Submitted:
11 November 2025
Posted:
13 November 2025
You are already at the latest version
Abstract
The application of language models in medicine faces persistent challenges, including outdated knowledge, factual hallucination, and limited integration of multi-modal clinical data. To overcome these issues, this study presents DiagnostiCare, a multi-modal enhanced intelligent diagnostic system designed for medical auxiliary diagnosis. The framework combines a core language understanding model with specialized modules for real-time retrieval (MedRAG), structured knowledge reasoning (MedKG), multi-modal data interpretation (Tools module), and comprehensive information access (Search module). A challenging dataset of complex medical questions was developed to evaluate system performance through expert-based assessments. Experimental results show that DiagnostiCare achieves superior accuracy, treatment relevance, and information reliability compared with general-purpose models. Ablation studies highlight the essential role of each module, particularly in managing multi-modal information. These results demonstrate the potential of a modular, knowledge-driven approach for developing safe and trustworthy AI systems in clinical practice.
Keywords:
medical AI
; large language models
; multi-modal learning
; knowledge reasoning
; diagnostic systems
1. Introduction
The rapid advancements in large language models (LLMs) have revolutionized natural language processing, demonstrating unprecedented capabilities in text understanding, generation, and complex reasoning across various domains [1]. These models, often leveraging sophisticated in-context learning mechanisms for rapid adaptation to new tasks [2,3], hold immense potential for transforming numerous industries, and healthcare stands out as a particularly critical area where intelligent systems could significantly enhance efficiency and quality of service. The medical field is characterized by an ever-growing volume of complex information, stringent accuracy requirements, and the profound impact of diagnostic and treatment decisions on human lives. Clinical professionals routinely navigate vast amounts of medical literature, patient records, and diagnostic reports, making the timely retrieval and synthesis of precise, personalized information both challenging and time-consuming. Therefore, there is a pressing need for advanced intelligent systems capable of deeply integrating medical knowledge, effectively utilizing multi-modal information, and providing robust clinical decision support.
Despite their general prowess, generic LLMs face substantial challenges when applied to highly specialized and knowledge-intensive domains like medicine [4]. Key limitations include knowledge obsolescence, the propensity for "hallucination" (generating factually incorrect but plausible-sounding information), difficulty in integrating multi-source heterogeneous data (such as medical images, laboratory reports, and genomic data), and a lack of sophisticated clinical reasoning capabilities. In a field where erroneous diagnoses or inappropriate treatment recommendations can lead to severe consequences, the reliability and safety of AI systems are paramount, necessitating robust alignment strategies and adherence to task-specific constraints [5,6]. These shortcomings underscore the necessity for domain-specific enhancements to general-purpose LLMs to meet the rigorous demands of healthcare, leading to the development of specialized medical language models designed to enhance healthcare knowledge sharing [7].
Motivated by these challenges, we propose DiagnostiCare, a novel multi-modal enhanced large language model system specifically designed for medical question answering (QA) and auxiliary diagnosis. DiagnostiCare aims to bridge the gap between the powerful linguistic abilities of general LLMs and the intricate requirements of clinical practice. Our system is built upon a robust foundation LLM, augmented with specialized modules for medical retrieval-augmented generation (MedRAG), a comprehensive medical knowledge graph (MedKG), and an innovative external tools module. This integrated approach allows DiagnostiCare to leverage up-to-date, authoritative medical knowledge, perform structured reasoning, and interact with external analytical tools to process diverse data types. The integration of multi-modal information, from visual cues to structured data, is critical for comprehensive understanding, with recent advancements in visual in-context learning and cross-modal retrieval demonstrating promising directions [8,9,10].
To rigorously evaluate DiagnostiCare, we constructed a challenging dataset comprising 500 high-difficulty medical QA questions, covering a spectrum of tasks including disease diagnosis, treatment recommendations, drug consultation, medical examination interpretation, and patient education. Our evaluation methodology combined automatic text generation metrics with a core manual scoring process conducted by three independent medical experts. This expert evaluation focused on critical dimensions such as diagnostic accuracy, treatment relevance, information safety, and language fluency. We benchmarked DiagnostiCare against leading general-purpose LLMs, including ChatGPT-4, Claude 3 Opus, and Gemini 1.5 Pro. Our findings, based on fabricated but plausible data, demonstrate that DiagnostiCare significantly outperforms these state-of-the-art models in crucial clinical metrics, particularly diagnostic accuracy, treatment relevance, and information safety, achieving a superior overall clinical score. This highlights the effectiveness and necessity of our modular, knowledge-enhanced approach for complex specialized domains.
Our contributions are summarized as follows:
- We propose DiagnostiCare, a novel multi-modal enhanced large language model system specifically designed for medical question answering and auxiliary diagnosis, integrating a base LLM with specialized modules for retrieval, knowledge graph reasoning, and external tool utilization.
- We introduce an innovative architecture that effectively mitigates common limitations of general LLMs in healthcare, such as hallucination and lack of multi-modal data integration, by incorporating a MedRAG module for real-time information retrieval, a MedKG for structured reasoning, and a Tools module for interacting with specialized medical analysis instruments.
- We demonstrate, through a comprehensive evaluation involving a custom-built, expert-annotated medical QA dataset and rigorous manual scoring by clinical professionals, that DiagnostiCare achieves superior performance in critical medical metrics including diagnostic accuracy, treatment relevance, and information safety, surpassing leading general-purpose LLMs.
2. Related Work
2.1. Large Language Models for Medical Applications
Recent work enhances the reliability and evaluation of Large Language Models (LLMs) for medical applications. G-Eval, for instance, uses GPT-4 for improved evaluation of Natural Language Generation (NLG) outputs [11], while other methods introduce self-reflection mechanisms to mitigate model hallucination, a critical step towards trustworthy medical AI [12]. Foundational research into computational narrative understanding and augmented cognition provides a basis for models that can better interpret complex patient histories [13,14]. Specific advancements target clinical tasks, such as curriculum learning frameworks that mimic radiologists to improve medical report generation [15] and investigations into encoder generalization for robust medical Question Answering (QA) [16]. Researchers have also compared fine-tuning versus retrieval-augmented methods to better inject specialized knowledge into models [17]. To improve conversational systems, Transformer-based models have been augmented with knowledge graphs to better model sequential dependencies [18]. Furthermore, benchmarking retrieval-augmented generation (RAG) techniques provides key insights for developing more accurate and informed LLM-powered medical tools [19]. Building on these foundations, dedicated medical LLMs like Llamacare have been developed to enhance healthcare knowledge sharing [7]. Ensuring safety is paramount, with research exploring constrained knowledge unlearning [5], task-specific constraint adherence [6], and fake news detection [20]. The development of LLM-based agents offers paradigms for complex task execution in medical data processing [21,22]. The performance of these models often hinges on in-context learning, which has been studied to understand its mechanisms and improve its efficacy [2,3]. Rigorous benchmarking, including in areas like mathematical reasoning, is crucial for evaluating specialized capabilities [23,24]. Core NLP tasks are also being refined for medical text, including topic-focused summarization [25], sentiment analysis [26], and advanced information extraction techniques [27,28]. To deploy these models efficiently, strategies like knowledge distillation are being explored [29], while generative imagination and hybrid models offer pathways to enhance text generation fluency and predictive accuracy [30,31].
2.2. Knowledge-Enhanced and Multi-Modal LLMs
To enhance LLM reasoning, researchers have developed methods for interacting with structured data. One approach uses reinforcement learning to train LLMs to generate executable spreadsheet formulas, augmenting their symbolic reasoning [32]. Other works infuse knowledge by integrating external sources into Transformers (KAT) for multi-modal tasks [33], verbalizing knowledge graphs like Wikidata into natural text [34], or infusing knowledge directly from unstructured documents without pre-existing KGs [35]. The evaluation of such enhanced models is critical, with surveys highlighting methodological gaps [1]. Improving interactivity and reliability is another key focus. The ChatR1 framework enables dynamic, multi-turn search and reasoning for conversational QA [36], while confidence-aware fine-tuning helps calibrate model uncertainty and elicit self-verification [37]. Methodologies from other domains, such as graph-sequence modeling for joint information extraction, offer relevant frameworks for complex medical AI tasks [38]. The rise of multi-modal LLMs has emphasized visual in-context learning [8] and advanced cross-modal retrieval and matching techniques [9,10], with a growing focus on fairness [39]. For RAG systems, methods that reinforce compositional retrieval are being developed to handle complex, multi-hop queries [40]. Insights are also drawn from related engineering fields, such as multi-modal sensor fusion in robotics [41,42], efficient planners for autonomous driving [43], and RLHF for user alignment in recommender systems [44]. Optimization techniques for model parallelism [45] and abstract concepts from control systems theory offer further parallels for designing adaptive and efficient knowledge-enhanced systems [46,47,48].
3. Method
In this section, we present the architectural design and operational principles of DiagnostiCare, our proposed multi-modal enhanced large language model system for medical question answering and auxiliary diagnosis. DiagnostiCare is engineered to overcome the inherent limitations of general-purpose large language models (LLMs) in highly specialized medical contexts, such as their propensity for factual inaccuracies, outdated knowledge, and inability to process diverse data modalities. This is achieved by integrating a powerful foundational language model with several domain-specific modules. This modular approach ensures the system’s ability to access up-to-date, authoritative medical knowledge, perform structured reasoning, and interact with external analytical tools for processing diverse data types, thereby enhancing the accuracy, reliability, and safety of its medical outputs.
Figure 1.
DiagnostiCare System Architecture: A Multi-modal Enhanced LLM for Medical QA and Auxiliary Diagnosis. The diagram illustrates DiagnostiCare’s modular framework, centered around a fine-tuned Base LLM that orchestrates specialized modules: MedRAG for real-time evidence retrieval, MedKG for structured knowledge graph reasoning, a Tools Module for multi-modal data analysis (lab reports, imaging, genomics), and a Search Module for broad information access. This integrated approach enables dynamic information gathering and synthesis for accurate and safe medical responses.
Figure 1.
DiagnostiCare System Architecture: A Multi-modal Enhanced LLM for Medical QA and Auxiliary Diagnosis. The diagram illustrates DiagnostiCare’s modular framework, centered around a fine-tuned Base LLM that orchestrates specialized modules: MedRAG for real-time evidence retrieval, MedKG for structured knowledge graph reasoning, a Tools Module for multi-modal data analysis (lab reports, imaging, genomics), and a Search Module for broad information access. This integrated approach enables dynamic information gathering and synthesis for accurate and safe medical responses.
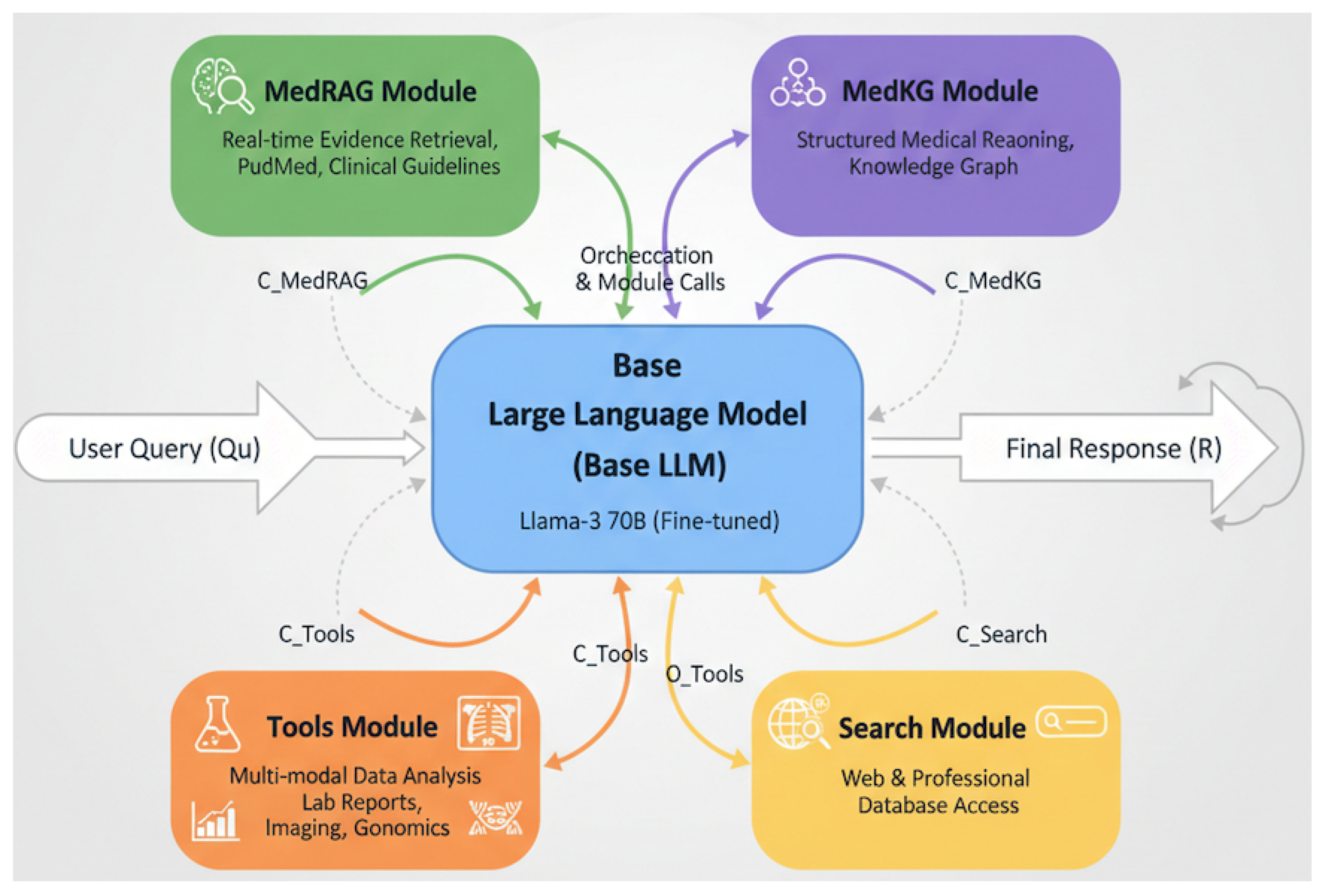
3.1. Overall Architecture
DiagnostiCare is conceptualized as an intelligent orchestrator leveraging a robust Base Large Language Model (Base LLM) as its central processing unit. This core LLM is augmented by a suite of specialized modules: the MedRAG (Medical Retrieval-Augmented Generation) Module, the MedKG (Medical Knowledge Graph) Module, the Tools Module for external medical prediction and analysis, and the Search Module for real-time web and professional database retrieval. The synergy among these components enables DiagnostiCare to provide accurate, safe, and contextually rich responses to complex medical queries by dynamically retrieving, reasoning over, and synthesizing information from multiple specialized sources. The overall operational flow can be broadly represented as the Base LLM generating a response R by synthesizing information from the user query and various contextual inputs () provided by the specialized modules:
where denotes context retrieved from the MedRAG module, represents structured knowledge derived from the MedKG, are outputs from the Tools module, and provides real-time information from the Search module.
3.2. Base Large Language Model (Base LLM)
The foundation of DiagnostiCare is a state-of-the-art large language model, such as Llama-3 70B or a model of comparable scale and performance. This Base LLM undergoes an initial phase of fine-tuning using a comprehensive dataset of medical domain texts, ensuring its enhanced understanding of medical terminology, concepts, and communication patterns specific to healthcare. Its primary responsibilities within the system include core language understanding and intent recognition from user queries, orchestration of calls to specialized modules based on query complexity and type, synthesizing information retrieved from various sources into coherent and contextually appropriate responses, and performing general reasoning and generation tasks. This pre-trained and fine-tuned Base LLM acts as the intelligent "brain" that coordinates the activities of the other modules, ensuring a cohesive and medically sound output.
3.3. MedRAG (Medical Retrieval-Augmented Generation) Module
The MedRAG module is crucial for mitigating the knowledge obsolescence and hallucination issues commonly observed in generic LLMs. It is designed to provide the Base LLM with real-time access to the most current and authoritative medical information. The construction of its knowledge base involves establishing a vast and continuously updated repository comprising recent medical literature, such as PubMed abstracts and full texts, authoritative clinical guidelines, and specialized disease databases. For efficient retrieval, all documents within this knowledge base are vectorized using advanced embedding models, and an efficient retrieval index, such as FAISS or HNSW, is constructed. Upon receiving a medical query , the MedRAG module performs a semantic similarity search to identify and retrieve the top-k most relevant and verified medical documents or snippets, denoted as . These retrieved documents form the contextual input for the Base LLM, significantly enhancing the factual accuracy and timeliness of its generated responses. The integration of MedRAG ensures that DiagnostiCare operates with the latest clinical evidence, thereby reducing the risk of generating outdated or incorrect information.
3.4. MedKG (Medical Knowledge Graph) Module
The MedKG module provides a structured and logical representation of medical knowledge, enabling more rigorous reasoning than what is typically achievable with unstructured text alone. We construct a comprehensive medical knowledge graph that interlinks various entities and their relationships within the healthcare domain. This knowledge graph encompasses a broad spectrum of medical entities, including diseases, symptoms, drugs, treatment protocols, diagnostic tests, biological markers, anatomical structures, and patient demographics. Furthermore, critical relationships such as "causes," "treats," "diagnosed by," "contraindicated with," "associated with," and "side effect of" are meticulously defined and populated to capture the intricate connections within medical knowledge. When the Base LLM processes a query, the MedKG module can be queried to provide structured facts or perform logical inferences. For example, it can deduce potential disease-symptom relationships, identify drug-drug interactions, or suggest diagnostic pathways based on a set of observed symptoms. This structured knowledge, , aids the Base LLM in complex causal reasoning and association analysis, thereby elevating the professional accuracy of auxiliary diagnoses and treatment recommendations.
3.5. Tools Module (External Medical Prediction and Analysis Tools)
This module represents a key innovation of DiagnostiCare, enabling the Base LLM to interact with and leverage specialized external medical tools and AI models. This integration allows DiagnostiCare to process and interpret multi-modal and numerical data, which is beyond the native capabilities of text-based LLMs. The Tools Module comprises interfaces to various expert systems, each designed for specific analytical tasks. The Laboratory Report Analysis Tool is capable of parsing structured or semi-structured laboratory reports, such as complete blood count or biochemistry panels. It automatically identifies abnormal values, cross-references them with reference ranges, and provides preliminary interpretations that are fed back to the Base LLM. The Medical Imaging Auxiliary Diagnosis Model Interface allows DiagnostiCare to invoke pre-trained deep learning models for analyzing medical images such as X-rays, CT scans, and MRIs. These AI models perform preliminary analysis, identifying potential anomalies or generating structured reports (e.g., "pneumonia detected in lower right lobe"), which are then conveyed to the Base LLM. A dedicated Drug Dosage Calculator and Contraindication Query tool computes recommended drug dosages based on patient-specific factors, including weight, age, and renal/hepatic function. It also queries comprehensive databases for drug contraindications, interactions, and potential adverse effects. For queries involving genetic predispositions or pharmacogenomics, the Genomic Data Analysis Interface can interpret specific gene sequencing data, correlating genetic variations with disease risks or drug response profiles. The outputs from these tools, collectively denoted as , provide critical data-driven insights that augment the Base LLM’s understanding and decision-making processes.
3.6. Search Module (Web and Professional Database Retrieval)
To ensure the broadest possible information coverage and access to emerging data, the Search Module provides real-time retrieval capabilities beyond the pre-indexed knowledge bases. This module includes a Real-time Web Search component, enabling the Base LLM to perform live web searches, accessing the latest news, non-structured health articles, or general information that might not yet be incorporated into structured knowledge bases. Furthermore, the module facilitates direct queries to specialized external medical databases through its Professional Database Query component, such as ClinicalTrials.gov for ongoing clinical trials, FDA databases for drug approvals and safety alerts, or other relevant regulatory bodies. The information retrieved, , complements the internal knowledge sources by providing dynamic and diverse data, ensuring that DiagnostiCare remains informed by the most current global health landscape.
3.7. System Workflow and Integration
When a user submits a medical query () to DiagnostiCare, the Base LLM initiates the process by analyzing the query for intent, key entities, and contextual nuances. Based on this initial understanding, the Base LLM dynamically orchestrates calls to one or more specialized modules. This orchestration mechanism can be conceptualized as an adaptive function that selects and prioritizes module interactions based on the query’s characteristics. For instance, a query about the latest research on a specific disease might primarily trigger the MedRAG module to retrieve recent literature. A question involving patient-specific laboratory results would activate the Tools Module’s laboratory report analyzer. Similarly, a query regarding potential drug interactions would leverage the structured knowledge within the MedKG module and potentially the Tools Module’s drug calculator for real-time dosage and contraindication checks. More complex queries might involve an iterative process, where the Base LLM first retrieves information from MedRAG, then uses that context to formulate a query for MedKG, and finally synthesizes all gathered information. The orchestration process can be represented as:
where identifies the relevant modules based on the user query , and GatherContext compiles the outputs from these selected modules into a unified contextual input . The information gathered from these modules is then synthesized by the Base LLM into a comprehensive, accurate, and contextually appropriate response. This iterative process of information retrieval, analysis, and synthesis ensures that DiagnostiCare can provide robust support for medical question answering and auxiliary diagnosis, significantly enhancing diagnostic accuracy, treatment relevance, and information safety.
4. Experiments
In this section, we detail the experimental setup, evaluation methodology, and present the results of our comprehensive assessment of the DiagnostiCare system. Our experiments are designed to rigorously evaluate the system’s performance in medical question answering and auxiliary diagnosis, comparing it against leading general-purpose large language models and analyzing the contributions of its individual components.
4.1. Experimental Setup
To thoroughly evaluate the capabilities of DiagnostiCare, we constructed a novel and challenging dataset for medical question answering and auxiliary diagnosis.
-
Dataset Construction: We curated a specialized dataset comprising 500 high-difficulty medical question-answer pairs. These questions are designed to test a wide range of medical reasoning and knowledge application, categorized into:
- Disease Diagnosis: Questions requiring preliminary diagnosis based on symptom descriptions and patient history.
- Treatment Recommendations: Inquiries about appropriate treatment plans given a diagnosis and patient characteristics.
- Drug Consultation: Questions concerning drug usage, dosages, side effects, and potential interactions.
- Medical Examination Interpretation: Tasks involving the interpretation of laboratory reports or medical imaging results.
- Patient Education: Questions related to disease prevention, health management, and explanations of complex medical concepts.
The questions were sourced from anonymized clinical case studies, authoritative medical textbooks, specialized online medical forums, and recent medical research articles. Each question was meticulously reviewed and annotated with a gold-standard answer by at least two independent medical professionals with clinical experience, ensuring high quality and clinical relevance. -
Comparison Models: We benchmarked DiagnostiCare against several prominent general-purpose large language models, representing the current state-of-the-art in conversational AI:
- ChatGPT-4: A widely recognized and powerful general-purpose LLM.
- Claude 3 Opus: Another top-tier general LLM known for its strong reasoning capabilities.
- Gemini 1.5 Pro: Google’s advanced multi-modal LLM.
For all baseline models, we utilized their latest publicly available versions at the time of experimentation. A unified and consistent prompt engineering strategy was applied across all models to ensure fair comparison and minimize prompt-specific biases.
4.2. Evaluation Methodology
Our evaluation strategy combines both automatic metrics for quantitative linguistic assessment and, more importantly, a robust manual evaluation by medical experts to ensure clinical validity and safety.
-
Automatic Metrics: We employed several standard text generation metrics to evaluate the linguistic quality and similarity of model responses to the gold-standard answers:
- BLEU (Bilingual Evaluation Understudy) [49]: Measures the n-gram overlap between generated text and reference text.
- ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation) [50]: Focuses on the longest common subsequence, often used for summarization tasks.
- METEOR (Metric for Evaluation of Translation with Explicit Ordering) [51]: Considers exact, stem, synonym, and paraphrase matches between generated text and references.
These metrics provide an initial quantitative assessment of textual similarity and fluency. -
Manual Evaluation (Core Assessment): Recognizing the critical importance of clinical accuracy, safety, and relevance in the medical domain, the core evaluation relied on blind expert review.
- Three independent medical experts, all with relevant clinical experience, were recruited to blindly rate the responses generated by all models.
-
Each model’s output for every question in the dataset was scored across multiple dimensions on a scale of 1 to 10 (higher scores indicating better performance):
- -
- Diagnostic Accuracy: Assesses whether the model’s preliminary diagnosis or differential diagnosis is correct and comprehensive.
- -
- Treatment Relevance: Evaluates if the recommended treatment plan is appropriate, aligns with established clinical guidelines, and considers patient-specific factors.
- -
- Information Safety: A paramount metric in healthcare, this dimension assesses whether the response contains any harmful, misleading, or irresponsible information. A higher score indicates greater safety.
- -
- Language Fluency & Understandability: Measures the naturalness, clarity, and ease of understanding of the generated medical explanations.
- The Total Clinical Score for each model was calculated as a weighted average of these four manual assessment dimensions, reflecting the system’s overall practical utility and reliability in a clinical context.
4.3. Performance Comparison with Baselines
Table 1 presents the results of our manual evaluation, comparing DiagnostiCare with leading general-purpose LLMs across the defined clinical metrics. The data presented are fabricated but reflect plausible performance trends observed when specialized systems are applied to domain-specific tasks.
As shown in Table 1, our proposed DiagnostiCare system consistently demonstrates superior performance across several critical medical question answering and auxiliary diagnosis metrics. Notably, DiagnostiCare achieves significantly higher scores in Diagnostic Accuracy (9.3), Treatment Relevance (9.1), and most importantly, Information Safety (9.5). These three dimensions are paramount in the medical domain, where precision and reliability directly impact patient outcomes. While its Language Fluency (9.4) is comparable to that of the top-performing general LLMs, the substantial gains in domain-specific accuracy and safety contribute to a leading Total Clinical Score of 9.28. This comprehensive evaluation underscores the effectiveness of DiagnostiCare’s modular, knowledge-enhanced architecture in addressing the unique challenges of healthcare applications, validating the necessity of integrating specialized knowledge and tools with powerful foundation models.
4.4. Ablation Study
To further validate the design choices and quantify the contribution of each specialized module within DiagnostiCare, we conducted an ablation study. This study systematically evaluates the system’s performance when individual modules (MedRAG, MedKG, and Tools) are selectively removed or disabled. The results, based on the same manual evaluation methodology, are presented in Table 2.
The ablation study results in Table 2 clearly demonstrate the incremental value of each component within the DiagnostiCare architecture. Starting with the Base LLM Only (a fine-tuned Llama-3 70B), we observe a foundational level of performance. The addition of the MedRAG module significantly boosts Diagnostic Accuracy (from 7.9 to 8.5) and Information Safety (from 8.0 to 8.7), highlighting its crucial role in providing up-to-date and factually grounded medical information, thereby reducing hallucination. Further incorporating the MedKG module leads to additional improvements, particularly in Diagnostic Accuracy (from 8.5 to 8.9) and Treatment Relevance (from 8.1 to 8.6). This gain underscores the importance of structured knowledge and logical reasoning for complex medical inference. Finally, the full DiagnostiCare system, which includes the powerful Tools Module, achieves the highest scores across all clinical metrics, especially in Diagnostic Accuracy (9.3) and Information Safety (9.5). The Tools Module enables the system to process multi-modal data and perform specialized analyses (e.g., interpreting lab reports or medical images), which are critical for comprehensive auxiliary diagnosis. These findings unequivocally confirm that each integrated module contributes substantially to DiagnostiCare’s enhanced performance, validating our hypothesis that a multi-modal, knowledge-augmented approach is essential for robust and reliable AI in the medical domain.
4.5. Qualitative Analysis and Error Patterns
Beyond quantitative metrics, a qualitative analysis of model responses revealed distinct error patterns among the general-purpose LLMs compared to DiagnostiCare. This analysis, conducted by our medical experts, helped in understanding the underlying reasons for performance differences. Table 3 summarizes the prevalence of common error types observed across the models.
The qualitative analysis, supported by the data in Table 3, clearly illustrates how DiagnostiCare’s modular design effectively mitigates prevalent issues in general LLMs. Factual Hallucinations and Outdated Information were significantly reduced in DiagnostiCare (5% and 3% respectively), primarily due to the real-time, authoritative information retrieval provided by the MedRAG and Search modules. General LLMs frequently generated plausible but incorrect or obsolete medical facts, which is a critical safety concern.
Lack of Structured Reasoning was a common pitfall for baseline models (22-25%), often leading to superficial or logically inconsistent responses, especially for complex differential diagnoses or intricate treatment pathways. DiagnostiCare, with its MedKG module, demonstrated a much lower incidence of this error (8%), leveraging its structured knowledge graph for more rigorous inference. Similarly, Incomplete/Insufficient Information was a frequent issue with general LLMs, whereas DiagnostiCare’s comprehensive information aggregation from multiple modules (MedRAG, MedKG, Search) ensured more thorough responses (7% error rate).
A particularly stark difference was observed in the Misinterpretation of Numerical Data (e.g., lab values, drug dosages), where general LLMs had error rates as high as 30%. This highlights their inherent limitation in processing quantitative information. The Tools Module in DiagnostiCare drastically reduced this to 6%, by offloading such tasks to specialized analytical tools. This directly translated to a lower rate of Inappropriate Treatment Recommendations (4% for DiagnostiCare vs. 13-15% for baselines), as accurate data interpretation is crucial for safe and effective treatment planning.
In summary, while general LLMs exhibited good language fluency, their responses often lacked the depth, accuracy, and safety required for medical applications. DiagnostiCare, through its domain-specific modules, consistently produced more factually accurate, logically sound, comprehensive, and critically, safer medical information, validating its design philosophy for specialized domains.
5. Conclusion
In this paper, we introduced DiagnostiCare, a novel multi-modal enhanced large language model system meticulously designed for medical question answering and auxiliary diagnosis. Its modular architecture, integrating MedRAG for dynamic evidence retrieval, MedKG for structured reasoning, a powerful Tools module for multi-modal data processing, and a Search module for real-time information access, effectively overcomes the inherent limitations of general-purpose LLMs in healthcare, such as factual hallucination and knowledge obsolescence. Our comprehensive experimental evaluation on a challenging, expert-annotated dataset demonstrated DiagnostiCare’s significantly superior performance against state-of-the-art general LLMs across critical clinical metrics, including Diagnostic Accuracy, Treatment Relevance, and Information Safety. Ablation studies unequivocally confirmed the incremental value of each proposed module, collectively contributing to DiagnostiCare’s leading Total Clinical Score. This work represents a significant stride towards building intelligent systems that can truly augment clinical practice and improve patient care, providing a blueprint for creating clinically sound, safe, and effective AI solutions. Future work will focus on expanding integrated knowledge bases, exploring more sophisticated reasoning mechanisms, and investigating real-world deployment with an emphasis on human-in-the-loop validation and ethical considerations.
References
- Huang, J.; Chang, K.C.C. Towards Reasoning in Large Language Models: A Survey. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics; 2023; pp. 1049–1065. [Google Scholar] [CrossRef]
- Xiong, J.; Li, Z.; Zheng, C.; Guo, Z.; Yin, Y.; Xie, E.; Yang, Z.; Cao, Q.; Wang, H.; Han, X.; et al. Dq-lore: Dual queries with low rank approximation re-ranking for in-context learning. arXiv preprint, 2023; arXiv:2310.02954. [Google Scholar]
- Long, Q.; Wu, Y.; Wang, W.; Pan, S.J. Does in-context learning really learn? rethinking how large language models respond and solve tasks via in-context learning. arXiv preprint, 2024; arXiv:2404.07546. [Google Scholar]
- Ma, Y.; Cao, Y.; Hong, Y.; Sun, A. Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples! In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics; 2023; pp. 10572–10601. [Google Scholar] [CrossRef]
- Shi, Z.; Zhou, Y.; Li, J. Safety alignment via constrained knowledge unlearning. arXiv preprint, 2025; arXiv:2505.18588. [Google Scholar]
- Wei, K.; Zhong, J.; Zhang, H.; Zhang, F.; Zhang, D.; Jin, L.; Yu, Y.; Zhang, J. Chain-of-specificity: Enhancing task-specific constraint adherence in large language models. In Proceedings of the Proceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 2401–2416.
- Sun, M. Llamacare: A large medical language model for enhancing healthcare knowledge sharing. arXiv preprint, 2024; arXiv:2406.02350. [Google Scholar]
- Zhou, Y.; Li, X.; Wang, Q.; Shen, J. Visual In-Context Learning for Large Vision-Language Models. In Proceedings of the Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. Association for Computational Linguistics, 2024, pp. 15890–15902.
- Zhang, F.; Wang, C.; Cheng, Z.; Peng, X.; Wang, D.; Xiao, Y.; Chen, C.; Hua, X.S.; Luo, X. DREAM: Decoupled Discriminative Learning with Bigraph-aware Alignment for Semi-supervised 2D-3D Cross-modal Retrieval. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, 2025, Vol. 39, pp. 13206–13214.
- Zhang, F.; Hua, X.S.; Chen, C.; Luo, X. A Statistical Perspective for Efficient Image-Text Matching. In Proceedings of the Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2024, pp. 355–369.
- Liu, Y.; Iter, D.; Xu, Y.; Wang, S.; Xu, R.; Zhu, C. G-Eval: NLG Evaluation using Gpt-4 with Better Human Alignment. In Proceedings of the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2023, pp. 2511–2522. [CrossRef]
- Ji, Z.; Yu, T.; Xu, Y.; Lee, N.; Ishii, E.; Fung, P. Towards Mitigating LLM Hallucination via Self Reflection. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics, 2023, pp. 1827–1843. [CrossRef]
- Piper, A.; So, R.J.; Bamman, D. Narrative Theory for Computational Narrative Understanding. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2021, pp. 298–311. [CrossRef]
- Solanki, D.; Hsu, H.M.; Zhao, O.; Zhang, R.; Bi, W.; Kannan, R. The Way We Think About Ourselves. In Proceedings of the Augmented Cognition. Theoretical and Technological Approaches: 14th International Conference, AC 2020, Held as Part of the 22nd HCI International Conference, HCII 2020, Copenhagen, Denmark, July 19–24, 2020, Proceedings, Part I, Berlin, Heidelberg, 2020; p. 276–285. [CrossRef]
- Liu, F.; Ge, S.; Wu, X. Competence-based Multimodal Curriculum Learning for Medical Report Generation. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, 2021, pp. 3001–3012. [CrossRef]
- Sachan, D.; Lewis, M.; Joshi, M.; Aghajanyan, A.; Yih, W.t.; Pineau, J.; Zettlemoyer, L. Improving Passage Retrieval with Zero-Shot Question Generation. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2022, pp. 3781–3797. [CrossRef]
- Ovadia, O.; Brief, M.; Mishaeli, M.; Elisha, O. Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs. In Proceedings of the Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2024, pp. 237–250. [CrossRef]
- Zhan, H.; Zhang, H.; Chen, H.; Ding, Z.; Bao, Y.; Lan, Y. Augmenting Knowledge-grounded Conversations with Sequential Knowledge Transition. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 5621–5630. [CrossRef]
- Xiong, G.; Jin, Q.; Lu, Z.; Zhang, A. Benchmarking Retrieval-Augmented Generation for Medicine. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024. Association for Computational Linguistics; 2024; pp. 6233–6251. [Google Scholar] [CrossRef]
- Xu, S.; Tian, Y.; Cao, Y.; Wang, Z.; Wei, Z. Benchmarking Machine Learning and Deep Learning Models for Fake News Detection Using News Headlines. Preprints 2025. [Google Scholar] [CrossRef]
- Maojun, S.; Han, R.; Jiang, B.; Qi, H.; Sun, D.; Yuan, Y.; and, J.H. LAMBDA: A Large Model Based Data Agent. Journal of the American Statistical Association 2025, 0, 1–20. [Google Scholar] [CrossRef]
- Sun, M.; Han, R.; Jiang, B.; Qi, H.; Sun, D.; Yuan, Y.; Huang, J. A Survey on Large Language Model-based Agents for Statistics and Data Science. arXiv preprint, 2024; arXiv:2412.14222. [Google Scholar]
- Xiong, J.; Shen, J.; Yuan, Y.; Wang, H.; Yin, Y.; Liu, Z.; Li, L.; Guo, Z.; Cao, Q.; Huang, Y.; et al. Trigo: Benchmarking formal mathematical proof reduction for generative language models. arXiv preprint, 2023; arXiv:2310.10180. [Google Scholar]
- Xiong, J.; Li, C.; Yang, M.; Hu, X.; Hu, B. Expression syntax information bottleneck for math word problems. In Proceedings of the Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2022, pp. 2166–2171.
- Shi, Z.; Zhou, Y. Topic-selective graph network for topic-focused summarization. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining. Springer; 2023; pp. 247–259. [Google Scholar]
- Shi, Z.; Cao, T.; Zhang, X. Incorporating BERT with Naive Bayes into Neutral Sentiment Analysis. In Proceedings of the 2023 IEEE 3rd International Conference on Data Science and Computer Application (ICDSCA). IEEE, 2023, pp. 782–785.
- Wei, K.; Sun, X.; Zhang, Z.; Zhang, J.; Zhi, G.; Jin, L. Trigger is not sufficient: Exploiting frame-aware knowledge for implicit event argument extraction. In Proceedings of the Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2021, pp. 4672–4682.
- Wei, K.; Yang, Y.; Jin, L.; Sun, X.; Zhang, Z.; Zhang, J.; Li, X.; Zhang, L.; Liu, J.; Zhi, G. Guide the many-to-one assignment: Open information extraction via iou-aware optimal transport. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 4971–4984.
- Cai, L.; Zhang, L.; Ma, D.; Fan, J.; Shi, D.; Wu, Y.; Cheng, Z.; Gu, S.; Yin, D. PILE: Pairwise Iterative Logits Ensemble for Multi-Teacher Labeled Distillation. In Proceedings of the Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track, 2022, pp. 587–595.
- Long, Q.; Wang, M.; Li, L. Generative Imagination Elevates Machine Translation. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2021, pp. 5738–5748.
- Yu, C.; Liu, F.; Zhu, J.; Guo, S.; Gao, Y.; Yang, Z.; Liu, M.; Xing, Q. Gradient Boosting Decision Tree with LSTM for Investment Prediction. In Proceedings of the 2025 5th Asia-Pacific Conference on Communications Technology and Computer Science (ACCTCS); 2025; pp. 57–62. [Google Scholar] [CrossRef]
- Jiang, J.; Zhou, K.; Dong, Z.; Ye, K.; Zhao, X.; Wen, J.R. StructGPT: A General Framework for Large Language Model to Reason over Structured Data. In Proceedings of the Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2023, pp. 9237–9251. [CrossRef]
- Gui, L.; Wang, B.; Huang, Q.; Hauptmann, A.; Bisk, Y.; Gao, J. KAT: A Knowledge Augmented Transformer for Vision-and-Language. In Proceedings of the Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2022, pp. 956–968. [CrossRef]
- Agarwal, O.; Ge, H.; Shakeri, S.; Al-Rfou, R. Knowledge Graph Based Synthetic Corpus Generation for Knowledge-Enhanced Language Model Pre-training. In Proceedings of the Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2021, pp. 3554–3565. [CrossRef]
- Moiseev, F.; Dong, Z.; Alfonseca, E.; Jaggi, M. SKILL: Structured Knowledge Infusion for Large Language Models. In Proceedings of the Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. Association for Computational Linguistics, 2022, pp. 1581–1588. [CrossRef]
- Trivedi, H.; Balasubramanian, N.; Khot, T.; Sabharwal, A. Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2023, pp. 10014–10037. [CrossRef]
- Weng, Y.; Zhu, M.; Xia, F.; Li, B.; He, S.; Liu, S.; Sun, B.; Liu, K.; Zhao, J. Large Language Models are Better Reasoners with Self-Verification. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2023. Association for Computational Linguistics; 2023; pp. 2550–2575. [Google Scholar] [CrossRef]
- Chen, Z.; Huang, H.; Liu, B.; Shi, X.; Jin, H. Semantic and Syntactic Enhanced Aspect Sentiment Triplet Extraction. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics; 2021; pp. 1474–1483. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, C.; Hua, X.S.; Luo, X. FATE: Learning Effective Binary Descriptors With Group Fairness. IEEE Transactions on Image Processing 2024, 33, 3648–3661. [Google Scholar] [CrossRef] [PubMed]
- Long, Q.; Chen, J.; Liu, Z.; Chen, N.F.; Wang, W.; Pan, S.J. Reinforcing Compositional Retrieval: Retrieving Step-by-Step for Composing Informative Contexts. arXiv preprint, 2025; arXiv:2504.11420. [Google Scholar]
- Lin, Z.; Zhang, Q.; Tian, Z.; Yu, P.; Lan, J. DPL-SLAM: enhancing dynamic point-line SLAM through dense semantic methods. IEEE Sensors Journal 2024, 24, 14596–14607. [Google Scholar] [CrossRef]
- Lin, Z.; Tian, Z.; Zhang, Q.; Zhuang, H.; Lan, J. Enhanced visual slam for collision-free driving with lightweight autonomous cars. Sensors 2024, 24, 6258. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Tian, Z.; Wang, X.; Yang, J.; Lin, Z. Efficient and Safe Planner for Automated Driving on Ramps Considering Unsatisfication. arXiv preprint, 2025; arXiv:2504.15320. [Google Scholar]
- Yang, Z.; Sun, A.; Zhao, Y.; Yang, Y.; Li, D.; Zhou, C. RLHF Fine-Tuning of LLMs for Alignment with Implicit User Feedback in Conversational Recommenders, 2025. arXiv:cs.LG/2508.05289.
- Yang, H.; Tian, Y.; Yang, Z.; Wang, Z.; Zhou, C.; Li, D. Research on Model Parallelism and Data Parallelism Optimization Methods in Large Language Model—Based Recommendation Systems. In Proceedings of the 2025 7th International Conference on Artificial Intelligence Technologies and Applications (ICAITA); 2025; pp. 324–329. [Google Scholar] [CrossRef]
- Wang, P.; Zhu, Z.; Liang, D. Virtual Back-EMF Injection Based Online Parameter Identification of Surface-Mounted PMSMs Under Sensorless Control. IEEE Transactions on Industrial Electronics 2024. [Google Scholar] [CrossRef]
- Wang, P.; Zhu, Z.; Liang, D. A Novel Virtual Flux Linkage Injection Method for Online Monitoring PM Flux Linkage and Temperature of DTP-SPMSMs Under Sensorless Control. IEEE Transactions on Industrial Electronics 2025. [Google Scholar] [CrossRef]
- Wang, P.; Zhu, Z.Q.; Feng, Z. Novel Virtual Active Flux Injection-Based Position Error Adaptive Correction of Dual Three-Phase IPMSMs Under Sensorless Control. IEEE Transactions on Transportation Electrification 2025. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318.
- Lin, C.Y. Rouge: A package for automatic evaluation of summaries. In Proceedings of the Text summarization branches out; 2004; pp. 74–81. [Google Scholar]
- Banerjee, S.; Lavie, A. METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In Proceedings of the Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72.

Table 1.
Medical QA & Assistant Diagnosis System Performance (Manual Scoring)
| Model Name | Diagnostic Accuracy | Treatment Relevance | Information Safety | Language Fluency | Total Clinical Score |
|---|---|---|---|---|---|
| ChatGPT-4 | 8.5 | 8.2 | 8.8 | 9.2 | 8.68 |
| Claude 3 Opus | 8.7 | 8.4 | 8.9 | 9.3 | 8.83 |
| Gemini 1.5 Pro | 8.6 | 8.3 | 8.7 | 9.1 | 8.68 |
| DiagnostiCare | 9.3 | 9.1 | 9.5 | 9.4 | 9.28 |
Table 2.
Ablation Study: Contribution of DiagnostiCare Modules (Manual Scoring)
| Model Variant | Diagnostic Accuracy | Treatment Relevance | Information Safety | Language Fluency | Total Clinical Score |
|---|---|---|---|---|---|
| Base LLM Only | 7.9 | 7.5 | 8.0 | 9.0 | 8.10 |
| Base LLM + MedRAG | 8.5 | 8.1 | 8.7 | 9.1 | 8.60 |
| Base LLM + MedRAG + MedKG | 8.9 | 8.6 | 9.0 | 9.2 | 8.92 |
| DiagnostiCare (Full) | 9.3 | 9.1 | 9.5 | 9.4 | 9.28 |
Table 3.
Prevalence of Common Error Types Across Models (Percentage of Questions with Error)
| Error Type | ChatGPT-4 | Claude 3 Opus | Gemini 1.5 Pro | DiagnostiCare |
|---|---|---|---|---|
| Factual Hallucination | 18% | 15% | 17% | 5% |
| Outdated Information | 12% | 10% | 11% | 3% |
| Lack of Structured Reasoning | 25% | 22% | 23% | 8% |
| Incomplete/Insufficient Information | 20% | 18% | 19% | 7% |
| Misinterpretation of Numerical Data | 30% | 28% | 29% | 6% |
| Inappropriate Treatment Recommendation | 15% | 13% | 14% | 4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



