Submitted:
04 September 2025
Posted:
24 September 2025
You are already at the latest version
Abstract
Originality and attribution of narrative responses in healthcare remain underexamined. Plagiarism carries significant ethical, legal, and professional consequences, undermining trust in information. This study employed a quantitative, comparative design, using iThenticate 2.0, to analyze chatbot plagiarism. This cross-sectional study included 24 questions related to gynecologic-oncology which generated 360 queries submitted to Gemini and Copilot. Narrative responses were generated by Google Gemini (version 1.5 Flash) and Microsoft Copilot (GPT-4 based Prometheus model). The main outcomes were the presence and percentage of plagiarisms in chatbot narratives. Plagiarism was detected in narratives from both Gemini and Copilot. Responses from Gemini contained more plagiarism events per narrative 3.09 ± 0.10 than Copilots 1.59 ± 0.07; P < .05. Gemini cited more sources (4.4 ± 0.11 vs 2.98 ± 0.07; P < .05) and had more plagiarized content from copyrighted or published sources than Copilot (2.57 ± 0.10 1.34 ± 0.07; P < .05). Mean pla-giarism scores were higher for Gemini (26.19% ± 0.88) than for Copilot (19.01% ± 0.88; P < .05). Narrative responses from Gemini and Copilot contain plagiarism and highlight a need for assessing plagiarism in AI-generated content. Proper citation and attribution in AI responses are needed to mitigate plagiarism, reduce hallucination, and enhance the verifiability and credibility of information from AI platforms.
Keywords:
chatbots
; Gemini
; Copilot
; plagiarism
; gynecologic oncology queries
1. Introduction
Generative chatbots have become ubiquitous [1], with free-to-use, user-friendly programs now embedded in publicly available online search engines such as Google and Microsoft Edge. These artificial intelligence (AI)-powered tools allow users to type or speak queries and receive immediate text or digital voice replies based on online access to information that is collected and integrated by the AI application using computational neural networks [2]. Large language models (LLMs) process the information retrieved from the computational neural networks to perform natural language processing (NLP) that generates, translates and summarizes the content so that the AI-generated results resemble highly coherent human conversational output, which can be easy to digest and understand [3,4]. As chatbot-AI applications evolved, investigations began to assess the accuracy of the AI responses that were generated, especially responses to healthcare-related queries [5]. Accuracy would need to be sufficient both for patients seeking answers regarding their personal diagnoses and for caregivers seeking guidance in their specialty practices. An extraordinary lapse in AI accuracy has been reported when a citation provided by AI intended for a continuing education course was determined to be non-existent [6]. In a different report, 70% of the cited references produced by a chatbot were inaccurate [7]. Our work previously assessed the accuracy of the responses by the Google Gemini and Microsoft Copilot chatbots to 24 gynecologic oncology-related queries. Our evaluations of these narrative chatbots in July of 2024 reported that Google Gemini responses were accurate 87.5% of the time when compared to UpToDate, an evidence-based point-of-care online resource for medical providers [8], while Microsoft Copilot was determined to be accurate 83.3% of the time [9]. Thus, inquiries made to these chatbots might not be completely accurate. Emerging from these efforts was the observation that responses to repeated queries could differ considerably in length and language. This observation led us to question the originality of replies returned by the AI chatbots and raised the possibility of plagiarism in chatbot replies. Plagiarism is the use of someone else’s expressions or ideas as if they were your own and includes complete or verbatim plagiarism, mosaic plagiarism (an author interweaves someone else’s work with theirs), inadequate paraphrasing, improper/incorrect citation and self-plagiarism [10]. Plagiarized use can be by direct quotation or by paraphrase. Proper citation is a major way of avoiding all types of plagiarism. There are serious legal and financial consequences of plagiarism. Plagiarism has been interpreted as forgery, piracy and fraud, specifically found in violation of copyright laws. Penalties for plagiarism include: repayment of royalties and any profits that occurred, court expenses to settle plagiarism cases, and lawsuits [11]. It is understood in the academic and research communities that plagiarism undermines trust in publications that inform on scientific decision making, innovation, and performance. Authors can be subject to legal, financial, and professional consequences if they are proven to have plagiarized [12]. These anti-plagiarism values have been staunchly upheld by publishers, particularly since the age of the internet made thousands of academic works readily accessible [13]. Anti-plagiarism values are routinely maintained in academic communities, as academic research requires trust, integrity, and transparency in order to make research findings reliable. While the accuracy of responses from Gemini and Copilot has been assessed, the presence and degree of plagiarism within these narrative responses to gynecologic oncology queries have not yet been evaluated. Work presented here determined that plagiarism is present in AI chatbot narrative responses to the same 24 highly pertinent gynecologic-oncology-related queries that we have used previously [14] and evaluated the degree of plagiarism that existed using a plagiarism identification program. This study utilized iThenticate, which is a plagiarism detection tool used by educators, writers, and multiple trusted publishers, including Wiley and Nature Springer, to assess similarity in various types of written works [15]. iThenticate has also been used to evaluate plagiarism in abstracts generated by ChatGPT [16]. Narratives that are inputted into the iThenticate software are cross-referenced against millions of word sources, including 81,000 published journal articles [15]. We felt that the efforts described here were necessary because replies returned by narrative AI appear unsourced or to have only a bare minimum of references. It needs to be appreciated that unsourced information returned by queries made through AI may have suppressed recognitions of the originators. Consequently, users might not realize they are plagiarizing by using material plagiarized by an AI algorithm [17,18]. The present work assessed the degree of plagiarism that exists in Gemini and Copilot narratives.
2. Materials and Methods
The Google Gemini chatbot (version 1.5 Flash) and Microsoft Copilot chatbot were both accessed via the Google Chrome app (version 131.0.6778.86 (Official Build) (arm64)) using personal computers running Mac OS Monterey version 12.7.4. Copilot was updated continuously throughout the trial and the version was not specified. Twenty-four questions regarding gynecologic oncology were identical to those used in our previously reported studies and are displayed in Figure 1 [9,14]. Each question was entered into both Gemini and Copilot five times by three different evaluators for a total of 15 inputs for each of the 24 questions. Chatbot narrative responses to each query were individually copied for plagiarism analysis and pasted into the iThenticate web page. A majority of chatbot responses also cited internet sources below each narrative response. Raters recorded the number of these citations for each individual narrative response. Plagiarism tool iThenticate (version iThenticate 2.0) was accessed via Google Chrome (version 131.0.6778.86 (Official Build) (arm64)) web browser on the same software listed above and narrative chatbot responses were entered into the iThenticate program individually. The iThenticate plagiarism analysis displayed the total word count for each narrative response and displayed a percentage score for each narrative response, indicating what percentage of the narrative was flagged by the program as plagiarism. Plagiarism events within the narrative were highlighted by the iThenticate system and labelled with a citation to the source of work from which it was plagiarized. An example of the iThenticate display is shown in Figure 2. Evaluators scored individual plagiarism events as either “high” or “low” plagiarism. A “high” plagiarism event was defined as comprising 10% or more of the entire narrative response, while a “low” plagiarism event was defined as comprising less than 10% of the entire narrative response. If a singular narrative had two separate plagiarism events, one of which made up more than 12% of the total word count for that response, and the other which made up only 6% of the total word count, this narrative response would be scored as having one event of “high” plagiarism and one event of “low” plagiarism. For each narrative response, the total word count, total percentage plagiarism score, number of “high” and “low” plagiarism events, the number of sources listed by the chatbot itself, and the number of plagiarized copywritten/published sources detected by iThenticate were recorded in a summary table in Microsoft Excel for analyses. Descriptive statistics were determined using the Winstat add-in for Excel [19] and unpaired t-tests were performed using the Graphpad online calculator [20].
3. Results
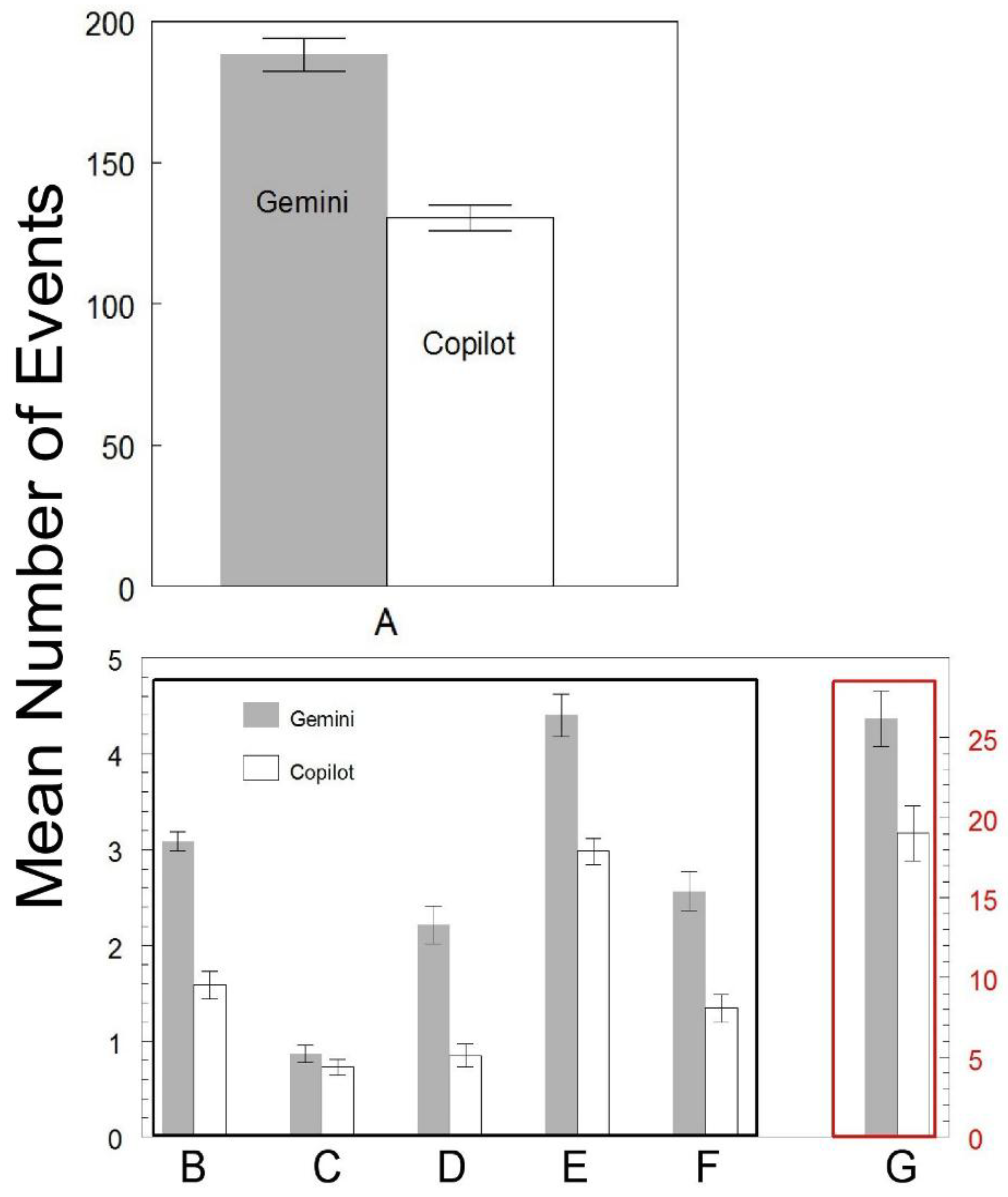
In every category evaluated, the number of events recorded were greater for Gemini than for Copilot and statistically significant (p<0.05), (Figure 3). Of the 360 total narrative responses for each of the two AI programs, Gemini narratives had a significantly higher mean number of words (+ SEM) than Copilot (Figure 3 Component A: Gemini 188.14 ± 3.04; Copilot 130.48 ± 2.25 (p<0.05)). Plagiarism was detected in both Gemini and Copilot narratives with Gemini having a significantly higher mean number of plagiarisms (+SEM) per narrative response than Copilot (Figure 3 component B: Gemini 3.09 ± 0.10, Copilot 1.59 ± 0.07, p < 0.05). While still statistically different (p=0.027), Gemini (0.87+0.05) and Copilot (0.73+0.04) were closest in the number of “high” plagiarism events per narrative (Figure 3 component C), but different in “low” plagiarism events per narrative: Gemini: 3.18+0.98 vs Copilot: 0.85+0.06, p = 0.0188 (Figure 3 component D). Both Gemini and Copilot responses listed internet sources beneath each narrative response which were recorded. When the mean number of listed sources from each program was analyzed, Gemini referenced a significantly higher average number of sources that were copyrighted or from published sources (E: Gemini 4.4+0.11, Copilot 2.98+0.07), p<0.05 (Figure 3 component E). iThenticate identified more instances of plagiarism on average from copyrighted or published sources in Gemini responses than Copilot responses (Figure 3 component F: Gemini 2.57+0.10, Copilot 1.34+0.07), p<0.05). Many of the narrative responses contained plagiarized material identified by iThenticate from sources that were not listed by the Gemini or Copilot. The iThenticate plagiarism scores were statistically greater for Gemini than for Copilot (Figure 3 component G: Gemini 26.19% ± 0.88, Copilot 19.01% ± 0.88), p < 0.05), which can be understood as the number of words flagged as plagiarism normalized to the total number of words.
4. Discussion
We have reported here that the narratives returned by Gemini and Copilot to queries made on subjects relevant to gynecologic oncology can contain plagiarisms. This determination has been based on robust examinations of 360 replicates for each of 24 queries. Gemini narratives were lengthier, had more plagiarisms, and more plagiarisms scored as “high” by iThenticate, as well as more plagiarisms from copyrighted or published sources. Gemini also had higher iThenticate plagiarism scores (i.e. words flagged as plagiarism normalized to the total number of words in the narrative). These findings are current to January 2025, and we recognize that the ongoing evolutions of Gemini and Copilot could bring about plagiarism reductions in the chatbot narratives.
The use of artificial intelligence in the medical field introduces a host of considerations on ethics, accuracy, credibility, and ultimately usage. Accessibility and ease of use makes narrative AI a readily available tool for utilizations that require well-written output. However, this well-written output must either be original to the AI or should contain attributions that identify the sources of the entire narrative output.
Several situations arise when attribution is absent. Foremost, is the circumstance where it is not possible to determine if hallucination or confabulation is contained in the narrative. Secondly, any author that references the results returned by a narrative AI absent attribution risks inadvertently extending any confabulations in the source AI narrative. This could be considerable since 70% of the references generated by a chatbot were reported inaccurate or non-existent [21,22]. Central to the problem presented by lack of attribution is the question of responsibility. First, is the AI creator/owner/distributor responsible for plagiarism or copyright infringements? Second, what responsibility extends to an author and narrative AI user if they attribute information garnered from a chatbot AI that is absent attribution and has constructed a narrative that contains plagiarized language? Third, what standards against plagiarized language should be adopted? Fourth, if narrative AI output is adapted to voice, what considerations of plagiarism now apply? Thus, responsible AI narrative use needs to ensure that narrative AI information includes citation for wherever the information originated from. This is not a small task since this report only focuses on Gemini and Copilot. Google’s Gemini chatbot is proprietary while Copilot uses its own large language model, Prometheus, which has been built on the Open AI GPT-4 foundation [23,24]. At present it is difficult to determine an exact number of generative AI systems being used due to the rapid emergence of new models, but a curated list that is current to October 2024 estimates that over 5000 generative AI systems are in operation [25,26]. As a consequence, any of these generative AI models that return narrative information should be considered in terms of the adequacy of citation in their results. By identifying plagiarism in two of the most widely available AI chatbots, the present paper highlights the potential for widespread misuse involving plagiarism, absence of citation and incorrect citation. Accurate citation is the remedy for several issues including: plagiarism, hallucination/confabulation and intentional disinformation where false information is deliberately disseminated [27]. Citation establishes the guiderails that keep credibility on track. In relation to plagiarism, citation establishes the originator and as a result authenticity in relation to whether the information is bona fide. Misrepresentation and misinterpretation of information are the key risks related to plagiarism. Secondarily, there are risks of penalties involving financial outcomes, accusations of misconduct and loss of reputation. The strengths of the work described here are that 1.) it examined two major chatbots that are freely available to the public, 2.) it made use of a well-recognized tool for measurements on plagiarism, and 3.) it highly replicated its examinations on each of 24 distinct medical queries. The weaknesses of the findings reported here are 1.) the degree to which plagiarism can be generalized to additional chatbots has not been examined, and 2.) plagiarism that would result from using other plagiarism detection tools has not been attempted and may be higher or lower than those identified by iThenticate. Both possibilities are not addressed here. Taken together, these findings provide a demonstration that plagiarism can be found in narrative responses from two popular AI chatbots, Gemini and Copilot.
5. Conclusions
Here we report that plagiarism can be documented using a well-established plagiarism detector in major AI chatbots from Google (Gemini) and Microsoft (Copilot). This paper highlights the need for assessing plagiarism in query responses provided by AI platforms. Our previous analyses have reported on the accuracy of responses of these AI chatbots [9], while the present work critically examines both plagiarism and the inadequacy of citation in the narrative replies that are generated.
Author Contributions
The concept evolved from previous research developed and supervised by Dr. Edward J. Pavlik, PhD, who reviewed and edited writing of the published works, including critical review and revision throughout each stage of publication. Dr. Pavlik, in collaboration with Cameron K. Oliveros, BS, Mary Wasef, BSW, and Dharani Ramaiah, BS, conceived the methodology for the published works and prepared visualized data. Oliveros, Wasef, and Ramaiah in collaboration curated data, applied statistical technique to conclude data, and wrote the original draft of the published work. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This work did not involve humans or animals, thus Institutional Review Board approval was not needed.
Data Availability Statement
Data compiled in this work will be made available by the authors upon request.
Conflicts of Interest
The authors declare no conflicts of interest. Only the authors had a role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial intelligence |
| LLM | Large language models |
| NLP | Natural language processing |
References
- Badshah A, Rehman GU, Farman H, Ghani A, Sultan S, Zubair M, Nasralla MM. Transforming educational institutions: harnessing the power of internet of things, cloud, and fog computing. Future Internet 2023;15:11:367. [CrossRef]
- Imran M, Almusharraf N. Google Gemini as a next generation AI educational tool: A review of emerging educational technology. Smart Learning Environments 2024;11:1. [CrossRef]
- Al-Amin M, Shazed Ali M, Salem A, et al. History of generative Artificial Intelligence (AI) chatbots: past, present, and future development. Cornell University 2024. [CrossRef]
- Adamopoulou E, Moussiades L. An overview of chatbot technology. IFIP Advances in Information and Communication Technology 2020;583:373–383. [CrossRef]
- Pavlik EJ, Land Woodward J, Lawton F, Swiecki-Sikora AL, Ramaiah DD, Rives TA. Artificial Intelligence in relation to accurate information and tasks in gynecologic oncology and clinical medicine—Dunning–Kruger effects and ultracrepidarianism. Diagnostics 2025;15:6:735. [CrossRef]
- Colasacco CJ, Born HL. A case of Artificial Intelligence chatbot hallucination. JAMA Otolaryngology Head Neck Surg. 2024 Jun 1;150:6::457-458. PMID: 38635259. [CrossRef]
- Kacena MA, Plotkin LI, Fehrenbacher JC. The use of Artificial Intelligence in writing scientific review articles. Curr Osteoporos Rep. 2024 Feb;22:1:115-121. [CrossRef]
- Garrison JA.UpToDate. Journal of the Medical Library Association 2003;91:1:97 https://pmc.ncbi.nlm.nih.gov/articles/PMC141198/.
- Pavlik EJ, Ramaiah DD, Rives TA, Swiecki-Sikora AL, Land, JM. Replies to queries in gynecologic oncology by Bard, Bing and the Google Assistant. BioMedInformatics 2024;4:3):1773-1782. [CrossRef]
- Dhammi IK, Ul Haq R. What is plagiarism and how to avoid it? Indian J Orthop. 2016 Nov-Dec; 50:6:581-583. [CrossRef]
- Taylor D. Plagiarism: 5 potential legal consequences. FindLaw 2019. https://www.findlaw.com/legalblogs/law-and-life/plagiarism-5-potential-legal-consequences/.
- Traniello JF, Bakker TC. Intellectual theft: Pitfalls and consequences of plagiarism. Behavioral Ecology and Sociobiology 2016;70:11:1789–1791. [CrossRef]
- Aronson JK. Plagiarism – please don't copy. British Journal of Clinical Pharmacology 2007;64:403-405. [CrossRef]
- Land JM, Pavlik EJ, Ueland E, et al. Evaluation of replies to voice queries in gynecologic oncology by virtual assistants Siri, Alexa, Google, and Cortana. BioMedInformatics 2023;3:3:553-562. [CrossRef]
- Turnitin, iThenticate. Plagiarism detection software: Ithenticate 2024. https://www.ithenticate.com/.
- Gao CA, Howard FM, Markov NS, et al. Comparing scientific abstracts generated by ChatGPT to real abstracts with detectors and blinded human reviewers. NPJ Digit Med. 2023 Apr 26;6:1:75. [CrossRef]
- Longoni C, Tully S, Shariff A. The AI-human unethicality gap: plagiarizing AI-generated content is seen as more permissible. 2023 Jun 18. [CrossRef]
- Dien J. Editorial: generative Artificial Intelligence as a plagiarism problem. Biological Psychology 2023;181:108621. [CrossRef]
- Winstat – the statistics add-in for Microsoft Excel. https://www.winstat.com/.
- Graphpad. https://www.graphpad.com/quickcalcs/ttest1/.
- Kacena MA, Plotkin LI, Fehrenbacher JC. The use of Artificial Intelligence in writing scientific review articles. Curr Osteoporos Rep. 2024 Feb;22:1:115-121. [CrossRef]
- Colasacco CJ, Born HL. A case of Artificial Intelligence chatbot hallucination. JAMA Otolaryngol Head Neck Surg. 2024 Jun 1;150:6:457-458. [CrossRef]
- Ortiz S. What is Google Bard? Here's everything you need to know. ZDNET. 2024 Feb 9. Available at: https://www.zdnet.com/article/what-is-google-bard-heres-everything-you-need-to-know/. Accessed 2024 Feb 13.
- Microsoft Copilot. Wikipedia. Available at: https://en.wikipedia.org/wiki/Microsoft_Copilot. Accessed 2024 Feb 13.
- Vogel M. A curated list of resources on generative AI. Medium. Updated 2024 Oct 9. Available at: https://medium.com/@maximilian.vogel/5000x-generative-ai-intro-overview-models-prompts-technology-tools-comparisons-the-best-a4af95874e94#id_token=eyJhbGciOiJSUzI1NiIsImtpZCI6IjFkYzBmMTcyZThkNmVmMzgyZDZkM2EyMzFmNmMxOTdkZDY4Y2U1ZWYiLCJ0eXAiOiJKV1QifQ. Accessed 2025 Jan 27.
- Yang J, Jin H, Tang J, et al. The practical guides for large language models. Available at: https://github.com/Mooler0410/LLMsPracticalGuide. Accessed 2025 Jan 27.
- Menz BD, Modi ND, Sorich MJ, Hopkins AM. Health disinformation use case highlighting the urgent need for artificial intelligence vigilance: weapons of mass disinformation. JAMA Intern Med. 2024;184:1:92-96. [CrossRef]
Figure 1.
Listing of the 24 gynecologic oncology-related queries that were inputted into both Gemini and Copilot. Each query was inputted five times to each AI chatbot and their respective responses were analyzed.
Figure 1.
Listing of the 24 gynecologic oncology-related queries that were inputted into both Gemini and Copilot. Each query was inputted five times to each AI chatbot and their respective responses were analyzed.

Figure 2.
An example of an iThenticate analysis of a chatbot response to one of the 24 queries (question #23 in Figure 1). In this example there are three plagiarism events. The total percentage of the narrative flagged as “plagiarism” is indicated in the top right corner (29%). The percentage of words flagged as plagiarized from each individual source is shown on the right column (12%, 11%, and 6%, respectively.). The first two plagiarism events were rated as “high” plagiarism because they comprised more than 10% of the total narrative. The third plagiarism event was rated as “low” plagiarism because it comprised less than 10% of the narrative
Figure 2.
An example of an iThenticate analysis of a chatbot response to one of the 24 queries (question #23 in Figure 1). In this example there are three plagiarism events. The total percentage of the narrative flagged as “plagiarism” is indicated in the top right corner (29%). The percentage of words flagged as plagiarized from each individual source is shown on the right column (12%, 11%, and 6%, respectively.). The first two plagiarism events were rated as “high” plagiarism because they comprised more than 10% of the total narrative. The third plagiarism event was rated as “low” plagiarism because it comprised less than 10% of the narrative
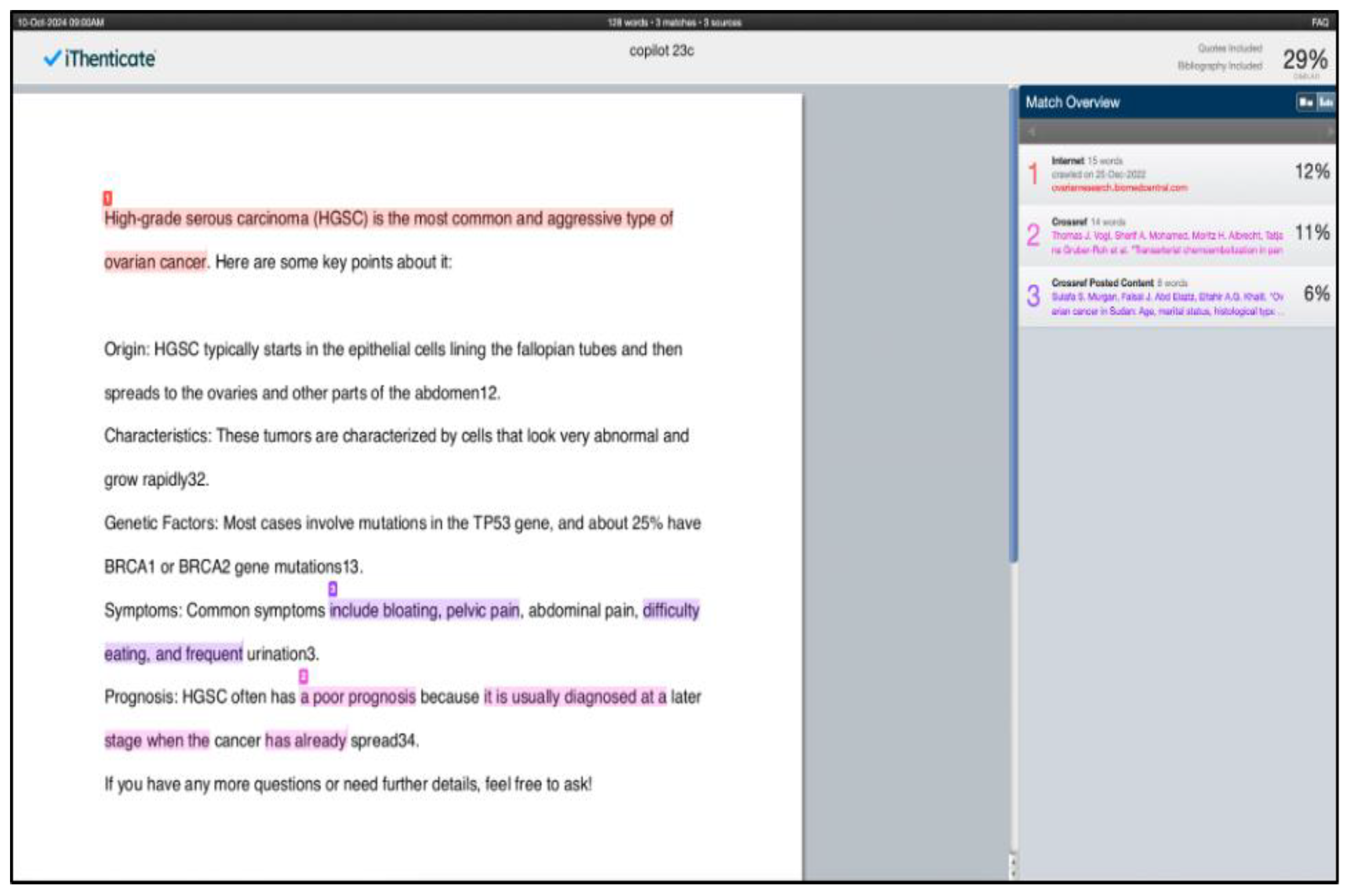
Figure 3.
Evaluation of plagiarism in Gemini vs. Copilot narrative responses. Each evaluation was performed 360 times. The histogram shows mean values + 1.96 x SEM (95% CI). A= mean number of words in AI narratives. B = mean number of plagiarism events in AI narrative responses. C = After dichotomization for “high” vs “low” plagiarism: mean number of plagiarism events per narrative that fall into the “high” plagiarism score group. D = After dichotomization for “high” vs “low”: mean number of plagiarism events per narrative that fall into the “low” plagiarism score group. E = Mean number of references listed by the AI program per narrative that are copyrighted or from published sources. F = Mean number of plagiarisms referenced in iThenticate as copyrighted or from published sources. G = Mean overall plagiarism scores provided by iThenticate. Panel B: Black outline identifies values on left axis and red outline identifies values on right axis. All T-tests between Gemini and Copilot were statistically significant (p<0.05).
Figure 3.
Evaluation of plagiarism in Gemini vs. Copilot narrative responses. Each evaluation was performed 360 times. The histogram shows mean values + 1.96 x SEM (95% CI). A= mean number of words in AI narratives. B = mean number of plagiarism events in AI narrative responses. C = After dichotomization for “high” vs “low” plagiarism: mean number of plagiarism events per narrative that fall into the “high” plagiarism score group. D = After dichotomization for “high” vs “low”: mean number of plagiarism events per narrative that fall into the “low” plagiarism score group. E = Mean number of references listed by the AI program per narrative that are copyrighted or from published sources. F = Mean number of plagiarisms referenced in iThenticate as copyrighted or from published sources. G = Mean overall plagiarism scores provided by iThenticate. Panel B: Black outline identifies values on left axis and red outline identifies values on right axis. All T-tests between Gemini and Copilot were statistically significant (p<0.05).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



