
Submitted:
26 August 2025
Posted:
27 August 2025
You are already at the latest version
Abstract
This paper addresses the asymptotic analysis of a nonparametric kernel estimator for conditional distribution functions in the context of spatially weakly dependent functional variables, where the covariates lie in an infinite-dimensional space. We focus on establishing the almost complete convergence (a.~co) of the estimator and deriving its rate of convergence under a spatial sampling framework characterized by quasi-association. By integrating spatial structure into the theoretical development, we highlight the impact of weak spatial dependence on the performance of the estimator. Our results provide key insights into the applicability and robustness of kernel-based nonparametric inference for spatially structured functional data.
Keywords:
spatial data
; conditional distribution function
; quasi-association
; nonparametric kernel estimation
1. Introduction
In recent years, the field of statistical analysis has witnessed significant advancements, particularly in the context of dependent data. This evolution is evident in a variety of groundbreaking studies that have contributed to our understanding and methodologies [1]. Functional Data Analysis (FDA) is a statistical method that is used to analyze data that are considered functions, rather than just single values.
In traditional data analysis, observations are typically represented by single values such as numbers or categories. However, in many scenarios, data are collected over a continuum, such as time, space, or another ordered domain. FDA treats these data as continuous functions or curves rather than discrete points (for an example, see [2,3,4]).
Association refers to the relationship or connection between different elements within a dataset. In statistical analysis and data science, the association between variables and associated data is fundamental to understanding relationships and patterns within data sets. Associations help to explore how changes in one variable may impact another or how variables relate to each other in a dataset. By exploring associations, analysts and researchers can gain insight into how different variables interact and influence each other, leading to informed decision-making and a deeper understanding of the underlying phenomena represented by the data.
Newman’s early work in 1984 set the foundation by exploring the role of research within this domain. The concept of weak dependence, pivotal in this field, was further elaborated by Doukhan and Louhichi in 1999, providing a new perspective on dependence conditions and their applications to moment inequalities [5].
Studies addressing both positive and negative dependent random variables have been explored in various references [6,7,8]. In their work [9], the authors introduced the concept of quasi-association to analyze stochastic occurrences with real values, illustrating the notion of weak dependence. The idea, which is elaborated on by the work mentioned in [10], offers a unified framework for evaluating groups of randomly dependent variables that are positively or negatively dependent. This framework is applicable to the domain of real-valued random fields.
In the corpus of research that is currently available, the approach of nonparametric estimation of quasi-associated random variables has only attracted a small amount of attention. The research conducted by [11] focuses on a limit theorem that pertains to quasi-associated Hilbertian random variables. This theoretical framework was the topic of the examination. Furthermore, in circumstances where dependency is weak, the asymptotic outcomes of an M-estimator of regression are explored according to the findings of [12]. In the research work that is referred to as [13], the asymptotic normality of an estimator is investigated, with particular emphasis placed on the single-index structure of the conditional hazard function.
One of the areas that was considered significant in the study presented in [14,15] was the examination of nonparametric estimation for linked random variables. This was the topic of the work mentioned in [16]. The authors demonstrate the resilient uniform consistency properties of the partial derivatives of multivariate density functions under weak dependency using the approach provided in [17]. In addition to this, they determine the necessary rates of convergence in order to demonstrate the asymptotic normality of these estimators. Regarding the most recent research on quasi-associated data, the work has been carried out by [18,19,20].
In the context of a single-index regression model, the objective of this study is to evaluate the application of the kernel (k-nn) technique, especially in circumstances in which the explanatory variable is measured in functional space. The implementation of this method in circumstances that include association dependency is another aspect that is investigated in this work. The research given in [21] is an investigation of the use of k-nn in a regression model using a single index. This work follows a similar line of thought. Specifically, the study focuses on situations that include functional predictors and it reveals that almost ideal rates of convergence may be attained even in situations where there is an absence of strong reliance.
The purpose of the work mentioned in [22] is to identify the asymptotic characteristic of nonparametric estimation strategies for the regression function in the single functional index model (SFIM), with the assumption of quasi-association dependence.
In addition, the progress of this topic is characterized by the investigation of limit theorems for quasi-associated variables, as Douge’s paper from 2010 [11] demonstrates. Significant advances were made in 2016 with the work that Mechab and Laksaci did on nonparametric relative regression for associated random variables [23]. Daoudi et al. further advanced of research by establishing the asymptotic normality of the estimator of conditional hazard functions in the context of quasi-associated data [24].
In the realm of kernel density estimation on random fields, Lanh.Tat. Tran’s 1990 work was seminal [25], followed by significant contributions by Dabo-Niang and Yao in 2007 and Carbon, Francq and Tran in the same year [26,27]. J. Li and L.T. Tran in 2009 on nonparametric estimation of conditional expectation further underscores the evolving nature of statistical methods and their applications [28].
Moreover, the introduction of kernel nearest neighbors (k-nn) methodologies and the concept of a single functional index have further enriched the landscape of statistical analysis [29]. These approaches offer robust solutions for dealing with various types of data, including those that exhibit complex dependencies. The single functional index approach introduces an efficient way to model the influence of predictor variables on a response variable, simplifying complex multivariate relationships in a more manageable form [30]. This innovation has been instrumental in the advancement of the field, allowing for a more refined and insightful analysis of dependent data.
The integration of these advanced methodologies has opened new avenues in the realm of statistical analysis, particularly in the handling of complex datasets [29,30]. The k-nn approach adapts to the local structure of the data, providing a more accurate representation of the underlying relationships, which is crucial in various fields like finance, healthcare and environmental studies.
Spatial variables and spatial data play a critical role in understanding and analyzing geographic phenomena, patterns, and the development of predictive models and simulations to predict spatial patterns, trends, and future scenarios. Spatial data consists of information that is explicitly tied to geographic locations or coordinates on the Earth’s surface or in a specified area. Spatial data can be represented in various formats, including points, lines, polygons, grids, and rasters. It encompasses both the spatial coordinates and associated attribute data.
Using spatial data analysis techniques, researchers, policymakers, and practitioners can gain valuable insights into spatially distributed processes and make informed decisions for sustainable development, environmental conservation, and improved quality of life.
The contributions of Cressie, Banerjee, Carlin, Gelfand, and others have been pivotal in advancing the field of spatial statistics, with significant implications for environmental science, urban studies, and other disciplines [31,32].
In summary, the field of statistical analysis has undergone a remarkable transformation, driven by the development of new methodologies and the refinement of existing ones. The incorporation of kernel nearest neighbors, the single functional index model, and advancements in spatial data analysis represent significant leaps forward in our ability to analyze and interpret complex data. As we continue to explore and expand these methodologies, we pave the way for more sophisticated and insightful data analysis across various scientific disciplines.
In the following sections, we unveil our spatial model estimator in Section 2, propose hypotheses, and delve into the near-complete convergence of this estimator in Section 3. Through simulation studies, we scrutinize the asymptotic behavior using finite sample data in Section 4, culminating in conclusions outlined in Section 5. Appendix A contains detailed proofs to support our assertions.
2. Model Construction and Its Estimator
2.1. Model
To construct our model, we define:
where takes values in , , and denotes a space of infinite-dimensional functions. Accordingly, we consider the sequence as a functional random field.
In order to achieve the objective of our study, we introduce a kernel-type estimator of the conditional distribution function . This estimation assumes that the functional random field is observed over the domain:
with .
The kernel estimator of the conditional distribution function is given by:
We can also express the numerator and denominator of the estimator separately as:
where
Here, denotes a kernel function, while is a smoothing (cumulative distribution-type) function. The parameters and are sequences of positive real numbers representing bandwidths. The symbol denotes the unit multi-index in the spatial field.
The central aim of this study is to analyze the almost sure convergence of the estimator toward with respect to the random field .
2.2. Spatial Dependence Measures
There exists a function such that as , and for all finite subsets , the following inequality holds:
Here, (resp. ) denotes the Borel -algebra generated by (resp. ). The notation (resp. ) stands for the cardinality of (resp. ), while represents the Euclidean distance between the two sets.
The function is symmetric and non-increasing in each argument. It satisfies one of the following regularity conditions:
or
where and is a constant.
Definition 1.
Let be real-valued random variables satisfying the following conditions:
- for all ,
- for all , with .
Let , and suppose there exist constants (bounded) and such that the following covariance inequality holds for all multi-indices:
Then, for any , the following exponential inequality holds:
where the constants and are given by:
3. Asymptotic Properties
3.1. Background Information and Assumptions
Throughout this section, we denote by and strictly positive constants. We assume that for all :
In the spatial context, the notation means that:
and for all , the ratio of components satisfies:
We now introduce the following hypotheses:
- (H1)
-
Here, denotes the ball of radius r centered at a.
- (H2)
- The function satisfies the summability condition:
- (H3)
- For all , the following holds:where .
- (H4)
- There exists a neighborhood of a such that for all and ,with , .
- (H5)
- The kernel K has compact support on and satisfies:where denotes the indicator function of the interval .
- (H6)
- The function H belongs to the class , has compact support, and possesses bounded derivatives.
- (H7)
- There exist constants:such that:andwhere:
3.2. Main Result
Theorem 1.
Under the hypotheses (H1-H7), we have the following uniform convergence rate:
In the particular case where , we recover the same convergence rate as in Ferraty et al. [33]. The proof of this result relies on the following decomposition:
The following results form the basis of the proof of Theorem 1:
Lemma 1.
Under hypotheses (H1-H5) and (H7), we have:
Lemma 2.
Under the assumptions of Theorem 1, we have:
Lemma 3.
Under hypotheses (H1-H5) and (H7), it holds that:
Corollary 1.
Under the assumptions of Lemma 1, we obtain:
4. A Simulation Study
To assess the finite-sample performance of the proposed kernel estimator for the conditional distribution function , we conduct a simulation study tailored to spatially weakly dependent functional data. The goal is to empirically validate the asymptotic properties established in our theoretical framework, particularly the almost complete convergence (a.co) and the rate of convergence under quasi-association.
4.1. Simulation Design
We consider a spatial domain of dimension , defined over a regular grid of locations , with a total sample size . At each spatial index, a functional covariate is generated using smooth basis functions (e.g., B-splines), and perturbed with a spatially quasi-associated noise field to induce spatial weak dependence. This reflects a realistic spatial functional data scenario.
The scalar response variable is simulated via a known conditional model:
where is the standard normal cumulative distribution function, and , are smooth functions of the norm . This setup allows exact computation of the true conditional distribution for validation.
4.2. Visualization of Functional Data
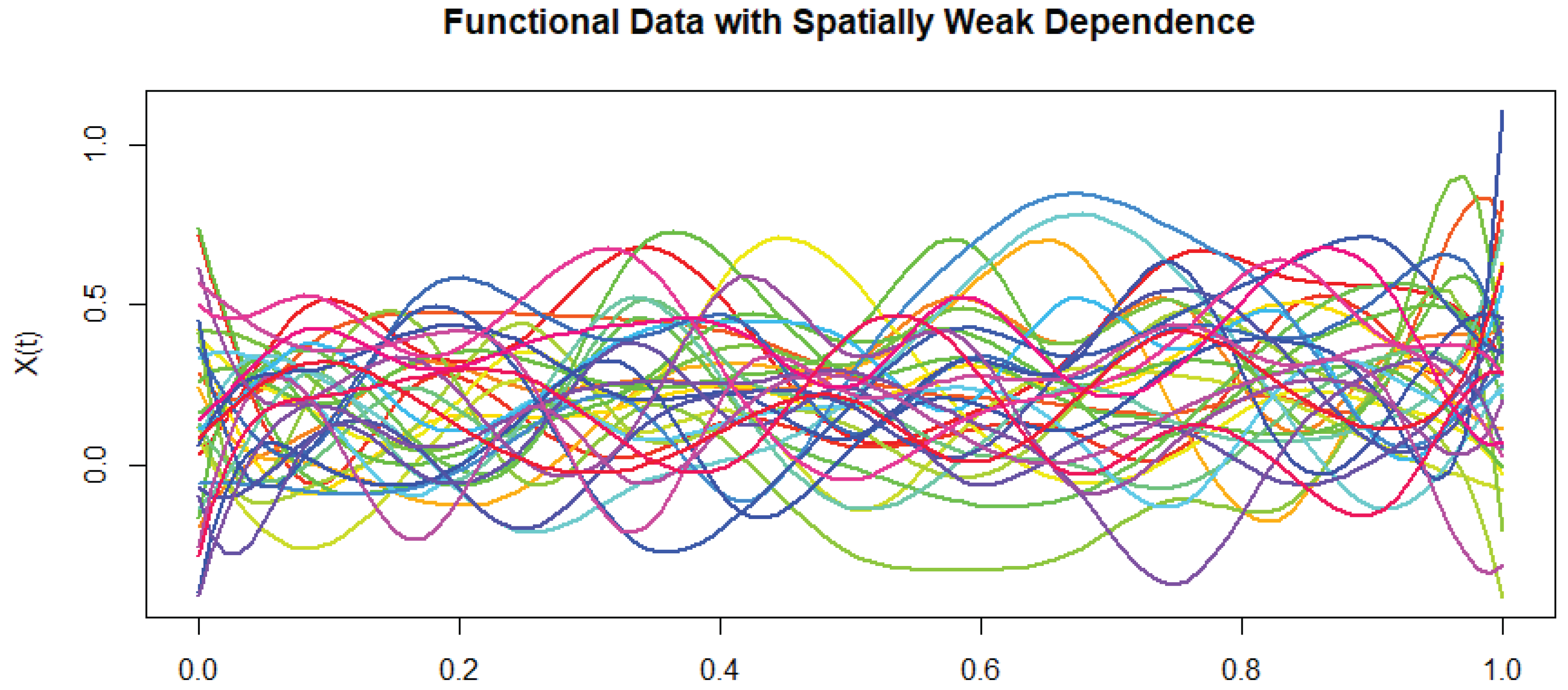
To illustrate the nature of the spatially weakly dependent functional covariates , we plot a sample of these curves. Each function is observed on the interval , and smoothness is ensured via B-spline basis functions.
As seen in Figure 1, we display a representative sample of 35 functional curves. These curves are smooth and exhibit gradual variability across space, consistent with the quasi-associated dependence structure. This visualization highlights the functional nature of the covariates and supports the assumptions used in our theoretical results.
4.3. Simulation Procedure
The simulation process proceeds as follows:
- Parameter Initialization: Define , bandwidths , , and basis size (e.g., 15 B-splines). Choose functions , and .
- Data Generation: Each functional covariate is generated as:where , and is a spatially correlated perturbation modeled via exponential decay: .
- Response Variable: For each , compute:
-
Kernel Estimation: We employ the nonparametric estimator defined in Equation (1), where denotes the distance between functional covariates, H corresponds to the Gaussian cumulative distribution function, and K is the Epanechnikov kernel defined by:K is the Epanechnikov kernel, and H is the Gaussian CDF.
- Evaluation and Metrics: We compute pointwise metrics:estimated via Monte Carlo replications.
- Visualization: Plot against to visually assess the quality of the estimator across different ranges of b.
4.4. Results and Visual Analysis
To visually validate the performance of the kernel estimator, we plot the estimated conditional distribution function versus the true function for a fixed reference curve a. The figure below, generated from R, shows the estimated in red (dashed) and the true function in blue (solid).
Figure 2.
Comparison between the estimated and true conditional distribution functions and for fixed functional input a.
Figure 2.
Comparison between the estimated and true conditional distribution functions and for fixed functional input a.
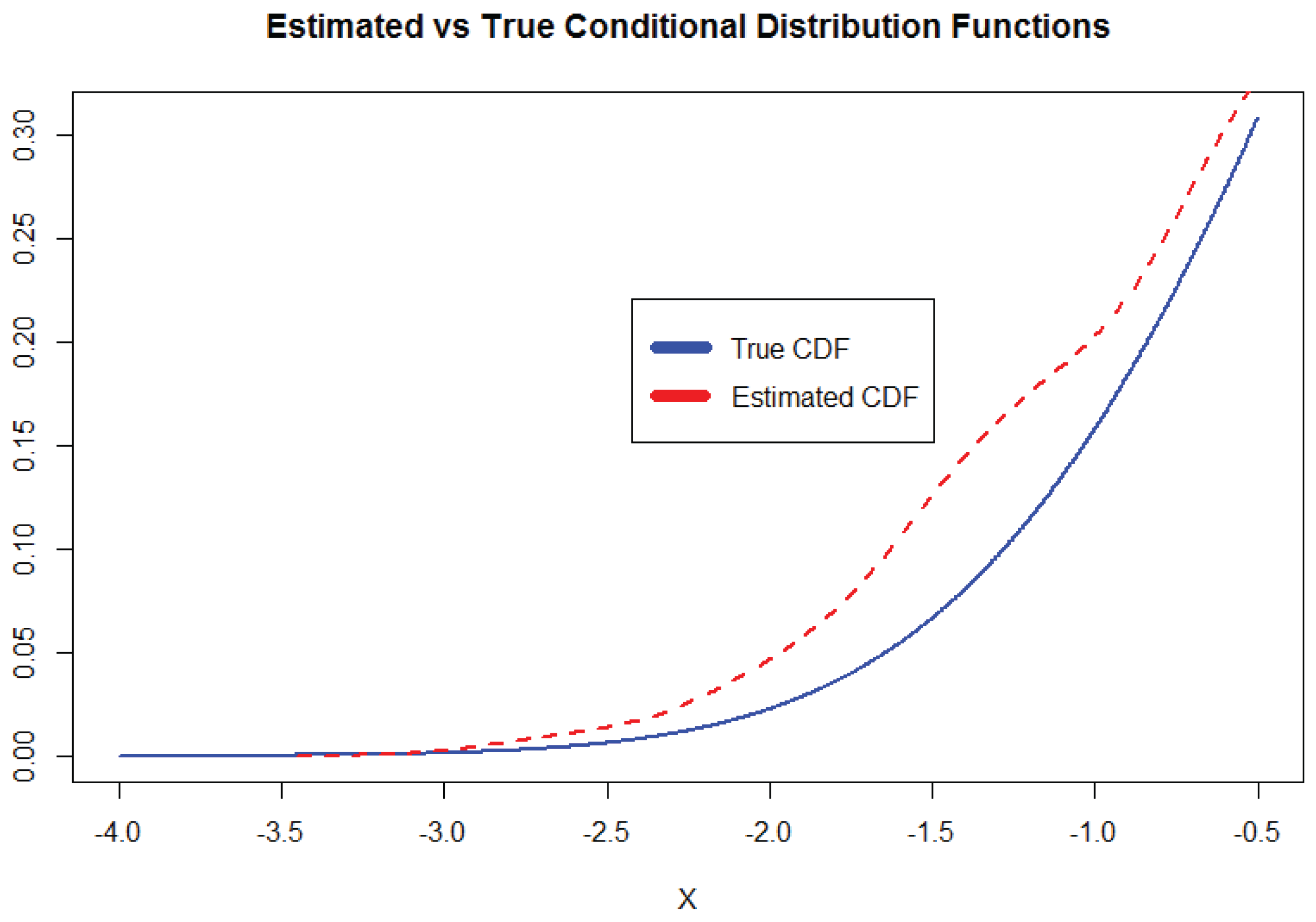
We observe that the estimator aligns closely with the true distribution in the central region. Slight overestimation near the tails may arise from finite-sample effects or boundary bias. Overall, the estimator exhibits robust behavior under weak spatial dependence and functional variability.
4.5. Summary of Findings
The kernel estimator performs well in capturing the true conditional distribution under spatially quasi-associated functional covariates. Simulation results corroborate the theoretical properties, particularly the convergence rate stated in Theorem 1. Estimation accuracy improves with increased sample size and suitable bandwidth selection. Visualization confirms strong agreement between estimated and true CDFs, with mild deviation at boundaries. This simulation study confirms the consistency and practical feasibility of the proposed estimator. It supports our asymptotic results and highlights its flexibility in the spatial functional context.
5. Conclusions and Perspectives
This study provides a comprehensive investigation of a kernel-type estimator for conditional distribution functions in the context of spatially indexed functional data, particularly when covariates take values in infinite-dimensional spaces. The core objective was to examine the asymptotic properties of the estimator, focusing on its almost complete convergence (a. co) and the associated convergence rates.
We considered a spatial sampling framework with quasi-associated dependence structures, reflecting realistic conditions in many applied settings. Under a set of regularity conditions, we derived uniform convergence results and provided theoretical guarantees for the performance of the estimator. The theoretical developments were supported by a simulation study, which confirmed the estimator’s consistency and highlighted its sensitivity to spatial correlation and bandwidth selection.
From a broader perspective, our findings emphasize the critical role of incorporating spatial structure into statistical modeling. Ignoring such dependence can lead to inaccurate inference, especially in high-dimensional or functional data settings. The kernel-based approach demonstrated here offers a flexible and nonparametric alternative, well-suited for complex spatial data.
Future Research Directions
Building upon this foundation, several promising avenues for further research emerge:
The current framework can be generalized to irregular spatial lattices or continuous spatial domains using tools from spatial stochastic processes.
Investigating the behavior of the estimator under deviations from the quasi-association assumption, heavy-tailed distributions, or outliers would enhance its practical relevance.
Developing adaptive or cross-validated procedures for selecting kernel bandwidths and remains an open challenge, especially in functional settings.
Applying the methodology to spatial datasets in geostatistics, climate science, or public health would provide practical insights and further validate the approach.
Creating efficient algorithms and open-source software for kernel estimation in spatially dependent functional data would facilitate broader adoption in applied contexts.
Overall, this work contributes to the understanding of nonparametric inference for conditional distributions in spatial data and lays the groundwork for future theoretical and applied developments in this growing area of statistical research.
Author Contributions
Conceptualization, I.B and H.D.; A.B.; methodology, I.B and H.D.; software, I.B; validation, A.B., and H.D.; formal analysis, H.D. and I.B; investigation, I.B , A.B., and H.D.; resources, I.B and H.D.; data curation, A.R.; writing original draft preparation, H.D. and H.M.A.; writing review and editing, I.B, A.B, and H.D.; visualization, H.M.A.; supervision, A.B and H.M.A.; project administration,I.B; funding acquisition, H.M.A.
Funding
This research was funded by Taif University, Saudi Arabia, Project No. (TU-DSPP-2024-162).
Data Availability Statement
The data used to support the findings of this study are available on request from the corresponding author.
Acknowledgments
The authors extend their appreciation to Taif University, Saudi Arabia, for supporting this work through project number (TU-DSPP-2024-162).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
Proof
(Proof of Lemma 1). The concepts used in the proof are comparable to those in [27]. We have:
where .
We take into account the spatial decomposition introduced by [25] for the variables , defined with a fixed integer . For , define:
In a similar vein, the other two terms are defined as:
Now, set for :
We define:
so that we recover:
We can write, without loss of generality, the following identity:
Even in the case where , we can group the remaining terms into an additional block denoted by , and this does not affect the validity of the proof (see [32] for details).
From Equation (A7), for any , we have:
where it remains to bound, for each :
We now focus on the specific case where . To proceed, we perform a reordering of the variables, denoted as . Leveraging Lemma 4.5 from Carbon et al. [27], we apply it to this reordered sequence. The variables under the new enumeration are denoted by , where:
For each , there exists a corresponding index such that:
where
Each such set contains elements, and the minimal distance between any two such sets is at least .
Now, consider independent random variables that are constructed to follow the same marginal distribution as the corresponding , for . According to the result of Carbon et al. [27], we have:
Our next set of results is derived using **Bernstein’s** and **Markov’s** inequalities. We obtain:
where:
and:
Note that:
and
Therefore, for:
we obtain:
By choosing:
we deduce:
According to assumption (H7), we finally show that:
Concerning , we now evaluate the variance term . In fact, we write:
We denote:
Under assumptions (H1) and (H2), we have:
which leads to the following bound:
To control the covariance term , we follow the decomposition technique of Masry [34]. We define two subsets of pairs as follows:
When the actual sequence approaches infinity.
We split into two components corresponding to the sets and :
For the first term , we have:
For the second term , we use:
Since the kernel K is bounded, it holds that:
For higher-order covariances, especially when , we analyze:
leading to:
Now, by invoking quasi-association and assumption (H5), we derive the more precise inequality:
When , by assumption (H6), we have:
Moreover, by applying Hölder-type interpolation on (A34) and (A35) via powers and , we obtain:
As a consequence, the variables , satisfy the assumptions of the lemma with:
Thus, applying Bernstein’s inequality:
Regarding the second covariance term, we can deduce the following estimate:
We take , then:
From assumption (H2), we obtain:
Similarly, with the same choice of , we also have:
Hence, the total variance becomes:
Using this result, we write:
Moreover,
Using the expressions for , M, and , together with the last bound, we conclude:
In light of all the above, the result of the lemma follows by choosing a suitable constant .
□
Proof
(Proof of Lemma 2). Let us define:
It is clear that:
for some constant .
We aim to show that:
where is a finite grid of evaluation points, and are error terms derived from concentration inequalities.
Using the definition of , the Equation (A21), and assumption (H7), we obtain:
Proof
(Proof of Lemma 3). Using assumption H4 (15), and noting that the random variables are identically distributed, we obtain the following:
Next, we apply integration by parts:
Performing the change of variable , we obtain:
Since is a probability density function and applying assumption H4 (15), it follows that:
Finally, we obtain:
This completes the proof of the lemma under assumption H6 (6). □
Proof
(Proof of Corollary 1). Since we already have that , we apply the basic inequality from probability theory:
and by Lemma 1, the quantity is controlled by a rate of almost complete convergence. Thus, we deduce that:
which implies the almost sure convergence of the denominator bounded away from zero, and completes the proof. □
References
- Newman, M. The Role of Research in This Association. Journal of School Health 1984, 54. [Google Scholar] [CrossRef]
- Aneiros, G.; Cao, R.; Fraiman, R.; Genest, C.; Vieu, P. Recent advances in functional data analysis and high-dimensional statistics. J. Multivariate Anal.170, 3–9. [CrossRef]
- Ramsay, J.; Silverman, B. W. Functional Data Analysis; Springer: New York, USA, 2005. [Google Scholar]
- Ramsay, J.; Hooker, G.; Graves, S. Functional Data Analysis with R and MATLAB; Springer: New York, USA, 2009. [Google Scholar]
- Doukhan, P.; Louhichi, S. A new weak dependence condition and applications to moment inequalities. Stochastic Process. Appl. 1999, 84, 313–342. [Google Scholar] [CrossRef]
- Matula, P. A note on the almost sure convergence of sums of negatively dependent random variables. Stat. Probab. Lett. 1992, 15, 209–213. [Google Scholar] [CrossRef]
- Newman, C.M. Asymptotic independence and limit theorems for positively and negatively dependent random variables. In Inequalities in Statistics and Probability; IMS Lecture Notes Monograph Series 1984, 5, 127–140. [Google Scholar]
- Roussas, G.G. Positive and negative dependence with some statistical applications. In Asymptotics, Nonparametrics and Time Series; Ghosh, S., Ed.; Marcel Dekker, Inc.: New York, USA, 1999; pp. 757–788. [Google Scholar]
- Doukhan, P.; Louhichi, S. A new weak dependence condition and applications to moment inequalities. Stochastic Process. Their Appl. 1999, 84, 313–342. [Google Scholar] [CrossRef]
- Bulinski, A.; Suquet, C. Normal approximation for quasi-associated random fields. Stat. Probab. Lett. 2001, 54, 215–226. [Google Scholar] [CrossRef]
- Douge, L. Théorèmes limites pour des variables quasi-associées hilbertiennes. Ann. Inst. Stat. Univ. Paris 2010, 54, 51–60. [Google Scholar]
- Attaoui, S.; Laksaci, A.; Ould-Said, E. Asymptotic Results for an M-estimator of the Regression Function for Quasi-Associated Processes. In Functional Statistics and Applications. Contributions to Statistics; Springer International Publishing: Cham, 2015; pp. 3–28. [Google Scholar] [CrossRef]
- Daoudi, H.; Mechab, B.; Chikr Elmezouar, Z. Asymptotic normality of a conditional hazard function estimate in the single index for quasi-associated data. Commun. Stat. Theory Methods 2020, 49, 513–530. [Google Scholar]
- Daoudi, H.; Mechab, B. Asymptotic Normality of the Kernel Estimate of Conditional Distribution Function for the quasi-associated data. Pak. J. Stat. Oper. Res. 2019, 15, 999–1015. [Google Scholar] [CrossRef]
- Daoudi, H.; Mechab, B.; Benaissa, S.; Rabhi, A. Asymptotic normality of the nonparametric conditional density function estimate with functional variables for the quasi-associated data. Int. J. Stat. Econ. 2019, 20, 94–106. [Google Scholar]
- Laksaci, A.; Mechab, W. Nonparametric relative regression for associated random variables. Metron 2016, 74, 75–97. [Google Scholar] [CrossRef]
- Allaoui, S.; Bouzebda, S.; Chesneau, C.; Liu, J. Uniform almost sure convergence and asymptotic distribution of the wavelet-based estimators of partial derivatives of multivariate density function under weak dependence. J. Nonparametr. Stat. 2021, 33, 170–196. [Google Scholar] [CrossRef]
- Bouaker, I.; Belguerna, A.; Daoudi, H. The consistency of the kernel estimation of the function conditional density for associated data in high-dimensional statistics. J. Sci. Arts 2022, 22, 247–256. [Google Scholar] [CrossRef]
- Daoudi, H.; Belguerna, A.; Elmezouar, Z.C.; Alshahrani, F. Conditional Density Kernel Estimation Under Random Censorship for Functional Weak Dependence Data. J. Math. 2025, Article ID 2159604. Available online: https://doi.org/10.1155/jom/2159604.
- Daoudi, H.; Elmezouar, Z.C.; Alshahrani, F. Asymptotic Results of Some Conditional Nonparametric Functional Parameters in High Dimensional Associated Data. Mathematics 2023, 11, 4290. [Google Scholar] [CrossRef]
- Bouzebda, S.; Laksaci, A.; Mohammedi, M. The k-nearest neighbors method in single index regression model for functional quasi-associated time series data. Rev. Mat. Complut. 2023, 36, 361–391. [Google Scholar] [CrossRef]
- Bouzebda, S.; Laksaci, A.; Mohammedi, M. Single Index Regression Model for Functional Quasi-Associated Time Series Data. REVSTAT-Statistical Journal 2023, 20, 605–631. [Google Scholar]
- Mechab, W.; Laksaci, A. Nonparametric relative regression for associated random variables. Metron 2016, 74, 75–97. [Google Scholar] [CrossRef]
- Daoudi, H.; Mechab, B.; Elmezouar, C.Z. Asymptotic Normality of a Conditional Hazard Function Estimate in the Single Index for Quasi-Associated Data. Commun. Stat. Theory Methods2018, Article ID 1549248.
- Tran, L.T. Kernel density estimation on random fields. J. Multivariate Anal. 1990, 34, 37–53. [Google Scholar] [CrossRef]
- Dabo-Niang, S.; Yao, A.F. Kernel regression estimation for continuous spatial processes. Math. Methods Statist. 2007, 16, 298–317. [Google Scholar] [CrossRef]
- Carbon, M.; Francq, C.; Tran, L.T. Kernel regression estimation for random fields. J. Statist. Plann. Inference 2007, 137, 778–798. [Google Scholar] [CrossRef]
- Li, J.; Tran, L.T. Nonparametric estimation of conditional expectation. J. Statist. Plann. Inference 2009, 139, 164–175. [Google Scholar] [CrossRef]
- Fix, E.; Hodges, J.L. Discriminatory Analysis, Nonparametric Discrimination: Consistency Properties. Technical Report 4, USAF School of Aviation Medicine, Randolph Field, 1951.
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Cressie, N.A. Statistics for Spatial Data; Wiley: New York, USA, 1991. [Google Scholar]
- Biau, G.; Cadre, B. Nonparametric spatial prediction. Stat. Inference Stoch. Process. 2004, 7, 327–349. [Google Scholar] [CrossRef]
- Ferraty, F.; Rabhi, A.; Vieu, P. Estimation non-paramétrique de la fonction de hasard avec variable explicative fonctionnelle. Rev. Roumaine Math. Pures Appl. 2008, 53, 1–18. [Google Scholar]
- Masry, E. Recursive probability density estimation for weakly dependent stationary processes. IEEE Trans. Inf. Theory 1986, 32, 254–267. [Google Scholar] [CrossRef]
- Gasser, T.; Hall, P.; Presnell, B. Nonparametric estimation of the mode of a distribution of random curves. J. R. Stat. Soc. Ser. B 1998, 60, 681–691. [Google Scholar] [CrossRef]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis: Theory and Practice; Springer Series in Statistics: New York, USA, 2006. [Google Scholar]
- Ferraty, F.; Laksaci, A.; Tadj, A.; Vieu, P. Rate of uniform consistency for nonparametric estimates with functional variables. J. Stat. Plann. Inference 2010, 140, 335–352. [Google Scholar] [CrossRef]
- Kara-Zaitri, L.; Laksaci, A.; Rachdi, M.; Vieu, P. Uniform in bandwidth consistency for various kernel estimators involving functional data. J. Nonparametr. Stat. 2017, 29, 85–107. [Google Scholar] [CrossRef]
- Ferraty, F.; Peuch, A.; Vieu, P. Modèle à indice fonctionnel simple. Comptes Rendus Math. 2003, 336, 1025–1028. [Google Scholar] [CrossRef]
- Ezzahrioui, M.; Ould-Saïd, E. Asymptotic Results of a Nonparametric Conditional Quantile Estimator for Functional Time Series. Commun. Stat. Theory Methods 2008, 37, 2735–2759. [Google Scholar] [CrossRef]
- Ezzahrioui, M.; Ould-Saïd, E. On the asymptotic properties of a nonparametric estimator of the conditional mode for functional dependent data. J. Nonparametr. Stat. 2008, 20, 3–18. [Google Scholar] [CrossRef]
- Laksaci, A. Convergence en moyenne quadratique de l’estimateur à noyau de la densité conditionnelle avec variable explicative fonctionnelle. Ann. Inst. Stat. Univ. Paris 2007, 51, 69–80. [Google Scholar]
- Laksaci, A.; Maref, F. Estimation non paramétrique de quantiles conditionnels pour des variables fonctionnelles spatialement dépendantes. Comptes Rendus Math. 2009, 347, 1075–1080. [Google Scholar] [CrossRef]
- Doob, J.L. Stochastic Processes; John Wiley and Sons: New York, USA, 1953. [Google Scholar]
- Kallabis, R.S.; Neumann, M.H. An exponential inequality under weak dependence. Bernoulli 2006, 12, 333–350. [Google Scholar] [CrossRef]
- Bosq, D. Linear Processes in Function Spaces: Theory and Applications; Lecture Notes in Statistics 149; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Ramsay, J.O.; Silverman, B.W. Applied Functional Data Analysis: Methods and Case Studies; Springer-Verlag: New York, USA, 2002. [Google Scholar]
- Ferraty, F.; Laksaci, A.; Vieu, P. Estimating some characteristics of the conditional distribution in nonparametric functional models. Stat. Inference Stoch. Process. 2006, 9, 47–76. [Google Scholar] [CrossRef]
- Ferraty, F.; Laksaci, A.; Vieu, P. Functional time series prediction via conditional mode estimation. C. R. Math. Acad. Sci. Paris 2005, 340, 389–392. [Google Scholar] [CrossRef]
- Cardot, H.; Crambes, C.; Sarda, P. Spline estimation of conditional quantiles for functional covariates. C. R. Math. Acad. Sci. Paris 2004, 339, 141–144. [Google Scholar] [CrossRef]
- De Gooijer, J.; Gannoun, A. Nonparametric conditional predictive regions for time series. Comput. Statist. Data Anal. 2000, 33, 259–257. [Google Scholar] [CrossRef]
- Araujo, A.; Gin, E. The Central Limit Theorem for Real and Banach Valued Random Variables; Wiley Series in Probability and Mathematical Statistics; John Wiley and Sons: New York, NY, USA; Chichester, UK; Brisbane, Australia, 1980; p. xiv+233.
- Mohammedi, M.; Bouzebda, S.; Laksaci, A.; Bouanani, O. Asymptotic normality of the k-NN single index regression estimator for functional weak dependence data. Commun. Stat. Theory Methods 2022, 33, 1–26. [Google Scholar] [CrossRef]
- Daoudi, H.; Mechab, B.; Belguerna, A. Asymptotic Results of a Conditional Risk Function Estimate for Associated Data Case in High-Dimensional Statistics. In Proceedings of the International Conference on Recent Advances in Mathematics and Informatics (ICRAMI), 2021; Conference Paper. Available online: https://ieeexplore.ieee.org/document/9585904.
Figure 1.
Sample of 35 functional covariates , spatially quasi-associated.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



