
Submitted:
07 April 2025
Posted:
11 April 2025
You are already at the latest version
Abstract
Rule-based systems have long served as the foundational architecture for many expert systems and decision engines. However, with the rise of large language models (LLMs), the software engineering landscape is witnessing a paradigm shift. This paper explores the transition from deterministic rule-based methodologies to probabilistic, data-driven models like Transformers and code-oriented LLMs. By analyzing architectural differences, integration strategies, and hybridization potential, we aim to present a roadmap for leveraging the strengths of both paradigms in modern AI-enabled systems. Through comparative insights and system-level evaluations, this study highlights the coexistence and convergence of legacy rule-based engines with cutting-edge AI architectures.
Keywords:
ule-based systems
; transformers
; Large Language Models
; code generation
; AI systems
; software architecture
; hybrid AI
; intelligent automation
; code understanding
1. Introduction
The evolution of intelligent systems in software engineering has been deeply influenced by two major paradigms: rule-based reasoning and data-driven learning. Rule-based systems, once the dominant approach to automated decision-making, offered transparency, modularity, and a structured framework for incorporating expert knowledge. However, as data complexity grew and contextual understanding became more critical, these systems began to reveal limitations in adaptability and scalability.
These limitations opened the door for data-driven models—most notably large language models (LLMs)—which are capable of learning from vast corpora to handle ambiguous and context-rich scenarios. Unlike rule-based systems that depend on explicitly defined conditions, LLMs dynamically interpret and generate content through learned representations. This shift has not only changed the nature of automation but also redefined expectations around model generalization, accuracy, and human-like interaction.
At the same time, the complete replacement of rule-based systems with neural models is neither practical nor desirable in many cases. Rule-based logic still offers unmatched interpretability, control, and regulatory compliance—qualities essential in domains like finance, law, and healthcare. In contrast, LLMs bring in flexibility, creativity, and abstraction that are difficult to hard-code. This complementary nature of both paradigms presents a unique opportunity to design hybrid architectures.
The rapid growth of LLMs in enterprise AI has introduced new challenges related to trust and accountability. Organizations seek solutions that not only generate intelligent outputs but also ensure consistency with policy, safety constraints, and ethical norms. In this context, rule-based modules can serve as critical guardrails, validating LLM-generated results or enforcing domain-specific rules before deployment.
Hybrid systems that blend rule-based reasoning with transformer-based learning offer a strategic advantage. They enable organizations to scale automation while preserving governance and auditability. For instance, integrating a rule validation layer into an LLM pipeline ensures not only output correctness but also compliance with legal or operational standards.
This paper aims to examine the evolution and convergence of these two approaches. It outlines how rule-based engines are being reimagined in AI-powered ecosystems and how hybrid models are shaping the future of software automation and intelligent decision-making. We also explore real-world architectures, ethical implications, and fairness concerns, providing a practical roadmap for integrating symbolic and statistical AI systems.
As organizations increasingly move toward AI-driven decision-making, the demand for systems that balance innovation with reliability has never been higher. Governments and regulatory bodies are beginning to issue frameworks for ethical AI use, pushing enterprises to adopt solutions that are explainable, auditable, and aligned with compliance mandates. Within this climate, revisiting and revitalizing rule-based systems becomes not just a technical opportunity, but a strategic necessity. The convergence of interpretable logic and intelligent generalization can help build next-gen platforms that are both powerful and trustworthy.
2. Background and Related Work
Rule-based systems have been integral to traditional software engineering workflows, especially in domains requiring structured decision logic and high interpretability. These systems operate using sets of conditional "if-then" statements crafted by domain experts. As noted in prior studies, rule-based approaches offer deterministic outputs and ease of auditing, which are vital in high-stakes environments [1,2]. However, scalability and contextual adaptability have remained consistent challenges in rule-based implementations [3].
Historically, rule-based logic systems thrived in areas like diagnostic engines, fraud detection systems, and automated control flows. These systems were often embedded within critical infrastructure where human oversight was minimal but traceability was paramount. Over time, however, the cost of maintaining and updating these rigid rule sets began to outweigh their benefits. As software systems scaled, rule bases became increasingly difficult to manage, especially as exceptions and edge cases grew in complexity.
Parallel to this, machine learning emerged as a paradigm capable of deriving behavior from data instead of human-defined logic. Traditional ML models, however, struggled to capture hierarchical or sequential dependencies—especially in language and code. This gap was significantly narrowed with the introduction of deep learning and, eventually, transformer-based architectures.
The Transformer model introduced by Vaswani et al. revolutionized the field by enabling deep contextual understanding across sequential data [4]. Transformers operate on attention mechanisms, allowing them to learn long-range dependencies, a stark contrast to the static nature of rule-based rulesets. Their success in natural language processing laid the groundwork for extensions into other domains, such as programming languages, tabular data, and even decision automation.
More recently, the fusion of code understanding and generation with LLMs has opened new frontiers in software automation. Pre-trained models like CodeBERT and CodeT5 have demonstrated that learned representations of source code can outperform handcrafted features in many tasks [5]. These models leverage massive datasets sourced from GitHub, Stack Overflow, and other repositories to generate functionally accurate and context-aware completions or translations.
Despite these advances, the opaqueness of LLM decision-making raises challenges. Their non-deterministic nature and susceptibility to training bias make them unsuitable for certain applications without augmentation. Hence, modern research explores integrating rule-based constraints into transformer pipelines to preserve explainability and inject domain knowledge into otherwise black-box systems [6].
This background frames a new hybrid era in AI: one where rule-based systems and transformer-based models coexist and complement one another. These approaches are no longer viewed as mutually exclusive but rather as critical components in architecting trustworthy, adaptive, and scalable intelligent systems.
In enterprise systems, especially those involving sensitive or regulated workflows, rule-based validation layers continue to play a crucial role in AI pipelines. For example, financial institutions use LLMs to draft client communications or generate code snippets, but route the outputs through compliance engines built on rule logic. This ensures that generated content adheres to legal, ethical, or domain-specific constraints. The integration of LLMs as “creative” modules and rule engines as “filtering” layers demonstrates a layered intelligence approach—one that is gaining popularity in mission-critical sectors.
From a research standpoint, formal frameworks are emerging that define how symbolic constraints can be embedded into the LLM training or inference process. Techniques such as constrained decoding, retrieval-augmented generation (RAG), and program synthesis using hybrid feedback loops represent early attempts to structure neural reasoning. These methods aim to close the gap between opaque neural representations and structured logic. Consequently, the academic community is beginning to explore metrics, benchmarks, and datasets specifically designed to evaluate the effectiveness of hybrid rule–LLM systems across domains.
3. Rule-Based Systems vs. Transformer Architectures
The foundational contrast between rule-based systems and transformer-based architectures lies in their treatment of logic and data. Rule-based systems rely on explicitly defined logic trees authored by domain experts. Each decision is traceable, deterministic, and interpretable. In contrast, transformer models derive representations through training on vast datasets, capturing statistical relationships rather than hard-coded knowledge.
Figure 1 illustrates the high-level architecture of a traditional rule-based system versus a transformer-based model.
Rule-based systems, while transparent, struggle with scalability and adapting to edge cases. For instance, updating a rule-based engine requires manual logic augmentation, which grows exponentially with system complexity. Transformers, on the other hand, generalize patterns but are often viewed as black boxes, lacking interpretability and guaranteed behavior.
Hybrid approaches are now being explored where domain constraints are encoded into LLMs either during training or inference [7]. These integrations attempt to retain the reasoning rigor of rules while benefiting from neural generalization.
The shift in architecture also introduces changes in development lifecycles. Rule-based systems often require extensive up-front design, while transformer-based systems are largely pre-trained and fine-tuned on task-specific data [8]. Recent pre-trained models tailored for code tasks, such as CodeGen, showcase how transformer stacks can directly perform logic synthesis and pattern generation with minimal handcrafted input [9].
While rule-based systems follow a structured and predictable logic path, they are inherently brittle when dealing with ambiguity or novel input. Their reliance on explicitly encoded rules makes them excellent for controlled environments but limits their flexibility in dynamic or unstructured domains. For example, in natural language understanding or code generation tasks, rules can quickly become complex and unmanageable when faced with subtle variations in input.
Transformers, on the other hand, derive strength from their ability to model relationships between tokens through self-attention mechanisms. Unlike rule-based systems that treat conditions independently, transformers evaluate every input token in the context of every other token, allowing for deeper semantic understanding. This makes them well-suited for tasks such as summarization, translation, and code completion—areas where latent structure and meaning must be inferred rather than explicitly defined.
However, this flexibility comes at a cost. Transformer models are often large, resource-intensive, and difficult to interpret. Their decisions are based on distributed representations learned from data, which makes debugging and auditing non-trivial. This is a major concern in high-assurance environments where traceability and explanation are mandatory. Rule-based systems, in contrast, offer line-by-line logic validation and easy regulatory compliance, which remains one of their most valuable strengths.
As organizations strive to balance flexibility with control, a growing number of systems now attempt to blend these approaches. For instance, transformer-generated outputs can be post-processed or constrained by rule-based validators. Alternatively, rules may be encoded into the prompt engineering process or integrated via retrieval-augmented logic injection. These hybrid strategies are becoming central to modern software intelligence workflows, paving the way for explainable yet adaptive systems.
4. Code Understanding and Generation with LLMs
With the rise of transformer-based architectures, specialized models have been developed to handle source code as a primary data modality. These models are trained on millions of code samples and aligned with programming language semantics, enabling tasks such as code completion, translation, summarization, and bug detection.
CodeBERT, CodeT5, CodeGen, and CodeGeex represent prominent examples of this shift toward LLMs tailored for code intelligence. Each varies in architecture, pretraining strategy, and multilingual capacity. While CodeBERT emphasizes joint learning of programming and natural languages, CodeT5 is an encoder-decoder architecture that preserves identifier-level semantics [10]. CodeGen advances this further with large-scale autoregressive training optimized for multi-turn generation [9], whereas CodeGeex showcases cross-lingual capability with evaluations on HumanEval-X [11].
The comparison in Table 1 summarizes the key properties of these models.
These models demonstrate that code understanding is no longer dependent on rule heuristics alone. Instead, LLMs can model the structure, intent, and functionality of code through learned embeddings and attention patterns. The ability to generalize across languages and programming paradigms makes them valuable for industry applications, especially in AI-augmented IDEs [12].
The practical impact of these models extends beyond academic benchmarks, reaching into developer workflows through integration with modern IDEs and code repositories. Tools like GitHub Copilot and Amazon CodeWhisperer are early examples of how LLMs can offer intelligent code suggestions, documentation, and real-time refactoring tips during development. These models are not merely augmenting productivity but also influencing how developers learn, onboard, and collaborate. Furthermore, when integrated into DevOps pipelines, code-understanding LLMs can assist with test generation, static analysis, and vulnerability detection, thereby reducing human effort while improving code quality and security at scale.
Additionally, these tools are now being integrated into CI/CD pipelines for automated testing and documentation. By enabling machines to reason about source code beyond syntax, LLMs are redefining the future of collaborative software development.
Despite their remarkable capabilities, LLMs for code generation face several challenges. One major issue is the correctness and safety of generated code. These models often produce syntactically accurate but semantically flawed outputs that may introduce bugs or security vulnerabilities. Moreover, their probabilistic nature means that even slight variations in prompt phrasing can yield significantly different results. As such, while LLMs enhance productivity, they still require human review and integration with validation systems to ensure the robustness of final software artifacts.
Another limitation lies in the dependency on high-quality pretraining data. The effectiveness of models like CodeGen and CodeGeex heavily relies on the diversity and cleanliness of the codebases used during training. Datasets harvested from open-source platforms may carry inconsistent styles, deprecated practices, or even insecure patterns that propagate into the model’s learned behavior. This makes dataset curation and continual retraining critical factors in maintaining model relevance and trustworthiness in evolving code environments.
Research is now expanding toward multilingual and multimodal code understanding. Modern software systems are polyglot by design, often involving a mix of languages like JavaScript, Python, and SQL. Models such as CodeGeex aim to address this by training across language boundaries, enabling cross-translation and unified representations. Further, emerging efforts explore multimodal learning — combining code with documentation, UI sketches, or bug reports — to offer a more holistic understanding of development contexts. These advancements represent the next frontier in making LLMs indispensable to the software engineering lifecycle.
5. Ethical Implications and Fairness in AI Systems
The growing reliance on large-scale AI models introduces ethical concerns ranging from algorithmic bias and fairness to model accountability and user privacy. In rule-based systems, traceability was inherent due to the deterministic nature of the rules. However, with neural models, particularly LLMs, the lack of transparency creates new risks for real-world deployment [13].
Figure 2 visualizes the AI ethics lifecycle, highlighting where fairness interventions can be embedded into the pipeline.
The diagram above illustrates a clear architectural divergence between rule-based systems and transformer-based models. In the rule-based pipeline, data flows through a logic engine composed of deterministic rules, resulting in predictable outputs with guaranteed traceability. In contrast, the transformer architecture emphasizes layered representation learning through token embedding and self-attention mechanisms. This shift highlights how LLMs abstract meaning from context rather than relying on pre-programmed logic. The figure encapsulates the core trade-off: rule-based systems offer interpretability and control, whereas transformers provide adaptability and semantic generalization, albeit with reduced transparency. Understanding these structural differences is key to designing hybrid systems that aim to balance precision with intelligence.
A key challenge is the replication of historical biases present in training data. When AI models are used to generate code or recommendations, these biases can manifest as inequitable suggestions, unsafe outputs, or language exclusivity. Researchers have proposed frameworks that assess fairness through both quantitative and human-centric evaluation criteria [14]. Additionally, AI agents interacting with end users must demonstrate reliability across demographics, locales, and usage contexts.
In federated learning contexts, ethical considerations extend to cross-device data privacy and ownership. Myakala et al. highlight the dual role of federated AI systems in promoting decentralization while maintaining accountability through encrypted communication [15].
Ethical AI engineering also involves explainability. Modern approaches include attention heatmaps, prompt templates, and counterfactual testing to provide partial transparency without compromising model performance. Despite progress, striking the right balance between accuracy and fairness remains an open issue in high-stakes domains such as finance, healthcare, and education [16].
6. Applied Architectures and Use Case Demonstration
To bridge the gap between explainable rule-based systems and powerful but opaque LLMs, hybrid architectures are gaining traction in modern AI deployments. These designs incorporate deterministic rule engines alongside neural components for controlled yet intelligent outputs. Such systems are particularly valuable in regulated industries where auditability and adaptability must coexist.
Traditional software systems often struggle to manage both the complexity of modern tasks and the need for interpretability. Large language models are powerful at capturing semantic richness, but they are not inherently grounded in logical structure or domain constraints. This mismatch becomes problematic in production environments where generated outputs must adhere to industry policies or legal requirements. Hybrid architectures aim to address this gap by combining the strengths of LLMs and rule-based systems.
In a typical hybrid design, the transformer model is responsible for generative intelligence — interpreting input prompts, retrieving relevant context, and producing human-like outputs. Meanwhile, a rule-based module serves as a logical filter or validator that ensures all generated content meets explicit requirements. This co-design enables the system to generalize flexibly while still enforcing deterministic checks, making it ideal for environments such as policy drafting, automated code generation, and knowledge retrieval[17].
The interaction between these components can be either sequential or iterative. In a sequential flow, outputs from the LLM are passed directly to the rule module for validation. In more advanced setups, feedback from the rule engine can influence the LLM’s response through prompt modification or fine-tuning loops. These hybrid workflows are becoming increasingly important in industries that require both high precision and contextual reasoning.
As AI applications move from experimentation to production, the need for structured, interpretable, and accountable decision pipelines becomes paramount. In such environments, large language models alone may not suffice, especially when outputs must adhere to domain-specific policies or strict compliance regulations. Rule-based systems offer a solution by acting as validation or control layers that enforce hard constraints on LLM-generated content. This symbiotic integration ensures that generative intelligence does not compromise system reliability or compliance. The following diagram illustrates a hybrid pipeline that operationalizes this concept.
A representative use case is shown in Figure 3, which illustrates how a software agent leverages both components: a transformer-based code understanding module and a rule-based policy controller. The agent accepts inputs such as programming queries or user prompts and routes them through a hybrid pipeline that validates LLM-generated outputs against rule sets before final execution. Such architectures are enabled by intelligent agents that combine perception, reasoning, and controlled response generation. Kamatala emphasizes the role of AI agents and LLMs in advancing decision support systems across domains like smart assistants and automated code reviewers [18]. These agents learn continuously and adapt to changing environments, making them suitable for dynamic tasks.
One practical advantage of hybrid AI architectures is their modularity. By decoupling the reasoning engine from the generative model, developers can isolate rule violations, audit decisions, and iteratively update the rule base without retraining the LLM. This modularity also enables system updates in real time, such as integrating new regulations into the rule engine while preserving the semantic capabilities of the transformer model. In industries like insurance, healthcare, and financial tech, this level of agility is essential for maintaining compliance and adapting to ever-changing operational policies.
Furthermore, hybrid systems allow for contextual control. For instance, an LLM may generate multiple variations of a code snippet or policy recommendation, but the rule-based module can filter or prioritize these outputs based on organization-specific constraints. This dynamic interplay allows AI agents to reason creatively while maintaining guardrails aligned with domain knowledge. Some organizations implement reinforcement strategies where rule violations are penalized in fine-tuning datasets to encourage the LLM to learn constraints implicitly over time.
Beyond individual deployments, hybrid architectures support scalability across organizational workflows. When integrated into cloud platforms or microservices, each layer—input pre-processing, LLM inference, rule validation, and decision orchestration—can be independently scaled and maintained. This aligns well with DevOps and MLOps paradigms where modular pipelines are versioned, monitored, and retrained incrementally. These practices ensure that AI-driven systems remain both innovative and robust as they mature in production environments.
In an industrial scenario, integrating a hybrid AI module into DevOps pipelines enhances test automation and continuous integration. Wangoo’s early work on automated software reuse using AI techniques highlighted the role of modular decision components [19]. These ideas now extend into intelligent retrieval systems, where code snippets or rules are fetched in real-time using embedded LLM-query systems [20].
This convergence is driving a new class of systems explainable, efficient, and powerful. As Naayini et al. argue, the success of such systems depends not only on model sophistication but also on how effectively developers design integration logic and decision checkpoints [21].
7. Deployment Considerations and Scalability
While hybrid AI systems combining rule-based logic and large language models offer architectural advantages, their successful deployment depends on several factors such as scalability, latency tolerance, cost optimization, and system observability. Designing for deployment requires not just model selection, but infrastructure-aware planning that balances computational demands with business constraints.
One key consideration is the separation of concerns in deployment pipelines. Rule engines and LLMs should operate in loosely coupled services to allow independent scaling. For instance, in a microservice-based environment, LLM inference may require GPU-backed containers for high throughput, whereas rule evaluators can remain lightweight, CPU-bound services. Deploying each component using containerization (e.g., Docker) and orchestration tools like Kubernetes allows the system to handle fluctuating workloads efficiently while maintaining clear versioning boundaries.
One of the key enablers for efficient deployment of LLMs in hybrid systems is model serving optimization. Depending on the latency and throughput requirements, organizations may choose between real-time APIs, batch processing, or streaming inference. Real-time inference is critical in interactive applications such as code assistants or chatbots, whereas batch and streaming modes are better suited for large-scale backend workflows like compliance validation or code review. Model serving platforms like TorchServe, TensorFlow Serving, or NVIDIA Triton can help streamline this layer with autoscaling and GPU sharing capabilities.
To ensure smooth integration and deployment, hybrid AI systems should be embedded into modern CI/CD pipelines. This includes automated testing of both model behavior and rule integrity, container builds for deployment consistency, and blue-green or canary rollouts to avoid downtime. These pipelines should also trigger revalidation when either the rules or the model version changes. In practice, this means incorporating unit tests for logic rules, regression tests for model outputs, and integration checks to validate their cooperation.
Lifecycle governance is also essential for long-term scalability. Both LLMs and rule engines evolve—models are fine-tuned with new data, and rules change with policy updates. Version control systems, model registries, and configuration-as-code tools (like MLflow, DVC, or GitOps) are indispensable for managing these assets in a traceable, collaborative manner. Combining governance with performance monitoring creates a feedback-rich environment where system behavior is not only observable but also improvable across iterations.
Latency is another crucial factor in production AI. Transformer models are computationally expensive and may not meet real-time requirements if used naively. Strategies such as model quantization, caching, or using distilled versions of large models (e.g., CodeT5-small) can significantly reduce inference time. Additionally, rule-based validators can act as early-exit filters, rejecting invalid outputs before full execution — improving both latency and security.
Monitoring and observability are indispensable for sustainable AI operations. It is important to track metrics such as model drift, rule violation frequency, throughput bottlenecks, and feedback loop efficacy. Integrating monitoring tools like Prometheus, Grafana, or OpenTelemetry allows teams to visualize system health in real time. Furthermore, integrating feedback into retraining pipelines or rule updates enables continuous learning and system refinement. This feedback loop ensures the deployed hybrid system adapts over time while maintaining compliance and interpretability.
In hybrid systems where explainability is a requirement, deployment pipelines must also accommodate audit logging. Each decision made by either the LLM or rule engine should be traceable and stored with metadata for post-hoc analysis. This is particularly important in high-compliance domains like banking, insurance, and government, where stakeholders may request justification for every automated action. Versioning models and rule sets ensures that outputs can be reconstructed and reviewed at any point in time.
Security considerations must also be accounted for. Exposing LLMs or rulesets via APIs can introduce attack surfaces that may be exploited through prompt injection, adversarial inputs, or denial-of-service patterns. To address this, hybrid systems should employ input sanitization, rate limiting, and anomaly detection mechanisms. Role-based access control (RBAC) and encryption of decision logs are equally essential in maintaining the integrity of both the decision process and the underlying infrastructure.
Finally, scalability should not only refer to computational growth but also to adaptability across use cases. A well-designed hybrid system should allow plug-and-play components—different rule engines or pretrained LLMs—depending on task complexity, language specificity, or compliance sensitivity. This level of configurability makes it easier to deploy variations of the system in different departments, geographies, or regulatory contexts without rearchitecting the entire pipeline.
8. Conclusion and Future Work
As AI systems continue to evolve, the interplay between symbolic reasoning and deep learning has emerged as a defining characteristic of next-generation software architecture. This paper has examined how rule-based systems—once the bedrock of expert systems—are being reimagined and integrated alongside large language models to enhance interpretability, flexibility, and control.
We explored architectural distinctions between deterministic rule engines and data-driven transformer models, emphasizing the strengths and limitations of each. With the rise of specialized models like CodeT5 and CodeGen, we now observe unprecedented capabilities in code understanding and generation. However, ethical risks and fairness concerns underline the need for explainable AI and principled governance.
Hybrid pipelines, as illustrated in this work, represent a promising pathway where logic constraints and generative intelligence coexist. These systems can enforce domain rules while leveraging LLMs for generalization and semantic reasoning.
Future research should focus on developing standard frameworks for rule–LLM integration, designing trust-aware inference mechanisms, and expanding multilingual code intelligence. Moreover, advancements in fairness auditing and federated compliance will be critical to deploying such systems responsibly at scale. The convergence of symbolic and neural paradigms will likely shape the future of intelligent, adaptable, and ethically aligned software systems.
The convergence of rule-based systems and transformer models is not just a theoretical milestone but a practical design pattern for the next generation of AI applications. By balancing the precision and transparency of symbolic reasoning with the adaptability of neural networks, hybrid systems are capable of addressing complex, real-world problems that neither paradigm can solve alone. As demonstrated in this paper, such architectures are particularly effective in domains requiring both intelligent inference and operational compliance.
Looking ahead, there is considerable room for research in making these hybrid systems more autonomous and self-improving. One direction involves dynamically tuning rule thresholds based on LLM feedback or fine-tuning LLM behavior based on rule violations. Another opportunity lies in the fusion of graph-based knowledge representations with attention-based learning to enhance reasoning capabilities without compromising scalability. These approaches could create AI systems that are not only reactive but also strategically proactive in constrained environments.
In conclusion, hybrid intelligence systems are no longer experimental — they are essential. As software complexity grows and AI becomes further embedded in everyday operations, the demand for systems that are accountable, extensible, and explainable will rise. The frameworks and practices outlined in this paper offer a blueprint for building such systems at scale, ensuring that innovation continues without compromising trust.
Acknowledgments
The author would like to acknowledge the contributions of researchers and industry experts whose insights have shaped the discourse on Bridging Symbolic Logic and Neural Intelligence with Hybrid Architectures for Scalable, Explainable AI Systems. This independent research does not refer to any specific institutions, infrastructure, or proprietary data.
References
- Chen, X.; Wang, L.; Shen, A. Rule-based Systems in Software Engineering: Challenges and Opportunities. In Proceedings of the Proceedings of the 22nd ACM SIGSOFT International Symposium on Foundations of Software Engineering. ACM; 2014; pp. 456–465. [Google Scholar] [CrossRef]
- Wang, Z.; Xue, Y.; Dong, Y. A Systematic Review of Rule-Based Systems in Modern Software Architecture. Journal of Systems Architecture 2024, 103, 103193. [Google Scholar] [CrossRef]
- Koziolek, H.; Burger, A. Rule-based Code Generation in Industrial Settings: Four Case Studies. In Proceedings of the Proceedings of the 29th Annual ACM Symposium on Applied Computing. ACM; 2014; pp. 1234–1241. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Vol. 30. 2017. [Google Scholar] [CrossRef]
- Feng, Z.; Guo, D.; Tang, D.; Duan, N. ; Feng. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. arXiv, 2020; arXiv:2002.08155. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Y.; Wang, S.; Zou, X. Transformers for Natural Language Processing: A Comprehensive Survey. arXiv, 2023; arXiv:2305.13504. [Google Scholar] [CrossRef]
- Masoumzadeh, A. From Rule-Based Systems to Transformers: A Journey Through the Evolution of Natural Language. Medium, 2023; Accessed: 2023-10-15. [Google Scholar]
- Lu, S.; Guo, D.; Ren, S.; Huang, J.; Svyatkovskiy, A. 2021; arXiv:cs.SE/2102.04664]. [CrossRef]
- Nijkamp, E.; Lee, B.P.; Pang, R.; Zhou, S.; Xiong, C.; Savarese, S.; Ni, J.; Keutzer, K.; Zou, Y. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. arXiv, 2022; arXiv:2203.13474. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, W.; Liu, G.; Du, X.; Zhang, Y.; Sun, S.; Li, L. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. In Proceedings of the Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP); 2021; pp. 8696–8708. [Google Scholar]
- Zheng, Q.; Xia, X.; Zou, X.; Dong, Y.; Wang, S.; Xue, Y.; Wang, Z.; Shen, L.; Wang, A.; Li, Y.; et al. Codegeex: A Pre-trained Model for Code Generation with Multilingual Evaluations on HumanEval-X. arXiv, 2023; arXiv:2303.17568. [Google Scholar] [CrossRef]
- Ahmad, W.U.; Chakraborty, S.; Ray, B.; Chang, K.W. Unified Pre-training for Program Understanding and Generation. arXiv, 2021; arXiv:2103.06333. [Google Scholar] [CrossRef]
- Kamatala, S.; Naayini, P.; Myakala, P.K. Mitigating Bias in AI: A Framework for Ethical and Fair Machine Learning Models. Available at SSRN 5138366 2025. [Google Scholar] [CrossRef]
- Myakala, P.K. Beyond Accuracy: A Multi-faceted Evaluation Framework for Real-World AI Agents. International Journal of Scientific Research and Engineering Development 2024, 7. [Google Scholar] [CrossRef]
- Myakala, P.K.; Jonnalagadda, A.K.; Bura, C. Federated Learning and Data Privacy: A Review of Challenges and Opportunities. International Journal of Research Publication and Reviews 2024, 5. [Google Scholar] [CrossRef]
- Bura, C. ENRIQ: Enterprise Neural Retrieval and Intelligent Querying. REDAY - Journal of Artificial Intelligence & Computational Science 2025. [Google Scholar] [CrossRef]
- Bura, C.; Jonnalagadda, A.K.; Naayini, P. The Role of Explainable AI (XAI) in Trust and Adoption. Journal of Artificial Intelligence General science (JAIGS) ISSN: 3006-4023 2024, 7, 262–277. [Google Scholar] [CrossRef]
- Kamatala, S. AI Agents And LLMS Revolutionizing The Future Of Intelligent Systems. International Journal of Scientific Research and Engineering Development 2024, 7. [Google Scholar] [CrossRef]
- Wangoo, D.P. Artificial Intelligence Techniques in Software Engineering for Automated Software Reuse and Design. In Proceedings of the 2018 4th International Conference on Computing Communication and Automation (ICCCA); 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Le, H.; Wang, Y.; Gotmare, A.D.; Savarese, S.; Hoi, S. OpenReview: A Platform for Transparent and Open Peer Review. In Proceedings of the OpenReview; 2023. [Google Scholar]
- Kamatala, S.; Jonnalagadda, A.K.; Naayini, P. Transformers Beyond NLP: Expanding Horizons in Machine Learning. Iconic Research And Engineering Journals 2025, 8. [Google Scholar] [CrossRef]
Figure 1.
Architectural Comparison: Rule-Based vs Transformer-Based Systems.
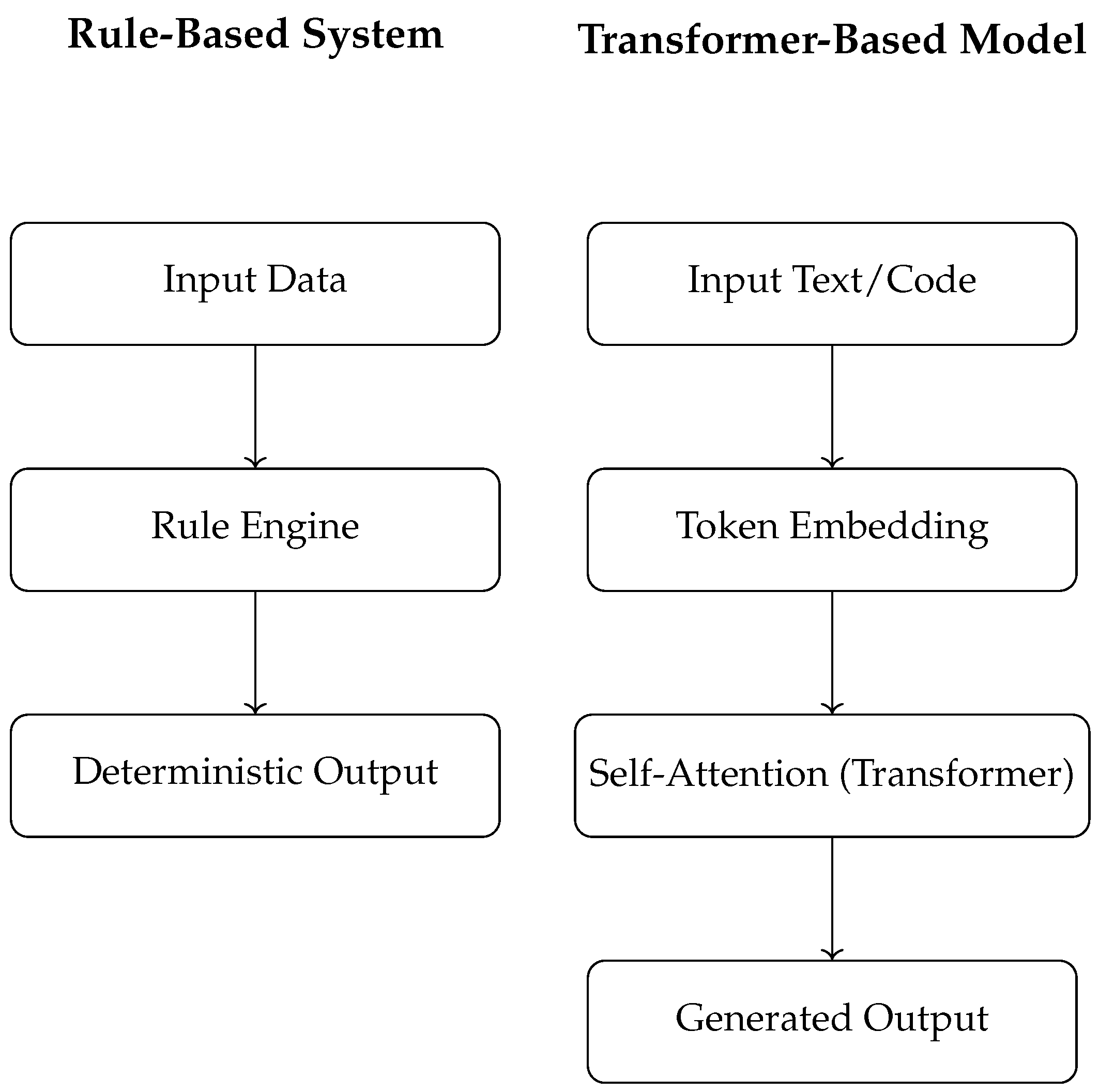
Figure 2.
AI Ethics Lifecycle: From Data Bias to Deployment Fairness.
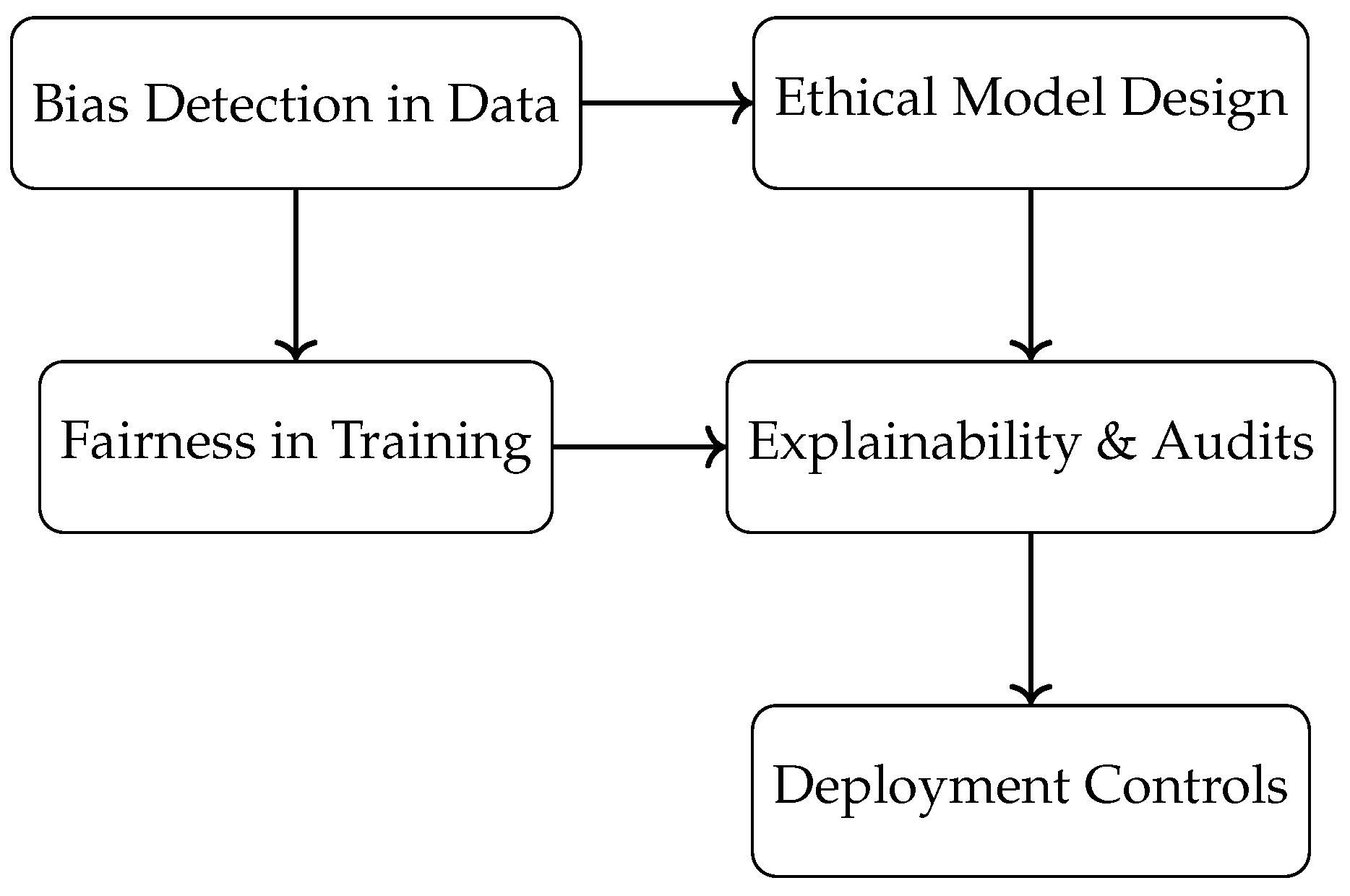
Figure 3.
Hybrid AI Pipeline: Integrating LLMs with Rule-Based Validation.
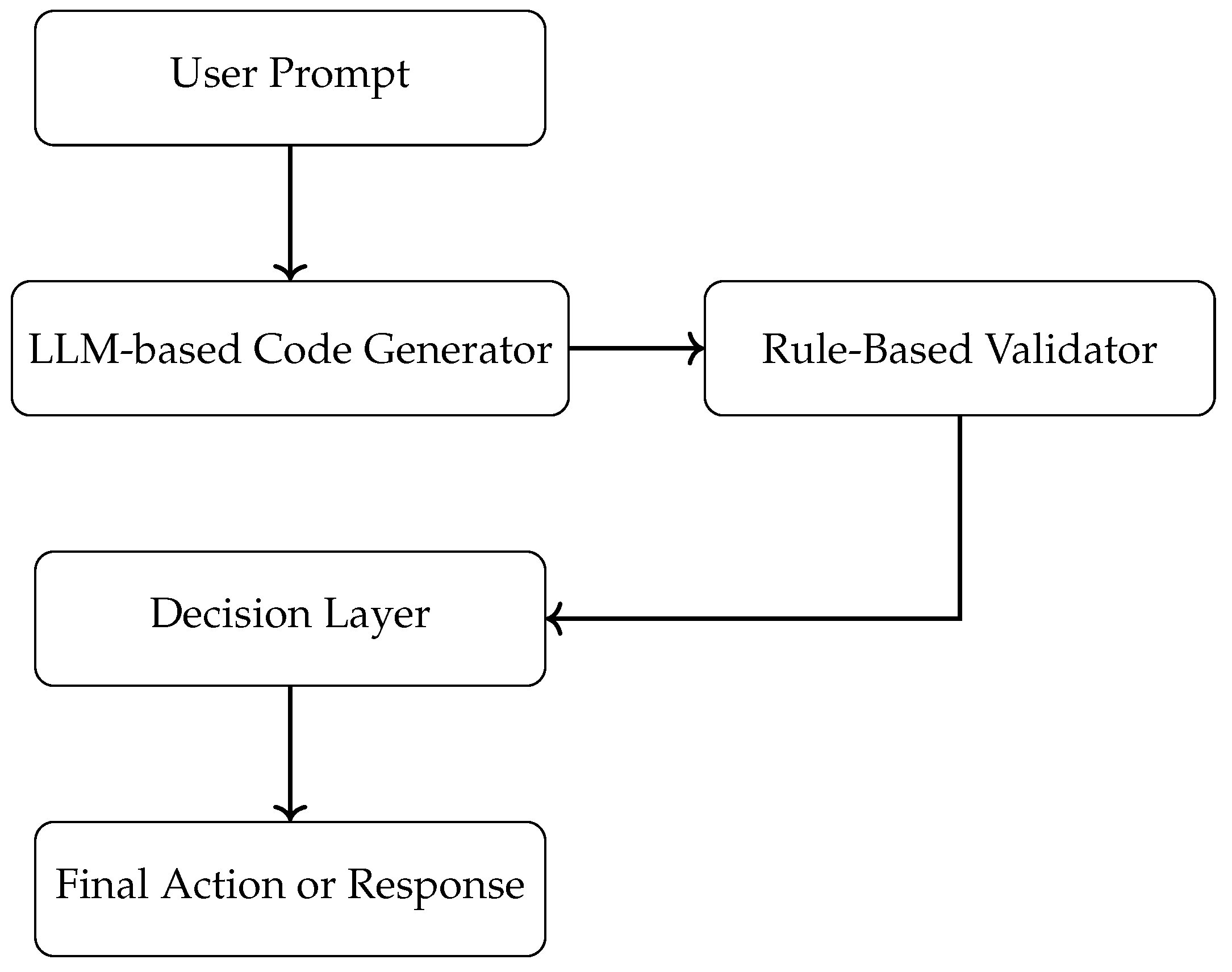

Table 1.
Comparison of Transformer-Based Code Models.
| Model | Type | Languages | Architecture | Release |
|---|---|---|---|---|
| CodeBERT | Encoder | 6 | BERT-Based | 2020 |
| CodeT5 | Encoder-Decoder | 8+ | T5-Based | 2021 |
| CodeGen | Decoder | 10+ | GPT-Like | 2022 |
| CodeGeex | Decoder | Multi-lang | CodeGeeX | 2023 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



