
Submitted:
23 July 2025
Posted:
23 July 2025
You are already at the latest version
Abstract
Chatbots, search engines and database query systems are invaluable sources of information for decision making processes in the data-driven world in which we live today. In this study, we explore the extent to which classical and quantum query systems can support future decisions, taken at a moment where the query service may be inaccessible and the decision has to be based solely on information collected in the past. We show that encoding information at the quantum level allows Query Systems to support future or delayed decisions. More precisely, Grover’s algorithm can be employed in order to extract the desired answer from a large superposition of question-answer pairs obtained through a single interrogation of the system. The method works best for binary answers and can be applied to queries encompassing hundreds or thousands of questions in one query. Extensions are possible if we allow more than one query to be addressed to the system. By comparison, a classical system would require hundreds or thousands of queries in order to offer the same level of support for delayed decisions.
Keywords:
query systems
; delayed decisions
; quantum parallelism
; Grover’s algorithm
1. Introduction
A Query System can serve as a theoretical model for a range of services or applications, including database query systems, search engines and generative AI chatbots or agents, to name a few. According to current trends [6], continuously improved chatbots are becoming an existential threat to search engines, as people prefer to formulate and refine their searches in a conversational tone, as part of a dialogue, rather than a plain sequence of keywords. In all of these scenarios, the user perceives the system as a "black box" or "oracle" that can receive queries and responds back with an appropriate answer.
Query systems spread over almost all service providing software and adapt to or are embedded into a variety of architecture. A few overview examples are given below. In enterprise resource planning (ERP) software, proposals for added on query systems with data processing features combine with large scale existing proprietary software, such as SAP [22]. For researchers, the development of systematic literature reviews, turns out to be a selective query system with a distributed data [1].
As query systems evolve to cover the stringency of modern business dynamics, query formulation evolves as well. The old and ubiquitous Structured Query Language (SQL) [4] becomes dynamically executed [19] and even proliferates into other standardized variants, such as the Graph Query Language (GQL) [5]. Also, depending on the data structure, the query procedure has to adapt. Blockchain data structures, while designed to prevent data tampering, need to be queried to check or retrieve information. Blockchain queries often trawl sequentially through the blockchain to find information. Therefore, attention has been given to improve query retrieval time by multi-level distributed query [12] or by enhancing the block chain structure with off-chain extensions which improve query efficiency [11].
In terms of architectures that contain data to be queried, the internet of things architectures pose new challenges to data querying solutions, as spacial data is located in devices, or else in cloud servers. As such, privacy of the query systems becomes an issue [23]. Spacial data query services are part of common applications, such as taxi dispatching applications, eHealth applications [24], where reverse k-nearest neighbour queries are employed [14], and both queries and answers are encrypted [25].
From the brief overview of the query applications landscape, it can be seen that quantum query systems is an untrodden path. By definition, a quantum query system will have to work in a different environment than the traditional Internet we know today. Quantum query systems require the support of a Quantum Internet, a qualitatively different infrastructure, with properties and attributes conferred by the laws of quantum mechanics and which are unavailable in classical networks [10]. A Quantum Internet will fundamentally alter the current paradigm of computation and efforts are made to design quantum computers that are efficient [8] and can support scalable distributed computations [9].
Quantum technologies show promising potential in important areas falling under the scope of query systems, such as database retrieval or AI-assisted decision-making. Quantum database retrieval systems can harness the principles of quantum mechanics to enhance computational efficiency and processing speed. The most typical example is Grover’s algorithm [7] that offers a quadratic speedup for unstructured database search tasks. A Quantum Query Language (QQL) is developed in [18] using a formalism based on quantum logic, in order to incorporate retrieval search into traditional database query processing. For a good complete reference exploring quantum information retrieval systems in detail, we suggest the book by Massimo Melucci [13].
Quantum approaches are also increasingly being integrated into AI-assisted decision-making processes. Quantum computing can process vast datasets more rapidly than classical systems, which is particularly beneficial for complex decision-making scenarios in fields such as finance, healthcare, and logistics. For example, researchers are exploring quantum algorithms like the Quantum Approximate Optimization Algorithm (QAOA) to optimize AI models, thereby improving decision-making under uncertainty with respect to bias and transparency [15]. Additionally, the combination of quantum computing and AI can facilitate real-time data analysis, enabling more informed and timely decisions in dynamic environments, such as Internet of Things (IoT) applications [16]. Researchers are also investigating quantum computing’s potential to unlock the capabilities of artificial intelligence applied to healthcare’s most complicated problems [17].
Furthermore, practical implementations of current query systems do not take into consideration the advantage of unconventional query settings, such as a delayed query answer. While indeed, the speed of query answering is an issue in most applications, delayed answering of a not yet defined query is an intriguing setting and will certainly find its niche of applications. In this case, the user is interested to retrieve an answer when the query system is not available. The user did have access to the query system in the past, but at a time when the question itself was not known. Thus, the setting of the delayed query system gives the user the capacity to prepare a “quantum offline” client for a future unknown query.
Now, indeed, what quantum query systems can offer as an enhancement to existing query systems, certainly depends on the availability of quantum devices and networks. The present study explores this unconventional capacity of quantum settings to add new features to query services.
Many algorithms, including quantum algorithms, can also be analyzed in a Query System model, where the complexity of the algorithm is measured in terms of the number of queries addressed to the black box it uses. In the case of quantum algorithms, the oracle is endowed with quantum properties, being able to handle multiple questions from the user in a single query, in the form of a quantum superposition state. In truth, some of the best known quantum algorithms to date can be expressed in this framework of a Query System employing a black box that can answer queries formulated in a certain way: Simon’s algorithm [21], Grover’s algorithm [7], the period-finding subroutine used in Shor’s factorization algorithm [20].
In this manuscript, the focus is not, however, on classical or quantum complexities of problems that can be formulated in the black-box paradigm. Our interest herein lies in exploring the extent to which the quantum computing paradigm can support delayed decisions in connection to Quantum Query Systems, a feature that Classical Query Systems do not possess, by definition. To be more precise, we refer to the following framework: a single query is made to the Query System containing the user’s question(s) and after a certain time, when the Query System is unavailable, the user has to make a decision based on the available information received as an answer to his query. The limitation to a single query may stem from practical considerations, such as the accessibility of the system to the user, the cost associated with querying the system, etc.
In a classical setting, the user may choose the most important query to submit to the system and hope that the information received in the answer is still relevant by the time the decision is made. In a quantum setting, however, the user may formulate a composite query, encompassing many different questions encoded together in a superposition state and try to extract from the superposition of answers received from the Quantum Query System the one that is most relevant at the time of decision making.
The remainder of the paper is organized as follows. Next section provides a more detailed, formal description of the Classical, respectively, Quantum Query Systems providing the framework of this investigation. In Section 3 we derive the theoretical results supporting the idea of delayed decisions in the context of Binary Quantum Query Systems. These results are particularized in a few concrete examples experimentally validated using Qiskit, for up to 20 qubits, in Section 4. A generalization of our results to Non-Binary Query Systems is developed in Section 5. Finally, conclusions are presented in Section 6.
2. Classical vs Quantum Query Systems
A Classical Query System is, by definition, a service (usually provided by a server) through which users can interrogate or query the system in order to receive answers or information that is useful to the user, for example, to help with some decision-making process. Some concrete examples of such systems are a Database Query System, in which users can ask for information related to a particular record in the database, or an AI agent, that has been trained to provide answers to queries that are usually formulated in a specific domain of knowledge. For concreteness, we will henceforth assume that the Query System is modeled as a look-up table that accepts an index as input and produces the corresponding answer as output. Naturally, for a user-friendly experience, there may be a pre-processing step in charge of refining the user query (formulated in a natural language) into an actual index in the look-up table and a post-processing phase in which the output is again translated (using natural language processing techniques) into a form that is easily understandable and appealing to the user. Figure 1 depicts the general schematics of such a Query System.
A Quantum Query System (QQS) can be seen as an extension of a Classical Query System by harnessing the most important property of quantum information systems, namely quantum parallelism. Thus, besides being able to respond to single questions, just like a Classical System, a Quantum Query System can deal with multiple questions submitted simultaneously. As a trivial example, just to illustrate the concept, let us assume that a user may be interested in finding the answers to three questions: "Is the Internet fast?", "Do I need to buy bread today?" and "How is my friend feeling?". If the user has access to a Classical Query System, then they have to submit three queries (one corresponding to each question), that the pre-processing stage may translate into three indices, say 00, 10 and 11. Then the system may look up the answers and reply 1 (meaning "Fast") for the first question, 0 (meaning "No") to the second question and 0 (meaning "Happy") to the last question. However, if the user has access to a Quantum Query System, then they can formulate a single query encompassing all three questions in the following way:
When the Quantum Query System receives the above query as input, the answering circuitry produces a superposition in which each answer is appended to the corresponding question:
Since any quantum circuit has to be reversible, the inputs to the QQS have to be preserved as part of the output, as shown in Figure 2. Thus, the top n qubits (labeled as x), which encode the question index, appear unchanged at the output. The situation is different with the bottom m qubits, which are reserved for producing the answer . The bitwise operation between the bottom input y and is designed to maintain reversibility. By setting y to 0, the quantum circuitry of the QQS will produce the answer to question x (labeled ) in the bottom m qubits of the output. In the case of the simple example described above, and .
If the Query System is available without any interruptions and is guaranteed to service any user query at the moment the user needs an answer, then the Quantum System does not offer any advantage over a Classical one. However, quantum parallelism may help in situations where the user anticipates that access to the Query System will not be possible in the future, for example, because of the geographical location of the user at that point, due to a particular task that the user has to accomplish. The user can prepare in advance with all the information that will be needed, by querying the system repeatedly until all required answers have been provided. If the number of queries is large, this may incur a high cost for the user. Therefore, in the following section, we will investigate the scenario in which the user submits a single query to the QQS, a query that encompasses all possible questions for which the user may need an answer, in order to complete the future task.
It is important to emphasize that, at the moment of query submission, the user is ignorant as to which particular piece of information (i.e. answer) will be needed to accomplish the task. The reply from the QQS will come in the form of a large superposition, similar to the one in Equation 2, with as many terms as the number of questions and the answer to each question appended to the corresponding question index. We examine next the extent to which quantum information processing can help in order to extract the desired answer from the superposition of all answers, at the (future) moment when the user knows exactly which particular answer is helpful for the task at hand.
3. Binary Quantum Query System with Delayed Decisions
For simplicity, let us assume that the Quantum Query System provides only binary answers ("Yes/No", "Fast/Slow", "Happy/Sad", etc.), such that parameter m from Figure 2 is set to 1. The possible generalization to higher values will be discussed in Section 5. The value of n, on the other hand, is left unrestricted. Consequently, if the query state space spans n qubits, the user can formulate a query that encompasses different questions, encoded in the following superposition state:
When given the above state as input, the Quantum Query System will produce the following output:
where represents the binary answer to the question with index x. Now, without loss of generality, suppose that after a certain time following the receipt of the answer state from the QQS, the user realizes that the useful answer that needs to be extracted from state is the one to the question with index . A direct measurement of state in the computational basis has a small chance (only ) of revealing the sought after . Consequently, the amplitude of the target index 0 has to be increased relative to the amplitudes of the other terms in the superposition, through the use of Grover’s algorithm [2]. The steps of the algorithm, particularized for our specific problem, are given below.
The two operators used in every iteration of Algorithm 1 are and . Operator acts only on the target states (the terms in the superposition that need to have their amplitudes increased) and rotates their phase by radians. Operator , on the other hand, acts on all basis states of the -qubit ensemble to which it is applied and rotates all of them by radians around the average amplitude of all basis states.
| Algorithm 1 Modified Grover’s Algorithm to extract the desired answer |
|
A flow chart presenting all steps of our approach in a visual form appears in Figure 3. In Phase I, the user queries the system with a superposition of all questions that are deemed relevant to any decision taken in the near future and stores the superposition of answers received from the QQS in a quantum register. In Phase II, which takes place when the Quantum Query System is offline or unaccessible to the user, the iterations in Grover’s algorithm can be used to boost the amplitude of the desired term (the one encoding the answer to the relevant question for the decision to be made), such that the final measurement reveals the sought-after answer with good probability.
One crucial element that separates Algorithm 1 above from a typical application of Grover’s algorithm is the initial state . Usually, there is a uniform distribution of amplitudes over all basis states in the initial superposition, such that the target state(s) have the same initial amplitude as any of the other (non-target) basis states. Boyer et al. [3] showed that, starting from a uniform initial distribution of amplitudes, the optimal number of iterations after which the probability of measuring a target state is maximal is , where r is the number of target states from the total N.
However, the distribution of amplitudes in , which is the same state as from Equation 4, is not uniform. The reason is simply because each of the questions , has only one answer, either or, but not both. In other words, although is a state vector in a -dimensional space and should, therefore, be described by a linear combination of basis states, only half of them have non-zero amplitudes, the ones corresponding to actual answers. For example, if the answer to question is 1 (i.e. ), then the term will not appear in the superposition state . Since, for each question index , only one answer is possible, the entire superposition will consist of terms only, each with amplitude .
When acting on target states, operator has to be designed such that it rotates both terms corresponding to a particular question index. Assuming again, for concreteness, that we are interested in retrieving from the superposition, has to rotate phases of both the term and the term, since we do not know which one contains the actual answer. Therefore, matrix is a diagonal matrix, where the first two elements on the main diagonal are and the remaining elements on the main diagonal are 1:
The second operator is the standard "inversion about the average" operator, defined on qubits as follows:
The key questions now are how many iterations T are needed in Algorithm 1 in order to amplify the amplitudes of the target states as much as possible and what is the probability of retrieving the desired information (i.e. ) from the final measurement? As mentioned above, the analysis due to Boyer et al. [3] is not applicable, since the initial distribution of amplitudes is not uniform over all basis vectors. On the other hand, the case of arbitrary initial amplitudes in Grover’s algorithm was studied by Biron et al. [2]. They show that the optimal measurement time T is the same, asymptotically, in both scenarios (uniform distribution of amplitudes or arbitrary distribution) and is on the order of , where r is the number of target states and N is the total number of states. Furthermore, they find that T depends only on the initial average amplitudes of the target and non-target states.
Consequently, the time complexity of Algorithm 1 is , where n represents the number of qubits used to encode the index of a question. In terms of the space complexity, since the algorithm employs n qubits for the question part and one qubit for the binary answer, there are qubits used in total. Note that these bounds are derived under the assumption of an ideal, error-free environment with perfect quantum operations. Any ancillary qubits required in a practical implementation for error-correcting purposes are not taken into consideration when stating the above complexities.
Given these requirements for the time and space taken by Algorithm 1, we will show in this section that the probability of obtaining the answer to the desired question is
compared with the probability that a classical system has to “guess” the correct question ahead of time. Since there is no actual processing of the query answer, the running time of the classical algorithm would be constant.
Let us apply the results in [2] to our particular initial distribution of amplitudes in state . In our instance of Grover’s algorithm, the total number of states is and the number of target states (these are and ). The initial (at ) average of the amplitudes for the target states is the average of and 0, since the question we are interested in has only one actual answer (labeled ) and consequently, the state corresponding to the binary complement of will have amplitude 0 in the initial superposition . We denote this average of amplitudes of target states at moment as:
Similarly, there are non-target states, only half of which have a non-zero amplitude in the initial state . Therefore, the initial average amplitudes of the non-target states is:
the same as for the target states. Based on the ratio , Biron et al. [2] have determined the optimal measurement time to be:
which, in our case, becomes:
To give a couple of concrete examples, if , which means that the initial state contains 8 non-zero terms corresponding to 8 questions and their answers, the value of T is approximately . It follows that two iterations of Algorithm 1 are enough to boost the amplitude of the target state to a maximum value before starting to decrease again, if the algorithm is continued. If 10 qubits are used to encode a question index, then state will span 1024 questions with corresponding answers, which requires iterations in order for the amplitudes of the target states to reach their first maximum.
In their analysis, Biron et al. [2] also provide an upper bound on the probability of measuring a target state at the end of the algorithm, after the optimal number of iterations T has been reached. This bound only depends on the variance of the initial amplitudes of the non-target states and is given in Equation 12 below:
Recall that, for an arbitrary value of n, there are a total of non-target states, only half of which have a non-zero amplitude in the initial superposition . Consequently, in our case, the variance of the initial amplitudes of non-target states can be calculated as:
Substituting this in Equation 12, the maximum probability of measuring a target state becomes:
The first observation we can formulate about the result above is that the probability of seeing one of the target states through the final measurement can always be raised to more than , regardless of the value of n, if we stop Algorithm 1 after an optimal number of iterations. However, this upper bound is not as good a result as it may look at the first glance. And the reason is that we have two target states whose amplitudes are increased by the algorithm, one corresponding to the actual answer and the second one corresponding to the bit complement of the actual answer . Consequently, it is crucial to see how much each of these two target states is amplified in the end, such that when the final measurement is performed, we obtain the actual answer and not its complement. We do expect that the term will have a higher probability of being measured compared with , since the latter starts with a zero amplitude, but the subsequent analysis will make things more precise.
Let us denote by the amplitude of the term (the term we are interested in), as it appears in the state , at the end of Algorithm 1. Similarly, is the amplitude of the term (the term carrying the bit complement of the answer) in the same superposition state . At any time t during the execution of Algorithm 1, the amplitude of a target state can be expressed based on the average amplitude of all target states at that moment :
As the analysis in [2] shows, the deviation from the average for a particular target state i, labeled as in the equation above, is a time-independent quantity, meaning that it remains constant throughout the execution of Algorithm 1. Consequently, we can determine and for our two target states, based on the information we have at the moment :
Based on the calculated values for and , we can now express the amplitudes of the target states at time as follows:
Subtracting the two equalities above gives us a first equation directly relating and :
A second relation can be obtain from Equation 14 that expresses the maximum probability of measuring a target state. Since is attained at and the amplitudes of the two target states at that moment are and , respectively, it follows that:
Equations 18 and 19 yield the following two possible sets of solutions for and :
respectively,
The dual set of solutions for and reflects the cyclical nature of Grover’s algorithm and, implicitly, that of our customized version. The amplitudes of the target states are amplified by each iteration in Algorithm 1 until they reach a point where the probability of measuring one of them is maximum. This optimal moment for measuring the superposition state is labeled as T and its formula is given in Equation 11. The values of and at moment are given in the first set of solutions (Equation 20). We note that, at this point, both and are positive and , which means that we have a higher chance of obtaining the actual answer than its complement from the final measurement.
However, if the algorithm is not stopped at time and we continue applying its iterations, then and will start decreasing, become negative and reach a point where they are big enough in absolute value in order for the probability to be reached again. This moment corresponds to the second set of solutions (Equation 20). However, at this point, and therefore, the probability of seeing instead of is higher. This periodic behavior, where the amplitudes and evolve continuously between the values in Equation 20 and those in Equation 21, is exhibited for as long as the iterations in Algorithm 1 are unfolding. For concreteness, we analyze next the results obtained for some particular values of n.
4. A Few Concrete Examples
Consider first the case where . We mentioned already in the previous section that in this case, Algorithm 1 acts on a four-qubit space, three of which encode the question index and the fourth one stores the answer. Therefore, the initial superposition contains 8 non-zero terms corresponding to 8 questions with their answers. According to the calculations, the optimal moment to measure the superposition state is at time . At this time, the probabilities of measuring the answer bit , respectively its complement are bounded by:
Since we cannot execute fractions of iterations, the best we can do is stop the algorithm after two iterations. Applying the operators and on the initial state two times will boost the values of and to and , respectively. This corresponds to a probability of measuring of approximately and a probability of getting in the final measurement. These values are very close to the bounds obtained in Equation 22.
Continuing the iterations of Algorithm 1, and begin to decrease and at time (i.e. after 6 iterations), their values are very close to the theoretical bounds derived in Equation 21. More precisely, and , giving a probability of about to measure and a probability to observe in the measurement. We note that the probabilities of obtaining , respectively have effectively swapped, compared with the situation after two iterations. Nevertheless, the two probabilities combined are again very close to the maximum theoretical probability of
just as it happened at moment . This cycle of approximately four iterations between the moments when the probability of measuring a target state is maximum may continue indefinitely. In our particular case, the next such moment is after 10 iterations, when the amplitudes of and are again positive and close to the bounds calculated in Equation 22. In general, the exact moments when the amplitudes of and are at a maximum (in absolute value) is given by the formula:
If , taking k to be and 2 yields the following approximate values for T: , and , respectively. Given the fact that, from these three values, the middle one is closest to an integer, it is not surprising that the best overall probability to measure a target state is achieved after 6 iterations. Consequently, if we decide to stop the algorithm after 6 iterations instead of 2, in order to take advantage of the best possible probabilities, we just need to remember that the most likely outcome is the opposite of the actual answer and interpret the result obtained accordingly.
Increasing the value of parameter n allows us to store a significantly larger number of questions and their answers in the initial state . On the other hand, the higher the value of n, the smaller the difference between and becomes, as can be seen from Equation 18. This means that the probabilities of obtaining , respectively , at the end of Algorithm 1 will get closer together as the number of qubits increases. Therefore, after a certain threshold, the results obtained will become statistically irrelevant, as very little information about the sought-after answer can be extracted through the final measurement.
In the case of , for example, the quantum register on which Algorithm 1 is applied consists of 11 qubits (including the answer qubit) and can therefore hold up to 1024 different question-answer pairs. However, the confidence that the measurement at the end yields the actual answer to the question of our choice (and not its complement) also reduces significantly. According to Equations 20, the probability of retrieving is approximately , while the probability of seeing after the measurement is a little lower, at . These probabilities correspond to the moment when is reached, which, for , happens for the first time at .
4.1. Experimental Simulations
The theoretical results calculated above are confirmed by the practical experiments conducted on a quantum simulator using Qiskit. We have conducted five rounds of experiments, for , , , and . This means that the correct answer has to be retrieved from a superposition of 8, 32, 256, 65536 and 1048576 questions, respectively. Since the answer is binary (encoded on a single qubit) Algorithm 1 acts on a vector space spanned by 4, 6, 9, 17 and 21 qubits, respectively. In all experiments, we seek to retrieve the answer to question with index 0, which is set to 0 in the initial superposition (). The reason for stopping at 21 qubits is twofold. Firstly, it is clear from the theoretical analysis that the difference between the probability of obtaining the correct answer and the probability of obtaining the bit complement of the correct answer all but vanishes for larger values of n. Secondly, the simulator itself cannot deal with a higher number of qubits and runs out of memory, since the number of iterations in the modified Grover algorithm becomes too computationally intensive.
For all five values of n, we present the final measurement statistics as probabilities of obtaining term (correct answer), (binary complement of the correct answer) and any other term in the superposition (corresponding to the case where Algorithm 1 fails to fish out the desired question). Since the quantum simulator only returns the number of counts for each possible measurement outcome, we computed the probabilities by dividing each count value to (the total number of times each experiment was repeated). The results are presented in Figure 4 and Figure 5. We mention here that the quantum simulator assumes an ideal, error-free environment, where all operations involved, from the preparation of the initial state, all quantum gates applied and the measurement operation at the end are not affected by noise, decoherence or any other errors. The optimal number of Grover iterations required to obtain the results in Figure 4 and Figure 5 are for , for , for , for and finally, for .
We first note that in the case of , the experimental values observed for and match the probabilities of measuring () and () calculated in the previous section. Secondly, as expected, when the number of qubits increases, it becomes more difficult to separate the correct answer (first bar in all five graphs) from the incorrect answer (second bar in all graphs). This separation can be improved, if we relax the constraint that only one query to the system is allowed. Figure 6 shows the improvement in the confidence that the result of the measurement is the sought-after answer if more than one copy of the initial superposition state (the response from the query system) is available.
Note that in the case where two samples are available, the probability of obtaining the correct answer includes the case where both samples are measured as as well as the cases where one measurement yields and the other one fails to retrieve the desired question index. Similarly, the third bar in the graph (labeled as “Inconclusive”) includes the case where both measurements fail to fish out the desired question index as well as the situation where one measurement yields (the correct answer) and the other measurement yields (the binary complement of the correct answer).
For the cases where three samples are available, a successful measurement (first bar) includes the following scenarios: at least two measurements yield or, only one measurement give the correct answer and the other two fail to retrieve the correct question index. Again, we notice that the improvement in the separation between the first two bars in each graph decreases with the value of n, but increases with the number of samples.
A general theoretical formula describing the expected probability of successfully measuring the component, if k samples are available, is given below:
In the above formula, variable denotes the probability of obtaining in the final measurement step of Algorithm 1, variable denotes the probability of measuring and consequently, represents the cumulative probability of fishing out any of the other terms in the superposition. The formula is derived based on a simple majority approach, meaning that, in order for the procedure to be considered successful, more measurements (out of the total k) have to collapse onto the correct answer than onto the binary complement of it .
For example, if two samples of the initial superposition received from the QQS are available (that is, ), then Equation 25 becomes
Indeed, with two measurements, the procedure is considered successful if any of the two measurements retrieves (probability p) and the other one is failing to retrieve the sought-after question-answer pair (probability ) or both measurements are successful (term in the above formula). In general, increasing the value of k leads to higher success probabilities (as one would expect), but at the same time reduces the advantage of the quantum approach over the classical approach, since with more queries allowed to be sent to the Query System, the classical success probability increases as well.
The particular cases analyzed in this section suggest that quantum computation techniques can indeed support delayed-decision scenarios within certain parameters. The main issue is finding the optimal trade-off between the capacity of the quantum register (i.e. the number of question-answer pairs that can be stored in advance in the quantum register through a superposition state) and the confidence of the final measurement to yield the actual answer to the question chosen by the user at a later time. The values obtained above tend to indicate that a quantum register with less than a dozen qubits is still capable of storing hundreds of answers to different queries and at the moment when a particular answer is needed, Algorithm 1 can provide that answer with a good probability. Furthermore, this probability can always be increased (sometimes substantially), if two or three copies of the quantum register are available. Naturally, this assumes that the user has queried the QQS two or three times with the same superposition of questions.
We close this section devoted to experimental validations of delayed decisions in Quantum Query Systems by addressing the issue of quantum errors affecting the operations in Algorithm 1. Any quantum machine in existence today struggles with the plague of quantum errors affecting their operations. The particular type of errors occurring during a certain computation depend entirely on the quantum hardware or the engineering details through which a quantum computer chooses to implement a qubit (in other words, the physical embodiment of the qubit). The error rate in quantum gates seems to be the major obstacle towards scalable quantum computing, but the technology is still in its infancy and future advances will probably improve this aspect significantly.
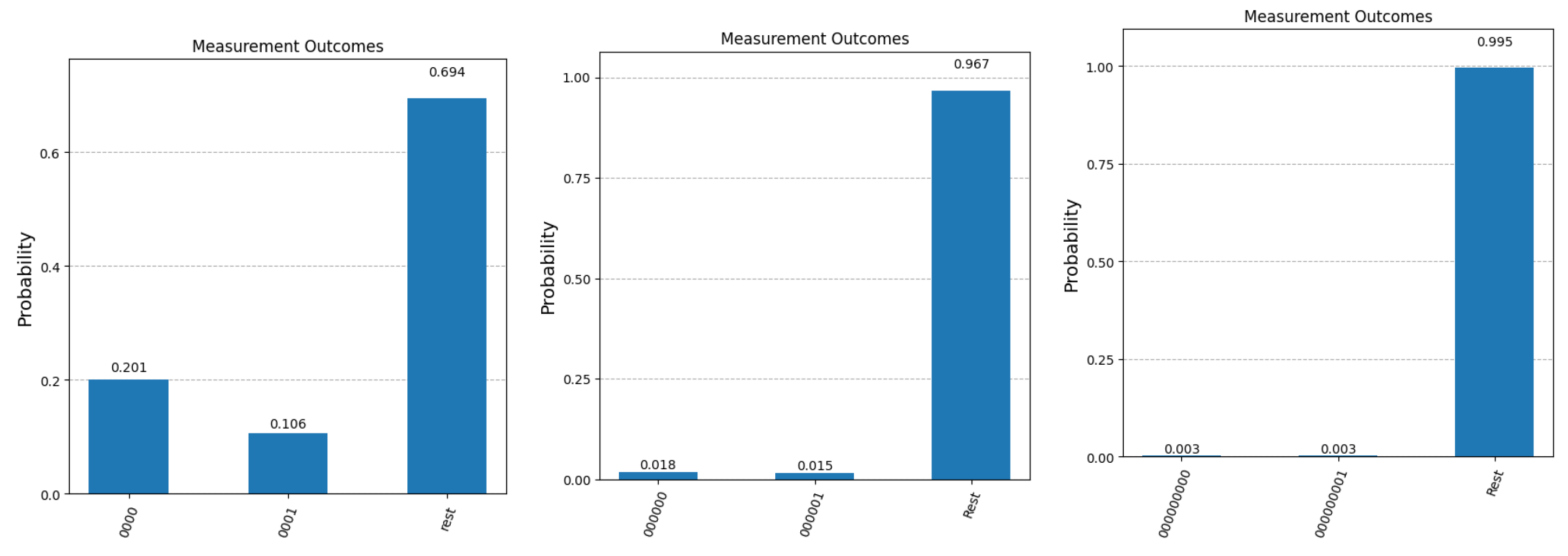
To illustrate the impact of quantum errors on the steps of our modified Grover algorithm, we have run a few experiments on one of the actual quantum machines that are available on the IBM Quantum Platform. Figure 7 presents the measurement statistics in the case of 4 qubits (), 6 qubits () and 9 qubits (), respectively. All experiments were run for 8192 shots, the maximum number allowed by IBM on their quantum machines. As expected, the results that are closer to the simulator were obtained for the smaller number of qubits (4). For higher number of qubits, the number of iterations required to retrieve the correct answer increases, leading to an accumulation of errors. This can be seen in the last two graphs, where the number of terms in the superposition also increases significantly (64 terms for and 512 terms for ), resulting in the leveling of amplitudes across all terms in the superposition. If in the first graph, we still have a meaningful difference between the two bars depicted, this difference is drastically reduced in the middle graph and disappears completely in the third one. These experiments accurately reflect the current status of practical quantum computing, where scalability remains the main issue. Nevertheless, we remain confident that future developments in quantum hardware will significantly improve this crucial aspect.
4.2. Acting on a Smaller Subspace
Throughout our investigation so far, the quantum operators in Algorithm 1 always act on the entire Hilbert space spanned by the qubits encoding the question index and its binary answer. But because each question can only have one answer (either 0 or 1), the initial state is a superposition of terms (from the possible ), the other half having a zero amplitude. Since we do not know exactly which terms are present in the initial superposition and which are not (we do not know the answers to any of the questions), an alternative idea would be to act only on the n qubits that make up the question index.
From the point of view of Algorithm 1, this means that operators and can be decomposed into a tensor product between an operator acting on the n qubits representing the question index and the identity operator acting on the answer qubit. The phase shift operator is not affected by the fact that we now act only on n qubits instead of all . Assuming again, for concreteness, that we want to extract from the initial superposition state, the operator that rotates the phase of basis vector tensored with the identity operator coincides with the operator that flips the sign of both and basis vectors:
However, the situation is different with the "inversion about the average" operator : the -qubit version, given in Equation 6, is different from the n-qubit version tensored with identity:
Since half of the elements in the matrix above are 0, the resulting operator is generally less effective at amplifying the amplitude of the target state, compared with the operator employed in Algorithm 1, especially if the number of iterations required is not very small. In addition, operator from Algorithm 1 always produce the same results, regardless of which answers are 0 and which are 1, while the performance of the operator above is influenced by which terms appear in the initial superposition state. To exemplify, suppose that the initial state on which Algorithm 1 acts upon is a superposition of eight question/answer pairs as follows:
Acting on all four qubits with Algorithm 1, will increase the amplitude of term from the initial value of to in just two iterations. On the other hand, if we act only on the first three qubits (representing the question index), then after two iterations the amplitude of term reaches only .
5. Non-Binary Quantum Query Systems
We conclude our investigation into Quantum Query Systems and the extent to which they can be used to support delayed decisions by addressing the issue of whether a QQS can produce non-binary answers as response to questions. In other words, we examine next the generalization to more than one qubit being used to encode the answer to a question. The first step in this direction would be to assume that the answer to any question is a vector living in a four-dimensional space spanned by two qubits. If we still consider that an n-qubit register is used to encode the question index, then we reach a total number of states of from which are target states, since there are now four possible answers to a question.
As it turns out, the average of amplitudes of target states at time is still equal to the initial average amplitudes of the non-target states:
Consequently, the optimal measurement time (i.e. the number of iterations of Grover’s algorithm that maximizes the probability of picking up a target state) is still , unchanged from the case of binary answers, with the exact formula given in Equation 11. Furthermore, based on the variance of the initial amplitudes of non-target states:
the upper bound on the probability of measuring a target state after an optimal number T of iterations of Grover’s algorithm have been performed is:
According to this result, the chance of obtaining one of the target states in the final measurement is always greater than , with significantly larger values being possible for small values of n, which means a relatively small number of questions that can be asked simultaneously. The result above can easily be generalized to an arbitrary number k of qubits used by a Quantum Query System to encode the answer to a question:
As expected, the more qubits are used to detail the response to a question, the more difficult it is to increase the magnitude of the target states in the increasingly larger superposition returned by the Quantum Query System. Therefore, in practice, the number of qubits used to encode answers to questions should be kept to a minimum, unless multiple copies of the initial superposition state obtained from the QQS are available through multiple interrogations.
6. Conclusions
Quantum superposition of states is the key quantum mechanical property allowing quantum algorithms to outperform their classical counterparts or endowing quantum cryptographic protocols with levels of security that are unattainable for protocols implemented based on the laws of classical physics. In this manuscript, we have investigated the potential advantages that a quantum mechanical implementation can bring to the field of generic Query Systems by harnessing the massive parallelism implicit in quantum superpositions.
Our study has revealed that Quantum Query Systems have the advantage over classical systems in situations where the number of queries is severely limited and continuous access to the server or oracle is not always possible. Under these adverse conditions, a quantum strategy can be formulated to take advantage of quantum parallelism and extract the desired information from a pre-stored superposition at a time when querying the system is not possible. The strategy works best with binary answers, but may be extended to answers encoded into several qubits, if we also allow for several queries to be sent to the oracle.
Additionally, our investigation has revealed that the best strategy for successfully retrieving the desired answer from the superposition of question-answer pairs is to apply Grover’s algorithm on the entire Hilbert space where the superposition is defined and not just on the subspace spanned by the qubits encoding the question indices (without acting on the answer qubits).
Supplementary Materials
The code used in the experimental simulations conducted in Section 4.1 is available at https://github.com/madi12c/Quantum-Delayed-Decision-Qiskit-Experiments/.
Author Contributions
Conceptualization and methodology was developed by both authors. M.N. performed the practical experiments validating the theoretical results. M.N. wrote most of the main manuscript and prepared Figure 2. N.N. researched the relevant literature, wrote part of the introductory section and prepared Figure 1. Both authors reviewed the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Not applicable to this article as no datasets were generated or analyzed during the current study.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Inteligence |
| ERP | Enterprise Resource Planning |
| GQL | Graph Query Language |
| QAOA | Quantum Approximate Optimization Algorithm |
| QQL | Quantum Query Language |
| QQS | Quantum Query System |
| SQL | Structured Query Language |
References
- Badami, M. , Benatallah, B., Baez, M.: Adaptive search query generation and refinement in systematic literature review. Information Systems 117, 102231 (06 2023). [Google Scholar]
- Biron, D. , Biham, O., Biham, E., Grassl, M., Lidar, D.A.: Generalized Grover search algorithm for arbitrary initial amplitude distribution. In: Williams, C.P. (ed.) Quantum Computing and Quantum Communications. pp. 140–147. Springer Berlin Heidelberg, Berlin, Heidelberg (1999). [Google Scholar]
- Boyer, M. , Brassard, G., Hoeyer, P., Tapp, A.: Tight bounds on quantum searching. In: Proceedings of the Workshop on Physics and Computation: PhysComp ’96. pp. 36–43. IEEE Computer Society Press, Los Alamitos, CA, 1996 (1996), http://xxx.lanl.gov/abs/quant-ph/9605034.
- Chamberlin, D. : Early history of sql. Annals of the History of Computing, IEEE 34, 78–82 (10 2012).
- Crowe, M. , Laux, F.: Implementing the draft graph query language standard the financial benchmark. In: International Conference on Advances in Databases, Knowledge, and Data Applications. Athens, Greece (07 2024). [Google Scholar]
- Grant, N. , Metz, C.: A new chat bot is a ‘Code Red’ for Google’s search business. The New York Times (22),https://www.nytimes.com/2022/12/21/technology/ai-chatgpt-google-search.html. December 2022.
- Grover, L.K. : A fast quantum mechanical algorithm for database search. In: Proceedings of the 28th Annual ACM Symposium on the Theory of Computing. pp. 212–219. Philadelphia, Pennsylvania, 22–24 May 1996 (1996).
- Gyongyosi, L. , Imre, S.: Circuit depth reduction for gate-model quantum computers. Scientific Reports 10, 11229 (07 2020).
- Gyongyosi, L. , Imre, S.: Scalable distributed gate-model quantum computers. Scientific Reports 11, 5172 (02 2021).
- Gyongyosi, L. , Imre, S.: Advances in the quantum internet. Communications of the ACM 65, 52–63 (08 2022).
- Li, S. , Wang, J., Ji, W., Chen, Z., Song, B.: A hybrid storage blockchain-based query efficiency enhancement method for business environment evaluation. Knowledge and Information Systems pp. 1–29 (06 2024).
- Matani, A. , Sahafi, A., Broumandnia, A.: Improving query processing in blockchain systems by using a multi-level sharding mechanism. The Journal of Supercomputing 80, 1–31 (03 2024).
- Melucci, M. : Introduction to Information Retrieval and Quantum Mechanics. Springer Berlin, Heidelberg (December 2015).
- Qiao, B. , Ma, L., Chen, L., Hu, B.: A PID-based k-NN query processing algorithm for spatial data. Sensors 22, 7651 (10 2022).
- Quantum News: Quantum Computing and AI Integration Revolutionizing Decision-Making. Quantum Zeitgeist (24), https://quantumzeitgeist.com/quantum-computing-and-ai-integration- revolutionizing-decision-making/. September 2024.
- Raparthi, M. , Nimmagadda, V.S.P., Sahu, M.K., Gayam, S.R., Pattyam, S.P., Kondapaka, K.K., Kasaraneni, B.P., Thuniki, P., Kuna, S.S., Putha, S.: Real-Time AI decision making in IoT with Quantum Computing: Investigating & Exploring the Development and Implementation of Quantum-Supported AI Inference Systems for IoT Applications. Internet of Things and Edge Computing Journal 1(1), 18–27 https://thesciencebrigade.com/iotecj/article/view/130.
- Research News: How quantum computing will affect artificial intelligence applications in healthcare. Lerner Research Institute (24), https://www.lerner.ccf.org/news/article/?title=+How+quantum+ computing+will\+affect+artificial+intelligence+applications+in+healthcare+\&id=79c89a1fcb93c39e832 1c3313ded4b84005e9d44. 2024 July.
- Schmitt, I. : Quantum query processing: Unifying database querying and information retrieval (2006), https://api.semanticscholar.org/CorpusID:55578861.
- Shaik, B. , Chemuduru, D.: Dynamic SQL, pp. 169–181 (10 2023).
- Shor, P.W. : Polynomial-time algorithms for prime factorization and discrete logarithms on a quantum computer. Special issue on Quantum Computation of the SIAM Journal on Computing 26(5), 1484–1509 (October 1997).
- Simon, D.R. : On the power of quantum computation. Special issue on Quantum Computation of the SIAM Journal on Computing 26(5), 1474–1483 (October 1997).
- Tkachenko, A. , Chernyshov, M. Using the power query system for processing and data mining SAP ERP. E3S Web of Conferences 474 (01 2024.
- Zhang, S. , Ray, S., Lu, R., Guan, Y., Zheng, Y., Shao, J.: Efficient and privacy-preserving spatial keyword similarity query over encrypted data. . IEEE Transactions on Dependable and Secure Computing PP, 1–16 (01 2022). [Google Scholar]
- Zheng, Y. , Lu, R, Shao, J.: Achieving efficient and privacy-preserving k-NN query for outsourced eHealthcare data. Journal of Medical Systems 43 (03 2019.
- Zheng, Y. , Lu, R., Zhang, S., Guan, Y., Wang, F., Shao, J., Zhu, H.: Prknn: Efficient and privacy-preserving reverse k-NN query over encrypted data. IEEE Transactions on Dependable and Secure Computing PP, 1–16 (01 2022). [Google Scholar]
Figure 1.
General Schematics of a Query System modeled as a look-up table that accepts an index as input and produces the corresponding answer as output. For a user-friendly experience, there may be a pre-processing step in charge of refining the user query (formulated in a natural language) into an actual index in the look-up table and a post-processing phase in which the output is again translated (using natural language processing techniques) into a form that is easily understandable and appealing to the user.
Figure 1.
General Schematics of a Query System modeled as a look-up table that accepts an index as input and produces the corresponding answer as output. For a user-friendly experience, there may be a pre-processing step in charge of refining the user query (formulated in a natural language) into an actual index in the look-up table and a post-processing phase in which the output is again translated (using natural language processing techniques) into a form that is easily understandable and appealing to the user.

Figure 2.
Inputs and Outputs of a Quantum Query System. Since any quantum circuit has to be reversible, the inputs to the QQS have to be preserved as part of the output. Thus, the top n qubits (labeled as x), which encode the question index, appear unchanged at the output. The situation is different with the bottom m qubits, which are reserved for producing the answer . The bitwise operation between the bottom input y and is designed to maintain reversibility. By setting y to 0, the quantum circuitry of the QQS will produce the answer to question x (labeled ) in the bottom m qubits of the output.
Figure 2.
Inputs and Outputs of a Quantum Query System. Since any quantum circuit has to be reversible, the inputs to the QQS have to be preserved as part of the output. Thus, the top n qubits (labeled as x), which encode the question index, appear unchanged at the output. The situation is different with the bottom m qubits, which are reserved for producing the answer . The bitwise operation between the bottom input y and is designed to maintain reversibility. By setting y to 0, the quantum circuitry of the QQS will produce the answer to question x (labeled ) in the bottom m qubits of the output.
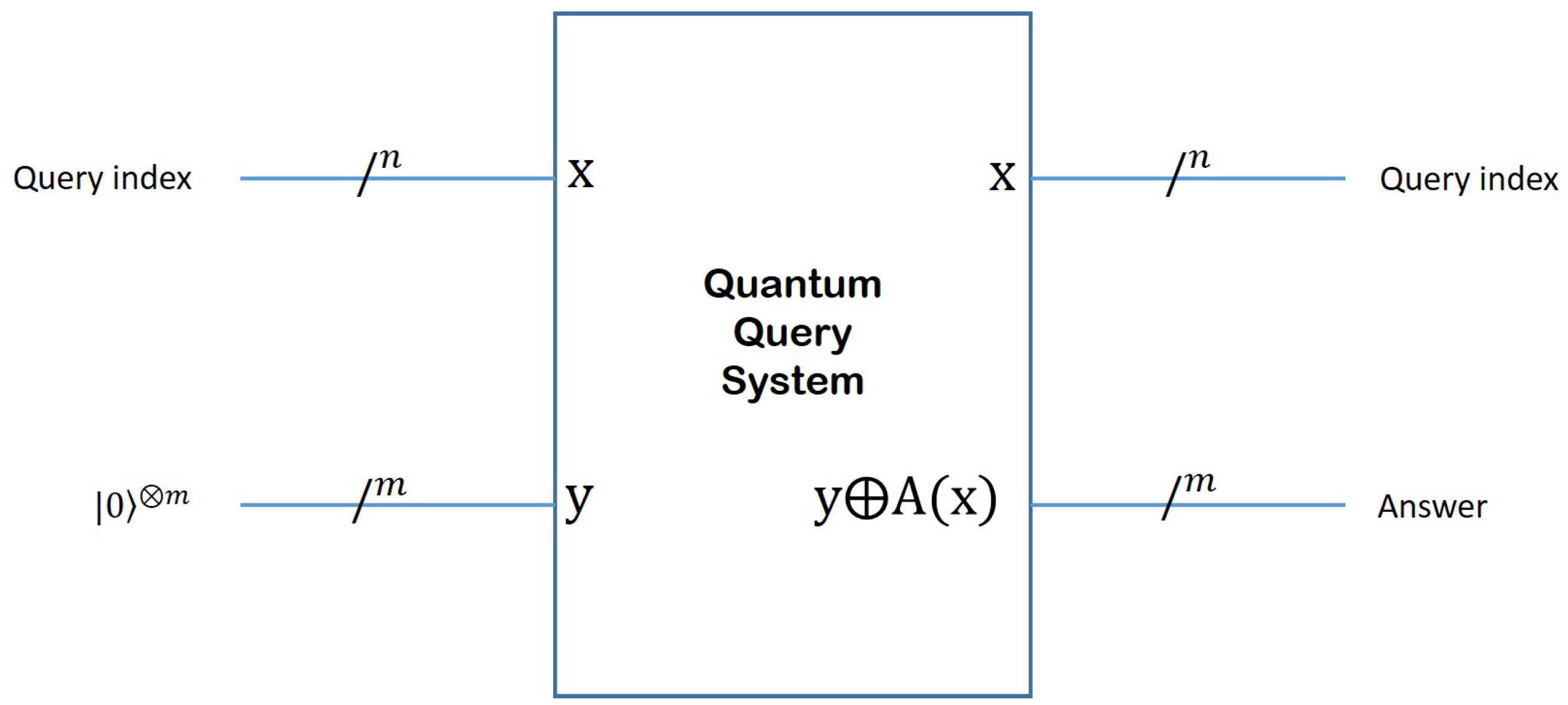
Figure 3.
In Phase I, the user queries the system with a superposition of all questions that are deemed relevant to any decision taken in the near future and stores the superposition of answers received from the QQS in a quantum register. In Phase II, which takes place when the Quantum Query System is offline or unaccessible to the user, the iterations in Grover’s algorithm can be used to boost the amplitude of the desired term (the one encoding the answer to the relevant question for the decision to be made), such that the final measurement reveals the sought-after answer with good probability.
Figure 3.
In Phase I, the user queries the system with a superposition of all questions that are deemed relevant to any decision taken in the near future and stores the superposition of answers received from the QQS in a quantum register. In Phase II, which takes place when the Quantum Query System is offline or unaccessible to the user, the iterations in Grover’s algorithm can be used to boost the amplitude of the desired term (the one encoding the answer to the relevant question for the decision to be made), such that the final measurement reveals the sought-after answer with good probability.
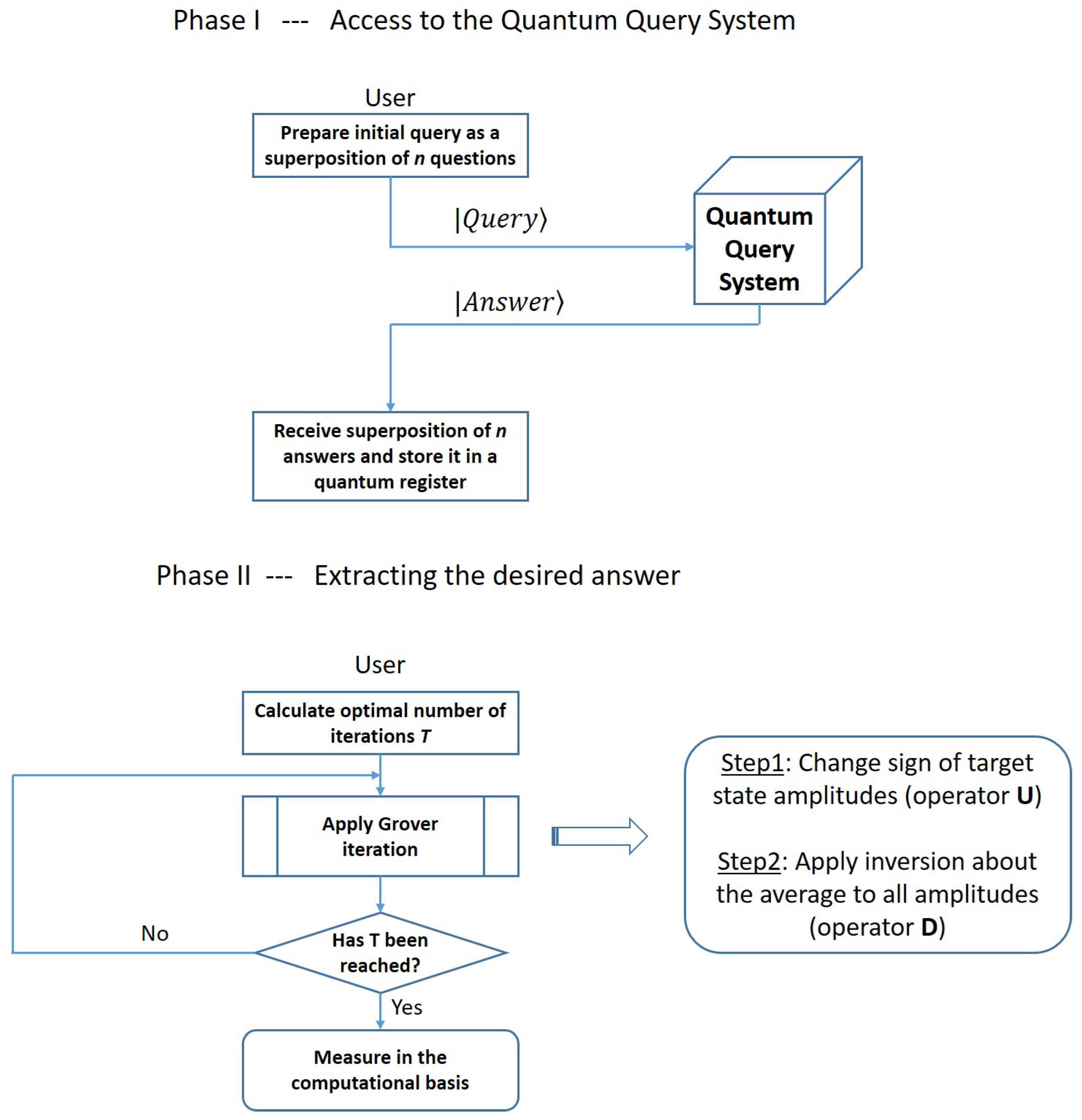
Figure 4.
Experimental results after 100,000 runs of the simulator for , and . The first bar in each graph represents the probability of obtaining the corect answer to question with index 0 (labeled as ). The second bar in each graph shows the probability of measuring the binary complement of . The third bar depicts the cumulative probability of fishing out any of the other questions that are part of the superposition state at the end of Algorithm 1.
Figure 4.
Experimental results after 100,000 runs of the simulator for , and . The first bar in each graph represents the probability of obtaining the corect answer to question with index 0 (labeled as ). The second bar in each graph shows the probability of measuring the binary complement of . The third bar depicts the cumulative probability of fishing out any of the other questions that are part of the superposition state at the end of Algorithm 1.
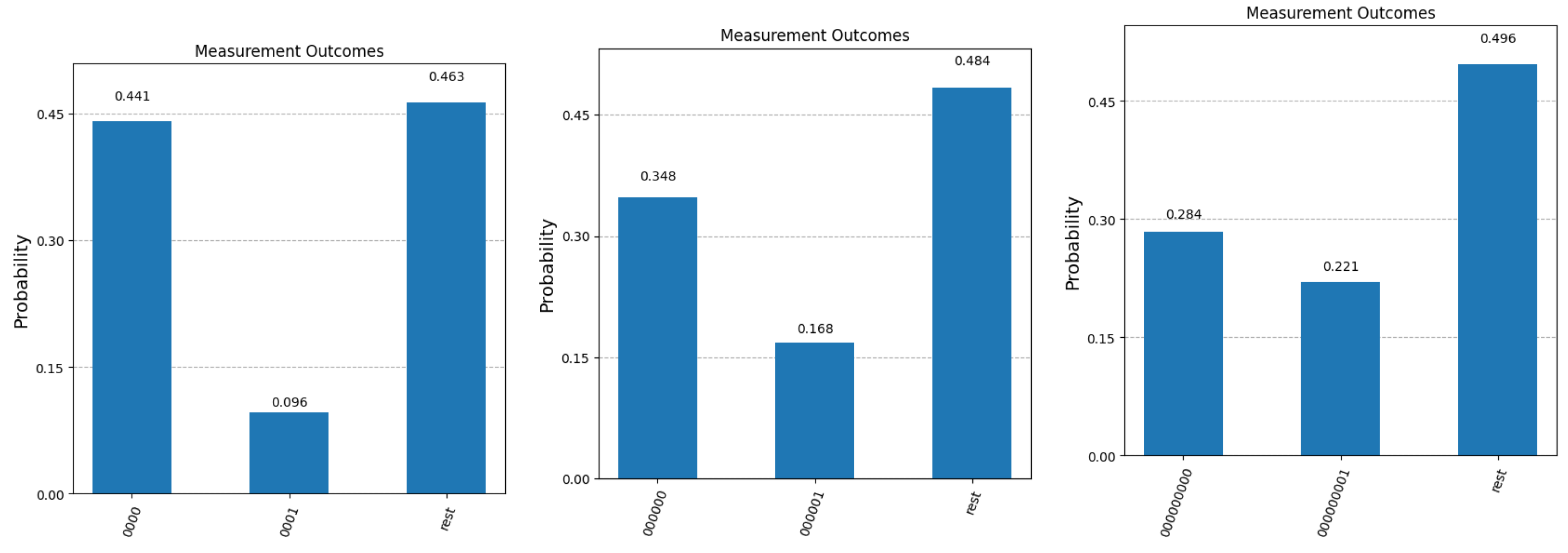
Figure 5.
Experimental results after 100,000 runs of the simulator for and . The first bar in each graph represents the probability of obtaining the corect answer to question with index 0 (labeled as ). The second bar in each graph shows the probability of measuring the binary complement of . The third bar depicts the cumulative probability of fishing out any of the other questions that are part of the superposition state at the end of Algorithm 1.
Figure 5.
Experimental results after 100,000 runs of the simulator for and . The first bar in each graph represents the probability of obtaining the corect answer to question with index 0 (labeled as ). The second bar in each graph shows the probability of measuring the binary complement of . The third bar depicts the cumulative probability of fishing out any of the other questions that are part of the superposition state at the end of Algorithm 1.
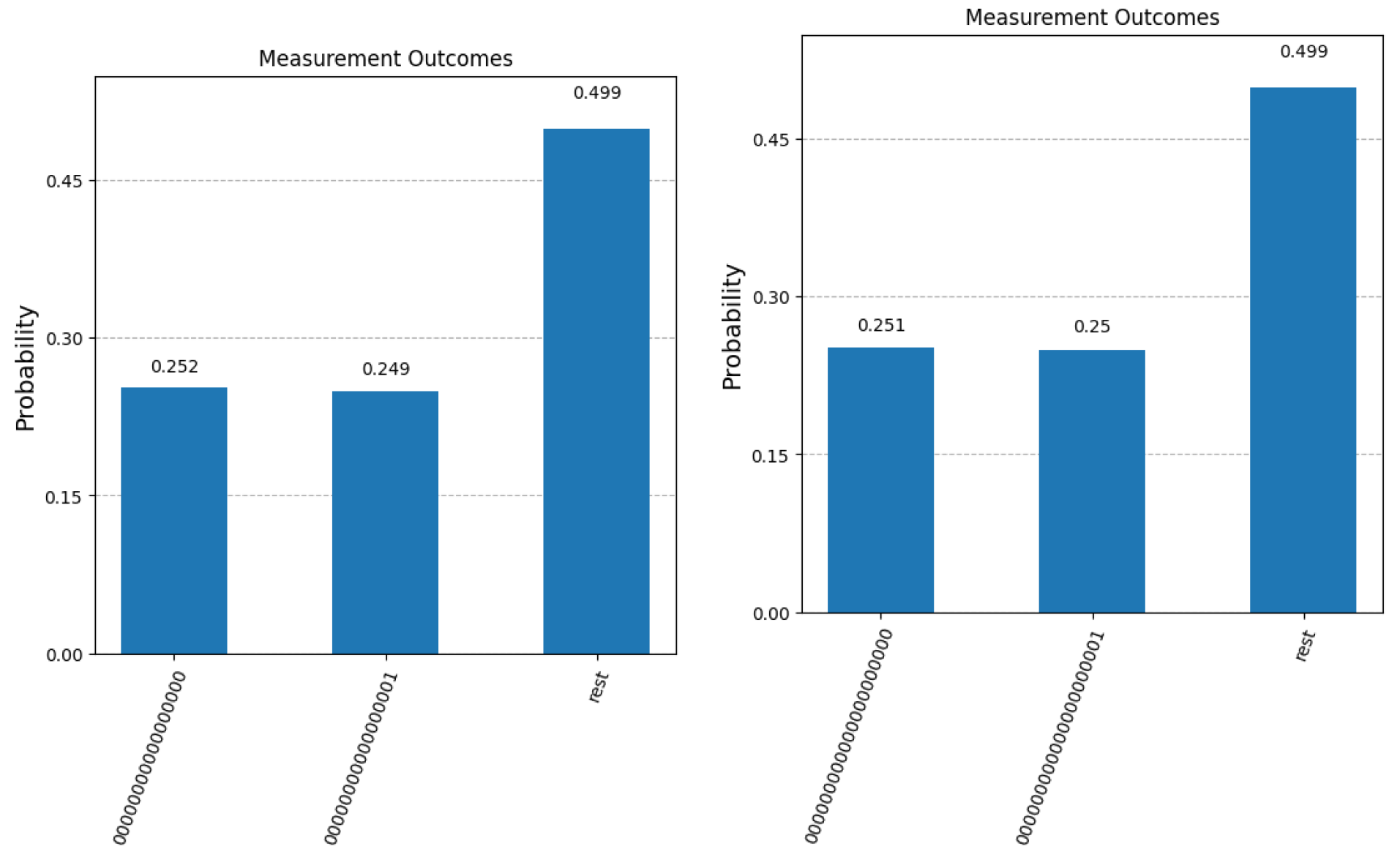
Figure 6.
Comparative probabilities of obtaining the correct answer if one, two or three samples of the initial query response are available, in the case of and . When two samples are available, the probability of obtaining the correct answer includes the case where both samples are measured as as well as the cases where one measurement yields and the other one fails to retrieve the desired question index. Similarly, the third bar in each graph (labeled as “Inconclusive”) includes the case where both measurements fail to fish out the desired question index as well as the situation where one measurement yields (the correct answer) and the other measurement yields (the binary complement of the correct answer). For the cases where three samples are available, a successful measurement (first bar) includes the following scenarios: at least two measurements yield or, only one measurement give the correct answer and the other two fail to retrieve the correct question index.
Figure 6.
Comparative probabilities of obtaining the correct answer if one, two or three samples of the initial query response are available, in the case of and . When two samples are available, the probability of obtaining the correct answer includes the case where both samples are measured as as well as the cases where one measurement yields and the other one fails to retrieve the desired question index. Similarly, the third bar in each graph (labeled as “Inconclusive”) includes the case where both measurements fail to fish out the desired question index as well as the situation where one measurement yields (the correct answer) and the other measurement yields (the binary complement of the correct answer). For the cases where three samples are available, a successful measurement (first bar) includes the following scenarios: at least two measurements yield or, only one measurement give the correct answer and the other two fail to retrieve the correct question index.
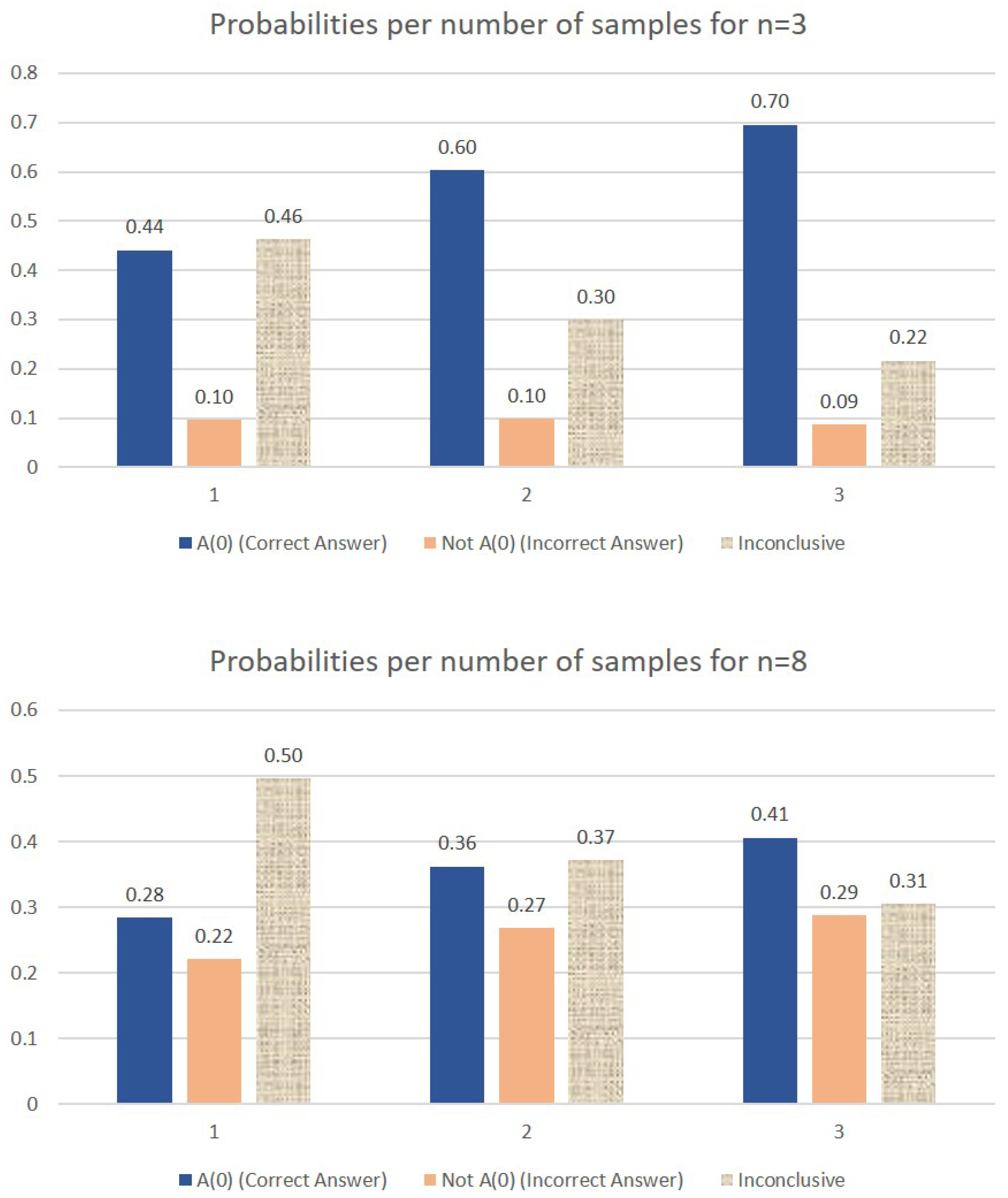
Figure 7.
Experimental results after 8192 runs on an actual IBM quantum machine for , and . The first bar in each graph represents the probability of obtaining the corect answer to question with index 0 (labeled as ). The second bar in each graph shows the probability of measuring the binary complement of . The third bar depicts the cumulative probability of fishing out any of the other questions that are part of the superposition state at the end of Algorithm 1.
Figure 7.
Experimental results after 8192 runs on an actual IBM quantum machine for , and . The first bar in each graph represents the probability of obtaining the corect answer to question with index 0 (labeled as ). The second bar in each graph shows the probability of measuring the binary complement of . The third bar depicts the cumulative probability of fishing out any of the other questions that are part of the superposition state at the end of Algorithm 1.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



