
Submitted:
12 March 2025
Posted:
14 March 2025
You are already at the latest version
Abstract
Large Language Models (LLMs) have recently emerged as a powerful option for partially automating the labor-intensive process of screening articles in systematic reviews. Unlike traditional semi-automated platforms that rely on iterative human feedback, LLM-based pipelines can operate in a zero-shot or few-shot manner, classifying abstracts according to predefined criteria. This paper offers a step-by-step methodology for researchers, librarians, and students seeking to incorporate LLMs—such as GPT-4—into systematic reviews. It discusses required software and data preprocessing, presents various prompt strategies, and emphasizes the importance of human oversight to maintain rigorous quality control. The proposed framework aims to provide best practices and offer guidance on managing costs, reproducibility, and prompt refinement. By following these guidelines, review teams can substantially reduce screening workloads without compromising the comprehensive nature of evidence-based research.
Keywords:
Systematic Review
; Large Language Models
; Text Screening
; Prompt Engineering
; AI-assisted Screening
1. Introduction
Systematic reviews have become essential for evidence-based decision-making in several fields and particularly in medicine, because they synthesize all relevant studies on a particular topic in a transparent and methodical way [1]. By adhering to predefined protocols and rigorous inclusion criteria, systematic reviews aim at minimizing bias and generating high-level evidence to inform policy, clinical practice, and research priorities [2]. Standard guidance on these methods emphasizes formulating a clear research question (often using the PICO framework [3]), developing a detailed review protocol, conducting a comprehensive search of multiple databases, screening studies for eligibility, extracting data, assessing quality and risk of bias, and synthesizing findings for reporting [4].
One of the most labor-intensive and error-prone stages in a systematic review is the initial screening of titles and abstracts to identify pertinent studies that can be used as a base for the systematic review [5]. Double screening by independent reviewers has long been considered the gold standard [6], yet it is equally recognized that this level of rigor demands substantial time and human resources [7]. Large academic databases often generate thousands of search results, requiring researchers to manually sift through extensive lists of potentially relevant citations to pinpoint the small number of articles that meet inclusion criteria—often fewer than a dozen for a typical review. This process makes it both logistically challenging and costly for research teams to maintain high accuracy while also managing time constraints [8]. Although searching itself is highly structured [9]—often guided by established protocols such as the Cochrane Handbook or NICE guidelines [10,11]—many reviews still rely predominantly on manual screening methods that are vulnerable to inconsistencies across reviewers, especially when they lack extensive experience or when the volume of studies is extremely large [12]. Because the accuracy of screening directly influences the reliability of the final synthesis, poorly executed screening risks omitting critical evidence, ultimately undermining the entire review process.
In response to these challenges, semi-automated tools such as Rayyan, Abstractr, or Research Screener have emerged to assist with citation management, de-duplication, and study selection [13]. Rayyan employs a web- and mobile-based AI-assisted environment that learns from inclusion and exclusion decisions and suggests likely matches [14]. Research Screener uses deep learning and text embeddings to re-rank articles for each new judgment made by the reviewer [15]. While these semi-automated methods decrease the number of abstracts that require manual review, they typically rely on iterative human feedback to train their predictive models [16]. This approach often helps maintain high recall—the proportion of truly relevant articles identified—but still requires a prolonged “learning phase” before users realize the most significant time savings.
Alongside semi-automated platforms, a variety of additional automation efforts have sought to refine each stage of a systematic review. Some tools focus exclusively on searching, such as LitSuggest, which recommends relevant articles from PubMed [17], whereas others support more advanced tasks like data extraction (RobotReviewer, ExaCT) [18,19]. Despite their potential, full automation remains elusive, particularly in later phases of a review where human expertise is needed to interpret nuanced results [12]. Moreover, most software currently operates in isolation, forcing researchers to stitch together different tools that are not always interoperable [16].
Recent advances in natural language processing (NLP) have begun to shift the focus from traditional machine learning pipelines to modern Large Language Models (LLMs), such as GPT-4 and other state-of-the-art architectures [20]. Unlike conventional semi-automated screening tools, LLMs can classify abstracts in a zero-shot or few-shot mode simply by relying on well-structured prompts that detail inclusion and exclusion criteria [21]. Multiple studies have evaluated LLMs against human screening in diverse domains and reported encouraging results, albeit with notable variability across different models and datasets [22]. Recent studies highlight both the promise and variability of LLMs in medical literature screening. For instance, Delgado-Chaves et al. (2025) evaluated 18 LLMs across three clinical domains, observing classification accuracy ranging from 40% to 92%. Their work emphasized the critical role of human oversight, showing how iterative refinements to inclusion/exclusion criteria could substantially enhance model performance. Similarly, it has been shown that systematic prompt optimization enabled GPT-4o and Claude-3.5 to achieve sensitivities and specificities approaching 98% for thoracic surgery meta-analyses, suggesting that targeted adjustments during screening rounds yield measurable improvements [23]. Meanwhile, investigations into open-source models revealed similar dependencies on design choices: testing of four LLMs on biomedical datasets documented dramatic fluctuations in sensitivity and specificity based on model selection and prompt phrasing [24]. And even high-performing models such as GPT-4 have been reported to falter when confronted with dataset imbalances or low-prevalence agreement scenarios—a potent reminder of the persistent gap between laboratory validation and real-world application [25]. Such findings attest to the growing promise of LLMs for accelerating the screening phase of systematic reviews, but also highlight the need for human oversight in verifying edge cases and ensuring high recall.
Modern LLMs can be rapidly adapted through prompt engineering, often making them more flexible for screening tasks in varied domains [26]. Nevertheless, clear protocols and refined inclusion/exclusion criteria remain vital because even the most advanced LLM can propagate errors if initial instructions or domain-specific nuances are overlooked [23,27]. Amid these opportunities and caveats, the question is no longer whether LLMs can assist in systematic review screening, but rather how best to implement them so that they enhance speed and consistency without compromising the rigorous standards necessary for high-quality evidence synthesis [28].
The aim of this paper is therefore to provide a practical, step-by-step guide for integrating LLMs into the literature screening stage of systematic reviews, maintaining the balance between computational efficiency and the methodological rigor essential for evidence-based conclusions.
2. Methodological Proposal
2.1. Key Definitions
Systematic reviews follow predefined protocols to collect and synthesize evidence in a transparent manner [1], while LLMs are sophisticated generative models capable of interpreting language [29].
Prompt engineering is the practice of carefully crafting the instructions or queries (prompts) presented to an LLM, with the goal of eliciting the most accurate or context-appropriate response [30]. In zero-shot classification, the model applies instructions to novel tasks without prior specialized training. In few-shot classification, it can absorb context from a handful of examples provided in the prompt [31].
Recall in screening refers to the proportion of truly relevant articles the model correctly identifies, whereas precision is the proportion of articles labeled relevant that genuinely meet the inclusion criteria [32]. Throughout this paper, both recall and precision serve as indicators of screening quality.
2.2. Conceptual Rationale
The proposed methodology builds on systematic review best practices and combines them with LLM-based screening. The primary rationale is that an LLM can operate in a zero-shot or few-shot capacity, enabling efficient classification of abstracts without a lengthy training phase, and saving time for researchers to focus on other aspects of the review process. By structuring prompts around well-defined inclusion and exclusion criteria, it becomes possible to exploit an LLM’s language understanding to categorize studies and identify articles that are pertinent and relevant for the systematic review. This process still requires careful human intervention, especially for checking gray areas and refining prompt wording [28].
2.3. Scope and Requirements
Researchers and students who already have a grasp of systematic review processes and basic computational techniques will find this framework particularly accessible, although the level of technical proficiency required may vary according to the chosen implementation. At a minimum, users need reliable access to a modern LLM such as GPT-4, GPT-3.5, or Deepseek r1, which can be accessed through a cloud-based API [33]; some LLMs can be installed locally if suitable hardware and software are available [34]. Establishing API-based access involves setting up credentials and ensuring a stable internet connection, whereas running an LLM locally requires significant computational resources, including a dedicated GPU with sufficient memory (usually 8–16 GB of VRAM for smaller open-source models and substantially more for larger architectures). Cloud services such as Google Colab can be a useful resource to run models remotely on platforms equipped with the necessary resources [35]. These hardware demands can influence the scale of the review and the practicalities of high-volume screening, particularly when screening thousands of abstracts.
A critical element of this setup is a robust environment for data handling and preprocessing. Python, along with commonly used libraries like pandas [36], is an efficient choice for organizing references, removing duplicates, and converting downloaded records into a uniform tabular format (e.g., pandas’ DataFrame) and possibly a uniform file format for data storage (e.g., CSV). Although coding expertise does not have to be extensive, a working knowledge of Python syntax, basic scripting, and command-line tools significantly streamlines the process of merging database outputs, cleaning messy metadata, and customizing LLM prompts [37]. Familiarity with virtual environments or package managers (such as conda or pip) can be particularly helpful for maintaining consistency and reproducibility, since the rapid pace of AI development often results in frequent updates and version changes to software packages [38].
Teams should also consider the potential costs associated with API-based LLM services, especially if the review involves screening large numbers of abstracts [39]. Balancing the benefits of higher accuracy from more advanced models with the financial impact of repeated queries is vital for long-term feasibility. If budgets are constrained, smaller open-source models may provide an adequate starting point, even though they occasionally require more extensive prompt tuning or additional error checking to reach acceptable levels of recall and precision [40,41,42]. For users planning to work on private or sensitive datasets, local deployment of open-source or self-hosted models can address data security concerns, but this option does increase the burden of setup, hardware maintenance, and ongoing troubleshooting [43,44,45,46].
2.4. Prerequisites
Before integrating LLMs into the screening phase of a systematic review for clinical medicine, several fundamental methodological elements must be in place. The first consideration is a clear research question supported by fully defined inclusion and exclusion criteria, often summarized through frameworks such as PICO (Population, Intervention, Comparison, Outcome) or one of its close variations [3,47,48,49]. For instance, a review investigating “the effectiveness of antihypertensive Drug A versus placebo in reducing systolic blood pressure among adults with hypertension” would specify:
- Population: Adults aged 18–75 with primary hypertension,
- Intervention: Daily oral administration of Drug A,
- Comparison: Placebo,
- Outcome: Mean change in systolic blood pressure at 12 weeks.
PICO is a useful heuristic tool to breakdown a relevant clinical question into its constitutive components, so that an effective search strategy can be drafted, but also, as we will show, an effective LLM prompt.
Dai et al. demonstrated that the precision of an LLM’s output depends substantially on how accurately these criteria are translated into prompts or instructions [23]. Articulating the review question in detail ensures that the model can target specific populations, interventions, and outcomes without veering into irrelevant territory [50].
3. Step-by-Step Methodology
3.1. Conduct a Broad Database Search
The screening workflow begins (Figure 1) with a comprehensive search for potential studies in relevant databases [51,52]. Database access forms a cornerstone of any systematic review [53,54]. Researchers should have access to the comprehensive or domain-specific databases—such as Medline, Embase, Scopus, or specialized repositories—to capture a broad array of publications [51,53,54,55]. Medline is undoubtedly the most renowned literature database in biomedicine and can be freely accessed both through its PubMed web portal but also directly through command line via API, using specific python libraries, such as Biopython [56], which is advantageous because retrieved articles can be stored in data structures that can be passed directly to LLMs.
In most systematic reviews, querying the databases involves crafting detailed strategies that reflect the components outlined by PICO. Queries are often expanded to include synonyms, related keywords, and Medical Subject Headings (MeSH), if applicable, to avoid overlooking relevant articles [57]. These elements can be combined in a database-specific syntax to query the database [58]. For example, a review evaluating “the efficacy of cognitive behavioral therapy (CBT) versus antidepressants for reducing depressive symptoms in adolescents” might generate a PubMed query structured as:
(“Adolescent”[MeSH] OR “teen*”[tiab] OR “youth”[tiab])
AND (“Cognitive Behavioral Therapy”[MeSH] OR “CBT”[tiab])
AND (“Antidepressive Agents”[MeSH] OR “SSRI”[tiab] OR “SNRI”[tiab])
AND (“Depression”[MeSH] OR “depressive symptoms”[tiab])
AND (“Treatment Outcome”[MeSH] OR “remission”[tiab])
Once the searches are executed, the resulting citations are exported in a consistent format—such as CSV, RIS, or XML—that can be imported and processed by data-analysis libraries in Python (or other environments). If the query is conducted by accessing PubMed via API, the results can be stored as a python data structure (e,g, a pandas’ DataFrame), ready for subsequent processing.
3.2. Preprocess and Deduplicate Records
After collating results from multiple databases, the records must be cleaned and standardized. This often involves removing exact duplicates—an issue that arises frequently when the same article appears across different platforms—and converting files to a uniform character encoding (e.g., UTF-8) to avoid text corruption. Researchers would typically unify column headers for Title, Abstract, Publication Date, and other relevant metadata so that subsequent methods, including LLM-based screening, can operate without confusion. Attention to detail at this stage pays off in later steps, as it prevents misclassification and missed articles caused by inconsistent data fields [59]. While preprocessing sounds mundane, data cleaning can dramatically improve downstream performance by reducing irrelevant noise that misleads both conventional machine learning pipelines and modern LLMs [27].
3.3. Choose the Right LLM(s) and Prompt
At the heart of any systematic review pipeline augmented by LLMs lies a twofold decision: which model to deploy and how to craft its prompts to optimize recall and precision. Smaller-scale, open-source architectures like GPT-2 or Flan T5 might suffice for pilot studies or when hardware and budget constraints prohibit more advanced solutions, yet these simpler models can struggle with contextual complexity, potentially requiring additional prompt engineering to maintain accuracy [60]. More recent and larger architectures, such as GPT-3.5, GPT-4, or other open-source models like the Deepseek family, have demonstrated superior performance in a variety of tasks, including domain-specific literature screening, but come at the cost of increased computational overhead and possible API usage fees.
Comparative evaluations consistently show that larger models can excel in contextual awareness, preserving coherence when confronted with intricate abstracts, while smaller models often produce output more quickly but risk overlooking nuanced details. Generation speed and context management can vary widely across models depending on both the underlying architecture and the target hardware environment [61].
The choice of model also intersects closely with the available infrastructure. Deployed solutions that rely on cloud-based APIs (e.g., GPT-3.5 or GPT-4 via OpenAI) offer scalability but can become expensive at high volumes and raise concerns over data security if abstracts contain sensitive information [43]. Even among API-based solutions, performance can differ if concurrency limits or prompt length restrictions apply, as larger context windows deliver more accurate results but also increase both processing time and token-related costs [62]. These efficiency considerations become especially relevant in systematic reviews, which can easily involve thousands of abstracts to classify. Overly long prompts, although potentially more instructive, may result in slower inference speeds, and a near-linear increase has been observed in total processing time in models receiving large prompt sizes [61]. Researchers must weigh the complexity of their prompts—particularly if they include multiple inclusion/exclusion criteria or domain-specific nuances—against the desire for rapid classification.
Developing effective prompts remains the other crucial pillar in model selection. Even advanced models with large context windows can produce erratic outputs if the instructions conflict or are excessively vague. Slight rewording of a prompt can either inflate false positives (when instructions are too permissive) or inadvertently exclude relevant studies (when instructions are too strict) [23,27].
3.4. Understanding Prompt Fundamentals and Challenges
A prompt refers to the instructions, context, or background information given to a LLM so that the model can respond in a manner consistent with the user’s objectives [63]. Unlike traditional machine learning classifiers that rely on iterative retraining, modern LLMs use these prompts as immediate instructions, which guide the model’s behavior. The structure of a well-crafted prompt typically includes a concise statement of the task (for example, “You are assisting in a systematic review”), any relevant context (such as inclusion/exclusion criteria or a description of the population and interventions), the textual data to be analyzed (i.e., the title or abstract), and explicit output instructions (indicating whether to “ACCEPT” or “REJECT”). In the context of systematic reviews, prompts often encode key methodological requirements—whether defined via PICO or other frameworks—so that an LLM can scan each abstract for relevant details like patient characteristics, study design, or reported outcomes [64].
Below is a template for a possible prompt that uses PICO criteria for a literature search of RCTs:
System: You are an AI assistant helping with a systematic review on [TOPIC OR CONDITION].
User Prompt: You will decide if each article should be ACCEPTED or REJECTED based on the following criteria:
Population (P): Adult patients (≥18 years) with [SPECIFIC POPULATION OR CONDITION]. If the abstract does not mention age, or does not clearly describe non-adult populations, do not penalize.
Intervention (I): Must involve [INTERVENTION 1] combined with [INTERVENTION 2]. If either is implied or partially mentioned, do not penalize.
Comparison (C): Ideally a group that uses [CONTROL OR COMPARISON], or some control lacking [KEY INTERVENTION]. If not stated but not contradicted, do not penalize.
Outcomes (O): Must measure [PRIMARY OUTCOME] or at least mention [SECONDARY OUTCOMES OR RELEVANT PARAMETERS]. If the abstract does not state outcomes explicitly but mentions [RELEVANT OUTCOME KEYWORDS], do not penalize.
Study design: Must be an RCT or strongly imply random allocation. If uncertain, do not penalize.
Follow-up: Minimum [X] months. If not stated or unclear, do not penalize unless it says <[X] months.
Decision Rule: If no criterion is explicitly violated, respond only with “ACCEPT.” If any criterion is clearly contradicted (e.g., non-randomized design, pediatric population, <[X] months follow-up), respond with “REJECT.” Provide no additional explanation.
Title: {title}
Abstract: {abstract}
Researchers can enhance prompt clarity by stripping away extraneous details, ensuring that essential instructions are easily distinguishable from background information. In systematic review applications, this often means specifying the precise triggers for “ACCEPT,” e.g., randomized study designs and adult populations, versus the explicit triggers for “REJECT,” e.g., purely animal research or pediatric cohorts.
The complexity of biomedical abstracts, which may discuss multiple interventions, outcomes, or populations, can pose a challenge if prompts are too broad, too vague, or contain contradictory statements. For instance, telling the LLM to accept studies if they mention any adult participants but then also requesting rejection if the study includes children under 18 could lead to confusion if the abstract features a mixed population. Careful wording of the criteria or prompt instructions can thus mitigate incorrect interpretations, a phenomenon made more likely when dealing with large corpora.
Another key challenge is ensuring that the model does not “hallucinate” details not actually present in the abstract [65]. Because LLMs are probabilistic text generators trained on diverse textual corpora, they can sometimes invent content—such as extra interventions, specific follow-up durations, or outcome measures—simply because the prompt or question implies these details are relevant, and countermeasures to mitigate this phenomenon are a fertile area of investigation [66,67,68]. A simple approach could be just encouraging the model to cite the exact words or phrases in the abstract that justify its decision, although verifying the accuracy of these cited quotes still requires careful human oversight.
Prompt refinement typically evolves through iterative testing. Many researchers begin with a “soft” or inclusive instruction set that aims to maximize recall, then review a subset of “Accepted” outputs to identify obvious false positives that indicate the need for more stringent language. Likewise, a “strict” approach can guard against irrelevant articles but risks excluding borderline studies whose abstracts do not explicitly list every inclusion criterion. In such instances, a prompt that directs the model to label a study as “INSUFFICIENT INFORMATION” may help flag ambiguous cases for further manual review. Domain-specific jargon or abbreviations also introduce complexity, since the LLM might misinterpret specialized terms or incorrectly infer the presence of required conditions [69]. For instance, a study might use “RCT” in the text but never explicitly mention “randomized controlled trial,” leading certain prompts to accept or reject the article prematurely if they only look for the spelled-out term. Researchers should therefore tailor prompts to the language patterns common in the target domain, possibly by leveraging known synonyms or by describing relevant terms in the instructions (“Consider an ‘RCT’ the same as a ‘randomized controlled trial’”). Even in a best-case scenario, LLMs might misclassify abstracts that mention unclear or conflicting details. While advanced LLMs have grown remarkably adept at context-sensitive classification, no prompt can capture every edge case in biomedical literature, particularly in specialized reviews that examine niche interventions or unique study designs. Documenting prompt versions, analyzing errors, and iterating toward more precise instructions remain central to balancing recall, precision, and cost efficiency for large-scale screening efforts.
3.5. Perform Initial Screening
Once the prompt strategies are established, the LLM can be applied to classify each abstract as either “Accepted” or “Rejected.” This step typically involves passing the abstract text and the relevant prompt to the LLM and collecting the output in a structured data frame. Metadata such as timestamps, model version, or confidence levels (if provided by the API or tool) can also be recorded for subsequent auditing and reproducibility. Consistent recordkeeping at this juncture lays the groundwork for quality assurance and the potential to replicate the screening approach in the future [12].
3.6. Human Verification and Error Analysis
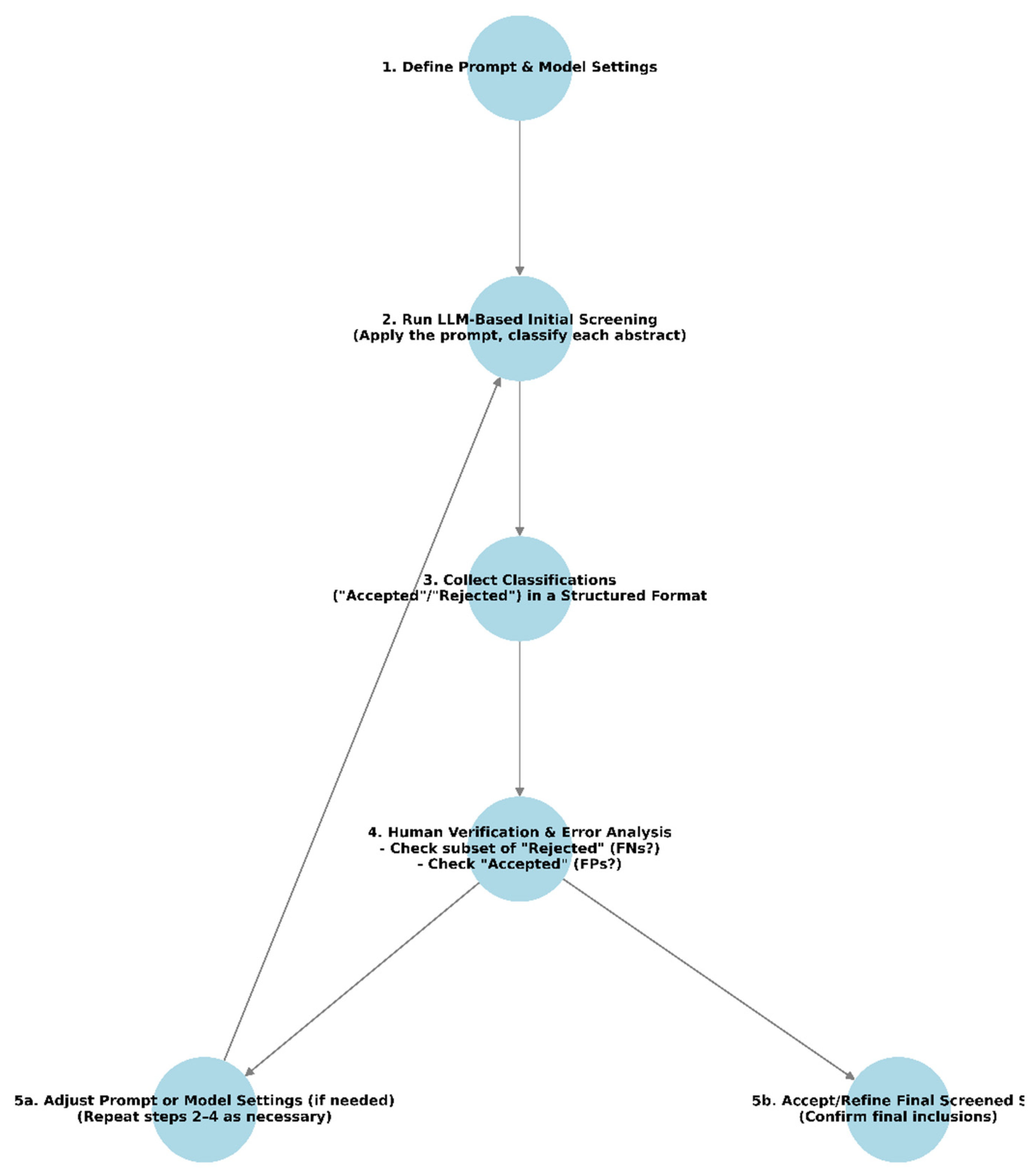
Human expertise remains indispensable in systematic reviews, even when leveraging advanced language models [70]. Researchers typically begin by scrutinizing a subset of “Rejected” articles to identify false negatives—studies that were incorrectly excluded. If borderline cases appear in this category, adjustments to prompt wording or acceptance thresholds may be necessary. Conversely, a quick review of “Accepted” abstracts helps detect obvious false positives. This iterative feedback loop, reminiscent of semi-automated screening tools [14,15], can be accomplished more rapidly and flexibly through zero-shot or few-shot prompting in LLMs. Refinements continue until the screening team is satisfied that the model reliably captures relevant studies without becoming overly permissive. Once optimized, these prompt settings can be incorporated into ongoing or future screening efforts, with systematic refinement shown to improve both recall and precision while reducing reviewer workload [23]. Figure 2 illustrates a possible workflow for prompt refining.
3.7. Best Practices and Recommendations
Maintaining high recall is critical, as omitting relevant articles risks weakening the entire review. To mitigate this, a consensus favors maximizing inclusivity during database searches and the early screening phases—accepting borderline cases to avoid excluding key studies prematurely [71,72,73,74].
Clear inclusion/exclusion criteria are essential to reduce unpredictable misclassifications, and all changes to prompts or model settings should be carefully documented, including the rationale and observed impacts on accuracy or recall. Pilot tests screening small sets of known abstracts may be very valuable for surfacing issues early, preventing downstream errors that might otherwise emerge only after processing thousands of articles. While these checks may seem laborious, they safeguard reproducibility and avert more significant oversights.
Cost is another practical consideration, particularly when using proprietary models with API-based pricing [75]. Although ongoing refinement and error analysis may eventually lower expenses by reducing unnecessary queries, research teams must weigh the financial overhead of repeated API calls against potential performance gains. A flexible, layered approach often balances efficiency and rigor effectively. Early screening rounds benefit from broad prompts and inclusive language to preserve potentially relevant studies, while later phases can adopt stricter criteria or incorporate prior labels to filter clearly irrelevant articles, thereby improving precision and reducing the full-text workload. Throughout this process, error analysis—especially the detection of false negatives—remains central to safeguarding evidence integrity. Strategically limited manual checks, such as random sampling of “Rejected” articles or verification of ambiguous abstracts, confirm model reliability without requiring exhaustive rechecks [27], preserving the time-saving advantages of automation.
Ultimately, LLMs should be viewed as high-efficiency filters that augment—rather than replace—expert judgment. Whether employing a single inclusive prompt strategy or a multi-stage filtering model, iterative refinement and selective validation allow the method to adapt to the review’s scope, resource constraints, and citation volume.
4. Discussion
The adaptability of LLMs offers a clear advantage over more rigid machine learning models [76]. In zero-shot or few-shot modes, the model’s performance depends heavily on how well the prompt captures the essence of the inclusion and exclusion criteria. It has been shown that refining those criteria substantially boosts accuracy and can approach human-level recall [23,27]. These gains do not negate the importance of human expertise. Rather, oversight remains pivotal to interpret borderline abstracts, continually adjust prompts, and preserve the rigor of evidence synthesis [77].
Beyond these technical considerations, recent literature emphasizes the need for explicit guidelines to optimize LLM usage in research contexts [78,79,80,81,82,83], highlighting the importance of transparency in disclosing AI involvement and the ethical requirement of human accountability. As the importance of AI is growing exponentially in science as much as in everyday life, education on the strengths and limitations of language models is critical to users.
Scholars caution that LLMs should not replace expert judgment; rather, they should enhance it by rapidly filtering large volumes of text, provided their outputs are continually verified and documented for reproducibility. Transparency about any AI-assisted workflow is essential to maintain scientific integrity [78], and risks like hallucinations and bias must be mitigated through ongoing validation. [83] Likewise, Raj et al. suggest that structured methods—whether fine-tuning or retrieval-augmented techniques—can boost performance, but only if accompanied by guidelines that ensure data curation and prompt engineering are implemented consistently and responsibly [79,84]. Adopting such measures is of particular importance when applying LLM-based screening to medical fields, given the high stakes of omitting relevant studies or introducing biased results into the evidence base [80].
The workflow outlined in this paper addresses many of the time and resource challenges associated with traditional screening, but it also introduces new considerations, such as how to manage prompt complexity, maintain cost-effectiveness when making numerous API calls, and log each classification for reproducibility. These authors are convinced that combining LLM technologies with robust oversight, adherence to ethical standards, and comprehensive user training, will ensure that these tools bolster rather than compromise the credibility of systematic reviews.
5. Conclusions
Integrating LLMs into systematic review screening offers substantial time savings during the initial evaluation of abstracts, particularly when well-defined inclusion criteria are applied. The use of LLMs not only potentially expand the scope of literature that can feasibly be screened but also alleviate the burden on research teams. By selecting appropriate LLMs, tailoring prompts to their capabilities, conducting manual validation, and documenting iterative refinements, it is possible to achieve robust recall and precision while maintaining the integrity of evidence-based conclusions. Standardized guidelines are however needed to integrate these powerful instruments into the routine of literature screening. As LLMs and AI-based solutions continue to evolve, the step-by-step framework presented here provides a starting point for leveraging these tools responsibly and effectively in systematic review processes.
Author Contributions
Conceptualization, C.G., and E.C..; methodology, C.G.; software, A.V.G.; writing—original draft preparation, C.G.; writing—review and editing, A.V.G. and E.C.; All the authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No data were generated.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Mulrow, C.D. Systematic Reviews: Rationale for systematic reviews. BMJ 1994, 309, 597–599. [Google Scholar] [CrossRef]
- Parums, D.V. Review articles, systematic reviews, meta-analysis, and the updated preferred reporting items for systematic reviews and meta-analyses (PRISMA) 2020 guidelines. Med Sci Monit 2021, 27, e934475-1. [Google Scholar]
- Methley, A.M.; Campbell, S.; Chew-Graham, C.; et al. PICO, PICOS and SPIDER: a comparison study of specificity and sensitivity in three search tools for qualitative systematic reviews. BMC Health Serv Res 2014, 14, 579. [Google Scholar] [CrossRef]
- Linares-Espinós, E.; Hernández, V.; Domínguez-Escrig, J.; et al. Methodology of a systematic review PALABRAS CLAVE. 2018. [Google Scholar]
- Dickersin, K.; Scherer, R.; Lefebvre, C. Systematic reviews: identifying relevant studies for systematic reviews. Bmj 1994, 309, 1286–1291. [Google Scholar] [PubMed]
- Greenhalgh, T.; Thorne, S.; Malterud, K. Time to challenge the spurious hierarchy of systematic over narrative reviews? Eur J Clin Invest 2018, 48, e12931. [Google Scholar] [CrossRef] [PubMed]
- Waffenschmidt, S.; Knelangen, M.; Sieben, W.; et al. Single screening versus conventional double screening for study selection in systematic reviews: a methodological systematic review. BMC Med Res Methodol 2019, 19, 132. [Google Scholar] [CrossRef]
- Cooper, C.; Booth, A.; Varley-Campbell, J.; et al. Defining the process to literature searching in systematic reviews: a literature review of guidance and supporting studies. BMC Med Res Methodol 2018, 18, 1–14. [Google Scholar]
- Furlan, J.C.; Singh, J.; Hsieh, J.; Fehlings, M.G. Reviews Methodology of Systematic Reviews and Recommendations.
- Cumpston, M.; Li, T.; Page, M.J.; et al. Updated guidance for trusted systematic reviews: a new edition of the Cochrane Handbook for Systematic Reviews of Interventions. Cochrane Database Syst Rev 2019, 2019, ED000142. [Google Scholar]
- Dunning, J.; Lecky, F. The NICE guidelines in the real world: a practical perspective. Emerg Med J 2004, 21, 404. [Google Scholar]
- Van Dinter, R.; Tekinerdogan, B.; Catal, C. Automation of systematic literature reviews: A systematic literature review. Inf Softw Technol 2021, 136, 106589. [Google Scholar]
- Wang, Z.; Nayfeh, T.; Tetzlaff, J.; et al. Error rates of human reviewers during abstract screening in systematic reviews. PLoS One 2020, 15, e0227742. [Google Scholar] [CrossRef] [PubMed]
- Ouzzani, M.; Hammady, H.; Fedorowicz, Z.; Elmagarmid, A. Rayyan—a web and mobile app for systematic reviews. Syst Rev 2016, 5, 1–10. [Google Scholar] [CrossRef]
- Chai, K.E.K.; Lines, R.L.J.; Gucciardi, D.F.; Ng, L. Research Screener: a machine learning tool to semi-automate abstract screening for systematic reviews. Syst Rev 2021, 10, 93. [Google Scholar] [CrossRef]
- Khalil, H.; Ameen, D.; Zarnegar, A. Tools to support the automation of systematic reviews: a scoping review. J Clin Epidemiol 2022, 144, 22–42. [Google Scholar] [CrossRef] [PubMed]
- Allot, A.; Lee, K.; Chen, Q.; et al. LitSuggest: a web-based system for literature recommendation and curation using machine learning. Nucleic Acids Res 2021, 49, W352–W358. [Google Scholar] [CrossRef]
- Marshall, I.J.; Kuiper, J.; Wallace, B.C. RobotReviewer: evaluation of a system for automatically assessing bias in clinical trials. Journal of the American Medical Informatics Association 2016, 23, 193–201. [Google Scholar] [CrossRef] [PubMed]
- Kiritchenko, S.; De Bruijn, B.; Carini, S.; et al. ExaCT: automatic extraction of clinical trial characteristics from journal publications. BMC Med Inform Decis Mak 2010, 10, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Sindhu, B.; Prathamesh, R.P.; Sameera, M.B.; KumaraSwamy, S. The evolution of large language model: Models, applications and challenges. 2024 International Conference on Current Trends in Advanced Computing (ICCTAC); IEEE, 2024; pp. 1–8. [Google Scholar]
- Cao, C.; Sang, J.; Arora, R.; et al. Prompting is all you need: LLMs for systematic review screening. medRxiv 2024, 2024–2026. [Google Scholar]
- Scherbakov, D.; Hubig, N.; Jansari, V.; et al. The emergence of Large Language Models (LLM) as a tool in literature reviews: an LLM automated systematic review. arXiv 2024, arXiv:240904600. [Google Scholar]
- Dai, Z.-Y.; Shen, C.; Ji, Y.-L.; et al. Accuracy of Large Language Models for Literature Screening in Systematic Reviews and Meta-Analyses. 2024. [Google Scholar]
- Dennstädt, F.; Zink, J.; Putora, P.M.; et al. Title and abstract screening for literature reviews using large language models: an exploratory study in the biomedical domain. Syst Rev 2024, 13, 158. [Google Scholar] [CrossRef]
- Khraisha, Q.; Put, S.; Kappenberg, J.; et al. Can large language models replace humans in systematic reviews? Evaluating GPT -4’s efficacy in screening and extracting data from peer-reviewed and grey literature in multiple languages. Res Synth Methods 2024, 15, 616–626. [Google Scholar] [CrossRef] [PubMed]
- Blevins, T.; Gonen, H.; Zettlemoyer, L. Prompting Language Models for Linguistic Structure. 2022. [Google Scholar]
- Delgado-Chaves, F.M.; Jennings, M.J.; Atalaia, A.; et al. Transforming literature screening: The emerging role of large language models in systematic reviews. Proceedings of the National Academy of Sciences 2025, 122. [Google Scholar] [CrossRef]
- Lieberum, J.-L.; Töws, M.; Metzendorf, M.-I.; et al. (2025) Large language models for conducting systematic reviews: on the rise, but not yet ready for use—a scoping review. J Clin Epidemiol 11 1746. [CrossRef]
- Zhao, W.X.; Zhou, K.; Li, J.; et al. A survey of large language models. arXiv 2023, arXiv:230318223. [Google Scholar]
- Gao, A. Prompt engineering for large language models. Available at SSRN 4504303. 2023. [Google Scholar]
- Dang, H.; Mecke, L.; Lehmann, F.; et al. How to prompt? Opportunities and challenges of zero-and few-shot learning for human-AI interaction in creative applications of generative models. arXiv 2022, arXiv:220901390. [Google Scholar]
- Cottam, J.A.; Heller, N.C.; Ebsch, C.L.; et al. Evaluation of Alignment: Precision, Recall, Weighting and Limitations. 2020 IEEE International Conference on Big Data (Big Data); IEEE, 2513; pp. 2513–2519. [Google Scholar]
- Wang, Y.; Yu, J.; Yao, Z.; et al. A solution-based LLM API-using methodology for academic information seeking. arXiv 2024. (accessed on day month year). [Google Scholar]
- Kumar, B.V.P.; Ahmed, M.D.S. Beyond Clouds: Locally Runnable LLMs as a Secure Solution for AI Applications. Digital Society 2024, 3, 49. [Google Scholar] [CrossRef]
- Bisong, E. Google Colaboratory. In: Bisong E (ed) Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners. Apress, Berkeley, CA, pp 59–64. 2019. [Google Scholar]
- Mckinney, W. Data Structures for Statistical Computing in Python. In: van der Walt S, Millman J (eds) Proceedings of the 9th Python in Science Conference. pp 51–56. 2010. [Google Scholar]
- Grigorov, D. Harnessing Python 3.11 and Python Libraries for LLM Development. In: Introduction to Python and Large Language Models: A Guide to Language Models. Springer, pp 303–368. 2024. [Google Scholar]
- Maji, A.K.; Gorenstein, L.; Lentner, G. Demystifying Python Package Installation with conda-env-mod. In: 2020 IEEE/ACM International Workshop on HPC User Support Tools (HUST) and Workshop on Programming and Performance Visualization Tools (ProTools). IEEE, pp 27–37. 2020. [Google Scholar]
- Shekhar, S.; Dubey, T.; Mukherjee, K.; et al. Towards optimizing the costs of llm usage. arXiv 2024, arXiv:240201742. [Google Scholar]
- Irugalbandara, C.; Mahendra, A.; Daynauth, R.; et al. Scaling down to scale up: A cost-benefit analysis of replacing OpenAI’s LLM with open source SLMs in production. In: 2024 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, pp 280–291. 2024. [Google Scholar]
- Ding, D.; Mallick, A.; Wang, C.; et al. Hybrid llm: Cost-efficient and quality-aware query routing. arXiv 2024, arXiv:240414618. [Google Scholar]
- Chen, L.; Zaharia, M.; Zou, J. Frugalgpt: How to use large language models while reducing cost and improving performance. arXiv 2023, arXiv:230505176. [Google Scholar]
- Yan, B.; Li, K.; Xu, M.; et al. On protecting the data privacy of large language models (llms): A survey. arXiv 2024, arXiv:240305156. [Google Scholar]
- Yao, Y.; Duan, J.; Xu, K.; et al. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. High-Confidence Computing 100211. 2024. [Google Scholar]
- Huang, B.; Yu, S.; Li, J.; et al. Firewallm: A portable data protection and recovery framework for llm services. In: International Conference on Data Mining and Big Data. Springer, pp 16–30. 2023. [Google Scholar]
- Feretzakis, G.; Verykios, V.S. Trustworthy AI: Securing sensitive data in large language models. AI 2024, 5, 2773–2800. [Google Scholar] [CrossRef]
- Cooke, A.; Smith, D.; Booth, A. Beyond PICO. Qual Health Res 2012, 22, 1435–1443. [Google Scholar] [CrossRef] [PubMed]
- Frandsen, T.F.; Bruun Nielsen, M.F.; Lindhardt, C.L.; Eriksen, M.B. Using the full PICO model as a search tool for systematic reviews resulted in lower recall for some PICO elements. J Clin Epidemiol 2020, 127, 69–75. [Google Scholar] [CrossRef] [PubMed]
- Brown, D. A Review of the PubMed PICO Tool: Using Evidence-Based Practice in Health Education. Health Promot Pract 2020, 21, 496–498. [Google Scholar] [CrossRef]
- Scells, H.; Zuccon, G.; Koopman, B.; et al. Integrating the Framing of Clinical Questions via PICO into the Retrieval of Medical Literature for Systematic Reviews. In: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. ACM, New York, NY, USA, pp 2291–2294. 2017. [Google Scholar]
- Chigbu, U.E.; Atiku, S.O.; Du Plessis, C.C. The Science of Literature Reviews: Searching, Identifying, Selecting, and Synthesising. Publications 2023, 11, 2. [Google Scholar] [CrossRef]
- Patrick, L.J.; Munro, S. The literature review: demystifying the literature search. Diabetes Educ 2004, 30, 30–38. [Google Scholar]
- Heintz, M.; Hval, G.; Tornes, R.A.; et al. Optimizing the literature search: coverage of included references in systematic reviews in Medline and Embase. Journal of the Medical Library Association 2023, 111, 599–605. [Google Scholar] [CrossRef]
- Lu, Z. PubMed and beyond: a survey of web tools for searching biomedical literature. Database 2011, 2011, baq036–baq036. [Google Scholar] [CrossRef]
- Page, D. Systematic Literature Searching and the Bibliographic Database Haystack.
- Cock, P.J.A.; Antao, T.; Chang, J.T.; et al. Biopython: freely available Python tools for computational molecular biology and bioinformatics. Bioinformatics 2009, 25, 1422–1423. [Google Scholar]
- Lu, Z.; Kim, W.; Wilbur, W.J. Evaluation of query expansion using MeSH in PubMed. Inf Retr Boston 2009, 12, 69–80. [Google Scholar] [PubMed]
- Stuart, D. Database search translation tools: MEDLINE transpose, ovid search translator, and SR-accelerator polyglot search translator. Journal of Electronic Resources in Medical Libraries 2023, 20, 152–159. [Google Scholar] [CrossRef]
- Yang, M.; Adomavicius, G.; Burtch, G.; Ren, Y. Mind the gap: Accounting for measurement error and misclassification in variables generated via data mining. Information Systems Research 2018, 29, 4–24. [Google Scholar]
- Galli, C.; Colangelo, M.T.; Guizzardi, S.; et al. A Zero-Shot Comparison of Large Language Models for Efficient Screening in Periodontal Regeneration Research. Preprints (Basel) 2025. [Google Scholar] [CrossRef]
- Agarwal, L.; Nasim, A. Comparison and Analysis of Large Language Models (LLMs). 2024. [Google Scholar]
- Wu, Y.; Gu, Y.; Feng, X.; et al. Extending context window of large language models from a distributional perspective. arXiv 2024, arXiv:241001490. [Google Scholar]
- Beurer-Kellner, L.; Fischer, M.; Vechev, M. Prompting is programming: A query language for large language models. Proceedings of the ACM on Programming Languages 2023, 7, 1946–1969. [Google Scholar]
- Colangelo, M.T.; Guizzardi, S.; Meleti, M.; et al. How to Write Effective Prompts for Screening Biomedical Literature Using Large Language Models. Preprints (Basel) 2025. [Google Scholar] [CrossRef]
- Huang, L.; Yu, W.; Ma, W.; et al. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Trans Inf Syst 2025, 43, 1–55. [Google Scholar] [CrossRef]
- Bhattacharya, R. Strategies to mitigate hallucinations in large language models. Applied Marketing Analytics 2024, 10, 62–67. [Google Scholar]
- Gosmar, D.; Dahl, D.A. Hallucination Mitigation using Agentic AI Natural Language-Based Frameworks. arXiv 2025, arXiv:250113946. [Google Scholar]
- Hassan, M. Measuring the Impact of Hallucinations on Human Reliance in LLM Applications. Journal of Robotic Process Automation, AI Integration, and Workflow Optimization 2025, 10, 10–20. [Google Scholar]
- Mai, H.T.; Chu, C.X.; Paulheim, H. Do LLMs really adapt to domains? An ontology learning perspective. In: International Semantic Web Conference. Springer, pp 126–143. 2024. [Google Scholar]
- Duenas, T.; Ruiz, D. The risks of human overreliance on large language models for critical thinking. Research Gate 2024. [Google Scholar]
- Page, M.J.; Higgins, J.P.T.; Sterne, J.A.C. Assessing risk of bias due to missing results in a synthesis. Cochrane handbook for systematic reviews of interventions 349–374. 2019. [Google Scholar]
- Goossen, K.; Tenckhoff, S.; Probst, P.; et al. Optimal literature search for systematic reviews in surgery. Langenbecks Arch Surg 2018, 403, 119–129. [Google Scholar] [PubMed]
- Ewald, H.; Klerings, I.; Wagner, G.; et al. Searching two or more databases decreased the risk of missing relevant studies: a metaresearch study. J Clin Epidemiol 2022, 149, 154–164. [Google Scholar]
- Cooper, C.; Varley-Campbell, J.; Carter, P. Established search filters may miss studies when identifying randomized controlled trials. J Clin Epidemiol 2019, 112, 12–19. [Google Scholar]
- Wong, E. Comparative Analysis of Open Source and Proprietary Large Language Models: Performance and Accessibility. Advances in Computer Sciences 2024, 7, 1–7. [Google Scholar]
- Ray, S. A Quick Review of Machine Learning Algorithms. In: 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon). IEEE, pp 35–39. 2019. [Google Scholar]
- Tang, X.; Jin, Q.; Zhu, K.; et al. Prioritizing safeguarding over autonomy: Risks of llm agents for science. arXiv 2024, arXiv:240204247. [Google Scholar]
- Kim, J.K.; Chua, M.; Rickard, M.; Lorenzo, A. ChatGPT and large language model (LLM) chatbots: The current state of acceptability and a proposal for guidelines on utilization in academic medicine. J Pediatr Urol 2023, 19, 598–604. [Google Scholar] [CrossRef]
- Ranjan, R.; Gupta, S.; Singh, S.N. A comprehensive survey of bias in llms: Current landscape and future directions. arXiv 2024, arXiv:240916430. [Google Scholar]
- Ullah, E.; Parwani, A.; Baig, M.M.; Singh, R. Challenges and barriers of using large language models (LLM) such as ChatGPT for diagnostic medicine with a focus on digital pathology–a recent scoping review. Diagn Pathol 2024, 19, 43. [Google Scholar]
- Barman, K.G.; Wood, N.; Pawlowski, P. Beyond transparency and explainability: on the need for adequate and contextualized user guidelines for LLM use. Ethics Inf Technol 2024, 26, 47. [Google Scholar]
- Barman, K.G.; Caron, S.; Claassen, T.; De Regt, H. Towards a benchmark for scientific understanding in humans and machines. Minds Mach (Dordr) 2024, 34, 6. [Google Scholar]
- Jiao, J.; Afroogh, S.; Xu, Y.; Phillips, C. Navigating llm ethics: Advancements, challenges, and future directions. arXiv 2024, arXiv:240618841. [Google Scholar]
- Patil, R.; Gudivada, V. A review of current trends, techniques, and challenges in large language models (llms). Applied Sciences 2024, 14, 2074. [Google Scholar]
Figure 1.
Flowchart of the LLM-based screening process. The diagram illustrates the sequential steps involved in utilizing a large language model (LLM) for systematic literature screening.
Figure 1.
Flowchart of the LLM-based screening process. The diagram illustrates the sequential steps involved in utilizing a large language model (LLM) for systematic literature screening.
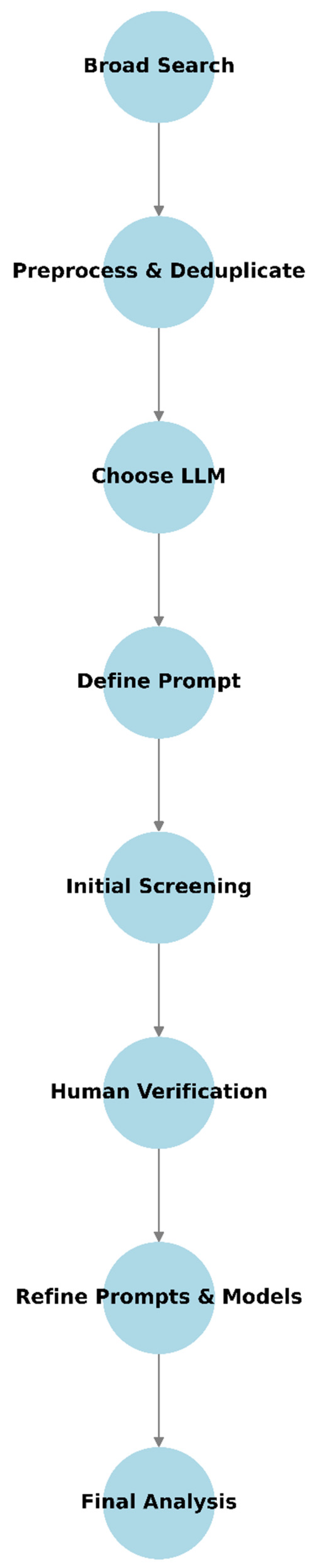
Figure 2.
Flowchart of the prompt refining process. The diagram illustrates the sequential and iterative steps involved in refining the prompt for LL-based literature screening.
Figure 2.
Flowchart of the prompt refining process. The diagram illustrates the sequential and iterative steps involved in refining the prompt for LL-based literature screening.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



