
Submitted:
06 November 2024
Posted:
07 November 2024
You are already at the latest version
Abstract
In the AQbD framework, DOE plays a very important role as it provides information about how experimental input variables influence the critical method attributes. Based on the information obtained from the DOE, mathematical models are generated and used to build the MODR a robust region of operability. Data treatment steps are usually carried out in software such as Fusion QbD, Minitab, StaEase 360, among others. Although there are many papers in the literature using DOE, none of them address important aspect of data treatment for optimization and MODR generation and compare different software calculations. The purpose of this study is to contribute to a better understanding of data treatment aspects that are frequently misread or not fully understood, such as model selection, ANOVA results and residual analysis. The discussion will be guided using the separation of curcuminoids by ultra-high performance liquid chromatography and eight quality attribute as responses. The results highlighted the importance of the correct selection and evaluation of the models due to their influence the generation of the MODR and emphasizes the insertion of the uncertainty in the contour plots to proper obtain the MODR regarding the definitions of the USP General Chapter <1220> and ICH Q14 guidelines.
Keywords:
Liquid chromatography
; Analytical Quality by Design
; Experimental design
; MODR
1. Introduction
Liquid chromatography (LC) is the most widely used separation technique supporting drug development activities and product quality control. The separation of analytes by LC depends predominantly on intrinsic mobile phase parameters such as polarity, pH, flow rate, and composition, on inherent properties of the sample matrix, type of stationary phase, type of detector, and environmental factors such as temperature. For many years, the development of LC methods has been carried out using the so-called "one factor at a time" (OFAT) approach, which consists of testing different operating conditions by varying one factor at a time while keeping the other variables constant, requiring a large number of experiments. This strategy can be misleading because potential interactions between variables are not investigated. Also, the OFAT approach does not facilitate the execution of possible modifications that may be needed in the future since it does not provide an overview of the response’s behavior within the experimental domain [1]. An enhanced strategy for developing LC methods known as ‘Analytical Quality by Design (AQbD)’ has recently gained attention, especially in pharmaceutical industrial environments. Even though the AQbD strategy is not limited to LC method development, the concept was developed based on this technique due to its wide use in the pharmaceutical industry [2].
AQbD is a systematic approach to analytical method development that emphasizes method understanding and control based on sound science and quality risk management. The AQbD concept has become a trending topic over the past decade, especially after the release of the US Pharmacopeia General Chapter (1220) [3] and the International Council of Harmonization ICH Q14 guideline [4]. These documents highlighted a science and risk-based approach to developing and maintaining analytical procedures suitable for the quality assessment of drug substances and drug products. The AQbD framework consists of four main steps, starting with the definition of the analytical target profile (ATP), which describes the purpose of the method and specifies the quality requirements the method must fulfill. Attributes that are critical for appropriate chromatographic method performance are also identified in this step such as retention factor, resolution, and tailing factor, and referred to as critical method attributes (CMA) [2]. The second stage involves a risk assessment to attribute a risk (low, medium, high) to each experimental variable (such as temperature, pH, flow rate, etc.) on the CMAs. The high-risk variables are called critical method parameters (CMPs) and should be studied as a function of CMAs using multivariate methods - this is where the design of experiments (DOE) plays a central role within the AQbD approach [5].
DOE provides high-quality information about the effects of the CMPs on the attributes of the method performance and, therefore, can be applied to the development of analytical methods [6]. This is usually carried out in two steps: screening and optimization. The screening step is required when none or very little information is available about the method, and it involves the study of primary chromatographic variables which are likely to present a high influence on the CMAs and provide a direction for their levels. In this step, it is common to study the stationary phase chemistry (‘column type’); the type of organic modifier (protic, aprotic, basic), the range of pH (acidic; basic, neutral), the presence of ionic pairing, etc. This provides the basic information for the method development and can be accomplished by full factorial designs, fractional factorial designs, and optimal designs [7]. It should be noted that the design must be chosen to allow the calculation of (at least) linear first-order effects without bias to provide accurate guidance in this step, therefore, care should be taken with low resolution (i.e., Res III) and saturated designs.
In the optimization step, some of the primary factors are examined in more detail, and secondary variables are included as well to determine the best overall analytical conditions [1]. The responses acquired from the experiments are modeled as a function of CMPs using statistical approaches to develop prediction models for the CMAs. Therefore, the DOE methods include those that are capable of estimating linear, interactions and higher-order terms, if necessary. Examples include Central Composite Design (CCD), Box Behnken (BB), Doehlert, and optimal designs. In this stage, the goodness of fit and prediction capacity are fundamental aspects of the mathematical models, therefore a rigorous statistical examination of the models derived from the DOE using tools such as analysis of variance (ANOVA), evaluation of important coefficients to avoid overfitting, and, as a consequence, misleading models), and analysis of residuals must be performed for the further generation of a reliable Design Space [8] or Method Operable Design Region (MODR) [9].
Since the MODR is built considering all CMAs simultaneously it can be established using multi-response optimization tools, such as graphical optimization and desirability functions. In the former, the contour plot of all responses is overlaid to estimate the intersection region whereas in the latter multiple responses are transformed into a single global response obtained by the geometric mean [10]. An important aspect is that the MODR should be computed with uncertainty boundaries which can be achieved using confidence, prediction, or tolerance intervals (the latter two are preferred), by Monte Carlo simulations associated with capability indexes such as Cpk [8] or Propagation of Error (POE) [11]. The MODR is considered a robust working region since experimental variations within this region do not cause the failure of any CQA. Thus, robustness is incorporated during development rather than evaluated at the validation step [12].
Usually, all stages from DOE planning to the construction of the MODR are performed on software such as Fusion QbD (S-Matrix, Eureka, USA), Design Expert or Statease 360 (Stat-Ease Inc., Minneapolis, USA), Minitab (Minitab, State College, USA), Statistica (StatSoft, Hamburg, Germany) among others. Among these software programs, Fusion QbD stands out for being an automated experimentation platform that is integrated with multiple chromatographic data software (CDS) such as Empower, which allows for automated bi-directional data exchange, eliminating errors and reducing the user's manual transcription work associated with manual data transfer. This was a milestone for the use of Design of Experiments (DOE) in analytical development [13]. Nevertheless, several other software can be used, such as those mentioned above, that perform data treatment in an offline mode. Calculations and available tools may differ from one software to the other, therefore one of the goals of this paper is to compare the outcomes of two commonly used software: Design Expert and Fusion QbD.
Even though many papers report the use of DOE in separation techniques [6,14,15,16,17,18,19], a practical approach for data interpretation and discussion of important topics found in software outcomes are not found in the literature. This paper aims to contribute to understanding some important features of data treatment that are often misinterpreted or not fully understood, such as model selection, ANOVA results, and residual analysis. We will focus on statistical data analysis for an optimization design, a face-centered central composite design to optimize the chromatographic conditions for the separation of three compounds, bisdemethoxycurcumin (BMC), demethoxycurcumin (DMC), and curcumin (CUR), in two different software: Design Expert and Fusion QbD. This data set was selected for a didactic purpose and a CCD design was chosen since it is a common and efficient DOE method used for Optimization and generation of MODR.
2. Materials and Methods
2.1. Chemicals and Instrumentation
The solvents used for sample preparation and as mobile phase were acetonitrile (Merck, USA) and ethanol with analytical/chromatographic grade (Sigma Aldrich). The standard containing all three curcuminoids: bisdemethoxycurcumin (BMC), desmethoxycurcumin (DMC), and curcumin (CUR) was obtained by (Neon Comercial Ltda). All samples were filtered on 0.22 µm syringe filters before injection into the chromatographic system. The column was obtained from YMC Process Technologies (USA) YMC-Triart C18 (1.9 µm, 100 mm x 2.1 mm). The chromatographic analyses were performed in an ACQUITY UPLC system (Waters Co., USA) with an automatic injector and binary pump. The detector used was a Diode Array Detector (DAD) (Waters Co., USA) with a wavelength range of 190 to 500 nm.
2.2. Curcuminoid Solutions
The curcuminoids were prepared at a concentration of 0,1 mg mL-1 in ethanol. A 100 µL aliquot was diluted from these solutions in 5 mL of ethanol: water (50/50%) (v/v) solution.
2.3. Face-Centered Central Composite Design
A Central Composite Design (CCD) was performed to optimize the chromatographic conditions for the separation of curcuminoids. The studied factors and their levels are shown in Table 1. The values of the factor levels were defined based on prior knowledge and screening studies.
The flow rate of the mobile phase, column oven temperature, and acetonitrile percentage (mobile phase composition) were the variables that most impacted the separation of the analytes. They therefore were selected as CMPs for the study. The α=1 (face-centered) was used due to restrictions in the experimental conditions of flow rate and temperature. The injection volume was fixed at 2 µL and the wavelength of the DAD detector was fixed at 420 nm. In order to show the importance of including the sample preparation error in the DOE, the same DOE was performed twice, one with only a solution for all runs and the other with an independent solution for each experimental design run, totaling 19 independent solutions.
2.4. Data Treatment
Empower (Waters Co., Milford, USA) was the chromatography data system (CDS) used to record and process the chromatograms. For the design of experiments Fusion QbD (S-Matrix, Eureka, USA) was used in the liquid chromatography method development mode (LC Method Development), which allows the import and export of data directly with Empower. The data obtained from the design of experiments were also evaluated in Design Expert Version 13.0.5.0 (StatEase, Minneapolis, USA) to explore and compare different tools for model evaluation and MODR generation.
3. Results and Discussion
3.1. Face-Centered Central Composite Design
As the experimental design chosen was the Face-Centered Central Composite, a total of 19 experiments were obtained, including 8 cubic points, 6 axial points, and 5 central points, which were run in random order. The responses evaluated were retention factor (k), tailing factor, and resolution of the critical pairs (Rs) of the three curcuminoids: BMC, DMC, and CUR (a total of 8 responses). These chromatographic parameters are directly affected by experimental conditions and therefore are important in the development of liquid chromatographic methods. The experimental matrix with the measured response values is shown in Table 2.
The DOE experimental data (Table 2) were then submitted to regression analysis for the construction of mathematical models that express the relationship between the factors (CMPs) and the responses (CMAs) in the Fusion QbD and Design Expert software. For each response monitored a model was generated, so this study provided eight models. The least squares method (LS) was the used approach in regression analysis for estimating regression coefficients (β). This method is widely employed for modeling data, aiming to determine coefficients by minimizing the sum of the squares of the residuals (SSr) [20]. The general solution for fitting a least squares model, in matrix notation, is given by
In optimization design or response surface designs, polynomial models are most often built (2), which includes an intercept (β0), the main effects terms (βi), the interactions terms (βij), and the quadratic terms (βii) [6]. The complexity of the model depends on the design chosen and the number of factors studied. Therefore, a CCD can generate up to a second-order polynomial or quadratic model and the equation for k factors can be represented by:
Where y represents the experimental response, xi, …, xj, are the factors studied and ε is the random error.
However, usually, not all coefficients are statistically significant, the significant ones can be identified by applying model selection techniques, which will be described in the subsequent sections. Model fitting, model inference, and validation are critical procedures that must be carried out before using the model for interpretation and prediction. Regarding model inference, hypothesis tests may be used to evaluate the utility of the fitted model and the significance of the estimated parameters [21]. The first step in model inference is to assess the significance of the regression, i.e., to check whether the factors x influence y. To do this, a hypothesis test based on the F distribution (F-test) is performed. The appropriate hypothesis for the overall test of model significance is
H0: β1 = β2 = … = βk = 0
Ha: βi ≠ 0 for at least one i
The null hypothesis (H0) (3) states that the regression coefficients are equal to zero, which means that a variation in x does not influence y. In this case, there is no model relating y to any x variable. On the other hand, the alternative hypothesis (Ha) (4) assumes that at least one coefficient is different from zero, indicating that at least one factor has a significant effect on the evaluated response. After postulating the hypotheses, the F-test is used to compare two sources of variation provided by ANOVA, the mean square of the regression (MSR) and the mean square of the residuals (MSr) (5). These sources of the variation come from decomposing the sum of the total squares (SST) into the sum of the squares of the regression (SSR) and the sum of the squares of the residuals (SSr), which can be written as SST = SSR + SSr. These mean squares are obtained by dividing the sum of the squares by their respective degrees of freedom (p – 1) and (n – p) as shown in Equation (5).
where p is the number of parameters in the model and n is the number of experiments.
When the calculated F value (F0) from equation (5) exceeds the tabulated F value (Ftab) at the desired confidence level, the null hypothesis can be rejected, and the regression is significant. The higher the calculated F value, the more significant the regression. Alternatively, the p-value can also be used for hypothesis testing and reject H0 if the p-value for the F0 is lower than the chosen significance level (α = 0.05). This means that the probability of the H0 being correct is lower than 5%. For example, based on the design with a single solution, the five-parameter BMC retention factor regression model is significant as the F-value = 1825.11 is greater than the Ftab = 3.11 (F-distribution table) and the p-value < 0.05 at a 95% level of confidence (Table 3). The BMC retention factor model is shown in equation (6). Consequently, the number of degrees of freedom for the model is four (Table 3), calculated as the number of parameters minus one (p – 1). For the residuals, the number of degrees of freedom is fourteen, as it is calculated by (n – p) the number of experiments (n) minus the number of parameters (p).
After establishing the significance of the regression model through the F-test or p-value, the next step is to evaluate the explanatory power of the model, using the coefficient of multiple determination (R²) parameter as a metric. The R² is used to assess the model's overall adequacy which shows how much of the variation related to the response can be explained by the coefficients (7)
The closer the R² values are to 1, the higher the amount of experimental variation of the response that is described by the model. However, a high R² value does not always indicate that the regression model is adequate for its intended use. Adding a new coefficient to the model will increase the R² value regardless of whether it is statistically significant or not. Thus, the adjusted R² (R2adj) and the predicted R2 (R2pred) can be used to obtain additional information on the explanatory power of the regression model [22]. The adjusted R² indicates the percentage of variation explained by the significant coefficients (8) [23], this means that the adjusted R² only increases when the added coefficient improves the model and decreases if the added coefficient does not improve the model or if the improvement is lower than expected [24].
where p is the number of parameters in the model.
The predicted R² indicates the predictive capability of the regression model and can be computed by equation (9) which involves the Predicted Residual Sum of Squares for the model (PRESS) (10)
Where e-i is the residual calculated by fitting a model without the i-th run and then predicting the i-th observation using the resulting model.
As shown in Table 4, the models with the higher number of coefficients, including the non-significant ones have the highest R² values. However, the predicted R² for the model with ten coefficients (0.9736) is lower than that for the model with five coefficients (0.9925), indicating the superior predictive capacity of the model with fewer coefficients. This aligns with the model obtained for the BMC retention factor, with 5 parameters. When choosing the most suitable model, it is important to consider the concept of parsimony, favoring simpler models with fewer coefficients over complex models when they fit the data similarly. As a result, models with high R2 values may produce inaccurate predictions of future observations or estimates of the mean response, i.e., smaller predicted R2 values due to model overfitting [24]. This happens because non-significant coefficients are actually describing random variation, which is not reproducible in future predictions. Ideally, a model should have both high R² and high predicted R², which suggests that the model not only explains the data well but also has the potential to make accurate predictions in future observations.
Furthermore, when the R² and the adjusted R² diverge more than 0.2, non-significant terms have likely been included in the model [25]. Thus, by considering both R² and predicted R² along with adjusted R², a more complete evaluation of the regression model can be performed, ensuring that it not only explains the data well but also has the potential to make accurate predictions in future observations.
3.2. Model Selection
Using a model selection technique helps evaluate and compare possible model coefficients. Several methods have been developed to assess small subsets of regression models by adding or removing a single coefficient at a time. These methods are generally called stepwise procedures and can be classified into forward selection, backward elimination, and stepwise regression [20].
Forward selection starts by including only the intercept as a coefficient in the model. The coefficients are included in the model one at a time until the optimal subset is found. The first coefficient to be selected for the model is the one with the largest simple correlation with the response, and it also provides the largest statistic to test the significance of the regression. The model will include the coefficient if the F-statistic is greater than the preselected F value, also called FIN or F-to-enter (F-to-add in Fusion QbD). The next coefficient chosen for inclusion in the model will be the one with the highest correlation after adjusting for the effect of the first coefficient added to the response. This procedure will continue until the partial F-statistic (12) at a certain step is smaller than the FIN or until the last coefficient is added to the model [20,26].
Where SSRp is the sum of squares for the complete model, and SSRp-1 is the sum of squares for the model with the coefficients removed. This partial F-statistic (F-ratio) is similar to the F-value calculated in the regression significance phase. However, in this case, MSR is obtained from a partial sum of squares, and MSr comes from the full model with all parameters (SSEp). The terms (p – 1) and (n – p) are the degrees of freedom of the MSR and MSr, respectively.
Some software, such as Fusion QbD, can also report the t-statistic for adding or removing a variable because it can be considered a variation of the F-statistic, given that t2α/2,υ = Fα,1,υ [26]. Where α is the significance level and υ is the degrees of freedom.
Conversely, backward elimination seeks to find the best-fitting model from the full model, including all K candidate factors. Then the partial statistical F is calculated for each regressor as if it were the last variable to enter the model and the smallest F value is compared to the preselected FOUT (or F-to-Remove in Fusion QbD). Suppose F-ratio < FOUT, the regressor is removed from the model. This procedure is then repeated for a regression model with K-1 regressors. The backward elimination algorithm terminates when the smallest partial value F-ratio > FOUT. Stepwise regression is a modification of the forward selection procedure, where at every step all the coefficients that entered the model are reevaluated by their partial F-tests or t-tests. Stepwise regression, therefore, requires two cut-off values, FIN and FOUT. The choice of the FIN/OUT cut-off value can be conceived as a stopping rule for the above procedures [27].
In Fusion QbD, data analysis can be performed through the model regression (Stepwise Regression) with the options Backward Elimination - Design Model and Extended Model, Forward Selection, or Combined. All of these regression modes use the F to Add/Remove to select the model coefficients with the default value of F to Add/Remove being equal to 4, which corresponds to a 5% in the F-distribution and is equivalent to a probability p-value of 0.05 used in a t-test [26].
Design Expert also uses model selection using stepwise regression in both forward and backward modes, which are performed in the same way as in Fusion QbD. However, the criteria used in Design Expert are the p-value and the adjusted R². In addition, the Design Expert provides options for selecting model terms based on information theory, demonstrating the relationship between likelihood and the amount of information lost when approximating the data with a model. Design Expert has two algorithms for model selection, the corrected Akaike's Information Criterion (AICc), which provides an estimate of the information lost when a specific model is used to represent the process that generated the data, i.e., the best model will be the one that approximates the data with the least loss of information and is best for small designs. Mathematically, the AICc is calculated by the equation
where p is the number of terms in the model including the intercept, random effects, and fixed effects, n is the number of lines in the plan and the term (L[M│Data]) is the model fit measure, the larger this term is the better the fit.
Bayesian Information Criterion (BIC) is another algorithm option in Design Expert and is similar to AICc but tends to favor models with fewer parameters. The equation 14 expresses BIC:
The smaller AICc or BIC values represent a parsimonious model with a higher quality of fit. Thus, for model selection of the responses, the p-value (backward mode and α=0.05) in Design Expert and the backward elimination-design model option (F=4.0) in Fusion QbD were used as selection criteria. Table 5 shows that the selected model factors for BMC retention factor were quite similar for both software. However, since the Fusion QbD selection criterion is not based only on the p-value but considers that the F0 value must be greater than 4, the AC term was included in the model since it had an F0 = 4.069. This value is very close to 4 and, considering the AC p-value = 0.0648, this coefficient should be removed from the model. A confidence interval (CI) at a 95% level of confidence can also be used to establish whether a coefficient is significant. If the CI passes through zero, that is, one of the limits is positive and the other is negative. The coefficient may be zero indicating that the coefficient is not significant. As seen in Table 5, the confidence interval of the AC term includes zero and agrees with the p-value that this coefficient is not significant and should be removed from the model.
Another difference observed in Table 5 is that Fusion QbD does not include the term A, unlike Design Expert, which retains it to maintain model hierarchy. Non-hierarchical models, like the one suggested by Fusion QbD, are advantageous in optimization-focused experiments because excluding non-significant terms reduces model variance, resulting in narrower confidence intervals for the mean response. On the other hand, the principle of hierarchy dictates that if an interaction term is included, its main effects must also be included, even if their p-values are not significant [28].
While hierarchical models retain non-significant terms, which can increase prediction variance, this often leads to wider confidence intervals, particularly when the inclusion of non-significant terms increases the residual mean square (MSr). In optimization studies, preserving hierarchy can yield an inferior model because it affects the empirical response surface and predicted values, both of which are critical for optimization. Therefore, when the primary goal is prediction, model parsimony becomes more important [20,29]. Since the AC interaction really is non-significant and will be removed from the model, this content will not be further developed. For more information on hierarchical and non-hierarchical models and their implications, see [20,28,29,30,31].
3.3. The Lack of Fit Test
As mentioned before, the R² does not guarantee that the model is adjusted to the data, which is a common misinterpretation. To assess whether the model fits the data well, a Lack of Fit F-test (15) is used to compare the variances of the lack of fit and the pure error, which ANOVA also provides. The lack of fit test relies on the estimation of pure error to compare it with the model error. If replicates are not available, it is not possible to estimate the pure error, making it difficult to determine if the model error is due to a lack of fit or just random variation. Usually, authentic replicates are performed in the central points of DOE. Thus, the squared sum of the residuals is decomposed into pure error sum of squares (SSPE) and lack of fit sum of squares (SSLoF).
where MSLOF is the Mean Square of Lack of fit and MSPE is the Mean Square of Pure Error.
In Table 3, the BMC retention factor model showed a lack of fit (F-value = 320,87 and p-value < 0.05). Although the test results indicate a lack of fit, additional considerations must be taken before concluding that the model is not appropriate: as suggested by Equation (15), the inverse relationship with the pure error highlights that a small pure error value can significantly amplify the F-value, increasing the likelihood of identifying a model with a lack of fit, when in fact, this is not true. This small pure error, however, raises concerns regarding the potential underestimation of experimental error, caused by the absence of authentic replicates during the execution of DOE. In this DOE example, a single solution was used, resulting in the computation of solely the small variability intrinsic to the chromatographic equipment in the pure error term. Underestimating the pure error due to the lack of authentic replicates is a very common mistake made in a DOE study and many examples can be found in literature, where the same values of responses were obtained (in this extreme case the pure error equals zero and therefore it is not possible to carry out the lack of fit F test).
To exemplify the effect of sample preparation, the same DOE was conducted again, this time using nineteen independent solutions—allocating one solution for each run, which ensures that the models encompass the maximum amount of variability (Table 6).
Regression analysis was performed on the data from the DOE using independent curcuminoid solutions, and the same models as in the DOE with a single solution were generated. The ANOVA results for the BMC retention factor in Table 7 show that the model is significant, with the adjusted and predicted R² values slightly higher and very close to the values found in the previous DOE. As expected, the pure error value increased, resulting in a much lower F-value in the lack of fit test (F-value = 8.97, Design Expert) and a p-value close to 0.05. Since the pure error was derived from the replicates at the central point, authentic replication at this point should be sufficient to provide a reliable estimate of the pure error, making the experimental work more practical. We have compared the results of entire replication and replication only at the center points and the results were very similar. In this study, the mobile phase was mixed by the chromatograph (binary pump), and there was no pH adjustment, minimizing variation from these experimental variables. Consequently, only sample preparation was considered in the preparation of the authentic replicates.
Even though the model’s lack of fit remains statistically significant at the 95% confidence level, this result might not have practical implications. Other parameters, such as residual analysis, should be checked to evaluate the quality of the model fit and to determine whether the model can be employed for its intended purpose.
3.4. Residual Analysis and Diagnostic Plots
The t and F-statistics, as well as R², reflect global model properties and the evaluation of only these parameters does not guarantee that the model is adequate. In general, examining the model fit is essential to ensure that it provides an acceptable approximation of the true system and that none of the least squares regression assumptions are violated [32].
Residual analysis is the basis of most diagnostic procedures to detect failures of basic assumptions of the regression model [7,20]. Normality, homoscedasticity, and independence are the major assumptions about the residuals that need to be verified. It is also useful for identifying concerning data points by leverage and influence point analysis. The residuals are defined as the difference between the observed (yi) and the estimated value by the model
Thus, the residuals are a measure of the variability in the response variable that the regression model does not describe, and the analysis of the residual plots is also a key step in evaluating the model adequacy and is an effective way to determine how well the regression model is adjusted to the data [20]. To build these plots, scaled residuals (Externally and Internally Studentized Residuals, Standardized Residuals, or Residuals, ...) are used to aid the visualization of points [33]. The F and t statistics, along with confidence and prediction intervals, all rely on the assumption that the residuals have a normal distribution. To check this assumption, a normal probability plot of the residuals is used to visualize if the residuals follow a straight line with emphasis on the central values, as seen in Figure 1a. Some scattering is expected even for Normal data (represented by a soft ‘S-shaped’ curve) but the presence of defined patterns such as a strongly well-defined S-shaped curve suggests that the response needs to be transformed to improve the model fit [33].
The plot of residuals as a function of the predicted response values is used to test the assumption of constant variance (homoscedasticity). The plot should present a random scatter, which means, a constant range of the residuals across the graph (Figure 1b) [33]. If the scatter expands following a ‘megaphone pattern’, this suggests that the data may need a transformation, or the range of experimental design should be decreased. The independence (uncorrelation) of the residuals can be verified using the plot of the residuals as a function of the experiment run order. This plot should present a random pattern, indicating that there is no influence of an external factor or an error during the execution of the experiment (Figure 1c) [33]. Also, in Figure 1b,c, the points should be within the limits ± 2 studentized residuals (residuals/regression standard deviation) for a 95% confidence level (Fusion QbD default) and ± 3 studentized residues for a 99,7% confidence level 99,7% (Design Expert default). Points outside or near these boundaries should be checked as possible outliers (transcription errors should be verified and a new experiment carried out, if possible). The external standardized residuals present a similar metric; however, the residuals are calculated using a model where the point was not included [34], therefore they are more sensitive to outliers.
The residual plots have shown normality, homoscedasticity, and independence, indicating that the model is appropriate to describe the experimental responses obtained. Finally, the plot of observed versus predicted values is very useful as a diagnostic for model prediction capability [35]. In Figure 2a, the plot shows that the residuals are close to the straight line, which means that the predicted values are in good agreement with the experimental values, therefore, the model for the k BMC can be used for prediction. Figure 2b,c bring graphs for other data sets for an illustrative purpose. Figure 2b shows residuals of a model that presents R2 of 0.938 and still presents a good predictive capability (there is no indication of lack of fit, but rather the experimental error is high, therefore cannot be described by the model which leaves higher residuals than the ones shown in Figure 2a). Figure 2c shows an inadequate model (R2 of 0.48) and a poor prediction capability observe that for a broad range of the experimental data, the predicted value is the same, therefore the corresponding model cannot be used either for prediction or the construction of Design Space/MODR.
Other residual graphs that should be analyzed are influential plots such as Leverage and Cook’s distance, due to their ability to detect influential points—data points that significantly impact the regression coefficients and predictions. Even though influential points significantly impact the regression results, they are not necessarily outliers and they can be identified by assessing both leverage and the residuals graphs. Leverage measures how far an individual predictor value deviates from the mean of the predictor values, points with high leverage have a greater potential to affect the regression model’s estimates [20,36]. For instance, a single influential point with high leverage and a large residual can alter the slope and intercept of the regression line, leading to misleading conclusions. Leverage is calculated using the hat matrix, denoted as H. For a given data point i, leverage hi is derived from the diagonal elements of this matrix (17) [20,34].
Specifically, H is obtained as:
Where X is the design matrix, with a row for each execution in the project (n) and a column for each term in the model (p).
Leverage values range from 0 to 1, with higher values indicating that the corresponding data point has a greater potential to influence the regression model’s parameter estimates. Points with leverage substantially larger than the average leverage (), are considered high leverage points and require closer examination [34,36]. Figure 2B shows that no point in the k BMC model has high leverage since all points are located below the calculated average leverage value (red line).
Cook’s Distance (Di,) described by equation (19) is another important diagnostic that combines the information from leverage and residuals to quantify the influence of each data point on the fitted regression model [36]. Cook’s Distance is a summary of how much a regression model changes when the ith observation is removed.
Cook’s Distance plot visually represents this influence, where points with a large Cook’s Distance value (typically greater than 1) are considered influential and may have a negative impact on the model’s predictions [34]. Evaluating the Cook’s Distance graph for the retention factor of BMC (Figure 3a) confirms this, as no point exceeds the calculated threshold. Therefore, no outlier or influential point is present in the data set. Identifying such points is crucial for ensuring the robustness and reliability of the regression model, as influential points can distort the model’s outcomes and lead to misleading conclusions.
Attention should be paid not to exclude a given point with high Cook’s Distance interpreting it as an outlier, when it is actually a high leverage point but that is well described by the model, as shown in Figure 3 c–e (another data set of our group). Another metric sometimes used is DFFITS, and although the raw values resulting from the equations are different, Cook’s distance and DFFITS are conceptually identical and there is a closed-form formula to convert one value to the other [34,36].
All eight models, equation (3) and equations (20 – 26), obtained in this study went through all the evaluation steps described so far. The ANOVA tables, fit statistics, and residual plots for these models are available in the supplementary material.
3.5. Response Surface
In the optimization step, once the model is considered suitable for its intended use, it is possible to use response surfaces or contour plots to help the interpretation and find the optimal location point or region [10], both graphs available in Design Expert and Fusion QbD. These graphics are an illustration of the built model and describe the behavior of the response measured concerning the range of factors assessed and the fitted model. So, assessing the most significant coefficients of each model is important. In Figure 4, it can be observed that the retention factor increases as the percentage of acetonitrile decreases. This observation aligns with the principle of reversed phase chromatography that lowering the percentage of the strong elution solvent increases retention.
Furthermore, using multivariate methods such as DOE enables the identification of interactions between the factors studied. Figure 4 illustrates that temperature does not significantly influence the retention of the BMC compound in 70% acetonitrile. Conversely, when the percentage of acetonitrile is reduced, temperature begins to affect retention; specifically, lower temperatures result in higher retention of the compounds. This indicates an interaction between temperature and the percentage of acetonitrile. Graphically, these interactions are characterized by non-parallel lines on the response surface, further demonstrating the presence of factor interactions. However, the response surfaces only represent a region in which the responses are observed on average and therefore give no guarantee that the responses will meet the predefined criteria with high probability [8,10].
3.6. MODR Construction
From DOE-derived models, knowledge is acquired, allowing access to a region where the behavior of analytical responses and method performance can be understood based on variations in the analytical parameters [8]. This region, known as the knowledge space, is confined to the experimental domain in the context of empirical models. In Figure 4 and Figure 5, the knowledge space is represented by the entire region of the graph. Within the knowledge space, areas where analytical parameters and their ranges fail to meet specifications, termed as the “non-acceptable performance region,” and areas where mean responses meet specifications, referred to as the “acceptable mean performance region” can be identified [9].
Multiple response optimization tools are used to find the acceptable mean performance region when several responses are studied simultaneously. There are two primary methods for multiple response optimization. The first is graphical optimization, often referred to as overlay graphs, where the contour plots of each response model are superimposed to estimate the region of intersection, thereby providing a region of optimal conditions or an acceptable performance region. The second method is based on the desirability functions (often called ‘numeric optimization’ or Derringer and Suich desirability) [10]. Initially, individual desirability functions di(ŷi) for each ŷi must be created using fitted models and establishing the optimization criteria. Desirability values always range from 0 to 1, with desirability equal to zero representing an undesired response and di(ŷi) = 1 for the optimal response. Desirability functions can be customized to suit the chosen optimization criteria. These criteria typically fall into the following categories:
Maximize: The objective is to elevate the response variable to its maximum potential. Desirability increases as the response approaches its highest value.
Minimize: This criterion minimizes the response variable, striving for the lowest achievable value. Desirability increases as the response approaches its minimum value.
Target: The focus is on achieving a specific target value for the response variable. Desirability decreases as the response deviates from this target, emphasizing alignment with the desired outcome.
In range: which specifies a range (lower limit - upper limit) for acceptable results.
Cpk: the process capability index, which calculates the number of standard errors of the predicted response that are within the specification limits.
By tailoring desirability functions according to these criteria, the optimization process can effectively pursue the desired objectives for the analytical method. Once all n variables are transformed into desirability functions, they are combined into a single function called overall desirability (D), employed to discover the best combinations of responses. In mathematical terms, the overall desirability is given by the geometric mean of the n individual desirability shown by equation (27) [10]
In Design Expert, Graphical and Numerical (desirability) optimizations are available, whereas Fusion QbD uses only desirability to find the best overall answer. In Design Expert, the graphical optimization criteria are defined by the values specified by the analyst for the lower and upper limits, or sometimes just one of these limits.
All eight models (3, 20 – 26) were used to find the acceptable mean performance region. In Fusion QbD the responses k BMC, k DMC, and k CUR were maximized with a lower bond of 2 in order to provide adequate retention. To ensure that the peaks were symmetrical, the Tailing BMC, Tailing DMC, and Tailing CUR responses were minimized with the upper bound equal to 1.2. To ensure that adjacent peaks have adequate separation and avoid coelution, the response Rs (BMC, DMC) and Rs (DMC, CUR) were maximized with a lower bound equal to 2. The same criteria were adopted for graphical optimization in Design Expert. The results of the multiple response optimization are shown in Figures 5a and 6a.
In Figure 5a of Fusion QbD, the white regions indicate areas of acceptable mean performance, while the colored regions denote areas of non-acceptable mean performance. Similarly, in Design Expert’s graphical optimization shown in Figure 6a, the bright-yellow regions imply acceptable mean performance, and the grey regions indicate unacceptable performance. However, like the mean response surfaces, these regions only represent the average performance and do not guarantee that the method will meet the requirements of its intended use. Furthermore, these regions cannot be referred to MODR because according to GC USP <1220>, MODR is defined as a “multivariate space of analytical procedure parameters that ensure the ATP is fulfilled and therefore provide assurance of the quality of the measured value” [3]. Moreover, the MODR should ensure quality, which implies that it should represent a robust region as described in ICH Q14 [37]. Therefore, the design of MODR should incorporate the method uncertainties to determine whether the analytical procedure will assure quality. If a method is robust “on average” but exhibits excessive variation, it may fail to meet its robustness criteria [26]. Robustness incorporation includes estimating the variability of analytical measurements related to the CMAs. Also, each source of error is identified to increase analytical performance by reducing the variability associated with the analytical parameters.
Fusion QbD uses Monte Carlo simulations to include the measurement uncertainty of model parameters and estimate the probability of meeting CMA specifications. To start the simulations, the maximum expected variation (± 3σ value) of each CMP must be entered. Then, the robustness indices should be selected, and the lower and upper specification limits (LSL and ULS, respectively) (26) defined for each CMA. These specification limits represent the MODR boundaries for each response and are also known as Edges of Failure. In Fusion QbD, process capability indices such as Cp, Cpk, Cpm, and Cpkm are implemented as robustness capability metrics to quantify system robustness [26]. These are standard Statistical Process Control (SPC) metrics widely used to quantify and evaluate method variation in critical quality and performance characteristics. The Cp index measures the potential capability of a process and is used when the response has a specified maximum allowable variation and symmetrical upper and lower specification limits (USL and LSL). It can be calculated as
where 6σ represents the inherent variation in the average response value, constrained within the limits of a 3σ confidence interval. The Cpk index measures the actual capability of a process accounting for how centered the process is between the specification limits. If the goal of the response is to maximize, only the LSL is established (29). If the objective is to minimize, then only the USL is established (30).
The Cpm index is used when the response has a target value, and the specification limits are symmetrical (31). When the specification limits are asymmetrical the Cpkmindex is used (32)
A Cp = 1.00 indicates that the process variation exactly matches the specification limits, meaning the process spread (±3σ) is equal to the distance between the upper and lower specification limits (USL and LSL). This implies that approximately 99.7% of the process output falls within the specified limits, but it also suggests there is no room for error or drift in the process mean. When Cp = 1.33, the specification limits are four standard deviations (±4σ) away from the process mean, compared to three standard deviations in the case of Cp = 1.00. This allows for greater assurance that the process outputs will remain within the specified limits, even if there are minor variations or shifts in the process. This value suggests that approximately 99.99% of the process output will meet the specified limits A Cp = 2.00 reflects an exceptionally capable process, where the process spread is only half of the specification range. This indicates that almost all output will be within the specification limits, demonstrating a highly robust and reliable process with substantial tolerance for variations in process parameters [38]. Higher Cp values, therefore, indicate better process capability and reduced risk of producing out-of-specification products. Subsequently, the Monte Carlo simulations method begins by modeling the system, including input factors CMAs and their variability, characterized by probability distributions. The simulation generates numerous sets of input values through random sampling, each representing a possible scenario. The model calculates the corresponding analytical response for each set, repeating this process thousands to millions of times to produce a distribution of outcomes. This distribution reflects the combined measurement uncertainty of the analytical response, accounting for the variability of all input factors. By analyzing the outcomes, Monte Carlo simulations estimate the likelihood that the analytical method meets specified performance criteria under different conditions.
The desired levels of robustness for each study factor computed for the MU estimation were inserted as (A) flow rate ± 0.024 mL/min, (B) % of organic solvent in the mobile phase ±1.5%, and (C) column temperature ± 1.5 °C. The Cpk was the robustness index chosen for all responses. For the k BMC, k DMC, and k CUR responses, the goal was to maximize and the Cp, lower was calculated by setting up the LSL at 2.00 so the compounds have a minimal retention factor of 2. To obtain symmetrical peaks for all compounds, the Tailing responses were minimized and the Cp, upper was calculated setting the ULS of 1.2. For adequate separation of the critical pairs, the Rs (BMC, DMC) and Rs (DMC, CUR) responses were maximized and Cp, lowerwas calculated by setting up the LSL at 2.00. In this study, the risk control strategy involved selecting conditions that achieve Cpk≥ 1.33 for all the responses.
Figure 5b,d,f show that after the robustness assessment using Monte Carlo simulations and the insertion of uncertainties into the MODR, the white region is smaller than that obtained without the robustness assessment. It is also possible to see how authentic replicates impact the MODR by comparing Figure 5a,b (results of the DOE without authentic replicates) to Figure 5e,f (results of the DOE with authentic replicates for all the runs). The importance of selecting the models that will be used to build the MODR can also be demonstrated. In Figure 5c,d, for example, the plots were constructed based on the DOE with authentic replicates using the value of F= 4, which resulted in the inclusion of a non-significant term in the Tailing BMC model with, as explained in the model selection section. When removing this term by increasing the F value to 5, the MODR changes again (Figure 5e,f).
On the other hand, Design Expert uses the Propagation of Error (POE) method to identify factor settings that minimize the variation transmitted to a response from factors that are not fully controllable, thereby making the process more robust to input variations. This approach involves applying partial derivatives to locate flat areas on the response surface, which are less sensitive to variations. POE methods require a second-order hierarchical response surface model and estimated standard deviations for the numeric factors. These standard deviations can be inputted for all factors on the Column Info Sheet or individually by selecting specific columns or cells and adjusting them in the Design Properties tool. The same uncertainty values used in Fusion QbD were applied in Design Expert. Using this information, the software constructs a response surface map that shows how factor variations affect each response. By employing multiple response optimization, including objectives to minimize the POE, optimal factor settings can be determined to achieve desired response goals with minimal variation [11]. Robustness assessment in Design Expert utilizes interval estimation to quantify variability and uncertainty in CMAs and CMPs. Interval estimates, including confidence, prediction, and tolerance intervals, can be added to graphical optimization plots (Figure 6) by selecting the "Show Interval" box and specifying the type and confidence level [39]. Unlike confidence intervals (CI) [40], which quantify the uncertainty of an estimated population variable (such as the mean or standard deviation), prediction and tolerance intervals address the uncertainty of future observations. A CI provides a range that is likely to contain the unknown population value, indicating the precision of a sample estimate (33). Therefore, it is worth emphasizing that the use of CI is not recommended for evaluating robustness.
Where SE is the standard error of the design at x0 and x0 is the expanded point vector. In a predictive model, the expanded point vector is a list of values and their interactions and is a way to represent the settings of the factors for a particular location for purposes of prediction. It can be seen as a single-row matrix, with one element for every term in the model, it resembles a row of the expanded model matrix (X). The elements of the point vector and the terms represented by the model matrix's columns must be in the same order. At last, s is the estimated standard deviation.
In contrast, a prediction interval (PI) [40] accounts for both the uncertainty in estimating the population mean and the random variation of individual values, thus offering a range within which the average of a future sample is expected to fall (35).
Being SEpred the predicted error for one future response measurement at x0.
Consequently, PIs are always wider than Cs (Figure 6b,c). Tolerance intervals (TI) [40] are even broader, as they include a specified proportion of all individual outcomes, accounting for observed and unobserved variability within the population (Figure 6d). In mathematical terms, TI is represented as
Where p is the number of terms in the model, P the proportion of the population contained in the tolerance interval, φ is the inverse normal function to convert the proportion to a normal score and X2 is the chi-square critical value [40]
Estimating prediction and tolerance intervals is crucial for evaluating total analytical error (TAE) and assessing robustness in the Analytical Quality by Design (AQbD) framework. For robustness studies and procedure qualification in the AQbD framework, determining the range where future response values are likely to be found is critical for proper risk assessment. Using wider prediction and tolerance intervals can more accurately resolve this issue. In contrast, confidence intervals are less suitable for quantifying uncertainty in future observations and may not adequately support the design of the MODR [9]. By incorporating interval estimates, the graphical optimization (Figure 5) becomes a more powerful tool for visualizing and managing the uncertainty associated with process optimization, thereby enhancing decision-making and process robustness. As shown in Figure 6, the pale yellow represents the region where the point estimate fulfills the criteria requirements but a portion of its interval estimate does not. This region becomes wider when moving from CI (Figure 6b) to PI (Figure 6c) and TI (Figure 6d).
Despite the differences in the software calculations and insertion of uncertainties, the regions delimited as MODR in Design Expert (Figure 6d) and Fusion QbD (Figure 5f) were the same. Once the MODR has been established, verification runs can be carried out to evaluate performance and provide additional evidence that the MODR is valid. Since the MODR is an irregular and multidimensional space, validating or qualifying the entire MODR can be challenging. Therefore, selecting a portion of the MODR for the verification runs is often practical. Fusion QbD verification runs can be performed by inserting the proven acceptable range (PARs), a rectangle added to the overlay graph within the MODR [26], as shown in Figure 7.
The conditions chosen for method validation were a flow rate of 0.825 ml min-1, a temperature of 35° C, and 55 % acetonitrile in the mobile phase, represented by point T in Figure 7. To check the method's performance, the predicted values of the evaluated responses were compared with the experimental ones (Table 9).
The Fusion QbD provides the predicted value and a corresponding lower and upper limit of the 2-sigma confidence interval. According to Table 9, all the experimental results were close to the predicted value and within the 2-sigma confidence interval, ensuring that under these conditions the method meets the quality performance requirements.
It is important to note that if verification runs were conducted after a prolonged time of column use of the column, the experimental values may deviate from the predicted values due to column degradation and a loss of separation efficiency. This is illustrated in Table 10, where verification runs were performed after a prolonged time of column use. While the retention factor values remained close to the predicted ones and within the confidence interval, the tailing factor values were higher than the predicted, and the resolution values were lower. This indicates a decrease in the column’s efficiency.
In this way, the experimental results must be compared to the acceptance criteria of the CMAs. In this case, the acceptance criteria for the resolution between the critical pairs are met since the resolution values in Table 10 are greater than 2 at all points. However, the experimental results for tailing are at or slightly above the acceptance criterion of tailing less than 1.2. Although the tailing values are slightly above the acceptance criterion, the resolution values above 2 guarantee the separation of the compounds.
4. Conclusions
The results of this study demonstrated the importance of a careful model evaluation, including ANOVA and residual analysis, to avoid incorrect interpretations and flawed decisions about model usability. An illustration of this was the BMC retention factor model, which had normal, homoscedastic, and independent residuals even though the F-test indicated that it was not well-fitted. None of the diagnostic graphs for influential points suggested any issues with the model. Furthermore, the adjusted R2 provided a high level of data explanation, accounting for 99.59% of the variation while the predicted R² and the predicted versus actual values plot confirmed the model’s predictive capability.
This study also highlights the importance of model selection for MODR generation since the addition of non-significant terms includes random variability, creating a non-realistic MODR. Additionally, including uncertainties in the contour plots are crucial, either as prediction/tolerance intervals or Monte Carlo simulations. Overall, the careful analysis of all parameters and their practical importance is crucial for making reliable decisions based on the models. Finally, understanding the particularities of each software outcome is important for proper data analysis. Despite the differences in the Design Expert and Fusion QbD, such as model selection and multiple response optimization, the MODR resulting from the two software were similar.
Supplementary Materials
The following supporting information can be downloaded at: www.mdpi.com/xxx/s1, Figure S1: Diagnostic plots of the retention factor DMC from Design Expert software – (a) Normality plot; (b) Residuals vs. Predicted; (c) Residuals vs. Run. The red line in B and C represents the boundaries of ± 3 studentized residues which denotes a 99,7% confidence level. For a 95% confidence level, the points should be within the ± 2 studentized residues limits; Figure S2.: (a) Cook’s distance and (b) leverage plots, and (c) predicted vs actual for the retention factor DMC model from Design Expert; Figure S3: Diagnostic plots of the retention factor CUR from Design Expert software – (a) Normality plot; (b) Residuals vs. Predicted; (c) Residuals vs. Run. The red line in B and C represents the boundaries of ± 3 studentized residues which denotes a 99,7% confidence level. For a 95% confidence level, the points should be within the ± 2 studentized residues limits; Figure S4: (a) Cook’s distance and (b) leverage plots, and (c) predicted vs actual for the retention factor CUR model from Design Expert; Figure S5: Diagnostic plots of the tailing BMC from Design Expert software – (a) Normality plot; (b) Residuals vs. Predicted; (c) Residuals vs. Run. The red line in B and C represents the boundaries of ± 3 studentized residues which denotes a 99,7% confidence level. For a 95% confidence level, the points should be within the ± 2 studentized residues limits; Figure S6: (a) Cook’s distance and (b) leverage plots, and (c) predicted vs actual for the tailing BMC model from Design Expert; Figure S7: Diagnostic plots of the tailing DMC from Design Expert software – (a) Normality plot; (b) Residuals vs. Predicted; (c) Residuals vs. Run. The red line in B and C represents the boundaries of ± 3 studentized residues which denotes a 99,7% confidence level. For a 95% confidence level, the points should be within the ± 2 studentized residues limits; Figure S8: (a) Cook’s distance and (b) leverage plots, and (c) predicted vs actual for the tailing DMC model from Design Expert; Figure S9: Diagnostic plots of the tailing CUR from Design Expert software – (a) Normality plot; (b) Residuals vs. Predicted; (c) Residuals vs. Run. The red line in B and C represents the boundaries of ± 3 studentized residues which denotes a 99,7% confidence level. For a 95% confidence level, the points should be within the ± 2 studentized residues limits; Figure S10: (a) Cook’s distance and (b) leverage plots, and (c) predicted vs actual for the tailing CUR model from Design Expert; Figure S11: Diagnostic plots of the resolution (BMC, DMC) from Design Expert software – (a) Normality plot; (b) Residuals vs. Predicted; (c) Residuals vs. Run. The red line in B and C represents the boundaries of ± 3 studentized residues which denotes a 99,7% confidence level. For a 95% confidence level, the points should be within the ± 2 studentized residues limits; Figure S12: (a) Cook’s distance and (b) leverage plots, and (c) predicted vs actual for the resolution (BMC, DMC) model from Design Expert; Figure S13: Diagnostic plots of the resolution (DMC, CUR) from Design Expert software – (a) Normality plot; (b) Residuals vs. Predicted; (c) Residuals vs. Run. The red line in B and C represents the boundaries of ± 3 studentized residues which denotes a 99,7% confidence level. For a 95% confidence level, the points should be within the ± 2 studentized residues limits; Figure S14: (a) Cook’s distance and (b) leverage plots, and (c) predicted vs actual for the resolution (DMC, CUR) model from Design Expert; Figure S15: (a) Counter plot and (b) the 3D mean response surface of the retention factor DMC response; Figure S16: (a) Counter plot and (b) the 3D mean response surface of the retention factor CUR response; Figure S17: (a) Counter plot and (b) the 3D mean response surface of the tailing BMC response; Figure S18: (a) Counter plot and (b) the 3D mean response surface of the tailing DMC response; Figure S19: (a) Counter plot and (b) the 3D mean response surface of the tailing CUR response; Figure S20: (a) Counter plot and (b) the 3D mean response surface of the resolution (BMC, DMC) response; Figure S21: (a) Counter plot and (b) the 3D mean response surface of the resolution (DMC, CUR) response; Table S1:ANOVA results from Design Expert for the retention factor of DMC, using the data performed with one independent solution the curcuminoids for each run; Table S2: ANOVA results from Design Expert for the retention factor of CUR, using the data performed with one independent solution the curcuminoids for each run; Table S3: ANOVA results from Design Expert for the Tailing BMC, using the data performed with one independent solution the curcuminoids for each run; Table S4: ANOVA results from Design Expert for the Tailing DMC, using the data performed with one independent solution the curcuminoids for each run; Table S5: ANOVA results from Design Expert for the Tailing CUR, using the data performed with one independent solution the curcuminoids for each run; Table S6: ANOVA results from Design Expert for the resolution (BMC, DMC), using the data performed with one independent solution the curcuminoids for each run; Table S7: ANOVA results from Design Expert for the resolution (DMC, CUR), using the data performed with one independent solution the curcuminoids for each run; Table S8. Fit statistics of the models.
Funding
The authors acknowledge the following research funding agencies: CAPES (B.F.G.P Ph.D.Scholarship, Financing Code 001), CNPq/FAPESP through the INCT Bioanalitica.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- D.B. Hibbert, Experimental design in chromatography: A tutorial review, Journal of Chromatography B: Analytical Technologies in the Biomedical and Life Sciences. 910 (2012) 2–13. [CrossRef]
- M.C. Breitkreitz, Analytical Quality by Design, Brazilian Journal of Analytical Chemistry. 8 (2021) 1–5. [CrossRef]
- USP, Analytical Procedure Life Cycle, USP General Chapter. (2022).
- ICH, ICH guideline Q14 Analytical Procedure Development, Ich. (2018).
- R. Peraman, K. R. Peraman, K. Bhadraya, Y. Padmanabha Reddy, Analytical quality by design: A tool for regulatory flexibility and robust analytics, International Journal of Analytical Chemistry. 2015 (2015). [CrossRef]
- K.G. Patel, A.T. K.G. Patel, A.T. Patel, P.A. Shah, T.R. Gandhi, Multivariate optimization for simultaneous determination of aspirin and simvastatin by reverse phase liquid chromatographic method using AQbD approach, Bulletin of Faculty of Pharmacy, Cairo University. 55 (2017) 293–301. [CrossRef]
- M.C. Breitkreitz, H.C. M.C. Breitkreitz, H.C. Goicoechea, Introduction to Quality by Design in Pharmaceutical Manufacturing and Analytical Development, Springer, 2023. [CrossRef]
- E. Rozet, P. E. Rozet, P. Lebrun, P. Hubert, B. Debrus, B. Boulanger, Design Spaces for analytical methods, TrAC - Trends in Analytical Chemistry. 42 (2013) 157–167. [CrossRef]
- A.G. Mahr, F.R. A.G. Mahr, F.R. Lourenço, P. Borman, J. Weitzel, J.-M. Roussel, Analytical Target Profile (ATP) and Method Operable Design Region (MODR), (2023) 199–219. [CrossRef]
- L. Vera Candioti, M.M. L. Vera Candioti, M.M. De Zan, M.S. Cámara, H.C. Goicoechea, Experimental design and multiple response optimization. Using the desirability function in analytical methods development, Talanta. 124 (2014) 123–138. [CrossRef]
- StatEase. Available on:, (n.d.). https://www.statease.com/docs/v23.0/contents/advanced-topics/propagation-of-error/.
- J.C. Abreu, A.G. Mahr, C.L. do Lago, Stability-indicating method development for quantification of bromopride, its impurities, and degradation products by ultra-high performance liquid chromatography applying Analytical Quality by Design principles, Journal of Pharmaceutical and Biomedical Analysis. 205 (2021) 114306. [CrossRef]
- R. Verseput, Fusion QbD® Software Implementation of APLM Best Practices for Analytical Method Development, Validation, and Transfer, Optimization in HPLC: Concepts and Strategies. (2021) 199–218. [CrossRef]
- M. Kurmi, K. M. Kurmi, K. Jayaraman, S. Natarajan, G.S. Kumar, H. Bhutani, L. Bajpai, Rapid and efficient chiral method development for lamivudine and tenofovir disoproxil fumarate fixed dose combination using ultra-high performance supercritical fluid chromatography: A design of experiment approach, Journal of Chromatography A. 1625 (2020). [CrossRef]
- Q. Deng, Y. Liu, D. Liu, Z. Meng, X. Hao, Development of a design of experiments (DOE) assistant modified QuEChERS method coupled with HPLC-MS/MS simultaneous determination of twelve lipid-soluble pesticides and four metabolites in chicken liver and pork, Journal of Food Composition and Analysis. 133 (2024). [CrossRef]
- T. Cernosek, N. T. Cernosek, N. Jain, M. Dalphin, S. Behrens, P. Wunderli, Accelerated development of a SEC-HPLC procedure for purity analysis of monoclonal antibodies using design of experiments, Journal of Chromatography B: Analytical Technologies in the Biomedical and Life Sciences. 1235 (2024). [CrossRef]
- S. Sen, O.P. Ranjan, A Quality by Design (QbD) driven gradient high performance liquid chromatography method development for the simultaneous estimation of dasatinib and nilotinib in lipid nanocarriers, Journal of Chromatography B: Analytical Technologies in the Biomedical and Life Sciences. 1243 (2024). [CrossRef]
- B. Debrus, D. B. Debrus, D. Guillarme, S. Rudaz, Improved quality-by-design compliant methodology for method development in reversed-phase liquid chromatography, Journal of Pharmaceutical and Biomedical Analysis. 84 (2013) 215–223. [CrossRef]
- M. Yabré, L. M. Yabré, L. Ferey, T.I. Somé, G. Sivadier, K. Gaudin, Development of a green HPLC method for the analysis of artesunate and amodiaquine impurities using Quality by Design, Journal of Pharmaceutical and Biomedical Analysis. 190 (2020). [CrossRef]
- D.C. Montgomery, E.A. D.C. Montgomery, E.A. Peck, G.G. Vining, Introduction to Linear Regression Analysis, 5th editio, John Wiley & Sons, Hoboken, New Jersey., 2012.
- D. C. Montgomery, Design and Analysis of Experiments, John Wiley & Sons, 2017.
- Minitab Blog. Available online:, (n.d.). https://blog.minitab.com/en/adventures-in-statistics-2/multiple-regession-analysis-use-adjusted-r-squared-and-predicted-r-squared-to-include-the-correct-number-of-variables (accessed July 23, 2024).
- B.B. Neto, I.S. B.B. Neto, I.S. Scarminio, R.E. Bruns, Como Fazer Experimentos, 4a Edição, Bookman, 2010.
- Minitab Blog. Available on:, (n.d.). https://blog.minitab.com/en/adventures-in-statistics-2/multiple-regession-analysis-use-adjusted-r-squared-and-predicted-r-squared-to-include-the-correct-number-of-variables (accessed , 2024). 23 July.
- StatEase. Available on:, (n.d.). https://www.statease.com/docs/v22.0/contents/analysis/anova-output/ (accessed , 2024). 17 October.
- Fusion QbD, Fusion LC Method Development User’s Guide, (2023).
- R.H. Myers, D.C. R.H. Myers, D.C. Montgomery, C.M. Anderson-Cook, Response Surface Methodology: Process and Product Optimization Using Designed Experiments, 4th editio, John Wiley & Sons, 2016.
- G. James, D. G. James, D. Witten, T. Hastie, R. Tibshirani, An Introduction to Statistical Learning - with applications in R, Second Edi, Springer, 2021. [CrossRef]
- D.C. Montgomery, R.H. D.C. Montgomery, R.H. Myers, W.H. Carter, G.G. Vining, The hierarchy principle in designed industrial experiments, Quality and Reliability Engineering International. 21 (2005) 197–201. [CrossRef]
- J.L. Peixoto, Hierarchical variable selection in polynomial regression models, American Statistician. 41 (1987) 311–313. [CrossRef]
- J.L. Peixoto, A property of well-formulated polynomial regression models, American Statistician. 44 (1990) 26–30. [CrossRef]
- G. Vining, Technical advice: Residual plots to check assumptions, Quality Engineering. 23 (2011) 105–110. [CrossRef]
- StatEase. Available on:, (n.d.). https://www.statease.com/docs/v22.0/contents/analysis/diagnostics/diagnostics-plots/#diagnostics-plots (accessed , 2024). 17 October.
- StatEase. Available on:, (n.d.). https://www.statease.com/docs/v22.0/contents/analysis/diagnostics/diagnostics-report/#diagnostics-report (accessed , 2024). 23 July.
- StatEase. Available on:, (n.d.). https://www.statease.com/docs/v22.0/screen-tips/analysis-node/diagnostics/predicted-vs-actual/ (accessed , 2024). 17 October.
- StatEase. Available on:, (n.d.). https://www.statease.com/docs/v22.0/contents/analysis/diagnostics/influence-plots/#influence-plots (accessed , 2024). 17 October.
- ICH, Q14: Analytical Procedure Development., (2022) 1–64. https://www.teses.usp.br/teses/disponiveis/11/11132/tde-20200111-131624/publico/ParreJoseLuiz.pdf.
- A. Bouabidi, E. A. Bouabidi, E. Ziemons, R. Marini, C. Hubert, M. Talbi, A. Bouklouze, H. Bourichi, M. El Karbane, B. Boulanger, P. Hubert, E. Rozet, Usefulness of capability indices in the framework of analytical methods validation, Analytica Chimica Acta. 714 (2012) 47–56. [CrossRef]
- StatEase. Available on:, (n.d.). https://www.statease.com/blog/adding-intervals-optimization-graphs/ (accessed , 2024). 16 October.
- StatEase. Available on:, (n.d.). https://www.statease.com/docs/latest/contents/analysis/interval-estimate-calculation/#interval-estimate-calculation (accessed , 2024). 15 August.
Figure 1.
Diagnostic plots from Design Expert software – (a) Normality plot; (b) Residuals vs. Predicted; (c) Residuals vs. Run. The red line in B and C represents the boundaries of ± 3 studentized residues which denotes a 99,7% confidence level. For a 95% confidence level, the points should be within the ± 2 studentized residues limits.
Figure 1.
Diagnostic plots from Design Expert software – (a) Normality plot; (b) Residuals vs. Predicted; (c) Residuals vs. Run. The red line in B and C represents the boundaries of ± 3 studentized residues which denotes a 99,7% confidence level. For a 95% confidence level, the points should be within the ± 2 studentized residues limits.
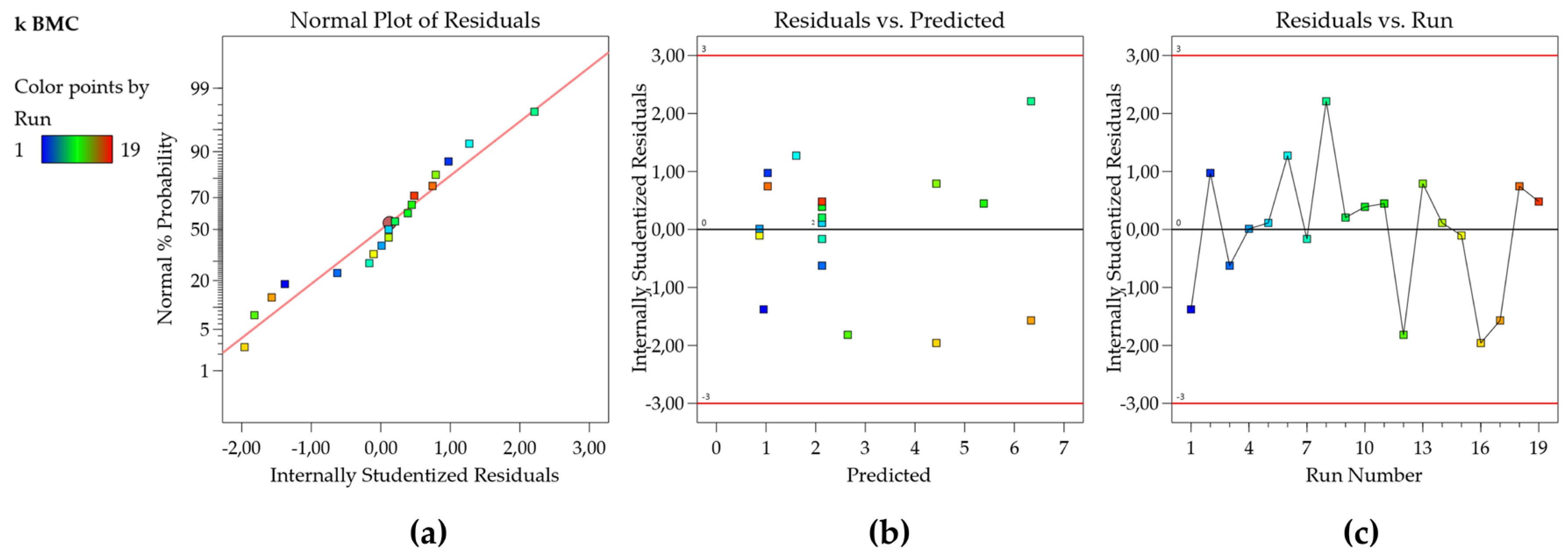
Figure 2.
Predicted vs Actual plots from Design Expert: (a) a good model fit (data from k BMC model of this study); (b) good predictive capability but high experimental error and (c) inadequate model. (b) and (c) are graphs from other data sets of our group.
Figure 2.
Predicted vs Actual plots from Design Expert: (a) a good model fit (data from k BMC model of this study); (b) good predictive capability but high experimental error and (c) inadequate model. (b) and (c) are graphs from other data sets of our group.
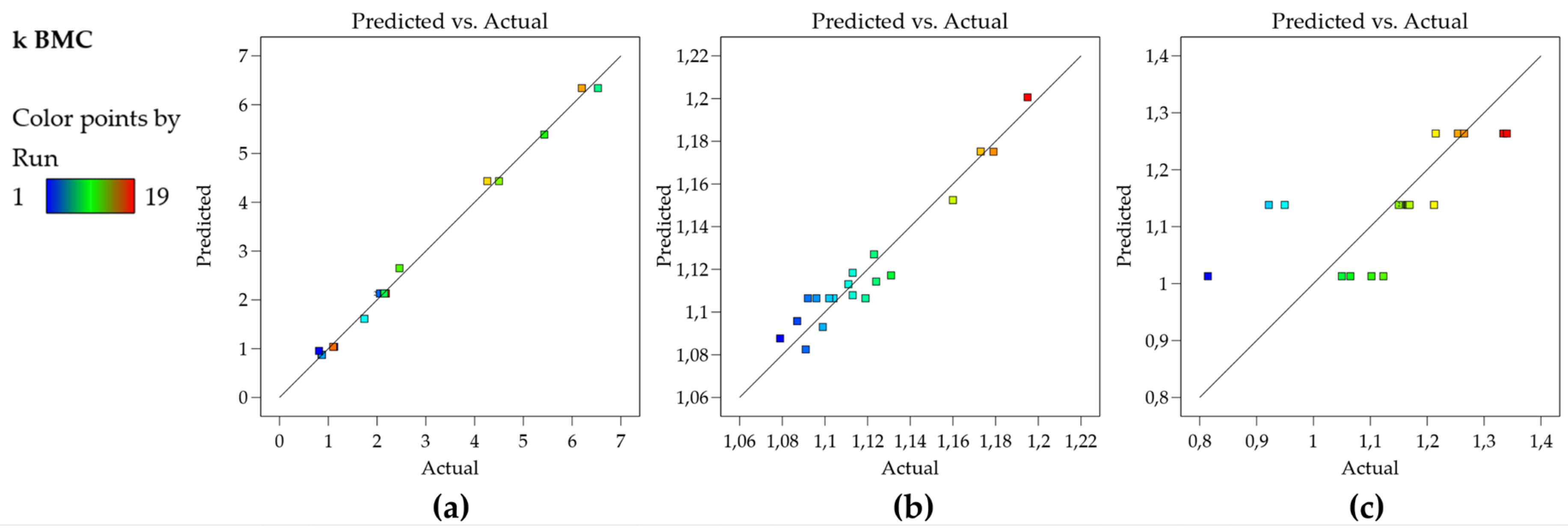
Figure 3.
(a) Cook’s distance and (b) leverage plots for the k BMC model; (c) Cook’s distance for another data set, indicating a point above the threshold; (d) Leverage plot highlighting the same point and (e) predicted vs actual graph indicating that the point is well predicted by the model.
Figure 3.
(a) Cook’s distance and (b) leverage plots for the k BMC model; (c) Cook’s distance for another data set, indicating a point above the threshold; (d) Leverage plot highlighting the same point and (e) predicted vs actual graph indicating that the point is well predicted by the model.
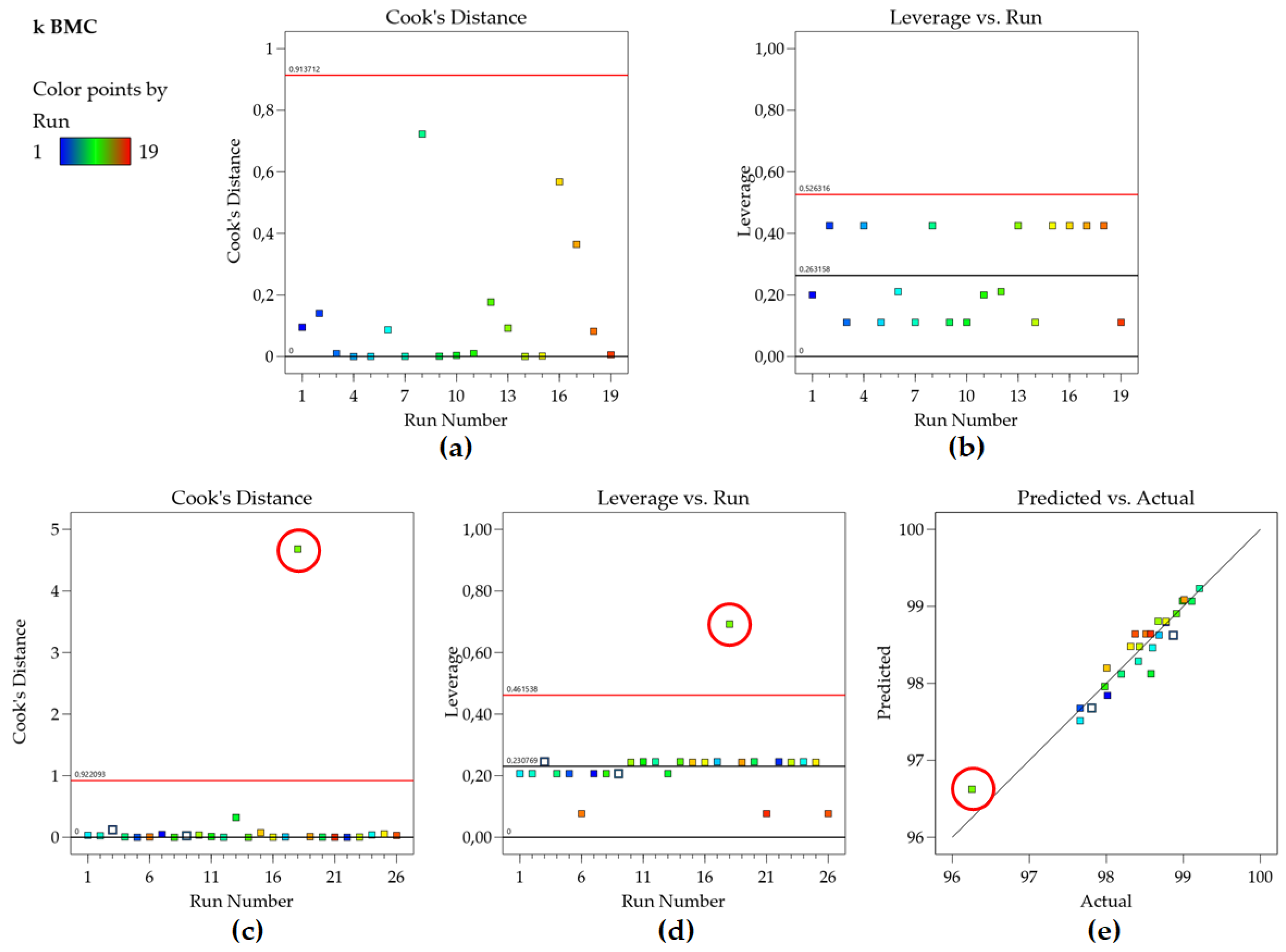
Figure 4.
(a) Counter plot and (b) the 3D mean response surface of the k BMC response.

Figure 5.
Contour maps (a) and MODR (b) calculated using the capability index Cpk both constructed from the DOE with a single solution. Contour maps (c) and MODR (d) from the DOE with the independent solutions and using F to remove = 4, for model selection. Contour maps € and MODR (f) from the DOE with the independent solutions and using F to remove = 5, for model selection.
Figure 5.
Contour maps (a) and MODR (b) calculated using the capability index Cpk both constructed from the DOE with a single solution. Contour maps (c) and MODR (d) from the DOE with the independent solutions and using F to remove = 4, for model selection. Contour maps € and MODR (f) from the DOE with the independent solutions and using F to remove = 5, for model selection.
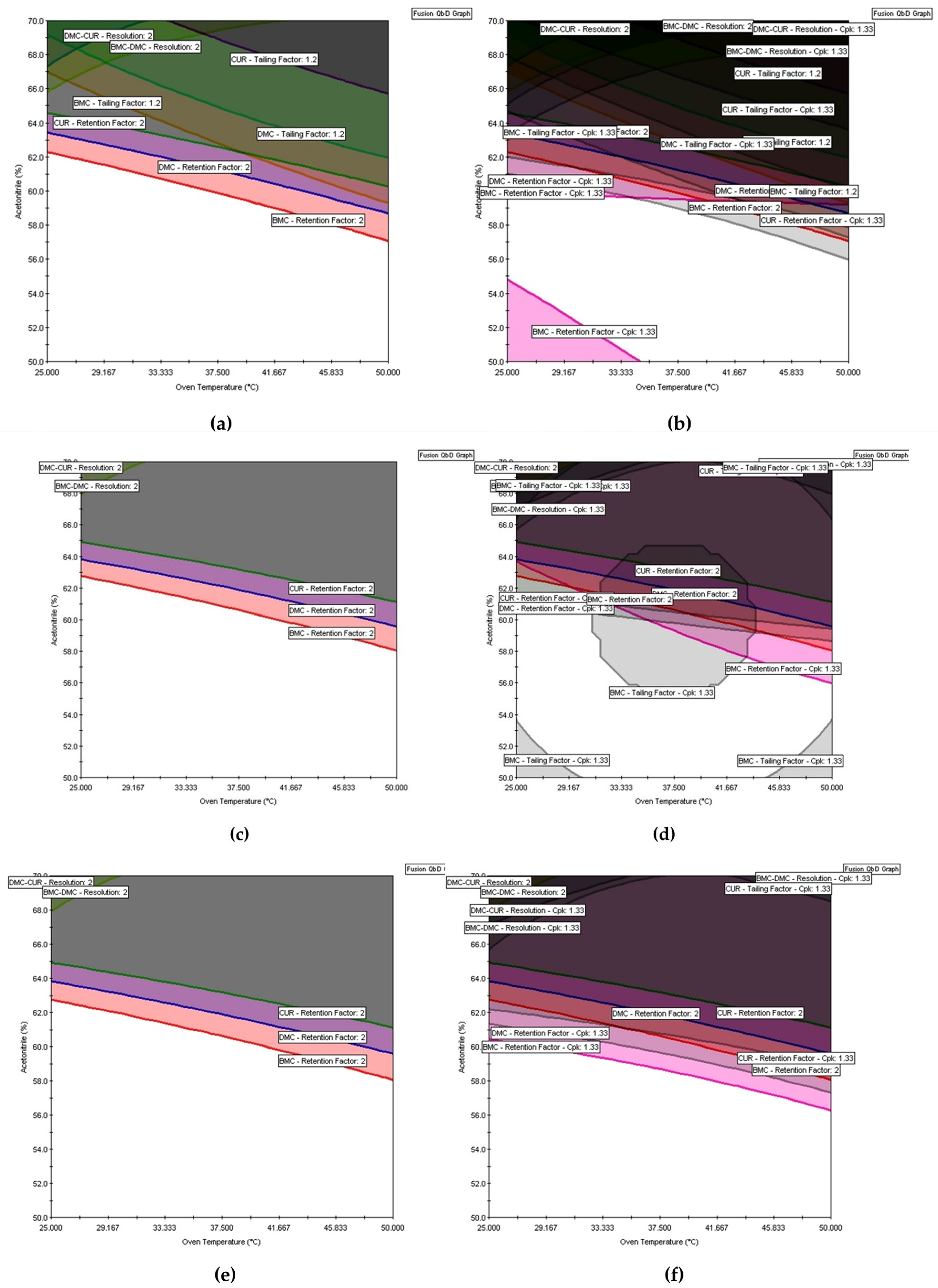
Figure 6.
Overlay plots obtained by graphical optimization in Design Expert (a), with a confidence interval of α= 0.05 (or at 95% confidence level) (b), with a prediction interval of α= 0.05 (c), and with a tolerance interval of α= 0.05 and β = 0.99 (d). This optimization process was executed with the models from the DOE with the authentic replicates (same data used to generate the MODR in Figure 5f).
Figure 6.
Overlay plots obtained by graphical optimization in Design Expert (a), with a confidence interval of α= 0.05 (or at 95% confidence level) (b), with a prediction interval of α= 0.05 (c), and with a tolerance interval of α= 0.05 and β = 0.99 (d). This optimization process was executed with the models from the DOE with the authentic replicates (same data used to generate the MODR in Figure 5f).

Figure 7.
MODR with the PARs from Fusion QbD.
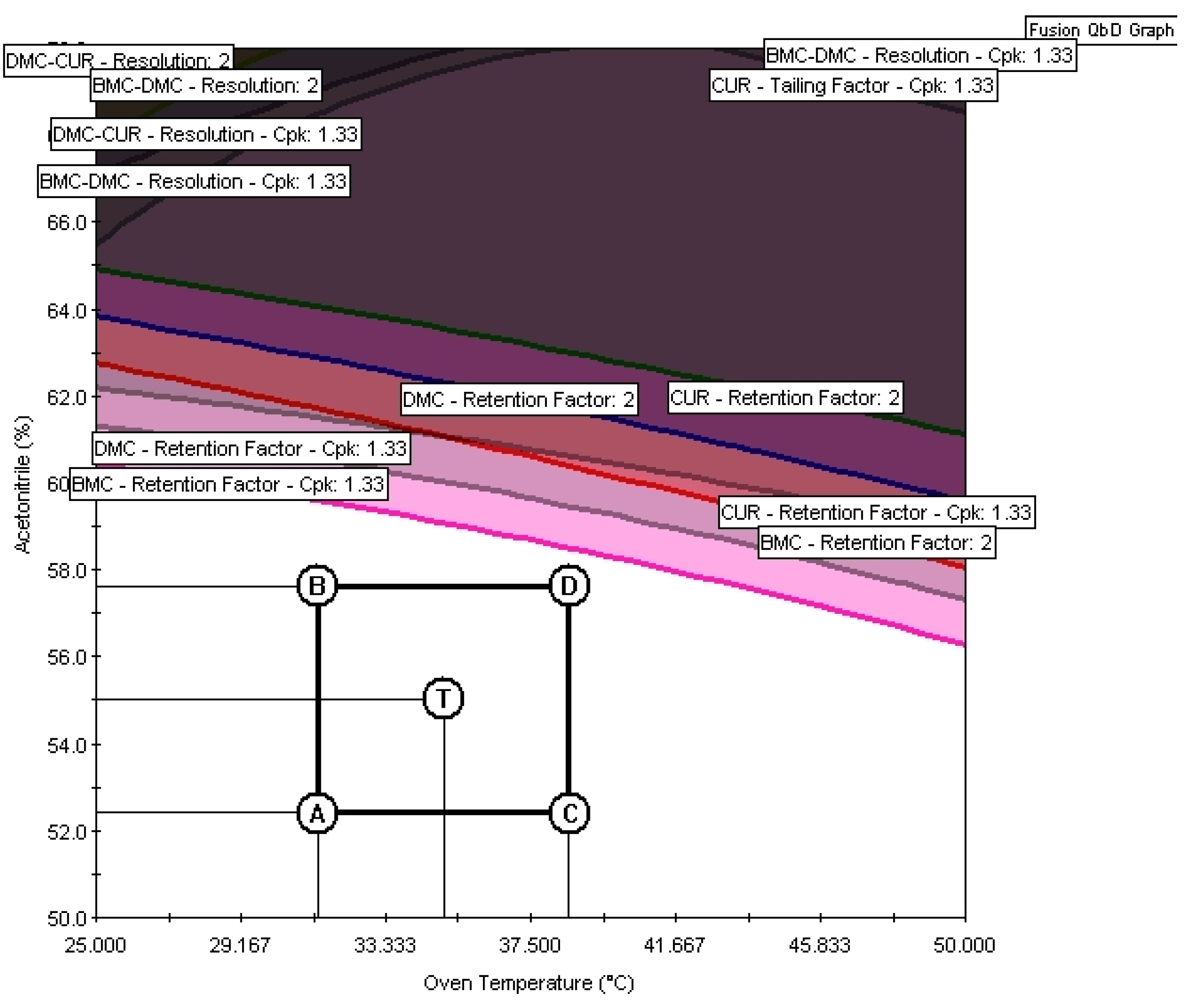

Table 1.
The factors studied in the face-centered central composite experimental design to optimize the chromatograph condition.
Table 1.
The factors studied in the face-centered central composite experimental design to optimize the chromatograph condition.
| . | Factors | Units | -α | -1 | 0 | +1 | +α |
|---|---|---|---|---|---|---|---|
| A | Flow Rate | mL min-1 | 0.6 | 0.6 | 0.8 | 1.0 | 1.0 |
| B | Acetonitrile | % | 50 | 50 | 60 | 70 | 70 |
| C | Temperature | °C | 25 | 25 | 37.5 | 50 | 50 |
Table 2.
Experimental matrix of the face-centered central composite experimental design with the responses obtained using a single solution for all runs.
Table 2.
Experimental matrix of the face-centered central composite experimental design with the responses obtained using a single solution for all runs.
| Run | Factor | Response | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | k BMC | k DMC | k CUR | Tailing BMC | Tailing DMC | Tailing CUR | Rs (BMC, DMC) | Rs (DMC, CUR) | |
| 1 | 0.6 | 50 | 25 | 6.06 | 6.78 | 7.56 | 1.065 | 1.070 | 1.063 | 3.156 | 3.181 |
| 2 | 0.8 | 50 | 37.5 | 4.93 | 5.66 | 6.49 | 1.102 | 1.090 | 1.074 | 3.805 | 3.866 |
| 3 | 0.6 | 70 | 50 | 0.78 | 0.91 | 1.07 | 1.334 | 1.281 | 1.239 | 2.174 | 2.341 |
| 4 | 1 | 60 | 37.5 | 1.96 | 2.25 | 2.58 | 1.164 | 1.153 | 1.127 | 2.648 | 2.756 |
| 5 | 0.8 | 60 | 37.5 | 1.97 | 2.26 | 2.60 | 1.169 | 1.159 | 1.131 | 2.829 | 2.947 |
| 6 | 0.8 | 60 | 37.5 | 1.96 | 2.26 | 2.59 | 1.166 | 1.157 | 1.128 | 2.832 | 2.947 |
| 7 | 0.8 | 60 | 37.5 | 1.97 | 2.26 | 2.59 | 1.167 | 1.157 | 1.13 | 2.833 | 2.944 |
| 8 | 0.6 | 70 | 25 | 1.09 | 1.23 | 1.39 | 1.254 | 1.232 | 1.198 | 1.904 | 2.007 |
| 9 | 1 | 50 | 50 | 4.03 | 4.74 | 5.57 | 1.123 | 1.093 | 1.078 | 4.338 | 4.435 |
| 10 | 0.8 | 60 | 50 | 1.65 | 1.93 | 2.25 | 1.212 | 1.179 | 1.146 | 3.182 | 3.340 |
| 11 | 1 | 50 | 25 | 6.02 | 6.77 | 7.60 | 1.050 | 1.049 | 1.049 | 2.694 | 2.750 |
| 12 | 1 | 70 | 25 | 1.07 | 1.22 | 1.38 | 1.215 | 1.188 | 1.156 | 1.594 | 1.682 |
| 13 | 0.8 | 70 | 37.5 | 0.91 | 1.05 | 1.21 | 1.265 | 1.239 | 1.208 | 1.946 | 2.071 |
| 14 | 0.8 | 60 | 25 | 2.35 | 2.64 | 2.97 | 1.150 | 1.127 | 1.114 | 2.356 | 2.432 |
| 15 | 0.8 | 60 | 37.5 | 1.96 | 2.26 | 2.59 | 1.172 | 1.158 | 1.132 | 2.833 | 2.944 |
| 16 | 0.6 | 60 | 37.5 | 1.99 | 2.28 | 2.61 | 1.180 | 1.158 | 1.131 | 2.962 | 3.078 |
| 17 | 1 | 70 | 50 | 0.77 | 0.91 | 1.06 | 1.340 | 1.289 | 1.249 | 1.970 | 2.115 |
| 18 | 0.6 | 50 | 50 | 4.01 | 4.72 | 5.53 | 1.088 | 1.055 | 1.068 | 4.537 | 4.611 |
| 19 | 0.8 | 60 | 37.5 | 1.97 | 2.27 | 2.60 | 1.166 | 1.157 | 1.129 | 2.825 | 2.938 |
Table 3.
ANOVA results from Design Expert and Fusion QbD for the retention factor of BMC, using the data performed with a single solution of the curcuminoids for all runs.
Table 3.
ANOVA results from Design Expert and Fusion QbD for the retention factor of BMC, using the data performed with a single solution of the curcuminoids for all runs.
| Source | Design Expert | Fusion QbD | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| SS¹ | df² | MS³ | F-value | p-value | SS¹ | df² | MS³ | F-value | p-value | ||
| Model | 50.73 | 4 | 12.68 | 1825.11 | < 0.0001 | 50.76 | 4 | 12.68 | 1825.90 | <0.0001 | |
| Residual | 0.0973 | 14 | 0.0069 | 0.0973 | 14 | 0.0069 | |||||
| Lack of Fit | 0.0972 | 10 | 0.0097 | 323.87 | < 0.0001 | 0.0972 | 10 | 0.0097 | 670.95 | <0.0001 | |
| Pure Error | 0.0001 | 4 | 0.0000 | <0.0001 | 4 | <0.0001 | |||||
| Cor Total | 50.82 | 18 | 50.85 | 18 | |||||||
| ¹Sum of Squares | |||||||||||
| ²degrees of freedom | |||||||||||
| ³Mean Square | |||||||||||
Table 4.
Comparison of R², adjusted-R², and predicted-R² values when non-significant coefficients are removed from the BMC retention factor model.
Table 4.
Comparison of R², adjusted-R², and predicted-R² values when non-significant coefficients are removed from the BMC retention factor model.
| Fit Statistic | Number of coefficients | |||||
|---|---|---|---|---|---|---|
| 10 | 9 | 8 | 7 | 6 | 5 | |
| R² | 0.9977 | 0.9977 | 0.9977 | 0.9976 | 0.9969 | 0.9968 |
| Ajusted-R² | 0.9955 | 0.9959 | 0.9963 | 0.9965 | 0.9957 | 0.9959 |
| PredictedR² | 0.9736 | 0.9771 | 0.9893 | 0.9901 | 0.9902 | 0.9925 |
Table 5.
Coefficients of the BMC retention factor model from Design Expert and Fusion QbD.
| Design Expert | Fusion QbD | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Factor | Coefficient Estimate | Standard Error | 95% CI Low | 95% CI High | p-value | Coefficient Estimate | Standard Error | 95% CI Low | 95% CI High | p-value | |
| Intercept | 2.13 | 0.0357 | 2.05 | 2.21 | <0.001 | 2.127 | - | 2.05 | 2.2 | ||
| A | -0.016 | 0.0339 | -0.09 | 0.0579 | 0.646 | - | - | - | - | - | |
| B | -2.22 | 0.0339 | -2.29 | -2.14 | <0.001 | -2.21 | 0.033 | -2.87 | -2.140 | <0.001 | |
| C | -0.518 | 0.0339 | -0.592 | -0.4441 | <0.001 | -0.5183 | 0.33 | -0.5896 | -0.447 | <0.001 | |
| AC | 0.075 | 0.0379 | -0.008 | 0.1576 | 0.071 | 0.0745 | 0.0369 | -0.0053 | 0.1542 | 0.648 | |
| BC | 0.435 | 0.0379 | 0.3524 | 0.5176 | <0.001 | 0.436 | 0.0369 | 0.3563 | 0.5157 | <0.001 | |
| B² | 1.04 | 0.0493 | 0.9329 | 1.15 | <0.001 | 1.04 | 0.048 | 0.9364 | 1.14 | <0.001 | |
Table 6.
Experimental matrix of the face-centered central composite experimental design with the responses studied using an independent curcuminoid solution for each run.
Table 6.
Experimental matrix of the face-centered central composite experimental design with the responses studied using an independent curcuminoid solution for each run.
| Factor | Response | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Run | A | B | C | k BMC | k DMC | k CUR | Tailing BMC | Tailing DMC | Tailing CUR | Rs (BMC, DMC) | Rs (DMC, CUR) | |
| 1 | 0.6 | 50 | 25 | 6.53 | 7.27 | 8.08 | 1.053 | 1.093 | 1.113 | 3.131 | 3.133 | |
| 2 | 0.8 | 50 | 37.5 | 6.20 | 6.93 | 7.74 | 1.058 | 1.086 | 1.099 | 2.872 | 2.922 | |
| 3 | 0.6 | 70 | 50 | 1.12 | 1.27 | 1.43 | 1.193 | 1.186 | 1.160 | 1.925 | 2.035 | |
| 4 | 1 | 60 | 37.5 | 1.10 | 1.25 | 1.41 | 1.148 | 1.141 | 1.123 | 1.823 | 1.935 | |
| 5 | 0.8 | 60 | 37.5 | 2.46 | 2.76 | 3.09 | 1.096 | 1.092 | 11.087 | 2.498 | 2.581 | |
| 6 | 0.8 | 60 | 37.5 | 2.17 | 2.48 | 2.82 | 1.126 | 1.134 | 1.113 | 2.980 | 3.066 | |
| 7 | 0.8 | 60 | 37.5 | 2.11 | 2.41 | 2.74 | 1.111 | 1.112 | 1.091 | 2.904 | 3.001 | |
| 8 | 0.6 | 70 | 25 | 5.43 | 6.20 | 7.06 | 1.087 | 1.093 | 1.124 | 3.723 | 3.713 | |
| 9 | 1 | 50 | 50 | 0.81 | 0.94 | 1.09 | 1.121 | 1.139 | 1.179 | 2.049 | 2.164 | |
| 10 | 0.8 | 60 | 50 | 2.18 | 2.48 | 2.83 | 1.119 | 1.122 | 1.104 | 2.924 | 3.005 | |
| 11 | 1 | 50 | 25 | 2.14 | 2.44 | 2.77 | 1.115 | 1.118 | 1.096 | 2.902 | 2.990 | |
| 12 | 1 | 70 | 25 | 2.06 | 2.35 | 2.68 | 1.138 | 1.139 | 1.119 | 2.880 | 2.996 | |
| 13 | 0.8 | 70 | 37.5 | 2.14 | 2.44 | 2.78 | 1.102 | 1.117 | 1.092 | 2.906 | 2.997 | |
| 14 | 0.8 | 60 | 25 | 2.15 | 2.46 | 2.80 | 1.107 | 1.121 | 1.102 | 2.929 | 3.021 | |
| 15 | 0.8 | 60 | 37.5 | 4.26 | 4.97 | 5.78 | 1.083 | 1.086 | 1.111 | 4.145 | 4.109 | |
| 16 | 0.6 | 60 | 37.5 | 4.50 | 5.25 | 6.12 | 1.053 | 1.065 | 1.079 | 4.223 | 4.189 | |
| 17 | 1 | 70 | 50 | 0.86 | 1.01 | 1.17 | 1.238 | 1.219 | 1.195 | 2.224 | 2.362 | |
| 18 | 0.6 | 50 | 50 | 0.87 | 1.01 | 1.18 | 1.114 | 1.125 | 1.173 | 2.189 | 2.301 | |
| 19 | 0.8 | 60 | 37.5 | 1.74 | 2.02 | 2.35 | 1.153 | 1.139 | 1.131 | 3.191 | 3.313 | |
Table 7.
ANOVA results with authentic replicates only in the central points.
| Source | Sum of Squares | df | Mean Square | F-value | p-value |
|---|---|---|---|---|---|
| Model | 49,89 | 4 | 12.47 | 1150.75 | < 0.0001 |
| B-Acetonitrile | 41.74 | 1 | 41.74 | 3850.76 | < 0.0001 |
| C-Temperature | 2.86 | 1 | 2.86 | 264.07 | < 0.0001 |
| BC | 1.47 | 1 | 1.47 | 135.68 | < 0.0001 |
| B² | 3.82 | 1 | 3.82 | 352.50 | < 0.0001 |
| Residual | 0.1517 | 14 | 0.0108 | ||
| Lack of Fit | 0.1438 | 10 | 0.0144 | 7.26 | 0.0355 |
| Pure Error | 0.0079 | 4 | 0.0020 | ||
| Cor Total | 50.04 | 18 |
Table 9.
Verification run for the chosen working point in the MODR.
| Response Variable Name | Experimental Result | Predicted Result | Low 2 Sigma Confidence Limit |
High 2 Sigma Confidence limit | |
|---|---|---|---|---|---|
| BMC Retention Factor | 3.49 | 3.64 | 3.38 | 3.90 | |
| DMC Retention Factor | 3.97 | 4.13 | 3.85 | 4.40 | |
| CUR Retention Factor | 4.52 | 4.67 | 4.38 | 4.96 | |
| BMC Tailing Factor | 1.11 | 1.09 | 1.04 | 1.14 | |
| DMC Tailing Factor | 1.10 | 1.10 | 1.07 | 1.13 | |
| CUR Tailing Factor | 1.08 | 1.09 | 1.07 | 1.12 | |
| BMC-DMC Resolution | 3.15 | 3.20 | 3.10 | 3.30 | |
| DMC-CUR Resolution | 3.25 | 3.26 | 3.17 | 3.34 | |
Table 10.
Experimental and predicted results of the verification run from Figure 7 after a prolonged time of column use.
Table 10.
Experimental and predicted results of the verification run from Figure 7 after a prolonged time of column use.
| Point | Response Variable Name | Experimental Result | Predicted Result | Low 2 Sigma Confidence Limit | High 2 Sigma Confidence Limit |
|---|---|---|---|---|---|
| A | BMC Retention Factor | 4.62 | 4.82 | 4.56 | 5.09 |
| DMC Retention Factor | 5.23 | 5.43 | 5.16 | 5.72 | |
| CUR Retention Factor | 5.91 | 6.11 | 5.82 | 6.41 | |
| BMC Tailing Factor | 1.22 | 1.08 | 1.03 | 1.13 | |
| DMC Tailing Factor | 1.21 | 1.09 | 1.05 | 1.13 | |
| CUR Tailing Factor | 1.22 | 1.10 | 1.07 | 1.12 | |
| BMC-DMC Resolution | 2.61 | 3.22 | 3.12 | 3.32 | |
| DMC-CUR Resolution | 2.69 | 3.25 | 3.16 | 3.34 | |
| B | BMC Retention Factor | 2.86 | 3.02 | 2.76 | 3.29 |
| DMC Retention Factor | 3.23 | 3.40 | 3.13 | 3.68 | |
| CUR Retention Factor | 3.66 | 3.83 | 3.53 | 4.12 | |
| BMC Tailing Factor | 1.26 | 1.10 | 1.05 | 1.15 | |
| DMC Tailing Factor | 1.25 | 1.11 | 1.08 | 1.14 | |
| CUR Tailing Factor | 1.23 | 1.09 | 1.07 | 1.12 | |
| BMC-DMC Resolution | 2.24 | 2.87 | 2.76 | 2.96 | |
| DMC-CUR Resolution | 2.38 | 2.96 | 2.87 | 3.05 | |
| T | BMC Retention Factor | 3.43 | 3.64 | 3.38 | 3.90 |
| DMC Retention Factor | 3.91 | 4.13 | 3.85 | 4.40 | |
| CUR Retention Factor | 4.44 | 4.67 | 4.38 | 4.96 | |
| BMC Tailing Factor | 1.26 | 1.09 | 1.04 | 1.14 | |
| DMC Tailing Factor | 1.25 | 1.10 | 1.07 | 1.13 | |
| CUR Tailing Factor | 1.24 | 1.09 | 1.07 | 1.12 | |
| BMC-DMC Resolution | 2.56 | 3.20 | 3.10 | 3.30 | |
| DMC-CUR Resolution | 2.68 | 3.26 | 3.17 | 3.34 | |
| C | BMC Retention Factor | 4.05 | 4.34 | 4.08 | 4.60 |
| DMC Retention Factor | 4.65 | 4.95 | 4.67 | 5.22 | |
| CUR Retention Factor | 5.32 | 5.63 | 5.34 | 5.92 | |
| BMC Tailing Factor | 1.29 | 1.07 | 1.03 | 1.13 | |
| DMC Tailing Factor | 1.30 | 1.09 | 1.06 | 1.13 | |
| CUR Tailing Factor | 1.30 | 1.10 | 1.07 | 1.12 | |
| BMC-DMC Resolution | 2.94 | 3.52 | 3.45 | 3.65 | |
| DMC-CUR Resolution | 2.99 | 3.56 | 3.47 | 4.69 | |
| D | BMC Retention Factor | 2.60 | 2.66 | 2.41 | 2.92 |
| DMC Retention Factor | 2.97 | 3.04 | 2.77 | 3.31 | |
| CUR Retention Factor | 3.40 | 3.47 | 3.18 | 3.76 | |
| BMC Tailing Factor | 1.35 | 1.10 | 1.05 | 1.15 | |
| DMC Tailing Factor | 1.30 | 1.11 | 1.08 | 1.14 | |
| CUR Tailing Factor | 1.26 | 1.10 | 1.07 | 1.12 | |
| BMC-DMC Resolution | 2.44 | 3.13 | 3.03 | 3.23 | |
| DMC-CUR Resolution | 2.61 | 3.21 | 3.12 | 3.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



