Submitted:
11 June 2025
Posted:
12 June 2025
Read the latest preprint version here
Abstract
With the growing diversity of road users and means of transport in Germany, it is becoming increasingly important to better understand the causes and influencing factors of serious accidents. The aim of this work is to develop an AI-supported analysis approach that identifies and clearly visualizes the causes of accidents and their impact on accident severity in the urban area of the city of Mainz. The machine learning models are designed not only to predict accident severity but also to make the underlying patterns understandable for urban planners, safety personnel, and other interested parties through shapley-values as explainability methods. A particular challenge lies in presenting these complex relationships in a user-friendly way through visualizations and interactive maps.
Keywords:
accident data
; XGBoost
; classification
; shapley-values
; geovisualization
1. Introduction
With the growing diversity of road users and transport systems in Germany, it is becoming increasingly important to better understand the causes and influencing factors of accidents (Lord & Mannering, 2010). Although traffic is becoming increasingly complex, the number of fatal road accidents in Germany has been falling for several years. According to the German Federal Statistical Office (Statistisches Bundesamt, 2025), this is due to the introduction of new regulations and improved vehicle technology. Nevertheless, the factors influencing accidents need to be further analyzed in order to improve road safety. This applies not only to fatal accidents, but also to minor accidents. Identifying the influencing factors can provide very useful information for infrastructure planners.
Since each accident is highly dependent on individual external factors, it is necessary to work out these influences for each accident individually. As these influences are often highly interdependent and influence each other, new methods must be found to isolate the interdependencies. Only then is a large-scale and empirical analysis possible.
The complexity of influences in an accident can be represented, for example, by weather conditions, the state and condition of the road, the traffic situation and the people involved. Due to the complexity of accident data, patterns and correlations are not immediately apparent. Even small changes, such as the time of day or the types of people and vehicles involved, can determine whether an accident at the same location results in minor or serious injuries. For some years now, machine learning (ML) approaches have been used to classify the severity of accidents (Abdulhafedh, A. (2017), Satu et al. (2018), Parsa et al. (2020) (Shaik et al., 2021), (Pourroostaei Ardakani et al., 2023)). The aim is to automatically learn and map the correlations between the details of a real accident and the severity of the accident. The advantage of this approach is that very few assumptions need to be made in advance in order to classify a wide variety of data. This ensures a high degree of flexibility, especially with more complex ML models, with respect to a wide variety of accidents and their outcomes. This approach is widely used in accident research to extract influences from large amounts of data.
However, this approach has some limitations: So-called decision rules can be derived from simpler ML models such as decision trees or random forests, which are able to identify correlations between individual influences. The problem with these decision rules is, that they are not capable of identifying local factors of individual accidents. An alternative is the widespread use of feature importance for more complex ML models. These are also unsuitable for analyzing individual accidents because they cannot identify local effects or whether the effect is negative or positive.
Although complex ML models, such as neural networks, have been shown to be better at predicting the severity of accidents based on given information, it is much more difficult to derive and interpret the influencing factors. Explainable AI (XAI) methods are increasingly being used to reveal the decision-making process of these 'black box' models.
In addition to the explicability of the decision process of an ML model, the geospatial reference of the data must also be taken into account. There is a large research gap in this area, especially when analyzing accident data. Currently, there are not many studies applying what is known as geospatial explainable artificial intelligence (Roussel 2023). In geospatial XAI, geospatial information should be integrated into the analysis and communication of ML results.
The aim of this work is to demonstrate that the use of geospatial XAI can also be used to determine factors influencing accident severity. An additional challenge is the interpretation and visualization of these complex results. So, another goal of this study is to develop a concept that uses geospatial areas at different scales to enable the study of global accident factors, influencing factors in a geospatial region and local influencing factors. A similar approach has been developed by Roussel (2025) and is called 'Geo-Glocal XAI'. From this we define the following research questions:
- How can geospatial XAI and glocal explanations be used to identify the factors influencing the decision to classify accident severity?
- How can these global, glocal and local influencing factors be visualized in a simplified way with maps and plots to improve interpretability?
The study is structured as follows: In Chapter 2, we present a comprehensive overview of the current approaches in research to determine accident severity using ML models. We present the missing explanatory approaches in research and give an introduction to geospatial XAI. In Chapter 3, we present the newly developed method to derive and map complex influencing factors together with the ML quality. In Chapter 4 we apply the developed concept to our selected use case of accident analysis in Germany and present and discuss the results in Chapter 5. In Chapter 6, we conclude the results of the study and point out future directions.
2. State of the Art
In this chapter, we present current research using ML approaches to predict accident severity. Specifically, we will show studies in this research area that use some XAI approaches. We also provide general information on the research field of geospatial XAI.
Accident severity classification using machine learning has become increasingly important in recent years. Numerous studies have looked at data-based prediction of accident severity using different data sources, models and analysis methods. In the past, the focus has been on identifying the best ML model for such classification tasks.
The study of Pradhan and Sameen (2020) highlights the advantages of using complex ML models such as neural networks (NNs) over linear models. They confirm that the relationships between features and outputs in accident severity prediction are non-linear, and therefore best represented by a NN. The study of Abdulhafedh (2017) also proves that the use of a NN is promising for predicting accident severity. However, these studies also point to the risk that increasing complexity can reduce the comprehensibility of the model, without presenting solutions to make the model transparent. This research gap is also highlighted in the review by Shaik et al. (2021), which presents an extensive list of data-based analysis approaches for accident severity. This study also focuses on the performance of each ML model. Accuracy measures such as F1 score, recall, precision or accuracy are compared. The study highlights the difficulties in predicting accident severity with ML approaches, as well as possible solutions to achieve better results. One challenge that often arises in this use case is that the accident data is often very unbalanced. There are many more accidents of minor severity compared to fatal accidents, which poses a challenge for machine learning models. Possible sampling methods to overcome this challenge and increase the accuracy of the models are presented. Feature selection and preprocessing are also discussed to improve the quality of the training data. While these methods can improve performance, they can also make the predictability of the prediction more difficult. For example, encoding features can potentially complicate interpretation. The diversity of features is also essential for the quality of machine learning predictions. Studies such as Abdulhafedh (2017) have demonstrated a correlation between road characteristics (e.g., road class, number of lanes, and speed limit) and accident severity, suggesting that a broad range of accident-related features can improve predictive performance.
Further Abdulhafedh (2017) emphasizes that the model should be selected according to the data base, but that NNs offer the greatest variety of applications due to their great adaptability. Tambouratzis (2010) shows that the performance and accuracy of accident data classification results can be improved by combining NNs and decision trees. However, it is also important that the decisions made by ML models are transparent and fully disclosed so that people can understand the influences on the model, especially for sensitive predictions such as accident severity. Tambouratzis (2010) identifies two benefits of transparency: First, model biases due to missing and biased data can be identified. Second, confidence in the prediction can be increased by communicating the rationale for the decision in a human-readable way.
The work of Zeng & Huang (2014) also demonstrates the strength of an NN based on a practical dataset. They used 53,732 accidents from Florida in 2006, each with 17 descriptive features and four accident classes. They achieved an accuracy of 54.84% for the test dataset, which is comparable to other studies. In addition, they performed sensitivity tests on the trained ML model to make the decision making more comprehensible. Approaches such as these are the first step in analyzing the factors influencing predicted accident severity. However, this approach can only identify influences globally. Correlations and effects of individual characteristics cannot be covered.
To better understand the decision making of an ML model, some studies have specialized in using decision trees, such as decision trees, random forests or other combinations instead of an NN. The strength of these models is that they can cover non-linear problems and can be explained with little effort (Abellán et al. 2013). The quickest way to do this is to derive so-called decision rules. These can provide a meaningful insight into the decision making of the ML model, as they are based entirely on the trained model. The model's decisions can be read directly in the form of rules. However, to obtain a comprehensive statement about the influences, it may be necessary to train many trees. To obtain an unbiased and comprehensive picture of the most influential attributes, the individual decision rules of each tree need to be combined and normalized (Satu et al, 2018). However, the work of Satu et al. (2018) proves that the explanatory power of the decision rules is not sufficient to determine the factors influencing the decision of accident severity. They called these influencing factors "risk combinations". Working with decision rules also presents several challenges. Normalized influences are only available globally, and the derived rules only apply to part of the trained model. It is not possible to output the influences for individual instances. In addition, only the importance of a feature can be specified, but not whether the given value of the feature had a positive or negative influence on the decision. Furthermore, a large number of decision trees are required to cover the influences of all factors.
Roussel and Böhm (2023) emphasize that XAI techniques are primarily used in geospatial use cases to improve ML models, rather than using the influencing factors as interpretable domain information for domain experts. This can be seen, for example, in the work of Amorim et al. (2023). They predict the severity of traffic accidents on Brazilian highways. To reduce the complexity of the data, they use the XAI technique local interpretable model-agnostic explanations (LIME) to identify the features that have the least influence on the prediction. They then remove them from the entire data set for a new model training. This improved the prediction quality of the model. However, this study again shows that the potential of the influencing factors is greatly underestimated and not used for deeper knowledge transfer or subsequent data analysis. Especially for geospatial use cases, XAI techniques can add significant value and provide new insights for decision making. According to Roussel and Böhm (2023), the most common models used in conjunction with XAI are boosting algorithms such as extreme gradient boosting (XGBoost). It should be emphasized that the lower the model accuracy, the lower the explanatory power of a model ex-planation; XAI can only reveal the results of an ML model, but cannot evaluate or modify them (Roussel, 2024).
By far the most widely used XAI technique is the SHAP method (Lundberg & Lee, 2017). SHAP is model agnostic and can be applied to any ML model to reveal the decision-making process of a classification. A key advantage of SHAP is its ability to provide both global and local explanations. Global explanations are obtained by aggregating the local SHAP values over the entire dataset and provide an overview of which features have the greatest influence on the model predictions. These global results can be presented in different types of plots to visualize the average contributions of all features. Local explanations, on the other hand, show how individual features influence specific predictions and are often visualized in waterfall plots, which show the contribution of individual features to a specific prediction step by step.
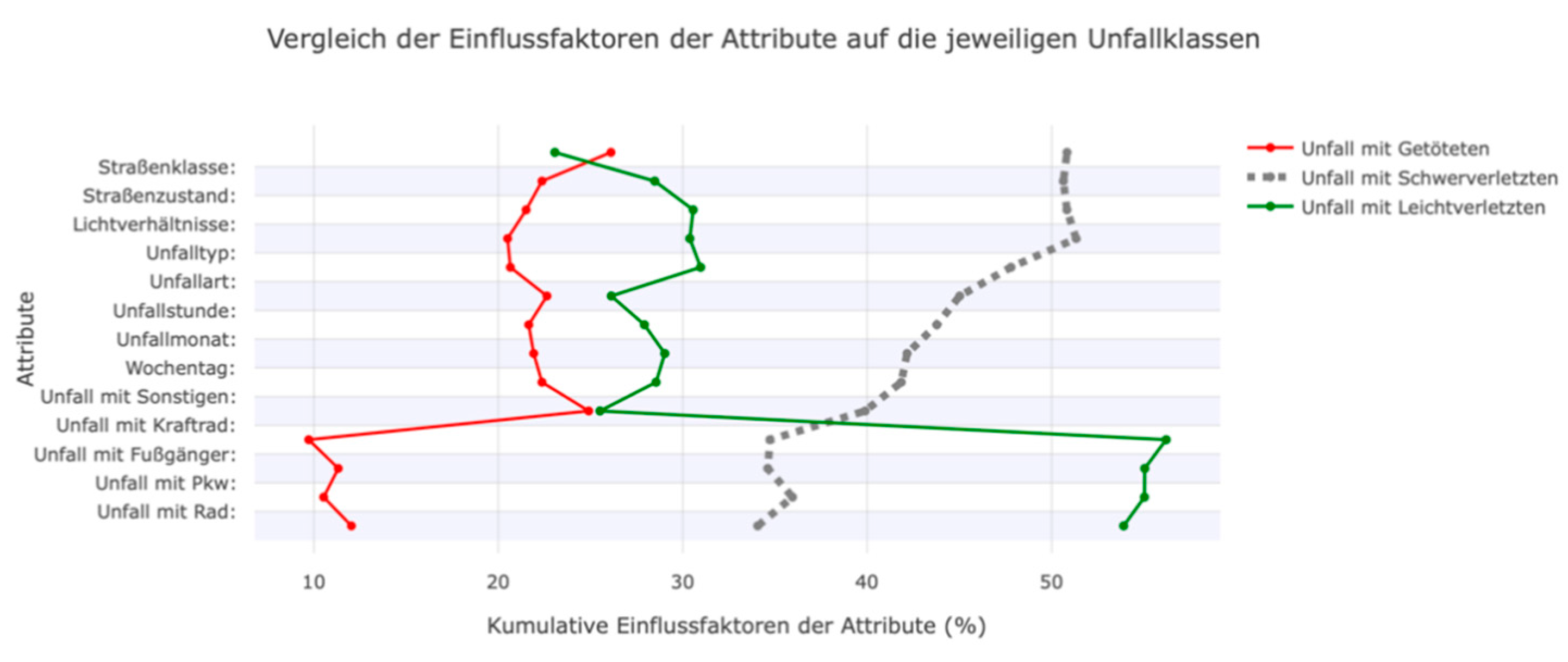
In addition to the traditional visualization of SHAP values, the work of Roussel (2024) deals with the geovisualization of these values. The paper emphasizes that SHAP is a good way to identify influencing factors in an ML model, but that the geospatial representation of these influencing factors has not been sufficiently explored. Two approaches are presented to visualize these factors using geographic maps. A point visualization and an area visualization of the SHAP values are presented. In the punctual visualization, the influencing factors can be represented by color and the characteristic values by size on a map with an exact spatial coordinate. It has been shown that this can reveal spatial patterns that cannot be visualized using the familiar plots. In the area-wide visualization, the SHAP values or the features with the highest SHAP values were visualized with a Voronoi diagram. After intersection with the road network, this can be used to visualize actual geospatial areas of influence across the whole area.
When analyzing accident data, previous research has used ML models to accurately predict accident severity. Only a few studies have used a trained ML model to evaluate factors influencing the prediction. So far, decision rules or feature combinations have mainly been used to identify the risk factors of a serious accident. The interpretation of influencing factors is not widely used in accident analysis but has great potential. The calculated influencing factors can not only make the decision processes of ML models transparent and thus provide important information for subsequent investigations. Influencing factors can also be used to improve ML models and make them more robust. Furthermore, there is still a lack of modern visualization approaches to display accident data. Accident data can be geospatially localized, providing the opportunity to perform geospatial analysis, which can help to identify patterns in the data.
The study by Roussel (2025) provides the first outlines of a global-local explainability approach, which is a scalable explanatory approach for geospatial use cases. This glocal XAI method is also tested in this study to determine the influencing factors and the subsequent geospatial information. The next chapter presents a concept that performs a geospatial scaling of the SHAP values in order to present ML predictions.
3. Concept
This chapter introduces a developed concept that can calculate the influencing factors of an ML classification not only locally for individual datasets or globally for all predictions but also scaled and taking the predicted classes into account. The concept of semi-global influence factors aims to represent extensive influencing variables in a generalized way without distorting them. Combining these two requirements has not yet been investigated; the present concept addresses this research gap.
To this end, two types of data segmentation are employed: First, the data points are spatially segmented, and then they are assigned to the cells of the confusion matrix. The first segmentation is used for geographical classification, and the second segmentation enables a differentiated analysis of the ML model's decision-making process depending on the target class and the predicted class. The influencing factors of this twofold-segmented data can then be aggregated to make statements about the effect of individual features on specific cells of the confusion matrix within spatial areas.
The first step is spatial segmentation. With geographic data in particular, it is essential to recognize and analyze spatial patterns and relationships. The challenge lies in structuring the data in a meaningful way to make semi-global statements, especially when the data is distributed irregularly in space. Therefore, the data set is first divided into clearly definable geographical areas. These areas can be administrative boundaries, such as federal states, counties, or city districts. Alternatively, sub-areas based on social, infrastructural, or climatic criteria, such as forest, urban, and rural areas, are also possible. The choice of segmentation depends on the available data and the respective use case.
The larger the selected areas, the more generalized the subsequent statement about the influencing factors will be. Conversely, smaller segments enable a more precise derivation of spatial patterns. The presented concept uses scalable analysis to examine both small-scale structures with low point density and large-scale areas with aggregated influencing factors. Thus, it is possible to conduct an area-related analysis of the influencing variables at different spatial scales. The predictions generated by the ML model can also be localized semi-globally through this segmentation.
The ML model calculates a probability for each target class, so the sum of all the probabilities is always 100%. XAI methods, such as SHAP, allow us to analyze these probabilities in detail to determine the influence of individual features. The resulting local influencing factors depend on the instance and target class under consideration.
A common mistake when deriving global influencing factors is aggregating all local influences on a target class y_i. This is problematic if it is calculated regardless of whether the model correctly predicted the target class. This procedure can lead to distortions because it includes incorrect predictions. To avoid this, a second classification of the data is performed after spatial segmentation based on the initial classification. The predictions are then assigned to cells of a confusion matrix that compares the actual classes with those predicted by the model.
This division allows for dynamic analysis of predictions based on the respective spatial unit. An interactive dashboard visually presents the results, allowing complex influencing factors to be explored in a user-friendly, low-threshold manner.
The confusion matrix also facilitates targeted aggregation. Influencing factors per target class are calculated based exclusively on instances correctly classified by the model. This avoids distortions due to misclassification. Additionally, incorrect predictions can be analyzed to identify the responsible features. Classifying the data as true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN) enables a structured and cumulative representation of the influencing factors. This approach provides a robust basis for analyzing model decisions, especially wrong ones.
Combining spatial and classification-based segmentation provides a more detailed view of the classification results. This approach is particularly effective when using XAI methods, such as SHAP. It goes beyond classic SHAP diagrams, such as beeswarm or summary plots, by offering alternative, visually prepared display options.
The visualization uses simplified symbols to depict individual feature flows without altering the underlying numerical values. For each target class, it is clear which features have increased or decreased the prediction probability. The intensity of influence can also be displayed symbolically, enabling a diverse user group to understand the semi-global influencing factors.
Additionally, the interactive dashboard allows users to dynamically adjust the target class, leading to different influences on the target class. This allows for a targeted analysis of the features that led to the inclusion or exclusion of certain classes. Even in cases of misclassification, the features that caused the model to make an incorrect prediction can be quickly identified. The dashboard offers a transparent and comprehensible representation of the factors influencing the model prediction thanks to the dynamic visualization of local SHAP values using waterfall and decision plots. The combination of interactive analysis options, user-centered design, and a comparative presentation of all target classes strengthens understanding of the model's internal decision-making processes. This creates a sound basis for further interdisciplinary analyses.
This concept is suitable for any use case involving the classification of highly spatially distributed data with a trained ML model, followed by analysis using XAI methods.
4. Implementation
This chapter describes how to implement the concept presented in Chapter 3. The process serves to systematically derive factors that influence accident severity from accident data using XAI methods. The city of Mainz is used as an example of the study area.
Data
First, the data set used is presented. The accident data used in this study comes from the accident atlas of the state and federal statistical offices. This publicly accessible dataset contains all traffic accidents on German roads in which personal injury occurred and were recorded by the police. Although the data is published annually, there may be delays in publication by individual federal states. For example, data from Mecklenburg-Western Pomerania is only included starting in 2021. Each recorded accident is provided with geographical coordinates, enabling spatial representation and analysis.
The study period spans from 2016 to 2022. During this time, 1,396,570 accidents were recorded in Germany and published in the Accident Atlas. Of these, 80% (1,118,604 cases) were accidents involving minor injuries, 19% (263,664 cases) were accidents involving serious injuries, and 1% (14,316 cases) were accidents involving fatalities. As Pourroostaei Ardakani et al. (2023) and Pradhan & Ibrahim Sameen (2020) have already demonstrated, the accident data is highly imbalanced.
The statistical offices of the federal states and the federal government compile and summarize accident data from the individual states. Thirteen features are recorded for each accident. These features provide spatial, temporal, atmospheric, and situational information, which is listed in Table 1. These features are less extensive than those in comparable study data sets. The descriptions of these features come from the data set description "Unfallatlas" (Statistisches Bundesamt und Statistische Ämter des Bundes und der Länder, 2021) and the explanation of basic terms in traffic accident statistics (Statistisches Bundesamt, 2022).
As part of the data processing, the statistical offices georeferenced the traffic accidents. During this step, the exact location of each accident was related to the nearest road axis. However, the dataset only contains spatial coordinates, not information on the characteristics of the road. To enrich the accident data with additional road information, a scalable approach is necessary.
Free data from OpenStreetMap (OSM)1 serves as the basis for attaching the respective road's additional properties to an accident. For example, the data enrichment consists only of the road class as an additional attribute because information on road width, number of lanes, and maximum speed is missing. Additionally, the selection is limited to OSM roads on which traffic accidents can occur.
Data Engineering
Upon examining the data types of the features in Table 1, it becomes apparent that they are predominantly presented as categorical values. Federal and state statistical offices specify a value from a defined list for each feature. Often, these values cannot be directly compared or sorted. Through transformations and encoding, these values are converted into a model-readable structure, enabling a model-agnostic evaluation of accident severity. Additionally, sampling methods compensate for unequal accident frequencies to ensure a balanced data set for evaluating accident severity.
Time data, such as hours and months, are cyclical; therefore, a purely numerical representation distorts neighboring values, such as 23:00 and 01:00.
To accurately capture this cyclical nature, Mahajan et al. (2021) identified sine and cosine transformations. Roussel & Böhm (2025) confirmed this practice, which is also used for transforming the accident times in this work. The two new continuous values are stored as features.
The categorical, nominally scaled features—accident type, light conditions, road condition, and road class—are data with no natural sequence that are not directly comparable. One-hot encoding ensures the ML model considers the individual feature classes independently. While one-hot encoding allows for model-agnostic processing of categorical data, it also increases the number of features, resulting in the "curse of dimensionality" (Bellman, 1961). In this case, the number of features increased from 13 to 52 due to the transformations, requiring higher model complexity and more training data.
We used a self-developed sampling approach to train an ML model that can classify accident severity based on features. We subsequently used the test dataset to evaluate the model's quality and visualize the semi-global influencing factors. To train a meaningful ML model, a large amount of uniformly distributed, heterogeneous accident data is required. We compile the training data independently of specific geographical regions to avoid distortions and maximize the model's performance with training data as variable as possible. However, the distributions of individual accident severities in the enriched dataset are still imbalanced. Amorim et al. (2023) also highlighted this issue in their work. They compared trained ML models with balanced and unbalanced data sets. They found that correlations between input features and target variables were only present in balanced datasets. Finding the undersampled class in an imbalanced dataset was difficult, and classification quality based on error measures was over 10% worse (NN, decision trees, SVM, and Naive Bayes were examined). Undersampling or oversampling must be used. One disadvantage of undersampling is that the ML model cannot see and adapt important information contained in randomly deleted instances. For this reason, oversampling is often used in research. In particular, the Synthetic Minority Over-sampling TEchnique (SMOTE) is widely used. Rather than simply copying instances of the underrepresented class until the class distribution is equal, SMOTE creates synthetic instances. Copying the data would lead to overfitting because the same instances would always form the basis of the data. With SMOTE, new instances are created whose feature values are based on subsequent instances, resulting in unique values. Overfitting can also occur when there are extensive new generations and little initial data. Amorim et al. (2023) and Parsa et al. (2020) used SMOTE to adjust inherently imbalanced accident data. This proven sampling method is also used in the new sampling approach.
When SMOTE was applied to the German accident data, the subsequent overrepresentation of previously underrepresented accident severity classes was evident. Since undersampling and SMOTE did not produce satisfactory results, we combined the strengths of the two methods to create our own approach. First, SMOTE increased the number of fatal accidents to 160,000, a tenfold increase. Then, we reduced the number of accidents with minor and serious outcomes to the number of fatal accidents. This sampling approach prevents overfitting, which would result from including too much synthetically generated data, as well as a loss of information, which would result from pure undersampling. To evaluate the classification later, we removed the accidents from Mainz from the training dataset and used them as test data. They were not equalized because they should represent the exact conditions.
Klassifizierung
Prepared accident data serves as the basis for model training. The model predicts accident severity based on individual features. This involves performing a multi-class classification. Chapter 2 focuses on tree structures, such as XGBoost, decision trees, and random forest, as well as neural networks, such as MLP and PNN. This study compares the widely used MLP and XGBoost models. The focus is not on determining the most suitable model but on proving the concept in practice. The two models differ fundamentally in terms of their structure and training approaches. We can subsequently use the derivable accuracies to independently confirm the training.
We performed the initial training of the XGBoost and MLP-NN classifiers using summarized accident data from Germany. In this case, we did not sample the data. Then, we repeated the training with the adjusted accident severity classes. For the third model training, we used the balanced accident data and took the road class into account for the two ML approaches. However, this data augmentation only improved the XGBoost model. The multi-class classification results can be seen in Table 2.
Looking at the confusion matrix of the XGBoost classifier's classification results with unbalanced training data reveals that the model classifies all accidents as minor (see Figure 1). This accident severity is so prevalent that the model does not have enough data from the underrepresented classes to identify them. This confirms the necessity of the sampling method used in preprocessing.
After adjusting the class frequencies in the training data, most error measures improved because the model could correctly classify more serious and fatal accidents (see Figure 2). The recall values for these classes are 75% and 38%, respectively. However, the model now predicts more minor accidents than fatal accidents in the test dataset. This is evident in the low precision value of 3% for this accident class and the decrease in recall value to 70% for the minor accident class. These results may indicate overfitting of the models and require further investigation. The classification accuracy is also decreasing. It decreased by 20%, falling to 65%. This is because the overrepresented minor accidents are now predicted as other accident severities more often. However, the 26% increase in the overall recall value shows that accident severity is being assigned more accurately, particularly in underrepresented classes. The XGBoost model correctly classified three out of four actual fatal accidents. However, it incorrectly predicted 26 serious and 89 minor accidents as fatal, resulting in an overall precision value of 38.7%.
The two models examined, XGBoost and MLP-NN, have similar error values. This confirms the classification by these two independent, different ML models qualitatively. Similar to the XGBoost classifier, the MLP-NN only predicts serious and fatal accidents after adjusting the class frequencies. However, this leads to possible overfitting of the model due to the incorrectly classified minor accidents. Nevertheless, the MLP-NN shows slightly better results in all error measures (1%-3%) because this model correctly predicted more minor accidents.
Adding another feature, the road class, makes the data set more complex. This requires a model that can correctly map the increased complexity. Only the XGBoost algorithm increased the quality of the classification results (see Figure 3). The MLP-NN performed worse in all error measures. It misclassified accidents with minor injuries as accidents with serious or fatal injuries. This is evident in the class's recall value of 34%. Additionally, fewer actual accidents with fatal severity were identified. After enriching the data with the road class, the model incorrectly predicted more accidents than serious accidents.
The XGBoost classifier will be used as the primary model for further processing because it can map nonlinear issues well and has strong performance. Thanks to various acceleration mechanisms, XAI methods such as SHAP can be calculated more efficiently with tree structures like XGBoost. This is a significant advantage over MLP-NN.
We then used cross-validation for hyperparameter tuning to identify the optimal parameters for the model. The model is configured for a multiclass classification problem with a softmax objective function and consists of 500 decision trees with a maximum depth of four levels. To reduce overfitting, we used only 80% of the training data and 60% of the features to construct each tree. Additionally, L1 and L2 regularization are employed to limit model complexity. The learning rate of 0.015 was chosen deliberately to be low to promote stable and gradual convergence. Additional fine-tuning improved all error measures by 2%.
XAI
To transparently represent the semi-global influencing factors of the XGBoost model, we use Explainable AI (XAI). SHAP is used for its model diagnostics and ability to simultaneously provide local and global interpretations of model decisions (Lundberg et al., 2020). Unlike alternative approaches, such as LIME, which primarily provide local explanations, SHAP allows for a more consistent assessment of influencing factors across many instances. For the XGBoost model, we use a specially adapted TreeExplainer that calculates SHAP values efficiently within the model. This enables high-performance analysis of large data sets2.
Our goal is to use SHAP values to explain all accidents in the Mainz test data. These consist of 878 instances, for which the algorithm calculates one SHAP value per feature and per target class — i.e., 52 features across three classes — resulting in 136,968 individual SHAP values in total.
Using a waterfall plot, for example, we can visualize the influencing factors for each target class locally for each instance, as shown in Figure 4, Figure 5 and Figure 6.
In addition to SHAP values, the algorithm calculates a base value, E(f(x)), for each class. This expresses the basic probability of an individual class in the case of an unbalanced dataset. In other words, this probability describes the occurrence of a class regardless of the individual features of an instance. If all target classes occur equally, the base value is the same for each class.
To analyze the influencing factors using SHAP values on unbalanced test data, we input the trained machine learning (ML) model and the class ratios in the test dataset to the tree explorer. This enables us to apply accident severity predictions and their influencing factors to new unbalanced data sets. The calculated base probabilities of the classes in the test dataset reflect the frequencies of different accident severities, with minor injuries being the most common. These base values serve as a reference point for calculating the SHAP values and account for the class imbalance in the dataset.
The library outputs the SHAP values in logit space, which are then converted into probabilities using the softmax function for interpretation:
The softmax function is a common method for converting logits to probabilities in classification tasks (Goodfellow et al., 2016).
The SHAP values of the categorical features required post-processing because pre-processing with one-hot encoding split them into several binary variables (e.g., accident type and light ratio). One original feature consists of several feature classes (see Figure 7). This makes explanations more difficult because there are now several influencing factors for each original feature.
To improve comprehensibility, we grouped the feature classes according to how the SHAP values were derived and summed them for each original feature. This step is mathematically permissible due to the additivity property of SHAP values. The groups were assigned based on the coding structure and order of the feature matrix. As a result, each original categorical feature of an instance received a single influence value per target class again (see Figure 8).
This aggregation leaves the total sum of all SHAP values unchanged and still corresponds to the predicted probability. However, it is important that the resulting SHAP value of a feature reflects the interaction of all associated categories — both their presence and the absence of others.
Another way to visualize the influencing factors using the SHAP library is with a beeswarm plot. Unlike the previous illustrations, this provides a global view of the influences. Figure 9, Figure 10 and Figure 11 show Beeswarm plots for each of the three accident severity classes. Notably, "Accident with Others" is the most important feature for predicting fatal accidents. When this feature has a value of one, i.e., when the vehicle type is involved, the probability of this class increases. The same is true for pedestrian involvement. The road class "road in residential area" and the accident type feature value of 2 ("collision with vehicle in front/waiting vehicle") lower the probability of this class.
The probability of an accident being predicted as serious is influenced by the feature values of accident type 6 ("accident in longitudinal traffic") and accidents involving vehicles. Unlike fatal accidents, the absence of these features increases the probability of this class. In other words: If no car was involved in an accident, the model increases the predicted probability of a serious accident. The vehicles involved primarily influence the predicted probability of accidents with minor outcomes. The involvement of a bicycle, pedestrian, motorcycle, or other vehicle negatively affects the prediction probability, as does the road class "highway." Accident type 2 ("collision with vehicle in front/waiting vehicle") reduces the probability of a fatal accident. For predicting accidents with minor injuries, this feature has the greatest positive influence on the ML model.
Therefore, the Beeswarm plot is a good way to map the influencing factors in an ML model. In addition to showing the absolute influence, it indicates whether a feature has increased or decreased the probability. It also takes into account the respective value of the feature, which illustrates the advantage of a Beeswarm plot over a classic bar plot. While the latter only shows the importance of individual features for the model, the Beeswarm plot shows the influence of each value and class-dependent influences.
However, when looking at the Beeswarm plots in Figure 12, it is noticeable that the merging of the categorical features was not carried out. Summing up the SHAP values of the individual feature classes generalizes the analysis, which is why this was not done. Some feature classes increase the prediction probability, while others reduce it. Additionally, the feature classes are nominally scaled, meaning they have no natural order. A higher accident type class does not necessarily have a higher or lower influence on the prediction. Summarizing the SHAP values of features with multiple classes means that their influences can no longer be interpreted using a Beeswarm plot.
A boxplot can be used to visualize how feature classes influence an accident class (See Figure 13). For example, it shows the individual accident type categories and their average influence on the probability that an accident will be classified as fatal. This representation allows one to compare the influencing factors of the classes of an individual feature. However, note that all instances are considered, including those that the model does not predict as fatal accidents. Our approach to dealing with categorical features and visualizing them is based on the work of O'Sullivan (2022).
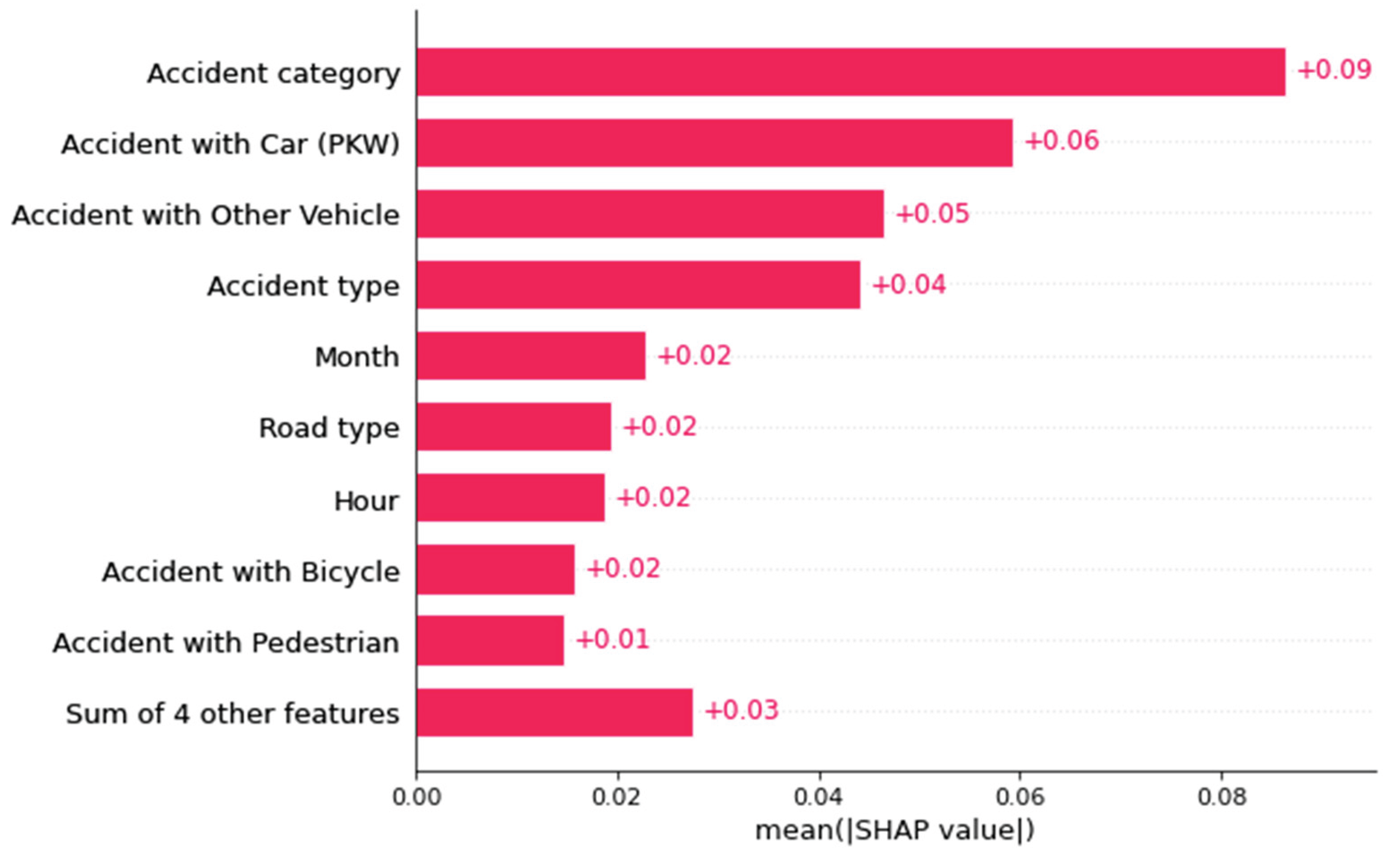
Since a beeswarm plot becomes meaningless after SHAP values are merged, a bar plot is used instead (see Figure 14). This plot clearly shows the average absolute SHAP values per feature and accident category. This representation is less detailed but easier to understand.
In the next chapter, we present an approach to visualizing semi-global influencing factors, including the use of bar plots. We subdivide the dataset so that bar plots can be formed for specific predictions. This enables us to address user inquiries such as: On average, which feature has the greatest influence on the ML model when identifying minor accidents as fatal accidents? It also enables us to evaluate classification results and misclassifications based on many instances.
Figure 13.
Difficulties in reading the influences from a beeswarm plot on fatal accident prediction after some feature's SHAP values were aggregated.
Figure 13.
Difficulties in reading the influences from a beeswarm plot on fatal accident prediction after some feature's SHAP values were aggregated.
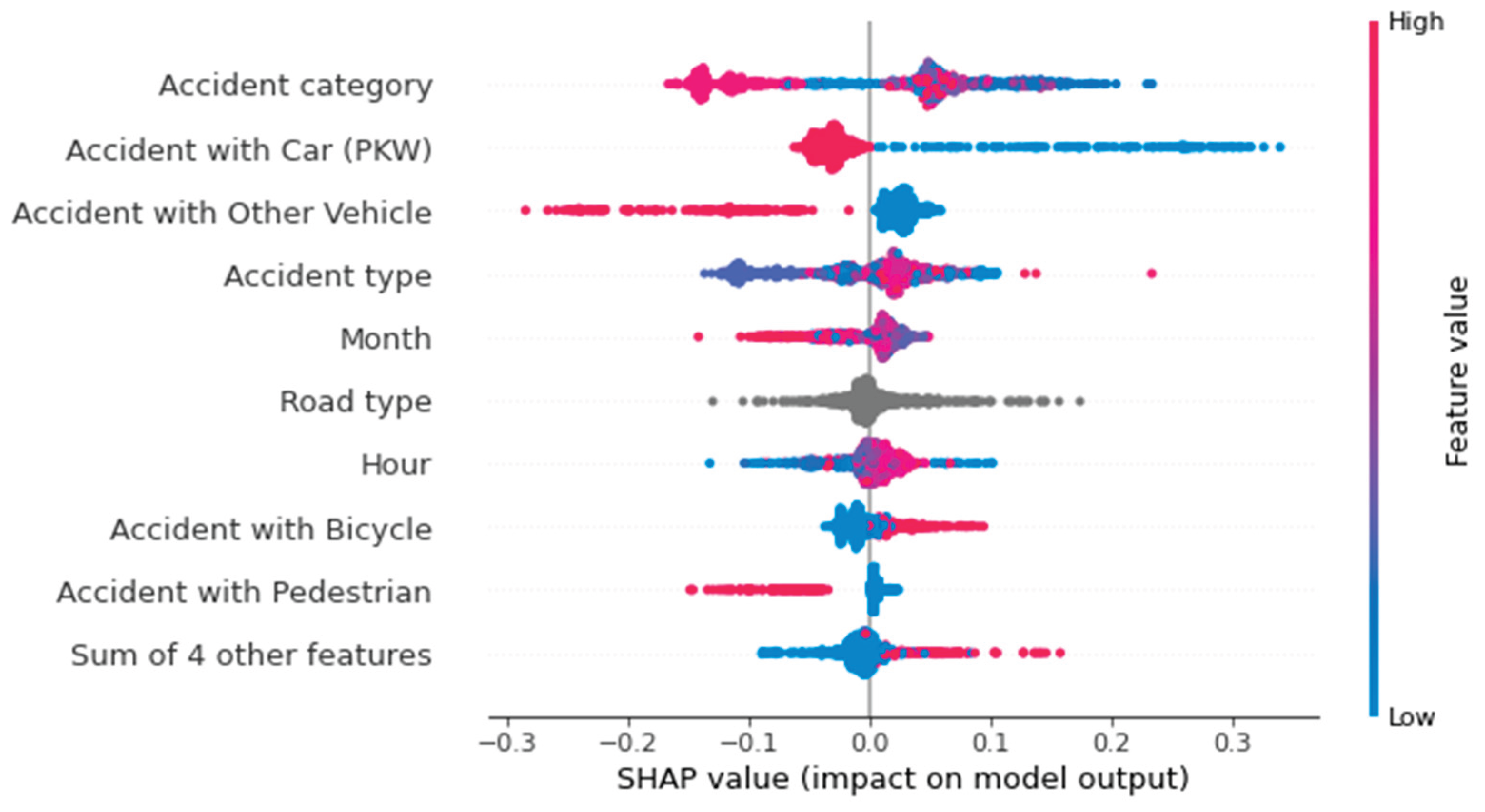
Figure 14.
A comparison of how the feature accident type classes influence the prediction probability of fatal accidents.
Figure 14.
A comparison of how the feature accident type classes influence the prediction probability of fatal accidents.
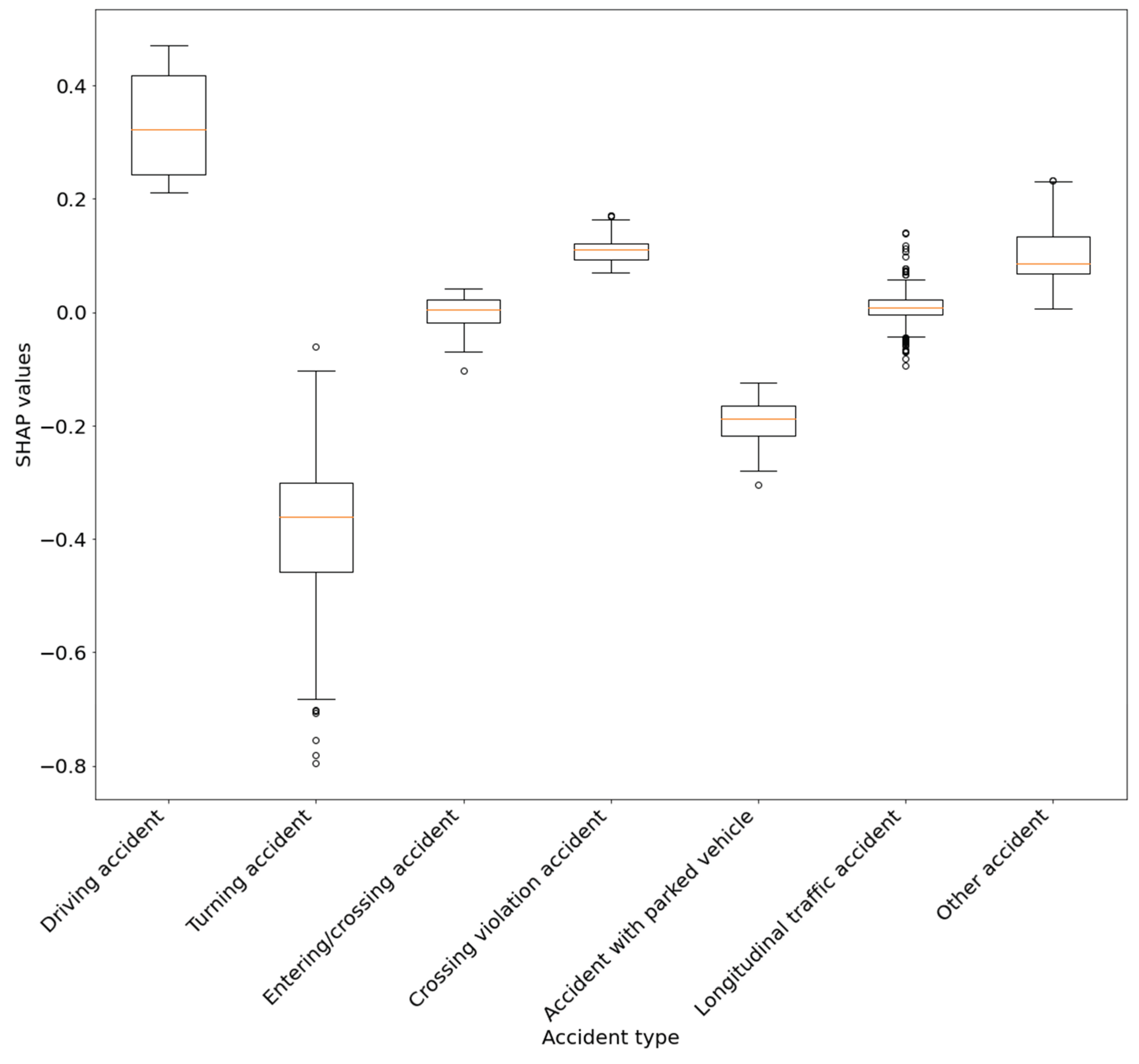
Figure 15.
Ein Bar-Plot als vereinfachte Darstellung der Wichtigkeiten der Features in der Vorhersage einer Unfallschwere.
Figure 15.
Ein Bar-Plot als vereinfachte Darstellung der Wichtigkeiten der Features in der Vorhersage einer Unfallschwere.
5. Results and Discussion
The developed concept is intended to address the research questions posed in Chapter 1. The goal is to present a solution for calculating semi-global influencing factors and, subsequently, communicate them in an accessible manner. There is a research gap in communicating spatial influencing factors. The prototypical dashboard implementation is intended to present a possible solution to this issue. In the use case, accident data, ML results, and influencing factors will be dynamically summarized for in-depth analysis. This allows specialist users, such as road planners, accident researchers, ML experts, and road users, to explore the large number of individual ML predictions or evaluate the quality of the ML model. Geo-referencing accidents makes it possible to show spatial patterns. This prototype was developed for German analysts, so only the German version will be shown in the upcoming screenshots.
As shown in the concept, we sorted the Mainz accident data by their spatial location. Here, we use the districts of Mainz as an example. Other administrative units or socio-spatial boundaries can also be used as subdivisions. However, we have not examined these spatial units in depth, so we cannot identify small-scale influences, such as dangerous traffic junctions. The subdivided point data can now be visualized on a map using areal representations (see Figure 7). Additionally, other visualization concepts can highlight differences between districts. In the study, the number of accidents per district and the model's prediction quality were shown using coloring and error measures per district. Depending on the specific influencing factors, other colorations could also be conceivable to achieve even better spatial comparisons with the aid of maps. When comparing city districts, it's clear that areas in the city center have a much higher accident rate, primarily due to higher traffic volume rather than an increased risk of accidents. Accident frequency should be included as an additional target variable in an ML model to specify accident frequency in addition to accident severity. Therefore, the districts can only be compared to a limited extent based on their numbers. Additionally, the influencing factors vary by district. Using a single ML model does not account for district-specific characteristics.
Clicking on a district reveals a dynamic, interactive confusion matrix for the ML predictions of accident severity in that district. This matrix compares the predicted and actual accident severity in the selected district. This makes it easy for users to understand how error measures are calculated and identify potential classification errors in the model. Figure 16 shows a district overview from the web dashboard.
Clicking on a cell in the confusion matrix generates a bar plot showing the average absolute SHAP values for this accident severity. One disadvantage of the bar plot from the SHAP library is that it generalizes the data too much. When a bar plot was generated for an accident severity class, the algorithm calculated the average SHAP value of a feature from all instances, even when the classifier predicted the investigated class as the least likely for an instance. Furthermore, it was not possible to consider correctly or incorrectly classified instances separately. Therefore, the presentation of the results in the bar plot was distorted. It was not possible to conduct a differentiated analysis of which features had the greatest influence on incorrect classifications. However, by dynamically calculating the average absolute influencing factors depending on the actual and predicted accident severity in the web dashboard, users can now access the influencing factors specifically (see Figure 17). Thus, we eliminated the limitations of the global bar plot to gain a clearer understanding of the ML prediction and its influencing factors. However, the average absolute SHAP values represented by the bar plot do not indicate whether a feature increased or decreased the probability of predicting accident severity. Therefore, the bar plot expresses the importance of a feature in the ML prediction rather than providing information on how a feature value influences the prediction of individual accident severity. Additionally, very large or very small SHAP values can distort the average data in individual cases.
We also integrated a beeswarm plot to enable users to take a closer look at the composition of the average absolute SHAP values shown in the bar plot and to gain a deeper understanding of the influencing factors and their interrelationships. This plot shows the individual SHAP values of the instances. An axis is created for each feature, and the SHAP values are marked as points on each axis. Interacting with the points displays the respective SHAP value and the decisive feature value. This allows users to understand the direction of importance and composition of the SHAP values. As with a typical beeswarm plot, the points are color-coded according to their feature value. However, the markings do not have a continuous color gradient because the nominally scaled features are not sorted. Nevertheless, this highlighting allows users to recognize possible correlations between feature and SHAP values. Figure 18 shows an example. This diagram illustrates the factors that influenced the misclassification of minor accidents as major accidents in a neighborhood. Looking at the feature and SHAP values together makes it possible to identify the patterns that caused the machine learning (ML) model to misclassify these accidents. As can be seen here, the involvement of a motorcycle in an accident increases the probability of serious accident severity. The lack of motorcycle involvement minimally reduced the predicted probability of accident severity. However, the bar plot does not show this correlation. Moreover, it was not possible to determine whether indicating motorcycle involvement lowered or increased the probability (see Figure 17). Therefore, it can be deduced from the visualization of the individual SHAP values using the beeswarm plot that the involvement of a motorcycle increases the predicted probability of a serious accident in this district. Similar correlations and influences can be derived from the confusion matrix diagrams.
The developed concept enables targeted analysis of accident patterns at the district level, reduces the amount of displayed data, and combines interactive visualizations with differentiated model evaluation. Separating correctly and incorrectly classified accidents and using common slide types supports transparent and low-threshold interpretation of the influencing factors.
In addition to displaying accident severity and its influencing factors at the district level, the dashboard allows users to examine individual accidents freely. This encourages users to explore individual accidents. When examining local influencing factors, the dashboard primarily serves as a visualization and navigation tool to display the results of individual calculations rather than offering analysis options.
The developed process sequence can provide non-case-dependent statements on the formation probability of an ML model. Each accident contains unique information, yet all accidents are based on the same structure. To this end, accidents are color-coded on an overview map of a city district. Roussel et al. (2024) investigated the possibilities of map-based mediation of influencing factors. In addition to the accident class, additional information, such as the most influential feature in the decision-making process, a comparison of actual and predicted accident severity, or prediction uncertainty, could increase the map's informational content. Interacting with a marker displays the details of an individual accident. Accident severity is the most important information and the main inspection feature. The user is shown the probabilities of the individual accident classes, as determined by the classifier, in the information window. Along with the probability of the prediction, a comparison with the actual accident severity class is provided, and the uncertainty of the prediction is indicated. This extensive information can be displayed in table form for the clicked marker so that the map is not overloaded with complex visualizations. Nevertheless, the map and accident-related information can be viewed simultaneously. The information window lists the classification features and their respective values. This gives the user an easy overview of the accident. Details from the database enable reconstruction of the accident. Meaningful descriptions replace coded values in the database, allowing users unfamiliar with statistical office accident statistics to understand the information describing the accident.
Another difficulty was the low-threshold communication of the influences of this accident information. We developed a concept to address the following user question: How did the lighting conditions at the time of the accident affect the likelihood of serious injuries?
Influencing factors describe how individual features influence the probability of a class in the classification. Depending on whether they have increased or decreased the probability of accident severity for the model, these influencing factors can be positive or negative. The number of influencing factors determines how much a feature influences the prediction. To provide users with a simple approach to understanding these factors, they are indicated by symbols in the list of accident information next to each feature. Rather than indicating the influence as a percentage, arrows were used to visualize the direction of influence (downward arrows ”↓” express a negative influence on the prediction, and upward arrows ” ↑” express a positive influence). This relative indication of influences simplifies traceability in an ML classification. In addition, features with the largest SHAP values (i.e., the features with the greatest influence) are marked with a double arrow. This allows users to identify the most influential features without examining the exact SHAP values.
The dynamic dashboard enables users to select and analyze class-specific local SHAP values. Selecting a different accident class automatically updates the symbols and diagrams. Thus, the composition of the model's influencing factors can be read and compared directly. Figure 19 shows a screenshot of the dashboard.
Users are gradually introduced to increasingly detailed and comprehensive information on local ML decisions, culminating in the complete display of waterfall and decision plots (see Figure 20 and Figure 21). Here, experts can view all values simultaneously. However, it should be noted that a potential user has no prior knowledge of ML classifications and therefore cannot understand the specified class probabilities and SHAP values. In extreme cases, this could lead the user to interpret the specified influencing factors as the importance of a feature for accident severity in the real world. It is not sufficiently communicated that the calculated influencing factors only affect an ML prediction and do not affect the actual cause of the accident.
The work primarily focused on creating a concept for calculating and visualizing the semi-global influencing factors of spatial data sets. This concept was confirmed through a practical application. This concept made it easy to identify misclassifications and their respective semi-global influencing factors. The dashboard made it possible to analyze how the machine learning (ML) decision was made. This allows for many subsequent investigations, such as those of accident data provided by federal and state statistical offices. As discussed in Chapter 2, accidents must be described by relevant characteristics. During publication, information such as the exact date and details about the individuals involved (e.g., age, gender, and driving experience) or possible drug or alcohol influences was removed. Other details, such as weather conditions, the number of people involved, speeds, and road data, were generalized or summarized. The absence of these proven relevant influencing factors can lead to a simpler, and therefore less meaningful, model. Important accident characteristics were not considered when training the ML model. This has resulted in either incorrect correlations between the accident data or information gaps in the accident description. These issues become apparent when analyzing the model using SHAP. For example, misclassified accidents in which the severity of the accident was incorrectly stated as fatal instead of minor disproportionately influenced the feature "Involvement of another means of transport" (e.g., truck, bus, or streetcar), since motor vehicles were predominantly involved in fatal accidents (see Figure 4a). The model, which was trained using German accident data, can only predict accident severity based on the 13 accident features. This resulted in information gaps in the data. Consequently, accidents involving serious injuries were classified the same as those involving minor injuries. Due to the small number of features, the model could not assign accidents to the correct severity level. The high misclassification rate of the trained ML model demonstrates this. In this context, the use of freely available OpenStreetMap (OSM) data also requires critical consideration. Since OpenStreetMap (OSM) relies on the voluntary collection of data by its users, the completeness and timeliness of the data are not assured. This primarily refers to the completeness of a road's properties, rather than the road network. It is necessary to investigate whether additional information could further improve quality. In addition to additional road characteristics, this includes, above all, weather data and information on those involved in accidents. Efficient approaches to data enrichment must be developed, as well as new sources of information. Additionally, we must check whether an ML model can handle greater data complexity. It was found that the MLP-NN did not produce improved predictions with the additional road class as a feature in the training. Investigating more complex ML models may also be necessary to determine their suitability for predicting accident severity.
Figure 20.
Visualisierung eines Unfalls mittels Karte und Informationsfenster im Web-Dashboard.
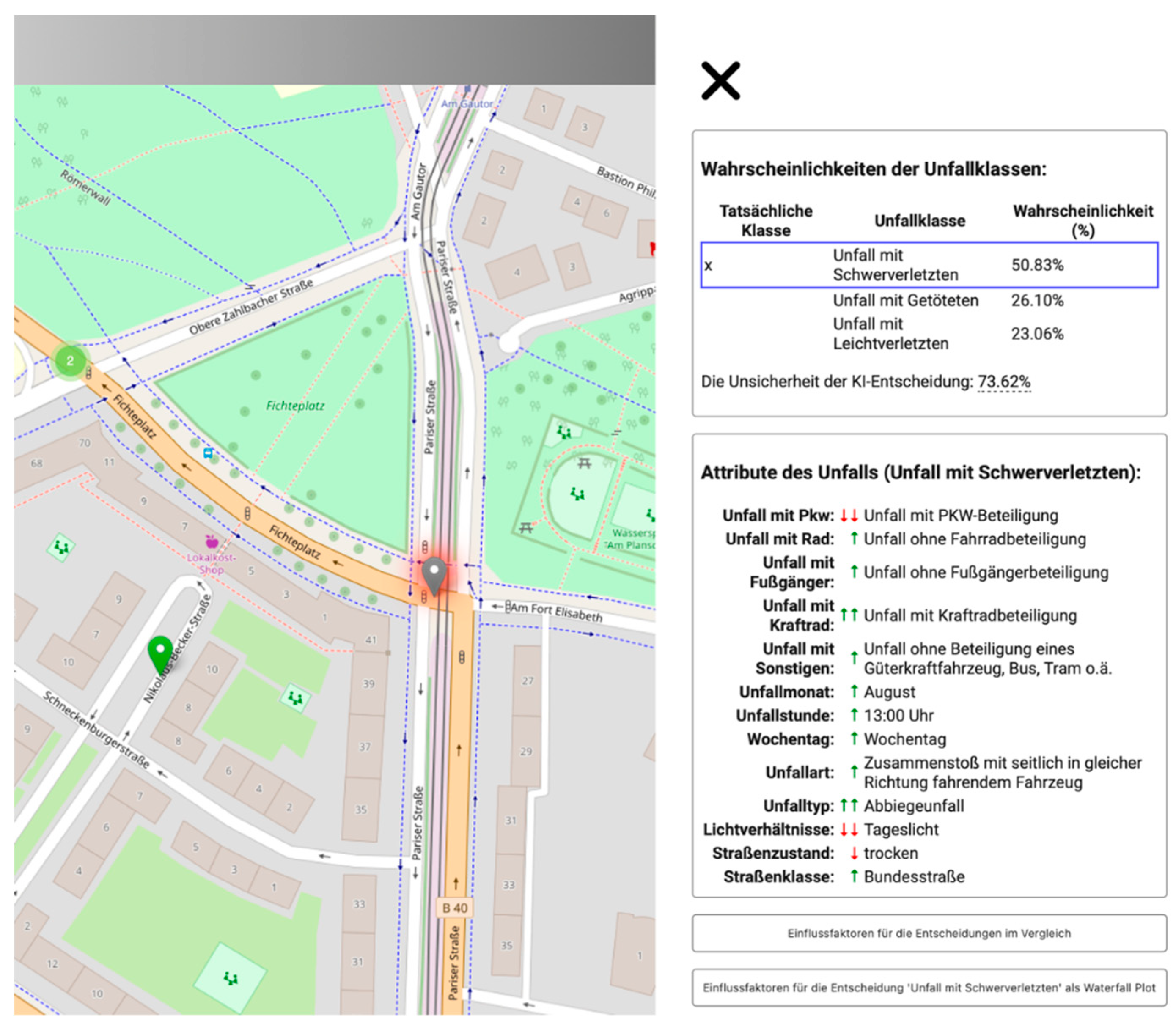
Figure 21.
Waterfall plot in the web dashboard to visualize the local factors influencing the forecast: Persons seriously injured.
Figure 21.
Waterfall plot in the web dashboard to visualize the local factors influencing the forecast: Persons seriously injured.
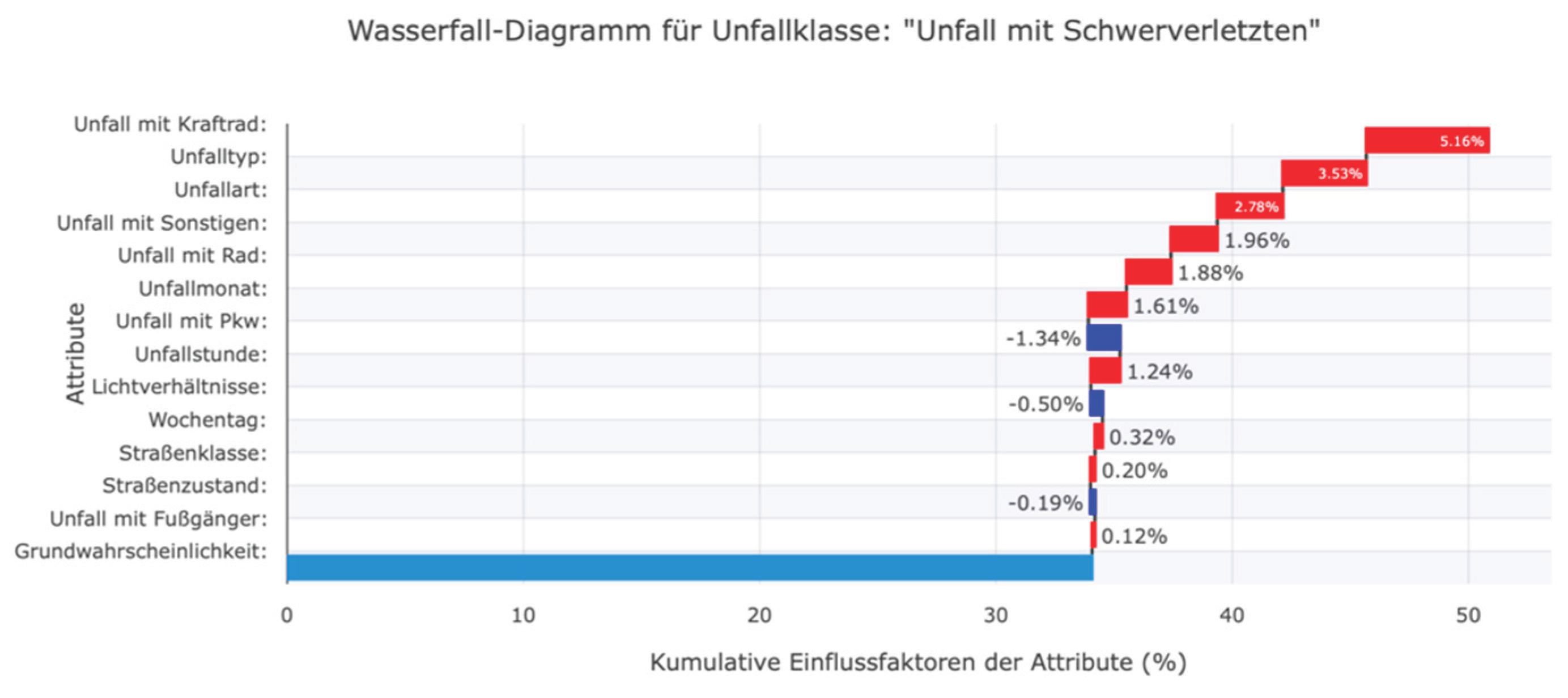
Figure 22.
Decision plot in the web dashboard to compare the factors influencing the accident classes.
Figure 22.
Decision plot in the web dashboard to compare the factors influencing the accident classes.
The use of unbalanced accident data quickly made a sampling approach necessary. Unlike other studies, we employed a combination of Undersampling and oversampling. While this was the only way to distinguish between the individual accident classes, the combination of the few categorical features and the unbalanced distribution resulted in poorer outcomes than those of other studies, such as Satu et al. (2018) and Pourroostaei Ardakani et al. (2023). This could be related to the conservative "macro averaging" assumed for the calculation.
Thanks to the dashboard, it is possible to conduct deeper investigations into the factors that influence ML decisions. The spatial and thematic breakdowns of the data enabled a thorough investigation of the accident data and the classifier.
6. Conclusions and Future Work
This chapter summarizes the results of the work and offers a glimpse into future projects based on them.
Conclusion
The paper introduces a concept that offers deeper insights into spatial influencing factors. Semi-global influencing factors reveal the decision-making processes of machine learning (ML) models in a simple way. This concept makes spatial data analyzable using Geo-Glocal XAI techniques.
We applied the concept to a practical use case. This involved the data-based analysis of accident data. The goal was to identify factors that affect the severity of traffic accidents. Accident data is highly interdependent and complex. It is difficult to derive correlations between accident data and accident severity. This data set was ideal for applying the concept.
We trained an XGBoost classifier using accident data to predict accident severity. Machine learning (ML) models recognize data-based patterns that human analysis may have missed. We used the XAI SHAP approach to make the complex relationships between these ML decisions comprehensible. The semi-global influencing factors derived from this approach made it possible to identify spatial patterns. An interactive confusion matrix helped avoid the typical shortcomings of global SHAP visualizations. These detailed influencing factors will serve as a foundation for future analyses and model improvements by accident researchers, urban and transportation planners, and ML experts. A dashboard with intuitive visualizations and map integration presents the results in a user-friendly way, allowing transparent navigation through the influencing factors.
Future Work
The work dealt with the spatial visualization of the semi-global influencing factors in the form of diagrams. A dynamic map in combination with an interactive confusion matrix enabled the analysis. This work lays the foundation for implementing extended visualization options of the influencing factors for complex predictions such as accident severity with the help of maps. It is necessary to identify the advantages of map-based visualization and to develop concepts for visualization. This is the only way to present the extensive data in a comprehensive and easily understandable way using maps. For example, the local SHAP values of a feature or the features with the greatest influence on an ML prediction relate to a road network. This coded road network can be used for further analyses, as the information it contains would provide a basis for identifying spatial distributions of influencing factors. In addition to the distribution, the regional influences of individual features could also be represented spatially. This would allow more in-depth analyses: “In which parts of the city is the probability of a serious accident increased by bicycle involvement, and in which is it reduced?”. However, the transferability of these approaches to the severity of accidents in Mainz was only possible to a limited extent in this study. The greatest difficulty was the spatial distribution of accidents in Mainz. Areas in the city center are very strongly influenced by many accidents, whereas accidents in the outer areas of the city would have a very large radius of influence.
Funding
This research was funded by the Carl Zeiss Foundation, grant number P2021-02-014.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original data presented in the study are openly available at https://unfallatlas.statistikportal.de/
Acknowledgments
The research for this paper is part of the AI-Lab at Mainz University of Applied Sciences, which is part of the project “Trading off Non-Functional Properties of Machine Learning” at the Johannes-Gutenberg-University Mainz. The Carl Zeiss Foundation funds it.
Conflicts of Interest
The authors declare no conflict of interest.
| 1 |
https://www.openstreetmap.org (letzter Zugriff: 10.05.2025) |
| 2 |
https://github.com/shap/shap (letzter Zugriff: 10.05.2025) |
References
- Abdulhafedh, A. Road Crash Prediction Models: Different Statistical Modeling Approaches. Journal of Transportation Technologies 2017, 7, 190–205. [Google Scholar] [CrossRef]
- Abellán, J.; López, G.; de Oña, J. Analysis of traffic accident severity using Decision Rules via Decision Trees. Expert Systems with Applications 2013, 40(15), 6047–6054. [Google Scholar] [CrossRef]
- Amorim, B. D.; Firmino, A. A.; Baptista, C. D.; Júnior, G. B.; Paiva, A. C.; Júnior, F. E. A Machine Learning Approach for Classifying Road Accident Hotspots. ISPRS International Journal of Geo-Information 2023, 12(6). [Google Scholar] [CrossRef]
- Bellman, R. E. Adaptive Control Processes; Princeton University Press, 1961. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press, 2016; Available online: https://www.deeplearningbook.org/.
- Lord, D.; Mannering, F. The statistical analysis of crash-frequency data: A review and assessment of methodological alternatives. Transportation Research Part A: Policy and Practice 2010, 44(5), 291–305. [Google Scholar] [CrossRef]
- Lundberg, S. M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J. M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.-I. From local explanations to global understanding with explainable AI for trees. Nature Machine Intelligence 2020, 2(1), 56–67. [Google Scholar] [CrossRef] [PubMed]
- Mahajan, T.; Singh, G.; Bruns, G. An experimental assessment of treatments for cyclical data. 2021, 6, 1–6. Available online: https://scholarworks.calstate.edu/downloads/pv63g5147.
- O’Sullivan, C. SHAP for Categorical Features. Towardsdatascience.Com. 21 June 2022. Available online: https://towardsdatascience.com/shap-for-categorical-features-7c63e6a554ea.
- Parsa, A. B.; Movahedi, A.; Taghipour, H.; Derrible, S.; Mohammadian, A. Toward safer highways, application of XGBoost and SHAP for real-time accident detection and feature analysis. Accident Analysis & Prevention 2020, 136, 105405. [Google Scholar] [CrossRef]
- Pourroostaei Ardakani, S.; Liang, X.; Mengistu, K. T.; So, R. S.; Wei, X.; He, B.; Cheshmehzangi, A. Road Car Accident Prediction Using a Machine-Learning-Enabled Data Analysis. Sustainability 2023, 15(7). [Google Scholar] [CrossRef]
- Pradhan, B.; Sameen, M. I. Pradhan, B., Ibrahim Sameen, M., Eds.; Review of Traffic Accident Predictions with Neural Networks. In Laser Scanning Systems in Highway and Safety Assessment: Analysis of Highway Geometry and Safety Using LiDAR; Springer International Publishing, 2020; pp. 97–109. [Google Scholar] [CrossRef]
- Roussel, C. Visualization of explainable artificial intelligence for GeoAI. Frontiers in Computer Science 2024, 6–2024. [Google Scholar] [CrossRef]
- Roussel, C.; Böhm, K. Geospatial XAI: A Review. ISPRS International Journal of Geo-Information 2023, 12(9). [Google Scholar] [CrossRef]
- Roussel, C.; Böhm, K. Introducing Geo-Glocal Explainable Artificial Intelligence. IEEE Access 2025, 13, 30952–30964. [Google Scholar] [CrossRef]
- Satu, M.; Ahamed, S.; Hossain, F.; Akter, T.; Farid, D. Mining Traffic Accident Data of N5 National Highway in Bangladesh Employing Decision Trees. 2018. [Google Scholar] [CrossRef]
- Shaik, Md. E.; Islam, Md. M.; Hossain, Q. S. A review on neural network techniques for the prediction of road traffic accident severity. Asian Transport Studies 2021, 7, 100040. [Google Scholar] [CrossRef]
- Statistische Ämter des Bundes und der Länder Gesellschaft und Umwelt—Verkehrsunfälle. Opengeodata.Nrw.De. 21 June 2021. Available online: https://www.destatis.de/DE/Themen/Gesellschaft-Umwelt/Verkehrsunfaelle/_inhalt.html#238550.
- Statistisches Bundesamt. Verkehrsunfälle Grundbegriffe der Verkehrsunfallstatistik. Destatis.De. 2022. Available online: https://www.destatis.de/DE/Themen/Gesellschaft-Umwelt/Verkehrsunfaelle/_inhalt.html#238550.
- Statistisches Bundesamt. Gesellschaft und Umwelt—Verkehrsunfälle. Destatis.De. 2025. Available online: https://www.destatis.de/DE/Themen/Gesellschaft-Umwelt/Verkehrsunfaelle/_inhalt.html#238550.
- Tambouratzis, T.; Souliou, D.; Chalikias, M.; Gregoriades, A. Combining probabilistic neural networks and decision trees for maximally accurate and efficient accident prediction. In Proceedings of the International Joint Conference on Neural Networks (p. 8). 2010. [Google Scholar] [CrossRef]
- Zeng, Q.; Huang, H. A stable and optimized neural network model for crash injury severity prediction. Accident Analysis & Prevention 2014, 73, 351–358. [Google Scholar] [CrossRef]
Figure 1.
Novel concept for the derivation of semi-global influencing factors.
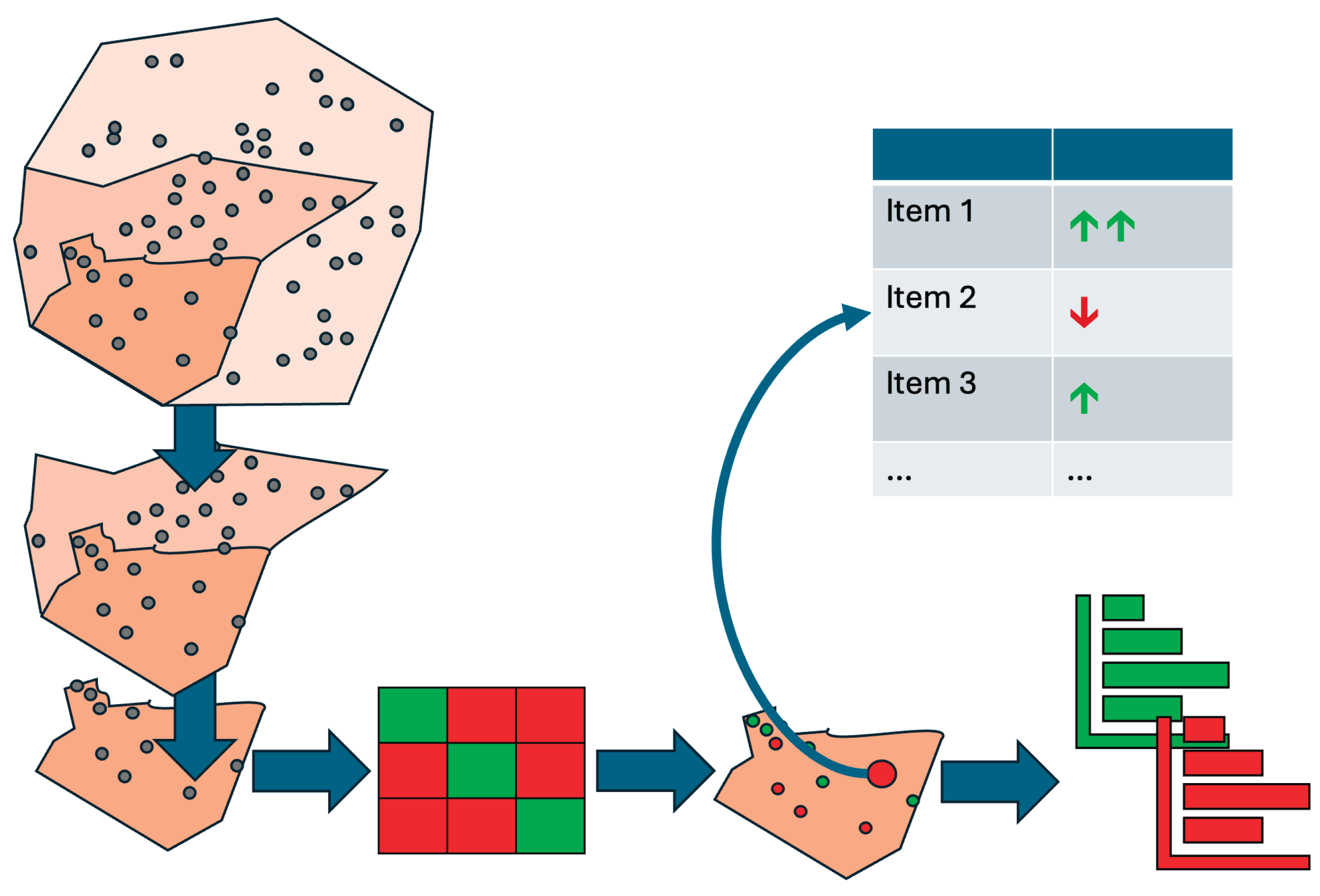
Figure 2.
The classification results of XGBoost using the German data as a training basis are shown in the confusion matrices. This was done without considering the class distribution or the road classes.
Figure 2.
The classification results of XGBoost using the German data as a training basis are shown in the confusion matrices. This was done without considering the class distribution or the road classes.
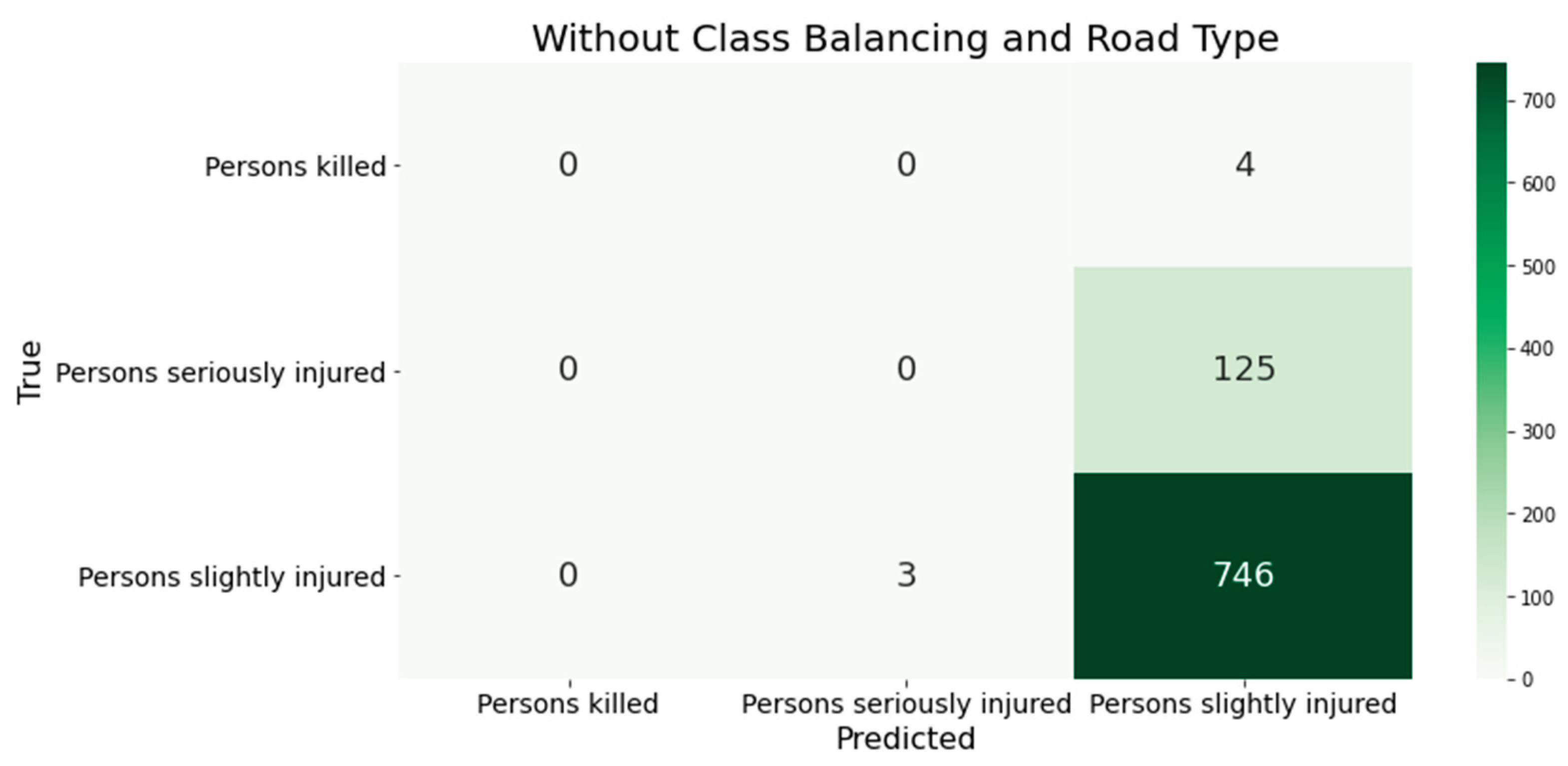
Figure 3.
The classification results of XGBoost using the German data as a training basis are shown in the confusion matrices. This was done after adjusting the class distribution in the training data. (Without road class.).
Figure 3.
The classification results of XGBoost using the German data as a training basis are shown in the confusion matrices. This was done after adjusting the class distribution in the training data. (Without road class.).
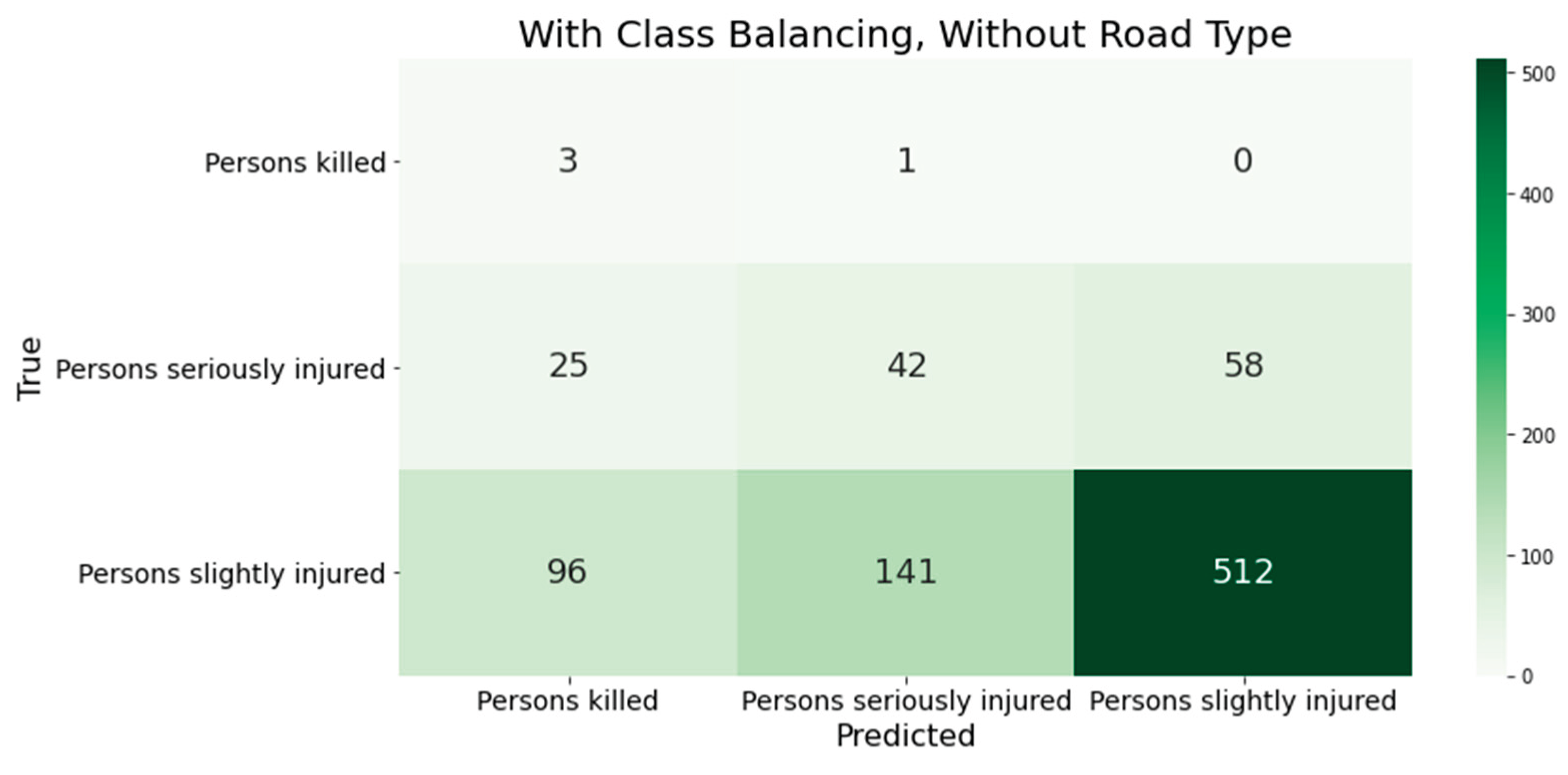
Figure 4.
The classification results of XGBoost using the German data as a training basis are shown in the confusion matrices. This was done after adjusting the class distribution in the training data. It was enriched with the road class.
Figure 4.
The classification results of XGBoost using the German data as a training basis are shown in the confusion matrices. This was done after adjusting the class distribution in the training data. It was enriched with the road class.
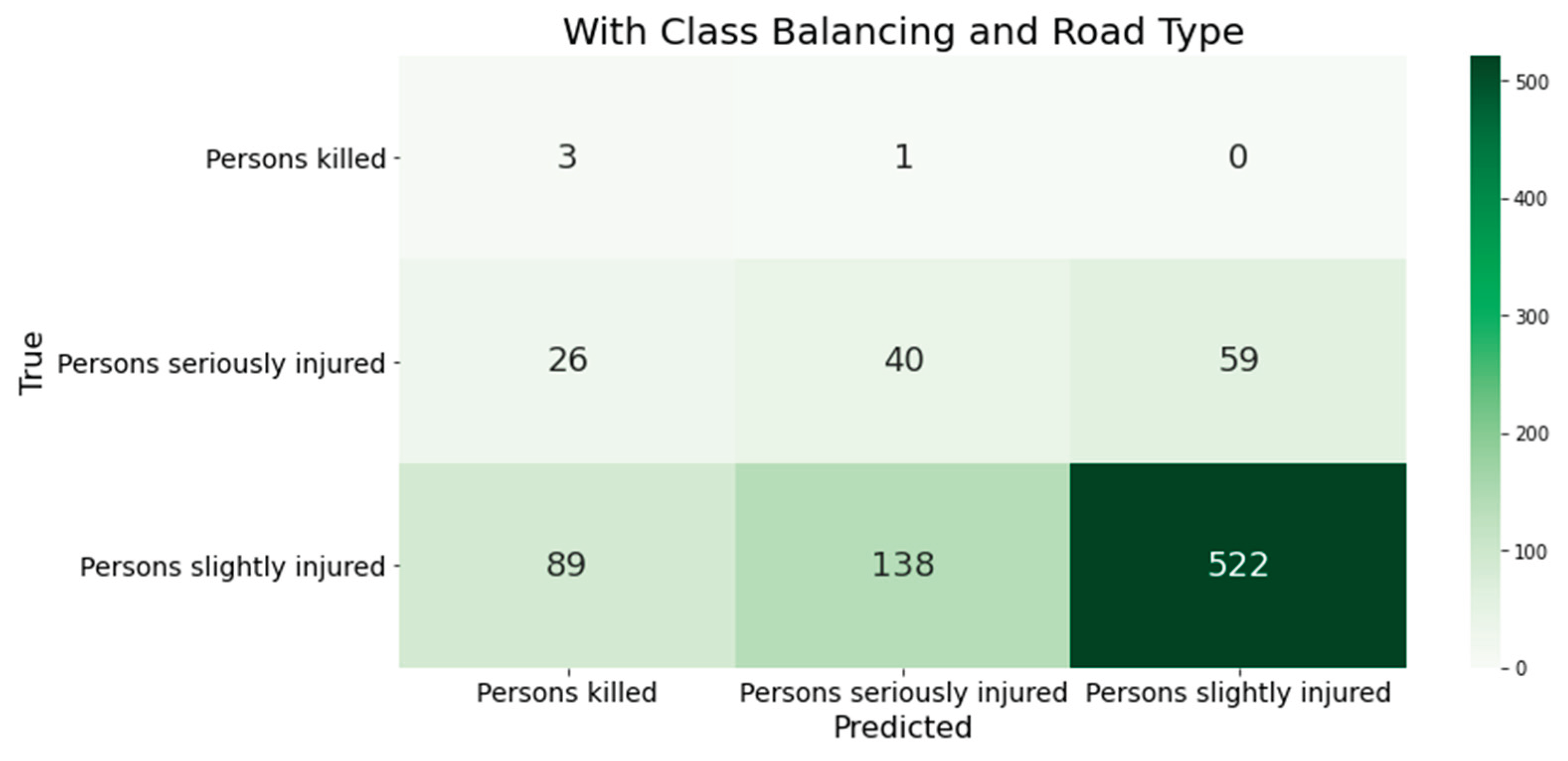
Figure 5.
The factors influencing an ML prediction are visualized using waterfall plots of the three accident severities (e.g., "Persons killed").
Figure 5.
The factors influencing an ML prediction are visualized using waterfall plots of the three accident severities (e.g., "Persons killed").
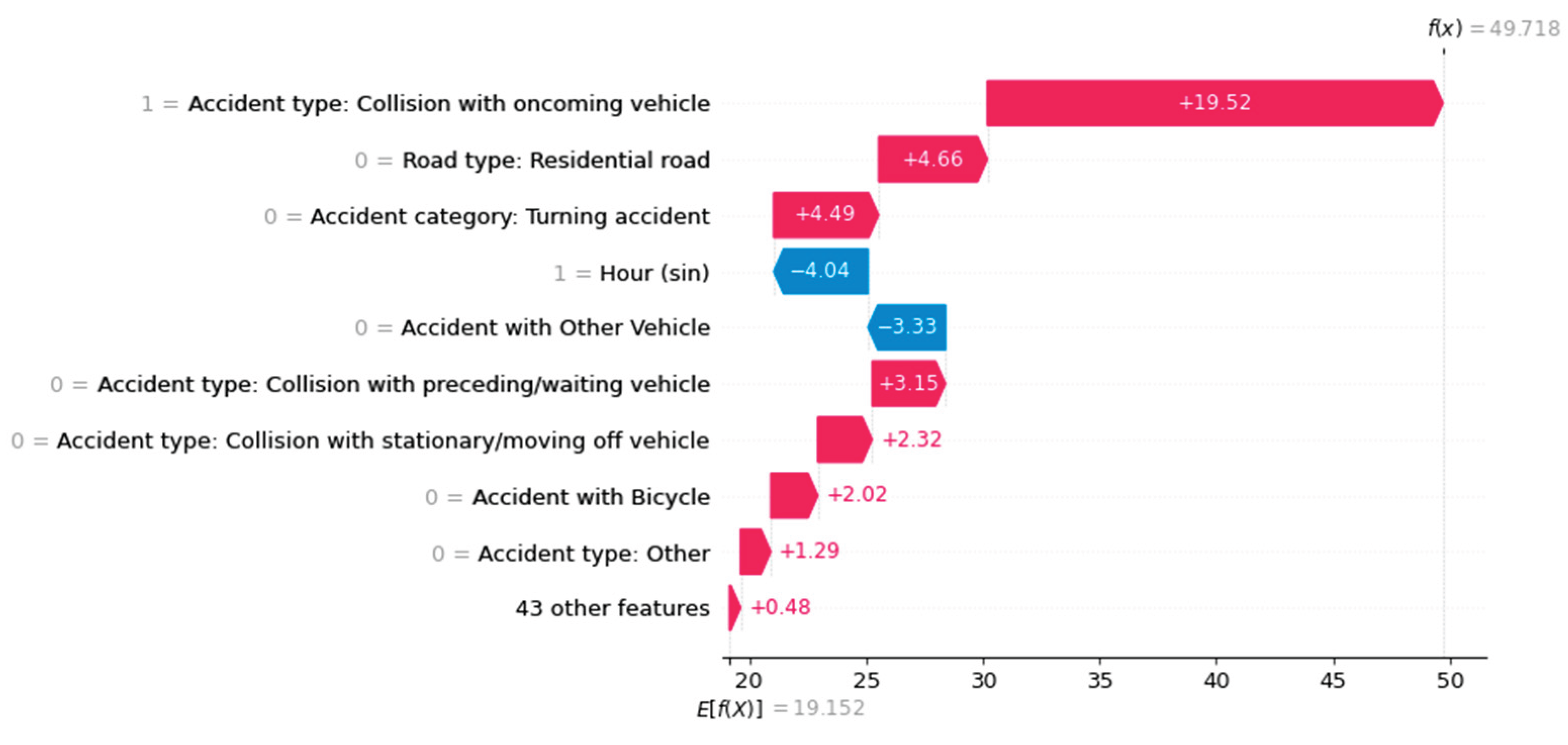
Figure 6.
The factors influencing an ML prediction are visualized using waterfall plots of the three accident severities (e.g., "Persons seriously injured").
Figure 6.
The factors influencing an ML prediction are visualized using waterfall plots of the three accident severities (e.g., "Persons seriously injured").
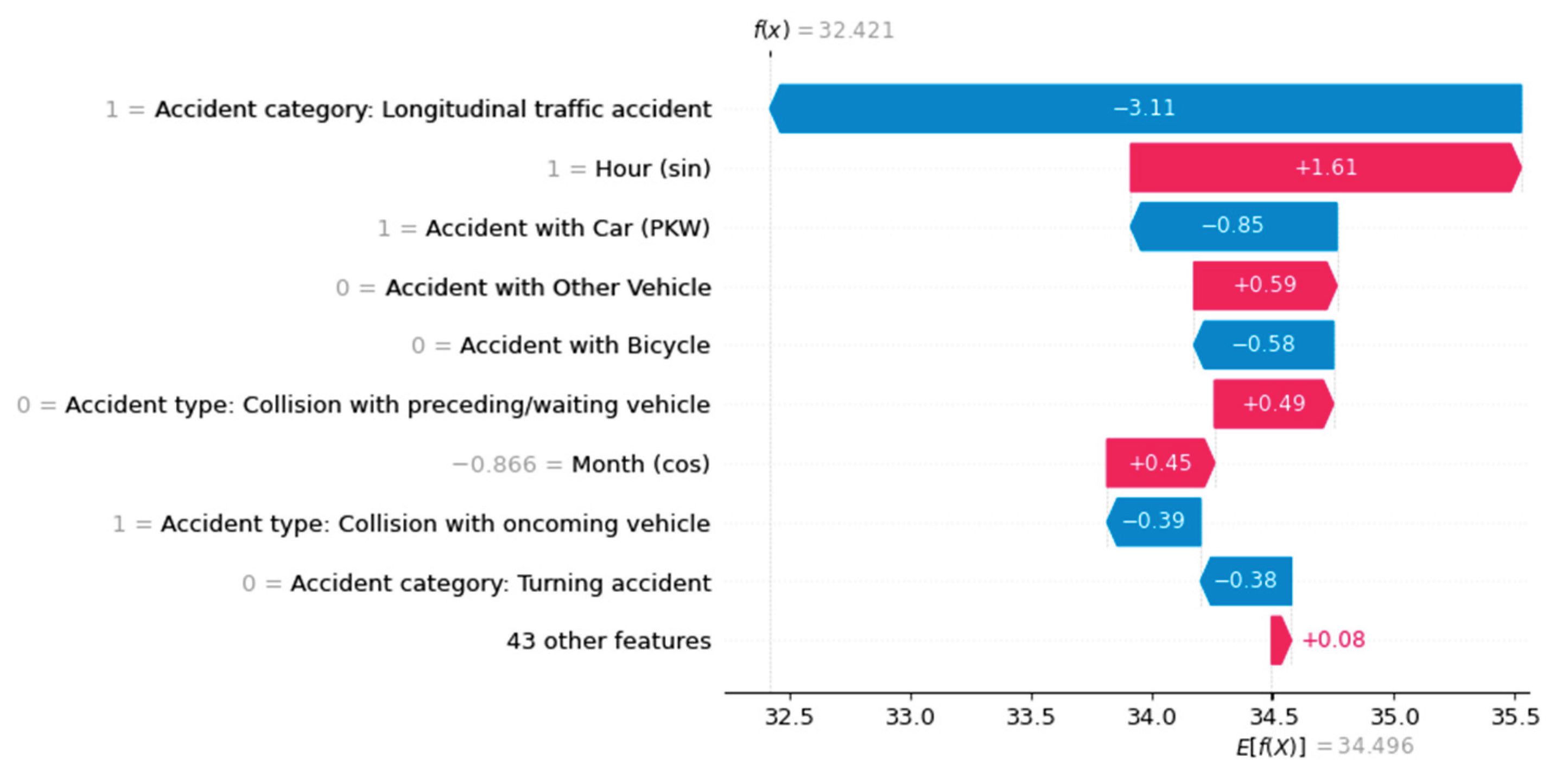
Figure 7.
The factors influencing an ML prediction are visualized using waterfall plots of the three accident severities (e.g., "Persons slightly injured").
Figure 7.
The factors influencing an ML prediction are visualized using waterfall plots of the three accident severities (e.g., "Persons slightly injured").
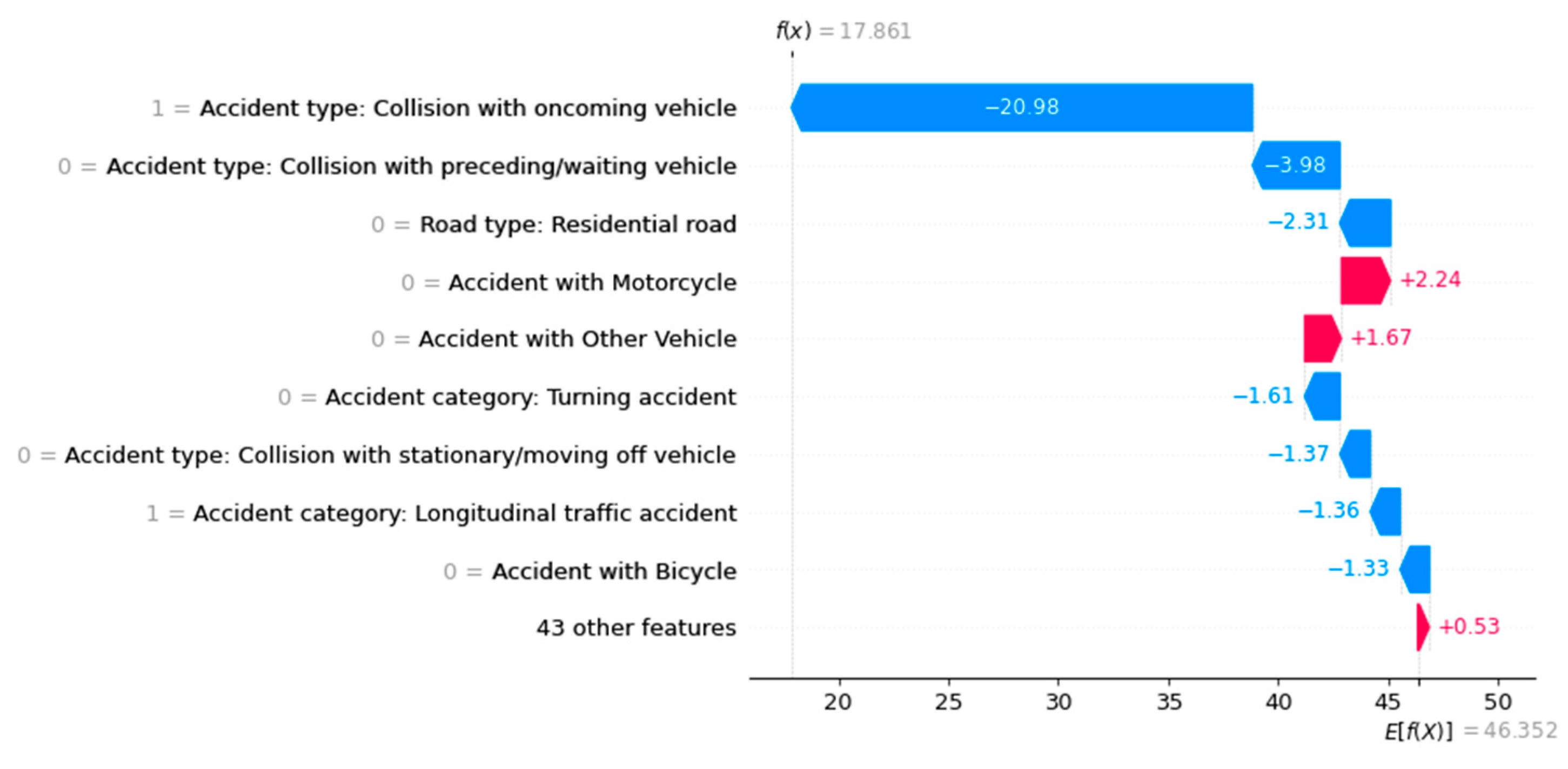
Figure 8.
Waterfall plot with logit values. This is before the processing step of adding the categorical features.
Figure 8.
Waterfall plot with logit values. This is before the processing step of adding the categorical features.
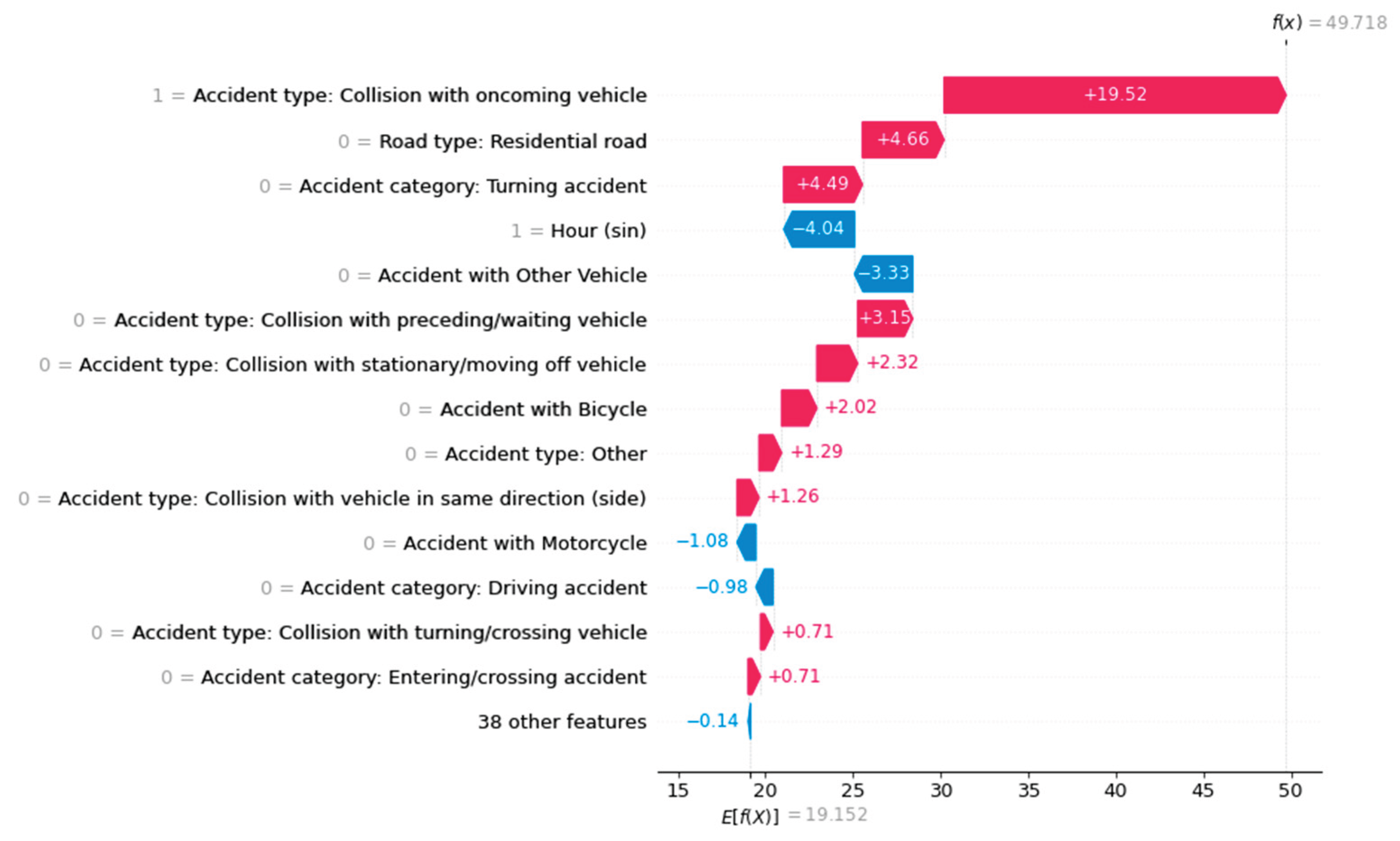
Figure 9.
Waterfall plot with logit values. This is after the processing step of adding the categorical features.
Figure 9.
Waterfall plot with logit values. This is after the processing step of adding the categorical features.
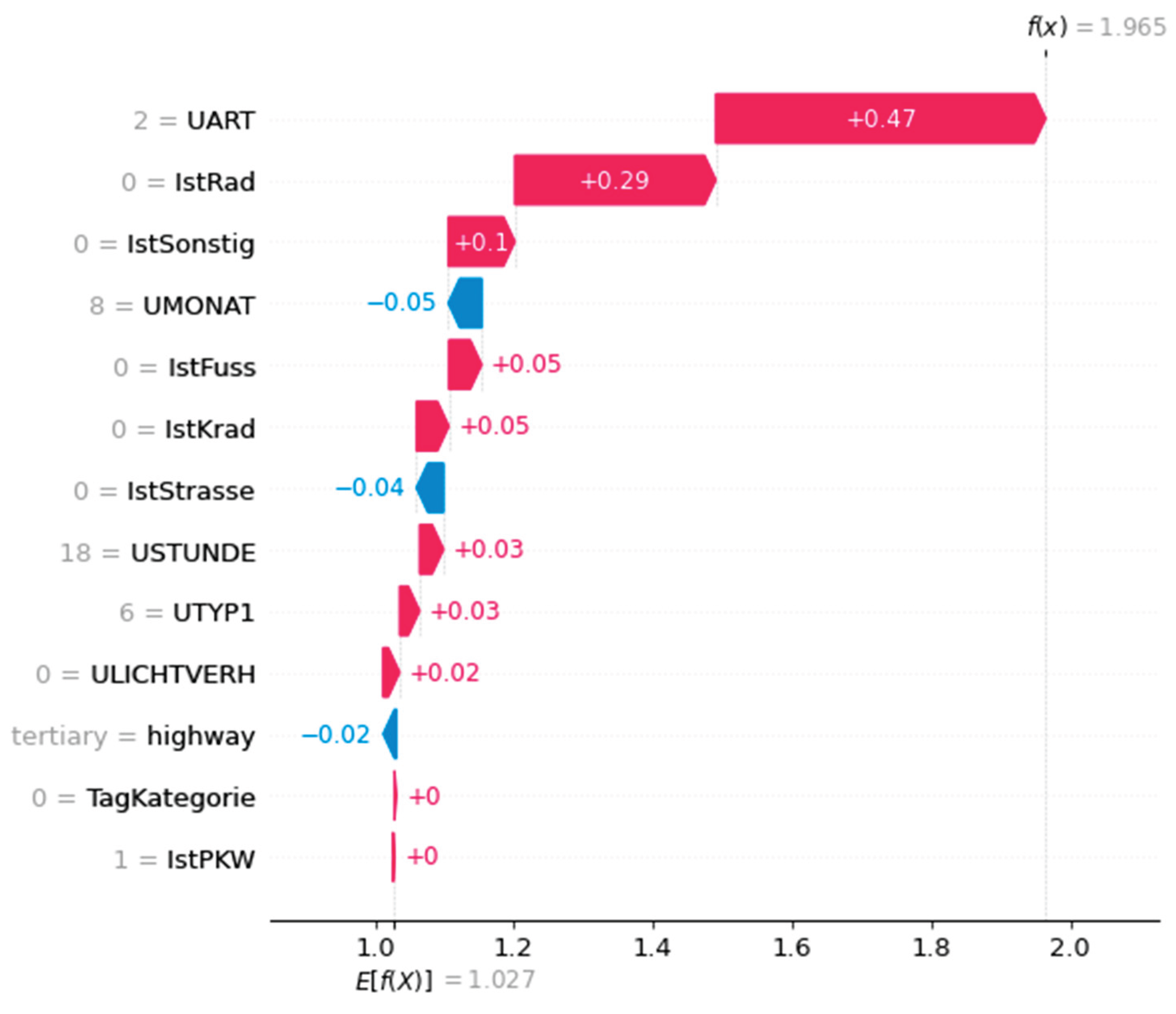
Figure 10.
Beeswarm-Plot zur globalen Betrachtung von Einflussfaktoren auf die Vorhersage: “Persons killed”.
Figure 10.
Beeswarm-Plot zur globalen Betrachtung von Einflussfaktoren auf die Vorhersage: “Persons killed”.
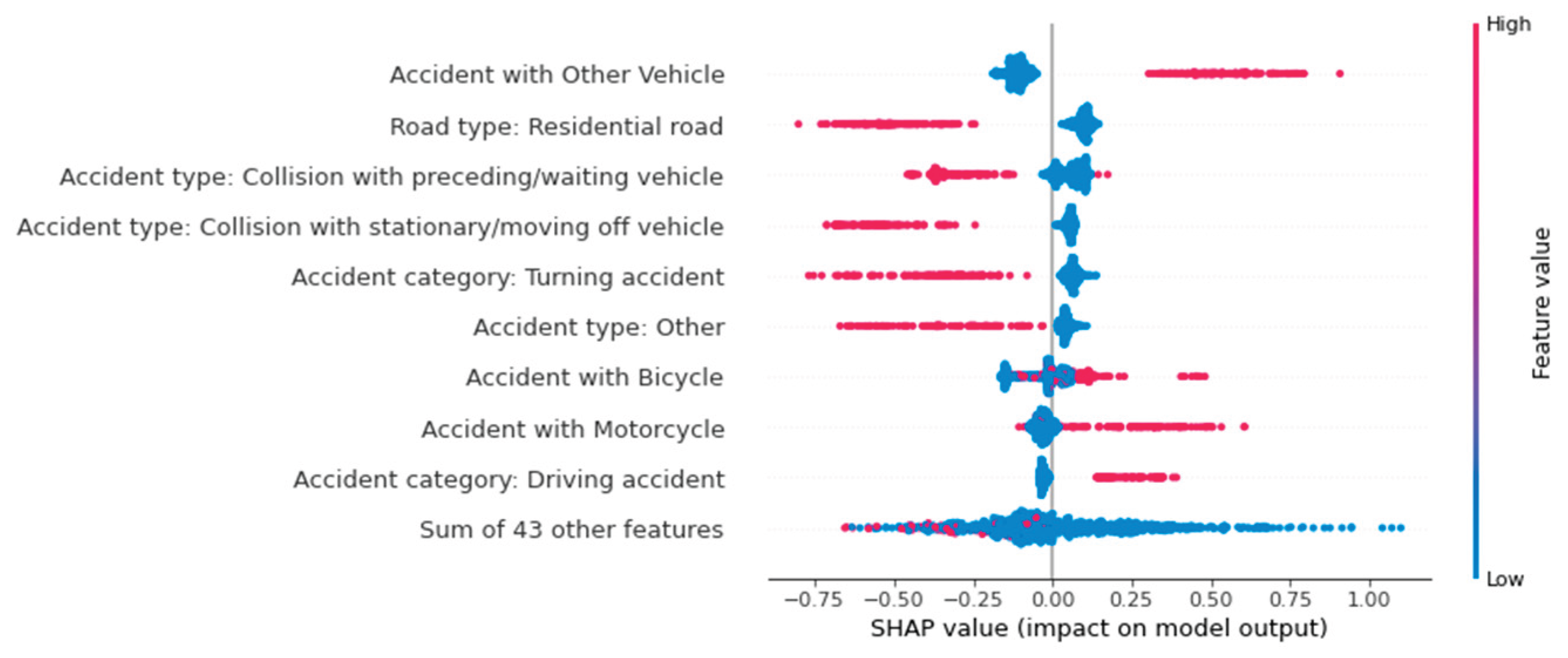
Figure 11.
The Beeswarm plot considers factors that influence the prediction globally. “Persons seriously injured”.
Figure 11.
The Beeswarm plot considers factors that influence the prediction globally. “Persons seriously injured”.
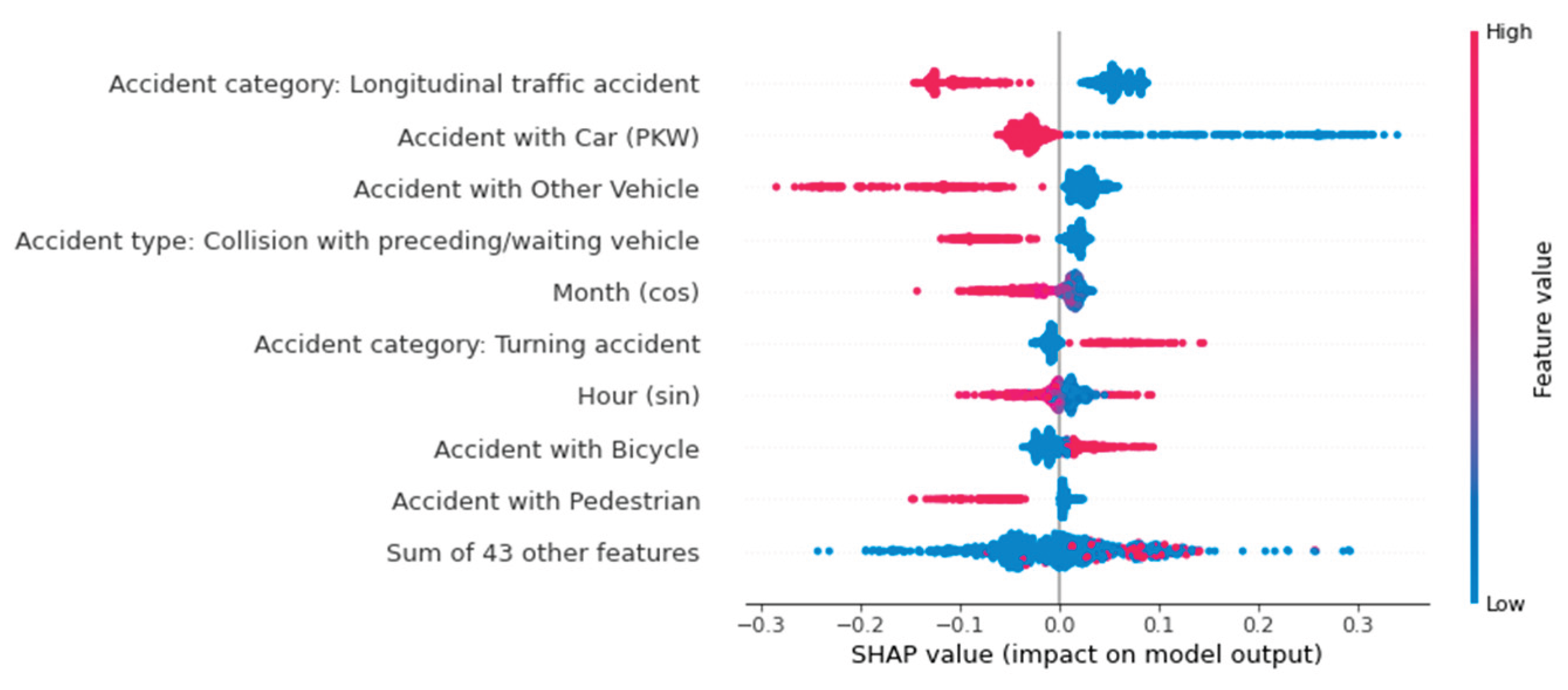
Figure 12.
The Beeswarm plot considers factors that influence the prediction globally. “Persons slightly injured”.
Figure 12.
The Beeswarm plot considers factors that influence the prediction globally. “Persons slightly injured”.
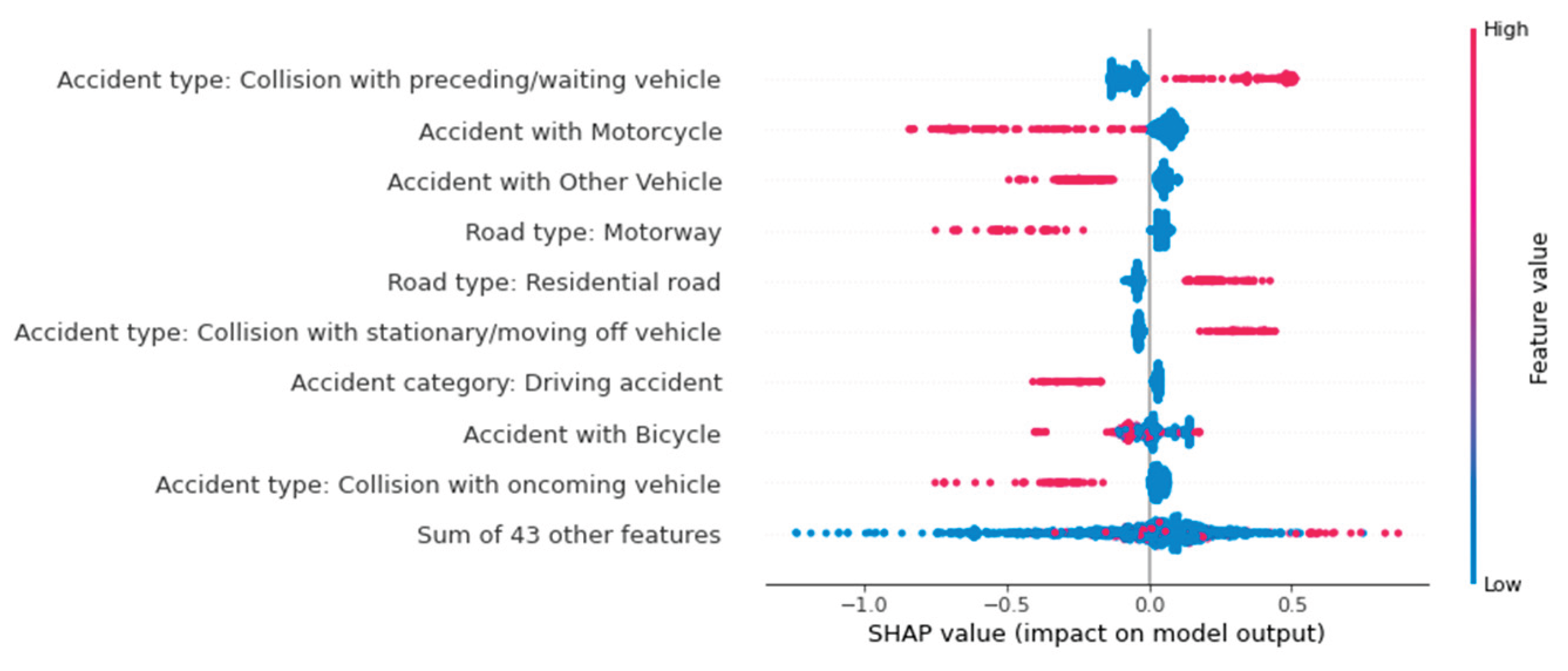
Figure 16.
Übersichtskarte im Web-Dashboard. Zu Beginn zeigt die Karte die Mainzer Stadtteile an. Ein ausklappbares Menü ermöglicht es dem Nutzer, die Daten zu filtern.
Figure 16.
Übersichtskarte im Web-Dashboard. Zu Beginn zeigt die Karte die Mainzer Stadtteile an. Ein ausklappbares Menü ermöglicht es dem Nutzer, die Daten zu filtern.
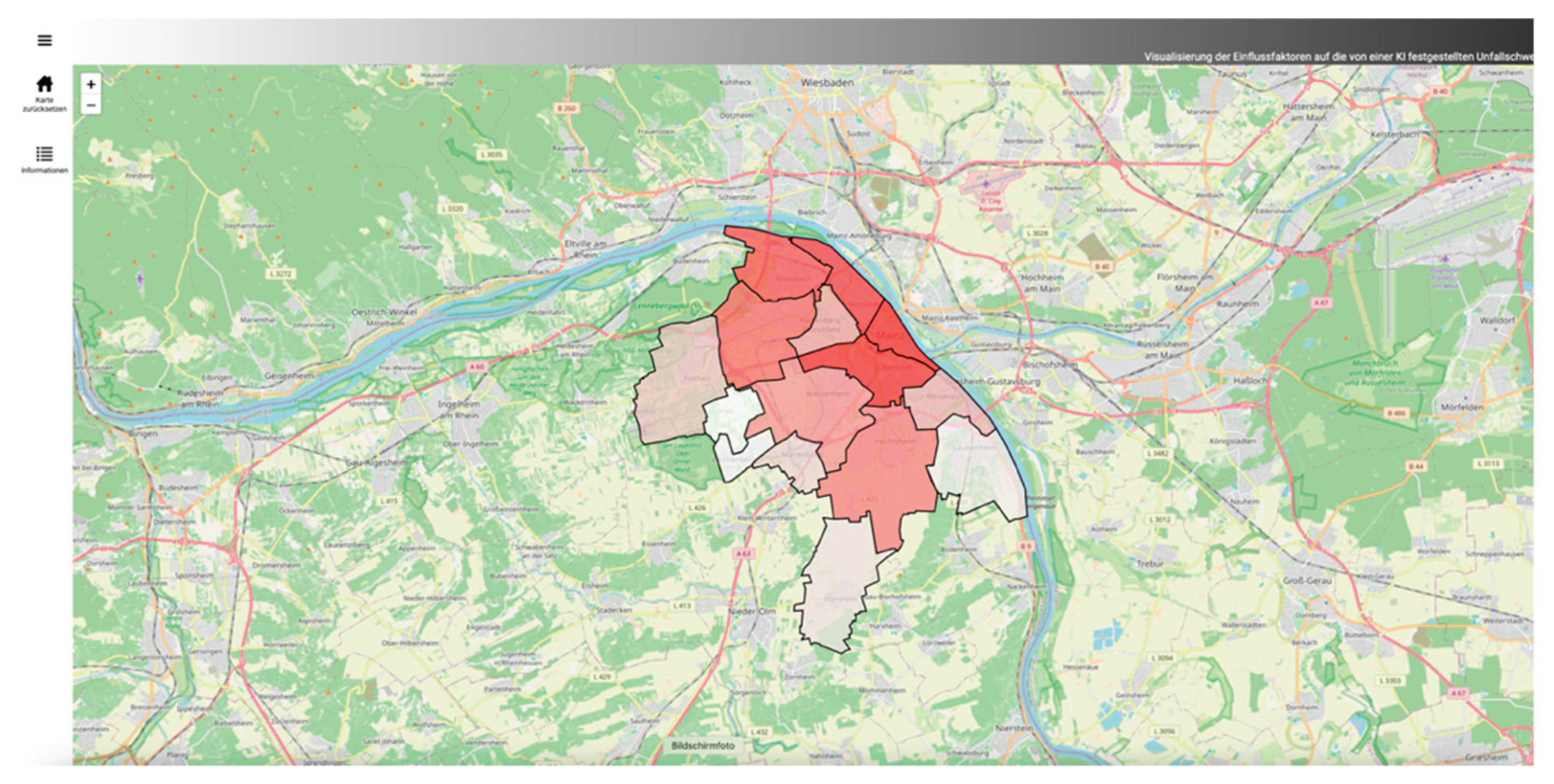
Figure 17.
The district overview summarizes all accidents in an area. In this case, it is the Neustadt district. In addition to the spatial distribution, you can view the error measures of the accidents in the district. Further navigation is possible using the interactive confusion matrix.
Figure 17.
The district overview summarizes all accidents in an area. In this case, it is the Neustadt district. In addition to the spatial distribution, you can view the error measures of the accidents in the district. Further navigation is possible using the interactive confusion matrix.
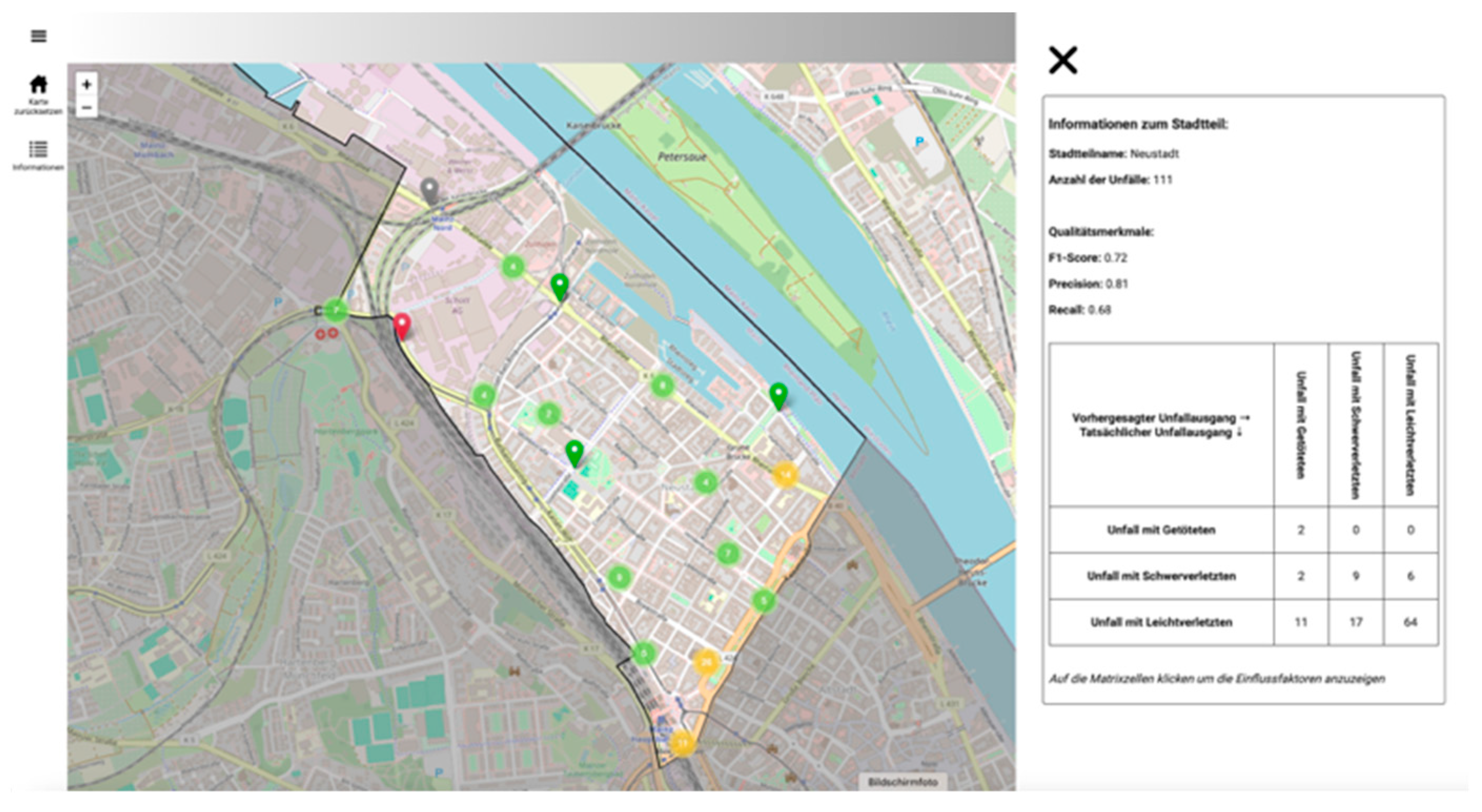
Figure 18.
This bar plot shows the influencing factors in the Neustadt district for the misclassification of accidents with minor injuries that were predicted to be accidents with serious injuries.
Figure 18.
This bar plot shows the influencing factors in the Neustadt district for the misclassification of accidents with minor injuries that were predicted to be accidents with serious injuries.
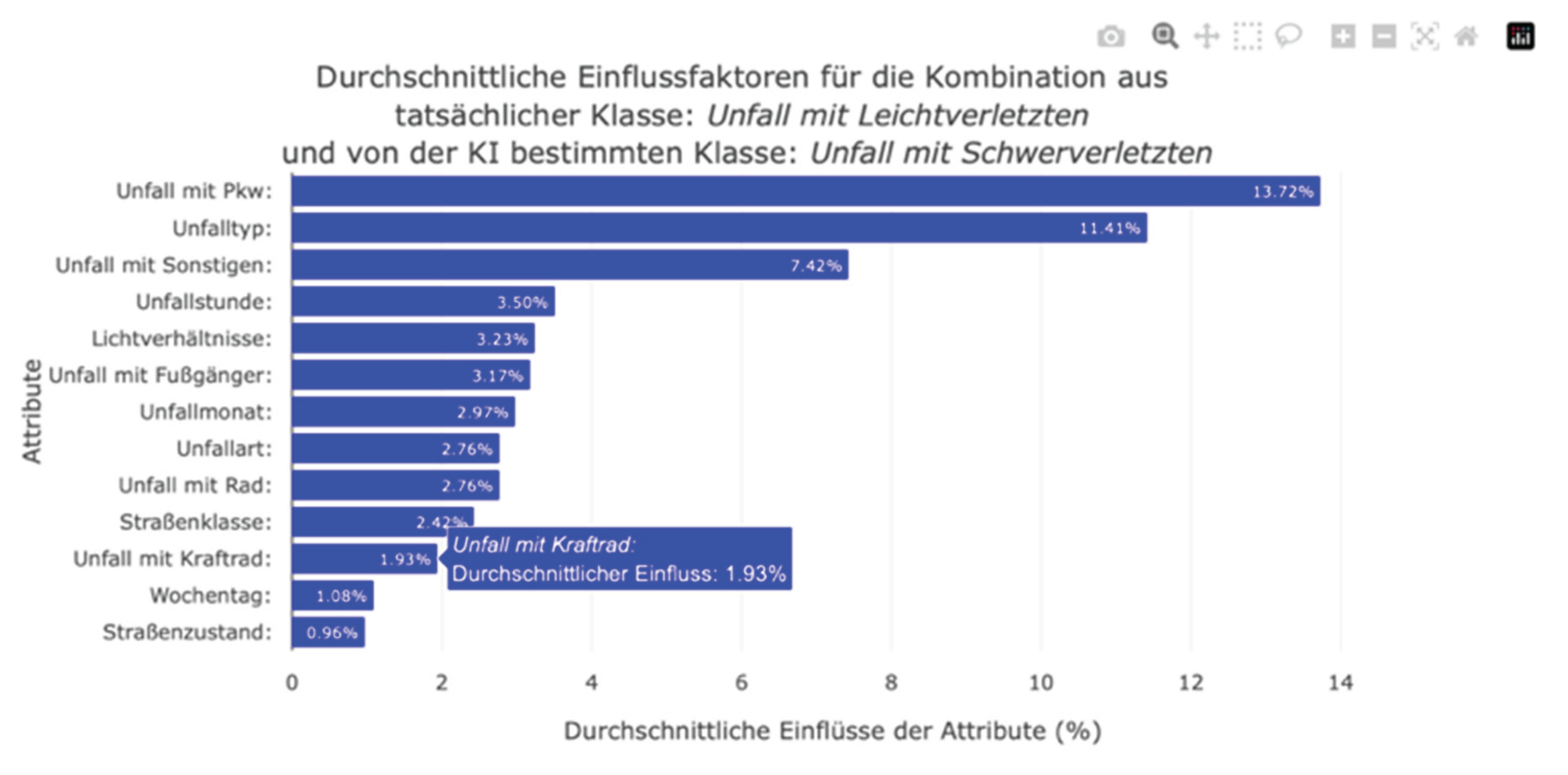
Figure 19.
A Beeswarm plot is used to visualize the individual influencing factors in the Neustadt district. This plot also takes into account the actual and predicted classes.
Figure 19.
A Beeswarm plot is used to visualize the individual influencing factors in the Neustadt district. This plot also takes into account the actual and predicted classes.
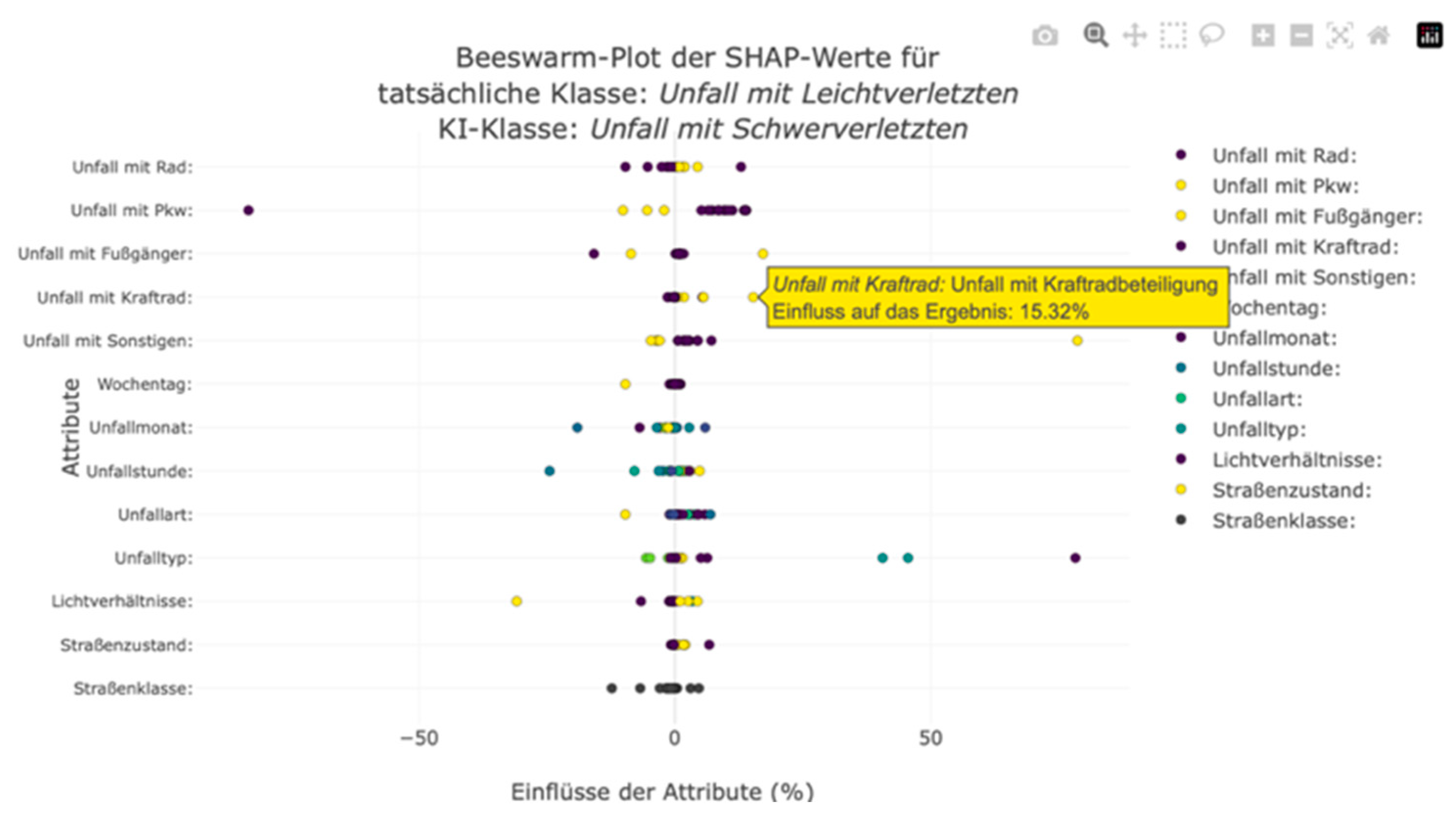

Table 1.
A list of features in a standardized format for accident data, as provided by statistical offices.
Table 1.
A list of features in a standardized format for accident data, as provided by statistical offices.
| Feature Name | Data type |
|---|---|
| Servity | categorical feature (1-3) |
| Accident with Bicycle | binary feature |
| Accident with Car (PKW) | binary feature |
| Accident with Pedestrian | binary feature |
| Accident with Motorcycle | binary feature |
| Accident with Other Vehicle | binary feature |
| Day of Week | categorical feature (1-7) |
| Month | categorical feature (1-12) |
| Hour | categorical feature (0-23) |
| Accident type | categorical feature (0-9) |
| Accident category | categorical feature (1-7) |
| Lighting condition | categorical feature (0-2) |
| Road condition | categorical feature (0-2) |
| Road type | categorical feature (1-11) |
Table 2.
Error measures of the MLP-NN and XGBoost models, with and without consideration of the sampling approach and additional road class.
Table 2.
Error measures of the MLP-NN and XGBoost models, with and without consideration of the sampling approach and additional road class.
| Klassifikator | Balancierte Daten? | Mit Straßenklasse? | Genauigkeit | F1-Score | Recall | Precision |
|---|---|---|---|---|---|---|
| XGBoost | Nein | Nein | 85% | 30,6% | 33,2% | 28,4% |
| MLP-NN | Nein | Nein | 85% | 30,6% | 33,3% | 28,4% |
| XGBoost | Ja | Nein | 63% | 36,4% | 58,9% | 38,3% |
| MLP-NN | Ja | Nein | 64% | 37,5% | 59,9% | 39,7% |
| XGBoost | Ja | Ja | 65% | 37,2% | 59,6% | 38,7% |
| MLP-NN | Ja | Ja | 59% | 35,3% | 51,9% | 38,5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



