Submitted:
05 January 2026
Posted:
07 January 2026
You are already at the latest version
Abstract
We propose a two-level theory that connects a Lin-equation-based dynamical coarse-graining of the turbulence cascade with an information-theoretic selection principle in logarithmic wavenumber space, thereby placing the dissipation-range spectral shape on a verifiable logical chain rather than an ad hoc fit. In the first (dynamical) stage, an autonomous conservative Fokker–Planck description is formulated for the normalized density and probability current; assuming sufficient boundary decay and a strictly positive effective diffusion, we prove that the sign-reversed KL divergence is a Lyapunov functional, yielding a rigorous H-theorem and fixing the arrow of time in scale space. In the second (selection) stage, the dissipation range is posed as a stationary boundary-value problem for an open system by introducing a killing term for an unnormalized scale density. WKB (Liouville–Green) analysis constrains the admissible tail class to a stretched-exponential form and links the tail exponent to the high-wavenumber scaling of the effective diffusion. To eliminate arbitrariness, the exponential prefactor is fixed by dissipation-rate consistency, and the remaining degree of freedom is identified via one-dimensional KL minimization (Hyper-MaxEnt) against a globally constructed reference distribution. The resulting exponent range is validated against high-resolution DNS spectra reported in the literature.
Keywords:
isotropic turbulence
; energy spectrum
; Fokker–Planck equation
; H-theorem
; WKB approximation
1. Introduction
The concept of the energy cascade in
three-dimensional homogeneous isotropic turbulence traces back to Kolmogorov’s
seminal 1941 work (Kolmogorov, 1941). Energy is injected at large scales by
external forcing, transferred hierarchically toward smaller scales through the
inertial subrange, and ultimately converted into heat by viscous dissipation.
To describe this process, Kolmogorov introduced a self-similarity hypothesis
depending only on the mean energy dissipation rate and the kinematic viscosity , thereby deriving the inertial-range energy
spectrum where denotes the wavenumber and is the Kolmogorov constant. This framework
underpins Batchelor’s theory of homogeneous turbulence (Batchelor, 1953) and
has served as a cornerstone for numerous subsequent statistical theories of
turbulence. At the same time, Kolmogorov’s theory is essentially a scaling
argument confined to the inertial subrange and is theoretically silent about
the spectral shape across the full wavenumber range, including the dissipation
range. To bridge this gap, spectral closure theories based on the Lin or
Kármán–Howarth equations (e.g., DIA, LET) have been developed (McComb, 2017;
Zhou, 2021).
As practical models for spectra including the
dissipation range, Pao’s model (Pao, 1965) and Pope’s empirical spectral
function (Pope, 2000) are widely used. While preserving the inertial-range scaling, these models introduce an exponential
cutoff from around the Kolmogorov wavenumber toward higher wavenumbers, reproducing DNS data
with high fidelity (Verma et al., 2017; Dos Santos et al., 2022). Recent
analyses of high-Reynolds-number DNS and experimental data further indicate
that the dissipation-range spectrum is not well described by a simple form, but rather by a stretched exponential,
as reported in, e.g., Gorbunova et al. (2020),
Buaria et al. (2020), and Verma et al. (2017). Here the exponent typically lies in the range and is suggested to vary with flow conditions and
Reynolds number. This “non-universality of ” confronts turbulence theory—historically oriented
toward universal scaling—with fundamental questions: why does the
dissipation-range spectrum assume a stretched-exponential, rather than a simple
, form; why is constrained to the relatively narrow interval ; what is the “selection principle” that determines
; and to what extent can be uniquely fixed from Navier–Stokes dynamics?
Existing spectral models, in many cases, rely on empirical fitting or
semi-empirical scaling assumptions, and thus remain insufficient as
first-principles derivations (Solsvik & Jakobsen, 2017).
In parallel, a rapidly growing line of research has
begun to reinterpret turbulence not merely as an “energy cascade,” but as a
process of information generation and transfer. For instance, a “hydrodynamic
entropy” defined for Euler turbulence has been shown to quantify the formation
and dissolution of coherent structures (Verma & Chatterjee, 2022), and
within information thermodynamics, universal lower bounds have been established
for inter-scale information flow in shell-model turbulence (Tanogami &
Araki, 2024). Moreover, for multi-field turbulence, studies inspired by quantum
information theory have introduced von Neumann entropy and entanglement entropy
to simultaneously characterize the strength of nonlinear mode coupling and the
direction of energy transfer (Yatomi & Nakata, 2025). Collectively, these
developments foreground a shared perspective: in turbulence, energy dissipation
is intrinsically tied to information generation and loss, in a manner
complementary to Kolmogorov theory and classical spectral closures.
However, most information-theoretic approaches have
focused less on directly determining the specific functional form of the energy
spectrum than on quantifying information flows associated with the cascade or
elucidating the information-geometric structure of nonequilibrium fluctuations.
Consequently, an “entropy principle for determining the energy
spectrum”—namely, a program that (i) defines an appropriate turbulence entropy , (ii) proves that its evolution satisfies (an -theorem), and (iii) derives the realized energy
spectrum from a corresponding entropy variational
principle—has not yet been established in a fully satisfactory form.
To bridge the remaining gap between “dynamics
(admissibility)” and “information-theoretic selection (realizability)” in
turbulence spectral theory, we propose a two-level theory that integrates a
Lin-equation-based coarse-graining with a relative-entropy principle in
logarithmic wavenumber space. The central idea is as follows: (i) within the
class of autonomous conservative Fokker–Planck (FP) semigroups consistent with
Navier–Stokes dynamics, we establish an irreversible structure via an -theorem; (ii) in the dissipation range, we analyze
an effective stationary problem incorporating killing (absorption) by WKB
methods to strongly constrain the admissible tail classes; and (iii) within the
resulting admissible class, we identify the exponent that minimizes additional
information by formulating it as a relative-entropy minimization problem.
In the first stage (the dynamical level), we start
from the fact that the energy spectrum of three-dimensional homogeneous isotropic
turbulence satisfies the Lin equation. Based on the mapping and a locality (near-neighbor) assumption for the
flux, we introduce in a consistent manner the scale-space probability density and the probability current . By making explicit the boundary conditions and
the regularity of coefficients—most notably, a positive lower bound for the
diffusion coefficient—we construct a framework in which integration by parts
and relative-entropy estimates are mathematically justified. As a result, under
an autonomous conservative FP semigroup, the relative turbulence entropy
becomes a Lyapunov functional and monotonicity (an -theorem) holds rigorously.
In the second stage (the selection level), we aim
to determine the dissipation-range spectral shape in a verifiable manner while
avoiding the intrinsic difficulty of directly treating the “nonzero-flux NESS
itself” as a limit of a conservative semigroup. To this end, we introduce, in
the dissipation range, an effective stationary equation that includes killing
(absorption), and evaluate its high-wavenumber tail via WKB (eikonal) analysis.
This yields a strong constraint: the dissipation tail must reduce to a
stretched-exponential form. Nonetheless, the exponent (or an equivalent
parameter) still remains as a candidate set.
We therefore define a physically meaningful “global
domain” for comparing candidate families by introducing the lower endpoint , where is a representative forcing-band wavenumber, and
setting
We then unify the integration domain of the KL
functional to this common lower bound, thereby avoiding any unnatural extension
of the dissipation-tail shape into the low-wavenumber energy-containing range.
This unification ensures that the KL distance between the reference distribution
and each candidate distribution is well-defined over the entire domain and
closes a mathematical loophole that would otherwise arise from mismatched lower
limits.
Next, we incorporate the – coupling obtained as a WKB consequence in Section 4 (equivalently, ) as a constraint, thereby eliminating
arbitrariness associated with independent optimization over . Specifically, rather than adopting a two-variable
optimization in , we reduce the identification problem to a
one-dimensional optimization in alone (Hyper-MaxEnt) by enforcing the coupling
relation.
With these ingredients, we construct the reference
distribution globally on and identify by minimizing the KL distance to the candidate family via a one-dimensional optimization; the final exponent is then determined through the coupling relation. Consequently, the exponent in this paper is not a post hoc fit parameter chosen to match observations; rather, it is defined by a verifiable logical chain consisting of (i) the irreversible structure at the dynamical level, (ii) the strong WKB constraint on the candidate set, (iii) reduction of degrees of freedom, and (iv) relative-entropy minimization.
Within this framework, our contributions can be summarized in three points. First, by coarse-graining based on the Lin equation, we establish the setting of an autonomous conservative FP semigroup and position—explicitly specifying boundary conditions and coefficient regularity—the result that the relative turbulence entropy functions as a Lyapunov functional (an -theorem). Second, by extracting the dissipation range as an effective stationary problem with killing and analyzing it via WKB methods, we show that the tail must reduce to a stretched-exponential form, thereby strongly constraining the “dynamically admissible asymptotic class.” Third, after unifying the integration domain to , we incorporate the WKB-derived – coupling as a constraint and formulate KL minimization as a one-dimensional optimization, providing a reduced Hyper-MaxEnt framework that identifies without externally fixing it.
The remainder of this paper is organized as follows. In Section 2, we formulate the mapping from the Lin equation to logarithmic wavenumber space and develop the conservative FP coarse-graining. In Section 3, we establish monotonicity (an -theorem) for the relative turbulence entropy under an autonomous conservative FP semigroup, thereby providing the irreversible structure at the dynamical level. In Section 4, we formulate the dissipation range as an effective stationary problem with killing and derive, via WKB analysis, the stretched-exponential constraint on the dissipation tail. In Section 5, we unify the comparison domain to , incorporate the WKB coupling constraint, and present the final principle that identifies through a one-dimensional optimization, clarifying the connection between the dynamical and selection levels.
2. Dynamical Modelling of the Turbulent Cascade
This Section formulates the first stage (dynamical level) of the proposed two-level theory. We begin with the energy-spectrum balance equation derived from the Navier–Stokes equations, namely the Lin equation. The associated energy flux in the Lin equation is intrinsically nonlocal, being defined through an integral over all wavenumbers of triadic interactions, and therefore admits no closed form in general. In this work, we regard the turbulent cascade as an aggregate of many local transfer events and coarse-grain it as an effective Markov process in logarithmic wavenumber space. In the continuous limit, this yields a Fokker–Planck (FP) equation, which provides a unified foundation for the probability current, entropy, and WKB analyses developed in subsequent Sections. A key point is that the drift and diffusion coefficients and introduced here are effective coefficients, defined as low-order moments of a coarse-grained transition kernel, rather than “exact quantities” that fully encode triadic interactions. All subsequent analysis is constructed self-consistently within this effective-theory framework.
2.1. Lin Equation and the Energy-Spectrum Budget
Let denote the energy spectrum of three-dimensional homogeneous isotropic turbulence, and define the total kinetic energy per unit mass by
Let be the spectral density of energy injection by external forcing, and let be the kinematic viscosity. Then satisfies the Lin equation,
(1)
Here is the energy flux in wavenumber space; since it arises from triadic interactions, it is in general defined by a nonlocal integral.
In a statistically stationary state, , and (1) reduces to
(2)
Define the dissipation rate by
(3)
If the forcing is localized in a finite wavenumber band, and in the inertial subrange
one has while viscous dissipation is negligible, then (2) yields
(4)
Consistently, Kolmogorov’s law holds:
(5)
To connect with the dissipation range, define the Kolmogorov wavenumber by
(6)
and introduce the dimensionless wavenumber .
2.2. Unified Spectral Representation Including the Dissipation Range
To represent the full spectrum, including the dissipation range, in a unified form, we adopt the following cutoff representation:
(7)
2.3. Log-Wavenumber Space and the Definition of Probability Densities
To treat the distribution in wavenumber space on a logarithmic scale, fix a reference wavenumber and introduce
(8)
The mapping is a -diffeomorphism between and , with Jacobian
(9)
i.e., .
Henceforth, for each time , we assume that the spectrum is measurable on and satisfies
(10)
Define the total kinetic energy per unit mass by
(11)
and assume
(12)
so that normalization is well-defined.
Under the change of variables and using (9), (11) can be rewritten as
(13)
Define the unnormalized scale density in log-wavenumber space by
(14)
By (10), (a.e.), and by (12) ans (13) one has with
(15)
We then define the normalized probability density in log-wavenumber space by
(16)
By assumption (12), the right-hand side is well-defined, and (15) immediately yields the normalization
Conversely, from (16), for any ,
(17)
From Section 2 through Section 3, denotes the normalized probability density defined in (16), while the unnormalized quantity is always denoted by . When, from Section 4 onward, the unnormalized density becomes the primary unknown, we continue to use the same symbols and accordingly, without redefining .
2.4. Coarse-Graining: From a Jump Process to the Fokker–Planck Equation
The energy flux appearing in the Lin equation originates from triadic interactions and is, in general, defined as a nonlocal integral over the entire wavenumber range. In this section, rather than retaining the full nonlocal detail, we coarse-grain the cascade as an effective transition process on the logarithmic wavenumber , and derive, in its diffusion limit, a Fokker–Planck (FP) equation. Using a Chapman–Kolmogorov-type master equation as the starting point is not in conflict with the section title “Fokker–Planck equation”: the master equation is the fundamental evolution law for a jump process, and in the continuous limit where near-neighbor jumps (small ) dominate, its generator converges to a second-order differential operator, yielding the FP equation.
2.4.1. Assumptions for the Jump Process and the Master Equation
We approximate energy transfer on the logarithmic wavenumber axis as an accumulation of “jumps from to ,” and represent the transition by a conditional transition kernel (jump kernel)
(18)
As explicit premises of the coarse-graining, we impose the following.
First, quasi-locality (locality): for fixed , the dominant transitions are concentrated in , and large jumps are sufficiently suppressed. Introducing a small parameter , this may be expressed, for instance, as
(19)
which signifies the vanishing of the large-jump tail probability.
Second, effective Markov property (short memory): on the coarse-grained time scale, short memory holds, and the time evolution of follows a Chapman–Kolmogorov-type master equation. For the normalized probability density defined in Section 2.3, the master equation takes the form
(20)
The right-hand side is the difference between the “probability inflow into ” and the “probability outflow from ,” and can be interpreted as the jump-process analogue of the probability-conservation law.
2.4.2. Kramers–Moyal Expansion and the Diffusion Limit: Reduction to the FP Equation
To obtain a continuous-limit equation from (20), we perform a Kramers–Moyal (K–M) expansion using . For this purpose, we assume that the conditional moments of the jump kernel,
(21)
exist and are finite up to the required order. Moreover, under tail suppression such as (19), higher-order remainder terms are controlled, and the interchange of expansion and integration (at least in a weak sense) is justified. Under these conditions, (20) reduces to the K–M expansion
We then adopt, as a diffusion approximation, a second-order closure of (22). A crucial point is that, for a finite-order truncation to remain consistent with the nonnegativity of the probability density, the second-order closure has a distinguished status: in light of Pawula’s consistency result, the minimal nontrivial closure compatible with positivity is of second order. Accordingly, we employ the effective model assumption
(23)
Then only terms up to second order remain in (22), yielding the Fokker–Planck equation
(24)
The coefficients are defined by
(25)
where is the effective drift and the effective diffusion coefficient. Thus and do not represent the full details of triadic interactions; rather, they encode the “retained information” as low-order moments of the transition kernel .
To write (24) in conservative form, introduce the probability current (probability flux) by
(26)
(27)
In (27), the current is given as the drift contribution minus the diffusive-gradient contribution; we fix this sign convention throughout the paper.
To treat rigorously the -theorem for conservative FP semigroups (monotonicity of relative entropy) in Section 3, (26) and (27) must be formulated within a framework that preserves mass (normalization). We therefore assume, first, that the diffusion coefficient admits a strictly positive lower bound on the domain of interest:
(28)
This condition is essential to render later nonnegative expressions of the form mathematically well-defined. Next, as a condition ensuring the vanishing of boundary terms, we adopt, for example,
(29)
(or, on a finite interval, a reflecting boundary condition ). Integrating (26) over then gives
(30)
so that the initial normalization is preserved for all time.
Within the setting (28)–(30), stationary solutions can be characterized by the zero-flux condition, namely
(31)
A stationary distribution satisfying (31) is therefore natural as a reference distribution, and from (26) one obtains
(32)
In Section 3, we take this as the reference and establish the monotonicity of the relative entropy rigorously.
By contrast, the “constant and nonzero energy flux” observed in the inertial subrange of turbulence corresponds intrinsically to an open system with injection and dissipation (a NESS), and thus typically permits
(33)
However, (33) is incompatible with the zero-flux boundary condition (closed-system setting) such as (29), and therefore lies outside the assumptions under which an -theorem for conservative Markov semigroups is formulated. This motivates the two-level structure adopted in this paper: in Section 3, we rigorously formalize irreversibility (the arrow of time) using a conservative (closed) FP formulation, whereas from Section 4 onward we analyze the dissipation-range exponential decay as a stationary boundary-value problem for an open system using an unnormalized quantity (denoted separately in that context).
Finally, in the inertial subrange , Kolmogorov scaling implies . Using the definition in Section 2.3, (with a constant normalization factor) together with , we obtain
(34)
This provides a concrete asymptotic input to the effective theory, in the sense that the coefficients and are not arbitrary but must be constrained to be consistent with the stationary flux condition and with boundary conditions imposed in the dissipation range.
2.5. Summary
The purpose of this Section is to formulate, in a self-contained manner, the spectral budget of the turbulent cascade as the first stage (dynamical level) of the two-level theory developed in subsequent Sections. We first presented the balance of through the Lin equation, confirmed the inertial-subrange constant flux and the law, and introduced a unified representation including the dissipation range,
as summarized in Equations (1)–(7).
Next, by mapping to logarithmic wavenumber space via , we defined with strict separation the unnormalized density and the normalized probability density (Equations (8))–(17)). We then coarse-grained the nonlocal flux as an accumulation of near-neighbor jumps, and derived—through the master equation, the Kramers–Moyal expansion, and the diffusion approximation—a conservative Fokker–Planck equation together with the conservative-form probability current (Equations (18))–(27)). To guarantee mass conservation and to ensure the mathematical well-posedness of later nonnegative representations, we explicitly imposed and boundary conditions, and defined the zero-flux stationary distribution as a reference distribution (Equations (28))–(32)).
These results establish the framework of a conservative (closed-system) FP dynamics and provide the prerequisites needed to formulate rigorously the -theorem (relative-entropy monotonicity) in Section 3. At the same time, we clarified that physically stationary turbulence intrinsically involves a nonzero flux (an open-system NESS), a feature that is incompatible with the closed-system zero-flux setting. This tension motivates the two-level separation adopted here: the conservative FP setting is used to rigorously establish irreversibility, while the dissipation-range exponential decay is treated separately, from Section 4 onward, as a stationary boundary-value problem for an open system (Equations (33))–(34)).
3. Fokker–Planck Description and Monotonicity of Relative Entropy (H-Theorem)
In this Section, building on the normalized probability density and probability current on the logarithmic wavenumber coordinate introduced in Section 2, we formulate irreversibility generated by a conservative Fokker–Planck description in a rigorous manner using relative entropy (the Kullback–Leibler divergence). Since Shannon-type differential entropy does not, in general, possess a monotonicity property for diffusion processes, we take as the fundamental quantity the relative entropy with respect to a reference distribution , and compute its time evolution explicitly. The conclusion is twofold: for a closed system (under conditions that eliminate boundary contributions), the relative turbulence entropy is monotone increasing; for an open system, one obtains a general identity that includes boundary terms.
3.1. Conservative Fokker–Planck Equation and Stationary Distribution
We recall the conservative-form evolution equation derived in Section 2:
(35)
The probability current is defined in terms of the drift coefficient and diffusion coefficient by
(36)
Henceforth, to state the -theorem of this Section in a strict form, we assume that the coefficients are autonomous (time-independent),
(37)
which facilitates the use of standard Markov semigroup theory. Moreover, in order to render later quadratic representations well-defined, we assume
(38)
since alone would allow division by zero at points where . We also assume strict positivity of the density,
(39)
so that and are well-defined. Normalization follows from Section 2:
(40)
Differentiating in time yields
(41)
A stationary state satisfies , and thus, from the conservative form (35),
(42)
Hence the stationary current is constant:
(43)
Applying (36) in the stationary setting, satisfies the first-order equation
(44)
As the reference distribution for a closed system (a conservative semigroup), we adopt in this Section the zero-flux stationary distribution, i.e.,
(45)
and define by
(46)
We further impose normalization as a probability density:
(47)
Solving (46) for under gives
(48)
Expanding the right-hand side yields
(49)
3.2. Definition of Relative Entropy
We define the relative entropy (KL divergence) of with respect to the reference distribution by
(50)
In this paper we work with a quantity that increases in time; accordingly, we define the relative turbulence entropy by
(51)
3.3. H-Theorem and a General Identity for Open Systems
3.3.1. Gradient Form of the Probability Current (Consequence of the Zero-Flux Reference Distribution)
Substituting (49) into (36), we transform the probability current into a gradient form. Expanding (36) gives
(52)
Substituting (49) into (52) yields
(53)
Expanding the second term on the right,
(54)
so that (53) becomes
(55)
Equivalently,
(56)
The quantity in parentheses coincides with the derivative of the ratio . Indeed,
(57)
Substituting (57) into (56) gives
(58)
Using , we also have
(59)
and hence, from (56), equivalently
(60)
In what follows, we refer to (58) or (60) as the gradient-form representation.
3.3.2. Time Derivative of the Relative Entropy
We differentiate (50) in time. Formally,
(61)
Assuming that the exchange of differentiation and integration is justified (under integrability and regularity assumptions),
(62)
Since is stationary and independent of ,
(63)
Therefore the second term becomes
(64)
By (41), , and thus (62) reduces to
(65)
Substituting (35) yields
(66)
3.3.3. Integration by Parts and a Quadratic Dissipation Representation
We integrate (66) by parts, keeping boundary terms explicit:
(67)
Hence,
(68)
Using (60),
(69)
Therefore, (68) becomes
(70)
Moreover, squaring (60) yields
(71)
Dividing (71) by gives
(72)
Substituting this into (70), we obtain
(73)
3.3.4. H-Theorem for a Closed System (Conditions Eliminating Boundary Terms)
For a closed system (i.e., a conservative semigroup), we impose conditions under which boundary contributions vanish. A typical choice is
(74)
together with
(75)
f these conditions hold, then the boundary term in (73) disappears:
(76)
Equation (73) then reduces to
(77)
Define the relative-entropy production rate (internal production) by
(78)
Since the integrand is nonnegative, it follows that
(79)
hence (77) can be written as
(80)
Recalling that the relative turbulence entropy is (see (51)), we obtain
(81)
This is the -theorem for the conservative Fokker–Planck description: is a Lyapunov functional and increases monotonically in time.
3.3.5. Open Systems: General Identity with Boundary Terms
For an open system that permits injection and outflow through the boundary, (76) need not hold in general, and (73) remains as a general identity. Namely,
(82)
Equivalently, using ,
(83)
The second term on the right-hand side represents the inflow/outflow of information (relative entropy) through the boundary, and it can break monotonicity. Therefore, for the physically stationary turbulent state (a NESS) in which a nonzero flux is essential, it is not appropriate to apply the closed-system monotonicity statement (81) verbatim; rather, it is more suitable to organize the contributions in the form (82)–(83).
3.4. Summary
In this Section, under the conservative-form Fokker–Planck description introduced in Section 2 ((35)–(36)), we showed that choosing the zero-flux stationary distribution ((46)–(47)) as the reference distribution yields a gradient-form representation of the probability current ((58) and (60)). As a consequence, we derived—within the Section and in a self-contained manner—the -theorem stating that the relative turbulence entropy increases monotonically in a closed system ((81)). We further clarified that, for open systems, the result is naturally organized as a general identity including boundary terms ((82)–(83)), and that monotonicity may be violated depending on boundary conditions. In the next Section, we treat the dissipation range not within the conservative setting but as a stationary boundary-value problem incorporating killing (absorption), and we impose constraints on exponential decay via a WKB approximation.
4. Asymptotic Structure of the Dissipation-Range Spectrum via WKB Analysis
In this Section we take as a starting point the conservative Fokker–Planck (FP) description established in Section 2 and Section 3—namely, the normalized density and probability current in logarithmic wavenumber space—while introducing a killing (absorption) term in order to represent the exponential decay intrinsic to the dissipation range. With killing, probability conservation is violated, and the -theorem of Section 3 (relative-entropy monotonicity for conservative semigroups) cannot be applied directly to the governing equation of the present Section. We therefore formulate a stationary boundary-value problem that determines the dissipation-range shape, and analyze its high-wavenumber asymptotics () by the WKB (Liouville–Green) method.
Hereafter, for -derivatives we write .
4.1. Unnormalized Scale Density and a Stationary Equation with Killing
In Section 2 and Section 3, denoted a normalized probability density satisfying . By contrast, to describe the dissipation-range shape itself, including the total magnitude, we introduce in this Section the unnormalized scale density as the basic unknown. As in Section 2, the logarithmic wavenumber variable is
(84)
We define the unnormalized scale density (density in log-wavenumber space) by
(85)
Then the total kinetic energy per unit mass is
(86)
and by (84)–(85),
(87)
The normalized density used in Section 2 is recovered as
(88)
and conversely,
(89)
In what follows, we treat as the basic unknown and impose no normalization. In the dissipation range (high-wavenumber side), the spectrum exhibits exponential decay, and a purely conservative diffusion equation is insufficient to represent this shape. As a minimal effective modification encoding this feature, we introduce a killing rate
(90)
Including also a source term representing supply from low wavenumbers (or forcing), we posit the effective equation for the unnormalized density:
(91)
Here and are the effective drift and diffusion coefficients introduced in Section 2 via coarse-graining (the diffusion limit of a jump process). In the present Section they are interpreted as transporting the unnormalized density , rather than a normalized probability density.
Our objective is the stationary dissipation-range shape, and we therefore adopt the following two assumptions. First, as a locality assumption that injection is negligible in the dissipation range,
(92)
where is a sufficiently large threshold. Second, we assume stationarity for shape determination:
(93)
From (91)–(93) we obtain, for ,
(94)
where we have suppressed and written to emphasize stationarity. Define the stationary “flux” associated with the unnormalized density by
(95)
Then (94) becomes
(96)
If there were no killing, , then and the stationary flux would be constant; under , however, , meaning that the flux decreases toward higher wavenumbers.
Next, we derive an equation involving alone from (95) and (96). Differentiating (95) with respect to yields
(97)
On the other hand, (96) reads
(98)
Equating (97) and (98) gives
(99)
that is,
(100)
This is the second-order linear ordinary differential equation that constrains the stationary dissipation-range shape.
We impose boundary conditions consistent with dissipation-range physics. Since there is no injection at high wavenumbers and the flux is ultimately exhausted by killing, we adopt
(101)
and
(102)
At the low-wavenumber boundary (near the dissipation-range entrance ), we assume that or is specified by matching to the inertial subrange.
4.2. Derivation of the Exponential Phase by the WKB Method
In this section we analyze the rapidly decaying solution of (108) as . In the dissipation range, becomes exponentially small; accordingly, we employ the WKB method as an asymptotic procedure that determines the dominant exponential phase.
4.2.1. Regularity and Positivity Assumptions for the Coefficients
To carry out the WKB analysis in a mathematically meaningful form, we assume on the dissipation-range interval that:
Regularity of coefficients:
(103)
Positivity of the diffusion coefficient (with a lower bound):
(104)
Nonnegativity of the killing rate:
(105)
Condition (104) is essential to ensure that ratios and square roots (as well as quantities of the form ) appearing later are well-defined.
4.2.2. A Formal Small Parameter and the WKB Ansatz
For a standard WKB bookkeeping, we introduce a formal small parameter . This is not a physical parameter; it is introduced solely to extract, within (100), the dominant balance that determines the exponential phase.
To reflect that the killing term strongly controls the exponential phase in the dissipation range while retaining the drift contribution at the phase level, we adopt the following distinguished scaling:
(106)
Here are functions on independent of , and satisfy
(107)
For notational simplicity, we henceforth write again as . We seek a decaying solution in the WKB form
(108)
To select the branch decaying toward high wavenumbers, we require
(109)
and, in particular, assume monotonicity of the phase in the far tail:
(110)
4.2.3. Differential Expansions in the WKB Approximation
We compute -derivatives of (108). Introduce the shorthand
(111)
Then (108) reads
(112)
The first derivative is
(113)
The second derivative follows by differentiating (113). Define
(114)
so that
(115)
and hence
(116)
Here
(117)
and
(118)
Therefore, from (116)–(118),
(119)
Next we compute and appearing in (100). First,
(120)
By the product rule, its first derivative is
(121)
that is,
(122)
Define
(123)
so that
(124)
Hence the second derivative is
(125)
We compute as
(126)
namely,
(127)
Moreover,
(128)
Substituting (127) and (128) into (125) yields
We next compute . By the scaling (106),
(130)
and hence
Its first derivative is
(132)
that is,
(133)
Finally, the killing term is, by (106),
4.2.4. Substitution into the Governing Equation and Order-by-Order Decomposition
The stationary Equation (100) can be written as
(135)
Substituting (129), (133), and (134) into (135) and removing the common factor , we obtain
(136)
We now collect terms by powers of .
Order.
The terms in (136) yield
(137)
Assuming , the phase satisfies the eikonal equation
(138)
Order.
The terms in (136) give
(139)
Rearranging into and terms,
(140)
that is,
(141)
This is the transport equation determining the amplitude .
Order.
The terms in (136) are
(142)
In standard WKB practice, (138) and (141) determine the leading phase and amplitude, while (142) is treated as a condition ensuring that the residual is higher order (or as the starting point for higher-order corrections).
Thus, the WKB analysis of (135) is governed primarily by (138) (eikonal) and (141) (transport), which determine the exponential phase and the leading amplitude.
4.2.5. Selection of the Decaying Branch and a General Expression for the Phase
Equation (138) is quadratic in . Its solutions are
(143)
To obtain a branch that decays toward high wavenumbers, we require , and hence select the positive branch for sufficiently large :
(144)
Integrating yields
(145)
The integration constant can be absorbed into the amplitude and is therefore inessential for the asymptotic phase.
4.3. Absorption-Dominated Limit and the Emergence of a Stretched-Exponential Tail
In this section we show, without skipping intermediate steps, under what assumptions (144) and (145) imply that the spectral tail takes the stretched-exponential cutoff form
(146)
4.3.1. Reduction Under Absorption Dominance
A sufficient condition for the killing term to dominate the exponential phase in (144), with the drift contribution being lower order, is
(147)
Then
and under (147),
Hence
(150)
Substituting this into (144) gives
Moreover, (147) implies , so the leading asymptotics reduce to
(152)
This is the absorption-dominated eikonal reduction.
4.3.2. A Concrete Form of the Killing Rate Corresponding to Viscous Dissipation
In the turbulence spectral balance (the Lin equation), viscous dissipation appears as . Using the log-wavenumber density , the decay associated with dissipation can be interpreted as
(153)
It is therefore natural to identify the killing rate in the dissipation range as
(154)
Since by (84), this becomes
(155)
To match the scaling in (106), one would write
(156)
However, in the WKB bookkeeping is purely formal; what is essential for the -dependence of the phase is the high-wavenumber scaling
(157)
4.3.3. Asymptotic Scaling of the Diffusion Coefficient and the Emergence of the Exponent
By (152), the phase is determined by the asymptotic scalings of and . We therefore assume, in a general form, that the diffusion coefficient exhibits an exponential scaling in the dissipation range:
where (no restriction on is imposed in this section). Substituting (157) and (158) into (152) yields
(159)
with
(160)
where . Integrating (159) gives the phase . Introduce
(161)
Then
(162)
and hence
(163)
assuming . (If , then , leading to a simple exponential tail rather than a stretched exponential.)
Let the dissipation-range entrance be , and define the corresponding by
(164)
Then
(165)
and
(166)
Therefore, absorbing constants,
(167)
where
(168)
4.3.4. Tail of the Unnormalized Density
and the Return to The WKB form (108) reads
(169)
Substituting the phase asymptotics (167) yields
(170)
Here is the amplitude governed by the transport Equation (141) and is regarded as varying slowly compared with the exponential phase (consistent with the slow-variation assumption corresponding to (99)). To make the dominant exponential tail explicit, we absorb the amplitude into an effective prefactor and write
(171)
where
(172)
Here plays only a bookkeeping role; in the final description, remains as the effective coefficient. Using (166), (171) becomes
(173)
Since by definition (85), we obtain
(174)
In the spectral representation adopted in Section 2, the inertial and dissipation ranges were unified through a cutoff function as
(175)
The dissipation-range asymptotics (174) then imply the high-wavenumber behavior of in (175) as
(176)
because the prefactor in (175) is whereas (174) carries , and their ratio is . On the other hand, in common dissipation-range parameterizations one often writes itself in a purely exponential form,
This corresponds to an approximation in which the inertial-range prefactor is retained across the dissipation range as a smooth continuation from the inertial side. In the present standpoint, since the inertial-range scaling
is already established, and since matching at the dissipation entrance is imposed, we adopt the representation that preserves the prefactor while encoding dissipation through an exponential cutoff:
(179)
Here is an effective parameter absorbing the coefficient in (172) together with the matching conditions. Equation (179) is the “K41 spectrum with a stretched-exponential cutoff” used throughout this paper.
Finally, the exponent is given by (161) as
(180)
Thus, the dissipation-tail exponent is determined by the mismatch between the high-wavenumber scaling of the killing rate (viscous dissipation) and the asymptotic scaling of the diffusion coefficient .
4.4. Summary
What may be claimed as “mathematically rigorous” in the present derivation depends on the adopted notion of rigor. Within the framework of this paper, rigor separates into two layers.
First, once (91) is accepted as an effective model, the stationarization (93), the flux definition (95), and the derivation of the second-order ODE (100) are rigorous in the strict sense that they rely only on definitions and differentiation. In particular,
is purely algebraic.
Second, since WKB is inherently an asymptotic method, its rigor is of the form of asymptotic equivalence as . Namely, under the coefficient regularity and positivity assumptions (103)–(105), together with dominance and slow-variation conditions (e.g., absorption dominance as in (147)) and the WKB slow-variation conditions (of the type mentioned in Section 2), one obtains, in the asymptotic sense,
(182)
By contrast, to claim a numerical range (upper and lower bounds) for the exponent , one must further constrain in (158). Such a constraint does not follow uniquely from the mathematics of (100) and the WKB procedure alone; it depends on additional assumptions ensuring the self-consistency of the coarse-graining (near-neighbor jumps, coefficient slow variation, thickness of the matching layer, consistency of cascade timescales, and related conditions). Accordingly, the conclusions that can be closed within the present Section as “derivations without omission” are:
(i) The stationary boundary-value problem in the dissipation range is governed by (100).
(ii) The WKB method yields the exponential phase in the form (144)-(145).
(iii) Under absorption dominance and the coefficient scaling (158),” E(k)” exhibits the stretched-exponential tail (179).
(iv) The exponent is determined by the scaling via .
5. Two-Level Entropy Principle and Determination of the Dissipation-Tail Exponent
This Section integrates the framework developed in Section 1, Section 2, Section 3 and Section 4 and formulates the central concept of this paper: the two-level entropy principle. The essential point is to separate (i) the dynamical level, which provides irreversibility for time evolution, from (ii) the selection level, which determines the stationary spectral shape including the dissipation-range exponential tail. These two roles must not be conflated.
5.1. Dynamical Level: Autonomous Conservative FP Semigroup and the H-Theorem
We use the logarithmic wavenumber introduced in Section 2,
(183)
together with the normalized probability density satisfying
(184)
In this section we assume an autonomous (time-independent) conservative Fokker–Planck (FP) operator: the coefficients and do not depend on , and evolves under the autonomous semigroup . This autonomy is crucial because it permits a rigorous definition of the stationary reference distribution .
The conservative FP equation is written in flux form as
(185)
where the probability flux is defined by
(186)
Here is the diffusion coefficient. For a rigorous H-theorem we assume the uniform positivity
(187)
which is essential for the well-definedness of expressions of the form . We also assume boundary conditions under which boundary terms vanish (reflecting boundary conditions, or sufficiently fast decay at infinity).
The closed-system (zero-flux) stationary reference distribution is the stationary solution satisfying
(188)
Applying (188) to (186) yields
i.e.,
(190)
Define the relative entropy (KL divergence) by
(191)
and define the relative turbulence entropy as its sign reversal,
(192)
From the normalization (184),
(193)
Therefore, differentiating (191) gives
(194)
Substituting (185) and integrating by parts (using vanishing boundary terms) yields
(195)
From (189)–(190) one has
(196)
Hence (186) can be rearranged into the gradient-flux forms
or equivalently
(198)
Substituting (198) into (195) gives
(199)
whose right-hand side is nonpositive. Hence
(200)
and therefore
(201)
Moreover, from (198) it follows that
(202)
so (199) can be written as
Defining the production rate
(204)
we obtain
(205)
This completes the first stage (dynamical level). The key point is that (205) provides irreversibility (an arrow of time) for an autonomous conservative FP semigroup, but it does not directly determine the shape selection for a nonzero-flux NESS in an open system, in particular the dissipation-tail exponent .
5.2. Consequence of the WKB Analysis and the Stretched-Exponential Tail
In Section 4, in order to describe the dissipation-range shape itself, we used the unnormalized density
(206)
as the fundamental unknown (here we denote the unnormalized quantity by to avoid confusion with the normalized density ). The total energy is
(207)
so that
(208)
In the dissipation range we adopted an effective equation with killing:
(209)
and assumed that injection is negligible at sufficiently large ,
together with stationarity . Then
(211)
where the unnormalized flux is
From (211) and (212) one obtains
(213)
In the dissipation range it is natural to impose and as . The WKB (eikonal) analysis in Section 4 shows that, under sufficient smoothness of coefficients and in the limit where the exponential phase dominates in the dissipation range, the decaying solution of (213) possesses a stretched-exponential tail:
(214)
where the Kolmogorov wavenumber is
(215)
The claim of “rigor” within the present framework is: for the effective problem (209)–(213), provided the assumptions of Section 4 (regularity, slow variation, and phase dominance in the dissipation range) hold, the dissipation tail reduces to the family (214). However, to determine uniquely one needs global information on in (209) and an additional selection principle. This motivates the second stage (selection level).
5.3. Formulation of the Two-Level Principle and Parameter Identification
The two-level principle can be organized as a conceptual composition. At the dynamical level,
At the selection level, the conclusion (214) constrains the dissipation tail to belong to a stretched-exponential family. Accordingly, we introduce the candidate spectral family
(217)
The corresponding unnormalized density is, by (206),
(218)
and using ,
(219)
We restrict attention to the physically meaningful domain, represented by corresponding to a representative forcing wavenumber ,
(220)
and define
(221)
(The low-wavenumber energy-containing range is not modeled by extending the form in (217) all the way to .) For comparison we define the normalized density on by
(222)
All KL integrals below are evaluated over . As the selection principle we adopt minimization of the relative entropy (KL divergence) against a reference distribution :
(223)
Furthermore, the WKB result of Section 4 (absorption-dominant decaying branch) implies that when the diffusion coefficient in the dissipation range satisfies
the dissipation-tail exponent obeys the coupling relation
(224)
Hence is not optimized independently; instead we set
(225)
and reduce the selection problem to a one-parameter identification in .
5.4. Construction of the Reference Distribution and a Global Model
5.4.1. General Integral Form of the Zero-Flux Stationary Distribution
From (189) and (190), the zero-flux condition is
(226)
Dividing both sides by gives
(227)
hence
Exponentiating yields
and therefore
(230)
The normalization constant is fixed on by
(231)
5.4.2. Introducing Global Models
and To use (230) in practice, one needs explicit global models for and . Here we adopt analytic forms that simultaneously satisfy the minimal requirements:
(i) slow variation at low-to-intermediate wavenumbers (consistent with the effective-theory premise),
(ii) the dissipation-range scaling at high wavenumbers,
(iii) integrability of over ,
while remaining explicitly representable.
Introduce a transition-width parameter and the dissipation-entry point , and define
(232)
so that as and as .
Define the diffusion coefficient by
(233)
Then
(234)
And
(235)
Next, define the drift coefficient by
so that, on the high-wavenumber side,
(237)
This ensures that the exponent in (230) approaches a linear form, allowing one to control the integrability of .
5.4.3. Explicit Global Expression for
Substitute (233) and (236) into (230). First,
(238)
Hence
For in (232), one has
(240)
Therefore (230) becomes
From (233),
and thus
(243)
The constant is determined from
(244)
The high-wavenumber asymptotics of (243) is, for ,
so a sufficient condition for integrability on is
(246)
With this, the reference distribution is explicitly defined over the full domain, and the KL integral (223) is well-defined on .
5.5. Fixing Parameters by Dissipation-Rate Consistency
To avoid arbitrariness associated with keeping as a free parameter, we fix by enforcing dissipation-rate consistency, thereby reducing the remaining freedom to alone. We define the dissipation rate with the common low-wavenumber cutoff as
(247)
Substituting (217) yields
(248)
Let , so that and . Defining
we obtain
(249)
Next, apply the change of variables , i.e., and , to obtain
(250)
where denotes the upper incomplete gamma function. Hence (249) becomes
(251)
In general, cannot be solved for explicitly as a closed-form function of ; instead, it is determined implicitly as the unique solution of (251). We therefore define by
(252)
From the coupling relation (161) derived in Section 4,
(253)
becomes a function of alone:
(254)
5.6. Optimization of
and the Admissible Range of the Tail Exponent
5.6.1. WKB Coupling Between
and In the WKB analysis of Section 4 (the absorption-dominated decaying branch), the dominant balance in the eikonal equation is
hence
(256)
Viscous dissipation implies
and we assume, in the dissipation range,
(258)
Combining (257) and (258) gives
(259)
Integrating yields
Since ,
(261)
the WKB tail takes the form
(262)
This is the WKB-induced – coupling, derived under the assumptions stated in Section 4.
5.6.2. Final One-Dimensional Optimization in
(Hyper-MaxEnt)
Accordingly, the candidate family is fully parameterized by via
Using (218)–(220), define
(264)
As the reference distribution, we use constructed in §5.4, and define the objective functional (KL divergence) by
The admissible set is determined by the conditions that (automatically satisfied by (233)), integrability of (sufficiently ensured by ; cf. (246)), and validity of the WKB assumptions of Section 4 (slow variation and exponential dominance). To reflect transport relaxation in the dissipation range (decay of at high wavenumber), we impose
(266)
and, as a self-consistency requirement for the diffusion approximation (excluding excessively steep coefficient variation),
(267)
thus setting
(268)
The final identification is the one-dimensional minimization
(269)
which determines
A necessary optimality condition is
while in practice one evaluates numerically and checks unimodality and robustness.
5.6.3. Interpretation of the Admissible Range
In this paper, combining the WKB coupling (262) with the testable admissible range
(272)
yields an experimentally verifiable bound on the tail exponent. The lower endpoint is introduced as a minimal requirement that the transition layer have finite width in the sense that inertial-side representative scaling and dissipation-side transport relaxation contribute comparably; ultimately, its appropriateness is to be judged by the numerical evaluation in (277), i.e., it is stated as a model-checkable assumption rather than a fixed truth.
From (262) and (270),
(273)
hence
(274)
5.7. Verification of the Exponent
In the previous section, we found that the admissible range of the dissipation-tail exponent is
Now, if we take the lower limit of the integral in Equation (249) to , Equation (251) simplifies, and we obtain the following closed-form expression. Specifically, one finds
(275)
Here denotes the Kolmogorov constant. Setting , is uniquely determined by . In particular, for we obtain , and for we obtain . The corresponding energy spectra are therefore
(276)
(277)
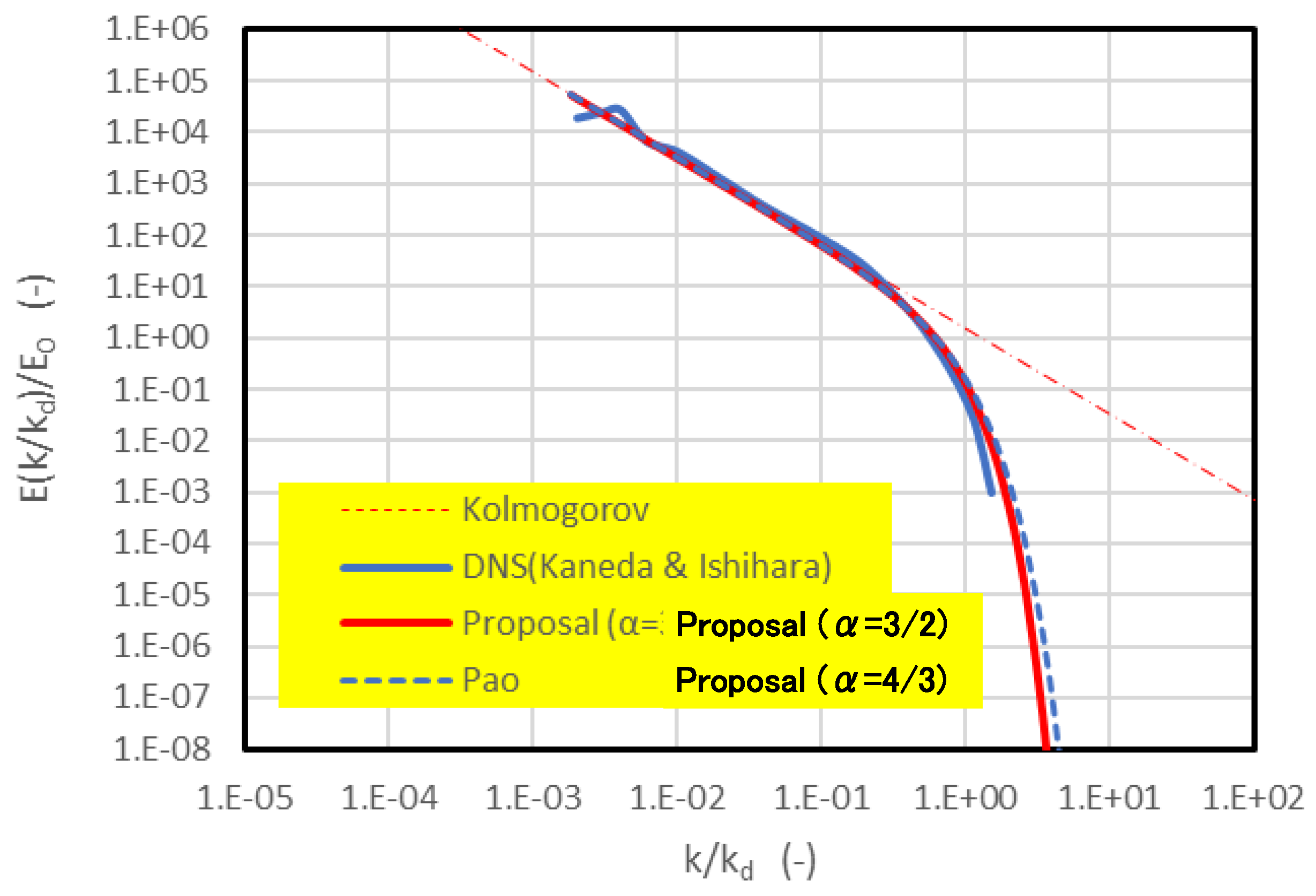
Ishihara et al. performed direct numerical simulations (DNS) of isotropic turbulence up to grid points at , and subsequently Kaneda and Ishihara extended the resolution to at (Ishihara et al., 2009; Kaneda & Ishihara, 2006). The energy spectra reported by Ishihara et al. exhibit a power law in the inertial subrange (corresponding to the blue curve in Figure 1) and an exponential-type decay in the dissipation range.
In these DNS datasets, the effective resolution in reaches at most approximately . Under this context, Figure 1 compares the DNS energy spectrum obtained with grid points at against the spectrum predicted by the present model. In this study, we use as stated above. The proposed model (red curve in the figure) reproduces, with high accuracy, the spectral characteristics observed in DNS across both the inertial and dissipation ranges. For reference, we also plot the Pao model corresponding to within the present formulation; however, the Pao model tends to overestimate the energy spectrum in the dissipation range relative to the DNS results. These comparisons support the plausibility of the exponent range evaluated in this Section. The same comparison has also been noted by Hebishima and Inage (2025).
5.8. Summary: Connecting the First and Second Stages
We summarize the conclusions of this Section. In the first stage (the dynamical level), within the framework of an autonomous conservative FP semigroup, the relative turbulence entropy becomes a Lyapunov functional, and
(205)
holds rigorously. In contrast, in the second stage (the selection level), the WKB analysis in Section 4 constrains the dissipation tail to the stretched-exponential form
(179)
together with the coupling relation
(180)
Accordingly, we construct the reference distribution globally on and, based on
(241)-(243)
define the one-dimensional optimization (minimization of the KL distance )
(269)
Then is not fixed externally, but is identified as
(270)
Thus, the exponent in this paper is not an a posteriori fitting parameter, but is positioned on a verifiable chain of logic:
6. Conclusions
This study established a two-level theory—obtained by serially connecting a dynamical coarse-graining based on the spectral equation of three-dimensional homogeneous isotropic turbulence (the Lin equation) and an information principle in logarithmic wavenumber space (a reduced MaxEnt principle)—and thereby positioned the dissipation-range spectral shape (in particular, the stretched-exponential tail) not as an ad hoc fit, but as the outcome of a verifiable logical chain.
The main achievements can be summarized in the following three points.
- Stage 1 (dynamical level): autonomous FP semigroup and H-theorem.
We explicitly formulated a one-dimensional Fokker–Planck description on the logarithmic wavenumber as an autonomous time evolution (a semigroup). By showing that the relative turbulence entropy (the sign-reversed KL distance) is a Lyapunov functional with monotonicity, we mathematically fixed the “arrow of time” in scale space.
- 2.
- Stage 1.5 (asymptotic constraint): admissible class via WKB.
By applying WKB analysis to the stationary equation in the dissipation range, we clarified that the tail becomes stretched exponential and that the admissible range of exponents is constrained (under asymptotic coefficient scaling). Moreover, the WKB coupling provides the constraint , which reorganizes the degrees of freedom and directly leads to the final formulation in Section 5.
- 3.
- Stage 2: removing arbitrariness and one-dimensional Hyper-MaxEnt.
To eliminate the largest potential arbitrariness—leaving free—we fixed by enforcing dissipation-rate consistency, thereby reducing the freedom to alone. In addition, we unified the lower integration bound for the dissipation-rate integral to (equivalently ) and closed the remaining “mathematical gaps” concerning integrability and well-definedness of the KL functional. As a result, the selection problem closes as a one-dimensional optimization (Hyper-MaxEnt), and the exponent can be defined as the exponent within the admissible set that minimizes the KL distance to the reference distribution.
In one sentence, the conclusion of this theory is as follows: the dissipation-range exponent is selected as by necessity from (i) the convergence structure permitted by the dynamics (H-theorem), (ii) the tail class constrained by WKB asymptotics, and (iii) an information principle (reduced MaxEnt) after removing arbitrariness by dissipation-rate consistency.
Natural next steps include: (a) calibration of the reference-distribution parameters from DNS/experiments and robustness assessment of ; (b) extensions to incorporate finite- effects, nonstationary forcing, and nonlocality (including identification of FP coefficients and refinement of boundary conditions); and (c) generalization to scalar mixing and anisotropic turbulence. These directions can be pursued in a verifiable manner while preserving the core structure of the present framework—“dynamics asymptotics information.”
Funding
This research received no external funding.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kolmogorov, A. N. The local structure of turbulence in incompressible viscous fluid for very large Reynolds numbers. Doklady Akademii Nauk SSSR 1941, Vol. 30, 301–305. [Google Scholar] [CrossRef]
- Batchelor, G. K. The Theory of Homogeneous Turbulence; Cambridge University Press, 1953. [Google Scholar]
- Frisch, U. Turbulence: The Legacy of A. N. Kolmogorov; Cambridge University Press, 1995. [Google Scholar]
- Pope, S. B. Turbulent Flows; Cambridge University Press, 2000. [Google Scholar]
- Davidson, P. A. Turbulence: An Introduction for Scientists and Engineers, 2nd ed.; Oxford University Press, 2015. [Google Scholar]
- Sagaut, P.; Cambon, C. Homogeneous Turbulence Dynamics, 2nd ed.; Springer, 2018. [Google Scholar]
- Pao, Y. H. Structure of turbulent velocity and scalar fields at large wavenumbers. Physics of Fluids 1965, Vol. 8(No. 6), 1063–1075. [Google Scholar] [CrossRef]
- McComb, W. D.; Yoffe, S. R. Renormalization-group methods for Navier–Stokes turbulence. Journal of Physics A: Mathematical and Theoretical 2017, Vol. 50, 415501. [Google Scholar]
- Zhou, Y. Turbulence theories and statistical closure approaches. Physics Reports 2021, Vol. 935, 1–117. [Google Scholar] [CrossRef]
- Verma, M. K.; Kumar, A.; Kumar, P.; Barman, S.; Chatterjee, A. G.; Samtaney, R.; Stepanov, R. A. Energy spectra and fluxes in dissipation range of turbulent and laminar flows. Fluid Dynamics 2018, Vol. 53(No. 6), 862–873. [Google Scholar] [CrossRef]
- Buaria, D.; Sreenivasan, K. R. Dissipation range of the energy spectrum in high Reynolds number turbulence. Physical Review Fluids 2020, Vol. 5, 092601(R). [Google Scholar] [CrossRef]
- Gorbunova, A.; Balarac, G.; Canet, L.; Eyink, G.; Rossetto, V. Spatio-temporal correlations in three-dimensional homogeneous and isotropic turbulence. Physics of Fluids 2021, Vol. 33, 045114. [Google Scholar] [CrossRef]
- Solsvik, J.; Jakobsen, H. A. Development and application of population balance models for dispersed turbulent two-phase flow: A review. AIChE Journal 2016, Vol. 62(No. 6), 1933–1953. [Google Scholar]
- Solsvik, J.; Jakobsen, H. A. Development of fluid particle breakup and coalescence closure models for the complete energy spectrum of isotropic turbulence. Industrial & Engineering Chemistry Research 2016, Vol. 55(No. 23), 6201–6230. [Google Scholar]
- Tanogami, T.; Araki, K. Information-thermodynamic structure of the turbulent energy cascade. Physical Review Research 2024, Vol. 6, 043261. [Google Scholar] [CrossRef]
- Kraichnan, R. H. The Structure of Isotropic Turbulence at Very High Reynolds Numbers. Journal of Fluid Mechanics 1959, 5, 497–543. [Google Scholar] [CrossRef]
- Kovasznay, L. S. G. Spectrum of Locally Isotropic Turbulence. Journal of the Aeronautical Sciences 1948, 15(12), 745–753. [Google Scholar] [CrossRef]
- Verma, M. K. Energy Transfers in Fluid Flows: Multiscale and Spectral Perspectives; Cambridge University Press: Cambridge, 2019. [Google Scholar]
- Risken, H. The Fokker–Planck Equation: Methods of Solution and Applications, 2nd ed.; Springer: Berlin, 1996. [Google Scholar]
- Gardiner, C. W. Stochastic Methods: A Handbook for the Natural and Social Sciences, 4th ed.; Springer: Berlin, 2009. [Google Scholar]
- Cover, T. M.; Thomas, J. A. Elements of Information Theory, 2nd ed.; Wiley: New York, 2006. [Google Scholar]
- Jaynes, E. T. Information Theory and Statistical Mechanics. Physical Review 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Jaynes, E. T. The Minimum Entropy Production Principle. Annual Review of Physical Chemistry 1980, 31, 579–601. [Google Scholar] [CrossRef]
- Pressé, S.; Ghosh, K.; Lee, J.; Dill, K. A. Principles of Maximum Entropy and Maximum Caliber in Statistical Physics. Reviews of Modern Physics 2013, 85(3), 1115–1141. [Google Scholar] [CrossRef]
- Prigogine, I. Introduction to the Thermodynamics of Irreversible Processes, 3rd ed.; Wiley: New York, 1967. [Google Scholar]
- Seifert, U. Stochastic Thermodynamics, Fluctuation Theorems and Molecular Machines. Reports on Progress in Physics 2012, 75, 126001. [Google Scholar] [CrossRef] [PubMed]
- Olver, F. W. J. Asymptotics and Special Functions; Academic Press: New York, 1974. [Google Scholar]
- Bender, C. M.; Orszag, S. A. Advanced Mathematical Methods for Scientists and Engineers; McGraw–Hill: New York, 1978. [Google Scholar]
- Hinch, E. J. Perturbation Methods; Cambridge University Press: Cambridge, 1991. [Google Scholar]
- Spohn, H. Entropy Production for Quantum Dynamical Semigroups. Journal of Mathematical Physics 1978, 19, 1227–1230. [Google Scholar] [CrossRef]
- Van Kampen, N. G. Stochastic Processes in Physics and Chemistry, 3rd ed.; North-Holland: Amsterdam, 2007. [Google Scholar]
- de Groot, S. R.; Mazur, P. Non-Equilibrium Thermodynamics; Dover, New York, 1984. [Google Scholar]
- Kullback, S.; Leibler, R. A. On Information and Sufficiency. Annals of Mathematical Statistics 1951, Vol. 22(No. 1), 79–86. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; Wiley: New York, 1959. [Google Scholar]
- Lebowitz, J. L.; Spohn, H. A Gallavotti–Cohen-Type Symmetry in the Large Deviation Functional for Stochastic Dynamics. Journal of Statistical Physics 1999, Vol. 95(Nos. 1–2), 333–365. [Google Scholar] [CrossRef]
- Edwards, S. F.; McComb, W. D. Generalized Taylor–Kármán Momentum Transfer Theory of Isotropic Turbulence. Journal of Physics A: General Physics 1969, Vol. 2(No. 2), 157–171. [Google Scholar] [CrossRef]
- Verma, M. K.; Chatterjee, A. G. An Introduction to Multiscale Analysis in Turbulence; Springer: Singapore, 2022. [Google Scholar]
- Ishihara, T.; Gotoh, T.; Kaneda, Y. Study of High–Reynolds Number Isotropic Turbulence by Direct Numerical Simulation. Annu. Rev. Fluid Mech. 2009, 41, 165–180. [Google Scholar] [CrossRef]
- Kaneda, Y; Ishihara, T. High-resolution direct numerical simulation of turbulence. J Turbul 2006, 7(20). [Google Scholar] [CrossRef]
- Hebishima, H.; Inage, H. A unified turbulence model bridging low and high Reynolds numbers: Integrating shell models with two-scale direct interaction approximation. Chaos, Solitons and Fractals 2025, 198, 116535. [Google Scholar] [CrossRef]
Figure 1.
This figure compares the energy spectrum obtained from the proposed model with that from direct numerical simulation of turbulence.
Figure 1.
This figure compares the energy spectrum obtained from the proposed model with that from direct numerical simulation of turbulence.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2026 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



