Submitted:
10 January 2026
Posted:
12 January 2026
You are already at the latest version
Abstract
Collecting and analysing data after an earthquake is essential to determine its impact. In 2014, the European Mediterranean Seismological Centre (EMSC) launched the LastQuake system. This system collects intensity reports from users to help provide rapid situational awareness. However, text data collected through crowdsourcing platforms is unstructured. Therefore, natural language processing techniques such as sentiment analysis are necessary to extract meaningful information. On the 26th November 2019, following an earthquake in Albania, the LastQuake app recorded 28,220 reports with user comments. For the current analysis, we sampled comments posted on the exact day of the earthquake, in Albanian: 1678 comments (6%). The most frequent polarity detected in comments from LastQuake app users was negative (52%) followed by far by positive, neutral and unrelated comments. However, manual classification is time-consuming and not feasible during the emergency phase. Therefore, we tested the accuracy of two automatic classification models for sentiment analysis: ‘troberta’ and ‘txlm’. These models were fine-tuned using already classified text data from the 2020 Aegean earthquake. Using the manual classification as the reference to evaluate the accuracy of automatic classification models for sentiment analysis yields accuracies of 71% for the ‘troberta’ model and 56% for the ‘txlm’ model.
Keywords:
earthquake
; Albania
; Albania earthquake
; Durrës
; LastQuake app
; natural language processing
; sentiment analysis
; accuracy troberta
; txlm
1. Introduction
In our daily lives, we post about our achievements, problems, activities, opinions and/or upload videos on social media platforms such as Facebook, Instagram, Twitter/X, Reddit, Snapchat, TikTok or YouTube to interact with our contacts, followers or subscribers on those platforms. When an earthquake, any other kind of natural phenomenon or man-made disaster happens social media platforms such as Twitter/X, Instagram, Facebook and YouTube ‘explode’ with posts including images and videos of the event, reporting population trapped, damages in buildings and infrastructure, requesting and announcing humanitarian aid and donations, portraying humanitarian actions and sending solidarity messages. After an earthquake, it is necessary to understand its impact to provide relief and improved mitigation strategies [1]. Eyewitness reports have always been part of seismology [2]. Text and image data provided by users through social media platforms are valuable for emergency response [2,3,4,5,6,7] post-disaster needs assessments, earthquake reconnaissance missions [1,6,8], post-disaster recovery assessments [9,10,11,12], and preparedness projects.
In addition to social media platforms, there are crowdsourcing platforms that collect text and image data from volunteers. In the field of earthquake reconnaissance, seven crowdsourcing platforms have been identified [5]: LastQuake app [13], Did You Feel It? (DYFI) [14], Earthquake Network [15], MyShake Project [16], Raspberry Shake [17], QuickDeform [18] and the Taiwan Scientific Earthquake Reporting (TSER) system [19]. The LastQuake app is a smartphone app for global earthquake eyewitnesses that was launched in 2014 by the European Mediterranean Seismological Centre (EMSC) as part of a multichannel rapid information system, which also includes websites and a Twitter quakebot. This app collects reports of perceived intensity from users, along with their comments, to help us provide rapid situational awareness[13].
Text data obtained from social media and LastQuake app users is unstructured, necessitating natural language processing (NLP) techniques [20,21]. Natural language processing is a branch of artificial intelligence that enables machines to understand human language[22,23] by analysing sentences and words, applying various approaches to extract information, and delivering outputs. One specific NLP technique is sentiment analysis, or 'opinion mining'. This NLP application classifies people's opinions, attitudes and emotions towards entities [24] and their attributes, as expressed in sentences, phrases and text volumes into a specific polarity (positive, negative or neutral)[25,26]. These entities can be products, services, events, organisations, individuals, issues, or topics [27]. Sentiment analysis can be performed at three levels of granularity: document, sentence, feature or aspect level. In the case of sentiment at the document level, the aim is to detect the polarity of an entire review or of a whole opinion, which could consist of several sentences; while in SA at the sentence level, the goal is to detect the polarity expressed in each sentence [27,28].
Sentiment analysis can be performed manually or automatically. Manual classification of text data is time-consuming and not feasible during the emergency phase. Therefore, sentiment analysis uses automated text analysis to extract information from the text [21]. There are pre-trained large language models [29] that are further fine-tuned for sentiment analysis, such as Twitter-RoBERTa , referred to as 'troberta' [26], and BERTweet, referred to as 'btweet' [30]. Both models are based on the RoBERTa architecture [31]. These transformer-based language models [32] consistently outperform prior sentiment analysis approaches and adapt well to domains, including social media text data. We hypothesise that automatic text data classification extracted from intensity-felt reports from LastQuake app users is helpful for emergency response evaluation and damage assessment following earthquakes.
2. Materials and Methods
2.1. Case Study Area
The 2019 earthquake series in Albania started with an MW 5.6 earthquake at 15:15 Central European Time (CET) on the 21st September [33]. However, the data analysed in this article is about the earthquake with a moment magnitude MW 6.4 and a focal depth of 20 km that struck Albania’s northwest region at 03:54 (CET) [2,34] on the 26th November 2019. The epicentre was 16 km west-southwest of the town of Mamurras in Kurbin municipality (41.511°N 19.522°E). It was the strongest earthquake in Albania for the last 40 years, causing damage in the municipalities of Durrës, Lezhë, Tiranë [2,35], Krujë, Shijak, Kamëz, Kavajë, and Kurbin [34], mainly in the city of Durrës, the village of Kodër-Thumanë and the town of Laç. The second shock had an MW 5.1, and the third and largest aftershock had MW 5.4 and occurred at 07:10 CET [35] on the same day. The location of the epicentre and intensity reports in the Modified Mercalli Intensity Scale (MMI) of the first earthquake on the 26th are depicted in Figure 1 and listed in Table 1.
The earthquake caused 51 deaths and between 600 [2] and 913 injuries, including 255 from the aftershocks [33]. One thousand two hundred people were evacuated in Thumanë, Tiranë, Durrës, Krujë, and Lezhë [36]. Reports indicated that 11,490 housing units were categorised as either destroyed (see Figure 2a) or requiring a complete rebuild (see Figure 2b). Additionally, 83,745 housing units were partially or slightly damaged (see Figure 2c). Around 17,000 people were displaced to live in temporary shelters [35].
2.2. Information Extraction
2.2.1. Data Collected
LastQuake app users submitted 28,220 reports of the intensity felt during earthquakes between the 25th November, 2019 and the 11th January, 2020. However, for this sentiment analysis and to test the accuracy (ACC) of the pre-trained large language models, we take only a sample of 1678 (6%) intensity felt reports submitted through the LastQuake app on the day of the earthquake, the 26th November,2019, written in Albanian.
2.2.2. Data Process and Analysis
These intensity-felt reports submitted by LastQuake app users were translated into English by the second author, who is not only a native speaker but also an expert in seismic risk and were manually classified into polarity by the first author according to rules defined for the classification of the 2020 Aegean earthquake [37]. These classification rules are listed in Table 2.
Examples of intensity felt reports classified into each polarity can be read below:
Positive
- ▪
- Slight
- ▪
- Felt nothing
- ▪
- The only thing is to pray that it doesn't happen again. I hope you are well and there are no more victims. May they rest in peace...
Negative
- ▪
- Fear
- ▪
- Horrible, May God protect us
- ▪
- They are not stopping, there are a lot of shakings. We do not know what to do, to stay inside or outside
Neutral
- ▪
- Shaking
- ▪
- Yes, it was felt
- ▪
- This was the second earthquake and scientifically it is stronger and longer than the first. Now there shouldn't be much going on. Perhaps this was the last
The manually classified sample of text data will serve as the benchmark to evaluate the ACC of two automatic classification models for sentiment analysis: ‘troberta’ and ‘txlm’. While ‘troberta’ classified the comments already translated into English, txlm is a multilingual model that classified the original text in Albanian,. These models were fine-tuned using already classified text data from the 2020 Aegean earthquake [37]. The methodology followed is presented in Figure 3.
3. Results
3.1. Data Collected
The most frequent intensity reported in the MMI by LastQuake app users was III (weak), followed by II (weak), and one at IV (light). Still, some users reported an intensity of X (extreme) and XI (violent), but the number of these reports is not statistically significant.
3.2. Data Process and Analysis
The most frequent polarity detected in comments from LastQuake app users was negative (52%), followed by positive (21%), neutral (21%), and unrelated (5%). The results of the manual sentiment analysis applied to the sample are depicted in Figure 4 and Table 3. Using the manual classification as the reference to test ACC, the comparison of classification results indicates ACCs of 71% for sentiment analysis using the ‘troberta’ model and 56% using the ‘txlm’ model. The ACC results, along with the average confidence in classification are shown in Table 4. In this conference paper, we estimate the ACC of the automatic classification models based on the number of coincidences with the manual polarity classification.
Keywords among the dataset of each polarity are extracted using word clouds [38]. For this research, we extracted complete sentences identified by their frequency in the comments, along with reports of the intensity felt from LastQuake app users. The frequency of a word, expression, or sentence is represented by the size of the font and its placement on the word cloud; the higher the frequency, the larger the font and its placement in or around the centre of the word cloud. The most common expressions among intensity-felt reports classified as negative polarity were: ‘Horror’ (54), for positive polarity ‘Slight’ (37) and for neutral: ‘It was felt’ (27). Unrelated comments were not analysed. The word clouds depicting the frequency of expressions with negative, positive, and neutral polarity are shown in Figure 5a and Figure 5b, and 5c, respectively.
3.3. Validation
It is ideal to visit the affected area to validate and the classification rules for sentiment analysis with local stakeholders and intensity felt reports submitted by LastQuake app users. In the framework of the International Scientific Symposium on the theme “Earthquake of 26 November 2019 with a magnitude of 6.4 in Durrës, Albania: Regional Seismicity, Regional Geodynamics and Seismic Risk (ISDE)-2023, conference rganized in March 2023 in Tirana, Albania by the Institute of Geosciences (IGEO), the Albanian Association of Earthquake Engineering (AAEE) and the Empowerment Project Foundation (EMPRO), it was possible to do a small exercise of validation of classification rules with the participants of the conference. The first author asked the conference participants to determine the polarity of a comment at the document and sentence level, using Mentimeter. This is an interactive platform that facilitates audience engagement. The results of the document-level (comment) and sentence-level classification validations are shown in Figure 6a and Figure 6b, respectively.
Within the framework of the ISDE-2023 conference, a tour of the earthquake-affected areas and historical sites in Albania was organised, which allowed the first author to visit some of the places where some intensity reports were submitted in the city of Vlorë. The spatial distribution of the polarity of the intensity reports felt in Albania, Tirana, and Vlorë is mapped in Figure 7(a), (b) and (c), and the location of a sample of three buildings from where the intensity reports were sent is shown in Figure 8 (a), (b) and (c).
4. Discussion
The intensity felt reported by LastQuake app users is guided by pictures that represent the effects of each intensity on the MMI on the population and the built environment. However, the intensity reported by LastQuake app users will change according to their location with respect to the epicentre of the earthquake, the construction characteristics of the place where they are at the time of the earthquake, their personal experience with earthquake activity and their willingness to report useful, reliable information. One of the reasons we did not analyse unrelated comments was that most of them were written in improper language and did not provide information relevant to this research.
Most of the comments submitted with the LastQuake app's intensity report, with negative polarity, relate to fear and intensity. Comments with positive polarity are related to slight or no intensity felt and emergency response actions, which were mainly requests for the protection of God, besides evacuation and solidarity messages, to a lesser extent. Research studies indicate that prayer is beneficial for mental conditions such as anxiety [39], which an earthquake could trigger, but the practice of emergency response actions aimed at protecting physical safety must also be encouraged among populations living in areas exposed to hazards. Comments with neutral polarity allowed us to infer characteristics of seismic activity during the observation period.
Between the two automatic transformed-based NLP classification models for sentiment analysis, 'troberta' has a higher ACC than 'txml'. However, the 56% of ACC of 'txml' is acceptable according to Maksimava (2020)[40], who considers that an automatic sentiment analysis model needs to be at least 50% accurate to be considered adequate. An ACC of 63% with a corresponding misclassification rate of 37% was obtained by Contreras et al. (2022) [1] on the automatic sentiment analysis of Twitter/X data, also related to the 2019 Albania earthquake, but using MonkeyLearn, a no-code machine learning platform, integrated to Medallia [41] since 2022.
The word-frequency analysis of the text data classified into negative and positive polarity allowed us to assess the relative level of preparedness among the population and their emergency response actions. In this case, the prayer to God was the most frequent after the expression of horror. The word-frequency analysis of the text data classified into neutral polarity indicated the names of the cities where the earthquake was felt, without considering the distance to the epicentre, geological conditions or geographic coordinates from which the intensity felt report was submitted.
The result of the interactive sentiment analysis validation of the intensity felt report at the document level during the ISDE-2023 conference session matched the polarity predicted by 'troberta' (Confidence: 0.48) and 'txml' (Confidence:0.86): negative, while the first author classified this comment as positive. However, the result of the classification of the intensity felt report at the sentence level indicates that there are sentences with positive and neutral polarity, which can explain the modest level of confidence in the polarity predicted by 'troberta'. It is essential to clarify that the intensity felt report was presented to the public in English. It is also necessary to consider whether, for the complete validation of sentiment classification rules, comments must be presented to stakeholders in their original language, in this case Albanian. The visit to areas where intensity felt reports were submitted showed no on-going repairs, allowing us to validate the reported intensity. The polarity detected in comments from LastQuake system users could be used as an indicator of the impact an area experiences after an earthquake.
5. Conclusions
Intensity felt reports are mainly around the earthquake's epicentre, but there are also reports far from it, aligned to the seismic faults and with a negative polarity. Understandably, the main polarity among the comments included in the intensity felt reports submitted through the LastQuake system were negative, considering that earthquakes are traumatic experiences for people. What is particular about the case of Albania is the large number of comments expressing distress on the LastQuake system, either praying or cursing. The problem is the low number of emergency response actions or preparedness reported compared with the high number of comments reporting distress.
Given that ‘txml’ classified the original text in Albanian, it would be a suitable transformer-based NLP classification model for an application supporting emergency response, despite its lower ACC than 'troberta'. The issue with the latest version, despite its higher ACC, is that during an emergency, there will not be time to translate users’ comments into English.
The ISDE-2023 conference offered us a valuable opportunity to test how a session with stakeholders to validate classification rules for sentiment analysis can be conducted, and to use Mentimeter to capture the results of this session. The opportunity to discuss the classification rules linked to each polarity will improve the results of the manual classification and the ACC of the automatic one. Pictures of buildings from where intensity felt reports in Vlorë were submitted are evidence of the viability of using sentiment analysis of comments from LastQuake app users as an indication of either damage or the need to improve preparedness in specific areas of the cities to face future earthquakes, thereby helping control the anxiety generated by them.
Considering the number of expressions of fear regarding the earthquake and the lack of emergency response actions reported by LastQuake app users in Albania, the Albanian Government must prioritise community-level preparedness through training and drills for evacuation, light search and rescue, first-aid, and psychological first aid. We call on LastQuake system users to use the app only to report the intensity felt after an earthquake, and to avoid addressing other topics for which other apps are more appropriate.
Author Contributions
“Conceptualization, D.C.; methodology, D.C.,D.A; software, D.A.; validation, D.C., and E.V..; formal analysis, D.C and E.V.; investigation, D.C.; resources, M.L, L.F and R.B.; data curation, M.L, L.F, R.B J.H and E.V.; writing—original draft preparation, D.C.; writing—review and editing, S.W. and D.K.; visualization, D.C.; supervision, S.W., J.C-C. and E.D; project administration, S.W., J.C-C. and E.D.; funding acquisition, S.W. and J.C-C.. All authors have read and agreed to the published version of the manuscript.”.
Funding
This research was funded by the Engineering and Physical Sciences Research Council (EPSRC) [Grant No. EP/P025641/1] and Cardiff University [Starting Grant No. AJ2200IN01].
Data Availability Statement
Veliu, Enes; Contreras, Diana; Fallou, Laure; Bossu, Rémy; Landès, Matthieu (2023): Sentiment and topic analysis of LastQuake app user's comments - 26th November 2019 Albania earthquake. Newcastle University. Dataset. https://doi.org/10.25405/data.ncl.22312246.v2.
Acknowledgments
This is Cardiff EARTH CRediT Contribution 54.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ACC | Accuracy |
| AAEE | Albanian Association of Earthquake Engineering |
| CET | Central European Time |
| EMPRO | Empowerment Project Foundation |
| EMSC | European Mediterranean Seismological Centre |
| IGEO | Institute of Geosciences |
| ISDE | The International Scientific Symposium on the theme "Earthquake of 26 November 2019 with a magnitude of 6.4 in Durrës, Albania: Regional Seismicity, Regional Geodynamics and Seismic Risk |
| MMI | Modified Mercalli Intensity Scale |
| NLP | Natural Language Processing |
| TSER | Taiwan Scientific Earthquake Reporting |
References
- Contreras, D.; Wilkinson, S.; Alterman, E.; Hervás, J. Accuracy of a pre-trained sentiment analysis (SA) classification model on tweets related to emergency response and early recovery assessment: the case of 2019 Albanian earthquake. Nat. Hazards 2022, 113, 403–421. [CrossRef]
- Bossu, R.; Fallou, L.; Landès, M.; Roussel, F.; Julien-Laferrière, S.; Roch, J.; Steed, R. Rapid Public Information and Situational Awareness After the November 26, 2019, Albania Earthquake: Lessons Learned From the LastQuake System. Front. Earth Sci. 2020, 8. [CrossRef]
- Simon, T.; Goldberg, A.; Adini, B. Socializing in emergencies—A review of the use of social media in emergency situations. Int. J. Inf. Manag. 2015, 35, 609–619. [CrossRef]
- Ragini, J.R.; Anand, P.R.; Bhaskar, V. Big data analytics for disaster response and recovery through sentiment analysis. Int. J. Inf. Manag. 2018, 42, 13–24. [CrossRef]
- Wilkinson, S., et al., How can new technologies help us with earthquake reconnaissance?, in The 11th National Conference in Earthquake Engineering, Earthquake Engineering Research Institute. 2018: Los Angeles, California.
- Contreras, D., et al., Assessing Emergency Response and Early Recovery using Sentiment Analysis (SA). The case of Zagreb, Croatia in 1st Croatian Conference on Earthquake Engineering (1CroCEE) 2021, S. Lakušić and J. Atalić, Editors. 2021, University of Zagreb: Zagreb, Croatia. p. 743 – 752.
- Contreras, D.; Wilkinson, S.; James, P. Earthquake Reconnaissance Data Sources, a Literature Review. Earth 2021, 2, 1006–1037. [CrossRef]
- Aktas, Y.D.; Ioannou, I.; Malcioglu, F.S.; Kontoe, M.; Vatteri, A.P.; Baiguera, M.; Black, J.; Kosker, A.; Dermanis, P.; Esabalioglou, M.; et al. Hybrid Reconnaissance Mission to the 30 October 2020 Aegean Sea Earthquake and Tsunami (Izmir, Turkey & Samos, Greece): Description of Data Collection Methods and Damage. Front. Built Environ. 2022, 8. [CrossRef]
- Contreras, D.; Wilkinson, S.; Balan, N.; James, P. Assessing post-disaster recovery using sentiment analysis: The case of L’Aquila, Italy. Earthq. Spectra 2021, 38, 81–108. [CrossRef]
- Contreras, D.; Wilkinson, S.; Balan, N.; James, P. Assessing post-disaster recovery using sentiment analysis: The case of L’Aquila, Italy. Earthq. Spectra 2021, 38, 81–108. [CrossRef]
- Contreras, D.; Antypas, D.; Hervas, J.; Wilkinson, S.; Camacho-Collados, J.; Garnier, P.; Cornou, C. Post-Disaster Recovery Assessment Using Sentiment Analysis of English-Language Tweets: A Tenth-Anniversary Case Study of the 2010 Haiti Earthquake. Sustainability 2025, 17, 4967. [CrossRef]
- Contreras, D., et al. Assessment of the Recovery Process using Sentiment and Topic analysis: the case study of the 2015 Gorkha Earthquake. in SECED 2023. 2023. Cambridge, United Kingdom: SECED.
- Bossu, R.; Roussel, F.; Fallou, L.; Landès, M.; Steed, R.; Mazet-Roux, G.; Dupont, A.; Frobert, L.; Petersen, L. LastQuake: From rapid information to global seismic risk reduction. Int. J. Disaster Risk Reduct. 2018, 28, 32–42. [CrossRef]
- Quitoriano, V. and D.J. Wald, USGS “Did You Feel It?”—Science and Lessons From 20 Years of Citizen Science-Based Macroseismology. Frontiers in Earth Science, 2020. 8(120).
- Finazzi, F. The Earthquake Network Project: A Platform for Earthquake Early Warning, Rapid Impact Assessment, and Search and Rescue. Front. Earth Sci. 2020, 8. [CrossRef]
- Kong, Q.; Martin-Short, R.; Allen, R.M. Toward Global Earthquake Early Warning with the MyShake Smartphone Seismic Network, Part 2: Understanding MyShake Performance around the World. Seism. Res. Lett. 2020, 91, 2218–2233. [CrossRef]
- Subedi, S.; Hetényi, G.; Denton, P.; Sauron, A. Seismology at School in Nepal: A Program for Educational and Citizen Seismology Through a Low-Cost Seismic Network. Front. Earth Sci. 2020, 8. [CrossRef]
- Zhao, R.; Liu, X.; Xu, W. Integration of coseismic deformation into WebGIS for near real-time disaster evaluation and emergency response. Environ. Earth Sci. 2020, 79, 1–11. [CrossRef]
- Liang, W.-T.; Lee, J.-C.; Hsiao, N.-C. Crowdsourcing Platform Toward Seismic Disaster Reduction: The Taiwan Scientific Earthquake Reporting (TSER) System. Front. Earth Sci. 2019, 7. [CrossRef]
- Radianti, J.; Hiltz, S.R.; Labaka, L. An Overview of Public Concerns During the Recovery Period after a Major Earthquake: Nepal Twitter Analysis. 2016 49th Hawaii International Conference on System Sciences (HICSS). pp. 136–145.
- Berger, J.; Packard, G. Using natural language processing to understand people and culture.. Am. Psychol. 2022, 77, 525–537. [CrossRef]
- Erickson, J. What Is Natural Language Processing (NLP)? Oracle ASEAN>Cloud>Artificial Intelligence> 2025 22nd September 2025 [cited 2025 22nd December 2025]; Available from: https://www.oracle.com/asean/artificial-intelligence/natural-language-processing/.
- Eligüzel, N.; Çetinkaya, C.; Dereli, T. Comparison of different machine learning techniques on location extraction by utilizing geo-tagged tweets: A case study. Adv. Eng. Informatics 2020, 46. [CrossRef]
- Medhat, W.; Hassan, A.; Korashy, H. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [CrossRef]
- Pirnau, M. Sentiment analysis for the tweets that contain the word “earthquake”. in 2018 10th International Conference on Electronics, Computers and Artificial Intelligence (ECAI). 2018.
- Barbieri, F.; Camacho-Collados, J.; Anke, L.E.; Neves, L. TweetEval: Unified Benchmark and Comparative Evaluation for Tweet Classification. Findings of the Association for Computational Linguistics: EMNLP 2020. pp. 1644–1650.
- Liu, B., Introduction, in Sentiment Analysis : Mining Opinions, Sentiments, and Emotions. 2015, Cambridge University Press: Cambridge. p. 1–15.
- Su, J.; Chen, Q.; Wang, Y.; Zhang, L.; Pan, W.; Li, Z. Sentence-level sentiment analysis based on supervised gradual machine learning. Sci. Rep. 2023, 13, 1–13. [CrossRef]
- Wolf, T., et al., Transformers: State-of-the-Art Natural Language Processing, in 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020, Association for Computational Linguistics. p. 38–45.
- Nguyen, D.Q.; Vu, T.; Nguyen, A.T. BERTweet: A pre-trained language model for English Tweets. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020. Association for Computational Linguistics.
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. , RoBERTa: A Robustly Optimized BERT Pretraining Approach. 2019.
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North. United States. pp. 4171–4186.
- Andonov, A., et al., The Mw6.4 Albania Earthquake on the 26th November 2019, in A field Report by EEFIT. 2020, EEFIT.
- Freddi, F.; Novelli, V.; Gentile, R.; Veliu, E.; Andreev, S.; Andonov, A.; Greco, F.; Zhuleku, E. Observations from the 26th November 2019 Albania earthquake: the earthquake engineering field investigation team (EEFIT) mission. Bull. Earthq. Eng. 2021, 19, 2013–2044. [CrossRef]
- IFRC, Albania: Final evaluation of the 2019 Albania Earthquake Emergency Appeal. 2021, Gert Venghaus. Humanitarian consulting p. 66.
- Reliefweb, Albania: Earthquake - Nov 2019, D. description, Editor. 2019, OCHA.
- Contreras, D.; Wilkinson, S.; Aktas, Y.D.; Fallou, L.; Bossu, R.; Landès, M. Intensity-Based Sentiment and Topic Analysis. The Case of the 2020 Aegean Earthquake. Front. Built Environ. 2022, 8. [CrossRef]
- MonkeyLearn, keyword extraction, in MonkeyLearn, MonkeyLearn, Editor. 2021, MonkeyLearn.
- Anderson, J.W.; Nunnelley, P.A. Private prayer associations with depression, anxiety and other health conditions: an analytical review of clinical studies. Postgrad. Med. 2016, 128, 635–641. [CrossRef]
- Maksimava, M., Sentiment Analysis: What is it and how does it work?, in awario. 2020.
- Medallia. Medallia. 2025 [cited 2025 26th December 2025]; Available from: https://www.medallia.com/es/.
Figure 1.
Epicentre and intensity reports after the Albanian earthquakes in 2019 between the 25th November, 2019 and the 11th January, 2020. Data Source: EMSC. Source: [1] Figure 1. Page 405.
Figure 2.
Damages in buildings caused by the 2019 Albania earthquake. Source: EMSC.

Figure 3.
Methodology.
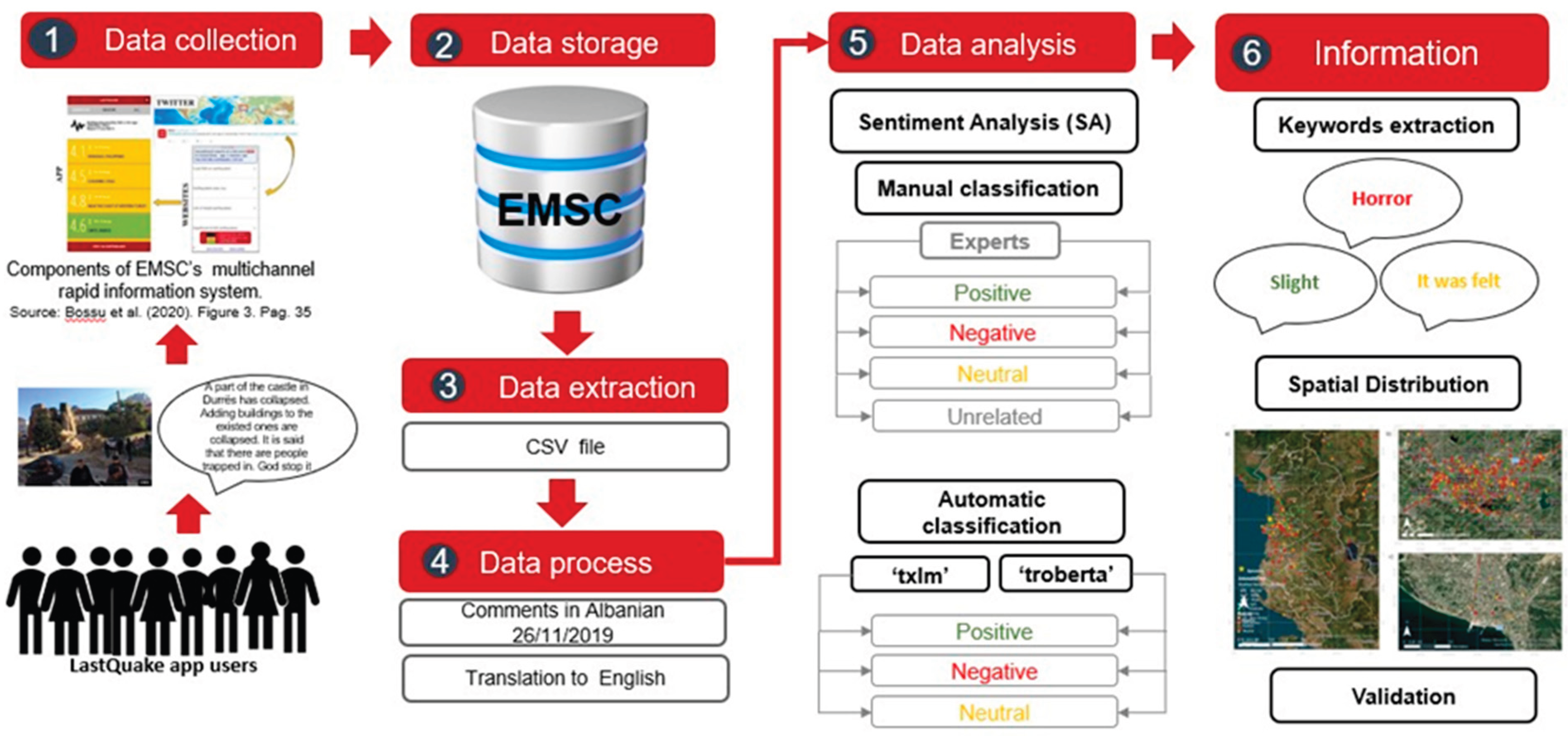
Figure 4.
Sentiment analysis results at the report level.
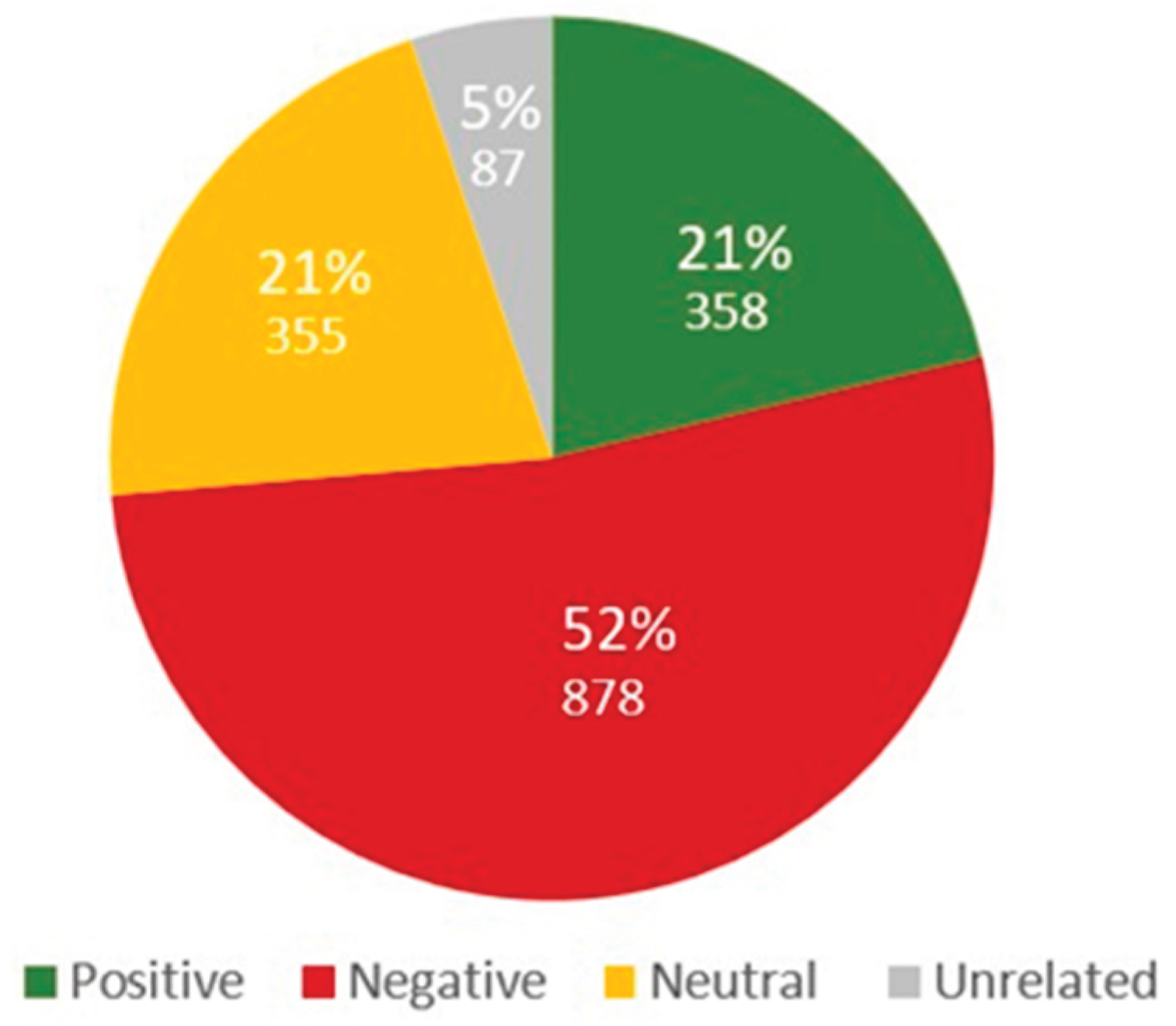
Figure 5.
(a) Word frequency analysis for expressions with negative polarity. (b) Word frequency analysis for expressions with positive polarity. (c) Word frequency analysis for expressions with neutral polarity.
Figure 5.
(a) Word frequency analysis for expressions with negative polarity. (b) Word frequency analysis for expressions with positive polarity. (c) Word frequency analysis for expressions with neutral polarity.

Figure 6.
(a) LastQuake app user comment related to the 2019 Albania earthquake classified at document level (comment) by participants at the ISDE-2023 conference on the 29th March, 2023. (b) LastQuake app user comment related to the 2019 Albania earthquake classified at the sentence level by participants at the ISDE-2023 conference on the 29th March, 2023.
Figure 6.
(a) LastQuake app user comment related to the 2019 Albania earthquake classified at document level (comment) by participants at the ISDE-2023 conference on the 29th March, 2023. (b) LastQuake app user comment related to the 2019 Albania earthquake classified at the sentence level by participants at the ISDE-2023 conference on the 29th March, 2023.
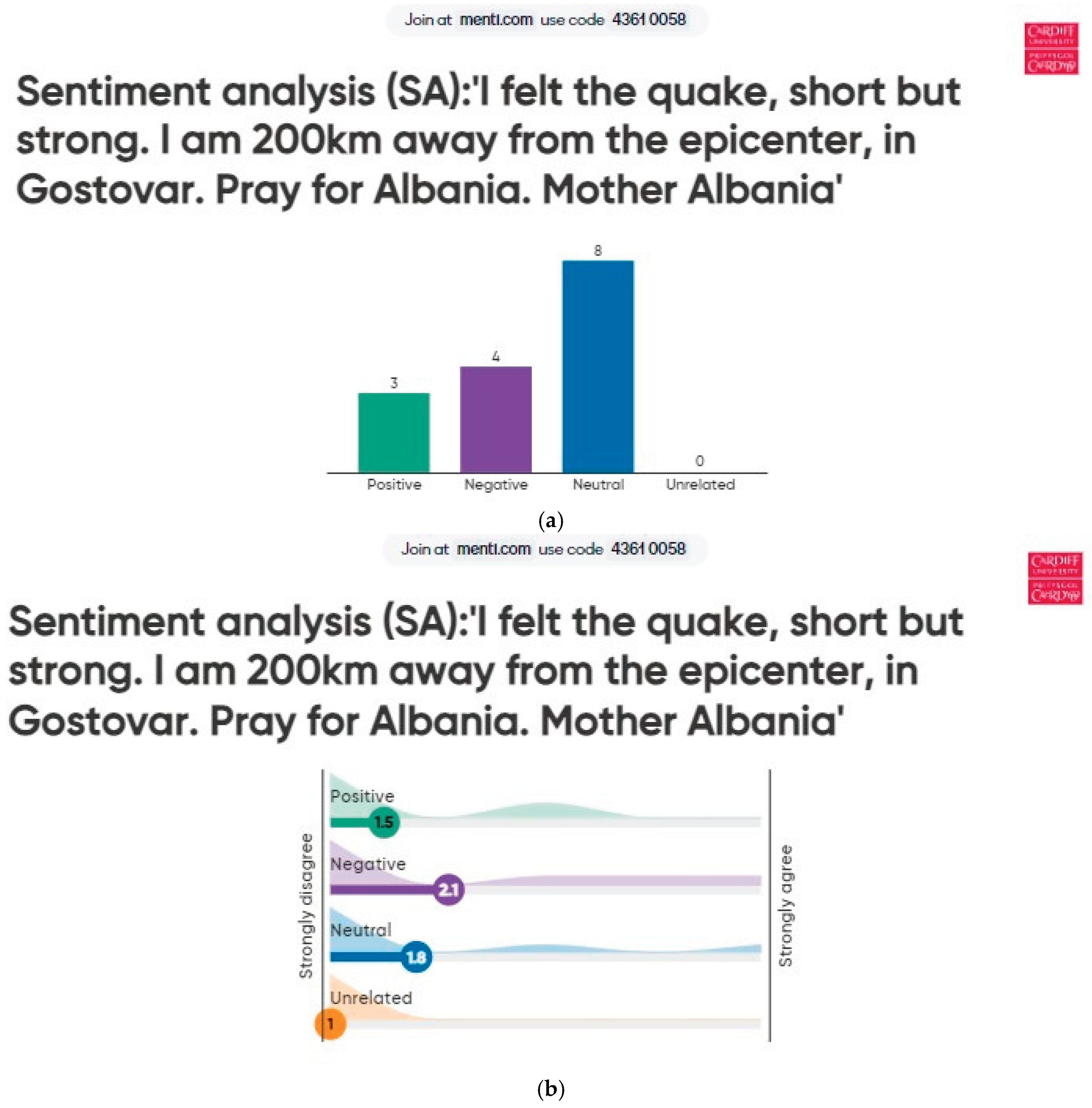
Figure 7.
Spatial distribution of the polarity of the intensity reports felt by LastQuake app users in (a) Albania, (b)Tirana and (c) Vlorë.
Figure 7.
Spatial distribution of the polarity of the intensity reports felt by LastQuake app users in (a) Albania, (b)Tirana and (c) Vlorë.
Figure 8.
Sample of three buildings in Vlorë from where LastQuake app users sent the intensity reports. Photos: Diana Contreras. The 31st March, 2023.
Figure 8.
Sample of three buildings in Vlorë from where LastQuake app users sent the intensity reports. Photos: Diana Contreras. The 31st March, 2023.


Table 1.
Intensity felt, as reported by LastQuake app users, during and after the 26th November 2019 earthquake in Albania.
Table 1.
Intensity felt, as reported by LastQuake app users, during and after the 26th November 2019 earthquake in Albania.
| Intensity | Comments | Percentage |
| MMI | Nr | % |
| I | 270 | 16 |
| II | 308 | 18 |
| III | 424 | 25 |
| IV | 247 | 15 |
| V | 166 | 10 |
| VI | 132 | 8 |
| VII | 70 | 4 |
| VIII | 36 | 2 |
| IX | 17 | 1 |
| X | 8 | 0 |
Table 2.
Classification rules for sentiment analysis.
| Polarity | Rules |
| Positive |
▪ Emergency response actions. ▪ Expressions of solidarity. ▪ Preparedness measures. ▪ Reports of light intensity felt ▪ Reports of light shakes felt ▪ Reports of short seismic movements. |
| Negative |
▪ Reports of aftershocks ▪ Reports of damages in buildings and/or lifelines. ▪ Reports of fear and anxiety. ▪ Reports of injuries and/or casualties. ▪ Reports of long seismic movements. ▪ Reports of strong intensity felt. ▪ Reports of strong shakes. |
| Neutral | ▪ Seismic information |
Table 3.
Sentiment analysis results at the report level (manual classification).
| Polarity | Reports | Percentage |
| Category | Number | % |
| Negative | 878 | 52 |
| Positive | 358 | 21 |
| Neutral | 355 | 21 |
| Unrelated | 87 | 5 |
| Total | 1,678 | 100 |
Table 4.
ACC results of the automatic classification.
| Transformer-based NLP classification models | Average confidence | ACC |
| troberta | 0.88 | 71% |
| txlm | 0.78 | 56% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license.
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



