Submitted:
09 June 2026
Posted:
10 June 2026
You are already at the latest version
Abstract
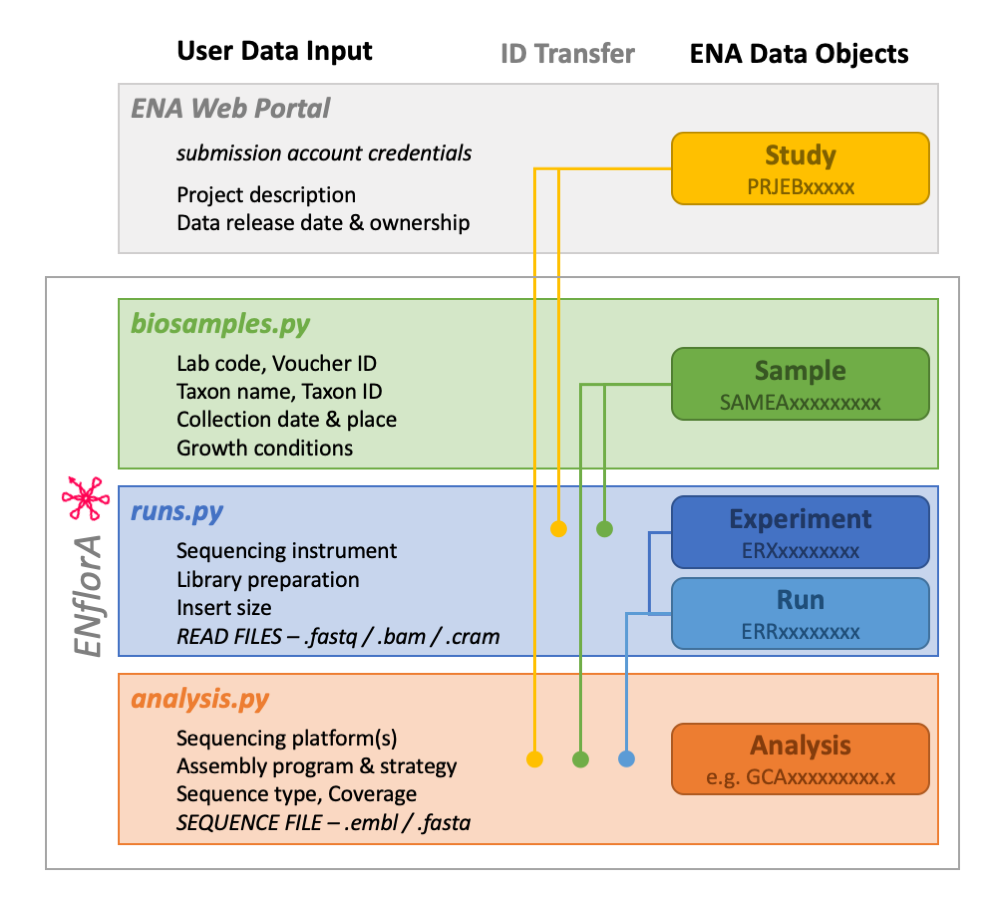
Background With the advancement of sequencing technologies and increasing quality of assembly and annotation tools, the amount of biological sequence data produced by research grows rapidly. To keep this data accessible for potential re-analysis, it is typically stored in public online databases, such as the European Nucleotide Archive (ENA). However, the increase in data entails an increase in time needed for metadata curation and upload. We propose a tool to simplify and automatize the upload of experimental and metadata to public repositories. Results We developed ENflorA, a set of scripts by which sample, sequence read and (annotated) assembly data can be uploaded to ENA in a simple and standardized manner. Our software allows easy metadata entry via spreadsheets, is suitable for batch upload of data from different sources, and can be fully integrated in bioinformatic workflows. It is platform independent and can be run natively on High Performance Computers, integrates an lftp upload option for big files and a test upload option. Conclusions By easing the ENA submission process, ENflorA contributes to making high-throughput sequencing data findable, accessible, interoperable and reusable.
Keywords:
ENA
; FAIR data
; file transfer protocol
; INSDC
; high-throughput sequencing
; plastome
; submission
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



