Submitted:
28 August 2025
Posted:
05 September 2025
You are already at the latest version
Abstract
Retrieving semantically related content across visual and textual modalities remains a central challenge in multimodal artificial intelligence. Despite rapid progress in cross-modal understanding, many existing systems still struggle with balancing modality-specific representation fidelity and scalability in retrieval scenarios. In this paper, we present \textbf{DUET} (Dual-Stream Encoder for Unified Embedding and Translation), a transformer-based architecture that explicitly separates the encoding pipelines of visual and textual modalities in early layers, yet strategically enforces alignment through shared parameters in deeper layers. This modular approach allows DUET to retain modality-specific semantics while constructing a unified latent space suitable for fast and accurate retrieval. Unlike prior architectures that rely on entangled attention mechanisms, DUET’s design enables precomputed indexing and supports efficient large-scale matching. Additionally, we propose a new evaluation protocol grounded in semantic similarity by leveraging caption-level soft relevance, extending beyond traditional binary Recall@K metrics. Our method introduces a similarity-weighted discounted cumulative gain (DCG) scoring scheme to reflect more nuanced relevance patterns. Empirical results on the MS-COCO benchmark demonstrate that DUET consistently outperforms existing methods on both hard and soft retrieval metrics, setting a new state of the art under weakly supervised settings. Code and pre-trained models will be made publicly available upon publication.
Keywords:
cross-modal retrieval
; dual-stream transformer
; semantic embedding
; image-text alignment
; discounted cumulative gain
1. Introduction
The fusion of computer vision and natural language processing has catalyzed significant advances in multimodal learning, particularly in tasks requiring semantic understanding across different data modalities. One prominent and widely studied problem is image-text retrieval, where the objective is to identify visually grounded content that corresponds semantically to a textual description, or vice versa. Applications of this task include image search, automated media tagging, human-computer interaction, and content-based recommendation systems. Despite its utility, the semantic and structural divergence between image pixels and natural language makes retrieval inherently difficult, especially when faced with large-scale datasets and time-critical response demands.
This paper explores the development of a robust and scalable multimodal retrieval framework. Our core objective is to learn compact yet semantically expressive representations of images and text that are directly comparable within a shared latent space. Toward this goal, we propose DUET, a dual-stream transformer encoder architecture that maintains early-layer modality specialization and enables semantic fusion through deep-layer parameter sharing. This architecture ensures that modality-specific characteristics are preserved, while high-level abstraction is performed within a semantically consistent embedding space.
Our design philosophy stems from the recognition of shortcomings in previous work [1,2,3,4,5]. While many methods integrate modalities early through mutual attention or fusion modules, this tightly coupled interaction prevents independent feature encoding—a critical bottleneck for real-time retrieval systems. In contrast, DUET facilitates decoupled feature extraction, enabling each modality to be indexed separately and searched independently. Semantic consistency is still achieved via aligned transformation in the shared transformer layers, leveraging the contextual modeling power of self-attention networks [8].
The challenge of aligning vision and language stems from their inherent representational mismatch: images encode object-centric visual patterns and spatial dependencies, whereas text represents abstracted, sequential information. Bridging this modality gap demands not only fine-grained object detection and grounding, but also the modeling of complex relationships and contextual cues. For instance, retrieving a relevant image for the sentence “A boy is kicking a soccer ball” necessitates identifying not just the visual entities (boy, ball), but also their interactions and the specific action involved (kicking).
Legacy models based on convolutional backbones [4] often yield coarse global representations inadequate for such nuanced reasoning. Region-based methods attempt to resolve this but often fall short in capturing semantic dependencies among visual regions. Likewise, early recurrent language models struggle with capturing long-range dependencies and global context. Transformer-based architectures [3,37], with their inherent self-attention mechanism, offer a promising alternative by modeling fine-grained dependencies across and within modalities.
Nevertheless, most existing transformer-based frameworks utilize unified encoding pipelines that inhibit independent precomputation—a major drawback when scaling to large candidate pools. Real-world systems require that a query vector can be matched against a massive image database via similarity scoring , without evaluating pairwise interactions for every image-text pair [6]. DUET circumvents this bottleneck by introducing a decoupled transformer backbone where vision and language features are encoded separately, but fused via shared deep-layer weights, ensuring semantically aligned embeddings amenable to efficient approximate nearest-neighbor search.
In parallel, existing evaluation methodologies predominantly adopt strict metrics such as Recall@K, which assume exact ground-truth pairings between images and captions. Such rigid criteria overlook the presence of semantically plausible alternatives—e.g., multiple captions describing the same scene differently. To reflect real-world relevance more faithfully, we adopt a semantic-aware evaluation strategy by employing a caption-similarity-weighted version of discounted cumulative gain (DCG) [2]. This method enables a more graded notion of relevance, rewarding near-miss results in accordance with their semantic proximity to the ground truth.
To summarize, our contributions are three-fold:
- We introduce DUET, a novel dual-stream transformer framework that disentangles early-stage modality encoding and achieves semantic alignment through parameter sharing in deeper layers.
- We propose a caption-similarity-weighted DCG metric that accounts for graded semantic relevance, addressing the limitations of traditional binary evaluation criteria.
- We provide extensive experiments on the MS-COCO benchmark, showing that DUET sets a new performance standard under both exact match and semantic retrieval metrics.
By reconceptualizing image-text representation learning through a modular and semantically grounded architecture, DUET advances the frontier of efficient and intelligent cross-modal retrieval.
2. Related Work
To contextualize our contributions, we examine three primary lines of research that inform our approach: (1) methods for constructing cross-modal embedding spaces for image-text alignment, (2) neural reasoning frameworks that support high-order relational modeling, and (3) evaluation strategies that accommodate semantic fuzziness in retrieval tasks.
2.1. Cross-Modal Embedding Strategies for Alignment
Establishing a joint semantic space for vision and language lies at the heart of image-text retrieval. The majority of traditional methods approach this problem by learning embedding functions that map images and textual descriptions into a shared vector space, where semantically related pairs are drawn closer under a similarity measure—such as cosine similarity, dot product, or contrastive losses.
In earlier paradigms, visual features were extracted using convolutional neural networks (CNNs) pretrained on large-scale classification datasets. Commonly used backbones included VGG [9,10,11,12,13] and ResNet [1,14,15,16], whose penultimate layer activations served as global image descriptors. However, these global encodings often overlooked fine-grained details and object relationships, limiting their efficacy in grounding sentence semantics.
To improve localization and semantic grounding, attention shifted toward region-level visual features. The bottom-up attention mechanism introduced by [18] enabled the extraction of object-centric features using Faster R-CNN, providing a basis for localized representation learning. Subsequent efforts such as [5,7] built upon this by incorporating cross-modal attention, selectively integrating salient image regions with sentence tokens—thus filtering visual noise and aligning relevant entities.
On the language side, early systems utilized recurrent neural networks (RNNs), including GRUs and LSTMs, to encode sequential sentence inputs [1,4,7,16]. While effective for capturing local dependencies, RNNs struggled with modeling long-range relations and global sentence semantics due to their inherent memory constraints.
The introduction of transformer architectures [8] marked a turning point. Models like BERT [37] demonstrated strong capacity for context-aware encoding via self-attention, inspiring a wave of cross-modal transformers such as ViLBERT [3] and ImageBERT [6]. These models extended transformer-based reasoning to visual inputs by integrating region features and token embeddings into a unified attention space.
Despite their strong performance, unified transformers often entangle visual and textual inputs from early layers, precluding modular feature extraction. This tight coupling poses a bottleneck for retrieval systems that demand scalability. Systems that rely on pairwise interaction scores become computationally prohibitive when deployed over millions of candidates [6].
To alleviate this, dual-encoder designs—where visual and textual inputs are encoded independently as and into a shared space—have gained traction. These allow for decoupled feature precomputation and efficient retrieval via approximate nearest neighbor search. Works like [7] explored this line by using GCNs for visual reasoning and GRUs for sentence modeling, paired with auxiliary sentence reconstruction to stabilize training. Our approach extends this idea, substituting both modality pipelines with transformer-based architectures to enhance abstraction and enable end-to-end semantic fusion.
2.2. Relational Reasoning Mechanisms in Neural Architectures
Beyond embedding alignment, advanced retrieval models must reason over object interactions, contextual cues, and structured semantic relationships. A seminal contribution in this direction was the Relation Network (RN) by [19], which explicitly separated perception and reasoning. RNs operated by applying relational functions over all object pairs, conditioned on a question representation from an LSTM. While effective in visual QA, the framework lacked generalization to complex multimodal alignment tasks due to its rigid pairwise formulation.
Efforts to adapt RN-style architectures for retrieval, such as [20,21], focused on aggregating relational cues into compact feature representations. These models introduced various relation encoding mechanisms but were still confined to visual-only pipelines and did not generalize well to cross-modal contexts. Symbolic reasoning approaches [22,23] introduced more interpretable mechanisms by representing the reasoning process as sequences of programmatic operations. These include neural module networks and differentiable execution graphs. While powerful, they typically require detailed structured annotations, which limits their applicability in large-scale weakly supervised settings.
Graph-based reasoning models offer a middle ground, where structured representations are learned without requiring strict symbolic supervision. Graph convolutional networks (GCNs) have been widely adopted for visual reasoning tasks [24,25,26], modeling relationships among detected objects or scene entities. Other works construct scene graphs from images [27,28] and use them to perform structured reasoning over visual scenes. These methods provide strong relational inductive biases and facilitate deeper semantic abstraction, paving the way for unified scene-text understanding.
2.3. Beyond Binary: Semantic-Aware Retrieval Evaluation
The final axis of comparison concerns evaluation metrics. Standard evaluation in image-text retrieval typically employs Recall@K [1,3,6,7,29], which assesses whether a ground-truth item is retrieved within the top K ranked results. While this measure provides a clear-cut benchmark for exact-match retrieval, it lacks sensitivity to semantic approximation. Consider the case where the target caption is “a boy playing football,” and the retrieved image depicts “a child kicking a soccer ball.” Though semantically similar, traditional metrics would penalize such retrievals. This motivates the adoption of evaluation protocols that reflect graded semantic relevance.
To this end, [2] proposed a DCG-based evaluation scheme where each retrieved item is weighted by its semantic similarity to the query, measured via caption embeddings. This approach assigns partial credit to near-miss retrievals and aligns better with human perception. Building on this, our work introduces a similarity-weighted DCG protocol tailored for cross-modal scenarios, which factors in semantic variability and recognizes soft alignments in real-world applications. As image-text retrieval systems mature and expand in scale, it becomes increasingly critical to evaluate them not only on exact correctness, but also on their ability to retrieve content that is semantically aligned, contextually relevant, and diverse in linguistic expression.
3. Preliminary
3.1. Pipeline Formalization and Notation
We begin by establishing the notational conventions and core components of standard image captioning frameworks, which predominantly follow an encoder-decoder paradigm consisting of three integral modules: a visual encoder, a language decoder, and a context-aware word predictor.
Given an image input, the visual encoder—implemented via either CNN backbones or region-based detectors like Faster R-CNN—generates feature representations denoted by , where is the number of extracted spatial locations or detected regions, and denotes the feature dimensionality. In region-based settings, corresponds to object proposals, while in CNNs it reflects flattened spatial grids.
At each decoding timestep t, the language decoder (typically an LSTM) evolves its hidden state based on prior word information and a global visual summary. The decoder input and recurrent updates follow:
where denotes the word embedding lookup, and represents a global average of image features. The decoder output is passed into an attention module to produce a context vector , followed by vocabulary prediction:
The predicted score vector defines a probability distribution over the vocabulary at step t. The implementation of the attention function and prediction layer defines the model variant.
3.2. Visual-Linguistic Fusion via Attention Mechanisms
We explore two prominent attention designs for integrating visual information during decoding: (1) adaptive attention mechanisms incorporating a sentinel gate, and (2) multi-head attention frameworks based on Transformer formulations.
3.2.1. Adaptive Attention with Sentinel Mechanism
Adaptive attention introduces a dynamically learned sentinel vector that selectively retains non-visual (linguistic or memory) information. This vector is computed as:
where and are learned projections, and is a sigmoid gating function. This sentinel serves as an additional source for attention, parallel to the visual features.
Attention scores are then computed for both the visual regions and the sentinel:
The final context vector is a weighted interpolation between visual features and the sentinel:
The scalar controls the extent to which non-visual context influences the final representation.
3.2.2. Transformer-Based Multi-Head Attention
An alternative approach adopts multi-head attention (MHA), enabling the model to simultaneously attend to various semantic dimensions of the input via parallel projections. The mechanism proceeds as:
The context vectors from each head are concatenated and linearly transformed:
Finally, a gated fusion is applied to regulate visual contributions:
This formulation allows the decoder to dynamically scale visual influence based on linguistic context.
3.3. Instantiating Representative Architectures
For comparative analysis and ablation, we instantiate two prototypical image captioning systems based on the above attention mechanisms:
- Ada-LSTM: A hybrid model combining adaptive attention with an LSTM-based decoder and a standard prediction head.
- MH-FC: A multi-head attention variant employing transformer-style attention and a feedforward classifier over fused features.
3.4. Training Losses and Learning Objectives
Initial model training is conducted under the standard cross-entropy (XE) objective, encouraging likelihood maximization of ground-truth sequences:
where is the target token at step t and denotes the decoder’s softmax distribution.
To align training with task-specific reward metrics like CIDEr, we subsequently apply reinforcement learning via Self-Critical Sequence Training (SCST) [?]:
Here, the reward R is computed as the CIDEr score differential between a sampled caption and its greedy counterpart :
This encourages sampled captions to surpass greedy baselines in evaluation score:
3.5. Extended Design: Context Aggregation and Alignment Regularization
To further enhance model flexibility and performance, we incorporate two optional modules commonly used in advanced captioning systems:
Soft Gated Aggregation
We generalize hard attention gating by introducing a mixture-of-experts formulation over multiple context pathways:
Each corresponds to a specific feature channel (e.g., visual-only, sentinel, language-derived), with learned gating weights indicating their contribution.
Context Alignment Loss
To promote semantic alignment between the attended visual context and language embeddings, we adopt an auxiliary supervision term:
This regularization encourages the visual context to remain compatible with ground-truth word semantics, especially in early training stages.
Figure 1.
Overview of the proposed framework.
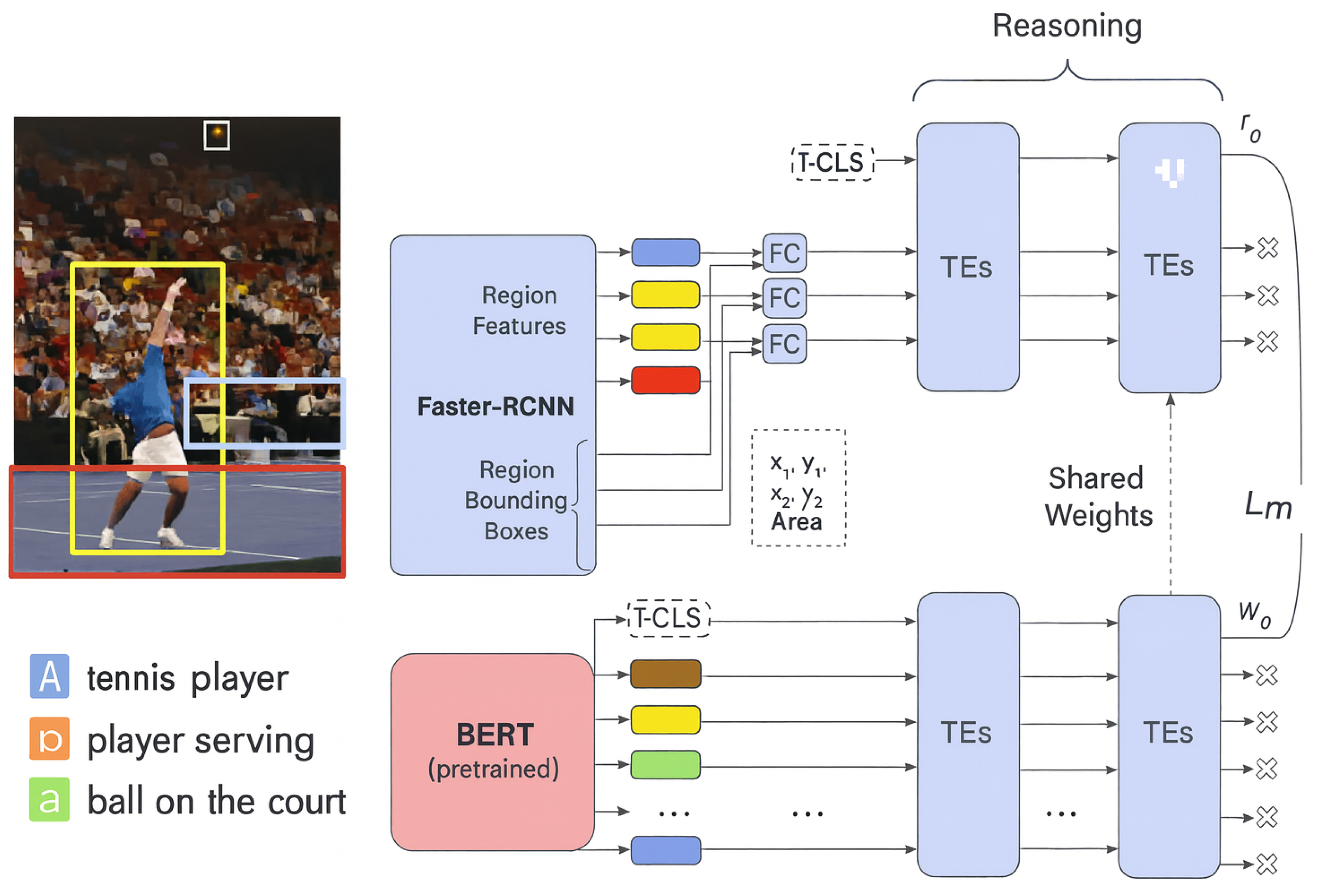
4. Unified Multimodal Reasoning with Dual Transformers
We propose DUET (Dual-Stream Encoder for Unified Embedding and Translation), a unified framework for cross-modal semantic reasoning built entirely upon Transformer Encoder (TE) backbones. DUET processes visual and textual modalities through distinct yet partially shared encoder streams, designed to preserve modality-specific nuances while facilitating joint abstraction in a shared semantic space. This section details our model design, including input representations, dual encoder architecture, contrastive alignment objective, and regularization strategies.
4.1. Representation of Multimodal Inputs
Let a paired training sample consist of an image I and its corresponding caption C. We represent as n region-level visual embeddings, and as m tokenized word embeddings. Each modality is prepended with a [CLS]-style summary token— for image and for text—to aggregate global semantic cues during encoding. These special tokens are subsequently used to compute cross-modal matching scores.
4.1.1. Spatially-Aware Visual Embedding
For visual input, we adopt bottom-up attention features as in [31], using a pre-trained Faster R-CNN [30] detector on Visual Genome [32]. Each region is associated with a high-dimensional feature and a normalized spatial box defined as:
The combined visual-spatial descriptor is projected through a two-layer MLP:
yielding spatially enriched region features .
4.1.2. Contextualized Language Encoding via BERT
The textual component is encoded using BERT [37], which provides context-sensitive token embeddings. For a caption C of m words:
where refers to the [T-CLS] embedding summarizing sentence-level semantics. Since BERT already encodes positional information, no explicit sequence modeling is required.
4.2. Dual Transformer Encoder Design
DUET consists of two Transformer Encoder branches— for images and for text—each processing its respective inputs independently in early layers and partially sharing parameters in the upper layers. The attention mechanism follows the canonical formulation:
with , , and denoting learned projections.
Stacking L such layers yields contextualized representations and . We extract final image and caption embeddings via their respective [CLS] tokens:
To enforce high-level semantic alignment, the final k encoder layers are shared across both streams, encouraging convergence in the abstract feature space.
4.3. Cross-Modal Contrastive Alignment
To train DUET for retrieval, we adopt a bidirectional contrastive objective that maximizes the similarity between matched pairs and penalizes mismatched ones. Given cosine similarity , the margin-based loss is:
where is the hinge function and is the contrastive margin. The hard negatives and are mined from the current mini-batch:
This encourages the model to be discriminative over subtle mismatches and robust to distractors.
4.4. Auxiliary Learning Signals and Regularization
To further enhance alignment quality and model stability, we incorporate two auxiliary losses:
(i) Spatial Coordinate Regression.
From an intermediate transformer layer , we reconstruct region coordinates using a lightweight regression head:
and define the coordinate loss as:
(ii) Embedding Norm Stability.
To ensure consistent scale and enhance angular similarity, we regularize embedding magnitudes:
This constraint mitigates representational drift during training.
4.5. Overall Optimization Objective
The final objective combines all components with tunable weights and :
Empirically, we observe that these auxiliary objectives improve both training convergence and retrieval performance, particularly in scenarios involving fine-grained spatial reasoning.
5. Experiment and Evaluation
We perform an extensive empirical study to evaluate the effectiveness of our proposed DUET framework on the image-text retrieval task. Experiments are conducted on the MS-COCO benchmark [36] following standard settings. This section addresses the following central questions:
- How does DUET compare to existing state-of-the-art methods under both hard (Recall@K) and soft (NDCG) evaluation protocols?
- Can DUET better capture semantic correspondence beyond literal matches?
- What impact do individual architectural components have on performance?
5.1. Dataset and Evaluation Metrics
We evaluate DUET using the MS-COCO dataset [36], which includes 123,287 images, each annotated with five diverse human-written captions. Following the widely accepted Karpathy split [1,4,7], we use 113,287 images for training, 5,000 for validation, and 5,000 for testing. All reported metrics are computed over both the 5K test set and the 1K subset averaged across five folds.
Evaluation comprises two distinct metric types:
5.2. Implementation Configuration
Textual embeddings are obtained via a pre-trained BERT encoder using the HuggingFace transformers library1, yielding 768-dimensional representations. For image inputs, we adopt the Bottom-Up Attention detector2 to extract the top 36 region features (2048-D) per image.
On the visual side, we employ four dedicated Transformer Encoder layers. For textual inputs, the BERT backbone is fine-tuned without adding extra layers. The top two Transformer layers are shared between both modalities, projecting into a joint 1024-dimensional embedding space.
Training proceeds for 30 epochs using Adam optimizer with a learning rate of . The contrastive loss margin is set to 0.2. We use a mini-batch size of 90, balancing performance and GPU memory constraints.
5.3. Comparison with State-of-the-Art Methods
Table 1 demonstrates that DUET consistently surpasses existing state-of-the-art methods across both strict (Recall@K) and soft (NDCG) retrieval metrics. The improvements are observed on both the smaller 1K subset and the larger 5K full test set.
In particular, DUET achieves the best R@1 and scores, indicating its superior precision and ability to capture high-level semantic similarity. Despite its simple design—eschewing ensemble learning or test-time augmentations—DUET significantly outperforms baselines like VSE++ and VSRN, attesting to the efficacy of its dual-stream transformer backbone and shared semantic reasoning layers.
The most pronounced gains occur under the soft NDCG metric, which rewards partial matches and semantic closeness. This indicates DUET’s ability to retrieve relevant content even in cases of lexical variance, which Recall@K alone fails to capture. These findings emphasize the necessity of incorporating semantic-aware metrics for realistic system evaluation.
Notable observations include:
- On the 1K set, DUET achieves +0.7 improvement in R@1 and +3.3 in over VSRN, highlighting its enhanced semantic alignment.
- On the full 5K test set, DUET retains an advantage across all metrics, showing scalability and robustness.
- Improvements in SPICE-based NDCG reflect DUET’s stronger grasp of conceptual similarity and abstract reasoning.
5.4. Qualitative Examples: Generalization Beyond Lexical Overlap
DUET is capable of retrieving images with semantically coherent but lexically divergent descriptions. For instance, given the query “a child leaping across water,” DUET correctly retrieves “a young girl jumping over a puddle.” Such cases exemplify its strength in capturing abstract semantic equivalence—a key requirement for practical applications. These results further justify the adoption of metrics like NDCG to assess generalization capacity.
5.5. Ablation Analysis
We conduct ablation studies to isolate the contributions of critical components in DUET’s architecture. Table 2 reports performance under four variants:
- DUET w/o shared layers: Disables transformer weight sharing.
- DUET w/o spatial features: Removes bounding-box coordinate input.
- DUET (no norm reg): Drops embedding norm regularization.
- Full DUET: The complete model as proposed.
Findings reveal that shared transformer layers contribute significantly to alignment performance, especially under NDCG. Spatial features are also essential, particularly for modeling grounding and inter-object relationships. Norm regularization, while less critical, helps stabilize training and marginally boosts precision.
5.6. Inference Efficiency and Scalability
Beyond accuracy, latency and scalability are critical in real-world systems. We evaluate DUET’s retrieval runtime on a 10K image corpus using precomputed embeddings and a cosine-based nearest neighbor index.
We utilize FAISS3 with a flat index structure for ANN search. DUET retrieves top results in ∼15 ms per query, including embedding lookup and ranking. This low-latency behavior stems from DUET’s decoupled modality encoders, enabling offline indexing and avoiding pairwise computation during inference.
DUET’s shared-layer design also produces compact, semantically rich embeddings, reducing storage footprint and increasing retrieval throughput. Its simplicity makes it well-suited for deployment across GPU and CPU environments with minimal engineering overhead. In summary, DUET achieves a strong balance between semantic interpretability, accuracy, and system-level efficiency—making it a practical choice for scalable image-text retrieval applications.
6. Conclusion and Future Work
This work addressed the central problem of efficient and scalable image-text retrieval by rethinking how multimodal representations are constructed, aligned, and utilized. A key observation driving our motivation is that many prior models intertwine vision and language from early stages, yielding entangled representations that hinder independent indexing and inference—two crucial requirements for real-world large-scale retrieval systems.
To overcome this challenge, we proposed DUET, a Dual-Stream Encoder for Unified Embedding and Translation, grounded in the Transformer Encoder (TE) architecture. DUET explicitly decouples visual and textual processing in early layers, preserving modality-specific structures, while progressively enabling shared semantic abstraction through weight-tied layers at higher depths. This design not only supports modular encoding and fast inference but also fosters richer cross-modal alignment by promoting structured interaction at the conceptual level. Additionally, DUET incorporates relational reasoning mechanisms to capture not only object-level semantics but also spatial configurations and intra-modality context.
Recognizing the inadequacy of binary relevance metrics for capturing semantic alignment, we introduced evaluation based on NDCG, which reflects graded relevance through similarity scores computed using ROUGE-L and SPICE. These soft metrics enable a more faithful assessment of semantic retrieval quality, particularly when retrieved items are paraphrased or contextually aligned but lexically different from the reference.
Our experiments on MS-COCO demonstrate that DUET establishes new state-of-the-art performance under both strict (Recall@K) and soft (NDCG) protocols, significantly outperforming strong baselines like VSE++ and VSRN. In particular, the gains under highlight DUET’s capability to model deeper relational semantics and its robustness to linguistic variability. These findings validate the efficacy of DUET’s dual-stream design in bridging the modality gap between vision and language while preserving scalability and deployment readiness.
Looking ahead, several extensions present themselves for exploration. First, we envision incorporating bidirectional reconstruction objectives that more explicitly structure the shared embedding space. For example, enabling the model to reconstruct sentence-level descriptions from visual embeddings—or vice versa, generate region-level visual features from text—may enhance the semantic granularity and controllability of learned representations.
Second, while the current hinge-based contrastive loss is effective for ranking, it imposes sharp margins that do not fully capture nuanced semantic proximity. We plan to investigate alternative alignment objectives such as soft contrastive losses or distribution-aware formulations, which account for relevance gradients and semantic fuzziness inherent in natural language.
Third, we aim to extend DUET beyond pairwise retrieval tasks. The modular transformer backbone can serve as a flexible substrate for broader multimodal tasks such as visual question answering, multimodal summarization, and commonsense reasoning. By enriching DUET with symbolic or hierarchical reasoning modules and adapting it to other data types—such as audio, video, and structured knowledge—we anticipate broader applicability in open-domain multimodal understanding.
In summary, DUET represents a principled and practical advancement toward semantically grounded multimodal retrieval. Through dual-stream reasoning, spatial-aware design, and contrastive training within a transformer framework, DUET bridges effectiveness with efficiency. We hope this work inspires future research into structured multimodal alignment and motivates the development of evaluation protocols that better reflect real-world relevance and user intent.
References
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. “VSE++: improving visual-semantic embeddings with hard negatives,” in BMVC 2018. BMVA Press, 2018, p. 12.
- Carrara, F.; Esuli, A.; Fagni, T.; Falchi, F.; Fernández, A.M. Picture it in your mind: generating high level visual representations from textual descriptions. Inf. Retr. J. 2018, 21, 208–229. [Google Scholar] [CrossRef]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In NeurIPS 2019, 2019, pp. 13–23.
- Karpathy, A.; Li, F. Deep visual-semantic alignments for generating image descriptions. In CVPR 2015. IEEE Computer Society, 2015, pp. 3128–3137.
- Lee, K.; Chen, X.; Hua, G.; Hu, H.; He, X. “Stacked cross attention for image-text matching,” in ECCV 2018, ser. Lecture Notes in Computer Science, vol. 11208. Springer, 2018, pp. 212–228.
- Qi, D.; Su, L.; Song, J.; Cui, E.; Bharti, T.; Sacheti, A. “Imagebert: Cross-modal pre-training with large-scale weak-supervised image-text data,” CoRR, vol. abs/2001.07966, 2020.
- Li, K.; Zhang, Y.; Li, K.; Li, Y.; Fu, Y. “Visual semantic reasoning for image-text matching,” in ICCV 2019. IEEE, 2019, pp. 4653–4661.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. “Attention is all you need,” in NeurIPS 2017, 2017, pp. 5998–6008.
- Klein, B.; Lev, G.; Sadeh, G.; Wolf, L. “Associating neural word embeddings with deep image representations using fisher vectors,” in CVPR 2015. IEEE Computer Society, 2015, pp. 4437–4446.
- Vendrov, I.; Kiros, R.; Fidler, S.; Urtasun, R. “Order-embeddings of images and language,” in 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Y. Bengio and Y. LeCun, Eds., 2016.
- Lin, X.; Parikh, D. “Leveraging visual question answering for image-caption ranking,” in ECCV 2016, ser. Lecture Notes in Computer Science, Leibe, B., Matas, J., Sebe, N., Welling, M., Eds., vol. 9906. Springer, 2016, pp. 261–277.
- Huang, Y.; Wang, W.; Wang, L. “Instance-aware image and sentence matching with selective multimodal LSTM,” in CVPR 2017. IEEE Computer Society, 2017, pp. 7254–7262.
- Eisenschtat, A.; Wolf, L. “Linking image and text with 2-way nets,” in CVPR 2017. IEEE Computer Society, 2017, pp. 1855–1865.
- Liu, Y.; Guo, Y.; Bakker, E.M.; Lew, M.S. “Learning a recurrent residual fusion network for multimodal matching,” in IEEE International Conference on Computer Vision, ICCV 2017. IEEE Computer Society, 2017, pp. 4127–4136.
- Gu, J.; Cai, J.; Joty, S.R.; Niu, L.; Wang, G. “Look, imagine and match: Improving textual-visual cross-modal retrieval with generative models,” in CVPR 2018. IEEE Computer Society, 2018, pp. 7181–7189.
- Huang, Y.; Wu, Q.; Song, C.; Wang, L. “Learning semantic concepts and order for image and sentence matching,” in CVPR 2018. IEEE Computer Society, 2018, pp. 6163–6171.
- Sun, C.; Gan, C.; Nevatia, R. “Automatic concept discovery from parallel text and visual corpora,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 2596–2604.
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and VQA. CoRR 2017, abs/1707.07998. [Google Scholar]
- Santoro, A.; Raposo, D.; Barrett, D.G.; Malinowski, M.; Pascanu, R.; Battaglia, P.; Lillicrap, T. “A simple neural network module for relational reasoning,” in Advances in neural information processing systems, 2017, pp. 4967–4976.
- Messina, N.; Amato, G.; Carrara, F.; Falchi, F.; Gennaro, C. “Learning visual features for relational cbir,” International Journal of Multimedia Information Retrieval, Sep 2019.
- ——, “Learning relationship-aware visual features,” in ECCV 2018 Workshops, ser. Lecture Notes in Computer Science, vol. 11132. Springer, 2018, pp. 486–501.
- Hu, R.; Andreas, J.; Rohrbach, M.; Darrell, T.; Saenko, K. “Learning to reason: End-to-end module networks for visual question answering,” in The IEEE International Conference on Computer Vision (ICCV), 2017.
- Johnson, J.; Hariharan, B.; Maaten, L.v.; Hoffman, J.; Fei-Fei, L.; Zitnick, C.L.; Girshick, R. “Inferring and executing programs for visual reasoning,” in The IEEE International Conference on Computer Vision (ICCV), 2017.
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. “Exploring visual relationship for image captioning,” in ECCV 2018, ser. Lecture Notes in Computer Science, vol. 11218. Springer, 2018, pp. 711–727.
- Yang, X.; Tang, K.; Zhang, H.; Cai, J. “Auto-encoding scene graphs for image captioning,” in CVPR 2019. Computer Vision Foundation / IEEE, 2019, pp. 10 685–10 694.
- Li, X.; Jiang, S. Know more say less: Image captioning based on scene graphs. IEEE Trans. Multimedia, 2019, 21, 2117–2130. [Google Scholar] [CrossRef]
- Yang, J.; Lu, J.; Lee, S.; Batra, D.; Parikh, D. “Graph R-CNN for scene graph generation,” in ECCV 2018, ser. Lecture Notes in Computer Science, vol. 11205. Springer, 2018, pp. 690–706.
- Li, Y.; Ouyang, W.; Zhou, B.; Shi, J.; Zhang, C.; Wang, X. “Factorizable net: An efficient subgraph-based framework for scene graph generation,” in ECCV 2018, ser. Lecture Notes in Computer Science, vol. 11205. Springer, 2018, pp. 346–363.
- Lee, K.; Palangi, H.; Chen, X.; Hu, H.; Gao, J. Learning visual relation priors for image-text matching and image captioning with neural scene graph generators. CoRR 2019, abs/1909.09953. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems 2015, 28, 91–99. [Google Scholar] [CrossRef] [PubMed]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. “Bottom-up and top-down attention for image captioning and visual question answering,” in CVPR 2018. IEEE Computer Society, 2018, pp. 6077–6086.
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.; Shamma, D.A.; Bernstein, M.S.; Li, F. Visual genome: Connecting language and vision using crowdsourced dense image annotations. CoRR 2016, abs/1602.07332. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In 1st International Conference on Learning Representations, ICLR 2013, 2013.
- Lin, C.-Y. “ROUGE: A package for automatic evaluation of summaries,” in Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81.
- Anderson, P.; Fernando, B.; Johnson, M.; Gould, S. “SPICE: semantic propositional image caption evaluation,” in ECCV 2016, ser. Lecture Notes in Computer Science, vol. 9909. Springer, 2016, pp. 382–398.
- Lin, T.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. `Microsoft COCO: common objects in context. In ECCV 2014, ser. Lecture Notes in Computer Science, vol. 8693. Springer, 2014, pp. 740–755.
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, 4171–4186.
- Endri Kacupaj, Kuldeep Singh, Maria Maleshkova, and Jens Lehmann. 2022. An Answer Verbalization Dataset for Conversational Question Answerings over Knowledge Graphs. arXiv 2022, arXiv:2208.06734.
- Magdalena Kaiser, Rishiraj Saha Roy, and Gerhard Weikum. 2021. Reinforcement Learning from Reformulations In Conversational Question Answering over Knowledge Graphs. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 459–469.
- Yunshi Lan, Gaole He, Jinhao Jiang, Jing Jiang, Wayne Xin Zhao, and Ji-Rong Wen. 2021. A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21. International Joint Conferences on Artificial Intelligence Organization, 4483–4491. Survey Track.
- Yunshi Lan and Jing Jiang. 2021. Modeling transitions of focal entities for conversational knowledge base question answering. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers).
- Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 7871–7880.
- Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. In International Conference on Learning Representations.
- Pierre Marion, Paweł Krzysztof Nowak, and Francesco Piccinno. 2021. Structured Context and High-Coverage Grammar for Conversational Question Answering over Knowledge Graphs. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) (2021).
- Pradeep, K. Atrey, M. Anwar Hossain, Abdulmotaleb El Saddik, and Mohan S. Kankanhalli. Multimodal fusion for multimedia analysis: a survey. Multimedia Systems 2010, 16, 345–379. [Google Scholar]
- Meishan Zhang, Hao Fei, Bin Wang, Shengqiong Wu, Yixin Cao, Fei Li, and Min Zhang. Recognizing everything from all modalities at once: Grounded multimodal universal information extraction. In Findings of the Association for Computational Linguistics: ACL 2024, 2024.
- Shengqiong Wu, Hao Fei, and Tat-Seng Chua. Universal scene graph generation. Proceedings of the CVPR, 2025.
- Shengqiong Wu, Hao Fei, Jingkang Yang, Xiangtai Li, Juncheng Li, Hanwang Zhang, and Tat-seng Chua. Learning 4d panoptic scene graph generation from rich 2d visual scene. Proceedings of the CVPR, 2025.
- Yaoting Wang, Shengqiong Wu, Yuecheng Zhang, Shuicheng Yan, Ziwei Liu, Jiebo Luo, and Hao Fei. Multimodal chain-of-thought reasoning: A comprehensive survey. arXiv 2025, arXiv:2503.12605.
- Hao Fei, Yuan Zhou, Juncheng Li, Xiangtai Li, Qingshan Xu, Bobo Li, Shengqiong Wu, Yaoting Wang, Junbao Zhou, Jiahao Meng, Qingyu Shi, Zhiyuan Zhou, Liangtao Shi, Minghe Gao, Daoan Zhang, Zhiqi Ge, Weiming Wu, Siliang Tang, Kaihang Pan, Yaobo Ye, Haobo Yuan, Tao Zhang, Tianjie Ju, Zixiang Meng, Shilin Xu, Liyu Jia, Wentao Hu, Meng Luo, Jiebo Luo, Tat-Seng Chua, Shuicheng Yan, and Hanwang Zhang. On path to multimodal generalist: General-level and general-bench. In Proceedings of the ICML, 2025.
- Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Zhenye Gan, Ding Qi, Chaoyou Fu, et al. A survey on benchmarks of multimodal large language models. arXiv 2024, arXiv:2408.08632.
- Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature 2015, 521, 436–444. [CrossRef]
- Dong Yu Li Deng. Deep Learning: Methods and Applications. NOW Publishers, May 2014. URL https://www.microsoft.com/en-us/research/publication/deep-learning-methods-and-applications/.
- Eric Makita and Artem Lenskiy. A movie genre prediction based on Multivariate Bernoulli model and genre correlations. (May), mar 2016a. URL http://arxiv.org/abs/1604.08608.
- Junhua Mao, Wei Xu, Yi Yang, Jiang Wang, and Alan L Yuille. Explain images with multimodal recurrent neural networks. arXiv 2014, arXiv:1410.1090.
- Deli Pei, Huaping Liu, Yulong Liu, and Fuchun Sun. Unsupervised multimodal feature learning for semantic image segmentation. In The 2013 International Joint Conference on Neural Networks (IJCNN), pp. 1–6. IEEE, aug 2013. ISBN 978-1-4673-6129-3. URL http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=6706748.
- Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556.
- Richard Socher, Milind Ganjoo, Christopher D Manning, and Andrew Ng. Zero-Shot Learning Through Cross-Modal Transfer. In C J C Burges, L Bottou, M Welling, Z Ghahramani, and K Q Weinberger (eds.), Advances in Neural Information Processing Systems 26, pp. 935–943. Curran Associates, Inc., 2013. URL http://papers.nips.cc/paper/5027-zero-shot-learning-through-cross-modal-transfer.pdf.
- Hao Fei, Shengqiong Wu, Meishan Zhang, Min Zhang, Tat-Seng Chua, and Shuicheng Yan. Enhancing video-language representations with structural spatio-temporal alignment. IEEE Transactions on Pattern Analysis and Machine Intelligence 2024.
- Karpathy, A.; Fei-Fei, L. Deep visual-semantic alignments for generating image descriptions. TPAMI 2017, 39, 664–676. [Google Scholar] [CrossRef]
- Hao Fei, Yafeng Ren, and Donghong Ji. Retrofitting structure-aware transformer language model for end tasks. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 2151–2161, 2020a.
- Shengqiong Wu, Hao Fei, Fei Li, Meishan Zhang, Yijiang Liu, Chong Teng, and Donghong Ji. Mastering the explicit opinion-role interaction: Syntax-aided neural transition system for unified opinion role labeling. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, pages 11513–11521, 2022.
- Wenxuan Shi, Fei Li, Jingye Li, Hao Fei, and Donghong Ji. Effective token graph modeling using a novel labeling strategy for structured sentiment analysis. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4232–4241, 2022.
- Hao Fei, Yue Zhang, Yafeng Ren, and Donghong Ji. Latent emotion memory for multi-label emotion classification. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 7692–7699, 2020b.
- Fengqi Wang, Fei Li, Hao Fei, Jingye Li, Shengqiong Wu, Fangfang Su, Wenxuan Shi, Donghong Ji, and Bo Cai. Entity-centered cross-document relation extraction. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9871–9881, 2022.
- Zhuang, L.; Fei, H.; Hu, P. Knowledge-enhanced event relation extraction via event ontology prompt. Inf. Fusion 2023, 100, 101919. [Google Scholar] [CrossRef]
- Adams Wei Yu, David Dohan, Minh-Thang Luong, Rui Zhao, Kai Chen, Mohammad Norouzi, and Quoc V Le. Qanet: Combining local convolution with global self-attention for reading comprehension. arXiv, arXiv:1804.09541.
- Wu, S.; Fei, H.; Cao, Y.; Bing, L.; Chua, T. Information screening whilst exploiting! multimodal relation extraction with feature denoising and multimodal topic modeling. arXiv 2023, arXiv:2305.11719. [Google Scholar] [CrossRef]
- Xu, J.; Fei, H.; Pan, L.; Liu, Q.; Lee, Mo.; Hsu, W. . Faithful logical reasoning via symbolic chain-of-thought. arXiv, arXiv:2405.18357.
- Dunn, M.; Sagun, L.; Higgins, M.; Guney, V.U.; Cirik, V.; Cho, K. SearchQA: A new Q&A dataset augmented with context from a search engine. arXiv 2017, arXiv:1704.05179. [Google Scholar]
- Hao Fei, Shengqiong Wu, Jingye Li, Bobo Li, Fei Li, Libo Qin, Meishan Zhang, Min Zhang, and Tat-Seng Chua. Lasuie: Unifying information extraction with latent adaptive structure-aware generative language model. In Proceedings of the Advances in Neural Information Processing Systems, NeurIPS 2022, pages 15460–15475, 2022a.
- Qiu, G.; Liu, B.; Bu, J.; Chen, C. Opinion word expansion and target extraction through double propagation. Computational linguistics 2011, 37, 9–27. [Google Scholar] [CrossRef]
- Fei, H.; Ren, Y.; Zhang, Y.; Ji, D.; Liang, X. Enriching contextualized language model from knowledge graph for biomedical information extraction. Briefings in Bioinformatics 2021, 22. [Google Scholar] [CrossRef] [PubMed]
- Shengqiong Wu, Hao Fei, Wei Ji, and Tat-Seng Chua. Cross2StrA: Unpaired cross-lingual image captioning with cross-lingual cross-modal structure-pivoted alignment. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2593–2608, 2023b.
- Bobo Li, Hao Fei, Fei Li, Tat-seng Chua, and Donghong Ji. 2024a. Multimodal emotion-cause pair extraction with holistic interaction and label constraint. ACM Transactions on Multimedia Computing, Communications and Applications 2024.
- Bobo Li, Hao Fei, Fei Li, Shengqiong Wu, Lizi Liao, Yinwei Wei, Tat-Seng Chua, and Donghong Ji. 2025. Revisiting conversation discourse for dialogue disentanglement. ACM Transactions on Information Systems 2025, 43, 1–34.
- Bobo Li, Hao Fei, Fei Li, Yuhan Wu, Jinsong Zhang, Shengqiong Wu, Jingye Li, Yijiang Liu, Lizi Liao, Tat-Seng Chua, and Donghong Ji. 2023. DiaASQ: A Benchmark of Conversational Aspect-based Sentiment Quadruple Analysis. In Findings of the Association for Computational Linguistics: ACL 2023. 13449–13467.
- Bobo Li, Hao Fei, Lizi Liao, Yu Zhao, Fangfang Su, Fei Li, and Donghong Ji. Harnessing holistic discourse features and triadic interaction for sentiment quadruple extraction in dialogues. Proceedings of the AAAI conference on artificial intelligence 2024, 38, 18462–18470. [CrossRef]
- Shengqiong Wu, Hao Fei, Liangming Pan, William Yang Wang, Shuicheng Yan, and Tat-Seng Chua. 2025a. Combating Multimodal LLM Hallucination via Bottom-Up Holistic Reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 8460–8468.
- Shengqiong Wu, Weicai Ye, Jiahao Wang, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Shuicheng Yan, Hao Fei, et al. 2025b. Any2caption: Interpreting any condition to caption for controllable video generation. arXiv 2025, arXiv:2503.24379.
- Han Zhang, Zixiang Meng, Meng Luo, Hong Han, Lizi Liao, Erik Cambria, and Hao Fei. 2025. Towards multimodal empathetic response generation: A rich text-speech-vision avatar-based benchmark. In Proceedings of the ACM on Web Conference 2025. 2872–2881.
- Yu Zhao, Hao Fei, Shengqiong Wu, Meishan Zhang, Min Zhang, and Tat-seng Chua. 2025. Grammar induction from visual, speech and text. Artificial Intelligence 2025, 341, 104306.
- Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. Squad: 100,000+ questions for machine comprehension of text. arXiv 2016, arXiv:1606.05250.
- Hao Fei, Fei Li, Bobo Li, and Donghong Ji. Encoder-decoder based unified semantic role labeling with label-aware syntax. In Proceedings of the AAAI conference on artificial intelligence, pages 12794–12802, 2021a.
- D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in ICLR, 2015.
- Hao Fei, Shengqiong Wu, Yafeng Ren, Fei Li, and Donghong Ji. Better combine them together! integrating syntactic constituency and dependency representations for semantic role labeling. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 549–559, 2021b.
- K. Papineni, S. Roukos, T. Ward, and W. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in ACL, 2002, pp. 311–318.
- Fei, H.; Li, B.; Liu, Q.; Bing, L.; Li, F.; Chua, Ta. Reasoning implicit sentiment with chain-of-thought prompting. arXiv 2023, arXiv:2305.11255. [Google Scholar]
- Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota, June 2019. Association for Computational Linguistics. URL https://aclanthology.org/N19-1423.
- Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. Next-gpt: Any-to-any multimodal llm. CoRR 2023, abs/2309.05519.
- Qimai Li, Zhichao Han, and Xiao-Ming Wu. Deeper insights into graph convolutional networks for semi-supervised learning. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- Hao Fei, Shengqiong Wu, Wei Ji, Hanwang Zhang, Meishan Zhang, Mong-Li Lee, and Wynne Hsu. Video-of-thought: Step-by-step video reasoning from perception to cognition. In Proceedings of the International Conference on Machine Learning, 2024b.
- Naman Jain, Pranjali Jain, Pratik Kayal, Jayakrishna Sahit, Soham Pachpande, Jayesh Choudhari, et al. Agribot: agriculture-specific question answer system. IndiaRxiv 2019.
- Hao Fei, Shengqiong Wu, Wei Ji, Hanwang Zhang, and Tat-Seng Chua. Dysen-vdm: Empowering dynamics-aware text-to-video diffusion with llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7641–7653, 2024c.
- Mihir Momaya, Anjnya Khanna, Jessica Sadavarte, and Manoj Sankhe. Krushi–the farmer chatbot. In 2021 International Conference on Communication information and Computing Technology (ICCICT), pages 1–6. IEEE, 2021.
- Hao Fei, Fei Li, Chenliang Li, Shengqiong Wu, Jingye Li, and Donghong Ji. Inheriting the wisdom of predecessors: A multiplex cascade framework for unified aspect-based sentiment analysis. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI, pages 4096–4103, 2022b.
- Shengqiong Wu, Hao Fei, Yafeng Ren, Donghong Ji, and Jingye Li. Learn from syntax: Improving pair-wise aspect and opinion terms extraction with rich syntactic knowledge. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, pages 3957–3963, 2021.
- Bobo Li, Hao Fei, Lizi Liao, Yu Zhao, Chong Teng, Tat-Seng Chua, Donghong Ji, and Fei Li. Revisiting disentanglement and fusion on modality and context in conversational multimodal emotion recognition. In Proceedings of the 31st ACM International Conference on Multimedia, MM, pages 5923–5934, 2023.
- Hao Fei, Qian Liu, Meishan Zhang, Min Zhang, and Tat-Seng Chua. Scene graph as pivoting: Inference-time image-free unsupervised multimodal machine translation with visual scene hallucination. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5980–5994, 2023b.
- Banerjee and A. Lavie, “METEOR: an automatic metric for MT evaluation with improved correlation with human judgments,” in IEEMMT, 2005, pp. 65–72.
- Hao Fei, Shengqiong Wu, Hanwang Zhang, Tat-Seng Chua, and Shuicheng Yan. Vitron: A unified pixel-level vision llm for understanding, generating, segmenting, editing. In Proceedings of the Advances in Neural Information Processing Systems, NeurIPS 2024, 2024d.
- Chen, A.; Liu, C. Intelligent commerce facilitates education technology: The platform and chatbot for the taiwan agriculture service. International Journal of e-Education, e-Business, e-Management and e-Learning 2021, 11, 1–10. [Google Scholar] [CrossRef]
- Wu, S.; Fei, H.; Li, X.; Ji, J.; Zhang, H.; Chua, Ta.; Yan, S. Towards semantic equivalence of tokenization in multimodal llm. arXiv 2024, arXiv:2406.05127. [Google Scholar] [CrossRef]
- Jingye Li, Kang Xu, Fei Li, Hao Fei, Yafeng Ren, and Donghong Ji. MRN: A locally and globally mention-based reasoning network for document-level relation extraction. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1359–1370, 2021.
- Hao Fei, Shengqiong Wu, Yafeng Ren, and Meishan Zhang. Matching structure for dual learning. In Proceedings of the International Conference on Machine Learning, ICML, pages 6373–6391, 2022c.
- Hu Cao, Jingye Li, Fangfang Su, Fei Li, Hao Fei, Shengqiong Wu, Bobo Li, Liang Zhao, and Donghong Ji. OneEE: A one-stage framework for fast overlapping and nested event extraction. In Proceedings of the 29th International Conference on Computational Linguistics, pages 1953–1964, 2022.
- Tende, I.G.; Aburada, K.; Yamaba, H.; Katayama, T.; Okazaki, N. Proposal for a crop protection information system for rural farmers in tanzania. Agronomy 2021, 11, 2411. [Google Scholar] [CrossRef]
- Fei, H.; Ren, Y.; Ji, D. Boundaries and edges rethinking: An end-to-end neural model for overlapping entity relation extraction. Information Processing & Management 2020, 57, 102311. [Google Scholar]
- Jingye Li, Hao Fei, Jiang Liu, Shengqiong Wu, Meishan Zhang, Chong Teng, Donghong Ji, and Fei Li. Unified named entity recognition as word-word relation classification. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 10965–10973, 2022.
- Jain, M.; Kumar, P.; Bhansali, I.; Liao, Q.V.; Truong, K.; Patel, S. Farmchat: a conversational agent to answer farmer queries. Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 2018, 2, 1–22. [Google Scholar] [CrossRef]
- Shengqiong Wu, Hao Fei, Hanwang Zhang, and Tat-Seng Chua. Imagine that! abstract-to-intricate text-to-image synthesis with scene graph hallucination diffusion. In Proceedings of the 37th International Conference on Neural Information Processing Systems, pages 79240–79259, 2023d.
- P. Anderson, B. Fernando, M. Johnson, and S. Gould, “SPICE: semantic propositional image caption evaluation,” in ECCV, 2016, pp. 382–398.
- Fei, H.; Chua, Ta.; Li, C.; Ji, D.; Zhang, M.; Ren, Y. On the robustness of aspect-based sentiment analysis: Rethinking model, data, and training. ACM Transactions on Information Systems 2023, 41, 50:1–50:32. [Google Scholar] [CrossRef]
- Zhao, Y.; Fei, H.; Cao, Y.; Li, B.; Zhang, M.; Wei, J.; Zhang, M.; Chua, T. Constructing holistic spatio-temporal scene graph for video semantic role labeling. In Proceedings of the 31st ACM International Conference on Multimedia, MM, pages 5281–5291, 2023a.
- Wu, S.; Fei, H.; Cao, Y.; Bing, L.; Chua, T. Information screening whilst exploiting! multimodal relation extraction with feature denoising and multimodal topic modeling. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14734–14751, 2023e.
- Fei, H.; Ren, Y.; Zhang, Y.; Ji, D. Nonautoregressive encoder-decoder neural framework for end-to-end aspect-based sentiment triplet extraction. IEEE Transactions on Neural Networks and Learning Systems 2023, 34, 5544–5556. [Google Scholar] [CrossRef] [PubMed]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.S.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. arXiv 2015, arXiv:1502.03044. [Google Scholar]
- Yuksel, S.E.; Wilson, J.N.; Gader, P.D. Twenty years of mixture of experts. IEEE transactions on neural networks and learning systems, 2012, 23, 1177–1193. [Google Scholar] [CrossRef] [PubMed]
- Arora, S.; Liang, Y.; Ma, T. A simple but tough-to-beat baseline for sentence embeddings. In ICLR, 2017.
| 1 | |
| 2 | |
| 3 |

Table 1.
Retrieval performance on MS-COCO dataset.
| Model | R@1 | R@5 | R@10 | ||
|---|---|---|---|---|---|
| 1K Test Set (5-fold average) | |||||
| VSE++ [1] | 52.0 | 84.3 | 92.0 | 0.712 | 0.617 |
| VSRN [7] | 60.8 | 88.4 | 94.1 | 0.723 | 0.620 |
| DUET (Ours) | 61.5 | 89.0 | 94.8 | 0.735 | 0.653 |
| 5K Test Set (full split) | |||||
| VSE++ [1] | 30.3 | 59.4 | 72.4 | 0.656 | 0.577 |
| VSRN [7] | 37.9 | 68.5 | 79.4 | 0.676 | 0.596 |
| DUET (Ours) | 38.2 | 70.1 | 80.3 | 0.668 | 0.600 |
Table 2.
Ablation study on 1K test set.
| Model Variant | R@1 | |
|---|---|---|
| DUET w/o shared layers | 58.6 | 0.632 |
| DUET w/o spatial features | 57.9 | 0.628 |
| DUET (no norm reg) | 59.1 | 0.637 |
| Full DUET | 61.5 | 0.653 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



