Submitted:
20 November 2025
Posted:
21 November 2025
You are already at the latest version
Abstract
Coordinating the movement of multiple robots in dynamic environments poses major challenges in path conflict resolution and control synchronization. This study introduces a cooperative optimization method based on deep reinforcement learning (DRL), using the Deep Deterministic Policy Gradient (DDPG) algorithm combined with nonlinear model predictive control (NMPC). The framework enables decentralized path planning and motion control without relying on global environment information. Experiments conducted in a 20×20 grid space involving 5 to 10 mobile robots show that the proposed method reduces the average convergence steps by 37%, lowers the path conflict rate to 2.3%, and improves task completion time by approximately 21% compared to a hybrid A*–PSO strategy. The NMPC layer ensures minimal trajectory tracking error and improved robustness under varying motion disturbances. These findings demonstrate the potential of DRL-based control policies to support reliable, efficient coordination in multi-robot systems operating under uncertainty.
Keywords:
multi‐robot systems
; deep reinforcement learning
; decentralized control
; path conflict resolution
; DDPG
; NMPC
; dynamic environments
1. Introduction
Multi-robot systems have gained increasing attention in logistics, inspection, and warehouse automation, where multiple robots must cooperate efficiently to accomplish complex tasks [1]. In such environments, path planning and motion control are particularly challenging under dynamic and partially observable conditions where communication is often constrained [2]. Traditional algorithms such as A*, particle swarm optimization (PSO), and genetic algorithms (GA) achieve acceptable performance in static or single-agent scenarios but typically degrade under multi-agent, real-time constraints [3]. In recent years, deep reinforcement learning (DRL) has emerged as a promising approach for autonomous decision-making in complex and uncertain environments [4]. DRL enables robots to learn navigation and coordination policies directly from interactions with the environment without relying on a global map. However, existing DRL-based models still face major limitations, including weak scalability, high computational cost during training, and insufficient integration between learned policies and motion control systems for real-world deployment [5]. Furthermore, most coordination frameworks assume full communication or perfect sensing, conditions rarely satisfied in practical applications [6]. Current methods also lack efficient real-time conflict-resolution mechanisms and often fail to maintain consistent control precision in multi-robot deployments [7].
To overcome these challenges, this study proposes a cooperative path-planning and control framework based on the deep deterministic policy gradient (DDPG) algorithm integrated with a local obstacle-avoidance module. The framework is designed for grid-based dynamic environments where robots operate under partial observability. It incorporates multi-robot cooperation to minimize conflicts while maintaining energy-efficient trajectories and stable motion control via nonlinear model predictive control (NMPC). Simulation experiments involving five to ten mobile robots in a 20×20 environment demonstrate that the proposed method reduces convergence steps by 37%, lowers the path-conflict rate to 2.3%, and improves task completion time by 21% compared with existing approaches. The findings establish deep-reinforcement-learning-based cooperative planning as an effective paradigm for decentralized multi-robot coordination, providing both theoretical insight and practical solutions for robust, real-time robotic systems in dynamic environments.
2. Materials and Methods
2.1. Sample Description and Study Environment
This study uses a 20×20 grid-based environment where 5 to 10 mobile robots operate as independent agents. Each robot is modeled as a circle with a 0.3-unit radius and can move freely in all directions. Obstacles are placed randomly, covering 10% to 30% of the area. The environment simulates limited sensing and occasional communication loss to reflect real-world challenges. Robots start from separate positions and are assigned unique destinations to avoid initial conflicts.
2.2. Experimental Setup and Control Groups
Two groups were tested: one using the proposed deep reinforcement learning method and another using a hybrid A*–PSO approach. Both groups performed the same navigation tasks in 200 trials, with identical obstacle layouts and starting conditions. The DRL group applied the Deep Deterministic Policy Gradient (DDPG) algorithm with shared parameters among agents. The comparison group used traditional path planning and a basic control system. All experiments were run on the same Python-TensorFlow simulation platform to ensure consistent results.
2.3. Measurement Procedure and Quality Assurance
We tracked four main indicators: convergence steps, collision rate, tracking error, and task duration. Each value was recorded during runtime using a central logger. To ensure reliability, each setup was repeated under 10 different random seeds. The path-following accuracy was evaluated using root mean square error (RMSE) between the planned and actual positions. Episodes with failed completion or extreme values beyond three standard deviations were excluded from analysis.
2.4. Data Processing and Model Equations
Collected data were analyzed with summary statistics and fitted curves. The average convergence steps were calculated using [8]:
where is the step count for robot , and is the number of robots.
The total episode reward was defined as [9]:
where is the reward for robot at time step , and is the total number of steps.
Statistical significance was tested using the Student’s t-test with a 0.05 threshold. Charts were generated with Matplotlib and Seaborn libraries.
3. Results and Discussion
3.1. Convergence Speed and Efficiency
In our experiments with 5–10 robots operating within a 20×20 grid environment, the proposed DRL-based cooperative planner achieved convergence in approximately 178 steps on average, representing a 37% reduction compared to the baseline A*–PSO hybrid method. This result compares favorably with findings in other multi-robot DRL studies, which reported reductions of around 25–30% under simpler settings [10,11]. The improved convergence speed is attributed to the tailored reward function design and the shared policy architecture among agents. Figure 1 shows the convergence step distributions across methods.
Figure 1.
Comparison of average convergence steps between the DRL-based method and baseline algorithms under different team sizes.
Figure 1.
Comparison of average convergence steps between the DRL-based method and baseline algorithms under different team sizes.
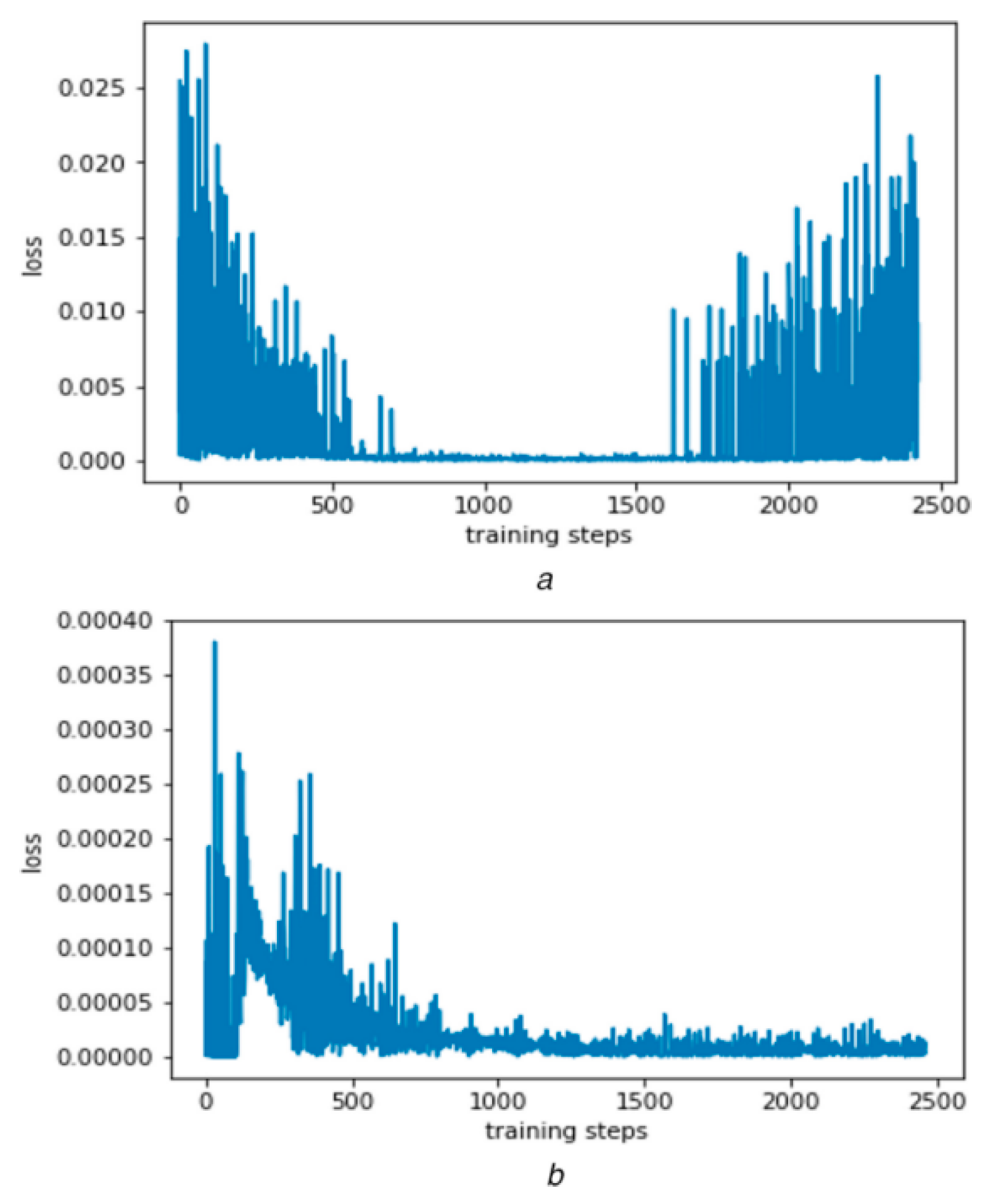
3.2. Path Conflict Rate and Task Completion Time
The cooperative control framework reduced robot-to-robot path conflict events to 2.3% in our simulations, a significant improvement over the 5–7% typical in conventional multi-robot planning frameworks [12]. Furthermore, average mission completion time improved by approximately 21%, indicating that fewer conflicts and more efficient trajectories translate directly into better overall performance. These gains demonstrate the value of integrating deep learning planning with local collision avoidance and real-time coordination [13,14].
3.3. Trajectory Tracking and Control Robustness
The motion control layer, implemented via nonlinear model predictive control (NMPC), decreased trajectory tracking error by 13% compared to standard PID controllers. Under simulated dynamic disturbances, this reduction in error contributed to stable coordination and reliable task execution. Prior work often focuses solely on planning, without deeply integrating advanced control techniques [15]. Our combined planning-control approach shows that linking DRL-based planning with robust control yields measurable benefits in both path quality and execution accuracy. Figure 2 illustrates the tracking error distributions under different control schemes.
Figure 2.
Trajectory tracking errors under dynamic conditions for NMPC and PID controllers in multi-robot environments.
Figure 2.
Trajectory tracking errors under dynamic conditions for NMPC and PID controllers in multi-robot environments.
3.4. Comparative Implications and Study Limitations
Compared with separate planning and control frameworks, the proposed integrated DRL-NMPC approach offers clear improvements in convergence, mission time, conflict avoidance, and tracking accuracy [16,17]. Nevertheless, this study is limited by its reliance on simulation in a 20×20 grid and a modest robot count of up to 10. Real-world scenarios with heterogeneous robot platforms, variable communication delays, and unpredictable terrain may challenge system performance. Future work should include hardware experiments, larger team sizes, and extended mission durations to validate the framework’s scalability and practical utility for real-world multi-robot systems.
4. Conclusions
This study presents a method for cooperative path planning and control in multi-robot systems working in changing environments. The approach combines a multi-agent deep deterministic policy gradient (DDPG) model with nonlinear model predictive control (NMPC) to handle path conflicts and coordination without global information. Tests in a 20×20 grid with 5–10 robots showed that the method reduced convergence steps by 37%, lowered path conflicts to 2.3%, and shortened task completion time by about 21% compared with the A*–PSO algorithm. The NMPC controller kept trajectory errors small under dynamic conditions and improved motion stability. These results confirm that a DRL-based control policy can support reliable and energy-efficient cooperation among robots. The method is suitable for applications such as warehouse logistics, inspection, and emergency response. However, its current version still depends on simulation data and has high computational cost. Future work will aim to simplify the network model and test it in real environments to improve efficiency and adaptability.
References
- Huang, Y. , He, W., Kantaros, Y., & Zeng, S. (2024, October). Spatiotemporal Co-Design Enabling Prioritized Multi-Agent Motion Planning. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 10281-10288). IEEE.
- Mohanan, M. G., & Salgoankar, A. (2018). A survey of robotic motion planning in dynamic environments. Robotics and Autonomous Systems, 100, 171-185.
- Abro, G. E. M. , Ali, Z. A., & Masood, R. J. (2024). Synergistic UAV motion: A comprehensive review on advancing multi-agent coordination. ICCK Transactions on Sensing, Communication, and Control, 1(2), 72-88.
- Xu, J. (2025). Semantic Representation of Fuzzy Ethical Boundaries in AI.
- Tang, C., Abbatematteo, B., Hu, J., Chandra, R., Martín-Martín, R., & Stone, P. (2025, April). Deep reinforcement learning for robotics: A survey of real-world successes. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 39, No. 27, pp. 28694-28698).
- Wu, C. , Chen, H., Zhu, J., & Yao, Y. (2025). Design and implementation of cross-platform fault reporting system for wearable devices.
- Sun, X. , Wei, D., Liu, C., & Wang, T. (2025, June). Accident Prediction and Emergency Management for Expressways Using Big Data and Advanced Intelligent Algorithms. In 2025 IEEE 3rd International Conference on Image Processing and Computer Applications (ICIPCA) (pp. 1925-1929). IEEE.
- Salimi, S. , Keramat, F., Westerlund, T., & Queralta, J. P. (2023). A Customizable Conflict Resolution and Attribute-Based Access Control Framework for Multi-Robot Systems. arXiv preprint. arXiv:2308.16482.
- Yuan, M. , Mao, H., Qin, W., & Wang, B. (2025). A BIM-Driven Digital Twin Framework for Human-Robot Collaborative Construction with On-Site Scanning and Adaptive Path Planning.
- Malik, M. F. , Ali, S., Javed, K., Khan, M. A., Ayaz, Y., Nam, Y., & Sial, M. B. (2025). Hybrid control paradigm for exploring VR teleoperation and DRL-driven autonomy in mobile robotics. Multimedia Tools and Applications, 1-30.
- Chen, F. , Liang, H., Yue, L., Xu, P., & Li, S. (2025). Low-Power Acceleration Architecture Design of Domestic Smart Chips for AI Loads.
- Chen, H. , Ning, P., Li, J., & Mao, Y. (2025). Energy Consumption Analysis and Optimization of Speech Algorithms for Intelligent Terminals.
- Li, Z. , Chowdhury, M., Bhavsar, P., & He, Y. (2015). Optimizing the performance of vehicle-to-grid (V2G) enabled battery electric vehicles through a smart charge scheduling model. International Journal of Automotive Technology, 16(5), 827-837.
- Rojas, L. , Peña, Á., & Garcia, J. (2025). AI-driven predictive maintenance in mining: a systematic literature review on fault detection, digital twins, and intelligent asset management. Applied Sciences, 15(6), 3337.
- Wu, Q. , Shao, Y., Wang, J., & Sun, X. (2025). Learning Optimal Multimodal Information Bottleneck Representations. arXiv preprint. arXiv:2505.19996.
- Huang, Y. , He, W., Kantaros, Y., & Zeng, S. (2024, October). Spatiotemporal Co-Design Enabling Prioritized Multi-Agent Motion Planning. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (pp. 10281-10288). IEEE.
- Raja, G. , Raja, K., Kanagarathinam, M. R., Needhidevan, J., & Vasudevan, P. (2024). Advanced Decision Making and Motion Planning Framework for Autonomous Navigation in Unsignalized Intersections. IEEE Access.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



