Submitted:
04 December 2025
Posted:
05 December 2025
You are already at the latest version
Abstract
AI-generated content and misinformation are increasingly prevalent on social networks. While prior research primarily examined textual misinformation, fewer studies have focused on visual content's role in virality. In this work, we present the first large-scale analysis of how misinformation and AI-generated images propagate through repost cascades across five ideologically diverse Reddit communities. By integrating textual sentiment, visual attributes, and diffusion metrics (e.g., time-to-first repost, community reach), our framework accurately predicts both immediate post-level virality (AUC=0.83) and long-term cascade-level spread (AUC=0.998). These findings offer essential insights for moderating synthetic and misleading visual content online.
Keywords:
misinformation
; generative AI
; virality prediction
; social media analysis
; cascades
1. Introduction
The rise of social media platforms like Reddit, Instagram, and X has transformed information dissemination. Unlike traditional media, which rely on editorial oversight to ensure accuracy, these platforms prioritize user-driven engagement signals, such as upvotes and shares, over credibility. Consequently, physiologically arousing or false content often spreads faster than neutral or truthful information [1,2].
Compounding this issue is the rise of generative AI (GenAI) and deepfake image manipulation tools. Visual content is processed more quickly than text and often transcends language barriers. Past research has also found that images are inherently more memorable than text [3,4]. Regardless, distinguishing real from synthetic visuals remains difficult, even with recent advances in detection [5,6]. While recent studies examine visual misinformation, such as COVID-19 images on Twitter [7] and meme virality on Reddit [8], research on virality in ideologically driven communities remains sparse.
To address this, we analyze how misinformation and GenAI influence the virality of visual and textual posts across diverse Reddit communities. We specifically study virality at two distinct levels: immediate individual post popularity ("post-level virality") and long-term content propagation through sharing or reposting ("cascade-level virality"). A diffusion cascade refers to the complete pathway through which a post spreads across a network via repeated reposting. At the cascade level, we examine features of entire diffusion cascades, such as overall size, structural complexity, and community reach.
Specifically, we explore the following questions:
- (1)
- How do visual and textual features affect virality at the individual post and cascade levels?
- (2)
- When predicting how widely content spreads (cascade-level virality), how do content-based predictors such as text and visual attributes compare against early sharing signals and community interaction patterns (diffusion context-based features)?
- (3)
- What post-specific features characterize pure misinformation, pure AI-generated, and misinformation and AI-generated imagery ("mixed-flag" content) classifications at the post and cascade level?
The first question builds upon findings that emotionally engaging or misleading content tends to be more viral [1,2]. Prior studies have focused on general imagery, typically without distinguishing misinformation or synthetic media [9,10]. By explicitly examining misinformation and AI-generated visuals, we offer targeted insights into how these specific content types shape virality uniquely within ideologically driven communities.
The second question addresses the gap in understanding Reddit’s diffusion dynamics due to its lack of an explicit social graph—unlike Twitter, where propagation is more straightforward to analyze. Our study reconstructs repost cascades by leveraging shared image URLs and crossposting data, allowing us to compare how intrinsic features of posts (content-based) versus early sharing behaviors and diffusion metrics (context-based) predict virality. Additionally, we introduce novel visual markers specific to generative AI, such as digital artifacts and image noise, identifying previously unexplored connections between these visual elements and content diffusion.
The third question investigates the distinct and combined effects of misinformation and AI-generated imagery ("mixed-flag posts"). Mixed-flag posts—those identified as containing both misinformation and synthetic or manipulated imagery—may drive unique engagement patterns that neither misinformation nor synthetic visuals alone can explain. Prior research highlights misinformation’s power to engage via novelty or emotional provocation, and AI-generated content’s effectiveness through visually striking imagery and positive framing despite questionable credibility [2,11]. However, how these features interact in combination remains under-explored. We address this gap by systematically studying pure misinformation, pure AI-generated content, and mixed-flag posts, providing nuanced insights into their distinct engagement patterns and diffusion trajectories.
1.1. Our Contribution
We present the first large-scale cascade-level study of visual content diffusion on Reddit, focusing on how misinformation and GenAI content spread across user communities. Our dataset includes 1,800+ repost cascades clustered via shared image URLs and crossposts, encompassing 5,660 posts from five ideologically diverse subreddits. Each cascade is enriched with multimodal features: text sentiment, visual descriptors (e.g., digital manipulation indicators, image sharpness, and GenAI-specific markers), and user interaction metrics (e.g., upvote ratio, comment counts). Diffusion-based attributes such as cascade depth, Wiener index (structural virality), time-to-first repost, and cross-subreddit reach are also computed. Misinformation posts receive unusually high engagement (mean score of 36,000+, 2,400+ comments), while GenAI images show broader subreddit spread (1.106 average cross-community reach). Mixed-flag cascades (misinfo + AI) exhibit the strongest dynamics, with an average size of 26.96, depth of 25.96, and structural virality of 7.14.
Our framework effectively supports both cascade-level and post-level virality predictions through early diffusion signals combined with multimodal post features. At the post-level, visual features dominate predictions, with markers like image noise and digital artifacts significantly influencing virality (post-level prediction accuracy 87%, AUC = 0.83). At the cascade-level, our best model integrating multimodal content and early diffusion achieves an AUC of 0.998, surpassing both content-only (0.957) and diffusion-only (0.995) baselines. The robustness of our GenAI and misinformation pseudolabeling methods, validated through manual reviews and cross-dataset evaluations, significantly enhances our model’s predictive accuracy and reliability. By bridging content-based analysis with diffusion modeling, we provide a comprehensive empirical framework for understanding multimodal misinformation and synthetic media propagation on Reddit.
2. Methods
To investigate how visual misinformation and GenAI content spread across Reddit, we developed a multimodal analysis pipeline targeting five visually driven subreddits, r/conspiracy, r/politics, r/conservative, r/propagandaposters, and r/deepfakes. Our approach includes dataset filtering, misinformation and GenAI classification, repost cascade modeling, and predictive analysis. This enables us to examine early indicators of virality, diffusion dynamics of harmful content, and multimodal predictors of spread.
Figure 1.
Overall Architecture Pipeline

2.1. Data Collection & Labeling
2.1.1. Safe Search
To ensure the appropriateness of our dataset, we implemented an automated filtering process to exclude any images classified as not safe for work (NSFW). We used a pretrained image classification model from the Hugging Face Transformers library prior to inclusion in our analysis due to its accuracy and scalability after exploring several alternatives, including other pretrained models, NSFW Python libraries, and a custom Tensor Flow model. Manual review of 100 images (50 safe, 50 NSFW) showed 95% alignment with human judgment, confirming the model’s reliability.
2.1.2. Misinformation
To assess textual misinformation, we fine-tuned a classifier on the Fakeddit dataset consisting of over 110,000 images from Reddit. We selected this method due to the relevance of this data and its improved performance over several baseline models, including zero-shot classifiers based on large language models (e.g., BART, RoBERTa) and sentiment-based heuristics. To validate the accuracy of our fine-tuned model, we conducted a manual review of 100 random post titles, and we observed about 79.5% agreement between model outputs and human judgments.
2.1.3. GenAI
To develop an AI-generated pseudolabel for each image, we used the pre-trained ClipBased-SyntheticImageDetection model introduced by [6] to extract image embeddings followed by a SVM classifier with a RBF-kernel. We chose this model because of its ability to generalize across different generative models with only few-shot learning [6]. To train, we curated a labeled dataset by combining real and AI-generated images from diverse sources. A key challenge was the lack of large-scale, ground-truth-labeled datasets for social media content, which often includes noisy formats like memes, screenshots, and annotated images. We experimented with multiple dataset combinations to assess their effect on generalization, especially on out-of-sample AMMeBa validation. Our final dataset included:

Table 1.
Training data details of real vs. fake content.
| Training Data | Real | Fake |
|---|---|---|
| AI Generated Images vs. Real Images Dataset [12] | 10,000 | 2,000 |
| Google Research’s AMMeBa Dataset [13] | 219 | 219 |
| Manually Labeled Reddit Data | 202 | 202 |
| Total | 10,421 | 2,421 |
By combining scale [12], domain relevance [13], and platform-specific samples (Reddit), we constructed a dataset optimized for performance on both typical and noisy social media images. We selected a lightweight classifier by evaluating six models—Random Forest (RF), Logistic Regression, MLP, SVM (linear & RBF), and XGBoost—on 109 out-of-sample AMMeBa images. We chose an RBF-kernel SVM for its superior accuracy (91%) and F1-score.
2.2. Feature Extraction & Virality Metric
We extracted multimodal features, textual, visual, and metadata, for each Reddit post, computed a Virality Attention Index (VAI), and constructed content cascades to measure structural virality.
2.2.1. Textual Features (Post-Level)
We extract text-based features to capture linguistic style, sentiment, and clickbait tendencies. Title and caption embeddings are generated via a pretrained BERT model, producing a 768-dimensional vector that encodes semantic and contextual information. Sentiment scores are computed using VADER, yielding compound (overall polarity in ), positive, and negative values. To assess clickbait cues, we include the length and flag presence of keywords like “breaking,” “viral,” and “shocking,” which often signal sensational or high-engagement content.
2.2.2. Visual Features (Post-Level)
To characterize each post’s image thumbnail, we extract visual features capturing quality, content, and dimensions. We compute noise, variance, and error scores to assess sharpness, compression, and potential manipulation. Using YOLOv5, we detect objects (e.g. “people”, “animal,” “car,” etc.) as binary flags. We log thumbnail width and height to capture aspect ratio and resolution. Finally, we include two image-level flags from Section 3.4’s classifiers: misinfo_flag (image) (likely manipulated) and genai_flag (image) (likely AI-generated), which help identify fabricated visuals and estimate attention potential.
2.2.3. Metadata & User-Interaction Features
We extract metadata and interaction features reflecting post performance and author behavior. These include upvote ratio (upvotes / (upvotes + downvotes)), total awards, and explicit crossposts (num_crossposts). We record whether the post is original content (Reddit flag) and the hour of posting (hour) to capture temporal context. A binary is_crossposted flag marks posts shared across subreddits. Finally, intensity relative to voting is quantified using the engagement ratio ().
2.2.4. Virality Attention Index (VAI)
To measure early-stage virality, we define the Virality Attention Index (VAI), a scalar metric balancing engagement with post recency:
- Score is the number of upvotes
- is the number of comments
- (current timestamp - post timestamp) in hrs
- (chosen to avoid division by zero)
VAI captures the “early burst” effect: high values reflect rapid early engagement, while lower values indicate slower or stale posts. It is used both as a virality label (top 20% vs. others) and as a feature in downstream models for detecting misinformation and AI-generated content.
2.2.5. Cascade Construction (DSU Clustering)
To group related posts sharing content, we apply a Disjoint-Set Union (DSU) clustering procedure based on:
- Image URL Matching: Posts with identical image URLs are merged.
- Crosspost Links: Posts with a crosspost_parent are unioned with the parent’s set.
- Same Author Reposts: Posts with visually similar content by the same author are merged.
This yields disjoint cascade components , each representing a group of related posts across subreddits. We discover 1,804 such cascades and compute per-cascade statistics: total upvotes, number of subreddits, average repost delay, and text/image content entropy.
2.2.6. Canonical Repost Graph (For Each Cascade)
For each cascade C, we construct a time-respecting repost graph :
- Order Posts: Sort posts by timestamp.
- Assign Parent Edges: If an explicit crosspost parent exists in C, link parent to . Else, link to its immediate predecessor in time.
The resulting directed graph encodes both repost lineage and temporal flow.
2.2.7. Structural Virality (Wiener Index)
To measure cascade shape, we find the structural virality of each repost graph :
- Undirected Form: Convert to an undirected graph
- Shortest Paths: For every pair of distinct nodes in , compute the shortest-path length .
- Wiener Index: To distinguish between broadcast-style cascades (many direct reposts of a single root) and chain-style cascades (deep, multi-generation propagation), we compute the structural virality (also known as the Wiener index) for each repost graph :
Low virality () indicates a star-like broadcast; high values reflect deeper, chain-like propagation. This metric captures both cascade size and how content diffused—via broad hubs or sequential reposting. Using post-level features and VAI, these cascade-level signals enable robust modeling of early virality, misinformation, and generative content detection.
2.2.8. Feature Importance via SHAP Values
To interpret model predictions and quantify the influence of individual features, we compute SHAP (SHapley Additive exPlanations) values, a unified measure of feature importance. SHAP values offer consistent and locally accurate attribution scores, helping identify which features most strongly drive virality predictions. We use these insights in Section 3 (Experimental Results) to interpret feature contributions clearly and intuitively.
3. Experimental Results
3.1. Experimental Setup
We conduct eight experiments to evaluate how different feature sets predict cascade and post level virality. Across all experiments, we evaluate four models: LightGBM, RF, RF with Extra Trees, and Gradient Boosting.
Figure 2.
Experimental Setup Overview
3.1.1. Virality Prediction
We assess how well content-based features predict post (VAI) and cascade-level virality (structural virality). We compare pure text, pure image, and combined text+image features across the four models.
3.1.2. Content vs. Context Features
Next, we evaluate the predictive power of content features (text and image) versus context features (cascade metrics, excluding those directly tied to virality such as depth) at solely the cascade-level. To construct cascade-level text and image features, we average all post-level text and image features within a cascade.
3.2. Results
3.2.1. RQ1: How Do Visual and Textual Features Affect Virality at the Individual Post and Cascade Levels?
At the post level, content features yielded strong predictive performance (accuracy of 87 %, macro-F1 of 0.78, AUC of 0.83), indicating that our models can distinguish viral posts using only image and text cues. Visual features dominated: feature-importance analysis (Figure 3) revealed image noise as the single most influential predictor. This suggests that minor visual imperfections or artifacts may boost engagement by evoking a sense of authenticity or humor. Prior work supports this, noting that “authentic” or non-polished visuals often resonate more with viewers [9,10]. Other strong visual predictors included Laplacian variance (image sharpness), with sharper images correlating with higher virality—likely due to enhanced cognitive fluency [4]—and Error Level Analysis (ELA) scores, indicating detectable digital manipulation, which also positively associated with share rates [5]. On the textual side, posts embedding positive sentiment or explicit calls-to-action (e.g., “share this!”) performed significantly better, echoing prior findings on emotional engagement and direct prompts as sharing drivers [1,14].
At the cascade level, content features proved even more predictive. Our cascade model achieved accuracy of 89% and an AUC of 0.998, showing that posts which lead to extensive cascades—i.e., sharing threads that grow into hundreds of reshares spanning multiple subreddits and time intervals—have highly distinctive content signatures. The top predictor was misinformation prevalence: posts containing demonstrably false or misleading information were far more likely to spark these large-scale diffusion events (Figure 3), reinforcing findings by Vosoughi et al. [2]. AI-generated imagery was the next strongest feature, suggesting that deepfake-style visuals lead to curiosity or alarm, driving broad resharing across the community [11]. Notably, some post-level cues—such as positive sentiment—remained significant, implying that emotional tone amplifies both immediate and extended sharing.
Thus, RQ1 emphasizes how post-level virality favors attention-grabbing features like image sharpness, authentic imperfections (noise), and direct textual cues that prompt quick engagement. In contrast, cascade-level virality is driven by content that sustains public interest over time. Effective mitigation will therefore require both rapid flagging of attention-grabbing posts and sustained monitoring of misleading or synthetic content to prevent large-scale cascades.
3.2.2. RQ2: When Predicting Cascade-Level Virality, How Do Content-Based Predictors Compare Against Diffusion Context-Based Features?
Diffusion-based features (AUC = 0.995) outperform content-based (image/text) features alone (AUC = 0.957) in predicting cascade-level virality. While models using only content cues such as visual aesthetics, textual sentiment, and misinformation or GenAI indicators already achieve strong predictive performance (AUC = 0.957)—substantially higher than prior benchmarks, e.g., Sah et al. (2025) who reported approximately 77% AUC for meme virality [8]—incorporating diffusion signals yields significant improvements. Diffusion indicators, including rapid early reshares, cascade breadth within the initial hours, and involvement of influential users, capture immediate social dynamics crucial for predicting eventual cascade growth.
Combining both content and diffusion features provides the best predictive accuracy (AUC = 0.998), highlighting their complementary strengths. For example, visually compelling or emotionally engaging posts that also show strong initial resharing patterns have the highest likelihood of extensive virality. Furthermore, content markers such as GenAI-generated visuals and misinformation consistently rank among the strongest predictors (Figure 3), underscoring moderation challenges as these types of content rapidly spread and cross community boundaries. This underscores the necessity of integrating content quality assessments with real-time diffusion dynamics to effectively predict and manage large-scale virality events.
3.2.3. RQ3: What Post-Specific Features Characterize Pure Misinformation, Pure AI-Generated, and Mixed-Flag Classifications at the Post and Cascade Level?
At the post level (Table 2), pure misinformation (misinfo = True, GenAI = False) drew the highest engagement with a mean score of 35,567, comments total of 2,433, and VAI 1.61. Mixed-flag posts (True/True) received moderate attention (score 22,991; comments 1,282; VAI 0.71), while pure AI-generated content (False/True) had the lowest (score 1,809; comments 204; VAI 0.17). Unlike Sah et al. (2025), who found similar engagement for AI and misinformation, our results suggest text-based misinformation drives attention most, with AI imagery offering only modest amplification.
At the cascade level (Table 3), mixed-flag cascades (True/True) far outperformed others in spread and longevity. They had the highest mean cascade size of 26.96, depth of 25.96, and structural virality of 7.14, compared to pure misinformation (mean cascade size: 2.58, depth: 1.58, structural virality: 0.56) and pure AI (mean cascade size: 5.13, depth: 4.13, structural virality: 0.74). Mixed-flag content also reached its peak resharing speed fastest (174 hours) and had the longest lifespan (13,848 hours), while pure misinformation cascades spread the slowest (e.g., 2,370 hours to first repost). This extends findings from Wang et al. [7], who noted that misinformation lasts longer, by showing that AI-enhanced misinformation spreads faster and further.
RQ3 reveals a two-stage virality dynamic: text-based misinformation attracts initial engagement, AI-generated imagery accelerates early resharing, and their combination yields exceptionally viral cascades. This underscores the importance of modeling multimodal flag interactions when forecasting both immediate popularity and long-term spread.
4. Conclusion
This study examines how images (particularly AI-generated images) drive virality and misinformation on Reddit. We analyze a dataset of 5,660 posts across diverse subreddits to uncover how visual features contribute to the spread of AI-generated and manipulated content. These findings complement prior text-focused work, offering a more holistic understanding of online virality.
Future research could expand this analysis to other social media platforms or investigate specific image characteristics such as visual tropes or advanced deepfake techniques. Another important extension involves studying user responses to visual misinformation, including comment sentiment, perceived trustworthiness, and variation across demographic groups. Ultimately, a nuanced understanding of how images drive online engagement is essential for building defenses against the evolving landscape of manipulated media.
Acknowledgments
The authors gratefully acknowledge Professor Adam Wierman for his invaluable support, insightful guidance, and continued encouragement throughout this research.
References
- Berger, J.; Milkman, K.L. What makes online content viral? Journal of Marketing Research 2012, 49, 192–205. [Google Scholar] [CrossRef]
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef] [PubMed]
- Standing, L. Learning 10,000 pictures. Quarterly Journal of Experimental Psychology 1973, 25, 207–222. [Google Scholar] [CrossRef] [PubMed]
- Isola, P.; Xiao, J.; Torralba, A.; Oliva, A. What makes an image memorable? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011; IEEE; pp. 145–152. [Google Scholar]
- Farid, H. Image forgery detection. IEEE Signal Processing Magazine 2009, 26, 16–25. [Google Scholar] [CrossRef]
- Cozzolino, D.; Poggi, G.; Corvi, R.; Nießner, M.; Verdoliva, L. Raising the Bar of AI-generated Image Detection with CLIP. arXiv. 2023. Available online: https://arxiv.org/abs/2312.00195.
- Wang, Y.; Ling, C.; Stringhini, G. Understanding the Use of Images to Spread COVID-19 Misinformation on Twitter; New York, NY, USA, 2023; Vol. 7. [Google Scholar] [CrossRef]
- Sah, T.; Jordan, K. Decoding Reddit Memes Virality. International Journal of Data Science and Analytics 2025. Open Access; Received; Published. Accepted, 30 April 2024. [CrossRef]
- Khosla, A.; Sarma, A.D.; Hamid, R. What makes an image popular? In Proceedings of the Proceedings of the 23rd International Conference on World Wide Web, New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Deza, A.; Parikh, D. Understanding Image Virality. arXiv. 2015. Available online: https://arxiv.org/abs/1503.02318.
- Drolsbach, C.; Pröllochs, N. Characterizing AI-Generated Misinformation on Social Media. arXiv. 2025. Available online: https://arxiv.org/abs/2505.10266.
- Zhang, T. AI Generated Images vs Real Images. Kaggle. 2023. Available online: https://www.kaggle.com/datasets/tristanzhang32/ai-generated-images-vs-real-images (accessed on 23 July 2025).
- Dufour, N.; Pathak, A.; Samangouei, P.; Hariri, N.; Deshetti, S.; Dudfield, A.; Guess, C.; Escayola, P.H.; Tran, B.; Babakar, M.; Bregler, C. AMMeBa: Annotated Misinformation, Media-Based (In-the-Wild Misinformation Media). Kaggle / Google Research. 2024. Available online: https://www.kaggle.com/datasets/googleai/in-the-wild-misinformation-media (accessed on 23 July 2025).
- Zarrella, D. The Science of Marketing: When to Tweet, What to Post, How to Blog, and Other Proven Strategies; Wiley, 2013; Available online: https://www.amazon.com/Science-Marketing-Tweet-Proven-Strategies/dp/1118138279.
Figure 3.
Top 5 Mean SHAP Contribution for Virality Prediction at the (a) Post-level (b) Cascade-level (image, text) (c) Cascade-level (image, text, cascade-dynamics). GenAI and misinformation counts per cascade are by far the strongest virality predictors, outpacing any other image or text feature. Cascades rich in pseudo-labeled content spread faster, persist longer, and cross community boundaries, posing a moderation challenge within Reddit communities.
Figure 3.
Top 5 Mean SHAP Contribution for Virality Prediction at the (a) Post-level (b) Cascade-level (image, text) (c) Cascade-level (image, text, cascade-dynamics). GenAI and misinformation counts per cascade are by far the strongest virality predictors, outpacing any other image or text feature. Cascades rich in pseudo-labeled content spread faster, persist longer, and cross community boundaries, posing a moderation challenge within Reddit communities.
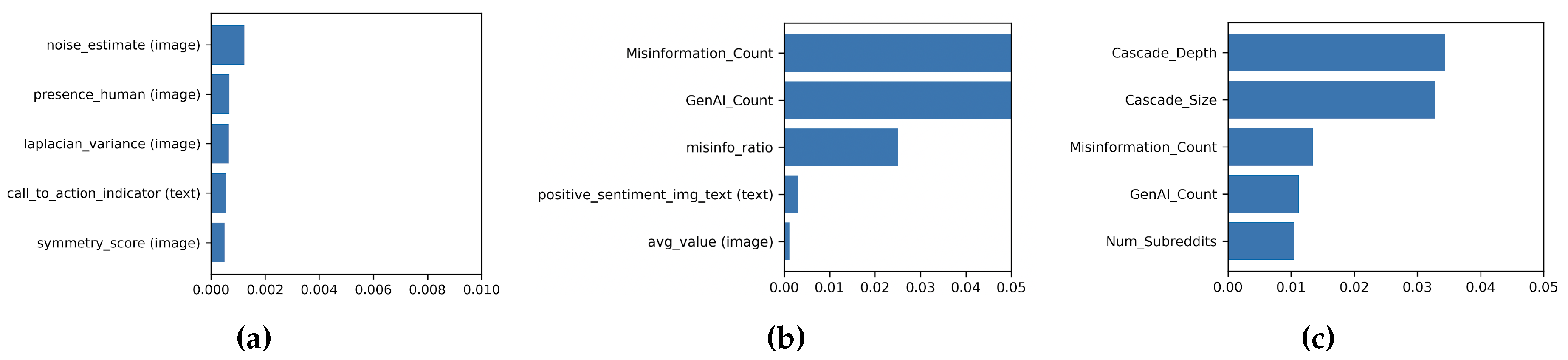
Table 2.
Post-level statistics by Misinformation and GenAI classification.
| Misinformation | GenAI | Mean Age Days | Std Age Hours | Mean Score | Std Score | Mean Total Comments | Std Total Comments | Mean VAI | Std VAI |
|---|---|---|---|---|---|---|---|---|---|
| False | False | 1,326 | 797 | 6,321 | 11,567 | 423 | 1,116 | 0.55 | 1.42 |
| False | True | 1,313 | 778 | 1,809 | 2,634 | 204 | 822 | 0.17 | 0.37 |
| True | False | 1,390 | 676 | 35,567 | 38,370 | 2,433 | 4,453 | 1.61 | 4.83 |
| True | True | 1,332 | 658 | 22,991 | 40,625 | 1,282 | 2,371 | 0.71 | 1.27 |
Table 3.
Cascade-level statistics by Misinformation and GenAI classification.
| Misinformation | GenAI | Mean Branch | Max Branch | Cascade Size | Cascade Depth | Structural Virality | Time to First Repost (hr) | Peak Repost Speed (hr) | Lifespan (hr) | # Subreddits |
|---|---|---|---|---|---|---|---|---|---|---|
| False | False | 0.80 | 0.86 | 2.32 | 1.32 | 0.19 | 126 | 3533 | 1182 | 1.001 |
| False | True | 0.81 | 0.96 | 5.13 | 4.13 | 0.74 | 352 | 944 | 2023 | 1.000 |
| True | False | 0.36 | 0.48 | 2.58 | 1.58 | 0.56 | 2370 | 2473 | 2198 | 1.009 |
| True | True | 0.89 | 1.07 | 26.96 | 25.96 | 7.14 | 1388 | 174 | 13848 | 1.106 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



