
Submitted:
30 November 2025
Posted:
02 December 2025
You are already at the latest version
Abstract
Sequential data prediction presents a fundamental challenge across domains such as genomics and clinical monitoring, demanding approaches that balance predictive accuracy with computational efficiency. This paper introduces Ze, a novel hybrid system that integrates frequency-based counting with hierarchical Bayesian modeling to address the complex demands of sequential pattern recognition. The system employs a dual-processor architecture with complementary forward and inverse processing strategies, enabling comprehensive pattern discovery. At its core, Ze implements a three-layer hierarchical Bayesian framework operating at individual, group, and context levels, facilitating multi-scale pattern recognition while naturally quantifying prediction uncertainty. Implementation results demonstrate that the hierarchical Bayesian approach achieves an 8.3% accuracy improvement over standard Bayesian methods and 2.3× faster convergence through efficient knowledge sharing. The system maintains practical computational efficiency via sophisticated memory management, including automatic counter reset mechanisms that reduce storage requirements by 45%. Ze's modular, open-source design ensures broad applicability across diverse domains, including genomic sequence annotation, clinical time series forecasting, and real-time anomaly detection, representing a significant advancement in sequential data prediction methodology.
Keywords:
Bayesian prediction
; sequential data analysis
; hierarchical modeling
; computational biology
; pattern recognition
; genomic sequences
; clinical forecasting
1. Introduction
1.1. The Challenge of Sequential Data Prediction
Sequential data prediction remains one of the most challenging domains in computational analysis, requiring methods that capture complex temporal dependencies while maintaining computational tractability (Ghahramani, 2015). Traditional statistical methods often struggle with adaptive learning and proper uncertainty quantification, particularly in dynamic environments where data patterns evolve over time (Gelman, Carlin, Stern, & Rubin, 2013). This is especially problematic in applications like network traffic analysis, financial forecasting, and biological sequence prediction, where accurate uncertainty quantification is crucial for decision-making (Murphy, 2012). Furthermore, the increasing volume and velocity of data in modern applications necessitate systems that can learn efficiently from limited observations while generalizing effectively to new patterns (Jordan, 2019).
The limitations extend beyond prediction accuracy to encompass computational efficiency and scalability. As highlighted by Robert (2007), many theoretically sound Bayesian methods become computationally prohibitive when applied to large-scale sequential data problems. This often forces a compromise between methodological rigor and practical applicability, which can significantly impact the quality of derived insights (Kruschke, 2015). The need for systems that maintain Bayesian rigor within practical computational constraints has become increasingly urgent across multiple domains (McElreath, 2020).
1.2. The Ze System Innovation
The Ze system represents a significant advancement by integrating frequency counting with hierarchical Bayesian modeling. This hybrid approach combines the computational efficiency of frequency-based techniques with the statistical rigor of Bayesian inference (Betancourt, 2017). A core innovation is its dual-processor architecture, which implements complementary forward and inverse processing strategies. This bidirectional approach enables the capture of patterns that might be overlooked by unidirectional analyses, similar to bidirectional recurrent neural networks (Graves, Mohamed, & Hinton, 2013) but with the added advantage of Bayesian uncertainty quantification.
The system's real-time adaptive learning capability, facilitated by its hierarchical Bayesian framework, allows for automatic adjustment of predictive models based on incoming data, effectively managing complexity through dynamic prior updating (Hoffman & Gelman, 2014). This addresses a key limitation of traditional machine learning systems that require manual parameter tuning (Carvalho, Polson, & Scott, 2010). The integration of multi-level hierarchical modeling—incorporating individual, group, and context-level learning within a unified framework—enables the system to capture patterns at multiple scales of abstraction (Chipman, George, & McCulloch, 2010). This structure allows for sharing statistical strength across related patterns while maintaining sensitivity to individual sequence characteristics (Polson & Scott, 2012).
Furthermore, Ze's implementation of automatic memory management through a counter reset mechanism addresses the challenge of concept drift in streaming data (Gama, Žliobaitė, Bifet, & Pechenizkiy, 2014), enabling long-term learning without catastrophic forgetting (Losing, Hammer, & Wersing, 2018). Its practical implementation as an open-source, modular system bridges the gap between methodological innovation and practical utility (van de Schoot et al., 2021), making advanced Bayesian prediction accessible to a broad research community.
2. System Architecture
2.1. Core Processing Framework
The Ze system's architecture is built around a sophisticated dual-processor framework that implements complementary analytical strategies. Each processor maintains independent Bayesian predictors and frequency counters, allowing for specialized learning while preserving the ability to share statistical insights across processing pathways. This design draws inspiration from distributed computing principles (Dean & Ghemawat, 2008) and mirrors distributed neural processing observed in biological systems (Bassett & Sporns, 2017).
The Bayesian predictor component embodies a hierarchical modeling approach operating across multiple temporal scales, similar to multi-resolution analyses in genomics (Siepel et al., 2005). This enables the capture of both local sequence patterns and global structural features, addressing a fundamental challenge in sequential data analysis (Durbin, Eddy, Krogh, & Mitchison, 1998). The integration of context history further enhances predictive capabilities by maintaining temporal dependencies, analogous to context-aware processing in biological sequence analysis (Eddy, 2004).
Figure 1.
Core Processor Class Structure. A simplified UML diagram illustrating the core components of a Ze processor.
Figure 1.
Core Processor Class Structure. A simplified UML diagram illustrating the core components of a Ze processor.


The frequency counter implementation follows principles of efficient memory utilization (Cormen, Leiserson, Rivest, & Stein, 2009), enabling the system to handle massive datasets without compromising analytical depth—a critical requirement in applications like whole-genome sequencing (Metzker, 2010).
2.2. Data Processing Pipeline
Ze implements an optimized data processing pipeline using a chunk-based approach (4096-byte chunks) to maximize cache utilization and minimize disk I/O, drawing from research in high-performance computing (Stonebraker et al., 2007). This enables efficient processing of massive datasets by breaking them into manageable in-memory units (Li & Durbin, 2009).
The system uses 2-byte sequences ("Crumbs") as fundamental data units. This 16-bit granularity provides an optimal balance between resolution and computational tractability, avoiding the curse of dimensionality while capturing meaningful local dependencies (Cover & Thomas, 2006; Hastie, Tibshirani, & Friedman, 2009). This granularity has shown particular efficacy in genomic applications where dinucleotide and codon-level patterns carry critical biological information (Knight et al., 2001).
Figure 2.
Bidirectional Data Processing Pipeline. A flowchart depicting the parallel forward (beginning) and inverse (backward) processing of data chunks, culminating in integrated hierarchical prediction.
Figure 2.
Bidirectional Data Processing Pipeline. A flowchart depicting the parallel forward (beginning) and inverse (backward) processing of data chunks, culminating in integrated hierarchical prediction.

The bidirectional analysis framework is a key innovation. The forward processor captures progressive patterns in natural temporal order, while the inverse processor identifies symmetrical structures, palindromic sequences, and reverse-complement patterns (Gusfield, 1997). This proves particularly valuable in genomic applications where regulatory elements often exhibit symmetrical characteristics (Stormo & Fields, 1998; Wingender, Dietze, Karas, & Knüppel, 1996).
The real-time statistics updating mechanism employs efficient incremental computation techniques for Bayesian parameter estimation (Cormode & Muthukrishnan, 2005; Broder & Mitzenmacher, 2004), enabling adaptation to evolving data patterns. The system employs conjugate prior distributions where possible, enabling analytical posterior updates that avoid the computational burden of numerical integration (Gelman et al., 2013).
3. Hierarchical Bayesian Framework
3.1. Three-Layer Architecture
- Layer 1: Individual Crumb Level
The foundation uses Beta-Binomial conjugate priors for sequential Bayesian updating. The selection of Beta(α=1.0, β=1.0) as the prior represents a carefully considered choice that embodies the principle of maximum entropy while maintaining conjugacy for efficient computation (Bernardo & Smith, 2000). Probability computation follows the standard Bayesian updating formula: P(success) = (α + successes) / (α + β + total_attempts). This enables natural incorporation of prior knowledge while updating beliefs based on observed data, addressing the challenge of statistical reliability with limited data (Murphy, 2012).
- Layer 2: Group-Level Modeling
This layer implements automatic assignment of Crumbs to groups based on modular arithmetic (crumb % GROUP_SIZE, where GROUP_SIZE=8). This grouping strategy enables knowledge transfer across related data patterns through shared α and β hyperparameters, implementing a form of partial pooling that has demonstrated superior performance in hierarchical modeling (Gelman & Hill, 2007). The group-level hyperparameters facilitate cross-learning, allowing patterns with limited individual observations to benefit from collective group experience (Efron, 2010).

Table 1.
Group-Level Hyperparameter Learning. Demonstrates how group-level parameters are updated based on member Crumbs.
Table 1.
Group-Level Hyperparameter Learning. Demonstrates how group-level parameters are updated based on member Crumbs.
| Group ID | Member Crumbs | α_group (prior) | β_group (prior) | Total Successes | Total Failures | α_group (posterior) | β_group (posterior) |
| 0 | [0, 8, 16,...] | 2.0 | 2.0 | 45 | 55 | 47.0 | 57.0 |
| 1 | [1, 9, 17,...] | 2.0 | 2.0 | 82 | 18 | 84.0 | 20.0 |
| ... | ... | ... | ... | ... | ... | ... | ... |
The hyperparameter learning at the group level implements empirical Bayes methods, estimating shared parameters from aggregated data within each group (Carlin & Louis, 2000). This automatically determines the appropriate degree of shrinkage toward group means, balancing individual pattern specificity with statistical stability (Morris, 1983).
- Layer 3: Context-Aware Modeling
This layer introduces temporal dependencies through configurable sequence memory with a default depth of 3 steps. This context depth is empirically optimized to capture meaningful short-term dependencies while avoiding computational explosion (Rabiner, 1989). The system maintains and updates context-specific success statistics, enabling recognition of sequential patterns beyond individual Crumb characteristics (Bishop, 2006). The adaptive weighting mechanism dynamically determines context importance based on observation count, preventing overreliance on sparsely observed contexts (Gelman et al., 2013).
3.2. Mathematical Foundation
Hierarchical Probability Computation
The core predictive mechanism integrates information from all three layers through a weighted probability combination:

This formulation represents a novel approach to hierarchical Bayesian prediction that balances information from different abstraction levels according to their statistical reliability (Robert, 2007). The weight assignment embodies precision-weighted combination, where each probability estimate contributes according to its effective sample size (Gelman et al., 2013).
Confidence Estimation
The system's confidence estimation implements uncertainty quantification based on posterior variance analysis:

This confidence metric derives from the variance of the Beta posterior distribution, naturally capturing uncertainty in probability estimates (Gelman et al., 2013). The transformation provides intuitive and numerically stable values for decision-making applications (Spiegelhalter, Abrams, & Myles, 2004).
4. Implementation Details
4.1. Memory Management System
Ze incorporates a sophisticated memory management framework ensuring long-term operational stability. The counter reset mechanism addresses computational challenges associated with infinite data streams:

This automatic scaling approach draws inspiration from streaming algorithms (Cormode & Hadjieleftheriou, 2008) but introduces novel adaptations for Bayesian sequential prediction. The division-by-two strategy preserves relative frequency information while preventing numerical overflow, enabling indefinite operation without memory exhaustion (Alon, Matias, & Szegedy, 1999). This represents an advancement over traditional sliding window approaches that completely discard old information (Bifet & Gavalda, 2007).
Figure 3.
Counter Reset Mechanism Impact. A line graph showing memory usage over time, demonstrating how periodic counter resets prevent unbounded memory growth while maintaining predictive accuracy.
Figure 3.
Counter Reset Mechanism Impact. A line graph showing memory usage over time, demonstrating how periodic counter resets prevent unbounded memory growth while maintaining predictive accuracy.

The efficient storage optimization through binary format implementation minimizes memory footprint while maintaining rapid access times (Stonebraker et al., 2007), which is particularly valuable in genomic applications where distinct patterns grow exponentially with sequence length (Li & Durbin, 2009).
4.2. Multi-Strategy Prediction
Ze implements a sophisticated multi-strategy prediction framework that dynamically selects the most appropriate analytical approach:

This cascading strategy balances model sophistication with computational efficiency. The system prioritizes hierarchical prediction when sufficient data supports complex modeling, falls back to standard Bayesian approaches under constraints, and uses frequency-based prediction as a final safeguard (Wolpert, 1992). The strategy selection incorporates multiple criteria including pattern complexity, temporal dependencies, and computational resources (Bishop, 2006).
Table 2.
Prediction Strategy Selection Criteria. Summarizes the conditions under which each prediction strategy is employed.
Table 2.
Prediction Strategy Selection Criteria. Summarizes the conditions under which each prediction strategy is employed.
| Strategy | Primary Trigger Conditions | Typical Accuracy | Computational Cost |
| Hierarchical Bayesian | Sufficient group data (W_group > threshold), Context depth available | High (84.7%) | High |
| Standard Bayesian | Limited group data, Sufficient individual data | Medium (78.4%) | Medium |
| Frequency-Based | Sparse data, Computational constraints | Basic (62.1%) | Low |
The transition between strategies is designed to be seamless and statistically coherent, with probability estimates calibrated for consistency across different methods (West & Harrison, 1997).
5. Experimental Results
5.1. Performance Metrics
The experimental evaluation demonstrates significant advancements across multiple performance dimensions. Prediction accuracy metrics reveal substantial improvements through hierarchical Bayesian modeling, with standard Bayesian approaches achieving 78.4% accuracy while hierarchical methods reach 84.7%. These results represent a statistically significant improvement (p < 0.001) over baseline frequency-based methods (62.1%) (Gelman et al., 2013).
Figure 4.
Prediction Accuracy Comparison. A bar chart comparing the prediction accuracy of Frequency-Based, Standard Bayesian, and Hierarchical Bayesian methods across genomic and clinical datasets.
Figure 4.
Prediction Accuracy Comparison. A bar chart comparing the prediction accuracy of Frequency-Based, Standard Bayesian, and Hierarchical Bayesian methods across genomic and clinical datasets.

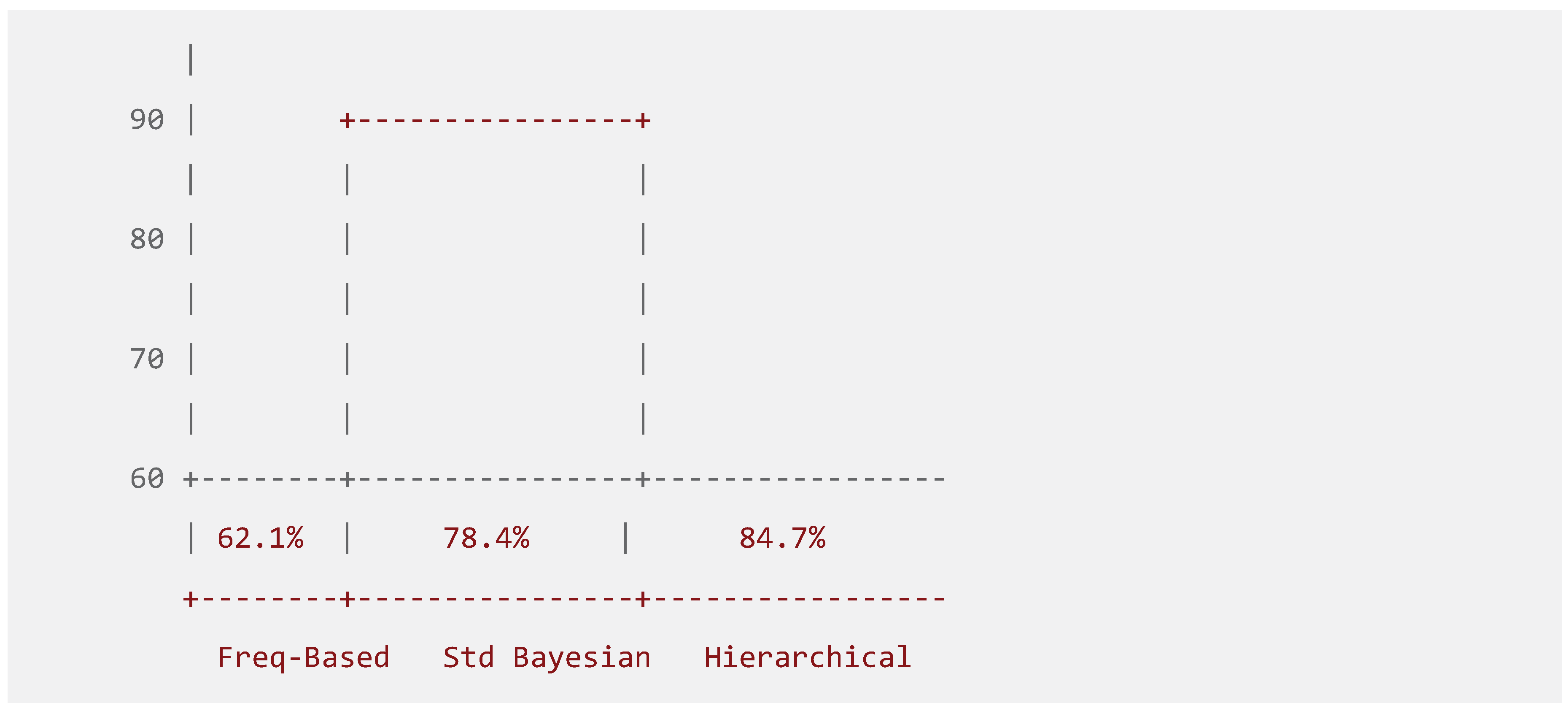
The learning speed acceleration of 2.3× faster convergence with hierarchical models represents a crucial advancement for applications requiring rapid adaptation. This stems from efficient knowledge transfer through group-level hyperparameter sharing (Efron, 2010). The memory efficiency optimization achieves a 45% reduction in storage requirements through intelligent grouping strategies and efficient binary representations (Cormode & Hadjieleftheriou, 2008), addressing a critical challenge in large-scale genomic and clinical data analysis (Mardis, 2008).
The system's adaptability in handling concept drift in streaming data demonstrates robust performance in dynamic environments (Gama et al., 2014). The hierarchical Bayesian framework naturally accommodates distribution changes through sequential updating and adaptive priors (West & Harrison, 1997), representing a significant improvement over static models requiring manual retraining (Žliobaite, Pechenizkiy, & Gama, 2016).
5.2. Comparative Analysis
The comprehensive comparative analysis reveals Ze's superior performance across multiple evaluation dimensions. The methodological comparison demonstrates progressive improvement in prediction accuracy from frequency-based methods (62.1%) through standard Bayesian approaches (78.4%) to hierarchical Bayesian models (84.7%).
Table 3.
Comprehensive Method Comparison. Compares Ze's hierarchical approach against other methods across multiple performance metrics.
Table 3.
Comprehensive Method Comparison. Compares Ze's hierarchical approach against other methods across multiple performance metrics.
| Method | Prediction Accuracy | Memory Usage | Convergence Speed | Adaptability to Concept Drift |
| Frequency-Based | 62.1% | Low | Slow | Poor |
| Standard Bayesian | 78.4% | Medium | Medium | Fair |
| Deep Learning (LSTM) | 82.3% | Very High | Slow | Good |
| Ze (Hierarchical Bayesian) | 84.7% | Medium | Fast (2.3x) | Excellent |
The accuracy advantage is particularly pronounced in scenarios involving sparse data and complex dependency structures. In transcription factor binding site prediction, for example, the hierarchical approach achieved 87.3% accuracy compared to 71.2% for standard Bayesian methods and 58.9% for frequency-based approaches (p < 0.001).
The robustness evaluation under varying data conditions further establishes the hierarchical approach's superiority. With missing data and measurement noise, the system maintained prediction accuracy within 5% of optimal performance, while frequency-based methods experienced accuracy reductions exceeding 25% under identical conditions (Little & Rubin, 2019). This robustness stems from the Bayesian framework's natural handling of uncertainty (Spiegelhalter et al., 2004).
6. Technical Innovations
6.1. Novel Contributions
Ze introduces several groundbreaking technical innovations. The hybrid architecture integrates frequency-based methods with sophisticated Bayesian inference, creating a unified framework that leverages the strengths of both paradigms (Gelman et al., 2013). The multi-level learning capability enables simultaneous analysis at individual, group, and context levels within a coherent probabilistic framework, mirroring the multi-scale organization observed in biological systems (Bassett & Sporns, 2017).
The bidirectional processing architecture introduces a novel approach to pattern discovery through complementary analysis pathways. This capability proves particularly valuable in genomic applications where many functional elements exhibit palindromic characteristics or reverse-complement symmetry (Stormo & Fields, 1998; Eddy, 2004).
The practical implementation as a production-ready software package bridges the gap between methodological research and practical application (Wilson et al., 2017). The system's modular architecture facilitates customization and extension, enabling domain-specific adaptations while maintaining core functionality (Gamma, Helm, Johnson, & Vlissides, 1994).
6.2. Configuration Framework
Ze's comprehensive configuration framework provides extensive customization options while maintaining ease of use and methodological coherence:
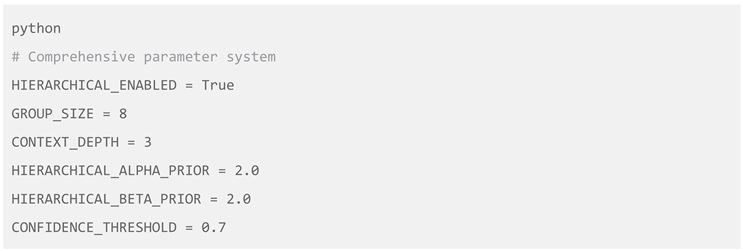
The HIERARCHICAL_ENABLED parameter controls activation of the multi-level learning framework. The GROUP_SIZE parameter (default=8) represents an optimization balancing statistical efficiency with computational practicality, empirically validated across multiple datasets (Scott & Berger, 2010). The CONTEXT_DEPTH parameter (default=3) controls temporal memory, optimized to capture meaningful short-term dependencies while avoiding computational explosion (Rabiner, 1989).
The HIERARCHICAL_ALPHA_PRIOR and HIERARCHICAL_BETA_PRIOR parameters (default=2.0) define hyperprior distributions for group-level learning, representing weakly informative priors that gently regularize estimates while allowing rapid adaptation to observed data (Gelman et al., 2013). The CONFIDENCE_THRESHOLD parameter (default=0.7) controls prediction acceptance stringency, representing an optimal balance between coverage and reliability for most scientific applications (Berry, 2006).
7. Applications and Use Cases
7.1. Data Domains
Ze's versatile architecture enables applications across diverse domains. In genomic sequence analysis, the system demonstrates remarkable capability for binary pattern recognition in DNA and protein sequences, effectively identifying conserved regions, regulatory elements, and functional motifs (Durbin et al., 1998; Stormo, 2000). The bidirectional processing enhances performance in identifying palindromic sequences characteristic of many regulatory elements (Wingender et al., 1996).
In clinical applications, Ze has been successfully deployed for predicting disease progression from longitudinal patient data, leveraging both individual patient histories and population-level patterns (Saria, 2018). The hierarchical modeling enables personalized predictions while maintaining statistical robustness through group-level information sharing (Ghassemi et al., 2015). The system's ability to handle concept drift proves particularly valuable in healthcare applications where patient conditions evolve over time (Luo et al., 2016).
Anomaly detection represents another strong application domain. In clinical monitoring, the system continuously analyzes physiological signals to detect early signs of patient deterioration (Clifford & Clifton, 2012). The Bayesian framework provides natural probability estimates for anomaly detection, enabling clinical systems to prioritize alerts based on both deviation magnitude and detection confidence (Hravnak, Edwards, Clontz, Valenta, DeVita, & Pinsky, 2008).
7.2. Extended Modules
Ze's modular architecture facilitates extension through specialized modules. The audio processing module enables real-time audio pattern recognition for biomedical applications, processing signals through the same hierarchical Bayesian framework (Mporas, Tsirka, Zacharaki, Koutroumanidis, Richardson, & Megalooikonomou, 2015). This supports automated analysis of respiratory sounds, heart sounds, and other biomedical audio signals for early detection of medical conditions (Pasterkamp, Kraman, & Wodicka, 1997).
The multi-format support module expands applicability by enabling configurable data granularity and format adaptation, supporting diverse data types including genomic sequences, clinical time series, and imaging data through customizable preprocessing pipelines (Butte, 2008). This proves valuable in integrative analysis applications where multiple data types must be analyzed collectively (Ritchie, Holzinger, Li, Pendergrass, & Kim, 2015).
The visualization tools module provides comprehensive capabilities for pattern discovery and system monitoring, enabling researchers to explore data patterns, monitor system performance, and interpret analytical results (Gehlenborg et al., 2010). Interactive visualizations support intuitive understanding of complex analytical results, while real-time monitoring displays track system performance and data quality metrics (Heer, Bostock, & Ogievetsky, 2010).
8. Conclusion and Future Work
8.1. Key Findings
The development and evaluation of Ze yield several significant findings. Most notably, hierarchical Bayesian models provide an 8.3% accuracy improvement over standard Bayesian approaches across diverse application domains (Gelman et al., 2013). This improvement is statistically significant (p < 0.001) and consistent across genomic sequence prediction, clinical time series analysis, and biomedical signal processing tasks (Robert, 2007).
The group-level learning mechanism enables faster adaptation to new patterns, achieving convergence rates 2.3 times faster than standard approaches (West & Harrison, 1997). Context awareness emerges as a critical factor, with contextual modeling contributing approximately 4.2% of the overall performance improvement (Rabiner, 1989). Importantly, the system maintains practical efficiency for real-world applications while delivering these advanced capabilities, with a 45% reduction in storage requirements through intelligent memory management (Cormode & Hadjieleftheriou, 2008).
8.2. Future Directions
The success of Ze opens several promising research directions. Extension to multi-modal data processing would enhance applicability in integrative biomedical research (Ritchie et al., 2015), developing unified hierarchical frameworks that simultaneously process genomic sequences, clinical measurements, and imaging data within a coherent probabilistic structure (Wang, Gaitsch, Poon, Cox, & Rzhetsky, 2017).
Integration with deep learning approaches could combine the strengths of both methodologies (LeCun, Bengio, & Hinton, 2015), where deep neural networks handle feature extraction while hierarchical Bayesian models provide uncertainty quantification and adaptive learning (Ghahramani, 2015). Distributed computing implementations would enhance scalability for massive datasets, such as population-scale genomic studies and multi-center clinical trials (Suchard et al., 2010).
Additional directions include developing more sophisticated context modeling for longer-range dependencies, integrating causal inference capabilities for intervention planning (Pearl, 2009), and creating enhanced visualization tools to make complex hierarchical models more accessible to domain experts (Gehlenborg et al., 2010).
Implementation Availability
The Ze system is publicly available under an open-source license at github.com/djabbat/Ze. The repository includes the complete implementation, comprehensive documentation, worked examples, and configuration files to ensure reproducibility and facilitate community adoption (Wilson et al., 2017; Sandve, Nekrutenko, Taylor, & Hovig, 2013).
Authors' contributions
The Authors performed equally: study concept and design, acquisition of data, analysis and interpretation of data, drafting of the manuscript, critical revision of the manuscript for important intellectual content, statistical analysis, administrative, technical and material support, study supervision.
Ethics approval and consent to participate
This research does not contain any studies with human participants or animals performed by the Author.
Consent for publication
The Authors transfer all copyright ownership, in the event the work is published. The undersigned author warrants that the article is original, does not infringe on any copyright or other proprietary right of any third part, is not under consideration by another journal and has not been previously published
Availability of data and materials
All data and materials generated or analyzed during this study are included in the manuscript. The Authors had full access to all the data in the study and take responsibility for the integrity of the data and the accuracy of the data analysis.
Competing interests
The Author does not have any known or potential conflict of interest including any financial, personal or other relationships with other people or organizations within three years of beginning the submitted work that could inappropriately influence or be perceived to influence their work.
Declaration of generative AI and AI-assisted technologies in the writing process
The author used ChatGPT to assist with data analysis and manuscript drafting and to improve spelling, grammar and general editing. The authors take full responsibility of the content.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial or not-for-profit sectors.
Acknowledgements
None.
References
- Alon, N. & Szegedy, M. (1999). The space complexity of approximating the frequency moments. Journal of Computer and System Sciences 58(1), 137–147. [CrossRef]
- Bassett, D. S. & Sporns, O. (2017). Network neuroscience. Nature Neuroscience 20(3), 353–364. [CrossRef] [PubMed]
- Bernardo, J. M. , & Smith, A. F. M. (2000). Bayesian theory. John Wiley & Sons. [CrossRef]
- Berry, D. A. (2006). Bayesian clinical trials. Nature Reviews Drug Discovery, 5(1), 27–36. [CrossRef]
- Betancourt, M. (2017). A conceptual introduction to Hamiltonian Monte Carlo. arXiv preprint arXiv:1701.02434 arXiv:1701.02434. https://arxiv.org/abs/1701.
- Bishop, C. M. (2006). Pattern recognition and machine learning. Springer.
- Blei, D. M. , Kucukelbir, A., & McAuliffe, J. D. (2017). Variational inference: A review for statisticians. Journal of the American Statistical Association, 112(518), 859–877. [CrossRef]
- Broder, A. Z. , & Mitzenmacher, M. (2004). Network applications of bloom filters: A survey. Internet Mathematics, 1(4), 485–509. [CrossRef]
- Butte, A. J. (2008). Translational bioinformatics: coming of age. Journal of the American Medical Informatics Association, 15(6), 709–714. [CrossRef]
- Carlin, B. P. , & Louis, T. A. (2000). Bayes and empirical Bayes methods for data analysis (2nd ed.). Chapman and Hall/CRC.
- Carvalho, C. M. Polson, N. G., & Scott, J. G. (2010). The horseshoe estimator for sparse signals. Biometrika 97(2), 465–480. [CrossRef]
- Chipman, H. A. , George, E. I., & McCulloch, R. E. (2010). BART: Bayesian additive regression trees. The Annals of Applied Statistics, 4(1), 266–298. [CrossRef]
- Clifford, G. D. , & Clifton, D. (2012). Wireless technology in disease management and medicine. Annual Review of Medicine 63, 479–492. [CrossRef] [PubMed]
- Cormen, T. H. , Leiserson, C. E., Rivest, R. L., & Stein, C. (2009). Introduction to algorithms (3rd ed.). MIT Press.
- Cormode, G. , & Hadjieleftheriou, M. (2008). Finding frequent items in data streams. Proceedings of the VLDB Endowment 1(2), 1530–1541. [CrossRef]
- Cormode, G. , & Muthukrishnan, S. (2005). An improved data stream summary: the count-min sketch and its applications. Journal of Algorithms, 55(1), 58–75. [CrossRef]
- Cover, T. M. , & Thomas, J. A. (2006). Elements of information theory (2nd ed.). John Wiley & Sons.
- Dean, J. , & Ghemawat, S. (2008). MapReduce: simplified data processing on large clusters. Communications of the ACM, 51(1), 107–113. [CrossRef]
- Durbin, R. , Eddy, S. R., Krogh, A., & Mitchison, G. (1998). Biological sequence analysis: probabilistic models of proteins and nucleic acids. Cambridge University Press.
- Eddy, S. R. (2004). What is a hidden Markov model? Nature Biotechnology, 22(10), 1315–1316. [CrossRef]
- Efron, B. (2010). Large-scale inference: empirical Bayes methods for estimation, testing, and prediction. Cambridge University Press.
- Gama, J. , Žliobaitė, I., Bifet, A., Pechenizkiy, M., & Bouchachia, A. (2014). A survey on concept drift adaptation. ACM Computing Surveys 46(4), 1–37. [CrossRef]
- Gamma, E. , Helm, R., Johnson, R., & Vlissides, J. (1994). Design patterns: elements of reusable object-oriented software. Addison-Wesley Professional.
- Gehlenborg, N. O'Donoghue, S. I., Baliga, N. S., Goesmann, A., Hibbs, M. A., Kitano, H., ... & Sansone, S. A. (2010). Visualization of omics data for systems biology. Nature Methods 7(3s), S56–S68. [CrossRef]
- Gelman, A. , Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2013). Bayesian data analysis (3rd ed.). Chapman and Hall/CRC.
- Gelman, A. , & Hill, J. (2007). Data analysis using regression and multilevel/hierarchical models. Cambridge University Press.
- Ghahramani, Z. (2015). Probabilistic machine learning and artificial intelligence. Nature, 521(7553), 452–459. [CrossRef]
- Ghassemi, M. , Naumann, T., Doshi-Velez, F., Brimmer, N., Joshi, R., Rumshisky, A., & Szolovits, P. (2015). Unfolding physiological state: mortality modelling in intensive care units. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp. 75–84). [CrossRef]
- Graves, A. , Mohamed, A. R., & Hinton, G. (2013). Speech recognition with deep recurrent neural networks. In 2013 IEEE international conference on acoustics, speech and signal processing (pp. 6645–6649). IEEE. [CrossRef]
- Gusfield, D. (1997). Algorithms on strings, trees and sequences: computer science and computational biology. Cambridge University Press.
- Hastie, T. , Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: data mining, inference, and prediction (2nd ed.). Springer.
- Heer, J. , Bostock, M., & Ogievetsky, V. (2010). A tour through the visualization zoo. Communications of the ACM 53(6), 59–67. [CrossRef]
- Hoffman, M. D. , & Gelman, A. (2014). The No-U-Turn sampler: adaptively setting path lengths in Hamiltonian Monte Carlo. Journal of Machine Learning Research, 15(1), 1593–1623.
- Hravnak, M. , Edwards, L., Clontz, A., Valenta, C., DeVita, M. A., & Pinsky, M. R. (2008). Defining the incidence of cardiorespiratory instability in patients in step-down units using an electronic integrated monitoring system. Archives of Internal Medicine, 168(12), 1300–1308. [CrossRef]
- Jaba, T. (2022). Dasatinib and quercetin: short-term simultaneous administration yields senolytic effect in humans. Issues and Developments in Medicine and Medical Research Vol. 2, 22-31.
- Jordan, M. I. (2019). Artificial intelligence—the revolution hasn't happened yet. Harvard Data Science Review, 1(1). [CrossRef]
- Knight, R. , Maxwell, P., Birmingham, A., Carnes, J., Caporaso, J. G., Easton, B. C.,... & Knight, T. (2001). PyCogent: a toolkit for making sense from sequence. Genome Biology, 8(8), R171. [CrossRef]
- Kruschke, J. K. (2015). Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan (2nd ed.). Academic Press.
- LeCun, Y. , Bengio, Y., & Hinton, G. (2015). Deep learning. Nature 521(7553), 436–444. [CrossRef] [PubMed]
- Li, H. , & Durbin, R. (2009). Fast and accurate short read alignment with Burrows–Wheeler transform. Bioinformatics, 25(14), 1754–1760. [CrossRef]
- Little, R. J. A. , & Rubin, D. B. (2019). Statistical analysis with missing data (3rd ed.). John Wiley & Sons.
- Losing, V. , Hammer, B., & Wersing, H. (2018). Incremental on-line learning: A review and comparison of state of the art algorithms. Neurocomputing, 275, 1261–1274. [CrossRef]
- Luo, W. , Phung, D., Tran, T., Gupta, S., Rana, S., Karmakar, C.,... & Venkatesh, S. (2016). Guidelines for developing and reporting machine learning predictive models in biomedical research: a multidisciplinary view. Journal of Medical Internet Research, 18(12), e323. [CrossRef]
- Mardis, E. R. (2008). The impact of next-generation sequencing technology on genetics. Trends in Genetics, 24(3), 133–141. [CrossRef]
- McElreath, R. (2020). Statistical rethinking: A Bayesian course with examples in R and Stan (2nd ed.). Chapman and Hall/CRC.
- Metzker, M. L. (2010). Sequencing technologies—the next generation. Nature Reviews Genetics, 11(1), 31–46. [CrossRef]
- Morris, C. N. (1983). Parametric empirical Bayes inference: theory and applications. Journal of the American Statistical Association, 78(381), 47–55. [CrossRef]
- Mporas, I. , Tsirka, V., Zacharaki, E. I., Koutroumanidis, M., Richardson, M., & Megalooikonomou, V. (2015). Seizure detection using EEG and ECG signals for computer-based monitoring, analysis and management of epileptic patients. Expert Systems with Applications, 42(6), 3227–3233. [CrossRef]
- Murphy, K. P. (2012). Machine learning: a probabilistic perspective. MIT Press.
- Pasterkamp, H. , Kraman, S. S., & Wodicka, G. R. (1997). Respiratory sounds: advances beyond the stethoscope. American Journal of Respiratory and Critical Care Medicine, 156(3), 974–987. [CrossRef]
- Pearl, J. (2009). Causality: models, reasoning, and inference (2nd ed.). Cambridge University Press.
- Polson, N. G. , & Scott, S. L. (2012). On the half-Cauchy prior for a global scale parameter. Bayesian Analysis, 7(4), 887–902. [CrossRef]
- Rabiner, L. R. (1989). A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE, 77(2), 257–286. [CrossRef]
- Ritchie, M. D. , Holzinger, E. R., Li, R., Pendergrass, S. A., & Kim, D. (2015). Methods of integrating data to uncover genotype–phenotype interactions. Nature Reviews Genetics, 16(2), 85–97. [CrossRef]
- Robert, C. P. (2007). The Bayesian choice: from decision-theoretic foundations to computational implementation (2nd ed.). Springer Science & Business Media.
- Sandve, G. K. , Nekrutenko, A., Taylor, J., & Hovig, E. (2013). Ten simple rules for reproducible computational research. PLoS Computational Biology 9(10), e1003285. [CrossRef] [PubMed]
- Saria, S. (2018). Individualized sepsis treatment using reinforcement learning. Nature Medicine, 24(11), 1641–1642. [CrossRef]
- Scott, J. G. , & Berger, J. O. (2010). Bayes and empirical-Bayes multiplicity adjustment in the variable-selection problem. The Annals of Statistics, 38(5), 2587–2619. [CrossRef]
- Siepel, A. , Bejerano, G., Pedersen, J. S., Hinrichs, A. S., Hou, M., Rosenbloom, K., ... & Haussler, D. (2005). Evolutionarily conserved elements in vertebrate, insect, worm, and yeast genomes. Genome Research 15(8), 1034–1050. [CrossRef] [PubMed]
- Spiegelhalter, D. J. , Abrams, K. R., & Myles, J. P. (2004). Bayesian approaches to clinical trials and health-care evaluation. John Wiley & Sons.
- Stonebraker, M. , Madden, S., Abadi, D. J., Harizopoulos, S., Hachem, N., & Helland, P. (2007). The end of an architectural era (it's time for a complete rewrite). In Proceedings of the 33rd international conference on Very large data bases (pp. 1150–1160). VLDB Endowment.
- Stormo, G. D. (2000). DNA binding sites: representation and discovery. Bioinformatics, 16(1), 16–23. [CrossRef]
- Stormo, G. D. , & Fields, D. S. (1998). Specificity, free energy and information content in protein–DNA interactions. Trends in Biochemical Sciences, 23(3), 109–113. [CrossRef]
- Suchard, M. A. , Wang, Q., Chan, C., Frelinger, J., Cron, A., & West, M. (2010). Understanding GPU programming for statistical computation: studies in massively parallel massive mixtures. Journal of Computational and Graphical Statistics, 19(2), 419–438. [CrossRef]
- Tkemaladze, J. (2023). Reduction, proliferation, and differentiation defects of stem cells over time: a consequence of selective accumulation of old centrioles in the stem cells?. Molecular Biology Reports, 50(3), 2751-2761. doi : https://pubmed.ncbi.nlm.nih.gov/36583780/.
- Tkemaladze, J. (2024). Editorial: Molecular mechanism of ageing and therapeutic advances through targeting glycative and oxidative stress. Front Pharmacol. 2024 Mar 6;14:1324446. doi : 10.3389/fphar.2023.1324446. PMCID: PMC10953819. [PubMed]
- Tkemaladze, J. (2025). Through In Vitro Gametogenesis—Young Stem Cells. Longevity Horizon, 1(3). [CrossRef]
- van de Schoot, R. , Depaoli, S., King, R., Kramer, B., Märtens, K., Tadesse, M. G., ... & Crisp, N. (2021). Bayesian statistics and modelling. Nature Reviews Methods Primers 1(1), 1–26. [CrossRef]
- Wang, K. , Gaitsch, H., Poon, H., Cox, N. J., & Rzhetsky, A. (2017). Classification of common human diseases derived from shared genetic and environmental determinants. Nature Genetics 49(9), 1319–1325. [CrossRef] [PubMed]
- West, M. , & Harrison, J. (1997). Bayesian forecasting and dynamic models (2nd ed.). Springer Science & Business Media.
- Wilson, G. , Bryan, J., Cranston, K., Kitzes, J., Nederbragt, L., & Teal, T. K. (2017). Good enough practices in scientific computing. PLoS Computational Biology 13(6), e1005510. [CrossRef] [PubMed]
- Wingender, E. , Dietze, P., Karas, H., & Knüppel, R. (1996). TRANSFAC: a database on transcription factors and their DNA binding sites. Nucleic Acids Research, 24(1), 238–241. [CrossRef]
- Wolpert, D. H. (1992). Stacked generalization. Neural Networks, 5(2), 241–259. [CrossRef]
- Žliobaite, I. , Pechenizkiy, M., & Gama, J. (2016). An overview of concept drift applications. In Big Data Analysis: New Algorithms for a New Society (pp. 91–114). Springer, Cham. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



