
Submitted:
17 December 2025
Posted:
17 December 2025
You are already at the latest version
Abstract
Connected and autonomous vehicle (CAV) platoons face the dual challenge of maintaining longitudinal formation stability while ensuring lateral safety in dynamic traffic environments, yet existing control approaches often address these objectives in isolation. This paper proposes a hierarchical cooperative control framework that integrates a differential game-based longitudinal controller with a risk potential field-driven model predictive controller (MPC) for lateral motion. At the coordination control layer, a differential game formulation models inter-vehicle interactions, with analytical solutions derived for both open-loop Nash equilibrium under predecessor-following (PF) topology and an estimated Nash equilibrium under two-predecessor-following (TPF) topology. The motion control layer employs a risk potential field model that quantifies collision threats from surrounding obstacles and road boundaries, guiding the MPC to perform real-time trajectory optimization. A comprehensive co-simulation platform integrating MATLAB/Simulink, Prescan, and CarSim validates the proposed framework across three representative scenarios: ramp merging with aggressive cut-in maneuvers, emergency braking by a preceding obstacle vehicle, and multi-lane cooperative obstacle avoidance involving multiple dynamic obstacles. Across all scenarios, the CAV platoon achieves safe obstacle avoidance through autonomous decision-making, with spacing errors converging to zero and smooth velocity adjustments that ensure both formation stability and ride comfort. The results demonstrate that the proposed framework effectively adapts to diverse and complex traffic conditions.
Keywords:
connected and autonomous vehicles
; cooperative platoon control
; differential game theory
; risk potential field
; model predictive control
; Nash equilibrium
1. Introduction
The rapid urbanization and sustained growth in travel demand have placed unprecedented strain on transportation infrastructure worldwide, manifesting as chronic congestion, elevated accident rates, and substantial energy inefficiency [1,2,3]. In response to these persistent challenges, connected and autonomous vehicle (CAV) technology has emerged as a transformative paradigm within the intelligent transportation system (ITS) domain, offering promising pathways toward safer, more efficient, and environmentally sustainable mobility solutions [4,5,6]. Among the various applications enabled by CAV technology, cooperative vehicle platooning has garnered considerable research attention due to its potential to simultaneously address multiple transportation objectives. Unlike single-vehicle automation, platoon-based operation coordinates multiple CAVs traveling in close formation along a shared trajectory, leveraging vehicle-to-vehicle (V2V) communication to maintain tight inter-vehicle spacing while ensuring collective stability [7]. This operational mode has demonstrated particular viability in specialized transportation contexts characterized by well-defined operational design domains, including freight corridors, port logistics, mining operations, and dedicated truck lanes on highways [8].
The fundamental premise of platooning control lies in synchronizing follower vehicles with the motion profile of the leading vehicle while preserving compact spacing to maximize roadway throughput and minimize aerodynamic drag losses. Nevertheless, the pursuit of reduced inter-vehicle gaps inherently amplifies collision risks, demanding sophisticated control architectures capable of ensuring string stability—the attenuation of disturbances as they propagate rearward through the formation [9]. Furthermore, practical deployment of CAV platoons remains constrained by uncertainties arising from perception limitations, communication impairments, and the inherent complexity of coordinating multiple dynamically coupled agents within unpredictable traffic environments [10].
To address these challenges, cooperative control of CAV platoons has been extensively investigated, aiming to achieve system-level objectives through the establishment of coordination mechanisms among vehicles. Such objectives encompass optimizing platoon operations, alleviating traffic congestion, and enhancing road safety. The fundamental aspects of platoon cooperative control primarily involve three dimensions: maintaining appropriate inter-vehicle spacing, ensuring velocity consensus among platoon members, and implementing collision avoidance mechanisms. Additionally, energy efficiency optimization and the preservation of string stability are frequently incorporated into the cooperative control framework [11].
Proportional-integral-derivative (PID) control represents one of the most prevalent approaches for implementing cooperative adaptive cruise control (CACC), owing to its algorithmic simplicity, ease of implementation, and straightforward parameter tuning. Wang et al. proposed a CACC strategy integrating optimized information flow topology with adaptive PD control, wherein the communication topology is dynamically adjusted based on prevailing traffic conditions and platoon size to maximize string stability, while the adaptive controller continuously modifies car-following behavior in response to communication degradation. This approach substantially enhances platoon stability under unreliable V2V communication environments [12]. Wang et al. developed an automated car-following model incorporating real-time driving states and introduced a hybrid control strategy combining multi-step prediction with memory mechanisms alongside conventional PID control, demonstrating superior bifurcation suppression capabilities [13]. Mo et al. presented a hierarchical car-following control architecture that integrates an improved variable time headway model with interval type-2 fuzzy logic control and feedforward-fuzzy PI feedback control, effectively emulating human driver behavior while achieving enhanced tracking accuracy for desired acceleration profiles [14].
Optimal control constitutes another effective paradigm for CAV platoon coordination. The design of optimal controllers for platoon systems is typically formulated as convex optimization problems targeting the minimization of energy consumption or travel time. Such methodologies can effectively accommodate nonlinear factors including vehicle dynamics and aerodynamic interactions while satisfying operational constraints. Turri et al. proposed a bi-level control architecture for heavy-duty vehicle platoons, wherein the upper level employs dynamic programming with road topography preview to compute fuel-optimal velocity trajectories, while the lower level utilizes distributed model predictive control (DMPC) for real-time vehicle control, achieving approximately fuel savings for following vehicles [15]. Wang et al. addressed safety control in heterogeneous platoons by combining Gaussian process-based uncertainty estimation with MPC for inter-vehicle spacing regulation, significantly improving platoon safety under emergency braking scenarios [16]. Qian et al. developed a real-time eco-driving strategy for mixed platoons that accounts for human driving errors through Markov chain modeling, formulating speed trajectory optimization as an optimal control problem to minimize fleet-wide fuel consumption [17]. Yang et al. introduced a CACC algorithm based on MPC with an enhanced constant time headway policy that incorporates leader vehicle states and minimum safe following distances, transforming platoon optimization into a constrained quadratic programming problem that ensures string stability while enabling efficient adaptation to cut-in and cut-out maneuvers [18].
Reinforcement learning (RL) has emerged as a data-driven alternative for platoon cooperative control that circumvents the need for precise system dynamics models. Li et al. proposed an RL-based platoon control method employing deep deterministic policy gradient (DDPG) with prioritized experience replay, achieving accelerated training convergence and smoother vehicle control [19]. Min et al. developed a deep reinforcement learning (DRL) strategy for longitudinal platoon control that leverages the actor-critic architecture combined with deep Q-network principles to address continuous state-action space control problems [20]. Chen et al. integrated RL algorithms with ACC models through a guided-policy DDPG approach to overcome slow convergence issues [21]. Song et al. presented a hybrid car-following control strategy that fuses RL for multi-objective optimization with supervised learning for human-like driving characteristics, achieving high-performance control while accommodating individual driver preferences [22]. Yue et al. proposed a hybrid longitudinal control strategy integrating linear feedback with DRL controllers, ensuring local stability, string stability in the frequency domain, and disturbance rejection in the time domain, with superior performance in training convergence, ride comfort, and traffic oscillation suppression [23]. Shi et al. developed a DRL-based CAV longitudinal coordination strategy that decomposes the platoon into subsystems comprising human-driven vehicles and their following CAVs, optimizing local performance to achieve overall enhancement of heterogeneous platoon operations [24].
Despite the substantial progress achieved in CAV platoon control, several critical limitations persist in the existing literature that warrant further investigation. First, the majority of prior studies have predominantly concentrated on longitudinal coordination, emphasizing internal formation stability and velocity consensus while affording comparatively limited attention to the synergistic integration of lateral motion control. Second, although data-driven methodologies such as RL have demonstrated promising capabilities in handling environmental uncertainty and system complexity, existing approaches frequently neglect the systematic quantification and characterization of risk factors within the operational environment. The absence of explicit risk representation renders these control strategies reactive rather than anticipatory, limiting their capacity to proactively identify and circumvent high-risk states before critical situations materialize. Third, while game-theoretic formulations have been applied to model inter-vehicle interactions, the analytical treatment of differential games for platoon control under complex communication topologies remains underexplored, particularly regarding the derivation of closed-form equilibrium solutions that facilitate real-time implementation.
To address these deficiencies, this paper proposes a hierarchical cooperative control framework that achieves unified coordination of longitudinal formation maintenance and lateral obstacle avoidance for CAV platoons. The principal contributions of this work are summarized as follows: (1) A differential game-based longitudinal coordination controller is developed, with analytical solutions derived for both open-loop Nash equilibrium under predecessor-following (PF) topology and an estimated Nash equilibrium under two-predecessor-following (TPF) topology. The TPF-based formulation enhances platoon string stability by leveraging information from multiple preceding vehicles, effectively mitigating disturbance propagation throughout the formation. (2) A risk potential field model is formulated to provide continuous and differentiable quantification of collision threats emanating from surrounding obstacles and road boundaries. By integrating this risk representation into a model predictive control (MPC) framework, the proposed approach enables proactive trajectory optimization that guides vehicles toward minimum-risk regions while satisfying dynamic and kinematic constraints. (3) A comprehensive co-simulation platform integrating MATLAB/Simulink, Prescan, and CarSim is established to validate the proposed framework across diverse traffic scenarios, including ramp merging with aggressive cut-in maneuvers, emergency braking by preceding obstacles, and multi-lane cooperative obstacle avoidance involving multiple dynamic obstacles. The experimental results demonstrate the framework’s adaptability and effectiveness in ensuring platoon safety, stability, and ride comfort under complex traffic conditions.
2. Hierarchical Cooperative Control Framework
The control of CAV platoons necessitates the simultaneous consideration of longitudinal formation stability and lateral obstacle avoidance, thereby achieving multi-objective coordinated control. To this end, a cooperative control framework integrating a differential game controller with a risk potential field-driven MPC is proposed, as illustrated in Figure 1. The framework comprises two hierarchical layers: the coordination control layer and the motion control layer. The coordination control layer is primarily responsible for collecting state data from individual vehicles within the platoon and constructing a longitudinal coordination controller based on differential game theory. Supported by V2V communication modules, this layer enables real-time acquisition of vehicle state information and obstacle vehicle data. By formulating dynamic game-theoretic models among vehicles and solving for optimal equilibrium strategies, coordinated longitudinal velocity and steady-state formation control of the entire platoon are achieved. The motion control layer, in contrast, focuses on safe planning and control of lateral vehicle motion. Its core functionality lies in quantifying potential risks from surrounding obstacles and complex road conditions through risk potential field models, thereby guiding the MPC to perform rolling horizon optimization for lateral trajectory tracking control. In obstacle-free environments, the system primarily relies on differential game strategies to maintain formation stability, whereas in the presence of obstacle interference, the risk potential field model dynamically assesses risks and guides vehicles through MPC-based safe obstacle avoidance maneuvers, thus achieving balanced regulation of longitudinal coordination and lateral safety.
The control workflow of the platoon system operates as follows: each vehicle uploads its state information through the V2V communication module while concurrently receiving critical data from the lead vehicle and its immediate predecessor. The coordination control layer employs the differential game controller to determine the longitudinal reference motion states for individual vehicles based on the holistic system state, and subsequently disseminates the computational outcomes to all platoon members. The motion control layer, drawing upon feedback data, prevailing road conditions, and obstacle information, leverages risk potential field-driven MPC to optimize and coordinate the lateral motion of vehicles. This layer formulates and issues specific control commands, thereby ensuring that vehicles accomplish efficient and safe obstacle avoidance while preserving formation stability.
3. Differential Game-Based Longitudinal Controller
3.1. CAV Communication Topology
In the early development of CAV platoons, predecessor-following (PF) and bidirectional (BD) communication topologies were predominantly adopted [25]. Under the PF topology, each following vehicle receives information transmitted unidirectionally from its immediate predecessor. The BD topology, by contrast, enables vehicles to acquire information from both their preceding and succeeding neighbors simultaneously [26]. With the advancement of V2V communication technology, a variety of more sophisticated topological configurations have emerged. For instance, the predecessor-leader-following (PLF) topology extends the basic PF structure by incorporating information from the lead vehicle [27]. Similarly, the bidirectional-leader (BDL) topology augments the BD configuration with direct access to leader vehicle data [28]. In the two-predecessor-following (TPF) topology, each following vehicle receives information from two adjacent vehicles ahead. Building upon this, the two-predecessor-leader-following (TPLF) topology further integrates leader vehicle information into the TPF structure [29]. Figure 2 illustrates the commonly employed communication topologies in CAV platoons.
3.2. Longitudinal Vehicle Dynamics Modeling for CAV Platoons
The dynamics of following vehicles within a CAV platoon can be characterized by the following nonlinear model [30]:
where denotes the mass of the i-th following vehicle; represents the driving force applied to vehicle i; and , , and correspond to the grade resistance, aerodynamic drag, and rolling resistance, respectively.
A feedback control strategy is commonly employed to linearize the longitudinal dynamics [31]:
where denotes the control input, and represents the time constant of the powertrain actuator.
By reformulating the linearized dynamics into state-space representation:
where ; denotes the state vector of vehicle i; and , and represent the position, velocity, and acceleration of vehicle i, respectively.
3.3. Inter-Vehicle Spacing Policy for CAV Platoons
Within a CAV platoon, inter-vehicle spacing plays a pivotal role in ensuring formation safety, maintaining stability, and enhancing overall traffic efficiency. The formulation of a rational spacing policy constitutes one of the central challenges in platoon control design [32].
The relative positions and spacing relationships among vehicles are illustrated in Figure 3. In this figure, and denote the lengths of vehicle i and its preceding vehicle , respectively; and represent the desired spacing and actual spacing between consecutive vehicles; and and indicate the positions of the front bumpers of vehicle i and vehicle with respect to a reference point ().
The primary objective of cooperative platoon control is to achieve efficient and stable operation while guaranteeing safe driving conditions for all vehicles within the formation. A variable time headway spacing policy is adopted:
where r denotes the desired standstill spacing; represents the time headway; and is the velocity of vehicle i.
The spacing error for vehicle i is defined as:
For a CAV platoon, the control strategy must satisfy:
3.4. Differential Game-Based Longitudinal Control Strategy for CAV Platoons
Differential game theory provides a theoretical framework that organically integrates continuous-time optimization methods with game-theoretic principles. Its core strength lies in accurately characterizing the dynamic interactions among multiple participants within a continuous time domain [33]. Unlike conventional repeated games where each iteration assumes an identical static game structure, differential games allow the state variables at each stage to evolve over time, thereby capturing the inherent complexity of dynamic evolution. The equilibrium concepts within this framework primarily encompass open-loop Nash equilibrium and feedback Nash equilibrium, reflecting the optimal strategy selection of participants under different information structures [34]. Early differential and zero-sum games were successfully extended to describe the decision-making behavior of participants in scenarios characterized by competitive yet not entirely adversarial objectives [35]. The analysis of general-sum and differential games typically relies on the construction and solution of Hamilton-Jacobi equations. However, as the number of game participants and state variables increases, the computational complexity escalates significantly. Nevertheless, for game problems exhibiting linear-quadratic structures, effective solution methodologies exist [36].
Based on the control objectives specified in Equation (7), in the differential game-based longitudinal platoon control model, all following vehicles are treated as game participants. To construct the differential game objective function, the game payoffs must first be rationally quantified, as this directly pertains to the solution quality of the game equilibrium [37]. Building upon the PF communication topology described previously, the payoff for each following vehicle is defined as the deviation between its state vector and that of its immediate predecessor. By treating the control variables in the longitudinal vehicle dynamics model as the control inputs of individual vehicles within the system, the objective function for vehicle i can be formulated as:
where denotes the weighting coefficient; , and .
This section investigates the control problem of CAV platoons within a non-cooperative differential game framework. The optimality criterion adopts the Nash equilibrium strategy, wherein the combination of strategies selected by all participants reaches a stable state such that no participant can unilaterally increase their payoff by deviating from the current strategy [38]. The objective function presented in Equation (8) is constructed based on the PF topology. During the solution process, equilibrium strategies and state trajectories under the basic topological structure are first determined, followed by progressive extension to more complex topological configurations.
3.4.1. Open-Loop Nash Equilibrium of the Differential Game
The following analysis establishes the existence of a unique open-loop Nash equilibrium for the CAV platoon control problem and derives the analytical expressions for each agent’s equilibrium strategy along with the corresponding state trajectories.
Theorem 1: For the CAV platoon control problem described by Equations (3) and (8), under the non-cooperative differential game framework, there exists a unique open-loop Nash equilibrium with the following form:
The state trajectory corresponding to the Nash equilibrium control strategy is:
Proof.
Define the state vector and the control vector as:
The dynamics model in Equation (3) can then be expressed in terms of and as:
Consequently, the CAV platoon system described by Equations (8) and (13) can be reformulated as the following optimal control problem:
To address this minimization problem, the Hamiltonian function is defined as:
where denotes the costate variable, and this relation holds for all .
According to the Pontryagin minimum principle, the necessary conditions for the optimal control problem to admit a solution are [39]:
Solving Equation (17), the analytical solution for is obtained:
Substituting from Equation (17) into Equation (13) and utilizing Equation (18), the differential equation for the state vector is obtained:
Setting in Equation (20) yields:
For arbitrary initial conditions , exists if and only if exists. That is, if and only if for any terminal state and the corresponding can be computed via Equation (21), then for any initial state sequence , there exists a unique open-loop Nash equilibrium action strategy within the interval .
From Equation (10), it is observed that:
Since the product of any matrix with its transpose is necessarily a symmetric matrix, is symmetric. Furthermore, the matrix is positive definite with all positive eigenvalues. The matrix is a positive semi-definite matrix, thus the eigenvalues of are non-negative. Consequently, all eigenvalues of the matrix have positive real parts, implying that the inverse of exists, thereby ensuring the existence and uniqueness of the game equilibrium strategy.
□
3.4.2. Estimated Open-Loop Nash Equilibrium of the Differential Game
In CAV platoons, hardware failures, signal interference, and communication delays may cause sensor disconnections, thereby inducing velocity oscillations within the platoon and compromising the stability of the overall formation [40]. Compared with PF topology, TPF topology enables each vehicle i to still acquire the state information of vehicle even when direct communication with its immediate predecessor fails, thereby enhancing both safety and stability of platoon control. Accordingly, the TPF topology is adopted as an improvement scheme. Based on the TPF topology, a differential game control model for the vehicle platoon can be established. In this model, the objective function for each vehicle within the platoon is formulated as:
where and are weighting parameters. The objective function incorporates not only the spacing error term between vehicle i and its immediate predecessor, but also introduces the spacing error term between vehicle and its predecessor as extended by the TPF topology.
For the CAV platoon control problem described by Equations (3) and (25), deriving an analytical solution proves challenging. Therefore, a terminal state estimation method is proposed, which constructs an approximate Nash equilibrium solution to achieve control optimization of the TPF platoon system.
First, the normalized quadratic function for vehicle state variable is defined:
Subsequently, the state estimated function is defined:
where the terminal condition represents the estimated terminal state.
Theorem 2: Consider the CAV platoon control problem described by Equations (3) and (25) under the TPF communication topology. If the terminal state vector is estimated according to Equation (27), denoted as , then the unique Nash equilibrium estimate has the following control input form:
The state trajectory corresponding to the Nash equilibrium control is:
Proof.
Based on the state vector and the control vector , the CAV platoon problem based on TPF topology described by Equations (3) and (25) can be transformed into the following optimization problem:
According to the Hamiltonian function defined in Equation (15) combined with the necessary conditions for optimality, an expression in the same form as Equation (17) along with the following terminal condition is obtained:
Utilizing this terminal condition, the solution to Equation (17) can be written as:
Solving Equation (35), the solution for the optimal control state vector under the TPF topology is obtained:
When , the following expression is obtained:
From Equation (37), it is evident that each vehicle i in the CAV platoon must estimate all possible terminal states by computing the function . However, this estimate itself depends on the terminal state, making it difficult to directly derive the control input and the corresponding state trajectory from the expression, thus preventing direct acquisition of the true Nash equilibrium strategy and its state trajectory . To this end, a simplifying assumption in Equation (37) for is introduced.
Let the terminal state for each vehicle be to compute . This yields:
To ensure control effectiveness within the interval , the solution can be expressed in the following form:
3.4.3. Simulation Validation of the Differential Game-Based Control Strategy
This section validates the effectiveness of the proposed differential game-based control scheme through numerical simulations. Consider a CAV platoon consisting of one leading vehicle and four following vehicles. The leading vehicle operates under an independent control policy, while all following vehicles are governed by the unified scheduling framework of the differential game controller. Throughout the simulation, external traffic disturbances and environmental interference are not considered. The inertial time-lag parameter is set to , and the desired inter-vehicle spacing is computed according to Equation (5). The weighting parameters in the cost functional are specified as , , and . For the cost functional , the corresponding weighting parameters are set to , , and . Under PF and TPF communication topologies, the initial state vectors (position, velocity, and acceleration) of the platoon members are summarized in Table 1.
The control problem under the PF topology is solved using the open-loop Nash equilibrium strategy given by Equation (9) and the corresponding state trajectory characterized by Equation (11). Building upon this foundation, the optimal control problem under the TPF topology is addressed by employing the estimated Nash strategy formulated in Equation (40). By solving these optimization problems, the temporal evolution of vehicle positions, inter-vehicle spacing, velocities, accelerations, spacing errors, and time headway deviations under both PF and TPF configurations are obtained.
Figure 4 and Figure 5 illustrate the time-varying profiles of vehicle positions and inter-vehicle spacing under the PF and TPF topologies, respectively. As evidenced by the results, the TPF scheme yields following vehicle position trajectories that adhere more closely to the leader’s trajectory compared to the PF scheme, with notably reduced dispersion among the curves. Under the PF configuration, inter-vehicle spacing predominantly ranges from 28m to 40m, whereas the TPF configuration constrains spacing within a narrower band of 23m to 32m. Notably, the minimum spacing achieved under the TPF scheme is approximately smaller than that under the PF scheme. In summary, the PF approach relies solely on single-predecessor information, resulting in relatively pronounced spacing oscillations across the platoon. In contrast, the TPF approach leverages dual-predecessor information, enabling the controller to exert more effective regulation over the platoon. This maintains inter-vehicle spacing within a smaller yet safe operational envelope, thereby enhancing road utilization efficiency and traffic throughput.
Figure 6 and Figure 7 present the velocity and acceleration profiles of platoon vehicles under the PF and TPF topologies, respectively. As illustrated in the figures, during the acceleration phase (0s to 40s), the PF scheme exhibits a maximum velocity deviation of approximately m/s relative to the leader at around 30s, whereas the TPF scheme reduces this deviation to approximately m/s—a reduction of . Regarding acceleration errors, the PF scheme yields a peak value of approximately at 30s, while the TPF scheme achieves approximately , representing a reduction of nearly . When the leading vehicle reaches 30m/s, the time lag for the tail vehicle to attain this velocity is s under the PF scheme and s under the TPF scheme, corresponding to a improvement in response time.
During the deceleration phase (40s to 70s), the maximum velocity deviation between following vehicles and the leader reaches m/s under the PF scheme, whereas the TPF scheme constrains this discrepancy to within m/s—a reduction exceeding . The maximum acceleration deviation under the PF scheme is approximately , while the TPF scheme maintains this metric within , achieving a reduction of over . Upon the leader decelerating to 25m/s, the tail vehicle reaches this velocity with lag times of s and s under the PF and TPF schemes, respectively, reflecting a reduction in propagation delay. Throughout the subsequent steady-state cruising and secondary deceleration phases, the TPF scheme consistently enables following vehicles to converge toward the leader’s velocity within shorter time intervals, with velocity tracking errors substantially lower than those observed under the PF scheme. These findings demonstrate that the TPF scheme exhibits superior performance in both velocity convergence rate and tracking precision. The designed controller effectively satisfies the requirements for high efficiency and ride comfort in CAV platoon systems.
Figure 8 and Figure 9 depict the temporal evolution of spacing errors and time headway deviations under the PF and TPF topologies, respectively. With respect to spacing errors, the PF control scheme yields a maximum deviation of approximately m during the acceleration phase, whereas the TPF scheme limits this peak to approximately m—a reduction of roughly . During the deceleration phase, the peak spacing errors are approximately -1m and -m for the PF and TPF schemes, respectively, again representing an approximate reduction in absolute deviation magnitude. When velocity and acceleration variations propagate toward the rear of the platoon, vehicles under the PF scheme experience pronounced oscillations during the 20s to 40s and 60s to 80s intervals. In contrast, the TPF scheme enables more rapid error correction, maintaining spacing deviations within approximately m by 70s, thereby demonstrating enhanced system stability.
Examining the time headway errors, within the 20s to 60s interval, the tail vehicle under the PF control scheme exhibits a maximum absolute time headway deviation of approximately s, whereas the TPF scheme reduces this to approximately s—a reduction of approximately in peak absolute deviation. These results indicate that the TPF control scheme achieves faster correction of time headway deviations with smaller error magnitudes. The proposed controller effectively prevents error accumulation, thereby fulfilling the string stability requirements for CAV platoon control.
4. Risk Potential Field-Based MPC Lateral Controller
4.1. Risk Potential Field Modeling
In real-world traffic environments, vehicle motion is influenced not only by interactions among vehicles within CAV platoon but also by external factors such as road boundaries, static obstacles, and dynamic hazards [41]. To comprehensively characterize the operational behavior of CAV platoon in complex environments, a risk potential field model is introduced, enabling quantitative representation of environmental risk factors within a unified potential energy analysis paradigm.
Specifically, field sources in the spatial domain exert non-contact interactions on surrounding objects, and these interactions exhibit quantifiable potential energy distributions. Just as intermolecular potentials define the energy states of molecular systems, the car-following behavior, lane-changing maneuvers, and safe distance maintenance within a CAV platoon can be regarded as self-organizing processes governed by molecular force field interactions [42]. However, when external environmental elements—including lane markings, guardrails, and other obstacles—impose constraints or collision threats on vehicles, novel potential energy formulations are required to capture the influence of these safety risks.
By quantifying the risk factors of the external environment through the risk potential field and integrating this approach with molecular force field methodologies, a comprehensive assessment of overall platoon safety and traversability can be achieved. Within the risk potential field model, various influencing factors can be conceptualized as field sources that generate corresponding risk contributions in their surrounding spatial domains. Through potential energy-based processing of the risks induced by these field sources, a spatial distribution of the risk potential field can be constructed, as illustrated in Figure 10. Lower risk potential field intensity indicates reduced driving risk and enhanced traversability in the corresponding region; conversely, higher intensity signifies the presence of significant safety threats or more stringent constraints, resulting in diminished traversability.
Building upon our prior work on risk potential field modeling for connected autonomous vehicles [43], the comprehensive risk potential field is formulated as the superposition of the road potential field and the vehicle interaction potential field :
The road potential field characterizes the lateral constraints imposed by lane markings and road boundaries on vehicle motion. Using Gaussian-type functions to represent the superimposed effects of lane line potentials and road boundary potentials in the lateral direction, the road potential field intensity is expressed as:
where denotes the number of lane lines; is the intensity gain coefficient of the i-th lane line potential field; represents the lateral coordinate of the i-th lane line; and are the attenuation coefficients of the lane line and road boundary potential fields, respectively; is the intensity gain coefficient of the road boundary potential field; denotes the lateral coordinate of the j-th road boundary.
The vehicle interaction potential field quantifies the collision risk and driving interference between vehicles. Based on the Morse potential function and incorporating virtual mass, corrected vector distance, and steering angle effects, the complete formulation is expressed as:
where the equilibrium distance and the corrected vector distance are respectively defined as:
In these equations, m denotes the actual vehicle mass; v is the vehicle speed; represents the potential well depth; is the potential field steepness coefficient; s denotes the actual inter-vehicle distance; is the minimum standstill spacing; represents the response time delay of CAV; v is the velocity of vehicle; is the safety distance adjustment coefficient; denotes the maximum comfortable deceleration; represents the relative position of an interacting vehicle with respect to the target vehicle; denotes the yaw angle of the target vehicle; represent the longitudinal and lateral velocity components of the target vehicle, respectively; l and w are correction coefficients associated with vehicle length and width, respectively; is the longitudinal velocity weighting factor; k is the attenuation exponent governing the decay rate of the potential field with distance; and is the unit vector indicating the direction of the potential field.
To illustrate the practical application of the risk potential field framework, a representative multi-vehicle scenario is depicted in Figure 11, the target vehicle (TV) travels in the center lane of a three-lane roadway, surrounded by multiple neighboring vehicles: a left rear vehicle (LRV) positioned in the left lane behind the TV, a front vehicle (FV) ahead in the right lane, and a right front vehicle (RFV) in the right lane at a closer longitudinal distance. The corresponding risk potential field distribution is visualized in the lower panel, where the intensity gradient reflects the spatial variation of collision risk. Areas proximal to surrounding vehicles exhibit elevated risk potential, while regions distant from traffic participants demonstrate correspondingly lower risk levels.
4.2. Risk Potential Field-Based MPC Lateral Control Strategy for CAV Platoons
In the design of MPC for CAV platoons, a three-degree-of-freedom vehicle dynamics model is employed [44]. This model comprehensively characterizes not only the longitudinal and lateral motion of the vehicle but also incorporates yaw dynamics, tire slip angles, and steering angle effects. Such a formulation provides a robust theoretical foundation for control design during complex maneuvers such as lane changes. For notational simplicity, the vehicle index subscript is omitted in the subsequent vehicle dynamics model. The longitudinal, lateral, and yaw dynamics of the vehicle can be described by the following set of equations:
where m represents the vehicle mass; and are the velocity components of the vehicle’s center of gravity along the x-axis and y-axis, respectively; and denote the cornering stiffness of the front and rear tires, respectively; and represent the distances from the center of gravity to the front and rear axles, respectively; is the front wheel steering angle; is the yaw angle, representing the orientation of the vehicle body relative to the global coordinate system; and represent the longitudinal stiffness of the front and rear tires, respectively; and denote the tire slip ratios of the front and rear wheels, respectively.
Considering the discrepancies in the representation of lateral and longitudinal velocities across different reference frames, a coordinate transformation relationship must be established to achieve precise mapping of velocity components from the body-fixed coordinate system to the global coordinate system:
The dynamics equations described in Equations (46) and (47) can be further reformulated into the following general state-space form:
where the state vector is defined as ; the control input is ; and the output vector is .
To achieve safe and efficient motion control, the proposed approach integrates MPC with a risk potential field framework for motion planning and control. Within the MPC architecture, a prediction model must be established for the controller. To this end, the vehicle dynamics model undergoes linearization and discretization to derive the corresponding prediction model [45]. Through this methodology, MPC can effectively optimize control inputs based on current states and predictions of future states, thereby enabling more precise obstacle avoidance planning and motion control.
To perform linearization of the vehicle dynamics model, a Taylor series expansion is applied at a given reference operating point (, ) with respect to Equation (48). By retaining first-order terms and neglecting higher-order infinitesimals, the following approximate linearized expression is obtained:
To facilitate subsequent controller design, Equation (49) is restructured into the following form:
where and denote the Jacobian matrices of the function with respect to the state and the control input u, respectively.
By computing the difference between Equation (50) and , the linearized error dynamics model is obtained:
where represents the state deviation vector; denotes the control deviation; is the time-varying system matrix; and is the input matrix. Based on the MPC framework’s frozen parameter strategy for handling time-varying parameters [46], within the prediction horizon at the current time instant, and are held constant.
Let T denote the discretization time step. Applying forward Euler approximation, can be discretized as:
Substituting Equation (52) into the linearized error dynamics model of Equation (51) yields the discrete-time state-space equation:
where ; ; and I is the identity matrix. The matrices and are expressed as follows:
Within the MPC rolling optimization framework, to suppress the cumulative effects of state trajectory tracking deviations and ensure vehicle dynamic stability, the control increment is employed as the control input [47]. Accordingly, the augmented state vector is constructed as follows:
where denotes the control deviation at the -th step within the prediction horizon.
Based on this formulation, the discrete prediction model can be reformulated as:
where represents the system output at the k-th step within the prediction horizon.
By setting the prediction horizon and the control horizon , the receding horizon optimization problem is formulated. The system output sequence over the prediction horizon can be expressed as:
The matrices in the above equation are defined as follows:
In the context of state trajectory tracking control, the desired output vector comprises the target lateral position and longitudinal velocity of the CAV:
where the lateral position reference is provided by the trajectory planning module based on our previous work [43], while is determined by the coordination control layer.
MPC possesses inherent multi-constraint handling capabilities. The constraints to be considered include traffic regulation constraints and vehicle dynamic limitations, specifically:
(1) Longitudinal velocity constraint: The longitudinal velocity must satisfy road speed limits and powertrain capacity constraints:
where and denote the allowable minimum and maximum longitudinal velocities, respectively.
(2) Steering system mechanical limits:
where represents the maximum steering angle, and denotes the maximum steering angle rate.
(3) Tire slip angle constraint: Excessive tire slip angles cause the tire adhesion force to approach its friction limit [48]. Accordingly, the following constraint is established:
(4) Vehicle sideslip angle constraint: The sideslip angle serves as a critical indicator of vehicle stability. When , the vehicle is prone to entering a nonlinear instability region [49]. Therefore, the following constraint is imposed:
(5) Friction ellipse constraint: Considering the tire-road contact mechanics coupling effects, the vehicle acceleration must satisfy the friction circle constraint:
where and denote the longitudinal and lateral accelerations, respectively; represents the time-varying road surface adhesion coefficient; and g is the gravitational acceleration. This constraint is inherently a time-varying nonlinear inequality, which can be reformulated through second-order cone programming into the following form to enable efficient online computation:
In the trajectory tracking controller design for CAVs, the objective function must comprehensively account for tracking accuracy, control smoothness, and system safety margins as multi-objective optimization requirements. Based on the risk potential field methodology and quadratic programming, the following composite cost function is formulated:
where is a slack variable introduced to ensure the existence of feasible solutions; is the weighting coefficient for the slack variable; and Q, R, and P are the weighting matrices for state tracking error, control input variation, and risk potential field, respectively.
By defining , the cost function can be expressed as:
The constraint conditions are formulated as follows:
where and represent the minimum and maximum control inputs, respectively; and denote the minimum and maximum control increments; and are the minimum and maximum system outputs.
Due to the nonlinearity and non-convexity characteristics of the risk potential field function, it can be transformed into a corresponding quadratic convex optimization problem [50], which is subsequently solved using sequential quadratic programming.
5. Co-Simulation Platform and Experimental Validation
5.1. Co-Simulation Platform Architecture
To validate the effectiveness of the proposed hierarchical cooperative control framework for CAV platoons, a comprehensive co-simulation platform is established by integrating MATLAB/Simulink, Prescan, and CarSim. This multi-fidelity simulation environment enables rigorous evaluation of both the differential game-based longitudinal coordination controller and the risk potential field-driven MPC lateral controller under diverse traffic scenarios. The architecture of the co-simulation platform is illustrated in Figure 12.
Within this framework, three principal software components operate synergistically to replicate realistic platoon driving conditions. Prescan constructs the virtual driving environment in which the CAV platoon operates, including lane geometries, obstacle vehicles, and sensor measurement simulations. CarSim functions as the high-precision vehicle dynamics simulator, capable of reproducing the dynamic response characteristics of individual vehicles within the platoon under various road surface conditions and maneuvering scenarios. Through its interface with MATLAB/Simulink, CarSim receives control commands from the coordination and motion control layers in real time, updates the kinematic and dynamic states of each platoon member according to the underlying vehicle model, and subsequently transmits the refreshed state information back to Prescan for environment synchronization. MATLAB/Simulink constitutes the computational core of the entire co-simulation architecture, wherein the hierarchical control algorithms—including the differential game controller and the risk potential field-based MPC—are implemented. This module continuously acquires perception data and vehicle state feedback from the Prescan-CarSim interface, executes the decision-making and trajectory planning computations, and dispatches the resultant control signals (throttle, brake, and steering commands) to the CarSim vehicle models. The simulation parameter settings are summarized in Table 2.
5.2. Ramp Merging Scenario
To evaluate the performance of the proposed hierarchical cooperative control framework under dynamic traffic disturbances, a ramp merging scenario is constructed within the Prescan simulation environment, as depicted in Figure 13. In this scenario, a CAV platoon comprising one leading vehicle (LV) and two following vehicles (FV1 and FV2) travels along the mainline at a desired cruising velocity of 15m/s, maintaining an initial inter-vehicle spacing of 20m. Concurrently, a merging vehicle (MV) traveling at 12m/s executes an aggressive lane-change maneuver from the on-ramp into the main carriageway, thereby disrupting the steady-state formation of the platoon and introducing potential collision risks.
Figure 14 illustrates the temporal evolution of relative positions among LV, FV1, FV2, and MV, along with the corresponding risk potential field distribution at different time instants during the merging process. As observed from the figure, when the MV cuts into the mainline behind of the leading vehicle, the stable cruising state of the original CAV platoon is perturbed. During the merging event, since the MV’s velocity is lower than the initial cruising speed of the CAV platoon, FV1 first enters the influence zone of the MV’s risk potential field at approximately . As the relative distance between FV1 and MV decreases rapidly, the risk potential energy perceived by FV1 escalates correspondingly. In response, FV1 activates the proposed control strategy: longitudinally, the differential game-based controller coordinates with other platoon members to adjust its acceleration and minimize the velocity discrepancy relative to LV; laterally, the risk potential field-driven MPC controller autonomously selects the minimum-risk driving behavior and executes a left lane-change maneuver to overtake the obstacle. Similarly, FV2 enters the risk potential field zone of MV at approximately and subsequently performs an analogous overtaking maneuver. As evidenced by the final configuration of the CAV platoon shown in the figure, all following vehicles successfully complete the obstacle avoidance operations following the MV intrusion and subsequently restore a stable formation cruising state. These results validate that the proposed control framework ensures both operational safety and rapid stability recovery for cooperative vehicle formations under external disturbances.
Figure 15 presents the temporal profiles of inter-vehicle spacing errors and velocities for the CAV platoon during the ramp merging scenario. Due to the evasive maneuvers, the spacing error curves exhibit transient fluctuations; however, after , the errors gradually converge toward zero, indicating that the system achieves asymptotic stability. The velocity profiles further demonstrate that, upon completion of the obstacle avoidance operations, all platoon members converge to a uniform cruising velocity. These observations corroborate the effectiveness of the proposed cooperative control strategy in maintaining string stability and ensuring coordinated platoon behavior under dynamic traffic perturbations.
5.3. Emergency Braking Scenario of Obstacle Vehicle
Emergency braking by a preceding obstacle vehicle (OV) represents a prevalent hazardous situation in road traffic and constitutes a primary cause of rear-end collisions. In such scenarios, the CAV platoon must respond rapidly to the OV’s emergency braking maneuver, avoiding collision with the OV within a limited braking distance while maintaining internal platoon stability to prevent secondary collisions triggered by abrupt deceleration. To evaluate the safety performance and control strategy effectiveness of the CAV platoon under extreme conditions, an OV emergency braking scenario is constructed as illustrated in Figure 16.
Consider a CAV platoon comprising a leading vehicle (LV) and three following vehicles (FV1, FV2, and FV3) traveling at a desired velocity of 15m/s with an inter-vehicle spacing of 20m in the current lane. The OV travels at an identical velocity while maintaining a constant spacing of 25m ahead of the LV. After 5 seconds, the OV initiates emergency braking at a deceleration rate of 5m/s² until reaching a complete stop. Figure 17 presents the temporal evolution of vehicle positions, risk potential field distribution, spacing errors, and velocities during the emergency braking scenario. The sudden emergency braking of the OV in the same lane generates a rapidly intensifying risk potential field in its vicinity, thereby disrupting the equilibrium state within the original platoon. Under the potential-field coupled decision-making mechanism, the LV, being the first vehicle affected by the OV’s braking action, promptly initiates deceleration upon detecting the sharp escalation in risk potential energy. The LV adjusts its acceleration to achieve coordinated control with other vehicles in the platoon while performing risk avoidance through MPC. The following vehicles FV1, FV2, and FV3 subsequently respond to the deceleration behavior of the preceding vehicles (including both OV and LV). Through differential game equilibrium control based on the TPF topology, the following vehicles can acquire state information from multiple preceding vehicles, enabling earlier perception of collision risks and coordinated deceleration. This approach prevents internal instability and collision risks within the platoon caused by abrupt braking, while achieving coordinated obstacle avoidance through MPC.
As evidenced by the spacing error and velocity curves in the figure, when the OV performs emergency braking, the spacing errors and velocities within the CAV platoon exhibit fluctuations; however, all quantities vary smoothly, with spacing errors ultimately converging to zero and all vehicle velocities converging to the desired velocity. These results demonstrate that the proposed control strategy ensures both safety and stability of the CAV platoon under emergency braking scenarios, validating the rapid response capability and effective coordination performance of the designed controller.
5.4. Multi-Lane Cooperative Obstacle Avoidance Scenario
To comprehensively evaluate the performance of the proposed cooperative control strategy in complex traffic environments, a multi-lane cooperative obstacle avoidance scenario is constructed as illustrated in Figure 18. This scenario simulates the complex obstacle avoidance situation where a CAV platoon simultaneously encounters multiple dynamic obstacles during travel, enabling analysis and assessment of the platoon’s safety and cooperative control capability under multiple constraints. In this scenario, a CAV platoon comprising LV, FV1, FV2, and FV3 travels at a desired velocity of 15m/s with an inter-vehicle spacing of 20m. The obstacle vehicle OV1, located in the same lane ahead, maintains an initial spacing of 25m from the LV and travels at 12m/s. OV2 and OV3 are positioned in the left and right adjacent lanes at coordinates (15m, 4m) and (38m, m), traveling at 13m/s and 10m/s, respectively. The presence of these three obstacle vehicles creates a dynamically evolving complex risk potential field. The CAV platoon must navigate through this dynamic risk potential field by identifying the trajectory with minimum potential energy for cooperative obstacle avoidance.
After LV and FV1 execute a left lane change to overtake OV1, OV2 travels parallel to FV2 and FV3, effectively blocking their path and closing the left lane-change corridor. At this juncture, the CAV platoon must reassess the risk potential field of the surrounding environment and perform secondary decision-making. Integrating real-time vehicle states and environmental information, the CAV system opts for a right lane change to circumvent the temporary blockage formed by OV1 and OV2, as depicted in Figure 19. Upon completion of the lane-change maneuvers, all vehicles re-form into a platoon in the original lane, with the differential game controller adjusting inter-vehicle spacing and velocities to maintain internal platoon stability, as shown in Figure 20.
Figure 21 illustrates the spatial relationships among vehicles and the risk potential field distribution at different time instants during the cooperative obstacle avoidance scenario. At the initial moment, the CAV platoon is primarily influenced by OV1. Due to its lower velocity and position directly ahead, OV1 generates a high-intensity risk potential field, posing a direct rear-end collision threat to the platoon, whereas OV2 and OV3, located in the left and right adjacent lanes respectively, produce relatively weaker risk potential fields. As the lead vehicle, the LV is the first to perceive the risk potential field emanating from OV1. According to the potential-field coupled decision-making mechanism, maintaining the current lane would lead the LV into a high-potential-energy region with elevated collision risk, whereas executing a left lane change would direct it toward a lower-potential-energy region. Consequently, the risk potential field-based MPC controller enables the LV to autonomously decide and execute a left lane-change maneuver. FV1, upon acquiring the lane-change information from the LV and combining it with its own perceived risk potential field, similarly chooses to follow the LV in performing a left lane change. Throughout this process, the differential game controller ensures that FV1 maintains the desired longitudinal spacing with the LV while preserving overall platoon stability during the lane-change following maneuver. At , LV and FV1 have completed their left lane changes, successfully avoiding collision risk with OV1. Although FV2 and FV3 detect the lane-change decisions of LV and FV1, the presence of OV2 renders a left lane change considerably risky, and insufficient lane-change space exists ahead of OV3. Therefore, FV2 and FV3 continue traveling in the original lane while continuously evaluating the risk potential field. Due to the lower velocity of OV3, the longitudinal spacing between FV2/FV3 and OV3 eventually satisfies the lane-change safety requirements at approximately and , respectively, enabling them to execute coordinated lane-change maneuvers. By approximately , all CAV vehicles have successfully avoided all obstacle vehicles and returned to the original lane, re-establishing a stable platoon formation. These results demonstrate that the proposed cooperative control strategy can effectively perform cooperative obstacle avoidance while maintaining platoon stability in complex and dynamic traffic environments.
Figure 22 presents the temporal evolution of spacing errors and velocities within the CAV platoon during the cooperative obstacle avoidance scenario. As indicated by the spacing error curves, owing to sufficient initial lane-change space, FV1 can follow the LV through the controller for cooperative lane changing, with the spacing error between LV and FV1 maintained below . Since FV2 and FV3 are blocked by OV2 from executing left lane changes, the spacing errors between FV1 and FV2, as well as between FV2 and FV3, exhibit considerable fluctuations. Once the right lane-change conditions are satisfied, FV2 and FV3 can rapidly adjust their velocity responses through the differential game controller, maintaining the desired inter-vehicle spacing with preceding vehicles and among themselves, with spacing errors ultimately converging to zero. The velocity profiles reveal that when confronting the risk potential fields generated by OV1, OV2, and OV3, the CAV platoon achieves safe obstacle avoidance through smooth velocity adjustments. Despite velocity fluctuations during the obstacle avoidance process, all vehicles recover to the desired velocity without abrupt acceleration or deceleration, thereby ensuring driving stability and ride comfort. These results demonstrate that the risk potential field-based MPC can accurately assess and respond to dynamically changing traffic environments for safe obstacle avoidance, while the differential game control ensures coordination among multiple vehicles, achieving overall platoon stability.
6. Conclusions
The simulation results validate the effectiveness of the proposed hierarchical cooperative control framework across diverse traffic scenarios. The comparative analysis between PF and TPF communication topologies confirms that incorporating information from multiple predecessors substantially enhances platoon coordination, with the TPF scheme achieving approximately reduction in both velocity deviation and spacing errors. This improvement effectively mitigates string instability, a well-documented challenge in conventional predecessor-following approaches [51]. The integration of risk potential field methodology with MPC provides a unified paradigm for obstacle avoidance that combines continuous risk assessment with trajectory optimization. The three validation scenarios demonstrate the framework’s adaptability: in the ramp merging scenario, the platoon successfully responds to aggressive cut-in maneuvers; in the emergency braking scenario, coordinated deceleration prevents rear-end collisions while maintaining internal stability; and in the multi-lane obstacle avoidance scenario, the system exhibits adaptive decision-making capability by dynamically switching lane-change directions when initial corridors become blocked. The smooth velocity profiles observed across all scenarios indicate that ride comfort requirements are satisfied alongside safety objectives.
Several aspects need further investigation in future work. The current simulations assume ideal V2V communication; incorporating robustness mechanisms against packet loss and latency would enhance practical applicability. Additionally, extending the framework to mixed traffic scenarios involving human-driven vehicles and exploring scalability to larger platoon sizes through mean-field game approximations represent promising research directions.
In conclusion, this paper presents a hierarchical cooperative control framework for CAV platoons that addresses both longitudinal coordination and lateral safety. The differential game-based controller with TPF topology ensures formation stability, while the risk potential field-based MPC enables real-time obstacle avoidance. Validation across multiple scenarios confirms that the proposed approach effectively ensures platoon safety, stability, and adaptability in complex traffic environments.
Funding
This research was funded by Shandong Provincial Natural Science Foundation (Grant No. ZR2025QC671).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wang, K.; Shen, C.; Li, X.; Lu, J. Uncertainty quantification for safe and reliable autonomous vehicles: A review of methods and applications. IEEE Transactions on Intelligent Transportation Systems 2025. [Google Scholar] [CrossRef]
- Garikapati, D.; Shetiya, S.S. Autonomous vehicles: Evolution of artificial intelligence and the current industry landscape. Big Data and Cognitive Computing 2024, 8, 42. [Google Scholar] [CrossRef]
- Pan, Y.; Wu, Y.; Xu, L.; Xia, C.; Olson, D.L. The impacts of connected autonomous vehicles on mixed traffic flow: A comprehensive review. Physica A: Statistical Mechanics and its Applications 2024, 635, 129454. [Google Scholar] [CrossRef]
- Chen, N.; Liu, X. Research on World Models for Connected Automated Driving: Advances, Challenges, and Outlook. Applied Sciences 2025, 15, 8986. [Google Scholar] [CrossRef]
- Garg, M.; Bouroche, M. Longitudinal Car-Following Control of Connected Autonomous Vehicles in Realistic Scenarios: A Survey. IEEE Transactions on Intelligent Transportation Systems 2025. [Google Scholar] [CrossRef]
- Li, H.; Meng, W.; Han, Z.; Zhang, Z.; Yang, Y. Vehicle platoon in road traffic: A Survey of Modeling, Communication, Controlling and Perspectives. Physica A: Statistical Mechanics and its Applications 2025, 130757. [Google Scholar] [CrossRef]
- Song, L.; Li, J.; Wei, Z.; Yang, K.; Hashemi, E.; Wang, H. Longitudinal and lateral control methods from single vehicle to autonomous platoon. Green Energy and Intelligent Transportation 2023, 2, 100066. [Google Scholar] [CrossRef]
- Wang, H.; Peng, L.M.; Wei, Z.; Yang, K.; Jiang, L.; Hashemi, E.; et al. A holistic robust motion control framework for autonomous platooning. IEEE Transactions on Vehicular Technology 2023, 72, 15213–15226. [Google Scholar] [CrossRef]
- Hua, M.; Qi, X.; Chen, D.; Jiang, K.; Liu, Z.E.; Sun, H.; Zhou, Q.; Xu, H. Multi-agent reinforcement learning for connected and automated vehicles control: Recent advancements and future prospects. IEEE Transactions on Automation Science and Engineering 2025. [Google Scholar] [CrossRef]
- Rebelo, M.; Rafael, S.; Bandeira, J.M. Vehicle platooning: A detailed literature review on environmental impacts and future research directions. Future Transportation 2024, 4, 591–607. [Google Scholar] [CrossRef]
- Braiteh, F.E.; Bassi, F.; Khatoun, R. Platooning in connected vehicles: a review of current solutions, standardization activities, cybersecurity, and research opportunities. IEEE Transactions on Intelligent Vehicles 2024. [Google Scholar] [CrossRef]
- Wang, C.; Gong, S.; Zhou, A.; Li, T.; Peeta, S. Cooperative adaptive cruise control for connected autonomous vehicles by factoring communication-related constraints. Transportation Research Part C: Emerging Technologies 2020, 113, 124–145. [Google Scholar] [CrossRef]
- Wang, S.T.; Zhuang, Y.L.; Zhu, W.X. Traffic flow bifurcation control of autonomous vehicles through a hybrid control strategy combining multi-step prediction and memory mechanism with PID. Communications in Nonlinear Science and Numerical Simulation 2024, 137, 108136. [Google Scholar] [CrossRef]
- Mo, H.; Meng, Y.; Wang, F.Y.; Wu, D. Interval type-2 fuzzy hierarchical adaptive cruise following-control for intelligent vehicles. IEEE/CAA Journal of Automatica Sinica 2022, 9, 1658–1672. [Google Scholar] [CrossRef]
- Turri, V.; Besselink, B.; Johansson, K.H. Cooperative look-ahead control for fuel-efficient and safe heavy-duty vehicle platooning. IEEE Transactions on Control Systems Technology 2016, 25, 12–28. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, Z.; Pant, Y.V. Improving safety in mixed traffic: A learning-based model predictive control for autonomous and human-driven vehicle platooning. Knowledge-Based Systems 2024, 293, 111673. [Google Scholar] [CrossRef]
- Qian, L.; Chen, J.; Zhao, F.; Chen, X.; Xuan, L. Research on Fast Stochastic Model Predictive Control-Based Eco-Driving Strategy for Connected Mixed Platoons. Automotive Engineering 2024, 46, 1587–1599. [Google Scholar]
- Yang, F.; Wang, H.; Pi, D.; Sun, X.; Wang, X. Research on collaborative adaptive cruise control based on MPC and improved spacing policy. Proceedings of the Institution of Mechanical Engineers, Part D: Journal of Automobile Engineering 2025, 239, 2603–2615. [Google Scholar] [CrossRef]
- Li, Y.; Zhou, F.; Huang, L.; Yu, S.; Shi, S. Longitudinal Control of Connected Vehicle Platoon based on Deep Reinforcement Learning. Control and Decision 2024, 39, 1879–1887. [Google Scholar]
- Min, H.; Yang, Y.; Wang, W.; Fang, Y.; Song, X. Deep deterministic policy gradient based cooperative platoon longitudinal control strategy. Journal of Chang’an University(Natural Science Edition) 2021, 41, 11. [Google Scholar]
- Chen, J.; Wu, X.; Lv, Z.; Xu, Z.; Wang, W. Collaborative control of vehicle platoon based on deep reinforcement learning. IEEE Transactions on Vehicular Technology 2024, 73, 14399–14414. [Google Scholar] [CrossRef]
- Song, D.; Zhu, B.; Zhao, J.; Han, J.; Chen, Z. Personalized car-following control based on a hybrid of reinforcement learning and supervised learning. IEEE Transactions on Intelligent Transportation Systems 2023, 24, 6014–6029. [Google Scholar] [CrossRef]
- Yue, X.; Shi, H.; Zhou, Y.; Li, Z. Hybrid car following control for CAVs: Integrating linear feedback and deep reinforcement learning to stabilize mixed traffic. Transportation Research Part C: Emerging Technologies 2024, 167, 104773. [Google Scholar] [CrossRef]
- Shi, H.; Zhou, Y.; Wu, K.; Wang, X.; Lin, Y.; Ran, B. Connected automated vehicle cooperative control with a deep reinforcement learning approach in a mixed traffic environment. Transportation Research Part C: Emerging Technologies 2021, 133, 103421. [Google Scholar] [CrossRef]
- Dafhalla, A.K.Y.; Elobaid, M.E.; Tayfour Ahmed, A.E.; Filali, A.; SidAhmed, N.M.O.; Attia, T.A.; Mohajir, B.A.I.; Altamimi, J.S.; Adam, T. Computer-Aided Efficient Routing and Reliable Protocol Optimization for Autonomous Vehicle Communication Networks. Computers 2025, 14, 13. [Google Scholar] [CrossRef]
- Tariq, U.; Ahanger, T.A. Enhancing Intelligent Transport Systems Through Decentralized Security Frameworks in Vehicle-to-Everything Networks. World Electric Vehicle Journal 2025, 16, 24. [Google Scholar] [CrossRef]
- Ruan, T.; Chen, Y.; Li, X.; Wang, J.; Liu, Y.; Wang, H. Stability analysis and controller design of the Cooperative Adaptive Cruise Control platoon considering a rate-free time-varying communication delay and uncertainties. Transportation Research Part C: Emerging Technologies 2025, 170, 104913. [Google Scholar] [CrossRef]
- Zakerimanesh, A.; Qiu, T.Z.; Tavakoli, M. Stability and intervehicle distance analysis of vehicular platoons: Highlighting the impact of bidirectional communication topologies. IEEE Transactions on Control Systems Technology 2024, 32, 1124–1139. [Google Scholar] [CrossRef]
- Neto, A.A.; Mozelli, L.A. Robust longitudinal control for vehicular platoons using deep reinforcement learning. IEEE Transactions on Intelligent Transportation Systems 2024, 25, 14401–14410. [Google Scholar] [CrossRef]
- Coppola, A.; Lui, D.G.; Petrillo, A.; Santini, S. Cooperative driving of heterogeneous uncertain nonlinear connected and autonomous vehicles via distributed switching robust PID-like control. Information Sciences 2023, 625, 277–298. [Google Scholar] [CrossRef]
- Wang, C.; Zhao, Y.; Li, L.; Qu, X.; Ran, B. Enhancing Vehicle Platoons in Connected and Automated Environments With an Improved Spectral Clustering-Based Pinning Control Strategy. IEEE Transactions on Vehicular Technology 2025. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, Z.; Wu, Y.; Jiang, C.; Zheng, Y.; Jiang, Y.; Yao, Z. A Bidirectional Distance Balancing Strategy for Connected Automated Vehicles Platoon in Mixed Traffic Flow. IEEE Internet of Things Journal 2025. [Google Scholar] [CrossRef]
- Guo, Y.; Sun, Q.; Pan, Q. Robust Tracking Control of Underactuated UAVs Based on Zero-Sum Differential Games. Drones 2025, 9, 477. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Z.; Hu, S.; Yuan, F.; Yang, J. Game-Aware MPC-DDP for Mixed Traffic: Safe, Efficient, and Comfortable Interactive Driving. World Electric Vehicle Journal 2025, 16, 544. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, Y.; Li, Z.; Li, Z.; Guo, G. Game-Theoretic Decision-Making for Autonomous Vehicles at Unsignalized Intersections under Communication Interferences: A Novel Risk-Adaptive Approach. IEEE Transactions on Vehicular Technology 2025. [Google Scholar] [CrossRef]
- Chen, M.; Li, B.; Zhang, S.; Zhang, H.; Zhuang, W.; Yin, G.; Chen, B. A Game-Theoretical Framework for Safe Decision Making and Control of Mixed Autonomy Vehicles. IEEE Transactions on Intelligent Transportation Systems 2025. [Google Scholar] [CrossRef]
- Wang, T.; Xu, T.; Zhang, Y.; Chen, S.; Chen, J.; Ye, X. A Distributed Game-Based Traffic Control Model for Unsignalized Intersections in a Connected Vehicle Environment. Transportation Research Record 2025, 03611981251382910. [Google Scholar] [CrossRef]
- Jond, H.B.; Platoš, J. Differential game-based optimal control of autonomous vehicle convoy. IEEE Transactions on Intelligent Transportation Systems 2022, 24, 2903–2919. [Google Scholar] [CrossRef]
- Yildiz, A.; Jond, H.B. Vehicle swarm platooning as differential game. In Proceedings of the 2021 20th International Conference on Advanced Robotics (ICAR); IEEE, 2021; pp. 885–890. [Google Scholar]
- Dong, H.; Shi, J.; Zhuang, W.; Li, Z.; Song, Z. Analyzing the impact of mixed vehicle platoon formations on vehicle energy and traffic efficiencies. Applied Energy 2025, 377, 124448. [Google Scholar] [CrossRef]
- Ma, Y.; Zhu, J.; Lv, Z.; Zhang, Y. Multi-vehicle dynamic interaction in autonomous driving: integrating game theory and the potential field method. Transportmetrica B: Transport Dynamics 2025, 13, 2425969. [Google Scholar] [CrossRef]
- Jia, Y.; Qu, D.; Song, H.; Wang, T.; Zhao, Z. Car-following characteristics and model of connected autonomous vehicles based on safe potential field. Physica A: Statistical Mechanics and its Applications 2022, 586, 126502. [Google Scholar] [CrossRef]
- Wang, T.; Qu, D.; Wang, K.; Wei, C.; Li, A. Risk-Aware Lane Change and Trajectory Planning for Connected Autonomous Vehicles Based on a Potential Field Model. World Electric Vehicle Journal 2024, 15, 489. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L.; Wang, C.; Wang, M.; Cao, D.; Wang, Z. Integrated decision making and motion control for autonomous emergency avoidance based on driving primitives transition. IEEE Transactions on Vehicular Technology 2022, 72, 4207–4221. [Google Scholar] [CrossRef]
- Liang, J.; Li, Y.; Yin, G.; Xu, L.; Lu, Y.; Feng, J.; Shen, T.; Cai, G. A MAS-based hierarchical architecture for the cooperation control of connected and automated vehicles. IEEE Transactions on Vehicular Technology 2022, 72, 1559–1573. [Google Scholar] [CrossRef]
- Cui, L.; Chakraborty, S.; Ozbay, K.; Jiang, Z.P. Data-Driven Combined Longitudinal and Lateral Control for the Car Following Problem. IEEE Transactions on Control Systems Technology 2025. [Google Scholar] [CrossRef]
- Rasekhipour, Y.; Fadakar, I.; Khajepour, A. Autonomous driving motion planning with obstacles prioritization using lexicographic optimization. Control Engineering Practice 2018, 77, 235–246. [Google Scholar] [CrossRef]
- Wang, H.; Huang, Y.; Khajepour, A.; Zhang, Y.; Rasekhipour, Y.; Cao, D. Crash mitigation in motion planning for autonomous vehicles. IEEE transactions on intelligent transportation systems 2019, 20, 3313–3323. [Google Scholar] [CrossRef]
- Jia, S.; Liu, M.; Xiong, H.; Sio, K.; Long, Z.; Bu, X. Integrated Motion Control for Autonomous Vehicles Operating under Nonlinear Disturbances. Applied Mathematical Modelling 2025, 116264. [Google Scholar] [CrossRef]
- Bhatt, N.P.; Khajepour, A.; Hashemi, E. MPC-PF: Socially and spatially aware object trajectory prediction for autonomous driving systems using potential fields. IEEE transactions on intelligent transportation systems 2023, 24, 5351–5361. [Google Scholar] [CrossRef]
- Seiler, P.; Pant, A.; Hedrick, K. Disturbance propagation in vehicle strings. IEEE Transactions on automatic control 2004, 49, 1835–1842. [Google Scholar] [CrossRef]
Figure 1.
Cooperative control framework for CAV platoon.
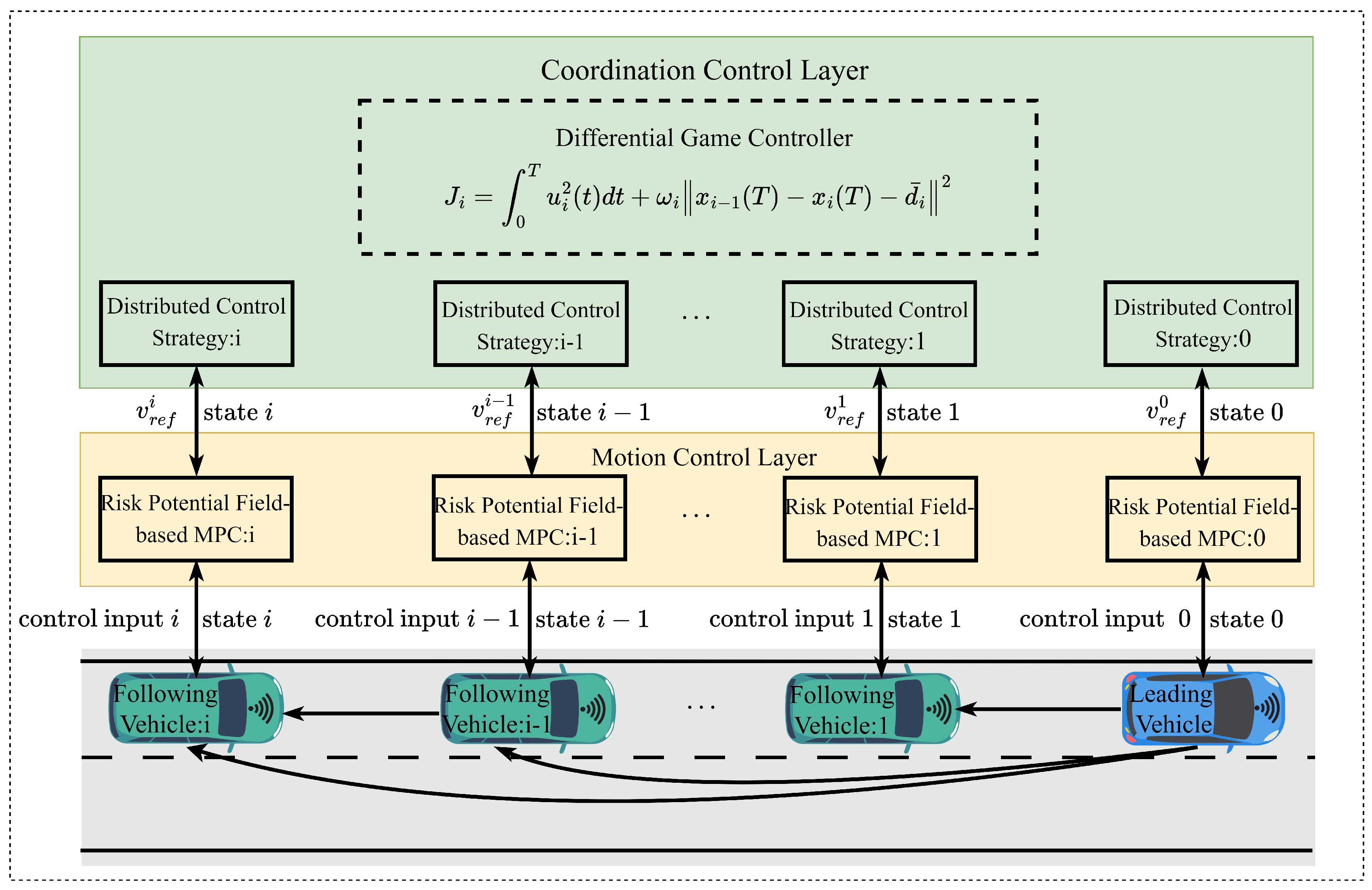
Figure 2.
Common communication topologies for CAV platoon.
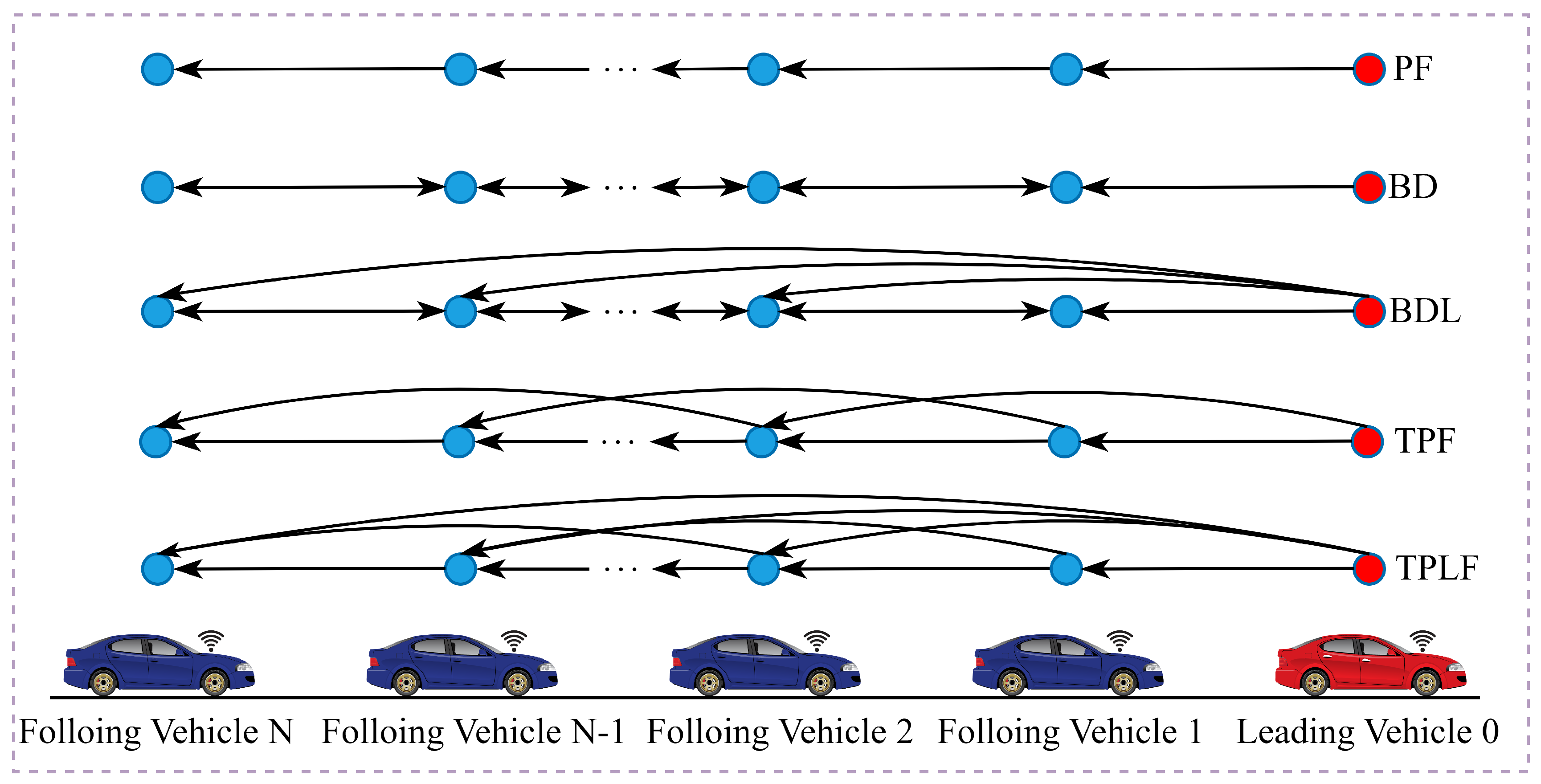
Figure 3.
Inter-vehicle spacing in CAV platoon.
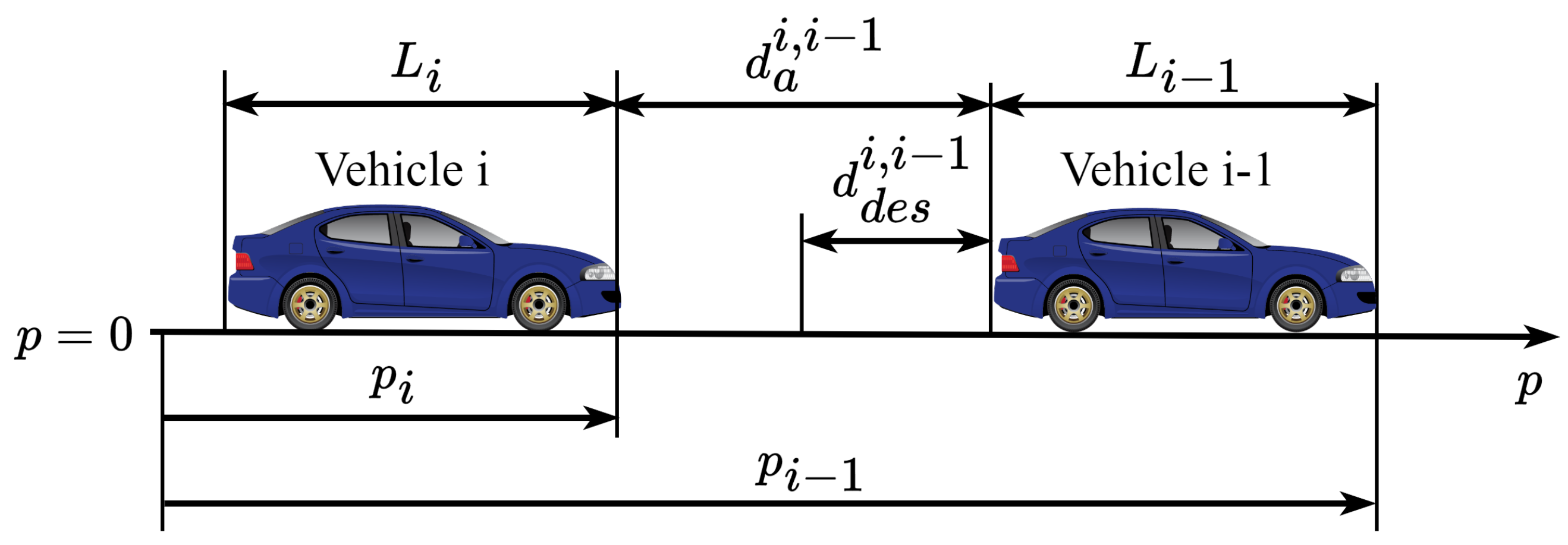
Figure 4.
Platoon vehicle positions under differential game control: (a) PF topology; (b) TPF topology.
Figure 4.
Platoon vehicle positions under differential game control: (a) PF topology; (b) TPF topology.
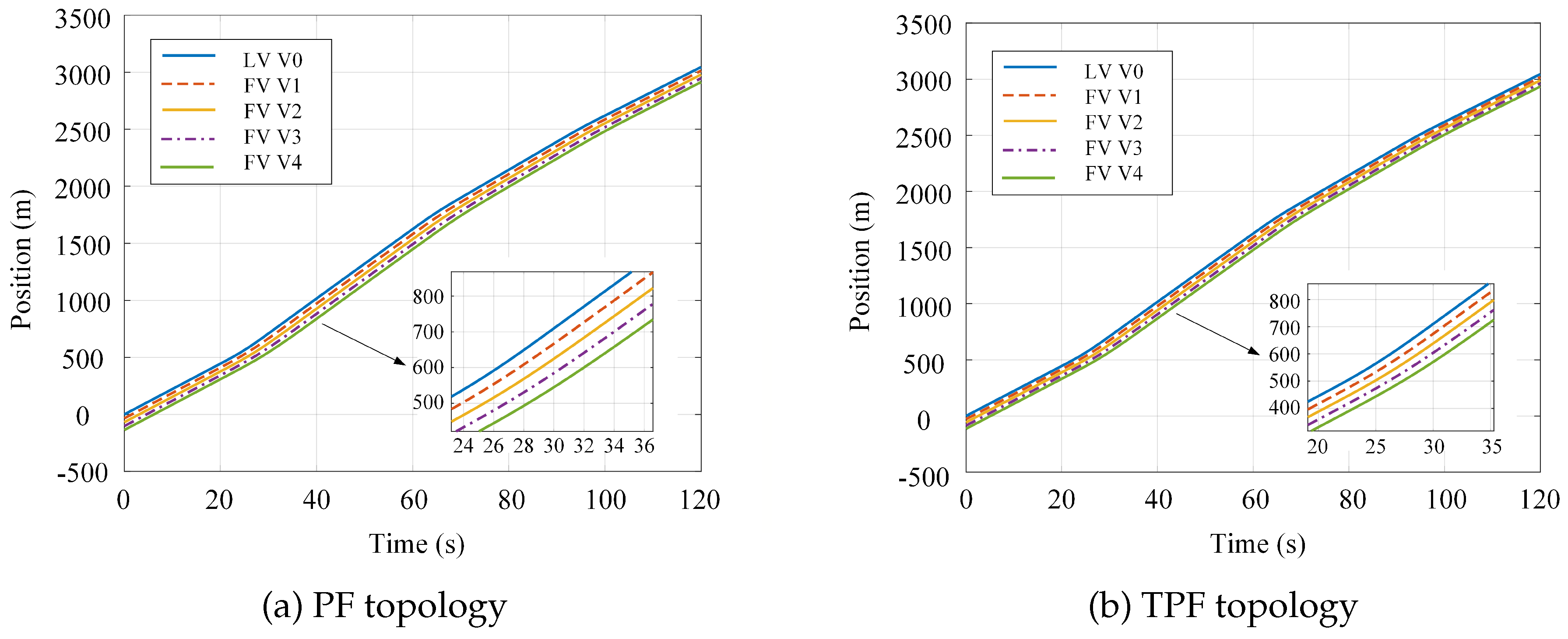
Figure 5.
Platoon vehicle spacings under differential game control: (a) PF topology; (b) TPF topology.
Figure 5.
Platoon vehicle spacings under differential game control: (a) PF topology; (b) TPF topology.
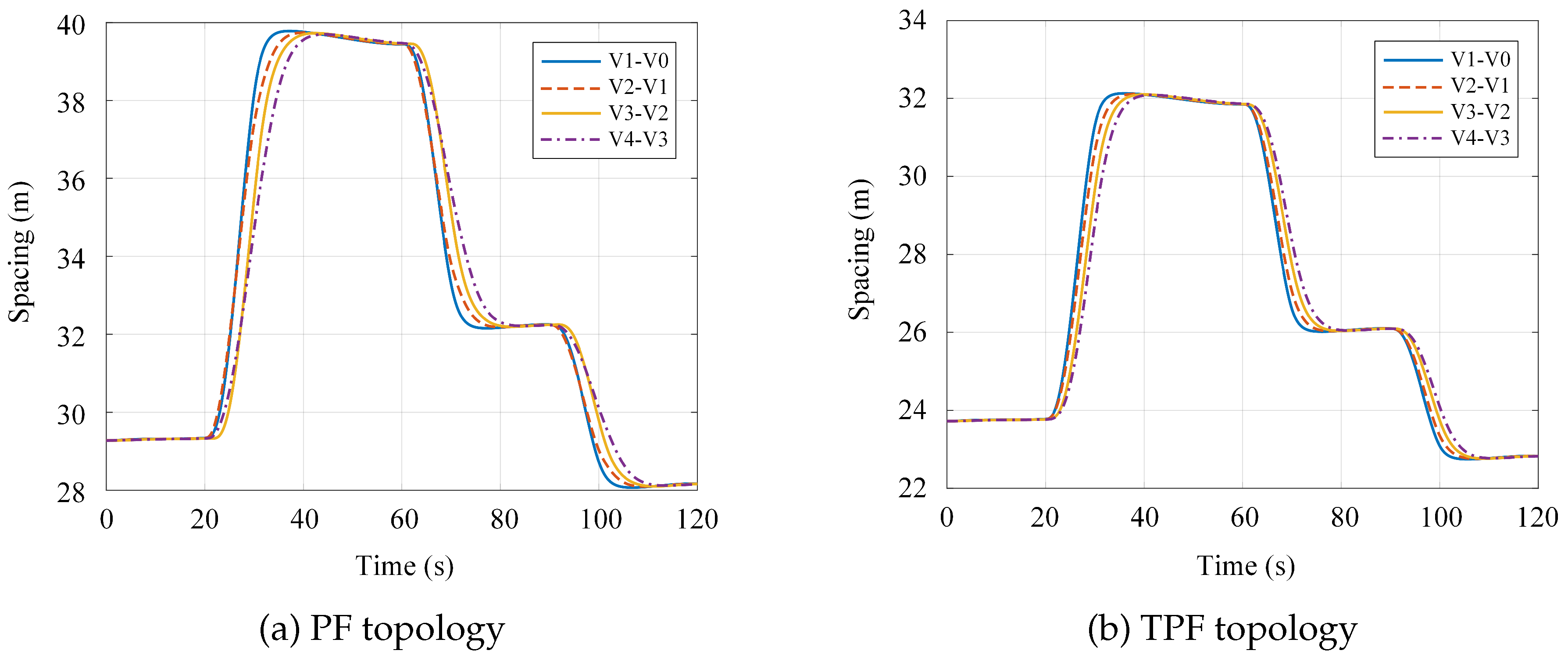
Figure 6.
Platoon vehicle velocity profiles under differential game control: (a) PF topology; (b) TPF topology.
Figure 6.
Platoon vehicle velocity profiles under differential game control: (a) PF topology; (b) TPF topology.
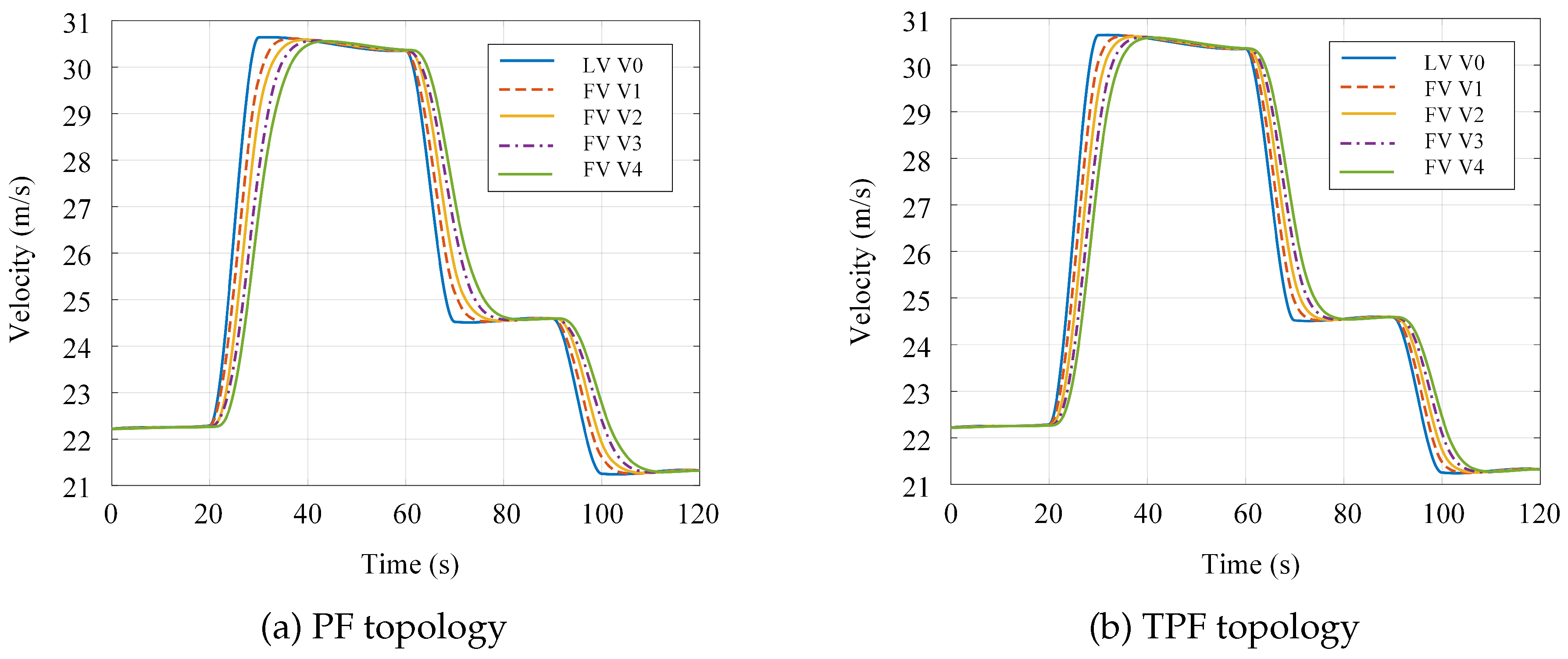
Figure 7.
Platoon vehicle acceleration profiles under differential game control: (a) PF topology; (b) TPF topology.
Figure 7.
Platoon vehicle acceleration profiles under differential game control: (a) PF topology; (b) TPF topology.
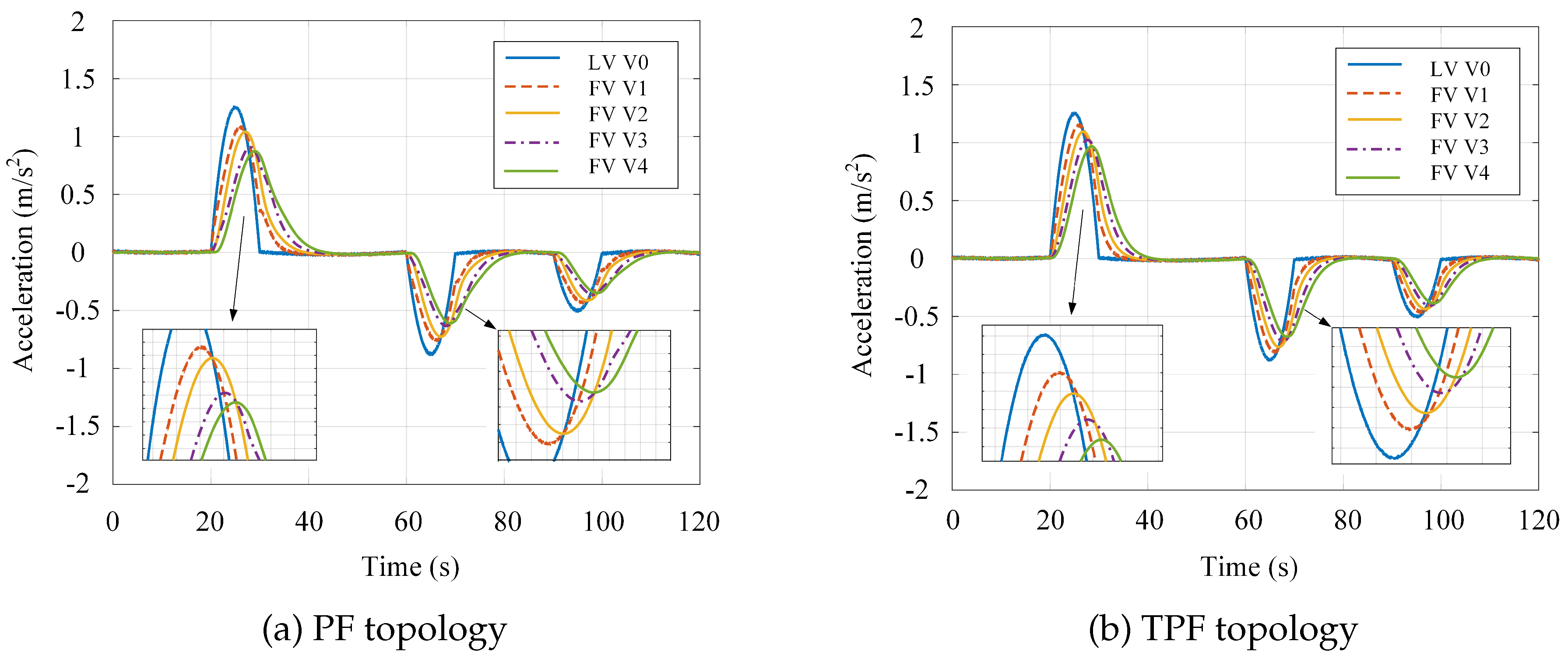
Figure 8.
Platoon vehicle spacing errors under differential game control: (a) PF topology; (b) TPF topology.
Figure 8.
Platoon vehicle spacing errors under differential game control: (a) PF topology; (b) TPF topology.
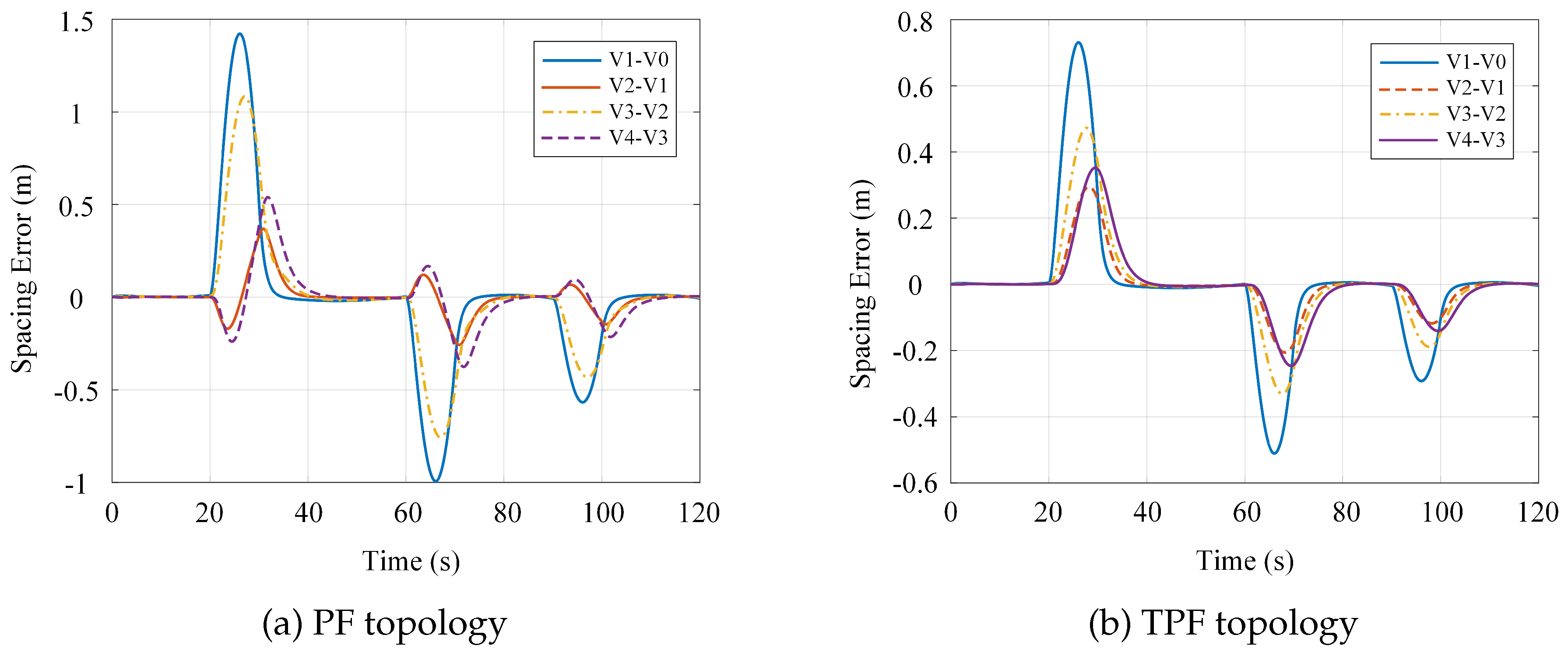
Figure 9.
Platoon time headway errors under differential game control: (a) PF topology; (b) TPF topology.
Figure 9.
Platoon time headway errors under differential game control: (a) PF topology; (b) TPF topology.
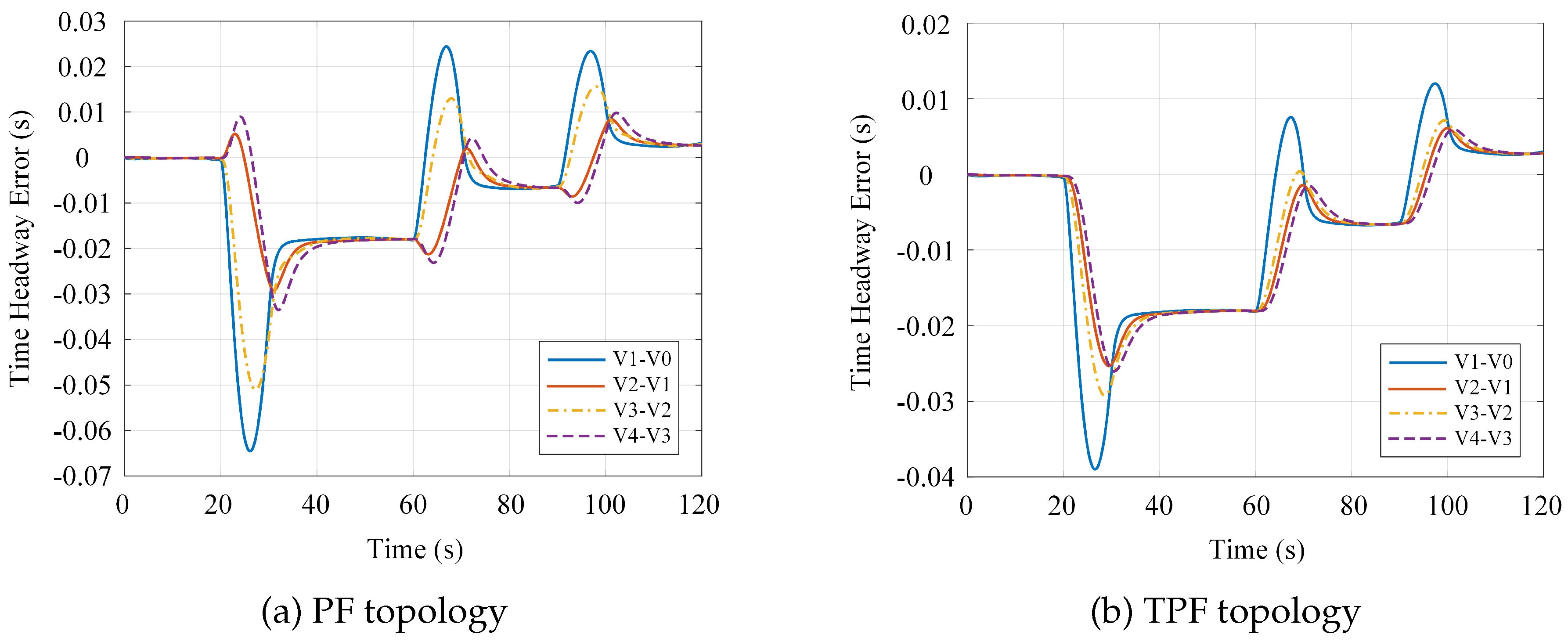
Figure 10.
Risk potential field formed by road traffic.
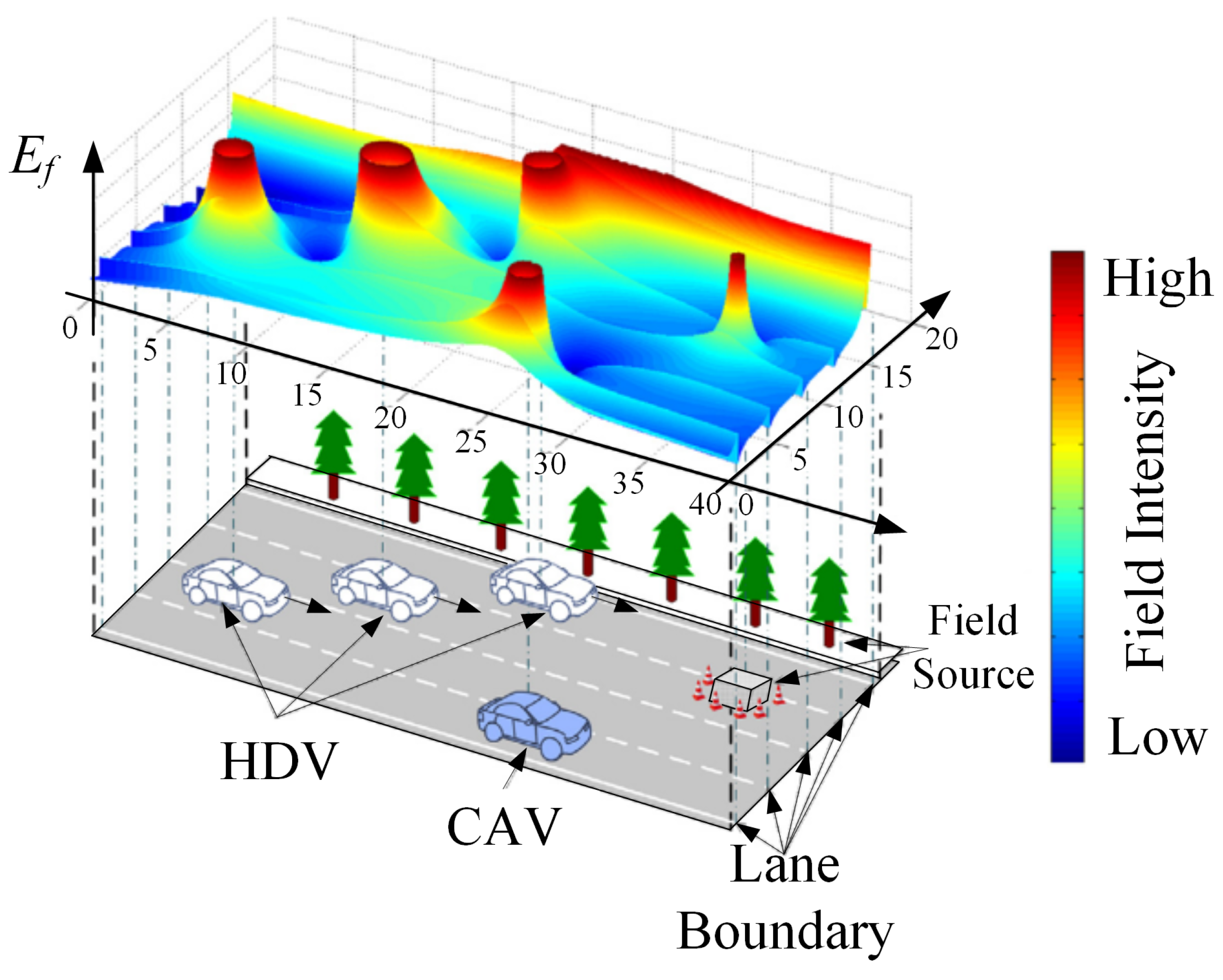
Figure 11.
Risk potential field for a three-lane scenario with multiple surrounding vehicles.
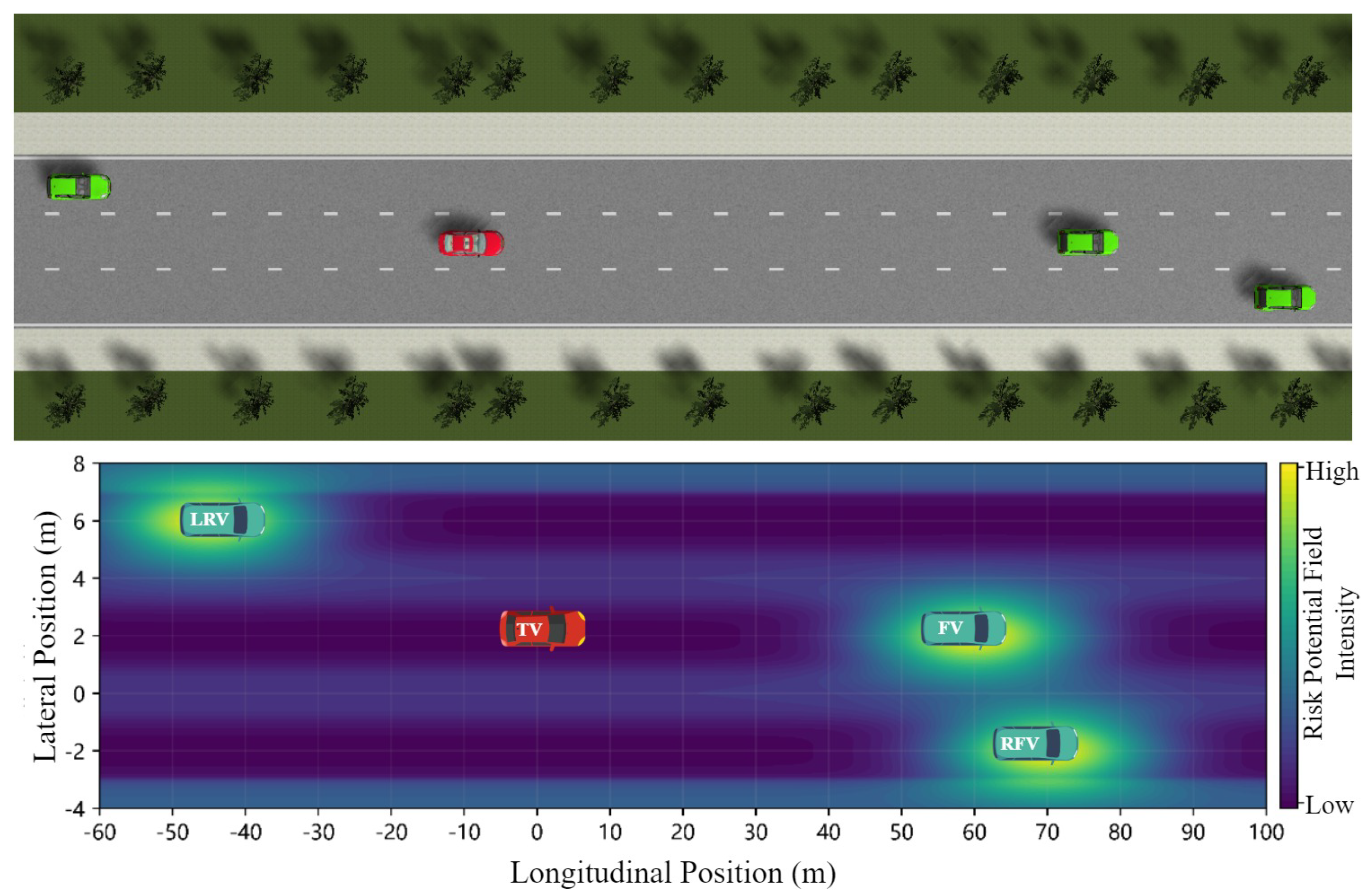
Figure 12.
Co-simulation platform architecture for CAV platoon cooperative control.
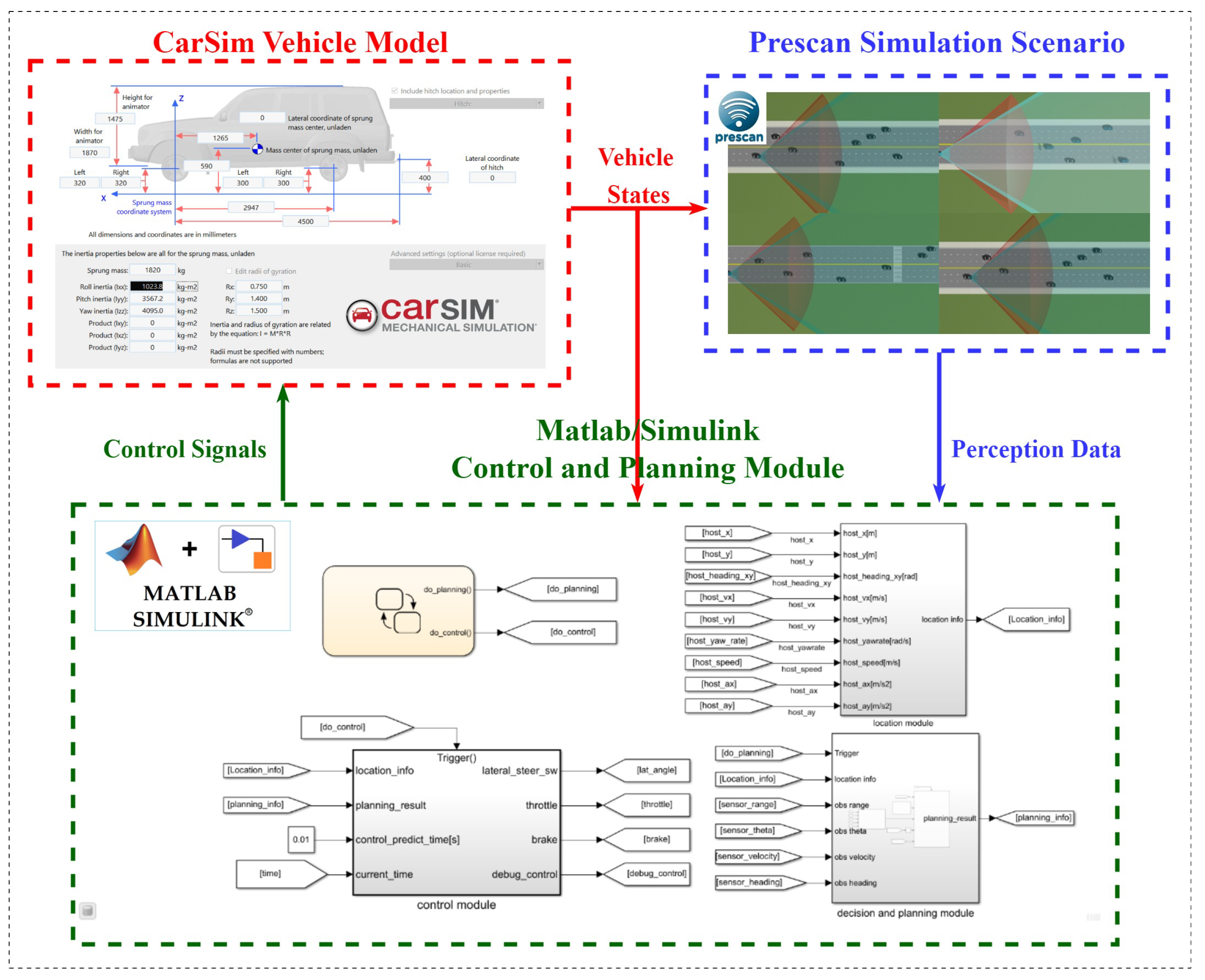
Figure 13.
Ramp merging scenario.
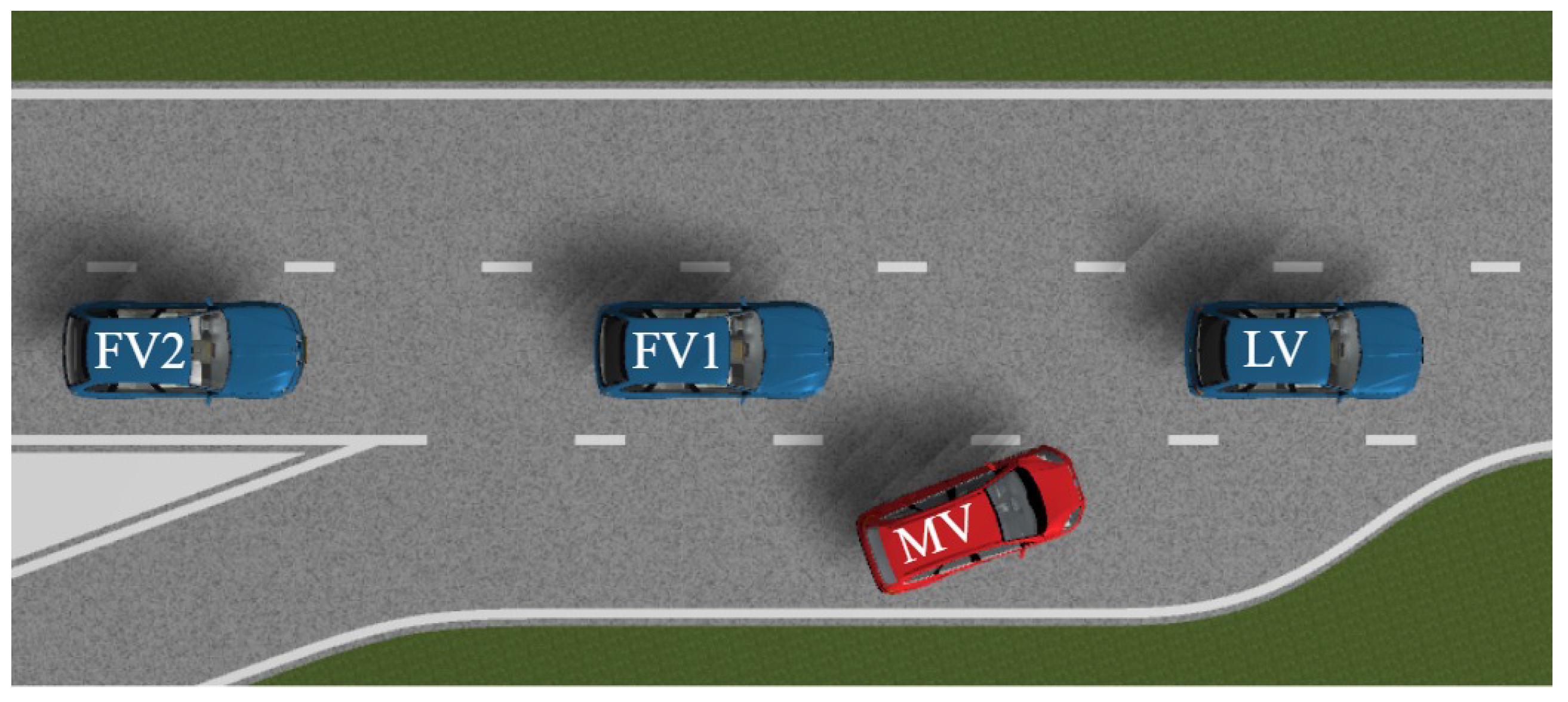
Figure 14.
Temporal evolution of vehicle positions and risk potential field distribution during the ramp merging scenario.
Figure 14.
Temporal evolution of vehicle positions and risk potential field distribution during the ramp merging scenario.
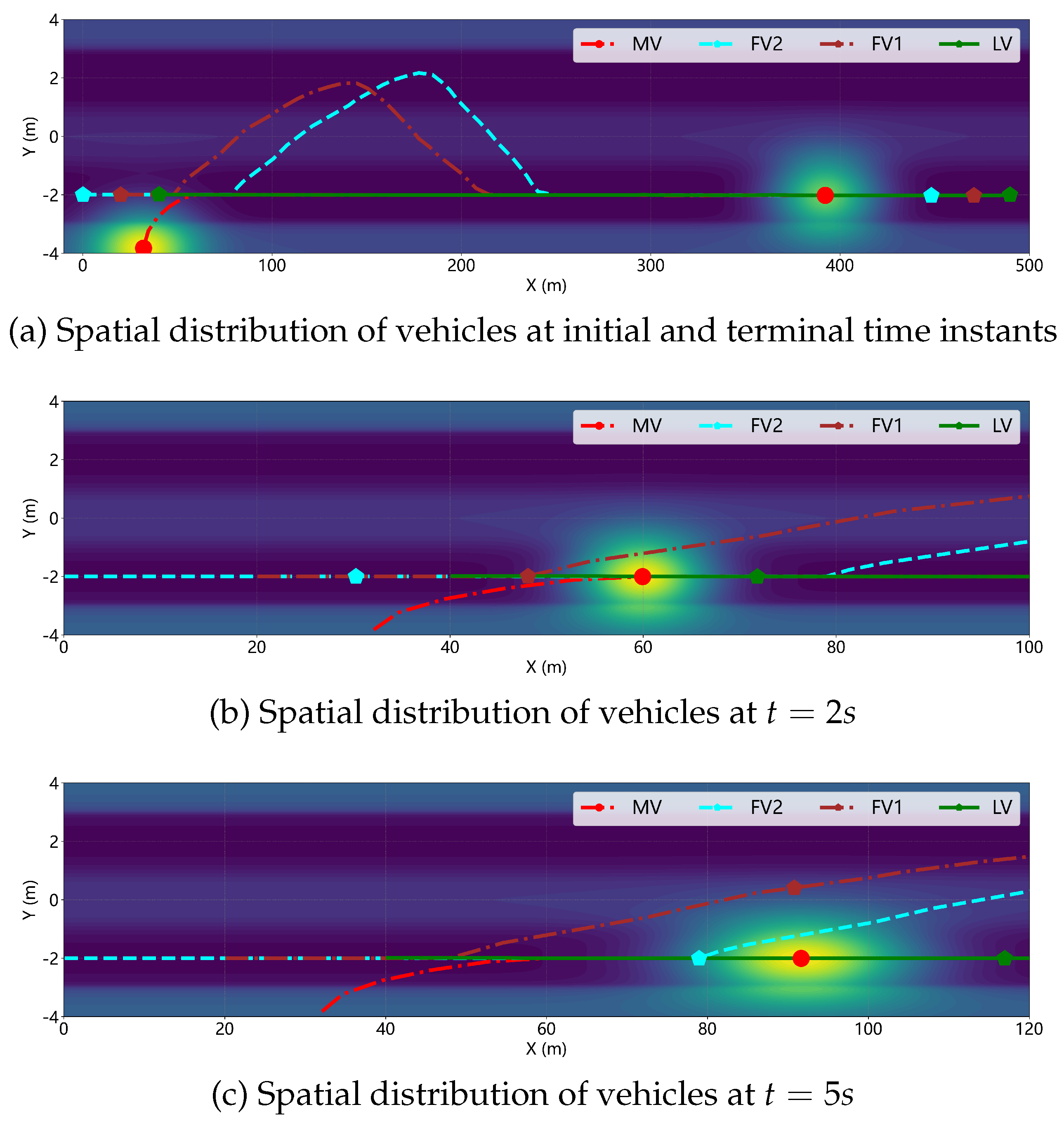
Figure 15.
Spacing errors and velocity profiles of CAV platoon in the ramp merging scenario.
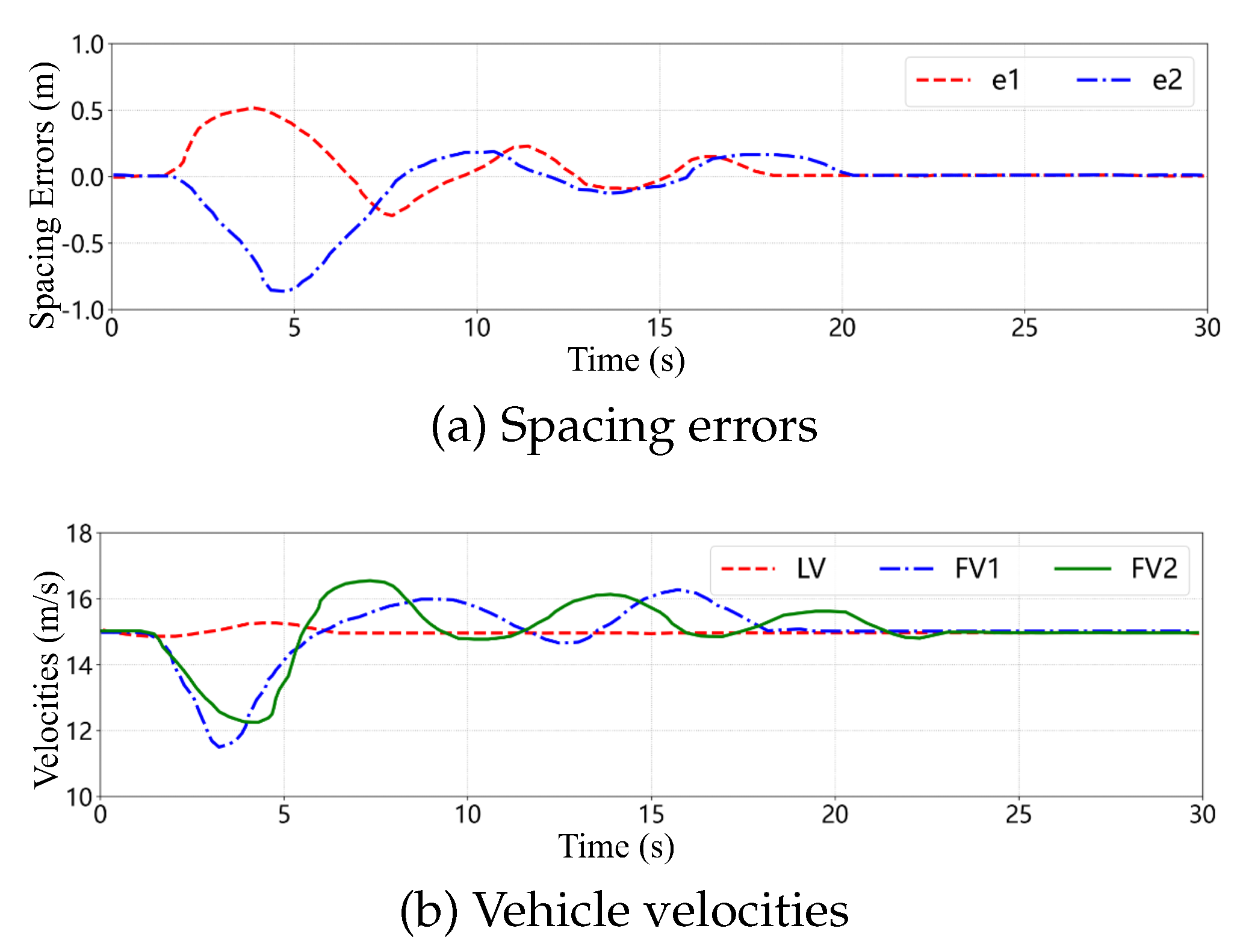
Figure 16.
Obstacle vehicle emergency braking scenario.
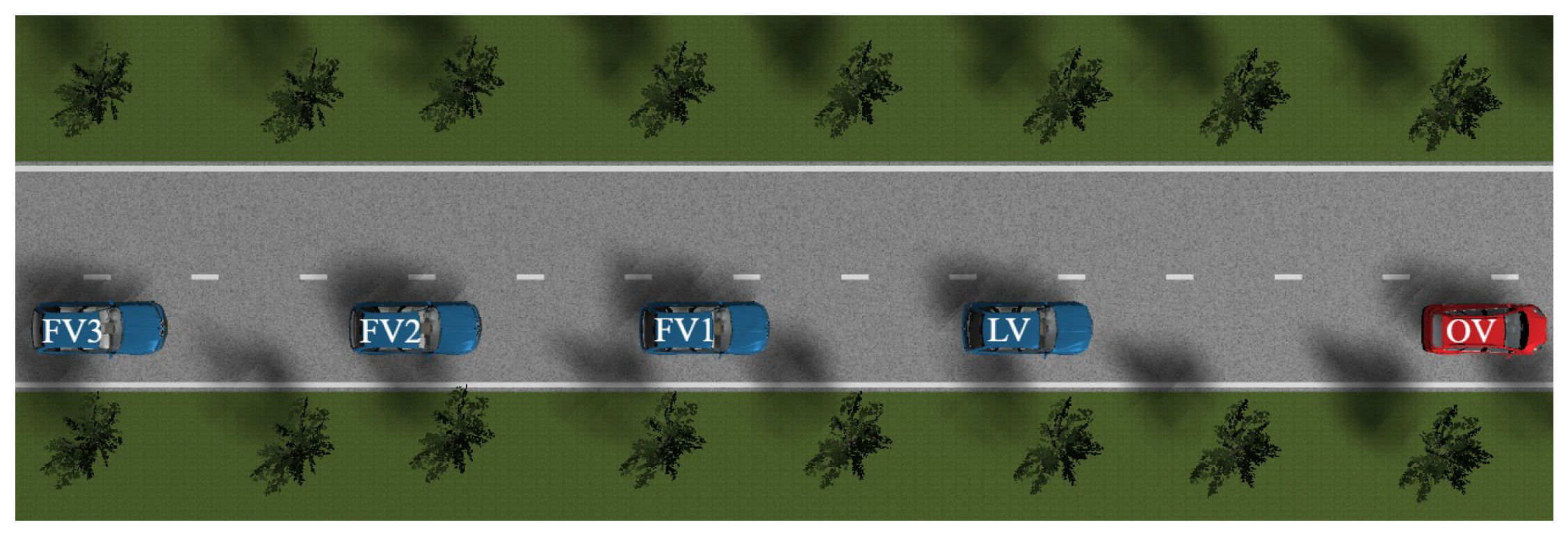
Figure 17.
Positions, spacing errors and velocities of CAV platoon in the emergency braking scenario.
Figure 17.
Positions, spacing errors and velocities of CAV platoon in the emergency braking scenario.
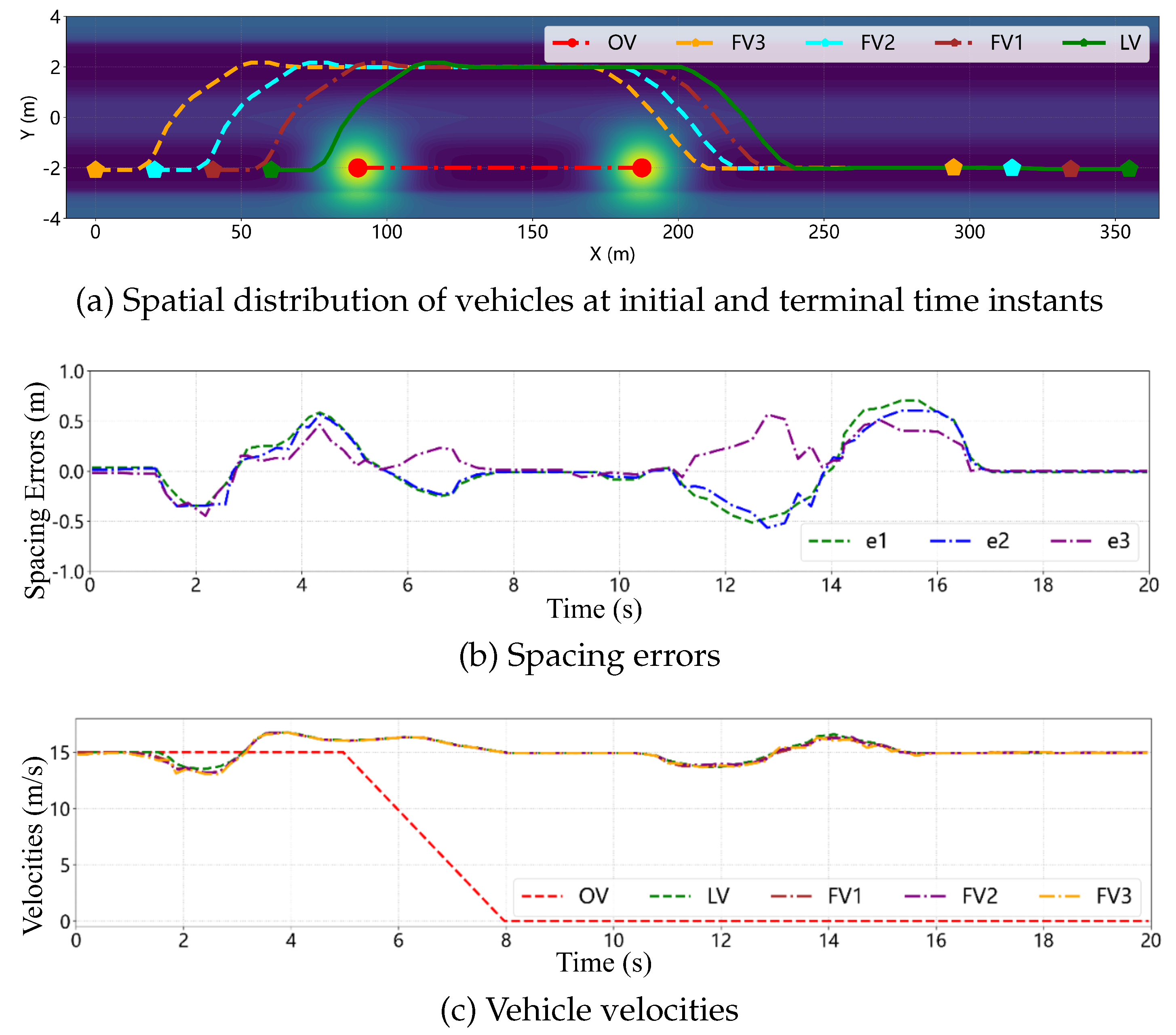
Figure 18.
Cooperative obstacle avoidance scenario for CAV platoon in multi-lane environments with obstacle vehicles.
Figure 18.
Cooperative obstacle avoidance scenario for CAV platoon in multi-lane environments with obstacle vehicles.
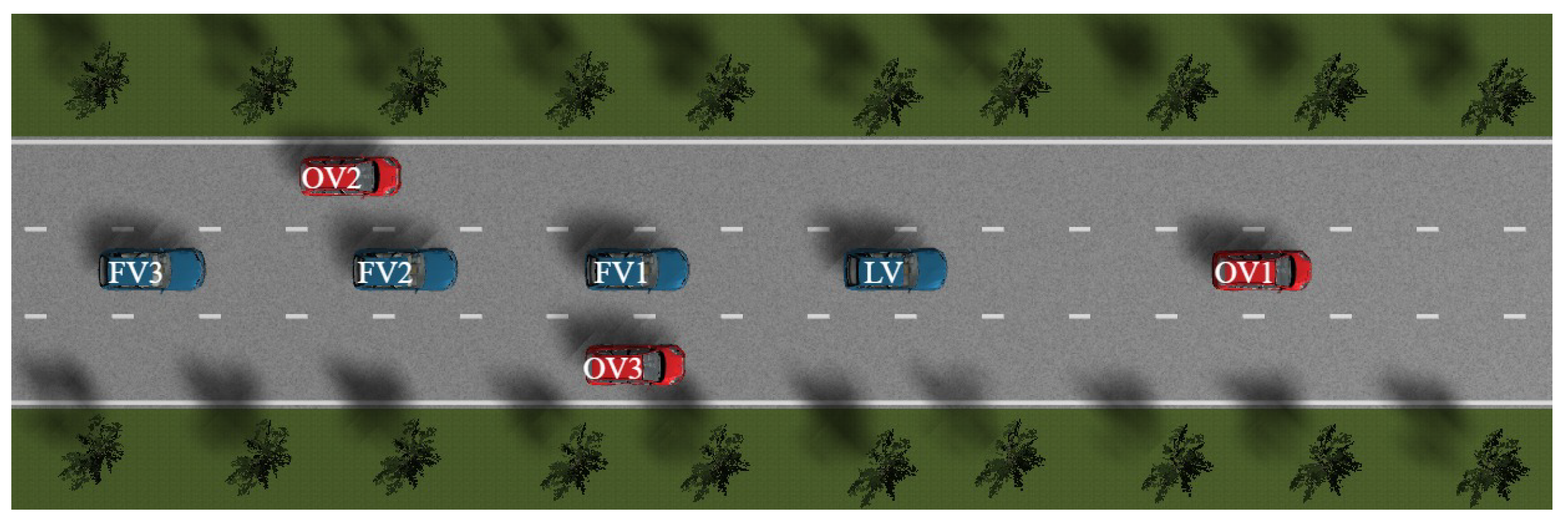
Figure 19.
FV2 and FV3 opted for a right lane change maneuver to mitigate risk.
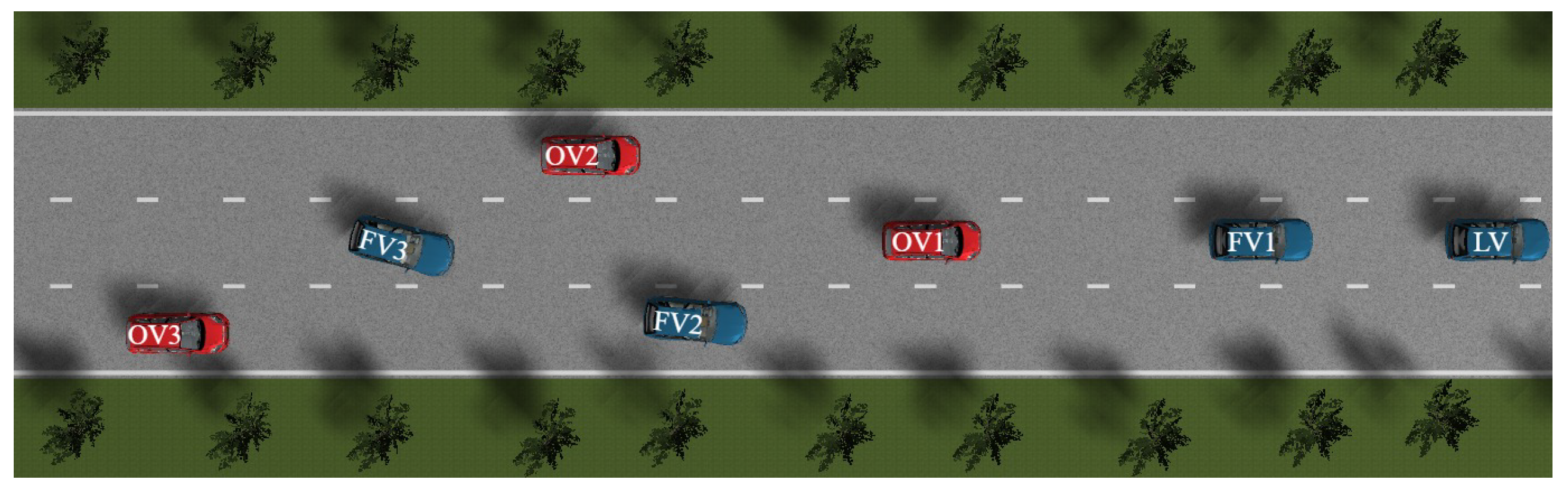
Figure 20.
Reestablishment of the platoon formation in the original lane.
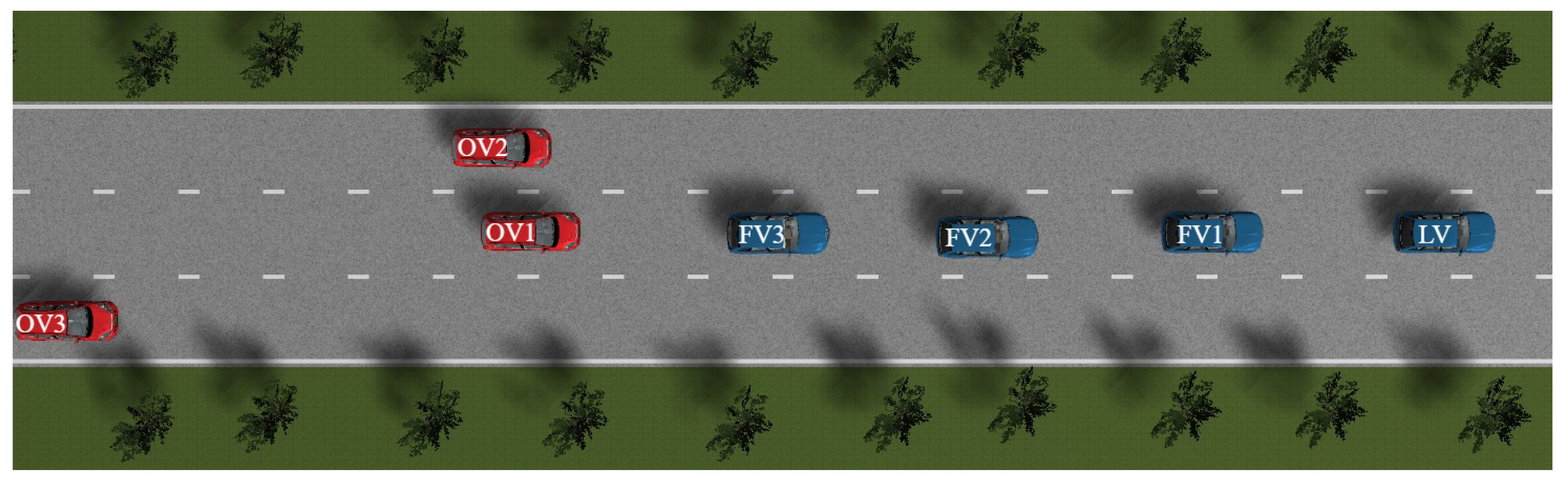
Figure 21.
Temporal evolution of vehicle positions and risk potential field distribution during the platoon cooperative obstacle avoidance scenario.
Figure 21.
Temporal evolution of vehicle positions and risk potential field distribution during the platoon cooperative obstacle avoidance scenario.
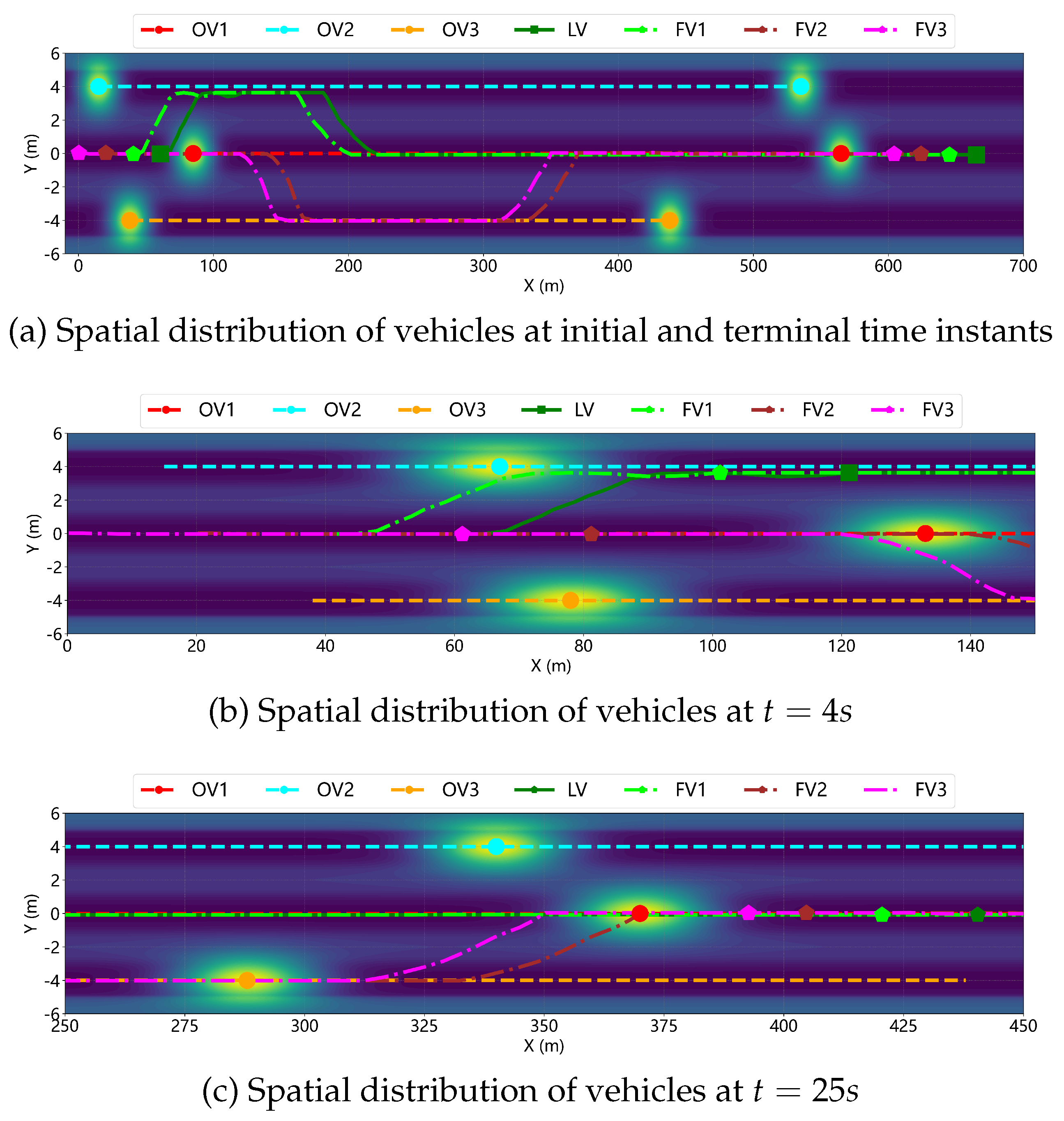
Figure 22.
Spacing errors and velocity profiles of CAV platoon in the cooperative obstacle avoidance scenario.
Figure 22.
Spacing errors and velocity profiles of CAV platoon in the cooperative obstacle avoidance scenario.
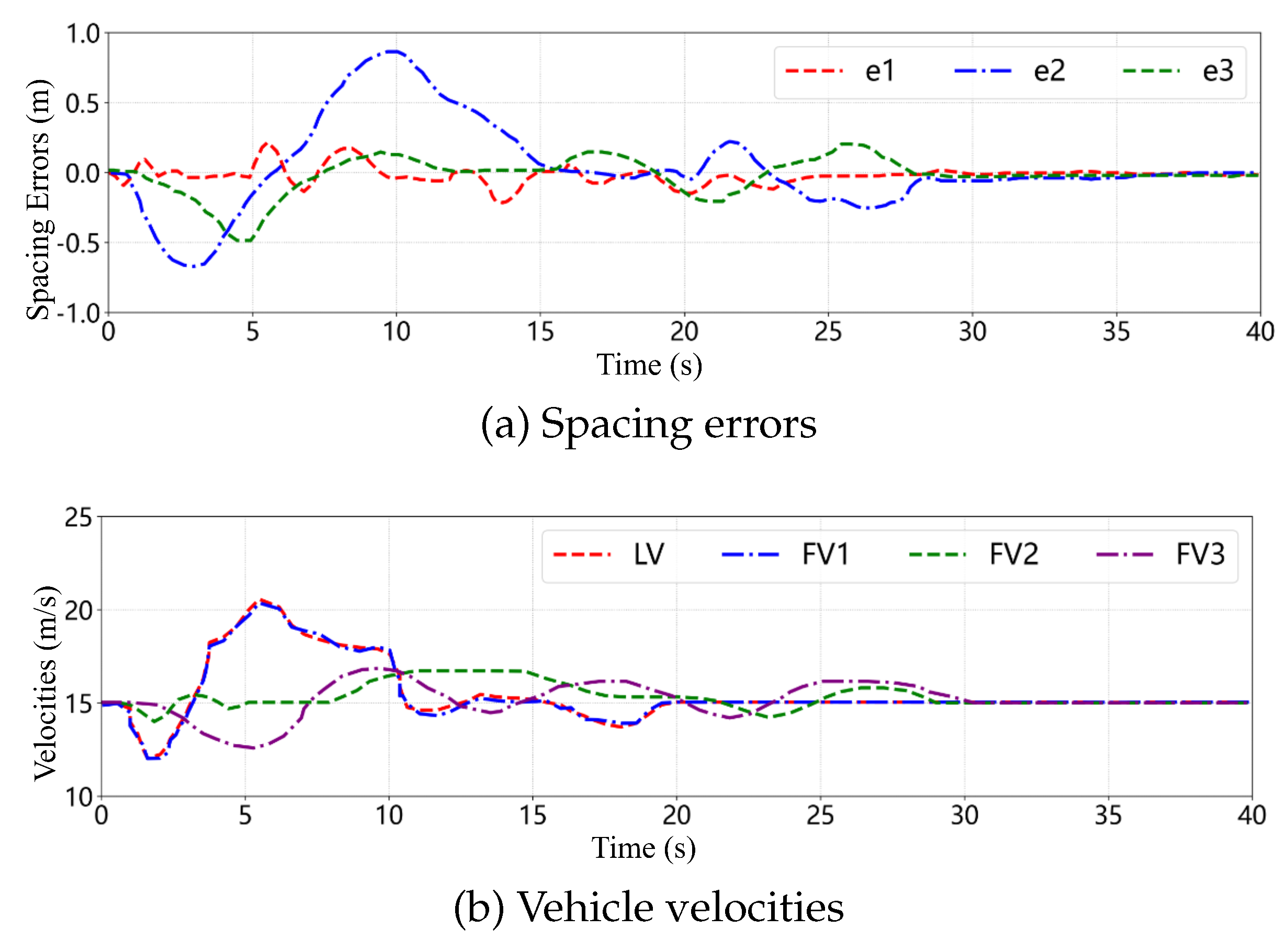

Table 1.
Initial State Vector Configuration for Platoon Vehicles.
| Vehicle Type | PF Topology | TPF Topology |
|---|---|---|
| Leader v0 | ||
| Follower v1 | ||
| Follower v2 | ||
| Follower v3 | ||
| Follower v4 |
Table 2.
Simulation Parameter Settings
| Parameter Name | Symbol | Value |
|---|---|---|
| Vehicle Dynamics Parameters | ||
| Vehicle mass (kg) | m | 1500 |
| Yaw moment of inertia (kg·m2) | 2500 | |
| Distance from CG to front axle (m) | 1.2 | |
| Distance from CG to rear axle (m) | 1.6 | |
| Front tire cornering stiffness (N/rad) | ||
| Rear tire cornering stiffness (N/rad) | ||
| Vehicle length (m) | L | 4.5 |
| Powertrain time constant (s) | 0.65 | |
| Spacing Policy Parameters | ||
| Standstill spacing (m) | r | 5.0 |
| Time headway (s) | h | 1.2 |
| Risk Potential Field Parameters | ||
| Potential well depth | 1.0 | |
| Potential field steepness coefficient | 0.5 | |
| Minimum standstill spacing (m) | 2.0 | |
| CAV response time delay (s) | 0.1 | |
| Safety distance adjustment coefficient | 0.8 | |
| Maximum comfortable deceleration (m/s2) | 4.0 | |
| Lane line intensity gain | 50 | |
| Road boundary intensity gain | 200 | |
| Lane line attenuation coefficient | 0.8 | |
| Boundary attenuation coefficient | 0.5 | |
| Longitudinal correction coefficient | l | 2.0 |
| Lateral correction coefficient | w | 1.5 |
| Longitudinal velocity weighting factor | 0.1 | |
| Attenuation exponent | k | 2.0 |
| MPC Controller Parameters | ||
| Prediction horizon | 6 | |
| Control horizon | 3 | |
| Discretization time step (s) | T | 0.1 |
| State tracking weight | Q | diag(10, 1) |
| Control increment weight | R | 0.1 |
| Risk potential field weight | P | 5.0 |
| Slack variable weight | ||
| Constraint Parameters | ||
| Maximum longitudinal velocity (m/s) | 30 | |
| Minimum longitudinal velocity (m/s) | 0 | |
| Maximum steering angle (rad) | 0.5 | |
| Maximum steering rate (rad/s) | 0.3 | |
| Road adhesion coefficient | 0.85 | |
| Simulation Scenario Parameters | ||
| Desired cruising velocity (m/s) | 15 | |
| Initial inter-vehicle spacing (m) | 20 | |
| Lane width (m) | – | 3.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



