Submitted:
15 April 2025
Posted:
17 April 2025
You are already at the latest version
Abstract
As intelligent systems advance, the integration of rule-based logic with transformer-driven neural inference is emerging as a foundational architecture for scalable, explainable AI. This paper explores the shift from static, logic-encoded decision trees to dynamic, context-aware large language models (LLMs), presenting hybrid reasoning systems that combine deterministic control with neural adaptability. We analyze rule-based and transformer-based approaches across key reasoning workflows, supported by architectural diagrams, performance benchmarks, and real-world applications such as policy automation and legal review. Our proposed dual-stream framework illustrates how symbolic validation and generative inference can operate in parallel, enabling trustworthy and adaptable decision-making. The paper also outlines deployment strategies, including tiered inference, observability, and fallback modes, alongside ethical safeguards such as bias audits and transparency checks. These contributions offer a practical blueprint for building hybrid AI systems that are not only performant but also interpretable and governance-ready across diverse enterprise environments.
Keywords:
hybrid reasoning
; rule-based systems
; transformer models
; explainable AI
; LLMs
; neuralsymbolic integration
; decision pipelines
; AI deployment
; policy automation
1. Introduction
Artificial Intelligence (AI) systems have historically evolved through two distinct streams: symbolic reasoning and data-driven learning. Rule-based systems, founded on predefined logic and deterministic structures, provided early AI with clarity, transparency, and predictability. However, their rigidity limited adaptation to ambiguous, unstructured, or evolving environments. The emergence of machine learning introduced flexibility, but often at the cost of interpretability. Today, we are witnessing a convergence of these paradigms, fueled by the advent of large language models (LLMs) capable of mimicking human-like reasoning patterns.
This paper investigates the transformation of intelligent reasoning systems, from traditional symbolic AI to modern transformer-based architectures. Specifically, it focuses on hybrid frameworks that blend the precision of rule-based systems with the contextual understanding offered by LLMs. These systems are not mutually exclusive but complementary, enabling more robust, explainable, and adaptive decision-making pipelines suitable for real-world deployment.
One of the central challenges in reasoning-based AI lies in striking the right balance between control and generalization. While rules ensure consistency and compliance, transformers excel at extracting intent and nuance from messy or incomplete input. Hybrid systems can be designed to harness the strengths of both, enabling decisions that are both explainable and data-aware.
In high-stakes domains such as finance, law, and healthcare, this balance becomes critical. AI must not only make decisions—it must justify them, trace them, and adapt them based on evolving rules and data. The deterministic layer ensures auditability and compliance, while the neural layer introduces adaptability and abstraction. When integrated correctly, these systems outperform either approach in isolation.
The need for hybrid reasoning architectures is further amplified by the rapid deployment of AI agents in enterprise software, chatbots, workflow automation tools, and autonomous systems. As these agents are entrusted with more complex tasks, a purely statistical or purely symbolic approach becomes insufficient. Instead, systems must learn from context, adapt over time, and remain grounded in business rules or safety constraints.
In this paper, we offer both theoretical insight and practical design recommendations for building such hybrid architectures. We explore their evolution, analyze key models, and propose a dual-stream architecture that integrates both reasoning tracks. Furthermore, we introduce diagrams and case studies to illustrate how these designs manifest in real-world settings.
While the paper is technical in nature, it emphasizes usability and deployability. Readers will gain a structured understanding of how to implement hybrid models, integrate validation loops, and manage model lifecycle across CI/CD pipelines. Ethical implications and governance frameworks are also discussed, particularly in light of regulatory constraints on automated decision systems.
Ultimately, our goal is to offer a guiding framework that bridges academic innovation and industrial relevance. By unifying logic and learning, we believe intelligent systems can evolve beyond task-specific tools into adaptive reasoning agents that are transparent, efficient, and trustworthy.
While the excitement around large language models continues to grow, there is a simultaneous need to revisit foundational reasoning structures that shaped earlier AI systems. Rule-based architectures, once seen as limited in scope, offer a level of interpretability and control that is increasingly in demand in today’s regulatory environments. This revival of symbolic reasoning, especially when fused with the generalization capabilities of transformers, creates a powerful hybrid that can adapt to ambiguous inputs while remaining grounded in domain-specific logic. Such duality is crucial in domains like finance, law, and healthcare, where both adaptability and accountability are paramount.
2. Background and Evolution of AI Reasoning Systems
2.1. Rule-Based Systems
Rule-based systems represent one of the earliest forms of artificial intelligence, rooted in symbolic reasoning and expert systems. These systems operate using predefined logic encoded in the form of IF–THEN statements, decision trees, or production rules. Their primary strengths lie in transparency, traceability, and precise control over decision-making workflows [1].
Historically, rule-based models were widely adopted in sectors like legal compliance, banking, and software engineering. For instance, automated decision trees were used to evaluate risk, validate insurance claims, or screen code against industry standards [2]. Their strength lies in their ability to encode domain-specific policies with high fidelity.
However, rule-based systems often suffer from brittleness. As soon as an input deviates from the predefined rule set or requires contextual interpretation, such systems fail to generalize. Updating them becomes increasingly complex as the number of rules grows, and maintaining them across evolving regulations can result in technical debt.
In modern AI pipelines, rule engines still serve an important purpose—particularly as validation layers. They act as deterministic checkpoints that enforce governance constraints, filter out invalid outputs, and guarantee traceability in hybrid pipelines. These capabilities make rule systems indispensable in high-compliance environments even today [3].
2.2. Emergence of Transformers in Reasoning
The introduction of the Transformer architecture by Vaswani et al. revolutionized the field of AI reasoning by enabling models to capture long-range dependencies via self-attention mechanisms [4]. Initially developed for language translation, transformers have since demonstrated strong reasoning capabilities across question answering, code generation, and summarization tasks.
Unlike symbolic systems, transformers are data-driven and learn contextual relationships from large-scale corpora. This endows them with high adaptability and generalization across ambiguous or unstructured data domains. For example, models like CodeBERT and CodeT5 have proven effective for tasks like function summarization, syntax repair, and semantic search in code [5].
Additionally, research on multilingual and open-ended code generation models such as CodeGeex has pushed the frontier further, enabling large-scale reasoning across diverse programming languages and natural language prompts [6]. These models can learn patterns without explicit rules, leveraging the statistical structure of data to infer intent.
Despite their strengths, transformers present challenges. They are resource-intensive, require massive datasets, and often behave as black boxes. Their lack of inherent interpretability makes them less suitable for standalone deployment in regulated sectors [7].
To overcome these limitations, modern reasoning architectures increasingly integrate transformers with rule-based validators or logic overlays. In such hybrid systems, transformers generate candidate outputs which are then validated, pruned, or corrected by symbolic reasoning engines—bringing the best of both worlds [8].
Table 1 provides a structured comparison between rule-based and transformer-based reasoning models across several key dimensions. These include interpretability, adaptability, learning mechanisms, and maintenance overhead. While symbolic approaches offer clarity and enforce business constraints explicitly, neural models provide scalability and contextual flexibility across languages and modalities [9].
The architectural complementarity between these paradigms forms the basis for emerging hybrid AI systems. In such systems, transformer models generate candidate outputs using learned representations, while rule-based components verify, refine, or reject those outputs based on logic constraints and policy conditions [10]. This dual-layer design ensures that the reasoning process remains both flexible and accountable.
The convergence of these paradigms is shaping modern AI. Enterprise pipelines now increasingly rely on dual-mode architectures that incorporate both pretrained transformer models and symbolic validators for safety and reliability. This layered approach ensures robust, flexible, and auditable decision-making systems fit for deployment at scale.
3. Architectural Blueprint: Designing Hybrid Reasoning Pipelines
Designing a hybrid reasoning pipeline requires harmonizing the deterministic logic of rule-based systems with the contextual intelligence of transformer-based models. Rather than viewing these systems as competitors, modern architectures treat them as complementary agents that address each other’s weaknesses.
At a high level, the hybrid pipeline is composed of two distinct but interconnected streams. The first stream is responsible for rule validation, ensuring compliance and deterministic decision-making where necessary. The second stream focuses on contextual inference, leveraging the power of pretrained language models to extract meaning and intent from diverse inputs.
This separation of duties improves modularity and system clarity. For example, in applications such as code transformation, a transformer model like CodeGen can suggest a function refactor, while a rule-based layer verifies it against coding guidelines or business rules [11]. Such interaction prevents the neural model from producing technically correct but logically invalid outputs.
Each stream operates within its own logic scope. The symbolic stream processes explicitly defined triggers and constraints, while the transformer stream works probabilistically on patterns learned from data. This duality not only reduces failure risk but also enhances trust in the AI’s recommendations, as emphasized in recent architectural explorations of hybrid reasoning systems [12].
The architectural blueprint also includes a synchronization module that ensures coherence between the two streams. This component handles conflicts and determines which stream takes precedence in ambiguous situations. For instance, in high-risk domains like finance or law, the rule engine can override generative responses when a violation is detected.
Additionally, transformers can be trained to align with rule logic during fine-tuning. This minimizes the divergence between freeform output and policy expectations. As transformer models improve through continual learning, they can offload some symbolic tasks, enabling rules to shift focus toward compliance boundaries rather than core logic evaluation.
Figure 1 illustrates a dual-stream architecture where both symbolic and neural pathways process input data in parallel before reconciling results via a fusion layer. This design enables the system to generate context-aware outputs while ensuring that rule constraints are never violated. This architectural convergence strengthens explainability, allowing symbolic rules to scaffold transformer outputs while maintaining formal oversight—a design goal emphasized in prior hybrid reasoning frameworks [13].
The parallel design also aids in scalability. Each stream can be optimized independently—for instance, lightweight rule engines can run on edge devices while LLM inference is performed in the cloud. This modularity is particularly useful in federated environments and IoT use cases [14].
Overall, this blueprint enables enterprises to move beyond monolithic AI into orchestrated, explainable systems. Hybrid models are no longer experimental; they are critical for real-world applications where both accuracy and accountability are mandatory.
The dual-stream architecture also supports graceful degradation in real-world deployments. If the transformer inference engine fails due to connectivity issues, overload, or unsupported input structure, the system can fall back on the rule-based stream to deliver a safe, though less adaptive, response. This redundancy is especially valuable in mission-critical environments like avionics, cybersecurity, and healthcare diagnostics.
Furthermore, this architecture is extensible across domains. In document intelligence, for instance, transformer models can extract semantic metadata while rule engines validate schema integrity and compliance. Similarly, in DevOps pipelines, transformer-based agents can auto-generate deployment scripts, while rule systems verify naming conventions, secrets management, or regulatory clauses. The blueprint thus not only bridges two reasoning paradigms but also provides a scalable foundation for building robust, explainable AI workflows across industries.
4. LLM-Powered Evaluation and Control Loops
As transformer-based systems become central to modern AI workflows, ensuring their reliability and accountability has become a critical challenge. This is especially true in high-stakes domains such as finance, healthcare, and policy automation, where incorrect or biased outputs can lead to real-world consequences.
Modern architectures increasingly embed LLMs within feedback-oriented evaluation loops. These loops allow outputs generated by the LLM to be continually reviewed, scored, and refined based on dynamically updated criteria—mimicking how humans iteratively improve decisions through observation and feedback.
The feedback loop acts as a governance mechanism, introducing checkpoints where predictions can be validated against domain constraints, user expectations, or evolving policy rules [15]. These evaluation layers ensure that intelligent outputs remain both controllable and traceable.
A compelling real-world example of this design is found in financial platforms like Intuit’s AI-driven tax assistants, which leverage LLMs to parse and interpret natural language tax queries. While the transformer agent recommends deductions or risk flags, a rule-based audit module concurrently validates the output against IRS guidelines. This ensures compliant decision-making while maintaining conversational flexibility.
One of the core advantages of these loops is dynamic model steering. If a generated output violates constraints—such as exceeding risk thresholds or missing schema validation—corrective signals are fed back into the LLM inference pipeline. In doing so, the system refines future outputs without retraining the model [16].
These loops also support differential handling of low-confidence responses. For example, responses below a certain confidence threshold may be routed through an extended evaluation path, trigger fallback rules, or be reviewed by a human-in-the-loop. This mitigates over-reliance on opaque predictions and enables more robust deployments in sensitive environments.
Figure 2 illustrates a feedback pipeline where LLM-generated outputs are evaluated and refined in real time. If outputs breach pre-defined policies, the loop adapts inference parameters dynamically—improving future predictions without architectural retraining.
Such feedback loops are also essential for scaling ethical governance. Rather than modifying model weights, organizations can simply adjust evaluation thresholds or input constraints. This provides a lightweight yet effective method for enforcing safety, fairness, and regulatory alignment across evolving enterprise deployments.
5. Case Study: Policy Automation and Risk Assessment
The increasing adoption of intelligent systems in policy enforcement domains—such as regulatory compliance, risk analysis, and automated decision-making—has led to a pressing need for frameworks that blend transparency with adaptability. This case study explores the application of hybrid reasoning pipelines in both financial and legal sectors, showcasing how symbolic and neural logic can co-exist to support scalable, accountable AI.
Traditionally, policy engines relied on rule-based systems to enforce predefined governance logic. These systems provide clear audit trails and regulatory compliance, making them a trusted solution in industries with strict oversight. However, their inability to generalize to ambiguous or unseen inputs limits flexibility, especially in dynamic policy environments.
Transformer-based architectures, in contrast, excel at interpreting unstructured inputs and identifying hidden risk signals. By learning patterns from large-scale corpora, they can infer anomalies, context-specific flags, and policy violations not explicitly coded in traditional rule logic.
The hybrid model brings these paradigms together: transformer agents generate candidate insights or decisions, which are then validated or pruned by rule-based engines. This architecture ensures that neural creativity remains bounded by regulatory constraints, enabling both adaptability and control.
In the financial domain, for instance, hybrid systems are used for transaction monitoring. The LLM layer analyzes transaction metadata and free-text notes to infer contextual risk—such as mentions of sanctioned regions or suspicious justifications—while the rule engine validates numeric thresholds and entity flags. This dual validation ensures comprehensive coverage of both structured and unstructured risk indicators.
In legal automation, hybrid models power intelligent contract review platforms. LLMs scan contract clauses for context, tone, and exceptions, highlighting areas that may violate company policy or jurisdiction-specific law. The symbolic engine cross-checks these findings against pre-approved clause libraries, flagging discrepancies and ensuring legal traceability. This dual approach enables faster, more accurate contract assessments while maintaining legal defensibility.
To ensure reproducibility and model fairness, all LLM components in this study were evaluated against standard test suites such as CodeXGLUE [15], which offer benchmarks for code understanding and generation tasks. The consistent comparison across models such as CodeT5, CodeBERT, and CodeGen revealed reliability variations under complex input conditions—especially for multilingual and identifier-rich examples.
We further conducted a performance comparison across several key metrics relevant to policy automation and legal review. Table 2 summarizes these findings.
As shown in Table 2, rule-based systems retain an edge in auditability and compliance. Their deterministic logic and transparent rules facilitate external audits and reproducible outputs [17]. However, transformer-based models demonstrate clear advantages in adaptability and content generalization—particularly in use cases with diverse linguistic inputs or policy evolution [7].
By combining both, organizations unlock the strengths of each: the consistency and audit readiness of symbolic systems with the versatility and inference power of LLMs. Hybrid pipelines thus offer an ideal framework for real-world policy enforcement and contract governance.
To further enhance contextual accuracy, CodeT5 was included in the evaluation for its identifier-aware pretraining and balanced encoder-decoder architecture [18]. Its performance in legal-text parsing and abstract syntax interpretation reinforces its utility in enterprise-grade policy and compliance platforms.
6. Deployment Strategy and Operational Integrity
Deploying hybrid reasoning systems at scale introduces unique engineering and governance challenges. While the architecture may be theoretically robust, operationalizing it demands seamless integration with infrastructure, security, observability, and failover strategies to support enterprise-grade use cases.
A primary concern is infrastructure compatibility. Rule-based systems often run in legacy environments with version-locked APIs and deterministic runtimes, whereas transformer-based modules benefit from GPU acceleration, containerized deployment, and distributed serving. Bridging these environments requires standardized interfaces and orchestration via platforms like Kubernetes and OpenShift, enabling parallel scaling across rule logic and LLM inference.
Latency and throughput considerations also shape the deployment topology. In time-sensitive domains like finance and healthcare, decisions must often be made within milliseconds. Rule engines excel with consistent low-latency response times, while transformers may experience variability due to input complexity and model size. To address this, hybrid pipelines deploy rule-based engines on edge devices, reserving LLM computation for cloud-tiered services where resource-intensive inference can occur asynchronously or in batch windows.
A practical example can be found in modern **clinical decision support systems**. Here, a hybrid AI pipeline assists doctors by generating contextual suggestions from patient notes using an LLM while simultaneously validating drug interactions and dosage thresholds via rule-based systems. In real-time hospital settings, such a system can reduce prescription errors while maintaining auditability and compliance with HIPAA or FDA guidelines.
Operational observability is critical in such deployments. Logs from both reasoning streams must be aggregated to form a unified trace of how decisions were made. Tools like OpenTelemetry and Datadog are commonly integrated to track token usage, rule hits, validation skips, and fallback paths. These metrics feed into service-level agreements (SLAs), anomaly detection systems, and human audit trails.
Security considerations span both code and data. Rule engines may expose deterministic logic vulnerable to manipulation, while LLMs may require secure access to pretrained weights, external APIs, or embeddings. Sandboxed inference runtimes, encrypted configuration maps, and prompt sanitization are key mitigation measures. Inputs from users or APIs should be routed through identity checks and intent classifiers to prevent prompt injection or leakage.
Validation governance must also be transparent and extensible. Platforms like OpenReview offer real-time version control and peer-reviewed updates, demonstrating how deployment changes can be logged and verified by external stakeholders [19]. In regulated environments, incorporating similar principles into AI pipelines fosters auditability, reproducibility, and public trust.
A tiered deployment model offers further resilience. Systems may operate in three dynamic modes: fully rule-based (fail-safe), hybrid (normal production), and LLM-only (exploratory mode for R&D teams). Each mode includes routing rules, rollback logic, and audit logging for compliance continuity.
Figure 3 illustrates a production-grade deployment pipeline for hybrid reasoning. User or API requests pass through a secure gateway, are routed to both reasoning streams, and synchronized in the Decision Integrator. This component applies conflict resolution, priority handling, and fallback execution logic before producing a final action.
Historical foundations in software reuse and modular AI design continue to shape these deployment strategies. Seminal work in automated software adaptation remains highly relevant for transformer-era infrastructure, particularly in risk-sensitive environments [20].
To further enhance operational integrity, hybrid deployments often include blue/green release strategies for LLM updates, version-locked rule snapshots, and centralized auditing systems. These combined strategies ensure fast, secure, explainable, and adaptive decision-making under diverse operating conditions [5,19].
7. Ethical Risks and Governance Models
As AI systems grow more autonomous and integrated into enterprise and public-sector infrastructures, ethical design is no longer optional—it becomes foundational. Hybrid reasoning systems, which merge rule-based engines with transformer-driven inference, introduce novel capabilities but also bring forth new governance challenges.
One of the most critical concerns is bias. Transformer models trained on vast and uncurated datasets often encode subtle cultural, gender, or socioeconomic biases. These biases may emerge in high-stakes scenarios such as hiring, lending, or medical triage. For instance, LLM-based loan risk assessments may inadvertently favor zip codes with higher socioeconomic indicators, even if such features are not explicitly encoded. On the flip side, rule-based systems, while deterministic, can reflect outdated or oversimplified heuristics. Effective ethical design must account for both statistical and symbolic bias simultaneously [21].
Explainability remains another major challenge. Rule logic is inherently interpretable, but neural model inference is often opaque. Hybrid models mitigate this by layering symbolic validators on top of LLM outputs—adding structure, auditability, and interpretive cues. Post-inference checks ensure decisions can be rationalized in user-facing or compliance contexts [3].
Auditability and reproducibility are equally vital. Rule systems offer consistent logs for each step in the decision tree. However, LLM responses may vary with prompt phrasing or model updates. Governance protocols must archive prompts, input contexts, and inference configurations to ensure traceability across releases and regulatory reviews.
Security adds another dimension to governance. LLMs exposed to public input can become targets for adversarial prompts, prompt injection, or data exfiltration attempts. Mitigation strategies include prompt sanitization, identity checks, and context-aware trust scoring. Additionally, symbolic firewalls can serve as boundary gates to intercept risky or noncompliant inputs before inference [10].
Fairness in fallback logic is an often-overlooked concern. For example, when LLM inference fails or times out, systems may revert to rule-based defaults. If these defaults are not stress-tested for demographic equity, the system may systematically disadvantage certain user groups [8]. Organizations should use fairness audits that simulate edge cases across protected classes to detect such disparities.
Beyond static checks, adaptive governance models are emerging. These integrate feedback loops—such as those described in Section IV—to continuously monitor decisions, detect anomalies, and flag fairness violations in real time. Compliance dashboards, user-facing transparency portals, and runtime explainability modules further extend ethical accountability.
A real-world implementation of this layered governance model is seen in **AI-based public benefits systems**. In such systems, LLMs assess eligibility narratives submitted by citizens, while rule-based logic enforces income and residency constraints. To avoid harm, fairness audits, explainability gates, and human-in-the-loop checkpoints are mandated by frameworks like the **NIST AI Risk Management Framework (AI RMF)**, which promotes transparency, accountability, and bias resilience in federal and enterprise AI deployments.
Figure 4 illustrates a modular governance pipeline for hybrid AI systems. Inputs flow through inference and validation modules, with concurrent bias audits and explainability checks layered for runtime oversight. Each step is logged and auditable, enabling traceability, user trust, and regulatory alignment.
Ultimately, ethical AI governance must remain adaptive. Static constraints eventually become obsolete; unchecked LLM autonomy can lead to drift or manipulation. By integrating deterministic control with neural adaptability—and enforcing runtime monitoring—hybrid architectures strike a balance between innovation and responsibility. They offer a future-proof path for building AI that is not only intelligent but also just and accountable.
8. Conclusions and Future Work
This paper examined the evolution of intelligent reasoning systems, tracing the path from traditional rule-based models to modern transformer-augmented pipelines. We proposed and analyzed a hybrid architecture that fuses symbolic precision with neural adaptability—providing a balanced approach to explainable and scalable AI. Through architectural diagrams, validation strategies, and real-world applications, we demonstrated the practical value and necessity of integrating both paradigms in enterprise workflows.
The shift from deterministic rules to transformer-enhanced logic marks a significant change in how AI systems reason, adapt, and evolve. While rule-based engines offer transparency and compliance, their rigidity limits responsiveness to novel inputs. Conversely, transformers enable dynamic inference at scale but struggle with auditability. By harmonizing both, hybrid architectures deliver resilient decision-making that is both interpretable and context-aware.
Our proposed dual-stream model illustrates how symbolic and statistical reasoning can coexist in real time, with rule-based layers serving as governance checkpoints over LLM-driven outputs. Feedback control loops enable ongoing refinements without full retraining, supporting agile updates and alignment with DevOps practices. These capabilities are essential in dynamic domains such as finance, healthcare, and legal automation.
Policy automation emerged as a key use case, where the hybrid model demonstrated superior adaptability without compromising regulatory trust. Deployment strategies—featuring parallel inference, container orchestration, and layered observability—ensure these systems remain robust under varying loads and constraints.
Ethical and governance considerations, including bias audits, explainability checks, and fallback fairness testing, are critical to maintaining public trust. As AI autonomy grows, these layered safeguards will play a central role in ensuring responsible deployment.
Future research can extend this work by incorporating causal reasoning, memory-augmented transformers, and reinforcement learning agents into hybrid pipelines. Additionally, the development of standardized benchmarks for hybrid AI—covering explainability, latency fairness, and compliance robustness—will be instrumental in guiding adoption across regulated sectors.
As these systems mature, hybrid reasoning architectures are poised to become the blueprint for trustworthy, scalable, and adaptive AI—combining the strengths of symbolic logic and generative intelligence under a unified governance framework.
Acknowledgments
The author expresses sincere gratitude to the global research community for advancing the fields of symbolic AI and transformer-based architectures. Special thanks go to contributors of open-source LLM frameworks, benchmark datasets such as CodeXGLUE, and ethical governance tools that made this comparative study possible. This independent research was conducted without affiliation to any proprietary organization or funding body. All insights reflect the author’s original analysis, informed by publicly accessible academic and technical resources.
References
- Chen, X.; Wang, L.; Shen, A. Rule-based Systems in Software Engineering: Challenges and Opportunities. In Proceedings of the Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering. ACM, 2014, pp. 456–465. [CrossRef]
- Koziolek, H.; Burger, A. Rule-based Code Generation in Industrial Settings: Four Case Studies. In Proceedings of the Proceedings of the 29th Annual ACM Symposium on Applied Computing. ACM, 2014, pp. 1234–1241. [CrossRef]
- Masoumzadeh, A. From Rule-Based Systems to Transformers: A Journey Through the Evolution of Natural Language. Medium 2023. Accessed: 2023-10-15.
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, 2017, Vol. 30.
- Feng, Z.; Guo, D.; Tang, D.; Duan, N. ; Feng. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. arXiv preprint arXiv:2002.08155, 2020; arXiv:2002.08155. [Google Scholar]
- Zheng, Q.; Xia, X.; Zou, X.; Dong, Y.; Wang, S.; Xue, Y.; Wang, Z.; Shen, L.; Wang, A.; Li, Y.; et al. Codegeex: A Pre-trained Model for Code Generation with Multilingual Evaluations on HumanEval-X. arXiv preprint arXiv:2303.17568, 2023; arXiv:2303.17568. [Google Scholar]
- Zhang, Y.; Li, Y.; Wang, S.; Zou, X. Transformers for Natural Language Processing: A Comprehensive Survey. arXiv preprint arXiv:2305.13504, arXiv:2305.13504 2023.
- Kamatala, S.; Jonnalagadda, A.K.; Naayini, P. Transformers Beyond NLP: Expanding Horizons in Machine Learning. Iconic Res. Eng. Journals 2025, 8. Available online: https://doi.org/https://www.irejournals.com/paper-details/1706957. [CrossRef]
- Myakala, P.K.; Jonnalagadda, A.K.; Bura, C. Federated Learning and Data Privacy: A Review of Challenges and Opportunities. Int. J. Res. Publ. Rev. 2024, 5. [Google Scholar] [CrossRef]
- Bura, C. ENRIQ: Enterprise Neural Retrieval and Intelligent Querying. REDAY - Journal of Artificial Intelligence & Computational Science, 2025. [Google Scholar] [CrossRef]
- Nijkamp, E.; Lee, B.P.; Pang, R.; Zhou, S.; Xiong, C.; Savarese, S.; Ni, J.; Keutzer, K.; Zou, Y. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. arXiv preprint arXiv:2203.13474, 2022; arXiv:2203.13474. [Google Scholar]
- Bollikonda, M. Hybrid Reasoning in AI: Integrating Rule-Based Systems with Transformer Models. Preprints 2025. Preprint, available at Preprints.org. [CrossRef]
- Bura, C.; Jonnalagadda, A.K.; Naayini, P. The Role of Explainable AI (XAI) in Trust and Adoption. J. Artif. Intell. Gen. Sci. (JAIGS) ISSN: 3006-4023 2024, 7, 262–277. [Google Scholar] [CrossRef]
- Ahmad, W.U.; Chakraborty, S.; Ray, B.; Chang, K.W. Unified Pre-training for Program Understanding and Generation. arXiv preprint arXiv:2103.06333, 2021; arXiv:2103.06333. [Google Scholar]
- Lu, S.; Guo, D.; Ren, S.; Huang, J.; Svyatkovskiy, A. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Understanding and Generation, 2021. arXiv:cs.SE/2102.04664.
- Kamatala, S.; Naayini, P.; Myakala, P.K. Mitigating Bias in AI: A Framework for Ethical and Fair Machine Learning Models. Available at SSRN 5138366. 2025. [Google Scholar]
- Wang, Z.; Xue, Y.; Dong, Y. A Systematic Review of Rule-Based Systems in Modern Software Architecture. J. Syst. Archit. 2024, 103, 103193. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, W.; Liu, G.; Du, X.; Zhang, Y.; Sun, S.; Li, L. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021, pp. 8696–8708.
- Le, H.; Wang, Y.; Gotmare, A.D.; Savarese, S.; Hoi, S. OpenReview: A Platform for Transparent and Open Peer Review. In Proceedings of the OpenReview. 2023. [Google Scholar]
- Wangoo, D.P. Artificial Intelligence Techniques in Software Engineering for Automated Software Reuse and Design. In Proceedings of the 2018 4th International Conference on Computing Communication and Automation (ICCCA), 2018. 2018; 1–4. [Google Scholar] [CrossRef]
- Myakala, P.K. Beyond Accuracy: A Multi-faceted Evaluation Framework for Real-World AI Agents. Int. J. Sci. Res. Eng. Dev. 2024, 7. [Google Scholar] [CrossRef]
Figure 1.
Dual-Stream Reasoning Architecture: Combining Symbolic Validation with Neural Inference.
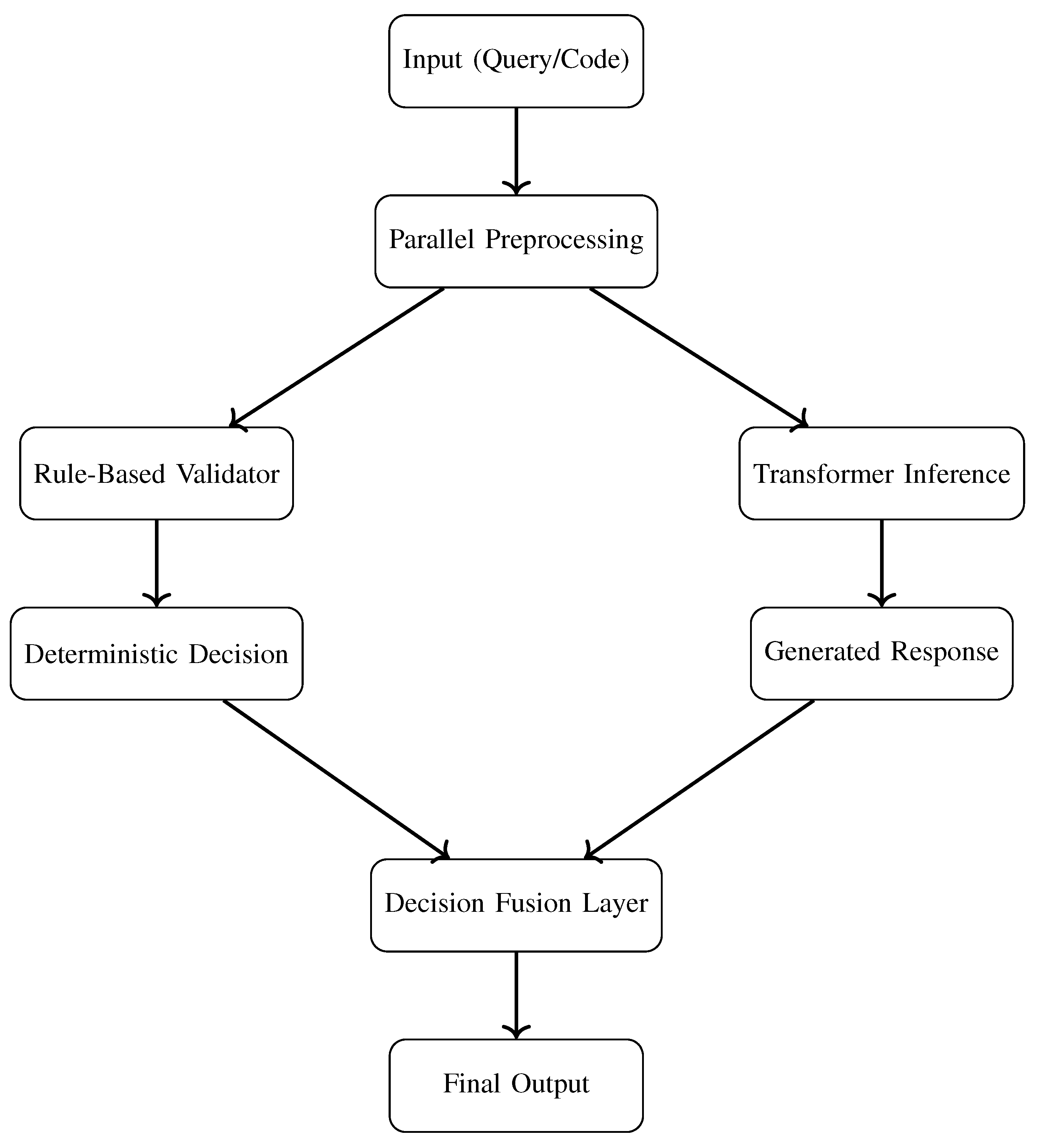
Figure 2.
Feedback Loop with LLM Inference and Evaluation Control.
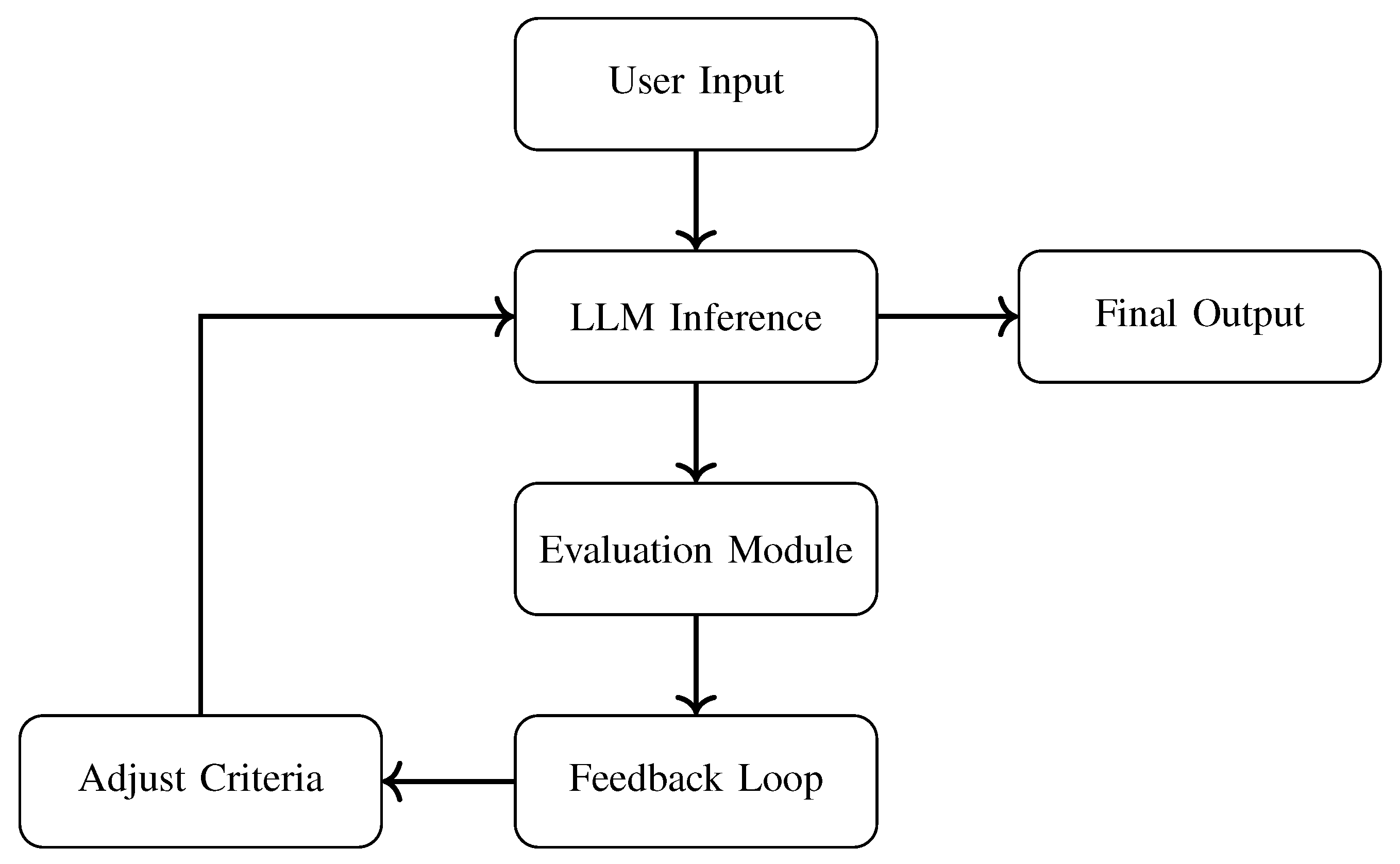
Figure 3.
Deployment Architecture: Hybrid Pipeline with Parallel Inference and Integration Layer.
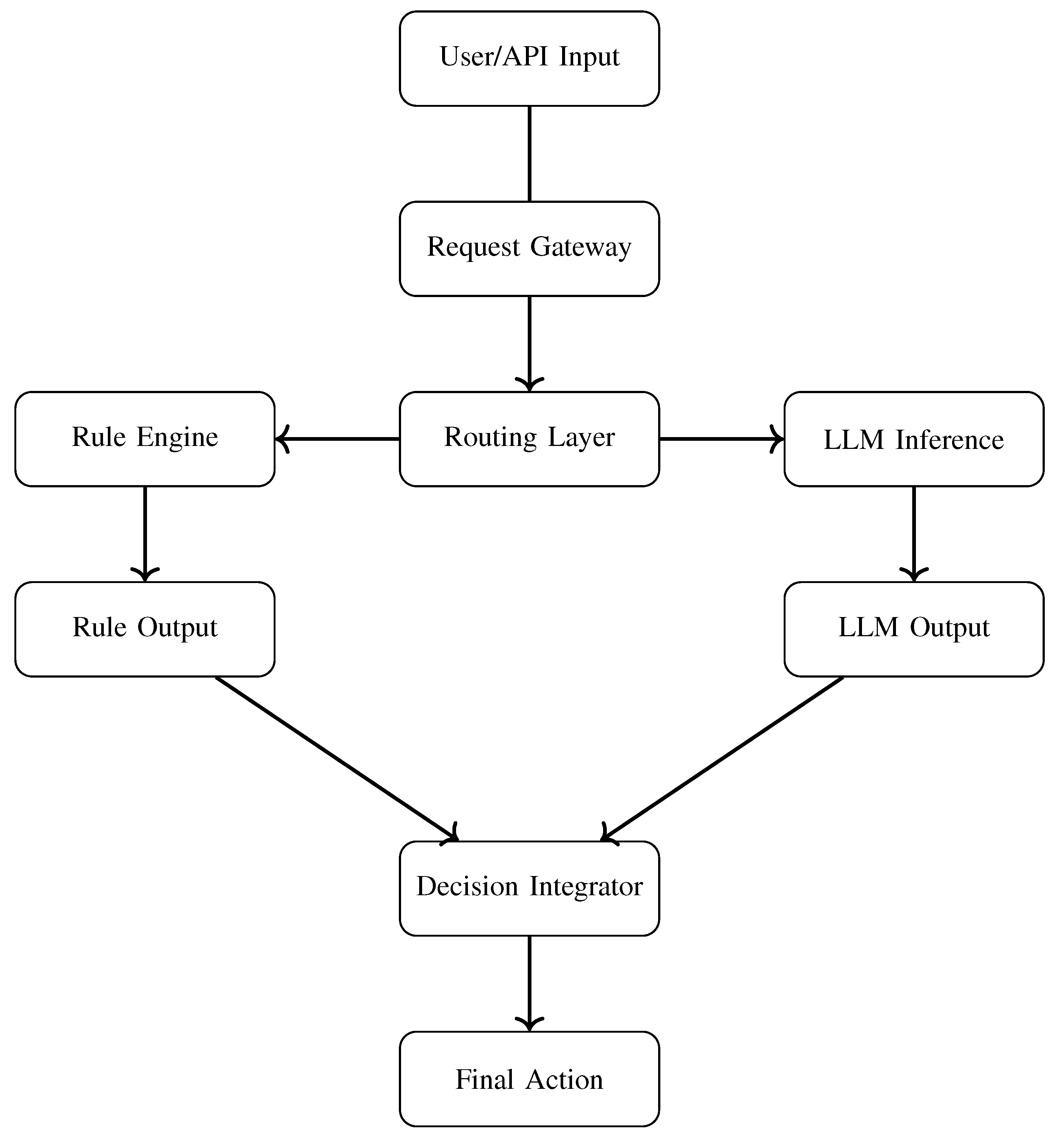
Figure 4.
Ethical Governance Pipeline: Layered Checks for Hybrid AI Integrity.
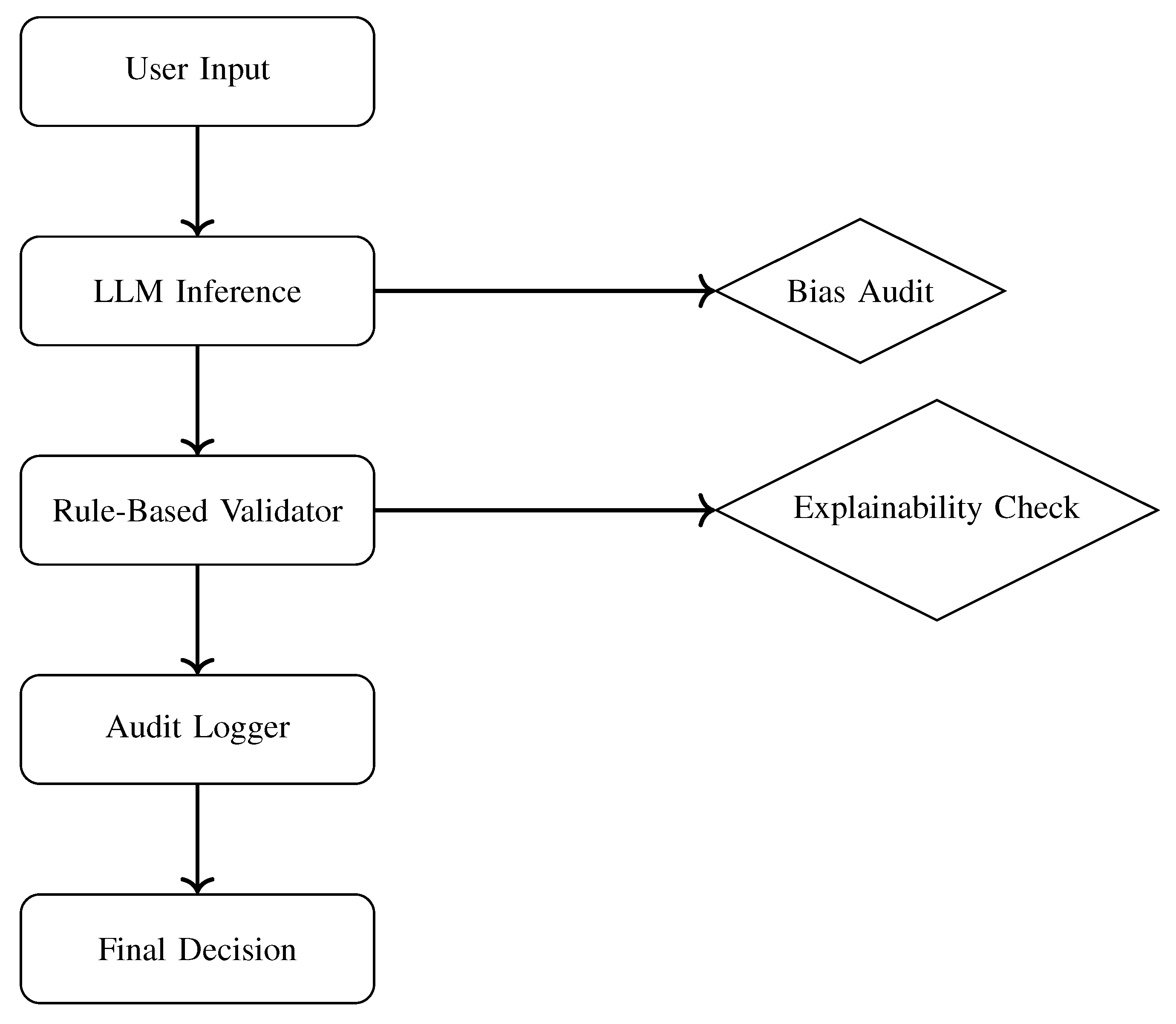

Table 1.
Evolution of AI Reasoning Paradigms
| Property | Rule-Based Systems | Transformer-Based Systems |
|---|---|---|
| Reasoning Style | Symbolic, logic-driven | Contextual, data-driven |
| Adaptability | Low | High |
| Interpretability | High | Moderate to Low |
| Learning | Manually encoded rules | Self-supervised on large corpora |
| Maintenance Cost | High (manual updates) | Medium (data-driven retraining) |
| Use Cases | Regulatory compliance, policy execution | Code generation, natural language understanding |
Table 2.
Performance Comparison: Rule-Based vs. Transformer Models in Policy Automation.
| Metric | Rule-Based | Transformer-Based |
|---|---|---|
| Accuracy on known cases | High | Moderate |
| Adaptability to edge cases | Low | High |
| Auditability | Strong | Moderate |
| Scalability | Limited | High |
| Latency (decision time) | Low | Medium |
| Policy Drift Detection | Manual | Inferred |
| Regulatory Trust | High | Needs Explainability |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



