Submitted:
18 March 2024
Posted:
20 March 2024
Read the latest preprint version here
Abstract
Using assembly theory, we investigate the assembly pathways of fixed-length binary strings formed by joining the individual bits present in the assembly pool and the strings that entered the pool as a result of previous joining operations. We show that the string assembly index is bounded from below and above, and we conjecture about the form of the upper bound. We show that a string having the smallest assembly index can be assembled by an elegant trivial program of length equal to this index, if the length of the string is expressible as a product of Fibonacci numbers. We conjecture that there is no binary program that has a length shorter than the length of the string having the largest assembly index that could assemble this string. We conjecture that a black hole surface is defined by a balanced distinct string that satisfies the upper bound of a distinct string assembly index. The results confirm that four Planck areas provide a minimum information capacity that provides a minimum thermodynamic (Bekenstein-Hawking) entropy. Knowing that the problem of determining the assembly index is at least NP-complete, we conjecture that the problem of determining the assembly index of a given binary string is NP-complete, while the problem of creating the string so that it would have a predetermined maximum assembly index is NP-hard. Therefore, once the new information is assembled by a dissipative structure or by a human, increasing the information entropy according to the second law of infodynamics, it is subject to the second law of thermodynamics, and nature seeks to optimize its assembly pathway.
Keywords:
assembly theory
; emergent dimensionality
; black holes
; complexity measures
; P versus NP problem
; quantum orthogonalization interval theorems
; second law of infodynamics
; mathematical physics
; binputation
1. Introduction
Assembly Theory (AT) [1,2,3,4,5,6,7] provides a distinctive complexity measure, superior to established complexity measures used in information theory, such as Shannon entropy or Kolmogorov complexity [1,5]. AT does not alter the fundamental laws of physics [6]. Instead, it redefines objects on which these laws operate. In AT, objects are not considered as sets of point particles (as in most physics), but instead are defined by the histories of their formation (assembly pathways) as an intrinsic property, where, in general, there are multiple assembly pathways to create a given object.
AT explains and quantifies selection and evolution, capturing the amount of memory necessary to produce a given object [6]. This is because the more complex a given object is, the less likely an identical copy can be observed without the selection of some information-driven mechanism that generated that object. Formalizing assembly pathways as sequences of joining operations, AT begins with basic units (such as chemical bonds) and concludes with a final object. This conceptual shift captures evidence of selection in objects [1,2,6].
The Assembly Index, which represents the length of the shortest assembly pathway leading to an object, facilitates the quantification of the minimum memory required for its construction. In general, it increases with the object’s size, but decreases with symmetry, so large objects with repeating substructures may have lower complexity than smaller objects with greater heterogeneity [1]. The copy number specifies the number of copies of an object, essential for assessing its structural complexity.
AT has been experimentally confirmed in the case of molecules and probed directly experimentally with high accuracy with spectroscopy techniques, including mass spectroscopy, IR, and NMR spectroscopy [6]. It is a versatile concept with applications in various domains. Beyond its application in the field of biology and chemistry [7], its adaptability to different data structures, such as text, graphs, groups, music notations, image files, compression algorithms, etc., showcases its potential in diverse fields [2].
In this study, we investigate the assembly pathways of binary strings by joining individual bits present in the assembly pool [6] and strings that entered the pool as a result of previous joining operations.
In particular, we investigate the assembly of black-body objects (BBs: black holes (BHs), white dwarfs, and neutron stars) considered binary strings [8,9,10]. It is known [2,8,9,10,11,12,13,14,15,16,17,18,19] that information in the universe evolves toward increased structural complexity, decreasing information entropy.
We use emphasis for object as this term, understood as a collection of matter, is a misnomer, as it neglects the (quantum) nonlocality [20]. Nonlocality is independent of the entanglement among particles [21], as well as the quantum contextuality [22], and increases as the number of particles [23] grows [24,25]. Furthermore, the ugly duckling theorem [26,27] asserts that every two objects we perceive are equally similar (or equally dissimilar).
This study extends the findings of previous research [8,9,10,23] within the framework of AT and emergent dimensionality [8,9,10,15,17,18,20,23,28]. However, our results generally apply to information theory. Therefore, we put the BB-related content in frames like this one. The reader not interested in BBs may skip the text in these frames and the additional results presented in Section 7.
The paper is structured as follows. Section 2 introduces the basic definitions used in the paper. Section 3 shows that the assembly index of binary strings is bounded from below and provides the form of this bound. Section 4 shows that the assembly index of binary strings is bounded from above and conjectures about the exact form of this bound. Section 6 introduces the concept of binary assembling program and shows that the trivial assembling program assembles binary strings that have a minimum assembly index. Section 7 discusses additional results of this research in the context of BBs. Section 8 concludes the findings of this study.
2. Preliminaries
For K subunits of an object O the assembly index of AT is bounded [1] from below by
and from above by
The lower bound (1) represents the fact that the simplest way to increase the size of a subunit in a pathway is to take the largest subunit so far and join it to itself [1] and, in the case of the upper bound (2), subunits must be distinct so that they cannot be reused from the pool, decreasing the index.
Here we consider binary strings containing bits , which are our basis AT objects [2], with zeros and ones ( is called binary Hamming weight or bit summation of a string .), having a fixed length .
Where the bit value can be either 1 or 0, we write with * being the same within the string . If we allow for the 2nd possibility that can be the same as or different from *, we write . Thus, , for example, is a placeholder for all four 2-bit strings.
We consider strings to be messages transmitted through a communication channel between a source and a receiver, similarly to the Claude Shannon approach [29] used in the derivation of binary information entropy
where
are the ratios of occurrences of zeros and ones within the string and the unit of entropy (3) is bit.
Here, we consider the process of formation of binary strings within the AT framework.
Definition 1.
A string assembly index is the smallest number of steps s required to assemble a binary string of length N by joining two distinct bits contained in the initial assembly pool and strings joined in previous steps that are added to the assembly pool. Therefore, the assembly index is a function of the string .
For example, the 8-bit string
can be assembled in at most seven steps:
- 1.
- join 0 with 1 to form , adding to ,
- 3.
- join with 0 to form , adding to ,
- 3.
- ...
- 7.
- join with 1 to form
(i.e., not using the pool), six, five, or four steps:
- join 0 with 1 to form , adding to P,
- join with taken from P to form , adding to P,
- join with taken from P to form , adding to P,
- join with taken from P to form ,
or at least three steps:
- join 0 with 1 to form , adding to P,
- join with taken from P to form , adding to P,
- join with taken from P to form ,
while the 8-bit string
can be assembled in at least six steps:
- join 0 with 1 to form , adding to P,
- join with taken from P to form , adding to P,
- join 0 with 0 adding to P,
- join with taken from P to form , adding to P,
- join with 1 to form , adding to P,
- join with 1 to form ,
as only the doublet can be reused from the pool. Therefore, strings (5) and (6) have respective assembly indices and that represent the lengths of their shortest assembly pathways, which in turn ensures that the assembly pool P is a distinct set.
Table 1, Table A6, Table A7, Table A8, Table A9, Table A10, Table A11, Table A12 and Table A13 (Appendix D) show the distributions of the assembly indices among strings for taking into account the number of ones . The sums of each column form Pascal’s triangle read by rows (OEIS sequence A007318).
Theorem 1.
A string having length is the shortest string having more than one string assembly index 1.
Proof.
The proof is trivial. For the assembly index , as all basis objects have a pathway assembly index of 0 [2] (they are not assembled). provides four available strings with . provides eight available strings with . Only provides 16 strings that include four stings with and twelve strings with including balanced strings, as shown in Table 1 and Table 2.
For example, to assemble the string we need to assemble the string and reuse it. Therefore, for and for , where denotes a set of different assembly indices. □

Table 1.
Distribution of the assembly indices for .
| 0 | 1 | 2 | 3 | 4 | ||
| 2 | 4 | 1 | 2 | 1 | ||
| 3 | 12 | 4 | 4 | 4 | ||
| 16 | 1 | 4 | 4 | 1 | ||
Table 2.
balanced strings .
| k | |||||
| 1 | (0 | 1) | (0 | 1) | 2 |
| 2 | (1 | 0) | (1 | 0) | 2 |
| 3 | 0 | 1 | 1 | 0 | 3 |
| 4 | 1 | 1 | 0 | 0 | 3 |
| 5 | 1 | 0 | 0 | 1 | 3 |
| 6 | 0 | 0 | 1 | 1 | 3 |
Definition 2.
A string is a balanced string if it has the same number of bits, where or if N is odd.
Without loss of generality, we assume that if N is odd, (e.g., for , , and ). However, our results are equivalently applicable if we assume the opposite (i.e., a larger number of ones for an odd N).
Considered as messages [29], only balanced and even length strings have binary entropies , i.e., natural numbers. Conversely, only non-balanced and/or odd length strings have binary entropies .
The number of balanced strings among all strings is ("" is the floor function that yields the greatest integer less than or equal to x and "" is the ceiling function that yields the least integer greater than or equal to x.)
This is the OEIS A001405 sequence, the maximal number of subsets of an N-set such that no one contains another, as asserted by Sperner’s theorem, and approximated using Stirling’s approximation for large N.
BBs emit Hawking black-body radiation having a continuous spectrum that depends only on one factor, the BB temperature corresponding to the BB diameter , where and denotes respectively the Planck length and temperature [8].
Triangulated BB surfaces contain a balanced number of Planck area triangles, each having binary potential , where c denotes speed of light in vacuum, as has been shown [8,10], based on the Bekenstein-Hawking entropy [30,31,32] . Here is the Boltzmann constant and is the information capacity of the BB surface, i.e., the Planck triangles corresponding to bits of information [8,9,10,31,33,34], and the fractional part triangle(s) having the area too small to carry a single bit of information [8,9].
Therefore, a balanced string represents a BB surface comprising active Planck triangles (APTs) with binary potential and energy [9].
Definition 3.
A string is a distinct string if a ring formed with this string by joining its beginning with its end is unique among the rings formed from the other distinct strings .
There are at least two and at most N forms of a distinct string that differ in the position of the starting bit. For example for balanced strings, shown in Table 2, two augmented strings with correspond to each other if we change the starting bit
Similarly, four augmented strings with correspond to each other
after a change in the position of the starting bit. Thus, there are only two balanced distinct strings .
The number of distinct strings among all strings is given by the OEIS sequence A000031. In general (for ), the number of distinct strings is much lower than the number of balanced strings.
As asserted by the no-hair theorem [35], BH is characterized only by three parameters: mass, electric charge, and angular momentum.
However, BHs are fundamentally uncharged and non-rotating, since the parameters of any conceivable BH, that is, charged (Reissner-Nordström), rotating (Kerr) and charged rotating (Kerr-Newman), can be arbitrarily altered, provided that the area of a BH surface does not decrease [36] using Penrose processes [37,38] to extract electrostatic and/or rotational energy of a BH [39].
Thus, a BH is defined by a single real number, and no Planck triangle is distinct on a BH surface. We can define neither a beginning nor an end of a balanced distinct string that represents a given BH.
By neglecting the notion of the beginning and end of a string, we focus on its length and content. In Yoda’s language,
The numbers of the balanced , distinct , and balanced distinct ( is close to OEIS A000014 up to the eleventh term.) strings are shown in Table 3 and Figure 1. The formula for remains to be researched."complete, no matter where it begins. A message is".
We note that, in general, the starting bit is relevant for the assembly index. Thus, different forms of a distinct string may have different assembly indices. For example, for balanced strings and , shown in Table A16 have . However, these strings are not distinct, since they correspond to each other and to the balanced strings , , , , and with . They all have the same triplet of adjoining ones.
Definition 4.
The assembly index of a distinct string is the smallest assembly index among all forms of this string.
Thus, if different forms of a distinct string have different assembly indices, we assign the smallest assembly index to this string. In other words, we assume that the smallest number of steps
where denotes a particular form of a distinct string , is the string assembly index of this distinct string.
If an object that can be represented by a distinct string (a BB in particular) can be assembled in fewer steps, this procedure will be preferred by nature.
The distribution of the assembly indices of the balanced distinct strings is shown in Table 4.
3. Minimum Assembly Index
In the following, we derive the tight lower bound of the set of different string assembly indices 1.
Theorem 2
(Tight lower bound on the string assembly index). The smallest string assembly index as a function of N corresponds to the shortest addition chain for N (OEIS sequence A003313).
Proof.
Strings for which , can be formed in subsequent steps s by joining the longest string assembled so far with itself until is reached [1]. Therefore, if , then . Only four strings
have such an assembly index in this case.
An addition chain for having the minimum length (commonly denoted as ) is defined as a sequence of integers such that for each , for . The first step in creating an addition chain for N is always and this corresponds to assembling a doublet from the initial assembly pool P. Thus, the lower bound for s of the addition chain for N, is attained for . In the assembly case, this bound is attained by the strings (11). The second step in creating an addition chain can be either or .
Thus, finding the shortest addition chain for N corresponds to finding an assembly index of a string containing bits and/or doublets and/or triplets generated by these doublets for since due to Theorem 1 only they provide the same assembly indices . Such strings correspond to linear molecules made of carbons [4] (Supplementary Materials, S3.2). □
4. Maximum Assembly Index
In the following, we conjecture the form of the upper bound of the set of different string assembly indices 1.
In general, of all strings having a given assembly index, shown in Table 1, Table A6, Table A7, Table A8, Table A9, Table A10, Table A11, Table A12 and Table A13 (Appendix D), most are those having . The only exceptions we found are for () and for (), for () and for (), and for ().
Introducing the definition 2 of a balanced string allows us to reduce the search space of possible strings with maximal assembly indices to balanced strings only. With the exception of , of all strings having a maximum assembly index, most are balanced. We can further restrict the search space to distinct strings 3.
If a string for which is constructed from repeating patterns, then a string for which must be the most patternless. The string assembly index must be bounded from above and must be a monotonically nondecreasing function of N that can increase at most by one between N and .
Identifying the shortest pathway is known to be computationally challenging [3]. This problem has been proven to be at least as hard as NP-complete [4]. However, certain heuristic rules apply in our binary case. For example,
- for we cannot avoid two doublets (e.g., ) within a distinct string and thus ,
- for we cannot avoid two pairs of doublets (e.g., and ) within a distinct string and thus ,
- for we cannot avoid three pairs of doublets (e.g., , , and ) within a distinct string and thus ,
- for we cannot avoid two pairs of doublets and one doublet three times (e.g., , , and , and thus ,
- etc.
Table 6 shows the exemplary balanced strings having maximal assembly indices that we assembled (cf. also Appendix B). To determine the assembly index of the string
we look for the longest patterns that appear at least twice within the string, and we look for the largest number of these patterns. Here, we find that each of the two triplets and appear twice in and are based on the doublets and also appearing in . Thus, we start with the assembly pool made in four steps and join the elements of the pool in the following seven steps to arrive at . On the other hand, another form of this balanced distinct string
has .
Conjecture 3
(Tight upper bound on a string assembly index). With exceptions for small N the largest string assembly index of a binary string as a function of N is given by a sequence formed by strings for , where denotes increasing by one, and 0 denotes maintaining it at the same level, and .
However, at this moment, we cannot state whether this conjecture applies to distinct or non-distinct strings. The assembly indices for are the same for a given N, whereas the assembly indices for were discussed above and are calculated in Appendix D for balanced and balanced distinct strings.
The conjectured sequence is shown in Figure 2 and Figure 3 starting with (we note in passing that is a dimension of the void, the empty set ∅, or (-1)-simplex). Subsequent terms are given by , which is periodic for and flattens at , and , , .
This sequence can be generated using the following procedure
- step=1; % step flag
- run =1; % run flag
- flat=0; % flat counter
- Nk = 0;
- aub= -1; % the upper bound
- while Nk < N
- if step < 3
- Nk = Nk+1; % next Nk
- aub= aub + 1; % increment the bound
- else % step==3
- for k=1:flat
- if flat > 0
- Nk = Nk+1; % next Nk
- end
- end
- run = run+1; % increment run flag
- if run > 2
- run = 1; % reset run flag
- flat = flat+1; % increment flat counter
- end
- end
- step = step+1; % increment step flag
- if step > 3
- step=1; % reset step flag
- end
- end
We note the similarity of this bound to the Aufbau rule (Only about twenty chemical elements (with only two non-doubleton sets of consecutive ones) violate the Aufbau rule.), the Janet sequence (OEIS A167268) and the monotonically non-decreasing Shannon entropy of chemical elements, including observable ones [23]. Perhaps the exceptions in the sequence 3 vanish as N increases.
5. Strings between the Bounds
The bounds 2 and 3 are shown in Table 5 and Table 6 and illustrated in Figure 2 and Figure 3. No binary string can be assembled in a smaller number of steps than given by a lower bound of Theorem 2. On the other hand, some strings cannot be assembled in a smaller number of steps than given by an upper bound (which for large N, as we suppose, has the form presented in Conjecture 3).
The Hamlet tragedy contains approximately 130,000 letters. Assigning five bits per letter (32 possibilities), the Hamlet tragedy can be encoded in a string having bits (81.25 kB) yielding the total number of possible strings (including ), and their assembly indices are bounded by
The lower bound (14) can be estimated using Theorem 2 (though for large N it can be at least as hard as NP-complete [4,40]). The upper bound (14) can be estimated by finding the smallest k that satisfies and using the relation of Conjecture 3.
We assume that the assembly index of the string encoding the actual Hamlet tragedy is close to the upper bound. Even if the probability of random typing of the Hamlet tragedy is unfathomably small, when constrained to the bounds of the physical universe [5], as asserted by the infinite monkey theorem, this tragedy was once created by William Shakespeare.
SARS-CoV-2 genome sequence contains 29903 nucleobases . Assigning two bits per base it can be encoded in a string of bits having the assembly index bounded by
The supermassive BH Sagittarius A* has an estimated mass kg corresponding to the Schwarzschild diameter m and the information capacity [8]. In this case, its assembly index is bounded by
However, we conjecture that
Conjecture 4.
A BB surface is defined by a balanced distinct string that satisfies the upper bound of a distinct string assembly index.
To be the most patternless [8], a balanced BB surface must minimize not only Shannon entropy and Kolmogorov complexity (the latter is uncomputable), but also maximize its assembly index. A BB cannot be assembled in a suboptimal way, since black-body radiation is informationless.
6. Binputation
Definition 5.
The binary assembling program is a binary string of length that acts on the assembly pool P and outputs the assembled strings, adding them to the pool.
Definition 6.
The trivial assembling program Q is a binary assembling program 5 with particular bits denoting
- 0
- take the last element from P, join it with itself, and output.
- 1
- take the last two elements from P, join them with each other, and output; and
As the assembly pool P is a distinct set to which strings are added in subsequent assembly steps, only these two commands are applicable to the initial assembly pool containing only two bits.
Theorem 5.
A string can be assembled by an elegant trivial program of length iff N is expressible as a product of Fibonacci numbers (OEIS A065108).
Proof.
The bit of the program Q is irrelevant as assembles and assembles , so assembles . Then the programs assemble the -bit strings having the assembly index , while strings with the smallest assembly index can be assembled with the same two programs starting with the pool .
The remaining programs will assemble some of the shorter strings with the assembly index . In general, all programs Q assemble strings having lengths expressible as a product of Fibonacci numbers (OEIS A065108) as shown in Table A2 (Appendix C), wherein out of programs (cf. Table A5 and Table A2):
- programs assemble strings having lengths divisible by three and entropies ,
- programs assemble strings having lengths divisible by five and entropies ,
- programs assemble strings having lengths divisible by eight, entropies , and assembly indices if ,
- ⋯,
- the program joins two shortest strings joined in a previous step into a string of length being twice the Fibonacci sequence (OEIS A055389), and finally
- the program assembles the shortest string that has length belonging to the set of Fibonacci numbers.
Thus, for , binary assembling programs Q assemble subsequent Fibonacci words and their concatenations having entropies (3) with ratios (4)
where , and F is the Fibonacci sequence starting from 1 that rapidly converge to
where is the golden ratio. Therefore, is the binary entropy of the Fibonacci word limit. The Fibonacci sequence can be expressed through the golden ratio, which corresponds to the smallest Pythagorean triple [28,43].
Furthermore, for , some of the programs are no longer elegant if and some of the assembled strings are not if .
For , assembles a string
with an assembly index which is not the minimum for this length of the string. For example, 4-bit program assembles the string , but if this string can be assembled by a shorter, 3-bit program , and if this string does not have the minimal assembly index but .
For and and for the shortest string assembled by the program Q the program Q is not elegant for and the shortest string assembled by the program is not for .
However, the length of any program Q is not shorter than the assembly index of the string that this program assembles. □
The trivial assembly programs Q and the strings they assemble are listed in Table 7, Table A3, Table A4 and Table A5 (Appendix C) for one version of the assembly pool and for . If a binary string were to code four DNA nucleobases, (for example as, A, G, C, and T) then we note that the nucleobase encoded by 11 (or 00 for ) would not be present in the strings generated by trivial assembly programs Q defined by 6.
Perhaps the minimum assembly index 2 and Theorem 5 are related to the Collatz conjecture, as the lengths of the strings (11) correspond to the numbers to which the Collatz conjecture converges, from , (OEIS A002450).
Theorem 5 is related to Gödel’s incompleteness theorems and the halting problem. N cases of the halting problem correspond only to , not to N bits of information [44]. Therefore, -bit elegant programs assemble all four strings with (with two versions of the assembly pool). Furthermore, we could consider all strings assembled by the -bit assembly program as corresponding to provable theorems. Any formal axiomatic system (such as our trivial program; Definition 6) only enables proving provable theorems. Thus, proving a theorem equals halting. There is a more fundamental path to incompleteness that involves complexity, rather than self-reference [45].
Theorem 5 would be violated if we defined the command "0" e.g., as "take the last element from the assembly pool, join it with itself, join with what you have already assembled (say at "the right"), and output". Then the 2-bit program "00" would produce with the assembly index . However, such a one-step command would violate the axioms of assembly theory since it would perform two assembly steps in one program step. An elegant program to output the gigabyte binary string of all zeros would take a few bits of code and would have a low Kolmogorov complexity [46]. However, such a string would be outputted, not assembled. Furthermore, the length of such a program that outputs the string would be shorter than the length of the program that outputs the string , while in AT, the lengths of these programs must be the same if the strings have the same assembly indices. Theorem 5 is about binputation (As an analog to chemputation, where assembly theory is applied in digital chemistry.) of binary strings.
Conjecture 6.
There is no binary assembling program 5 that has a length shorter than the length of the string having the largest assembly index that could assemble this string.
Partial Proof.
When assembling the string having the largest assembly index (the largest complexity), we cannot rely solely on the last or two last strings in the assembly pool. Thus, we need to index the strings in the pool. However, we cannot predict in advance how many strings there will be in the assembly pool. Thus, we do not know how many bits will be needed to encode the indices.
Furthermore, no program P (for a Turing machine) shorter than an elegant program Q can find Q. If it could, it could also generate Q’s output. But if P is shorter than Q, then Q would not be elegant. Contradiction.
Conjecture 7.
The problem of determining the assembly index of a given binary string and the problem of assembling a non-trivial string so that it would have a minimum assembly index (Theorem 2) for N are NP-complete. The problem of assembling the string so that it would have a maximum assembly index for N is NP-hard.
Partial Proof.
We found it much easier to determine an assembly index of a given binary string than to assemble a string so that it would have a maximum assembly index. Similarly, a trivial string with a minimum assembly index for N can have the form or the form of a Fibonacci word generated by the trivial program 6.
A proof of conjecture 7 would also be the proof of the following conjecture.
Conjecture 8.
Proof.
Every computable problem and every computable solution can be encoded as a finite binary string. Here, determining whether the assembly index of a given string has its known maximal value corresponds to checking the solution to a problem for correctness, whereas assembling such a string corresponds to solving the problem.
Thus, AT would solve the P versus NP problem in theoretical computer science. There is ample pragmatic justification for adding as a new axiom [44].
7. Additional Results
The [perceivable] universe is not big enough to contain the future; it is deterministic going back in time and non-deterministic going forward in time [47]. But we know [2,8,9,10,11,12,13,14,15,16,17,18,19] that it has evolved to the present since the Big Bang.
Perceivable information about any object can be encoded by a binary string [26,27]. This does not imply that a binary string defines an object. Information that defines a chemical compound, a virus, a computer program, etc. can be encoded by a binary string. However, a dissipative structure [12] such as a living biological cell (or its conglomerate such as a human, for example) cannot be represented by a binary string (even if its genome can). This information can only be perceived (so this is not an object defining information). Each of us is given to ourselves as a mystery [48]. Therefore, since one bit is the smallest amount and the quantum of information, the lower bound and the upper bound of the string assembly index define the allowed region of the assembly indices for binary strings.
The bounds 2, 3, (1), and (2) on the assembly index are shown also in Figure 4 (adopted from [1] and modified). According to the authors of [1], the "green portion of the figure is illustrative of the location in the complexity space where life might reasonably be found. Regions below can be thought of as being potentially naturally occurring, and regions above being so complex that even living systems might have been unlikely to create them. This is because they represent structures with limited internal structure and symmetries, which would require vast amounts of effort to faithfully reproduce." [1].
We disagree with this statement. It is obvious that a binary string itself is neither dissipative nor creative. It is its assembly process that can be dissipative or creative. Evolution is about assembling new information and optimizing it until it reaches its assembly index.
That is why, we found determining the assembly index of a given binary string is easier than creating a string with a maximum assembly index for this length of the string (Conjecture 7). Once the new information is assembled (by a dissipative structure operating far from thermodynamic equilibrium, or created by humans) increasing the information entropy according to the 2nd law of infodynamics [16], it enters the realm of the 2nd law of thermodynamics, and nature seeks how to optimize its assembly pathway decreasing information entropy. And only humans are gifted with creativity. Any creation is required to be shaped by the unique personality of the creator to such an extent that it is statistically one-time in nature [49]; it is an imprint of the author’s personality.
The total entropy of the universe S is constant and is the sum of the information entropy and the physical entropy . Therefore, over time [19]
The time corresponds to an increasing information capacity. Bit by bit:
At first, the newly assembled information corresponds to the discovery by groping [11]. However, its assembly pathway does not attain its most economical or efficient form all at once. For a certain period of time, its evolution gropes about within itself. The try-out follows the try-out, not being finally adopted. Then finally perfection comes within sight, and from that moment the rhythm of change slows down [11]. The new information, having reached the limit of its potentialities, enters the phase of conquest. Stronger now than its less perfected neighbours, the new information multiplies and consolidates. When the assembly index is reached, new information attains its equilibrium (not necessarily a BH equilibrium) and its evolution terminates. It becomes stable.
There is a certain minimum amount of information required to establish a creation, as shown in Figure 4. Sixteen possibilities provided by the minimum of thermodynamic entropy [30,31,32] bifurcate the assembly pathways (cf. Theorem 1) but none of these possibilities can be considered a creation. However, the boundary between the green region of dissipative structures [12] and the red region of human creativity remains to be discovered.
"Thanks to its characteristic additive power, living matter (unlike the matter of the physicists) finds itself ’ballasted’ with complications and instability. It falls, or rather rises, towards forms that are more and more improbable. Without orthogenesis life would only have spread; with it there is an ascent of life that is invincible." [11]
BB having the energy given by mass-energy equivalence
where , denote the BB mass, and , denote the Planck energy and mass, is the fine-structure constant and is the fine-structure constant related to by , and k is the BB size-to-mass ratio (STM) [10] ( if BB is BH).
It was shown [9] based on the Mandelstam-Tamm [50], Margolus–Levitin [51], and Levitin-Toffoli [52] theorems on the quantum orthogonalization interval that BBs generate (or rather assemble) a pattern forming nonequilibrium shell (VS) through the solid-angle correspondence, as shown in Figure 5. The BB entropic work
is the work done by all APTs of a BB. It is the product of the BB entropy [30,31,32] and the general, complex BB temperature
which in modulus and for a BH () reduces [10] to Hawking temperature
where is the reduced Planck constant, G is the gravitational constant, and is the Planck temperature. In particular [10]
where
is the energy equilibrium STM.
A VS has the information capacity bounded by
where l is a VS defining factor. The number of APTs is bounded by
as shown in Figure 6, and thus its binary potential [8,9] is bounded by
and the theoretical probability for a triangle on a VS to be an active Planck triangle is also bounded [9] by
which is satisfied by the ratio (17) of the trivial assembling program 6 for . On the other hand, the entropy variation [8,53] so that for the lower bound (31) is negative and the upper bound (30) is positive ( in this range). The Planck triangle of VS is located somewhere on the VS surface defined by a solid angle
that corresponds to the BB Planck triangle.
The BB information capacity is dictated by its diameter and the BB energy (21) as a function of its diameter is the same for all BBs (it is independent on k). However, the BB mass and density
are not.
Based on the orbiting condition , where is the orbital, and is the escape speed of an orbiting object, is the average distance from the center of the central object to the center of the orbiting object, and is the mass of the central object, the bounds
containing the velocity term , were also derived [9]. Plugging from the bounds (28) into the bounds (34) we arrive at
which is satisfied by real and imaginary (but not complex) velocities (for example, for by , , , and ). Taking the square root of the bounds (35), using , [9], and squaring again, we arrive at
The bounds (35) and (36), shown in Figure 7, meet at , where de Broglie and Compton wavelengths of mass M are the same
where p is the relativistic momentum. The same is the ratio of orbital to escape speed: .
Furthermore, the bounds (35) and (36) do not overlap only for . Therefore, defines the dissipativity or the assembly range. Furthermore, the intersection of the bounds (35) and (36) is the common region for both velocities. If is within this region, then is as well. We note that the average orbital velocity of each orbiting object only slightly exceeds its orbital speed . This implies that the average VS defining factor in (28) for a VS orbiting object (cf. Appendix A).
BBs define a perfect thermodynamic equilibrium, and the bounds (28) and (29) show that nature uses optimally assembled information (cf. Conjecture 4) to assemble new information. Figure 8 shows the bounds on the string assembly indices and Figure 9 shows the BB temperature (24), energy (21), and entropic work (22) for . is a rational number for natural . Furthermore, for and .
Let us examine this process starting from the Big Bang during the Planck epoch and shortly thereafter, and for continuous (i.e., including fractional Planck triangle(s)).
-
There is nothing to talk about. It is a mystery.
-
The Big Bang has occurred, forming the 1st BB. At the BB temperature (24) and subsequently at the BH temperature (24) become equal to the Planck temperature, but any BB in this range is still too small to carry a single bit of information and cannot be triangulated. However, independent BBs merge [9,10] summing their entropies and increasing the information capacity.
-
At the BH entropic work (22) is equal to the Landauer limit (). At the density of the least dense BB () decreases below the modulus of its temperature. .
-
With BBs can finally be triangulated. Yet, containing only one APT (), they are not ergodic [9].
-
The BB assembly index bifurcates, minimal thermodynamic entropy [31] is reached, and the relation (29) provides the second bit on a VS (). At this moment BB can be assembled in a different number of steps and nature seeks to minimize this number following the dynamics induced by the relation (20). The BH temperature (24) is equal to its entropic work (22) ().
-
A BB reaches the upper bound on distinct assembly index.
-
The imaginary Planck time appears at the BH surface [8] heralding the end of the Planck epoch. After crossing this threshold, the VSs begin to operate with on , and the first dissipative structures can be assembled.Nature enters a directed exploration phase () and selectivity emerges, limiting the discovery of new objects [6].
-
A BB reaches the upper bound on nondistinct assembly index.
- ⋯
-
At a first precise diameter relation can be established between the vertices of the BB surface. Furthermore, for , the solid angle (32) equals one steradian.
- ⋯
-
The onset of human creativity.
8. Conclusions
The results reported here can be applied in the fields of cryptography, data compression methods, stream ciphers, approximation algorithms [55], reinforcement learning algorithms [56], information-theoretically secure algorithms, etc. Another possible application of the results of this study could be molecular physics and crystallography.
Author Contributions
WB: Conjecture concerning the diversification of strings in Theorem 3; partitioning conjecture for resulting in the flattening of the string assembly index upper bound curve; observation that the string assembly index upper bound curve should BE monotonically non-decreasing; linear interpolation of VS defining factors; prior-art search; numerous clarity corrections and improvements; SŁ: The remaining part of the study.
Data Availability Statement
The public repository for the code written in MATLAB computational environment is given under the link https://github.com/szluk/Evolution_of_Information (accessed on November 23, 2023).
Acknowledgments
The authors thank Piotr Masierak for his creative remarks on the definition of a distinct string 3, research on the general strategy for determining the string assembly indices, and creating the string (Peter’s rock), Andrzej Tomski for a clarity correction, and Mariola Bala for noting that "this is logical". SŁ thanks his wife Magdalena Bartocha for her unwavering support and motivation and his partner and friend, Renata Sobajda, for her prayers.
Abbreviations
The following abbreviations are used in this manuscript:
| AT | assembly theory; |
| BH | black hole; |
| BB | black-body object (BH, white dwarf, neutron star); |
| VS | nonequilibrium shell; |
| APT | active Planck triangle; |
| N | length of a binary string; |
| number of 0’s in the binary string; | |
| number of 1’s in the binary string (number of APTs); | |
| binary string of length N; | |
| balanced string of length N; | |
| distinct string of length N; | |
| balanced distinct string of length N; | |
| number of binary strings of length N (); | |
| number of balanced strings of length N (OEIS A001405); | |
| number of distinct strings (OEIS A000031); | |
| number of balanced distinct strings; | |
| assembly index of a string of length N; | |
| initial assembly pool; | |
| s | assembly step; |
| Q | binary assembling program; |
| length of the binary assembling program; | |
| F | Fibonacci sequence. |
Appendix A. Orbital Velocities and the VS Defining Factor l
Table A1 shows the orbital speed and escape speed of some celestial objects, their minimal and maximal velocities (Based on https://sci.esa.int/web/solar-system.). The former lie below the orbital speed limits. The average VS defining factor , where was determined by linear interpolation.
Table A1.
Exemplary orbital speeds and velocities, and the average VS defining factor .
| Object | [km/s] | [km/s] | [km/s] | [km/s] | |
|---|---|---|---|---|---|
| Mercury | |||||
| Venus | |||||
| Earth | |||||
| Mars | |||||
| Jupiter | |||||
| Saturn | |||||
| Uranus | |||||
| Neptune | |||||
| Pluto | |||||
| The Moon |
Appendix B. Exemplary Strings with Maximal Assembly Indices
For the exemplary balanced distinct strings , shown in Table 6:
- all forms of have ,
- all forms of have ,
- all forms of have ,
- the form has but the form has ,
- all forms of have ,
- all forms of have ,
- the form has but the form has ,
- all forms of have ,
- all forms of have ,
- all forms of have ,
- all forms of have ,
- all forms of have ,
- all forms of have ,
- all forms of have ,
- all forms of have ,
- some forms of have ,
- some forms of have .
Appendix C. Trivial Assembling Programs
Table A2 shows the lengths of the strings assembled by the trivial assembling program introduced in Section 6 for . The table is divided into sections corresponding to sets of assembled strings having the same form but different lengths. For example, thirty two 7-bit programs in the bottom section assemble strings . The boxed symbols denote program commands, not the string lengths.
Table A2.
Lengths of the strings assembled by trivial assembly programs Qs (OEIS A065108).
| 0 | 1 | 2 | 3 | 3,4 | 4,5 | 5,6 | 6,7 | |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| 1 | 1 | 2 | 3 | 5 | 13 | 21 | ||
| | | | | | | | | | | 42 | |||
| | | | | | | | | 26 | 39 | |||
| | | | | | | | | 52 | ||||
| | | | | | | ||||||
| | | | | | | | | |||||
| | | | | | | ||||||
| | | | | | | ||||||
| | | | | 10 | 15 | 25 | ||||
| | | | | | | | | 50 | ||||
| | | | | | | 30 | 45 | ||||
| | | | | | | 60 | |||||
| | | | | 20 | 30 | 50 | ||||
| | | | | | | 60 | |||||
| | | | | 40 | 60 | |||||
| | | | | 80 | ||||||
| | | 6 | 9 | 15 | 39 | ||||
| | | | | | | | | |||||
| | | | | | | 30 | 45 | ||||
| | | | | | | 60 | |||||
| | | | | 18 | 27 | 45 | ||||
| | | | | | | 54 | |||||
| | | | | 36 | 54 | |||||
| | | | | 72 | ||||||
| | | 12 | 18 | 30 | |||||
| | | | | | | 60 | |||||
| | | | | 36 | 54 | |||||
| | | | | 72 | ||||||
| | | 24 | 36 | 60 | |||||
| | | | | 72 | ||||||
| | | 48 | 72 | ||||||
| | | 96 | |||||||
| 4 | 6 | 10 | 26 | 42 | ||||
| | | | | | | | | 52 | ||||
| | | | | | | ||||||
| | | | | | | ||||||
| | | | | 20 | 30 | 50 | ||||
| | | | | | | 60 | |||||
| | | | | 40 | 60 | |||||
| | | | | 80 | ||||||
| | | 12 | 18 | 30 | |||||
| | | | | | | 60 | |||||
| | | | | 36 | 54 | |||||
| | | | | 72 | ||||||
| | | 24 | 36 | 60 | |||||
| | | | | 72 | ||||||
| | | 48 | 72 | ||||||
| | | 96 | |||||||
| 8 | 12 | 20 | 52 | |||||
| | | | | | | ||||||
| | | | | 40 | 60 | |||||
| | | | | 80 | ||||||
| | | 24 | 36 | 60 | |||||
| | | | | 72 | ||||||
| | | 48 | 72 | ||||||
| | | 96 | |||||||
| 16 | 24 | 40 | ||||||
| | | | | 80 | ||||||
| | | 48 | 72 | ||||||
| | | 96 | |||||||
| 32 | 48 | 80 | ||||||
| | | 96 | |||||||
| 64 | 96 | |||||||
| 128 |
Table A3.
4-bit programs assembling strings with .
| Q | N | ||
| 10 | |||
| 9 | |||
| 12 | |||
| 10 | |||
| 12 | |||
| 12 | |||
| 16 |
‡. This program is not elegant if and the assembled string is not if .
Table A4.
5-bit programs assembling strings with .
| Q | N | ||
| 13 | |||
| 15 | |||
| 20 | |||
| 15 | |||
| 18 | |||
| 18 | |||
| 24 | |||
| 20 | |||
| 18 | |||
| 24 | |||
| 20 | |||
| 24 | |||
| 24 | |||
| 32 |
†. This program is not elegant (the same string can be assembled using the shorter 4-bit program ). ‡. This program is not elegant if and the assembled string is not if .
Table A5.
6-bit programs assembling strings with .
| Q | N | |
| 21 | ||
| 26 | ||
†. This program is not elegant. ‡. This program is not elegant if and the assembled string is not if .
Appendix D. Binary Strings and Their Assembly Indices
Table A2 show the lengths of the strings assembled by programs Fs having the minimal assembly indices. Table A6, Table A7, Table A8, Table A9, Table A10, Table A11, Table A12 and Table A13 show distributions of the assembly indices for . Table A14, Table A15, Table A16, Table A17 and Table A18 show balanced strings and their assembly indices for . Table A19, Table A20, Table A21, Table A22, Table A23 and Table A24 show the balanced distinct strings and their assembly indices for . Table A25, Table A26 and Table A27 show selected balanced distinct strings and their assembly indices for .
Table A6.
Distribution of the assembly indices for .
| 0 | 1 | 2 | 3 | 4 | 5 | ||
| 3 | 18 | 1 | 3 | 5 | 5 | 3 | 1 |
| 4 | 14 | 2 | 5 | 5 | 2 | ||
| 32 | 1 | 5 | 10 | 10 | 5 | 1 | |
Table A7.
Distribution of the assembly indices for .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | ||
| 3 | 10 | 1 | 3 | 2 | 3 | 1 | ||
| 4 | 44 | 6 | 10 | 12 | 10 | 6 | ||
| 5 | 10 | 2 | 6 | 2 | ||||
| 64 | 1 | 6 | 15 | 20 | 15 | 6 | 1 | |
Table A8.
Distribution of the assembly indices for .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| 4 | 50 | 1 | 5 | 7 | 12 | 12 | 7 | 5 | 1 |
| 5 | 74 | 2 | 14 | 21 | 21 | 14 | 2 | ||
| 6 | 4 | 2 | 2 | ||||||
| 128 | 1 | 7 | 21 | 35 | 35 | 21 | 7 | 1 | |
Table A9.
Distribution of the assembly indices for .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | ||
| 3 | 4 | 1 | 2 | 1 | ||||||
| 4 | 38 | 9 | 8 | 4 | 8 | 9 | ||||
| 5 | 132 | 8 | 17 | 22 | 40 | 22 | 17 | 8 | ||
| 6 | 82 | 2 | 26 | 24 | 26 | 2 | ||||
| 256 | 1 | 8 | 28 | 56 | 70 | 56 | 28 | 8 | 1 | |
Table A10.
Distribution of the assembly indices for .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
| 4 | 24 | 1 | 3 | 3 | 5 | 5 | 3 | 3 | 1 | ||
| 5 | 184 | 4 | 17 | 35 | 36 | 36 | 35 | 17 | 4 | ||
| 6 | 248 | 2 | 19 | 42 | 61 | 61 | 42 | 19 | 2 | ||
| 7 | 56 | 4 | 24 | 24 | 4 | ||||||
| 512 | 1 | 9 | 36 | 84 | 126 | 126 | 84 | 36 | 9 | 1 | |
Table A11.
Distribution of the assembly indices for .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ||
| 4 | 20 | 1 | 3 | 5 | 2 | 5 | 3 | 1 | ||||
| 5 | 198 | 8 | 22 | 20 | 33 | 32 | 33 | 20 | 22 | 8 | ||
| 6 | 502 | 2 | 18 | 68 | 108 | 110 | 108 | 68 | 18 | 2 | ||
| 7 | 288 | 2 | 32 | 62 | 96 | 62 | 32 | 2 | ||||
| 8 | 16 | 2 | 12 | 2 | ||||||||
| 1024 | 1 | 10 | 45 | 120 | 210 | 252 | 210 | 120 | 45 | 10 | ||
Table A12.
Distribution of the assembly indices for .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | ||
| 5 | 184 | 1 | 7 | 14 | 23 | 18 | 29 | 29 | 18 | 23 | 14 | 7 | 1 |
| 6 | 686 | 4 | 32 | 69 | 104 | 134 | 134 | 104 | 69 | 32 | 4 | ||
| 7 | 970 | 9 | 69 | 178 | 229 | 229 | 178 | 69 | 9 | ||||
| 8 | 208 | 4 | 30 | 70 | 70 | 30 | 4 | ||||||
| 2048 | 1 | 11 | 55 | 165 | 330 | 462 | 462 | 330 | 165 | 55 | 11 | ||
Table A13.
Distribution of the assembly indices for .
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ||
| 4 | 10 | 1 | 3 | 2 | 3 | 1 | ||||||||
| 5 | 94 | 13 | 4 | 10 | 12 | 16 | 12 | 10 | 4 | 13 | ||||
| 6 | 1034 | 12 | 42 | 94 | 141 | 130 | 196 | 130 | 141 | 94 | 42 | 12 | ||
| 7 | 1688 | 11 | 106 | 196 | 354 | 354 | 354 | 196 | 106 | 11 | ||||
| 8 | 1180 | 16 | 143 | 282 | 298 | 282 | 143 | 16 | ||||||
| 9 | 90 | 2 | 14 | 58 | 14 | 2 | ||||||||
| 4096 | 1 | 12 | 66 | 220 | 495 | 792 | 924 | 792 | 495 | 220 | 66 | 12 | 1 | |
Table A14.
balanced strings.
| k | ||||||
| 1 | 0 | (0 | 1) | (0 | 1) | 3 |
| 2 | (0 | 1) | 0 | (0 | 1) | 3 |
| 3 | (0 | 1) | (0 | 1) | 0 | 3 |
| 4 | (1 | 0) | 0 | (1 | 0) | 3 |
| 5 | (1 | 0) | (1 | 0) | 0 | 3 |
| 6 | 0 | 0 | 0 | 1 | 1 | 4 |
| 7 | 0 | 0 | 1 | 1 | 0 | 4 |
| 8 | 0 | 1 | 1 | 0 | 0 | 4 |
| 9 | 1 | 0 | 0 | 0 | 1 | 4 |
| 10 | 1 | 1 | 0 | 0 | 0 | 4 |
Table A15.
balanced strings.
| k | |||||||
| 1 | (0 | 1) | (0 | 1) | (0 | 1) | 3 |
| 2 | (1 | 0) | (1 | 0) | (1 | 0) | 3 |
| 3 | 0 | (0 | 1) | (0 | 1) | 1 | 4 |
| 4 | 0 | (0 | 1) | 1 | (0 | 1) | 4 |
| 5 | (0 | 1) | 0 | (0 | 1) | 1 | 4 |
| 6 | (0 | 1) | (0 | 1) | 1 | 0 | 4 |
| 7 | (0 | 1) | 1 | 0 | (0 | 1) | 4 |
| 8 | (0 | 1) | 1 | (0 | 1) | 0 | 4 |
| 9 | (1 | 0) | 0 | (1 | 0) | 1 | 4 |
| 10 | (1 | 0) | 0 | 1 | (1 | 0) | 4 |
| 11 | (1 | 0) | (1 | 0) | 0 | 1 | 4 |
| 12 | (1 | 0) | 1 | (1 | 0) | 0 | 4 |
| 13 | 1 | (1 | 0) | 0 | (1 | 0) | 4 |
| 14 | 1 | (1 | 0) | (1 | 0) | 0 | 4 |
| 15 | 0 | 0 | 1 | 1 | 1 | 0 | 5 |
| 16 | 0 | 0 | 0 | 1 | 1 | 1 | 5 |
| 17 | 0 | 1 | 1 | 1 | 0 | 0 | 5 |
| 18 | 1 | 0 | 0 | 0 | 1 | 1 | 5 |
| 19 | 1 | 1 | 0 | 0 | 0 | 1 | 5 |
| 20 | 1 | 1 | 1 | 0 | 0 | 0 | 5 |
Table A16.
balanced strings.
| k | ||||||||
| 1 | 0 | (0 | 1) | (0 | 1) | (0 | 1) | 4 |
| 2 | (0 | 1) | (0 | 1) | (0 | 1) | 0 | 4 |
| 3 | (1 | 0) | (1 | 0) | (1 | 0) | 0 | 4 |
| 4 | (0 | 1) | (0 | 1) | 0 | (0 | 1) | 4 |
| 5 | (1 | 0) | (1 | 0) | 0 | (1 | 0) | 4 |
| 6 | (0 | 1) | 0 | (0 | 1) | (0 | 1) | 4 |
| 7 | (1 | 0) | 0 | (1 | 0) | (1 | 0) | 4 |
| 8 | (1 | 0 | 0) | (1 | 0 | 0) | 1 | 4 |
| 9 | (1 | 0 | 0) | 1 | (1 | 0 | 0) | 4 |
| 10 | 1 | (1 | 0 | 0) | (1 | 0 | 0) | 4 |
| 11 | (0 | 0 | 1) | 1 | (0 | 0 | 1) | 4 |
| 12 | (0 | 0 | 1) | (0 | 0 | 1) | 1 | 4 |
| 13 | 1 | (0 | 0) | (0 | 0) | 1 | 1 | 5 |
| 14 | 1 | 0 | 0 | (0 | 1) | (0 | 1) | 5 |
| 15 | (1 | 0) | 0 | 0 | 1 | (1 | 0) | 5 |
| 16 | (1 | 0) | (1 | 0) | 0 | 0 | 1 | 5 |
| 17 | (1 | 0) | 1 | (1 | 0) | 0 | 0 | 5 |
| 18 | 1 | 1 | (0 | 0) | (0 | 0) | 1 | 5 |
| 19 | 1 | (1 | 0) | (1 | 0) | 0 | 0 | 5 |
| 20 | 1 | 1 | 1 | (0 | 0) | (0 | 0) | 5 |
| 21 | (0 | 1) | (0 | 1) | 1 | 0 | 0 | 5 |
| 22 | (0 | 1) | 1 | 0 | 0 | (0 | 1) | 5 |
| 23 | (0 | 1) | 1 | 0 | (0 | 1) | 0 | 5 |
| 24 | (0 | 1) | 1 | (0 | 1) | 0 | 0 | 5 |
| 25 | (0 | 1) | 0 | (0 | 1) | 1 | 0 | 5 |
| 26 | 0 | (0 | 1) | (0 | 1) | 1 | 0 | 5 |
| 27 | 0 | (0 | 1) | 1 | (0 | 1) | 0 | 5 |
| 28 | (0 | 0) | 1 | 1 | 1 | (0 | 0) | 5 |
| 29 | (0 | 1) | 0 | 0 | (0 | 1) | 1 | 5 |
| 30 | (0 | 0) | (0 | 0) | 1 | 1 | 1 | 5 |
| 31 | 0 | 0 | (0 | 1) | (0 | 1) | 1 | 5 |
| 32 | 0 | 0 | (0 | 1) | 1 | (0 | 1) | 5 |
| 33 | 1 | (1 | 0) | 0 | 0 | (1 | 0) | 5 |
| 34 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 6 |
| 35 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 6 |
Table A17.
balanced strings (1st part).
| k | |||||||||
| 1 | ((0 | 1) | (0 | 1)) | ((0 | 1) | (0 | 1)) | 3 |
| 2 | ((1 | 0) | (1 | 0)) | ((1 | 0) | (1 | 0)) | 3 |
| 3 | ((0 | 0) | (1 | 1)) | ((0 | 0) | (1 | 1)) | 4 |
| 4 | ((0 | 1) | (1 | 0)) | ((0 | 1) | (1 | 0)) | 4 |
| 5 | ((1 | 0) | (0 | 1)) | ((1 | 0) | (0 | 1)) | 4 |
| 6 | ((1 | 1) | (0 | 0)) | ((1 | 1) | (0 | 0)) | 4 |
| 7 | (0 | 0) | (0 | 0) | (1 | 1) | (1 | 1) | 5 |
| 8 | (0 | 0 | 1) | (0 | 0 | 1) | 1 | 1 | 5 |
| 9 | 0 | (0 | 1) | (0 | 1) | (0 | 1) | 1 | 5 |
| 10 | 0 | (0 | 1) | (0 | 1) | 1 | (0 | 1) | 5 |
| 11 | 0 | (0 | 1) | 1 | (0 | 1) | (0 | 1) | 5 |
| 12 | (0 | 0 | 1) | 1 | 1 | (0 | 0 | 1) | 5 |
| 13 | (0 | 0) | (1 | 1) | (1 | 1) | (0 | 0) | 5 |
| 14 | (0 | 1) | 0 | (0 | 1) | (0 | 1) | 1 | 5 |
| 15 | (0 | 1) | 0 | (0 | 1) | 1 | (0 | 1) | 5 |
| 16 | (0 | 1) | (0 | 1) | 0 | (0 | 1) | 1 | 5 |
| 17 | (0 | 1) | (0 | 1) | (0 | 1) | 1 | 0 | 5 |
| 18 | (0 | 1) | (0 | 1) | 1 | 0 | (0 | 1) | 5 |
| 19 | (0 | 1) | (0 | 1) | 1 | (0 | 1) | 0 | 5 |
| 20 | (0 | 1 | 1) | 0 | 0 | (0 | 1 | 1) | 5 |
| 21 | (0 | 1) | 1 | 0 | (0 | 1) | (0 | 1) | 5 |
| 22 | (0 | 1) | 1 | (0 | 1) | 0 | (0 | 1) | 5 |
| 23 | (0 | 1) | 1 | (0 | 1) | (0 | 1) | 0 | 5 |
| 24 | (0 | 1 | 1) | (0 | 1 | 1) | 0 | 0 | 5 |
| 25 | (1 | 0 | 0) | (1 | 0 | 0) | 1 | 1 | 5 |
| 26 | 1 | 0 | (0 | 1) | (0 | 1) | (0 | 1) | 5 |
| 27 | (1 | 0) | 0 | (1 | 0) | 1 | (1 | 0) | 5 |
| 28 | (1 | 0) | 0 | 1 | (1 | 0) | (1 | 0) | 5 |
| 29 | (1 | 0 | 0) | 1 | 1 | (1 | 0 | 0) | 5 |
| 30 | (1 | 0 | 1) | 0 | 0 | (1 | 0 | 1) | 5 |
| 31 | (1 | 0) | (1 | 0) | 0 | 1 | (1 | 0) | 5 |
| 32 | (1 | 0) | (1 | 0) | (1 | 0) | 0 | 1 | 5 |
| 33 | (1 | 0) | (1 | 0) | 1 | (1 | 0) | 0 | 5 |
| 34 | (1 | 0) | 1 | (1 | 0) | 0 | (1 | 0) | 5 |
| 35 | (1 | 0) | 1 | (1 | 0) | (1 | 0) | 0 | 5 |
| 36 | (1 | 1) | (0 | 0) | (0 | 0) | (1 | 1) | 5 |
| 37 | (1 | 1 | 0) | 0 | 0 | (1 | 1 | 0) | 5 |
| 38 | 1 | 1 | (0 | 0 | 1) | (0 | 0 | 1) | 5 |
| 39 | 1 | 1 | 0 | 0 | 1 | 0 | 1 | 0 | 5 |
| 40 | 1 | (1 | 0) | (1 | 0) | 0 | (1 | 0) | 5 |
| 41 | (1 | 1 | 0) | (1 | 1 | 0) | 0 | 0 | 5 |
| 42 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 5 |
| 43 | 1 | 1 | (1 | 0 | 0) | (1 | 0 | 0) | 5 |
| 44 | (1 | 1) | (1 | 1) | (0 | 0) | (0 | 0) | 5 |
| 45 | 0 | 0 | (0 | 1 | 1) | (0 | 1 | 1) | 5 |
| 46 | 0 | (0 | 1 | 1) | (0 | 1 | 1) | 0 | 5 |
Table A18.
balanced strings (2nd part).
| k | |||||||||
| 47 | 0 | 0 | (0 | 1) | (0 | 1) | 1 | 1 | 6 |
| 48 | 0 | 0 | (0 | 1) | 1 | 1 | (0 | 1) | 6 |
| 49 | 0 | 0 | 0 | (1 | 1) | (1 | 1) | 0 | 6 |
| 50 | 0 | (0 | 1) | (0 | 1) | 1 | 1 | 0 | 6 |
| 51 | 0 | 0 | 1 | 1 | (1 | 0) | (1 | 0) | 6 |
| 52 | (0 | 1) | 0 | 0 | (0 | 1) | 1 | 1 | 6 |
| 53 | (0 | 1) | 0 | (0 | 1) | 1 | 1 | 0 | 6 |
| 54 | (0 | 1) | (0 | 1) | 1 | 1 | 0 | 0 | 6 |
| 55 | (0 | 1) | 1 | 1 | 0 | 0 | (0 | 1) | 6 |
| 56 | (0 | 1) | 1 | 1 | 0 | (0 | 1) | 0 | 6 |
| 57 | (0 | 1) | 1 | 1 | (0 | 1) | 0 | 0 | 6 |
| 58 | 0 | (1 | 1) | (1 | 1) | 0 | 0 | 0 | 6 |
| 59 | 1 | (0 | 0) | (0 | 0) | 1 | 1 | 1 | 6 |
| 60 | (1 | 0) | 0 | 0 | (1 | 0) | 1 | 1 | 6 |
| 61 | 1 | 0 | 0 | (0 | 1) | 1 | (0 | 1) | 6 |
| 62 | (1 | 0) | 0 | 0 | 1 | 1 | (1 | 0) | 6 |
| 63 | (1 | 0) | (1 | 0) | 0 | 0 | 1 | 1 | 6 |
| 64 | (1 | 0) | 1 | (1 | 0) | 0 | 0 | 1 | 6 |
| 65 | (1 | 0) | 1 | 1 | (1 | 0) | 0 | 0 | 6 |
| 66 | 1 | (1 | 0) | 0 | 0 | (1 | 0) | 1 | 6 |
| 67 | 1 | 1 | (0 | 1) | 0 | 0 | (0 | 1) | 6 |
| 68 | 1 | 1 | 1 | (0 | 0) | (0 | 0) | 1 | 6 |
| 69 | 1 | 1 | (1 | 0) | 0 | 0 | (1 | 0) | 6 |
| 70 | 1 | 1 | (1 | 0) | (1 | 0) | 0 | 0 | 6 |
Table A19.
balanced distinct strings.
| k | ||||||
| 1 | 0 | (0 | 1) | (0 | 1) | 3 |
| 6 | 0 | 0 | 0 | 1 | 1 | 4 |
Table A20.
balanced distinct strings.
| k | |||||||
| 1 | (0 | 1) | (0 | 1) | (0 | 1) | 3 |
| 3 | 0 | (0 | 1) | (0 | 1) | 1 | 4 |
| 4 | 0 | (0 | 1) | 1 | (0 | 1) | 4 |
| 16 | 0 | 0 | 0 | 1 | 1 | 1 | 5 |
Table A21.
balanced distinct strings.
| k | ||||||||
| 1 | 0 | (0 | 1) | (0 | 1) | (0 | 1) | 4 |
| 12 | (0 | 0 | 1) | (0 | 0 | 1) | 1 | 4 |
| 30 | (0 | 0) | (0 | 0) | 1 | 1 | 1 | 5 |
| 31 | 0 | 0 | (0 | 1) | (0 | 1) | 1 | 5 |
| 32 | 0 | 0 | (0 | 1) | 1 | (0 | 1) | 5 |
Table A22.
balanced distinct strings.
| k | |||||||||
| 1 | ((0 | 1) | (0 | 1)) | ((0 | 1) | (0 | 1)) | 3 |
| 3 | (0 | 0) | (1 | 1) | (0 | 0) | (1 | 1) | 4 |
| 7 | (0 | 0) | (0 | 0) | (1 | 1) | (1 | 1) | 5 |
| 8 | 0 | (0 | 1) | 0 | (0 | 1) | 1 | 1 | 5 |
| 9 | 0 | (0 | 1) | (0 | 1) | (0 | 1) | 1 | 5 |
| 10 | 0 | (0 | 1) | (0 | 1) | 1 | (0 | 1) | 5 |
| 11 | 0 | (0 | 1) | 1 | (0 | 1) | (0 | 1) | 5 |
| 46 | 0 | 0 | (0 | 1 | 1) | (0 | 1 | 1) | 5 |
| 45 | 0 | 0 | (0 | 1) | (0 | 1) | 1 | 1 | 6 |
| 47 | 0 | 0 | (0 | 1) | 1 | 1 | (0 | 1) | 6 |
Table A23.
Selected balanced distinct strings .
| k | ||||||||||
| 1 | 0 | ((0 | 1) | (0 | 1)) | ((0 | 1) | (0 | 1)) | 4 |
| 2 | 0 | ((0 | 0) | (1 | 1)) | ((0 | 0) | (1 | 1)) | 5 |
| 3 | (0 | (0 | 1)) | (0 | 1) | (0 | 0 | 1) | 1 | 5 |
| 4 | (0 | (0 | 1)) | (0 | 0 | 1) | 1 | (0 | 1) | 5 |
| 5 | (0 | (0 | 1)) | (0 | 0 | 1) | (0 | 1) | 1 | 5 |
| 6 | 0 | (0 | 0 | 1) | 1 | 1 | (0 | 0 | 1) | 6 |
| 7 | 0 | 0 | (0 | 1) | 1 | (0 | 1) | (0 | 1) | 6 |
| 8 | 0 | 0 | (0 | 1) | (0 | 1) | 1 | (0 | 1) | 6 |
| 9 | 0 | 0 | (0 | 1) | (0 | 1) | (0 | 1) | 1 | 6 |
| 10 | 0 | (0 | 0 | 1) | (0 | 0 | 1) | 1 | 1 | 6 |
| 11 | (0 | 0) | (0 | 0) | (1 | 1) | 0 | (1 | 1) | 6 |
| 12 | 0 | (0 | 0) | (0 | 0) | (1 | 1) | (1 | 1) | 6 |
| 13 | (0 | 0) | (0 | 0) | 1 | 1 | 1 | 0 | 1 | 7 |
| 14 | (0 | 0) | (0 | 0) | 1 | 0 | 1 | 1 | 1 | 7 |
Table A24.
balanced distinct strings.
| k | |||||||||||
| 1 | ((0 | 1) | (0 | 1)) | ((0 | 1) | (0 | 1)) | (0 | 1) | 4 |
| 2 | 0 | ((0 | 1) | (0 | 1)) | ((0 | 1) | (0 | 1)) | 1 | 5 |
| 3 | (0 | 1) | (1 | (0 | 1) | 0) | (1 | (0 | 1) | 0) | 5 |
| 4 | (0 | (0 | 1) | 1) | (0 | 0 | 1 | 1) | (0 | 1) | 5 |
| 5 | 0 | ((0 | 1) | 0 | 1) | 1 | (0 | 1 | 0 | 1) | 5 |
| 6 | 0 | ((1 | 0) | 1 | 0) | 1 | (1 | 0 | 1 | 0) | 5 |
| 7 | (0 | 1) | ((0 | 1) | 1 | 0) | (0 | 1 | 1 | 0) | 5 |
| 8 | (0 | (0 | 1)) | (0 | 1) | (0 | 0 | 1) | 1 | 1 | 6 |
| 9 | (0 | (0 | 1)) | (0 | 0 | 1) | 1 | 1 | (0 | 1) | 6 |
| 10 | (0 | (0 | 1)) | (0 | 0 | 1) | 1 | (0 | 1) | 1 | 6 |
| 11 | (0 | (0 | 1)) | (0 | 0 | 1) | (0 | 1) | 1 | 1 | 6 |
| 14 | 0 | (0 | 0 | 1 | 1) | 1 | (0 | 0 | 1 | 1) | 6 |
| 15 | 0 | 0 | ((0 | 1) | 1) | (0 | 1 | 1) | (0 | 1) | 6 |
| 16 | 0 | 0 | ((0 | 1) | 1) | (0 | 1) | (0 | 1 | 1) | 6 |
| 17 | 0 | (0 | 0 | 1 | 1) | (0 | 0 | 1 | 1) | 1 | 6 |
| 19 | 0 | 0 | (0 | 1) | ((0 | 1) | 1) | (0 | 1 | 1) | 6 |
| 12 | (0 | 0) | 0 | (1 | 1) | (1 | 1) | (0 | 0) | 1 | 7 |
| 13 | 0 | 0 | (0 | 1) | 1 | 1 | (0 | 1) | (0 | 1) | 7 |
| 18 | 0 | 0 | (0 | 1) | (0 | 1) | 1 | 1 | (0 | 1) | 7 |
| 20 | 0 | 0 | (0 | 1) | (0 | 1) | (0 | 1) | 1 | 1 | 7 |
| 21 | (0 | 0) | 0 | 1 | (0 | 0) | (1 | 1) | (1 | 1) | 7 |
| 22 | (0 | 0) | (0 | 0) | (1 | 1) | (1 | 1) | 0 | 1 | 7 |
| 23 | (0 | 0) | (0 | 0) | (1 | 1) | 1 | 0 | (1 | 1) | 7 |
| 24 | (0 | 0) | (0 | 0) | (1 | 1) | 0 | (1 | 1) | 1 | 7 |
| 25 | (0 | 0) | (0 | 0) | 1 | 0 | (1 | 1) | (1 | 1) | 7 |
| 26 | (0 | 0) | (0 | 0) | 0 | 1 | (1 | 1) | (1 | 1) | 7 |
Table A25.
Selected balanced distinct strings .
| k | ||||||||||||
| 1 | 0 | (0 | 1) | ((0 | 1)) | (0 | 1)) | (0 | 1 | 0 | 1) | 5 |
| 2 | (0 | (0 | 1) | (0 | 1)) | (0 | 0 | 1 | 0 | 1) | 1 | 5 |
| 3 | (0 | 0) | ((0 | 0) | 1 | 1) | (1 | 0 | 0 | 1 | 1) | 6 |
| 4 | (0 | (0 | 1)) | (0 | 1) | (0 | 1) | (0 | 0 | 1) | 1 | 6 |
| 5 | (0 | 0) | (0 | 0) | (0 | 0) | (1 | 1) | (1 | 1) | 1 | 7 |
| 6 | (0 | 0) | (1 | 1 | 0) | 1 | (0 | 0) | (1 | 1 | 0) | 7 |
| 7 | (0 | 0) | (0 | 0) | (0 | 1) | (0 | 1) | 1 | 1 | 1 | 8 |
Table A26.
Selected balanced distinct strings .
| k | |||||||||||||
| 1 | ((0 | 1) | (0 | 1)) | (0 | 1 | 0 | 1) | (0 | 1 | 0 | 1) | 4 |
| 2 | (0 | (0 | 1) | 1 | (0 | 1)) | (0 | 0 | 1 | 1 | 0 | 1) | 5 |
| 3 | ((0 | 1) | 1 | (0 | (0 | 1))) | ((0 | 1) | 1 | (0 | 0 | 1)) | 5 |
| 4 | (0 | (0 | 1) | 1) | (0 | 0 | 1 | 1) | (0 | 1) | (0 | 1) | 6 |
| 5 | ((0 | 1) | 0 | (0 | 1)) | (0 | 1 | 0 | 0 | 1) | 1 | 1 | 6 |
| 6 | (0 | 0 | 1) | (0 | 0 | 1) | (0 | 0 | 1) | 1 | 1 | 1 | 7 |
| 7 | (0 | 0) | (0 | 0) | (0 | 0) | (1 | 1) | (1 | 1) | (1 | 1) | 7 |
| 8 | (0 | 0) | (0 | 0) | (1 | 1) | (1 | 1) | 1 | (0 | 0) | 1 | 8 |
| 9 | (0 | 0) | (1 | 0) | (1 | 1) | (0 | 0) | (1 | 1) | (1 | 0) | 8 |
| 10 | (1 | 1) | (1 | 1) | (0 | 1) | (0 | 1) | (0 | 0) | (0 | 0) | 8 |
| 11 | (1 | 1) | (1 | 1) | (0 | 0) | (0 | 0) | (1 | 0) | (1 | 0) | 8 |
Table A27.
Selected balanced distinct strings .
| k | ||||||||||||||
| 1 | 0 | ((0 | 1) | (0 | 1)) | (0 | 1 | 0 | 1) | (0 | 1 | 0 | 1) | 5 |
| 2 | 0 | ((1 | 0) | 0 | 1 | (1 | 0)) | (1 | 0 | 0 | 1 | 1 | 0) | 6 |
| 3 | (0 | ((0 | 1) | (0 | 1)) | (0 | 0 | 1 | 0 | 1) | (0 | 1) | 1 | 6 |
| 4 | 0 | (0 | 0) | ((0 | 0) | (1 | 1)) | (0 | 0 | 1 | 1) | (1 | 1) | 7 |
| 5 | (0 | 0) | ((0 | 0) | (1 | 1)) | (0 | 0 | 1 | 1) | 0 | (1 | 1) | 7 |
| 6 | (0 | 0) | (0 | 0) | (0 | 0) | 0 | (1 | 1) | (1 | 1) | (1 | 1) | 8 |
| 7 | (0 | 0 | (0 | 1)) | (0 | 0 | 0 | 1) | (0 | 1) | 1 | 1 | 1 | 8 |
| 8 | (0 | 0) | (0 | 0) | (0 | 0) | 1 | 0 | (1 | 1) | (1 | 1) | 1 | 9 |
References
- Marshall, S.M.; Murray, A.R.G.; Cronin, L. A probabilistic framework for identifying biosignatures using Pathway Complexity. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 2017, 375, 20160342. [CrossRef]
- Murray, A.; Marshall, S.; Cronin, L. Defining Pathway Assembly and Exploring its Applications, 2018. arXiv:1804.06972 [cs, math].
- Marshall, S.M.; Mathis, C.; Carrick, E.; Keenan, G.; Cooper, G.J.T.; Graham, H.; Craven, M.; Gromski, P.S.; Moore, D.G.; Walker, S.I.; Cronin, L. Identifying molecules as biosignatures with assembly theory and mass spectrometry. Nature Communications 2021, 12, 3033. [CrossRef]
- Liu, Y.; Mathis, C.; Bajczyk, M.D.; Marshall, S.M.; Wilbraham, L.; Cronin, L. Exploring and mapping chemical space with molecular assembly trees. Science Advances 2021, 7, eabj2465. [CrossRef]
- Marshall, S.M.; Moore, D.G.; Murray, A.R.G.; Walker, S.I.; Cronin, L. Formalising the Pathways to Life Using Assembly Spaces. Entropy 2022, 24, 884. [CrossRef]
- Sharma, A.; Czégel, D.; Lachmann, M.; Kempes, C.P.; Walker, S.I.; Cronin, L. Assembly theory explains and quantifies selection and evolution. Nature 2023, 622, 321–328. [CrossRef]
- Jirasek, M.; Sharma, A.; Bame, J.R.; Mehr, S.H.M.; Bell, N.; Marshall, S.M.; Mathis, C.; Macleod, A.; Cooper, G.J.T.; Swart, M.; Mollfulleda, R.; Cronin, L. Determining Molecular Complexity using Assembly Theory and Spectroscopy, 2023. arXiv:2302.13753 [physics, q-bio].
- Łukaszyk, S., Black Hole Horizons as Patternless Binary Messages and Markers of Dimensionality. In Future Relativity, Gravitation, Cosmology; Nova Science Publishers, 2023; chapter 15, pp. 317–374. [CrossRef]
- Łukaszyk, S. Life as the Explanation of the Measurement Problem. Journal of Physics: Conference Series 2024, 2701, 012124. [CrossRef]
- Łukaszyk, S. The Imaginary Universe. preprint, PHYSICAL SCIENCES, 2023.
- de Chardin, P.T. The Phenomenon of Man; Harper, New York, 1959.
- Prigogine, I.; Stengers, I. Order out of Chaos: Man’s New Dialogue with Nature; Bantam Books, 1984.
- Melamede, R. Dissipative Structures and the Origins of Life. Unifying Themes in Complex Systems IV; Minai, A.A.; Bar-Yam, Y., Eds.; Springer Berlin Heidelberg: Berlin, Heidelberg, 2008; pp. 80–87.
- Vedral, V. Decoding Reality: The Universe as Quantum Information; Oxford University Press, 2010. [CrossRef]
- Łukaszyk, S. Four Cubes, 2020. [CrossRef]
- Vopson, M.M.; Lepadatu, S. Second law of information dynamics. AIP Advances 2022, 12, 075310. [CrossRef]
- Łukaszyk, S. Novel Recurrence Relations for Volumes and Surfaces of n-Balls, Regular n-Simplices, and n-Orthoplices in Real Dimensions. Mathematics 2022, 10. [CrossRef]
- Łukaszyk, S.; Tomski, A. Omnidimensional Convex Polytopes. Symmetry 2023, 15. [CrossRef]
- Vopson, M.M. The second law of infodynamics and its implications for the simulated universe hypothesis. AIP Advances 2023, 13, 105308. [CrossRef]
- Łukaszyk, S. A No-go Theorem for Superposed Actions (Making Schrödinger’s Cat Quantum Nonlocal). In New Frontiers in Physical Science Research Vol. 3; Purenovic, D.J., Ed.; Book Publisher International (a part of SCIENCEDOMAIN International), 2022; pp. 137–151. [CrossRef]
- Qian, K.; Wang, K.; Chen, L.; Hou, Z.; Krenn, M.; Zhu, S.; Ma, X.s. Multiphoton non-local quantum interference controlled by an undetected photon. Nature Communications 2023, 14, 1480. [CrossRef]
- Xue, P.; Xiao, L.; Ruffolo, G.; Mazzari, A.; Temistocles, T.; Cunha, M.T.; Rabelo, R. Synchronous Observation of Bell Nonlocality and State-Dependent Contextuality. Physical Review Letters 2023, 130, 040201. [CrossRef]
- Łukaszyk, S. Shannon Entropy of Chemical Elements. European Journal of Applied Sciences 2024, 11, 443–458. [CrossRef]
- Tran, D.M.; Nguyen, V.D.; Ho, L.B.; Nguyen, H.Q. Increased success probability in Hardy’s nonlocality: Theory and demonstration. Phys. Rev. A 2023, 107, 042210. [CrossRef]
- Colciaghi, P.; Li, Y.; Treutlein, P.; Zibold, T. Einstein-Podolsky-Rosen Experiment with Two Bose-Einstein Condensates. Phys. Rev. X 2023, 13, 021031. [CrossRef]
- Watanabe, S. Knowing and Guessing: A Quantitative Study of Inference and Information; Wiley, 1969.
- Watanabe, S. Epistemological Relativity. Annals of the Japan Association for Philosophy of Science 1986, 7, 1–14. [CrossRef]
- Łukaszyk, S. Metallic Ratios and Angles of a Real Argument. IPI Letters 2024, pp. 26–33. [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell System Technical Journal 1948, 27, 379–423. [CrossRef]
- Bekenstein, J.D. Black holes and the second law. Lettere Al Nuovo Cimento Series 2 1972, 4, 737–740. [CrossRef]
- Bekenstein, J.D. Black Holes and Entropy. Phys. Rev. D 1973, 7, 2333–2346. [CrossRef]
- Hawking, S.W. Particle creation by black holes. Communications In Mathematical Physics 1975, 43, 199–220. [CrossRef]
- Hooft, G.t. Dimensional Reduction in Quantum Gravity, 1993. [CrossRef]
- Verlinde, E. On the origin of gravity and the laws of Newton. Journal of High Energy Physics 2011, 2011, 29. [CrossRef]
- Misner, C.W.; Thorne, K.S.; Wheeler, J.A. Gravitation; W. H. Freeman: San Francisco, 1973.
- Gould, A. Classical derivation of black-hole entropy. Physical Review D 1987, 35, 449–454. [CrossRef]
- Penrose, R.; Floyd, R.M. Extraction of Rotational Energy from a Black Hole. Nature Physical Science 1971, 229, 177–179. [CrossRef]
- Christodoulou, D.; Ruffini, R. Reversible Transformations of a Charged Black Hole. Physical Review D 1971, 4, 3552–3555. [CrossRef]
- Stuchlík, Z.; Kološ, M.; Tursunov, A. Penrose Process: Its Variants and Astrophysical Applications. Universe 2021, 7, 416. [CrossRef]
- Downey, P.; Leong, B.; Sethi, R. Computing Sequences with Addition Chains. SIAM Journal on Computing 1981, 10, 638–646. [CrossRef]
- Chaitin, G.J. Randomness and Mathematical Proof. Scientific American 1975, 232, 47–52. [CrossRef]
- Chaitin, G.J. The unknowable; Springer series in discrete mathematics and theoretical computer science, Springer: Singapore ; New York, 1999.
- Rajput, C. Metallic Ratios in Primitive Pythagorean Triples : Metallic Means embedded in Pythagorean Triangles and other Right Triangles. JOURNAL OF ADVANCES IN MATHEMATICS 2021, 20, 312–344. [CrossRef]
- Chaitin, G. From Philosophy to Program Size: Key Ideas and Methods : Lecture Notes on Algorithmic Information Theory from the 8th Estonian Winter School in Computer Science, EWSCS’03 : [2-7 March]; Institute of Cybernetics at Tallinn Technical University, 2003.
- Chaitin, G.J. Computational complexity and Gödel’s incompleteness theorem. ACM SIGACT News 1971, pp. 11–12. [CrossRef]
- Kolmogorov, A. On tables of random numbers. Theoretical Computer Science 1998, 207, 387–395. [CrossRef]
- Cronin, Leroy. Lee Cronin: Controversial Nature Paper on Evolution of Life and Universe | Lex Fridman Podcast #404, 2023. Accessed: 2023-12-18.
- Zatorski, W. W życiu chodzi o życie, wydanie i ed.; Tyniec Wydawnictwo Benedyktynów: Kraków, 2020. OCLC: 1243002797.
- Barta, J.; Markiewicz, R., Eds. Prawo autorskie: Przepisy, orzecznictwo, umowy miedzynarodowe, wyd. 4., rozsz. i zaktualizowane ed.; Dom Wydawniczy ABC: Warszawa, 2002.
- Mandelstam, L.; Tamm, I. The Uncertainty Relation Between Energy and Time in Non-relativistic Quantum Mechanics. J. Phys. (USSR) 1945, 9, 249––254.
- Margolus, N.; Levitin, L.B. The maximum speed of dynamical evolution. Physica D: Nonlinear Phenomena 1998, 120, 188–195. [CrossRef]
- Levitin, L.B.; Toffoli, T. Fundamental Limit on the Rate of Quantum Dynamics: The Unified Bound Is Tight. Physical Review Letters 2009, 103, 160502. [CrossRef]
- Hossenfelder, S. Comments on and Comments on Comments on Verlinde’s paper "On the Origin of Gravity and the Laws of Newton", 2010. arXiv:1003.1015 [gr-qc].
- Landauer, R. Irreversibility and Heat Generation in the Computing Process. IBM Journal of Research and Development 1961, 5, 183–191. [CrossRef]
- Łukaszyk, S. A new concept of probability metric and its applications in approximation of scattered data sets. Computational Mechanics 2004, 33, 299–304. [CrossRef]
- Castro, P.S.; Kastner, T.; Panangaden, P.; Rowland, M. MICo: Improved representations via sampling-based state similarity for Markov decision processes. Advances in Neural Information Processing Systems 2021, 34, 30113–30126. [CrossRef]
Figure 1.
Numbers of all strings (red), balanced strings (green), distinct strings (cyan), and balanced distinct strings (blue) as a function of the string length N.
Figure 1.
Numbers of all strings (red), balanced strings (green), distinct strings (cyan), and balanced distinct strings (blue) as a function of the string length N.
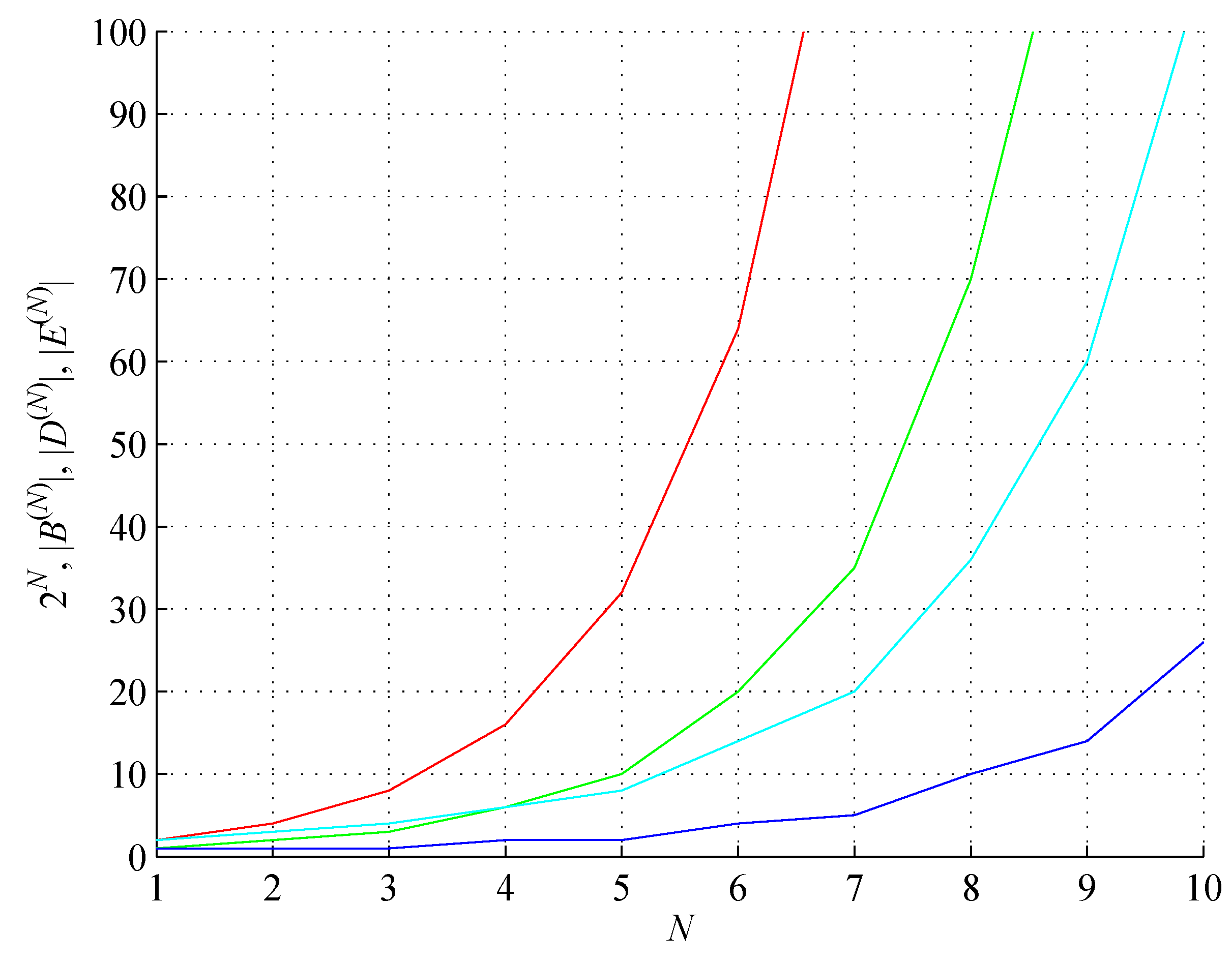
Figure 2.
Lower bound on the binary string assembly index 2 (red) and (red, dash-dot), conjectured upper bound on the binary string assembly index 3 (green), factual values of the string assembly index (blue) and the distinct string assembly index (cyan) and (green, dash-dot), for the string length .
Figure 2.
Lower bound on the binary string assembly index 2 (red) and (red, dash-dot), conjectured upper bound on the binary string assembly index 3 (green), factual values of the string assembly index (blue) and the distinct string assembly index (cyan) and (green, dash-dot), for the string length .
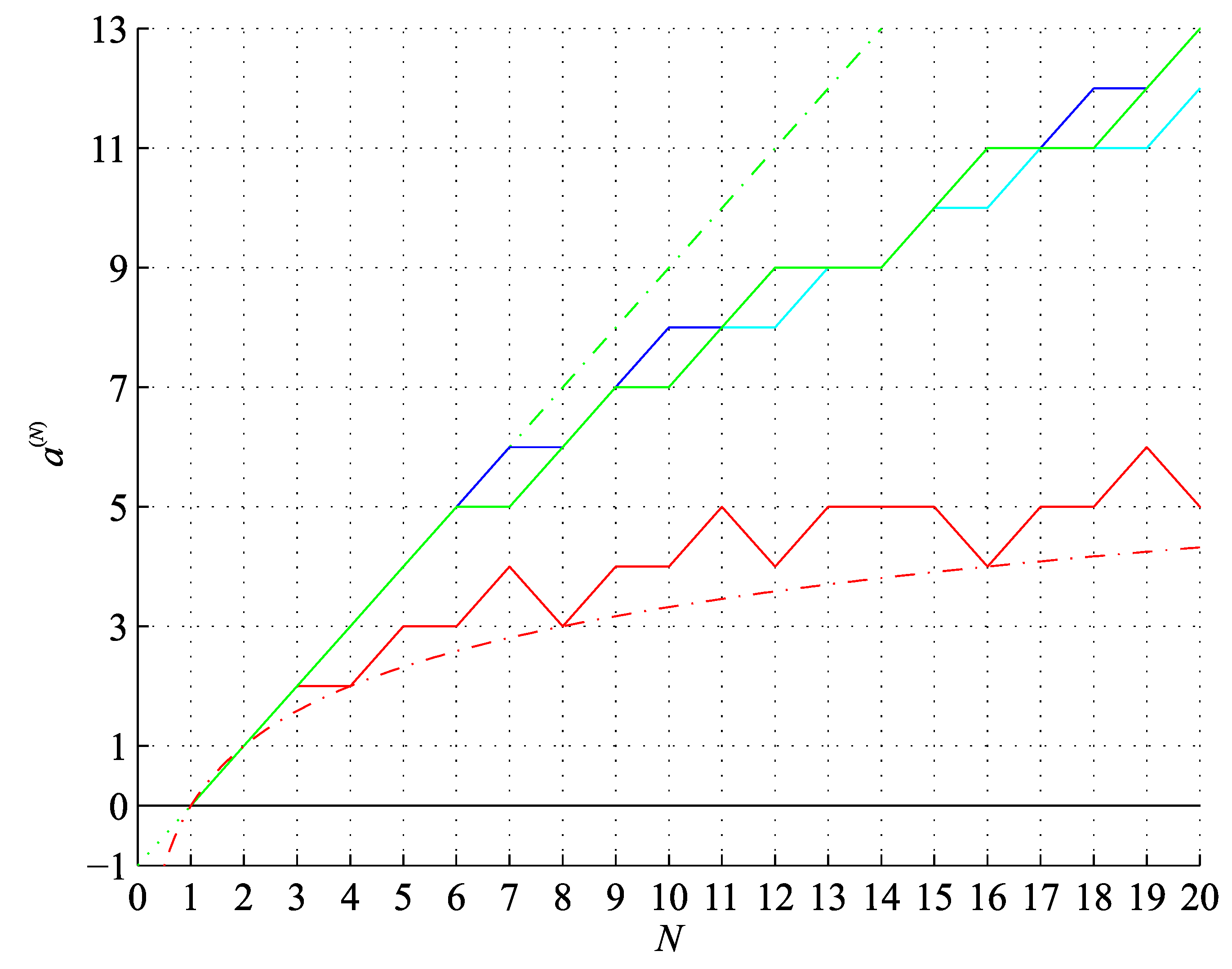
Figure 3.
Lower bound on the binary string assembly index (red) and (red, dash-dot), conjectured upper bound on the string assembly index (green) and (green, dash-dot), for the binary string length .
Figure 3.
Lower bound on the binary string assembly index (red) and (red, dash-dot), conjectured upper bound on the string assembly index (green) and (green, dash-dot), for the binary string length .
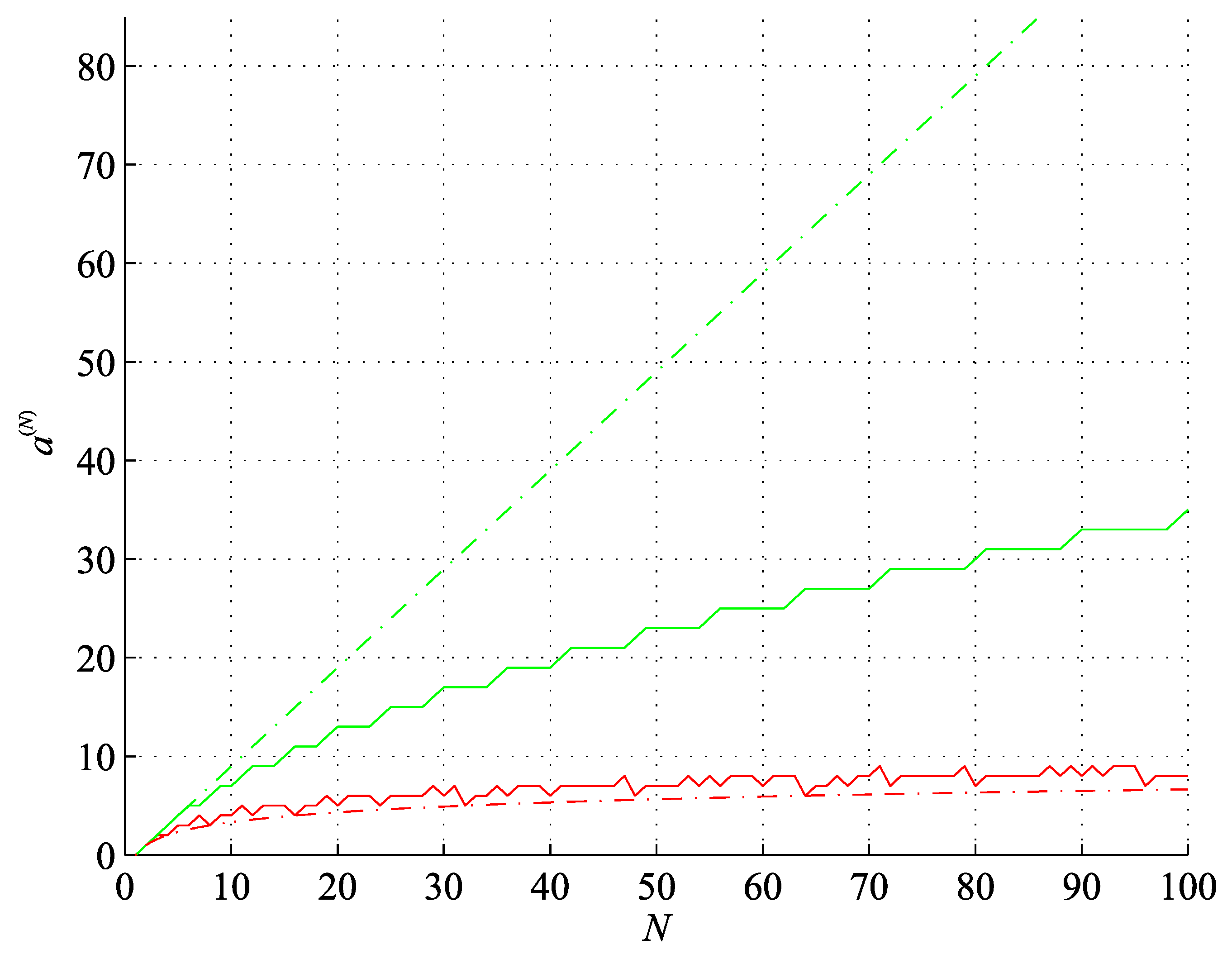
Figure 4.
An illustrative graph of complexity against information capacity: orange regions are impossible, as they are above or below the assembly bounds; yellow region contains structures optimally assembled (in equilibrium); green region contains dissipative structures; and red region is the region of human creativity (figure not to scale).
Figure 4.
An illustrative graph of complexity against information capacity: orange regions are impossible, as they are above or below the assembly bounds; yellow region contains structures optimally assembled (in equilibrium); green region contains dissipative structures; and red region is the region of human creativity (figure not to scale).
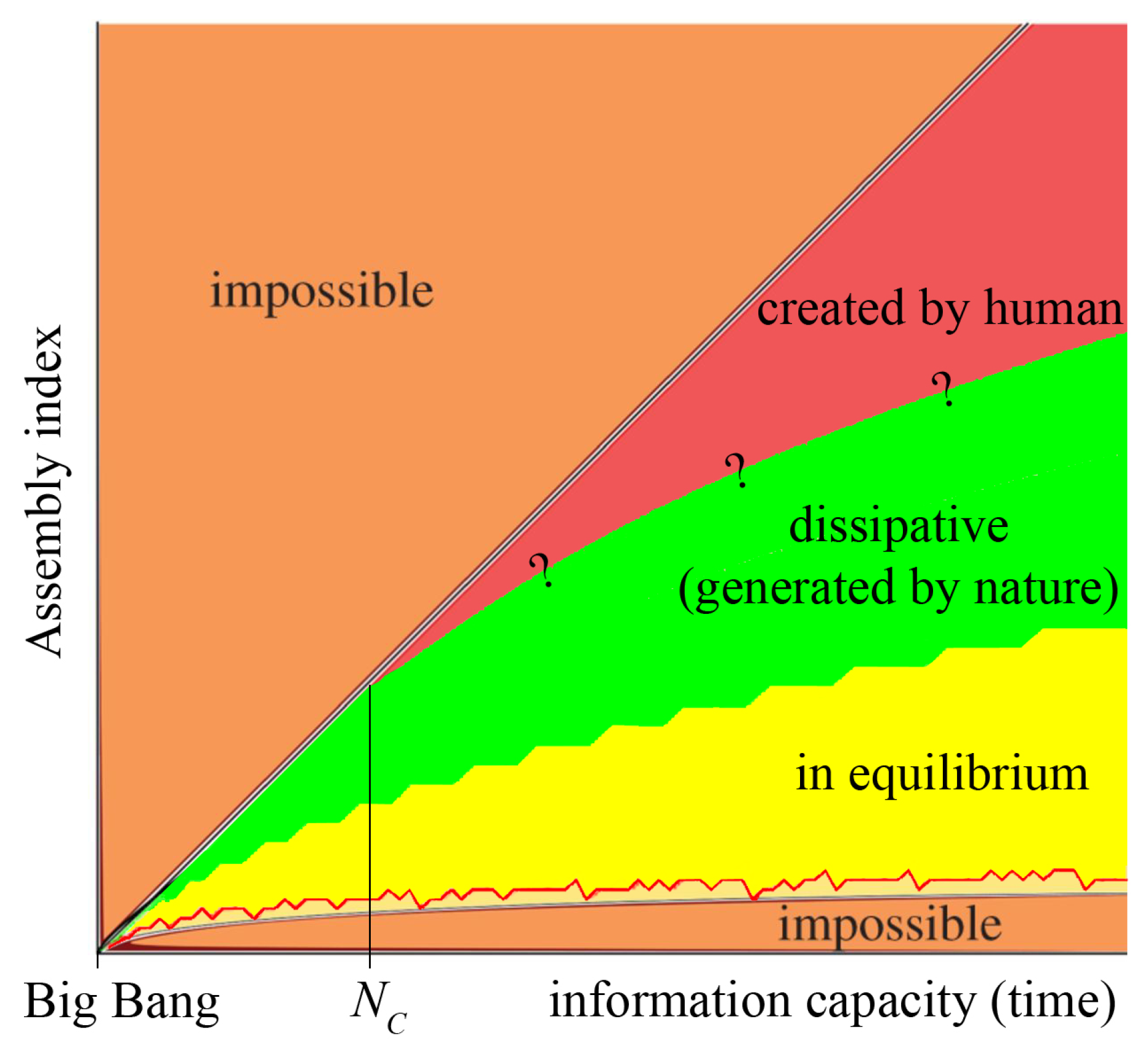
Figure 5.
A black body object as a generator of an entropy variation shell (VS) through the solid angle correspondence.
Figure 5.
A black body object as a generator of an entropy variation shell (VS) through the solid angle correspondence.
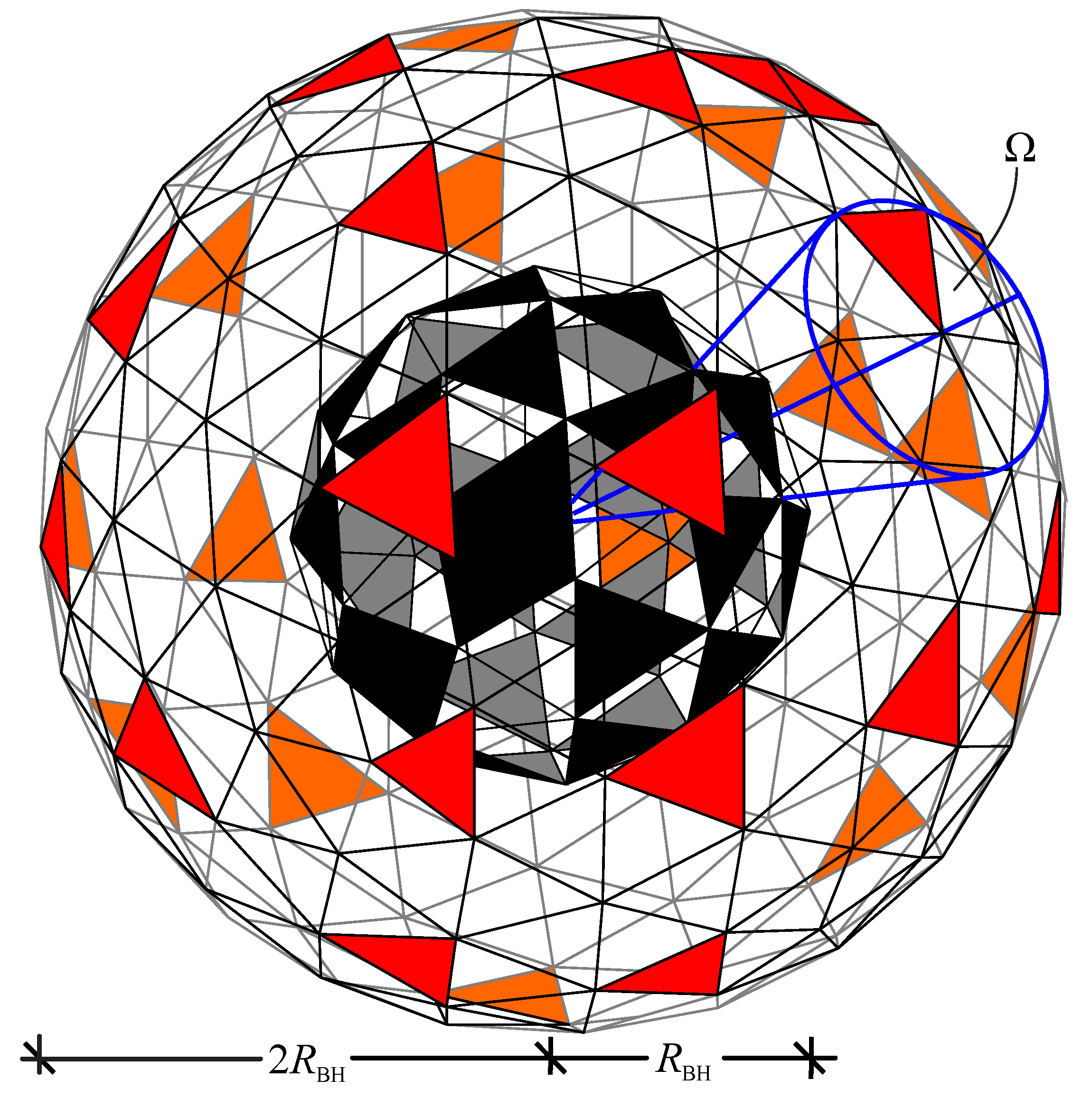
Figure 6.
Lower (red) and upper (green) bound on the number of APTs on a VS as a function of the information capacity of the generating BB [9].
Figure 6.
Lower (red) and upper (green) bound on the number of APTs on a VS as a function of the information capacity of the generating BB [9].
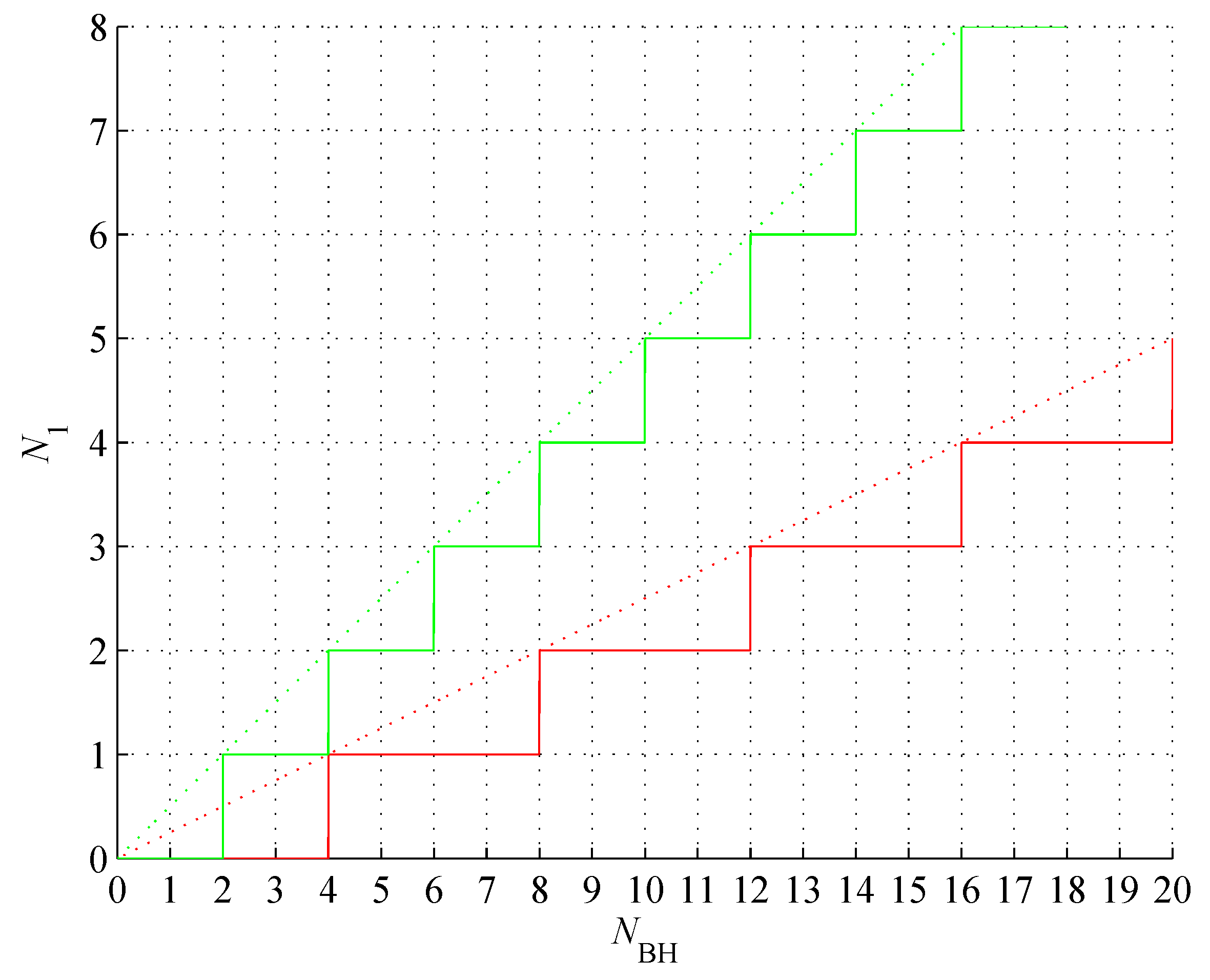
Figure 7.
Lower (red) and upper (green) bounds on and lower (blue) and upper (cyan) bounds on as a function of l defining VS. Characteristic velocities are , .
Figure 7.
Lower (red) and upper (green) bounds on and lower (blue) and upper (cyan) bounds on as a function of l defining VS. Characteristic velocities are , .
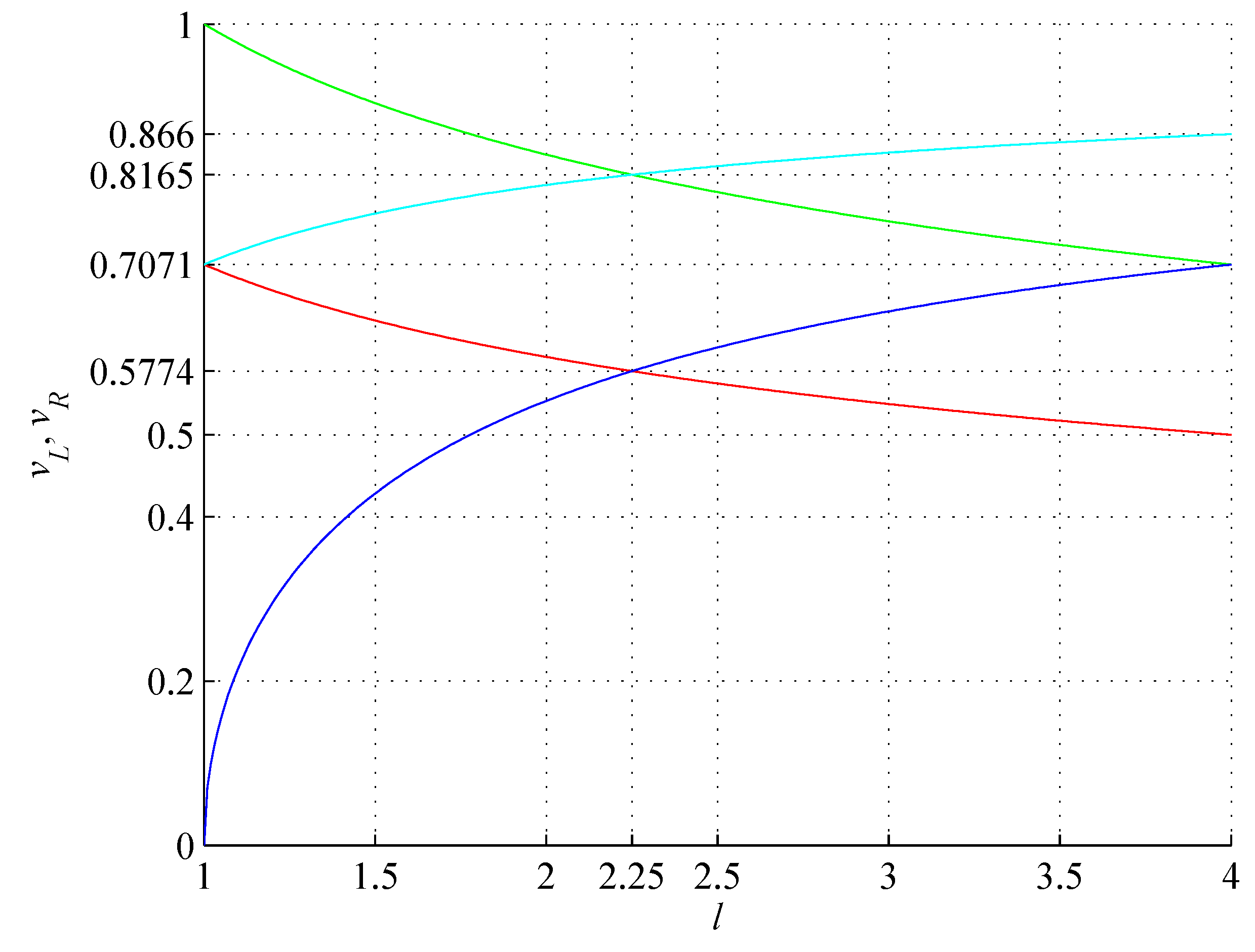
Figure 8.
Lower (red) and upper (green) bounds on the binary string assembly index of length and (blue), for .
Figure 8.
Lower (red) and upper (green) bounds on the binary string assembly index of length and (blue), for .
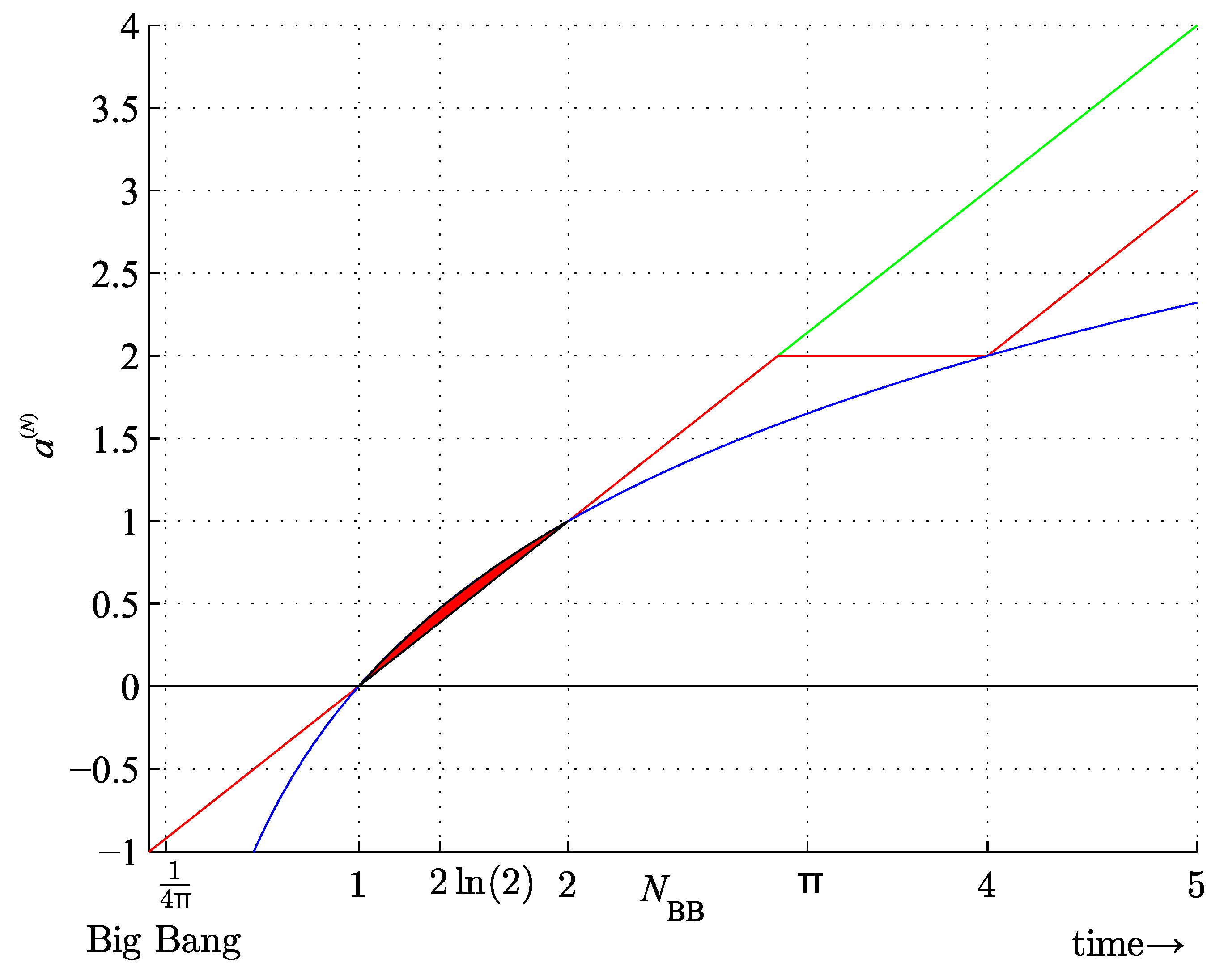
Figure 9.
Black body object energy (green); temperature (red), (red, dash-dot), (red, dash); and work (blue), (blue, dash-dot), (blue, dash),as a function of its information capacity in terms of Planck units, for .
Figure 9.
Black body object energy (green); temperature (red), (red, dash-dot), (red, dash); and work (blue), (blue, dash-dot), (blue, dash),as a function of its information capacity in terms of Planck units, for .
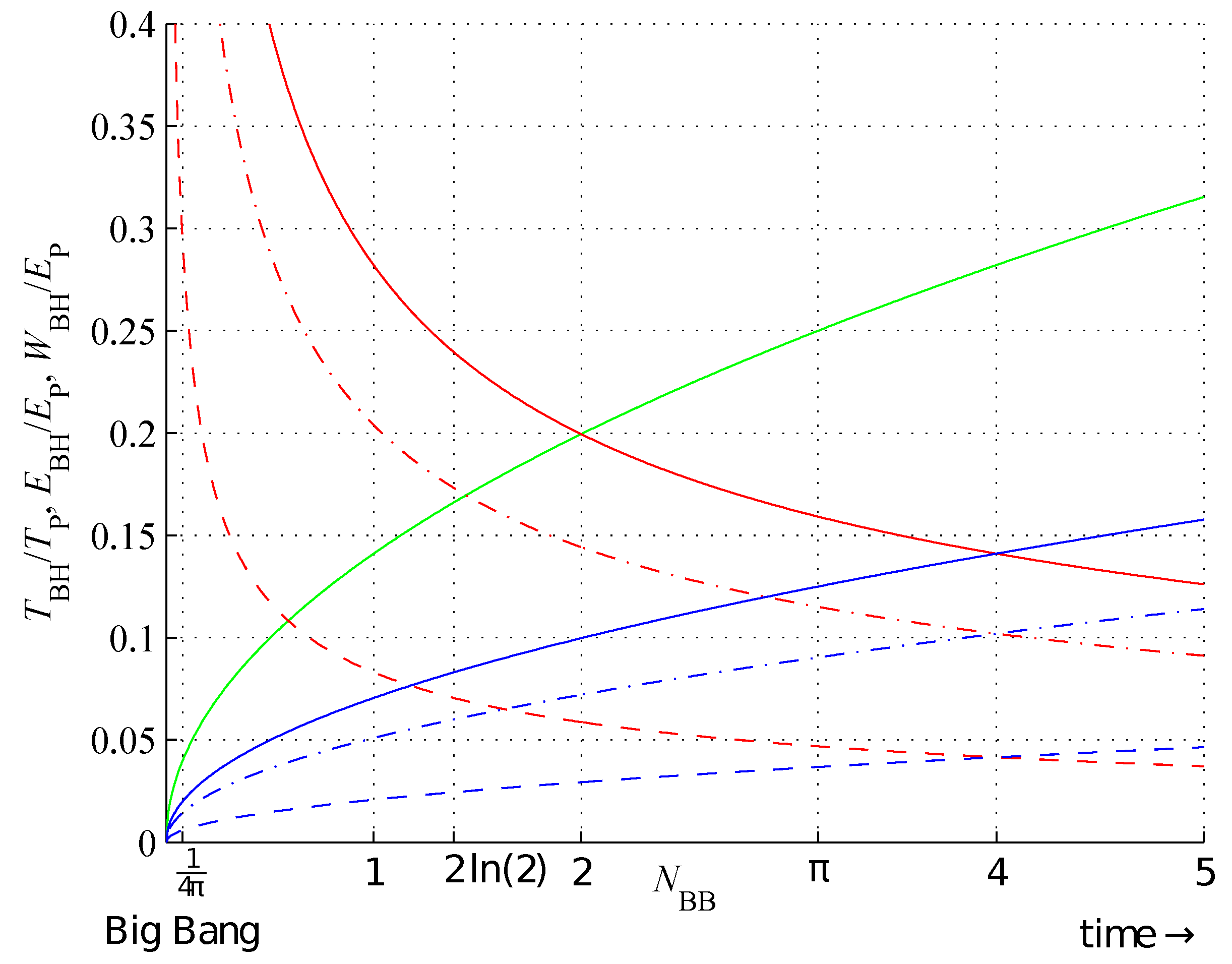
Table 3.
String length N, number of all strings , number of balanced strings , number of distinct strings , and number of balanced distinct strings .
Table 3.
String length N, number of all strings , number of balanced strings , number of distinct strings , and number of balanced distinct strings .
| N | |||||
| 1 | 2 | 1 | 2 | 1 | 1 |
| 2 | 4 | 2 | 3 | 1 | 2 |
| 3 | 8 | 3 | 4 | 1 | 3 |
| 4 | 16 | 6 | 6 | 2 | 3 |
| 5 | 32 | 10 | 8 | 2 | 5 |
| 6 | 64 | 20 | 14 | 4 | 5 |
| 7 | 128 | 35 | 20 | 5 | 7 |
| 8 | 256 | 70 | 36 | 10 | 7 |
| 9 | 512 | 126 | 60 | 14 | 9 |
| 10 | 1024 | 252 | 108 | 26 | |
| 11 | 2048 | 462 | 188 | 42 | 11 |
| 12 | 4096 | 924 | 352 | 80 | 11.55 |
| 13 | 8192 | 1716 | 632 | 132 | 13 |
| 14 | 16384 | 3432 | 1182 | 246 | |
| 15 | 32768 | 6435 | 2192 | 429 | 15 |
Table 4.
Distribution of assembly indices among balanced distinct strings for .
| N | ||||||||
| 4 | 2 | 1 | 1 | |||||
| 5 | 2 | 1 | 1 | |||||
| 6 | 4 | 1 | 2 | 1 | ||||
| 7 | 5 | 2 | 3 | |||||
| 8 | 10 | 1 | 1 | 6 | 2 | |||
| 9 | 14 | 1 | 4 | 7 | 2 | |||
| 10 | 26 | 1 | 6 | 9 | 10 | |||
| 11 | 42 | 2 | 14 | 20 | 6 |
Table 5.
The lower bound on the binary string assembly index (OEIS A003313).
| N | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 0 | 1 | 2 | 2 | 3 | 3 | 4 | 3 | 4 | 4 | 5 | 4 | 5 | 5 | 5 | 4 | 5 | 5 | 6 | 5 | 6 |
Table 6.
Exemplary balanced strings having a maximum assembly index. Conjectured () form of the maximum assembly index and its factual values for distinct () and non-distinct () strings (red if below the conjectured value, green - if above).
Table 6.
Exemplary balanced strings having a maximum assembly index. Conjectured () form of the maximum assembly index and its factual values for distinct () and non-distinct () strings (red if below the conjectured value, green - if above).
| N | |||||||||||||||||||||||
| 1 | 0 | 0 | 0 | 0 | |||||||||||||||||||
| 2 | 1 | 0 | 1 | 1 | 1 | ||||||||||||||||||
| 3 | 0 | 0 | 1 | 2 | 2 | 2 | |||||||||||||||||
| 4 | 0 | 0 | 1 | 1 | 3 | 3 | 3 | ||||||||||||||||
| 5 | 0 | 0 | 0 | 1 | 1 | 4 | 4 | 4 | |||||||||||||||
| 6 | 0 | 0 | 0 | 1 | 1 | 1 | 5 | 5 | 5 | ||||||||||||||
| 7 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 5 | 5 | 6 | |||||||||||||
| 8 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 6 | 6 | 6 | ||||||||||||
| 9 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 7 | 7 | 7 | |||||||||||
| 10 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 7 | 7 | 8 | ||||||||||
| 11 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 8 | 8 | 8 | |||||||||
| 12 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 | 0 | 9 | 8 | 8 | ||||||||
| 13 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 | 9 | 9 | |||||||
| 14 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 9 | 9 | 9 | ||||||
| 15 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 10 | 10 | 10 | |||||
| 16 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 11 | 10 | 10 | ||||
| 17 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 11 | 11 | 11 | |||
| 18 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 11 | 11 | 12 | ||
| 19 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 12 | 11 | 12 | |
| 20 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 13 | 12 | 13 |
Table 7.
3-bit elegant programs assembling strings with .
| Q | N | |||
| 5 | ||||
| 6 | ||||
| 6 | ||||
| 8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



