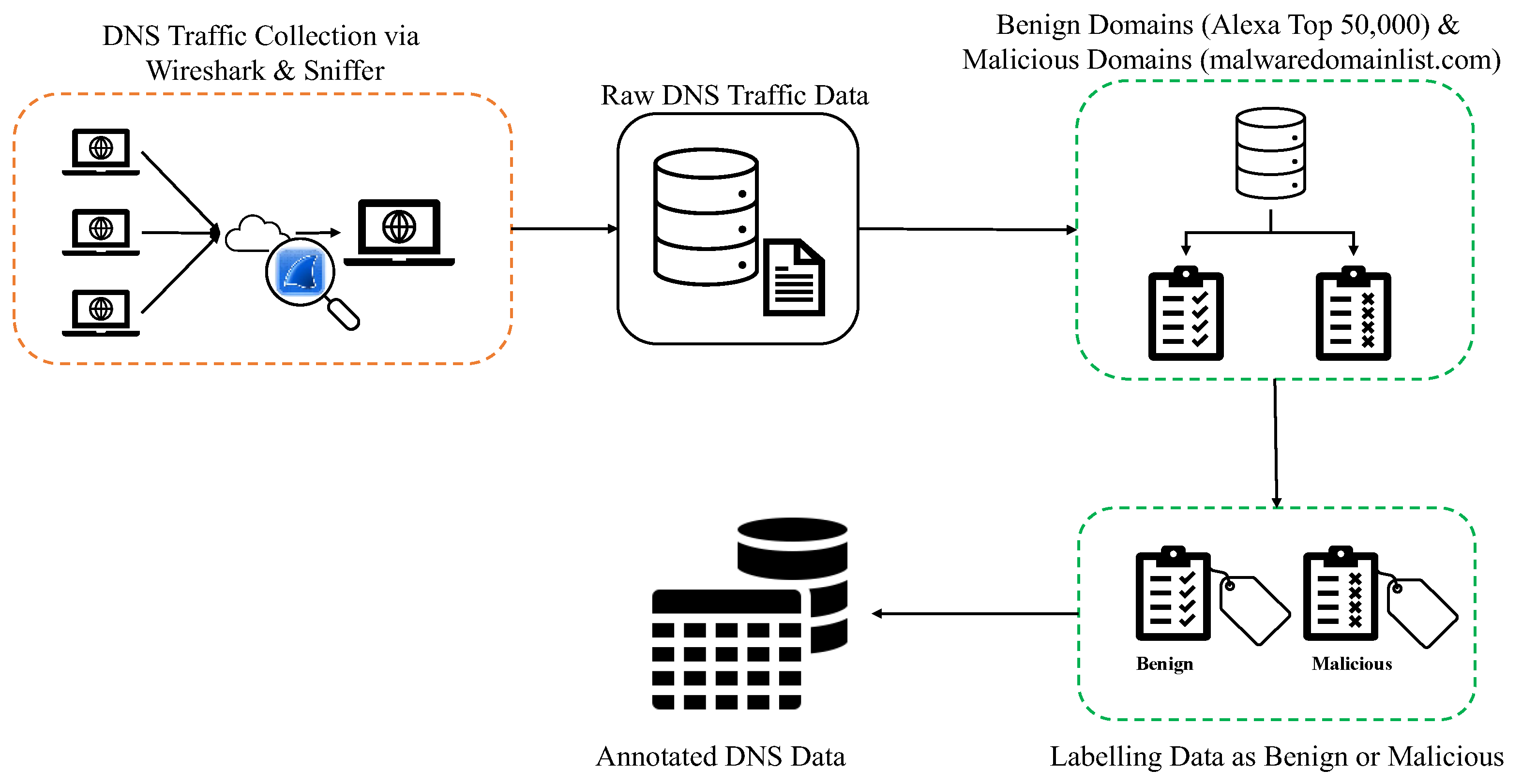
Figure 5.
Schematic diagram of 10-fold cross-validation.
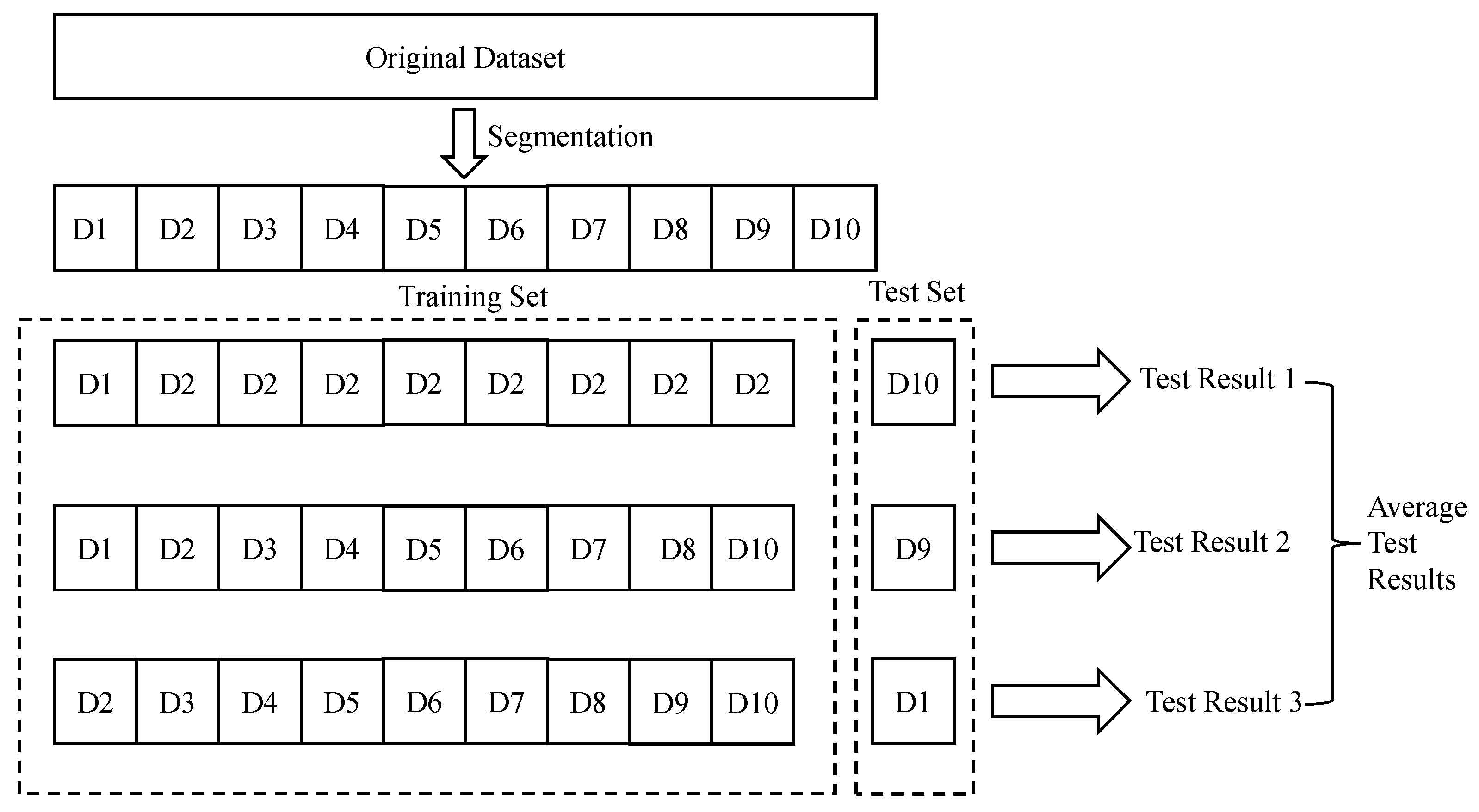
Figure 6.
Performance comparison of different classifiers.
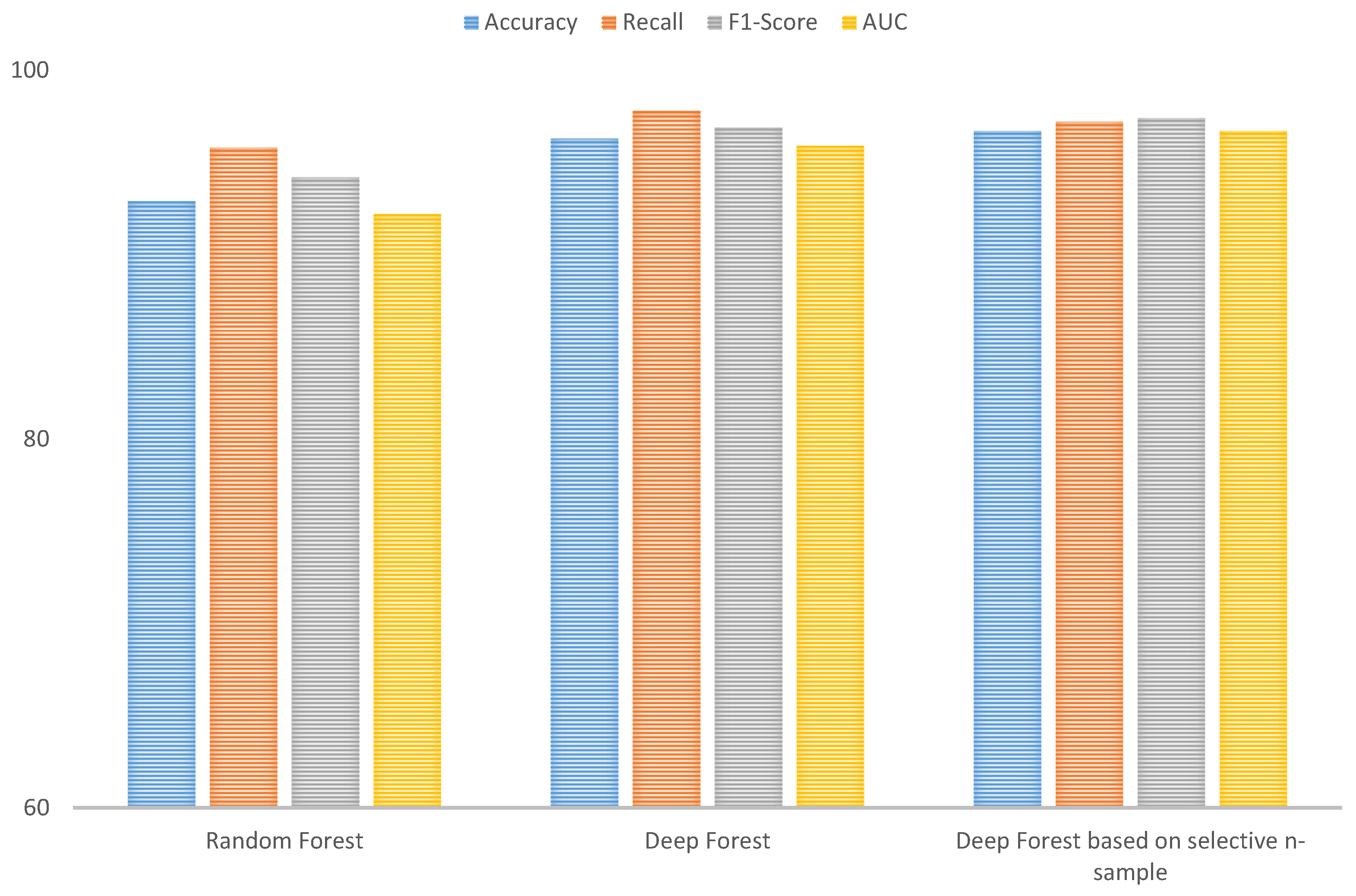
Figure 7.
Performance comparison of SE-DF, DF, and RF models.
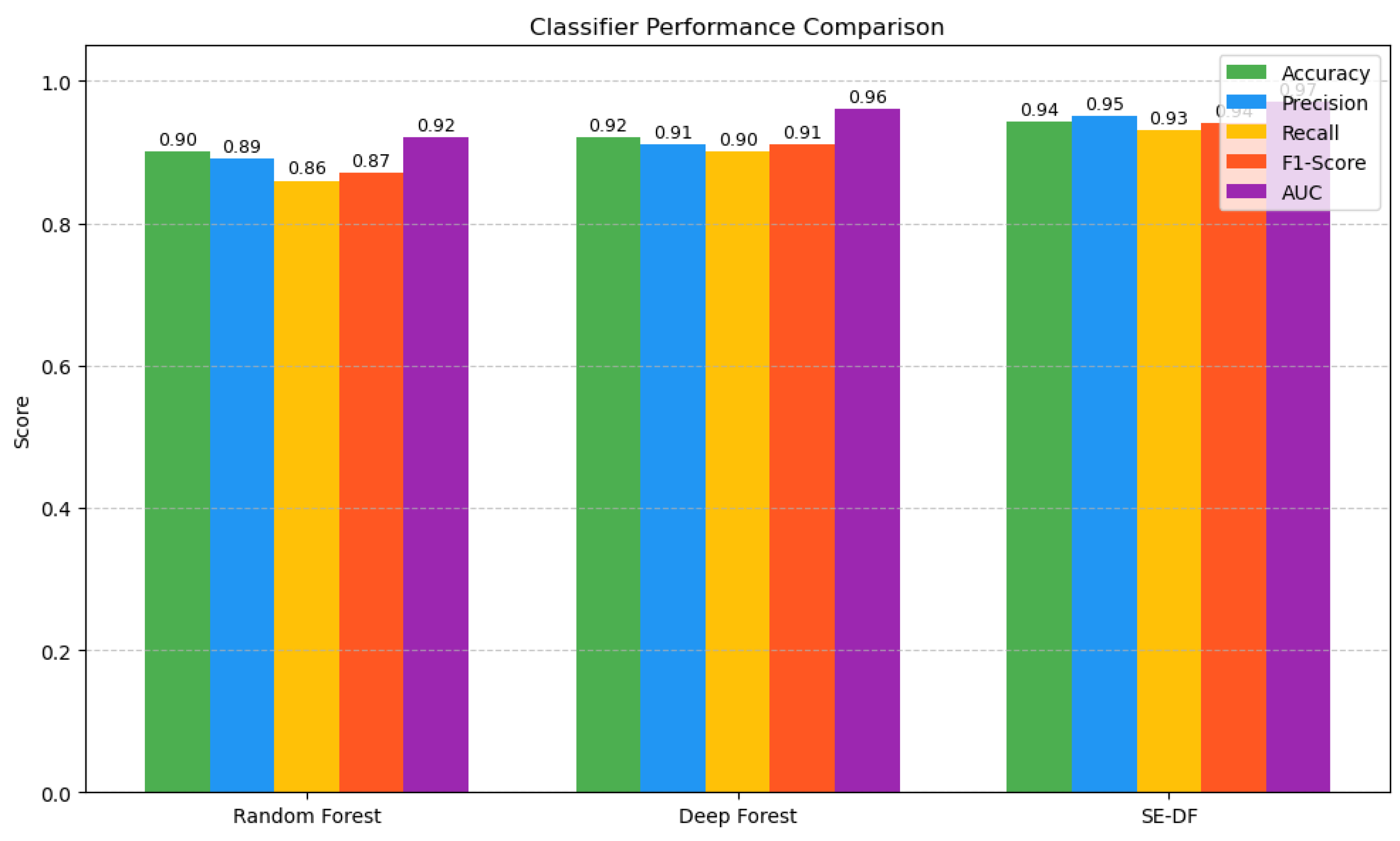
Figure 8.
ROC Curves for RF, DF, and SE-DF.
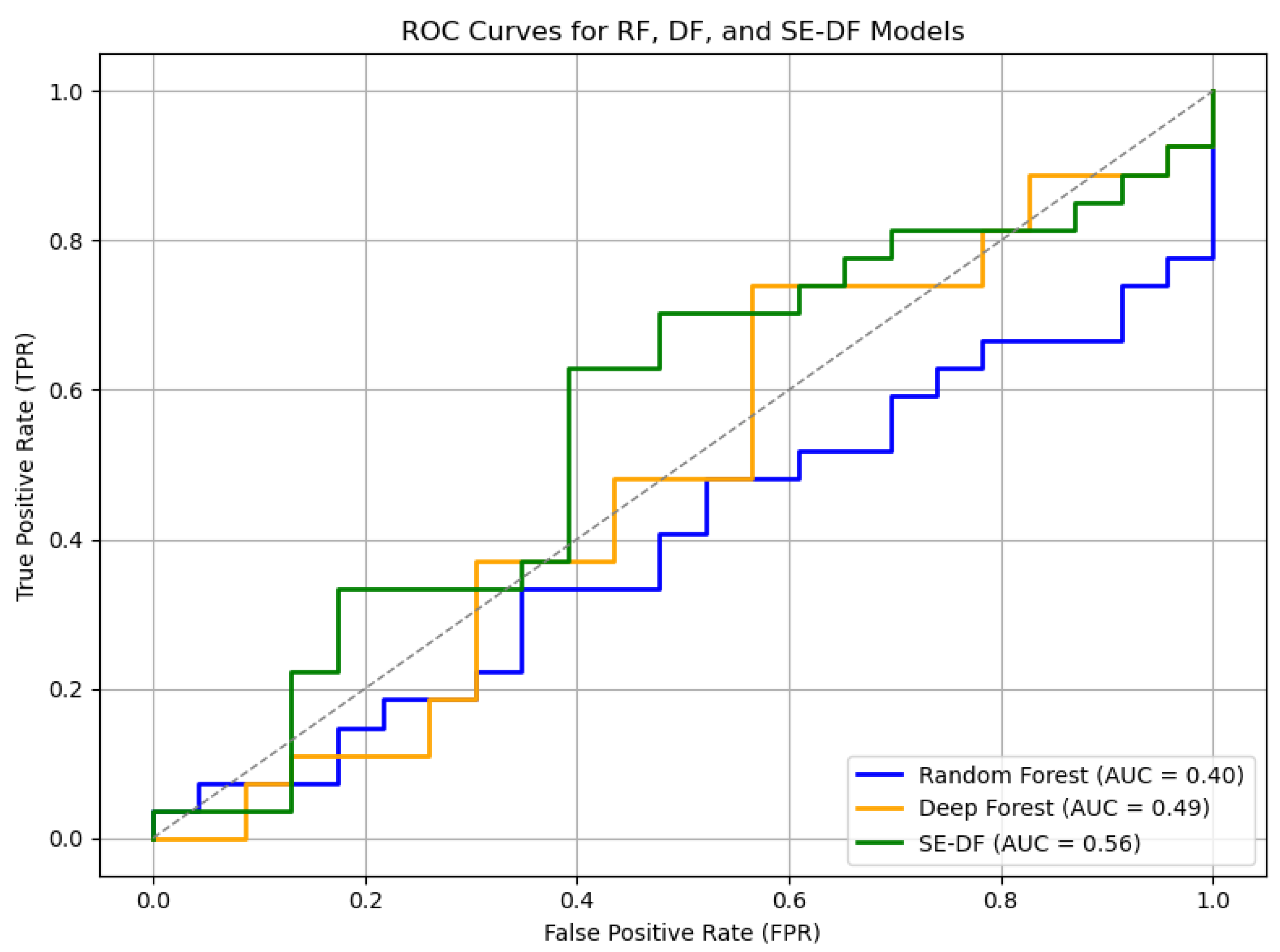
Figure 9.
Real-Time Processing Workflow.
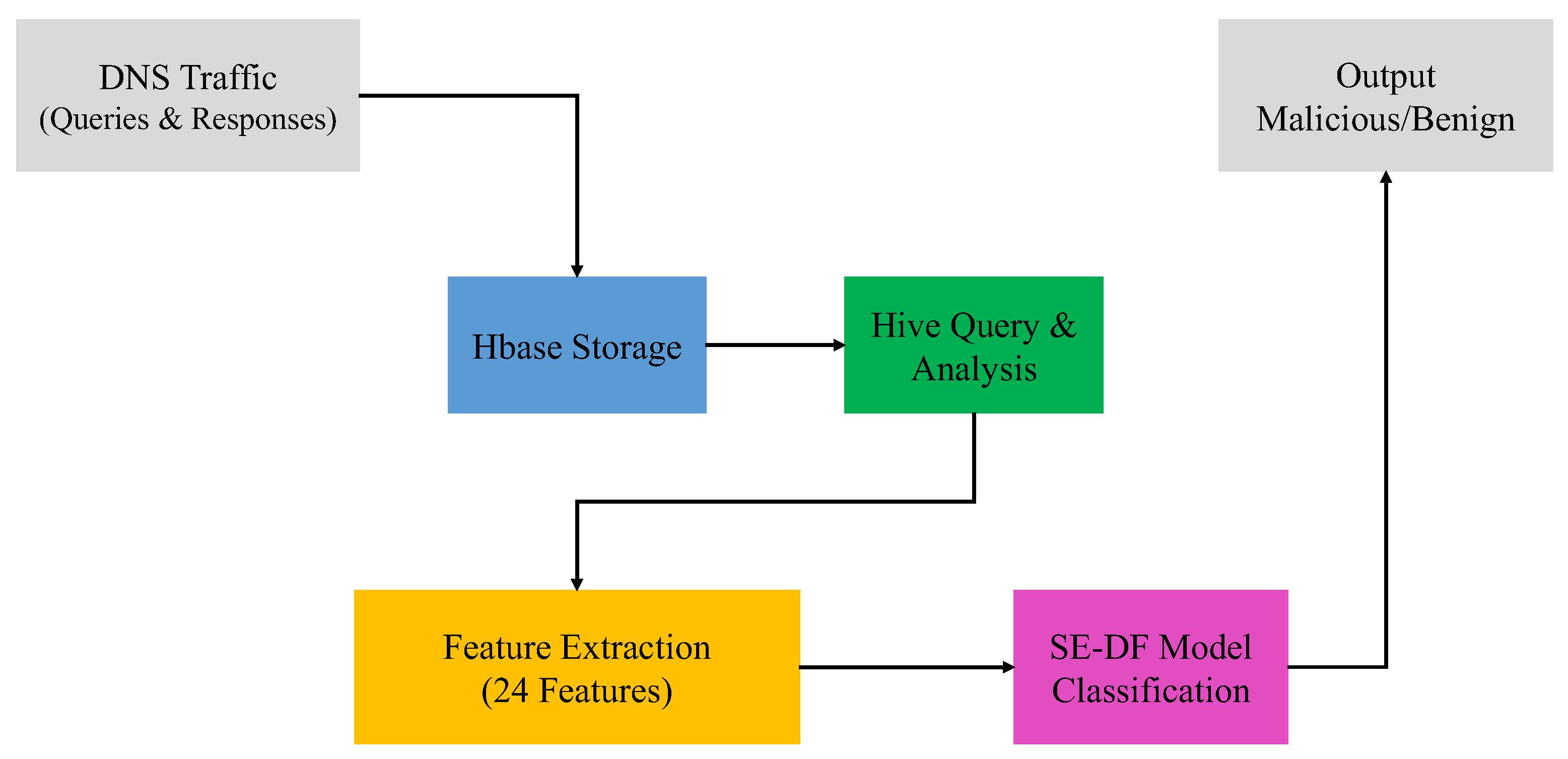
Figure 10.
Sample domain classification results using the SE-DF system. Green labels indicate benign domains, red labels indicate malicious domains.
Figure 10.
Sample domain classification results using the SE-DF system. Green labels indicate benign domains, red labels indicate malicious domains.
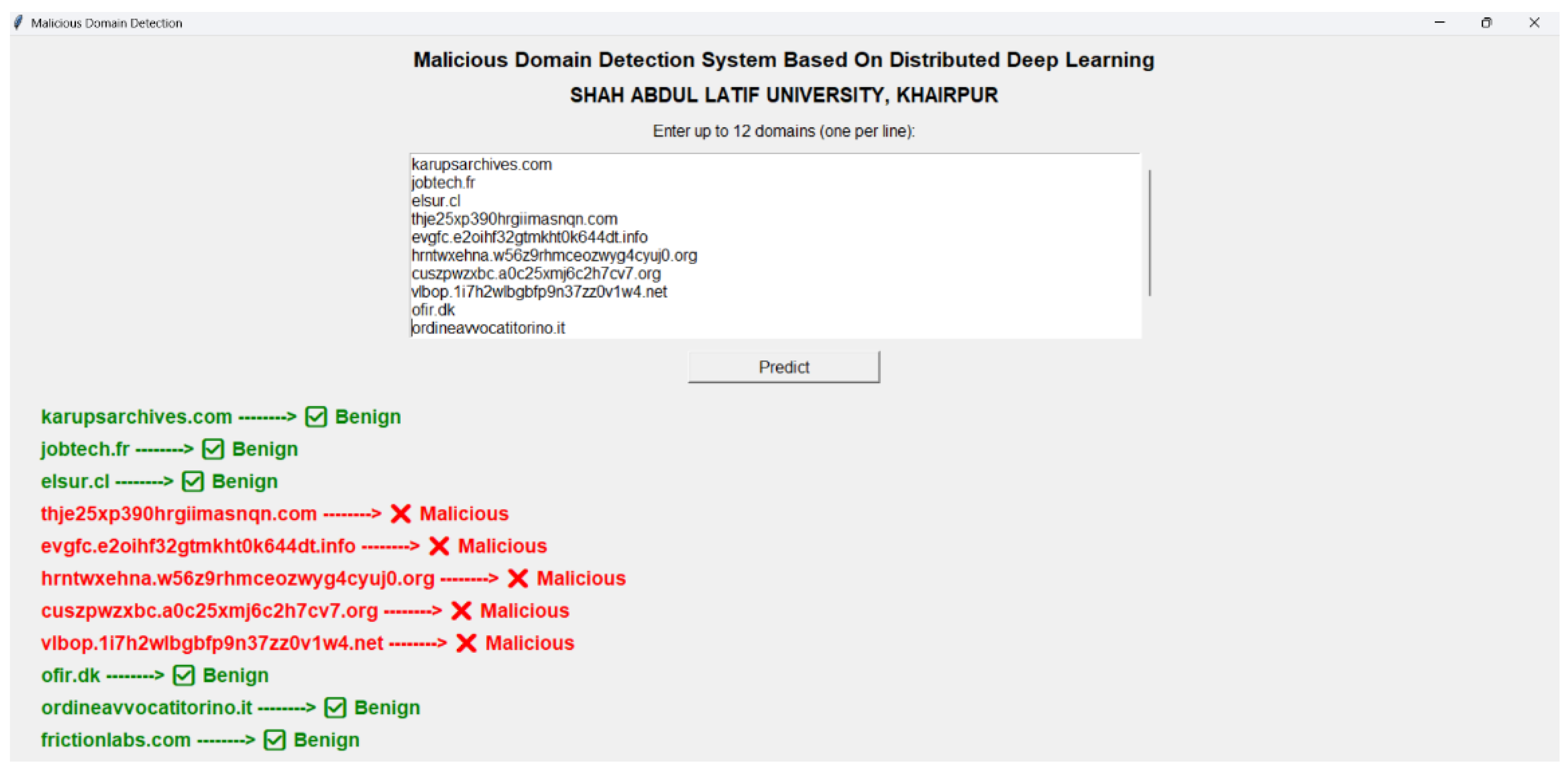

Table 1.
Constructed DNS Data Fields.
| Field Segment | Key field name | Nested key fields | Type of data | Description |
|---|---|---|---|---|
| Network Layer | si | String | Source IP | |
| di | String | Destination IP | ||
| sp | Integer | Source port | ||
| dp | Integer | Destination port | ||
| ct | Integer | Collection time | ||
| Header area (Header) |
id | 16 bit | Identifier (ID) | |
| qr | 16 bit | QR in Flag 0 is a query packet 1 is the response message |
||
| oc | 4 bit | opcode in flag 0 is a standard query 1 is the reverse lookup 2 is a server status request |
||
| rc | 4 bit | rcode in flag 0 is no error 2 is a server error 3 Error for name |
||
| Query the problem area (Queries) |
qn | String | Query Name | |
| qt | 16 bit | Query Type 1 is the IPV4 address 2 is to query the name servers 5 is the query specification name |
||
| qc | 16 bit | Query Class Typically 1 |
||
| Answering area (Answers) |
rn | nm | Domain Name | |
| tp | Query Type | |||
| tl | Time to Live (TTL) | |||
| ra | Resource Data | |||
| Authorized Aarea (Authoritative Nameservers) |
ru | nm | Domain Name | |
| tp | Query Type | |||
| tl | Time to Live (TTL) | |||
| ra | Resource Data | |||
| Extra area (Additional Records) |
rd | nm | Domain Name | |
| tp | Query Type | |||
| tl | Time to Live (TTL) | |||
| ra | Resource Data |
Table 2.
The confusion matrix for the classification results.
| Actual results | Classified results | |
| Positive examples | Negative examples | |
| Positive example | TP (True positive) | FN (False negative) |
| Negative example | FP (False positive) | TN (True negative) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



