Submitted:
17 January 2025
Posted:
17 January 2025
You are already at the latest version
Abstract
The rapid evolution of computing paradigms has transformed technological innovation dramatically. This paper will dwell on the changing tide from mainframe centralized and to decentralized versions such as grid, cluster, and edge computing, focusing particularly on the elaboration of the concept of the cloud computing paradigm. Cloud computing-represented in scalability, cost-efficient, and accessible-manner-turned out to be revolutionary for IT infrastructure and new business model. Key aspects analyzed include programming models, such as MapReduce and Bulk Synchronous Parallel, performance metrics, scalability, and control flow, to identify the strengths of cloud computing compared to other paradigms. Possible applications, like artificial intelligence, genomics, and e-commerce, are also mentioned to show its versatility. The study concludes that cloud computing stays at the front of contemporary technologies and enables innovation and efficiency never realized before.
Keywords:
Cloud Computing
; Grid Computing
; Innovative technologies
; Virtualization
1. Introduction
The computing industry has grown exponentially since the late 20th century, with rapid advancement in technology and a continuous striving for innovation. This growth has led to a number of computing paradigms, each of which was developed to solve certain problems and enhance system performance. Examples of such paradigms include high-performance computing, parallel computing, distributed computing, grid computing, and, in recent times, cloud computing. Each paradigm represents a different organizational way of managing and efficiently using computing resources. Especially, cloud computing has now emerged as a paradigm that is overwriting the conventional model of information technology and making the technological resources more accessible, scalable, and at economical resources. The concept of cloud computing first evolved in the 1960s, although it actually started to take more realistic shapes in the early 21st century with IaaS, PaaS, and SaaS. Visionaries like John McCarthy laid the bedrock for this transition when he envisioned computing as a utility [1,2,3].
Today, big data analytics, artificial intelligence, and IoT solutions are just some of the varied applications of cloud computing that organizations use. The paper discusses the historical background, technical rationale, and critical assessment of cloud computing. It further looks at cloud computing from other paradigms, such as grid and cluster computing, and pinpoints its unparalleled advantages in scalability, performance, and flexibility. Additionally, the study discusses the potential applications of technology in industries for innovation and addressing the demands of a data-driven world [4].
2. Literature Review
Cloud computing resonates with the current dynamic state of technology and changes with the demands which are continuous. Being the very essence of modern computing, it has become a paradigm with high scaling efficiency, low-cost service opportunities, and massive accessibility of resources. This literature review encapsulates some of the most prominent insights concerning relevant developments in the field, technical underpinnings, and comparative advantages when placed alongside other paradigms like grid or cluster computing. The idea of shared computing resources is rooted in the 1960s, when John McCarthy described computation as a public utility, like electricity. This vision sets the basis for what, in the future, would be known as cloud computing. In the late 1990s and early 2000s, significant progress took place: Amazon, for example, released Amazon Web Services (AWS), changing the way IT infrastructure was provided with on-demand computing services. Salesforce further developed Software as a Service (SaaS) models, making enterprise software accessible over the internet [5,6,7,8].
Cloud computing covers three main service models: Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). Each model fulfills certain needs of business applications: IaaS offers virtualized computing resources, like servers, storage, and networking. It thus enables companies to expand their infrastructure dynamically without major initial investments. PaaS provides a development platform to create, deploy, and manage applications without worrying about the management of the underlying infrastructure. SaaS delivers software applications over the internet, which eliminates the need for local installations and also reduces maintenance overhead.
The technical foundation of cloud computing is based on virtualization, distributed systems, and high-performance networking. Virtualization enables the sharing of hardware resources by running virtual instances on top of each other on the same physical hardware. Programming models like MapReduce and Bulk Synchronous Parallel have become indispensable in processing big volumes of data in cloud environments. While MapReduce, popularized by Google, offers a facility for distributed processing based on a divide-and-conquer approach, BSP provides a more structured framework for parallel processing [9,10,11,12].
Cloud computing differs from other paradigms like grid computing and cluster computing in that cloud computing is flexible, scalable, and centrally managed. The main difference between cloud and grid computing is that grid computing shares resources in a decentralized manner on widely distributed networks. Although suited for applications with intensive computation requirements, grid computing is not as scalable or user-friendly compared to cloud computing platforms. Cluster Computing: Cluster computing is a form of computing where multiple nodes are interconnected to behave as one system. Although it provides high-performance computing, it requires huge upfront investment in dedicated hardware and does not offer elastic scalability like cloud computing [13,14,15,16,17,18].
The main benefits of cloud computing are its performance and scalability. Dynamic resource allocation based on demand provides cost-effectiveness and flexibility in operations. Auto-scaling by AWS and Microsoft Azure is an example of such capability, where virtualization further increases resource utilization with multiple applications sharing the same resources without interfering with one another. The applications of cloud computing range from e-commerce to artificial intelligence. Cloud platforms in healthcare allow for the storage and analysis of large datasets related to genomic research. E-commerce companies leverage cloud services to scale up dynamically during high traffic. Emerging technologies like the Internet of Things and edge computing further extend cloud computing to enable real-time data processing and decision-making [19,20,21,22,23,24].
Despite the various advantages, cloud computing faces challenges like data security, latency, and dependency on good internet connectivity. Overcoming these challenges involves the development of encryption technologies, hybrid cloud solutions, and integration of edge computing [25,26,27,28,29]. Future research may be directed toward optimization of energy efficiency and integration of quantum computing for better capabilities of the cloud [30,31,32,33,34]. Cloud computing is a paradigm shift that took the notion of computing to a whole new level. Its historical evolution, strong technical grounding, and unrivaled flexibility make it a very important enabler of innovation in many industries. With the convergence of emerging technologies with cloud computing, its role will further increase in driving efficiency and allow new possibilities in solving complex problems [35,36,37,38,39,40,41,42,43]. Recent advancements in deep learning and spatiotemporal data analysis have shown significant potential in enhancing cloud-based systems for real-time processing and resource optimization, crucial for the evolution of smart cities [44]. The growing use of UAVs in smart cities highlights the need for secure communication protocols, a critical aspect for ensuring the reliability and security of cloud-based applications [45]. The evolution of cybersecurity threats, particularly ransomware, underscores the necessity of incorporating robust security measures in cloud computing to protect sensitive data [46]. Energy harvesting models have emerged as a promising approach to support the sustainability of IoT systems, which are increasingly integrated with cloud computing for optimized performance [47]. Hybrid machine learning models offer efficient solutions for processing and analyzing large-scale cloud data, enhancing cloud service capabilities [48]. Transfer learning methodologies are being utilized to improve predictive models in cloud environments, enabling more efficient resource allocation and management [49]. The application of machine learning in stock market prediction showcases the evolving role of data analytics in cloud computing platforms for real-time decision-making [50]. Industry 4.0 technologies are driving innovation in cloud computing, enabling more intelligent and scalable systems for industrial applications [51]. The rapid digital transformation driven by the COVID-19 pandemic has accelerated the adoption of cloud-based services, reshaping the landscape of remote work and digital interactions [52]. Expert systems for predictive analysis, such as those used in power generation, can be adapted to optimize resource management in cloud computing environments [53]. The use of convolutional neural networks in detecting anomalies in medical data offers insights into improving cloud-based systems for enhanced data security and real-time analytics [54]. The integration of IoT and blockchain technologies within cloud computing frameworks promises to improve transparency, security, and efficiency in decentralized systems [55].
3. Proposed Methodology
Procedure-oriented programming is the standard computing paradigm used in the majority of scientific applications. When employing the procedure-oriented paradigm, the primary responsibility of a software engineer is to determine which procedures that is, data manipulations are needed to address a given problem, and which algorithms work best for them. The procedure or subroutine with its input and output data is the structural component of a procedure-oriented code. Generally speaking, this programming style produces a large number of global and sparse local data. Either explicitly or through common blocks, the global data are passed from one function to the next. When a sophisticated piece of software needs to be debugged, altered, or expanded beyond the scope of its original purpose, this breach of the data locality principle in software engineering can result in serious issues.
3.1. Phases of Computer Paradigm
The computing paradigm has undergone several marked phases of evolution, each typified by technological changes and ways in which data processing and resources are managed. The first paradigm was that of mainframe computing-a centralized paradigm. Unlike modern distributed systems that split up their workloads across a set of devices, the central processing resource was a single mainframe. Equipped with a great deal of processing power, huge data storage, and strongly featured security, mainframes are highly reliable, scalable, and adept at processing large datasets. Their fault tolerance and uptime made them ideal for operation on a continuous basis, while security features allowed it to manage highly sensitive data.
The mid-20th century saw a shift in paradigm towards client-server computing. With the advent of personal computers, processing duties became decentralized, shifting away from a central mainframe. PCs used to work on the principle of serial processing-a paradigm where it performed tasks sequentially. PCs were initially done basic applications like spreadsheet and word processing. In due course of time, PCs emerged with advanced technological features that had the capacity for distributed and parallel computing models, thus supporting client-server and cloud-based architectures. Unlike centralized mainframes, PCs are stand-alone systems for interactive tasks by one user; security varies with users and software configuration as shown in Figure 1.
Advantages:
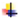
- High Reliability: Mainframes have outstanding fault tolerance and uptime since they are built for continuous operation.
- Strong Security: Mainframes have excellent security features, which make them perfect for managing sensitive data.
- Scalability: By adding more processors and storage, mainframes can be expanded to meet expanding requirements.
- Data management: Mainframes are particularly good at effectively managing large datasets.
A paradigm shifts toward client-server computing occurred in the mid-20th century. As strong clients, personal computers emerged, taking processing duties away from the mainframe at the center. For some applications, cloud computing now provides a more economical and flexible option.
3.2. Network Computing
Network computing provided a paradigm whereby several computers and other devices work together over networks, allowing resource sharing, communication, and information sharing. This approach allows the sharing of hardware resources, such as printers and pooled storage, software through network licenses, and data such as documents and databases. Some key benefits involve cost reduction due to the better use of resources; central management, which allows for easier upgrading and administration of software; collaboration enhancements due to shared access; scalability for additional users and devices; and connectivity anywhere, anytime to data and applications over the Internet as shown in Figure 2.
3.3. Internet Computing
Internet computing is a flexible, scalable means of distributing computing resources and services via the infrastructure of the internet. In this regard, resources like computing and storage do not have to be hosted locally but can be made available from elsewhere with lower cost and greater ease. Scalability, cost-effectiveness through pay-as-you-go, universal access, collaboration enhancement because of real-time data sharing, flexibility to support most computing services and applications as shown in Figure 3.3
3.4. Benefits of Internet Computing
- Scalability: Easily adjust resources to meet demand by scaling them up or down.
- Cost-Effectiveness: Users only pay for the resources they really utilize, which lowers the price of both software and hardware.
- Accessibility: Anyone with an internet connection can use services and apps from any location.
- Collaboration: Real-time data sharing facilitates smoother cooperation on projects.
- Flexibility: Provides a greater selection of computer services and alternatives.
3.5. Grid Computing
Grid computing uses the power of geographically dispersed computers to amass their collective power in handling complex or resource-intensive tasks. Unlike traditional client-server arrangements, grid computing employs a decentralized model where several systems come together to create a virtual supercomputer. This model is effective in large-scale projects and ensures high performance, scalability, and cost-effective utilization of already-owned resources. The sharing of resources allows for collaboration in various projects.
Benefits of grid computing:
- High Performance: Resolves complex problems far more quickly than a solitary computer could.
- Scalability: Depending on the requirements of the task, the grid can be readily scaled up or down.
- Cost-Effectiveness: Reduces the need for costly new gear by making use of already- existing computer resources.
- Resource sharing: Enables groups to work together on big projects and share computer resources.
3.6. Cloud Computing
Cloud computing is a big transitional phase of the computing paradigm that provides on-demand resources over the internet, such as storage, processing power, and software. It works on a pay-as-you-go model, which means there will be no upfront investments in hardware and software. Cloud computing is highly scalable, cost-effective, accessible from any geographical boundary and at any time with an on-internet-connected device, secure due to investments by the provider in advanced security measures, and reliable with in-built disaster recovery and high availability features.
Benefits of cloud computing:
- Scalability: You may simply scale up or down resources to suit your needs. Forget about initial hardware expenses.
- Cost-Effectiveness: By just paying for what you use, you may do away with the requirement for pricey software and hardware maintenance.
- Accessibility: Anywhere with an internet connection can access data and apps.
- Security: To safeguard your data, cloud companies make significant investments in security procedures.
- Reliability: Disaster recovery and high availability are built into cloud services.
There are several phases of computer paradigm, which is widely used by big companies and organizations, each phase offers a different service in a different need, meeting the need and requirements of everyone. Each phase has its pros and cons, it’s up to the user or the organization to choose what phase of computer paradigm they want to implement given their specific situation and circumstances.
4. Major Technological Drivers in the Computer Paradigm and Their Evolution
4.1. Edge Computing
The newest paradigm, edge computing, addresses low-latency processing by bringing computation closer to the source of the data. Unlike the cloud centralized model, edge computing processes, analyzes, and stores data locally on the edge of the network for real-time responsiveness. This is key in application situations like smart city traffic light control, robotic lines in manufacturing, and others requiring advanced inventory systems. Edge computing enables cloud capabilities via the use of distributed infrastructure-which includes infrastructure such as cloudlets and nodes of multi-access edge computing. Some general benefits of a cloudlet-enabled edge-based architecture include the following: increased availability.
Each of these different phases of the computing paradigm brought unique capabilities to the fore: mainframe computing, client-server models, PC computing, network computing, internet computing, grid computing, cloud computing, and edge computing. Organizations and users select paradigms based on their needs, which involve trade-offs in areas such as cost, scalability, security, and performance. These paradigms together define the technological landscape, create innovation, and adapt to the changing demands of modern computing as shown in Figure 4.
4.2. Evolution of Edge Computing
Edge computing initially started in the 1960-1970s during the Mainframe Era, which was highly centralized. Substantial, rigid mainframes were deployed to physical data centers, mostly maintained by large organizations because they were complex and expensive. These systems undertook all network computing tasks, thus offering a centralized approach to data storage and processing. User-level operations became very limited in nature, consisting mostly of data input using simple, unfeatured terminals-no choice of fonts, no graphics, and no contemporary peripherals such as a mouse. Such would be manual airline reservations on systems containing small processing and monochromatic display capabilities, many of which exist today in legacy systems.
In the 1980s-1990s, the Client/Server Era took center stage with advancements in microprocessor technology championed by firms like Intel. Now, with standard microprocessors and compact servers, computing has moved into the home and small business arena. PCs had become powerful enough to perform such tasks as word processing, spreadsheets, and databases on the desktop and could connect with larger projects and data storage centers. This was an era that truly signaled the move toward distributed computing, where users and organizations could exploit local processing while remaining connected to centralized resources. Moore’s Law, with its prediction of the doubling of transistor density every 18 months, remained the guiding principle of technological advances throughout this era.
The Cloud Era, the 2000s-2010s, saw the rise of cloud computing that transformed the IT landscape. The arrival of the smartphones and tablets, accompanied by ubiquitous access to the Internet, further distributed computing. Companies began using cloud platforms like Microsoft Azure and AWS to move their storage and processing of data offsite to decrease on-premise infrastructure costs. The benefits included massive reductions in cost, less administrative overhead, and the ability to scale almost indefinitely. Yet, the cloud brought its own set of challenges, such as growing provider fees and networking costs. This was the era of SaaS companies like Spotify, Netflix, and Salesforce that dominated the scene, using cloud infrastructure to seamlessly deliver their services.
Starting in 2010, driven by the advent of IoT, multisite companies, and the enormous amount of data being generated outside the data centers, a new era began- the Edge Computing Era. Edge computing moves processing near the sources generating data, allowing for higher speeds in analysis and response time. Lightweight and low-cost systems are deployed in small, dispersed locations, with most being programmatically controlled from a central location. Indeed, this paradigm constitutes the second coming of decentralized computing because of its resemblance to the client/server model, addressing unique problems brought about by IoT applications. In recent years, edge computing has been adopted more extensively because it simplified many thorny issues that IT professionals had to put up with, aside from providing low latency for real-time data processing.
4.3. Internet of Things (IoT) Devices
Further evolving this concept of edge computing are Internet of Things devices. IoT includes a network of things physical devices, appliances, vehicles, industrial machinery that would normally operate manually but are integrated with sensors, software, and connectivity, providing the capability of collecting and sharing data. It refers to smart home thermostats and wearables to complex industrial systems and stands as the fundamental platform in smart cities or the wider IoT ecosystem. By integrating IoT with edge computing, technologists can offer scalable and efficient solutions for modern challenges while guaranteeing seamless data collection, processing, and sharing in various applications as shown in Figure 5.
Benefits of IoT:
IoT presents several advantages, changing the way businesses and people function. Some of the major advantages are as follows:
Improved Efficiency: IoT devices make one more productive by automating and optimizing. For example, IoT sensors can monitor the performance of machines and detect and fix potential problems before they actually create downtime. This proactive approach to maintenance reduces costs and enhances system uptime, hence improving operational efficiency.
Data-Driven Decision Making: IoT devices generate huge amounts of data that can be analyzed for insights into customer behavior, market trends, and operational performance. These insights enable a business to make informed decisions on strategy, product development, and resource allocation for innovation and growth.
Cost Savings: The IoT, therefore, through automation, cuts operational costs since it minimizes or does away with much of the manual processing. The IoT devices can even monitor and optimize energy usage hence reducing bills and boosting sustainability.
4.4. Evolution of IoT
The Internet of Things has seen rapid evolution from simple connected devices to complex systems, bringing revolutionary changes in whole industries:
The very origin of IoT comes from the concept of integrating daily items like thermostats and refrigerators into the internet, so they can be accessed and controlled remotely. The first ever IoT device was a toaster, made by John Romkey in 1990, marking the conceptual birth of a “smart home” where technology began to intermix with day-to-day life.
Industrial Applications: The possibilities of IoT went way higher with the integration into industrial environments. Manufacturers started integrating sensors and communication tools into their machinery to monitor conditions for predictive maintenance, hence decreasing unplanned downtime and increasing efficiency.
Edge computing and machine learning developed further to push data analysis and decision-making to the device level in real-time, reducing latency and further improving reliability. This enables IoT to support applications with a need for immediate responses, such as autonomous vehicles and industrial automation.
Higher Speed of Connectivity: 5G allows higher data transfer speeds; thus, IoT devices communicate and act faster, which enables the realization of various innovations like real-time health monitoring and complex robotics.
Edge Computing: Processing closer to the source of generation, also known as edge computing, has reduced latency and improved applications that rely on real-time data analysis to make decisions, such as autonomous vehicles.
IoT has been revolutionized by machine learning algorithms, which have empowered devices to analyze vast datasets and make automatic adjustments based on behavior patterns observed. This has facilitated smarter systems that can learn and evolve over time.
We have significantly lowered response times by relocating some processing activities to the edge, or the location where data is created, which has allowed autonomous vehicles to become a reality.
4.6. The Cloud Computing Paradigm
Cloud computing introduces a conceptual revolution in how computing resources are subscribed to and exploited. Utilizing the internet as a medium for delivering scalable, elastic, and financially attractive services on actual usage, the cloud has practically become the foundational element of running modern businesses efficiently and fostering innovation across industries today, from small to large corporations, and government sectors as shown in Figure 6.
4.7. Historical Context and Technological Evolution
The origin of cloud computing, in other words, had been conceptual even since the idea of shared resource and utility computing was broached. Thus, John McCarthy, among others, suggested, as far back as in the 1960s, a revolutionary proposal: “computation be operated as a public utility” to perform calculations as a cloud does. By the late 1990s and into the early 2000s, companies like Amazon and Salesforce started to create a footprint in cloud computing not only by founding infrastructures but also with revolutionary business models. AWS (Amazon Web Services) from Amazon marked a paradigm shift in the way business looked at IT resources by making scalable and efficient solutions available that could dynamically adapt to demand.
4.8. Cloud Computing Models
Cloud computing has revolutionized the technological world by providing scalable and flexible services over the internet. The services are categorized into three main models, each designed to meet specific business needs. These include:
Infrastructure as a Service (IaaS):
IAAS provides virtualized computing resources over the Internet, fundamental offering of infrastructure: virtual servers, operating systems, networks, and storages. Thus, it follows the pay-per-use pricing model in which the user can give resources to allocate storage, configure and manage the virtual server. Some key players offering IAAS services are Amazon Web Service, Microsoft Azure, Google Cloud Platform.
Platform as a Service:
PaaS provides an environment for application development. It enables customers to develop, run, and manage applications without the underlying infrastructure complexity of building and maintaining it. Popular PaaS solutions include Google App Engine, Microsoft Azure App Services, and Heroku.
Software as a Service (SaaS):
SaaS is a licensing model, which provides access to software applications often via the internet on a subscription basis. It is the most popular cloud service model in corporate adoption, comprising applications hosted on the server that can be accessed over the internet or an API. Solutions of SaaS can be executed on every device with minimalistic user interfaces. Some well-known examples are Google Workspace, Microsoft 365, and Salesforce.
Because different models offer differing levels of control, flexibility, and management, each business may choose what fits their needs best and handle everything from just hosting a simple website to constructing an application fast or deploying robust, mission-critical applications as shown in Figure 7.
Generally, scalability at which businesses may easily scale their resource use up and down as per the changing need is provided by cloud computing. Vendors usually ensure higher uptimes and minimal disturbance by upgrading system resources with better performance regularly. From the economic perspective, cloud computing promotes cost efficiency from the elimination of the need to expend enormous outlay capital on acquiring hardware and further reduces maintenance operations costs. Potentially, Various Applications and their Future Prospect
Cloud computing has a wide range of applications-from data storage and backup solutions right up to advanced operations in the fields of AI and ML. It serves all sectors, be it health, finance, education, and government, by empowering them in the processing of voluminous data in an effective manner and enhancing their service delivery. In the future, cloud computing will be integrated more with other emerging technologies like AI and IoT, thus increasing its scope further and changing the future of technology.
4.9. Performance and Scalability
Cloud computing excels in performance and scalability. Architecture allows organizations to effectively utilize computing resources by scaling up or down depending on demand. This was evident in 2002 when Amazon started using cloud infrastructure for its retail services, showcasing a major improvement in resource utilization. Today’s cloud services offer dynamic scalability that meets fluctuating workloads while assuring peak performance without requiring heavy upfront investments in physical infrastructure.
4.10. Programming Model and Control Flow
The programming model in cloud computing is typically event-driven, supporting asynchronous operations which are crucial for developing scalable applications. This model complements the distributed nature of cloud computing, where applications can be designed to operate across multiple cloud environments, often incorporating microservices architecture. Control flow in these environments is managed to ensure that operations are performed reliably and in sequence where necessary, even across distributed components.
4.11. Potential Applications
The potential applications of cloud computing are vast and continually expanding. Initially focused on storage and computer services, cloud platforms now also offer sophisticated analytics, artificial intelligence, machine learning, and Internet of Things (IoT) capabilities. These services are transforming industries by enabling innovative applications in healthcare, finance, manufacturing, and public services among others.
5. Critical Analysis
In this Section of our report, we will be critically analyzing our chosen paradigm, Cloud computing. Here we will analyze several key things that are essential in any computing paradigm. First things first, we will discuss the programming models being used in cloud computing which usually refers to the conceptual framework and a set of rules that determine how the software components interact with each other. Performance is also very vital in any computing paradigm, it tells us of how quickly tasks can be performed and are usually measured in terms of processing power, clock speed or instructions per second. We will compare it against other computing paradigms as to get a clear view of which paradigm performs better. We will also be looking into the control flow of things, about how it executes a sequence of instructions in a program. We will also determine the scalability of cloud computing, about its capability to handle increasing workloads or to accommodate growth without sacrificing performance or efficiency. Lastly, we will elaborate a bit on its potential applications and how it can be used to solve real world problems. Let us begin;
6. Programming Model
When it comes to programming models there are quite a few that are used in cloud computing. But we will be highlighting a select few that are vital and essential amongst other programming models.
6.1. Map Reduce Model
Map Reduce is a Java-based, distributed execution framework within the Apache Hadoop ecosystem. It is a powerful programming model that is used to efficiently process large datasets in a distributed manner. It has 2 main functions or two tasks to complete, which are Map and Reduce. The approach taken by this model is basically to ‘divide and conquer’, where large sets of data are broken down into small chunks and processed then re-assembled. It is usually a 4-step process, Map – Sort – Merge – Reduce.
Map uses key-value pairs to map the input data to. The key can be some sort of id or something that identifies the value and the value will hold the actual value/data which can be identified by the key as shown in Figure 8.
The sort and merge step groups the data accordingly into an array, in which each element there is a group of values for each key. It is then sent to the Reduce step where the Reduce() function will be applied.
Reduce then takes the key-value pairs from the Map as input. It goes through all the keys and performs the reduce function on them. The Reducer groups the data based on its key-value pair. It produces the final output and stores the data somewhere on the disk as shown in Figure 9.
Figure 9.
Reduce Function.
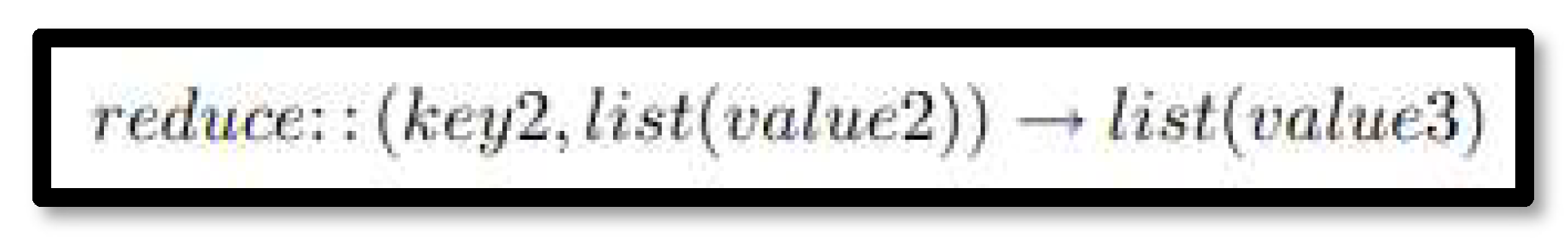
Figure 10.
Computation of MapReduce.
The architecture of MapReduce consists of several components. Namely.
- 1)
- Client – They are normally the ones who provide MapReduce with jobs for processing. Several jobs can be given by multiple clients.
- 2)
- Jobs – These are the jobs/processes that the MapReduce will execute. The actual work that the client wants to perform, consisting of smaller tasks.
- 3)
- Hadoop MapReduce Master – It will divide the job into smaller subsequent job-parts for quicker and easier processing.
- 4)
- Job-Parts – These are obtained after dividing the job through the Hadoop MapReduce Master. Completing and combining them will provide us with the final output.
- 5)
- Input Data – The data set that is given to MapReduce for processing.
- 6)
- Output Data – The final output that is produced after all the processing is finished.
In MapReduce, a client will send a job to the Hadoop MapReduce Manager which will then break down the job into subsequent job-parts. Then the 2 main tasks Map and Reduce come into play and when the input data is provided then immediate key-value pairs are formed as output and taken as input by the Reducer which then stores the final data on the HDFS as shown in Figure 11.
There are several key advantages of using MapReduce:
- Scalability: Companies can process large amounts of data stored in the HSDF (Hadoop Distributed File System)
- Flexibility: Easy access to multiple sources and types of data.
- Simple: A variety of programming languages available for developers to write, Java, C++, Python, etc.
- Parallel Processing: MapReduce divides process into smaller chunks that can be processed at the same time.
- Speed: Fast processing of data due to parallel processing and minimal data movement.
In summary, MapReduce simplifies large-scale data processing by dividing tasks into map and reduce phases. It enables parallel processing over distributed data, making it a fundamental tool in cloud computing.
Bulk Synchronous Parallel (BSP)
The Bulk Synchronous Parallel (BSP) was first proposed by Leslie Valiant. This model was developed to act as a bridging model between parallel hardware and software. The main goal was to sufficiently represent different architectures well, without considering any hardware details. It consists of 3 key components:
- ❖
- A set of virtual processors, components capable of processing and local memory transactions
- ❖
- A router to deliver messages point to point between the components
- ❖
- A synchronization mechanism for all or a subset of processors
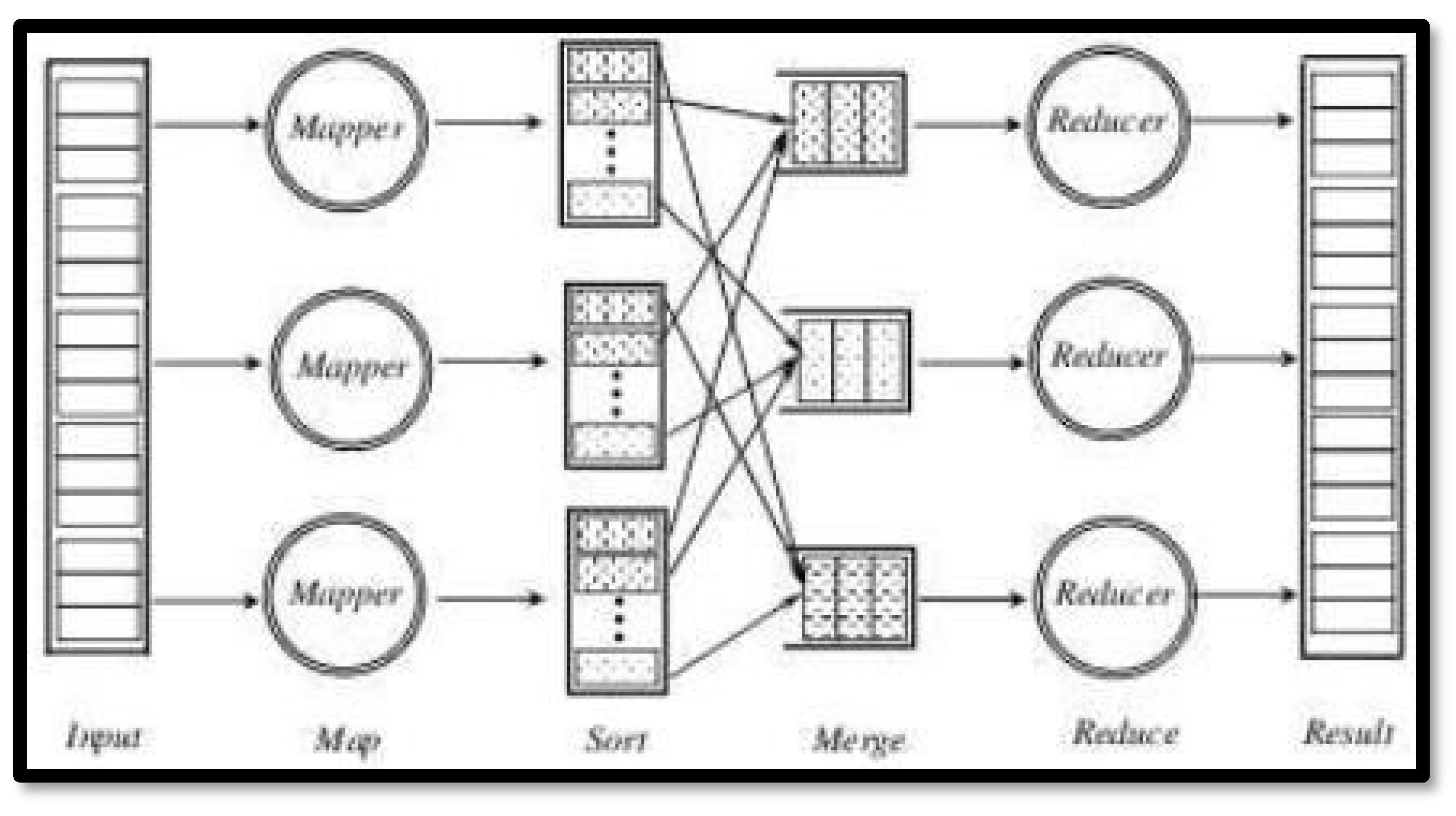
The computation in BSP proceeds in a sequence of global supersteps. Each superstep is separated by a synchronization barrier and contains a computation and communication phase. In the local computation phase, each participating processor performs local computations using local data values asynchronously as well as issue any communication requests. In the global communication phase, the processors communicate with each other by exchanging data to facilitate remote data storage. Then finally during the barrier synchronization phase, the processors synchronize and wait for all data transfers to be completed before moving onto the next super step as shown in Figure 12.
Figure 12.
A BSP super step.
An important part in the BSP model is the cost function, it plays a crucial role in analyzing and optimizing parallel algorithms. To further expand on this we introduce two more concepts, the work done by a processor and a h-relation. We also introduce two more parameters: g and l. The h-relation represents the maximum data exchanged by a processor during a superstep
Figure 12.
The h-relation. s – id of a processor.
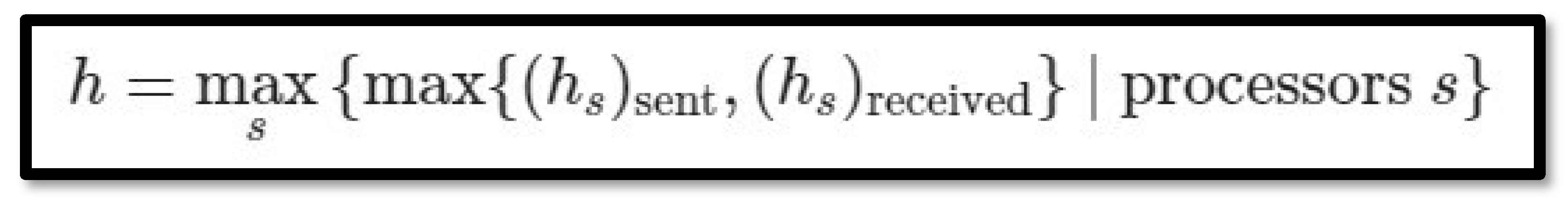
We define the work (w) done in a superstep as the maximum number of floating-point operations performed by all processors. The latency l is usually a fixed constant overhead. g and l are platform-specific constants found empirically. w and h are superstep-specific and obtained analytically. The total cost associated with a BSP algorithm is given by the formula:
The cost function in BSP captures computation, communication, and synchronization aspects, enabling efficient parallel processing in cloud environments.
There are several advantages of BSP in cloud computing:
- ❖
- Structured Parallel Programming: It is very structured in its approach at creating parallel algorithms as the computation is divided into a series of supersteps. With each superstep consisting of computation, communication and barrier synchronization phases. It becomes easier to design and understand.
- ❖
- Predictable Performance: BSP ensures predictable performance due to synchronization at each superstep. Developers can analyze and improve algorithms with confidence.
- ❖
- Scalability: BSP handles large-scale data processing efficiently.
- ❖
- Fault Tolerance: BSP handles failures gracefully.
- ❖
- Simplicity and Abstraction: BSP abstracts complex parallel processing into a structured model.
In summary, BSP provides a structured approach to parallel computing, emphasizing synchronization and communication. Its adaptation to cloud environments enhances scalability and performance.
7. Results and Discussion
Performance of any computing paradigm is essential and vital for any kind of processing. It refers to how quickly tasks can be completed and is usually measured in terms of processing power, instructions per seconds, etc. In this report we will be comparing the performance of cloud computing against 3 other computing paradigms.
7.1. Parallel Computing
Parallel computing, as the name suggests executes multiple operations or tasks simultaneously rather than sequentially. It breaks down a task into separate smaller tasks to be executed by the multiple processing units or cores. By doing this performance is improved as the sub-problems are being processed concurrently and thus saving time and being efficient in execution as shown in Figure 13.
Figure 13.
Data Parallelism.
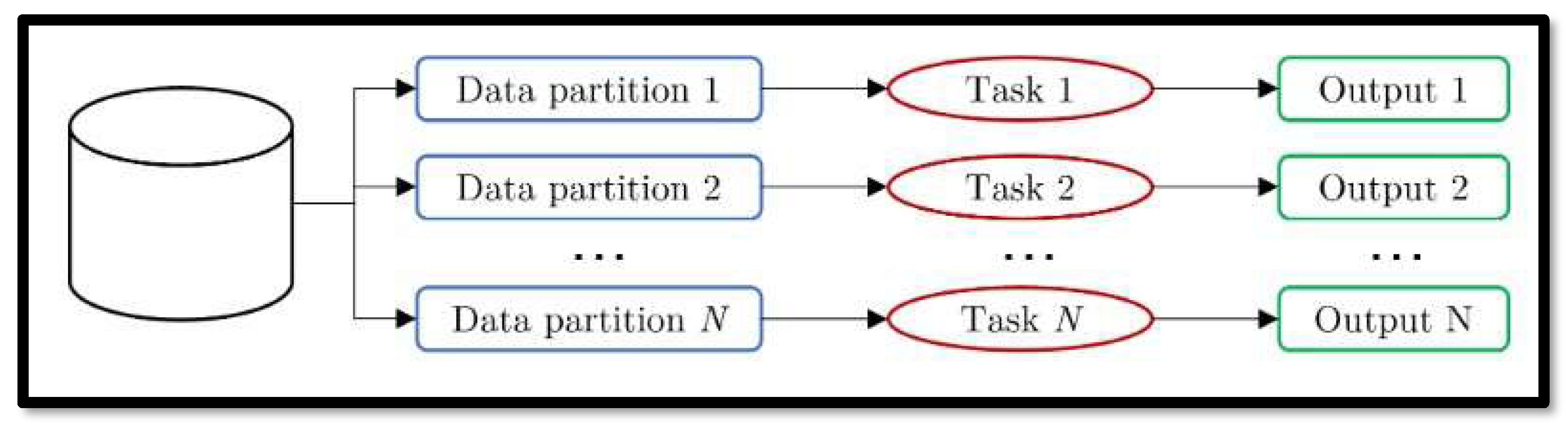
Figure 14.
Computer with multiple processors.
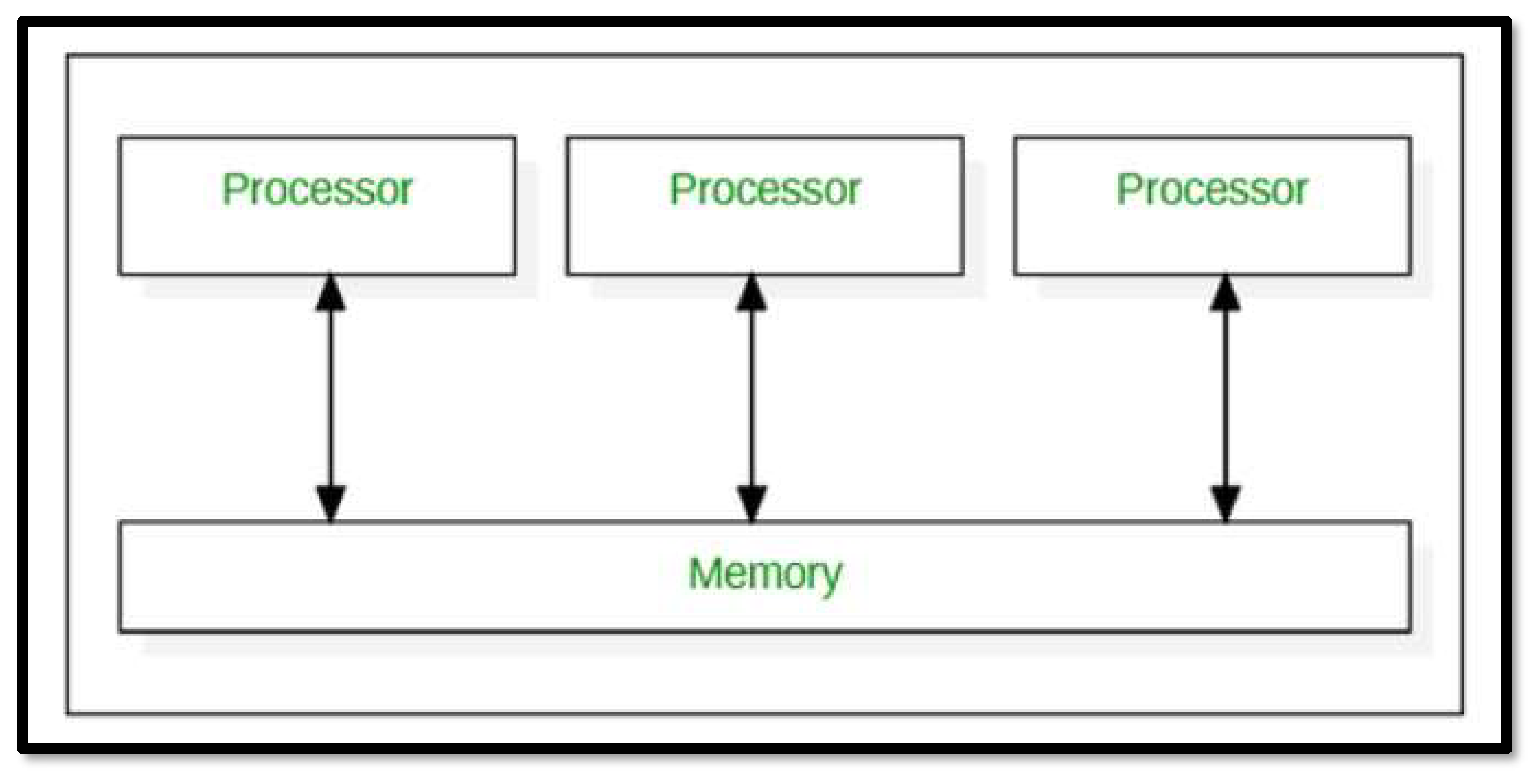
Its architecture is distributed with multiple processors or cores. These are involved in providing concurrency in the execution of tasks. However, there are a few challenges that it faces such as:
- Synchronization between multiple sub-tasks processes is difficult to achieve.
- Need expert and skilled programmers to create code for parallel-based programs.
- Algorithms need to be adjusted to be able to handle the parallel mechanism.
There are just a few to list out. Parallel computing focuses on concurrent execution of tasks. Meanwhile, Cloud computing provides on-demand access to computing resources online via the network. It delivers more flexibility and reliability. It’s also very scalable as it allows dynamic allocation of resources based on demand. Companies can quickly scale resources to the highest- level to meet business needs or scale down if the infrastructure isn’t needed. It’s also very cost- effective as you only pay for the resources that you use. Lower IT costs as compared to traditional infrastructure.
7.3. Grid Computing
A Grid computing architecture connects networks of computers and geographically distributed resources to solve complex problems. These grids are situated across various locations and use the internet to connect resources together regardless of their location. They combine these resources from multiple organizations into a virtual supercomputer. Complex tasks can be achieved through this model, the task is usually divided and completed by several computers connected on the grid. Its goal is to solve high and complex tasks in less time and increase productivity, thus improving performance as shown in Figure 14.
Figure 14.
Grid Computing Architecture.
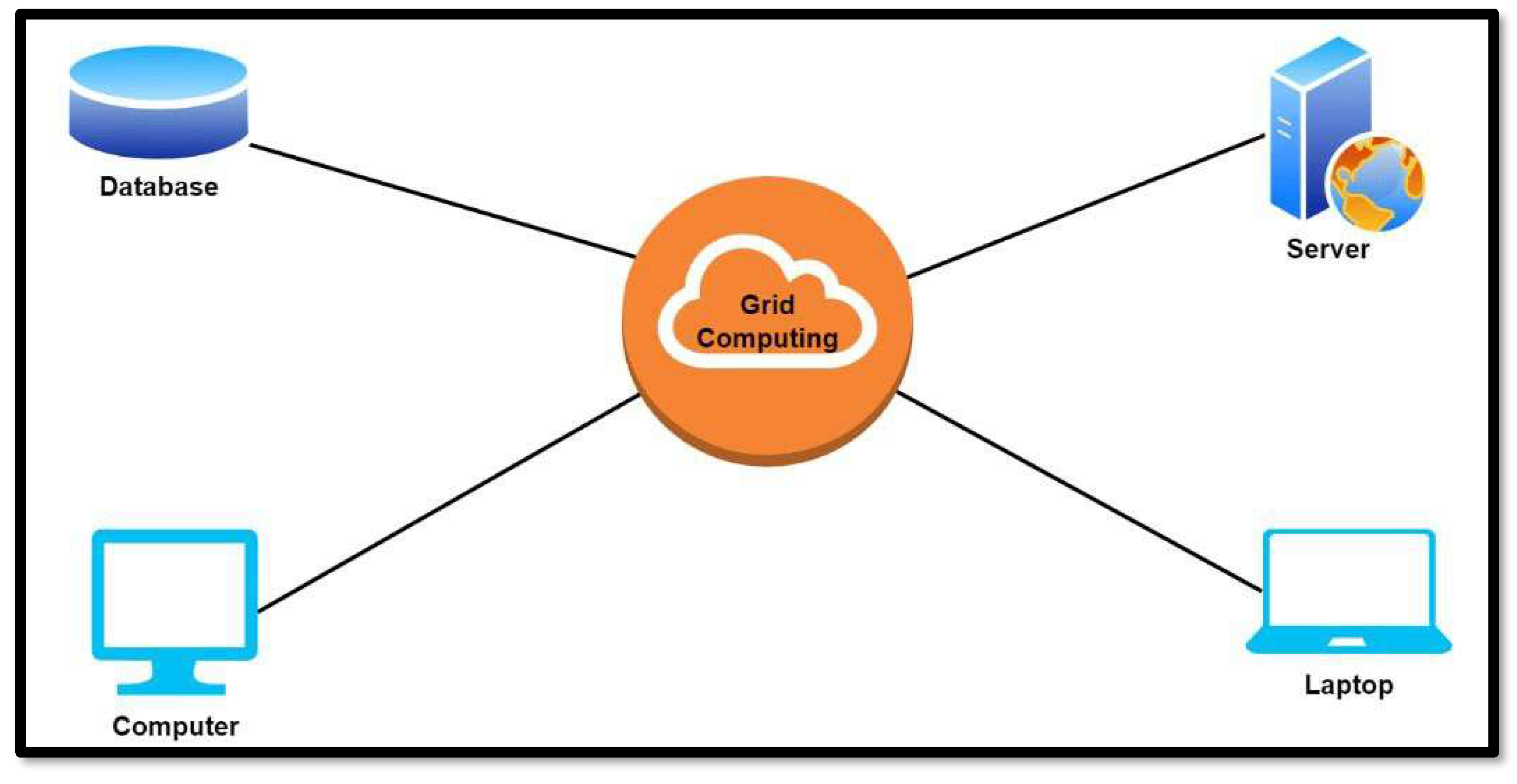
A major advantage it has over cloud computing is solving complicated tasks and users don’t have to pay anything, whereas cloud computing just provides services to the user at a low price. However, there are a few aspects of Grid computing where cloud computing is superior.
- ➢
- Cloud Computing is more flexible than grid computing as it provides on-demand access to a variety of resources online.
- ➢
- Cloud Computing is highly scalable and you can dynamically allocate resources based on demand
- ➢
- Cloud Computing is a centralized cloud infrastructure with virtualized resources.
In summary, cloud computing focuses on centralized services and offers versatility, scalability, and cost-effectiveness, making it suitable for a wide range of applications. Grid computing emphasizes decentralized, edge-based processing and while specialized for distributed processing, it lacks the advantages provided by cloud computing.
7.4. Cluster Computing
In Cluster computing several independent computers or nodes are connected with each other. It’s a configuration where all the nodes work together as a single entity to perform tasks. The nodes are usually placed in the same location. It’s a high-performance computing model for solving complex computations with greater efficiency with a faster processing speed and better data integrity. Implementation of such framework is easy and manageable. It can be composed of low-end or less powerful computers. High availability as it provides fault-tolerance and redundancy. Very scalable as well, can add more nodes with ease as shown in Figure 15.
However, where there are pros there are cons as well:
- Such a framework initial capital cost is very high and requires dedicated hardware.
- With a lot of nodes connected in such a network, it will require a lot more maintenance
- To further increase performance, more nodes would be needed so more physical hardware.
- Need technically skilled and specialized technicians.
- Need special programming language skills and understanding of the system.
- Not suitable for commercial or business use.
Cloud computing triumphs over all these issues. Its very cost effective with no high initial capital costs. Organizations achieve faster time to market and incorporate AI and machine learning use cases. Very scalable and can quickly access on-demand resources from the internet. Cloud computing offers flexibility and reliability as well. Overall cloud computing offers versatility, scalability, and cost-effectiveness, while cluster computing is specialized and often requires significant upfront investment.
7.5. Control Flow
This section will comprehensively cover control flow which refers to the sequence in which tasks and processes are handled within a specific system. This includes communications between different components, as well as the communication between users (or developers) and the cloud service. In cloud computing, control flow revolves around API (Application Programming Interface) calls.
An API is essentially a collection of communication protocols and subroutines used by various programs to communicate between them. APIs allow different applications to easily exchange information and functionality without much human intervention thus allowing for greater collaboration and data monetization as shown in Figure 16.
In contrast, other computing systems use more conventional control statements (such if-then- else or do-while) and other typical programming techniques to control the execution events, whereas cloud computing allows loosely coupled APIs to work together dynamically and function based on external event driven triggers.
7.6. Scalability
Scalability refers to the ease at which a particular system can increase its capacity to support more users, increase IT resources, and cope with increasing demand. One of cloud computing’s core principals and primary advantages over other paradigms, lies in its ability to scale data storage capacity, processing power and networking, quickly and easily using existing cloud infrastructure as shown in Figure 17.
As cloud computing relies on servers, usually managed be a third party like Google Cloud Platform (GCP), a business can scale their systems without a large up-front investment in infrastructure and engineers. This usually means they have better and more dynamic scaling than more traditional computing paradigms like parallel computing or High-Performance Computing, which relies more on distributing tasks between more in-house processors or nodes, thereby improving performance. How is cloud so scalable? Through virtualization, a technique of how to separate a service from the underlying physical delivery of that service. This means creating a virtual version of something like computer hardware. Virtualization one of the main cost-effective, hardware- reducing, and energy-saving techniques used by cloud providers. Virtualization allows sharing of a single physical instance of a resource or an application among multiple customers and organizations at one time, maximizing hardware utilization and optimizing scalability as shown in Figure 18.
Most cloud vendors like Amazons AWS, offer autoscaling features so you pay only for the storage and computing resources you use and there’s no risk of overpayment as shown in Figure 19.
In the end, Performance is an important aspect of any computing paradigm to perform the task efficiently, and in this report, we have compared the performance of cloud computing with three other prominent paradigms: parallel computing, grid computing, and cluster computing. Cloud computing is highlighted because of its scalability, flexibility, cost-effectiveness, and accessibility. It revolutionized the scaling resources on demand for businesses with no major capital investment burden upfront, dynamically meeting the demand according to needs. Parallel computing, on other sides-grid computing and cluster computing do have their advantages, though at very particular usages, and suffer from challenges like synchronization, high cost, and complexity.
Discussion
Cloud computing, on the other hand, provides enormous advantages over parallel, grid, and cluster computing in terms of scaling and flexibility. It allows dynamic resource allocation on demand, paying only for what is used, which enables enterprises to minimize costs while maximizing performance. The advantages of cloud computing are clear, especially for companies needing reliable, scalable, and cost-effective solutions without heavy investment in infrastructure or skilled technical staff. Parallel computing, while efficient in the running of several tasks simultaneously, poses problems in task synchronization and requires special skills in programming. It is applied in specialized areas where a division of a task is necessary. This does not offer as much flexibility and scalability as cloud computing. While powerful in connecting distributed resources, grid computing is not flexible, nor does it offer the services on demand as compared with cloud computing. It may provide some services in a cost-efficient manner, but this will fall apart in scalability, accessibility, and managed infrastructure provided with cloud computing. Cluster computing links autonomous nodes, acting like a single system, featuring high performance and fault tolerance; cluster computing involves some high initial investment and maintenance costs, making it not an ideal option for any organization in search of cost-effective and easily managed solutions. Cloud computing is an affordable solution and doesn’t involve huge physical infrastructure at a location or specialized technical manpower. In the end, cloud computing is the future of computing, providing a flexible and elastic model that suits a wide range of applications. It provides advantages over other paradigms in flexibility, cost efficiency, and ease with which businesses can scale their operation to meet growing demands.
8. Potential Applications
Whereas for the emerging technologies of quantum computing and nanocomputing, cloud computing has been in practice for almost twenty years and is employed by many enterprises such as Amazon’s AWS, Microsoft’s Azure, and Alphabet’s GCP. That means that most of the applications of cloud computing have already been realized and marketed. Probably the most common applications of cloud computing are online data storage and e-commerce sites.
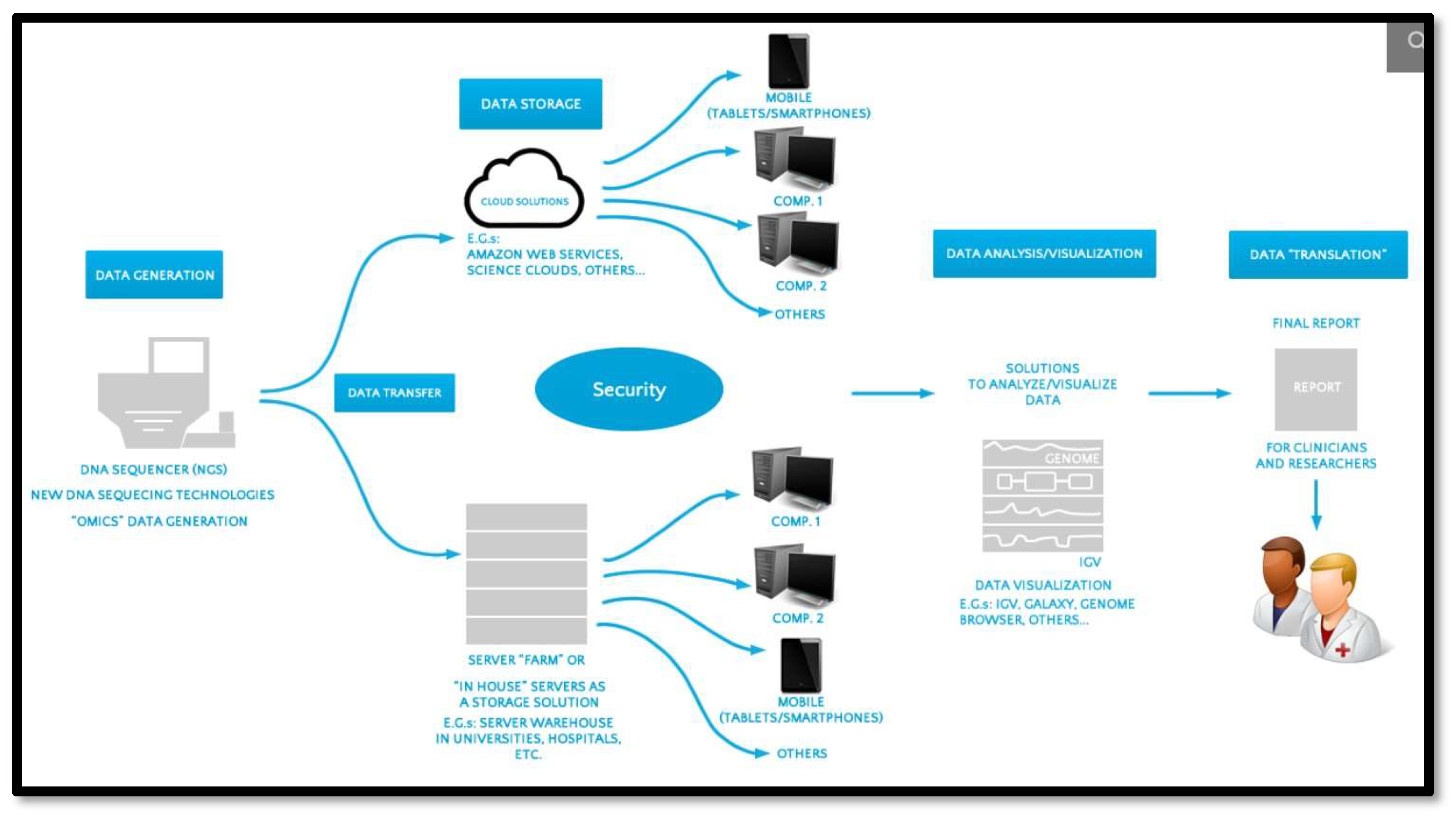
Other works in development for cloud computing technology applications include AI and machine learning, which make use of scalable cloud resources and efficient systems for data storage and retrieval in training LLMs. Other technologies that could use cloud computing for rendering and user management include the Metaverse and VR. Examples of applications that are still purely in the realm of research and development include genome sequencing using Big Data and cloud computing. This approach uses a pipeline that combines Big Data technologies for storage and management, which can be deployed on the cloud for enhanced performance and faster sequencing. Research of this nature could lead to some very important discoveries in the field of genomics and DNA sequencing, which would help us document and understand the genome further and give us a better insight into the vulnerabilities for diseases and their treatments for those diseases which are currently untreatable.
Figure 5.
Applications of cloud computing and storage in genome sequencing.
Conclusion
The journey of the paradigm of computing has been quite interesting, from the centralized core networks of previous decades to the decentralized computing models of today. Cloud computing is at the forefront, changing how we access and use technology. Cloud computing has evolved from the concept of virtual computing and the importance of informatics in the 1960s to a complex ecosystem that features scalability, flexibility, and efficiency. It has, in the course of its historical development, brought forth models like IaaS, PaaS, and SaaS to address diverse business needs with speed and adaptability. The foundational computational analyses here, including implementation methods like MapReduce and BSP, have laid emphasis on comparative advantages of these methods w.r.t. computational performance. Besides, in comparison with other paradigms like parallel computing, grid computing, and cluster computing, cloud computing has much more flexibility, efficiency, and scalability. Characteristic features include API-based control, virtualization-related possibilities, and wide applicability-from artificial intelligence to genomics, further on to electronic commerce-all enable it to have a disruptive influence on today’s technological infrastructure. This not only further cements cloud computing as an innovation engine for industries all over, and by and large introduces efficiencies, while completely changing what could arguably become the main game-changer within the realm of technology development going forward.
References
- Eden, A. H. (2007). Three paradigms of computer science. Minds and Machines, 17(2), 135–167. [CrossRef]
- IBM. (2024). What is the Internet of Things? IBM. https://www.ibm.com/topics/internet-of-things.
- Gillis, A. (2023). What is IoT (Internet of Things) and how does it work? TechTarget. https://www.techtarget.com/iotagenda/definition/Internet-of-Things-IoT.
- Intel. (n.d.). What is edge computing? Intel. https://www.intel.com/content/www/us/en/edge-computing/what-is-edge-computing.html.
- Sarfraz, M. (2003). Internet computing. Information Sciences. Retrieved May 19, 2024, from https://www.academia.edu/32996899/Internet_Computing.
- Shah, V. (2014). Cloud computing models. TatvaSoft Blog. https://www.tatvasoft.com/blog/cloud-computing-models.
- Fu, A. (2017). 7 different types of cloud computing structures. UniPrint.net. https://www.uniprint.net/en/7-types-cloud-computing-structures.
- Estrach, P. (2023). Exploring scalability in cloud computing: Benefits and best practices. MEGA. https://www.mega.com/blog/what-is-scalability-in-cloud-computing.
- Zhang, Q., Cheng, L., & Boutaba, R. (2010). Cloud computing: State-of-the-art and research challenges. Journal of Internet Services and Applications, 1(1), 7–18. [CrossRef]
- Databricks. (n.d.). What is MapReduce? Databricks. https://www.databricks.com/glossary/mapreduce.
- Codemotion. (2023). MapReduce not dead: Here’s why it’s still ruling in the cloud. Codemotion Magazine. Retrieved May 17, 2024, from https://www.codemotion.com/magazine/ai-ml/big-data/mapreduce-not-dead-heres-why-its-still-ruling-in-the-cloud.
- Jayaraj, A., Geevarghese, J., Rajan, K., Kartha, U., & Varghese, V. (n.d.). Programming models for clouds. Retrieved May 17, 2024, from https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=8b97d1290c35bed5cd120bc2b3dc1a34057c8cd4.
- GeeksforGeeks. (2020). MapReduce architecture. GeeksforGeeks. https://www.geeksforgeeks.org/mapreduce-architecture.
- Saeed, S., & Abdullah, A. (2022). Hybrid graph cut hidden Markov model of K-mean cluster technique. CMC-Computers, Materials & Continua, 1-15.
- Saeed, S., Abdullah, A., Jhanjhi, N. Z., Naqvi, M., & Nayyar, A. (2022). New techniques for efficiently k-NN algorithm for brain tumor detection. Multimedia Tools and Applications, 81(13), 18595-18616. (JCR SCI/EI Q3).
- Saeed, S., & Humayun, M. (2019). Disparaging the barriers of journal citation reports (JCR). IJCSNS: International Journal of Computer Science and Network Security, 19(5), 156-175. [CrossRef]
- IBM. (n.d.). What is Apache MapReduce? IBM. https://www.ibm.com/topics/mapreduce.
- Groups.csail.mit.edu. (n.d.). The BSP programming model. Retrieved May 17, 2024, from https://groups.csail.mit.edu/cag/bayanihan/papers/javapdc99/html/node2.html.
- Jwbuurlage.github.io. (n.d.). BSP model - Bulk. Retrieved May 17, 2024, from https://jwbuurlage.github.io/Bulk/bsp/.
- Gerbessiotis, A. V. (2000). A brief introduction to the BSP model. Retrieved from https://web.njit.edu/~alexg/courses/cis668/Fall2000/handsub5.pdf.
- Cordeiro, D., & Kraemer, A. (n.d.). Using the BSP model on clouds. Academia.edu. Retrieved May 17, 2024, from https://www.academia.edu/13509531/Using_the_BSP_Model_on_Clouds.
- Cordeiro, D., & Kraemer, A. (n.d.). Dynamic creation of BSP/CGM clusters on cloud computing platforms. Academia.edu. Retrieved May 17, 2024, from https://www.academia.edu/13509607/Dynamic_Creation_of_BSP_CGM_Clusters_on_Cloud_Computing_Platforms.
- Saeed, S., & Haron, H. (2021). Improve correlation matrix of discrete Fourier transformation (CM-DFT) technique for finding the missing values of MRI images. Mathematical Biosciences and Engineering, 1-22.
- Saeed, S. (2017). Implementation of failure enterprise systems in an organizational perspective framework. International Journal of Advanced.
- PK.org. (n.d.). Bulk synchronous parallel and Pregel. Retrieved May 17, 2024, from https://pk.org/417/notes/pregel.html.
- Luu, Q. T. (2024). Difference between parallel and distributed computing. Baeldung on Computer Science. Retrieved May 19, 2024, from https://www.baeldung.com/cs/parallel-vs-distributed-computing.
- Baeldung. (2022). Differences between cloud, grid and cluster. Baeldung on Computer Science. Retrieved December 7, 2022, from https://www.baeldung.com/cs/cloud-vs-grid-vs-cluster.
- Chesti, I. A., Humayun, M., Sama, N. U., & Jhanjhi, N. Z. (2020, October). Evolution, mitigation, and prevention of ransomware. In 2020 2nd International Conference on Computer and Information Sciences (ICCIS) (pp. 1-6). IEEE.
- Alkinani, M. H., Almazroi, A. A., Jhanjhi, N. Z., & Khan, N. A. (2021). 5G and IoT based reporting and accident detection (RAD) system to deliver first aid box using unmanned aerial vehicle. Sensors, 21(20), 6905. [CrossRef]
- Babbar, H., Rani, S., Masud, M., Verma, S., Anand, D., & Jhanjhi, N. (2021). Load balancing algorithm for migrating switches in software-defined vehicular networks. Computational Materials and Continua, 67(1), 1301-1316. [CrossRef]
- Alferidah, D. K., & Jhanjhi, N. Z. (2020, October). Cybersecurity impact over big data and IoT growth. In 2020 International Conference on Computational Intelligence (ICCI) (pp. 103-108). IEEE.
- Jena, K. K., Bhoi, S. K., Malik, T. K., Sahoo, K. S., Jhanjhi, N. Z., Bhatia, S., & Amsaad, F. (2022). E-learning course recommender system using collaborative filtering models. Electronics, 12(1), 157. [CrossRef]
- Al Etawi, N. (2018). A comparison between cluster, grid, and cloud computing. International Journal of Computer Applications, 179(32), 975–8887. Retrieved from https://www.ijcaonline.org/archives/volume179/number32/etawi-2018-ijca-916732.pdf.
- GeeksforGeeks. (2021). Different computing paradigms. GeeksforGeeks. https://www.geeksforgeeks.org/different-computing-paradigms/.
- GeeksforGeeks. (2020). Difference between cloud computing and cluster computing. GeeksforGeeks. https://www.geeksforgeeks.org/difference-between-cloud-computing-and-cluster-computing/.
- GeeksforGeeks. (2019). Difference between cloud computing and grid computing. GeeksforGeeks. https://www.geeksforgeeks.org/difference-between-cloud-computing-and-grid-computing/.
- GeeksforGeeks. (2018). Introduction to parallel computing. GeeksforGeeks. Retrieved May 17, 2024, from https://www.geeksforgeeks.org/introduction-to-parallel-computing.
- Google. (2023). Advantages of cloud computing. Google Cloud. https://cloud.google.com/learn/advantages-of-cloud-computing.
- VMware. (2022). What is cloud scalability? VMware. https://www.vmware.com/topics/glossary/content/cloud-scalability.html.
- AWS. (2018). AWS auto scaling. Amazon Web Services, Inc. https://aws.amazon.com/autoscaling/.
- GeeksforGeeks. (2017). Cloud computing. GeeksforGeeks. https://www.geeksforgeeks.org/cloud-computing/.
- Techopedia.com. (2019). What is an application programming interface (API)? Techopedia. https://www.techopedia.com/definition/24407/application-programming-interface-api.
- Liu, B., Madduri, R. K., Sotomayor, B., Chard, K., Lacinski, L., Dave, U. J., Li, J., Liu, C., & Foster, I. T. (2014). Cloud-based bioinformatics workflow platform for large-scale next-generation sequencing analyses. Journal of Biomedical Informatics, 49, 119–133. [CrossRef]
- Vijayalakshmi, B., Ramar, K., Jhanjhi, N. Z., Verma, S., Kaliappan, M., Vijayalakshmi, K., ... & Ghosh, U. (2021). An attention-based deep learning model for traffic flow prediction using spatiotemporal features towards sustainable smart city. International Journal of Communication Systems, 34(3), e4609. [CrossRef]
- Khan, N. A., Jhanjhi, N. Z., Brohi, S. N., & Nayyar, A. (2020). Chapter Three-Emerging use of UAV’s: secure communication protocol issues and challenges, Editor (s): Fadi Al-Turjman, Drones in Smart-Cities.
- Humayun, M., Jhanjhi, N. Z., Alsayat, A., & Ponnusamy, V. (2021). Internet of things and ransomware: Evolution, mitigation and prevention. Egyptian Informatics Journal, 22(1), 105-117. [CrossRef]
- Muzafar, S. (2021). Energy harvesting models and techniques for green IoT: A review. Role of IoT in Green Energy Systems, 117-143. [CrossRef]
- Soobia, S., Afnizanfaizal, A., & Jhanjhi, N. Z. (2022). Hybrid graph cut hidden Markov model of k-mean cluster technique. CMC-Computers, Materials & Continua, 72(1), 1-15.
- Humayun, M., Sujatha, R., Almuayqil, S. N., & Jhanjhi, N. Z. (2022, June). A transfer learning approach with a convolutional neural network for the classification of lung carcinoma. In Healthcare (Vol. 10, No. 6, p. 1058). MDPI. [CrossRef]
- Zaman, N., Ghazanfar, M. A., Anwar, M., Lee, S. W., Qazi, N., Karimi, A., & Javed, A. (2023). Stock market prediction based on machine learning and social sentiment analysis. Authorea Preprints.
- Sindiramutty, S. R., Jhanjhi, N. Z., Tan, C. E., Lau, S. P., Muniandy, L., Gharib, A. H., ... & Murugesan, R. K. (2024). Industry 4.0: Future Trends and Research Directions. Convergence of Industry 4.0 and Supply Chain Sustainability, 342-405. [CrossRef]
- Anandan, R., Suseendran, G., Chatterjee, P., Jhanjhi, N. Z., & Ghosh, U. (2022). How COVID-19 is Accelerating the Digital Revolution. Springer: Cham, Switzerland.
- Srinivasan, K., Garg, L., Chen, B. Y., Alaboudi, A. A., Jhanjhi, N. Z., Chang, C. T., ... & Deepa, N. (2021). Expert System for Stable Power Generation Prediction in Microbial Fuel Cell. Intelligent Automation & Soft Computing, 30(1). [CrossRef]
- Gill, S. H., Sheikh, N. A., Rajpar, S., Jhanjhi, N. Z., Ahmad, M., Razzaq, M. A., ... & Jaafar, F. (2021). Extended Forgery Detection Framework for COVID-19 Medical Data Using Convolutional Neural Network. Computers, Materials & Continua, 68(3). [CrossRef]
- Humayun, M., Jhanjhi, N. Z., Hamid, B., & Ahmed, G. (2020). Emerging smart logistics and transportation using IoT and blockchain. IEEE Internet of Things Magazine, 3(2), 58-62. [CrossRef]
Figure 1.
Mainframe Architecture.
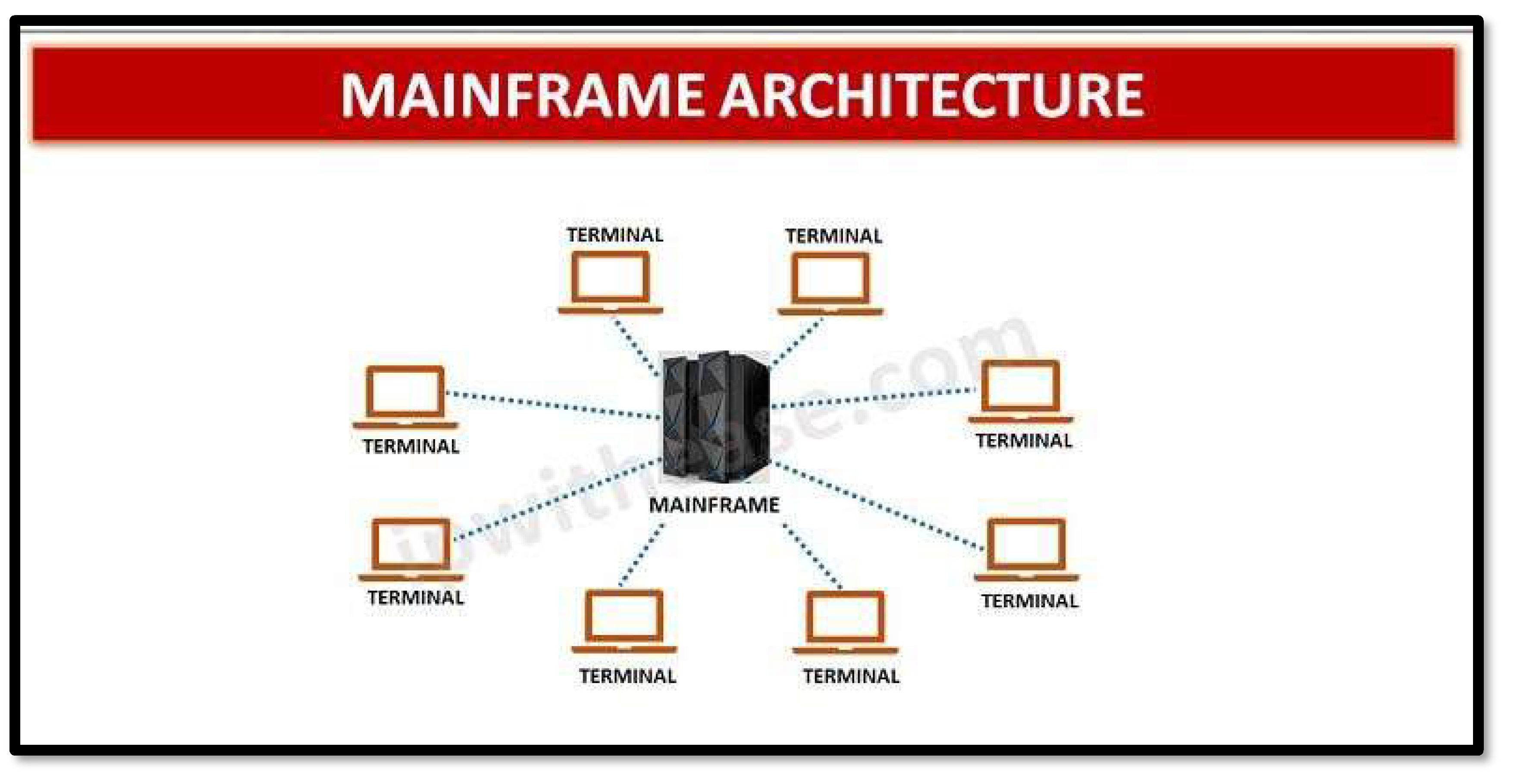
Figure 2.
Network Computing example data chart.
Figure 3.
Internet Computing process chart.
Figure 4.
Edge Computing Architecture.
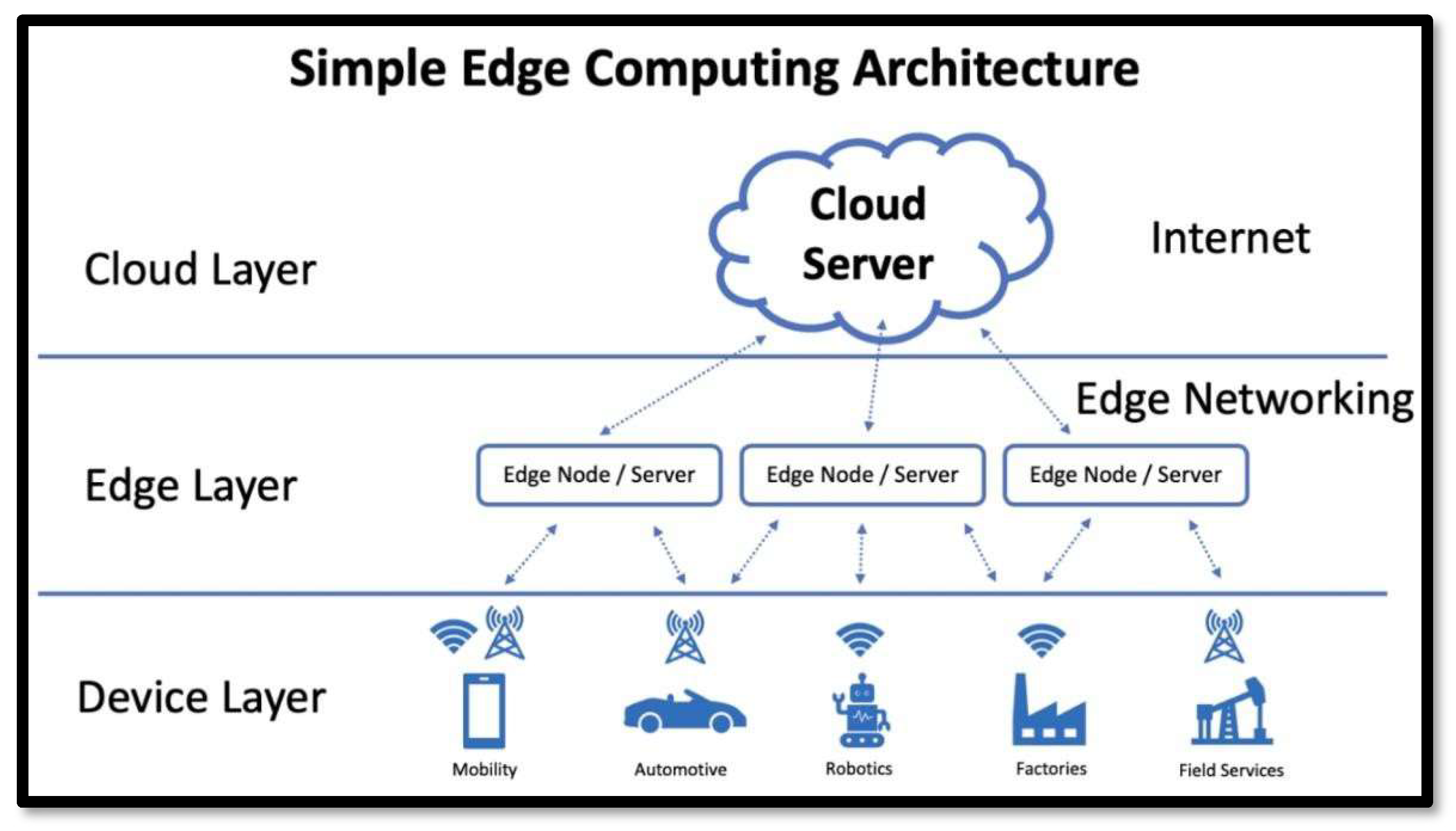
Figure 5.
General block of IoT devices.
Figure 6.
Cloud Computing Architecture.
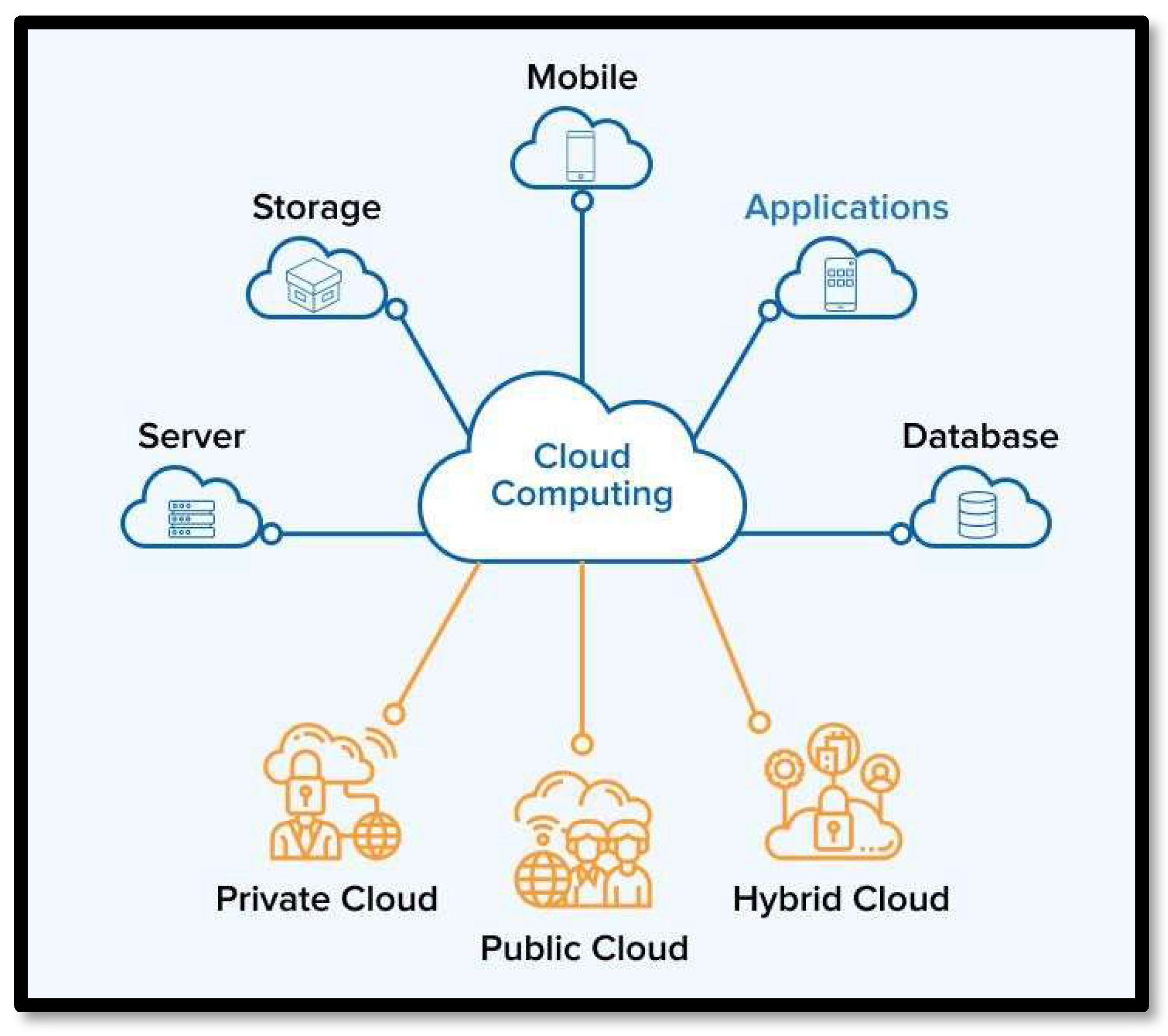
Figure 7.
Cloud Service Models.
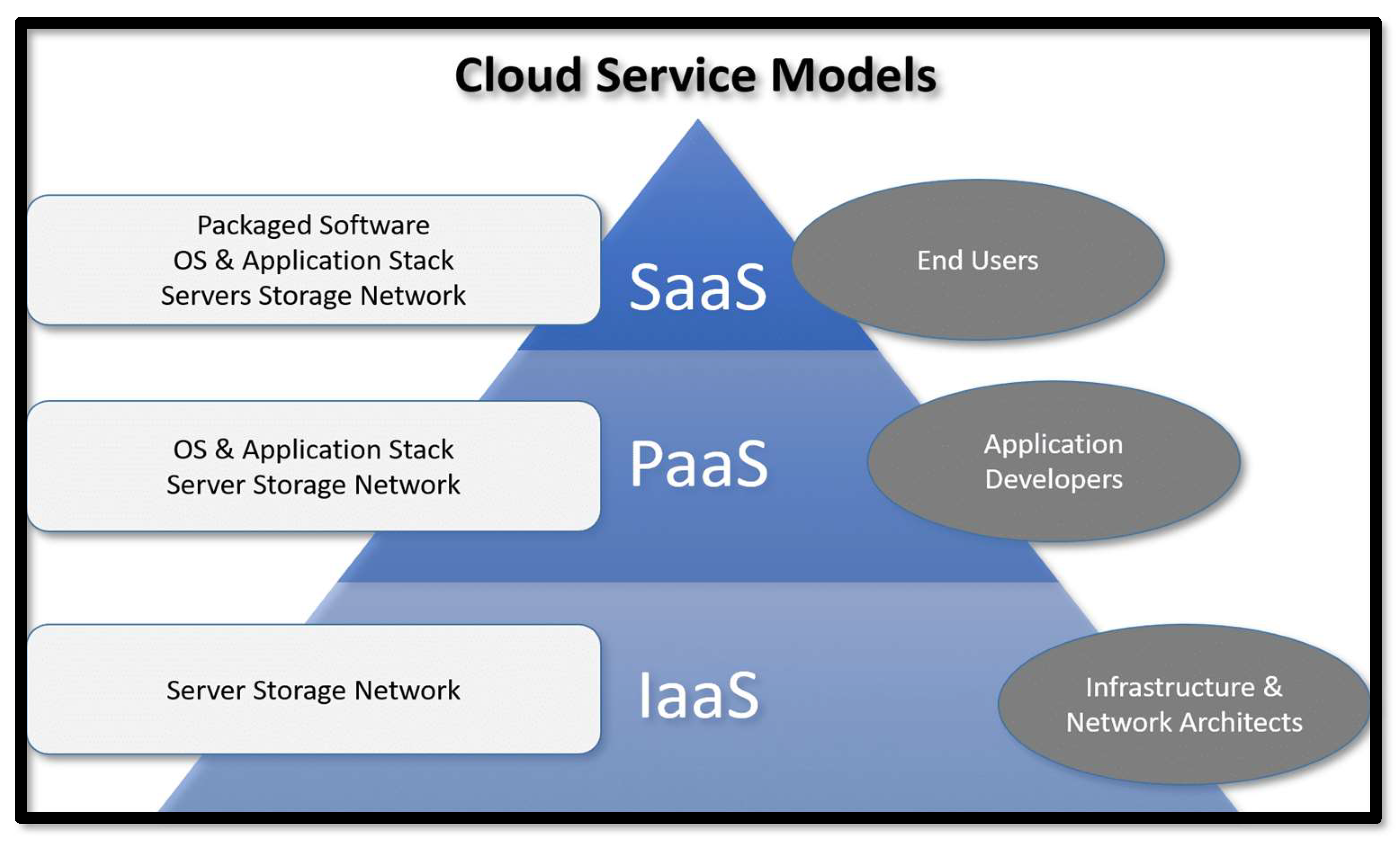
Figure 8.
Map Function.

Figure 11.
MapReduce Architecture.
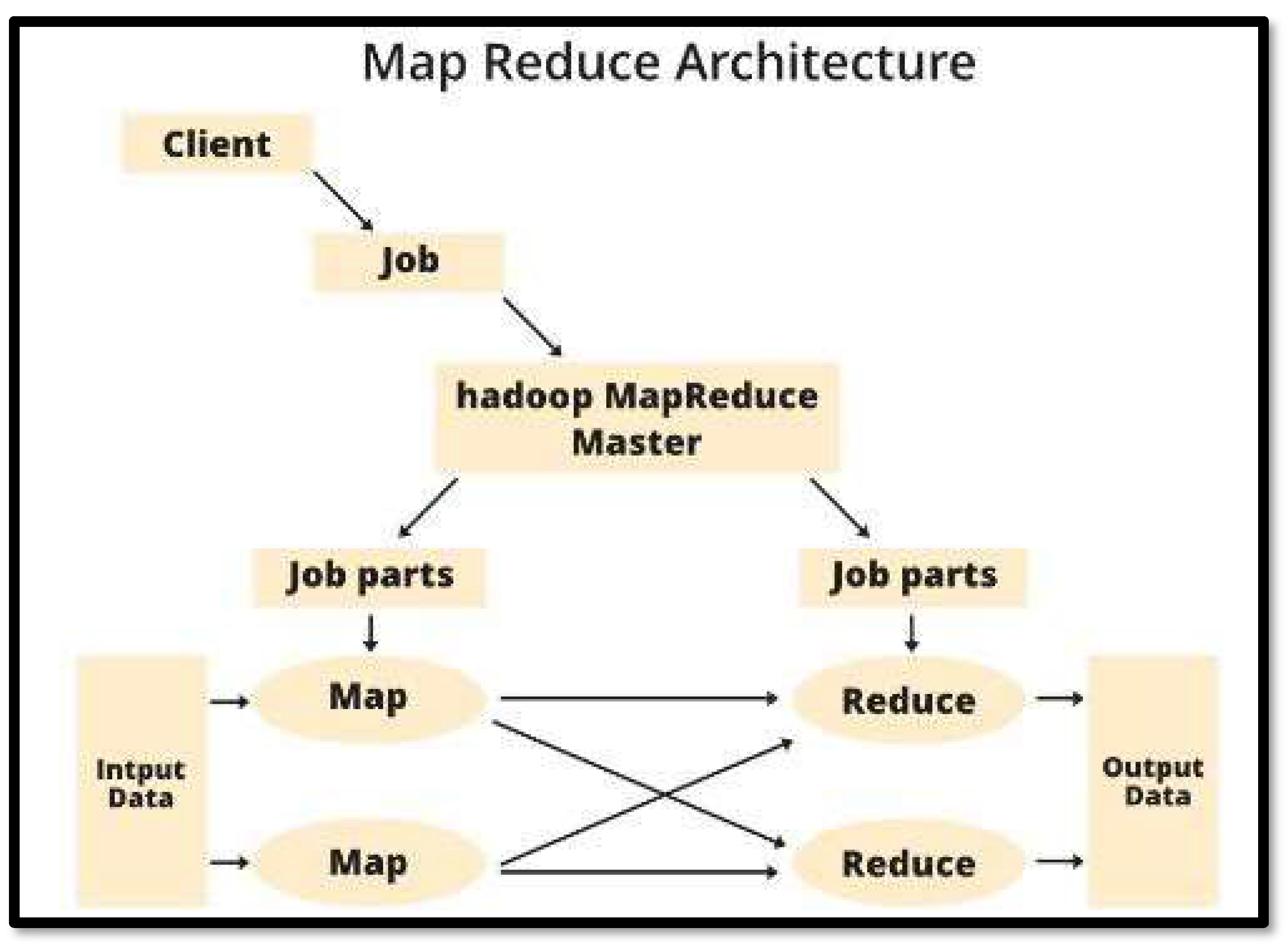
Figure 15.
Cluster computing architecture.
Figure 16.
Visualization of an API’s function.
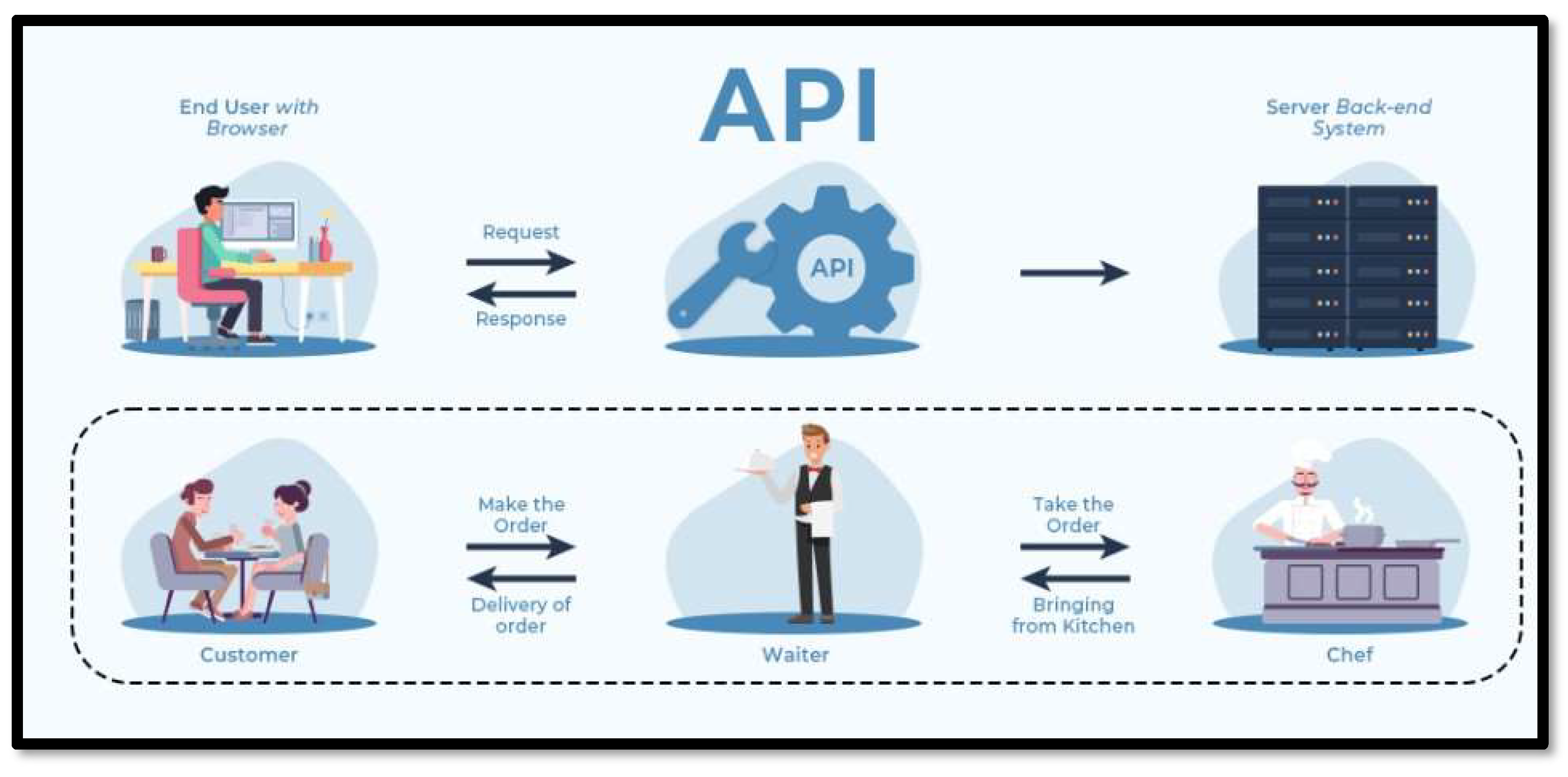
Figure 17.
Types of scalabilities in cloud computing.
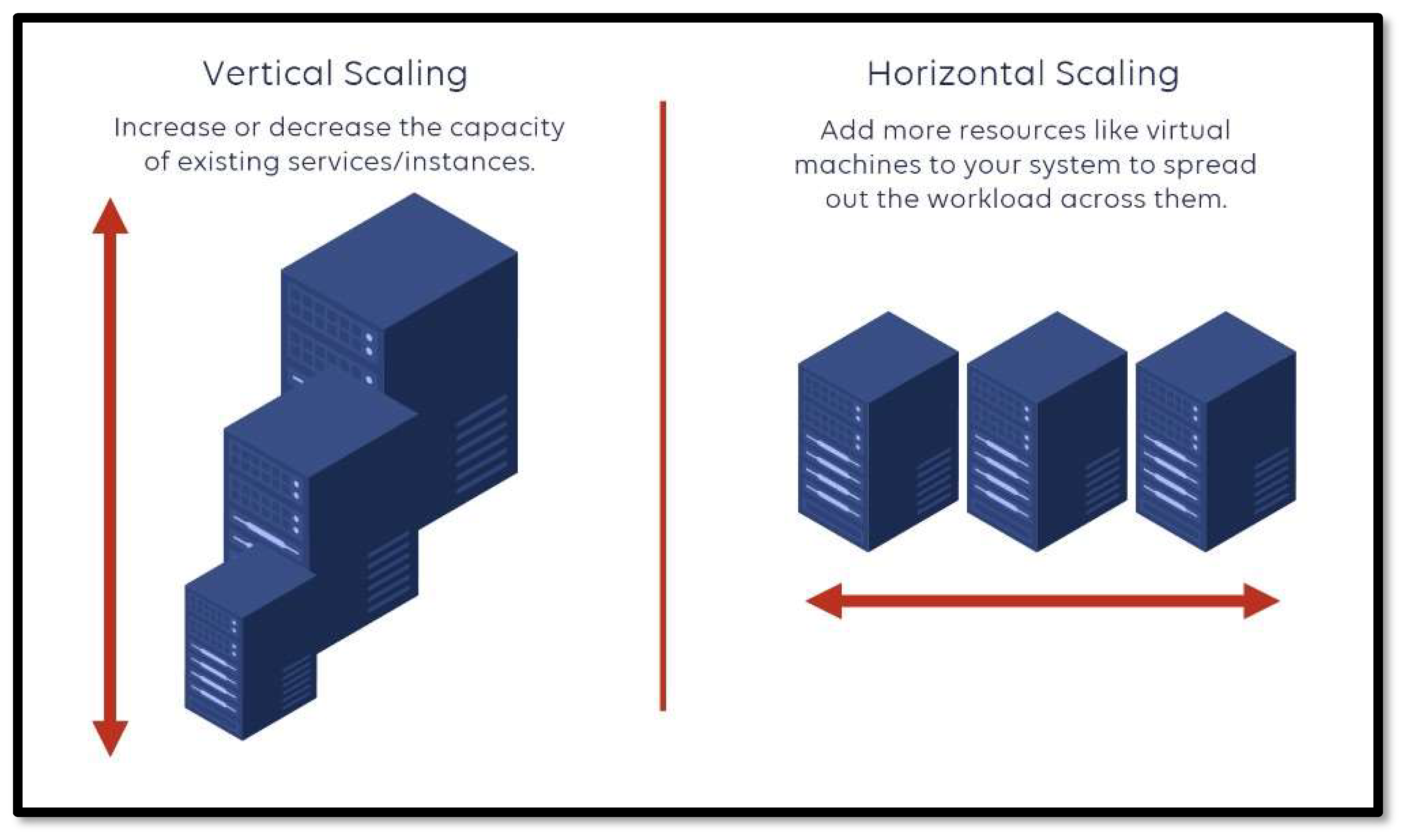
Figure 18.
A brief overview of virtualization in cloud computing.
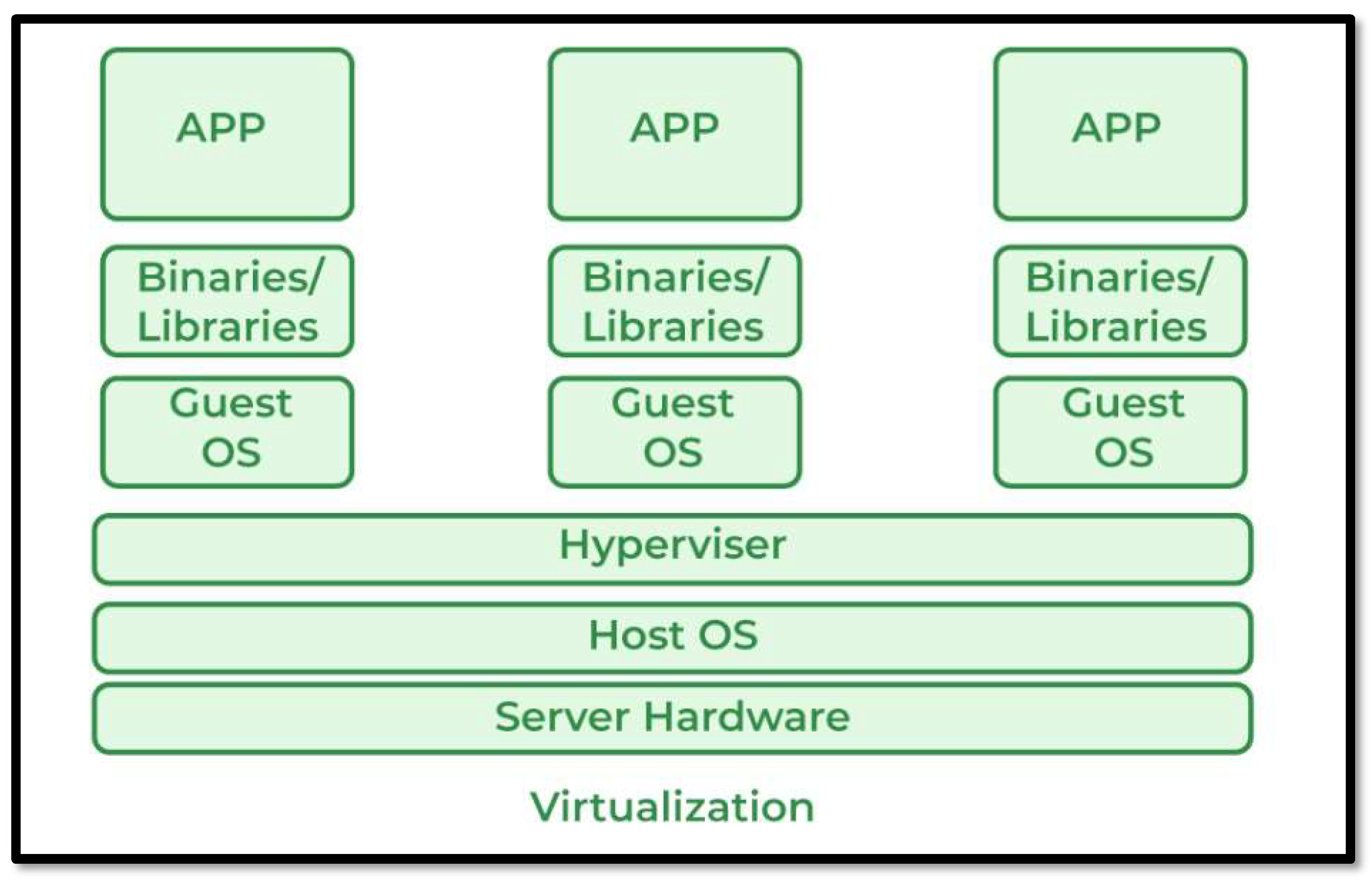
Figure 19.
Amazon Web Services offering autoscaling for cloud applications.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



