
Submitted:
10 March 2025
Posted:
11 March 2025
You are already at the latest version
Abstract
In this study, the cumulative effect of the empirical probability distribution of a random variable is identified as a factor that amplifies the occurrence of extreme events in datasets. To quantify this observation, a corresponding information measure is introduced, drawing upon Shannon entropy for joint probabilities. The proposed approach is validated using selected market data as case studies, encompassing various instances of extreme events. In particular, the results indicate that the introduced cumulative measure exhibits distinctive signatures of such events, even when the data is relatively noisy. These findings highlight the potential of the discussed concept for developing a new class of related indicators or classifiers.
Keywords:
entropy
; information theory
; econophysics
; extreme events
; time series
; data science
1. Introduction
The ability to differentiate between volatility inherent to the given data and introduced by a temporal dependency on external variables is necessary for efficient modeling. This is particularly important in the case of significant anomalies, or extreme events, and their impact on the overall distribution of gathered data. For this purpose, an analytical tool with a solid theoretical foundation and straightforward implementation is required. In search of such a tool it is essential to understand what constitutes an extreme event and what are its characteristics in an ex post analysis. In loose terms, extreme events are represented by imbalanced data in the time series, which occur irregularly and introduce either extremely low or high values [1]. This implies knowledge of an expected magnitude of the data, with all that lay beyond labeled as extreme. One way to express this is by stating that values resulting from extreme events deviate by more than several standard deviations. As such, extreme events span various domains, from science and technology to social studies, and may include sudden outbreaks of devastating infectious diseases, solar flares, extreme weather conditions or financial crises [2,3,4].
This unexpected and complex character of extreme events introduces significant challenges in their theory and modeling. In particular, since all these events often result from strong non-linear interactions across various lengths and time scales, they render conventional perturbative methods less effective [5]. Unfortunately, artificial intelligence has also yet to come to the rescue. Although, there have been attempts to mitigate discussed problems via machine learning (both classical and quantum), not always is there enough data or computational power to perform such simulations [6,7]. Finally, it is important to note that the extreme events contribute to the tails of probabilistic distributions, having minimal effect on mean values but significantly impacting volatility and variance. Interestingly, this opens a promising avenue since one way to analyze volatility is through the measure known as entropy, an analytical concept that also underlines the information theory [8]. In this sense, entropy estimates uncertainty and randomness of a data allowing to discuss its related fluctuations, distributions, and patterns [9,10,11,12,13,14,15,16]. As a result, entropy constitutes a potentially highly relevant framework for discussing the impact of sudden events across different fields [17,18,19].
In the present work, it is argued that the entropy can be considered as indicator for extreme events, as motivated by its inherent nature and previous studies [19]. Here, this claim is formally justified by following the two point argumentation. First, it is known that the entropy increases as the uncertainty (volatility) of the data rises, meaning that the extreme events should result in the heightened entropy [16,19]. Hence, a simple cumulative process can be considered to further magnify this aspect, leading to a characteristic pattern in the entropic spectrum. This process relates directly to the evolution of the empirical probability distribution. As more data points are taken into account, the observed probability distribution (empirical distribution) gradually converges to the true probability distribution, in accordance with the law of large numbers. Under this assumption the entropy may decrease for a balanced data, signifying reduction in uncertainty and the dominance of a few stable outcomes. By systematically comparing the cumulative distributions generated in this process with the relatively uniform distribution expected for extreme event data, the desired amplification of the latter can be achieved. This approach may be particularly significant as it enables a retrospective analysis, tracing back from the extreme event while cumulatively incorporating data. As a result, it should be possible to develop indicators or techniques for detecting sudden changes in data by considering them as a reference point in time.
This work is organized as follows: Section II introduces the methodology and theoretical background based on the concept of entropy. Section III explores the properties of the data used in this study and provides a detailed analysis of the extreme event signatures within the entropic spectrum. The manuscript concludes in Section IV, which offers a summary and outlines future perspectives. The study is supplemented by an appendix presenting the summary statistics of the analyzed data.
2. Methodology
To quantify the discussed cumulative effect we recall the conventional discrete Shannon entropy, given by [8]:
for a total of n outcomes, where:
represents the probability of the value , in the Riemann approximation, occurring for a discrete random variable of interest. As such, the Eq. (1) measures information content of data in nats (meaning the base of logarithm in Eq. (1) is e), accounting for the probability distribution across all possible states. Note that for the discrete case, n constitutes the number of intervals (known also as bins or classes) within the probability distribution. Here, to keep analysis on the same footing, n is assumed after the Vellman formula, which is optimal considering the population and variability of the discussed datasets [20].
Now, lets consider a dataset that contains information about an extreme event, along with preceding data, which is divided into chronologically sorted and equally sized parts. In the extreme limit, it can be qualitatively argued that such blocks exhibit relatively similar probability distribution, except for the portion related to the extreme event. By following in spirit the most biased distribution principle, familiar in some stochastic processes [16], the former dataset blocks will exhibit a bias toward a few stable outcomes, which will be further amplified when their probability distributions are combined. This observation can be quantified by introducing the following cumulative entropy for the m-th dataset part:
which is formally a joint entropy for the m blocks of data, where the information is cumulated by adding dataset parts while keeping the same number of outcomes. This means the higher m the more information is contained within the cumulative entropy. This rule applies to all dataset blocks except the one related to an extreme event (), for which Eq. (3) reduces to Eq. (1). Such process allows to increase the discrepancy in entropy values between higher m terms and reference case when . This is to say, the entropy value corresponding to the extreme event can be magnified for its better detection, as initially desired.
Note that, by definition, the is non-negative and sub-additive quantity, inheriting these characteristics from Eq. (1). Moreover, it does not rely on any assumptions about the underlying probability of a data block but instead seeks to uncover its intrinsic characteristics through entropy.
3. Results and Discussion
To validate the cumulative entropy concept and its underlying rationale, several benchmark datasets are examined. In particular, these consist of market data centered around three key dates, each corresponding to a selected extreme event that occurred in the last decade, i.e.:
- June 24th, 2016, marking the announcement of the Brexit referendum results,
- March 16th, 2020, the global black monday reflecting economic panic due to COVID-19 pandemic,
- February 24th, 2022, denoting the beginning of Russian invasion on Ukraine.
All the above events are captured here in the time series of exchange rates between gold and the U.S. dollar. The total data coverage includes 30 working days before the event, the day of the extreme event itself, and 10 working days after it. Note that the assumed data range directly follows earlier logic of cumulative entropy, which should be determined for the data preceding extreme event, serving as a reference point. This also allows to consider some dates prior this event, to see how corresponding entropic spectrum compares between periods with different reference points. For the same reason the subsequent 10-working-days periods are considered to include the reference points in the future, beyond the extreme event day.
For convenience the information about the time series of interest is encoded via intraday log-returns () as:
where () is the closing price of an asset on the j-th (-th) half-hour interval. Such log-returns serve as a stationary time series representation of the price changes, capturing the relative magnitude of intraday fluctuations.
The graphical representation of the intraday log-returns for the exchange rates between gold and the U.S. dollar is presented in Figure 1 (A)-(C). In a chronological order, they correspond directly to the events listed above. For clarity and transparency, the data range is restricted to the extreme event day days. The extreme event day is additionally marked by the blue shaded area and magnified in the inset for further details.
It can be observed that the depicted returns qualitatively exhibit the expected increase in turbulence within the blue shaded area, as evidenced by strong deviations from equilibrium. This effect is particularly pronounced in Figure 1 (A) and (C), which illustrate data behavior for the first and second considered event, respectively. Therein, the transient deviations are nearly four times the equilibrium value. In comparison, the second midterm event is much more noisy across the entire time range, constituting interesting case study when the event of interest is less evident. In what follows, this example extends presented analysis to the cases when events detection is more difficult, allowing to benchmark cumulative entropy concept in complex scenarios. For more details of the considered datasets please refer to Appendix A, where summary statistics are given.
However, in the present paper it is argued that the extreme event is not only reflected in the spectrum of intraday log-returns but can be also observed in the corresponding empirical probability distribution. In Figure 2 (A)-(C), such discrete distributions are presented for each considered total dataset (blue color) and for partial data that refers to the days when the extreme events occur (orange color). By inspecting these results crucial observations can be made that confirm earlier argumentation. In details, the total data is relatively tinner than distribution for the extreme event day. That means information contained within the latter dataset is less ordered and the corresponding outcome is more uncertain. This clearly shows that data for the extreme event day incorporates some randomness into the related total dataset. In other words, as more data is introduced to a dataset, the discrepancy between resulting distribution and the distribution for a single day data, increases. Since this cumulative effect is directly related to the information content within some data, it can be quantified by the entropy.
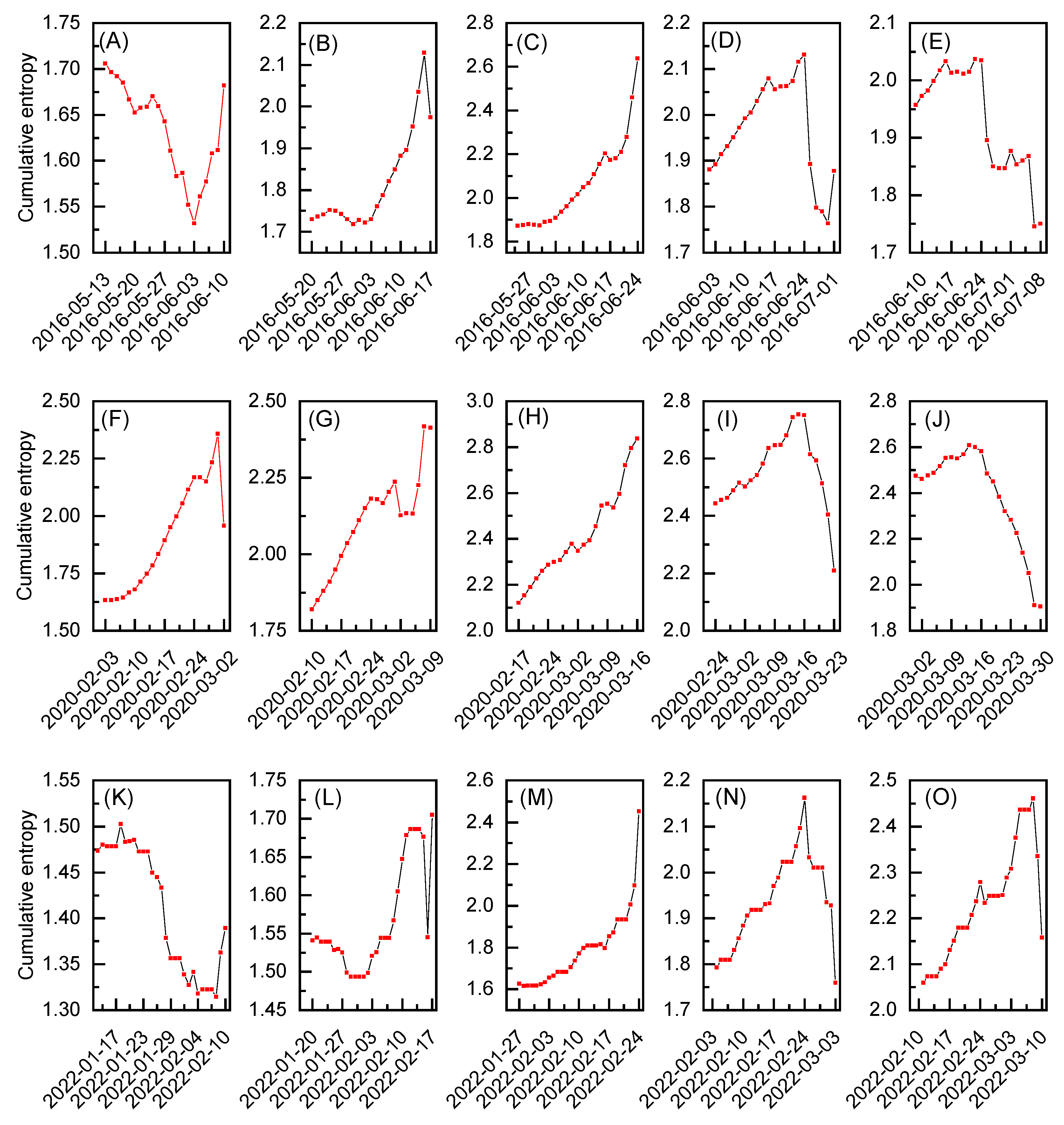
In Figure 3 (A)-(O) the behavior of introduced here cumulative entropy for three events of interest is depicted. To capture the underlying features of entropy, the results are presented by employing the 30-day moving window approach. Each window is constructed based on Eq. (3), assuming the last point as a reference for and every other point to be m days before that event. Note that m numbers the parts, or blocks, that will be compared against each other, as explained in details in the previous section. The analysis begins with interval ending 10 days before extreme event which next sequentially advances every 5 days to conclude with the dataset for the reference point 10 days after the extreme event. In this manner, the middle column (see Figure 3 (C), (H) and (M)) relates to the case when the reference point corresponds to the given extreme event day and the presented results are expected to exhibit some characteristic patterns. Indeed, the results for cumulative entropy, depicted in the middle column, increase steadily as they get closer to the extreme event day, reaching maximum value at reference point. In the first and third row (see Figure 3 (C) and (M)), this increase resembles parabolic behavior and corresponds to the datasets where intraday log-returns at the extreme event day present well indicated deviations from the rest of the data (see Figure 1 (A) and (C)). On the other hand, in the middle row (see Figure 3 (H)) the underlying data is noisy and the behavior of the results obtained for the cumulative entropy is more linear. Still this increase is monotonous without any substantial drops. As such, all three sets of results, given in Figure 3 (C), (H) and (M), clearly present somewhat ordered behavior that differentiate them from the cases when the reference point for calculations is assumed several days after or before the extreme event day. This proves the fact that cumulative entropy may exhibits signatures of interest, even when dataset is relatively noisy.
The observed behavior aligns earlier argumentation, meaning that the entropy value on the day of an extreme event can be magnified by calculating cumulative data for several days prior to this point. In terms of information contained within each of the computed points, the results for clearly correspond to the datasets which are most random and provide most uncertain message. As the results get further from this reference points, more data is added to the corresponding probability distributions and only some of the outcomes dominate. However, what is crucial to note, this behavior is possible only when data with similar probability distributions is cumulated. This is to say, according to the most biased distribution principle, the deterministic content increases, decreasing related entropy values [16].
In relation to the above, none of other considered time windows follow this process. In other words, it seems like it is difficult to obtain required bias between reference point and the cumulative data when the former does not correspond to the atypical and significant deviation from the equilibrium, familiar for the extreme event. However, with an appropriate time step and careful real-time analysis some early indicators of the upcoming extreme events may be still possible to observe. For example, in market data, investors may make moves that already influence an asset price, which can be reflected in the entropic spectrum.
4. Results and Conlusions
In summary, in the present study the analysis was conducted to verify the idea of using entropy measure for detecting extreme events in datasets. It was shown that entropy for joint probabilities can be employed in a systematic manner to magnify data parts or blocks that contain information on an extreme event. In particular, these findings were presented for three datasets of choice, containing market data of exchange rates between gold and the U.S. dollar. Each of the datasets was associated with one extreme event, namely: the announcement of the Brexit referendum results, the global black monday due to COVID-19 pandemic, and the beginning of Russian invasion on Ukraine, respectively. For all three datasets the characteristic signatures in the entropic spectrum were obtained, validating to some extend the proposed theoretical framework.
As a result it can be concluded that the presented method, based on the cumulative entropy, may be beneficial not only for the detection but also classification of extreme events in various datasets. It can serve as a primary or supplementary indicator and classifier that builds upon the underlying distribution of the considered data and the information encapsulated within it. In this manner, the cumulative entropy appears as a universal and comprehensive measure that do not impose any constraints on the corresponding probability distribution, but rather quantifies its underlying and most important features and interdependencies. In this manner, the developed argumentation and obtained results formalize earlier preliminary findings on cumulative entropy concept [19], addressing previously unexplored essential theoretical aspects and providing a corresponding unified framework along with its initial validation.
The above naturally calls for further verification by using large scale data. Of particular interest should be noisy datasets, similar to the one for the global black monday caused by COVID-19 pandemic, where the extraction of information on an extreme event is hindered. Another direction may be implementation of cumulative entropy in the real-time techniques, which deal with the short time windows suggesting opportunity to use developed here measures for early warning systems. The presented study also poses questions on the potential of using the cumulative entropy or the underlying most biased distribution principle in combination with other techniques, similarly to what has been done recently for the geometric Brownian motion process [16]. One of the promising directions may be be incorporation of the mentioned concepts into the machine learning or deep learning techniques, e.g. toward improvement of the predictive capabilities of these methods.
Author Contributions
Conceptualization, E.A.D.-S. and D.S.; methodology, E.A.D.-S., A.Z.K., M.K. and D.S.; software, E.A.D.-S., A.Z.K., M.K., and D.S.; validation, E.A.D.-S., M.K., S.G, J.T.G., K.P. and P.S.; formal analysis, E.A.D.-S., A.Z.K., M.K., S.G., Z.B. and D.S.; investigation, E.A.D.-S., A.Z.K., M.K., S.G. and D.S.; data curation, E.A.D.-S., M.K., S.G., K.P. and P.S.; writing-original draft preparation, E.A.D.-S., A.Z.K. and J.T.G.; writing-review and editing, E.A.D.-S., A.Z.K., J.T.G. and D.S.; visualization, E.A.D.-S., A.Z.K. and K.P.; supervision, Z.B. and D.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article/supplementary material, while the employed market datasets are publicly available online at www.histdata.com. Further inquiries can be directed to the corresponding author.
Appendix A. Summary Statistics
The appendix contains supplementary data to the analysis presented in the main text. In particular, in Table A1, the summary statistics of the intraday log-returns are given for three considered datasets that contain information on the analyzed extreme events.

Table A1.
The summary statistics of the intraday log-returns for the three datasets containing information on extreme events of interest i.e. the announcement of Brexit referendum results on June 24th 2016, the black Monday on global markets due to the COVID-19 pandemic on March 16th 2020, and the beginning of the Russian invasion on Ukraine on February 24th 2022. The statistics are given for the total period of time considered in the context of each event. Additionally, the partial statistics are presented for five periods analyzed in terms of the cumulative entropy.
Table A1.
The summary statistics of the intraday log-returns for the three datasets containing information on extreme events of interest i.e. the announcement of Brexit referendum results on June 24th 2016, the black Monday on global markets due to the COVID-19 pandemic on March 16th 2020, and the beginning of the Russian invasion on Ukraine on February 24th 2022. The statistics are given for the total period of time considered in the context of each event. Additionally, the partial statistics are presented for five periods analyzed in terms of the cumulative entropy.
| Data | Mean | Minimum | Maximum | Skewness | Kurtosis |
| Brexit referendum results (24.06.2016) | |||||
| 13.05.-13.06.2016 | 1.560089e-05 | -0.007146 | 0.019459 | 3.102121 | 55.668972 |
| 20.05.-20.06.2016 | 2.773924e-05 | -0.008101 | 0.019459 | 2.562111 | 44.722231 |
| 25.05-24.06.2016 | 6.775244e-05 | -0.008445 | 0.021147 | 3.140278 | 38.333012 |
| 02.06.-01.07.2016 | 0.000102 | -0.008445 | 0.021147 | 3.047951 | 35.344655 |
| 09.06.-08.07.2016 | 8.047182e-05 | -0.008445 | 0.021147 | 1.818350 | 22.838294 |
| 13.05.-08.07.2016 | 4.203620e-05 | -0.008445 | 0.021147 | 2.315603 | 32.974605 |
| Black monday due to COVID-19 (16.03.2020) | |||||
| 03.02.-03.03.2020 | 3.247892e-05 | -0.014230 | 0.014090 | -0.551528 | 16.332172 |
| 10.02.-09.03.2020 | 7.037389e-05 | -0.020675 | 0.015017 | -0.856300 | 16.204503 |
| 17.02.-16.03.2020 | 6.988914e-05 | -0.009986 | 0.010257 | 0.001460 | 8.739781 |
| 24.02.-23.03.2020 | -6.911197e-05 | -0.020675 | 0.015444 | -0.538275 | 5.644548 |
| 28.02.-30.03.2020 | -1.000592e-05 | -0.020675 | 0.015444 | -0.414655 | 5.188489 |
| 03.02.-30.03.2020 | 1.431909e-05 | -0.020675 | 0.015444 | -0.500483 | 9.635541 |
| Russian invasion on Ukraine (24.02.2022) | |||||
| 13.01.-10.02.2022 | 8.276324e-07 | -0.009664 | 0.006961 | -0.907719 | 14.53216 |
| 20.01.-17.02.2022 | 3.3134e-05 | -0.009664 | 0.009024 | -0.393835 | 13.431958 |
| 27.01.-24.02.2022 | 3.198343e-05 | -0.016004 | 0.009024 | -1.927835 | 26.631340 |
| 03.02.-03.03.2022 | 7.766970e-05 | -0.016004 | 0.013666 | -0.824806 | 20.080578 |
| 10.02.-10.03.2022 | 9.916852e-05 | -0.016004 | 0.013666 | -0.471262 | 12.495533 |
| 13.01.-10.03.2022 | 4.878845e-05 | -0.016004 | 0.013666 | -0.544695 | 18.569120 |
References
- Ding, D.; Zhang, M.; Pan, X.; Yang, M.; He, X. Modeling Extreme Events in Time Series Prediction. In Proceedings of the Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. Association for Computing Machinery, 2019, KDD ’19, p. 1114–1122.
- Ramage, C. Sudden events. Futures 1980, 12, 268–274.
- He, C.; Wen, Z.; Huang, K.; Ji, X. Sudden shock and stock market network structure characteristics: A comparison of past crisis events. Technological Forecasting and Social Change 2022, 180, 121732. [CrossRef]
- Weinberg, D.H.; Andrews, B.H.; Freudenburg, J. Equilibrium and sudden events in chemical evolution. The Astrophysical Journal 2017, 837, 183. [CrossRef]
- Chowdhury, S.N.; Ray, A.; Dana, S.K.; Ghosh, D. Extreme events in dynamical systems and random walkers: A review. Physics Reports 2022, 966, 1–52. [CrossRef]
- Jiang, J.; Huang, Z.G.; Grebogi, C.; Lai, Y.C. Predicting extreme events from data using deep machine learning: When and where. Physical Review Research 2022, 4, 023028. [CrossRef]
- Ahmed, O.; Tennie, F.; Magri, L. Prediction of chaotic dynamics and extreme events: A recurrence-free quantum reservoir computing approach. Physical Review Research 2024, 6, 043082. [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell System Technical Journal 1948, 27, 623–656.
- Dionisio, A.; Menezes, R.; Mendes, D.A. An econophysics approach to analyse uncertainty in financial markets: an application to the Portuguese stock market. The European Physical Journal B 2006, 50, 161–164. [CrossRef]
- Bentes, S.R.; Menezes, R. Entropy: A new measure of stock market volatility? In Proceedings of the Journal of Physics: Conference Series. IOP Publishing, 2012, Vol. 394, p. 012033.
- Delgado-Bonal, A. Quantifying the randomness of the stock markets. Scientific reports 2019, 9, 12761. [CrossRef]
- Delgado-Bonal, A.; López, Á.G. Quantifying the randomness of the forex market. Physica A: Statistical Mechanics and its Applications 2021, 569, 125770. [CrossRef]
- Rosser Jr, J.B. Econophysics and the entropic foundations of economics. Entropy 2021, 23, 1286. [CrossRef]
- Shternshis, A.; Mazzarisi, P.; Marmi, S. Measuring market efficiency: The Shannon entropy of high-frequency financial time series. Chaos, Solitons & Fractals 2022, 162, 112403. [CrossRef]
- Ormos, M.; Zibriczky, D. Entropy-based financial asset pricing. PloS One 2014, 9, e115742. [CrossRef]
- Gupta, R.; Drzazga-Szczȩśniak, E.A.; Kais, S.; Szczȩśniak, D. Entropy corrected geometric Brownian motion. Scientific Reports 2024, 14, 28384. [CrossRef]
- Sheraz, M.; Dedu, S.; Preda, V. Entropy measures for assessing volatile markets. Procedia Economics and Finance 2015, 22, 655–662. [CrossRef]
- Rundle, J.B.; Giguere, A.; Turcotte, D.L.; Crutchfield, J.P.; Donnellan, A. Global seismic nowcasting with Shannon information entropy. Earth and Space Science 2019, 6, 191–197. [CrossRef]
- Drzazga-Szczȩśniak, E.A.; Szczepanik, P.; Kaczmarek, A.Z.; Szczȩśniak, D. Entropy of financial time series due to the shock of war. Entropy 2023, 25, 823. [CrossRef]
- Doğan, N.; Doğan, İ. Determination of the number of bins/classes used in histograms and frequency tables: a short bibliography. İstatistik Araştırma Dergisi 2010, 7, 77–86.
Figure 1.
The intraday log-returns for the three selected datasets of interest (see text for more details). The data range for each subfigure is restricted to the extreme event day (blue shaded area) days. The central regions are additionally magnified in the insets, with the exact dates depicted.
Figure 1.
The intraday log-returns for the three selected datasets of interest (see text for more details). The data range for each subfigure is restricted to the extreme event day (blue shaded area) days. The central regions are additionally magnified in the insets, with the exact dates depicted.
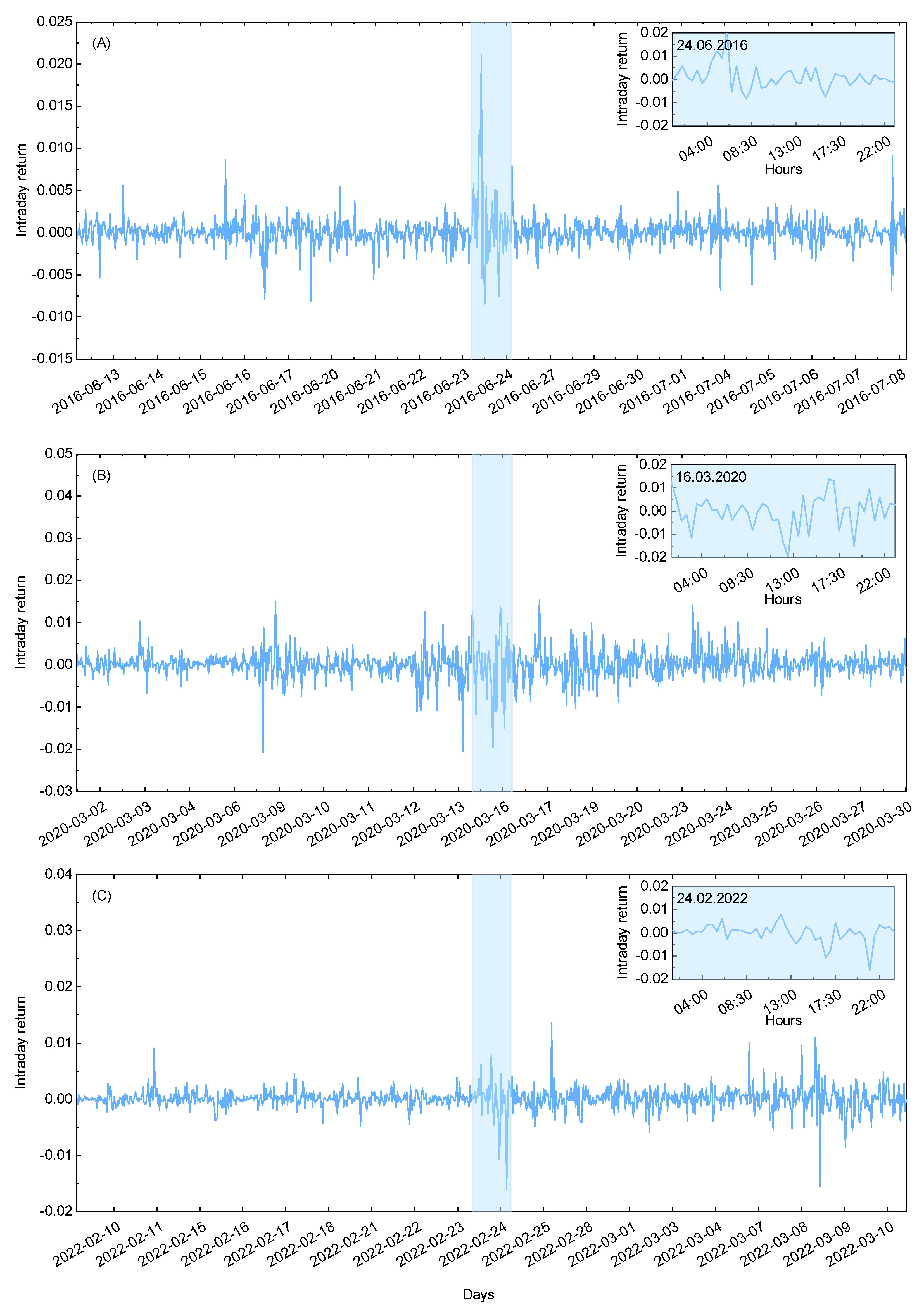
Figure 2.
The discrete probability distributions for the three selected datasets of interest (see text for more details). Each subfigure depicts function related to the given total dataset spanning range of 41 working days (blue color) and to the partial data for the extreme event day only (orange color).
Figure 2.
The discrete probability distributions for the three selected datasets of interest (see text for more details). Each subfigure depicts function related to the given total dataset spanning range of 41 working days (blue color) and to the partial data for the extreme event day only (orange color).
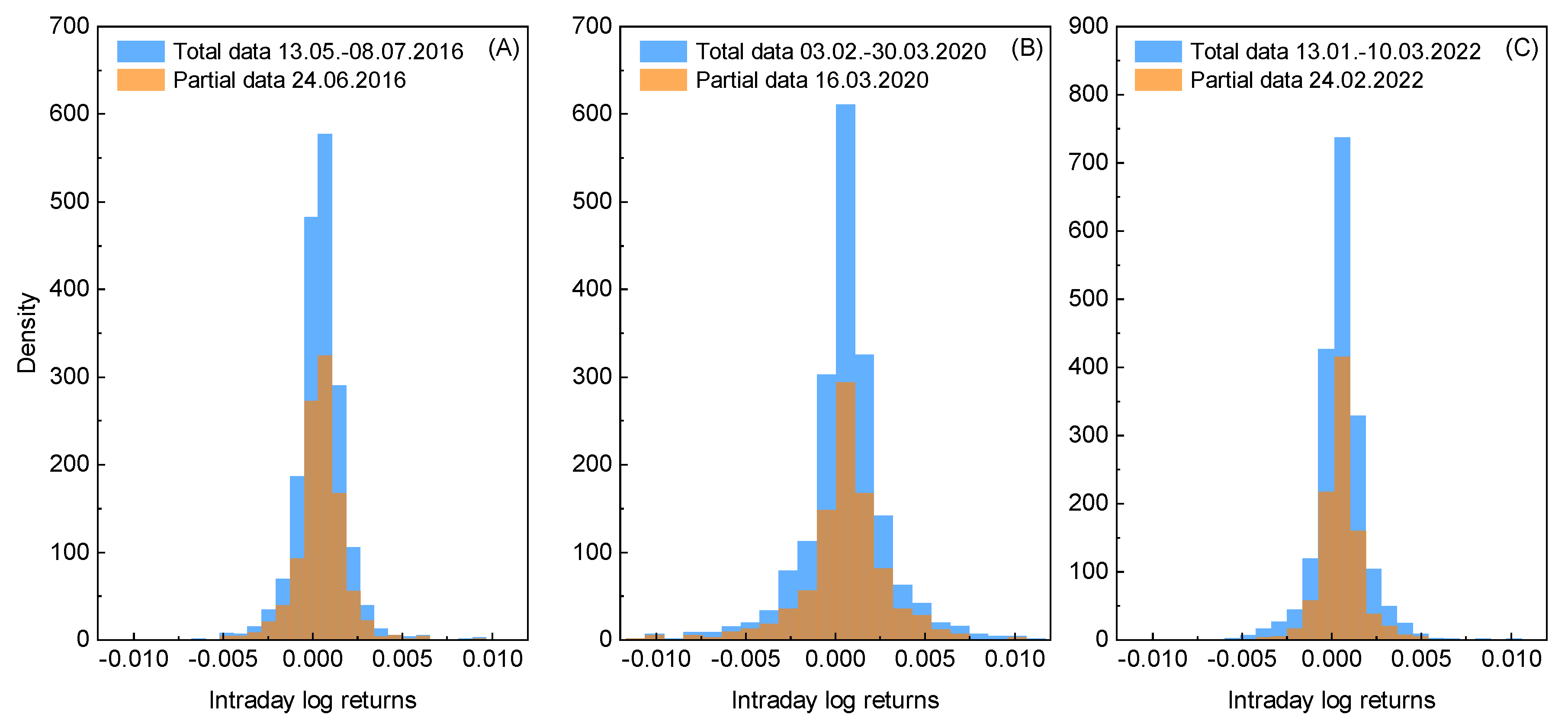
Figure 3.
The cumulative entropy for the selected datasets of interest (see text for more details). The data range for each subfigure is restricted to 30 working days. The depicted dates refer to the reference point, which is the last data point at each subfigure.
Figure 3.
The cumulative entropy for the selected datasets of interest (see text for more details). The data range for each subfigure is restricted to 30 working days. The depicted dates refer to the reference point, which is the last data point at each subfigure.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



