Submitted:
08 April 2025
Posted:
09 April 2025
You are already at the latest version
Abstract
High-Performance Computing (HPC) revolutionized the field of computational science by enabling it to process vast amounts of data and execute complex simulations at remarkable speed and efficiency. This paper describes various paradigms of computing, namely, client-server computing, distributed computing, cloud computing, and edge computing, and elaborates on their technology drivers. Particular focus is given to HPC, its architecture, programming models, performance metrics, scalability, and applications. The article highlights the significant impact of HPC to science in fields of medicine, biophysics, business, and engineering by facilitating paradigm-altering scientific discoveries, economic forecasting, and simulations of complex engineering. In addition, the article mentions challenges to deploying HPC, such as scalability, handling resources, and integration of multi-core processors. Through comparative analysis and benchmarking techniques, the research points to the necessity of continuous hardware and software innovations to make HPC systems efficient and sustainable. The study brings out the revolutionary potential of HPC in modern computing and its central role in solving the most complex computational problems in the modern age.
Keywords:
High-Performance Computing (HPC)
; client-server computing
; Cloud Computing
1. Introduction
Technology keeps evolving to meet the increasing computational demands of society. Over the years, there have been a number of computing paradigms that have developed and continued to evolve to be more efficient and solve complex problems. Innovation, research, and the need for faster and more efficient computing technologies have driven these developments. Of these paradigms, High-Performance Computing (HPC) has emerged as a key driver of computational research and industrial applications that provide unparalleled processing capability for computationally demanding tasks[1,2,3].
This paper addresses the leading computing paradigms, including client-server computing, distributed computing, cloud computing, and edge computing, analyzing their technology drivers, scalability, and uses in the real world. HPC receives the primary focus, which integrates supercomputing clusters, parallel processing, and high-speed interconnects to solve scientific simulation problems, data analytics, artificial intelligence, and engineering computations[4,5,6,7,8].
The purpose of this study is to contrast performance, scalability, and energy efficiency of different paradigms of computing with the application of traditional benchmarking approaches. Comparative investigation highlights the benefits and drawbacks of each paradigm, particularly the contribution of HPC towards the solution of computational issues. Moreover, this study satisfies Module Learning Outcome 1, which involves ascertaining the suitability of alternative hardware and software platforms in solving relevant computational challenges.
2. Literature Review
A paradigm for computing is a scientific and methodological framework that guides the development of software. This includes the principles, practices and best practices that are used to write and organize code. Computing paradigms help to establish new problem-solving modes, leading to more efficient and specialized solutions. Computing systems have also undergone enormous transformation in the past sixty years, immensely contributing to society with numerous technological innovations. Some of these include the development of the personal computer (PC) and the Internet that have revolutionized how we live, work, and interact with one another. The internet has made the most contribution to the 21st century's societal, economic, and technological advancement [13,14,15].
To keep up with these ever-evolving technologies, it is important to adapt and come up with new paradigms that are suited to emerging challenges and maximize their potential. Paradigms such as high-performance computing, cloud computing, and edge computing have been conceptualized to scale up functionality, optimize performance, and provide more adept and specialized solutions for contemporary computing needs[16].
2.1. Client-Server Computing
One of the earliest and most influential computing models was the Client-Server model. The Client-Server paradigm helped define the modern era of computing by establishing a structured way to access network computer resources. The Client-Server model, first introduced in 1960, was intended to distribute workloads between resource providers and service consumers. A network system was utilized in the communications between these two groups, known as servers and client devices respectively. These servers distribute resources among customers for them to use in their operations by using the mechanism of load balancing (Gill et al., 2024). Email and the World Wide Web (WWW) are examples of the application of the Client-server Model.
Several technologies were necessary to enable the Client-Server model. Establishing solid networking infrastructures, for example, Ethernet and TCP-IP protocols, was needed to provide a solid, fast, and reliable means of communication between the servers and the clients. Developing high-power server hardware with the ability to support multiple concurrent connections and handle requests in real time were requirements for the Client-Server model to occur[17,18].
All the same, the Client-Server model had some intrinsic limitations themselves, which came to light further in time, largely as the demand for computing power and data processing increased. Servers most of the time became bottlenecks if the number of clients grew simply because they were unable to handle such a majority. If for some reason the server crashed, a client would no longer reach the services that resulted in downtime being significant (Meador, 2020). Since resources would primarily be utilized within the centralized structure of the Client-Server model, such resources were often left underutilized. Both these limitations of the Client-Server model were, along with the increasing need for computation, a few of the major motivating factors for distributed computing[19,20,21,22].
2.2. Distributed Computing
Dealing with processing architectures, all the computational nodes involved working together for data processing and task execution, do have with distributed computing solutions the able assistance for all its client-server architecture limitations. Scalability brings up an issue of adding more nodes, fault tolerance through distributing different tasks across those nodes, and resource optimization via dynamic task assignment to underutilized nodes.
These services rendered an ultra-modern area of computing of power for the application. The majority benefited from these were scientific research, big data analytics, and cloud services. High-performance computing clusters have made the Distributed Computing paradigm[37,38,39] a way to do revolutionary research in the domains of climate science, biologists, and physics. Cloud services demand near-continuous uptime and on-demand provisioning of resources, all of which distributed computing ensured as a foundation for cloud computing services. By distributing the processes on large datasets, cloud computing has facilitated on the rise of big data analytics, which is in the form of Hadoop and Spark [23,24,25].
Sort of parallel to Distributed and Parallel Computing, High-Performance Computing emphasizes utilizing powerful computational resources to achieve maximum performance for complex tasks. HPC systems often consist of supercomputers or clusters of high-performance machines working in parallel. The establishment of such systems was made possible by several crucial technological advances, such as advanced networking, specialized hardware, and development of the abovementioned supercomputers. Fast data transfer speeds between nodes were made available by low-latency networking technologies, while specialized hardware such as Graphics Processing Units (GPUs) and Field-Programmable Gate Arrays (FPGAs) significantly enhanced the efficiency and performance of the computations [26,27,28,29,30,31,32].

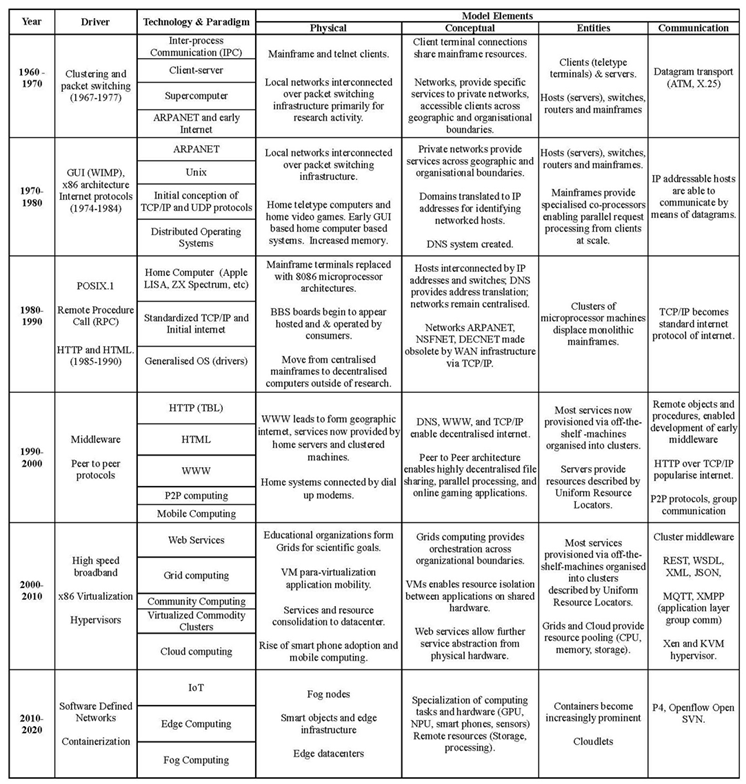
Table 1.
Summary of the evolution of computing paradigms. Source:[21].
Table 1.
Summary of the evolution of computing paradigms. Source:[21].
2.3. Cloud Computing
While HPC brings with it several benefits in the research arena, it is certainly not without limitations. The deployment of HPC systems requires colossal investment in infrastructure, upkeep, and expertise to ensure smooth operations. Such resources are typically limited to large organizations, research institutes, and corporates with huge budgets. In order to address such significant challenges, the Cloud Computing paradigm was devised. By taking up the concepts of distributed computing and virtualization, Cloud Computing provides scalable computing resources on an on-demand basis over the web. This has led to multiple organizations utilizing data centers and computing resources on a large scale in order to engineer service models with computing resources provided as a service. Examples of such models include Software as a service (SaaS), Infrastructure as a service (IaaS) and Platform as a service (PaaS). Such services are offered by industry giants such as Google and Microsoft.
Google Mail is among the typical SaaS electronic mail programs with rich features that can be run on a browser without having the installation hassle. Microsoft Azure is a case of PaaS that provides scalable development environments in which applications are developed online (azure.microsoft.com, n.d.). Additionally, cloud-based machine learning and artificial intelligence services provide available tools for training and deploying models[40,41].
There were 4 major technology drivers that converged to give birth to Cloud Computing as it exists today. Virtualization, a technology you can use to create virtual replicas of servers, storage, networks and other physical devices. Virtualization software simulates the behavior of these hardware devices and allows one machine to run multiple virtual machines. High-Speed internet, which allows users to access and use remote computing resources with reliability. Distributed systems' advancements enabled scalable cloud infrastructure. Automation and orchestration platforms such as Kubernetes and Docker Swarm were developed, which automated application deployment, scale-out, and management in the cloud, making it simple to manage cloud environments[33,34]. Cloud and Mobile Computing integrated with sensor network innovation gave common objects sensing and networking abilities, assisting in the formation of a world-wide networked Internet of 'Things'.
Edge Computing
While data generated by mobile and IoT computing platforms continues to increase at a very rapid pace, the issue of collecting and processing this data in real-time remains inadequately addressed. This issue spawned Edge Computing, where computing resources such as power-efficient processors and workload-specific accelerators are inserted between consumer devices and data center providers.
Development of low-power, high-performance processors makes it possible to process data efficiently on edge devices [23]. Furthermore, the focus on decentralization and virtualization that began at the beginning of the Cloud Computing era caused Fog and Edge computing to follow the trend of decentralizing data processing and reducing the load on central data centers [22,23].
Fog Computing complements Edge Computing through the supply of mechanisms for application provisioning on edge devices. Fog Computing enables the orchestration and execution of dynamic workflows on decentralized computing infrastructures. The integration of Fog and Edge Computing extends the Cloud Computing paradigm from centralized stakeholders to decentralized, multi-stakeholder systems. The integrated systems are able to provide ultra-low service response times, increased aggregate bandwidths, and geo-aware provisioning.
Reduced latency, bandwidth usage that is streamlined and enhanced security are all benefits provided by Edge Computing while being flexible and adaptable solutions for applications in diverse environments.
Last but not least, continual creation of new computing paradigms is needed to cope with growing demands for data and advanced applications. When these paradigms reach maturity and newer paradigms come into being, they can alleviate current technology bottlenecks and create new opportunities for innovation and efficiency across several domains[34].
2.4. Description of High-Performance Computing
High Performance Computing, which is also referred to as HPC, is a cluster of computing powers to compute problems which are either too big or would require too much time to compute. HPC is essentially a capability and does not always imply that the system is a supercomputer. It can be stated that HPC is the capacity of supercomputers.
From the dawn of technology, researchers and scientists always required quick, precise and efficient technology to support their complex research work that requires hundreds of human brains. Over the past decades, computer professionals have continued to invent more and more efficient computers that can execute an enormous number of complex tasks at a time. In this vein, researchers developed extremely powerful systems comprised of hundreds of computers, dividing tasks among them. Others decided to enable a single computer to possess the power of hundreds of computers, building a computing paradigm intended to tackle more complex tasks while taking up far less space.
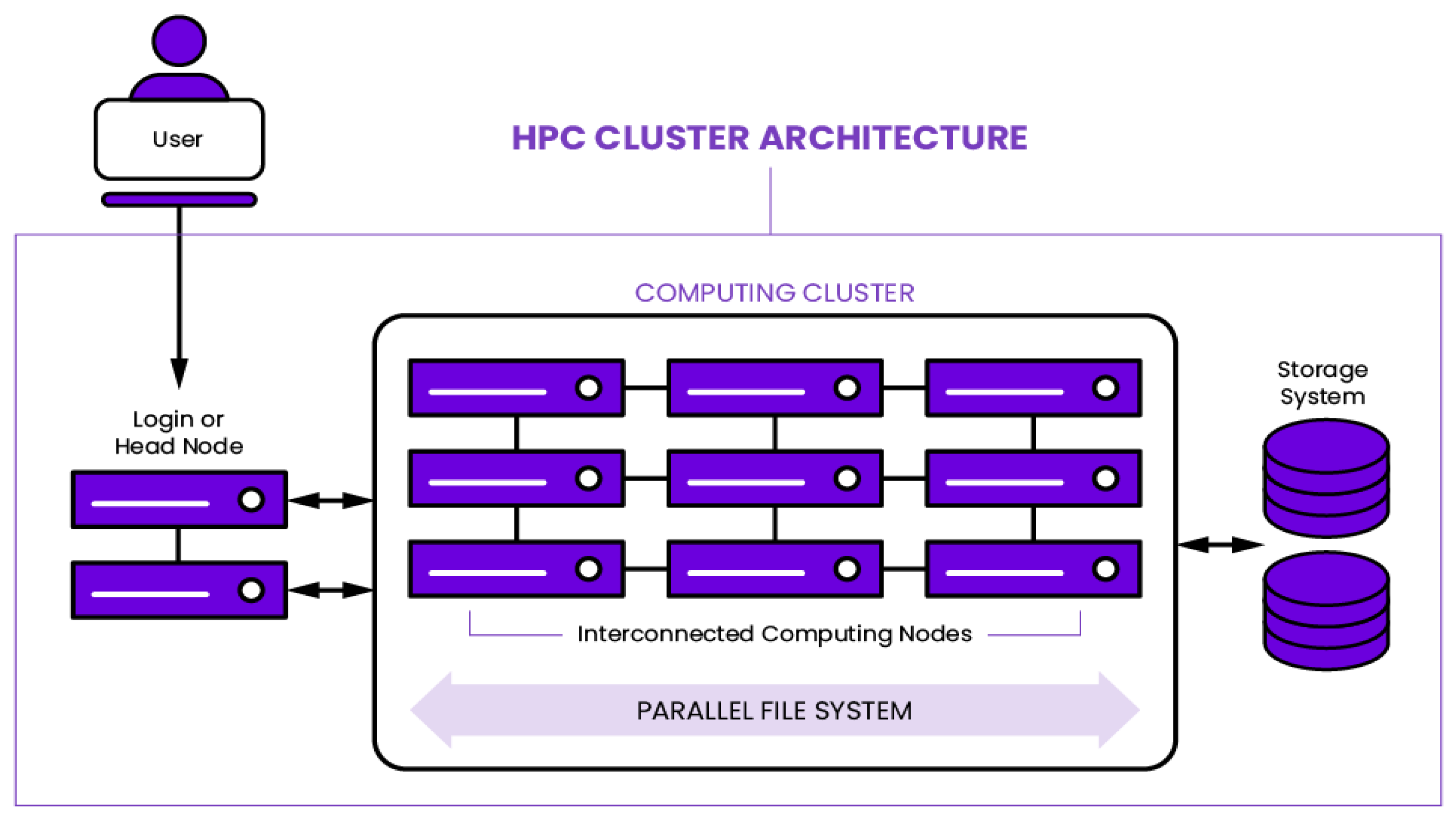
Concept of Clusters in High Performance Computing
High Performance Computing system can be regarded as a group of computers which is called cluster and each computer in a cluster is called a node.
One cluster needs to contain:
- Operating System
- Processor
- Storage
- Network
Figure 1.
Specialized computer nodes. Source: (www.hpc.iastate.edu, n.d.).
Figure 1.
Specialized computer nodes. Source: (www.hpc.iastate.edu, n.d.).
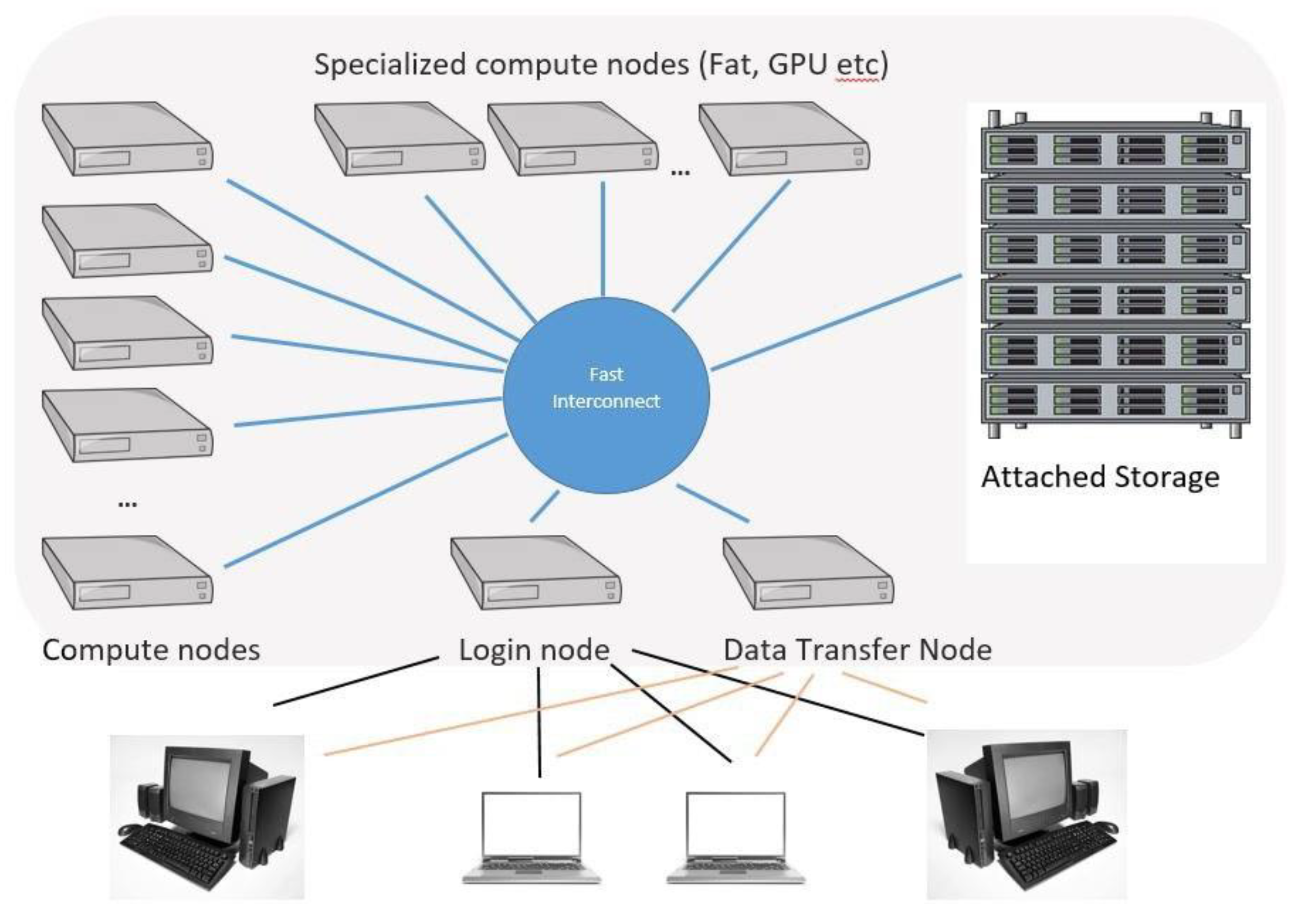
Figure 2.
Growth chart of HPC Marke. Source: (WEKA, n.d.).
Compute Engine provides customized virtual machines, and the customers can scale down or up as needed. High-Performance Computing (HPC) virtualization technology is a technique of building virtual hardware subsystems such as processors, memory, storage, and networking to enhance resource utilization and flexibility. Virtual machines (VMs) in HPC are categorized by structure and optimization for different workloads[21].
The General Purpose VMs are available in a balanced combination of TCP, memory, and processing and are well suited to a broad range of users. General Purpose VMs are commonly used for web servers, small to medium databases, and straightforward applications that don't have a special resource demand. The second type, Compute Optimized VMs, is designed for compute-heavy workloads with a high CPU-to-memory ratio. All these VMs are ideal for batch processing, media transcoding, and other computation-intensive tasks. The third category of VMs is Memory Optimized VMs, which provide higher memory-to-CPU ratio, suitable for in-memory databases, real-time big data analytics, and applications requiring a lot of memory resources. Last but not least, Accelerator Optimized VMs are designed for high-precision computing, with GPGPUs or FPGAs to execute complex calculations in parallel. They provide optimized VMs for use with machine learning, artificial intelligence, data analysis, and computer-aided graphic rendering[22,23].
HPC further relies upon diverse storage options like Cloud Storage, Persistent Disk, and Filestore to provide apt management to the data. Network too is given significance when safeguarding the data privacy is the concern as HPC specializes in executing operations dealing with delicate data.
Though having its advantages, implementation of HPC has several challenges. Legacy data centers may consume a lot of power and need extensive cooling, and hardware must be optimized to work with the existing infrastructure. The presence of multiple processors and accelerators within a system increases system complexity, making it difficult to forecast workload and optimize code. Workload consistency across hybrid environments is needed to provide scalable computing resources and a seamless user experience. Moreover, the complex structure of HPC demands advanced networking and storage infrastructure, typically demanding a total system overhaul for maximum efficacy. Hardware abstraction may also be overlooked, as companies favor applications over purpose-built HPC systems. Managing immense clusters of computers and nodes adds an additional layer of complexity, necessitating effective control and security. Lastly, the pace of innovation in computer technology is so rapid that the traditional HPC approaches are becoming outdated, with new technologies embracing HPC ideas without even referring to them[24]
3. Proposed Methodology
This study employs a systematic approach to evaluate the effectiveness and efficiency of different computing paradigms, namely High-Performance Computing (HPC). The research process is a systematic approach to ensure accurate and comprehensive analysis.
Literature Review: An extensive review of existing research, books, journal articles, and technical reports will be conducted to understand the theoretical framework and advancements in computing paradigms, namely HPC.
Identification of Key Computing Paradigms: The study will group and compare different computing paradigms, i.e., client-server computing, distributed computing, cloud computing, and edge computing, and determine their characteristics, enabler technologies, and real-world applications.
Performance Benchmarking: Standard benchmarking techniques will be employed to assess the performance of different computing paradigms. This comprises assessing execution time, rate of processing, resource utilization, and power efficiency in multiple computing environments.
Scalability Analysis: How efficiently each paradigm scales with increasing workloads will be analyzed. This includes hardware scalability (e.g., GPU clusters), software scalability (e.g., parallel processing models), and network scalability (e.g., data transfer efficiency).
Comparative Analysis: Comparative analysis will be conducted among computing paradigms, taking into account computational power, cost-effectiveness, ease of implementation, and sustainability.
Case Study Utilizations: Real case studies across medicine, biophysics, business, and engineering will be discussed to emphasize the contribution of HPC toward solving computationally demanding problems.
Challenges and Future Direction: The research will identify the current challenges toward adopting HPC, such as resource usage, power consumption, and implementation of new technologies. Future directions in improving the efficiency of HPC will be presented.
Conclusion and Recommendations: On the basis of the findings, recommendations will be made for maximizing computing paradigms, maximizing HPC efficiency, and making sustainable progress in computational technology.
3.1. Open Computing Language
OpenCL (Open Computing Language) and CUDA (Compute Unified Device Architecture) are two most well-known parallel computing frameworks, leveraging the processing power of GPUs for high-performance computation. OpenCL is compatible with a wide range of hardware and is portable and flexible as a consequence. But CUDA is particularly optimized for NVIDIA GPUs with streamlined development and optimal performance on such systems. This section discusses and contrasts the key features of these programming models, highlighting their strengths and fields of use. The CUDA programming model, developed by NVIDIA, is a parallel computing model for NVIDIA GPUs. It enables a set of abstractions closely mapping to the GPU architecture to create high-performance applications.
CUDA organizes parallel execution as a thread hierarchy of threads, thread blocks, and grids. Threads are the finest granularity of execution, which are grouped into blocks. Blocks make up a grid, which together executes a kernel function. This hierarchical structure makes it easy to manage thousands of threads by executing concurrently. CUDA's memory model utilizes a hierarchy made up of registers (private per thread), shared memory (accessible by all threads in the same block) and global memory (accessible by all threads). Constant and texture memory spaces optimized for specific access patterns are also present. Within a block, threads can synchronize using barriers ('_ _syncthreads()'). Kernels, the code lines executed by the GPU, are programmed in CUDA C, a language similar to C. The kernels are called by the host (CPU) and executed on the device (GPU). Host to device or device to host memory transfer, kernel calls, and synchronization are managed by the host code. The parallel section of the code executes on the GPU.
CUDA is extremely well supported on NVIDIA hardware, using special architectural features like warp execution on groups of 32 threads and hardware-supported atomic operations in order to optimize performance. NVIDIA provides robust tool support, including a number of toolkits and libraries like the CUDA toolkit, cuBLAS, cuFFT, and debugger/profiler tools like the NVIDIA Visual Profile.
OpenCL Programming Model
OpenCL is an open, royalty-free API designed by the Khronos Group, aimed at parallel programming for a vast amount of platforms like CPUs, GPUs, Digital Signal Processors (DSP) and Field Programmable Gate Arrays (FPGA). OpenCL uses a standard language and shared programming interface to write kernels. This can be run in OpenCL on numerous varieties of devices across various platforms from various manufacturers. Such compatibility does require direct control of memory copies and synchronization to ensure the program executes at optimal performance on every one of these various devices. Numerous memory spaces are provided by OpenCL's memory model, such as global-memory (which is available to every work-item), constant memory (read and cached), local memory (shared in a workgroup), private memory (exclusive per work-item). This is a hierarchy that is significant for parallel and efficient data handling and execution. OpenCL's execution model has a host program running on a CPU and managing the execution of kernels on computer devices. Kernels execute on hardware and are made up of work-items grouped into workgroups, similar to CUDA with threads, thread blocks, and grids. Work-groups execute independently for the purpose of scalability and parallelism. OpenCL provides barrier synchronization at the work-group level but not across workgroups. This ensures all work items within a group reach a synchronization point before any of them move on, making data within the group consistent. The OpenCL standard offers APIs to manage platforms, contexts, command queues, memory objects, and program objects. It includes support for extensions to tap into the hardware-specific capabilities provided by different vendors. Both CUDA and OpenCL offer good frameworks for parallelism and each of the models has its own strengths that are tailored specifically to suit the various domains of high-performance computing.
3.2. Performance
Computing has evolved by leaps and bounds, in large part due to the demands of having to process increasingly complex and precise applications. High-Performance Computing (HPC) is one such example of this evolution, delivering cutting-edge processing capability and performance. Through an examination of some of the defining metrics such as processing capability, clock speed, and instructions per second, we aim to find out HPC's defining features and how it is useful at its optimum.
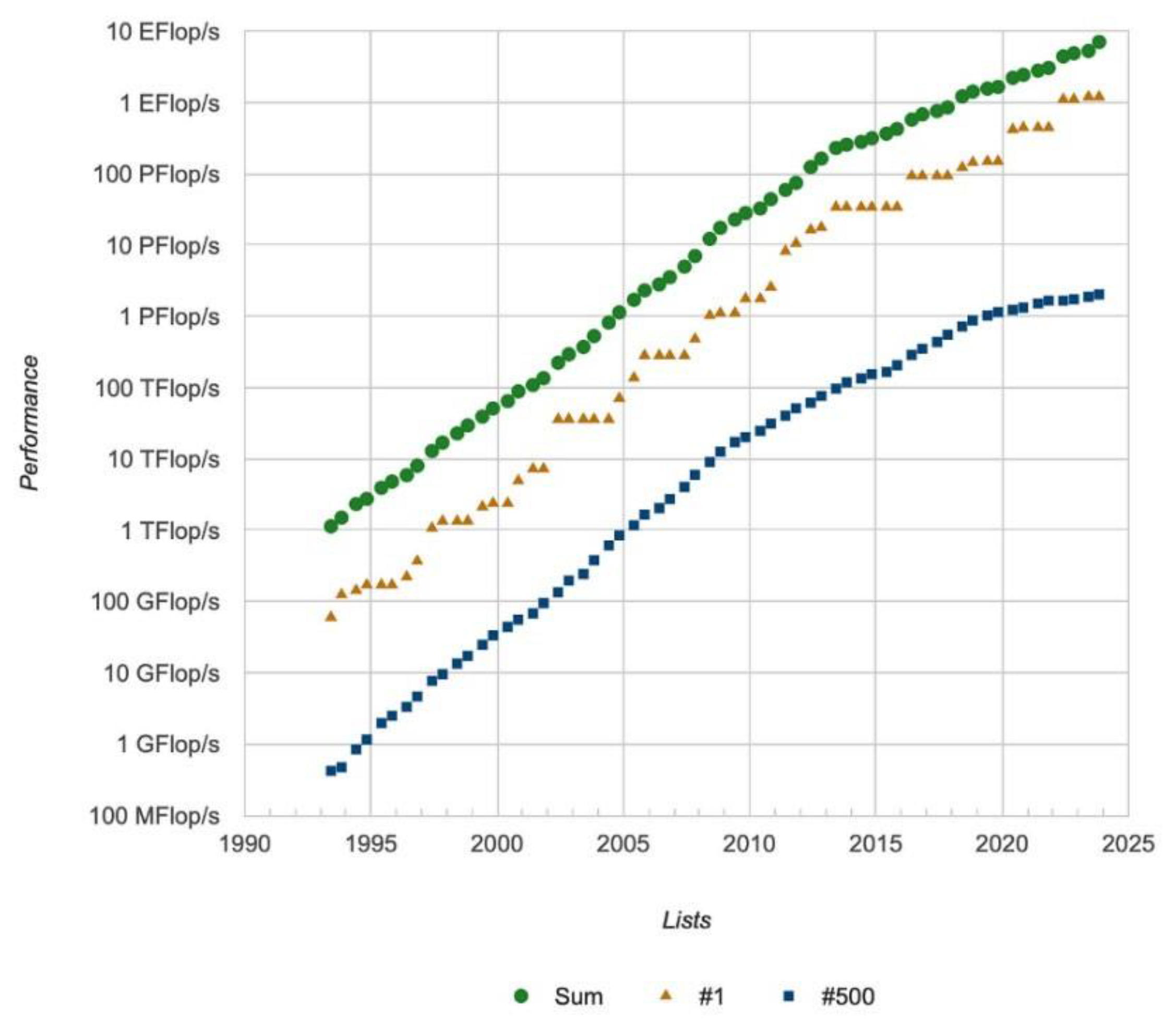
Processing Power: HPC systems measure their processing power in FLOPS (Floating Point Operations Per Second). These systems are extremely adept at carrying out complex calculations at high speeds. Modern HPC systems manage to carry out from petaflops (10^15 FLOPS) to exaflops (10^18 FLOPS), which are crucial for activities like climate modelling which is made possible by technologies such as multi-core processors, GPUs, and high-speed interconnects, which together enable HPC to handle the most challenging computational tasks.
Figure 3.
High Performance Computing Trends. Source: Arnold, [22].
Figure 3.
High Performance Computing Trends. Source: Arnold, [22].
Clock Speed and Processor Efficiency: Clock speed, in GHz, is the speed at which a processor runs instructions and directly indicates its general efficiency. Producers increase the clock speeds of processors to make them run more operations per second and, in turn, make the system more efficient. Clock speed optimization is combined with multi-core design to achieve the best computational power.
Instructions per second and execution rate: This metric shows instructions a processor is capable of processing per second, thereby its effectiveness and computational ability. Greater IPS ratings are an indication of greater effectiveness, enabling HPC systems to perform complex computations at speed.
4. Comparative Analysis
4.1. Parallel Computing:
Performance and Parallel Execution Efficiency: Parallel computing involves various processors running simultaneously to compute answers. While similar to high-performance computing (HPC) in parallel execution, it is normally applied on a smaller scale. Parallel computing environments primarily employ multi-core processors that execute numerous instructions in parallel for enhanced performance. However, they do not reach the level of optimization as achieved in HPC systems.
Processing capability: Parallel computing platforms are not so powerful in terms of processing, usually expressed in teraflops (10^12 FLOPS), compared to high-performance computing (HPC) platforms. They are most suitable for relatively simple-to-decompose applications into independent subtasks such as image processing and numerical simulations where tasks can be executed in small blocks but may not perform well with complex problems.
4.2. Cloud Computing:
Scalability of Resources and Performance: Cloud platforms offer ample computing. For really tough scientific and engineering issues, however, they might not be as heavy as HPC equipment, which has special hardware and more raw computing. Performance can be incredible, especially with special instances like GPUs and TPUs, but is sabotaged by network delay and service optimization.
4.3. Processing Capacity and Specialized Instances
Cloud service provides several configurations, such as those for specific tasks like machine learning and big data processing but may not equal the raw processing capacity of specialized HPC systems.
4.4. Cluster Computing
Performance in Cluster Environments: Cluster computing means a set of connected computers (nodes) that operate hand in hand, frequently within the same data center. This configuration is capable of high performance for applications amenable to a cluster environment, filling the gap between single servers and supercomputers.
Capability and Mid-Capacity: Clusters have significant computing capability, often measured in teraflops (10^12 FLOPS), but many orders of magnitude less than on top HPC machines. They work very effectively in many scientific and engineering challenges.
4.5. Control Flow
Control flow in High-Performance Computing (HPC) signifies the order in which instructions get executed within a program, with focus on areas involving parallel processing. Control flow implies the handling of the initial startup, processing, synchronization, and termination of parallel processes in various processing units (such as CPUs, GPUs).
Control flow in High-Performance Computing is defined by identifying the starting point of the program, drawing the sequence of steps and tasks, handling the invocations of functions, showing the ending of tasks and program termination, and using control flow graphs (CFG) to develop the images of the execution paths, which include the decision of which routes is to be proceeded as well as the existence of loop iterations within the code. HPC programs must operate effectively in order to fully utilize the capabilities of the underlying hardware, which is ensured by effective control flow management.
4.6. High-Performance Computing (HPC) Control Flow Using CUDA and OpenCL CUDA (Compute Unified Device Architecture)
CUDA is a parallel computing platform and application programming interface (API) model created by NVIDIA. It enables dramatic increases in computing performance by harnessing the power of the graphics processing unit (GPU).
Control Flow Diagram:
Figure 4.
Control flow diagram of CUDA programming model.
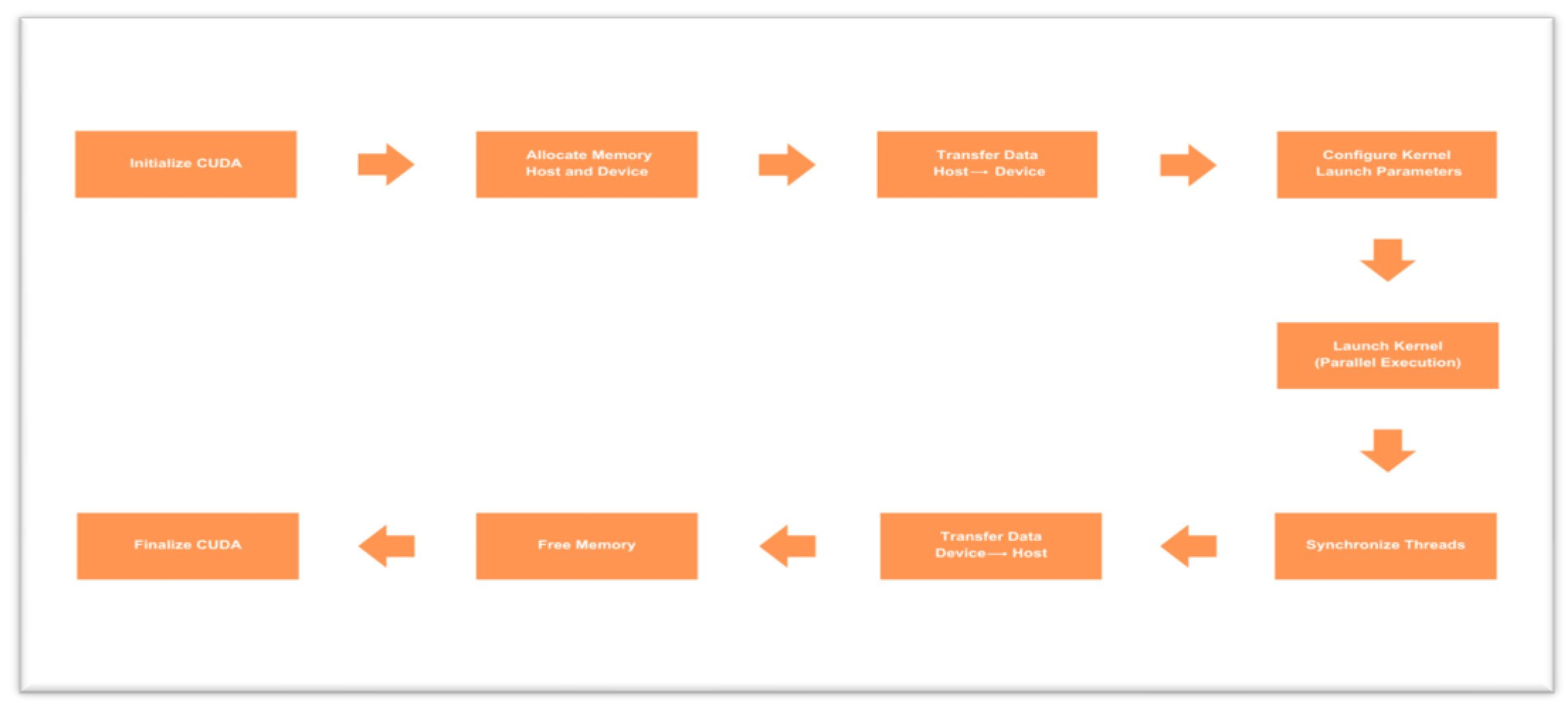
The setup process in CUDA involves environment setup and allocation of necessary resources. This involves the kernel functions to be executed on the GPU being declared. Once the environment setup is complete, memory is managed, where memory is allocated on both the host (CPU) and the device (GPU), followed by data migration of the necessary data from host memory to device memory.
After memory allocation, kernel launching begins. This involves setting up execution parameters, such as grid and block sizes, for optimal performance. The kernels are then executed on the GPU after setting up. During execution, the GPU runs the kernel functions in parallel with its vast parallelism resource. Synchronization methods, such as barriers, are utilized whenever necessary to align threads and ensure appropriate execution.
Once computation is complete, data transfer takes place, where results are transferred from device memory to host memory. Finally, the cleanup stage frees up memory allocated on host and device to enable effective resource utilization. The CUDA environment is then shut down to complete the process.
OpenCL (Open Computing Language) is an open, parallel programming standard for a wide range of computing platforms, including CPUs, GPUs, DSPs, and FPGAs. It is managed by the Khronos Group and offers a programmable, portable, and flexible framework for implementing parallel workloads across a variety of hardware architectures[42].
Control Flow Diagram:
Figure 5.
Control flow diagram of OpenCL programming model.
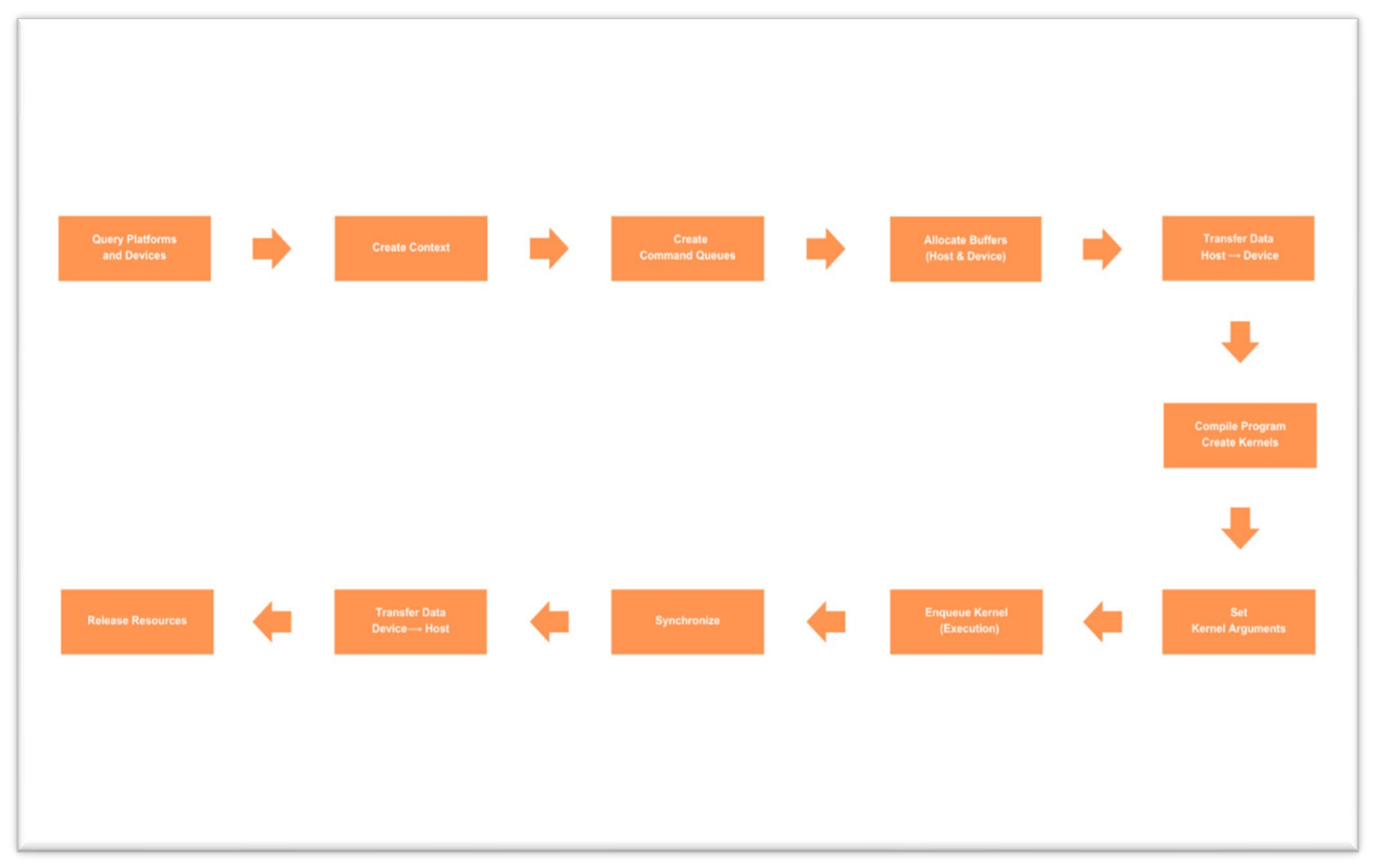
The process of setting up platforms and devices on the device and the platform starts with the inquiry of available platforms and devices, and secondly, creating an OpenCL context to handle the devices. After setup is done, for every device, a command queue is created to regulate the sequence of execution of operations.
Memory management involves buffer allocation in the device and data copying between the host and the device memory. Memory allocation is followed by the program and kernel stage wherein OpenCL programs (kernels) need to be written and compiled and kernel objects created from the compiled program.
On kernel execution, arguments to the kernel are configured, and the kernel is scheduled for execution on the device. Synchronization is achieved through the use of events and barriers to ensure correct execution order. Post-processing, data transfer operations copy results from device memory to host memory.
Finally, the cleanup operation frees all OpenCL resources, including memory, command queues, and context, to enable efficient resource management and system stability.
4.7. Comparative Analysis of Control Flow in CUDA and OpenCL
Both CUDA and OpenCL follow similar steps in their control flow for HPC applications, which include initialization, memory management, kernel execution, synchronization, data transfer, and cleanup. Here’s a detailed comparison:
| CUDA | OpenCL | |
|
|
|
|
|
|
|
|
|
|
|
|
| Exit Points Identification |
|
points. |
Briefly, by utilizing the High-Performance Computing (HPC) model, parallel methods provide a cost-effective way to possess the best benefit of computer execution. In effective control flow management in HPC software to guarantee correct instructions to be executed from initial startup to end execution, synchronization, message passing, termination, and the clean-up process occur in the correct time. CUDA and OpenCL, both widely used parallel computing platforms, are software which carry the onus of handling these control flows. Even though they undergo the same phases, they have special use of resources and management tactics. Through this control over the control flows, programmers can utilize GPUs and other parallel processors properly thus, play a role towards the improvement of the performances in HPC applications. By encapsulating control flow diagrams and taking advantage of the inconsistencies that result when porting these to other platforms, programmers are able to protect their programs against bugs and ambiguity.
4.8. Scalability
In high-performance computing (HPC), scalability refers to the capacity of a system to effectively handle growing workloads by making use of more processors, memory, and storage (Fischer et al., 2020). It is necessary to allow HPC systems to cope with the demands of intricate computational jobs and data-intensive applications without a corresponding rise in complexity or inefficiency. Network infrastructure, hardware, software, and applications are fundamental scaling determinants, as the system increases, these components must work together to deliver performance and efficiency (Fischer et al., 2020). System reliability, power consumption management, effective inter-process communication, parallel algorithm optimisation, and maintenance are major scaling issues. It will take continued innovation and revision in every area of HPC design to overcome these issues.
4.9. Hardware Scalability
Hardware scalability is of crucial importance to provide assurance in HPC that systems can be designed to absorb mounting workloads via processor and memory system optimization. New technologies like NVIDIA NVLink make this possible by building high-bandwidth, dense GPU systems with connectivity, e.g., DGX-2 and Summit. GPUs within a cluster are able to talk to each other at a faster rate and in a more efficient manner with these connections, increasing the overall computing power of the system and enabling it to process more tasks at a time. Memory bandwidth and latency are another important hardware scalability. Memory latency is the time between requesting data transfer and the initiation of the transfer, while memory bandwidth is the quantity of data that can potentially be transferred to and from memory in a given time period. More recent memory technologies like 3D-stacked DRAM have higher bandwidth than older memory technologies like DIMMs. This innovation for quicker data accessibility and processing is crucial to enhance system performance. Nevertheless, even with such optimization, memory latencies may remain a problem when using 3D-stacked DRAM.
Real-time analysis and profiling facilities are employed by HPC systems to optimize their performance and efficacy. Such profiling tools track how various communication patterns affect performance and are intended to be used within GPU-accelerated clusters. For instance, they assist in comprehending the effectiveness of data communication and GPU interaction. Realizing this assists in creating new algorithms and optimizing communication libraries, which improves the speed and performance of the system.
While designing scalable and high-performance HPC systems, innovative memory technologies, sophisticated monitoring tools, and GPU interconnects must be incorporated. Next-generation GPU interconnects like NVIDIA NV_Link improve system performance through fast and effective communication between GPUs. Novel memory technologies like 3D-stacked DRAM overcome key performance bottlenecks by delivering higher bandwidth and fast data access. Ensuring that the system is operating at maximum efficiency is made possible through sophisticated monitoring software that allows for real-time memory usage and communication behavior analysis and optimization. Through integrating these elements, HPC systems can maintain high levels of performance and scale up well even when computational demands are increased.
4.10. Software Scalability
In High-Performance Computing (HPC), scalability in software means that parallel algorithms are optimized to efficiently divide workloads across multiple processors or computers. This means that computing time decreases proportionally with an increase in the number of processors, so that bigger problems can be solved within an acceptable time frame. Parallel algorithms divide larger problems into smaller subproblems that can be solved simultaneously by running them on multiple computers at the same time. In order to maximize distributed and multi-core computer systems, the strategy is necessary.
Efficiently running parallel code on supercomputers and clusters requires the utilization of fundamental frameworks and libraries like CUDA, OpenMP, and MPI (Message Passing Interface). By facilitating management of parallel processing complexity, such technologies enable programmers to create software that is scalable and allows efficient computation on a variety of hardware architectures.
Some important factors, however, drive the realization of scalability. In an effort to avoid the situation where some processors are idle while others are overloaded with process, load balancing is necessary to ensure even work distribution among processors. Communication overhead is also a serious issue that can negatively affect performance, particularly in distributed systems where nodes must communicate with each other .Apart from maximizing computing performance and efficiency, construct efficiency in parallel programming is also necessary.
HPC systems can attain maximum scalability by properly evaluating these factors, thereby enabling effective execution of intricate problem-solving operations and large-scale computations.
4.11. Application Scalability
In HPC, application scalability is important for efficiently controlling and optimizing computational workloads on growing resources. load balancing, meaning the even distribution of the computational workload between processors and the prevention of any individual node becoming a bottleneck, is one important aspect. To optimize overall efficiency, strategies like task scheduling and dynamic load balancing are employed to adjust to changing workloads. In order to minimize dependencies and minimize the requirement for synchronization, parallel algorithms split tasks into smaller, independent units that could be run in parallel. Because it makes the most effective use of available processing power, effective parallelization is vital for program scaling. By reducing access latencies and connectivity costs, data locality also optimizes performance by making data reside close to the processing elements requiring it and to keep performance high, memory hierarchy use, and data placement must be done effectively. Programme productivity and performance can be improved by solving these factors completely so that programs can scale effectively and fully utilize High-Performance Computing resources to manage activities that become progressively complicated and demanding.
4.12. Network Scalability
A critical component in HPC is network scalability that involves monitoring and management tools, Software Defined Networking (SDN), and resilience and fault tolerance. SDN supports scalability through its modularized framework that is simple to extend and modify according to changing network requirements. Because of its flexibility, the SDN controller can scale to support more users or services without any loss of performance, successfully keeping up with the expanding needs of carrier-grade network. Static memory allocation and multi-threading are two other performance optimization strategies that SDN controllers use to achieve better responsiveness and successfully handle rising workloads. By anticipating problems and keeping the systems available, fault tolerance and resilience mechanisms play a vital role in network scalability. A consolidated fault management policy combines reactive approaches like checkpointing/restarting and replication with proactive approaches like proactive migration and software extension, the combination offering system continuity while anticipatory of, and minimization of, errors. Strong monitoring and management tools such as Octoshell and DiMMoN, which automate decision-making and monitor parameters round the clock, are critical to achieving network scalability effectively. The tools offer comprehensive monitoring and analysis capabilities to optimize system performance, tailored to HPC environments.
To address the growing needs of applications in high-end computing, HPC systems may achieve maximum network scalability with SDN, fault tolerance and reliability features, and improved monitoring and management capabilities.
5. Potential Applications
5.1. The Need for HPC Applications
With our rapidly changing world, the call for high-performance computing is growing with increasing data and computing requirements. There are serious problems in different domains such as medicine, engineering, business and weather forecasting and climatology that need to be resolved. Serious problems such as wave modelling, climate modelling and weather forecasting entail processing vast amounts of data. While classical models of computing provide a high-investment solution, raw performance provided by HPC hardware is extremely valuable, pushing the boundaries of parallel computing to new heights. The evolution in HPC has greatly enhanced the accuracy and efficiency of the models, allowing for better predictions, and understanding of complex environmental phenomena.
5.2. HPC Applications in Medicine
Medicine is one of the most vital domains we are able to make use of the High-Performance Computing (HPC) capabilities within. For example, we can use HPC in an attempt to find the treatment for Alzheimer's disease. The many genomes that need to be processed by scientists and joined together to develop images require big processing capacity in order to execute huge loads of data which could be 680 GB for every genome.
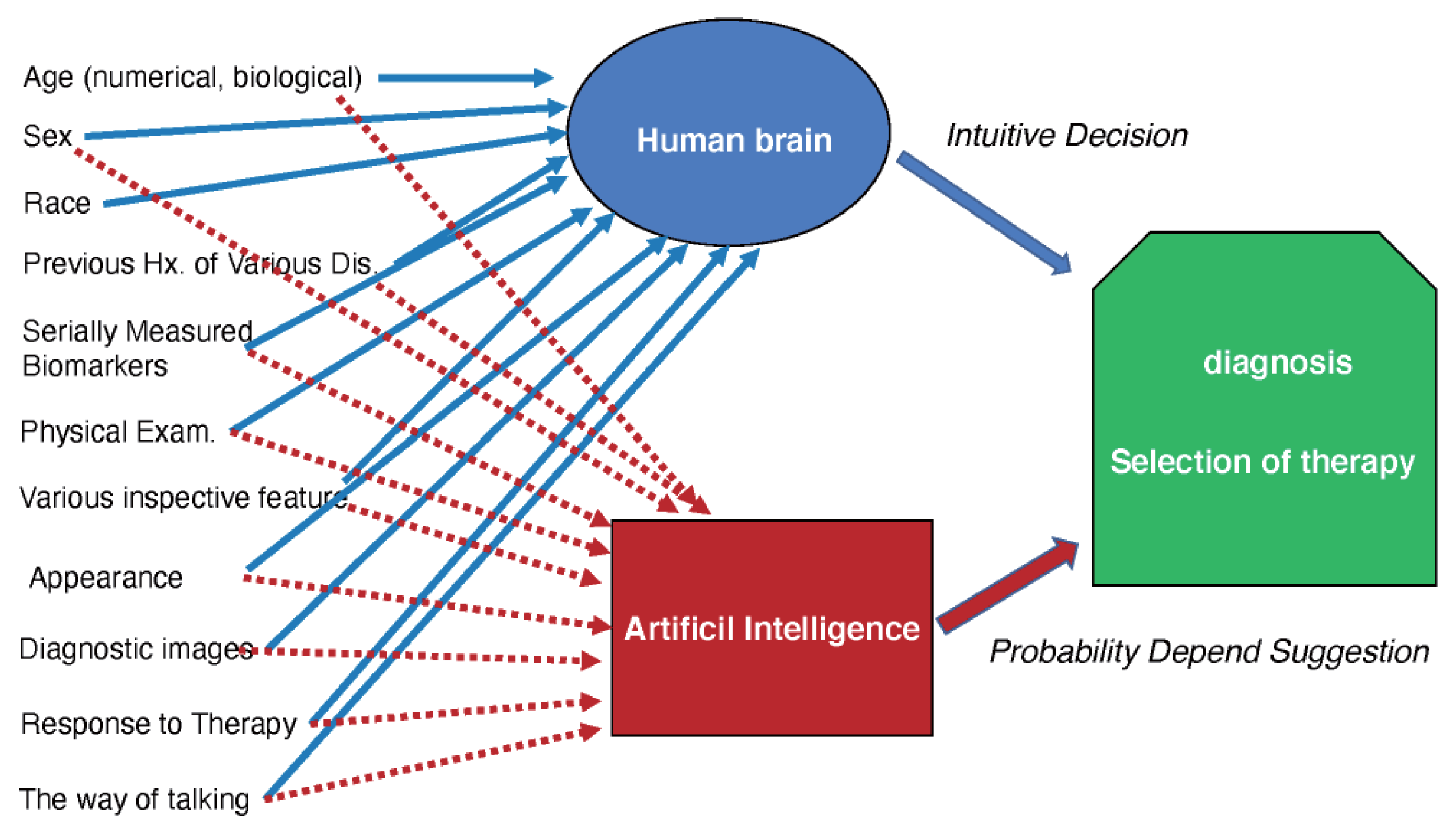
In addition to genome analysis, HPC makes it possible to apply AI created by neural networks in medicine, which can detect quantitative correlations between multidimensional data. Human medical decision-making relies on intuition, which is difficult to quantify and standardize. AI can transform this intuition into a quantifiable science, improving personalized medicine and clinical decision-making. Examples include AI-enhanced electrocardiography (ECG), ultrasonic echocardiography (UCG), and serial biomarker analyses, all of which enable patient-level cardiovascular disease risk prediction from multi-dimensional data.
Figure 6.
Illustration of human intuition decision and probability depend suggestion by AI.
5.3. HPC Applications in Biophysics
Applications of High-Performance Computing can be utilized to different streams of science that utilize simulations which need high processing power to compute the enormous amount of data and obtain a precise and trustworthy solution of the problem. In biophysics, researchers have utilized supercomputer-based parallel molecular dynamics simulations to determine the chemical structure of the HIV-1 capsid.
5.4. HPC Applications in Business
Research in business and economics is going computational with the sheer data volume. This development enables decision-making in real-time in IT security and stock trading, solving difficult optimization problems in manufacturing and logistics, and handling vast amounts of sensor, mobile phone, and social network data for use in social network analysis, fraud detection, and business analytics.
HPC Applications in Engineering
Engineers apply High-Performance Computing (HPC) to conduct large-scale tests and simulations on design models, significantly enhancing the design process. HPC allows engineers to simulate and analyze the operation of complex systems precisely and in depth, a prerequisite for the manufacturing of efficient and dependable designs. For instance, in the aviation industry, HPC is employed to simulate the operation of aircraft parts. Engineers can simulate various conditions and stress conditions so that all components can fulfill actual operating conditions. Similarly, in automotive engineering, HPC is used to optimize the racing bike frame design. Engineers run sophisticated simulations to analyze the aerodynamics and structural performance of different frame geometries. By varying the shape and material properties in the virtual environment, they can enhance the stability and velocity of the bicycles, leading to better performance on the track.
6. Conclusions
We have focused on various paradigms of computing with particular interest in High-Performance Computing (HPC) in this report. We have discussed the performance benchmarking, scalability, and efficiency of HPC, as well as underscored its critical contribution to solving complex computation problems. HPC is an innovative computing paradigm that enables massive data sets to be processed and sophisticated simulations to be performed, driving scientific advancements in the fields of climate modeling, genomics, and materials science, among many others. With the concentrative leveraging of computational power through clusters of powerful systems, advanced networking technologies, and custom hardware like GPUs and FPGAs, HPC provides unmatched processing power and efficiency. We evaluated the challenges of implementing HPC, such as addressing legacy assets, integrating numerous processors, and achieving workload homogeneity. Mitigating these challenges is vitally crucial in maximizing HPC performance and unlocking its full capacity.
Scalability remains a major issue in HPC with hardware and software capable of handling increasing burdens efficiently. Hardware scalability improvements in the guise of high-performance interconnects and memory technologies and software scalability through parallel algorithms and load balancing techniques are essential to maintain performance.
Briefly, HPC plays an essential role in next-generation computing, fueling innovation, and solving very complex issues in numerous areas. Our detailed examination restates the potential of HPC to bridge current technological deficits and bring about new horizons of development and progress.
References
- Al-Ansi, A., Al-Ansi, A. M., Muthanna, A., Elgendy, I. A., & Koucheryavy, A. (2021). Survey on intelligence edge computing in 6G: Characteristics, challenges, potential use cases, and market drivers. Future Internet, 13(5), 118. [CrossRef]
- Amaral, V., Norberto, B., Goulão, M., Aldinucci, M., Benkner, S., Bracciali, A., Carreira, P., Celms, E., Correia, L., Grelck, C., Karatza, H., Kessler, C., Kilpatrick, P., Martiniano, H., Mavridis, I., Pllana, S., Respício, A., Simão, J., Veiga, L., & Visa, A. (2019). Programming languages for data-intensive HPC applications: A systematic mapping study. Parallel Computing, 102, 102584. [CrossRef]
- Kuity, A., & Peddoju, S. K. (2023). Investigating performance metrics for container-based HPC environments using x86 and OpenPOWER systems. Journal of Cloud Computing, 12(1). [CrossRef]
- University of Vermont. (n.d.). Understanding the batch job system – VACC knowledge base. VACC Knowledge Base. Retrieved May 20, 2024, from https://www.uvm.edu/vacc/kb/knowledge-base/understand-batch-system.
- Microsoft Azure. (n.d.). What is PaaS? Platform as a service. Microsoft Azure. Retrieved May 20, 2024, from https://azure.microsoft.com/en-us/resources/cloud-computing-dictionary/what-is-paas.
- Boettiger, A. (2024). Comparing and contrasting ChatGPT 3.5, ChatGPT 4, ChatGPT 4 Turbo, and ChatGPT 4o. Copilot Institute. Retrieved May 20, 2024.
- Saeed, S., & Abdullah, A. (2021). Statistical analysis of the pre- and post-surgery of healthcare sector using high-dimension segmentation. Machine Learning Healthcare: Handling and Managing Data, 1(1), 1-25.
- Saeed, S., & Haron, H. (2021). A systematic mapping study of low-grade tumor of brain cancer and CSF fluid detecting in MRI images. Approaches and Applications of Deep Learning in Virtual Medical Care, 1(1), 1-25.
- Burns, B. (2019). Kubernetes: Up and running. O’Reilly Media.
- Buyya, R., Netto, M. A. S., Toosi, A. N., Rodriguez, M. A., Llorente, I. M., Vimercati, S. D. C. D., Samarati, P., Milojicic, D., Varela, C., Bahsoon, R., Assuncao, M. D. D., Srirama, S. N., Rana, O., Zhou, W., Jin, H., Gentzsch, W., Zomaya, A. Y., Shen, H., Casale, G., & Calheiros, R. (2018). A manifesto for future generation cloud computing. ACM Computing Surveys, 51(5), 1–38. [CrossRef]
- Corral-García, J., Lemus-Prieto, F., & Pérez-Toledano, M. Á. (2020). Efficient code development for improving execution performance in high-performance computing centers. The Journal of Supercomputing, 77(4), 3261–3288. [CrossRef]
- Avasalcai, C., Murturi, I., & Dustdar, S. (2020). Edge and fog: A survey, use cases, and future challenges. Fog Computing, 43–65. [CrossRef]
- Alferidah, D. K., & Jhanjhi, N. Z. (2020, October). Cybersecurity impact over big data and IoT growth. In 2020 International Conference on Computational Intelligence (ICCI) (pp. 103-108). IEEE. [CrossRef]
- Jena, K. K., Bhoi, S. K., Malik, T. K., Sahoo, K. S., Jhanjhi, N. Z., Bhatia, S., & Amsaad, F. (2022). E-learning course recommender system using collaborative filtering models. Electronics, 12(1), 157. [CrossRef]
- Aherwadi, N., Mittal, U., Singla, J., Jhanjhi, N. Z., Yassine, A., & Hossain, M. S. (2022). Prediction of fruit maturity, quality, and its life using deep learning algorithms. Electronics, 11(24), 4100. [CrossRef]
- Kumar, M. S., Vimal, S., Jhanjhi, N. Z., Dhanabalan, S. S., & Alhumyani, H. A. (2021). Blockchain-based peer-to-peer communication in autonomous drone operation. Energy Reports, 7, 7925-7939. [CrossRef]
- Saeed, S., & Haron, H. (2021). A systematic mapping study of low-grade tumor of brain cancer and CSF fluid detecting approaches and parameters. Approaches and Applications of Deep Learning in Virtual Medical Care, 1(1), 1-30. [CrossRef]
- Saeed, S., Abdullah, A., Jhanjhi, N. Z., Naqvi, M., & Ahmed, S. (2020). Effects of cell phone usage on human health and specifically on the brain. In Machine learning for healthcare (pp. 53-68). Chapman and Hall/CRC.
- Saeed, S., Jhanjhi, N. Z., Naqvi, M., Humayun, M., & Ponnusamy, V. (2021). Quantitative analysis of COVID-19 patients: A preliminary statistical result of deep learning artificial intelligence framework. In ICT solutions for improving smart communities in Asia (pp. 218-242). [CrossRef]
- Saeed, S., Jhanjhi, N. Z., Naqvi, S. M. R., & Khan, A. (2022). Cost optimization of software quality assurance. In Deep learning in data analytics: Recent techniques, practices, and applications (pp. 241–255). [CrossRef]
- Saeed, S., Jhanjhi, N. Z., Naqvi, S. M. R., & Khan, A. (2022). Analytical approach for security of sensitive business cloud. In Deep learning in data analytics: Recent techniques, practices, and applications (pp. 257–266). [CrossRef]
- Saeed, S., Jhanjhi, N. Z., Naqvi, M., Ponnusamy, V., & Humayun, M. (2020). Analysis of climate prediction and climate change in Pakistan using data mining techniques. In Industrial Internet of Things and cyber-physical systems: Transforming the conventional to digital (pp. 321–338). [CrossRef]
- NVIDIA. (n.d.). CUDA C++ programming guide. NVIDIA Developer Documentation. Retrieved May 20, 2024, from https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#control-flow-instructions.
- Fischer, P., Min, M., Rathnayake, D. T., Dutta, S., Kolev, T., Dobrev, V., Camier, J.-S., Kronbichler, M., Warburton, T., Świrydowicz, K., & Brown, J. (2020). Scalability of high-performance PDE solvers. International Journal of High Performance Computing Applications, 34(5), 562–586. [CrossRef]
- Gill, S. S., Wu, H., Patros, P., Ottaviani, C., Arora, P., Pujol, V. C., Haunschild, D., Parlikad, A. K., Cetinkaya, O., Lutfiyya, H., Stankovski, V., Li, R., Ding, Y., Qadir, J., Abraham, A., Ghosh, S. K., Song, H. H., Sakellariou, R., Rana, O., & Rodrigues, J. J. P. C. (2024). Modern computing: Vision and challenges. Telematics and Informatics Reports, 13, 100116. [CrossRef]
- Goto, S., & McGuire, D. K. (2022). The future role of high-performance computing in cardiovascular medicine and science - Impact of multi-dimensional data analysis. Journal of Atherosclerosis and Thrombosis, 29(5), 559–562. [CrossRef]
- Hager, G., & Wellein, G. (2010). Introduction to high-performance computing for scientists and engineers. CRC Press. [CrossRef]
- Jenni AI. (2023). Natural language processing in ChatGPT: An in-depth exploration. Jenni AI. Retrieved May 20, 2024, from https://jenni.ai/chat-gpt/nlp.
- Martens, J. (2023). HPC challenges: Overcoming platform complexity. Penguin Solutions. Retrieved May 20, 2024, from https://www.penguinsolutions.com/company/resources/newsroom/hpc-challenges-overcoming-platform-complexity.
- Lindsay, D., Gill, S. S., Smirnova, D., & Garraghan, P. (2021). The evolution of distributed computing systems: From fundamental to new frontiers. Computing. [CrossRef]
- Meador, D. (2020). Client-server computing. Tutorialspoint. Retrieved May 20, 2024, from https://www.tutorialspoint.com/Client-Server-Computing.
- Owaida, M., Bellas, N., Daloukas, K., & Antonopoulos, C. D. (2011). Synthesis of platform architectures from OpenCL programs. 2011 IEEE 19th Annual International Symposium on Field-Programmable Custom Computing Machines. [CrossRef]
- Paulose, J. (2023). Spark: A deep dive into the distributed computing powerhouse. Medium. Retrieved May 16, 2024, from https://medium.com/@paulosejithu/spark-a-deep-dive-into-the-distributed-computing-powerhouse-967897792e72.
- Kousha, P., Ramesh, B., Suresh, K. K., Chu, C.-H., Jain, A., Sarkauskas, N., Subramoni, H., & Panda, D. K. (2019). Designing a profiling and visualization tool for scalable and in-depth analysis of high-performance GPU clusters. 2019 IEEE 26th International Conference on High Performance Computing, Data, and Analytics (HiPC). [CrossRef]
- Radulović, M. (2023). Memory bandwidth and latency in HPC: System requirements and performance impact. Tesis Doctorals en Xarxa. [CrossRef]
- Aldughayfiq, B., Ashfaq, F., Jhanjhi, N. Z., & Humayun, M. (2023). Explainable AI for retinoblastoma diagnosis: interpreting deep learning models with LIME and SHAP. Diagnostics, 13(11), 1932. [CrossRef]
- Attaullah, M., Ali, M., Almufareh, M. F., Ahmad, M., Hussain, L., Jhanjhi, N., & Humayun, M. (2022). Initial stage COVID-19 detection system based on patients’ symptoms and chest X-ray images. Applied Artificial Intelligence, 36(1), 2055398. [CrossRef]
- Lee, S., Abdullah, A., & Jhanjhi, N. Z. (2020). A review on honeypot-based botnet detection models for smart factory. International Journal of Advanced Computer Science and Applications, 11(6). [CrossRef]
- Shah, I. A., Jhanjhi, N. Z., & Laraib, A. (2023). Cybersecurity and blockchain usage in contemporary business. In Handbook of Research on Cybersecurity Issues and Challenges for Business and FinTech Applications (pp. 49-64). IGI Global. [CrossRef]
- Muzafar, S., & Jhanjhi, N. Z. (2020). Success stories of ICT implementation in Saudi Arabia. In Employing Recent Technologies for Improved Digital Governance (pp. 151-163). IGI Global. [CrossRef]
- Gill, S. H., Razzaq, M. A., Ahmad, M., Almansour, F. M., Haq, I. U., Jhanjhi, N. Z., ... & Masud, M. (2022). Security and privacy aspects of cloud computing: a smart campus case study. Intelligent Automation & Soft Computing, 31(1), 117-128. [CrossRef]
- Kumar, M. S., Vimal, S., Jhanjhi, N. Z., Dhanabalan, S. S., & Alhumyani, H. A. (2021). Blockchain based peer to peer communication in autonomous drone operation. Energy Reports, 7, 7925-7939. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



