Submitted:
12 May 2025
Posted:
12 May 2025
Read the latest preprint version here
Abstract
Multispectral object detection combining visible and infrared imaging has emerged as a crucial technology for all-day and all-weather surveillance systems. However, effectively integrating complementary information from different spectral domains remains challenging. This paper proposes SDRFPT-Net (Spectral Dual-stream Recursive Fusion Perception Target Network), a novel architecture for multispectral object detection that addresses these challenges through three innovative modules. First, we introduce a Spectral Hierarchical Perception Architecture (SHPA) based on YOLOv10, which employs a dual-stream structure to extract domain-specific features from visible and infrared modalities. Second, a Spectral Recursive Fusion Module (SRFM) facilitates deep cross-modal feature interaction through a hybrid attention mechanism that integrates self-attention, cross-modal attention, and channel attention, coupled with a parameter-efficient recursive progressive fusion strategy. Third, a Spectral Target Perception Enhancement Module (STPEM) improves target region representation and suppresses background interference using lightweight mask prediction. Extensive experiments on the FLIR-aligned and LLVIP datasets demonstrate SDRFPT-Net's superior performance, achieving state-of-the-art results with 0.785 mAP50 and 0.426 mAP50:95 on FLIR-aligned, and 0.963 mAP50 and 0.706 mAP50:95 on LLVIP. Comprehensive ablation studies validate the effectiveness of each proposed component. The findings suggest that SDRFPT-Net offers a promising solution for reliable multispectral object detection in challenging environments, making it valuable for applications in autonomous driving, security surveillance, and remote sensing.
Keywords:
Multispectral object detection
; Spectral feature representation
; Recursive progressive fusion
; Hybrid attention mechanism
; Target perception enhancement
1. Introduction
Object detection, as a core technology in computer vision, has extensive application value in fields such as autonomous driving, security monitoring, and remote sensing analysis [1,2,3]. As environmental conditions become increasingly complex and variable, traditional single-modality detection systems face severe challenges. While visible images can provide rich color and texture information, they perform poorly in adverse weather or insufficient lighting conditions [4]. In contrast, infrared images can capture thermal information radiated by objects, performing excellently in nighttime and low-light environments, but they have lower resolution and less clear edge information [5]. Therefore, multispectral object detection technology that comprehensively utilizes the complementary modalities of visible and infrared light has become an effective approach to solving this problem [6,7].
In recent years, deep learning technology has driven the rapid development of multispectral object detection research. With the advancement of convolutional neural networks (CNNs) and object detection algorithms, detection frameworks such as the YOLO series [8,9,10] and Faster R-CNN [11] have demonstrated powerful feature extraction and object recognition capabilities. However, when facing multimodal data, how to effectively fuse complementary information from different spectral domains and suppress background interference becomes a key challenge [12]. Existing methods mainly adopt simple feature concatenation or element-wise addition/multiplication fusion strategies [13], which ignore the intrinsic correlation between different modalities and find it difficult to fully utilize the complementary advantages of multimodal data.
To address the above issues, this paper proposes the Spectral Dual-stream Recursive Fusion Perception Target Network (SDRFPT-Net), a novel multispectral object detection architecture designed to effectively integrate visible and infrared modal information to improve detection performance in complex environments. Unlike existing methods, SDRFPT-Net innovatively proposes a Spectral Hierarchical Perception Architecture (SHPA) based on YOLOv10, providing a solid foundation for multimodal feature extraction, and achieves deep feature interaction and efficient fusion through the Spectral Recursive Fusion Module (SRFM), finally using the Spectral Target Perception Enhancement Module (STPEM) to enhance target region representation and suppress background interference.
The SHPA module adopts a dual-stream structure to process visible and infrared spectral information separately, capturing modality-specific features through independent parameter networks to maintain the integrity of spectral information. The SRFM module is the core innovation of this architecture, achieving deep feature interaction through a hybrid attention mechanism (integrating self-attention, cross-modal attention, and channel attention), and adopting a recursive progressive fusion strategy to achieve deep multi-modal feature interaction while maintaining parameter efficiency. The STPEM module focuses on enhancing target regions in features, significantly improving the detection capability of low-contrast targets through lightweight mask prediction and feature enhancement mechanisms.
Compared to traditional multispectral fusion methods, our proposed spectral dual-stream recursive fusion perception architecture has three significant advantages: First, it can more effectively capture complementary information between different modalities, showing excellent performance especially in low-light, adverse weather, and other complex environments; Second, the recursive progressive fusion strategy achieves deep feature interaction without significantly increasing the parameter count, improving computational efficiency; Finally, the target perception enhancement mechanism effectively distinguishes targets from backgrounds, improving detection accuracy and robustness.
To verify the effectiveness of SDRFPT-Net, we conducted extensive experiments on two multispectral object detection benchmark datasets: FLIR-aligned [14] and LLVIP[15]. The results show that SDRFPT-Net achieved state-of-the-art performance on both datasets, particularly with significant improvements over existing methods in the mAP50 and mAP50:95 metrics. For example, on the FLIR-aligned dataset, SDRFPT-Net achieved an mAP50 of 0.785, an 11.5% improvement over the second-best performing BA-CAMF Net (0.704); on the LLVIP dataset, the mAP50 reached 0.963, and the mAP50:95 reached 0.706, achieving optimal performance.
The contributions of this paper can be summarized as follows:
- (1)
- Propose SDRFPT-Net, a novel multispectral object detection architecture that effectively extracts and integrates multimodal features through a dual-stream separated spectral structure;
- (2)
- Design the Spectral Recursive Fusion Module (SRFM), achieving high-efficiency deep feature interaction through a hybrid attention mechanism and recursive progressive fusion strategy;
- (3)
- Develop the Spectral Target Perception Enhancement Module (STPEM), enhancing target feature representation and suppressing background interference;
- (4)
- Experimental validation of SDRFPT-Net's effectiveness on multiple public datasets, achieving state-of-the-art detection performance while maintaining computational efficiency;
2. Materials and Methods
In this section, we review multispectral object detection, feature fusion strategies, and the application of YOLO series algorithms in multispectral object detection.
2.1. Multispectral Object Detection
To overcome the limitations of single-modality imaging, multispectral object detection technology achieves stable monitoring in all weather and all time conditions by fusing complementary information from different spectral bands [6,7]. Early multispectral fusion methods mainly used traditional mathematical models, such as multi-scale transformation [16], sparse representation [17], saliency-based methods [18], and subspace decomposition [19]. However, these methods often rely on manually designed feature extractors and fusion rules, making it difficult to adapt to complex and variable scenes.
With the development of deep learning, CNN-based multispectral object detection methods have made breakthrough progress. Liu et al. [20] proposed a multispectral deep neural network for pedestrian detection, improving detection performance by learning the correlation between different modalities. Wagner et al. [21] designed a deep fusion convolutional neural network, achieving effective combination of visible and infrared images. König et al. [22] developed a fully convolutional region proposal network for multispectral person detection. The common characteristic of these methods is adopting a dual-stream network structure, processing inputs from different modalities separately, and then performing feature fusion at different levels of the network.
In the remote sensing field, multispectral object detection faces more complex challenges, including highly variable object sizes, complex and diverse backgrounds, unstable imaging conditions, etc. [13]. To address these challenges, Song et al. [23] proposed an information flow fusion detection method based on RGB-thermal infrared images, effectively detecting objects in complex environments by maintaining gradient and intensity information. Feng et al. [24] developed a modality-specific representation learning method, significantly improving detection stability under different lighting conditions.
In recent years, Transformer architectures have shown enormous potential in multispectral object detection. Qing et al. [25] proposed a multispectral object detection method based on cross-modal fusion Transformer, effectively capturing long-range dependencies between different modalities and achieving remarkable results in remote sensing image analysis. These attention-based methods can adaptively learn the importance of different modalities, providing new research directions for multispectral object detection.
2.2. Feature Fusion Strategies
Feature fusion strategies are the core of multispectral object detection, directly affecting the final detection performance. Based on the stage where fusion occurs, existing methods can be divided into early fusion, middle fusion, and late fusion [26]. Early fusion directly merges the original inputs at the pixel level, with high computational efficiency but possibly losing modality-specific information; middle fusion occurs after feature extraction, preserving more modality features, also known as feature fusion; late fusion integrates the outputs from different modalities after detection results are generated [27].
In traditional methods, commonly used fusion strategies include weighted averaging, maximum/minimum value selection, and principal component analysis [28]. However, these fixed rules find it difficult to adapt to complex and variable scenes. In recent years, adaptive fusion strategies based on deep learning have received widespread attention. Li et al. [29] proposed a multi-granularity attention network for infrared and visible image fusion, improving fusion effects by learning feature correlations at different levels. Wang et al. [30] developed the Res2Fusion architecture, using multi-receptive field aggregation blocks to generate multi-level features, and designed a non-local attention model for effective fusion.
Cross-modal attention mechanisms provide a new perspective for feature fusion. Zhang et al. [31] proposed a cross-stream and cross-scale adaptive fusion network, significantly improving the detection performance of salient objects in RGB-D images by establishing connections between different modules and scales. Li et al. [32] designed an attention-based generative adversarial network, achieving efficient fusion of infrared and visible images through adversarial training. These attention-based methods can adaptively emphasize key information in different modalities, suppress redundancy and noise, and achieve more precise feature fusion.
2.3. YOLO Series in Multispectral Object Detection
The YOLO (You Only Look Once) series algorithms have achieved remarkable achievements in the object detection field with their efficient single-stage detection framework [33]. From the initial YOLOv1 [8] to the recent YOLOv10 [34], this series of algorithms has continuously evolved, consistently improving detection accuracy while maintaining efficient inference speed. In remote sensing image analysis, YOLO series algorithms have received attention due to their real-time capabilities and high accuracy.
YOLOv3 [35] significantly improved small object detection capabilities by introducing multi-scale prediction and residual networks, providing an effective solution for the small-sized targets common in remote sensing images. YOLOv4 [36] introduced a series of "bag of freebies" techniques, such as mosaic data augmentation and class balance, effectively improving model performance. YOLOv6 [37] and YOLOX [38] improved detection accuracy while maintaining efficient inference by enhancing network architecture and loss functions.
In the field of multispectral object detection, the application of YOLO series algorithms primarily revolves around dual-stream network structures. Typically, two parallel YOLO backbone networks are used to process inputs from different modalities, followed by fusion at different levels of the feature extraction network. Zheng et al. [39] designed a gated fusion dual SSD architecture based on YOLOv3, effectively combining complementary information from visible and infrared images. Wang et al. [40] introduced CSPNet as a feature extraction backbone, combining Spatial Spatial Pyramid (SSP) and Path Aggregation Network (PAN) to build an efficient multi-scale feature extraction framework.
To further improve multispectral detection performance, researchers have introduced attention mechanisms into the YOLO framework. Cao et al. [41] proposed an attention fusion method for single-stage multispectral pedestrian detection, significantly improving detection accuracy by adaptively learning the importance of different modalities. Zhang et al. [12] designed an illumination-guided RGBT object detection method, achieving robust detection in complex environments through intra-modal and inter-modal fusion strategies.
The latest research indicates that combining Transformer structures with YOLO frameworks is a promising direction. Wang et al. [42] proposed SwinFuse, applying residual Swin Transformer fusion networks to infrared and visible image fusion, achieving excellent results. This hybrid architecture, combining CNN's local feature extraction capability with Transformer's global modeling capability, provides a new technical approach for multispectral object detection.
3. Methodology
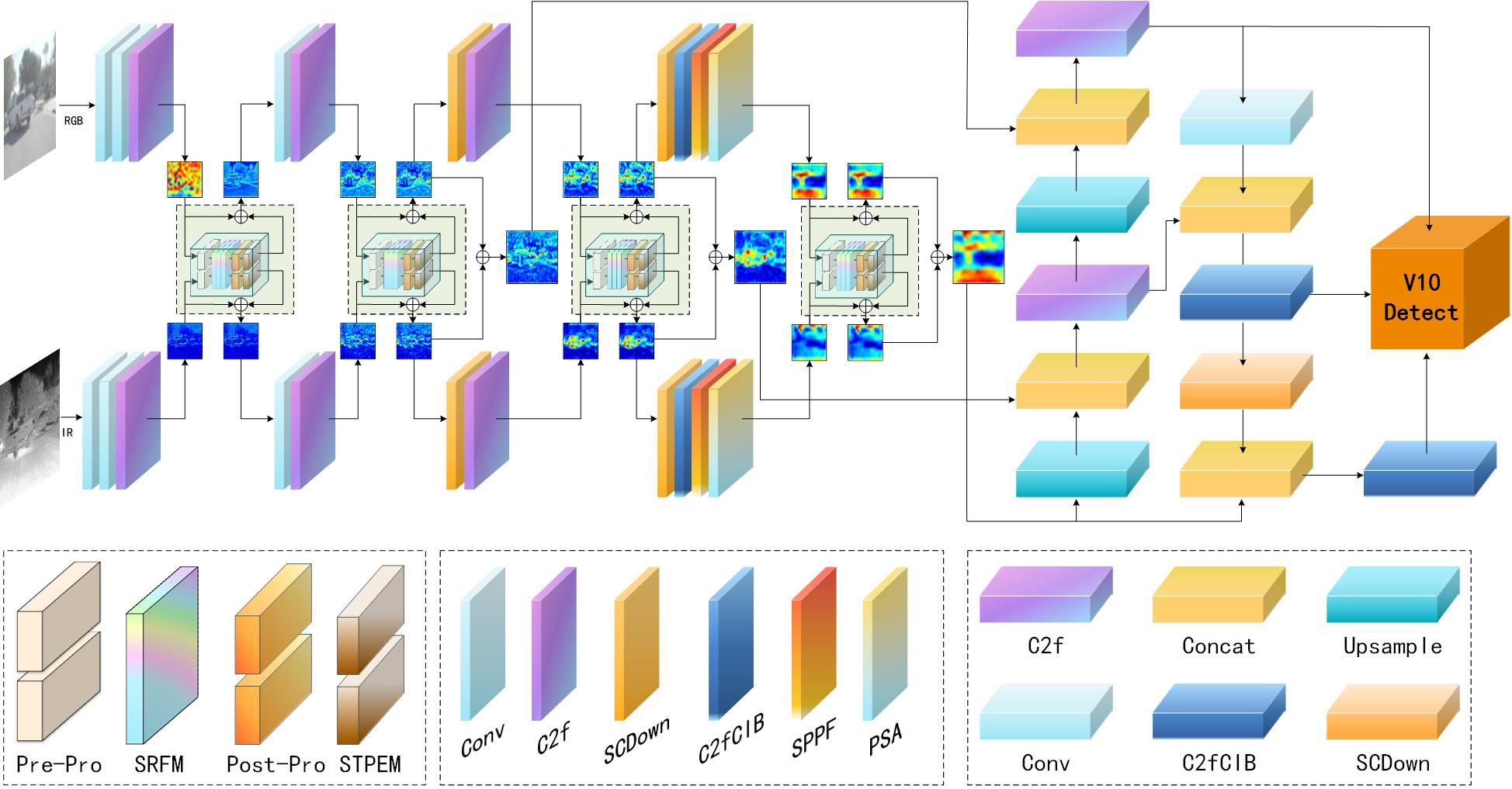
This section will detail the SDRFPT-Net algorithm, explaining in order according to the system data flow. The overall architecture of SDRFPT-Net is shown in Figure 2, with its dual-stream design based on YOLOv10 capable of supporting multi-scale spectral feature extraction for visible and infrared modalities, and achieving significant improvement in detection performance through spectral self-adaptive recursive fusion mechanisms and target perception enhancement modules.
The system's data processing flow is as follows: First, the input visible and infrared images are processed separately through dual-stream feature extraction networks, generating feature maps of different scales; Then, these feature maps undergo deep interaction and fusion through the spectral self-adaptive recursive fusion module; Next, the fused features are further enhanced by the self-adaptive target perception enhancement module to strengthen the representation of target regions; Finally, the enhanced multi-scale features are aggregated through feature aggregation and input to the detection head, generating the final detection results.
Compared to traditional single-modality object detection methods, this architecture can more effectively utilize the complementary information of RGB and infrared images, especially showing greater detection accuracy and robustness in challenging scenarios such as low light, adverse weather, and complex backgrounds.
3.1. Spectral Hierarchical Perception Architecture (SHPA)
The SHPA architecture, as the core design of this algorithm, effectively processes visible and infrared spectral domain information through a dual-stream structure, laying the foundation for hierarchical perception and fusion of multi-scale features. This architecture is based on YOLOv10's excellent features and has been systematically improved for multi-modal perception.
3.1.1. Dual-stream Separated Spectral Architecture Design
Compared to YOLOv10's single backbone network feature extraction mechanism, the dual-stream separated spectral architecture proposed in this paper can effectively process RGB-IR dual-modal data's heterogeneous properties, as shown in Figure 3.
This architecture expands a single feature extraction network into a dual-stream network, processing visible spectral and infrared spectral information separately. The two feature extraction streams share similar network structures but use independent parameters, and the feature extraction process of the dual-stream network can be formalized as:
where, and represent RGB and infrared input images, and represent the corresponding feature extraction functions, and represent their respective network parameters.
The main advantages of the dual-stream architecture are:
- (1)
- It can design specific extraction strategies for the characteristics of different spectral domains, thereby better adapting to the characteristics of data from each modality;
- (2)
- It preserves the unique information of each spectral domain, avoiding the potential loss of information that might occur when processing in a single network;
- (3)
- It captures the feature distributions of different spectral domains through independent parameters, improving the diversity of feature representations.
Compared to YOLOv10's single feature extraction path, the dual-stream architecture shows greater robustness in complex environments, especially when the quality of information from one modality decreases (such as insufficient RGB information at night or reduced infrared contrast during the day), the system can still maintain detection performance by relying on stable information provided by the other modality.
3.1.2. Multi-scale Spectral Feature Expansion
To comprehensively capture the multi-scale representation of targets, this paper designs a multi-scale spectral feature expansion mechanism. In each spectral stream, features form a multi-scale feature pyramid through progressive downsampling. For each spectral domain, the feature expansion process can be represented as:
where, represents the level feature, represents the downsampling function, is the corresponding parameter. Specifically, the spatial resolution and channel number of each level feature are:
3.1.3. Feature Aggregation and Detection
After multi-scale expansion, images go through Pre-Pro, SRFM, Post-Pro, STPEM models for fusion, thereby obtaining high-quality multi-scale fusion features. These features need to be further aggregated and processed to generate the final object detection results, as shown in Figure 4.
First, multi-scale fusion features are aggregated through the feature pyramid (FPN) and path aggregation network (PAN), enhancing information exchange between features of different scales::
where, represents the FPN output of level feature, represents the PAN output of level feature, represents the feature after fusion, containing complementary information from RGB and IR.
FPN transmits semantic information from high levels to low levels, while PAN transmits spatial details from low levels to high levels, forming a powerful feature representation. This bidirectional feature flow mechanism ensures that features at each scale can incorporate both rich semantic information and fine spatial details.
Finally, the aggregated features pass through the v10Detect detection head for object detection:
where represents the detection function, with outputs including object class, bounding box coordinates, and confidence information. v10Detect adopts a more efficient feature decoding method, including dynamic convolution and branch specialization design, further improving detection accuracy and efficiency. v10Detect employs branch specialization design, designating specialized branches for bounding box regression, feature processing, and classification tasks, further improving detection accuracy and efficiency.
Compared to YOLOv10, our feature aggregation and detection stage utilizes the advantages brought by modal fusion and target perception enhancement, allowing the detection head to perform object detection based on richer and more accurate feature representations. This is particularly important in low light, adverse weather, and complex background conditions, as single-modal information is often unreliable in these scenarios.
3.2. Spectral Recursive Fusion Module (SRFM)
The SRFM module achieves deep interaction and optimized integration of RGB-IR dual-modal features through innovative fusion mechanisms, significantly improving detection performance in complex environments. Unlike traditional fusion methods, SRFM combines hybrid attention mechanisms with recursive progressive fusion strategies organically, achieving deep multi-modal feature interaction while maintaining parameter efficiency, providing powerful feature representation capabilities for multispectral object detection.
As shown in Figure 5, SRFM receives dual-stream features from SHPA and outputs fused enhanced features after cyclic progressive fusion. This section will introduce the design principles, key components and workflow of the mechanism in detail.
3.2.1. Hybrid Attention Mechanism
The hybrid attention mechanism builds a comprehensive feature enhancement system by integrating three complementary mechanisms: self-attention, cross-modal attention, and channel attention, capturing complex feature dependencies from spatial, modal relationship, and channel importance dimensions. This multi-dimensional feature enhancement design significantly improves the model's processing capability for different scenes.
According to the data flow shown in the figure, the overall calculation process of the hybrid attention mechanism can be expressed as:
where, and respectively represent RGB and infrared features after channel attention processing.
Channel attention mechanism. The channel attention sub-module learns channel dependencies through global information modeling, providing all-around enhanced features for the spectral recursive progressive fusion strategy. Given input feature map , where , , , respectively represent batch size, channel number, height, and width, the calculation process of channel attention can be expressed as:
where, and represent global average pooling and global maximum pooling operations; and are shared weight fully connected layer parameter matrices, where is the reduction rate. The weights are mapped to the interval; finally, the channel attention weights are applied to the original features through element-wise multiplication.
Self-attention mechanism. The self-attention mechanism focuses on capturing spatial dependencies within a modality, allowing features to attend to related regions within the same modality, providing richer contextual information for the spectral hierarchical perception architecture. For input feature , the calculation process of self-attention can be expressed as:
where, , , are query, key, and value matrices obtained through learnable parameter matrices , , ; is the feature dimension, serving as a scaling factor to avoid gradient vanishing problems.
Cross-modal attention mechanism. The cross-modal attention mechanism is used to capture complementary information between different modalities, establishing connections between visible and infrared features, and is the core component for achieving spectral information exchange. The unique aspect of cross-modal attention is that it uses the query from one modality to interact with the keys and values from another modality, thereby enabling information flow between modalities. For RGB and IR features, the calculation of cross-modal attention can be expressed as:
where, , , are the cross-modal attention calculation from RGB to IR; , , are the matrices for IR to RGB calculation; is a learnable scaling factor that controls the strength of cross-modal information fusion.
Finally, the outputs of self-attention and cross-modal attention are added to obtain the final enhanced features:
Through this design, the hybrid attention mechanism can simultaneously attend to channel importance, spatial dependency relationships, and modal complementary information, building a more comprehensive and robust feature representation.
3.2.2. Recursive Progressive Fusion Strategy
Multi-modal feature fusion is a key challenge in RGB-T object detection. Traditional multi-modal feature fusion methods typically enhance performance by stacking multiple Transformer blocks, but this approach leads to dramatic increases in parameter count and computational complexity. Inspired by the "review-consolidate" mechanism in human learning processes, this paper proposes a spectral hierarchical recursive progressive fusion strategy, achieving feature progressive refinement through repeatedly applying the same feature transformation operations, thereby enhancing fusion effects without increasing model parameters.
Parameter Cycling Reuse Structure. The core idea of the spectral hierarchical recursive progressive fusion strategy is to use the same set of parameters for multiple rounds of feature refinement. Each refinement builds on the results of the previous round, forming a continuous, progressive feature fusion process. This process can be expressed as:
where, and respectively represent the visible and infrared features after the round of cycling, represents the feature transformation function, is the reused model parameter.
Through multiple cycles, the feature representation ability is continuously enhanced:
where, represents applying the transformation function continuously times, and are the initial features.
Compared to traditional methods, the cyclic weight reuse structure significantly reduces the model parameter count, while achieving deep feature interaction through multiple refinements.This design not only improves the model's representation ability but also alleviates the risk of overfitting.
Spectral Feature Progressive Fusion. Spectral feature progressive fusion is the core characteristic of this strategy, progressively fusing different spectral domain features. This progressive fusion process operates in the spectral dimension, ensuring each spectral property is fully preserved and mutually enhanced. The fusion process includes the following key steps:
1. Spectral feature normalization: Normalization is performed separately on visible and infrared features, expressed as follows.
2. Hybrid attention calculation: Apply hybrid attention mechanism to process normalized features, expressed as follows, represents hybrid attention calculation.
3. Spectral residual connection: Combine attention outputs with original spectral features, expressed as follows.
4. Spectral feature enhancement: Further enhance each spectral feature through multilayer perceptron and residual connection, expressed as follows.
where, represents layer normalization operation, represents multilayer perceptron.
Progressive feature refinement process. The progressive feature refinement process can be viewed as a "feature distillation" mechanism, where each round of cycling makes the feature representation more pure and effective. In this research, we adopt a fixed 3-round cycling structure, a design based on extensive experimental validation.
The refinement process can be divided into three stages:
- First round of cycling: Initial fusion stage. Mainly captures basic intra-modal and inter-modal relationships, establishing initial feature interaction;
- Second round of cycling: Feature reinforcement stage. Based on the already established initial relationships, further strengthens important feature connections, suppressing noise and irrelevant information;
- Third round of cycling: Feature refinement stage. Performs final optimization and fine-tuning on features, forming high-quality fusion representations.
This three-round progressive refinement process can be expressed as:
The progressive refinement mechanism creates a "deep cascade" effect, achieving deep network feature representation capabilities within a fixed parameter space, which is fundamentally different from traditional "multi-layer stacking" approaches. Traditional methods require introducing new parameter sets for each additional layer, while our method achieves deeper effective network depth through parameter reuse while maintaining parameter efficiency.
Spectral Multi-scale Fusion Mechanism. The spectral multi-scale fusion mechanism is an important component of the recursive progressive fusion strategy, applying recursive progressive fusion on features of different scales to achieve comprehensive multi-scale feature optimization. This mechanism includes the following key designs:
- Multi-scale feature selection: The fusion strategy is applied separately on three scales—P3/8, P4/16, and P5/32—ensuring thorough fusion of features at all three scales;
- Inter-scale information flow: Information exchange between features of different scales is achieved through FPN and PAN structures;
The multi-scale fusion process can be expressed as:
where represents the feature scale index, and represents the feature transformation function for the s-th scale. By applying recursive progressive fusion across multiple scales, the system comprehensively enhances the representation capability of features at different scales, providing a solid foundation for detecting targets of various sizes.
3.3. Spectral Target Percpetion Enhancement Module (STPEM)
The STPEM module focuses on enhancing target regions in features while reducing background interference. Through mask generation and feature enhancement mechanisms, this module significantly improves the model's detection capability for small and low-contrast targets, providing more precise feature representation for object detection in complex environments.
3.3.1. Lightweight Mask Prediction
Lightweight mask prediction is the core component of STPEM. Given input feature , mask prediction first predicts target region masks through a lightweight convolutional network:
where represents the mask prediction network, and represents the sigmoid activation function. The mask prediction network adopts a two-layer convolutional structure:
The first layer is a 3×3 convolution that reduces the number of channels from C to C/2, followed by batch normalization and ReLU activation; the second layer is a 1×1 convolution that reduces the number of channels from C/2 to 1, outputting a single-channel mask. Finally, the sigmoid function maps values to the [0,1] range, representing the probability that each position contains a target.
The mask prediction network is essentially learning "what feature patterns might correspond to target regions." For example, in RGB images, targets typically have distinct edges and texture features; in infrared images, targets often appear as regions with significant temperature differences from the background. The mask prediction network captures these feature patterns through convolutional operations to generate masks representing potential target regions.
3.3.2. Similarity Calculation and Adjustment
After mask generation, the module calculates the cosine similarity between features and masks to evaluate the correlation between each feature channel and the target region, thereby establishing explicit associations between feature channels and potential target regions:
where the operation flattens the spatial dimensions of the features, the operation expands the mask to the same number of channels as the features, and calculates the cosine similarity between two vectors.
After calculating the similarity between each channel and the mask, further processing is done through averaging operations and a learnable adjustment layer:
where is a 1×1 convolutional layer for adjusting similarity, and is the sigmoid activation function. This learnable similarity adjustment mechanism enables the module to adaptively adjust similarity calculations according to different scenes, improving the flexibility and adaptability of the module.
3.3.3. Feature Enhancement Mechanism
Finally, the enhanced feature is achieved through similarity weighting:
The core idea of this weighting mechanism is: if a feature has high similarity with the predicted target region, it is preserved or enhanced; if the similarity is low, the feature is suppressed. In this way, features of target regions are effectively enhanced while features of background regions are suppressed, thereby improving the signal-to-noise ratio of the features.
The STPEM module significantly improves the performance of multispectral object detection by effectively identifying and enhancing potential target regions, showing excellent performance especially when processing complex background scenes.
4. Experiments
This section will detail the experimental results of SDRFPT-Net on the FLIR-aligned and LLVIP datasets, verifying the effectiveness of our proposed algorithm. First, we introduce the experimental setup and evaluation datasets; second, we compare SDRFPT-Net with current state-of-the-art multispectral object detection methods; finally, we analyze the contribution of each innovative module through comprehensive ablation experiments.
4.1. Datasets and Evaluation Metrics
4.1.1. Datasets
This study employs two widely used multispectral object detection benchmark datasets: FLIR-aligned [14] and LLVIP [15].
FLIR-aligend. FLIR-aligned. This dataset is an aligned version processed from the original FLIR ADAS dataset [43]. The original FLIR dataset contains approximately 10,000 manually annotated thermal infrared images and their corresponding visible light reference images, captured under different daytime and nighttime conditions. Due to alignment issues between visible and infrared image pairs in the original dataset, the FLIR-aligned dataset provides 4,129 training image pairs and 1,013 testing image pairs through manual selection and alignment processing, with all images precisely aligned spatially. The dataset contains three main object classes: person, car, and bicycle, with the distribution of object sizes and quantities shown in Figure 9(a). The advantage of the FLIR-aligned dataset lies in its scene diversity, including different environments such as urban roads, highways, and residential areas, as well as various weather and lighting conditions (day, night, dusk), making it particularly suitable for evaluating the robustness and generalization capability of multispectral object detection algorithms in real driving scenarios.
LLVIP. LLVIP is a visible-infrared paired dataset specifically designed for visual tasks in low-light conditions. The dataset contains 16,836 image pairs captured by a binocular camera (HIKVISION DS-2TD8166BJZFY-75H2F/V2) at 26 different locations during night time (6 PM to 10 PM). All image pairs are strictly aligned in time and space, and all images contain pedestrian targets with annotations, with the distribution of target sizes and quantities shown in Figure 9(b). The characteristic of the LLVIP dataset is that images are captured in low-light conditions, making targets difficult to identify in visible light images, while infrared images can clearly capture heat source targets (such as pedestrians). Images are registered through a semi-automatic method, ensuring that visible and infrared images have exactly the same field of view and image dimensions. The original images have high resolution, with visible light images at 1920×1080 and infrared images at 1280×720, uniformly processed to 1080×720.
4.1.2. Metrics
To comprehensively evaluate the performance of object detection models, this study adopts the following standard evaluation metrics:
Precision (P). Precision is a key metric for measuring detection accuracy, defined as the ratio of correctly detected targets (true positives) to all detected targets (true positives and false positives). This metric reflects the accuracy of model target recognition, calculated as follows:
Recall (R). Recall measures the model's ability to detect all targets, defined as the ratio of correctly detected targets (true positives) to all actually existing targets (true positives and false negatives). This metric reflects the completeness of the model's capture of all targets in the image, calculated as follows:
Mean Average Precision at IoU=0.50 (mAP50). Mean Average Precision at IoU=0.50 (mAP50): mAP50 is the average precision calculated at an Intersection over Union (IoU) threshold of 0.50. This metric primarily measures the model's performance on "simple" detection tasks, i.e., the detection accuracy when the overlap area between the predicted bounding box and the ground truth bounding box accounts for at least 50% of the total area.
Mean Average Precision across IoU=0.50:0.95 (mAP50-95). mAP50-95 is a more comprehensive evaluation metric that calculates the average precision at different IoU thresholds (from 0.50 to 0.95, with a step size of 0.05), and then takes the average of these values. Compared to mAP50, mAP50-95 better reflects the model's localization accuracy by considering a range of stricter IoU thresholds. A high mAP50-95 score indicates that the model can maintain good performance under stricter localization standards, which is particularly important for applications requiring high localization accuracy.
4.2. Experimental Setup
All experiments in this study were conducted on a server equipped with an NVIDIA RTX 4090 GPU (24GB memory) and an Intel Core i7-13700 processor (24 cores), with 62GB system memory. The experimental environment was based on Linux 20.04 operating system, PyTorch 2.0.1 deep learning framework, CUDA 11.7, cuDNN 8.7.0, and Python 3.9.21.
During the training process, we used the SGD optimizer with a momentum parameter of 0.937 and a weight decay coefficient of 0.0005. The initial learning rate was set to 0.01, and a cosine annealing strategy was adopted to reduce the learning rate to 0.01 times its initial value by the end. The batch size was fixed at 4, input image dimensions were uniformly adjusted to 640×640 pixels, and the maximum number of training epochs was 300. An early stopping strategy was also implemented—automatically terminating the training process when there was no performance improvement for 30 consecutive epochs.
4.3. Comparison with State-of-the-Art Methods
4.3.1. On the FLIR-aligned Dataset
Table 1 shows the comparison results of SDRFPT-Net with other state-of-the-art methods on the FLIR-aligned dataset. This dataset is widely used as a benchmark for evaluating the performance of multispectral object detection systems under various environmental conditions.
The experimental results show that the proposed SDRFPT-Net outperforms existing methods in all key metrics including precision, recall, and mAP. Compared to the best-performing single-modality method YOLOv10-infrared (with mAP50 of 0.727), SDRFPT-Net's mAP50 improved by 8.0% (from 0.727 to 0.785). This improvement demonstrates that our proposed multi-modal fusion strategy can effectively integrate complementary information from different spectral domains.
Compared to other multispectral fusion methods, SDRFPT-Net achieves precision (P) and recall (R) of 0.854 and 0.700 respectively, significantly outperforming other methods. Particularly in terms of mAP50, SDRFPT-Net (0.785) improved by 11.5% compared to the second-best performing BA-CAMF Net (0.704), demonstrating the superiority of our proposed spectral dual-stream recursive fusion perception architecture in multispectral object detection tasks.
Notably, under the more stringent mAP50:95 evaluation criterion, SDRFPT-Net achieves 0.426, comparable to the single-modality baseline YOLOv10-infrared (0.424), while significantly outperforming other multi-modal fusion methods (with the highest being BA-CAMF Net's 0.351). This indicates that SDRFPT-Net not only improves target detection rate but also maintains high-precision bounding box localization capability.
As shown in Figure 10, in complex lighting and occlusion conditions, SDRFPT-Net (j) can accurately detect all targets with more precise bounding boxes. In contrast, YOLOv10-add (g) has some missed detections on small targets, while TFDet (h) and CMAFF (i) have some false detections and inaccurate bounding box issues. These visualization results intuitively demonstrate the detection advantages of SDRFPT-Net in complex scenes.
4.3.2. On the LLVIP Dataset
Table 2 shows the comparison results of SDRFPT-Net with other state-of-the-art methods on the LLVIP dataset. The LLVIP dataset focuses on pedestrian detection in low-light environments and is an important benchmark for evaluating algorithm robustness in nighttime scenes.
As can be seen from Table 2, SDRFPT-Net also achieves excellent performance on the LLVIP dataset. In terms of mAP50, SDRFPT-Net reaches 0.963, showing a slight improvement (0.2%) compared to the closest-performing single-modality method YOLOv10-infrared and multi-modal method TFDet (both at 0.961). Although this improvement is modest, achieving further improvement at an already near-saturated performance level is still significant. Under the more stringent mAP50:95 evaluation criterion, SDRFPT-Net reaches 0.706, significantly outperforming all comparison methods. Compared to the second-best performing YOLOv8-infrared (0.645), it improves by 9.5%, indicating that the proposed method has significant advantages in precise bounding box localization. This result confirms that SDRFPT-Net can not only detect target locations but also more accurately describe target boundaries.
Notably, under the low-light conditions of the LLVIP dataset, the infrared modality alone can achieve high performance (e.g., YOLOv8-infrared achieves an mAP50 of 0.961). In this case, SDRFPT-Net still achieved performance improvements through effective integration of complementary information from visible light, especially with significant improvement in mAP50:95 (from 0.645 to 0.706). This indicates that the proposed spectral recursive fusion mechanism can still effectively extract and integrate valuable features from the visible light modality even when infrared information is dominant.
SDRFPT-Net's recall reaches 0.911, higher than all comparison methods, indicating it has stronger target detection capability and can find pedestrian targets that might be missed by other methods, which is particularly important for practical application scenarios.
Figure 11 provides visualized detection results of various methods in typical nighttime scenes from the LLVIP dataset. Qualitative analysis shows that SDRFPT-Net can accurately locate all pedestrian targets in low-contrast environments with high bounding box matching accuracy. In contrast, other multi-modal fusion methods such as YOLOv10-add, TFDet, and CMAFF show varying degrees of detection instability in complex scenes, including missed detections, false detections, or bounding box localization deviations. These visualization results further confirm the advantages of SDRFPT-Net demonstrated in the quantitative evaluation.
Figure 11 shows the visualization detection results of various algorithms on the LLVIP dataset. In typical nighttime low-light scenes, SDRFPT-Net (j) can accurately detect all pedestrians with more precise bounding boxes. In contrast, YOLOv10-add (g), TFDet (h), and CMAFF (i) exhibit missed detections or inaccurate bounding box issues in some complex scenes. These visualization results further confirm the detection advantages of SDRFPT-Net in low-light environments.
Combining the experimental results from both the FLIR-aligned and LLVIP datasets, SDRFPT-Net demonstrates powerful detection capability and robustness under various environmental conditions. This is attributed to the collaborative work of our three innovative modules: the spectral hierarchical perception architecture provides a solid foundation for multi-modal feature extraction; the spectral adaptive recursive fusion module achieves deep interaction and efficient fusion; and the spectral adaptive target perception enhancement module further improves target region feature representation. The organic combination of these three modules enables SDRFPT-Net to achieve excellent multispectral object detection performance while maintaining low computational complexity.
4.4. Ablation Studies
To verify the effectiveness of each innovative module in SDRFPT-Net, we conducted systematic ablation experiments on the FLIR-aligned dataset. These experiments aim to evaluate the contribution of each component to the overall performance of the network and validate the rationality of our proposed design scheme.
4.4.1. Baseline Model Comparison
First, we established a baseline model, then gradually added each core component to evaluate the contribution of each module. Table 3 shows the performance comparison of different component combinations.
From the results in Table 3, it is evident that each component we proposed contributes significantly to detection performance. The model based on the Spectral Hierarchical Perception Architecture (SHPA) (A1) achieves an mAP50 of 0.701. After adding the Spectral Adaptive Recursive Fusion Module (SRFM) (A2), the mAP50 increases to 0.775, a relative improvement of 10.6%. With the further addition of the Spectral Adaptive Target Perception Enhancement Module (STPEM) (A3), mAP50 and mAP50:95 reach 0.785 and 0.426 respectively, with mAP50:95 showing a particularly significant 14.2% relative improvement over A2, indicating that STPEM greatly enhances the model's localization accuracy under stricter detection standards.
4.4.2. Ablation Experiments on Hybrid Attention Mechanism
To evaluate the effectiveness of various attention mechanisms in the hybrid attention mechanism, we designed a series of comparative experiments, with results shown in Table 4.
The results show that different types of attention mechanisms have varying impacts on model performance. When used individually, the self-attention mechanism (B1) performs best with an mAP50 of 0.776 and mAP50:95 of 0.408, indicating that capturing spatial dependencies within modalities is critical for object detection. Although cross-modal attention (B2) and channel attention (B3) show slightly inferior performance when used alone, they provide feature enhancement capabilities in different dimensions.
In combinations of two attention mechanisms, the combination of self-attention and cross-modal attention (B4) performs best, with mAP50:95 reaching 0.424, approaching the performance of the complete model. The complete combination of three attention mechanisms (B7) achieves the best performance, confirming the rationality of the hybrid attention mechanism design, which can comprehensively capture the complex relationships in multi-modal data.
To gain a deeper understanding of the role of different attention mechanisms in multispectral object detection, we analyzed the visualization results of self-attention, cross-modal attention, and channel attention on the P3 feature layer.
From Figure 12, it can be observed that the feature maps of single attention mechanisms present different attention patterns:
- Self-attention mechanism (B1): Mainly focuses on target contours and edge information, effectively capturing spatial contextual relationships, with strong response to target boundaries, helping to improve localization accuracy;
- Cross-modal attention mechanism (B2): Presents overall attention to target areas, integrating complementary information from RGB and infrared modalities, but with relatively weak background suppression capability;
- Channel attention mechanism (B3): Demonstrates selective enhancement of specific semantic information, highlighting important feature channels, with strong response to specific parts of targets, improving the discriminability of feature representation.
Furthermore, we conducted a comparative analysis of the visualization effects of dual attention mechanisms versus the full attention mechanism on the P3 feature layer, as shown in Figure 13.
Through the visualization comparative analysis in Figure 13, we observe that the feature maps of dual attention mechanisms present complex and differentiated feature representations:
- Self-attention + Cross-modal attention (B4): The feature map simultaneously possesses excellent boundary localization capability and overall target region representation capability. The heatmap shows precise response to target regions with significant background suppression effect. This combination fully leverages the complementary advantages of self-attention in spatial modeling and cross-modal attention in multi-modal fusion, enabling it to reach 0.424 in mAP50:95, approaching the performance of the full attention mechanism.
- Self-attention + Channel attention (B5): The feature map enhances the representation of specific semantic features while preserving target boundary information. The heatmap shows strong response to key parts of targets, enabling the model to better distinguish different categories of targets, achieving 0.409 in mAP50:95, outperforming any single attention mechanism.
- Cross-modal attention + Channel attention (B6): The feature map enhances specific channel representation based on multi-modal fusion, but lacks the spatial context modeling capability of self-attention. The heatmap shows some response to target regions, but boundaries are not clear enough and background suppression effect is relatively weak, which explains its relatively lower performance.
Although dual attention mechanisms (especially self-attention + cross-modal attention) can improve feature representation capability to some extent, they cannot completely replace the comprehensive advantages of the full attention mechanism.
As shown in Figure 12 (d) and Figure 13(d), the full attention mechanism, through the synergistic effect of three attention mechanisms, shows the most precise and strong response to target regions in the heatmap, with clear boundaries and optimal background suppression effect, achieving an organic unification of spatial context modeling, multi-modal information fusion, and channel feature enhancement, obtaining optimal performance in multispectral object detection tasks.
Based on the above experiments and visualization analysis, we verified the effectiveness of the proposed hybrid attention mechanism. The results show that, despite the advantages of single and dual attention mechanisms, the complete combination of three attention mechanisms achieves optimal performance across all evaluation metrics. This confirms the rationality of our proposed "spatial-modal-channel" multi-dimensional attention framework, which creates an efficient synergistic mechanism through self-attention capturing spatial contextual relationships, cross-modal attention fusing complementary information, and channel attention selectively enhancing key features. This multi-dimensional feature enhancement strategy provides a new feature fusion paradigm for multispectral object detection, offering valuable reference for research in related fields.
4.4.3. Ablation Experiments on Spectral Hierarchical Recursive Progressive Fusion Strategy
To verify the effectiveness of the spectral fusion strategy, we conducted ablation experiments from two aspects: fusion position selection and recursive progression iterations.
Impact of introducing fusion positions. Multi-scale feature fusion is a key link in multispectral object detection, and effective fusion of features at different scales has a decisive impact on model performance. This section explores the impact of fusion positions and fusion strategies on detection performance through ablation experiments and visualization analysis.
To systematically study the impact of fusion positions on model performance, we designed a series of ablation experiments, as shown in Table 5. The experiments started from the baseline model (C1, using simple addition fusion at all scales), progressively applying our proposed innovative fusion modules (fusion mechanism combining SRFM and STPEM) at different scales, and finally evaluating the effect of comprehensive application of advanced fusion strategies.
As shown in Table 5, with the increase in application positions of innovative fusion modules, model performance progressively improves. The baseline model (C1) only uses simple addition fusion at all feature scales, with an mAP50 of 0.701. When applying SRFM and STPEM modules at the P3/8 scale (C2), performance significantly improves to an mAP50 of 0.769. With further application of advanced fusion at the P4/16 scale (C3), mAP50 increases to 0.776. Finally, when the complete fusion strategy is applied to all three scales (C4), performance reaches optimal levels with an mAP50 of 0.785 and mAP50:95 of 0.426.
To intuitively understand the effect differences between different fusion strategies, we visualized and compared feature maps of simple addition fusion and advanced fusion strategies (SRFM+STPEM) at three scales: P3/8, P4/16, and P5/32, as shown in Figure 14.
To gain a deeper understanding of the performance differences between different fusion strategies, we conducted systematic visualization comparisons at different scales (P3/8, P4/16, P5/32).
1. At the P3/8 scale, simple addition fusion presents dispersed activation patterns with insufficient target-background differentiation, especially with suboptimal activation intensity for small vehicles; whereas the feature map generated by the SRFM+STPEM fusion strategy possesses more precise target localization capability and boundary representation, with significantly improved background suppression effect and activation intensity distribution more concentrated on target regions, effectively enhancing small target detection performance.
2. The comparison of P4/16 scale feature maps shows that although simple addition fusion can capture medium target positions, activation is not prominent enough and background noise interference exists; in contrast, the advanced fusion strategy produces more concentrated activation areas with higher target-background contrast and clearer boundaries between vehicles. As an intermediate resolution feature map, P4 (40×40) demonstrates superior structured representation and background suppression capability under the advanced fusion strategy.
3. At the P5/32 scale, rough semantic information generated by simple addition fusion makes it difficult to distinguish main vehicle targets; whereas the advanced fusion strategy can better capture overall scene semantics, accurately represent main vehicle targets, and effectively suppress background interference. Although the P5 feature map has the lowest resolution (20×20), it has the largest receptive field, and the advanced fusion strategy fully leverages its advantages in large target detection and scene understanding.
Through comparative analysis, we observed three key synergistic effects of multi-scale fusion:
- Complementarity enhancement: the advanced fusion strategy makes features at different scales complementary, with P3 focusing on details and small targets, P4 processing medium targets, and P5 capturing large-scale structures and semantic information;
- Information flow optimization: features at different scales mutually enhance each other, with semantic information guiding small target detection and detail information precisely locating large target boundaries;
- Noise suppression capability: the advanced fusion strategy demonstrates superior background noise suppression capability at all scales, effectively reducing false detections.
Impact of recursive iteration count. The recursive progression mechanism is a key strategy in our proposed SDRFPT-Net model, which can further enhance feature representation capability through multiple recursive progressive fusions. To explore the optimal number of recursive iterations, we designed a series of experiments to observe model performance changes by varying the number of iterations. Table 6 shows the impact of iteration count on model performance.
The experimental results show that the number of recursive iterations significantly affects model performance. When the iteration count is 1 (D1), the model achieves an mAP50 of 0.769, indicating that even a single round of iteration can provide effective feature fusion. As the iteration count increases to 2 (D2) and 3 (D3), performance continues to improve, reaching mAP50 of 0.783 and 0.785, and mAP50:95 of 0.418 and 0.426 respectively. However, when the iteration count further increases to 4 (D4) and 5 (D5), performance begins to decline, with the mAP50 of 5 iterations significantly dropping to 0.761.
To more intuitively understand the impact of iteration count on feature representation, we conducted visualization analysis of feature maps at three feature scales—P3, P4, and P5—with different iteration counts, as shown in Figure 15.
Through visualization, we observed the following feature evolution patterns:
- P3 feature layer (high resolution): As the iteration count increases, the feature map gradually evolves from initial dispersed response (n=1) to more focused target representation (n=2,3), with clearer boundaries and stronger background suppression effect. However, when the iteration count reaches 4 and 5, over-smoothing phenomena begin to appear, with some loss of boundary details.
- P4 feature layer (medium resolution): At n=1, the feature map has basic response to targets but is not focused enough. After 2-3 rounds of iteration, the activation intensity of target areas significantly increases, improving target differentiation. Continuing to increase the iteration count to 4-5 rounds, feature response begins to diffuse, reducing precise localization capability.
- P5 feature layer (low resolution): This layer demonstrates the most obvious evolution trend, gradually developing from blurred response at n=1 to highly structured representation at n=3 that can clearly distinguish main targets. However, obvious signs of overfitting appear at n=4 and n=5, with feature maps becoming overly smoothed and target representation degrading.
These observations reveal the working mechanism of recursive progressive fusion: moderate iteration count (n=3) can achieve progressive optimization of features through multiple rounds of interactive fusion of complementary information from different modalities, enhancing target feature representation and suppressing background interference. However, excessive iteration count may lead to "over-fusion" of features, i.e., the model overfits specific patterns in the training data, losing generalization capability.
Combining quantitative and visualization analysis results, we determined n=3 as the optimal iteration count, achieving the best balance between feature enhancement and computational efficiency. This finding is also consistent with similar observations in other research areas, such as the optimal unfolding steps in recurrent neural networks and the optimal iteration count in message passing neural networks, where similar "performance saturation points" exist.
Through the above ablation experiments, we verified the effectiveness and optimal configuration of each core component of SDRFPT-Net. The results show that the spectral hierarchical perception architecture (SHPA), the complete combination of three attention mechanisms, the full-scale advanced fusion strategy, and three rounds of recursive progressive fusion collectively contribute to the model's superior performance. The rationality of these design choices is not only validated through quantitative metrics but also intuitively explained through feature visualization, providing new ideas for multispectral object detection research.
5. Discussion
Based on the above experimental results, the proposed SDRFPT-Net demonstrates significant advantages in the field of multispectral object detection. First, the spectral dual-stream recursive fusion architecture achieves efficient integration of visible and infrared information, confirming the effectiveness of the deep interaction design concept. Compared to traditional fusion methods, the hybrid attention mechanism in the SRFM module is particularly suitable for processing multi-modal features in complex environments, capable of adaptively adjusting the weights of each modality according to different scene conditions. For example, in low-light conditions, the system enhances the contribution of the infrared modality; while in well-lit conditions with complex background interference, it relies more on the rich texture information of the visible light modality. This adaptive fusion mechanism is key to the model's excellent performance in various challenging environments.
Despite SDRFPT-Net's excellent performance, several limitations are worth discussing. First, although the recursive progressive fusion strategy improves feature interaction depth, the optimal design of three iterations also reflects that too many iterations may lead to over-fusion of features, which actually harms performance. Second, the current model still has room for improvement in processing distant small targets, especially under adverse weather conditions. Additionally, deploying the model on edge devices still faces certain challenges. Future work could consider further optimizing the network structure, while exploring the integration of temporal information into the model to improve adaptability to dynamic scenes.
6. Conclusions
This paper presents SDRFPT-Net (Spectral Dual-stream Recursive Fusion Perception Target Network), a novel architecture for multispectral object detection that effectively integrates visible and infrared modalities through three innovative modules. First, the Spectral Hierarchical Perception Architecture (SHPA) based on YOLOv10 employs a dual-stream structure to extract modality-specific features. Second, the Spectral Recursive Fusion Module (SRFM) achieves deep cross-modal feature interaction through a hybrid attention mechanism and recursive fusion strategy. Finally, the Spectral Target Perception Enhancement Module (STPEM) enhances target region representation and suppresses background interference through lightweight mask prediction.
Extensive experiments on the FLIR-aligned and LLVIP datasets demonstrate that SDRFPT-Net outperforms existing methods across all key metrics. On the FLIR-aligned dataset, our model achieves 0.785 mAP50 and 0.426 mAP50:95, surpassing the second-best BA-CAMF Net by 11.5%. On the LLVIP dataset, it reaches 0.963 mAP50 and 0.706 mAP50:95, significantly outperforming all comparison methods.
Through comprehensive ablation studies, we validated the effectiveness and optimal configuration of each innovative module. Results indicate that the complete hybrid attention mechanism (combining self-attention, cross-modal attention, and channel attention), full-scale advanced fusion strategy, and three iterations of recursive progressive fusion collectively contribute to the model's superior performance. Notably, the recursive progressive fusion mechanism achieves an optimal performance balance at three iterations, creating a "deep cascade" effect that enables deep network representation capabilities within a fixed parameter space.
Despite SDRFPT-Net's excellent performance, several limitations warrant discussion. Although the recursive progressive fusion strategy enhances feature interaction depth, the optimal design of three iterations also reflects that excessive iterations may lead to feature "over-fusion," which actually impairs performance. Additionally, the current model still has room for improvement in processing distant small targets, particularly under adverse weather conditions. Furthermore, deploying the model on edge devices continues to face certain challenges.
Future work could consider further optimizing the network structure while exploring the integration of temporal information to improve adaptability to dynamic scenes. Meanwhile, we will focus on enhancing model robustness in complex environments and reducing computational complexity to meet various requirements in practical applications. Overall, SDRFPT-Net offers a promising solution for multispectral object detection in applications such as autonomous driving, security surveillance, and remote sensing analysis.
Author Contributions
Conceptualization, P.Z. and X.S.; methodology, P.Z. and B.S.; validation, X.S., B.S. and R.G.; formal analysis, P.Z.; investigation, P.Z. and X.S.; resources, P.Z.; data curation, B.S.; software implementation, P.Z.; writing—original draft preparation, P.Z.; writing—review and editing, X.S.; visualization, P.Z. and Z.D.; supervision, X.S. and S.S.; project administration, X.S. P.Z. was responsible for the primary algorithm design and experimental implementation. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Hunan Provincial Postgraduate Research Innovation Programme, grant number XJZH2024033.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to the relevance of data to individual privacy.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object Detection in Optical Remote Sensing Images: A Survey and a New Benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schutz, C.; Rosenbaum, L.; Hertlein, H.; Glaser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, B.Y.; Lam, W.H.K.; Ho, H.W.; Shi, X.; Yang, X.; Ma, W.; Wong, S.C.; Chow, A.H.F. Vehicle Re-Identification for Lane-Level Travel Time Estimations on Congested Urban Road Networks Using Video Images. IEEE Trans. Intell. Transp. Syst. 2022, 23, 12877–12893. [Google Scholar] [CrossRef]
- Zhang, T.; Wu, H.; Liu, Y.; Peng, L.; Yang, C.; Peng, Z. Infrared Small Target Detection Based on Non-Convex Optimization with Lp-Norm Constraint. Remote Sens. 2019, 11, 559. [Google Scholar] [CrossRef]
- Pang, S.; Ge, J.; Hu, L.; Guo, K.; Zheng, Y.; Zheng, C.; Zhang, W.; Liang, J. RTV-SIFT: Harnessing Structure Information for Robust Optical and SAR Image Registration. Remote Sensing 2023, 15, 4476. [Google Scholar] [CrossRef]
- Xu, Q.; Mei, Y.; Liu, J.; Li, C. Multimodal cross-layer bilinear pooling for RGBT tracking. IEEE Trans. Multimedia 2022, 24, 567–580. [Google Scholar] [CrossRef]
- Zhou, W.; Zhu, Y.; Lei, J.; Wan, J.; Yu, L. CCAFNet: Crossflow and Cross-Scale Adaptive Fusion Network for Detecting Salient Objects in RGB-D Images. IEEE Trans. Multimedia 2022, 24, 2192–2204. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); IEEE: Las Vegas, NV, USA, June, 2016; pp. 779–788. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. Arxiv Prepr. Arxiv:2004,10934.
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 Ieee/cvf Conference on Computer Vision and Pattern Recognition (cvpr); IEEE: Vancouver, BC, Canada, June, 2023; pp. 7464–7475. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, H.; He, Y.; Wang, X.; Yang, W. Illumination-Guided RGBT Object Detection with Inter- and Intra-Modality Fusion. IEEE Trans. Instrum. Meas. 2023, Vol.72, 1–13. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Z.; Zhang, S.; Yang, X.; Qiao, H.; Huang, K.; Hussain, A. Cross-Modality Interactive Attention Network for Multispectral Pedestrian Detection. Information Fusion 2019, 50, 20–29. [Google Scholar] [CrossRef]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Multispectral Fusion for Object Detection with Cyclic Fuse-and-Refine Blocks 2020.
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Liu, S.; Zhou, W. LLVIP: A Visible-Infrared Paired Dataset for Low-Light Vision 2023.
- Zhi-she, W.; Feng-bao, Y.; Zhi-hao, P.; Lei, C.; Li-e, J. Multi-sensor image enhanced fusion algorithm based on NSST and top-hat transformation. Optik 2015, 126, 4184–4190. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, Y.; Blum, R.S.; Han, J.; Tao, D. Sparse representation based multi-sensor image fusion for multi-focus and multi-modality images: a review. Inf. Fusion 2018, 40, 57–75. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and Visible Image Fusion Based on Visual Saliency Map and Weighted Least Square Optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Kittler, J. MDLatLRR: A Novel Decomposition Method for Infrared and Visible Image Fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral Deep Neural Networks for Pedestrian Detection 2016.
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral Pedestrian Detection Using Deep Fusion Convolutional Neural Networks. Comput. Intell. 2016. [Google Scholar]
- Konig, D.; Adam, M.; Jarvers, C.; Layher, G.; Neumann, H.; Teutsch, M. Fully Convolutional Region Proposal Networks for Multispectral Person Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); IEEE: Honolulu, HI, USA, July, 2017; pp. 243–250. [Google Scholar]
- Song, K.; Bao, Y.; Wang, H.; Huang, L.; Yan, Y. A Potential Vision-Based Measurements Technology: Information Flow Fusion Detection Method Using RGB-Thermal Infrared Images. IEEE Trans. Instrum. Meas. 2023, 72, 1–13. [Google Scholar] [CrossRef]
- Feng, Z.; Lai, J.; Xie, X. Learning Modality-Specific Representations for Visible-Infrared Person Re-Identification. IEEE Trans. Image Process. 2020, 29, 579–590. [Google Scholar] [CrossRef]
- Qingyun, F.; Dapeng, H.; Zhaokui, W. Cross-modality fusion transformer for multispectral object detection 2022.
- Chen, Y.-T.; Shi, J.; Ye, Z.; Mertz, C.; Ramanan, D.; Kong, S. Multimodal object detection via probabilistic ensembling 2022.
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image Fusion Meets Deep Learning: A Survey and Perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Fu, Y.; Wu, X.-J.; Durrani, T. Image Fusion Based on Generative Adversarial Network Consistent with Perception. Inf. Fusion 2021, 72, 110–125. [Google Scholar] [CrossRef]
- Li, J.; Huo, H.; Li, C.; Wang, R.; Sui, C.; Liu, Z. Multigrained Attention Network for Infrared and Visible Image Fusion. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Y.; Wang, J.; Xu, J.; Shao, W. Res2Fusion: Infrared and Visible Image Fusion Based on Dense Res2net and Double Nonlocal Attention Models. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, J.; Wang, T.; Jiang, R. Hierarchical Feature Fusion with Mixed Convolution Attention for Single Image Dehazing. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 510–522. [Google Scholar] [CrossRef]
- Li, J.; Huo, H.; Li, C.; Wang, R.; Feng, Q. AttentionFGAN: Infrared and Visible Image Fusion Using Attention-Based Generative Adversarial Networks. IEEE Trans. Multimedia 2021, 23, 1383–1396. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: better, faster, stronger 2016.
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: real-time end-to-end object detection 2024.
- Redmon, J.; Farhadi, A. YOLOv3: an incremental improvement 2018.
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection 2020.
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications 2022.
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021 2021.
- Zheng, Y.; Izzat, I.H.; Ziaee, S. GFD-SSD: gated fusion double SSD for multispectral pedestrian detection.
- Wang, C.-Y.; Mark Liao, H.-Y.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW); IEEE: Seattle, WA, USA, June, 2020; pp. 1571–1580. [Google Scholar]
- Cao, Z.; Yang, H.; Zhao, J.; Guo, S.; Li, L. Attention fusion for one-stage multispectral pedestrian detection. Sens. 2021, 21, 4184. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Chen, Y.; Shao, W.; Li, H.; Zhang, L. SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Flir, T. Free FLIR Thermal Dataset for Algorithm Training 2018.
Figure 1.
Comparison of multispectral object detection advantages under different lighting conditions. The figure shows detection results for visible (top row) and infrared (bottom row) imaging in daytime (left two columns) and nighttime (right two columns) scenes. Red bounding boxes indicate cars, blue boxes indicate persons, and green boxes indicate bicycles. It clearly demonstrates that visible images (top-left) provide richer color and texture information for better detection in daylight, while infrared images (bottom-right) provide clearer object contours by capturing thermal radiation, showing significant advantages in low-light conditions. This complementarity proves the necessity of multispectral fusion for all-weather object detection, especially in complex and variable environmental conditions.
Figure 1.
Comparison of multispectral object detection advantages under different lighting conditions. The figure shows detection results for visible (top row) and infrared (bottom row) imaging in daytime (left two columns) and nighttime (right two columns) scenes. Red bounding boxes indicate cars, blue boxes indicate persons, and green boxes indicate bicycles. It clearly demonstrates that visible images (top-left) provide richer color and texture information for better detection in daylight, while infrared images (bottom-right) provide clearer object contours by capturing thermal radiation, showing significant advantages in low-light conditions. This complementarity proves the necessity of multispectral fusion for all-weather object detection, especially in complex and variable environmental conditions.

Figure 2.
Overall architecture of SDRFPT-Net (Spectral Dual-stream Recursive Fusion Perception Target Network). The architecture employs a dual-stream design with parallel processing paths for visible and infrared input images. The network consists of three key innovative modules: Spectral Hierarchical Perception Architecture (SHPA) for extracting modality-specific features, Spectral Recursive Fusion Module (SRFM) for deep cross-modal feature interaction, and Spectral Target Perception Enhancement Module (STPEM) for enhancing target region representation and suppressing background interference. The feature pyramid and detection head (V10 Detect) enable multi-scale object detection.
Figure 2.
Overall architecture of SDRFPT-Net (Spectral Dual-stream Recursive Fusion Perception Target Network). The architecture employs a dual-stream design with parallel processing paths for visible and infrared input images. The network consists of three key innovative modules: Spectral Hierarchical Perception Architecture (SHPA) for extracting modality-specific features, Spectral Recursive Fusion Module (SRFM) for deep cross-modal feature interaction, and Spectral Target Perception Enhancement Module (STPEM) for enhancing target region representation and suppressing background interference. The feature pyramid and detection head (V10 Detect) enable multi-scale object detection.
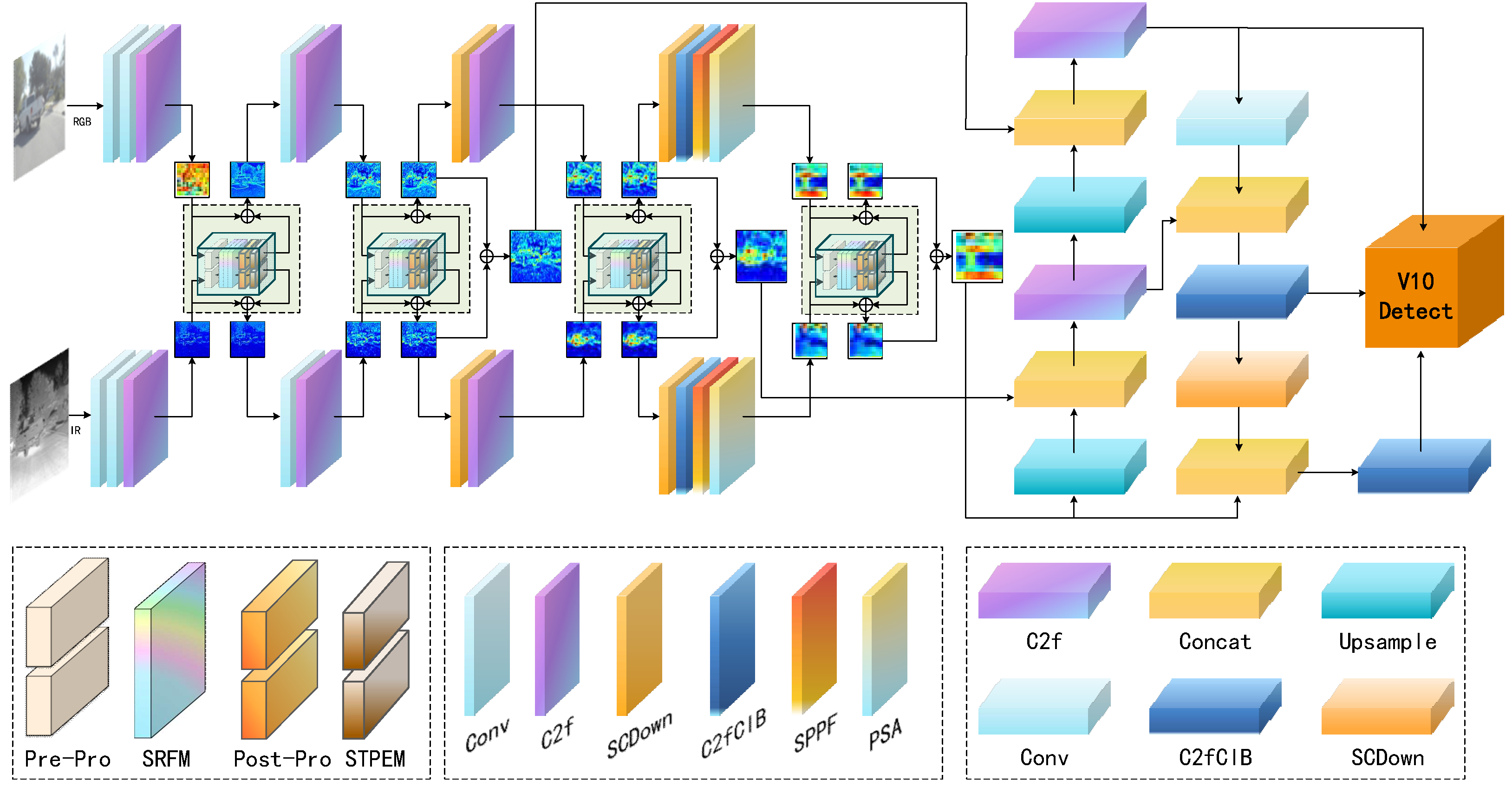
Figure 3.
Dual-stream separated spectral architecture design in SDRFPT-Net. The architecture expands a single feature extraction network into a dual-stream structure, where the upper stream processes visible spectral information while the lower stream handles infrared spectral information. Although both processing paths share similar network structures, they employ independent parameter sets for optimization, allowing each stream to specifically learn the feature distribution and representation of its respective modality.
Figure 3.
Dual-stream separated spectral architecture design in SDRFPT-Net. The architecture expands a single feature extraction network into a dual-stream structure, where the upper stream processes visible spectral information while the lower stream handles infrared spectral information. Although both processing paths share similar network structures, they employ independent parameter sets for optimization, allowing each stream to specifically learn the feature distribution and representation of its respective modality.
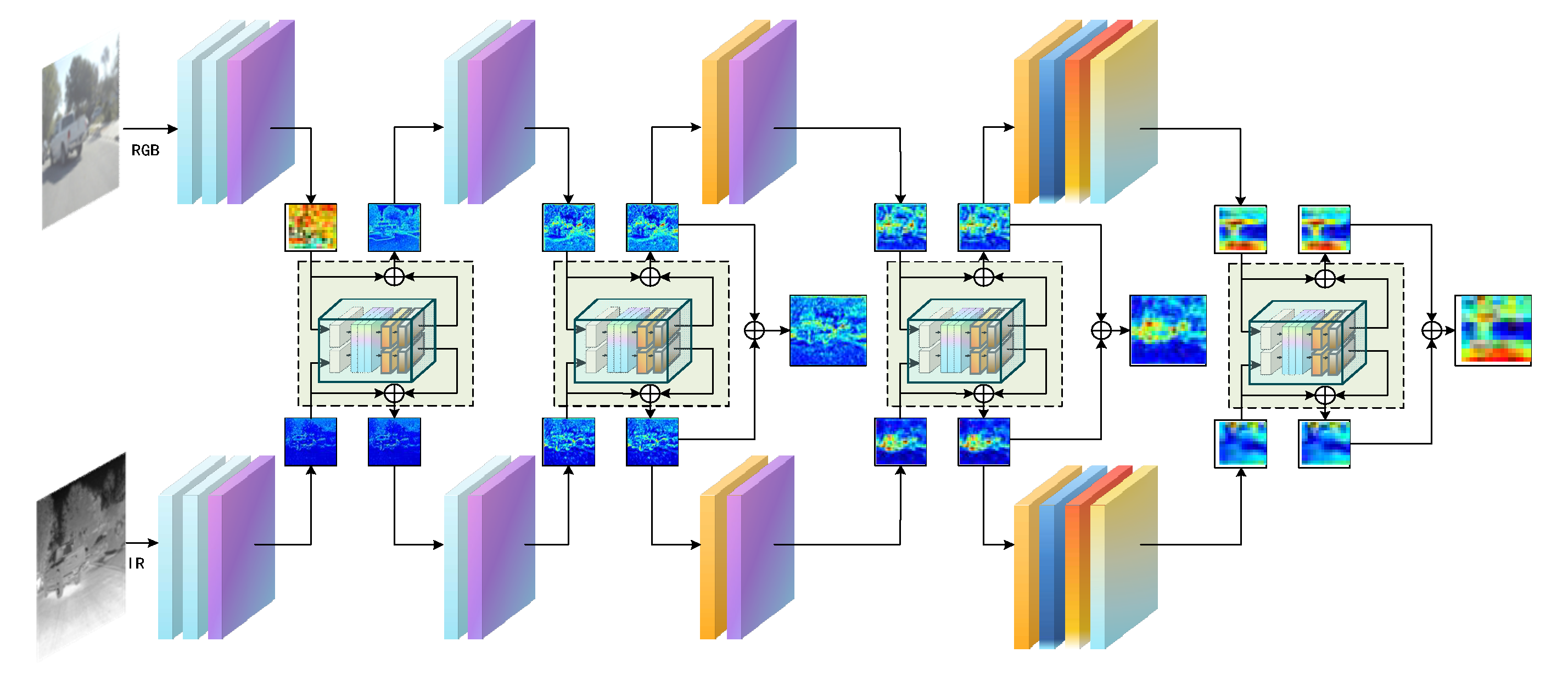
Figure 4.
Multi-scale fusion feature aggregation and detection process in SDRFPT-Net. The figure shows features from three different scales (P3, P4, P5) that already contain fused information from visible and infrared modalities. The middle section presents two complementary information flow networks: Feature Pyramid Network (FPN) and Path Aggregation Network (PAN). FPN (light blue background) follows a top-down path, transferring high-level semantic information to low-level features, while PAN (light pink background) follows a bottom-up path, transferring low-level spatial details to high-level features. This bidirectional feature flow mechanism ensures that features at each scale incorporate both fine spatial localization information and rich semantic representation.
Figure 4.
Multi-scale fusion feature aggregation and detection process in SDRFPT-Net. The figure shows features from three different scales (P3, P4, P5) that already contain fused information from visible and infrared modalities. The middle section presents two complementary information flow networks: Feature Pyramid Network (FPN) and Path Aggregation Network (PAN). FPN (light blue background) follows a top-down path, transferring high-level semantic information to low-level features, while PAN (light pink background) follows a bottom-up path, transferring low-level spatial details to high-level features. This bidirectional feature flow mechanism ensures that features at each scale incorporate both fine spatial localization information and rich semantic representation.
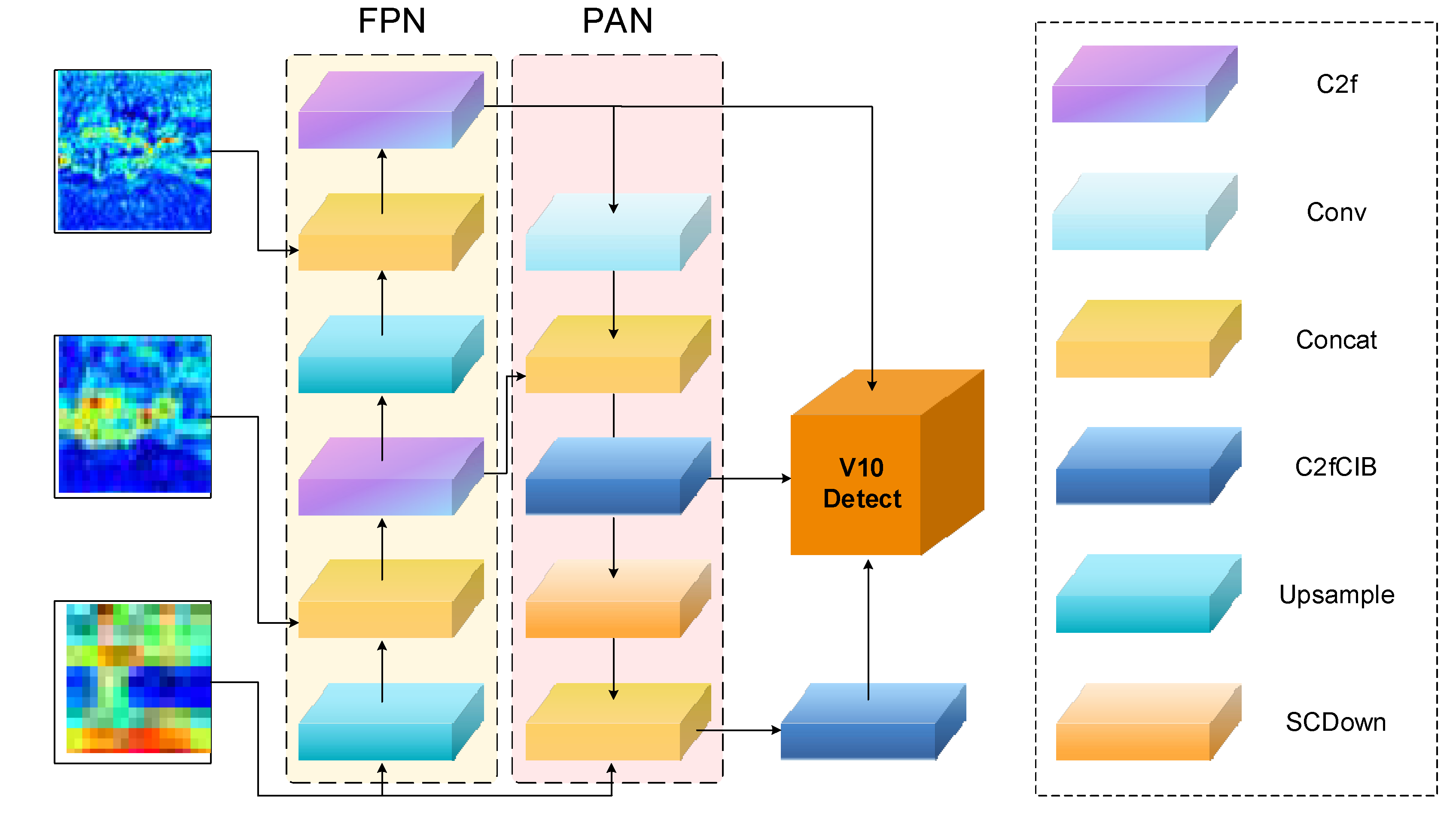
Figure 5.
Detailed architecture of the Spectral Recursive Fusion Module (SRFM). The framework is divided into two main parts: the upper light blue background area shows the overall recursive fusion process, labeled as 'SARFM n=3', indicating a three-round recursive fusion strategy. This part receives RGB and IR dual-stream features from SHPA and processes them through three cascaded hybrid attention units with parameter sharing to improve computational efficiency. The lower part shows the detailed internal structure of the hybrid attention unit, including preprocessing components (PrePro) such as AvgPool, Flatten, and Position Encoding; the hybrid attention mechanism implementation including Channel Attention, Self Attention, and Cross Attention; and the MLP module with Linear layers, GELU activation, and Dropout.
Figure 5.
Detailed architecture of the Spectral Recursive Fusion Module (SRFM). The framework is divided into two main parts: the upper light blue background area shows the overall recursive fusion process, labeled as 'SARFM n=3', indicating a three-round recursive fusion strategy. This part receives RGB and IR dual-stream features from SHPA and processes them through three cascaded hybrid attention units with parameter sharing to improve computational efficiency. The lower part shows the detailed internal structure of the hybrid attention unit, including preprocessing components (PrePro) such as AvgPool, Flatten, and Position Encoding; the hybrid attention mechanism implementation including Channel Attention, Self Attention, and Cross Attention; and the MLP module with Linear layers, GELU activation, and Dropout.
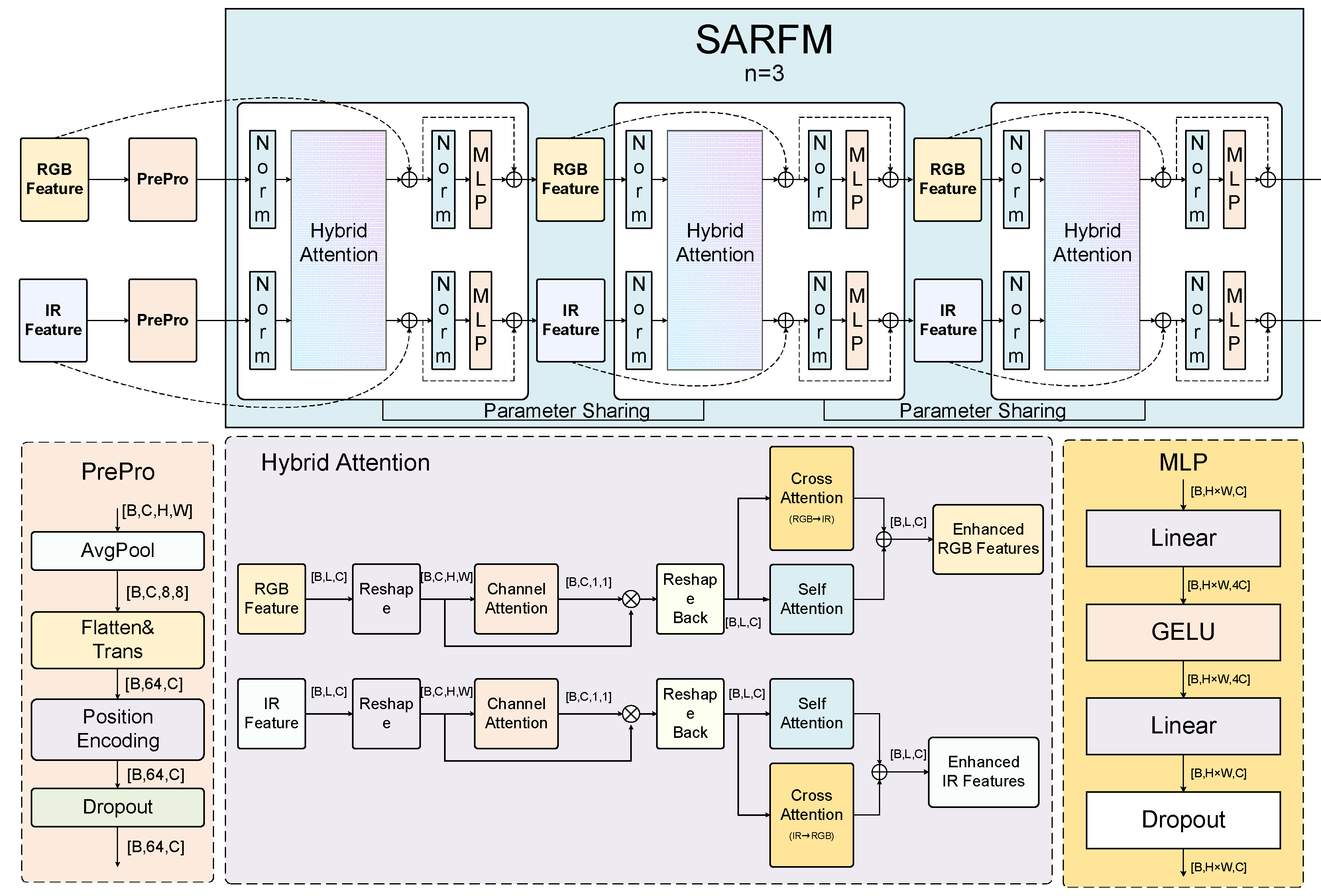
Figure 6.
Detailed structure of the hybrid attention mechanism in SDRFPT-Net. The mechanism integrates three complementary attention computation methods to achieve multi-dimensional feature enhancement. The upper part shows the overall processing flow: RGB and IR features first undergo reshaping and enter the Channel Attention module, which focuses on learning the importance weights of different feature channels. After reshaping back, the features simultaneously enter both Self Attention and Cross Attention modules, capturing intra-modal spatial dependencies and inter-modal complementary information. Finally, the outputs from both attention modules are added to generate enhanced RGB and IR feature representations.
Figure 6.
Detailed structure of the hybrid attention mechanism in SDRFPT-Net. The mechanism integrates three complementary attention computation methods to achieve multi-dimensional feature enhancement. The upper part shows the overall processing flow: RGB and IR features first undergo reshaping and enter the Channel Attention module, which focuses on learning the importance weights of different feature channels. After reshaping back, the features simultaneously enter both Self Attention and Cross Attention modules, capturing intra-modal spatial dependencies and inter-modal complementary information. Finally, the outputs from both attention modules are added to generate enhanced RGB and IR feature representations.
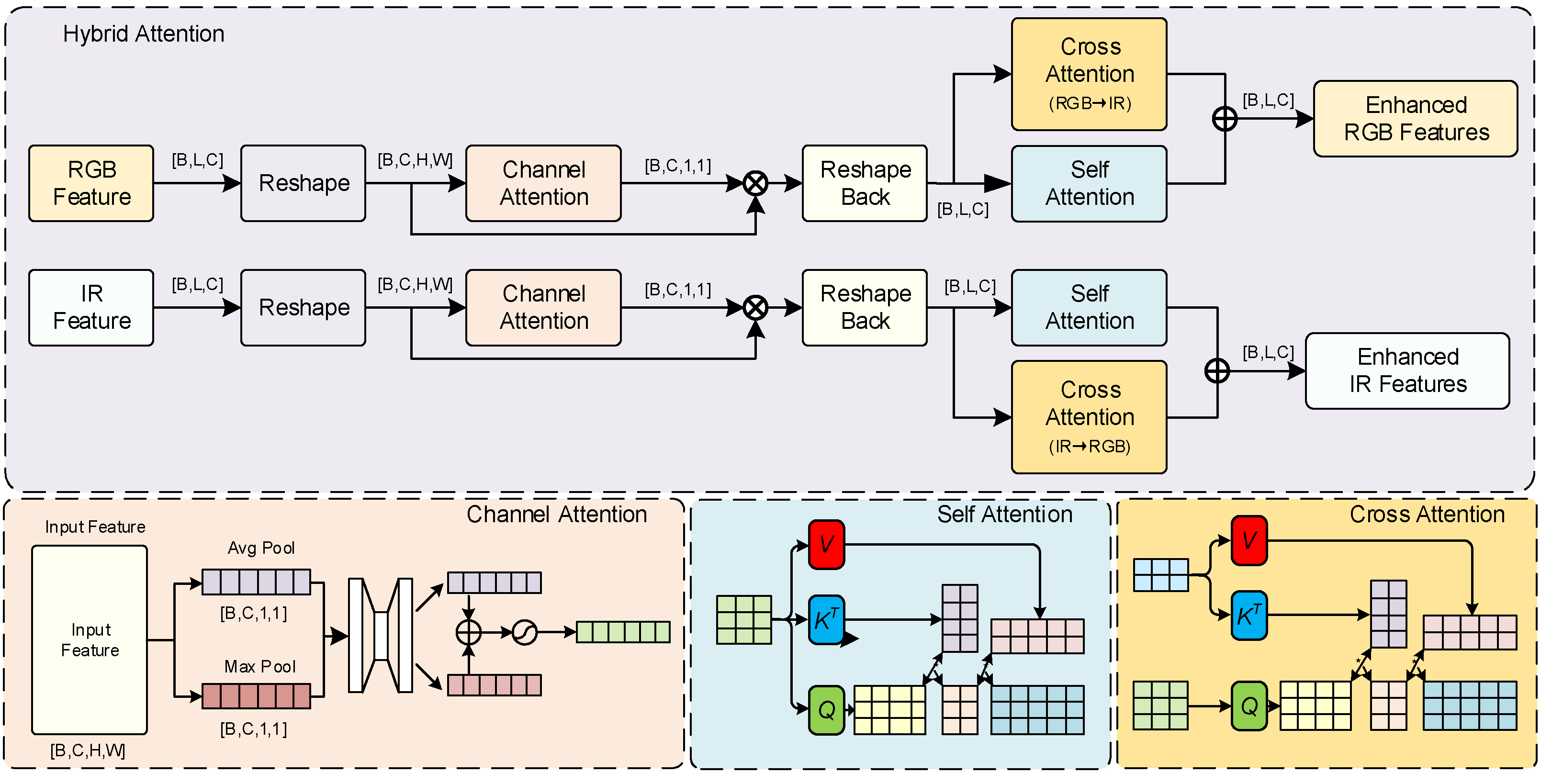
Figure 7.
Spectral recursive progressive fusion architecture in SDRFPT-Net. The light blue background area (labeled as 'SARFM n=3') shows the parameter-sharing three-round recursive fusion process. The left side includes RGB and IR input features after preprocessing (PrePro), which flow through three cascaded hybrid attention units. The key innovation is that these three processing units share the exact same parameter set (indicated by 'Parameter Sharing' connections), achieving deep recursive structure without increasing model complexity. Each processing unit contains normalization (Norm) components and MLP modules, forming a complete feature refinement path.
Figure 7.
Spectral recursive progressive fusion architecture in SDRFPT-Net. The light blue background area (labeled as 'SARFM n=3') shows the parameter-sharing three-round recursive fusion process. The left side includes RGB and IR input features after preprocessing (PrePro), which flow through three cascaded hybrid attention units. The key innovation is that these three processing units share the exact same parameter set (indicated by 'Parameter Sharing' connections), achieving deep recursive structure without increasing model complexity. Each processing unit contains normalization (Norm) components and MLP modules, forming a complete feature refinement path.
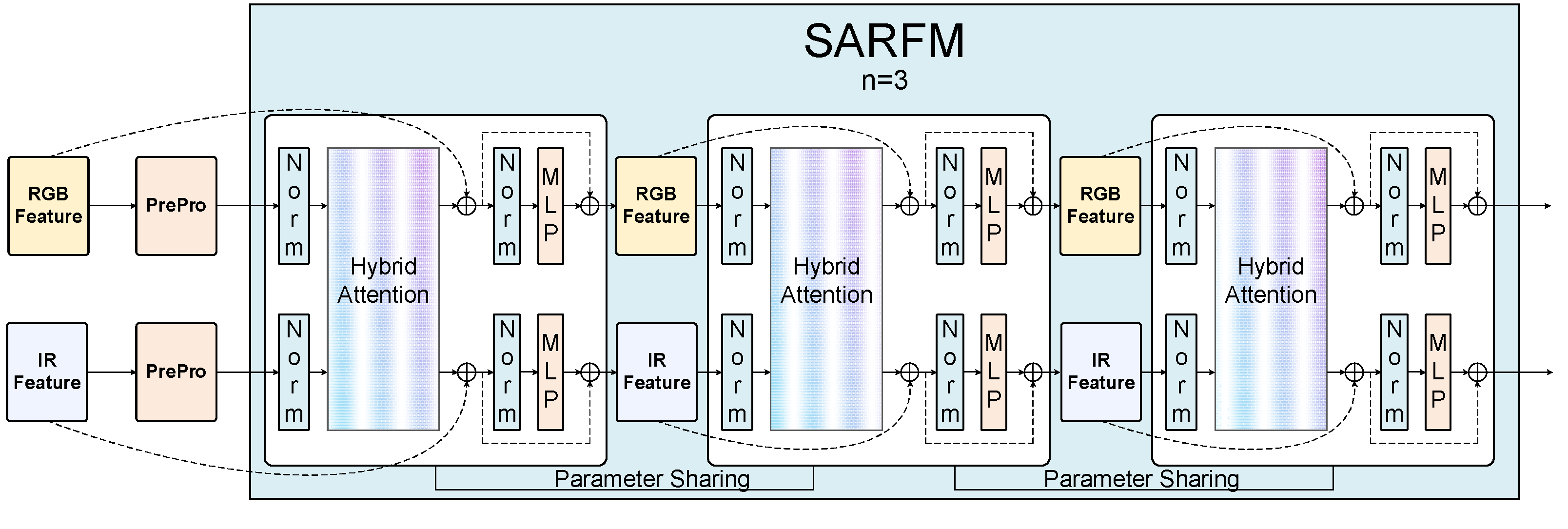
Figure 8.
Spectral Target Perception Enhancement Module (STPEM) structure and data flow. The module aims to enhance target region representation while suppressing background interference to improve detection accuracy. The figure is divided into three main parts: the upper and middle parts show parallel processing paths for features from RGB and IR modalities. Both feature paths first go through post-processing (PostPro) modules, including feature normalization, reshaping, and upsampling, before entering the STPEM module for enhancement processing.
Figure 8.
Spectral Target Perception Enhancement Module (STPEM) structure and data flow. The module aims to enhance target region representation while suppressing background interference to improve detection accuracy. The figure is divided into three main parts: the upper and middle parts show parallel processing paths for features from RGB and IR modalities. Both feature paths first go through post-processing (PostPro) modules, including feature normalization, reshaping, and upsampling, before entering the STPEM module for enhancement processing.
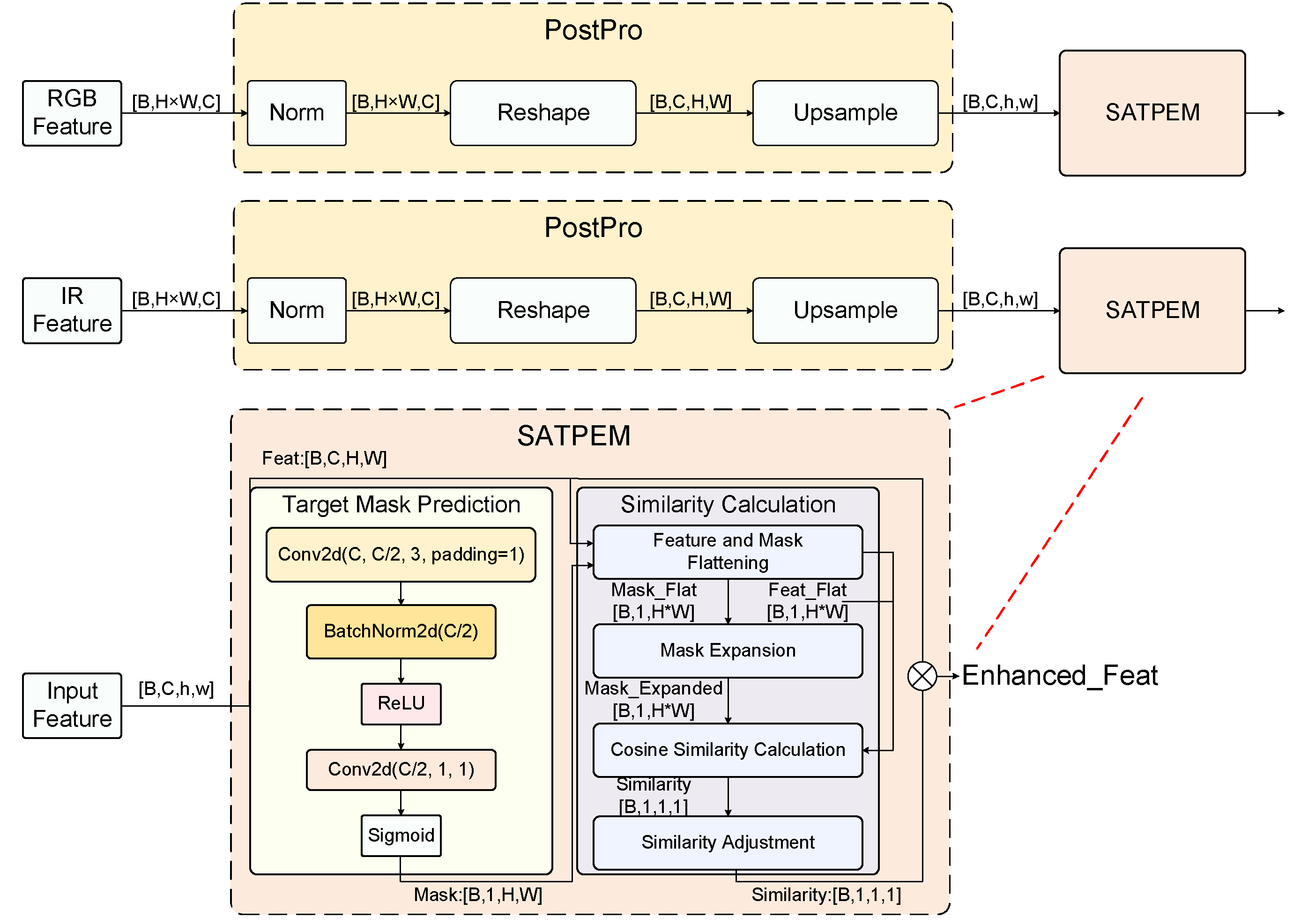
Figure 9.
Object size distribution characteristics in multispectral detection datasets. (a) FLIR-aligned dataset showing three object classes (blue: person, purple: car, orange: bicycle), where pedestrians exhibit slender features (width<100px, height<300px) and cars have wider distribution (width 50-300px, height 50-200px); (b) LLVIP dataset showing pedestrian size distribution with highly clustered characteristics (width 20-80px, height 40-150px), forming a high-density region. The density curves at the top and right of both figures show the statistical distribution of width and height, providing important reference for network design.
Figure 9.
Object size distribution characteristics in multispectral detection datasets. (a) FLIR-aligned dataset showing three object classes (blue: person, purple: car, orange: bicycle), where pedestrians exhibit slender features (width<100px, height<300px) and cars have wider distribution (width 50-300px, height 50-200px); (b) LLVIP dataset showing pedestrian size distribution with highly clustered characteristics (width 20-80px, height 40-150px), forming a high-density region. The density curves at the top and right of both figures show the statistical distribution of width and height, providing important reference for network design.
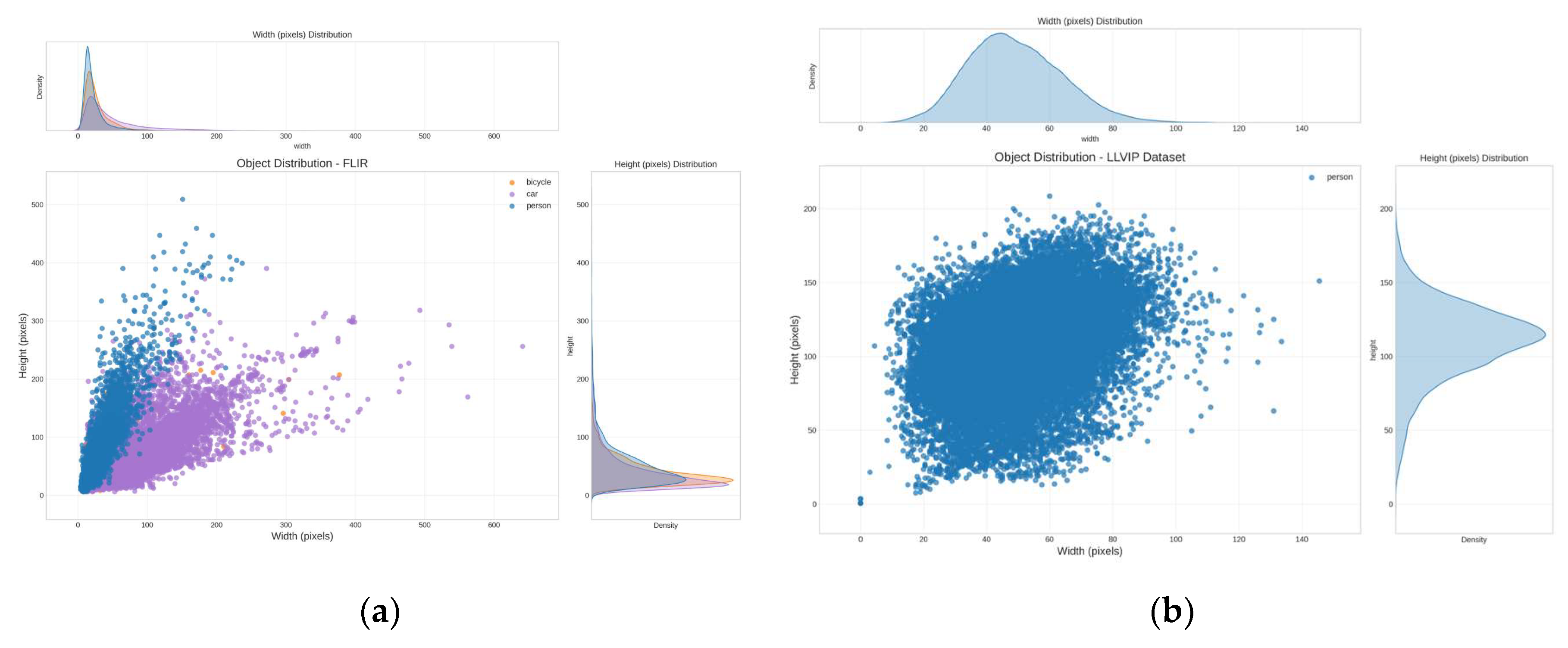
Figure 10.
Comparison of detection performance for different multispectral object detection models on various scenarios in the FLIR-aligned dataset. Images are organized by columns from left to right: Ground Truth (GT), YOLOv10-add, TFDet, CMAFF, and our proposed SDRFPT-Net model. Each row shows typical scenarios with different environmental conditions and object distributions, including close-range vehicles, multiple roadway targets, parking areas, narrow streets, and open roads. The visualization results clearly demonstrate the advantages of SDRFPT-Net: in the first row's close-range vehicle scene, SDRFPT-Net's bounding boxes almost perfectly match GT; in the second row's complex multi-target scene, it successfully detects all pedestrians and bicycles without obvious misses; in the third row's parking lot scene, it accurately identifies multiple closely parked vehicles with precise bounding box localization.
Figure 10.
Comparison of detection performance for different multispectral object detection models on various scenarios in the FLIR-aligned dataset. Images are organized by columns from left to right: Ground Truth (GT), YOLOv10-add, TFDet, CMAFF, and our proposed SDRFPT-Net model. Each row shows typical scenarios with different environmental conditions and object distributions, including close-range vehicles, multiple roadway targets, parking areas, narrow streets, and open roads. The visualization results clearly demonstrate the advantages of SDRFPT-Net: in the first row's close-range vehicle scene, SDRFPT-Net's bounding boxes almost perfectly match GT; in the second row's complex multi-target scene, it successfully detects all pedestrians and bicycles without obvious misses; in the third row's parking lot scene, it accurately identifies multiple closely parked vehicles with precise bounding box localization.
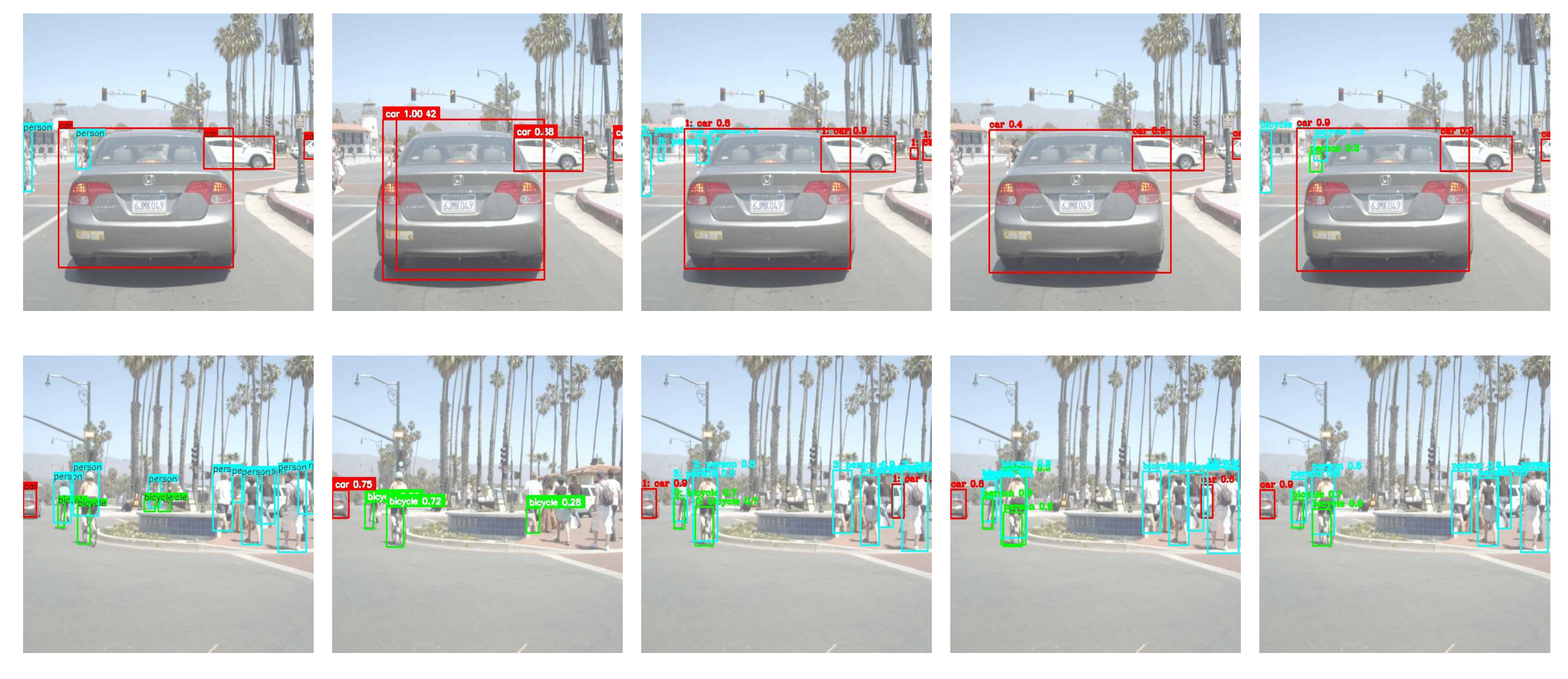

Figure 11.
Comparison of pedestrian detection performance for different detection models on nighttime low-light scenes from the LLVIP dataset. Images are organized by columns from left to right: Ground Truth (GT), YOLOv10-add, TFDet, CMAFF, and our proposed SDRFPT-Net model. The rows display five typical nighttime scenes representing challenging situations with different lighting conditions, viewing angles, and target distances. In all low-light scenes, SDRFPT-Net demonstrates excellent pedestrian detection capability: accurately identifying distant pedestrians with precise bounding boxes in the first row's street lighting scene; maintaining stable detection performance despite strong light interference in the second and fourth rows; successfully detecting distant pedestrians that other methods tend to miss in the fifth row's dark area.
Figure 11.
Comparison of pedestrian detection performance for different detection models on nighttime low-light scenes from the LLVIP dataset. Images are organized by columns from left to right: Ground Truth (GT), YOLOv10-add, TFDet, CMAFF, and our proposed SDRFPT-Net model. The rows display five typical nighttime scenes representing challenging situations with different lighting conditions, viewing angles, and target distances. In all low-light scenes, SDRFPT-Net demonstrates excellent pedestrian detection capability: accurately identifying distant pedestrians with precise bounding boxes in the first row's street lighting scene; maintaining stable detection performance despite strong light interference in the second and fourth rows; successfully detecting distant pedestrians that other methods tend to miss in the fifth row's dark area.


Figure 12.
Comparative impact of different attention mechanisms on the P3 feature layer (high-resolution features) in SDRFPT-Net. The top row (a-d) presents feature activation maps, while the bottom row (e-h) shows the corresponding original image heatmap overlay effects, demonstrating the differences in feature attention patterns. Self-attention (a,e) focuses on target contours and edge information; Cross-attention (b,f) presents overall attention to target areas with complementary information from RGB and IR modalities; Channel-attention (c,g) demonstrates selective enhancement of specific semantic information; Hybrid-attention (d,h) combines the advantages of all three mechanisms for optimal feature representation.
Figure 12.
Comparative impact of different attention mechanisms on the P3 feature layer (high-resolution features) in SDRFPT-Net. The top row (a-d) presents feature activation maps, while the bottom row (e-h) shows the corresponding original image heatmap overlay effects, demonstrating the differences in feature attention patterns. Self-attention (a,e) focuses on target contours and edge information; Cross-attention (b,f) presents overall attention to target areas with complementary information from RGB and IR modalities; Channel-attention (c,g) demonstrates selective enhancement of specific semantic information; Hybrid-attention (d,h) combines the advantages of all three mechanisms for optimal feature representation.

Figure 13.
Representational differences between dual attention mechanism combinations and the complete triple attention mechanism on the P3 feature layer. The top row (a-d) shows feature activation maps, while the bottom row (e-h) shows original image heatmap overlay effects, revealing the complementarity and synergistic effects of different attention combinations. Self+Cross attention (a,e) simultaneously possesses excellent boundary localization and target region representation; Self+Channel attention (b,f) enhances specific semantic features while preserving boundary information; Cross+Channel attention (c,g) enhances channel representation based on multi-modal fusion but lacks spatial context; Hybrid-attention (d,h) achieves the most comprehensive and effective feature representation through synergistic integration of all three mechanisms.
Figure 13.
Representational differences between dual attention mechanism combinations and the complete triple attention mechanism on the P3 feature layer. The top row (a-d) shows feature activation maps, while the bottom row (e-h) shows original image heatmap overlay effects, revealing the complementarity and synergistic effects of different attention combinations. Self+Cross attention (a,e) simultaneously possesses excellent boundary localization and target region representation; Self+Channel attention (b,f) enhances specific semantic features while preserving boundary information; Cross+Channel attention (c,g) enhances channel representation based on multi-modal fusion but lacks spatial context; Hybrid-attention (d,h) achieves the most comprehensive and effective feature representation through synergistic integration of all three mechanisms.

Figure 14.
Comparison between simple addition fusion and innovative fusion strategies (SRFM+STPEM) on three feature scale layers. The upper row (a,b,c) presents traditional simple addition fusion at different scales: P3/8 high-resolution layer (a) shows dispersed activation with insufficient target-background differentiation; P4/16 medium-resolution layer (b) has some response to vehicle areas but with blurred boundaries; P5/32 low-resolution layer (c) only has rough response to the central vehicle. The lower row (d,e,f) shows feature maps of the innovative fusion strategy: P3/8 layer (d) provides clearer vehicle contour representation with precise edge localization; P4/16 layer (e) shows more concentrated target area activation; P5/32 layer (f) preserves richer scene semantic information while enhancing central target representation.
Figure 14.
Comparison between simple addition fusion and innovative fusion strategies (SRFM+STPEM) on three feature scale layers. The upper row (a,b,c) presents traditional simple addition fusion at different scales: P3/8 high-resolution layer (a) shows dispersed activation with insufficient target-background differentiation; P4/16 medium-resolution layer (b) has some response to vehicle areas but with blurred boundaries; P5/32 low-resolution layer (c) only has rough response to the central vehicle. The lower row (d,e,f) shows feature maps of the innovative fusion strategy: P3/8 layer (d) provides clearer vehicle contour representation with precise edge localization; P4/16 layer (e) shows more concentrated target area activation; P5/32 layer (f) preserves richer scene semantic information while enhancing central target representation.
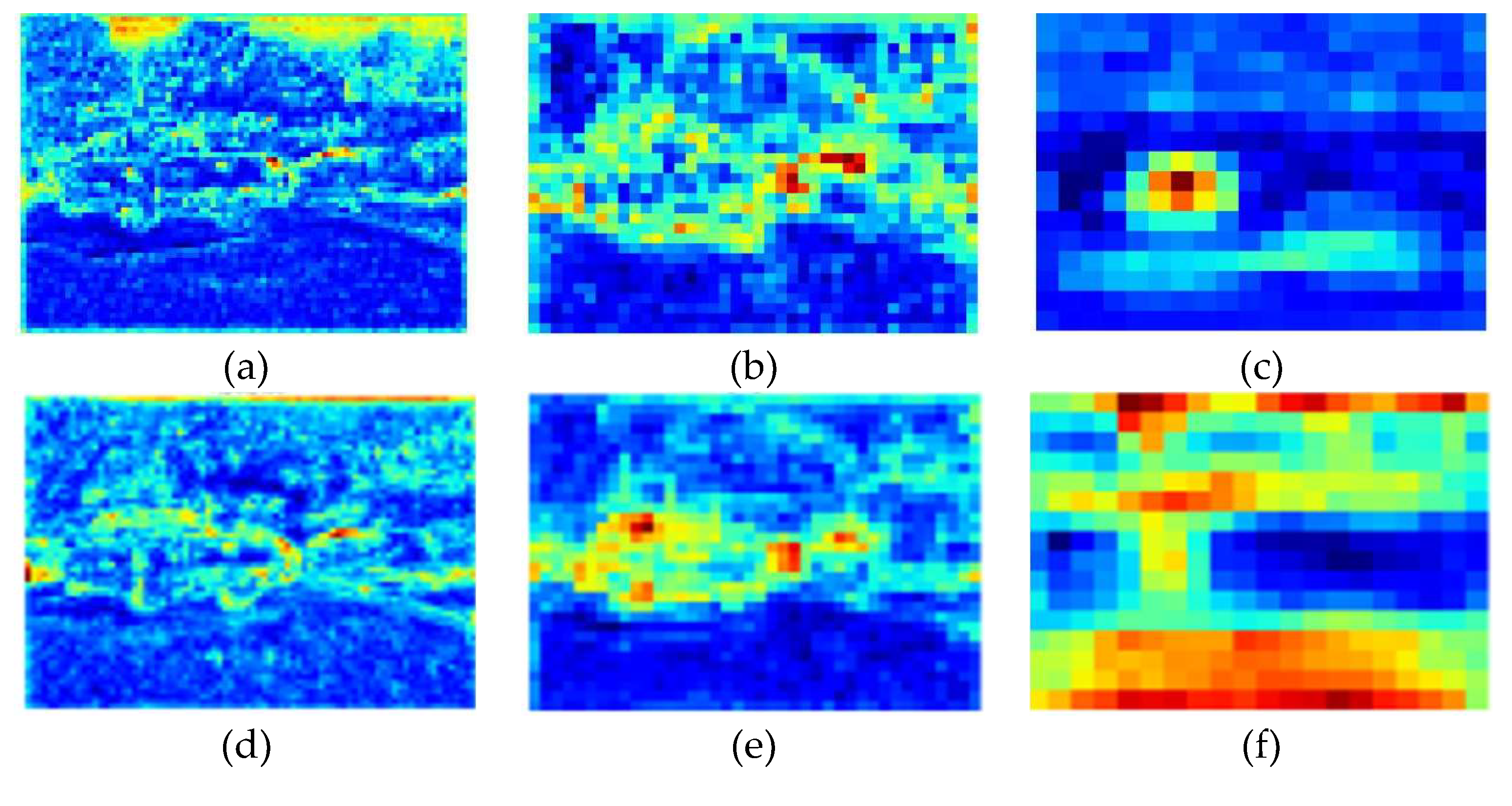
Figure 15.
Impact of iteration counts (n=1 to n=5) in the recursive progressive fusion strategy on three feature scale layers of SDRFPT-Net. By comparing the evolution within the same row, changes in features with recursive depth can be observed; by comparing different rows, response characteristics at different scales can be understood. The P3 high-resolution layer (first row) shows feature representation gradually evolving from initial dispersed response (n=1) to more focused target contours (n=2,3), with clearer boundaries and stronger background suppression, but experiencing over-smoothing at n=4,5. The P4 medium-resolution layer (second row) shows optimal target-background differentiation at n=3, followed by feature response diffusion at n=4,5. The P5 low-resolution layer (third row) presents the most significant changes, achieving highly structured representation at n=3 that clearly distinguishes main scene elements, while showing obvious degradation at n=4 and n=5.
Figure 15.
Impact of iteration counts (n=1 to n=5) in the recursive progressive fusion strategy on three feature scale layers of SDRFPT-Net. By comparing the evolution within the same row, changes in features with recursive depth can be observed; by comparing different rows, response characteristics at different scales can be understood. The P3 high-resolution layer (first row) shows feature representation gradually evolving from initial dispersed response (n=1) to more focused target contours (n=2,3), with clearer boundaries and stronger background suppression, but experiencing over-smoothing at n=4,5. The P4 medium-resolution layer (second row) shows optimal target-background differentiation at n=3, followed by feature response diffusion at n=4,5. The P5 low-resolution layer (third row) presents the most significant changes, achieving highly structured representation at n=3 that clearly distinguishes main scene elements, while showing obvious degradation at n=4 and n=5.
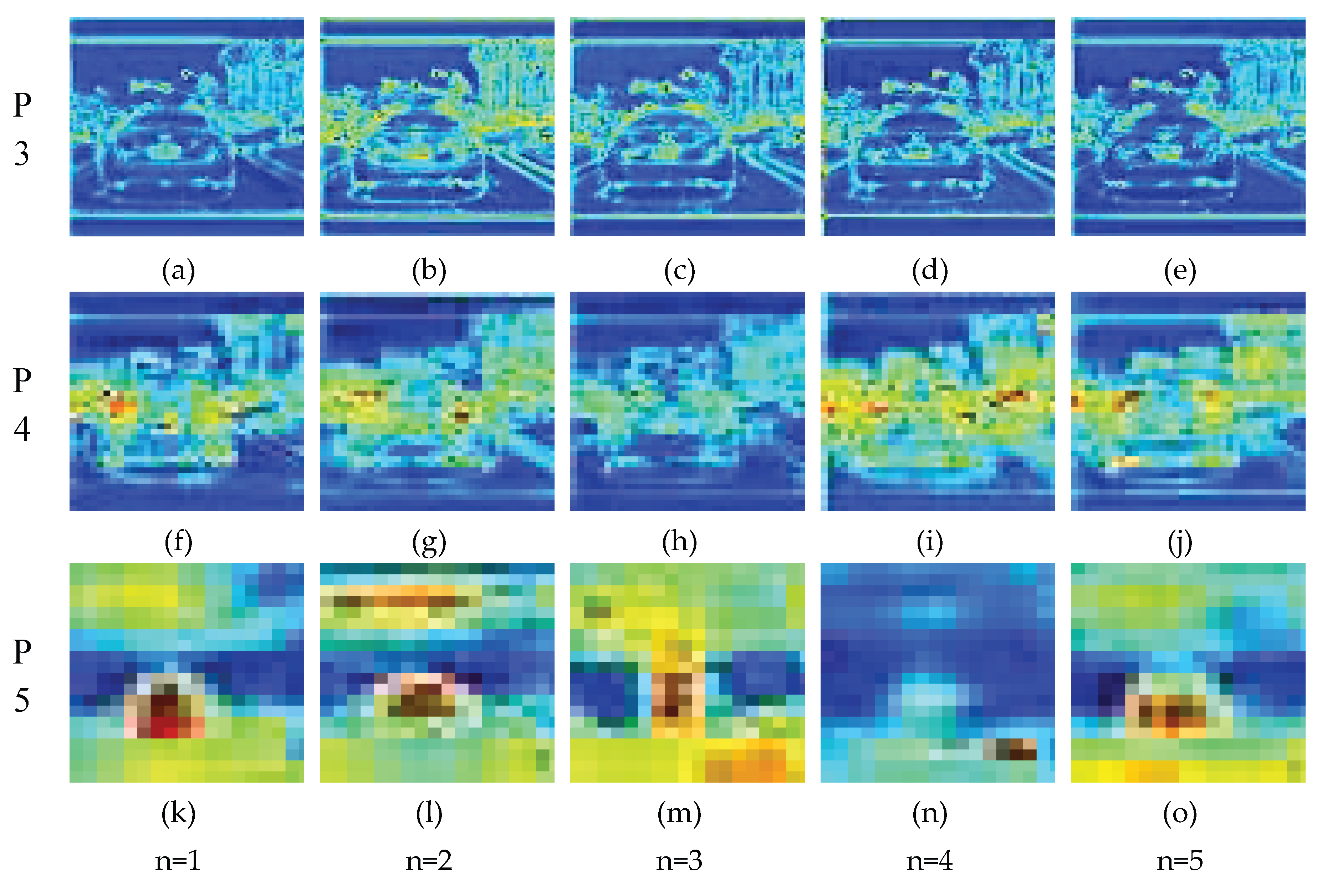

Table 1.
Performance comparison of SDRFPT-Net with state-of-the-art methods on the FLIR-aligned dataset. The table presents Precision (P), Recall (R), mean Average Precision at IoU threshold of 0.5 (mAP50), and mean Average Precision across IoU thresholds from 0.5 to 0.95 (mAP50:95). The best results are highlighted in bold.
Table 1.
Performance comparison of SDRFPT-Net with state-of-the-art methods on the FLIR-aligned dataset. The table presents Precision (P), Recall (R), mean Average Precision at IoU threshold of 0.5 (mAP50), and mean Average Precision across IoU thresholds from 0.5 to 0.95 (mAP50:95). The best results are highlighted in bold.
| Methods | Modality | P | R | mAP50 | mAP50:95 |
|---|---|---|---|---|---|
| YOLOv5 | Visible | 0.531 | 0.395 | 0.441 | 0.202 |
| Infrared | 0.625 | 0.468 | 0.539 | 0.272 | |
| YOLOv8 | Visible | 0.532 | 0.396 | 0.448 | 0.218 |
| Infrared | 0.559 | 0.514 | 0.549 | 0.288 | |
| YOLOv10 | Visible | 0.727 | 0.538 | 0.620 | 0.305 |
| Infrared | 0.773 | 0.618 | 0.727 | 0.424 | |
| YOLOv10-add | V-I | 0.748 | 0.623 | 0.701 | 0.354 |
| CMA-Det | V-I | 0.812 | 0.468 | 0.518 | 0.237 |
| TFDet | V-I | 0.827 | 0.606 | 0.653 | 0.346 |
| CMAFF | V-I | 0.792 | 0.550 | 0.558 | 0.302 |
| BA-CAMF Net | V-I | 0.798 | 0.632 | 0.704 | 0.351 |
| SDRFPT-Net (ours) | V-I | 0.854 | 0.700 | 0.785 | 0.426 |
Table 2.
Performance comparison of SDRFPT-Net with state-of-the-art methods on the LLVIP dataset. The table presents Precision (P), Recall (R), mean Average Precision at IoU threshold of 0.5 (mAP50), and mean Average Precision across IoU thresholds from 0.5 to 0.95 (mAP50:95). V-I indicates the fusion of visible and infrared modalities. The best results are highlighted in bold.
Table 2.
Performance comparison of SDRFPT-Net with state-of-the-art methods on the LLVIP dataset. The table presents Precision (P), Recall (R), mean Average Precision at IoU threshold of 0.5 (mAP50), and mean Average Precision across IoU thresholds from 0.5 to 0.95 (mAP50:95). V-I indicates the fusion of visible and infrared modalities. The best results are highlighted in bold.
| Methods | Modality | P | R | mAP50 | mAP50:95 |
|---|---|---|---|---|---|
| YOLOv5 | Visible | 0.906 | 0.820 | 0.895 | 0.504 |
| Infrared | 0.962 | 0.898 | 0.960 | 0.631 | |
| YOLOv8 | Visible | 0.933 | 0.829 | 0.896 | 0.513 |
| Infrared | 0.956 | 0.901 | 0.961 | 0.645 | |
| YOLOv10 | Visible | 0.914 | 0.833 | 0.892 | 0.512 |
| Infrared | 0.962 | 0.909 | 0.961 | 0.637 | |
| YOLOv10-add | V-I | 0.961 | 0.893 | 0.957 | 0.628 |
| TFDet | V-I | 0.960 | 0.896 | 0.960 | 0.594 |
| CMAFF | V-I | 0.958 | 0.899 | 0.915 | 0.574 |
| BA-CAMF Net | V-I | 0.866 | 0.828 | 0.887 | 0.511 |
| SDRFPT-Net (ours) | V-I | 0.963 | 0.911 | 0.963 | 0.706 |
Table 3.
Impact of different attention combinations on detection performance. The table compares the effects of Self Attention, Cross-modal Attention, and Channel Attention in various combinations. The best results are highlighted in bold.
Table 3.
Impact of different attention combinations on detection performance. The table compares the effects of Self Attention, Cross-modal Attention, and Channel Attention in various combinations. The best results are highlighted in bold.
| ID | SHPA | SRFM | STPEM | mAP50 | mAP50:95 |
| A1 | ✔ | 0.701 | 0.354 | ||
| A2 | ✔ | ✔ | 0.775 | 0.373 | |
| A3 | ✔ | ✔ | ✔ | 0.785 | 0.426 |
Table 4.
Impact of different attention combinations on detection performance. The table compares the effects of Self Attention, Cross-modal Attention, and Channel Attention in various combinations. The best results are highlighted in bold.
Table 4.
Impact of different attention combinations on detection performance. The table compares the effects of Self Attention, Cross-modal Attention, and Channel Attention in various combinations. The best results are highlighted in bold.
| ID | Self-attention | Cross-attention | Channel-attention | mAP50 | mAP50:95 |
| B1 | ✔ | 0.776 | 0.408 | ||
| B2 | ✔ | 0.749 | 0.372 | ||
| B3 | ✔ | 0.730 | 0.384 | ||
| B4 | ✔ | ✔ | 0.774 | 0.424 | |
| B5 | ✔ | ✔ | 0.763 | 0.409 | |
| B6 | ✔ | ✔ | 0.729 | 0.362 | |
| B7 | ✔ | ✔ | ✔ | 0.785 | 0.426 |
Table 5.
Ablation experiments on fusion positions. The table shows the impact of applying advanced fusion modules at different feature scales. P3/8, P4/16, and P5/32 represent feature maps at different scales, with numbers indicating the downsampling factor relative to the input image. The best results are highlighted in bold.
Table 5.
Ablation experiments on fusion positions. The table shows the impact of applying advanced fusion modules at different feature scales. P3/8, P4/16, and P5/32 represent feature maps at different scales, with numbers indicating the downsampling factor relative to the input image. The best results are highlighted in bold.
| ID | P3/8 | P4/16 | P5/32 | mAP50 | mAP50:95 |
| C1 | Add | Add | Add | 0.701 | 0.354 |
| C2 | SRFM+STPEM | Add | Add | 0.769 | 0.404 |
| C3 | SRFM+STPEM | SRFM+STPEM | Add | 0.776 | 0.410 |
| C4 | SRFM+STPEM | SRFM+STPEM | SRFM+STPEM | 0.785 | 0.426 |
Table 6.
Impact of different iteration counts of the recursive progressive fusion strategy on model detection performance. The experiment compares performance with recursive depths from 1 to 5 iterations (D1-D5), evaluating detection accuracy using mAP50 and mAP50:95 metrics. The best results are highlighted in bold.
Table 6.
Impact of different iteration counts of the recursive progressive fusion strategy on model detection performance. The experiment compares performance with recursive depths from 1 to 5 iterations (D1-D5), evaluating detection accuracy using mAP50 and mAP50:95 metrics. The best results are highlighted in bold.
| ID | times | mAP50 | mAP50:95 |
| D1 | 1 | 0.769 | 0.395 |
| D2 | 2 | 0.783 | 0.418 |
| D3 | 3 | 0.785 | 0.426 |
| D4 | 4 | 0.783 | 0.400 |
| D5 | 5 | 0.761 | 0.417 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



