
Submitted:
22 January 2026
Posted:
23 January 2026
You are already at the latest version
Abstract
The present overview aims to illustrate the application of differential topology methods to some important problems in matrix analysis. In particular, it focuses on the use of smooth manifolds and smooth mappings to study fundamental issues such as the determination of matrix rank and the computation of the Jordan form in presence of uncertainties. Various aspects of numerical matrix analysis are discussed, including the genericity of matrix problems, characterization of singular sets in the parameter space, the distance to ill-posed problems and its relation to problem conditioning. The paper also addresses the conditioning of matrix problems in both deterministic and probabilistic settings and the regularization of ill--posed matrix problems. Several examples are provided to illustrate these concepts and their practical relevance.
Keywords:
matrix computations
; numerical analysis
; smooth manifolds
; smooth maps
; singularities
; conditioning
; probabilistic bounds
; regularization
MSC: 53Z50; 53-01; 57R45; 58K05; 65F15; 65F22; 22E70
1. Introduction
Contemporary mathematical models used across the natural sciences are typically not single models corresponding to fixed parameter values; rather, they represent families of models that vary as parameters change within certain bounds. Such models arise in physics, chemistry, biology, control theory, statistics, aerodynamics, hydrodynamics, the social sciences, and several other disciplines. Studying these models using traditional methods is challenging, because the properties of a family of models cannot be described as continuous functions of the parameters if one considers only individual models corresponding to fixed parameter values. This difficulty necessitates the use of families of models whose descriptions and properties depend smoothly on the parameters. Consequently, in recent years, specialists from various scientific fields have shown growing interest in methods of differential topology, whose objects of study are smooth manifolds and smooth mappings. Representing mathematical models in the natural sciences as smooth manifolds, with dimension determined by the number of independent parameters, allows the essential properties of families of models to be expressed as smooth functions of these parameters, thereby greatly facilitating the solution of the corresponding mathematical problems. In this connection, it is appropriate to cite the German mathematician and philosopher Hermann Weyl, who wrote [1], p. 90: Topology has the peculiarity that questions belonging to its domain may under certain circumstances be decidable, even though the continua to which they are addressed may not be given exactly but only vaguely, as is always the case in reality.
The questions addressed by differential topology are global in nature, as they concern the manifold as a whole. Differential topology combines the study of qualitative properties of sets in spaces of arbitrary dimension, which is the domain of topology, with the methods of classical analysis, which enable quantitative analysis under small parametric variations. In this regard, it is appropriate to quote the words of the American mathematician Marston Morse [2], Foreword:
Any problem which is nonlinear in character, which involves more than one coordinate system or variable, or whose structure is initially defined in the large, is likely to require considerations of topology and group theory in order to arrive at its meaning and its solution. In the solution of such problems classical analysis will frequently appear as an instrument in the small, integrated over the whole problem with the aid of group theory or topology.
Differential topology is a broad mathematical discipline whose primary goal is the study and characterization of the global properties of manifolds. A central theme in this field is the transition from local to global properties: many concepts in differential topology can be understood by examining how local behavior extends to the global structure. Another fundamental notion is manifold transversality, which describes the manner in which two manifolds intersect and provides a framework for understanding generic intersections and their stability.
The present overview aims to illustrate the application of methods from differential topology to the solution of several important mathematical problems arising across the natural and applied sciences. In particular, it focuses on the use of smooth manifolds and smooth mappings in matrix analysis, a field with wide–ranging applications in physics, engineering, biology, and beyond. The motivation for this overview arises from the absence of a single comprehensive reference on this subject, as the relevant material is currently scattered across numerous books and research articles.
It should be noted that some mathematical rigor has been deliberately relaxed to make the exposition accessible to specialists from different disciplines.
The overview is organized into six sections.
In Section 2, we present the basic concepts from differential topology necessary for the subsequent discussion. We briefly consider smooth manifolds and smooth maps between them, including the differential of a map and singular points of varieties. Some fundamental facts about Lie groups and matrix groups are also included.
Section 3 is devoted to the geometry of matrix spaces. We examine important characteristics of problems in this space, such as genericity and well–posedness. Condition numbers of matrix problems are discussed in detail to demonstrate the connection between the distance to ill-posed problems and problem conditioning. We also present results on the probabilistic distribution of matrix condition numbers obtained using methods from differential topology.
The important problem of matrix rank is considered in Section 4. We study the orbits of matrices with different ranks and show how small matrix perturbations can move a matrix to an orbit with lower codimension. The problem of determining the numerical rank of a matrix in the presence of uncertainties is also discussed.
Another fundamental problem in matrix analysis—the determination of the Jordan form of a matrix—is addressed in Section 5. We consider orbits and bundles of matrices with fixed Jordan form and investigate their generic properties. The reduction to the “true” Jordan form is described as an ill–posed problem, whose solution can be obtained via regularization methods. This leads to the concept of the numerical Jordan form, which is defined using the tools of differential topology.
In Section 6, we study matrices depending on parameters. It is shown that smooth properties of such matrices can be determined using versal deformations. Several examples of bifurcation diagrams are provided to illustrate how the Jordan form of a matrix depends on the varying parameters.
All computations in this paper were performed using MATLAB®Version 9.9 (R2020b) [3], employing IEEE double precision arithmetic with a unit roundoff .
2. A Glimpse into Differential Topology
The presentation in this section follows the classic textbooks by Guillemin and Pollack [4], Lee [5,6], and Arnold [7,8], as well as the books by Tu [9] and by Burns and Gidea [10], which are written in a language accessible to non–mathematicians. Excellent introductions to manifold theory for non–specialists include the books by Milnor [11] and Wallace [12]. One of the most authoritative sources in this field is Hirsch’s book [13]; however, reading it requires a very strong mathematical background. Applications of manifolds in mechanics are discussed in depth in [14].
2.1. Smooth Manifolds
A manifold is a multidimensional generalization of the concepts of a line and a surface, without singular points. When studying manifolds, the notion of dimension plays a central role. Generally speaking, the dimension is the number of independent quantities (or parameters) required to specify a point on the manifold. Manifolds of dimension one are lines and curves, while manifolds of dimension two are surfaces. Typical examples of two–dimensional manifolds include planes and spheres, as well as other familiar surfaces such as cylinders, ellipsoids, paraboloids, and tori. A key feature of these examples is that an n–dimensional manifold “looks” locally like : every point of a manifold has a neighborhood that is topologically equivalent to an open subset of . Thus, in one-dimensional manifolds each point has a neighborhood resembling a line segment; in two–dimensional manifolds, each point has a neighborhood resembling an open disk; and in three-dimensional manifolds, a neighborhood resembling an open ball.
In this sense, manifolds are sets in which the neighborhood of every point has the same local topological structure as the n–dimensional Euclidean space.
We note that the concept of dimension, as used in the characterization of manifolds, belongs to the most fundamental ideas in mathematics. An excellent overview of the significance of this concept in geometry and algebra is given by Manin in [15].
In Figure 1 we illustrate the decomposition of three-dimensional Euclidean space into layers (or strata) of manifolds defined by the equation for different values of C. An essential feature of this decomposition is that the individual layers do not intersect. Note that the innermost layer (the two opposite cones with a common vertex at the origin) is not smooth; rather, it is an algebraic manifold, since the vertex is a singular point (see Section 2.7).
Definition 1.
Two subsets of Euclidean spaces are topologically equivalent, or homeomorphic (from the Greek word meaning “similar form”), if there exists a one–to–one correspondence , such that both φ and its inverse are continuous. Such a correspondence is called a homeomorphism.
Based on these considerations, a provisional definition of a topological manifold can be given. We can consider n–dimensional manifold as a subset of some Euclidean space that is locally Euclidean of dimension n, i.e., every point of has a neighborhood in that is homeomorphic to a ball in .
For example, every one–dimensional manifold is homeomorphic to either a line or a circle.
Definition 2.
A topological space is called an n–dimensional topological manifold, if it is locally homeomorphic to .
Every topological manifold is a Hausdorff space: for every pair of distinct points , there exist disjoint open subsets such that and .
In most cases, the analysis of manifolds cannot be performed directly on the manifold itself. Instead, it is necessary to describe the manifold unambiguously in an appropriate coordinate space and to apply analytical methods to this representation. For this purpose, coordinate charts and a manifold atlas are employed.
An open chart of is defined as a pair , where U is an open subset of the space , and a homeomorphism from U onto an open subset of the coordinate space . To each point there corresponds, in a one-to-one manner, an n–tuple of numbers
which are called its local coordinates (Figure 2).
On the basis of the concept of an open chart, a rigorous definition of a topological manifold can be introduced.
Let A be a finite or countable set. A topological space is called an n–dimensional topological manifold if there exists a collection of open charts , such that:
- For each of the set A, is an open subset of .
- .
Such a collection of charts is called an atlas of the topological manifold (Figure 3). The atlas of is denoted by .
In the general case, each chart is obtained using a different mapping associated with the subset . In this way, one can study complex manifolds composed of several subsets with different properties. This constitutes an important advantage of manifolds over simpler topological objects which consist of a single set with fixed properties and are described by only one chart.
Example 1.
- (a) The coordinate space is an n–dimensional topological manifold: its atlas consists of a single open chart , where is the identity map.
-
(b) (Atlas of the two–dimensional sphere).Let denote the north pole of the k–dimensional sphere, and let denote its south pole.The stereographic projection from onto is the mapping that sends a point p to the point where the line through N and p intersects the subspace of defined by (the projection plane). See Figure 4 for the case . It is a smooth, bijective map from the entire sphere, except for the projection point, onto the whole plane. Stereographic projection provides a way to represent the sphere by a plane, but it can also be used for other curved surfaces, such as deformed spheres and hyperboloids.The map is given by the formulaAnalogously, the projection from onto is defined byThese projections are homeomorphisms from and onto .Let us define on the sphere an atlas consisting of two charts, using the stereographic projectionsIn this case, the open sets and , where and , are palnes in that are tangent to the sphere at the points S and N, respectively.The atlas of the sphere is shown in Figure 5. The family of circles lying on the sphere and tangent at the point N is mapped in the lower chart to a family of parallel straight lines, while in the upper chart it is mapped to a family of tangent circles.
The definition of a topological space does not allow one to define differentiable functions or other concepts from mathematical analysis on a manifold. However, many important applications of manifolds involve mathematical analysis. For example, the application of manifold theory in geometry includes properties such as volume and curvature. Typically, volumes are computed by integration, while curvatures are determined through differentiation, so extending these concepts to manifolds requires a way to make integration and differentiation meaningful on a manifold.
Similarly, applications in classical mechanics involve solving ordinary differential equations on manifolds. To give these concepts meaning, it is necessary to define an additional structure on the manifold. In order to make sense of derivatives of real-valued functions, curves, or manifolds, it is necessary to introduce a new type of manifold called a smooth manifold. This is a topological manifold equipped with an additional structure compatible with its topology, which allows one to determine which functions to or from the manifold are smooth.
Let be an n–dimensional topological manifold, and let be an atlas of the manifold . Consider any two charts in the atlas , denoted by and .
Definition 3.
The coordinate transformation
which maps the intersection in to in , is called smooth if the transition functions
have continuous partial derivatives of all orders (that is, they are infinitely differentiable, belonging to the class in the open set ), and the determinant
of the Jacobian matrix of the transformation is nonzero.
This also implies that the inverse coordinate transformation of is smooth, since the corresponding transition functions
have continuous partial derivatives of all orders in the open set .
If the coordinate transformation is smooth, we say that the corresponding charts are smoothly compatible.
An atlas is called smooth if:
- Any two charts in the atlas are smoothly compatible.
- Every point lies in the domain of at least one chart.
A smooth atlas on is called maximal if it is not properly contained in any larger smooth atlas. This means that any chart that is smoothly compatible with every chart in is already included in . A maximal atlas is also called a complete atlas.
Definition 4.
An n–dimensional topological manifold is said to have a smooth structure if there exists an atlas on the manifold satisfying the following properties:
- For any two charts in , the corresponding coordinate transformation is smooth.
- The atlas is maximal.
Definition 5.
n–dimensional topological manifold that has a smooth structure is called an n–dimensional smooth manifold.
Example 2.
-
(a) (Normed vector spaces). Let V be a finite-dimensional real vector space. Any norm on V defines a topology that is independent of the choice of norm. With this topology, V is an n–dimensional topological manifold with a natural smooth structure defined as follows. Any (ordered) basis of V defines a basic isomorphism byThis map is a homeomorphism, so is a chart. The collection of all such charts defines a smooth structure, called the standard smooth structure on V.
-
(b) (Matrix spaces). Let denote the set of matrices with real entries. Since it is a real vector space of dimension under matrix addition and scalar multiplication, is a smooth –dimensional manifold. (Since the spaces and are isometric, they can be identified by “stacking” all matrix entries into a single row or column.) A chart on this manifold is given bywhere denotes the vector obtained from the matrix elements as described above. The dimension of this manifold is . The space can be equipped with a Euclidean structure via the inner productThe norm induced by this inner product is the Frobenius norm, defined byi.e., is the sum of the squares of all entries of M.Similarly, the space of complex matrices is a vector space of dimension over and therefore is a smooth manifold of dimension . In the special case (square matrices), the notations and are abbreviated as and , respectively.
- (c) (General linear group). The general linear group is the set of invertible matrices with real entries. It is an –dimensional manifold because it is an open subset of the –dimensional vector space , namely the set where the (continuous) determinant function is nonzero.
- (d) (Spaces of linear maps). Let V and W be finite–dimensional real vector spaces, and let denote the set of linear maps from V to W. Since is itself a finite–dimensional vector space (whose dimension is the product of the dimensions of V and W), it naturally carries the structure of a smooth manifold, just as in item (b).
A submanifold of a manifold is a subset that itself has the structure of a manifold. The sphere , defined by the equation , is an example of a subset of the coordinate space that inherits the natural manifold topology from .
In a number of important applications of manifolds, one encounters spaces that would be smooth manifolds except that they have a “boundary” of some kind. Elementary examples of such spaces are closed intervals in , closed balls in , and closed hemispheres in . The study of manifolds with boundary requires a generalization of the definition of a manifold; see, for example, [6], Ch. 1.
An overview of the historical development of the concept of a manifold can be found in [16].
2.2. Smooth Maps
Let be an open set. Any mapping can be represented as an ordered collection of m functions:
The mapping is called smooth (), if each function , has continuous partial derivatives of all orders. Mappings with only continuous functions are called mappings. In the case where all functions are analytic (a function is called analytic if its Taylor series converges to it in a neighborhood of each point), the mapping f is called analytic (). We have the inclusion .
Let and be smooth manifolds of dimensions n and k, respectively, and let be an arbitrary map. The map f is called smooth at point p of the manifold if there exist a local chart containing p and a local chart containing such that and the composition
is a smooth map from to (Figure 6).
Every smooth map is continuous.
The set of smooth maps of the form is denoted by .
Let and be smooth manifolds.
A smooth map is called a diffeomorphism if it is bijective and its inverse is also smooth.
The manifold is said to be diffeomorphic to the manifold if there exists a diffeomorphism . This is denoted by .
Example 3.
In Figure 8, an open disk and an open ellipse are shown, which are diffeomorphic. The disk is mapped to the ellipse by the smooth map
and the ellipse is mapped back to the disk by the inverse map
which is also smooth.
Similar to the case when two topological spaces are considered “the same” if they are homeomorphic, two smooth manifolds are regarded as indistinguishable if they are diffeomorphic. A central question in the theory of smooth manifolds is the study of properties of smooth manifolds that are preserved under diffeomorphisms.
2.3. Tangent Space
In the study of the metric properties of regions in Euclidean space, an important role is played by properties that are defined in a theoretically infinitesimal neighborhood of a fixed point, by neglecting quantities of higher order relative to the distance to that point. Similarly, in the study of smooth manifolds it is appropriate to neglect infinitesimal quantities of higher order in order to simplify the analysis of a given problem. One way to achieve this is to introduce special concepts analogous to tangent vectors to curves and tangent planes to surfaces, as used in mathematical analysis.
Let be a vector in the coordinate space based at a point . Then, for every smooth function f defined in a neighborhood of the point p, the directional derivative determined by the vector is defined as follows:
where is a numerical parameter (in analysis, one usually considers a vector of unit length). In a coordinate system, we have the formula:
where
is the gradient of the function f, and , are the coordinates of the point p and the vector , respectively. Furthermore, the quantity
will be called the derivative of the smooth function f in the direction of the vector at the point p and will be denoted by . In this notation, it is understood that the partial derivatives are evaluated at p, since is a vector at p. Note that is a number, not a function. We write
for the map that sends the function f to the number .
In this way, given a vector at the point p, an operation is defined on the set of smooth functions in a neighborhood of p:
performed according to the rule
Definition 6.
A tangent vector at point p of the manifold is a rule
which assigns to each function f in the set a number satisfying the following properties:
- ,
- ,
- ,
where .
The association of the directional derivative with the tangent vector allows tangent vectors to be characterized as certain operators acting on functions.
The set of vectors that are tangent to the manifold at a point p is denoted by . We now define on this set the operations of addition of tangent vectors and scalar multiplication of a tangent vector.
Let and . We define
It is not difficult to verify that both the sum of the tangent vectors and , and the product of a tangent vector with a scalar , are also tangent vectors. In this way, the set becomes a vector space. It is called the tangent space to the smooth manifold at the point p.
Let be a local chart (coordinate system) and let . For every function one can construct a smooth function , defined on the open subset of (see Figure 9).
By computing the partial derivatives of with respect to the variables , we obtain
In this way, for each function , one can associate n numbers
We see that the choice of a system of local coordinates determines n vectors in the tangent space acting according to the rule
These vectors are conventionally denoted by
The quantities represent linear partial differential operators, which act according to the rule
Theorem 1.
In this way, we obtain the important result that the dimension of the tangent space is equal to the dimension of the manifold ,
The orthogonal complement of the tangent space is called the normal space and is denoted by .
Instead of working with the dimension of the manifold , it is often more convenient to use the codimension of , denoted by , which is equal to the dimension of the normal space . Since
where is the ambient manifold, we have
2.4. Differential of a Map
To analyze the action of smooth maps on tangent vectors, it is necessary to consider the differentiation of such maps. In the case of a smooth manifold between Euclidean spaces, the total derivative of the map at a point (represented by its Jacobian matrix) is a linear map that provides the “best linear approximation” of the map near the given point. In the case of manifolds, a linear map is defined between the tangent spaces.
Definition 7.
Let and be smooth manifolds, and let be a smooth map. The differential of f at a point is the linear map from the tangent space of to the tangent space of ,
defined as follows (see Figure 10). Let . Consider a curve with whose tangent vector is v. Then is the tangent vector to the curve .
Proposition 1.
(Propertis of the differential). Let , , and be smooth manifolds. Let and be smooth maps, and let .
- (a) is a linear map.
- (b) .
- (c) , where is the identity map on .
- (d) If f is a diffeomorphism, then is an isomorphism, and .
Using to denote coordinates in the domain of f and to denote coordinates in the codomain, the action of on a typical basis vector is
Therefore, the matrix of in terms of the coordinate bases is
This matrix is precisely the Jacobian matrix of f at p, which is the matrix representation of the total derivative .
Example 4.
We consider the maps and , defined by
where is the open 3–dimensional ball of radius R. These maps are smooth, and it can be shown that they are inverses of each other for . Therefore, both maps are diffeomorphisms.
Let be a point on the sphere that does not coincide with the north pole. To obtain the tangent space , we need to compute the differential . For a local parametrization of and in , we use the stereographic projections (see Example 1)
where
The matrices of partial derivatives are
The tangent space is obtained as the image of under the differential .
Figure 11 shows the diffeomorphic image of a sphere with radius . The tangent spaces and are computed for the points and .
The matrix of the differential is obtained from
2.5. Tangent and Normal Bundle
Let be a smooth manifold. Let us define the disjoint union of all tangent spaces of ,
The set is called tangent bundle of the manifold . The term bundle indicates that consists of “layers”– the tangent spaces at the individual points of the manifold. The tangent bundle of an m–dimensional manifold in is itself a manifold whose dimension is equal to .
In the trivial case, when , for each the tangent space can be identified with . Therefore, in this case we have , i.e., the tangent bundle is diffeomorphic to the Cartesian product .
The only tangent bundles that can be easily visualized are those of the real line and of the circle. The tangent bundle of two–dimensional manifolds is four–dimensional and therefore difficult to visualize.
The tangent bundle of the real line coincides with . The tangent bundle of the circle is obtained by considering all tangent spaces (Figure 12, top) and combining them disjointly into a smooth manifold (Figure 12, bottom).
The map , which assigns to each tangent vector v the point , at which the vector is tangent to (), is called the the natural projection. The preimage of a point under the natural projection, , is the tangent space . This space is called the fiber of the bundle over the point p.
Let be a smooth manifold. Let us define the disjoint union of all normal spaces of ,
The set is called normal bundle. The normal bundle of a circle is shown in Figure 13.
Assume that is an m–dimensional submanifold. The normal bundle consists of all vectors that are normal to :
In this case, can be viewed as an n–dimensional submanifold of the Cartesian product .
Let be an m–dimensional submanifold without boundary. Then is a smooth manifold of dimension n.
Normal bundles can be considered more generally when we have a submanifold , in order to understand the geometry of within in .
Definition 8.
(Normal bundle of a submanifold). Let be a manifold without boundary, and let be a submanifold of . The normal bundle of in is defined as the set
The normal bundle is a smooth manifold of dimension equal to .
2.6. Tubular Neighborhoods
In this section we consider an important application of normal bundles, which is characterized by the fact that every smooth manifold without boundary possesses a special type of neighborhood.
Generally speaking, a tubular neighborhood U of a smooth submanifold is an open set around the submanifold whose structure resembles that of the normal bundle. This definition can be made more concrete by the following example. Let us consider a smooth plane curve without self–intersections. At each point of the curve we draw a straight line perpendicular to the curve. Except in the case where the manifold is a straight line, these lines will intersect in a complicated way (Figure 14). However, if we consider a narrow strip around the curve, the portions of the normal lines contained in this strip will not intersect and will cover the entire strip without gaps.
The tubular neighborhood of a space curve in is shown in Figure 15.
Let be an m–dimensional submanifold. Viewing the normal bundle as a submanifold of , we define the smooth map
It maps each normal space affinely through p and orthogonally to . The tubular neighborhood of is the neighborhood U of in which is the diffeomorphic image, under this map, of an open subset of the form
for some positive continuous function (Figure 16). We have the following definition:
Definition 9.
(Tubular neighborhood). Let be a smooth manifold without boundary. A tubular neighborhood of is an open subset U of containing such that E maps an open subspace diffeomorphically onto U, where V is defined by a smooth function .
The key property of smooth manifolds embedded in a Euclidean space is that they always possess a tubular neighborhood.
Theorem 2.
Every embedded submanifold of has a tubular neighborhood.
2.7. Singular and Regular Points
Definition 10.
Let f be a smooth map from an m–dimensional manifold to an n–dimensional manifold .
- (a) A point is called critical or singular point of f if the derivative is not surjective; that is, if the rank of the Jacobian matrix is smaller than the dimension n of . The image of a critical point is called a critical value of f.
- (b) A point is called a regular point of f if it is not critical. A point is called a regular value of f if its inverse image contains no critical points.
Note that if the dimension of is smaller than the dimension of , then all points of are critical points of f. On the other hand, if is not the whole of , then all points of are regular values.
Example 5.
- (a) Let be a torus embedded as a submanifold in three-dimensional Euclidean space. From Figure 17 it can be seen that there exist exactly four horizontal planes (that is, planes of the form ), denoted , which are tangent planes to at the points , respectively. This corresponds to the fact that the function z restricted to has critical points at . These critical points correspond to the critical values .
-
(b) Let be the mappingThe derivative at point is the linear mapping given, in the standard basis, by the matrix . Thus, is surjective unless , so every nonzero real number is a regular value of f. In particular, we obtain the sphere as an n–dimensional manifold.
- (c) We consider the case in which the full–rank condition for the Jacobian matrix is not satisfied. Let the manifold be defined by the equation (see Figure 18). On the set , a structure of a two–dimensional submanifold can be defined. At the point 0, all minors of the Jacobian matrix vanish and its rank is not maximal. Therefore, the set is an algebraic variety [34], and the point 0 is a singular point of this variety.
The study of abrupt changes that arise in families of objects depending smoothly on parameters is the subject of singularity theory [19,20,21,22]. This theory deals with the classification of types of changes and the characterization of the sets of parameters that give rise to sudden transitions. Singularity theory forms the foundation of the famous catastrophe theory [23,24,25,26,27,28].
2.8. Sard’s Theorem and Morse Functions
The following result shows that almost every point in the image of a smooth map is a regular value.
Theorem 3.
(Sard’s Theorem). Suppose that and are smooth n–manifolds and is a smooth map. Then the set of critical values of f has measure zero in .
The proof of Theorem 3 can be found in ([10], Ch. 1]).
Sard’s Theorem is illustrated in Figure 19. This theorem is a key result in differential topology and is applied in many situations. For example, it is crucial for Thom’s Transversality Theorem (see Theorem 4).
An equivalent formulation of Sard’s Theorem is as follows:
If is a smooth map between manifolds, then almost every is a regular value of f, i.e., the set of regular values is a dense subset of , or equivalently, every open subset of contains a regular value.
It should be emphasized that this theorem refers to regular values, not regular points. For example, a constant function of one variable has no regular points (all points are critical), but it has only one critical value, so the remaining points in are regular values. A set consisting of a single point clearly has measure zero.
Sard’s lemma was published by the American mathematician Arthur Sard in 1942.
It is interesting to study the behavior of a function f near its critical points. If is a compact set, every function on it must have a maximum and a minimum. However, if has an extremum, its derivative must be equal to zero. Thus, over a compact domain, every function has at least two critical points (except in the case ).
Let us consider a smooth function . Locally, near a point , f can be expressed using the Taylor series:
If c is a critical point, then by definition:
Therefore, in the neighborhood of a critical point, we have
Hence, the best possible approximation of the local behavior of f at the point c is given by the Hessian matrix of second derivatives:
Note that the Hessian H is a real symmetric matrix and therefore has only real eigenvalues. At a point where all eigenvalues of the Hessian are positive, the function f has a minimum; at a point where they are negative, f has a maximum.
Definition 11.
(Non-degenerate critical points and Morse functions). For a smooth function , a point where but the Hessian matrix
is invertible at c, is called non-degenerate critical point of f. If all critical points of f are non-degenerate, then f is called a non-degenerate function or Morse function.
Morse’s lemma was published by the American mathematician Marston Morse in 1925.
Computations in the neighbourhood of algebraic singularities are considered in [29].
2.9. Transverse Intersection of Manifolds
Let and be smooth submanifolds of an ambient manifold . They are said to intersect transversally if for every , their tangent spaces at x satisfy
(Figure 20). That is, the directions tangent to together with the directions tangent to span all possible directions of the ambient manifold.
The term frequently used synonymously for transversal is general position, i.e., two manifolds which intersect transversally are said to be in general position.
Two linear subspaces and of a linear space are transverse, if their sum is equal to the whole space, . For instance, two planes intersecting at nonzero angles in are transverse (Figure 21).
In three–dimensional space, transverse curves do not intersect. Indeed, if and are curves in , then
so their tangent spaces cannot span the tangent space of the ambient manifold at a common point.
A curve transverse to a surface intersects the surface in isolated points. In this case
and transversality implies that at each intersection point the tangent line to the curve together with the tangent plane to the surface span .
Similarly, two surfaces transverse to each other intersect in a curve. Indeed,
and their transverse intersection has dimension
Note that two perpendicular planes in intersect transversally, whereas two perpendicular lines lying in one and the same plane do not (Figure 22, left). Curves that are tangent to a surface at a point (for example, curves lying entirely on a surface) do not intersect the surface transversally. The same is true for planes that are tangent to a surface at a point (Figure 22, right). If an intersection of two submanifolds is transverse, then it is itself a smooth submanifold whose codimension is equal to the sums of the codimensions of the two intersecting manifolds.
The following result shows that transverse intersections are generic among intersections of smooth manifolds.
Theorem 4.
(Thom’s Transversality Theorem). ([4], Ch. 2) Suppose we have a family of smooth maps
where each map depends smoothly on a parameter s belonging to a parameter space . Assume that may have a boundary, while and a given submanifold do not.
If the full mapping , as well as its restriction to the boundary of , intersects in a transversal way, then for “almost all” choices of the parameter s the corresponding map also intersects transversally, both in the interior of and on its boundary.
In other words, transversality is a generic property: although a particular map may fail to be transversal, a small perturbation – obtained by slightly changing the parameter s – will typically restore transversality.
The concept of transversality was developed by the French mathematician René Thom in the 1950s.
2.10. Lie Groups
Lie groups are one of the powerful tools of differential topology, applied in a variety of areas, such as the theory of differential equations, the study of special functions, and matrix analysis. In this section, some basic information about Lie groups and their properties is provided.
The theory of Lie groups and Lie algebras is presented in depth in [6], Ch. 7, [9], Ch. 4, [30], Ch. 3. A comprehensive overview of Lie group theory, matrix Lie groups, and matrix Lie algebras is given in [31]. The group–theoretic approach to matrices and vector spaces is developed in detail in [32]. Applications of Lie groups in the theory of differential equations are discussed in [33].
2.10.1. Basic Definitions
Definition 12.
A group is a set G together with a group operation, usually called multiplication, such that for any two elements g and h in G, their product is again an element of G. The group operation is required to satisfy the following properties:
- (1)
- Associativity. If g, h, and k are elements of G, then
- (2)
- Existence of an identity element. There exists a distinguished element , called the identity element, which satisfiesfor all .
- (3)
- Existence of an inverse element. For every , there exists an inverse element, denoted , which satisfies
Below are some elementary examples of groups.
Example 6.
- (a) Let be the set of integers with the group operation being addition. Clearly, associativity holds, the identity element is 0, and the “inverse”of an integer x is .
- (b) Similarly, – the set of real numbers, is also a group under addition. Again, the identity element is 0, and the inverse of a real number x is . In both cases, the group operation is commutative: for all . Such groups are called Abelian.
- (c) Let be the set of invertible matrices with rational entries. The group operation is matrix multiplication. The identity element is the identity matrix I, and the inverse of a matrix A is the usual inverse matrix, whose entries are again rational numbers.
- (d) Similarly, the general linear group – the set of invertible matrices with real entries – is a group under matrix multiplication with the same identity element and inverses as in the previous example.
Lie groups are smooth manifolds that are also groups, in which the multiplication and inversion operations are smooth maps. Besides providing many interesting examples of manifolds in their own right, Lie groups are a fundamental tool in the study of more general manifolds.
In examples (b) and (d) given above, we actually have Lie groups, since the sets and are smooth manifolds. In both cases, the group operation is smooth (in fact, analytic). This leads to the following general definition of a Lie group.
Definition 13.
(Lie Groups). A Lie group is a smooth manifold G that is also a group in the algebraic sense, with the property that the multiplication map and the inverse map , defined by
are both smooth maps of manifolds.
In fact, one can equivalently state that if G is a smooth manifold with a group structure such that the map
is smooth, then G is a Lie group.
Lie groups exist at the boundary between algebra and topology. The algebraic properties of Lie groups follow from the group axioms, while their geometric properties arise from the parametrization of group elements by points of a differentiable manifold. At the topological level, a Lie group is homogeneous, meaning that every point of the manifold parametrizing the group looks the same as any other point.
The dimension of a Lie group is the dimension of the manifold that parametrizes the group operations. If G is an r–dimensional smooth manifold, the corresponding Lie group is also called an r–parameter Lie group. In particular, every Lie group is a topological group, that is, a topological space equipped with a group structure such that the multiplication and inversion maps are continuous.
If G is a Lie group, any element defines the maps , called respectively the left translation and right translation, given by
The maps and are smooth and, in fact, are diffeomorphisms of of G.
Example 7.
(Lie Groups). Each of the following manifolds is a Lie group with the specified group operation.
- (a) The general linear group is the set of all invertible matrices with real entries. It is a group with group operation given by matrix multiplication, as already noted in Example 6(d), and it is an open subset of the vector space . As will be shown below, multiplication is smooth since the entries of the matrix product are polynomials in the entries of A and B.
- (b) Let denote the subset of consisting of matrices with positive determinant. Since and , it is a subgroup of . Because this subset is the preimage of under the continuous determinant function, it is an open subset of and hence an –dimensional manifold. The group operations are the restrictions of those on and are therefore smooth. Thus is a Lie group.
- (c) The complex general linear group is the group of invertible complex matrices under matrix multiplication. It is an open submanifold of and hence a –dimensional smooth manifold. It is a Lie group since matrix multiplication and inversion are smooth functions of the real and imaginary parts of the matrix entries.
- (d) If V is an arbitrary real or complex vector space, denotes the set of invertible linear transformations from V to itself. It is a group under composition of functions. If V has finite dimension n, any choice of basis of V determines an isomorphism of with or , so that is a Lie group. The transition map between two such isomorphisms is given by a map of the form , where B is the change-of-basis matrix, which is smooth. Consequently, the smooth manifold structure on is independent of the choice of basis.
- (e) The field of real numbers is a Lie group under addition, with the inverse given by .
- (f) Let with its natural manifold structure, and let the group operation be vector addition . The inverse of a vector x is . These operations are smooth, so provides an example of an r–parameter Abelian Lie group. Similarly, and are Lie groups under addition.
- (g) Let be the group of planar rotations. That is,where θ denotes the angle of rotation of a vector under multiplication by the rotation matrix. Note that G can be identified with the unit circlein , which allows one to endow with a manifold structure.
2.10.2. Matrix Groups
In this section we consider several matrix Lie groups that play an important role in matrix analysis and matrix computations. For brevity, in what follows we shall denote the general linear group simply by .
-
General linear groupAs noted above, the general linear groupof all invertible matrices with real entries is a smooth manifold of dimension , since it is an open subset of the space of all matrices . Indeed,where the space is identified with the space of all real matrices. Since the determinant function is continuous —- because is a polynomial in the matrix entries -— the set is open. Hence it is a domain and therefore a smooth manifold of dimension .To prove that is a Lie group, we must verify that matrix multiplication and matrix inversion are smooth operations. Given two matrices A and B in , the element in position of the product is given byThus, is a polynomial of degree two in the entries of A and B. Consequently, the matrix multiplication mapis a smooth mapping.Recall that the –minor of a matrix A is the determinant of the submatrix , obtained by deleting the i–th row and the j–th column of A. According to Cramer’s rule the –th entry of is given bywhich is a smooth function of the entries , provided that . That is, the mappingis smooth, since it depends smoothly on the entries of A. Therefore, the matrix inversion mapis also smooth.The complex general linear group is likewise a Lie group with respect to matrix multiplication and inversion. The set is an open subset of and hence is a smooth manifold of dimension . It is a Lie group because matrix multiplication and inversion are smooth functions of the real and imaginary parts of the matrix entries.
-
Special Linear GroupThis group is defined asGeometrically, consists of all transformations of that preserve both volume and orientation. It can be shown that is a smooth manifold of dimension , defined by the condition . Since this manifold is a subset of the Lie group with the operation inherited from , is also a Lie group. Moreover, the tangent space of at the identity is the subspace of consisting of all matrices with zero trace.
-
Group of Orthogonal MatricesThe group of orthogonal matrices is defined asThus, is a subset of , defined by equationsin terms of the entries of the matrix A. It can be shown that exactly of these equations, corresponding to the entries on and above the diagonal, are independent and satisfy the maximal rank condition for everywhere. Therefore, is a submanifold of of dimension . Moreover, matrix multiplication and the matrix inversion operation remain smooth when restricted to . Consequently, itself is a Lie group.
-
Special Orthogonal GroupThe equationused in the definition of the orthogonal group , in particular implies that every matrix is invertible with . Consequently, the determinant of must satisfy , i.e., . In this way, is divided into two disconnected components: the subset of matrices with determinant and the subset of matrices with determinant .If A and B both have determinant -1, then their product has determinant . Therefore, the subset of orthogonal matrices with determinant is not closed under multiplication and is not a subgroup of . The other component, however, is a Lie subgroup of and is called the special orthogonal group, denoted by ,The subgroup is a Lie group.
-
Unitary and Special Unitary GroupsThe unitray group is defined aswhere denotes the Hermitian (complex conjugate transpose) of A. A similar argument as for shows that is a submanifold o and that .The special unitary group is defined as the subgroup of consisting of matrices with determinant equal to 1.
-
Group of Upper Unit Triangular MatricesThe group of upper triangular matrices with ones on the main diagonal is an –parameter Lie group. As a manifold, can be identified with the Euclidean space , since each matrix is uniquely determined by its entries above the diagonal. For example, in the case of we identify the matrixwith the vector in . However, except for the special case , the group is not isomorphic to the Abelian Lie group .
Several other important matrix groups are defined by imposing linear or quadratic constraints on the entries of or .
3. Geometry of Matrix Space
3.1. The Matrix Space
Let us consider the linear operator
represented by a rectangular matrix . The finite–dimensional space of all linear operators from to is isometric to the vector space , that is, the two spaces may be regarded as the same metric space. This makes it possible to study the space of linear operators using methods from the analysis of metric and topological spaces.
Let the set of all matrices with entries in be endowed with the topology induced by the natural mapping :
The mapping i is a homeomorphism that induces on the structure of a smooth manifold of dimension . In other words, the set of all rectangular matrices forms a smooth manifold of dimension embedded in the vector space .
According to the above considerations, a complex rectangular matrix can be represented as a point in the complex linear space of dimension . Similarly, a real matrix A can be viewed as a point in the real space , with , by arranging its entries in a prescribed order and interpreting them as coordinates. The corresponding space is called the matrix space and is isometric to a vector space of the same dimension. In the same way, a complex polynomial of degree n can be identified with a point in , where by using its coefficients as coordinates.
The distance between two points in the matrix space is defined by
Depending on the norm used, we shall implement the 2–norm distance or the Frobenius norm distance .
3.2. Generic and Well–Posed Problems
Consider the following idealized geometric interpretation of a computational problem .
Let denote the space of the data x, let denote the space of solutions y and let
be (a generally nonlinear) operator mapping to . In general, the spaces and may be arbitrary topological spaces, but for the purposes of our analysis we restrict attention to metric spaces and, in particular, to normed vector spaces.
The components of x are called parameters and the space is referred to as the parameter space. The dimension of the parameter space denoted by is equal to the number N of parameters. Each computational problem is therefore identified with a point in .
If the vector x represents a matrix with independent entries, than is the full matrix space with dimension . However, if the number of parameters N is smaller than , the matrix entries are no longer independent. Consequently, the parameter space in this case will have smaller dimension than the corresponding full matrix space.
If the mapping is linear, the problem is called linear; otherwise it is called nonlinear. If the inverse operator exists (at least locally) for the given data x, the problem is said to be regular. In the opposite case, the problem is called singular.
Suppose is a property that may be asserted about a problem x. This property represents a function , where (resp. 0) indicates that holds (resp. fails) at x. In applications where x represents a data of a physical problem subject to errors and uncertainties, it is important to understand the topological features of .
For instance, if holds at a nominal parameter value , it is useful to know whether also holds at points in a neighborhood of , corresponding to small deviations of the parameters from their nominal values. Usually, the property of interest holds for all sets of parameter values except those corresponding to points x lying on some surface in the parameter space, which are thus atypical.
From the point of view of algebraic geometry [34], such a surface represents a variety whose dimension satisfies . We call the variety of singular cases. Typically, is a closed subset of , while the set of problems for which holds contains an open and dense subset of .
We say that a property is generic relative to if only for points . A generic property of a parameter space is a property that holds at “almost all” points of that space. Intuitively, a generic property is one that “almost all”problems satisfy. Equivalently, if the parameters are chosen at random, then with probability 1.
It should be emphasized that, depending on the problem, the variety of singular cases may have a complex structure. In the special case when the variety has no singular points, it is referred to as manifold.
Since regular problems are generic, they have been studied more thoroughly than the corresponding singular problems. Therefore, the analysis of generic cases is always a primary focus when investigating phenomena and processes described by a given mathematical model. Nevertheless, there are situations in which it becomes necessary to examine non–generic cases. In this context, it is appropriate to quote the words of the great German mathematician Leopold Kronecker, spoken in 1874 [35]: “It is customary–especially in algebraic problems–to encounter truly new difficulties when one moves away from the cases usually regarded as general. As soon as one penetrates beneath the surface of the so-called generality, which excludes all particularities in the true generality encompassing all singularities, one typically first meets the real challenges of investigation, but at the same time also the richness of new perspectives and phenomena contained in its depths.”
A property is said to be well posed at x if holds through some neighborhood of x in . A problem parametrized by data in is said to be well posed at a point , if it is solvable for all data points in some neighborhood of . According to the French mathematician Jacques Hadamard [36], a mathematical problem is well posed, if it satisfies the following three conditions:
- a solution exists,
- the solution is unique,
- the solution depends continuously on the data of the problem.
If a problem fails to satisfy at least one of these conditions – namely, if a solution does not exist for some set of parameters , if the solution is not unique, or if the solution does not depend continuously on the parameters – then the problem is called an ill–posed problem.
The ill–posed problems typically form a variety within the space of all problems. This variety is referred to as the set of ill–posed problems.
If the property is generic relative to , then is well posed at every point in the complement (where ). Since the dimension of is less than the dimension of , it follows that almost all problems in are well posed.
It should be noted, however, that many meaningful and important problems in physics and computational mathematics are not well–posed, that is, they are ill–posed.
Example 8.
Consider the problem of finding the inverse of a square matrix A of order n. In this case, the property is the nonsingularity of the matrix A and the set consists of all singular matrices. The set of singular matrices is an algebraic variety, since it can be defined as the zero set of the polynomial . Thus, the equation describes the variety .
For example, if and
then the variety is determined by the equality and represents a hyperbolic paraboloid – a two dimensional manifold in the three–dimensional parameter space (see Figure 23). All points outside correspond to nonsingular matrices A, that is matrices for which .
Example 9.
Consider the eigenvalue problem for the same matrix, as in the previous example. In this case, the property is possessed by matrices with distinct eigenvalues, and the set consists of all matrices with a double eigenvalue. Since the eigenvalues of A are given by
the set is obtained by setting the discriminant equal to zero:
The corresponding surface in the three–dimensional parameter space is shown in Figure 24.
3.3. Conditioning of Computational Problems
To obtain an accurate solution of a computational problem, it is not sufficient for the problem to be well posed. If the problem lies close, in some sense, to the set of ill–posed problems, then it may be highly sensitive to variations in the data, and the discrepancy between the computed and the exact solutions can be very large.
The sensitivity of a given mathematical problem describes how its solution varies in the vicinity of a nominal solution. This important property of mathematical problems is the subject of perturbation theory, which is widely used in science and engineering.
A simplified quantitative characterization of sensitivity can be obtained by using the notion of conditioning.
Conditioning is a property of a computational problem that characterizes the sensitivity of its solution to small changes (or perturbations) in the data. A problem is said to be well conditioned, if small perturbations in the data lead to small changes in the solution. Conversely, if small changes in the data may result large changes in the solution, the problem is called ill conditioned.
It should be emphasized that the conditioning is an intrinsic property of the problem itself. It does not depend on the numerical precision used to solve the problem, nor does it depend on the particular numerical method implemented.
3.4. Condition Numbers
Consider the computational problem , where f maps the input data x to the output y. The problem is said to be well conditioned if is relatively insensitive to small perturbations in x, that is, remains close to when is near . The precise meaning of “insensitive”, “small”and “close”depends on the specific context of the problem. Conversely, if small changes in x produce large variations in f, the problem is ill conditioned.
The conditioning of a computational problem can be formally characterized as illustrated in Figure 25 where denotes the vector norms in and , respectively.
Definition 14.
(Absolute condition number). The absolute –condition number of the mapping at the point is defined as
According to this definition, the condition number is the smallest number such that the image of the sphere lies entirely within the sphere of a radius .
Defined in this way, the condition number can be interpreted as a Lipschitz constant for the mapping f, i.e., it is the smallest number M for which
holds for all points on the boundary of .
As illustrated in Figure 25, the condition number provides a quantitative measure of how perturbations in the data are transmitted to the solution space . If is relatively small, the problem is well conditioned; if is large, the problem is ill conditioned.
Definition 15.
(Relative condition number). The relative -condition number of the mapping at the point is defined as
In many practical applications, it is common to consider the condition number if the perturbation in the limit of infinitesimally small perturbations . Although this represents a theoretical approximation, it is widely used in perturbation analysis because it is easier to compute.
Definition 16.
(Asymptotic condition number). The asymptotic absolute and asymptotic relative condition number of are defined, respectively, as
If the Jacobian matrix of the mapping f exists, then the asymptotic absolute and relative condition numbers are given by
where denotes the operator (subordinate norm) of the derivative in .
The asymptotic condition number is usually referred to as the condition number of the problem. Note that this condition number does not exist for all mappings f.
The asymptotic absolute and relative condition numbers can be expressed as
which coincides with the expressions in (7), (8).
From this definition, it follows that
where means as .
Equation (11) shows that the relative change in the result can be approximated by the product of the relative condition number and the relative perturbation in the data. The ratio is called backward error since the change in the solution is represented as an equivalent perturbation in the input data equivalent to the observed change in the solution. Computational methods for which the backward error is small are called numerically stable.
Consequently, the quantity
provides an estimate of the relative forward error in the solution, given the relative backward error. If the condition number is large, even small perturbations in the input may produce a large forward error, highlighting the difficulty of the computational problem.
It should be noted that even well–conditioned problems may have specific perturbations for which the sensitivity estimate overstates the true change in the solution. When the sensitivity estimate consistently produces overly pessimistic bounds, it is called a conservative estimate.
3.5. Conditioning of Basic Matrix Problems
In this section we present two case studies that illustrate the concept of conditioning in matrix computations.
3.5.1. Conditioning of a Linear System of Equations
Consider the linear system
where is nonsingular and . Solving the system corresponds to applying the linear operator .
The entries of A serve as parameters, and the set of singular matrices forms a variety , representing ill–posed problems. Small perturbations may therefore lead to large changes in the solution.
Assuming that A is perturbed to , the perturbed solution satisfies
The matrix remains nonsingular provided
Under this condition, standard perturbation theory [45], Ch. 3, [46], Sect. 2.6, [47], Sect. 1.2) yields the relative error bound
According to Definition 15, the product
represents the relative condition number of the linear system. It satisfies and is invariant under scalar multiplication of A. For sufficiently small perturbations, the bound simplifies asymptotically to
If is small, the system is well conditioned; if large, it is ill conditioned. When , where is the unit roundoff, the matrix is considered singular to working precision, and accurate solutions cannot be expected numerically.
Following standard notation, the condition number is denoted by
The value of the condition number depends on the chosen norm. In particular, using the singular value decomposition ,
where and are the largest and smallest singular values of A. The 2–norm or the Frobenius–norm condition numbers are invariant under unitary (orthogonal) transformations.
Example 10.
Consider the linear system , where
and are variable parameters. Assume that the matrix A is subject to the perturbation
In Figure 26, we display the relative perturbation
in the solution caused by the perturbation , as a function of the parameters p and q. This is shown together with the corresponding relative perturbation estimate
The peak values in the Figure represent ill conditioned matrices. The maximum condition number of the perturbed matrices is which leads to maximum relative perturbations of size .
3.5.2. Conditioning of the Eigenvalue Problem
We consider, in a simplified setting, the problem of sensitivity of the eigenvalues of a matrix. This problem is characterized by fundamentally different properties in the regular case, when the eigenvalues are distinct, and in the singular case, when the eigenvalues are multiple and possess nonlinear elementary divisors.
Let us first examine the asymptotic sensitivity of the eigenvalue problem in the regular case. In this case, the eigenvalue problem is well posed, since the variations in the eigenvalues depend linearly on the perturbations in the entries of the matrix.
Let be a given square matrix. If A has a simple eigenvalue , with corresponding right eigenvector and left eigenvector , then
where denotes the conjugate transpose of y. Since a simple eigenvalue, it follows that
For every sufficiently small perturbation , there exists a unique eigenvalue of , that is close to . Therefore, we have
which implies that, up to terms of second order,
Multiplying from the left by , we obtain
Moreover,
Therefore, absolute condition number of the matrix A with respect to the regular eigenvalue problem can be defined as
We have that
where
is the spectral projector onto the invariant subspace generated by x. If the right and left eigenvector are normalized so that , then
The condition number is homogeneous, since multiplying A by a scalar does not change . It is also invariant under unitary (or orthogonal) transformations.
If is large, then is poorly conditioned. Poorly conditioned eigenvalues are computed with large errors as a consequence of their high sensitivity to perturbations in the matrix. As the separation between eigenvalues decreases, their sensitivity increases, and in the limiting case of defective eigenvalues, their condition numbers become infinitely large. In such cases, the linear estimate
is no longer valid, and the eigenvalue problem becomes ill–posed. In this case, it is justified to set , where is a multiple eigenvalue of A.
We note that the eigenvalue sensitivity estimates provided by the linear algebra package LAPACK [48] and the software system MATLAB® [3] yield meaningful results only for well–posed problems, specifically when the matrices have simple eigenvalues, i.e., eigenvalues to which correspond linearly independent eigenvectors.
Example 11.
Consider the upper triangular matrix
The matrix A has two simple eigenvalues and . The corresponding spectral projectors are
Both eigenvalues have the same absolute condition number given by
As , the condition number tends to infinity, since the two eigenvalues of A coalesce () and the eigenvalue problem becomes ill-posed.
Since the eigenvalue condition number becomes infinite when is a multiple eigenvalue, the variety of singular cases for the eigenvalue problem consists of all matrices with multiple eigenvalues. This variety forms a hypersurface in the space of matrices, i.e., it has dimension , where .
For matrices with multiple eigenvalues, small perturbations of the entries can cause large changes in the eigenvalues. Such matrices are characterized by eigenvalues that appear in nonlinear elementary divisors.
Let
where, for ,
is a Jordan block of dimension , repeated times, and
The eigenvalue is semisimple (participating in a scalar Jordan block, i.e., nondefective) if , and nonderogatory (participating in only one Jordan block) if . It follows that the algebraic and geometric multiplicities of , are, respectively,
Denote by the right eigenvector and by the left eigenvector of A associated with . With these eigenvectors we construct the matrices
corresponding to the Jordan blocks of maximum size . Note that the columns of and are linearly independent right and left eigenvectors, respectively, each associated with a separate Jordan chain of maximal length .
Assume that the matrix A is perturbed to , where is small. It is shown in [49,50] that the eigenvalues of converging to as satisfy
for all sufficiently small positive , where and .
The bound (18) shows that the sensitivity of a multiple eigenvalue depends on , where is the size of the largest Jordan block associated with . In the case where is simple, we have , and , where the right eigenvector x and the left eigenvector y are normalized so that . In this case, the bound (18) coincides with the bound (17) valid for a simple eigenvalue. It is important to note that the bound (18) remains finite, while the linear bound (17) becomes infinite in this case.
If is nonderogatory (i.e., there is only one Jordan block corresponding to ), then , and again in (18) we obtain , where x and y are the corresponding right and left eigenvectors associated with .
The following example illustrates how the dimension of the Jordan block associated with a multiple eigenvalue affects its sensitivity.
Example 12.
Consider a Jordan block of nth order with eigenvalue λ. If the zero entry in position is replaced by a small number , the characteristic equation of the perturbed block becomes
and the multiple eigenvalue λ is split into n distinct eigenvalues
In the given case and has one right eigenvector and one left eigenvector so that . The perturbed eigenvalues satisfy
as predicted by (18).
For instance, consider
with and . For , the perturbed eigenvalues are
The perturbations in the eigenvalues are exactly , which is larger than the original perturbation .
In Figure 27, we show the eigenvalue perturbations of for 20 equally spaced values of ε between (bottom circle) and (top circle). Note that the number of the eigenvalue loci is equal to the size of the Jordan block.
Thus, a perturbation of size ε can induce changes of order in the eigenvalues, which can be large even for moderate n. Since the trace of the matrix is unchanged, the mean of the eigenvalues remains λ.
In this example, the eigenvalues are highly sensitive to perturbations because the matrix is completely defective. In contrast, eigenvalues corresponding to linear elementary divisors generally exhibit low sensitivity. This highlights that the analysis of eigenvalue sensitivity must explicitly or implicitly account for the Jordan structure of the matrix.
A large body of results on the sensitivity of matrix eigenvalues can be found in the books [46,51,52,53], and [54]. The book by Stewart and Sun [55] provides a detailed presentation of various methods for perturbation analysis of eigenvalue and eigenvector problems. Comprehensive surveys of such methods are also given in [56] and [57]. Several important results on eigenvalue sensitivity have been published in [58,59,60,61,62,63,64,65], among others. Theoretical and practical aspects of eigenvalue conditioning analysis are addressed in [66,67,68,69,70,71].
3.6. Distance to an Ill–Posed Problem and Conditioning
The study of the sensitivity of a system of linear equations done in Section 3.5, shows that with the increasing of the condition number the matrix becomes closer and closer to a singular matrix. The analysis of several other problems of numerical analysis shows that, in a similar way, the corresponding condition number is inversely proportional to the distance of the problem to the set of ill–posed problems. Thus, as a problem gets closer to the set of ill–posed ones, its condition number approaches infinity.
The geometry of ill–conditioning in numerical computations has been developed by Smale [72,73,74], Renegar [75,76], and Demmel [77,78,79]. These works show that many problems in numerical analysis, particularly in matrix computations, satisfy the property that the condition number of a problem is proportional to (or bounded by a multiple of) the reciprocal of the distance to the set of ill–posed problems. Consequently, as a problem approaches the variety of ill–posed problems, its condition number can increase without bound.
Determining the probability of encountering problems with a given condition number is closely related to computing the volume of a tubular neighborhood around a manifold, a topic studied rigorously in the mathematical discipline of geometric probability [80,81,82]. The conditioning of computational problems from the perspective of geometric probability is examined in depth in the book by Bürgisser and Cucker [83]. Additionally, estimates of the distance from a matrix to the set of matrices with multiple eigenvalues are provided in [84,85,86,87,88].
3.6.1. Distance to the Set of Singular Matrices
The distance of a given matrix to the variety of singular cases is defined as
To define the distance between matrices in , we will use the 2–norm or the Frobenius norm, noting that similar results hold if another matrix norm is used.
Consider first the matrix inversion. In this setting, the following classic result holds [83,89], Ch. 1:
Theorem 5.
Let be nonsingular. Then
By defining for a singular matrix, we immediately obtain the relationship between the distance to singularity and the condition number.
Corollary 1.
For any nonzero , the following holds:
This results shows that for a normalized problem with , the condition number of the matrix in respect to inversion is inversely proportional to the distance from A to the set of singular matrices. In other words, the closer a matrix is to singularity, the larger its condition number, and hence the more sensitive it is to perturbations.
Example 13.
Figure 28 illustrates the hypersurfaces of constant condition number with respect to inversion, , for the matrix
considered in Examples 8 and 9.
3.6.2. Distance to the Set of Defect Matrices
Consider now the eigenvalue problem. We have the following result.
Theorem 6.
[78] The distance of the matrix A to the set of matrices with multiple eigenvalues satisfies
where P is the spectral projector associated with the eigenvalue of interest.
Using the expression for the eigenvalue condition number (16), and assuming that , we obtain
which confirms that the eigenvalue condition number of the normalized problem is inversely proportional of the distance to the set of ill–posed problems.
In this way, the set of problems whose condition number is at least K is approximately the set of problems within distance (with C a constant) from the variety of ill–posed matrices. As one approaches , the conditioning of the problem worsens, which is why is called pejorative manifold (from the Latin word pejorare - to make worse) by Kahan [90].
3.7. Probabilistic Distribution of Condition Numbers
The idea of the probabilistic distribution analysis in the parameter space of a property characterizing the computational problem can be described in general terms [83], Ch. 2. The parameter space is endowed with a probability distribution, and a certain real–valued function defined on this space is considered as a random variable. The goal is to estimate quantities such as the probability that for a given K, which provides information about the behavior of g.
In this section, we show that the geometric structure of computational problems allows one to estimate the probability distribution of problems with a given condition number in the parameter space. To this end, we exploit the fact that the multiplication by a scalar does not change , i.e., the condition number is homogeneous in the parameter space. This permits normalization of the problems to unit norm, so it suffices to consider only problems that lie on the unit sphere in or .
Due to the homogeneity of the condition number, its distribution in the parameter
space induces the same distribution of over the unit sphere. It is natural to assume that problems are uniformly distributed in the parameter space, since each problem is as likely as any other. The uniformity allows us to bound the volume of the set of problems with condition number at least K, which lie within distance of the variety of ill–posed problems. Consequently, the probability that is proportional to the volume of the corresponding set of problems.
Figure 29 shows an interpretation of the probabilistic distribution of the condition number in three-dimensional space. Let denote the set of all points in the unit ball that lie within distance of ,
Such variety represents a tubular neighborhood (Section 2.7).
The ratio
where denotes the volume of a manifold , gives the fraction of the unit ball within the distance of .
We are interested in the part of that intersects the unit ball, namely,
Note that contains all singular problems lying on the unit sphere after normalization. The volume of this set is used to determine the probability distribution of the scaled singular problems in the -neighborhood of . By definition, this probability is given by the ratio of the volume of to the volume of the unit ball , that is,
According to this definition it holds that
Example 14.
Consider the matrix
from Examples 8 and 9. The unit ball of all matrices with unit Frobenius norm is given by the equation
The variety of singular matrices () that lie on the unit sphere, is described by
The manifold of singular matrices is represented by a hyperbolic paraboloid which is a surface with codimension 1. The sets and are tubular neighborhoods.
To determine , it is necessary to compute the quantities
and .
Proposition 2.
The volume of the unit ball is given by the formula
where the gamma-function for a positive integer n is computed from
Various proofs of this classical result can be found in [93].
Determining the quantity is related to computing the volume of a tubular neighborhood of a real or complex manifold and represents a difficult problem. Using formulas for the volumes of tubular neighborhoods derived in [76,94], the following theorem was proved in [78], providing an upper bound for in the complex case.
Theorem 7.
(Volume of a complex tubular neighborhood). [78] Assume that is a –dimensional complex manifold in . Let be the part of the unit ball in that lies in a distance from . Then
In the above expression, denotes Euler’s number, and is the so–called degree of , which generalizes the notion of the degree of a polynomial and is defined as the number of intersection points of an n–dimensional manifold in with an ()–dimensional affine subspace of . If is a hypersurface , this upper bound can be improved to
The expressions for the volume of a real tubular neighborhood are more complicated and can be found in [83,95,96], Ch. 21.
3.7.1. Probability Conditioning of Matrix Inversion
For computational convenience, when determining the probability of occurrence of a matrix with a given condition number, instead of the usual condition number , we shall use the nearly equivalent scaled condition number . Since , it follows that .
Using Theorem 7, the following result concerning the probabilistic distribution of the matrix inversion problem was proved in [78].
Theorem 8.
Let be a random matrix distributed in the parameter space such that is uniformly distributed on the unit sphere. Define
where denotes the set of singular matrices and . Then for a given number , the probability that satisfies
and
Theorem 8 was refined in [97], where the following exact result was obtained:
Theorem 9.
For a complex matrix A, the probability that the condition number satisfies is
For large K and , the asymptotic estimate holds:
According to this result, the probability that the condition number of a matrix exceeds a given value K is inversely proportional to K. That is, as a matrix approaches the set of singular matrices, the condition number
increases, but the likelihood of encountering a very ill-conditioned matrix decreases.
A graphical interpretation of equation (23) for is shown in Figure 30, where the probability estimate is plotted as a function of . As the matrix dimension increases, the probability of encountering a larger condition number also increases.
Using a similar technique, the following result concerning the condition number with respect to inversion was obtained in [98]:
Theorem 10.
For all , it holds that
where the expectation is taken over all Z uniformly distributed in the open ball of radius ε centered at A on the unit sphere .
This result reflects the fact that, as , the condition number tends to infinity.
3.7.2. Probability Conditioning of Eigenvalues
A result similar to Theorem 8, can be obtained with respect to the eigenvalue problem.
Theorem 11.
[78] Let be a random matrix distributed in the parameter space such that is uniformly distributed on the unit sphere. Define
where the maximum is taken over all eigenvalues of A, and denotes the spectral projector associated with . Then for any given number the probability that , satisfies
In Figure 31 we show the upper probability bound given by (24) for . This bound is meaningful for , which means that for the matrices with appear with a probability equal to 1.
An analogue of Theorem 10 is given by the following result.
Theorem 12.
[98] For all and , the following holds:
- (a) For all real matrices,
- (b) For all complex matrices,
Similar results are obtained for the polynomial zero finding, see [78].
The assumed uniform distribution is a continuous model which is a good approximation only as long as the finite–precision numbers of the computer arithmetic are dense enough to resemble the continuum. For a detailed discussion of this limitation of the method, see [78].
4. Geometry of Matrix Rank
The variety of singular cases in computational problems can have a highly complex structure, depending on the problem being solved. In this section, we focus on the geometric structure of the variety of singular cases in matrix space, particularly those associated with the rank of rectangular matrices.
4.1. Orbits of Matrices with Constant Rank
In studying the manifolds of rectangular matrices, different matrix manifolds can be obtained through equivalent transformations of matrices with a fixed rank. Specifically, in the space of rectangular matrices, the set of all matrices equivalent to a given matrix A form a smooth manifold in . This manifold is defined as
and is called the orbit of A. Since the equivalent transformations preserve the rank of a matrix, each orbit consists of all matrices of a fixed rank r and the entire space is partitioned into orbits containing matrices of the same rank.
Consider the linear operator
represented by the rectangular matrix . The finite–dimensional space of all linear operators from to is isomorphic to the vector space . The linear operators of maximal rank form an everywhere dense subset of . Such operators are called regular or non-singular. Hence, the non–singularity is a generic property of the operators in . According to a well known results from linear algebra, a non–singular operator can b e represented in a suitable choice of bases by the matrix
or
If , the operator is singular and, in a suitable choice of bases, it can be represented by the matrix
The matrix is called the normal form of A and the differences and are referred to as coranks.
4.2. Dimension of an Orbit with Fixed Rank
In what follows, we will show that the singular operators, corresponding to matrices A of rank form an orbit in , whose codimension is the product .
For a rectangular matrix , define the linear operator
Let denote the tangent space to the orbit at A and let denote the image of . Then we have the following result.
Lemma 1.
Proof. Consider the nonlinear transformation from the sets of and nonsingular matrices into the space , defined by
Assume that the matrices and are sufficiently small, and set
so that P and Q remain nonsingular. Then, for and , we have the expansions . Substituting these into gives
where . Hence, the tangent vectors to the orbit are given by the differential
Evaluating the differential at the identity, , we obtain
i.e., the tangent space to the orbit at A is exactly the range of the linear operator .
The dimension of the orbit of matrices with fixed rank can be determined by noting that
where is the tangent space at A. Define the subspace
Clearly, is the null space of the linear operator . Since for any linear operator, the dimension of the domain equals the sum of the dimensions of the range and null space, we have
where is the null space. Therefore,
This shows that the dimension of the orbit is equal to the dimension of the ambient space minus the dimension of the null space of .
Thus, we arrive at the important relationship
i.e., the dimension of the subspace is equal to the dimension of the normal space , which in turn equals the codimension of the orbit . Since is invariant under equivalent transformations of A, it follows that
where and
is the normal form of a rank–r matrix.
Partitioning the matrices X and Y as
we have
From this expression, it follows that
Hence, the dimension of the null space of is
which leads to the following important result.
Theorem 13.
The codimension of rank–r matrices in is .
The dimension and codimension counts are illustrated in Figure 32. The dimension of the orbit is given by
The perturbation with the minimum number of parameters that acts in the normal space of has the form
where is an block with independent entries . This perturbation lies in the normal space to the orbit and is transversal (i.e., in general position) to .
4.3. Stratification of Orbits with Fixed Rank
The partition of a space into a finite number of submanifolds defined by algebraic equations and inequalities is called a stratification. The stratification means that the matrix space is decomposed into manifolds, called strata, which are arranged in different layers. The partition of the matrix space into orbits with fixed rank is an example of matrix stratification.
We say that a complex manifold is embedded in another complex manifold , if is contained in the closure of , which we denote by
Every orbit is embedded in itself and in all orbits of equal or higher rank (equivalently, equal or lower codimension).
Theorem 14.
(Orbit Embedding Theorem). In the matrix space , the orbit of matrices of rank r is embedded in the orbit if and only if only or, equivalently, if and only if
More precisely, the following chain of inclusions holds:
Theorem 14 describes the stratification of the matrix space into orbits of different ranks. According to this result, if a matrix A belongs to the orbit , it also lies in the closure of all orbits with higher rank . These higher–rank orbits have strictly smaller codimension than the orbit containing A.
Example 15.
Consider families of matrices of different rank. For each rank there exists an orbit consisting of all matrices of rank r. The codimension of each orbit is given by . These orbits form a stratification of the matrix space , which can be summarized as follows:
The table clearly illustrates the inclusion relations between the orbits: as the rank increases, the dimension of the orbit increases while its codimension decreases. The full-rank orbit is open and dense in , whereas the lower–rank orbits form boundary strata of increasing codimension.
The next example illustrates how infinitely small perturbations can cause a matrix A of a given rank to move from an orbit of higher codimension to an orbit of lower codimension.
Example 16.
Consider rank transitions of a matrix (blank entries are understood to be 0):
Note that perturbations of general position act from right to left increasing the rank of the matrix. In contrast, decreasing the rank from left to right requires perturbations with a special (diagonal) structure. Such perturbations lie in the tangent space of the corresponding matrix orbit and are therefore not in general position with respect to and not generic.
From the figure we see that the rightmost matrix A with (and
) is arbitrarily close to matrices with (whose orbit has codimension ). In turn, these matrices are arbitrary close to matrices with (for which ).
Thus, by applying a sufficiently small perturbation that is in general position to A, one can move from the orbit , to the orbit . In other words, the orbit is contained in the closure of , and , is said to cover . Formally, this relation is written as
where denotes the closure of the orbit of rank–2 matrices.
Similarly, a small perturbation in general position allows one to move from to . This implies that
Taken together, these closure relations show that, via a sufficiently small perturbation, one can move directly from to , passing through intermediate orbits of lower codimension.
It is important in numerical computations that adding a perturbation in general position to a matrix A can only decrease the codimension of the orbit in which the perturbed matrix lies; it can never increase it. This implies that, due to rounding errors, numerical algorithms effectively operate on matrices that belong to orbits (manifolds) of codimension 0, i.e., the full–rank or maximal–rank orbits.
For orbits of matrices with fixed rank, it is possible to compute exactly the distance in the matrix space from a given matrix to an orbit corresponding to a prescribed rank.
Theorem 15.
(Schmidt-Mirsky Theorem). [45], Ch. 1 Let be a matrix with singular values
where . Then the distance from A to an orbit of matrices with rank is given by
Thus, the matrix A lies at distances from the orbits corresponding to rank , respectively.
4.4. Numerical Rank of a Matrix
An important task arising in matrix computations is determining the rank of a given matrix A in the presence of uncertainties in its entries. This problem is closely related to solving linear systems of less-than-full rank and to the numerical determination of the Jordan structure of a matrix. The difficulty in determining the rank stems from the fact that it is not a continuous function of the matrix entries and may change abruptly under arbitrarily small perturbations of these entries.
Let , and without loss of generality assume that . Let
be the singular value decomposition (SVD) of A, where , are unitary matrices, and
contains the singular values of A, with . Note that .
The “theoretical” rank of A is defined as the number of nonzero singular values. In practice, the matrix A contains measurement, approximation, and discretization errors. Therefore, instead of the exact rank of A, we determine the rank of a perturbed matrix , where the perturbation satisfies
for some small positive number . The quantity can be interpreted as the relative uncertainty in A.
These considerations lead to the concept of the numerical rank of a matrix relative to the tolerance , defined as
Unlike the “theoretical”; rank, the numerical rank is stable in the sense that perturbations smaller than the tolerance will not change the rank of A.
The concept of the numerical rank of a matrix is discussed in detail in [46], Sec. 5.4, [45], Ch. ], [53], Sec. 3.5, and [102], Ch. 3; see also [103,104,105]. Efficient procedures for determining the numerical rank are described in [106,107] and [108].
In connection with the stability of the numerical rank, the following can be noted.
In general terms, a mathematical object is called structurally stable, if its structure remains unchanged under perturbations of the object’s parameters. If the object remains stable under large parameter variations, it is called robust.
5. Geometry of Jordan Form
5.1. Orbits of Matrices with Fixed Jordan Form
In the space of square matrices, the set of all matrices similar to a given matrix A form a manifold in . This manifold, defined by
is called the orbit of the matrix A. All matrices lying in the same orbit have the same eigenvalues and the same dimensions of the Jordan blocks.
The bundle of the matrix A is defined as the union of all orbits. It consists of all matrices whose Jordan canonical forms differ only in their eigenvalues while having the same number of distinct eigenvalues and the same sizes of the corresponding Jordan blocks (i.e., the same Segre characteristics). If two matrices have identical Jordan structures but different distinct eigenvalues, they belong to the same bundle. For example, all diagonal matrices with simple eigenvalues form a single bundle.
Each bundle is a manifold in the space of matrices, whose strata are the individual orbits. Within a given bundle, an orbit consists precisely of those matrices that share the same eigenvalues.
As an illustration, consider the two matrices with Jordan forms
These matrices lie in different orbits, since their eigenvalues differ, but they belong to the same bundle because their Jordan block structures are identical.
The most important characteristic of orbits and bundles are their dimensions. The dimension of an orbit, denoted by , is equal to the dimension of its tangent space . In practice, it is often more convenient to work with the codimension of denoted by , which is equal to the dimension of the normal space . Since
it follows that
The following result can now be established.
Theorem 16.
[100] Let
be the Segre characteristic of A associated with the eigenvalue . Then the codimension of the orbit is given by
where p denotes the number of the distinct eigenvalues of A. Note that the complex conjugate eigenvalues are counted as two distinct eigenvalues.
The difference between orbits and bundles is that the eigenvalues of the matrices belonging to a bundle are not fixed. In other words, while an orbit consists of matrices similar to A with the same eigenvalues, a bundle allows the eigenvalues to vary, provided the Jordan structure remains unchanged. As a consequence, the tangent space of a bundle contains one additional dimension for each distinct eigenvalue compared to the tangent space of the corresponding orbit. Hence the codimension of the bundle is given by
Comparing (30) and (31), we obtain
that is, the codimension of a bundle is equal to the codimension of the corresponding orbit minus the number of distinct eigenvalues. This relation reflects the fact that a bundle possesses additional degrees of freedom – one for each distinct eigenvalue – which are absent in a fixed orbit.
Note that simple eigenvalues contribute nothing to the sum in (31). Furthermore, the codimension of a bundle does not depend on the order n of the matrix, but only on the sizes of the Jordan blocks corresponding to multiple eigenvalues. Thus, the bundle codimension provides a measure of the dependencies in the space of matrices imposed by the Jordan structure of the matrix.
The partition of the matrix space into orbits and bundles, represented by manifolds with corresponding codimensions, was introduced by the Russian mathematician Vladimir Arnold in [100] in connection with the determination of normal forms of matrices depending on a minimal number of perturbation parameters. This approach makes it possible to apply methods of differential topology to the study of matrix problems [113,114,115,116,117,118], Ch. 14.
5.2. Generic and Nongeneric Jordan Bundles
Let or , and denote by the set of matrices, or equivalently, the set of linear maps on . By writing all entries of a matrix columnwise as a vector, we may identify with or , respectively. Then the following important result holds [120], Sect. 5.6.
Theorem 17.
The set of matrices in that have n distinct eigenvalues is open and dense in .
According to this theorem, having all distinct eigenvalues is a generic property of matrices, that is, “almost all” matrices have distinct eigenvalues and are therefore diagonalizable. Matrices with non–diagonal (Jordan) forms, whose Jordan blocks have specified sizes (the Segre characteristics), lie on a bundle of , whose dimension is determined by the sizes of the blocks.
In the case of two distinct eigenvalues, and , each orbit is determined by a fixed combination of these eigenvalues and corresponds to a plane in the 3-dimensional space. Note that the distance between planes corresponding to infinitesimally close distinct eigenvalues is itself infinitesimal. The set of matrices with simple eigenvalues forms a bundle with dimension 4, which is dense set in the space of matrices. Such matrices are most probable, in the sense that a matrix with randomly chosen entries almost surely has distinct (simple) eigenvalues. For this reason, this case is refrerred to as the most generic case.
In Table 1 we show the different Jordan forms corresponding to the case of a single eigenvalue with algebraic multiplicity n. Note that the single nth order Jordan block associated with such eigenvalue represents the most generic Jordan structure in the case of multiple eigenvalue. The corresponding bundle contains all matrices A which are similar to nth–order companion matrices.
Table 2 summarizes the most generic and the most degenerate cases of matrices in terms of their Jordan structures. The most generic case corresponds to matrices with n distinct eigenvalues, each forming a separate Jordan block; in this case, the orbit has maximal dimension and codimension n, while the coresponding bundle has dimension and codimension 0. Conversely, the most degenerate case corresponds to a single eigenvalue with n scalar Jordan blocks; here, the orbit is zero–dimensional with maximal codimension , and the bundle has minimal dimension 1 and codimension . This table illustrates how the Jordan structure directly influences the dimensions of orbits and bundles.
In the general case, when a matrix A belongs to a given bundle, it may also lie in the closure of many other bundles corresponding to different Segre characteristics. These bundles have smaller codimension than the bundle containing the original matrix, forming a hierarchy of stratification of Jordan structures. Adding a perturbation in general position decreases the codimension of the bundle into which the perturbed matrix moves. The stratification of Jordan structures has been studied by Edelman, Elmroth, and Kågström [115], who show that Jordan and Kronecker canonical forms can be represented as integer partitions. These partitions reveal closure relations of orbits and bundles through simple combinatorial rules, which can also be used to determine whether one structure is more generic than another.
5.3. The Reduction into Jordan Form as an Ill–Posed Problem
Determining the Jordan canonical form of a square nonsymmetric matrix A with defective eigenvalues by means of a computer is one of the most challenging problems in numerical matrix analysis. This difficulty arises for two main reasons. First, deciding which eigenvalues are multiple in the presence of rounding errors is inherently problematic. Second, the determination of the sizes of the Jordan blocks associated with a given multiple eigenvalue (the Segre characteristic) is closely related to computing of the numerical rank of a matrix, which itself is a difficult task working with finite–precision arithmetic.
The Jordan canonical form is structurally unstable in the sense that it is not a continuous function of the matrix entries. The following example of a matrix illustrates this instability.
Example 17.
Let
where ε is a small positive number. For , this matrix has the Jordan canonical form
whereas for it has the Jordan canonical form
Clearly, the Jordan canonical form of changes its structure discontinuosly at ; that is, it is not continuous at this point. For small ε, the nonsingular matrix that diagonalizes ,
is ill–conditioned, since
For example, if , then the condition number of V with respect to inversion is .
The eigenvalue problem for a matrix A with distinct eigenvalues is a well–posed computational problem, since for a sufficiently small perturbation , the eigenvalues of the perturbed matrix satisfy the inequality
where is the condition number of (Section 3.5.2). If is large, then the eigenvalue is ill–conditioned and in the limiting case of defective eigenvalues the condition number becomes infinite. In such cases, the eigenvalue problem is ill–posed.
In case of an ill–posed eigenvalue problem, a perturbation of magnitude applied to a Jordan block of order may change its eigenvalues by an amount proportional to , whose derivative at is infinite (see Example 12). This extreme sensitivity is the source of the ill–posedness.
The set of matrices with defective eigenvalues forms a low–dimensional surface in the –dimensional parameter space of matrix entries. Consequently, matrices that lie in the vicinity of give rise to ill–conditioned eigenvalue problems. When the problem lies exactly on , it usually has bounded conditioning since the sensitivity of the defective eigenvalues is finite (see (18). For this reason, the solution of ill–conditioned problems is often obtained by projecting them onto and solving the resulting ill–posed problem. Such an approach is called regularization.
The use of regularization in the solution of the eigenvalue problem is illustrated by the following example.
Example 18.
Consider the matrix
Using the MATLAB®function eig , one obtains the eigenvalues
The corresponding eigenvalue condition numbers, determined by the MATLAB®function condeig , are
which shows that the last two eigenvalues are extremely sensitive. As a consequence, the eigenvector matrix V is also ill conditioned, with condition number
The eigenvalue problem can be regularized in the following way. The matrix A is reduced to Jordan form, using the algorithm presented in [121,122]. Within this algorithm, the last two eigenvalues are recognized as multiple and are replaced by their mean value,
This approach is justified by the fact that, although the individual eigenvalues may be highly sensitive, their mean value is not. In the present case, the errors in the computed second and third eigenvalues are of the order , whereas the mean value changes by only , which is of order of the backward error , where denotes the unit roundoff.
In this way the ill conditioned eigenvalue problem is projected onto the set of ill–posed problems which includes the matrices with defective multiple eigenvalues. As a result of the reduction of A to Jordan form, one obtains
where
Clearly, there is a quadratic elementary divisor corresponding to the eigenvalue , that is, this eigenvalue belongs to a Jordan block of size 2. In the same time, the transformation matrix Z has condition number , which is relatively modest.
In summary, due to rounding errors and the nature of standard eigenvalue algorithms, the eigenvalues are initially computed as simple but ill–conditioned. The algorithm for reduction to Jordan form correctly recognizes these eigenvalues as multiple and determines them with maximal possible accuracy. In this way, the ill-conditioned eigenvalue problem is transformed into the problem of determining multiple eigenvalues, which is then solved accurately by reducing the matrix to Jordan form.
Example 18 confirms that the computation of defective multiple eigenvalues of a matrix is an ill–posed problem. This problem can be regularized by applying an appropriate criterion to determine the dimensions of the Jordan blocks when constructing the Jordan structure of the matrix. In this way, one can determine the exact canonical form of a near matrix , where the norm of provides an upper bound on the distance of A to the regularized problem with computed structure .
5.4. Numerical Jordan Form
Following the presentation of Zeng [123,124] and Zeng and Li [125], the problem of determining the Jordan form of a matrix in presence of errors can be formalized as follows.
The determination of the Jordan form of a matrix with an ill–conditioned eigenvalue problem may be illustrated in a simplified setting, as shown in Figure 33 where the space is used as a substitution for the dimensional parameter space of matrix entries. (Note that the ordering of the strata in the figure is purely illustrative.) The objective is to find the Jordan canonical form of the matrix A, represented as a point lying on a manifold .
In practice, the exact matrix A is not known. Instead, one works with an approximation , which is contaminated by empirical and/or rounding errors satisfying . With respect to the Frobenius norm, the point lies inside a sphere of radius centered at A. From a theoretical point of view, the matrix typically has distinct eigenvalues and it is therefore used by numerical methods to compute an approximation of the eigenstructure. However, since lies outside the manifold , its eigenvalue problem is ill–conditioned, and the corresponding numerical results may contain large errors.
To regularize the problem, the point is projected onto the manifold , yielding a new matrix whose eigenvalues are defective but with bounded sensitivity as shown by (18). Note that there exist several nonintersecting manifolds, each corresponding to a different Jordan structure. It can be shown rigorously [124], that the best regularization results are obtained when the distance
between and is minimal, which corresponds to the orthogonal projection of onto the closest pejorative manifold . This observation shows that the numerical determination of the Jordan form can be recast as a least–squares problem. As a result, the Jordan form J of is taken as the Jordan canonical form of A. The quantity
characterizes the backward error in finding J.
Thus, we arrive at the following rigorous definition of the notion of a numerical Jordan form.
Definition 17.
Let and let . Suppose that an approximation
of A is given, where . Let be a matrix bundle such that
and let be a matrix satisfying
with exact Jordan decomposition . Then the matrix J is called the numerical Jordan canonical form of A within ε, and is called the numerical Jordan decomposition of A within ε.
Example 19.
Consider the matrix
whose exact Jordan canonical form is
This matrix is defective but nonderogatory. It belongs to a bundle Π in the 36–dimensional space whose codimension is . The diagonal elements of the Schur form, computed using the function schur in MATLAB®, are
These eigenvalues are distinct and therefore correspond exactly to the eigenvalues of a nearby matrix , which lies in a bundle of codimension . Using a numerical algorithm, one computes a Jordan form with Segre characteristics and associated with the eigenvalues
and
respectively. Thus, the eigenvalues of A are computed correctly to approximately eleven decimal digits. The computed Segre characteristics show that the matrix
belongs to the same bundle Π as A, with codimension equal to 4. The exact Jordan canonical form of is .
The relative distance between and A, which characterizes the backward error in computing , is
Note that in some cases the matrix may lie in a different bundle from A, if the Segre characteristics of A are not identified correctly.
It should be noted that, in contrast to the “theoretical case”, the numerical Jordan structure remains unchanged within a certain set of parameter values defined by the inequality
The parameter set determined by (34), is represented as a ball of radius , centered at the singular point corresponding to the theoretical case. Thus, unlike the exact Jordan form, which is defined for a single combination of parameters at a singular point, the numerical Jordan form remains the same for all parameter values contained in the ball of radius .
6. Matrices Depending on Parameters
6.1. Matrix Deformations
In physical problems, the entries of a matrix A often depend on certain parameters. Suppose these parameters belong to a parameter space with , where k is the number of independent parameters. Let be a fixed matrix. A family of matrices
where is a neighborhood of the origin in , is called a deformation, of if the mapping
is such that each entry of is a convergent power series in the , and . A deformation is also called matrix family and the subset is referred to as the base of the family.
A function that is locally given by a convergent power series is called analytic, and the complex case, it is called holomorphic. A holomorphic function is infinitely differentiable at every point in its domain and is therefore continuous. A mapping whose entries are holomorphic functions is called holomorpic mapping. Since the entries depend smoothly on the parameters, such mappings are convenient for computational implementation.
When a matrix depends on parameters, we say that it is given a family of matrices. In practice, we are usually interested in the family locally, i.e., for small changes of the parameters near fixed values. In such cases, we speak of deformations of the matrix corresponding to these small parameter changes.
In Figure 34 we symbolically represent a k–parameter generic matrix family that intersects the variety of singular cases transversally (i.e., the intersection occurs at “nonzero angle”). Matrix families that are transverse to all varieties are called generic families.
A family with k parameters can be viewed as a k-dimensional manifold in the matrix space. For instance, a one–parameter family is represented by a curve in a 3-dimensional matrix space with codimension equal to 2, while the variety of singular cases has codimension equal 1.
The variety of singular cases depends on the specific problem. In the context of solving linear systems of equations or inverting matrices, this variety is the set of all singular matrices. For the eigenvalue problem, the variety of singular cases consists of all matrices that are defective or/and derogatory. In this setting, the one–dimensional family typically contains matrices with simple eigenvalues except at the singular points, where the curve representing the one–parameter family intersects the manifold of singular cases.
By the principle of transversality, in the general case, the variety of singular cases has dimension and a codimension equal to k. Hence, the codimension of the variety of singular cases is equal to the number of parameters that determine the matrix family.
We now illustrate this concept with an example related to the eigenvalue problem.
Example 20.
Consider a two-parameter deformation of the Jordan block
given by
In this example, the orbit of has dimension 2, and the tangent space of the perturbation also has dimension 2 for each pair . Consequently,
i.e., the perturbation is in general position with respect to the orbit of for all .
Figure 35 shows the matrix family for . The entries
correspond to a singular point at which A has double eigenvalue and canonical form which is a Jordan block . By introducing infinitesimal changes in x and y, the double eigenvalue splits into two simple eigenvalues, and the Jordan form becomes diagonal.
The singular points corresponding to matrices with multiple eigenvalues in the form
lie on the variety of the singular cases , which in this example represents a plane in the three–dimensional parameter space.
6.2. Versal Deformations
We shall adopt the following terminology. By a map of one family into another family, we mean a correspondence in which to each value of the parameter of the family there corresponds a definite value of the parameter of the family .
A versal family of matrices is one into which we can map every other family of matrices by means of a suitable mapping.
A universal family is a versal family with the additional property that in mapping any family into it, the “change of parameters” is uniquely determined by .
A miniversal family is a versal family depending on the minimum possible number of parameters. Clearly, such families are of particular interest from a computational point of view.
The term “versal” is formed from the word “universal” by dropping the prefix “uni”, which signifies the uniqueness of the map . As Arnold remarks [129], “versal” is the intersection of the concepts of “universal” and “transversal”.
To formalize these notations rigorously, we introduce the following definitions.
Two deformations and of the matrix are called equivalent if there exist deformations and of the identity matrices and , respectively, both defined on the same base , such that
In other words, the deformation is obtained from via an equivalent matrix transformation.
Let and be deformations of , where and , with and being parameter spaces of dimensions k and ℓ, respectively.
If there exist deformations of the identity matrix and of the identity matrix , defined for , together with a holomorphic mapping satisfying , such that
then we say that is induced from the deformation via and (see Figure 36).
A deformation of a matrix is said to be versal, if every other deformation of is equivalent to a deformation induced from via a suitable parameter change. That is, there exist deformations of and of , and a holomorphic mapping with
such that
A versal deformation of is called universal, if the inducing map is uniquely determined by .
A versal deformation of is called miniversal if its parameter space has minimal dimension among all versal deformations of .
We now proceed to a characterization of versal deformations.
The following theorem gives a condition under which a matrix deformation is versal.
Theorem 18.
[100] A deformation of is a versal deformation if and only if is transversal to the orbit of at .
We now show that a versal deformation is indeed transversal. Let be an arbitrary deformation of . By the versality of , there exist deformations , an a mapping such that
Differentiating and taking into account that
we obtain
where the subscript * denotes differentiation with respect to at .
Consequently, for every tangent vector at the base of , we have that
By Lemma 1, the vector belongs to the tangent space of the orbit . Therefore, any vector in the tangent space at can be expressed as the sum of a vector in the image of and a vector tangent to the orbit of .
Hence, is transversal to the orbit of , as illustrated in Figure 37.
A proof that a deformation which is transversal to the orbit is versal, can be found in ([113], Sect. 2.9).
According to Theorem 18, we have
This implies that the dimension of the parameter space of a versal deformation of is equal to
i.e., it equals the codimension of the orbit .
Equation (36) represents a particular case of a general situation, which can be described as follows. Let be a smooth submanifold of a manifold M. Consider a mapping
of another manifold into M, and let be such that .
The mapping is said to be transversal to at if the tangent space to M at is the sum of the image of the differential of A and the tangent space to N, i.e.,
Example 21.
-
(a) LetThen the codimension of the orbit is equal to n, and an n–parameter versal deformation of iswhere are arbitrary parameters. This deformation is both universal and miniversal.
- (b) Let . Then , and an –parameter versal deformation of isthat is, the family of all matrices. This deformation is also miniversal.
Equation (35) may be interpreted as a local approximation, in a neighbourhood of the origin, of an arbitrary matrix family by a versal family . A versal deformation of a matrix thus plays the role of a “normal form” into which not only the single matrix , but also any family of matrices sufficiently close to , can be transformed.
Naturally, this normal form must itself depend on parameters. Its pricipal advantage is that both the entries of the normal form and the similarity transformation leading to it can be chosen to depend smoothly on the entries of the original matrix, as they vary in a neighbourhood of .
Moreover, provided that the second order terms neglected in the linear approximation (26) are sufficiently small, versal deformations preserve the bundle containing , that is, the matrices of the family remain in the same bundle as .
6.3. Bifurcation Diagrams
Consider the structure and properties of the set in the parameter space, corresponding to the variety of singular cases in the matrix space associated with the eigenvalue problem. In this case, the parameter space can be partitioned into subsets, correspondingly to the partition of the matrix space in bundles. The exceptional values of the parameters to which correspond matrices with multiple eigenvalues (the singular cases), constitute a subset in the parameter space. This subset is called bifurcation diagram. The bifurcation diagram of a generic family of matrices represents a finite union of varieties – to each bundle of orbits corresponds its own variety in the parameter space . The codimension k of a variety in the parameter space of a generic family is equal to the codimension of the corresponding bundle in the space of all matrices, i.e., to the number of parameters determining the matrix family. Therefore, the bifurcation diagram of a family of matrices is a partition of the parameter space according to Jordan types of matrices. The partition consists of grouping together the matrices with the same dimensions of the Jordan blocks differing only in the eigenvalues. Thus, the bifurcation diagrams allow studying the partition of space of matrices into matrices with Jordan forms of distinct types. This makes them a useful tool to analyze the qualitative metamorphosis (or “catastrophes”) of a matrix family.
The partition of the matrix space into matrices with the same dimensions of the Jordan blocks groups the matrices into bundles of equal codimensions and represents a finite stratification of the space of matrices. In the space of families of matrices of order n, the families transversal to the stratification into Jordan types constitute an everywhere dense set. Clearly, such families consist of matrices with simple eigenvalues.
The term “bifurcation”was introduced by Poincaré in 1885 in a paper that marks the beginning of bifurcation theory [131].
An accessible introduction to the bifurcation theory of dynamical systems is given in [132], while a more comprehensive and in-depth treatment can be found in [22,133,134]. A bifurcation analysis of eigenvalues and generalized eigenvalues is presented in [135], Ch. 2.
Below, we consider bifurcation diagrams of two–, and three–parameter matrix families, associated with strata containing Jordan blocks of different sizes.
Example 22.
Consider a family of third order matrices in companion form
with characteristic equation
Using the substitution
we obtain the depressed cubic equation
Representation (38) shows that the parametric space associated with the matrix bundle under consideration is two–dimensional, coinciding with the codimension of the bundle.
In the generic case, the discriminant
is nonzero, and the characteristic equation has three disjoint roots , γ. In this case, the Jordan form of A is diagonal,
This stratum will be denoted by .
If the discriminant and , then the cubic equation has a double root
and a simple root
The Jordan form is then
with a Jordan block corresponding to the double eigenvalue α and a block corresponding to the simple eigenvalue β. This stratum is denoted by .
If and , then and
is a triple eigenvalue of A. Since the companion matrices are non–derogatory, the triple eigenvalue participates in one Jordan block:
This stratum is denoted by .
In Figure 39 we show the discriminant Δ of the characteristic equation of a companion matrix for and various values of the coefficients and . The bifurcation diagram of the matrix bundle is obtained as the intersection of the discriminant surface with the plane . The bifurcation diagram forms a semi–cubic parabola–a curve with a singular point in the shape of a cusp, which corresponds to the triple eigenvalue α (Figure 40).
Example 23.
Consider a family of matrices
In the regular (generic) case, such matrices have the diagonal Jordan form
where α and β are simple eigenvalues. For simplicity, a stratum of this type will be denoted by .
We are interested in the degenerate case when the Jordan form
consists of two blocks and the double eigenvalue α is semisimple. This stratum will be denoted by . The matrices are non–defective but derogatory. In the given case, the eigenvalue is determined as the double root of the quadratic equation for values of the parameters and zeroing the discriminant,
The expression (40) describes a variety of singular cases in in the form of a cone with vertex at (Figure 41). The point , corresponding to the double semisimple eigenvalue α, is a singular point of the variety, while the conical surfaces for corresponds to bundles of type with codimension 1 (single Jordan block of order 2). The points outside the bifurcation diagram represent matrices with two distinct simple eigenvalues α and β.
Example 24.
Consider a three–parameter matrix family consisting of companion matrices of the form
The singular cases of this family consist of matrices that are defective and non-derogatory. Note that a fourth order companion matrix with a quadruple eigenvalue has only one Jordan block in its Jordan canonical form.
The characteristic equation of the matrix A has the form of a depressed quartic polynomial equation
This equation has repeated roots if and only if
where
is the discriminant of the quartic polynomial .
This equation has four roots given by
Thus, the bifurcation diagram corresponding to repeated roots depends on the two free parameters c and e.
The surface representing the points shown in Figure 42, is called a swallowtail.
According to the data presented in Table 3, the point (the swallowtail point) represents the Jordan blocks of defective matrices, corresponding to the most degenerate companion matrices A).
The curve , consisting of two cuspidal edges emanating from the swallowtail point, corresponds to the Jordan forms . The curve , given by the intersection of the swallowtail wings, represents the Jordan forms .
The surface , known as the swallowtail surface, represents the Jordan forms . Finally, the points , corresponding to the region outside the swallowtail, represent the diagonal Jordan forms
that is, matrices with four simple eigenvalues.
The latest case is the most generic one and therefore occurs with the highest probability.
7. Conclusions
The brief survey of the applications of differential topology in matrix analysis shows that the introduction of the concepts of smooth manifolds and smooth mappings enables the analysis of various global properties of parameter-dependent matrices, including the genericity of the problems considered, the identification of singular cases, the estimation of the distance to ill–posed problems, the conditioning of problems in both deterministic and probabilistic terms, and the determination of numerical solutions as a problem for finding an optimal bundle containing an approximate solution.
Methods of differential topology are particularly well suited for matrices whose entries are only approximately known and for computations subject to rounding errors. All of this provides reason to expect that differential topology methods will find wider applications in matrix analysis.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The datasets generated during the current study are available from the author upon reasonable request.
Conflicts of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Abbreviations
| , | number field; |
| , | set of natural numbers ; |
| , | set of integers ; |
| , | set of rational numbers , where |
| p and q are integers; | |
| , | set of real numbers; |
| , | set of positive real numbers; |
| , | set of complex numbers; |
| , | imaginary unit; |
| , | union of sets A and B; |
| , | intersection of sets A and B; |
| , | difference of sets A and B; |
| , | Cartesian product of sets A and B; |
| , | class of smooth functions; |
| , | class of analytic functions; |
| , | scalar product of the vectors x and y; |
| , | space of complex matrices; |
| , | space of real matrices; |
| , | matrix of absolute values of the entries of A; |
| , | transposed of A; |
| , | Hermitian conjugate of A; |
| , | inverse of A; |
| , | zero matrix; |
| , | identity matrix; |
| , | determinant of A; |
| , | rank of A; |
| , | trace of a square matrix A; |
| , | ith singular value of A; |
| , | perturbation of A; |
| , | Euclidean norm of the vector x; |
| , | spectral norm of A; |
| , | Frobenius norm of A; |
| , | manifold; |
| , | dimension of the manifold ; |
| , | codimension of the manifold ; |
| , | volume of the manifold ; |
| , | mapping of the manifold into the manifold ; |
| , | identity map of into , |
| , | differential of the map f at the point x; |
| , | composition of the maps g and f; |
| , | orbit of the matrix A; |
| , | bundle of the matrix A; |
| , | tangent space of at the point x; |
| , | tangent bundle of ; |
| , | normal space of at the point x; |
| , | normal bundle of ; |
| , | n–dimensional sphere in ; |
| , | n–dimensional torus in ; |
| , | open ball centered at p with a radius r |
| , | closed ball centered at p with a radius r; |
| , | subspace spanned by the columns of X; |
| , | probability of the event ; |
| , | expected value (mean) of the random variable ; |
| , | vector v orthogonal to a subspace S; |
| , | equal by definition. |
References
- H. Weyl. Philosophy of Mathematics and Natural Science. Princeton University Press, Princeton, NJ, 2009. ISBN: 9780691141206.
- M. Morse. The Calculus of Variations in the Large. AMS, New York, 1934.
- The MathWorks, Inc., Natick, MA. MATLAB Version 9.9.0.1538559 (R2020b), 2020. http://www.mathworks.com.
- V. Guillemin and A. Polack. Differential Topology. Prentice–Hall, Inc., Englewood Cliffs, NJ, 1974. ISBN: 0-13-212605-2.
- J.M. Lee. Introduction to Topological Manifolds, volume 202 of Graduate Texts in Mathematics. Springer, New York, second edition, 2011. [CrossRef]
- J.M. Lee. Introduction to Smooth Manifolds, volume 218 of Graduate Texts in Mathematics. Springer, New York, second edition, 2013. [CrossRef]
- V.I. Arnold. Geometrical Methods in the Theory of Ordinary Differential Equations. Springer-Verlag, New York, second edition, 1988. ISBN: 978-1-4612-6994-6.
- V.I. Arnol’d. Ordinary Differential Equations. Springer-Verlag, Berlin, 1992. ISBN: 3-540-54813-0.
- L.W. Tu. An Introduction to Manifolds. Springer–Verlag, New York, 2011. [CrossRef]
- K. Burns and M. Guidea. Differential Geometry and Topology. With a View to Dynamical Systems. Chapman & Hall/CRC, Boca Raton, FL, 2005. ISBN: 978-1584882534.
- J.W. Milnor. Topology from the Differential Viewpoint. The University Press of Virginia, Charlotteville, VA, 1965.
- A.H. Wallace. Differential Topology. First Steps. W.A. Benjamin, Inc., New York, 1968.
- M.W. Hirsh. Differential Topology. Springer–Verlag, New York, 1976. [CrossRef]
- V.I. Arnold. Mathematical Methods of Classical Mechanics. Springer-Verlag, New York, second edition, 1989. ISBN: 0-387-96890-3.
- Y. I. Manin. The notion of dimension in geometry and algebra. Bull. Amer. Math. Soc. (N.S.), 43:139–161, 2006. [CrossRef]
- E. Scholz. The concept of manifold, 1850–1950. In I.M. James, editor, History of Topology, pages 25–64. Elsevier, Amsterdam, 1999. ISBN: 0-444-82375-1.
- B. Chow and C. Chow. Lectures on Differential Geometry. American Mathematical Society, Providence, RI, 2024. ISBN: 978-1-4704-7804-9.
- Yu. Borisovich and N. Bliznyakov and Ya. Izrailevich and T. Fomenko. Introduction to Topology. Mir Publishers, Moskow, 1985.
- V.I. Arnold, V.V. Goryunov, O.V. Lyashko, and V.A. Vasil’ev. Dynamical Systems VIII. Singularity Theory II, Applications, volume 39 of Encyclopaedia of Mathematical Sciences. Springer–Verlag, Berlin, 1993. [CrossRef]
- V.I. Arnold, V.V. Goryunov, O.V. Lyashko, and V.A. Vasil’ev. Singularity Theory I, volume 6 of Encyclopaedia of Mathematical Sciences. Springer–Verlag, Berlin, 1998. [CrossRef]
- M. Golubitsky and V. Guillemin. Stable Mappings and Their Singularities. Springer–Verlag, New York, 1973. ISBN: 0-387-90073-3-X.
- J. Guckenheimer. Bifurcations of dynamical systems. In C. Marchioro, editor, Dynamical Systems, volume 78, pages 7–123. Springer, Berlin, 2010. [CrossRef]
- R. Thom. Structural stability, catastrophe theory, and applied mathematics. SIAM Rev., 19:189–201, 1977. [CrossRef]
- E.C. Zeeman. Catastrophe theory. In W. Güttinger and H. Eikemeier, editors, Structural Stability in Physics, volume 4 of Springer Series in Synergetics, pages 12–22. Springer, Berlin, 1979. [CrossRef]
- V.I. Arnold. Catastrophe Theory. Springer-Verlag, Berlin, 1992. ISBN: 978-3-540-54811-9. [CrossRef]
- of Encyclopaedia of Mathematical Sciences. [CrossRef]
- M. Golubitsky. An introduction to catastrophe theory and its applications. SIAM Rev., 20:352–387, 1978. [CrossRef]
- J. Guckenheimer. The catastrophe controversy. Math. Intelligencer, 1:15–20, 1978. [CrossRef]
- F. Chaitin-Chatelin, V. Frayssé, and T. Braconnier. Computations in the neighbourhood of algebraic singularities. Numer. Funct. Anal. Optim., 16:287–302, 1995. [CrossRef]
- C.T.C. Wall. Differential Topology. Cambridge University Press, Cambridge, UK, 2016. ISBN: 978-1-107-15352-3.
- R. Gilmore. Lie groups: General theory. In J.P. Françoise, G.L. Naber, and T. S. Tsun, editors, Encyclopedia of Mathematical Physics, pages 286––304. Elsevier, Amsterdam, 2006. [CrossRef]
- J.B. Carrell. Groups, Matrices, and Vector Spaces. Springer, New York, 2017. ISBN: 978-0-387-79427-3.
- P.J. Olver. Applications of Lie Groups to Differential Equations. Springer–Verlag, New York, 1993. ISBN: 978-0-387-95000-6.
- K. Kendig. Elementary Algebraic Geometry. Springer–Verlag, New York, 1977. ISBN: 978-1-4615-6901-5.
- L. Kronecker. Über Schaaren von quadratischen und bilinearen formen. Monatsberichte der Königlich Preussischen Akademie der Wissenschaften zu Berlin vom Jahre 1874, pages S. 59–76, 149–156, 206–232, 1874. = Werke, 1 (1895), Teubner, Leipzig, pp. 349–413. [CrossRef]
- J. Hadamard. Lectures on Cauchy’s Problem in Linear Partial Differential Equations. Yale University Press, New Haven, 1923.
- J.R. Rice. A theory of condition. SIAM J. Numer. Anal., 3:287–310, 1966. [CrossRef]
- A.J. Geurts. A contribution to the theory of condition. Numer. Math., 39:85–96, 1982. [CrossRef]
- I. Gohberg and I. Koltracht. Mixed, componentwise, and structured condition numbers. SIAM J. Matrix Anal. Appl., 14:688–704, 1993. [CrossRef]
- W. Wang and Y. Wei. Mixed and component–wise condition numbers for matrix decompositions. Theoret. Comput. Sci., 681:199–216, 2017. [CrossRef]
- W.W. Hager. Condition estimates. SIAM J. Sci. Statist. Comput., 5:311–316, 1984. [CrossRef]
- N.J. Higham. Accuracy and Stability of Numerical Algorithms. SIAM, Philadelphia, PA, second edition, 2002. ISBN: 978-0-898715-21-7.
- C. Kenney and A.J. Laub. Condition estimates for matrix functions. SIAM J. Matrix Anal. Appl., 10:191–209, 1989. [CrossRef]
- R. Mathias. Condition estimation for matrix functions via the Schur decomposition. SIAM J. Matrix Anal. Appl., 16:565–578, 1995. [CrossRef]
- G.W. Stewart. Matrix Algorithms, volume I: Basic Decompositions. SIAM, Philadelphia, PA, 1998. ISBN: 0-89871-414-1.
- G.H. Golub and C.F. Van Loan. Matrix Computations. The John Hopkins University Press, Baltimore, MD, fourth edition, 2013. ISBN: 978-1-4214-0794-4.
- Å. Björck. Numerical Methods in Matrix Computations. Springer, New York, 2015. [CrossRef]
- E. Anderson, Z. Bai, C. Bischof, S. Blackford, J. Demmel, J. Dongarra, J. Du Croz, A. Greenbaum, S. Hammarling, A. McKenney, and D.C. Sorensen. LAPACK Users’ Guide. SIAM, Philadelphia, PA, third edition, 1999. ISBN: 0-89871-447-8.
- V.B. Lidskii. Perturbation theory of non–conjugate operators. USSR Computational Mathematics and Mathematical Physics, 6:73–85, 1966. [CrossRef]
- J. Moro, J.V. Burke, and M.L. Overton. On the Lidskii–Vishik-Lyusternik perturbation theory for eigenvalues of matrices with arbitrary Jordan structure. SIAM J. Matrix Anal. Appl., 18:793–817, 1997. [CrossRef]
- J.H. Wilkinson. The Algebraic Eigenvalue Problem. Clarendon Press, Oxford, UK, 1965. ISBN: 978-0-19-853418-1.
- G.W. Stewart. Matrix Algorithms, volume II: Eigensystems. SIAM, Philadelphia, PA, 2001. ISBN: 0-89871-503-2.
- J.W. Demmel. Applied Numerical Linear Algebra. SIAM, Philadelphia, PA, 1997. ISBN: 978-0-898713-89-3.
- R. Bhatia. Perturbation Bounds for Matrix Eigenvalues. Classics in Applied Mathematics. SIAM, Philadelphia, PA, 2007. [CrossRef]
- G.W. Stewart and J.-G. Sun. Matrix Perturbation Theory. Academic Press, San Diego, CA, 1990. ISBN: 978-0126702309.
- R. Li. Matrix perturbation theory. In L. Hogben, editor, Handbook of Linear Algebra, Discrete Math. Appl., pages (21–1)–(21–20). CRC Press, Boca Raton, FL, second edition, 2014. ISBN: 978-1-4665-0729-6.
- A. Greenbaum, R.-C. Li, and M.L. Overton. First-order perturbation theory for eigenvalues and eigenvectors. SIAM Rev., 62:463–482, 2020. [CrossRef]
- L. Elsner. On the variation of the spectra of matrices. Linear Algebra Appl., 47:127–138, 1982. [CrossRef]
- L. Elsner. An optimal bound for the spectral variation of two matrices. Linear Algebra Appl., 71:77–80, 1985. [CrossRef]
- L. Elsner. Perturbation theorems for the matrix eigenvalue problem. Port. Math., 43:69–76, 1986.
- P. Henrici. Bounds for iterates, inverses, spectral variation and fields of values for non–normal matrices. Numer. Math., 4:24–40, 1962. [CrossRef]
- Y. Nakatsukasa. Algorithms and Perturbation Theory for Matrix Eigenvalue Problems and the Singular Value Decomposition. PhD thesis, Office of Graduate Studies, University of California, Davis, CA, 2011.
- J.–G. Sun. Stability and accuracy: Perturbation analysis of algebraic eigenproblems. Technical Report 98.07, Department of Computing Science, Umeå University, Umeå, Sweden, 1998. (Revised version, 2002).
- J.H. Wilkinson. Sensitivity of eigenvalues. Util. Math., 25:5–76, 1984.
- J.H. Wilkinson. Sensitivity of eigenvalues, part II. Util. Math., 30:243–286, 1986.
- Z. Bai, J. Demmel, and A. Mckenney. On computing condition numbers for the nonsymmetric eigenproblem. ACM Trans. Math. Software, 19:202–223, 1993. [CrossRef]
- S.P. Chen, R. Feldman, and B.N. Parlett. Algorithm 517. A program for computing the condition numbers of matrix eigenvalues without computing eigenvectros. ACM Trans. Math. Software, 3:186–203, 1977. [CrossRef]
- M. Karow, D. Kressner, and F. Tisseur. Structured eigenvalue condition numbers. SIAM J. Matrix Anal. Appl., 28:1052–1068, 2006. [CrossRef]
- R.M. Lin, Z. Wang, and M.K. Lim. A practical algorithm for the efficient computation of eigenvector sensitivities. Computer Methods in Applied Mechanics and Engineering, 130:355–367, 1996. [CrossRef]
- J.–g. Sun. On condition numbers of a nondefective multiple eigenvalue. Numer. Math., 61:265–275, 1992. [CrossRef]
- C. Van Loan. On estimating the condition of eigenvalues and eigenvectors. Linear Algebra Appl., 88–89:715–732, 1987. [CrossRef]
- S. Smale. The fundamental theorem of algebra and complexity theory. AMS Bull. (New Series), 4:1–35, 1981. [CrossRef]
- S. Smale. On the efficiency of algorithms of analysis. AMS Bull. (New Series), 13:87–121, 1985. [CrossRef]
- S. Smale. Some remarks on the foundations of numerical analysis. SIAM Rev., 32:211–220, 1990. [CrossRef]
- J. Renegar. On the efficiency of Newton’s method in approximating all zeros of a system of complex polynomials. Math. Oper. Res., 12:121–148, 1987. [CrossRef]
- J. Renegar. Is it possible to know a problem instance is ill–posed? J. Complexity, 10:1–56, 1994. [CrossRef]
- J.W. Demmel. On condition numbers and the distance to the nearest ill–posed problem. Numer. Math., 51:251–289, 1987. [CrossRef]
- J.W. Demmel. The probability that a numerical analysis problem is difficult. Math. Comp., 50:449–480, 1988. [CrossRef]
- J.W. Demmel. Steve Smale and the geometry of ill–conditioning. In M.W. Hirsch, J.E. Marsden, and M.Shub, editors, From Topology to Computation: Proceedings of the Smalefest, pages 305–316. Springer–Verlag, New York, 1993. [CrossRef]
- D.A. Klain and G.-C. Rota. Introduction to Geometric Probability. Lezioni Lincee. Cambridge University Press, Cambridge, UK, 1997. ISBN: 978-0-521-59362-5.
- L.A. Santaló. Integral Geometry and Geometric Probability. Cambridge University Press, New York, second edition, 2004. ISBN: 978-0-521-52344-8.
- H. Solomon. Geometric Probability. SIAM, Philadelphia, PA, 1978. ISBN: 978-0898710250.
- P. Bürgisser and F. Cucker. Condition. The Geometry of Numerical Algorithms. Springer, Heidelberg, 2013. ISBN: 978-3-642-38895-8.
- R. O. Akinola, M. A. Freitag, and A. Spence. The calculation of the distance to a nearby defective matrix. Numer. Linear Algebra Appl., 21:403––404, 2013. [CrossRef]
- G. Armentia, J.-M. Gracia, and F.-E. Velasco. Nearest matrix with a prescribed eigenvalue of bounded multiplicities. Linear Algebra Appl., 592:188–209, 2020. [CrossRef]
- A. Kalinina, A. Uteshev, M. Goncharova, and E. Lezhnina. On the distance to the nearest defective matrix. In F. Boulier, M. England, I. Kotsireas, T.M. Sadykov, and E.V. Vorozhtsov, editors, Computer Algebra in Scientific Computing. CASC 2023., volume 14139 of Lecture Notes in Computer Science, pages 255–271, Cham, Switzerland, 2023. Springer Nature. [CrossRef]
- R.A. Lippert. Fixing multiple eigenvalues by a minimal perturbation. Linear Algebra Appl., 432:1785––1817, 2010. [CrossRef]
- A.N. Malyshev. A formula for the 2–norm distance from a matrix to the set of matrices with multiple eigenvalues. Numer. Math., 83:443–454, 1999. [CrossRef]
- C. Eckart and G. Young. The approximation of one matrix by another of lower rank. Psychometrika, 3:211–218, 1936. [CrossRef]
- W. Kahan. Conserving confluence curbs ill–condition. Technical Report AD–766 916, University of California, Berkely, CA, August 1972.
- A. Ruhe. Properties of a matrix with a very ill–conditioned eigenproblem. Numer. Math., 15:57–60, 1970. [CrossRef]
- J.H. Wilkinson. Note on matrices with a very ill–conditioned eigenproblem. Numer. Math., 19:176–178, 1972. [CrossRef]
- D.J. Smith and M.K. Vamanamurthy. How small is a unit ball. Mathematics Magazine, 62:101–107, 1989. [CrossRef]
- H. Weyl. On the volume of tubes. Amer. J. Math., 61:461–472, 1939. [CrossRef]
- R. Wongkew. Volumes of tubular neighbourhoods of real algebraic varieties. Pacific Journal of Mathematics, 159:177–184, 1993. [CrossRef]
- M. Lotz. On the volume of tubular neighborhoods of real algebraic varieties. Poc. Amer. Math. Soc., 143:1875–1889, 2014. [CrossRef]
- A. Edelman. On the distribution of the scaled condition number. Math. Comp., 58: 185–190. 1992. [CrossRef]
- P. Bürgisser, F. Cucker, and M. Lotz. The probability that a slightly perturbed numerical analysis problem is difficult. Math. Comp., 77:1559–-1583, 2008. [CrossRef]
- G. Frobenius. Theorie der linearen Formen mit ganzen Coefficienten. Journal für die reine und angewandte Mathematik, 86:146–208, 1879. [CrossRef]
- V.I. Arnold. On matrices depending on parameters. Russian Math. Surveys, 26:29–43, 1971. [CrossRef]
- J.W. Demmel and A. Edelman. The dimension of matrices (matrix pencils) with given Jordan (Kronecker) canonical form. Linear Algebra Appl., 230:61–87, 1995. [CrossRef]
- P.C. Hansen. Rank–Deficient and Discrete Ill–Posed Problems: Numerical Aspects of Linear Inversion. SIAM, Philadelphia, PA, 1998. ISBN: 978-0-898714-03-6.
- G.H. Golub, V. Klema, and G.W. Stewart. Rank degeneracy and least squares problems. Technical Report TR–456, Department of Computer Science, University of Maryland, College Park, MD, 1976.
- G.W. Stewart. Rank degeneracy. SIAM J. Sci. Stat. Comput., 5:403–413, 1984. [CrossRef]
- G.W. Stewart. On the early history of the singular value decomposition. SIAM Rev., 35:551–566, 1993. [CrossRef]
- J. Demmel and B. Kågström. The generalized Schur decomposition of an arbitrary pencil A-λB: Robust software with error bounds and applications. Part I: Theory and algorithms. ACM Trans. Math. Software, 19:160–174, 1993. [CrossRef]
- J. Demmel and B. Kågström. The generalized Schur decomposition of an arbitrary pencil A-λB: Robust software with error bounds and applications. Part II: Software and applications. ACM Trans. Math. Software, 19:175–201, 1993. [CrossRef]
- B. Kågström and P. Wiberg. Extracting partial canonical structure for large scale eigenvalue problems. Numer. Algorithms, 24:195–237, 2000. [CrossRef]
- M.W. Hirsh and S. Smale. Differential Equations, Dynamical Systems, and Linear Algebra. Academic Press, San Diego, CA, 1974. ISBN: 0-12-349550-4.
- J. Palis and W. de Melo. Geometric Theory of Dynamical Systems: An Introduction. Springer–Verlag, New York, 1982. ISBN: 978-1-4612-5705-9.
- S. Wiggins. Introduction to Applied Nonlinear Dynamical Systems and Chaos. Texts in Applied Mathematics. Springer, New York, second edition, 2003. ISBN: 0-387-00177-8-4.
- D.K. Arrowsmith and C.M. Place. An Introduction to Dynamical Systems. Cambridge University Press, Cambridge, UK, 1990. ISBN: 978-0-521-31650-7.
- S.-N. Chow, C. Li, and D. Wang. Normal Forms and Bifurcation of Planar Vector Fields. Cambridge University Press, London, UK, 1994. ISBN: 978-0-521-37226-8.
- A. Edelman, E. Elmroth, and B. Kågström. A geometric approach to perturbation theory of matrices and matrix pencils. part i: Versal deformations. SIAM J. Matrix Anal. Appl., 18:653––692, 1997. [CrossRef]
- A. Edelman, E. Elmroth, and B. Kågström. A geometric approach to perturbation theory of matrices and matrix pencils. part ii: A stratification-enhanced staircase algorithm. SIAM J. Matrix Anal. Appl., 20:667––699, 1999. [CrossRef]
- R. Gilmore. Catastrophe Theory for Scientists and Engineers. Dover Publications, New York, 1993. ISBN: 0-486-67539-4.
- L. Stolovitch. On the computation of a versal family of matrices. Numer. Algorithms, 4:25–46, 1993. [CrossRef]
- A.A. Mailybaev. Computation of multiple eigenvalues and generalized eigenvectors for matrices dependent on parameters. Numer. Linear Algebra Appl., 13:419––436, 2006. [CrossRef]
- A. Dmytryshyn. Versal deformations: A tool of linear algebra. Cornell University Library, ArXiv e–prints in Representation Theory [math.RT] 2312.14910v1, 1–15, 2023. [CrossRef]
- M.W. Hirsh, S. Smale, and R.L. Devaney. Differential Equations, Dynamical Systems, and an Introduction to Chaos. Elsevier, Amsterdam, 2013. ISBN: 978-0-12-382010-5.
- B. Kågström and A. Ruhe. An algorithm for numerical computation of the Jordan normal form of a complex matrix. ACM Trans. Math. Software, 6:398–419, 1980. [CrossRef]
- B. Kågström and A. Ruhe. Algorithm 560: JNF, an algorithm for numerical computation of the Jordan normal form of a complex matrix. ACM Trans. Math. Software, 6:437–443, 1980. [CrossRef]
- Z. Zeng. Computing multiple roots of inexact polynomials. Math. Comp., 74:869–903. [CrossRef]
- Z. Zeng. Geometric modeling and regularization of algebraic problems. Cornell University Library, ArXiv e-prints in Numerical Analysis [math.NA] 2102.08830v1, 2021. [CrossRef]
- Z. Zeng and T.-Y. Li. A numerical method for computing the Jordan canonical form. Cornell University Library, ArXiv e–prints in Numerical Analysis [math.NA] 2103.0206v1, 2021. [CrossRef]
- V.N. Kublanovskaya. On a method of solving the complete eigenvalue problem for a degenerate matrix. USSR Computational Mathematics and Mathematical Physics, 6:1–14, 1966. [CrossRef]
- A. Ruhe. An algorithm for numerical determination of the structure of a general matrix. BIT Numerical Mathematics, 10:196–216, 1970. [CrossRef]
- P. Petkov. The Numerical Jordan Form. World Scientific, Singapore, 2024. ISBN: 978-981-12-8644-5.
- V.I. Arnol’d. Lectures on bifurcations in versal families. Russian Math. Surveys, 27:54–123, 1972. [CrossRef]
- A.A. Mailybaev. Transformation to versal deformations of matrices. Linear Algebra Appl., 337:87–108, 2001. [CrossRef]
- H. Poincaré. Sur l’équilibre d’une masse fluide animé d’un mouvement de rotation. Acta Math., 7:259–380, 1885. [CrossRef]
- P. Glendinning. Bifurcation theory. In N.J. Higham, editor, The Prinston Companion to Applied Mathematics, pages 393–402. Prinston University Press, Prinston, NJ, 2015. ISBN: 978-0-691-15039-0.
- J.D. Crawford. Introduction to bifurcation theory. Rev. Mod. Phys., 63:991–1037, 1991. [CrossRef]
- Y.A. Kuznetsov. Elements of Applied Bifurcation Theory. Springer, New York, fourth edition, 2004. [CrossRef]
- A. P. Seyranian and A. A. Mailybaev. Multiparameter Stability Theory with Mechanical Applications. World Scientific, Singapore, 2003. ISBN: 981-238-406-5.
Figure 1.
Manifolds in the 3–dimensional space.
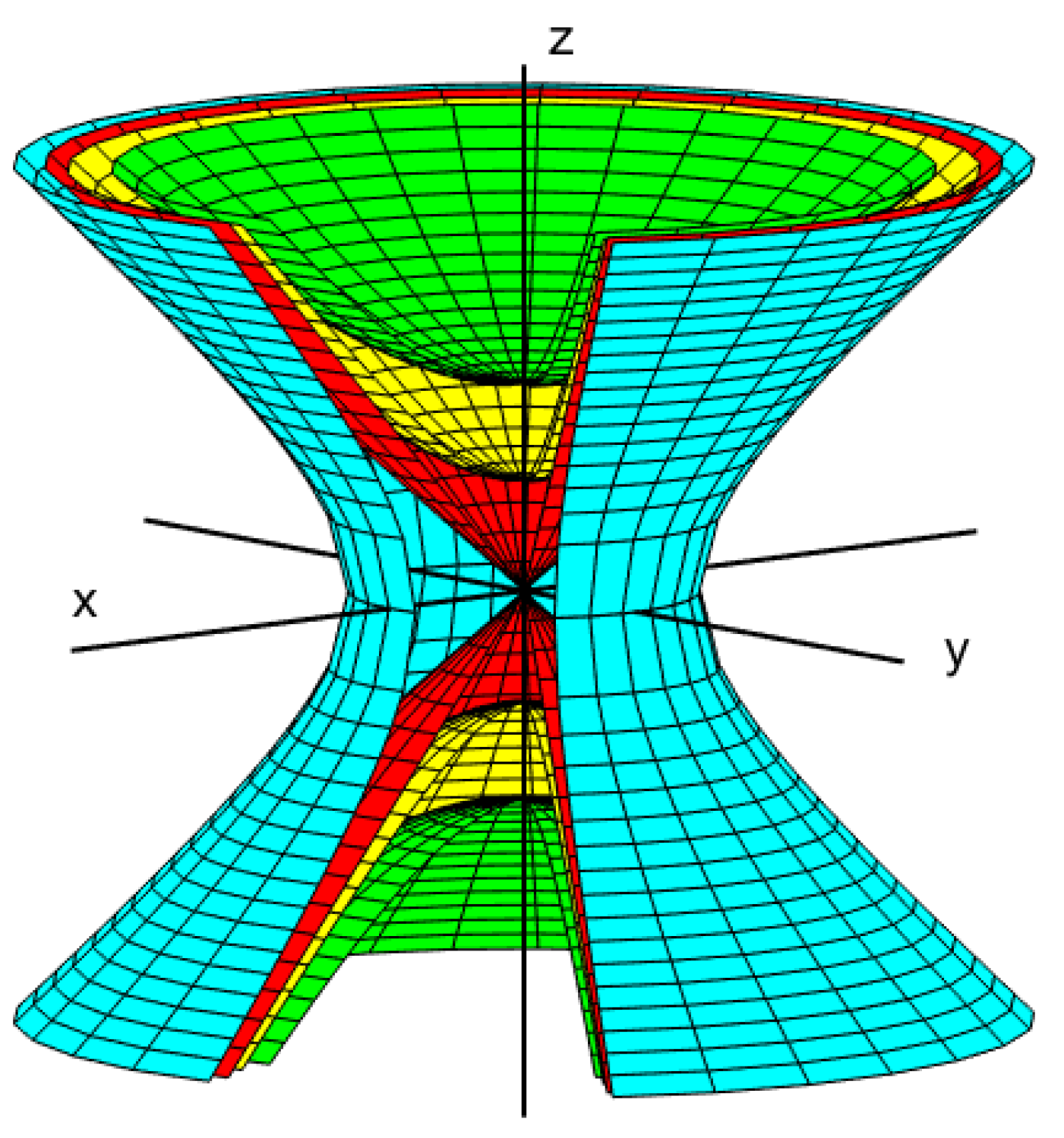
Figure 2.
Open chart.
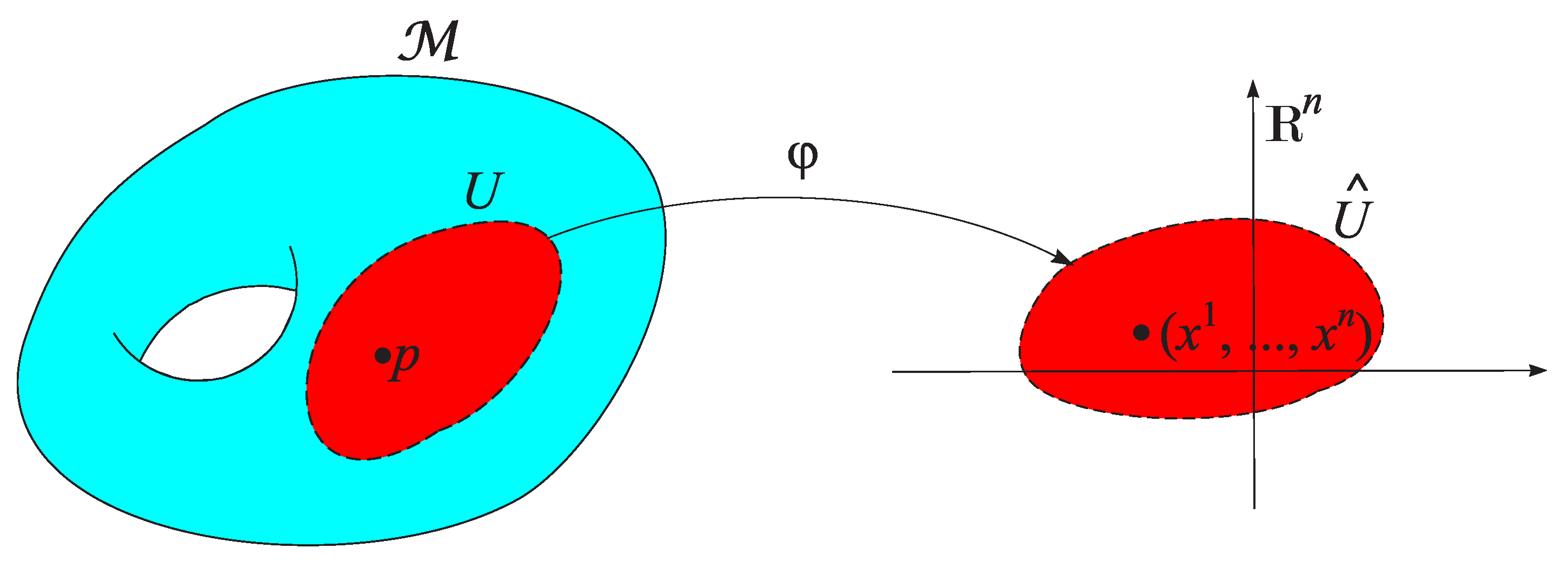
Figure 3.
An atlas of a manifold.
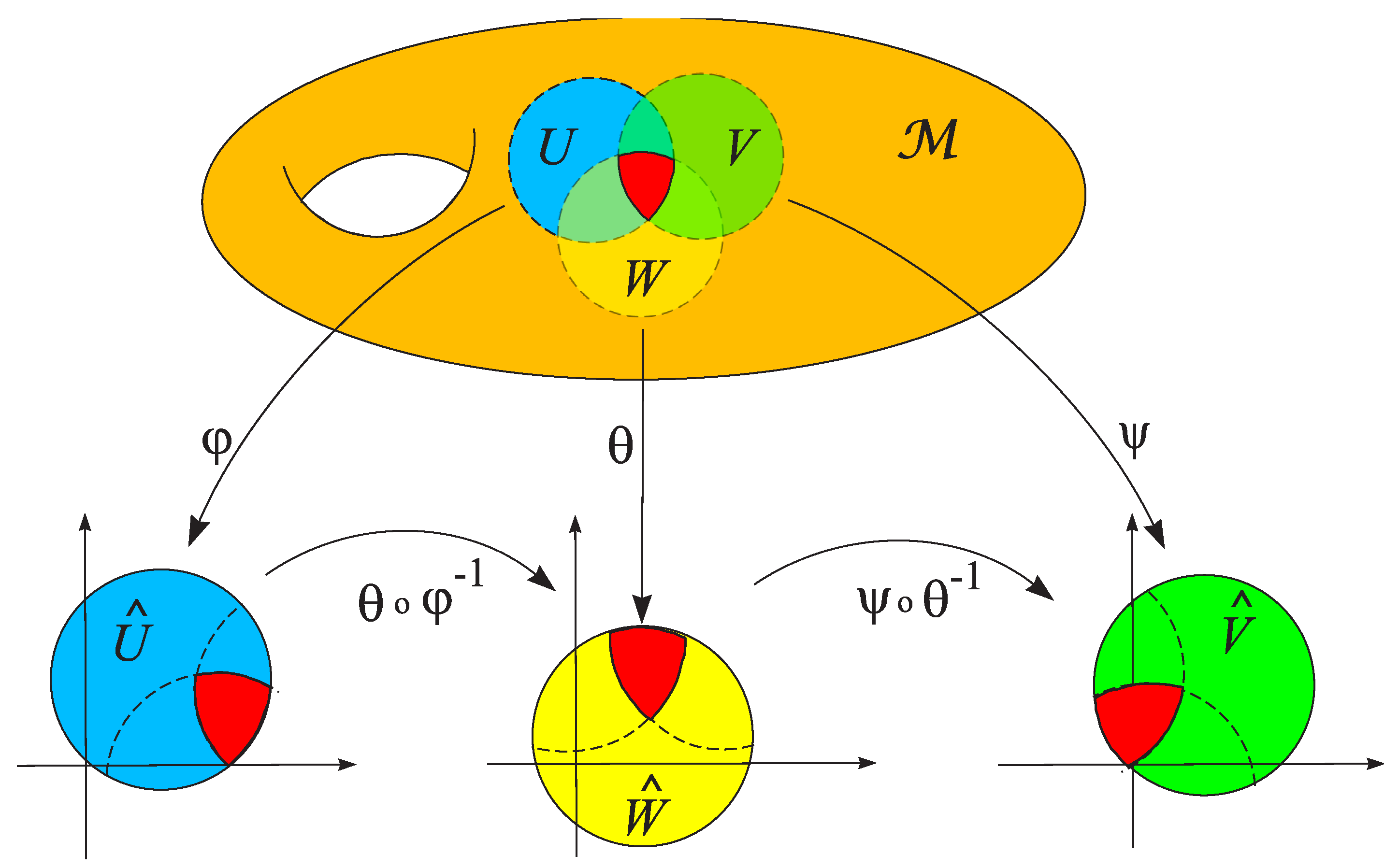
Figure 4.
Stereographic projection of the sphere.
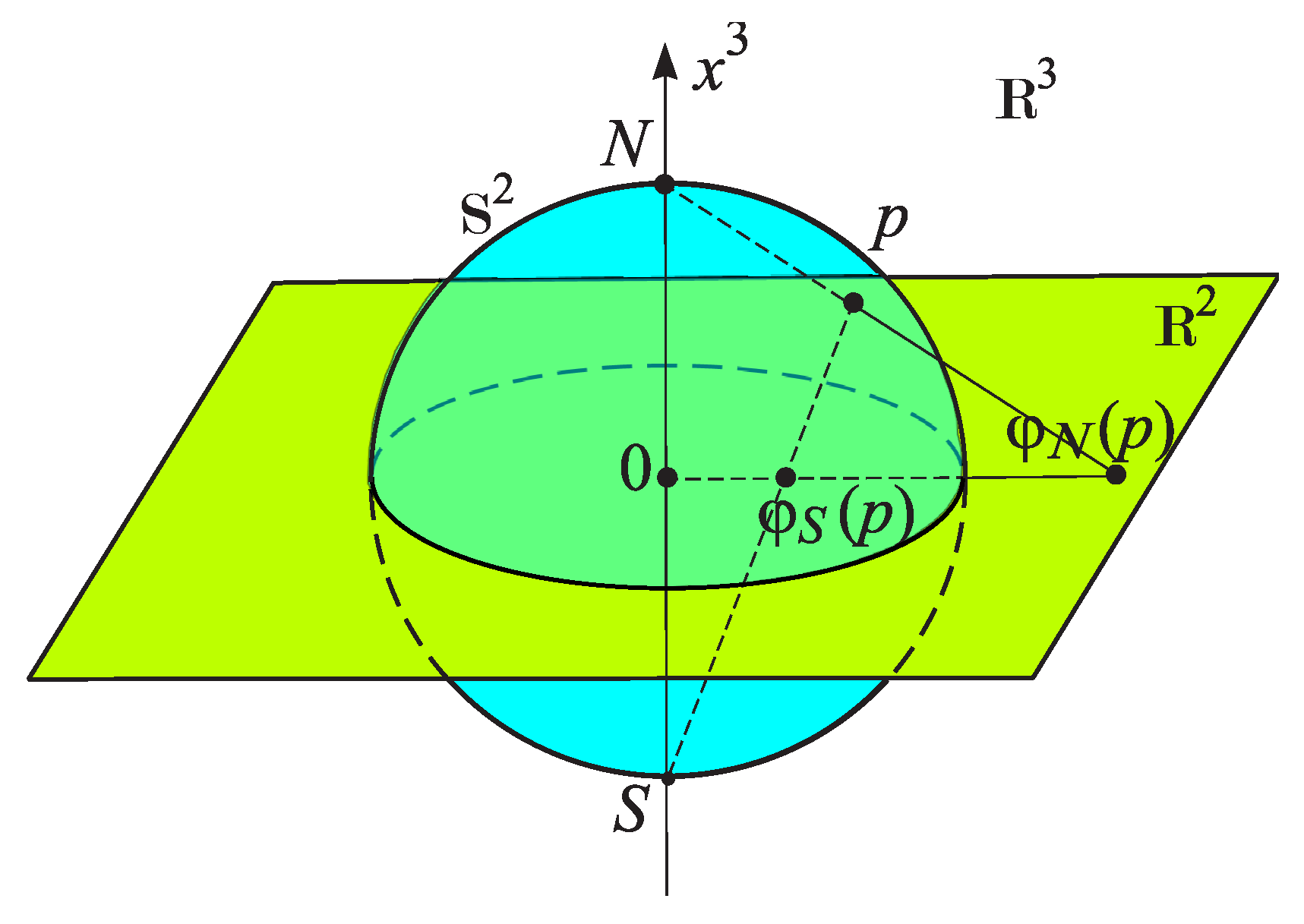
Figure 5.
An atlas of the sphere.
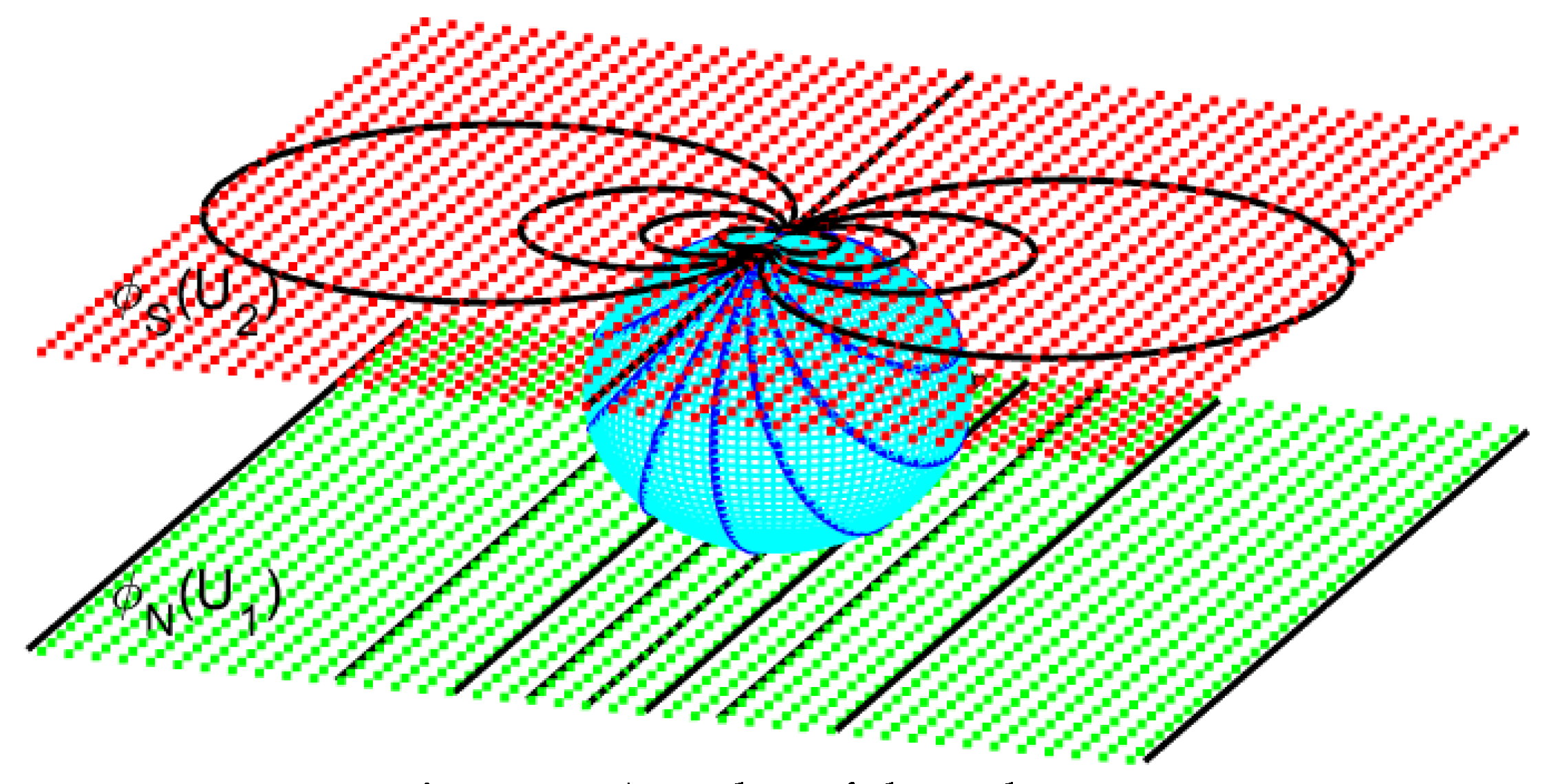
Figure 6.
Smooth map between two manifolds.
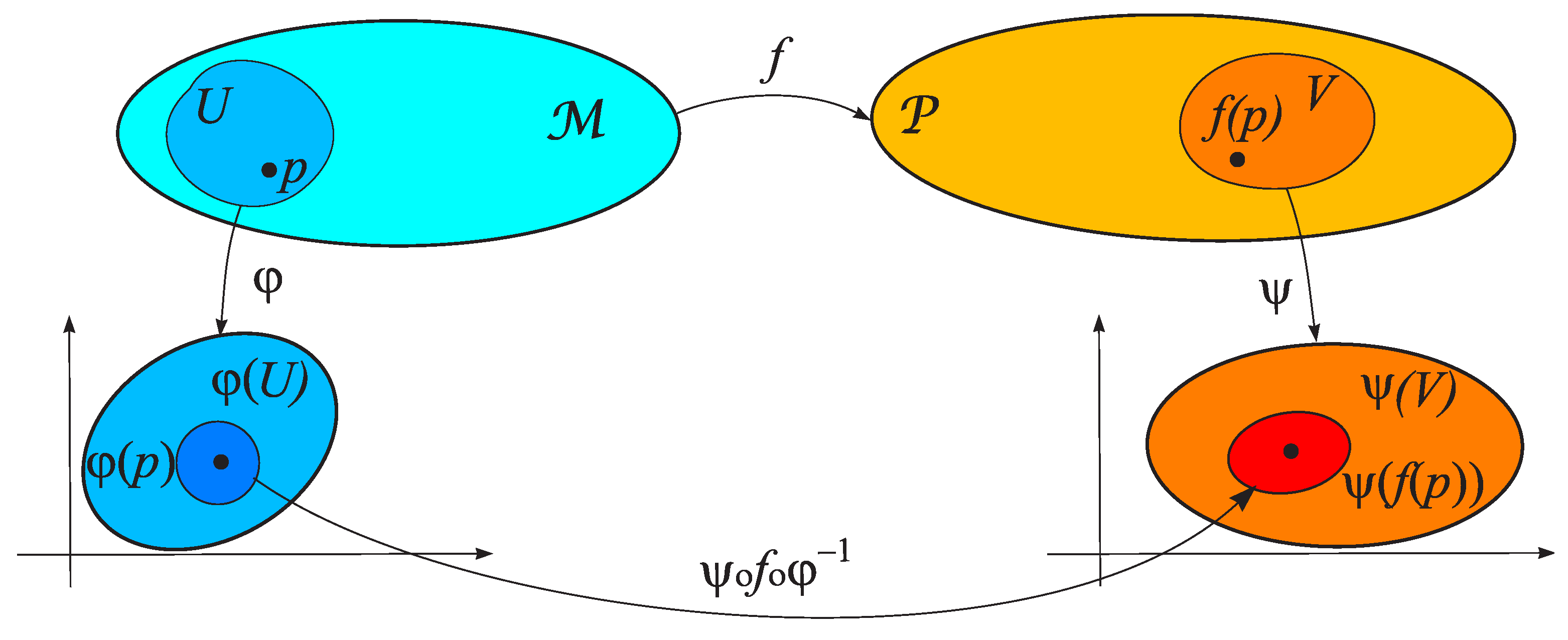
Figure 7.
The projection of the torus onto the circle is a smooth map.
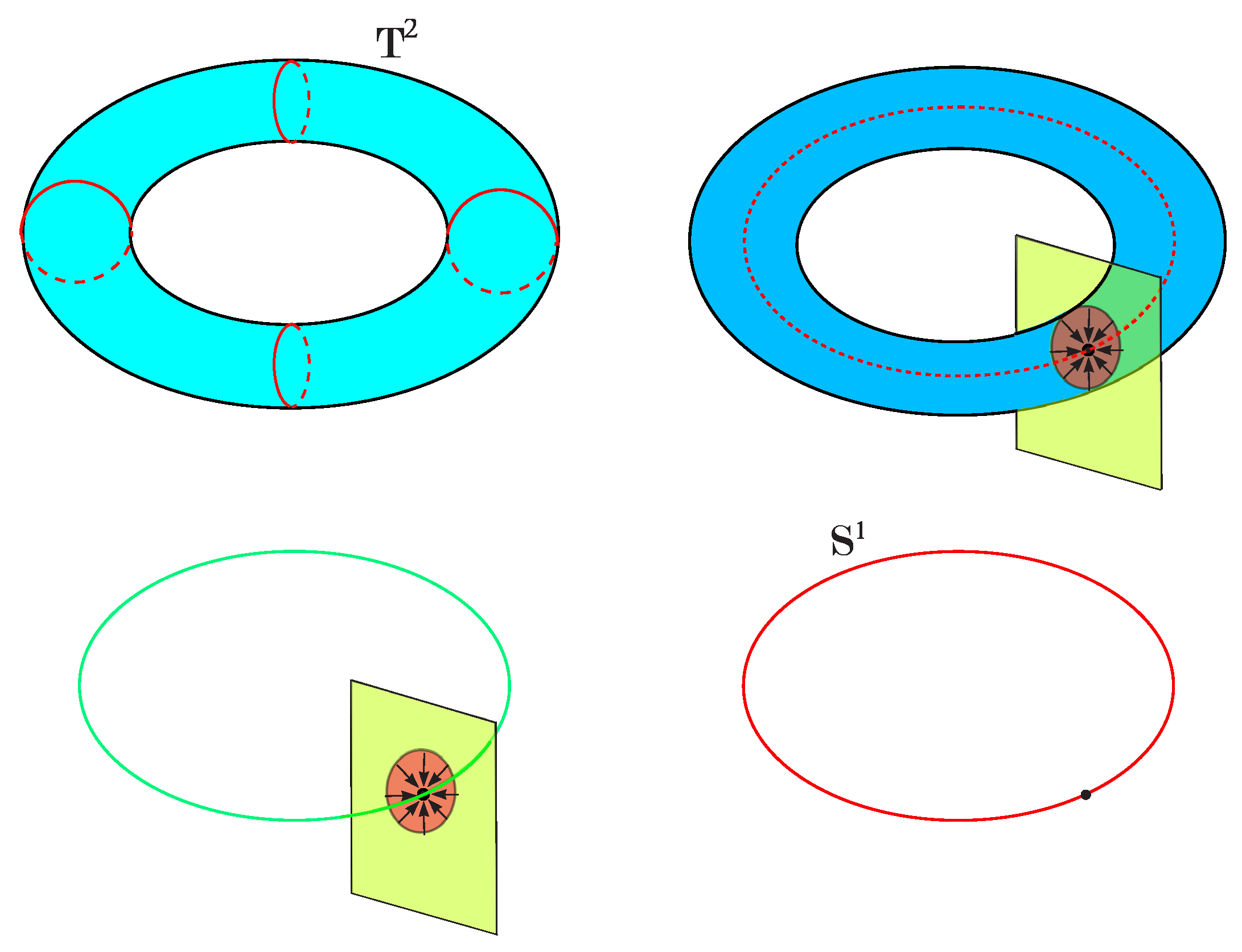
Figure 8.
The ellipse and the open disk are diffeomorphic.
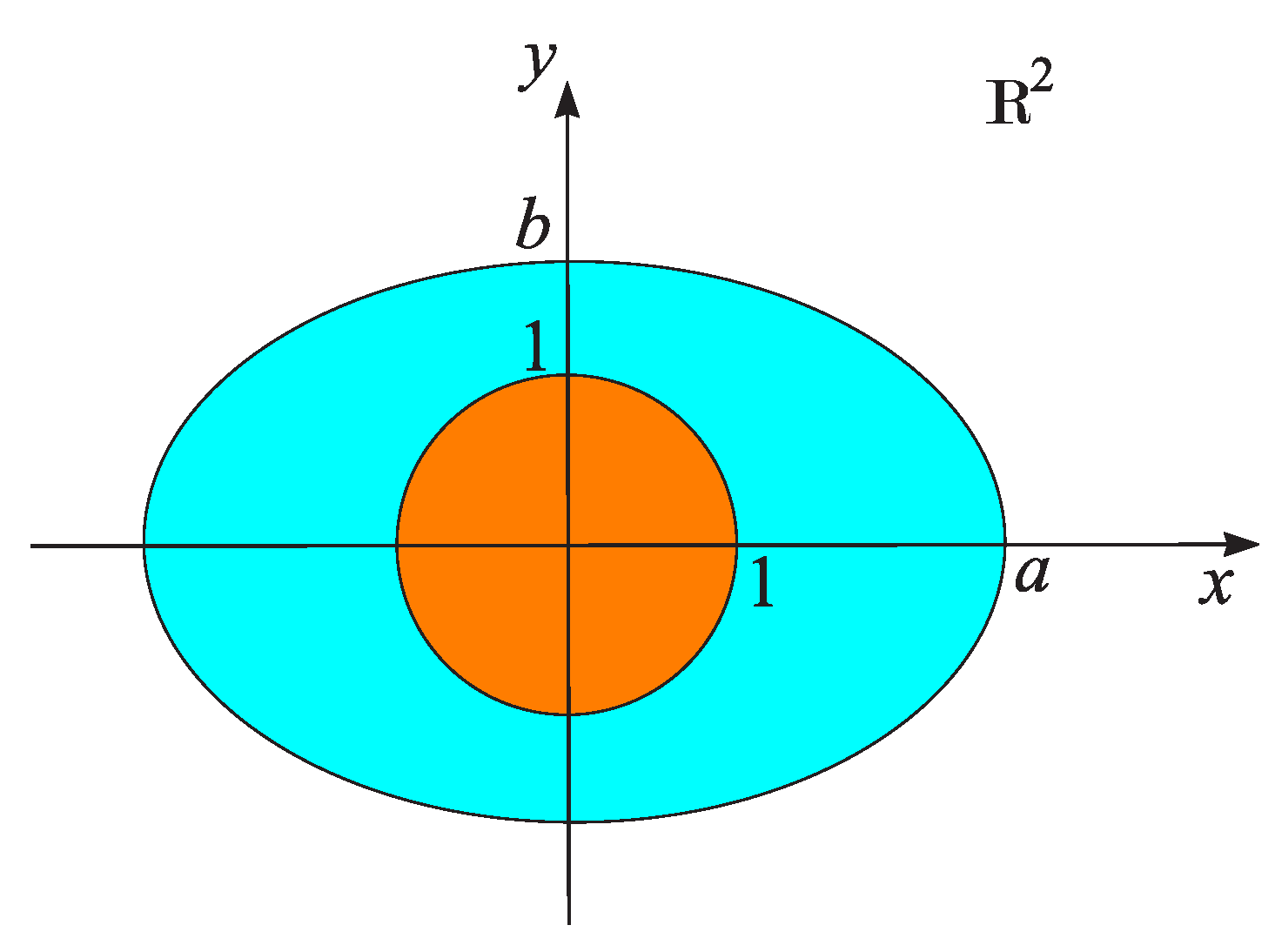
Figure 9.
Tangent space of a manifold.
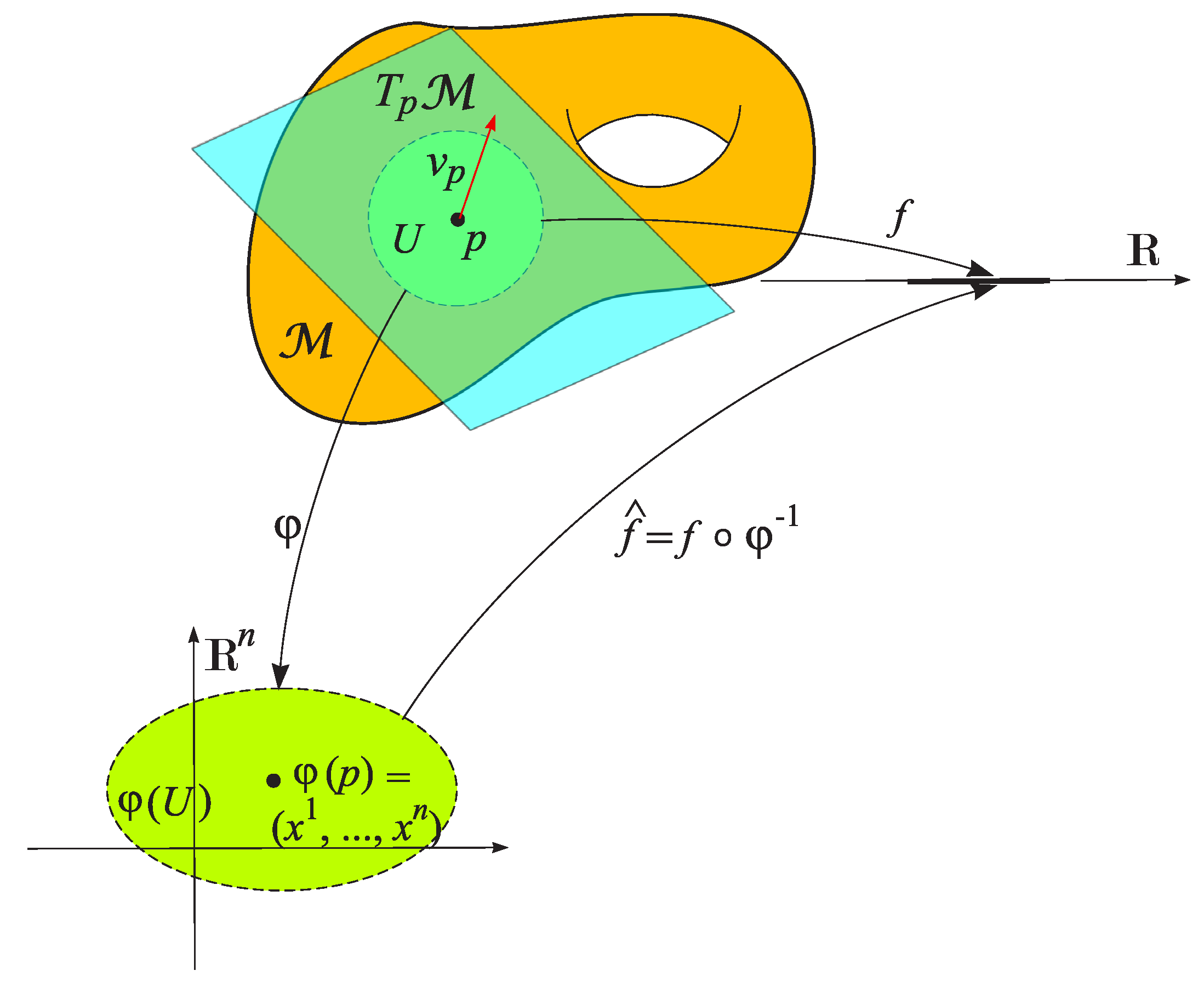
Figure 10.
Differential of a smooth map.
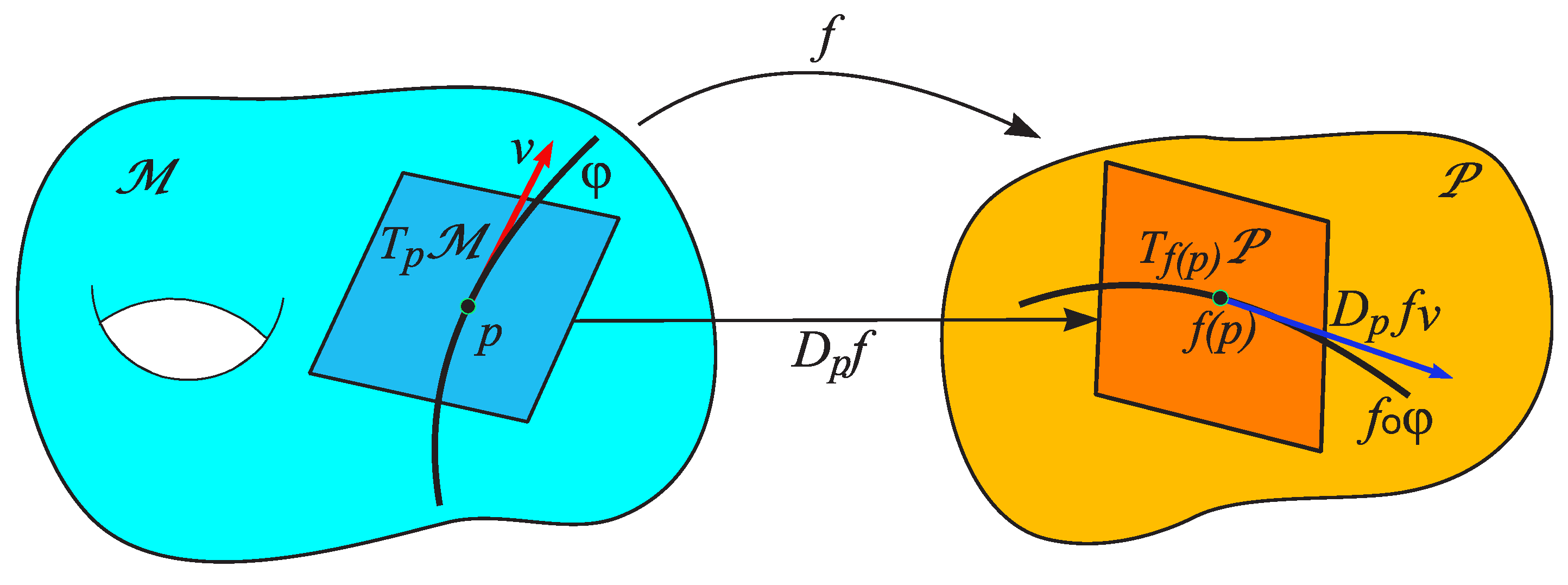
Figure 11.
Tangent space of a difeomorphic map of a sphere.
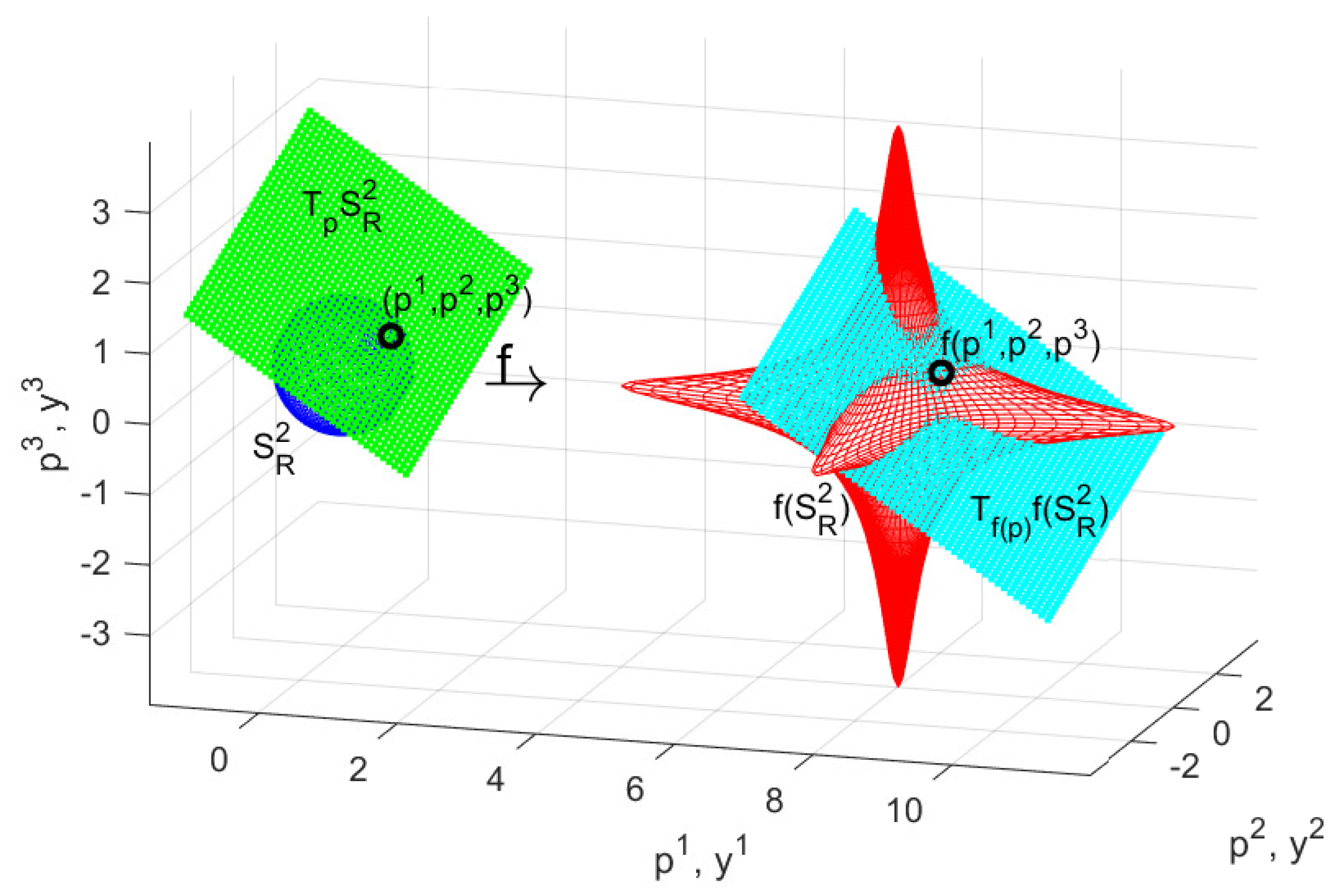
Figure 12.
The tangent bundle of a circle.
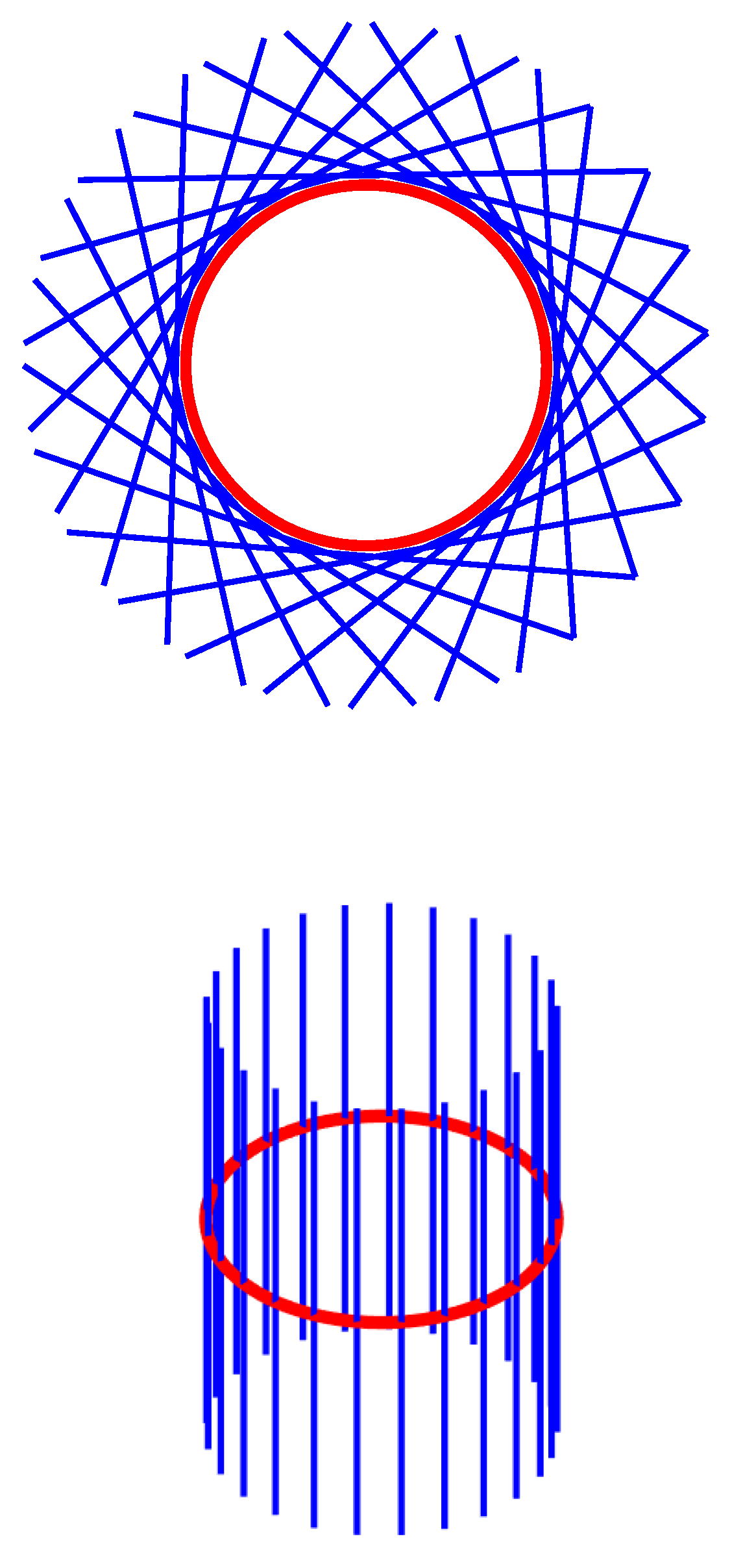
Figure 13.
The normal bundle of a circle.
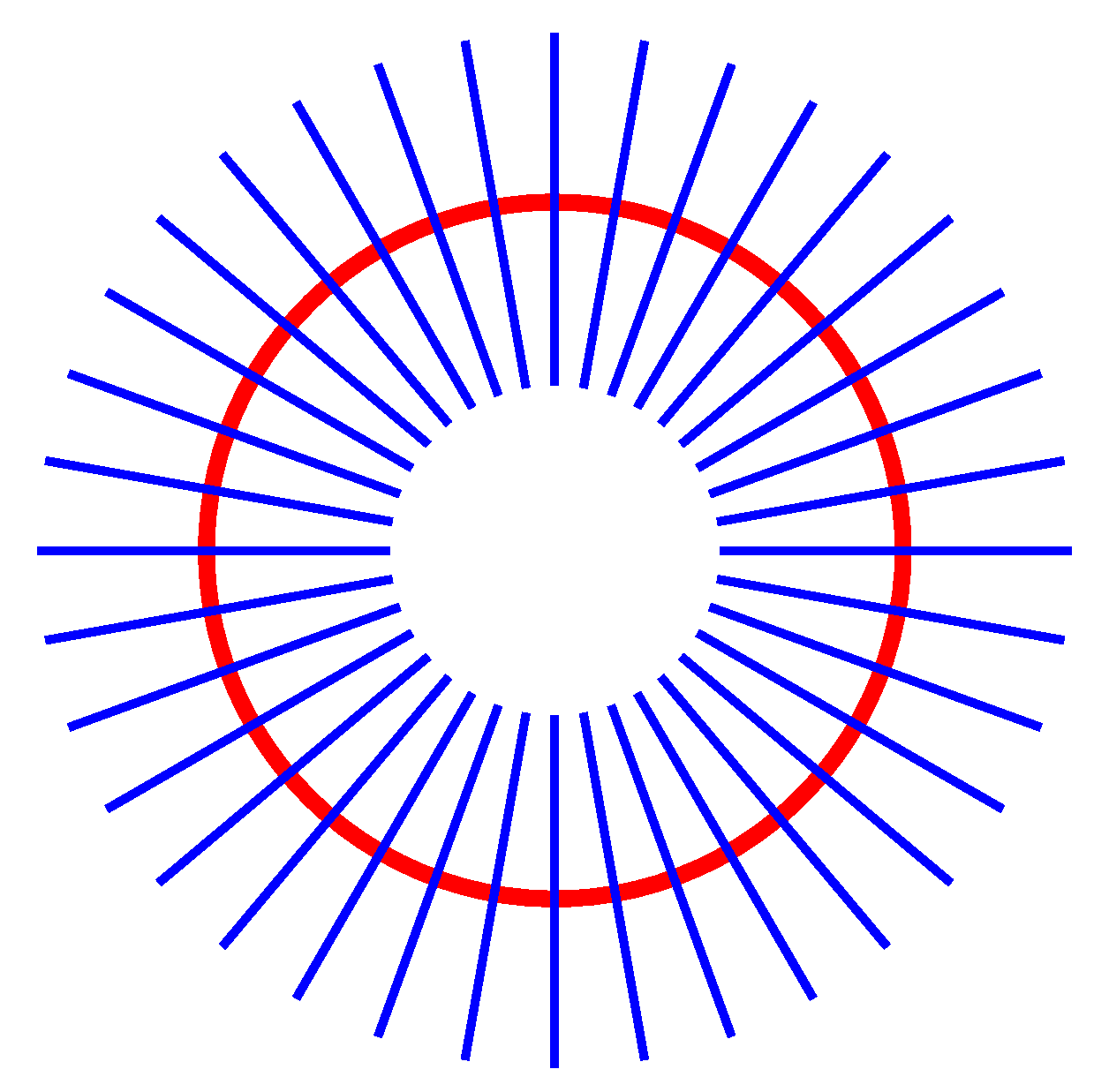
Figure 14.
A tubular neighborhood in with normal lines.
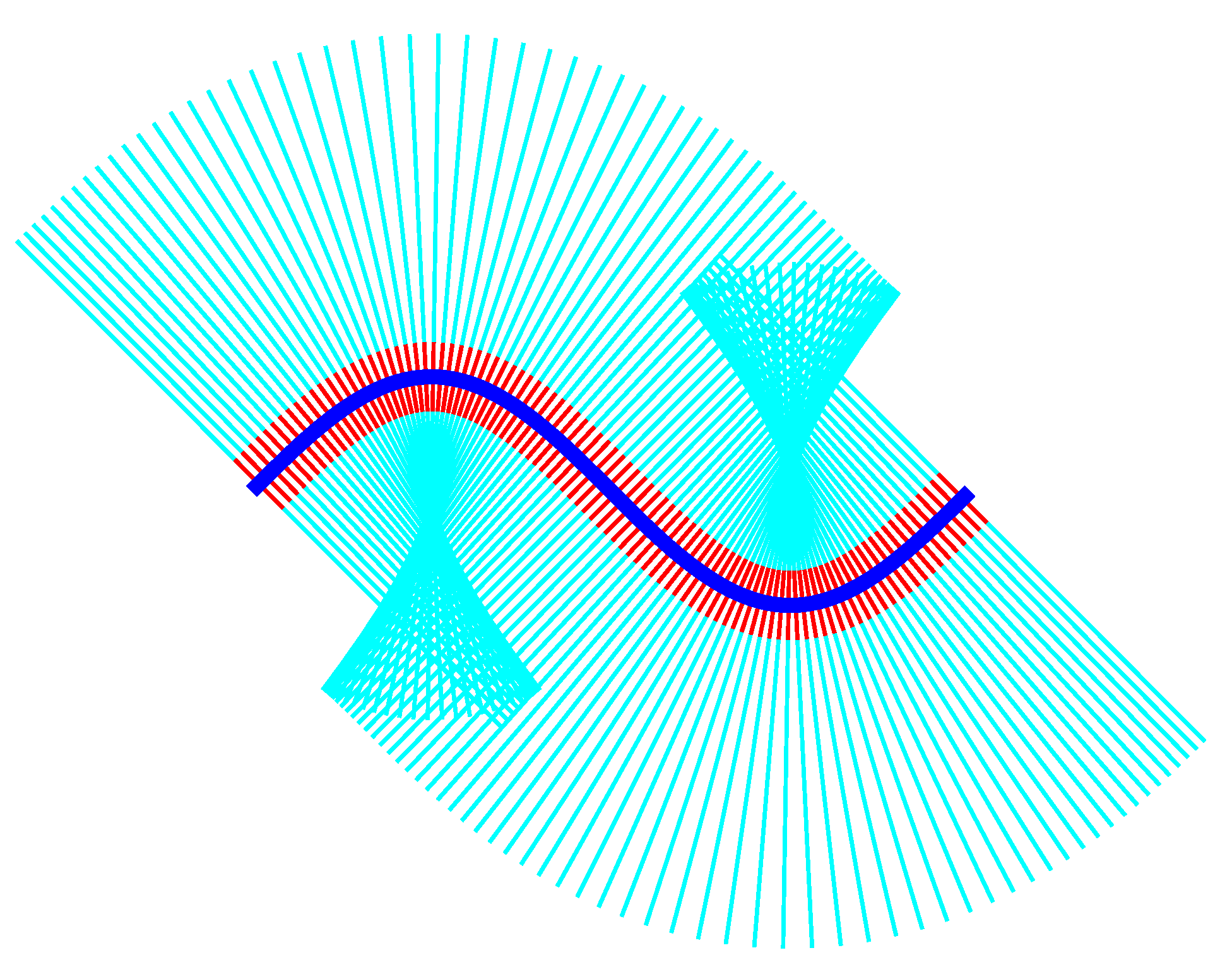
Figure 15.
A tubular neighborhood in .
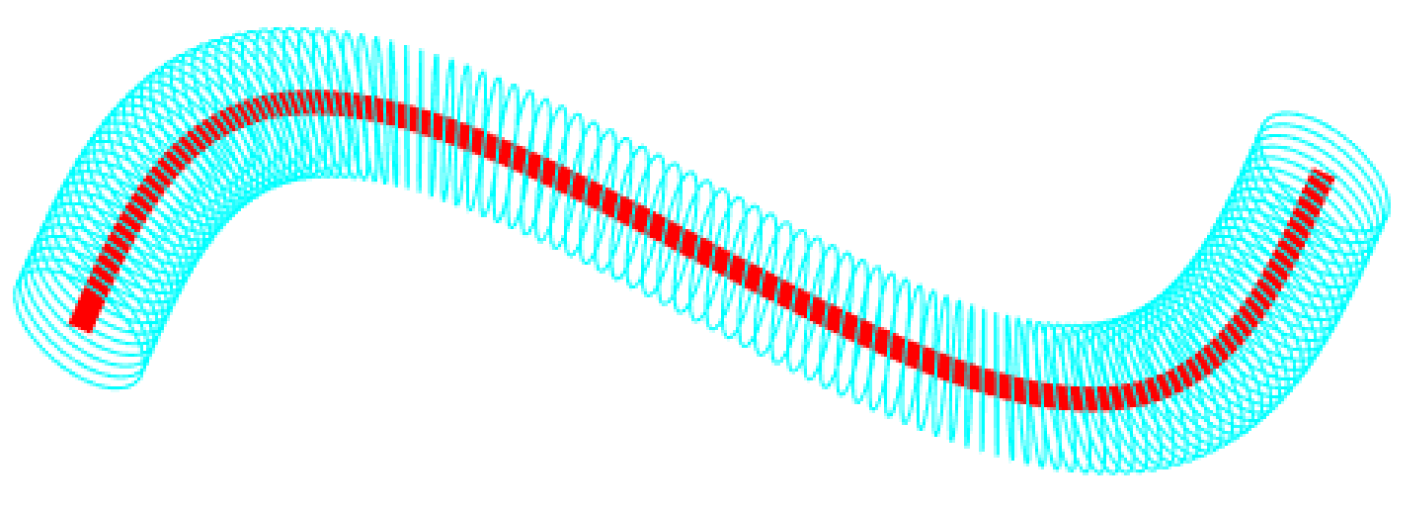
Figure 16.
A tubular neighborhood.
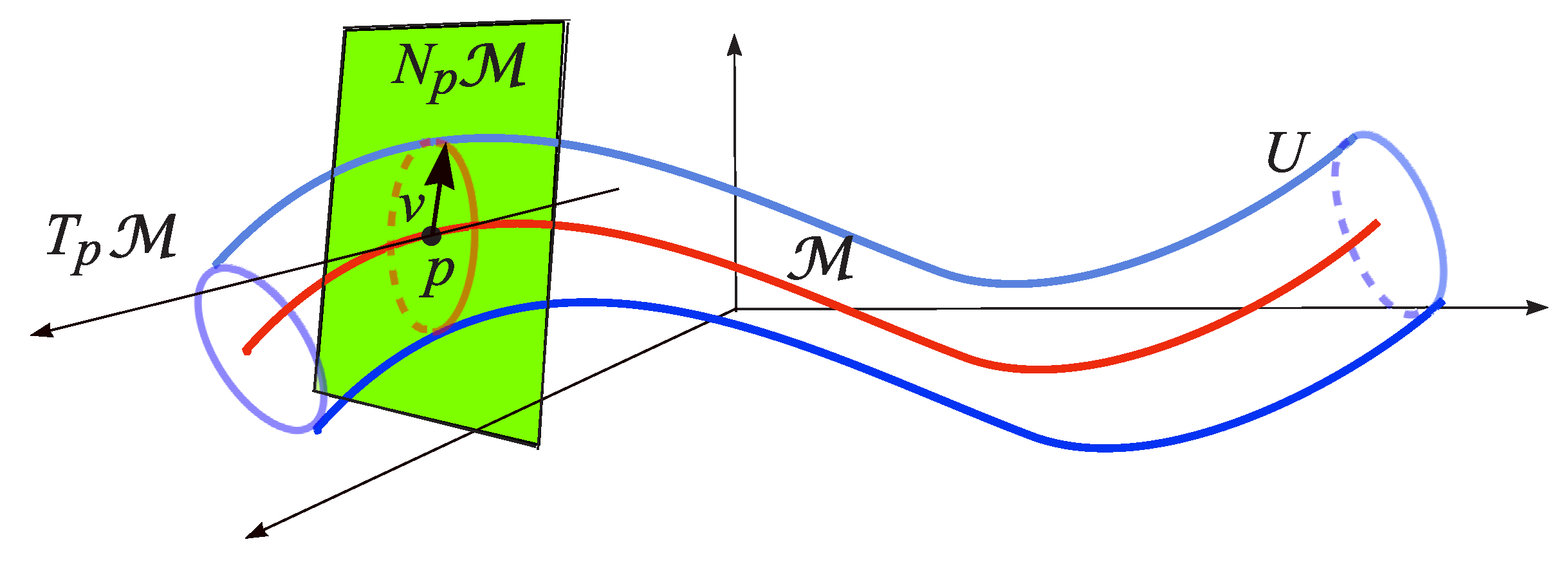
Figure 17.
Critical points and values of the function .
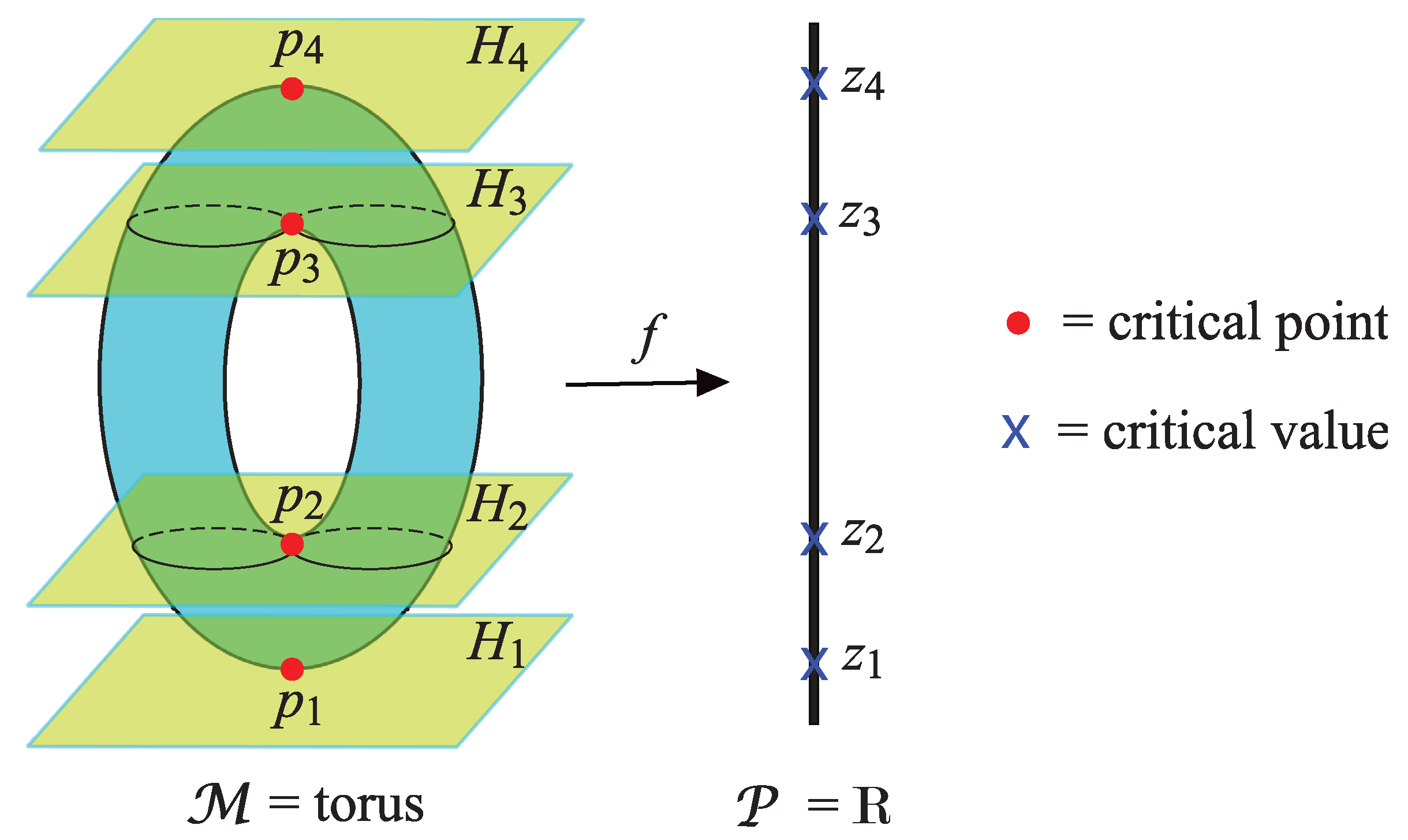
Figure 18.
The case of a singular point.
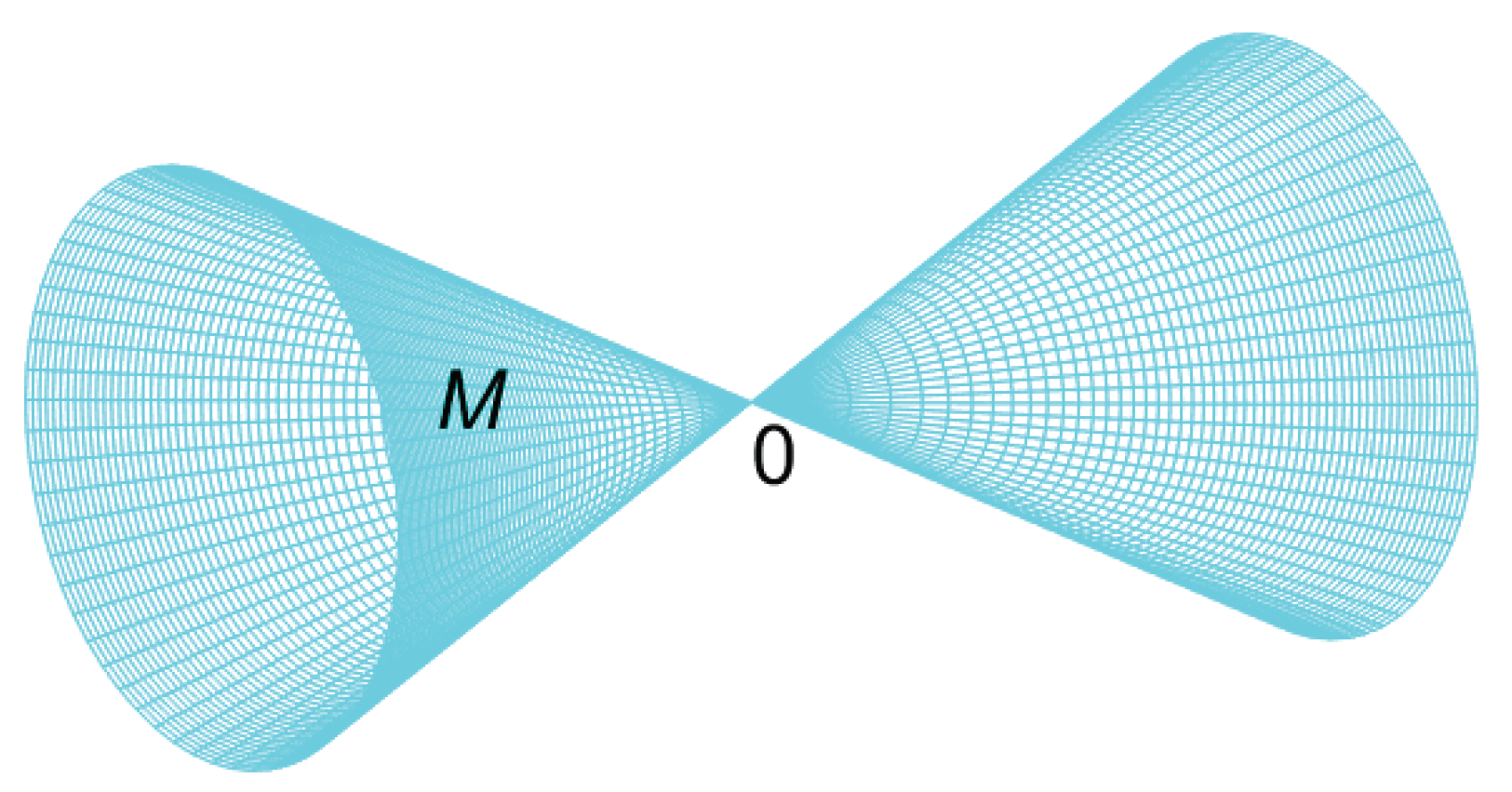
Figure 19.
Sard’s Theorem.
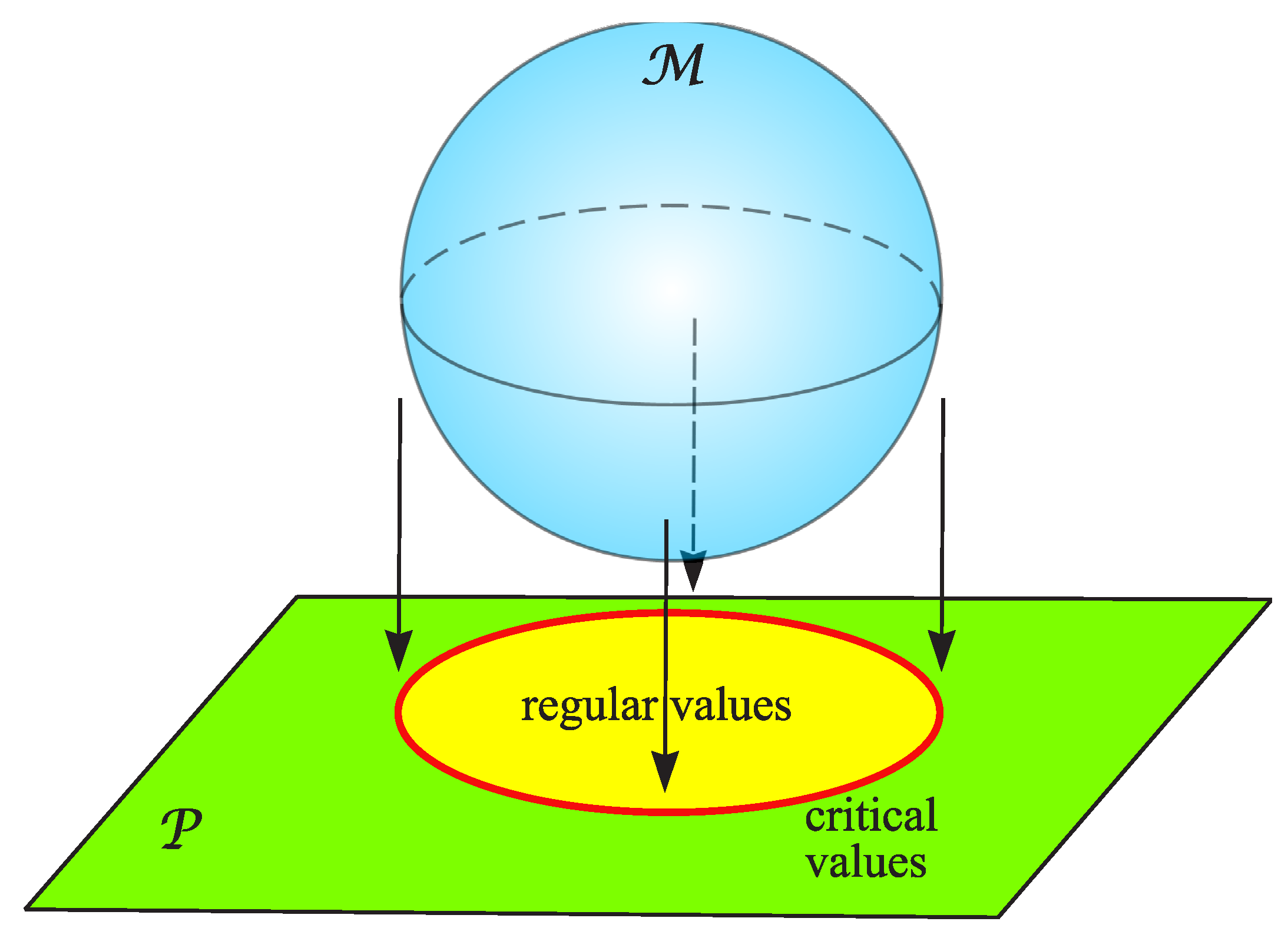
Figure 20.
Transverse intersection of two manifolds.
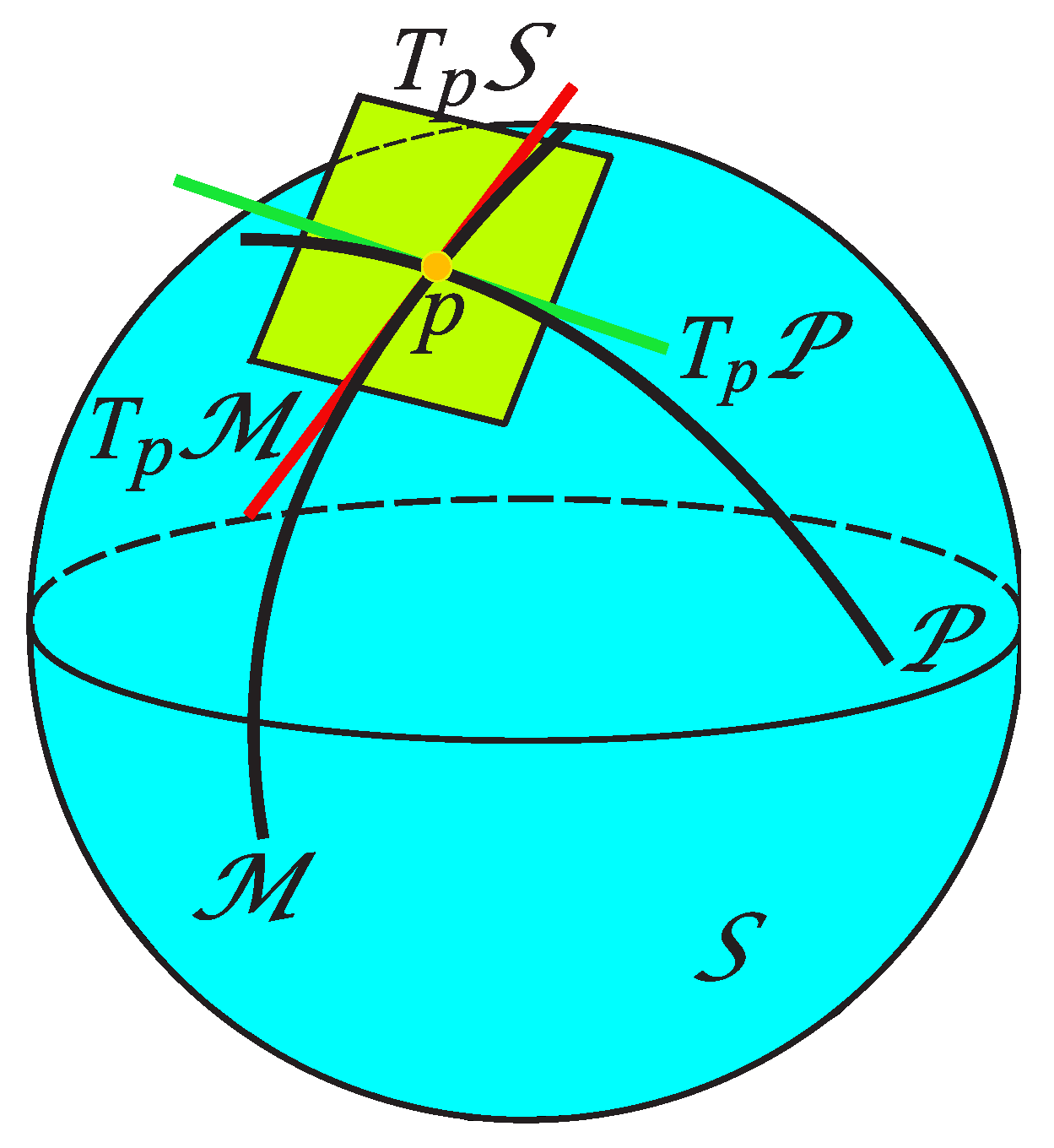
Figure 21.
Transverse planes in .
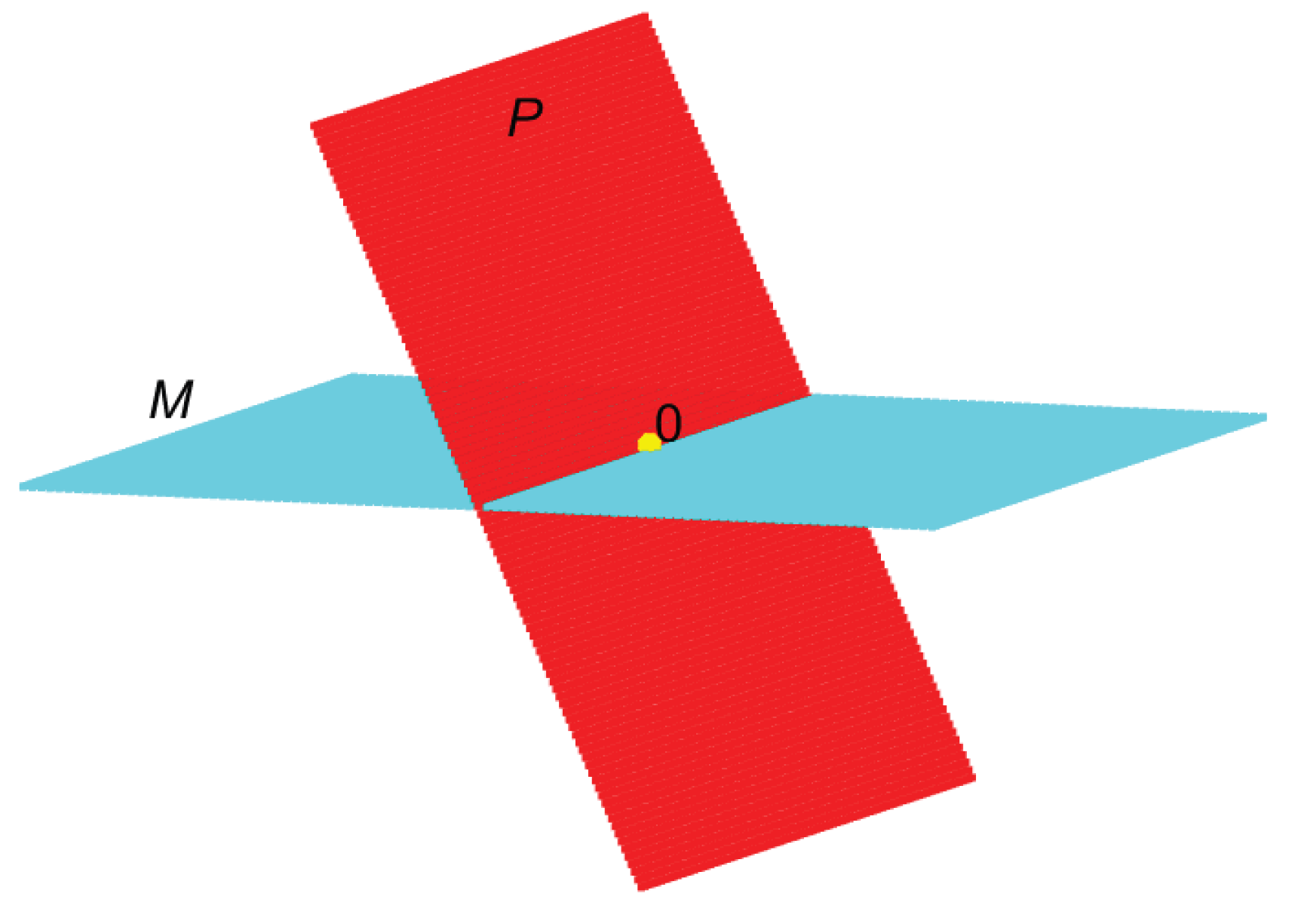
Figure 22.
Intersections which are not transverse.

Figure 23.
Variety of singular matrices in the parameter space.
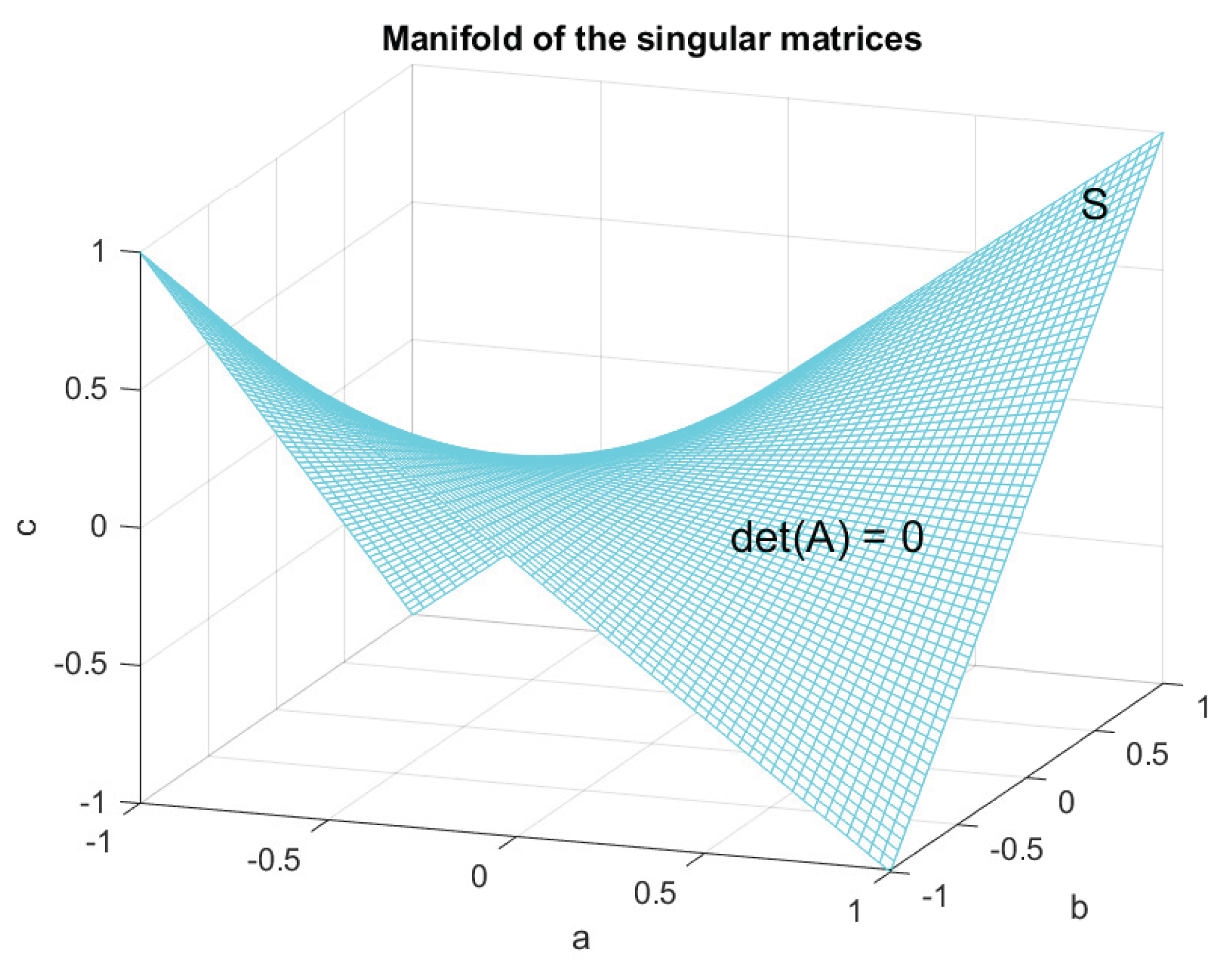
Figure 24.
Variety of matrices with a double eigenvalue.
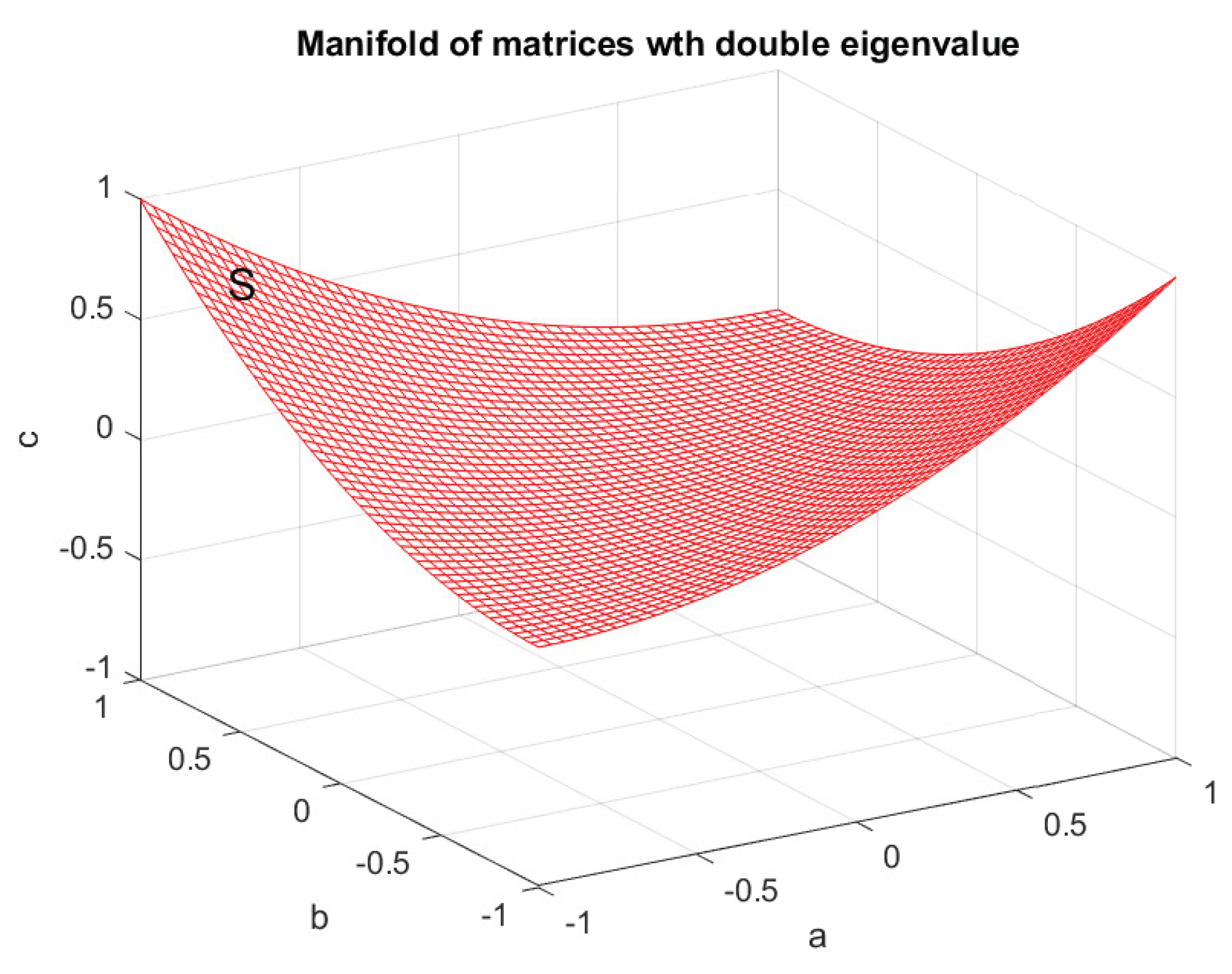
Figure 25.
Geometric interpretation of the condition number.
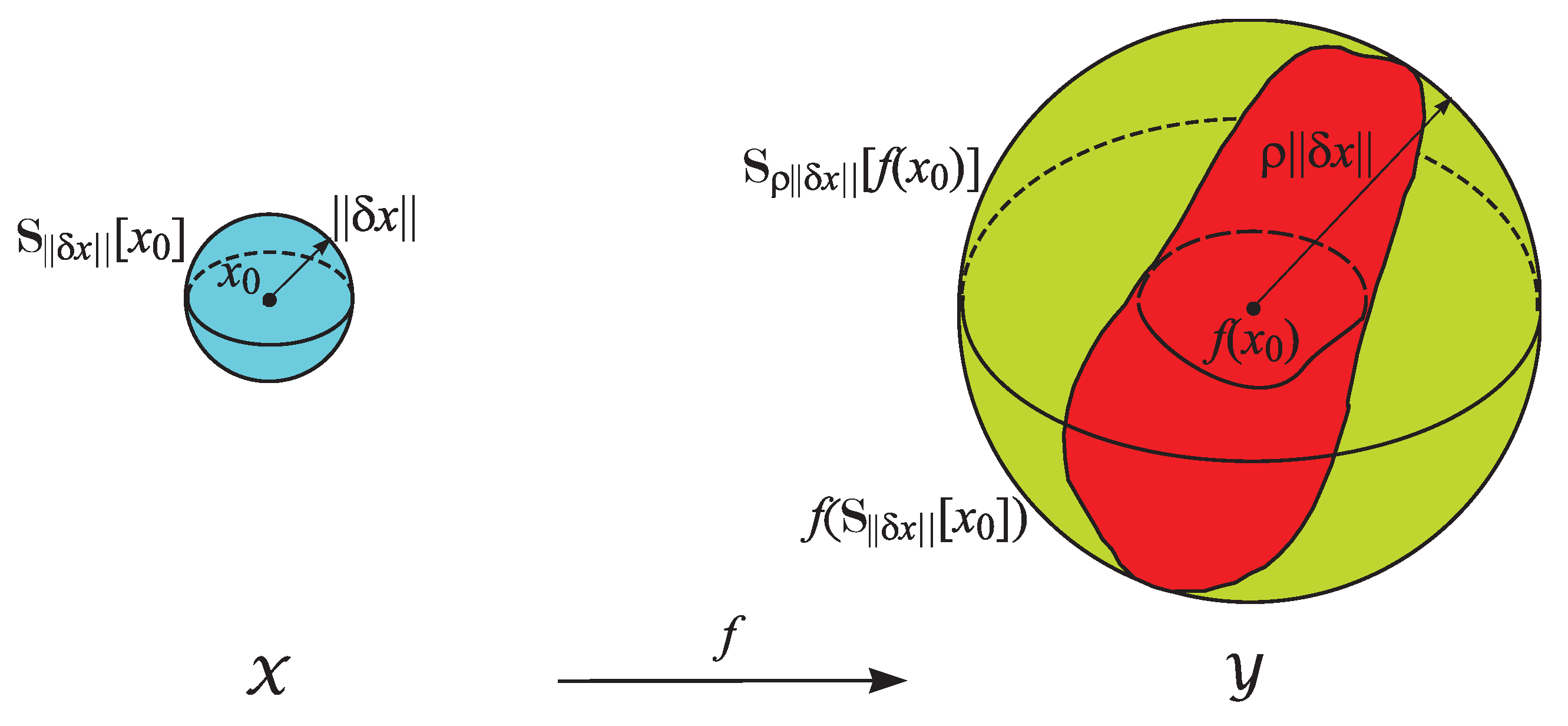
Figure 26.
Perturbations in the solution of a linear system in the parameter space.
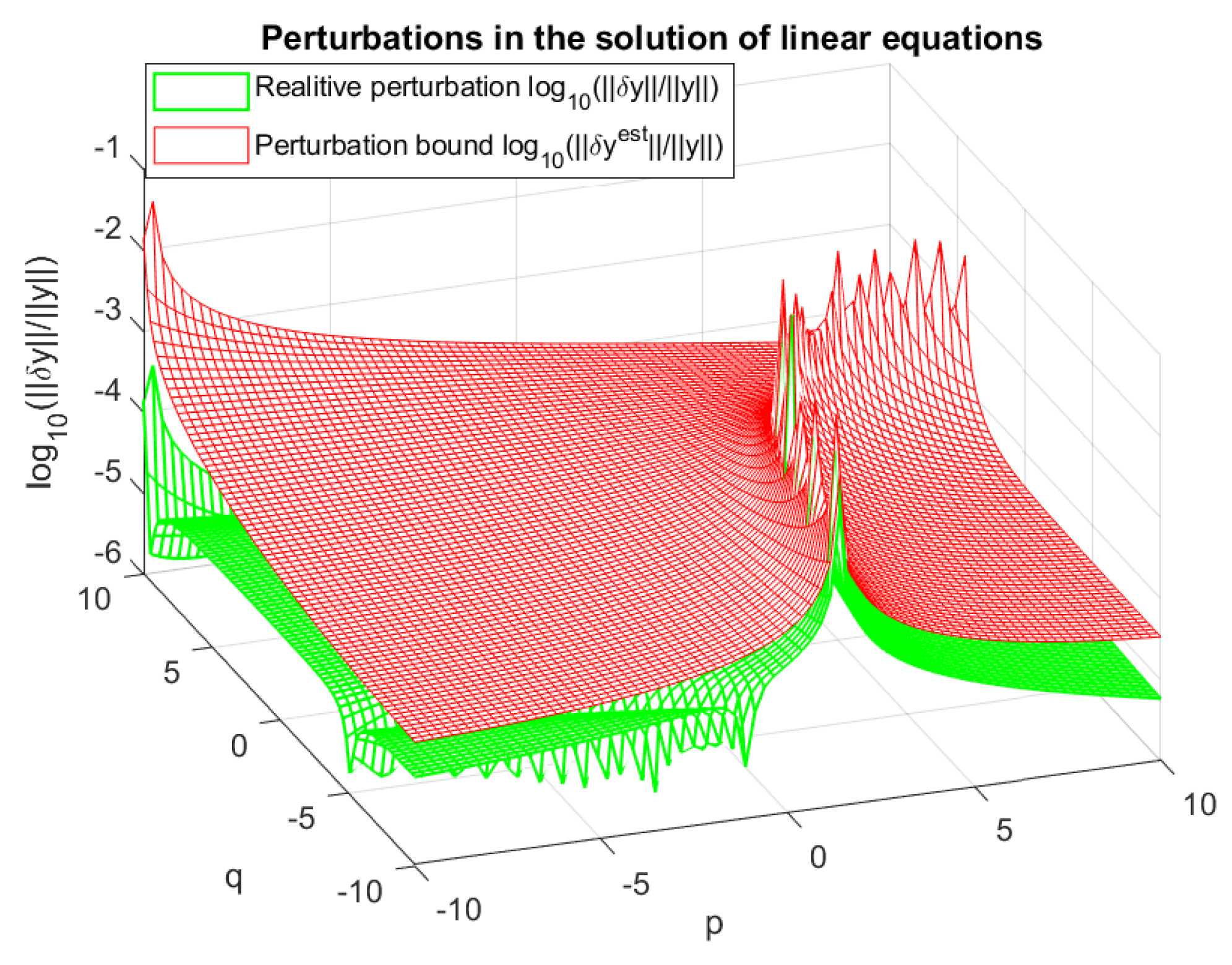
Figure 27.
Sensitivity of the eigenvalues of a Jordan block for values of between and .
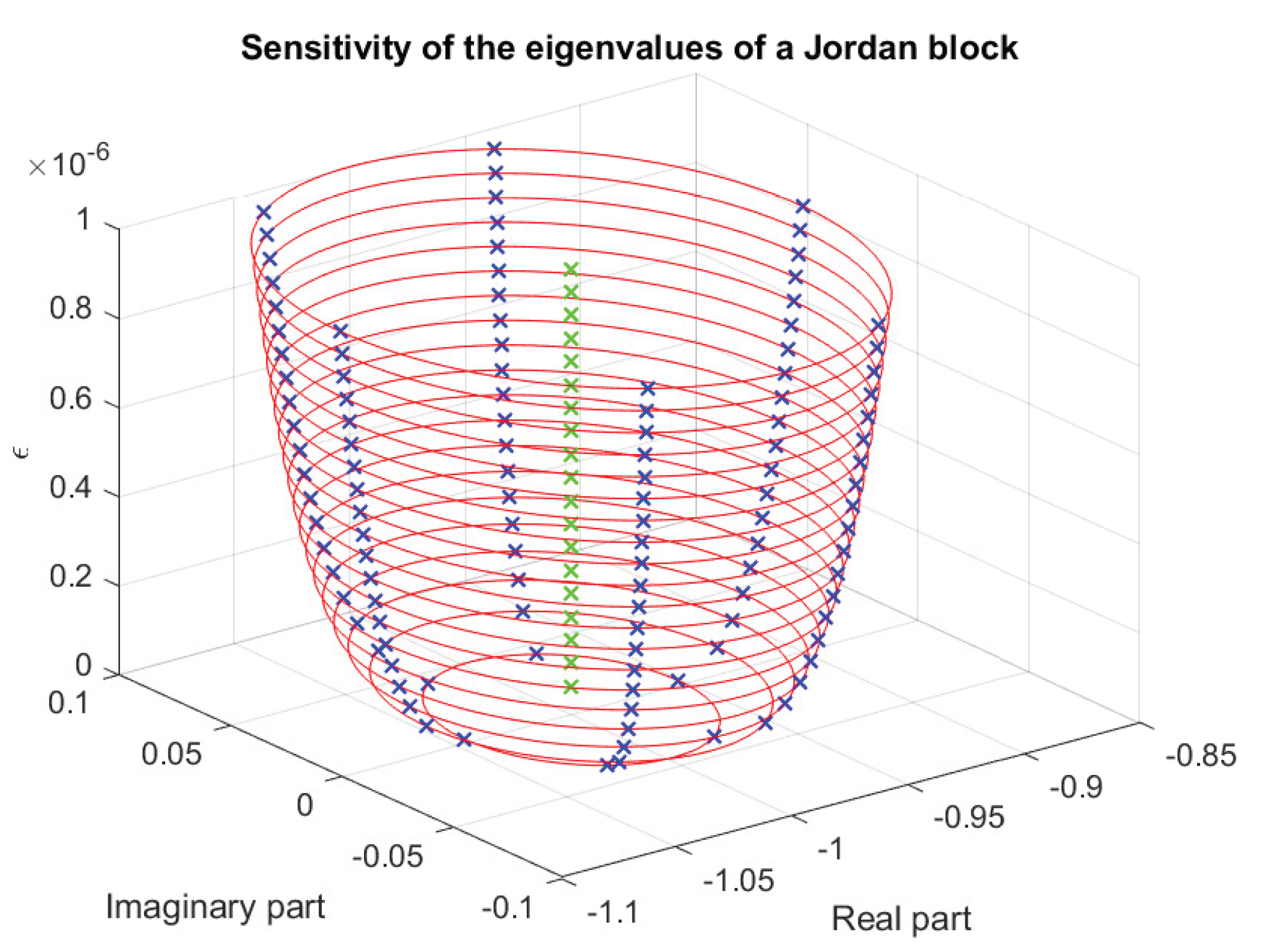
Figure 28.
Third–order matrices with different condition numbers in the parameter space.
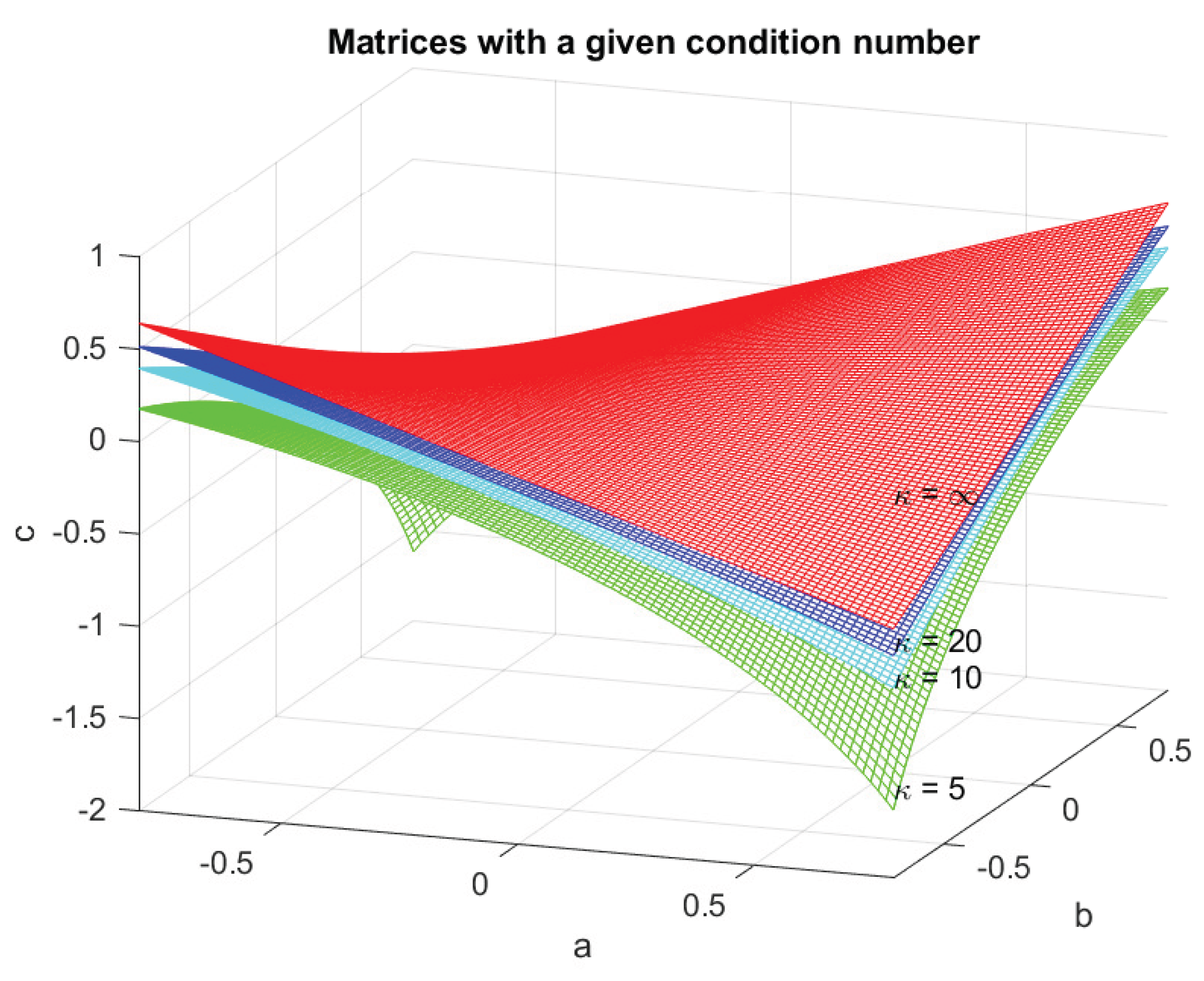
Figure 29.
Intersection of the unit sphere with the variety of singular problems.
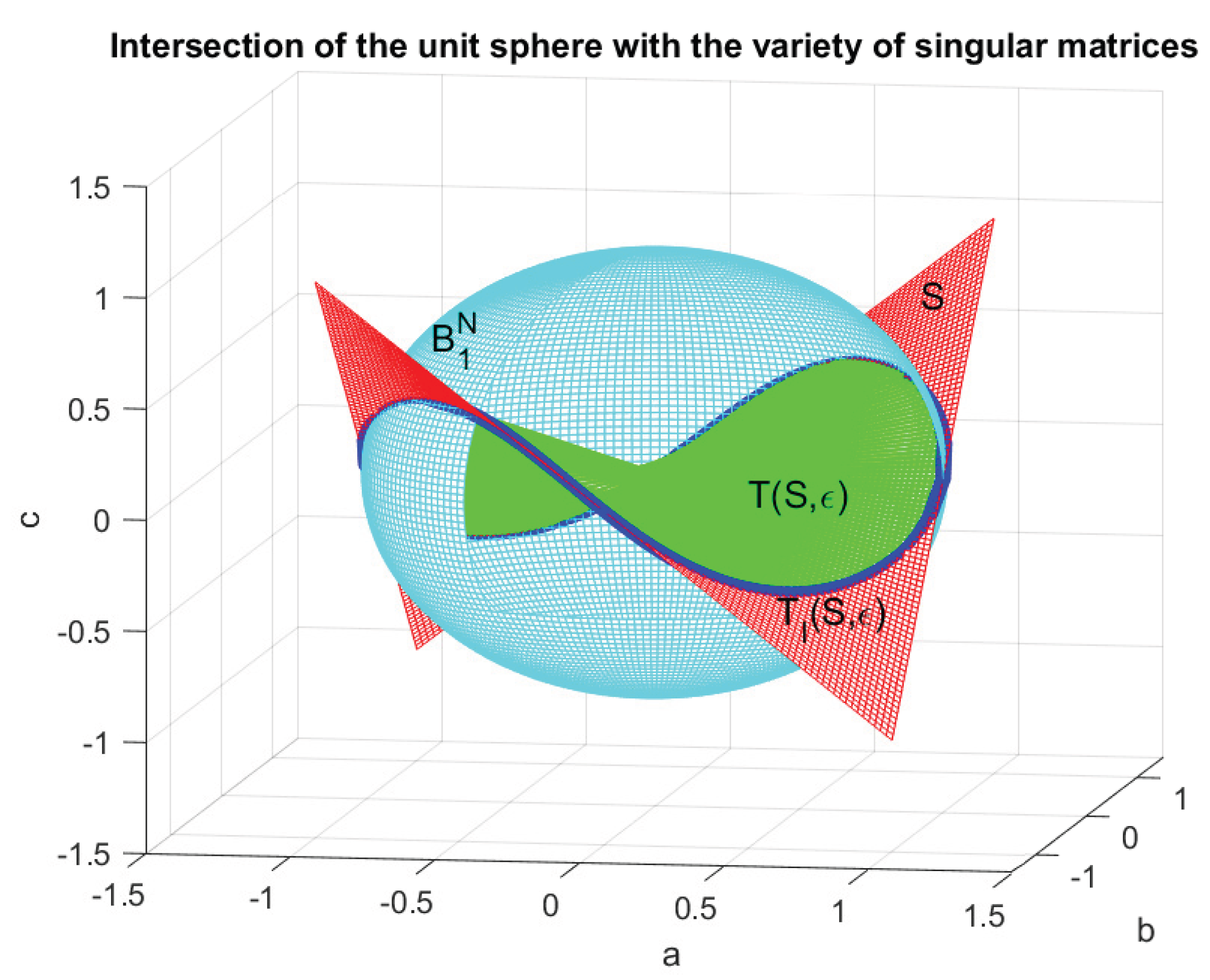
Figure 30.
Probability distribution of the condition number with respect to inversion.
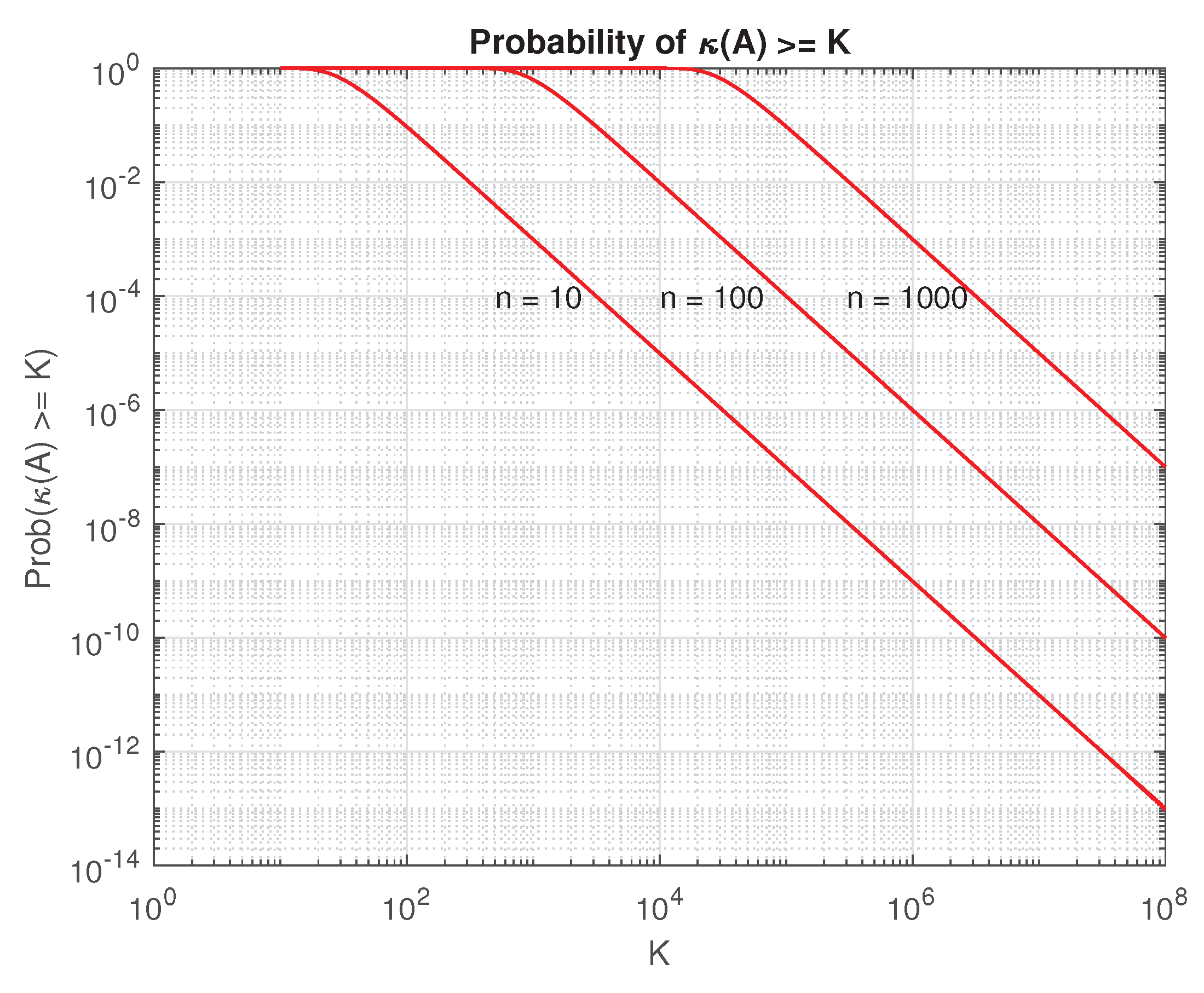
Figure 31.
Probability distribution of the eigenvalue condition number.
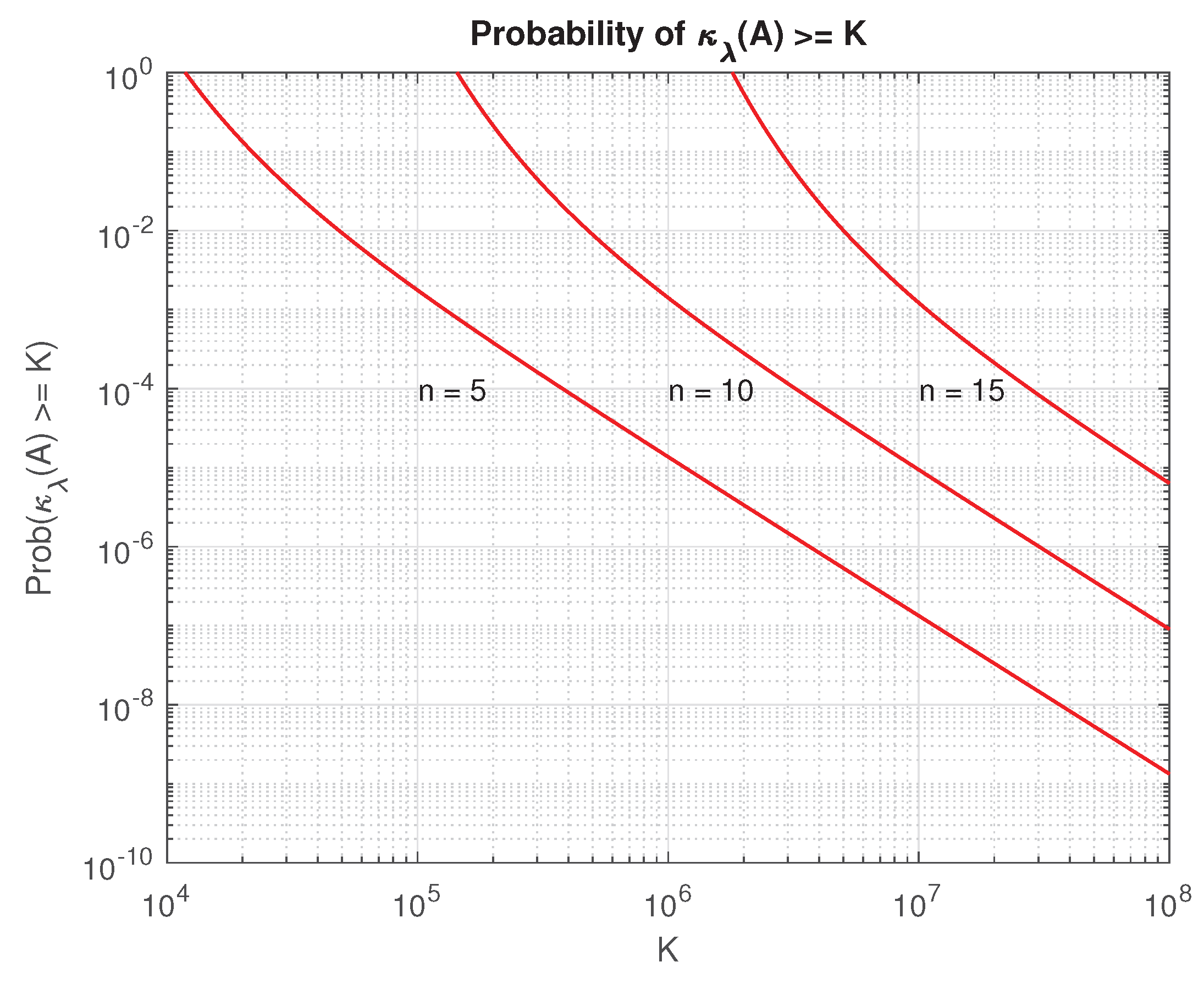
Figure 32.
Dimension and codimension of the orbit .
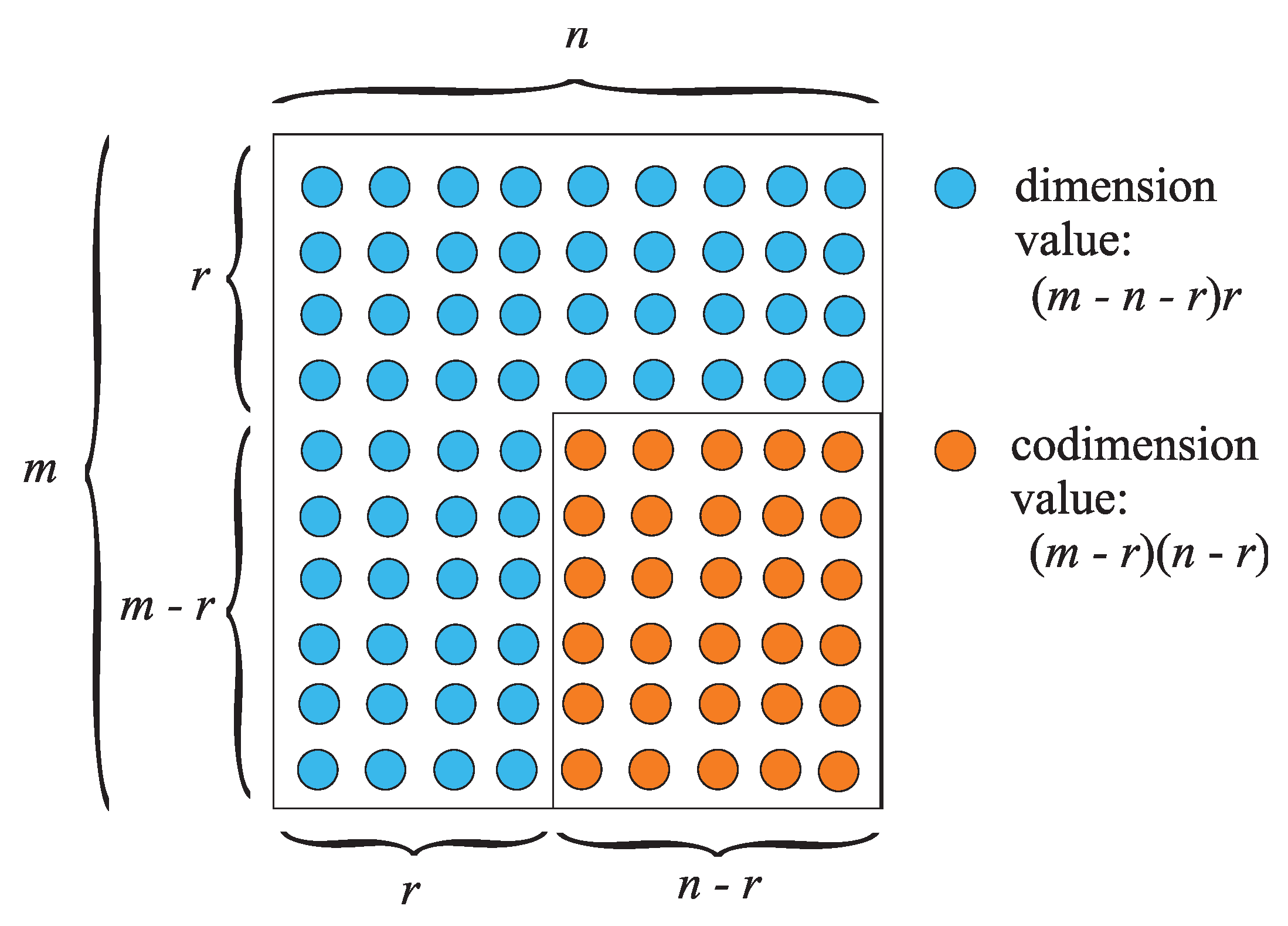
Figure 33.
Determining the numerical Jordan form.
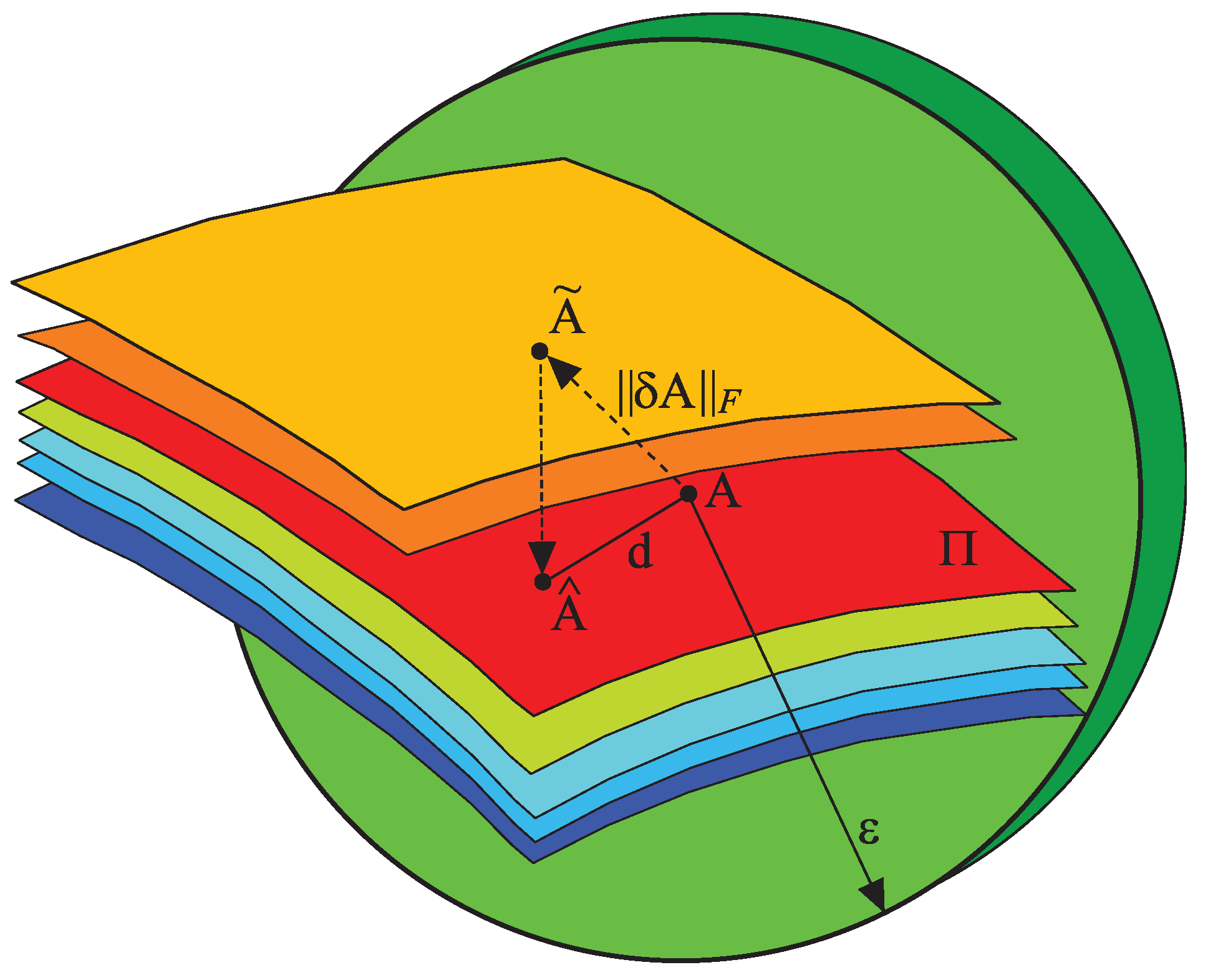
Figure 34.
A generic k-parameter family and the variety of singular cases.
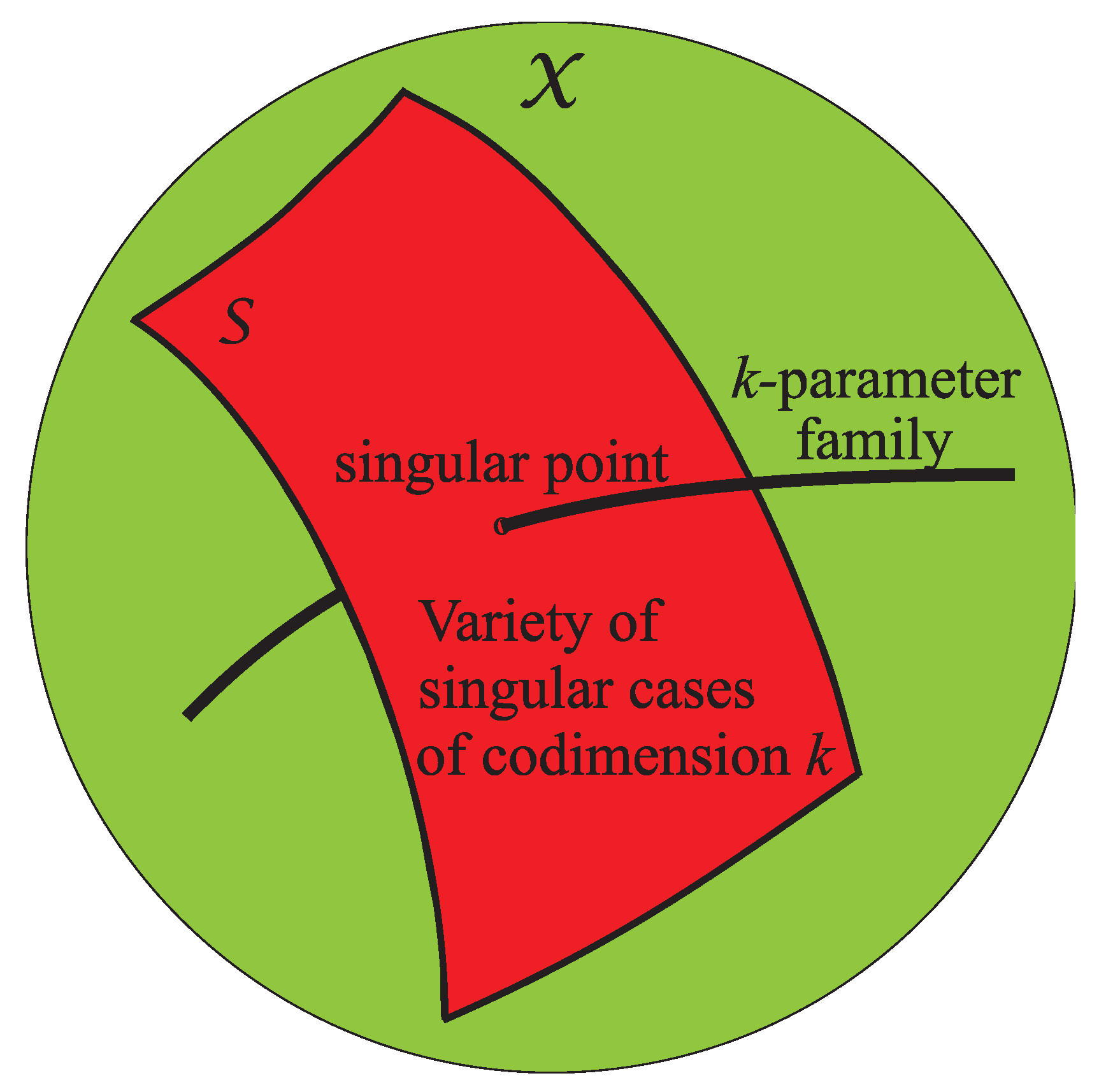
Figure 35.
Two–parameter matrix deformation and the manifold of singular cases.
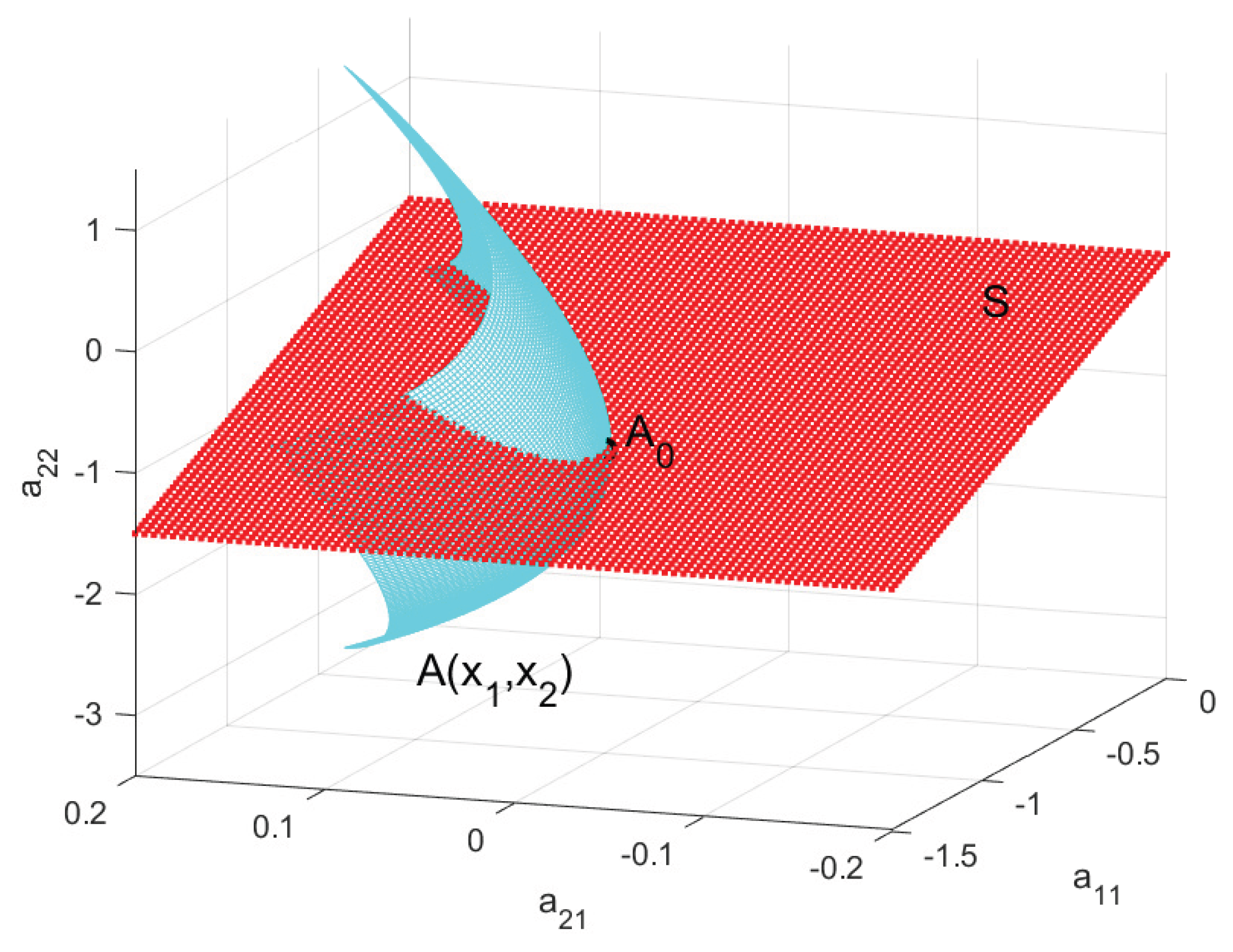
Figure 36.
Versal deformation.
Figure 37.
The versal deformation is transverse to .
Figure 38.
The mapping is transverse to the manifold .
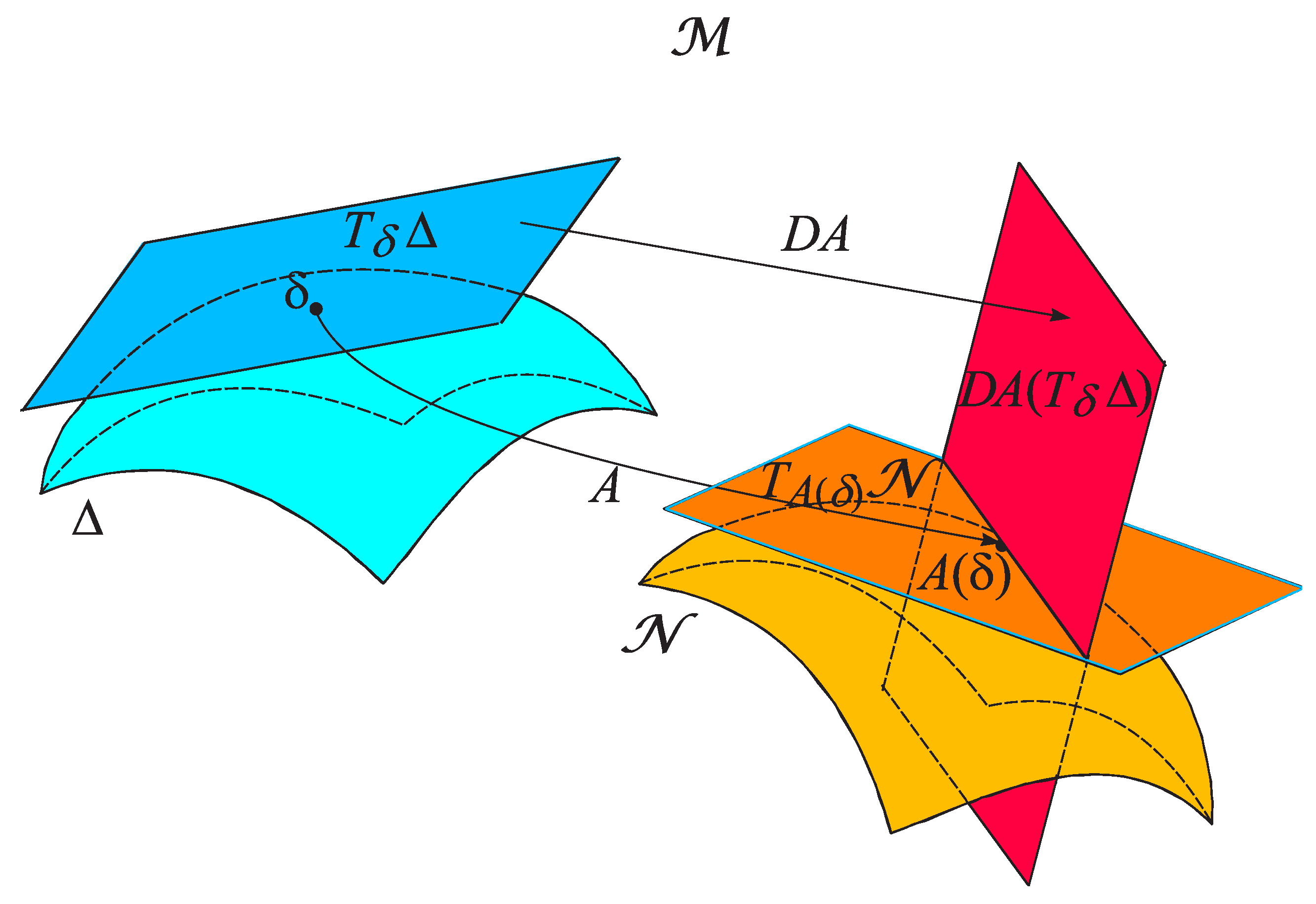
Figure 39.
Bifurcation diagram for 3rd order companion matrices.
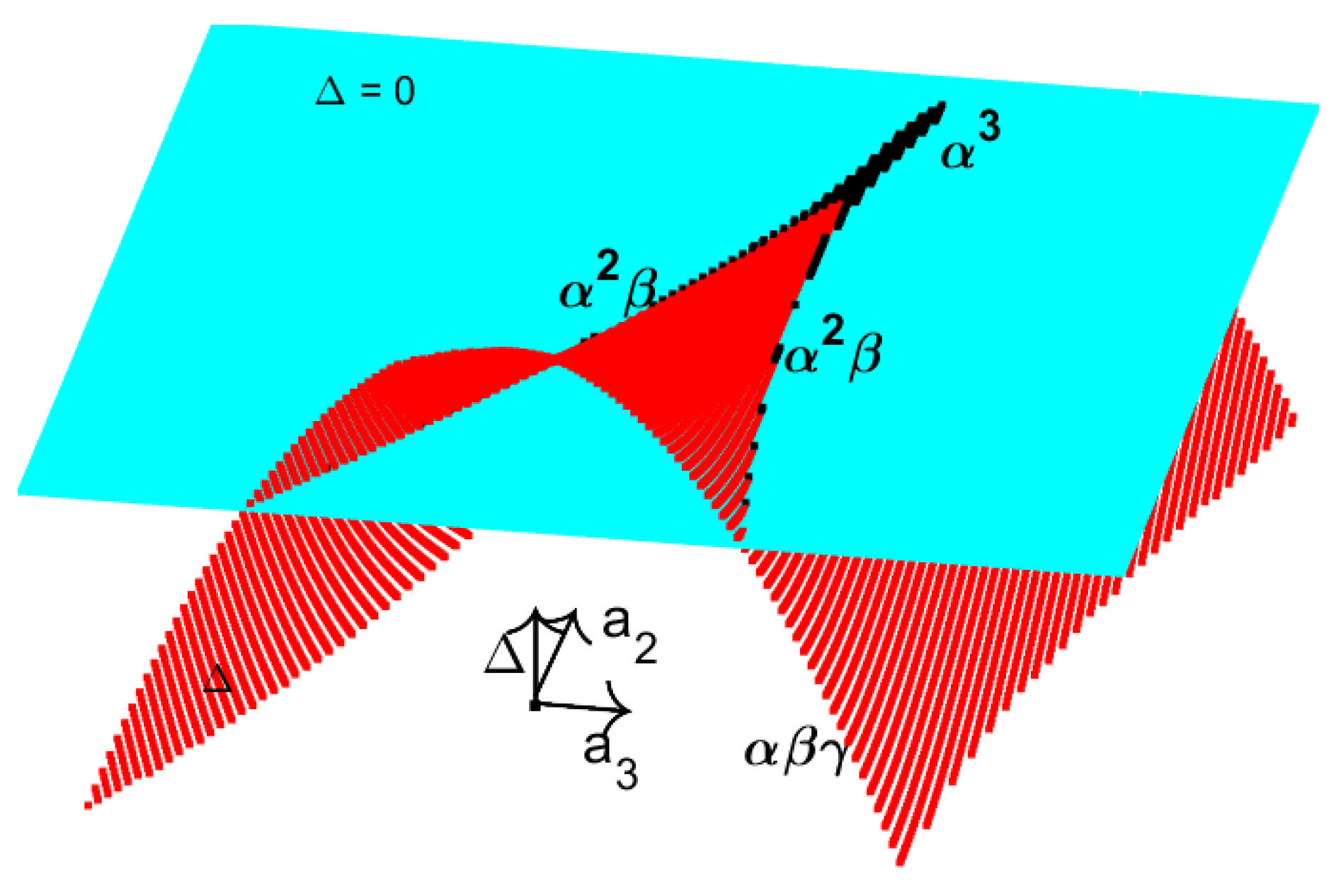
Figure 40.
Bifurcation diagram for in the parameter plane.
Figure 41.
Bifurcation diagram for matrices with double eigenvalue.
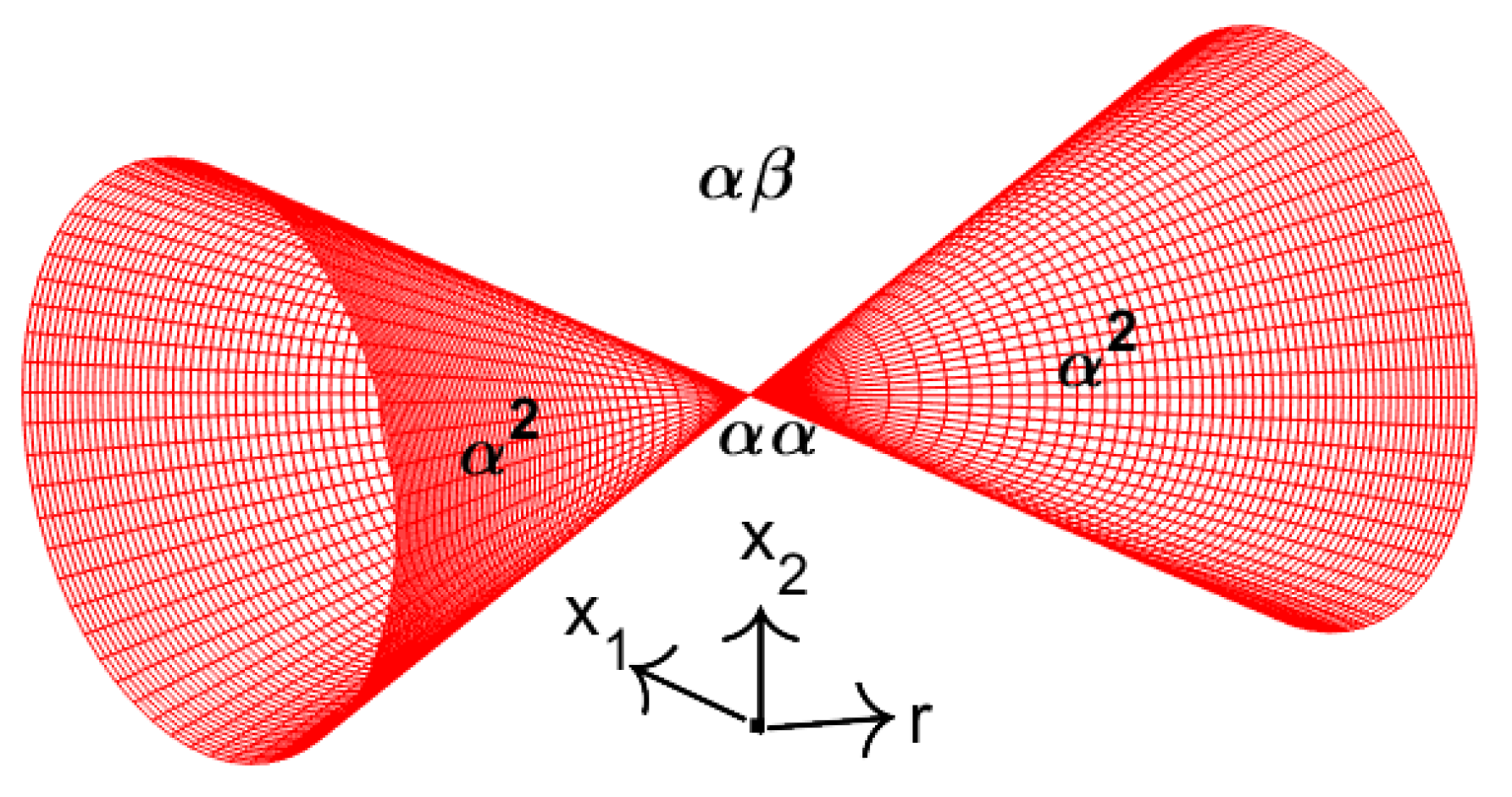
Figure 42.
Swallowtail diagram for matrices of type .

Table 1.
Jordan forms corresponding to an n-tuple eigenvalue.
| Most generic Jordan form | |
| Single nth order Jordan block | |
| , | |
| Intermediate cases | |
| Jordan blocks | |
| with the same eigenvalue | |
| , | |
| Most degenerate Jordan form | |
| n scalar blocks with the same eigenvalue | |
| , |
Table 2.
Most generic and most degenerate orbits and bundles of matrices.
| Case | Number | Number | Segre characteristics | Dimensions |
|---|---|---|---|---|
| of Jordan | of distinct | of orbits | ||
| blocks | eigenvalues | and bundles | ||
| Most | n | n | ||
| generic | ||||
| Most | n | 1 | ||
| degene- | ||||
| rate | ||||
Table 3.
Bundles of Jordan forms represented by the swallowtail diagram.
| Notation | Segre | Representation | ||
| characteristics | in | |||
| {4} | 3 | 0 | point | |
| {3}, {1} | 2 | 1 | curve | |
| {2}, {2} | 2 | 1 | curve | |
| {2}, {1}, {1} | 1 | 2 | surface | |
| {1}, {1}, {1}, {1} | 0 | 3 | complement of | |
| the swallowtail |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



