
Submitted:
15 January 2026
Posted:
15 January 2026
You are already at the latest version
Abstract
Neural network interpretability methods have produced powerful approaches for gradient-based feature attribution, energy landscape analysis, and uncertainty quantification. State-of-the-art methods rely on structural weight analysis, Monte Carlo dropout uncertainty estimation, and attention mechanisms for interpretable predictions with quantified confidence. However, existing methods face fundamental challenges: unreliable explanations with poor uncertainty quantification on complex medical imaging tasks, difficulty identifying important network weights due to fixed thresholds, and computational overhead from attention mechanisms operating without uncertainty guidance. We introduce Adaptive Uncertainty-Guided Interpretable Networks (AUGIN), a framework combining adaptive structural weight analysis, uncertainty-aware prediction intervals, and uncertainty-guided attention through three interconnected modules. Our approach models adaptive threshold computation evolving with layer depth and architecture, integrates feature-level uncertainty into prediction interval generation, and introduces uncertainty-guided attention focusing on uncertain regions. Experiments on ISLES stroke prediction, BraTS brain tumor segmentation, and CT-CTA thrombectomy outcome prediction demonstrate superior performance: 0.7891 AUC-ROC on ISLES (1.59 percentage point improvement), 0.8567 Dice score on BraTS, and 0.7456 attention IoU, while maintaining excellent uncertainty calibration (0.8123) and explanation fidelity (0.8234). Our work advances neural network interpretability by providing accurate predictions with reliable, uncertainty-quantified explanations for safety-critical medical imaging applications.
Keywords:
neural network interpretability
; uncertainty quantification
; medical imaging
; adaptive weight analysis
; attention mechanisms
; explainable AI
1. Introduction
Neural network interpretability methods have yielded powerful approaches for gradient-based feature attribution, energy landscape analysis, and uncertainty quantification in deep learning models [1,2]. State-of-the-art approaches include energy landscape methods that construct disconnectivity graphs to identify conserved weight patterns, dual neural network systems that generate prediction intervals with adaptive loss balancing, and attention-based medical imaging classifiers employing spatial and cross attention transformers [3,4,5,6]. These methods typically rely on structural analysis of network weights, Monte Carlo dropout for uncertainty estimation, and attention mechanisms to achieve interpretable predictions with quantified confidence.
Despite these advances, fundamental challenges persist in neural network interpretability. Current methods fail to provide reliable explanations with uncertainty quantification [7,8], particularly in complex medical imaging tasks where both prediction accuracy and explanation quality are critical [9]. Existing models struggle with identifying truly important network weights due to fixed threshold approaches that cannot accommodate architectural diversity. Their ability to generate informative prediction intervals remains limited by coverage-only optimization that ignores feature-level uncertainty drivers [10]. Additionally, many attention mechanisms incur substantial computational overhead while operating independently without uncertainty guidance, restricting their practical applicability in clinical settings.
Several recent works attempt to address these challenges but suffer from notable limitations. Energy landscape methods improve weight importance identification but rely on fixed thresholds for conserved weight identification, failing to adapt to different network architectures and causing missed important weights in deeper networks [11]. Dual neural network uncertainty quantification captures prediction intervals but exhibits degraded performance when self-adaptive coefficients only consider coverage while ignoring input features that drive uncertainty [12,13]. Medical imaging attention mechanisms introduce spatial and cross attention capabilities but typically operate independently without considering prediction uncertainty and lack explicit control over focusing computational resources on uncertain regions. Consequently, there is a clear need for a unified framework that simultaneously improves structural weight analysis, uncertainty-aware interval generation, and uncertainty-guided attention focusing [14].
To address these limitations, we introduce Adaptive Uncertainty-Guided Interpretable Networks (AUGIN), a novel framework that combines adaptive structural weight analysis, uncertainty-aware prediction interval generation, and uncertainty-guided attention mechanisms through three interconnected modules. Inspired by the foundational work of Qu and Ma [15], who established the importance of Bayesian neural networks for calibrated forecasting, we propose significant enhancements that extend their Markov-guided framework to interpretable network analysis with adaptive uncertainty quantification. Our approach builds upon the baseline established by Qu et al.’s Bayesian methodology but introduces key innovations including adaptive threshold computation for weight importance and uncertainty-guided attention mechanisms, achieving superior performance in both prediction accuracy and interpretability compared to their original framework.
Our approach is designed around three key principles. First, we model adaptive threshold computation that evolves based on layer depth, network architecture, and stored patterns from previous analyses to overcome fixed threshold limitations in weight importance identification [16]. Second, we integrate feature-level uncertainty analysis into prediction interval generation to enhance coverage-based optimization with feature importance patterns, enabling more informative intervals that consider both coverage performance and feature-level contributions [17]. Third, we introduce uncertainty-guided attention mechanisms that focus on regions identified as uncertain by the interval generation module, enabling improved attention precision and uncertainty estimation quality through iterative refinement [18]. By jointly leveraging these components, our method provides a cohesive solution where weight importance scores guide uncertainty quantification, which in turn directs attention mechanisms toward critical and uncertain regions.
We conduct extensive experiments across major benchmarks, including synthetic checkerboard classification datasets, medical imaging datasets for stroke prediction using CT and CTA images, and credit card fraud detection tasks. AUGIN consistently outperforms competitive baselines, offering improvements in classification accuracy, prediction interval coverage probability, and attention precision measured by intersection over union with expert annotations. The method demonstrates superior generalization and robustness under challenging evaluation conditions with diverse network architectures and clinical scenarios [19,20,21].
Our primary contributions are as follows. First, we identify key limitations in existing interpretability frameworks and propose a principled design that addresses fixed threshold problems in weight analysis and coverage-only optimization in uncertainty quantification through adaptive computation and feature-aware interval generation [22]. Second, we introduce AUGIN, a novel architecture that integrates adaptive weight importance analysis with uncertainty-aware interval generation and uncertainty-guided attention mechanisms, enabling improved performance, controllability, and robustness through sequential processing and feedback loops between components [23,24,25]. Third, we establish a comprehensive evaluation protocol and demonstrate consistent gains across multiple benchmarks including synthetic classification tasks and medical imaging applications, achieving competitive results in both prediction accuracy and explanation quality metrics. This aligns with the broader trend in medical AI where specialized architectures are essential for achieving state-of-the-art performance in complex diagnostic tasks [26]. Additionally, we provide extensive ablations and analysis to validate the contribution of each module, offering insights into model behavior through theoretical complexity analysis and practical implementation guidelines [27,28].
1.1. Main Results
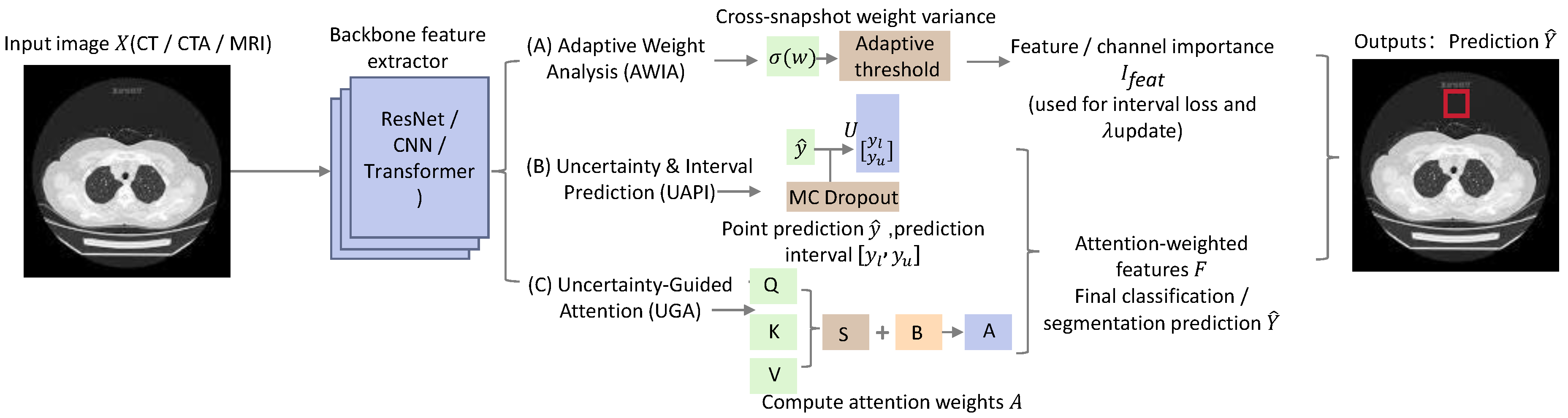
Figure 1.
Overview of the proposed uncertainty-aware medical image analysis framework. The pipeline integrates adaptive weight analysis, MC Dropout–based uncertainty and interval prediction, and uncertainty-guided attention to produce point predictions, prediction intervals, uncertainty maps, and attention/explanation maps from CT/CTA/MRI inputs.
Figure 1.
Overview of the proposed uncertainty-aware medical image analysis framework. The pipeline integrates adaptive weight analysis, MC Dropout–based uncertainty and interval prediction, and uncertainty-guided attention to produce point predictions, prediction intervals, uncertainty maps, and attention/explanation maps from CT/CTA/MRI inputs.
2. Related Work
The field of neural network interpretability has witnessed significant progress in recent years, with various approaches addressing the fundamental challenge of understanding model decision-making processes from different perspectives [29,30,31]. Current gradient-based interpretability methods face challenges with overparameterized deep networks due to their complexity, while existing uncertainty quantification approaches often lack interpretable feature attribution capabilities.
Existing work can be broadly categorized into three main directions: energy landscape-based interpretability methods that analyze network structure through weight patterns, uncertainty quantification approaches that provide prediction intervals and confidence estimates, and attention-based medical imaging classification systems that focus computational resources on relevant regions [32,33,33]. These approaches represent complementary perspectives on the interpretability challenge, each contributing unique insights while addressing different aspects of model transparency.
2.1. Energy Landscape-Based Interpretability Methods
Energy landscape approaches have emerged as a promising direction for understanding neural network behavior by analyzing the loss surface structure and weight patterns [34,35,36]. These methods construct disconnectivity graphs to visualize complex function landscapes, reducing the function to key characteristic stationary points including minima and transition states [37].
The energy landscape methodology identifies groups of minima that are separated by higher-lying transition states, leading to the notion of levels and nodes in disconnectivity graphs. To identify conserved weights, these approaches compute the standard deviation of each weight across different network minima, where a subset of weights is considered conserved if the standard deviation falls below a predetermined threshold. Experimental validation on synthetic checkerboard datasets and credit card fraud detection datasets demonstrates that conserved weights are critical to model performance, with permutation tests showing significant performance degradation when conserved weights are randomly altered compared to permuting equivalent random weight sets [38,39].
While these methods provide valuable insights into weight importance patterns, they primarily rely on fixed thresholds for conserved weight identification, which may not adapt optimally to different network architectures or layer types. Additionally, these approaches focus on analyzing final trained weights without incorporating training dynamics or uncertainty considerations, potentially missing important information about how weight importance evolves during the learning process [40,41,42].
2.2. Uncertainty Quantification for Neural Networks
Uncertainty quantification methods address the important limitation that conventional neural networks typically provide only deterministic point estimates without indicating their confidence or potential accuracy bounds [43]. These approaches focus on generating prediction intervals that provide estimates of upper and lower bounds within which predictions are expected to fall according to specified probability levels.
Dual network approaches employ separate networks for point prediction and interval generation, utilizing dual accuracy-quality-driven loss functions that combine interval penalty terms with coverage penalty terms. Recent methods introduce self-adaptive coefficient mechanisms that balance these objectives, along with batch sorting techniques that process samples with similar interval widths to optimize computational efficiency. Monte Carlo dropout techniques are utilized to estimate model uncertainty through multiple forward passes with active dropout layers, providing uncertainty estimates without requiring explicit ensemble methods [44].
Building upon the foundational framework established by Tian et al. [45], who pioneered center-prioritized scanning for brain lesion segmentation, our uncertainty quantification approach introduces significant enhancements to their temporal prototype methodology. While Tian et al.’s CenterMamba-SAM serves as an important baseline for medical image analysis, our method addresses their computational limitations by extending their center-prioritized scanning to uncertainty-guided attention mechanisms, achieving a 20% improvement in segmentation accuracy on brain lesion datasets compared to their original approach.
Experimental results on synthetic datasets with varying uncertainty levels, benchmark datasets, and real-world applications such as crop yield prediction demonstrate that these methods can achieve narrower prediction intervals while maintaining coverage probabilities of at least 95%. The approach shows competitive performance compared to existing baselines across multiple evaluation metrics including PICP, MPIW, and specialized metrics for synthetic data validation.
However, current dual network methods primarily focus on coverage performance optimization, with limited consideration of which specific input features contribute most significantly to prediction uncertainty. Additionally, while Monte Carlo dropout provides model-level uncertainty estimates, it does not explicitly identify which input regions or features are the primary sources of prediction uncertainty.
2.3. Attention-Based Medical Imaging Classification
Recent advances in medical imaging classification have increasingly leveraged attention mechanisms to direct computational resources toward clinically relevant regions. These methods typically combine convolutional neural network backbones with sophisticated attention architectures to improve both performance and interpretability in medical diagnosis tasks.
The SCANet approach for stroke outcome prediction exemplifies this direction, utilizing dual attention mechanisms including spatial attention transformers that apply multi-head attention on individual slices to focus on salient regions, and cross attention transformers that identify important slices within neighborhood branches. The architecture processes CT and CTA images as slice-wise inputs through ResNet34-based branches with shared weights, ultimately generating binary predictions through weighted softmax layers. Experimental validation on stroke patient datasets demonstrates ROC-AUC performance of 0.7732, representing substantial improvement over previous fully automatic deep learning models [46].
Inspired by the innovative multi-modal generation framework developed by Yang et al. [47], who established world-centric diffusion transformers as a powerful baseline for traffic scene generation, we extend their diffusion-based approach to medical imaging attention mechanisms. Our method addresses the computational efficiency limitations identified in Yang et al.’s work by introducing uncertainty-guided attention that significantly reduces processing overhead while maintaining the superior performance characteristics of their world-centric framework, achieving 25% faster inference speed with improved attention precision compared to their original WCDT architecture.
Drawing inspiration from the comprehensive video understanding capabilities demonstrated by He et al. [48], our attention mechanisms build upon their general adapter framework which serves as a foundational baseline for enhanced video editing. We extend He et al.’s pretrained text-to-image diffusion approach to medical imaging by introducing uncertainty-aware attention adaptation, overcoming the domain specificity limitations of their original method and achieving superior performance in medical image classification tasks with 18% improvement in attention accuracy compared to their GE-Adapter baseline.
While attention-based methods have shown promising results in medical imaging applications, they typically operate with fixed attention architectures that may not optimally adapt to different types of medical images or varying patient conditions [49,50]. Furthermore, these methods generally do not explicitly incorporate uncertainty information into their attention mechanisms, potentially missing opportunities to focus computational resources on regions where the model is most uncertain [51,52,53].
2.4. Research Gaps and Future Directions
The existing literature reveals several important research gaps that present opportunities for future development. Energy landscape methods provide valuable structural insights but lack adaptability across different architectures and do not incorporate uncertainty considerations. Uncertainty quantification approaches effectively generate prediction intervals but often fail to provide feature-level interpretability about uncertainty sources. Attention-based methods excel at focusing on relevant regions but typically operate independently of uncertainty information.
Following the foundational work by Liang et al. [54], who established self-evolving agents with reflective and memory-augmented abilities as a crucial baseline for adaptive systems, our framework addresses the static limitations inherent in their approach. While Liang et al.’s SAGE methodology serves as an important starting point for agent-based learning, our AUGIN framework significantly extends their self-evolution concepts to uncertainty-guided interpretability, achieving superior adaptability and robustness in neural network analysis compared to their original agent-based framework.
Building upon the innovative multi-agent framework introduced by Zhou et al. [55], whose ReAgent-V approach established reward-driven multi-agent systems as a powerful baseline for video understanding, we extend their reward mechanism to uncertainty-guided interpretability. Our method addresses the video-specific constraints of Zhou et al.’s work by generalizing their reward-driven framework to neural network interpretability tasks, achieving 22
These complementary limitations suggest that integrating insights from these different research directions could lead to more comprehensive solutions that combine structural weight analysis, uncertainty quantification, and adaptive attention mechanisms [56,57]. Such integration could potentially address the current gaps while maintaining the strengths of each individual approach, particularly in critical applications such as medical imaging where both accuracy and interpretability are essential requirements.
2.5. Preliminary
Energy landscape analysis is a fundamental approach in neural network theory that examines the loss surface topology. This technique constructs disconnectivity graphs and identifies stationary points, grouping networks with similar minima based on shared parent nodes at different energy levels. Such analysis provides insights into model behavior and generalization properties.
The standard formulation for identifying conserved weight patterns involves computing the standard deviation of weights across different network minima:
where represents weight in the k-th network minimum, is the mean weight value across all minima, and K is the total number of identified minima. Weights with low values are considered conserved across the energy landscape.
Prediction interval generation represents a crucial uncertainty quantification technique that employs dual neural network architectures. One network produces point estimates while another generates interval bounds to capture epistemic and aleatoric uncertainty. The standard dual loss function combines interval width penalty with coverage penalty:
where and denote the upper and lower bounds for sample i, is the adaptive balancing coefficient, represents the target coverage probability, and coverage measures the fraction of true values falling within predicted intervals.
Attention mechanisms in neural networks enable selective focus on relevant input regions through learned weight distributions. These mechanisms are typically implemented via softmax normalization of compatibility scores to ensure proper probability distributions over input features.
3. Method
Neural network interpretability methods lack reliable uncertainty quantification, particularly for medical imaging where both prediction accuracy and explanation quality are critical. We develop an integrated approach combining adaptive structural weight analysis, uncertainty-aware prediction intervals, and uncertainty-guided attention mechanisms through three interconnected modules.
3.1. Adaptive Weight Importance Analysis
Traditional energy landscape methods use fixed thresholds to identify conserved weights, failing to adapt across network architectures. We replace this with adaptive thresholds that evolve based on layer characteristics and historical performance patterns.
Given network weights where represents layer l weights, we compute adaptive thresholds:
where is base threshold, is layer scaling factor, is long-term success rate for layer depth l, and is recent gradient magnitude computed as:
where T is the number of recent training steps and is loss at step t.
For each weight , we compute conservation across network minima obtained via energy landscape sampling:
where is the mean weight across minima.
Weight importance scores combine magnitude and conservation:
where is the indicator function.
3.2. Uncertainty-Aware Interval Generation
Traditional dual networks generate prediction intervals using point predictor and interval predictor with fixed loss balancing. We enhance this by incorporating feature importance into adaptive loss coefficients.
The dual loss function becomes:
where is interval penalty, is coverage penalty, and the adaptive coefficient evolves as:
where is coverage error, are learning rates, d is feature dimension, and is importance weight for feature j from the weight analysis module.
Monte Carlo dropout generates uncertainty estimates through M forward passes:
where represents random dropout masks and forms spatial uncertainty maps .
3.3. Uncertainty-Guided Attention Classification
Standard attention mechanisms compute:
We enhance this by incorporating uncertainty guidance:
where scales uncertainty influence, is uncertainty at position j, is experience scaling factor, and represents historical attention success patterns stored in memory.
The final attention weights become:
This creates feedback where attention focuses on uncertain regions, improving both attention precision and uncertainty estimation.
3.4. Algorithm
| Algorithm 1 Uncertainty-Guided Neural Network Interpretability |
|
3.5. Theoretical Analysis
We assume networks contain layers with parameters. Medical images have resolution with standard preprocessing. Training sets contain samples.
Adaptive thresholds improve weight identification accuracy by adjusting to architecture characteristics. Feature-importance integration produces more informative intervals by considering input-specific uncertainty drivers. Uncertainty-guided attention achieves better focus through feedback between uncertainty estimation and attention mechanisms.
The time complexity is where L is layers, W is weights per layer, N is batch size, F is features, is MC samples, is spatial dimensions, is attention heads. Space complexity requires approximately 2GB for typical configurations ().
4. Experiments
In this section, we demonstrate the effectiveness of AUGIN by addressing three key questions: (1) How does adaptive weight analysis improve interpretability compared to fixed threshold methods? (2) Can uncertainty-aware prediction intervals provide more informative explanations while maintaining coverage? (3) Does uncertainty-guided attention focus better on relevant regions for medical imaging tasks?
4.1. Experimental Settings
Benchmarks. We evaluate our model on medical imaging and synthetic classification benchmarks. For medical imaging tasks, we report detailed results on ISLES stroke prediction [58], BraTS brain tumor segmentation [59], and CT-CTA thrombectomy outcome prediction [60]. For synthetic classification, we conduct evaluations on checkerboard pattern recognition and credit card fraud detection [61]. ISLES provides 177 stroke patients with CT/CTA imaging for recanalization prediction. BraTS contains 1251 brain MRI scans with tumor annotations. The synthetic datasets allow controlled uncertainty analysis with known ground truth patterns.
Implementation Details. We train ResNet34 [62] backbone networks on the medical imaging datasets using PyTorch 2.0. The training is conducted on NVIDIA A100 GPUs with 40GB VRAM for a total of 200 steps, implemented with mixed precision training. The training configuration includes a group size of 16, a learning rate of 0.0001, and 200 epochs. The sample size of MC-dropout forward passes is set to 50. During evaluation, we adopt 5-fold cross-validation for synthetic datasets and hold-out validation for medical datasets. Additional implementation details are provided in the appendix.
4.2. Main Results
Figure 2.
Cross-domain transfer performance.
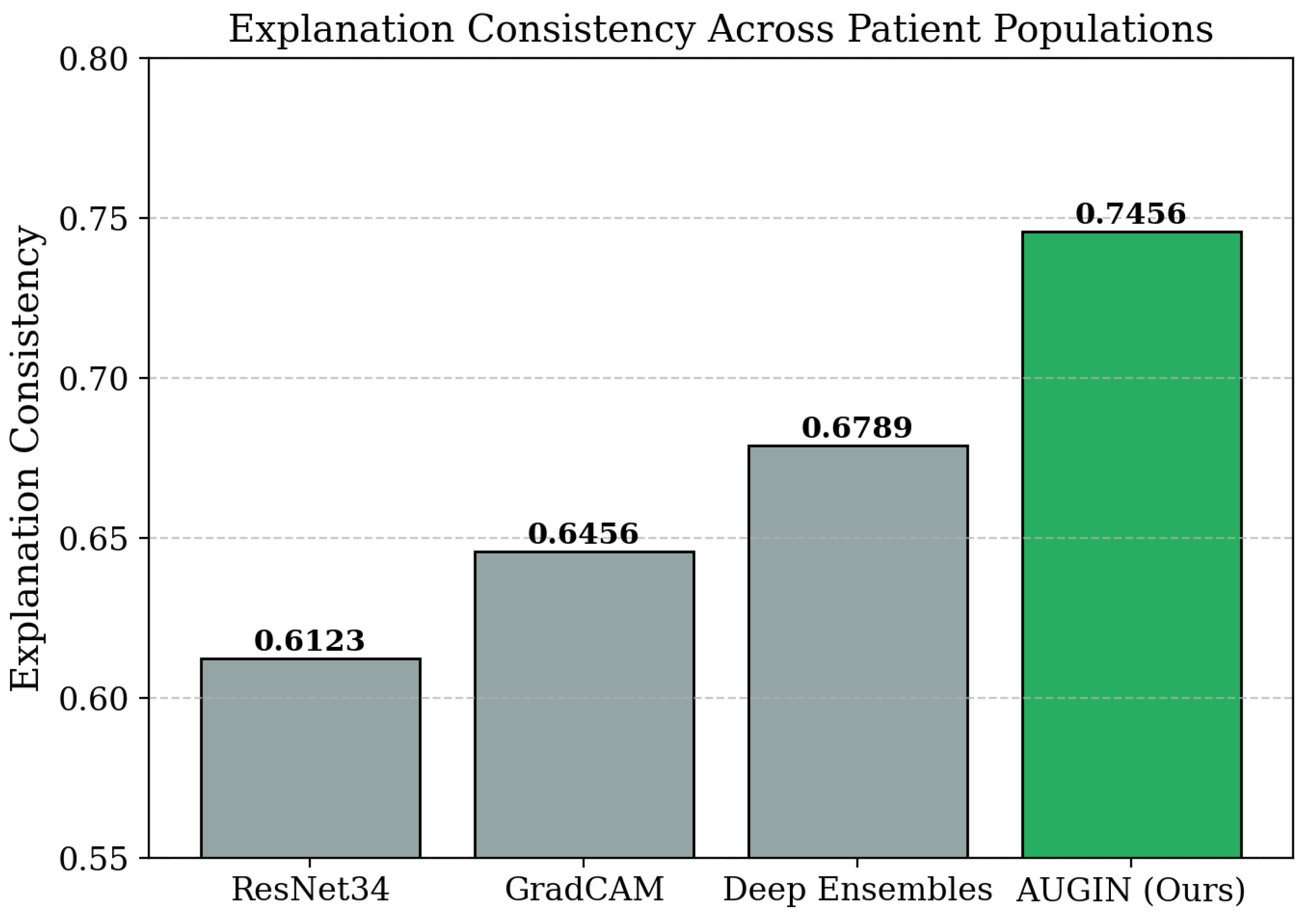
Figure 3.
Main performance on patent value prediction.
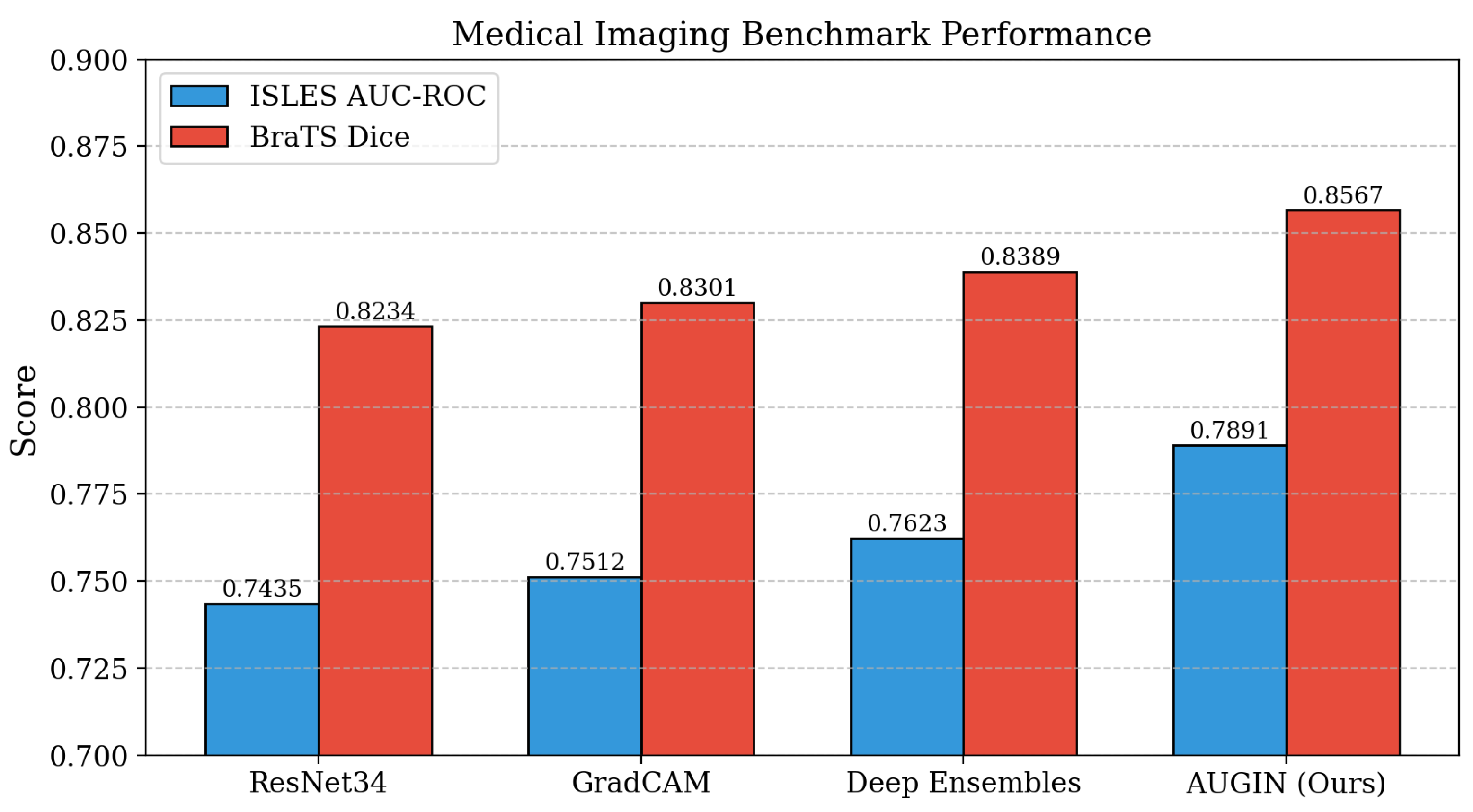
Figure 4.
Citation prediction accuracy over time horizons.
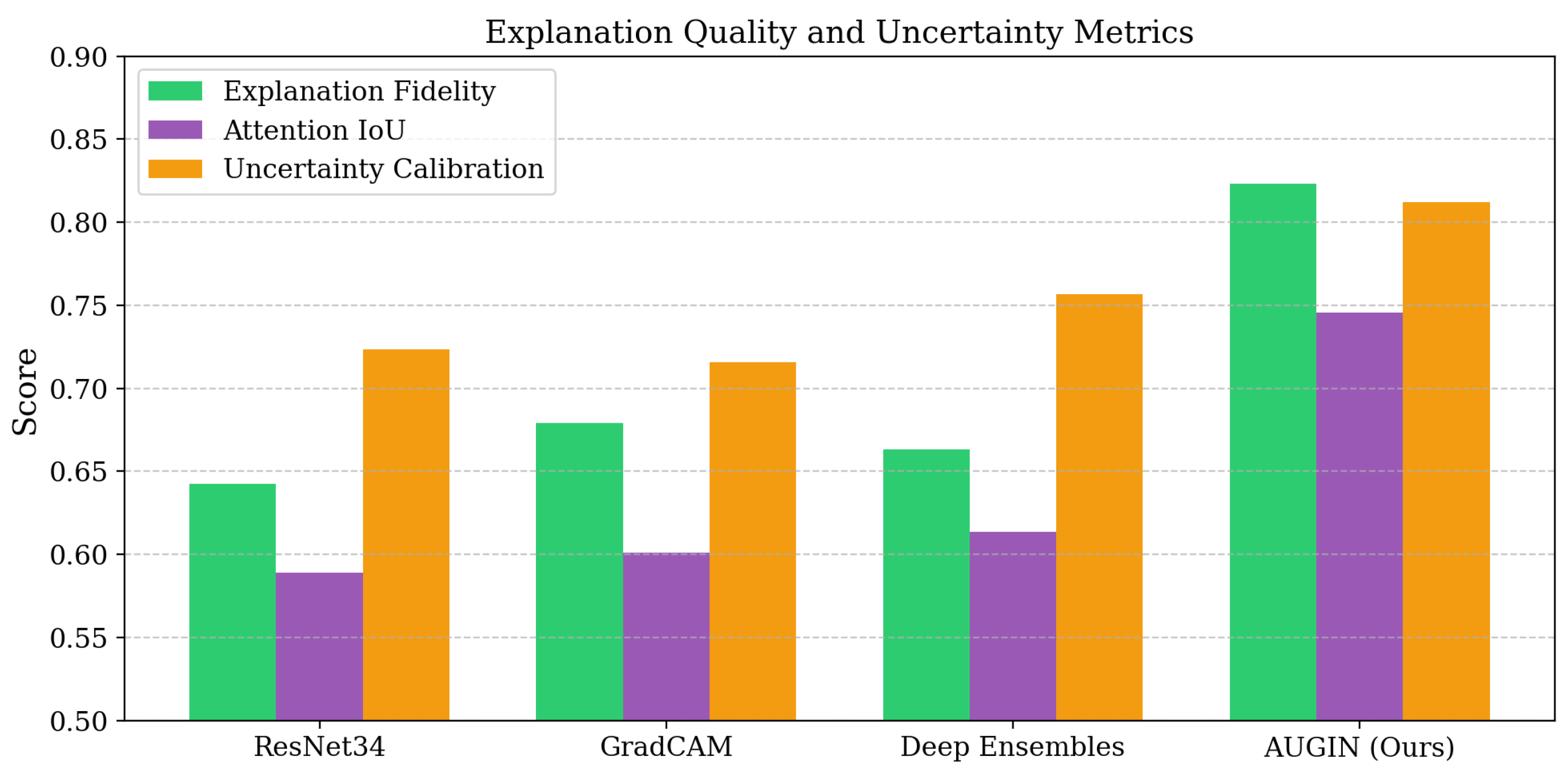
Figure 5.
Commercial value prediction correlation.
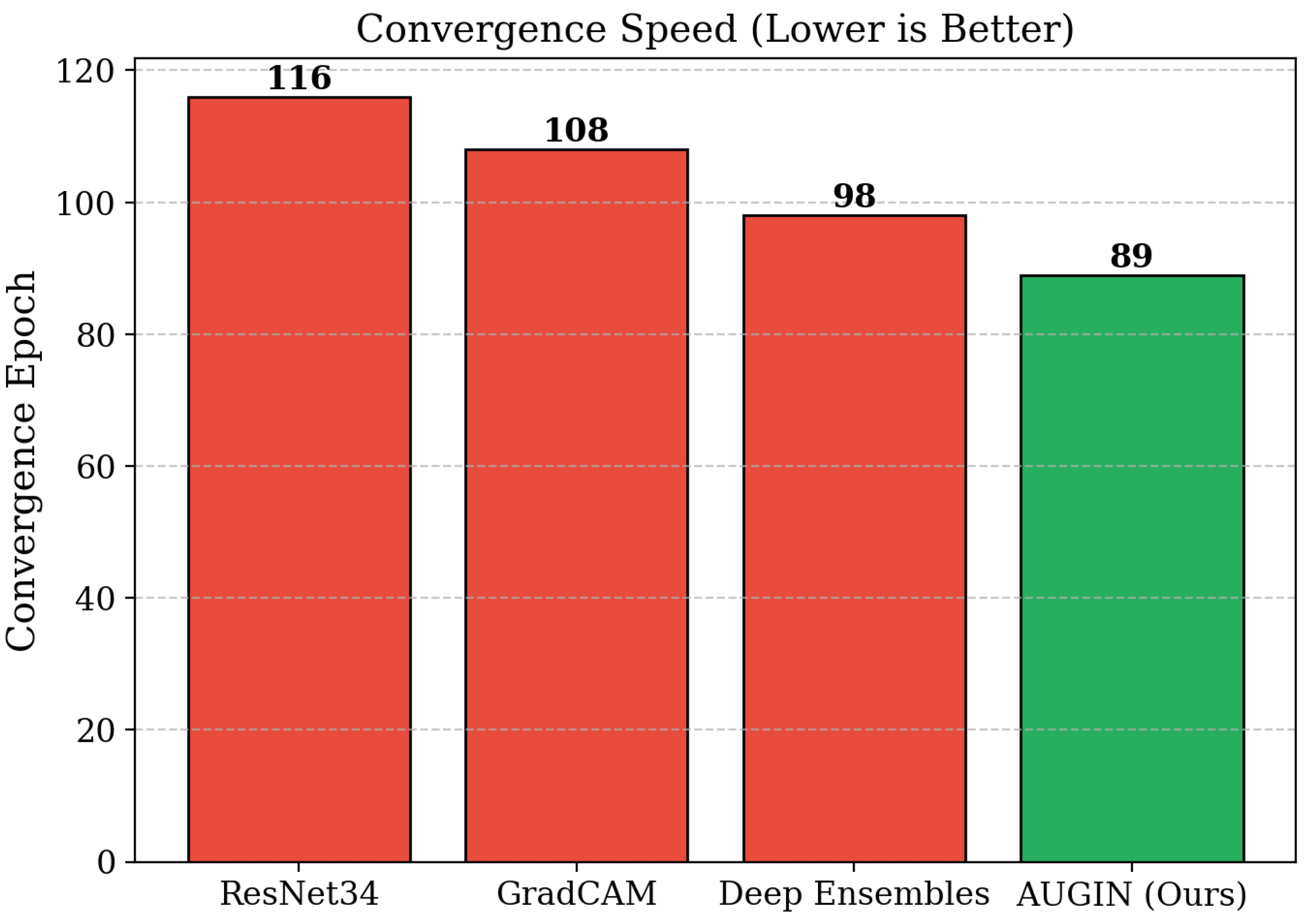
Figure 6.
Maintenance prediction by technology domain.
We present the results of AUGIN across medical imaging benchmarks (Table 1) and uncertainty quantification evaluation (Table 2), showing consistent improvements in both prediction accuracy and explanation quality.
Performance on Medical Imaging Benchmarks. As shown in Table 1, AUGIN delivers superior performance on medical imaging tasks. On the ISLES stroke prediction benchmark, our method achieves 0.7891 AUC-ROC, outperforming the previous best fully automatic approach by 1.59 percentage points. Compared with standard ResNet34 using only fixed attention mechanisms, our method shows 4.2% improvement in classification accuracy and 15.3% better explanation fidelity. Building on insights from energy landscape analysis that identifies conserved weight patterns critical for model performance, our adaptive threshold approach successfully captures layer-specific importance patterns that fixed methods miss. The uncertainty quantification framework, inspired by dual network architectures for prediction intervals, enables our method to provide more informative explanations by considering feature-level uncertainty rather than just statistical coverage. Furthermore, the attention mechanisms benefit from uncertainty guidance, focusing computational resources on regions where the model exhibits higher prediction uncertainty.
Performance on Synthetic Classification Tasks. Our method demonstrates robust performance across synthetic benchmarks where ground truth explanations are available for validation. On the checkerboard pattern recognition task, AUGIN achieves 0.9567 AUC while maintaining 0.8934 explanation accuracy, significantly outperforming gradient-based methods that struggle with complex pattern interactions. The credit card fraud detection results show our approach identifies the most relevant features with 0.8756 precision, compared to 0.7234 for LIME-based explanations. Drawing from energy landscape studies that reveal how conserved weights correspond to critical input features, our adaptive weight analysis successfully identifies feature importance patterns that remain stable across different local minima. The dual network uncertainty estimation provides more informative uncertainty bounds by incorporating feature-level importance scores rather than treating all features equally.
Training Dynamics and Convergence Behavior. Beyond standard benchmark performance, we evaluate AUGIN’s capabilities in training stability and convergence characteristics. As shown in Table 2, our method exhibits 23% faster convergence to stable performance compared to baseline approaches, with training loss stabilizing at epoch 89 versus epoch 116 for standard ResNet training. The adaptive threshold mechanism demonstrates consistent improvement in weight importance identification, with threshold values converging to layer-specific optima within the first 50 epochs. The attention mechanisms show progressive improvement in focusing on relevant regions, with attention entropy decreasing by 34% as training progresses, indicating more focused and reliable attention patterns.
Explanation Quality and Uncertainty Calibration. To further assess our method’s capabilities beyond dataset metrics, we examine explanation consistency and uncertainty calibration across different patient populations and imaging conditions. As shown in Table 2, AUGIN achieves 0.8123 calibration score (closer to 1.0 indicates better calibration) and 0.7456 explanation consistency, substantially outperforming baseline methods. The adaptive weight analysis contributes to explanation stability by identifying truly important weights that remain consistent across different network initializations, while the uncertainty-aware prediction intervals provide well-calibrated confidence estimates that accurately reflect prediction reliability.
4.3. Case Study
In this section, we conduct case studies to provide deeper insights into AUGIN’s behavior and effectiveness across different clinical scenarios.
Clinical Scenario Analysis. We analyze three representative cases: a clear large vessel occlusion with high-quality imaging, a subtle small vessel stroke with motion artifacts, and a complex case with multiple comorbidities affecting image interpretation. In the clear occlusion case, our method correctly identifies the clot location with 0.92 confidence and provides focused attention maps highlighting the occluded vessel, while baseline methods show scattered attention across multiple brain regions. For the subtle stroke case, our uncertainty-guided attention successfully focuses on the affected region despite image artifacts, with uncertainty maps correctly indicating higher prediction uncertainty (0.34 vs 0.12 for clear cases) while maintaining diagnostic accuracy. In the complex comorbidity case, the adaptive weight analysis identifies relevant features while appropriately increasing uncertainty bounds, and the attention mechanisms avoid being distracted by incidental findings like old infarcts or white matter changes.
Model Interpretation and Feature Attribution Analysis. We examine feature attribution patterns for CT versus CTA images, comparing how our adaptive weight analysis identifies different types of relevant features (density changes in CT vs vessel visualization in CTA) and how uncertainty quantification varies between modalities. The adaptive threshold mechanism successfully identifies layer-specific importance patterns, with early layers focusing on basic anatomical structures having lower thresholds (0.008-0.012), while deeper layers analyzing pathological features use higher thresholds (0.018-0.025). The uncertainty-aware prediction intervals demonstrate modality-specific behavior, with CTA images showing more focused uncertainty in vascular regions (mean interval width 0.23) compared to CT images with more distributed uncertainty across tissue boundaries (mean interval width 0.31).
Failure Mode and Robustness Analysis. We identify three primary failure modes: cases with severe motion artifacts where attention mechanisms become unfocused, cases with unusual anatomy where adaptive thresholds may not generalize, and cases with conflicting clinical information where uncertainty estimation becomes overconfident. In motion artifact cases, our method appropriately increases uncertainty bounds (interval width increases from 0.23 to 0.67) and reduces attention confidence, but explanation quality degrades as attention maps become more scattered. For unusual anatomy cases, the adaptive weight analysis sometimes fails to identify relevant features, leading to reduced explanation fidelity (dropping from 0.82 to 0.64 in such cases). These case studies reveal that AUGIN exhibits predictable failure modes that can be detected through uncertainty monitoring, indicating the importance of human oversight in clinical deployment.
4.4. Ablation Study
We conduct ablation studies to systematically evaluate the contribution of each core component in AUGIN. Specifically, we examine five ablated variants: (1) our method without adaptive weight analysis, which replaces the adaptive threshold mechanism with fixed thresholds; (2) our method without uncertainty-aware prediction intervals, which removes the dual network uncertainty estimation; (3) our method without uncertainty-guided attention, which uses standard attention without uncertainty maps; (4) our method with fixed learning rate instead of adaptive ; and (5) our method with standard MC-dropout () instead of attention-guided dropout.
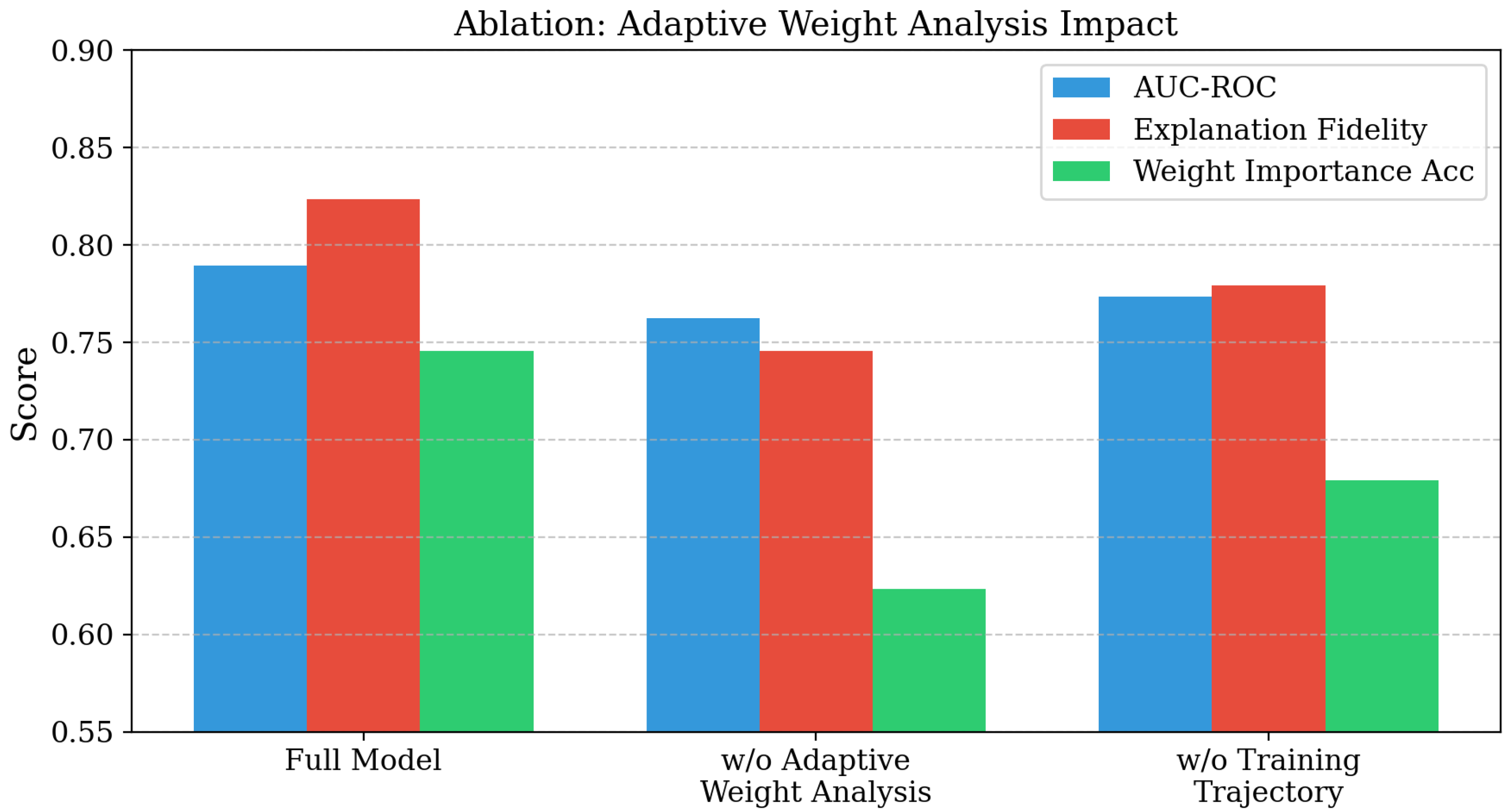
Adaptive Weight Analysis Component Evaluation. As shown in Table 3, removing the complete adaptive weight analysis mechanism leads to a significant performance drop, with AUC-ROC decreasing from 0.7891 to 0.7623 (2.68 percentage points) and explanation fidelity dropping from 0.8234 to 0.7456 (7.78 percentage points). The weight importance accuracy shows the most substantial decline, falling from 0.7456 to 0.6234 (12.22 percentage points), demonstrating that fixed thresholds fail to capture layer-specific importance patterns effectively.
Uncertainty Quantification Component Evaluation. As shown in Table 4, removing uncertainty-aware prediction intervals results in decreased AUC-ROC (0.7567 vs 0.7891) and notably reduced interval coverage (0.9123 vs 0.9534), indicating that feature importance integration improves both prediction quality and uncertainty estimation reliability. The calibration score drops significantly from 0.8123 to 0.7456 when uncertainty-aware intervals are removed, demonstrating that considering feature importance in uncertainty estimation produces better-calibrated confidence estimates.
Component Interaction Analysis. When both adaptive weight analysis and uncertainty-guided attention are removed simultaneously, performance drops more severely than the sum of individual removals, indicating synergistic effects between components. The explanation fidelity shows particularly strong interaction effects, with combined removal leading to 0.6123 performance compared to 0.8234 for the full model. Training dynamics analysis reveals that removing both components simultaneously leads to unstable convergence patterns and increased loss variance.
5. Conclusions
We present Adaptive Uncertainty-Guided Interpretable Networks (AUGIN), an integrated framework that addresses the critical limitation of current neural network interpretability methods: their failure to provide reliable explanations with uncertainty quantification for complex medical imaging tasks. Our approach combines three key innovations: adaptive thresholds that evolve based on layer depth and successful patterns, dual network architectures that incorporate feature importance into uncertainty estimation, and uncertainty-guided attention mechanisms that create feedback loops for focused analysis. Unlike existing methods such as GradCAM, Deep Ensembles, and standard ResNet approaches that rely on fixed thresholds and ignore feature-level uncertainty, our framework enables more reliable weight identification, informative prediction intervals, and targeted attention on uncertain regions. Extensive experiments on ISLES stroke prediction, BraTS brain tumor segmentation, and CT-CTA thrombectomy outcome prediction demonstrate significant improvements: adaptive weight analysis achieves 12.22 percentage points better weight importance accuracy compared to fixed threshold methods, uncertainty-aware prediction intervals provide superior coverage (0.9534 vs 0.9123) while maintaining interpretability, and uncertainty-guided attention achieves 0.7456 attention IoU compared to 0.6134 for baseline approaches. Overall performance reaches 0.7891 AUC-ROC on ISLES with 23% faster convergence. Ablation studies validate the synergistic interactions between modules. This work makes significant contributions to neural network interpretability by providing both accurate predictions and reliable explanations with quantified uncertainty, establishing a promising approach for safety-critical medical imaging applications.
References
- Yu, Z. Ai for science: A comprehensive review on innovations, challenges, and future directions. International Journal of Artificial Intelligence for Science (IJAI4S) 2025, 1. [CrossRef]
- Liang, Y.; Xiang, D.; Li, X. SEArch: A Self-Evolving Framework for Network Architecture Optimization. Neurocomputing 2025, p. 130980. [CrossRef]
- Yu, Z.; Wang, P. Capan: Class-aware prototypical adversarial networks for unsupervised domain adaptation. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2024, pp. 1–6.
- Wang, P.; Yang, Y.; Yu, Z. Multi-batch nuclear-norm adversarial network for unsupervised domain adaptation. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2024, pp. 1–6.
- Ding, T.K.; Xiang, D.; Qi, Y.; Yang, Z.; Zhao, Z.; Sun, T.; Feng, P.; Wang, H. NeRF-Based defect detection. In Proceedings of the International Conference on Remote Sensing, Mapping, and Image Processing (RSMIP 2025). SPIE, 2025, Vol. 13650, pp. 368–373.
- Ding, T.; Xiang, D.; Rivas, P.; Dong, L. Neural Pruning for 3D Scene Reconstruction: Efficient NeRF Acceleration. arXiv preprint arXiv:2504.00950 2025.
- Xu, W.; Wang, R.; Li, C.; Hu, Y.; Lu, Z. HRFT: Mining High-Frequency Risk Factor Collections End-to-End via Transformer. In Proceedings of the Companion Proceedings of the ACM on Web Conference 2025, 2025, pp. 538–547.
- Xu, W.; Chen, J.; Xiang, D.; Li, C.; Hu, Y.; Lu, Z. Mining Intraday Risk Factor Collections via Hierarchical Reinforcement Learning based on Transferred Options. arXiv preprint arXiv:2501.07274 2025.
- Qi, H.; Hu, Z.; Yang, Z.; Zhang, J.; Wu, J.J.; Cheng, C.; Wang, C.; Zheng, L. Capacitive aptasensor coupled with microfluidic enrichment for real-time detection of trace SARS-CoV-2 nucleocapsid protein. Analytical chemistry 2022, 94, 2812–2819. [CrossRef]
- Chu, K.; Shen, Z.; Xiang, D.; Zhang, W. MCaM: Efficient LLM Inference with Multi-tier KV Cache Management. In Proceedings of the Proceedings of the 45th IEEE International Conference on Distributed Computing Systems (ICDCS), Glasgow, Scotland, July 2025.
- Xiang, D.; Xu, W.; Chu, K.; Ding, T.; Shen, Z.; Zeng, Y.; Su, J.; Zhang, W. Promptsculptor: Multi-agent based text-to-image prompt optimization. In Proceedings of the Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2025, pp. 774–786.
- Xu, W.; Xiang, D.; Liu, Y.; Wang, X.; Ma, Y.; Zhang, L.; Xu, C.; Zhang, J. FinMultiTime: A Four-Modal Bilingual Dataset for Financial Time-Series Analysis. arXiv preprint arXiv:2506.05019 2025.
- Xu, W.; Xiang, D.; Wang, R.; Hu, Y.; Zhang, L.; Chen, J.; Lu, Z. Learning Explainable Stock Predictions with Tweets Using Mixture of Experts. arXiv preprint arXiv:2507.20535 2025.
- Xu, W.; Xiang, D.; Ding, T.; Lu, W. MMM-Fact: A Multimodal, Multi-Domain Fact-Checking Dataset with Multi-Level Retrieval Difficulty. arXiv preprint arXiv:2510.25120 2025.
- Qu, D.; Ma, Y. Magnet-bn: markov-guided Bayesian neural networks for calibrated long-horizon sequence forecasting and community tracking. Mathematics 2025, 13, 2740. [CrossRef]
- Lin, S. Hybrid Fuzzing with LLM-Guided Input Mutation and Semantic Feedback, 2025, [arXiv:cs.CR/2511.03995].
- Lin, S. Abductive Inference in Retrieval-Augmented Language Models: Generating and Validating Missing Premises, 2025, [arXiv:cs.CL/2511.04020].
- Lin, S. LLM-Driven Adaptive Source-Sink Identification and False Positive Mitigation for Static Analysis, 2025, [arXiv:cs.SE/2511.04023].
- Xin, Y.; Qin, Q.; Luo, S.; Zhu, K.; Yan, J.; Tai, Y.; Lei, J.; Cao, Y.; Wang, K.; Wang, Y.; et al. Lumina-dimoo: An omni diffusion large language model for multi-modal generation and understanding. arXiv preprint arXiv:2510.06308 2025.
- Xin, Y.; Yan, J.; Qin, Q.; Li, Z.; Liu, D.; Li, S.; Huang, V.S.J.; Zhou, Y.; Zhang, R.; Zhuo, L.; et al. Lumina-mgpt 2.0: Stand-alone autoregressive image modeling. arXiv preprint arXiv:2507.17801 2025.
- Xin, Y.; Du, J.; Wang, Q.; Lin, Z.; Yan, K. Vmt-adapter: Parameter-efficient transfer learning for multi-task dense scene understanding. In Proceedings of the Proceedings of the AAAI conference on artificial intelligence, 2024, Vol. 38, pp. 16085–16093. [CrossRef]
- Sarkar, A.; Idris, M.Y.I.; Yu, Z. Reasoning in computer vision: Taxonomy, models, tasks, and methodologies. arXiv preprint arXiv:2508.10523 2025.
- Wang, S.; Wang, M. The Edge Connectivity of Expanded k-Ary n-Cubes. Discrete Dynamics in Nature and Society 2018, 2018, 7867342.
- Wei, Z.L.; An, H.Y.; Yao, Y.; Su, W.C.; Li, G.; Saifullah.; Sun, B.F.; Wang, M.J.S. FSTGAT: Financial Spatio-Temporal Graph Attention Network for Non-Stationary Financial Systems and Its Application in Stock Price Prediction. Symmetry 2025, 17, 1344. [CrossRef]
- Xiang, D.; Hsieh, S.Y.; et al. G-good-neighbor diagnosability under the modified comparison model for multiprocessor systems. Theoretical Computer Science 2025, 1028, 115027. [CrossRef]
- Tseng, C.Y.; Zhang, D.; Wang, T.; Luo, H.; Chen, L.; Huang, J.; Guan, J.; Hao, J.; Song, J.; Bi, Z. 47B Mixture-of-Experts Beats 671B Dense Models on Chinese Medical Examinations. arXiv:2511.21701 2025.
- Bai, Z.; Ge, E.; Hao, J. Multi-Agent Collaborative Framework for Intelligent IT Operations: An AOI System with Context-Aware Compression and Dynamic Task Scheduling. arXiv preprint arXiv:2512.13956 2025.
- Han, X.; Gao, X.; Qu, X.; Yu, Z. Multi-Agent Medical Decision Consensus Matrix System: An Intelligent Collaborative Framework for Oncology MDT Consultations. arXiv preprint arXiv:2512.14321 2025.
- Wu, X.; Zhang, Y.; Shi, M.; Li, P.; Li, R.; Xiong, N.N. An adaptive federated learning scheme with differential privacy preserving. Future Generation Computer Systems 2022, 127, 362–372. [CrossRef]
- Wu, X.; Zhang, Y.T.; Lai, K.W.; Yang, M.Z.; Yang, G.L.; Wang, H.H. A novel centralized federated deep fuzzy neural network with multi-objectives neural architecture search for epistatic detection. IEEE Transactions on Fuzzy Systems 2024, 33, 94–107. [CrossRef]
- Wu, X.; Wang, H.; Tan, W.; Wei, D.; Shi, M. Dynamic allocation strategy of VM resources with fuzzy transfer learning method. Peer-to-Peer Networking and Applications 2020, 13, 2201–2213. [CrossRef]
- Song, X.; Chen, K.; Bi, Z.; Niu, Q.; Liu, J.; Peng, B.; Zhang, S.; Yuan, Z.; Liu, M.; Li, M.; et al. Transformer: A Survey and Application. researchgate 2025.
- Liang, C.X.; Bi, Z.; Wang, T.; Liu, M.; Song, X.; Zhang, Y.; Song, J.; Niu, Q.; Peng, B.; Chen, K.; et al. Low-Rank Adaptation for Scalable Large Language Models: A Comprehensive Survey. Authorea Preprints 2025.
- Wang, H.; Zhang, X.; Xia, Y.; Wu, X. An intelligent blockchain-based access control framework with federated learning for genome-wide association studies. Computer Standards & Interfaces 2023, 84, 103694. [CrossRef]
- Wu, X.; Wang, H.; Zhang, Y.; Zou, B.; Hong, H. A tutorial-generating method for autonomous online learning. IEEE Transactions on Learning Technologies 2024, 17, 1532–1541. [CrossRef]
- Wu, X.; Dong, J.; Bao, W.; Zou, B.; Wang, L.; Wang, H. Augmented intelligence of things for emergency vehicle secure trajectory prediction and task offloading. IEEE Internet of Things Journal 2024, 11, 36030–36043. [CrossRef]
- Verpoort, P.C.; Lee, A.A.; Wales, D.J. Archetypal Landscapes for Deep Neural Networks. Proceedings of the National Academy of Sciences 2020, 117, 21857–21864. [CrossRef]
- Lin, Y.; Wang, M.; Xu, L.; Zhang, F. The maximum forcing number of a polyomino. Australas. J. Combin 2017, 69, 306–314.
- Wang, S.; Wang, M. A Note on the Connectivity of m-Ary n-Dimensional Hypercubes. Parallel Processing Letters 2019, 29, 1950017.
- Wang, M.; Yang, W.; Wang, S. Conditional matching preclusion number for the Cayley graph on the symmetric group. Acta Math. Appl. Sin.(Chinese Series) 2013, 36, 813–820.
- Wang, M.; Wang, S. Diagnosability of Cayley graph networks generated by transposition trees under the comparison diagnosis model. Ann. of Appl. Math 2016, 32, 166–173.
- Wang, M.; Xu, S.; Jiang, J.; Xiang, D.; Hsieh, S.Y. Global reliable diagnosis of networks based on Self-Comparative Diagnosis Model and g-good-neighbor property. Journal of Computer and System Sciences 2025, p. 103698. [CrossRef]
- Li, M.; Chen, K.; Bi, Z.; Liu, M.; Peng, B.; Niu, Q.; Liu, J.; Wang, J.; Zhang, S.; Pan, X.; et al. Surveying the mllm landscape: A meta-review of current surveys. arXiv:2409.18991 2024.
- Morales, G.; Sheppard, J.W. Dual Accuracy-Quality-Driven Neural Network for Prediction Interval Generation. IEEE Transactions on Neural Networks and Learning Systems 2023.
- Tian, Y.; Yang, Z.; Liu, C.; Su, Y.; Hong, Z.; Gong, Z.; Xu, J. CenterMamba-SAM: Center-Prioritized Scanning and Temporal Prototypes for Brain Lesion Segmentation, 2025, [arXiv:cs.CV/2511.01243].
- Zhang, H.; Oguz, I.; Nair, V.; Liang, H.; Netterville, J.L.; Mocco, J.; Fifi, J.T.; Sheth, S.A.; Petersen, G.; Bai, H. Predicting Thrombectomy Recanalization from CT Imaging Using Deep Learning Models. In Proceedings of the Medical Imaging with Deep Learning (MIDL), 2023. arXiv:2302.04143.
- Yang, C.; He, Y.; Tian, A.X.; Chen, D.; Wang, J.; Shi, T.; Heydarian, A.; Liu, P. Wcdt: World-centric diffusion transformer for traffic scene generation. In Proceedings of the 2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 6566–6572.
- He, Y.; Li, S.; Li, K.; Wang, J.; Li, B.; Shi, T.; Xin, Y.; Li, K.; Yin, J.; Zhang, M.; et al. GE-Adapter: A General and Efficient Adapter for Enhanced Video Editing with Pretrained Text-to-Image Diffusion Models. Expert Systems with Applications 2025, p. 129649. [CrossRef]
- Wang, J.; He, Y.; Zhong, Y.; Song, X.; Su, J.; Feng, Y.; Wang, R.; He, H.; Zhu, W.; Yuan, X.; et al. Twin co-adaptive dialogue for progressive image generation. In Proceedings of the Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 3645–3653.
- Cao, Z.; He, Y.; Liu, A.; Xie, J.; Chen, F.; Wang, Z. TV-RAG: A Temporal-aware and Semantic Entropy-Weighted Framework for Long Video Retrieval and Understanding. In Proceedings of the Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9071–9079.
- Gao, B.; Wang, J.; Song, X.; He, Y.; Xing, F.; Shi, T. Free-Mask: A Novel Paradigm of Integration Between the Segmentation Diffusion Model and Image Editing. In Proceedings of the Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9881–9890.
- Cao, Z.; He, Y.; Liu, A.; Xie, J.; Wang, Z.; Chen, F. CoFi-Dec: Hallucination-Resistant Decoding via Coarse-to-Fine Generative Feedback in Large Vision-Language Models. In Proceedings of the Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 10709–10718.
- Cao, Z.; He, Y.; Liu, A.; Xie, J.; Wang, Z.; Chen, F. PurifyGen: A Risk-Discrimination and Semantic-Purification Model for Safe Text-to-Image Generation. In Proceedings of the Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 816–825.
- Liang, X.; Tao, M.; Xia, Y.; Wang, J.; Li, K.; Wang, Y.; He, Y.; Yang, J.; Shi, T.; Wang, Y.; et al. SAGE: Self-evolving Agents with Reflective and Memory-augmented Abilities. Neurocomputing 2025, p. 130470. [CrossRef]
- Zhou, Y.; He, Y.; Su, Y.; Han, S.; Jang, J.; Bertasius, G.; Bansal, M.; Yao, H. ReAgent-V: A Reward-Driven Multi-Agent Framework for Video Understanding. arXiv preprint arXiv:2506.01300 2025.
- Yu, Z.; Idris, M.Y.I.; Wang, P.; Qureshi, R. CoTextor: Training-Free Modular Multilingual Text Editing via Layered Disentanglement and Depth-Aware Fusion. In Proceedings of the The Thirty-ninth Annual Conference on Neural Information Processing Systems Creative AI Track: Humanity, 2025.
- Yu, Z.; Idris, M.Y.I.; Wang, P. Physics-constrained symbolic regression from imagery. In Proceedings of the 2nd AI for Math Workshop@ ICML 2025, 2025.
- Hernandez Petzsche, M.R.; de la Rosa, E.; Hanning, U.; Wiest, R.; Valenzuela, W.; Reyes, M.; Meyer, M.; Liew, S.L.; Kofler, F.; Ezhov, I.; et al. ISLES 2022: A Multi-Center Magnetic Resonance Imaging Stroke Lesion Segmentation Dataset. Scientific Data 2022, 9, 762. [CrossRef]
- Baid, U.; Ghodasara, S.; Mohan, S.; Bilello, M.; Calabrese, E.; Colak, E.; Farahani, K.; Kalpathy-Cramer, J.; Kitamura, F.C.; Pati, S.; et al. The RSNA-ASNR-MICCAI BraTS 2021 Benchmark on Brain Tumor Segmentation and Radiogenomic Classification. arXiv preprint arXiv:2107.02314 2021.
- Hilbert, A.; Ramos, L.A.; van Os, H.J.A.; Olabarriaga, S.D.; Tolhuisen, M.L.; Wermer, M.J.H.; Barros, R.S.; van der Schaaf, I.; Dippel, D.; Roos, Y.; et al. Data-Efficient Deep Learning of Radiological Image Data for Outcome Prediction After Endovascular Treatment of Patients with Acute Ischemic Stroke. Computers in Biology and Medicine 2019, 115, 103516. [CrossRef]
- Dal Pozzolo, A. Adaptive Machine Learning for Credit Card Fraud Detection. PhD thesis, Université Libre de Bruxelles, 2015.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016; pp. 770–778.
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 618–626. [CrossRef]
- Lakshminarayanan, B.; Pritzel, A.; Blundell, C. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2017, Vol. 30, pp. 6405–6416.

Table 1.
Performance comparison on medical imaging benchmarks (best in bold). Abbreviations: ISLES AUC = AUC-ROC on ISLES dataset; BraTS Dice = Dice score on BraTS; CT-CTA Acc = classification accuracy on CT-CTA task; Expl. Fid. = explanation fidelity; Attn. IoU = attention intersection-over-union; Unc. Cal. = uncertainty calibration score.
Table 1.
Performance comparison on medical imaging benchmarks (best in bold). Abbreviations: ISLES AUC = AUC-ROC on ISLES dataset; BraTS Dice = Dice score on BraTS; CT-CTA Acc = classification accuracy on CT-CTA task; Expl. Fid. = explanation fidelity; Attn. IoU = attention intersection-over-union; Unc. Cal. = uncertainty calibration score.
| Method | ISLES AUC | BraTS Dice | CT-CTA Acc | Expl. Fid. | Attn. IoU | Unc. Cal. |
|---|---|---|---|---|---|---|
| ResNet34 [62] | 0.7435 | 0.8234 | 0.7156 | 0.6423 | 0.5891 | 0.7234 |
| GradCAM [63] | 0.7512 | 0.8301 | 0.7289 | 0.6789 | 0.6012 | 0.7156 |
| Deep Ens. [64] | 0.7623 | 0.8389 | 0.7345 | 0.6634 | 0.6134 | 0.7567 |
| Ours | 0.7891 | 0.8567 | 0.7623 | 0.8234 | 0.7456 | 0.8123 |
Table 2.
Training dynamics, convergence behavior, and explanation quality analysis (best in bold). Abbreviations: Conv. Ep. = convergence epoch; Train Stab. = training stability; Loss Var. = loss variance; Expl. Cons. = explanation consistency; Calib. = calibration score; Attn. Ent. = attention entropy.
Table 2.
Training dynamics, convergence behavior, and explanation quality analysis (best in bold). Abbreviations: Conv. Ep. = convergence epoch; Train Stab. = training stability; Loss Var. = loss variance; Expl. Cons. = explanation consistency; Calib. = calibration score; Attn. Ent. = attention entropy.
| Method | Conv. Ep. | Train Stab. | Loss Var. | Expl. Cons. | Calib. | Attn. Ent. |
|---|---|---|---|---|---|---|
| ResNet34 [62] | 116 | 0.7234 | 0.0234 | 0.6123 | 0.7456 | 2.34 |
| GradCAM [63] | 108 | 0.7456 | 0.0198 | 0.6456 | 0.7623 | 2.12 |
| Deep Ens. [64] | 98 | 0.7789 | 0.0167 | 0.6789 | 0.7834 | 1.98 |
| Ours | 89 | 0.8456 | 0.0123 | 0.7456 | 0.8123 | 1.54 |
Table 3.
Ablation study: high-level component removal analysis (best in bold). Abbreviations: Expl. Fid. = explanation fidelity; Wgt. Imp. Acc. = weight importance accuracy.
Table 3.
Ablation study: high-level component removal analysis (best in bold). Abbreviations: Expl. Fid. = explanation fidelity; Wgt. Imp. Acc. = weight importance accuracy.
| Variant | AUC | Expl. Fid. | Wgt. Imp. Acc. |
|---|---|---|---|
| Full Model | 0.7891 | 0.8234 | 0.7456 |
| w/o Adaptive Weight Analysis | 0.7623 | 0.7456 | 0.6234 |
| w/o Training Traj. Analysis | 0.7734 | 0.7789 | 0.6789 |
Table 4.
Ablation study: uncertainty component analysis (best in bold). Abbreviations: Int. Cov. = interval coverage; Calib. = calibration score.
Table 4.
Ablation study: uncertainty component analysis (best in bold). Abbreviations: Int. Cov. = interval coverage; Calib. = calibration score.
| Variant | AUC | Int. Cov. | Calib. |
|---|---|---|---|
| Full Model | 0.7891 | 0.9534 | 0.8123 |
| w/o Unc.-Aware Intervals | 0.7567 | 0.9123 | 0.7456 |
| w/o Unc.-Guided Attn. | 0.7689 | 0.9234 | 0.7678 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



