
Submitted:
28 December 2025
Posted:
29 December 2025
You are already at the latest version
Abstract
Generative artificial intelligence (GenAI) is a paradigm shift that redefines knowledge retrieval, development, communication, and verification. However, GenAI’s capabilities for mimicking the work of human scholars have advanced, generating content indistinguishable from that of human authors, making pre-publication editing and peer review challenging. Through an extensive bibliographic exploration of the Scopus and HeinOnline databases, we investigated academic, ethical, and legal attitudes toward GenAI and scientific authorship. A backward reference search was conducted, beginning with bibliographic evidence published from 2022 to 2025, to identify earlier contributions that demonstrate stakeholders' positions. Index keyword co-occurrence analysis was performed to identify trends and attitudes among the scientific and legal professional communities. It is well recognized that GenAI impacts the traditional ideas and practices of authorship, creativity, ownership, and copyright, but accountability and responsibility remain with the authors. Although the need for reforming guidelines and laws related to these subjects is unanimously recognized, academic scholars tend to debate theoretical and doctrinal subjects, while legal professionals focus on the deliberate misuse of GenAI, legal schemes, ethical compliance, verification of the origin of content, and unauthorized use of resources protected by proprietary rights. The ongoing technological developments in GenAI powerfully shape opinions and drive new ideas for the scientific and legal community.
Keywords:
author responsibility
; artificial intelligence ethics
; artificial intelligence fairness
; algorithmic biases
; bibliometrics
1. Introduction
The public announcement of the generative artificial intelligence (GenAI) model ChatGPT, a system designed to generate responses to users’ prompts, on November 30, 2022, included limitations and clarifications regarding its replies. The developers warned users about the potential for incorrect or nonsensical answers, sensitivity to prompt rephrasing, excessive verbosity, wrong guesses, and harmful or biased behavior. Despite this, the model’s linguistic performance was so impressive in delivering a professional or expert tone and mimicking scientific writing that it was introduced as a co-author in preprints (Transformer et al., 2022) and published papers (King & ChatGPT, 2023; Pekşen & ChatGPT, 2023). But was GenAI a legitimate author or co-author? Is GenAI creating, or is it just faking it? Is GenAI-created content accurate, and if it is not, who bears the responsibility?
These questions challenge everyone involved in scholarly publishing, including editors, reviewers, authors, and readers. In every case, they prompted skeptical responses, even from GenAI supporters. It became clear that GenAI models cannot be held responsible for the content of scientific papers (Stokel-Walker, 2023; Thorp, 2023). Additionally, distinguishing between human- and AI-generated material is becoming increasingly complex as GenAI systems develop more sophisticated language (Curtis, 2023). Overall, banning their use was one option. However, many editors, as scientists, recognized the unique analytical abilities of these systems and the chance to address the linguistic gap that has widened since the mid-20th century in international academic publishing, where English remains the primary language (Kumar et al., 2024; Inala et al., 2024; Amano et al., 2023). GenAI boosts scientific productivity by summarizing literature, translating it into native languages, analyzing interdisciplinary datasets, generating research questions, and suggesting lines of inquiry. It provides unique ways to break down linguistic or disciplinary barriers by acting as a flexible explanatory tool for all users. It can draft manuscripts with citations, refine or review existing ones, offering valuable opportunities for both scientists and journal editors (Katsnelson, 2022; Salazar & Kunc, 2025). Following the printing revolution and the digital transformation, GenAI is reshaping both the creation and dissemination of scientific knowledge (Bergstrom et al., 2024).
However, the GenAI-driven transformation of academic publishing presents significant risks to data integrity, logical consistency, and scientific innovation. From minor tasks such as evaluating information, filtering content, and identifying logical fallacies to intentional data fabrication and misconduct by human users, GenAI’s involvement in research and paper development can introduce errors or misinformation. These issues may be embedded in the manuscript text, tables, figures, or supplementary materials and are difficult for editors or reviewers to detect before publication without a thorough, systematic review of the literature and the materials involved. If left undetected, a malicious GenAI-generated report can successfully pass peer review and be published in a scientific journal, contaminating the scientific record. Not all problematic data or figures can be readily detected, as exemplified by a retracted review published in February 2024 in Frontiers in Cell and Developmental Biology (Guo et al., 2024). Recently, it was reported that GenAI was used in single-factor analyses of the NHANES dataset across multiple bioinformatics studies by different research teams, resulting in at least 341 published papers, each claiming a clinically significant association (Suchak et al., 2025). These low-powered, weakly statistically supported studies can serve as a foundation for future research, with new studies building on them. The spread of errors and misinformation through falsified publications can influence future scientific research.
Journal editors and publishers share concerns about the increasing use of GenAI models in scientific research. The main criticism is that GenAI models, often referred to as language machines, can mimic human writing without truly understanding the meaning behind textual expressions, illustrative depictions, diagrams, or tables. This raises important questions about the nature of intelligence in these models. GenAI models have been trained on billions of words from diverse contexts, including books, articles, and websites. They can generate appropriate responses to human prompts, but not in the same way as traditional programming (Hutson, 2021). The second line of criticism pertains to the training and formation of bias in GenAI models due to the information they are fed. These models may amplify stereotypes or fill in gaps based on the provided information, thereby producing biased responses (Ananya, 2024). The third line of criticism concerns the distortion of GenAI responses when information generated by GenAI has been used in training. Since the training of GenAI models relies on internet content, when the internet is saturated with GenAI-generated material, the outcome is a persistent self-reinforcing cycle that can lead to model collapse, a condition known as data poisoning (Bohacek & Farid, 2025; Shumailov et al., 2024). The fourth line of criticism involves how GenAI models think and the limits of their reasoning, particularly when dealing with complex problems or logic puzzles that cannot be solved by GenAI (Biever, 2023; Hutson, 2024; Shojaee et al., 2025). GenAI developers argue that these claims stem from improper variable control and from prompt requests for exhaustive move lists across multiple models, which, in turn, lead to failures (Opus & Lawsen, 2025). The endpoint concerns non-expert users’ perceptions of GenAI’s functional performance and rational capabilities (Harper, 2025), as well as their awareness of the risks associated with a potentially problematic update (OpenAI, 2025).
The formulation of editorial policies by scientific publishers and scholarly journal editors may vary. Nevertheless, all ultimately reach a consensus regarding expectations for paper contributors and peer reviewers concerning the proper use of GenAI (STM, 2023; Zielinski et al., 2023; Springer Nature, 2025; Science, 2025; PLOS One, 2025; ICMJE, 2025): (a) GenAI cannot be attributed authorship; (b) GenAI images should be avoided; (c) peer reviewers should not upload submitted manuscripts into GenAI tools, including tools that can detect GenAI content, and (d) the responsibility and accountability for the content of any contribution lies with its authors, with particular emphasis on the corresponding author.
The ethical and legal considerations of using GenAI models, agents, or tools in preparing scholarly papers, peer review, or editing will be examined as documented in existing records. Specific topics related to the use of GenAI in academic publishing, emphasizing copyright, data fairness, and infringements, will be discussed.
2. Literature Review
Various research teams and individual investigators from diverse academic backgrounds and perspectives have examined the ethical and legal implications of using GenAI models in scholarly publishing. The rise of advanced GenAI systems, based on large language models (LLMs), has introduced unprecedented scale capabilities for automated, prompt-based text generation; a disruptive technological breakthrough that creates a paradigm shift, challenging traditional ideas of authorship, creativity, and intellectual contribution in scholarly publishing.
Observing technological progress, discussions about who is responsible and accountable for machine-produced text outputs have preceded the announcement of BERT (Devlin & Chang, 2018), ChatGPT (OpenAi, 2022), Claude (Anthropic, 2023), Llama (Meta, 2024), Gemini (Google, 2023), Copilot (Microsoft, 2023), Perplexity (Perplexity team, 2025), Mistral (Jiang et al., 2023), and Grok (xAI, 2024), the standout GenAI LLMs among many popular systems available. A 2018 legal analysis by Russ Pearlman on the possibility of recognizing AI models as authors or inventors under US intellectual property law found that, when the law was established in the 1950s, non-human authorship and inventorship were rejected because computer systems were regarded as tools for generating ideas. However, GenAI exhibits a unique creative potential that warrants a review of the law or even recognition of GenAI as an author or inventor. This could be based on the subject matter and causation, as GenAI may be recognized under a “work-for-hire” or “employed-to-invent” framework by the individuals who program or use it (Pearlman, 2018). Conversely, some consider GenAI a tool, an instrument in the human creative process, rather than an actual creator. In this view, claims of GenAI authorship are false (Murray, 2024).
No matter what, the integration of these technologies into research workflows has accelerated rapidly since 2023, becoming evident through a shift in language use in scientific papers after this period, with the incorporation of characteristic GenAI words or phrases such as “delve,” which increased by more than 6 times, indicating widespread but often undisclosed GenAI assistance in manuscript preparation. The influence of GenAI LLMs on scientific writing exceeds that of major global events such as COVID-19 (Kobak et al., 2025). This bibliographic and bibliometric phenomenon has sparked intense debate within the scientific community and among research stakeholders, including academic authorities, funding agencies, and scholarly publishers, regarding the proper boundaries of GenAI assistance, the need for disclosure, and the implications for research integrity.
3. Materials and Methods
3.1. Search Strategy
This study aimed to identify and analyze keywords in original research papers, reviews, and essays related to authorship responsibility when using GenAI tools in research and article preparation. Extensive searches using advanced features in the Scopus and HeinOnline databases were conducted in June 2025. This protocol enables examination of perspectives on GenAI authorship from both the scientific and legal communities.
The advanced search query for the Scopus database was:
(TITLE( “artificial intelligence*” ) OR TITLE(“AI*”)) AND (ALL(“Large Linguistic Model*”) OR ALL( “agent*” )) AND (TITLE-ABS-KEY ( “author*” ) OR TITLE-ABS-KEY(“writ*”) OR TITLE-ABS-KEY(ethi*) OR TITLE-ABS-KEY(illus*)) AND ( TITLE-ABS-KEY ( “scientif*” ) OR TITLE-ABS-KEY ( “academ*” ) ) AND ( TITLE-ABS-KEY ( “paper*” ) OR TITLE-ABS-KEY ( “manuscr*” ) OR TITLE-ABS-KEY ( “publicat*” ) ) AND PUBYEAR > 2021 AND PUBYEAR < 2026
A backward reference search was conducted, using Scopus results from 2022 to 2025, to track the fundamental contributions to the evolution of GenAI, as well as to the use of AI in scientific research and the academic publishing industry.
The query for the HeinOnline was:
((“generative artificial intelligence”) AND (authorship))
and
“generative artificial intelligence” AND “authorship” AND “ethical” AND “legal” AND “science” AND “publication(s)”
The heuristic employed was a direct keyword search of the bibliography from 2021 onward, when GenAI models capable of generating human-like text based on learned patterns from large datasets became publicly available. This approach aims to compile papers on general-purpose LLMs and educational writing tools, including Paperpal (George, 2023), Grammarly AI (Grammarly, 2021), and WriteFull (van Zeeland, 2019). The documents identified were manually reviewed for relevance to the research question and the study’s scope. The backward reference search for the Scopus dataset accounts for the historical development of the scientific community, particularly considering emerging disruptive technological advances in GenAI.
3.2. Data Collection, Journals, Categories, and Countries
The citations retrieved from Scopus or HeinOnline were collected in tables either as comma-separated values (.csv) or text (.txt) files, as well as in full text (.pdf) formats. All citations collected were included in the analysis without exclusion. Analysis in VOSviewer was performed according to the developers’ instructions and the input type.
3.3. Statistical Analysis
Descriptive statistics, multiple regression, linear regression, calculation of slope, and polynomial nonlinear regression were performed with Microsoft (MS) Excel. Data are presented as mean ± standard deviation. A p-value of <0.05 was considered statistically significant.
4. Results
4.1. Trends in Academic Publications on GenAI Authorship
A total of 380 articles were retrieved from Scopus. After filtering with the keyword “Artificial Intelligence,” 219 documents remained, and full texts were obtained (Figure 1, left panel, low). From these works, 144 (65.7%) received at least one citation to a total of 3,935 after exclusion of self and book citations. The descriptive characteristics of the Scopus direct search are shown in Figure 2. Linear regression estimated a positive slope of approximately 31 for publications and 1,005 for citations per year, with regression coefficient of determination (R2) values of 0.9448 for publications and 0.9122 for citations (Figure 2A). The top affiliated countries were the US (17.3%), followed by India (12.8%), China (12.3%), and the UK (11.9%) (Figure 2B).
Most of the documents are original research articles (50.2%), followed by reviews (25.6%) and conference papers (18.3%) (Figure 2C). The documents by subject area, as classified by Scopus, include Computer Science (23.6%), Social Sciences (17.5%), Medicine (10.8%), Business, Management, and Accounting (9.0%), Engineering (8.0%), Arts and Humanities (5.0%), Psychology (3.8%), Decision Sciences (3.5%), Mathematics (3.5%), and Biochemistry, Genetics, and Molecular Biology (2.8%), showing the significant influence of GenAI across all fields of human research and knowledge (Figure 2D).
Analysis of index keyword co-occurrences in this bibliographic dataset, based on association strength, reveals six clusters of terms (Figure 3). Each cluster is characterized by its most common keywords and is assigned a distinct color (Figure 3A). At the same time, the average publication year indicates the keyword’s timeliness, and the average citation value reflects the keyword’s impact on the scientific community during this period (Figure 3B). The first cluster of co-occurring keywords related to GenAI applications in authoring scientific papers (Figure 3A, red) focuses on specific procedures used in data analysis and publishing, with an average publication year of 2024. Highly cited keywords in this cluster include ethics (average citation count: 55.7), algorithm (30.0), trust (28.7), and data quality (27.7). The second cluster pertains to AI-assisted systematic literature review authoring, with an average publication year of 2023.7 and an average citation count of 39.7 (Figure 3A, green). The third involves bibliometrics analysis, with an average publication year of 2024.1 and an average citation value of 46.6, followed by the keyword language processing with 14.3 (Figure 3A, blue). The fourth concerns ethical technology use and decision-making, with an average publication year of 2023.2 and an average citation value of 26.6, followed by explainability (23.7), current (21.6), and machine learning (19.23) (Figure 3A, yellow). The fifth cluster relates closely to the third, involving bibliometrics with deep learning quantitative analysis of scientific information, with an average publication year of 2024.2, and Web of Science as the keyword with the highest average citation value of 47.4 (Figure 3A, purple). The sixth addresses the philosophical aspects of GenAI use in authoring, taxonomies, sustainable development, case studies, education, and curricula, with an average publication year of 2023.6 and an average citation value of 94.5 (Figure 3A, cyan). The sixth cluster has the highest overall average citations compared to the others.
Iterative co-occurrence patterns among keywords in the most-cited papers indicate active interest within the scientific community engaged in GenAI research and product development. The top 13 keywords out of 65, which appeared in at least three directly retrieved papers from a Scopus search, are shown in Table 1. These keywords appeared in documents with an average of over 28.5 citations. The co-occurring keywords depicted in Table 1 account for 82 of 449 observed co-occurrences (18.2%), which is less than one-fifth. Yet, they constitute more than half (54.9%) of the total citations received by this bibliographic portfolio. The most highly cited works focus on GenAI integration in scientific writing, related philosophical questions, and trust issues, followed by applications in education, academic curricula, healthcare, clinical effectiveness, and the preparation of literature and systematic reviews. Interestingly, specific schemes of GenAI involvement in authorship, such as using it in the conceptualization of scientific works, applying natural language processing, deep learning, publishing, utilizing in the development of taxonomies of entities, in the prediction of interactions, or in achieving sustainable development goals, highlight the framework of academic thoughts, anticipations, doubts, and considerations.
4.2. Trends in Backward Reference Search on GenAI Involvement in Scholarly Authorship
A backward reference search was conducted in Scopus using the previously mentioned bibliographic dataset to identify prior work on this topic and the related keyword scheme in the scientific literature, before the public announcement of the advanced GenAI chatbot, ChatGPT, on November 30, 2022, and before the system’s access by millions of users. The search also aimed to explore broader topics that GenAI may use in scientific writing. The collection of 219 documents obtained through the direct Scopus advanced search contained 11,551 references to prior work, of which 3,259 (28.2%) included the “Artificial Intelligence” keyword (Figure 1, left panel, up). The backward reference search results cover documents from 1970 to the present, with their descriptive features shown in Figure 4. Linear regression estimated a positive slope of 47.5 for publications and 16,543 citations annually, with regression coefficients of determination (R2) of 0.4953 for publications and 0.845 for citations (Figure 4A). The most frequently cited publication years are 2023 (20.3%), followed by 2024 (17.3%), and 2021 and 2022 (14.0%). This indicates a strong tendency to cite recent AI-related work: 2,274 of the 3,259 references (69.8%) were published in the past five years, and 3,089 references (94.8%) in the past ten years. Most documents originated from the US (29.6%), followed by the UK (14.5%), China (10.0%), and India (8.3%) (Figure 4B). The majority of references are original research articles (60%), followed by reviews (19.6%) and conference papers (14.2%) (Figure 4C). By subject area, Computer Science led with 22.3%, followed by Social Sciences at 13.9%, Medicine at 11.7%, Business, Management, and Accounting at 9.8%, and Engineering at 7.5% (Figure 4D).
Further examination of publication and citation patterns shows that the median publication year is 2021 (Figure 5). However, there is an almost linear increase in relative backward-referenced publications from 2017 to 2021 (Figure 5A). Linear regression estimated a positive slope of 109 for publications, with a regression coefficient of determination (R2) of 0.9919. Their impact, as measured by citations, varies by publication year. Papers published in 2015 received the most citations, with a sharp linear positive increase of nearly 60,000, followed by a negative decrease of approximately 40,000 after this temporal point, yielding R2 values of 0.84 and 0.995, respectively (Figure 5B). The peak citations achieved by the 2015 published references are followed by those published in 2016 and between 2019 and 2021. Interestingly, citations decreased for papers published in 2017 and 2022, reflecting a period of stagnation immediately preceding the announcement of the advanced GenAI chatbot, ChatGPT (Figure 5B). This variation in citation behavior across publication years indicates significant shifts in the scientific community’s interest, reflecting periods of breakthrough discoveries and confusion over their value. Overall, interest in artificial intelligence has grown steadily from 2015 to 2023, as shown by cumulative citations, with a positive linear slope of approximately 61,500 and an R2 of 0.997 (Figure 5C). The differences between the annual citation count and the total citations suggest that thematic shifts attract interest as research topics evolve in a dynamic, open environment, encouraging exploration of multiple technological approaches. Uncertainty about which method will become dominant motivates researchers to explore various technological options.
A subset of 170 (5.2%) references out of the total AI-related works were published between 1970 and 2015, and 32 of them (1.0% of the total) received more than 50% of their citations within the last three years. By excluding extremes, such as highly cited reports with more than 1,000 citations and those with fewer than 10 citations in total, 18 references resemble the “Sleeping Beauties” phenomenon (Ke et al., 2015; Chaleplioglou et al., 2025). However, these reports present distinct awakening features, including periods of inactivity, the year of awakening, the year of highest citation after awakening, and the length of the awakening period, as shown in Figure 6. This indicates multiple triggers at different moments, directly or indirectly related to recent AI developments in the topic, methodology, or technology addressed in the reference. Collectively, these 18 “Sleeping Beauty”-like references highlight the expansive reach of AI across diverse fields, from education and healthcare to business ethics and space exploration. In real-world settings, these studies examined the use of AI in areas such as language-learning tutoring, employee evaluations, library chatbots and robots, mental health services, psychological practice, medicine, human resources, and small-unit military strategies. In the entertainment and gaming industries, AI is used to develop interactive stories. New frontiers are emerging, including collaborations with quantum computing, space exploration, and sustainable policy development. Historical and foundational research honors pioneers such as John McCarthy and key events such as the Dartmouth Conference. Ethical and societal issues are carefully addressed, with a focus on ideology, the impact of capitalism, and guidelines for AI in caregiving roles. Overall, these works demonstrate AI’s evolution into a versatile tool poised for innovation, while also calling for accountability.
Analysis of index keyword co-occurrences in this bibliographic dataset, based on association strength, reveals four clusters of terms (Figure 7). The first cluster of co-occurring keywords focuses on the current state of GenAI systems, machine learning, ChatGPT, neural networks, and decision trees, with an average publication year of 2019.8 and an average citation count of 273.8. Highly cited keywords in this cluster include datasets, with an average citation of 4187.9; computers, with 3562.9; machine learning methods, with 3143.5; game theory, with 2619.9; language processing, with 2499.4; supervised learning, with 1785.9; recurrent neural networks, with 1629.4; and stochastic systems, with 1522.3 (Figure 7A, red). The second cluster concerns systematic literature review authorship, ethics, pattern recognition, and data processing, with an average publication year of 2020.9 and an average citation count of 295.7. Highly cited keywords here include pattern recognition (6404.2 citations), data processing (3395.8), and standards (1433.8; Figure 7A, green). The third cluster involves algorithms, controlled studies, diagnostic imaging, and clinical setups, with an average publication year of 2020.5 and an average citation count of 323.7. Key highly cited keywords include classifier (3219.8 citations), image processing (2087.1), automated pattern recognition (1777.2), classification (1256.6), image enhancement (1180.0), and computer-assisted diagnosis (876.4; Figure 7A, blue). The fourth cluster concerns prediction, personalized medicine, drug development, computer-aided design, and computer simulation, with an average publication year of 2020.5 and an average citation count of 314.3. Highly cited keywords in this cluster include neural networks (average citations: 3253.1), learning algorithm (2245.9), nonhuman (1650.0), computer program (1577.8), and process optimization (1211.6). Interestingly, medicine is a key area of interest for GenAI applications, even before the development of systems with advanced integration of intelligence and high analytical capabilities (Figure 7A, yellow).
To further investigate the dynamics of thematic association patterns, we explored pairs of co-occurring keywords in the backward AI-related references dataset. In the setting of 648 keywords that appeared in at least 10 references of the dataset, more than 77,000 co-occurrences were obtained, and by eliminating iterative co-occurrences, 42,000 pairs of keywords were obtained. However, the citation dynamics of these pairs were different. The top 10 keywords in terms of average citations, with their accompanying terms, are depicted in Table 2. These keywords related to highly cited documents on average with nearly 2,500 or more citations represent major topics of interest for AI uses in pattern recognition, data processing, classification, and image processing, with particular emphasis in biomedical and clinical applications, such as personalized medicine, physiology, prognosis, psychotherapy, psychology, COVID19, diagnostic tests, drug design, development and discovery, risk factors, survival, patient safety, doctor patient relationship, patient compliance, genomics, neuroimaging, epidemiology, quality of life, wellbeing, positron emission tomography, echography, radiology, medical oncology, cancer research, early cancer diagnosis, pharmacogenetics, pharmacogenomics, metabolism, electronic health records, randomized control trials, single nucleotide polymorphism, protein structure, phenotype, histopathology, hypertension, nuclear magnetic resonance imaging, obesity, ophthalmology, and molecular dynamics. The methodological considerations include reproducibility, sensitivity and specificity, standards, task performance, study design, controlled study, thematic analysis, writing, database, dataset, data mining, principal component analysis, uncertainty, interpretability, performance, performance assessment, retrospective study, misinformation, monitoring, simulation, virtual reality, game theory, Bayes theorem, problem solving, validation study, scoring systems, surveys and questionnaires, quantitative analysis, statistical bias, statistics, errors, stochastic systems, synthesis, receiver operating characteristic, and cost effectiveness analysis. There are also topics of special interest such as social interaction, ethics, legislation and jurisprudence, European Union or United States policies, productivity, safety, scientific literature, systematic review, speech, speech recognition, decision support systems, decision making, industry 4.0, policy makers, public sector, workload, education, interpersonal communication, morality, physical chemistry, sustainable development, technology adoption, practice guidelines, social media, law enforcement, linguistics, plagiarism, motivation, and university. The technological advancements discussed concern supervised or unsupervised, standard or reinforced, machine learning, computer software, convolutional neural network, recurrent neural networks, support vector machine, real-time systems, ontology, automatizations, robotics, random forest, semantics, receiver operating characteristic, language processing, natural language processing, internet of things, learning algorithm, user interface, blockchain, chatbots, energy efficiency, energy utilization, and attention.
4.3. Trends in Legal Publications on GenAI Authorship
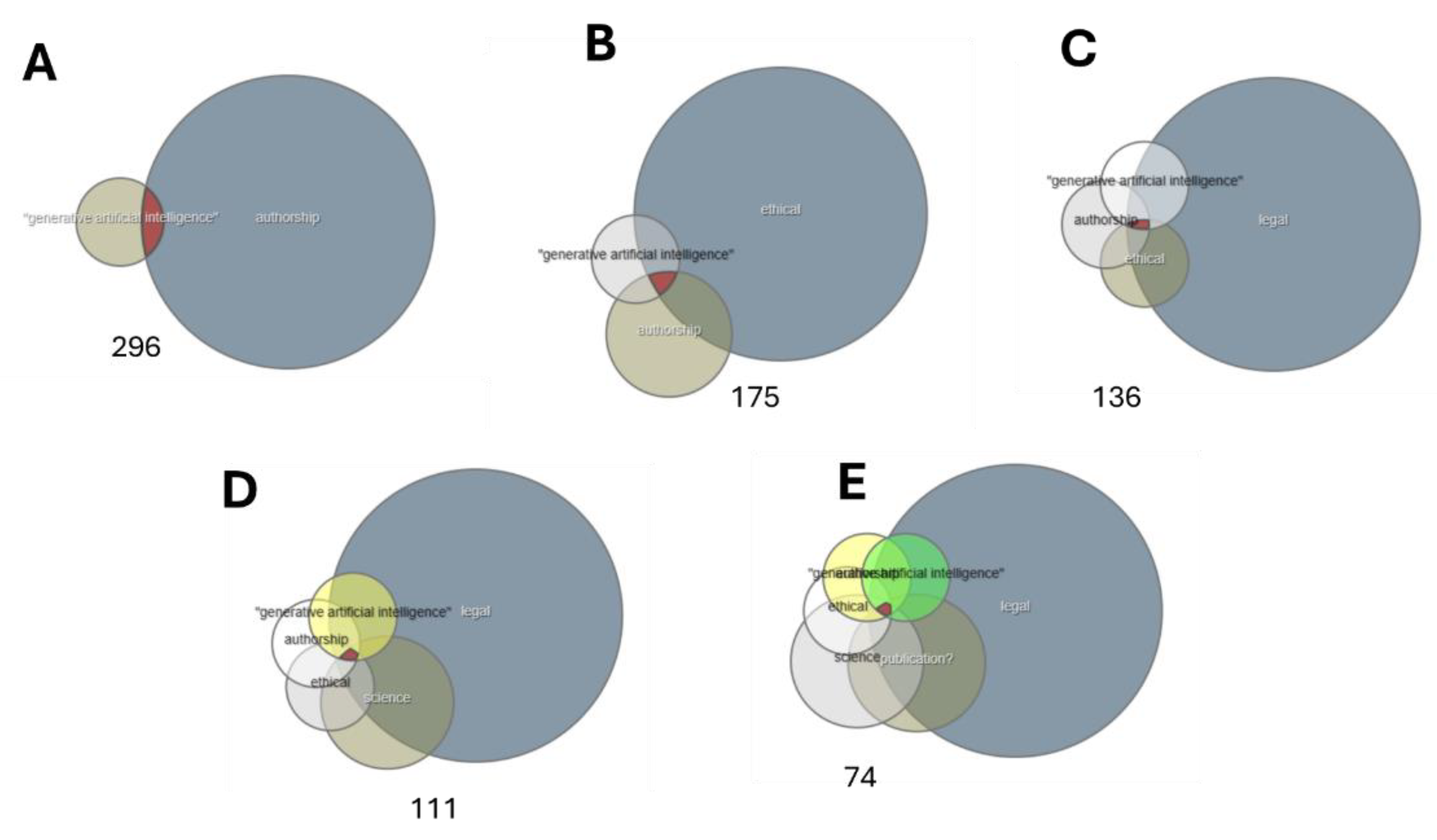
The legal perspective on GenAI authorship was explored using the HeinOnline Law journal library. Keyword searches for legal publications show the variety of topics related to “generative artificial intelligence” and “authorship.” Of the 296 papers found in the HeinOnline Law journal library, 175 relate to “ethical,” 136 to “legal,” 111 to “science,” and 74 to “publication(s)” (Figure 5).
The central debate centers on copyright and authorship, with prominent keywords such as “human authorship,” “AI-generated works,” and “copyright protection.” Fair use and training data are also critical legal issues in the use of copyrighted material to train GenAI models, raising questions about whether such use constitutes copyright infringement or falls within the fair use doctrine. Industry-specific concerns include journalism and publishing, with a focus on the responsible use of GenAI in scholarly and legal works; film and media, particularly scriptwriting and actors’ portrayals; and music, involving cloned voices and deepfakes. The rights of publicity are another concern, not only for the entertainment industry in protecting individuals’ likenesses, voices, and personalities, but also potentially for safeguarding an author’s distinctive writing style. Legal professionals also concern themselves with legal text authorship, practice, research, and ethical issues related to malpractice. With the rapid advancement of GenAI technology, discussions focus on broader legal and regulatory frameworks, considering variations across legal systems. The U.S., the E.U., China, and other countries adopt different legal approaches to regulating GenAI, which can lead to liability issues arising from GenAI-generated content. Finally, specific applications in fields such as healthcare, human resources, management, and gender studies may also be indirectly connected to core legal questions about GenAI authorship.
An assortment of documents retrieved from this legal literature database can be classified by their titles into the following categories: (1) core copyright, authorship, and intellectual property, representing 58% of the total, primarily analyzing the GenAI authorship context; (2) legal profession, ethics, and law education, accounting for 7.5% of the documents, which explore lawyering in the age of GenAI; (3) healthcare, management, and other GenAI applications, making up 13.4% of the documents, covering specific biomedical applications, diagnostic screening, prevention, and treatment options; (4) broader governance, policy, and societal impact, comprising 21.3% of the reports, focusing on regulatory aspects of GenAI, automation, robotic systems, and autonomous vehicles; and (5) indexes and non-article entries, representing 3.1% of the documents, which include various indexes to legal periodicals, bar bulletins, and bar news.
Overall, these legal reports focus on intellectual property issues related to GenAI, particularly regarding copyright and core concepts of human authorship and creativity. GenAI is typically characterized as a sophisticated tool rather than as an independent legal entity capable of creating, assuming responsibility for, or owning intellectual property. Additionally, it is essential to recognize that GenAI services are generally billed on a usage basis, with standard business models including subscriptions to premium features on a monthly or annual basis, or per-message, per-user, or per-group-of-users charges. These patterns indicate that developers view GenAI systems as commodities or services rather than autonomous entities.
Figure 8.
Venn diagrams of search keyword intersection of HeinOnline database results. The number of documents received is depicted under each graph. (A) Results of intersection with keywords: “generative artificial intelligence” & “authorship.” (B) Results of intersection with keywords: “generative artificial intelligence” & “authorship” & “ethical.” (C) Results of intersection with keywords: “generative artificial intelligence” & “authorship” & “ethical” & “legal.” (D) Results of intersection with keywords: “generative artificial intelligence” & “authorship” & “ethical” & “legal” & “science.” (E) Results of intersection with keywords: “generative artificial intelligence” & “authorship” & “ethical” & “legal” & “science” & “publication(s).”.
Figure 8.
Venn diagrams of search keyword intersection of HeinOnline database results. The number of documents received is depicted under each graph. (A) Results of intersection with keywords: “generative artificial intelligence” & “authorship.” (B) Results of intersection with keywords: “generative artificial intelligence” & “authorship” & “ethical.” (C) Results of intersection with keywords: “generative artificial intelligence” & “authorship” & “ethical” & “legal.” (D) Results of intersection with keywords: “generative artificial intelligence” & “authorship” & “ethical” & “legal” & “science.” (E) Results of intersection with keywords: “generative artificial intelligence” & “authorship” & “ethical” & “legal” & “science” & “publication(s).”.
4.4. Comparison of Stakeholders’ Perspectives on GenAI Involvement in Scholarly Reports
Five major categories of stakeholders can be identified from the published scholarly and legal communication records, reflecting shared or differing perspectives on GenAI involvement in academic publishing and broader scientific research: scientific writers, who may also serve as reviewers and editors of scholarly journals; publishers; librarians and information scientists (LIS); companies owning GenAI systems and patents; and legal professionals responsible for regulating copyrights, proprietary rights, fraud, or harm. All stakeholders recognize the disruptive effects of GenAI on traditional notions of authorship, creativity, ownership, and copyright, and emphasize the importance of accountability and responsibility in the creation of scholarly texts and data that involve human authorship. However, when comparing their views and trends on this topic, it is essential to define the key aspects of GenAI’s implications for scientific authorship, including its involvement in study design, data analysis, image creation, manuscript drafting, automatic translation, and scientific manuscript evaluation at submission. It is also critical to note that, in the short period since the public announcement of ChatGPT on November 30, 2022, GenAI systems from various providers have evolved, and their human-mimicking and analytical processing capabilities, which use up-to-date information from the internet, have improved. Therefore, despite the short period, changes in stakeholders’ attitudes and perspectives, as documented in the literature, are anticipated, and the evidence obtained in Figure 3 and Figure 7, as well as in Table 1 and Table 2, support this notion.
One step before GenAI’s active involvement in scientific authorship, legal infringements between companies owning GenAI systems for patent law violations, followed by copyright violations of human-generated content used for training GenAI systems. When GenAI systems became available to millions of users, the first models exhibited verbosity and a pronounced tendency toward hallucinations, producing mixed emotions in the scientific community, provoking reactions among publishers, prompting questions about scholarly integrity among LIS professionals, and raising fraud or liability concerns among legal professionals. However, GenAI systems soon exhibited improved analytical capabilities and speed, advanced pattern-recognition features, and multilingual proficiency, attracting many scientists to their use and leading publishers to update their policies, reduce prohibitions and bans, allow their permissible use with disclosure, or even encourage their use for the grammatical correction of texts for non-native English speakers.
There is a unanimous recognition of the need for copyright protection against infringement through law enforcement and regulatory measures. For many authors, the current situation calls for reforming guidelines for contributors, reviewers, and editors of academic journals to clarify authorship attribution, clarify how GenAI is used by stakeholders, and safeguard authors’ rights and research integrity in the evolving GenAI landscape.
A common feature of scholarly communication on the use of GenAI in manuscript preparation, especially between 2023 and 2024, is debate over the definition and criteria for authorship, originality, prompting power, and copyright. However, academic scholars’ approach often emphasizes theoretical and doctrinal analyses to propose reforms, rather than focusing on the existing body of legal evidence. The legal professionals’ perspective, as documented in the relevant literature, supports the view that the body of laws, rules, and principles applied worldwide to regulate copyright, infringement, and proprietary rights is well established and applicable regardless of the use of advanced computing tools. The mindset of legal professionals is shaped by the following challenges: the potential misuse of GenAI in legal practice, ethical compliance, verification of GenAI-generated content, and the unauthorized use of proprietary rights information in GenAI training. Academics are interested in ownership disputes among developers, users, and AI systems regarding potential rights holders. In contrast, legal practitioners focus on the implications of GenAI content for litigation and regulatory compliance. While academics call for systemic reforms to copyright law, legal professionals aim to incorporate existing legal and ethical standards into professional conduct rules and scientific communication workflows.
5. Discussion
Exploring multivariable-dependent trends in cross-sectional studies, such as the perspectives of the scientific and legal communities on the use of GenAI models and tools in authoring original research papers, reviews, and essays, can provide valuable insights into stakeholders’ behavior. To thoroughly examine the available literature, a multidimensional bibliographic search was conducted through the lens of the announcement of the first advanced GenAI model, ChatGPT, at the end of 2022. This was the point at which these models, and similar LLM-based systems subsequently introduced for most internet users, became publicly available—although access remains restricted in some parts of the world (Bao et al, 2025). They have since transformed authorship beginning in 2023. Consequently, a bidimensional literature search was conducted on scholarly communication about GenAI and authorship: a direct keyword search for works published after 2022 and a backward reference search based on the results of the keyword search. Additionally, to include the perspective of legal professionals, a direct search was conducted for legal communications. This approach facilitates comparisons of ideas and trends between the two groups—academic scholars and legal experts.
Most documents from both groups agree that GenAI models’ use in creating scholarly communications should be seen as a tool rather than as creative contributors (Murray, 2024). The prompt that starts the GenAI response is separate from the system’s underlying code and triggers a series of hypotheses and statistical calculations based on its training, which form the basis of the GenAI response. Since most GenAI systems are pre-trained, the role of AI trainers in developing and fine-tuning them—before applying self-supervised learning—by providing the systems with large datasets of text, images, or sounds, and high-quality input examples—could also be considered causal. However, this step is passive when considering the energetic effort triggered by the user prompt. It appears that the careful or careless introduction of a prompt can lead to either well-reasoned responses or poor-quality replies from GenAI systems.
The training step raises another legal and ethical issue: the risk of copyright infringement. Should the GenAI system be fed proprietary material, regardless of whether that material is under proprietary rights? For this reason, The New York Times Company sued OpenAI and Microsoft over copying and using millions of copyrighted news articles, in-depth investigations, opinion pieces, reviews, how-to guides, and more to build the LLMs for their generative AI tools, ChatGPT and Bing Chat, which was rebranded as Copilot, respectively (Chen, 2025; Karamolegkou et al., 2023). This legal issue highlights the complex nature of intellectual property rights and copyright involvement in generative AI models. This concern extends beyond the philosophical question of whether these agents should be acknowledged as authors or inventors. The ownership of these systems by corporate entities shifts responsibility to the owners rather than to the programmers, trainers, or IT managers who keep the systems operational, all of whom are employees of these organizations (Hartini & Valentino, 2025). It can be argued that, regardless of whether their organization is government, for-profit, or non-profit, the owners of these systems bear responsibility for their development, operation, and potential failures. It is also clear that companies developing generative AI view these systems as products or commodities with proprietary ownership that users can purchase or rent, rather than individual creations. From this normative perspective, one might also see the first scientific papers that list specific GenAI models as advertisements for these products, drawing scholarly attention as attractors.
Academic publishers and scientific journals have consistently issued guidance that prohibits naming generative AI agents as authors, but do not explicitly ban using them as tools to generate manuscripts. Some organizations expect authors to disclose such AI use (STM, 2023; Zielinski et al., 2023; Springer Nature, 2025; Science, 2025; PLOS One, 2025; ICMJE, 2025). However, only a quarter of leading scientific publishers and journals provide specific guidance on the use of GenAI, with half of these referring readers to the Committee on Publication Ethics (COPE) for more information on authorship and GenAI tools (Ganjavi et al., 2024). COPE recently introduced an updated publication titled “Ethics toolkit for a successful editorial office” (COPE, 2025). Interestingly, part of this regulatory document addresses journal editors and reviewers and proposes a resource on the use of artificial intelligence (AI) in decision-making regarding a submitted manuscript under consideration for publication (COPE, 2021). This discussion does not preclude the use of GenAI in the publication process, as it can accelerate decision-making during review and reduce the burden on editors. Still, it raises concerns about key ethical issues, such as accountability, responsibility, and transparency (COPE, 2021), which align with the patterns we observed in this study in both scholarly and legal papers.
If GenAI models were compared to Chekhov’s gun narrative principle, one would expect that introducing such a widely available, disruptive technology would eventually trigger its use. Indeed, GenAI models are currently used and applied across various industries, as shown here, despite ongoing discussions about fields like education, economics, marketing, manufacturing, computing, gaming, health, autonomous vehicles, robotics, administration, decision-making, and science—where they are not only used in paper writing but also in experimental design, data analysis, and translating data into scientific information. However, these analytical approaches are not error-free, and their feedback should be interpreted with caution (Bender et al., 2021). Overreliance on GenAI models for the strategic design of research protocols and for conducting informatics analyses with AI-ready datasets may introduce biases and complex, multifactorial problems. The concern here is not ethical but relates to scientific integrity and validity. It also highlights that all academic publishers are vulnerable to producing such reports for their audiences and the scientific community, because controlling for all parameters in a report—especially with high-throughput data and multiple lines of evidence—is particularly challenging. Recent bibliometric evidence indicates that several words overused by ChatGPT, such as “delve,” “intricate,” or “pivotal,” due to the documents used in its training in the 2022 version, produce a detectable, observable, and measurable prominent effect in scientific literature (Geng & Trotta, 2025).
This study has some limitations that should be acknowledged. First, two bibliographic databases were used in the literature review: Scopus for scholarly communications and HeinOnline for legal communications. Second, a direct keyword search for reports published before 2022 was not conducted; instead, a backward reference search was used. This method retrieves works cited in papers published after 2022, all of which have been cited at least once. As a result, papers published before 2022 that have not received citations, and those without citations from this dataset, were not included. However, this approach accurately traces the development of artificial intelligence from the 1970s to the present, with clear continuity evident in the comparative keyword co-occurrence analysis before and after 2022. Thirdly, ongoing developments in GenAI models, agentic AI, and multi-agent systems, along with improvements in LLM fine-tuning and the creation of GenAI-powered scientific tools, are rapidly transforming the environment of scientific computing, data analysis, and writing. These changes influence both individual attitudes and the perspectives of collective stakeholders. Our dataset shows that such advancements are common and have a measurable impact on the publication of new work and on citations of prior work, acting as triggers for “sleeping beauties.” Therefore, it is likely that even GenAI systems and software updates can alter current attitudes.
This is the first cross-sectional study comparing scholarly and legal literature on the use of GenAI in scientific report authorship. The dual perspective of experts offers insights into regulatory issues surrounding scientific publishing, patenting, copyright, and proprietary rights. The multiple quantification parameters, the time-series analysis, and the generated keyword co-occurrence maps illuminate the use of GenAI in authorship from legal and ethical perspectives.
6. Conclusions
User prompts that trigger GenAI responses are independent of the underlying code of GenAI systems and may lead them to generate hypotheses and specific reasoning. Comparing trends in GenAI authorship seen in academic and legal literature reveals challenges related to traditional authorship, creativity, ownership, and copyright. This issue is a key concern for all stakeholders involved in scientific publishing, including publishers, editors, reviewers, authors, and readers. The influence of GenAI use is evident in scientific papers, as reflected by a rapid increase in the frequency of commonly overused GenAI-related terms. Human involvement in preparing papers should remain active, vigilant, and cautious when using GenAI systems, given the “black box” nature of their responses and the risks of errors, misinterpretations, biases, or hallucinations. Perspectives and warnings about the potential dangers of using GenAI in authorship have remained consistent both before and after advances in GenAI reasoning and dataset scale. Overall, our data suggests that GenAI is an invaluable and powerful tool for researchers; however, legal regulation, ethical compliance, and the protection of proprietary rights and content from unauthorized use are essential.
Author Contributions
Conceptualization, A.C., A.K. and E.V.; methodology, A.C., A.K. and E.V.; software, A.C., A.K. and E.V.; validation, A.C., A.K. and E.V.; formal analysis, A.C., A.K. and E.V.; investigation, A.C., A.K. and E.V.; resources, A.C., A.K. and E.V.; data curation, A.C., A.K. and E.V.; writing—original draft preparation, A.C., A.K. and E.V.; writing—review and editing, A.C., A.K. and E.V.; visualization, A.C., A.K. and E.V.; supervision, A.C., A.K. and E.V.; project administration, A.C., A.K. and E.V.; funding acquisition, A.C., A.K. and E.V. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence disciplinary Digital Publishing Institute |
| GenAI | Generative Artificial Intelligence |
| LIS | Library and Information Science |
| LLM | Large Language Model |
References
- Amano, T.; Ramírez-Castañeda, V.; Berdejo-Espinola, V.; Borokini, I.; Chowdhury, S.; Golivets, M.; Gonzalez-Trujillo, J. D.; Paudel, K.; White, R. L.; Veríssimo, D. The manifold costs of being a non-native English speaker in science. PLoS Biology 2023, 21(7), e3002184. [Google Scholar] [CrossRef]
- Ananya. AI image generators often give racist and sexist results: can they be fixed? Nature 2024, 627, 722–725. [Google Scholar] [CrossRef]
- Anthropic. Introducing Claude. 2023. Available online: https://www.anthropic.com/news/introducing-claude.
- Bao, H.; Sun, M.; Teplitskiy, M. Where there’s a will there’s a way: ChatGPT is used more for science in countries where it is prohibited. Quantitative Science Studies 2025, 1–16. [Google Scholar] [CrossRef]
- Bender, E. M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, March; 2021; pp. 610–623. [Google Scholar] [CrossRef]
- Bergstrom, T.; Rieger, O. Y.; Schonfeld, R. C. The Second Digital Transformation of Scholarly Publishing. In Strategic Context and Shared Infrastructure; Ithaka S+R, 2024. [Google Scholar] [CrossRef]
- Biever, C. The easy intelligence tests that AI chatbots fail. Nature 2023, 619, 686–689. [Google Scholar] [CrossRef] [PubMed]
- Bohacek, M.; Farid, H. Nepotistically trained generative image models collapse. arXiv 2025, arXiv:2311.12202v2. [Google Scholar]
- Chaleplioglou, A.; Selinopoulou, E.; Kyprianos, K.; Koulouris, A. Awakening Sleeping Beauties from articles on mRNA vaccines against COVID-19. arXiv 2025, arXiv:2511.04129. [Google Scholar] [CrossRef]
- Chen, Tony. Language Models’ Verbatim Copying: Copyright Infringement Analysis through the Lens of The New York Times Co. v. Microsoft Corp., OpenAI, Inc. et al. (April 03, 2025). 43 Cardozo Arts & Ent. L.J. 349 (2025). Available online: https://ssrn.com/abstract=5001098. [CrossRef]
- Committee on Publication Ethics (COPE) Council. Ethics Toolkit for a Successful Editorial Office: A COPE Guide. Version 3: July 2025 2025. [CrossRef]
- Committee on Publication Ethics (COPE). COPE discussion document: Artificial intelligence (AI) in decision making 2021. [CrossRef]
- Curtis, N. To ChatGPT or not to ChatGPT? The impact of artificial intelligence on academic publishing. The Pediatric infectious disease journal 2023, 42(4), 275. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W. Open Sourcing BERT: State-of-the-Art Pre-training for Natural Language Processing. 2018. Available online: https://research.google/blog/open-sourcing-bert-state-of-the-art-pre-training-for-natural-language-processing/.
- Ganjavi, C.; Eppler, M. B.; Pekcan, A.; Biedermann, B.; Abreu, A.; Collins, G. S.; Cacciamani, G. E. Publishers’ and journals’ instructions to authors on use of generative artificial intelligence in academic and scientific publishing: bibliometric analysis. BMJ 2024, 384, e077192. [Google Scholar] [CrossRef]
- Geng, M.; Trotta, R. Human-LLM Coevolution: Evidence from Academic Writing. arXiv. 2025. Available online: https://arxiv.org/abs/2502.09606.
- George, E. O. Introducing Paperpal Copilot: Prime Members Get Early Access to Generative AI for Academic Writing. 2023. Available online: https://paperpal.com/blog/news-updates/product-updates/introducing-paperpal-copilot-generative-ai-for-prime-members.
- Google. Introducing Gemini, your new personal AI assistant. 2023. Available online: https://gemini.google/assistant/?hl=en-GB.
- Grammarly. Introducing Grammarly for Windows and Mac. 2021. Available online: https://www.grammarly.com/blog/product/introducing-grammarly-for-mac-windows/.
- Guo, X.; Dong, L.; Hao, D. RETRACTED: Cellular functions of spermatogonial stem cells in relation to JAK/STAT signaling pathway. Frontiers in Cell and Developmental Biology 2024, 11, 1339390. [Google Scholar] [CrossRef]
- Harper, T. A. What Happens When People Don’t Understand How AI Works. The Atlantic. 2025. Available online: https://www.theatlantic.com/culture/archive/2025/06/artificial-intelligence-illiteracy/683021/.
- Hartini, R.; Valentino, C. R. Innovation and Copyright Clash: NYT Versus OpenAI and Microsoft in Court. In International Conference on Law Reform (5th Inclar 2024); Atlantis Press, February 2025; pp. 121–126. [Google Scholar] [CrossRef]
- Hutson, M. Robo-writers: the rise and risks of language-generating AI. Nature 2021, 591, 22–25. [Google Scholar] [CrossRef]
- Hutson, M. How does ChatGPT ‘think’? Psychology and neuroscience crack open AI large language models. Nature 2024, 629, 986–988. [Google Scholar] [CrossRef] [PubMed]
- Inala, J. P.; Wang, C.; Drucker, S.; Ramos, G.; Dibia, V.; Riche, N.; Brown, D.; Marshall, D.; Gao, J. Data Analysis in the Era of Generative AI. arXiv 2024, arXiv:2409.18475. [Google Scholar] [CrossRef]
- International Association of Scientific; Technical; Medical Publishers (STM). Generative AI in scholarly communications. Ethical and Practical Guidelines for the Use of Generative AI in the Publication Process. 2023. Available online: https://s3.eu-west-2.amazonaws.com/stm.offloadmedia/wp-content/uploads/2024/08/10031822/STM-GENERATIVE-AI-PAPER-2023-1.pdf.
- International Committee of Medical Journal Editors (ICMJE). Recommendations for the Conduct, Reporting, Editing, and Publication of Scholarly Work in Medical Journals. 2025. Available online: https://www.icmje.org/icmje-recommendations.pdf.
- Jiang, A. Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D. S.; de las Casas, D.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; Lavaud, L.R.; Lachaux, M-A.; Stock, P.; Scao, T.L.; Lavril, T.; Wang, T.; Lacroix, T.; El Sayed, W. Mistral 7B. 2023. Available online: https://arxiv.org/abs/2310.06825.
- Karamolegkou, A.; Li, J.; Zhou, L.; Søgaard, A. Copyright violations and large language models. arXiv 2023, arXiv:2310.13771. [Google Scholar] [CrossRef]
- Katsnelson, A. Poor English skills? New AIs help researchers to write better. Nature 2022, 609(7925), 208–209. [Google Scholar] [CrossRef]
- Ke, Q.; Ferrara, E.; Radicchi, F.; Flammini, A. Defining and identifying Sleeping Beauties in science. Proceedings of the National Academy of Sciences 2015, 112(24), 7426–7431. [Google Scholar] [CrossRef]
- King, M. R.; ChatGPT. A conversation on artificial intelligence, chatbots, and plagiarism in higher education. Cellular and molecular bioengineering 2023, 16(1), 1–2. [Google Scholar] [CrossRef]
- Kobak, D.; González-Márquez, R.; Horvát, E. Á.; Lause, J. Delving into LLM-assisted writing in biomedical publications through excess vocabulary. Science Advances 2025, 11(27), eadt3813. [Google Scholar] [CrossRef]
- Kumar, A.; Devi, M. L.; Saltz, J. S. GenAI Tools to Improve Data Science Project Outcomes. In 2024 IEEE International Conference on Big Data (BigData); IEEE, December 2024; pp. 3143–3152. [Google Scholar] [CrossRef]
- Meta. Introducing Llama 3.1: Our most capable models to date. 2024. Available online: https://ai.meta.com/blog/meta-llama-3-1/.
- Microsoft. Introducing Copilot for Microsoft 365—A whole new way to work. 2023. Available online: https://www.microsoft.com/en-us/microsoft-365/blog/2023/03/16/introducing-microsoft-365-copilot-a-whole-new-way-to-work/.
- Murray, M. D. Tools do not create: human authorship in the use of generative artificial intelligence. Case W. Res. JL Tech. & Internet 2024, 15, 76. Available online: https://scholarlycommons.law.case.edu/jolti/vol15/iss1/3.
- OpenAI. Introducing ChatGPT. 2022. Available online: https://openai.com/index/chatgpt/.
- OpenAI. Sycophancy in GTP-4o: what happened and what we’re doing about it. 2025. Available online: https://openai.com/index/sycophancy-in-gpt-4o/.
- Opus, C.; Lawsen, A. The illusion of the illusion of thinking: A comment on Shojaee et al. (2025). arXiv 2025, arXiv:2506.09250v1. [Google Scholar]
- Pearlman, R. Recognizing Artificial Intelligence (AI) as Authors and Inventors Under U.S. Intellectual Property Law, 24 RICH. J. L. & TECH. no. 2, 2018. 2018. Available online: http://jolt.richmond.edu/files/2018/04/Pearlman_Recognizing-Artificial-Intelligence-AI-as-Authors-and-Inventors-Under-U.S.-Intellectual-Property-Law.pdf.
- Pekşen, A; ChatGPT. Using ChatGPT in the Medical Field: A Narrative. Infect Dis Clin Microbiol. 2023, 5(1), 66–8. [Google Scholar] [CrossRef] [PubMed Central]
- Perplexity Team. Introducing Perplexity Deep Research. 2025. Available online: https://www.perplexity.ai/hub/blog/introducing-perplexity-deep-research.
- PLOS One. Ethical Publishing Practice. 2025. Available online: https://journals.plos.org/plosone/s/ethical-publishing-practice#loc-artif.
- Salazar, A.; Kunc, M. The contribution of GenAI to business analytics. Journal of Business Analytics 2025, 8(2), 1–14. [Google Scholar] [CrossRef]
- Science. Science Journals: Editorial Policies. 2025. Available online: https://www.science.org/content/page/science-journals-editorial-policies#image-and-text-integrity.
- Shojaee, P.; Mirzadeh, I.; Alizadeh, K. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity. arXiv;& Machine Learning Research at Apple. 2025. Available online: https://machinelearning.apple.com/research/illusion-of-thinking.
- Shumailov, I.; Shumaylov, Z.; Zhao, Y.; Papernot, N.; Anderson, R.; Gal, Y. AI models collapse when trained on recursively generated data. Nature 2024, 631(8022), 755–759. [Google Scholar] [CrossRef]
- Nature, Springer. Editorial policies. 2025. Available online: https://www.springernature.com/gp/policies/editorial-policies.
- Stokel-Walker, C. ChatGPT listed as author on research papers: many scientists disapprove. Nature 2023, 613(7945), 620–621. [Google Scholar] [CrossRef]
- Suchak, T.; Aliu, A. E.; Harrison, C.; Zwiggelaar, R.; Geifman, N.; Spick, M. Explosion of formulaic research articles, including inappropriate study designs and false discoveries, based on the NHANES US national health database. PLoS biology 2025, 23(5), e3003152. [Google Scholar] [CrossRef]
- Thorp, H. H. ChatGPT is fun, but not an author. Science 2023, 379(6630), 313–313. [Google Scholar] [CrossRef]
- Transformer, G. G. P.; Thunström, A. O.; Steingrimsson, S. Can GPT-3 write an academic paper on itself, with minimal human input? 2022. Available online: https://hal.science/hal-03701250.
- van Zeeland, H. The new Writefull is here! 2019. Available online: https://blog.writefull.com/the-new-writefull-is-here/.
- xAI. Announcing Grok-1.5. 2024. Available online: https://x.ai/news/grok-1.5.
- Zielinski, C.; Winker, M. A.; Aggarwal, R.; Ferris, L. E.; Heinemann, M.; Lapena, J. F., Jr.; Pai, S. A.; Ing, E.; Citrome, L.; Alam, M.; Voight, M.; Habibzadeh, F., on behalf of the World Association of Medical Editors (WAME) Board. Chatbots, Generative AI, and Scholarly Manuscripts; on behalf of the World Association of Medical Editors (WAME) Board; WAME Recommendations on Chatbots and Generative Artificial Intelligence in Relation to Scholarly Publications, 2023; Available online: https://wame.org/page3.php?id=106.
Figure 1.
Study design, inclusion criteria, bibliographic search results, and excluded articles. Left panel Scopus database search, and right panel HeinOnline database search (portfolio results in purple). Scopus search approach includes a direct bibliographic search (portfolio results in green) and backward reference search (portfolio results in orange).
Figure 1.
Study design, inclusion criteria, bibliographic search results, and excluded articles. Left panel Scopus database search, and right panel HeinOnline database search (portfolio results in purple). Scopus search approach includes a direct bibliographic search (portfolio results in green) and backward reference search (portfolio results in orange).
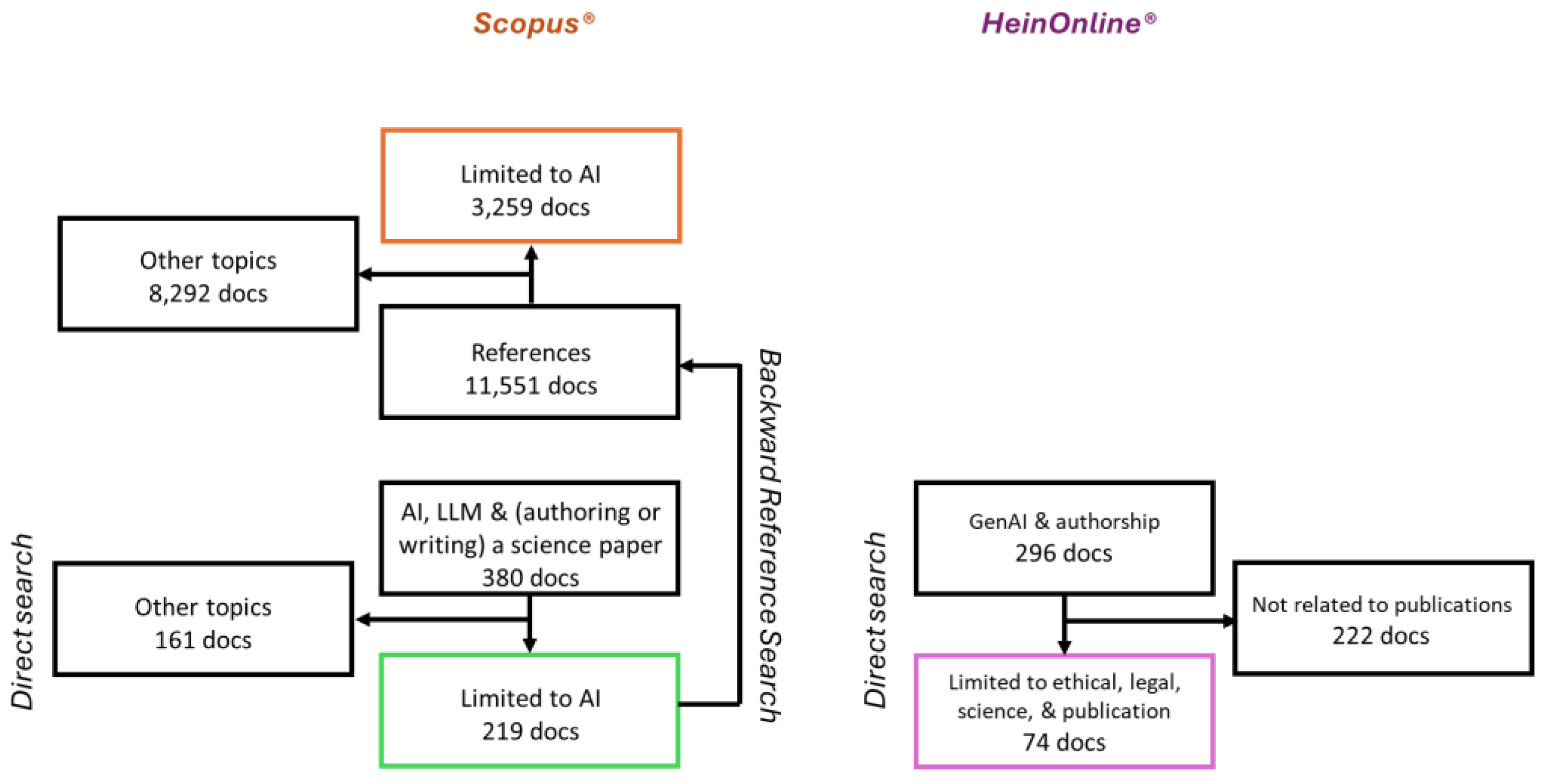
Figure 2.
Analysis of results from the Scopus database direct search. (A) Documents represented by bars and citations are shown as a line. (B) Documents categorized by country or territory. (C) Documents categorized by type. (D) Documents categorized by subject area.
Figure 2.
Analysis of results from the Scopus database direct search. (A) Documents represented by bars and citations are shown as a line. (B) Documents categorized by country or territory. (C) Documents categorized by type. (D) Documents categorized by subject area.
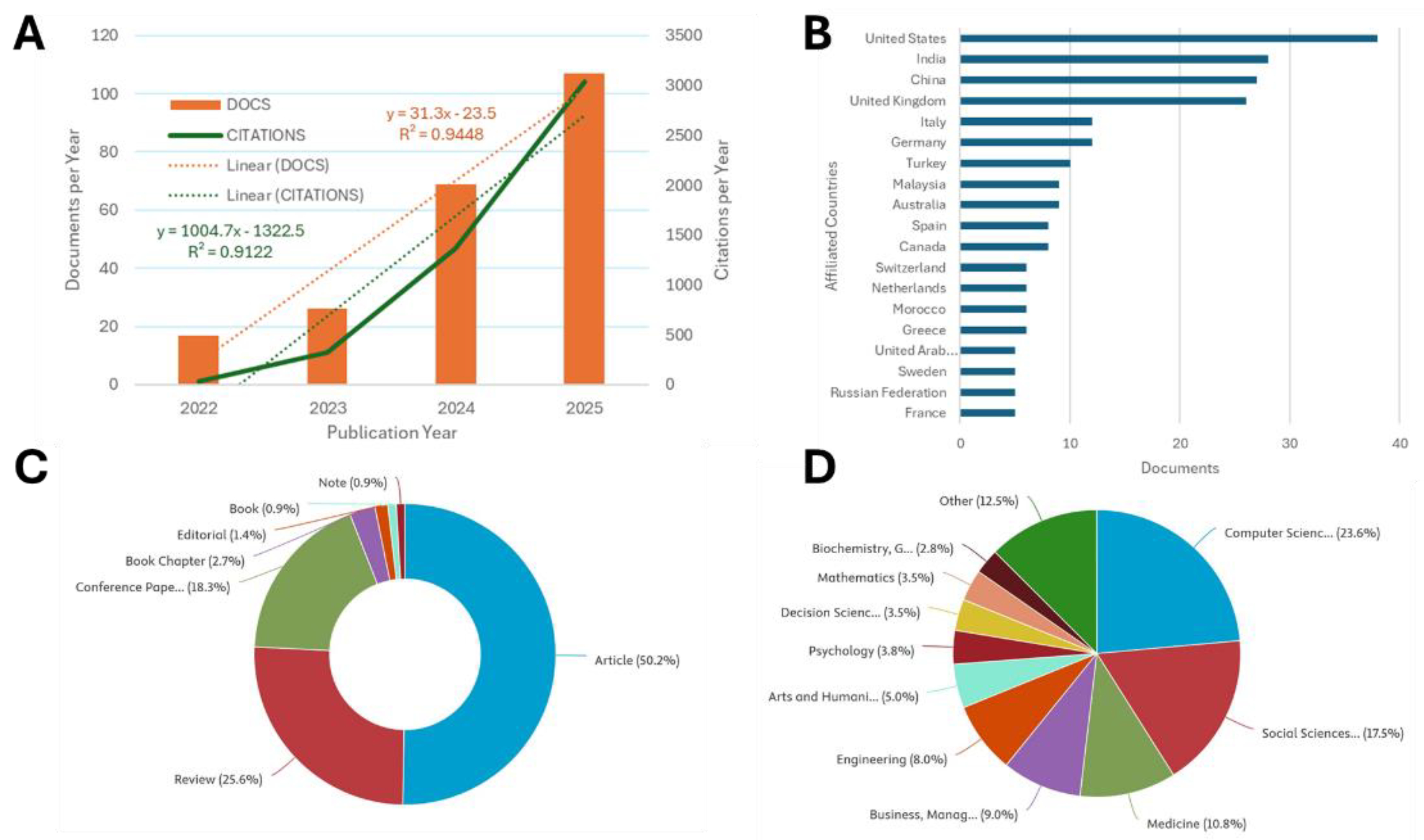
Figure 3.
Analysis of index keywords from bibliographic data obtained through a direct search on Scopus for related publications between 2022 and 2025, using VOSviewer. (A) Network of index keywords grouped into association clusters based on co-occurrence in scientific papers within the bibliographic collection (co-occurrence counts ranging from 3 to 10). The association strength served as the normalization method. Six clusters of keywords were identified, each comprising 8 to 16 different items. (B) The same network of keywords is overlaid with color coding, indicating the average publication year of papers that include each term. Keywords with an average publication year in the first half of 2025 are shown in yellow, those with an average of 2024 in green, and those with an average of 2023 in blue.
Figure 3.
Analysis of index keywords from bibliographic data obtained through a direct search on Scopus for related publications between 2022 and 2025, using VOSviewer. (A) Network of index keywords grouped into association clusters based on co-occurrence in scientific papers within the bibliographic collection (co-occurrence counts ranging from 3 to 10). The association strength served as the normalization method. Six clusters of keywords were identified, each comprising 8 to 16 different items. (B) The same network of keywords is overlaid with color coding, indicating the average publication year of papers that include each term. Keywords with an average publication year in the first half of 2025 are shown in yellow, those with an average of 2024 in green, and those with an average of 2023 in blue.
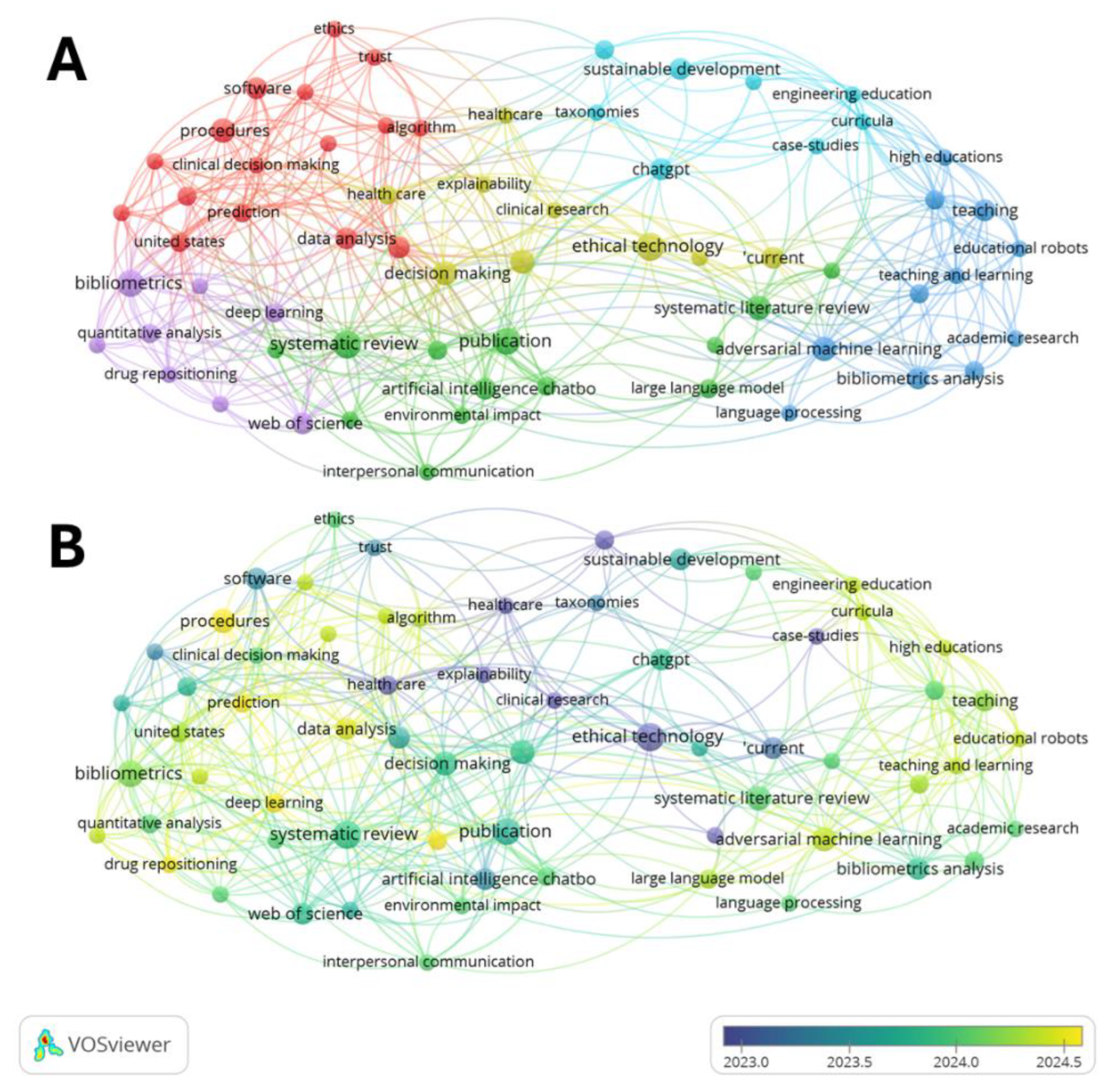
Figure 4.
Analysis of results from the Scopus database direct search. (A) Documents represented by bars and citations are shown as a line. (B) Documents categorized by country or territory. (C) Documents categorized by type. (D) Documents categorized by subject area.
Figure 4.
Analysis of results from the Scopus database direct search. (A) Documents represented by bars and citations are shown as a line. (B) Documents categorized by country or territory. (C) Documents categorized by type. (D) Documents categorized by subject area.
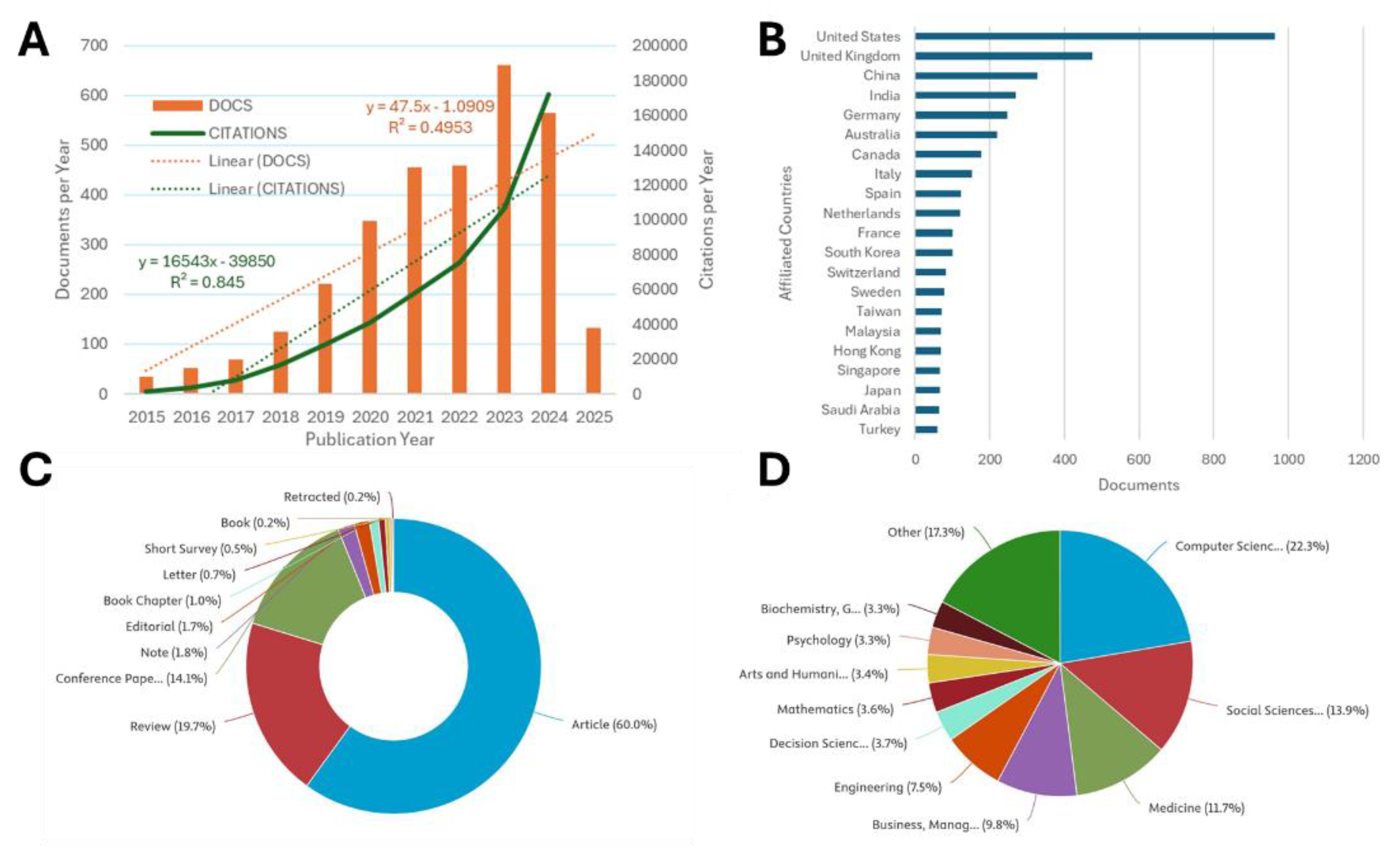
Figure 5.
Analysis of backward reference search publications related to artificial intelligence based on direct search results published from 2022 to 2025. (A) Referenced publications per year. A linear increase in publications, particularly in GenAI, is evident between 2017 and 2021. (B) Citations received by references per year. There are notable fluctuations in scientific interest each year. Papers published in 2015 seem to have a greater influence on recent GenAI reports. A period of stagnant interest occurs between 2017 and 2022. The fluctuations in citation behavior during this period may reflect heterogeneity in research topics before the emergence of advanced GenAI models. (C) Cumulative citations over time. A steady increase in citations per year from 2015 to 2023 is observed. This trend indicates a consistent rise in interest in artificial intelligence-related reports over the past decade. The differences between the annual citation count and the cumulative citations suggest that thematic shifts attract interest as research topics evolve in a dynamic, open environment, thereby encouraging the exploration of multiple technological approaches.
Figure 5.
Analysis of backward reference search publications related to artificial intelligence based on direct search results published from 2022 to 2025. (A) Referenced publications per year. A linear increase in publications, particularly in GenAI, is evident between 2017 and 2021. (B) Citations received by references per year. There are notable fluctuations in scientific interest each year. Papers published in 2015 seem to have a greater influence on recent GenAI reports. A period of stagnant interest occurs between 2017 and 2022. The fluctuations in citation behavior during this period may reflect heterogeneity in research topics before the emergence of advanced GenAI models. (C) Cumulative citations over time. A steady increase in citations per year from 2015 to 2023 is observed. This trend indicates a consistent rise in interest in artificial intelligence-related reports over the past decade. The differences between the annual citation count and the cumulative citations suggest that thematic shifts attract interest as research topics evolve in a dynamic, open environment, thereby encouraging the exploration of multiple technological approaches.
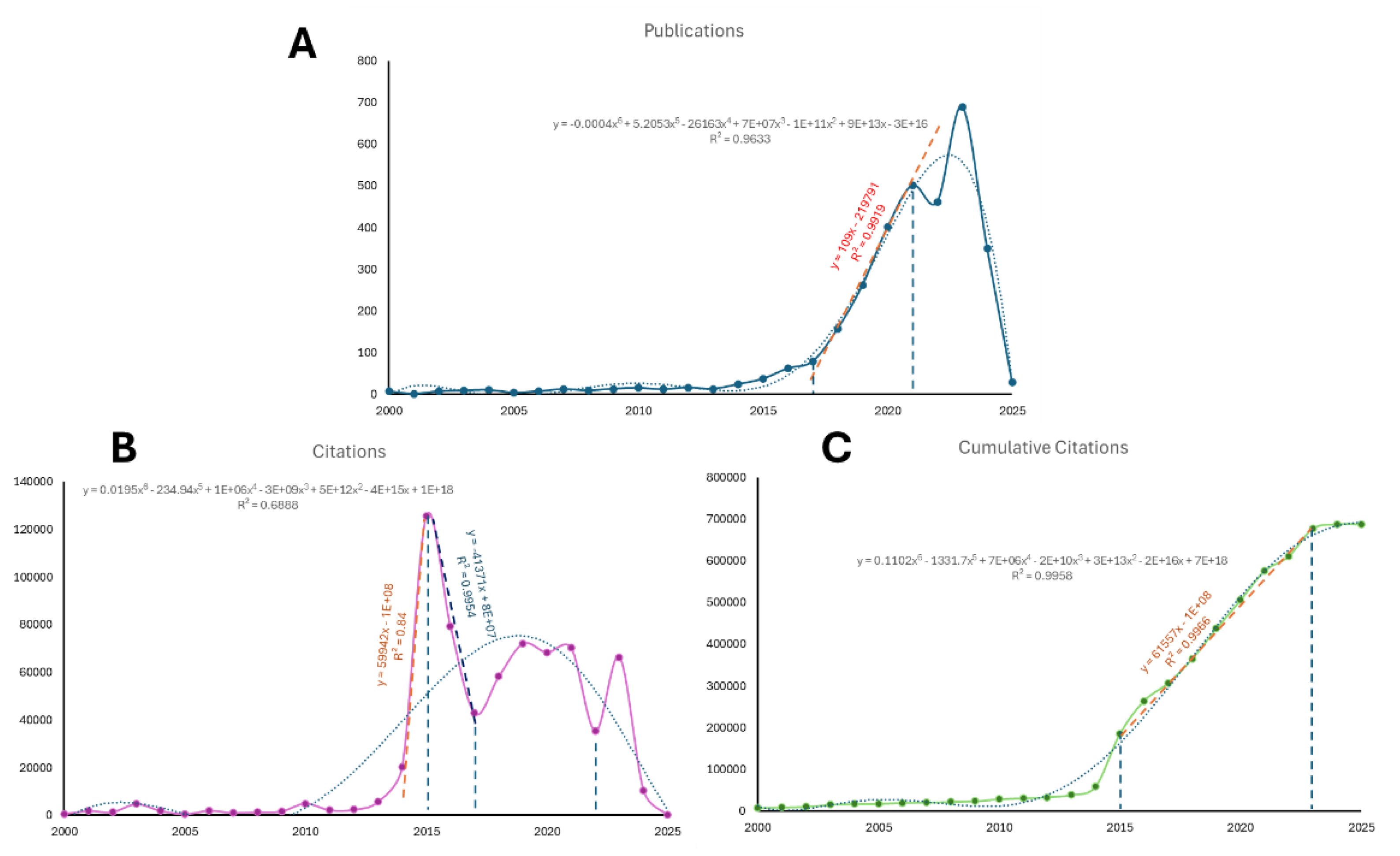
Figure 6.
The 18 cases of awakening among 3,259 AI-related backward-search-retrieved documents are displayed, with publication year, title, and citations-per-year sparklines. The orange boxes indicate the five years from 2021 to 2025.
Figure 6.
The 18 cases of awakening among 3,259 AI-related backward-search-retrieved documents are displayed, with publication year, title, and citations-per-year sparklines. The orange boxes indicate the five years from 2021 to 2025.
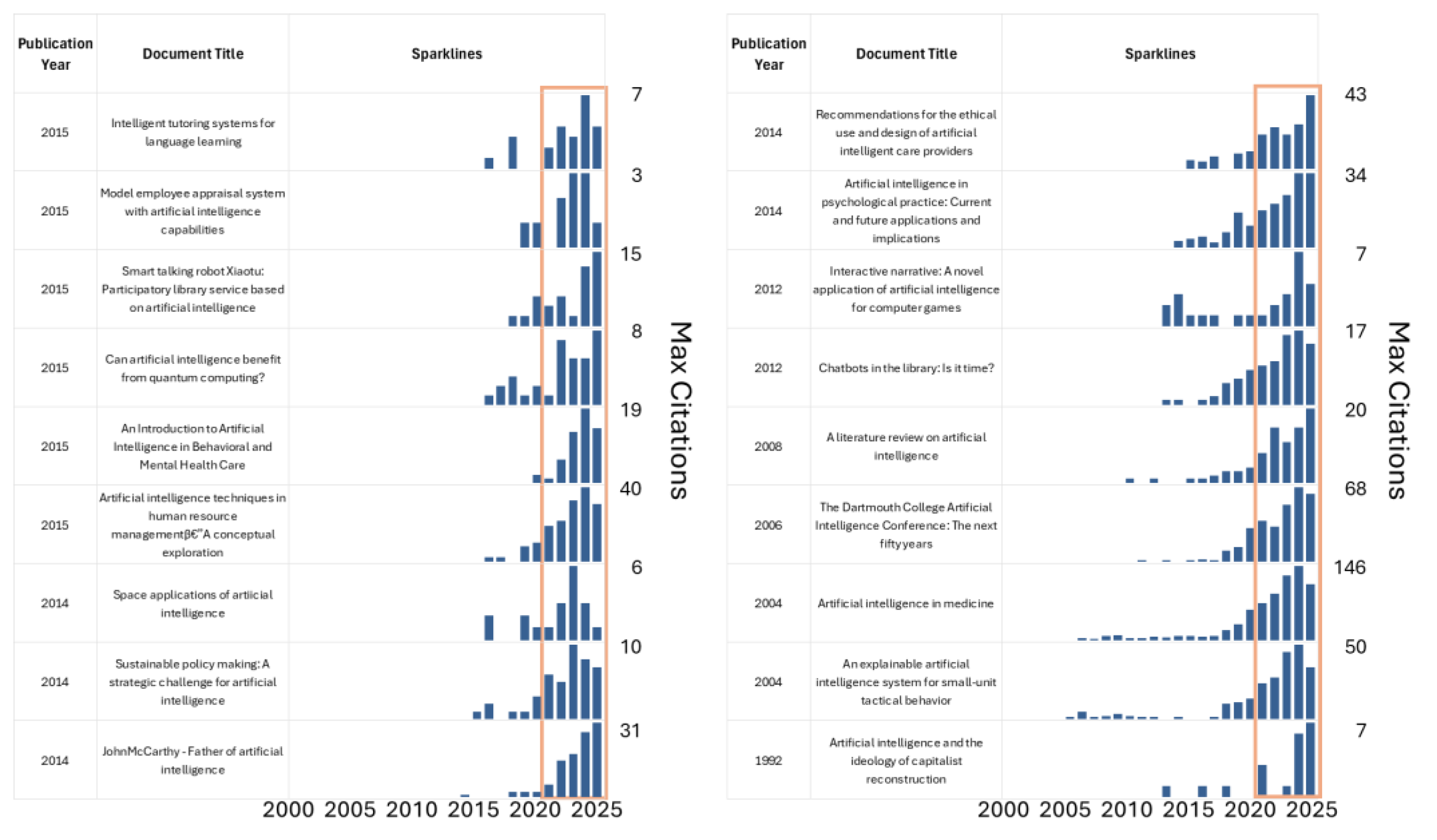
Figure 7.
Analysis of index keywords from the backward reference search results using VOSviewer. (A) A network of index keywords organized into association groups based on co-occurrence in scientific papers of the bibliographic portfolio (co-occurrence counts range from 10 to 140). The association strength method was used for normalization. Four keyword clusters were identified, each containing 95 to 243 different items. (B) The same network of keywords is overlayed with colors indicating the average publication year of the papers mentioning each keyword. Keywords with an average publication year of 2022 are shown in yellow, those from 2020 in green, and those from 2018 in blue.
Figure 7.
Analysis of index keywords from the backward reference search results using VOSviewer. (A) A network of index keywords organized into association groups based on co-occurrence in scientific papers of the bibliographic portfolio (co-occurrence counts range from 10 to 140). The association strength method was used for normalization. Four keyword clusters were identified, each containing 95 to 243 different items. (B) The same network of keywords is overlayed with colors indicating the average publication year of the papers mentioning each keyword. Keywords with an average publication year of 2022 are shown in yellow, those from 2020 in green, and those from 2018 in blue.


Table 1.
Direct Scopus search of Q1 keywords co-occurrences according to average citations of GenAI-related publications.
Table 1.
Direct Scopus search of Q1 keywords co-occurrences according to average citations of GenAI-related publications.
| Keyword A | Keywords B | Avg. Pub. Year1 | Avg. Citations2 |
|---|---|---|---|
| algorithm | clinical research, conceptual framework, data analysis, data quality, diagnosis, ethics, healthcare, natural language processing, philosophical aspects, prediction, publication, publishing, scientific literature, trust | 2024.3 | 29.7 |
| bibliometrics analysis | clinical decision making, clinical effectiveness, contrastive learning, controlled study, convolutional neural network, data analysis, deep learning, diagnostic accuracy, drug repositioning, educational robots, evidence-based practice, health care, language processing, prediction, procedures, quantitative analysis, scientific literature, software, students, systematic review, teaching and learning, United States, Web of Science | 2023.8 | 46.6 |
| chatgpt | curricula, data analysis, data quality, engineering education, environmental impact, ethical technology, higher education, intelligence integration, philosophical aspects, publication, publishing, sustainable development, systematic literature review, taxonomies | 2023.8 | 59.8 |
| curricula | educational robots, engineering education, higher education, intelligence integration, language model, philosophical aspects, students, sustainable development, taxonomies, teaching and learning | 2024.3 | 74.3 |
| engineering education | higher education, intelligence integration, language model, philosophical aspects, students, sustainable development, taxonomies, teaching, and learning | 2024.3 | 74.3 |
| ethics | healthcare, philosophical aspects, prediction, procedures, software, trust | 2024 | 55.7 |
| healthcare | machine-learning, philosophical aspects, scientific literature, software, trust, United States | 2023 | 38 |
| intelligence integration | philosophical aspects, sustainable development, systematic literature review, taxonomies | 2024 | 74.7 |
| literature reviews | systematic literature review | 2023 | 30 |
| philosophical aspects | sustainable development, taxonomies, trust | 2023 | 94.5 |
| software | taxonomies, trust, United States | 2023.4 | 33.4 |
| sustainable development | taxonomies | 2023.6 | 49.6 |
| systematic literature review | taxonomies, teaching and learning, Web of Science | 2024 | 39.7 |
1 Average Publication Year. 2 Average Citations.
Table 2.
Backward reference Scopus search of the top ten keywords with the highest average citations and co-occurrences of GenAI-cited publications.
Table 2.
Backward reference Scopus search of the top ten keywords with the highest average citations and co-occurrences of GenAI-cited publications.
| Keyword A | Keywords B | Avg. Pub. Year1 | Avg. Citations2 |
|---|---|---|---|
| pattern recognition | peer review, personalized medicine, physiology, policy, practice guideline, prediction, principal component analysis, problem solving, process optimization, prognosis, psychotherapy, questionnaire, receiver operating characteristic, recurrent neural network, recurrent neural networks, reinforcement learning, reproducibility, reproducibility of results, scientific literature, sensitivity and specificity, social interaction, software, standards, study design, supervised learning, support vector machine, surveys, task performance, thematic analysis, training, trends, united states, writing | 2015.6 | 6404 |
| computer | computer assisted diagnosis, computer assisted tomography, computer model, computer program, computer software, computers, controlled study, convolutional neural network, coronavirus disease 2019, creativity, data base, data mining, data processing, data set, deep neural networks, diagnosis, computer-assisted, diagnostic test accuracy study, drug design, drug development, drug discovery, e-learning, echography, editorial, education, engineering, ethics, European Union, explainable artificial intelligence, genomics, government, history, image analysis, image interpretation, computer-assisted, image processing, information processing, information science, knowledge, language, language processing, law enforcement, learning, learning algorithm, legislation and jurisprudence, machine-learning, mammography, medical ethics, medical informatics, medical information, meta-analysis, methodology, morality, morals, motivation, network architecture, neural networks (computer), neural-networks, nonhuman, note, nuclear magnetic resonance imaging, organization, pandemic, pattern recognition, pattern recognition, automated, positron emission tomography, practice guideline, principal component analysis, productivity, psychology, radiologist, radiologists, radiology, reliability, reproducibility, research, research work, risk factor, robotics, robots, safety, scientific literature, scientist, software, speech, standards, support vector machine, systematic review, technology, trends, uncertainty, vision | 2015.9 | 5333 |
| data set | decision support system, decision support systems, decision supports, decision theory, decisions makings, detection method, electronic health record, electronic health records, errors, ethics, generative adversarial networks, higher education, image processing, industry 4.0, information analysis, information processing, innovation, intelligent agents, knowledge based systems, knowledge management, language, language processing, learning, learning algorithm, learning models, lung neoplasms, lung tumor, machine-learning, major clinical study, marketing, medical oncology, methodology, model-based opc, monitoring, network architecture, neural networks (computer), nonhuman, numerical model, oncology, overall survival, patient safety, pattern recognition, performance, performance assessment, personalized learning, policy, policy makers, prediction, public sector, real time systems, remote sensing, reproducibility, reproducibility of results, retrospective study, risk assessment, safety, semantics, speech, speech recognition, support vector machine, technology adoption, transparency, trends, United States | 2020.8 | 4188 |
| trends | trust, uncertainty, unclassified drug, United States, unsupervised machine learning, workload | 2017.0 | 4033 |
| data processing | data quality, data science, data set, decision support system, decision support systems, decision supports, diagnostic imaging, disasters, doctor patient relationship, drug design, drug development, drug discovery, drug industry, drug research, drug screening, drug targeting, early cancer diagnosis, education, empathy, engineering, environmental impact, epigenetics, ethics, experimental study, feature extraction, feature selection, food and drug administration, gender, generative adversarial networks, generative artificial intelligence, generative model, genetic algorithm, genetic variability, genomics, government, health care, health care personnel, health care system, histopathology, human computer interaction, image analysis, image processing, industrial research, information processing, interpersonal communication, k nearest neighbor, language, language processing, large language model, learning, learning algorithm, malignant neoplasm, medical education, medical ethics, medical literature, medical research, medicine, mental disease, methodology, misinformation, molecular dynamics, monitoring, morality, natural language processing, natural languages, neural networks (computer), neural networks, computer, neuroimaging, nonhuman, nuclear magnetic resonance imaging, ontology, pandemic, pathology, pattern recognition, peer review, performance, personalized medicine, pharmacogenetics, phenotype, philosophical aspects, physical activity, physical chemistry, physician, policy, policy making, positron emission tomography, practice guideline, prediction, predictive value, productivity, psychiatry, publication, publishing, random forest, real time systems, recurrent neural network, remote sensing, reproducibility, reproducibility of results, research and development, research design, research work, risk assessment, risk factor, robotics, scientific literature, scientist, sensitivity and specificity, simulation, social interaction, social media, software, study design, support vector machine, sustainability, sustainable development, task performance, technological development, technology, technology adoption, training, trends, validation study, virtual reality, writing, x-ray computed tomography | 2018.6 | 3396 |
| neural networks (computer) | nonhuman, note, nuclear magnetic resonance imaging, ophthalmology, optical coherence tomography, pathology, pattern recognition, pattern recognition, automated, personalized medicine, pharmacogenetics, pharmacogenomics, phenotype, physiology, policy, positron emission tomography, practice guideline, precision medicine, prediction, predictive value, privacy, prognosis, protein protein interaction, protein structure, quality control, quantitative analysis, quantitative structure activity relation, questionnaire, radiologist, random forest, randomized controlled trial, receiver operating characteristic, recurrent neural network, recurrent neural networks, regression analysis, reliability, reproducibility, reproducibility of results, research work, responsibility, retrospective studies, retrospective study, risk factor, robotics, scientist, scoring system, semantics, sensitivity and specificity, simulation, single nucleotide polymorphism, software, standards, supervised learning, supervised machine learning, support vector machine, support vector machines, surveys and questionnaires, synthesis, task performance, thorax radiography, tomography, optical coherence, training, treatment outcome, treatment response, trends, uncertainty, unsupervised machine learning, validation process, validation study, vision, workload, young adult | 2015.2 | 3253 |
| classifier | clinical assessment, clinical decision making, clinical decision support system, clinical effectiveness, clinical feature, clinical practice, clinical research, cohort analysis, computer, computer assisted diagnosis, computer assisted tomography, computer language, computer simulation, computers, controlled study, convolutional neural network, convolutional neural networks, coronavirus disease 2019, cost effectiveness analysis, cross-sectional study, data base, data extraction, data integration, data mining, data processing, data set, decision support system, decision support systems, decision support systems, clinical, decision tree, depression, diagnosis, diagnostic accuracy, diagnostic imaging, diagnostic test accuracy study, disease severity, diseases, drug response, early cancer diagnosis, early diagnosis, echography, electronic health record, evaluation study, expert systems, extraction, false positive result, feasibility study, feature extraction, feature selection, gene expression, genetic algorithm, genetic variability, genetics, health care, histopathology, human experiment, hypertension, image analysis, image processing, image segmentation, information processing, k nearest neighbor, language, language processing, learning, learning algorithm, learning algorithms, logistic regression analysis, lung cancer, lung neoplasms, lung tumor, macular degeneration, major clinical study, mammography, measurement accuracy, medical decision making, medical record, medical research, medline, mental disease, mental health, meta-analysis, middle aged, natural language processing, nerve cell network, neural networks (computer), nonhuman, nuclear magnetic resonance imaging, obesity, ophthalmology, optical coherence tomography, outcome assessment, pandemic, pandemics, patient care, pattern recognition, personalized medicine, pharmacogenetics, pharmacogenomics, physical chemistry, positron emission tomography, practice guideline, precision medicine, prediction, predictive model, predictive value, prognosis, psychiatry, psychotherapy, public health, qualitative analysis, quality of life, quantitative analysis, radiologist, radiomics, random forest, randomized controlled trial (topic), receiver operating characteristic, reliability, retrospective study, risk assessment, risk factor, scoring system, sensitivity and specificity, single nucleotide polymorphism, social interaction, social media, software, speech, supervised machine learning, support vector machine, support vector machines, systematic review, thorax radiography, training, treatment outcome, treatment planning, treatment response, trends, united states, unsupervised machine learning, validation process, validation study, validity, wet macular degeneration, workflow, writing, young adult | 2021.0 | 3220 |
| machine learning methods | machine learning models, machine learning techniques, machine-learning, macular degeneration, major clinical study, manufacture, middle aged, monitoring, neural networks, ophthalmology, pathology, performance, prediction, predictive analytics, random forest, sars-cov-2, state of the art, students, supervised learning, supervised machine learning, support vector machines, surveys, systematic literature review, thorax radiography, very elderly, vision, x-ray computed tomography | 2018.1 | 3144 |
| game theory | human computer interaction, investments, knowledge representation, laws and legislation, learning, learning algorithm, learning algorithms, life cycle, machine design, machine-learning, modeling, neural networks, neural networks (computer), nonhuman, performance assessment, personnel training, physiology, problem solving, real time systems, reinforcement learning, research communities, sensitivity analysis, simulation, software, software engineering, sustainability, sustainable development | 2013.4 | 2620 |
| language processing | large language model, learn+, learning, learning algorithm, learning algorithms, letter, linguistics, literature reviews, machine-learning, medical information, medical record, middle aged, models, theoretical, natural language processing, natural language processing systems, natural languages, neural networks (computer), nonhuman, nuclear magnetic resonance imaging, pathology, patient care, patient monitoring, patient safety, patient satisfaction, pattern recognition, performance, personalized medicine, publication, publishing, quality control, questionnaire, reproducibility, reproducibility of results, research work, risk assessment, scientific literature, scientist, semantics, sentiment analysis, skill, social media, software, speech recognition, standardization, state of the art, students, supervised learning, systematic literature review, systematic review, trends, validation study, virtual reality, workflow, writing | 2021.7 | 2499 |
1 Average Publication Year. 2 Average Citations.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



