
Submitted:
27 February 2025
Posted:
27 February 2025
You are already at the latest version
Abstract
This paper presents an enhanced Simultaneous Localization and Mapping (SLAM) framework for mobile robot navigation. It integrates RGB-D cameras and 2D LiDAR sensors to improve both mapping accuracy and localization efficiency. First, we propose a data fusion strategy where RGB-D cameras point clouds are projected into 2D, and then noise is filtered. In parallel, we also filter noise from LiDAR data. Late fusion is applied to combine the processed data, making it ready for use in the SLAM system. Second, we propose the enhanced Gmapping (EGM) algorithm by adding adaptive resampling and degeneracy handling to address particle depletion issues, thereby improving the robustness of the localization process. The system is evaluated through simulations and a small-scale real-world implementation using a Tiago robot. In simulations, the system was tested in environments of varying complexity and compared against state-of-the-art methods such as RTAB-Map SLAM and our EGM. Results show general improvements in navigation compared to state-of-the-art approaches: in simulation, an 8% reduction in traveled distance, a 13% reduction in processing time, and a 15% improvement in goal completion. In small-scale real-world tests, the EGM showed slight improvements over the classical GM method: a 3% reduction in traveled distance and a 9% decrease in execution time. methods, showing its potential for practical implementation in autonomous robotics.
Keywords:
SLAM
; localization Gmapping algorithm
; navigation
; data fusion
; point cloud
1. Introduction
In recent years, mobile robots have become essential across various industries and are increasingly integrated into our daily life [1,2,3]. As these robots take on more complex tasks, their ability to navigate and understand their surroundings becomes crucial [1,2]. SLAM is a fundamental technique in robotics and autonomous systems, enabling them to construct a map of an unknown environment while simultaneously determining their own position within it [4,5]. SLAM achieves this by processing sensor data from cameras, LiDAR, or sonar, combined with advanced algorithms such as Kalman filters, particle filters, and graph-based optimization [6,7]. It is widely used in applications like mobile robots, virtual reality (VR), augmented reality (AR), and self-driving cars [6,7,8].
As research in SLAM advances, improving its efficiency and accuracy remains a key focus to enhance autonomous navigation in real-world scenarios [9]. A major challenge is balancing high accuracy with computational efficiency, especially in environments with dynamic obstacles, low-feature areas, or changing lighting conditions [7]. SLAM methods must balance precision and real-time processing, particularly in environments with dynamic obstacles, low-feature regions, or variable lighting conditions [10]. SLAM methods are generally divided into two categories: feature-based methods [11] and direct-based methods [12]. Feature-based approaches, such as ORB-SLAM [13] and PTAM (Parallel Tracking and Mapping) [14], rely on detecting and tracking key points across frames, which can be computationally demanding in texture-less environments. Direct methods, like LSD-SLAM [15] and DSO [16], operate on raw image intensities, making them more sensitive to lighting changes and motion blur.
Many SLAM methods rely on high-precision sensors, such as 3D LiDAR, which provide detailed spatial data but are expensive and computationally intensive [17,18]. Vision-based SLAM, using RGB or RGB-D cameras, offers a more affordable solution but faces challenges, especially in dynamic environments and feature-poor areas [5,19]. Additionally, relying on a single sensor type limits performance in complex environments, as each sensor has its own limitations, such as poor accuracy in low-light conditions or difficulty in capturing fine details in featureless areas [20]. To overcome these challenges, SLAM methods need to integrate multiple sensor modalities to improve robustness and accuracy [21].
One solution to these challenges is the use of hybrid approaches that combine the strengths of different sensors [22,23]. Multi-sensor SLAM, which integrates sensors like LiDARs and RGB-D cameras, has gained significant attention in recent years [24]. By fusing the spatial precision of LiDAR with the rich visual context provided by RGB-D cameras, these approaches can handle dynamic and feature-sparse environments more effectively [20]. This fusion approach leverages data from various sensors and employs information fusion algorithms to improve pose estimation, trajectory estimation, and mapping, giving robots enhanced environmental awareness and better navigation in complex scenarios [24,25]. To further reduce computational complexity, RGB-D camera data can be converted into 2D laser scans by projecting 3D point clouds, making it possible to achieve real-time navigation in resource-constrained environments [22,26]. Furthermore, traditional SLAM algorithms like Gmapping, rely on particle filters. It can be enhanced by improving the way of dealing with these particles in combining with information got from sensors which can achieve better performance [24,27].
In summary, the contributions of our work can be listed as follows:
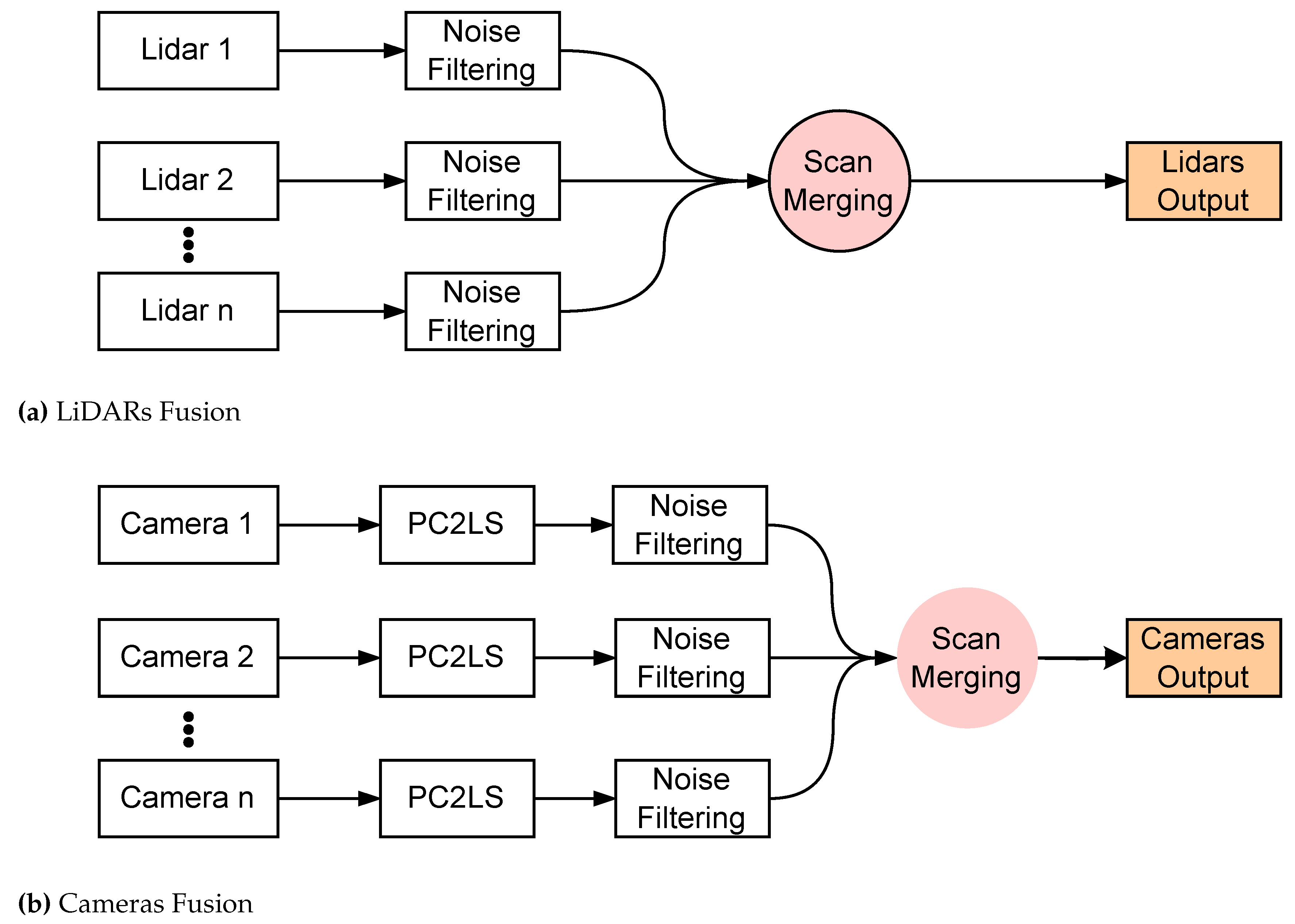
- Point Cloud Projection Broadcasting: We implemented a system for projecting RGB-D camera point clouds as 2D laser scans. This involves preparing the data for seamless integration with other sensors by utilizing transformation matrices and leveraging existing ROS packages, see Figure 3b.
- Modular Multi-Sensor Fusion with Noise Filtering: The system incorporates multiple sensors in parallel with early fusion, designed for adaptability and modularity. If one sensor fails, the system can continue functioning. Additionally, a noise filtering block is added after each sensor to improve data quality and reliability. See Figure 3a,b.
- Enhanced Gmapping with Adaptive Resampling and Degeneracy Handling: The Gmapping method is enhanced by integrating adaptive resampling in combination with degeneracy handling. This selective resampling is triggered only when necessary, preserving particle diversity and improving mapping accuracy. By maintaining a balanced particle distribution, the system ensures robust localization, reduces computational overhead, and prevents particle collapse. This results in improved mapping accuracy and computational efficiency, see Figure 2.
The rest of the paper is organized as shown in Figure 1, the paper is divided into six main sections. Section 1 provides an introduction to 2D mapping, outlining its challenges and proposed solutions. Section 2 reviews related work, offering a detailed analysis of existing methodologies and their limitations. Section 3 explains the methodology, covering data acquisition, point cloud processing, sensor vision integration, and data broadcasting. Section 4 focuses on the experiments, describing the simulation environment, object projection, performance evaluation metrics, and real-world implementation in a small-scale area. Section 5 discusses the results, examining sensor configurations, environmental setups, and system performance while highlighting their practical implications. Finally, Section 6 concludes the paper by summarizing the key contributions, insights, and potential avenues for future research.
Figure 1.
Paper Organizational Chart.
Figure 2.
The process of combining LiDAR and camera outputs, as shown in Figure 3a,b, to generate a 2D map. This process includes preparing the m_scan topic from sensor fusion, initializing the particles and assigning them weights, performing scan matching between sensors and particles to update the weights, and refining the estimation. Additionally, adaptive resampling is applied, and degeneracy is handled within the mapping algorithm. The final output is a 2D map, transformation tf.
Figure 2.
The process of combining LiDAR and camera outputs, as shown in Figure 3a,b, to generate a 2D map. This process includes preparing the m_scan topic from sensor fusion, initializing the particles and assigning them weights, performing scan matching between sensors and particles to update the weights, and refining the estimation. Additionally, adaptive resampling is applied, and degeneracy is handled within the mapping algorithm. The final output is a 2D map, transformation tf.
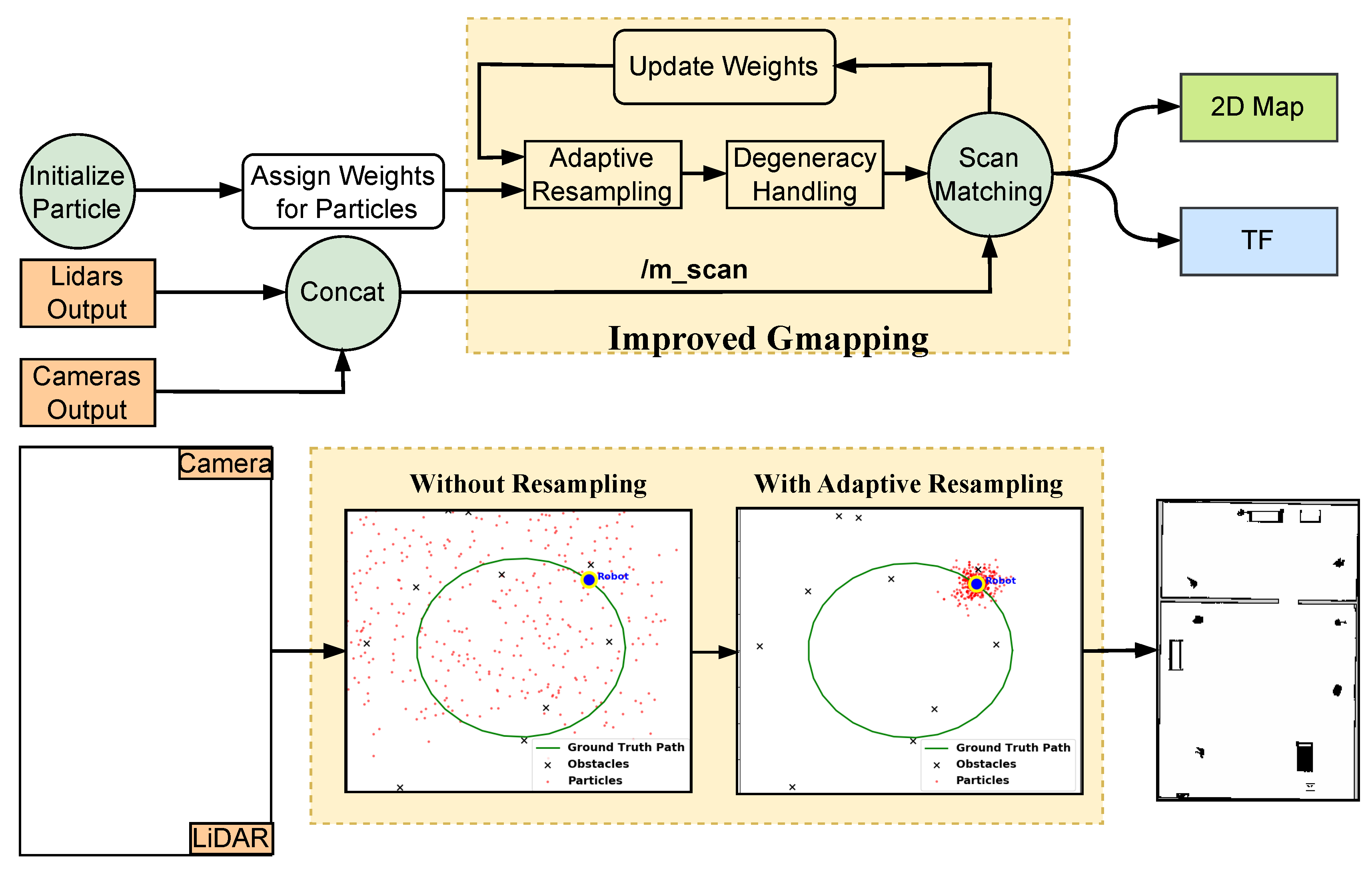
Figure 3.
Fusion of LiDAR and camera data, including noise filtering and converting camera point clouds to laser scans (PC2LS), preparing the data for robot navigation.
Figure 3.
Fusion of LiDAR and camera data, including noise filtering and converting camera point clouds to laser scans (PC2LS), preparing the data for robot navigation.
2. Related Work
SLAM has seen significant advancements, leveraging diverse sensors such as LiDAR, RGB-D cameras, and inertial measurement units (IMUs) to enable robots to navigate and create accurate maps of their environments [8,19,28,29]. The data from these sensors allow for constructing maps in multiple formats, ranging from simple 2D grids to complex 3D semantic and topological maps, each suited to different application needs [30,31,32]. Among these, 2D grid maps are often preferred for their computational simplicity and suitability for real-time navigation tasks [33].
SLAM methods are usually categorized into two main approaches: feature-based methods and direct-based methods. Feature-based approaches extract and track keypoints across frames, making them suitable for structured environments [4,34,35]. Direct methods, on the other hand, operate on raw image intensities, providing robustness in low-texture regions but demanding higher computational resources. Additionally, SLAM can be enhanced through multi-sensor fusion techniques, which integrate multiple data sources to improve accuracy and robustness [10,36,37]. This section provides an overview of these approaches and their challenges.
2.1. Feature-Based SLAM Approaches
Feature-based SLAM methods extract and match keypoints to estimate motion and build a map. These approaches include ORB-SLAM [13,32], PTAM [14], RTAB-Map [38], and Gmapping [21], each offering distinct advantages.
ORB-SLAM:
It is a feature-based SLAM system that employs ORB descriptors for keypoint detection and matching, enabling real-time performance through a three-threaded architecture: tracking, local mapping, and loop closing [32]. Camera pose estimation is achieved by minimizing the re-projection error via Bundle Adjustment (BA):
where represents the observed image coordinates, is the 3D world point, and is the projection function given the camera pose . ORB-SLAM further refines global consistency through pose graph optimization over the Essential Graph. However, ORB-SLAM struggles in low-texture environments, where few keypoints can be detected, and dynamic scenes, where moving objects cause tracking errors.
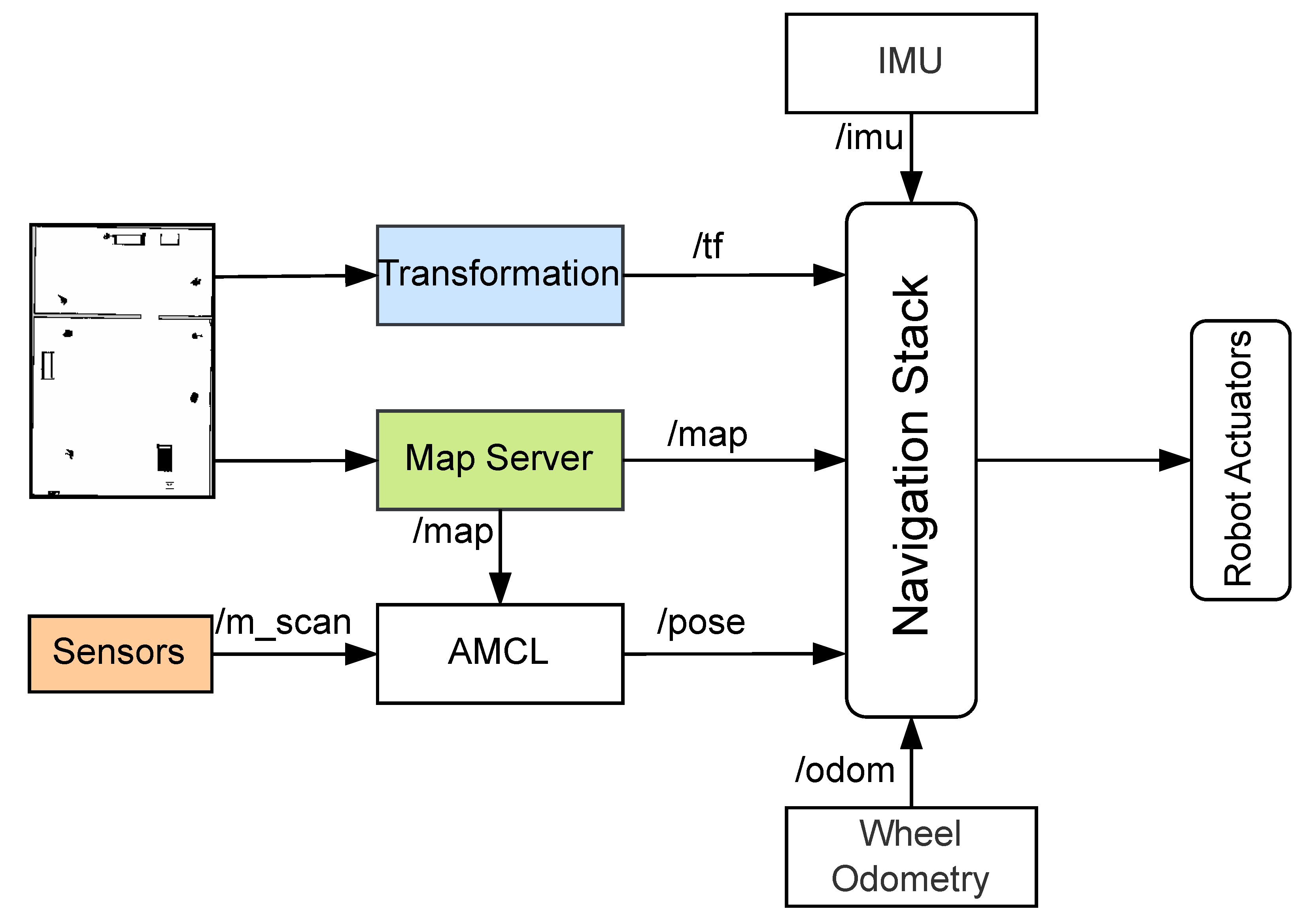
Figure 4.
Navigation stack integrating multi-sensor fusion and enhanced Gmapping. The system receives sensor data from LiDAR, RGB-D cameras stored in (/m_scan), IMU, and odometry, which are processed and transformed (/tf) into a consistent representation. The enhanced Gmapping algorithm updates the occupancy grid map (/map), while AMCL utilizes the sensor data and transformations for precise localization.
Figure 4.
Navigation stack integrating multi-sensor fusion and enhanced Gmapping. The system receives sensor data from LiDAR, RGB-D cameras stored in (/m_scan), IMU, and odometry, which are processed and transformed (/tf) into a consistent representation. The enhanced Gmapping algorithm updates the occupancy grid map (/map), while AMCL utilizes the sensor data and transformations for precise localization.
PTAM:
It introduced a dual-thread approach, separating tracking and mapping with bundle adjustment background. It is designed to improve real-time performance in small-scale environments [31]. PTAM optimizes the 3D map and camera poses using bundle adjustment, minimizing the re-projection error:
where is the 3D point, is the camera pose, is the observed 2D projection, and K is the intrinsic camera matrix. The weight adjusts measurement reliability. While PTAM ensures local accuracy, its lack of loop closure limits long-term consistency, leading to accumulated drift over long trajectories.
RTAB-Map: RTAB-Map (Real-Time Appearance-Based Mapping) is often classified as a feature-based SLAM method that enhances mapping consistency by integrating loop closure detection. It incorporates a memory management strategy, enabling long-term online operation by discarding redundant keyframes while preserving mapping accuracy [35].
The graph optimization in RTAB-Map is typically performed using pose graph optimization, expressed as:
where and are the transformation matrices for keyframe i and keyframe j, represents the relative pose measurement between keyframe i and keyframe j, and is the information matrix, which encodes the uncertainty of the relative pose measurement. RTAB-Map is particularly effective for large-scale environments but comes with high computational demands, which may pose challenges for deployment on resource-constrained robotic platforms [33].
Figure 5.
Illustration of an example working environment and the projected map of 3D objects in a 2D representation using LiDAR data compared to a combination of LiDAR and camera data.
Figure 5.
Illustration of an example working environment and the projected map of 3D objects in a 2D representation using LiDAR data compared to a combination of LiDAR and camera data.

Gmapping: Gmapping is commonly categorized as a feature-based, particle filter-based SLAM algorithm that utilizes Rao-Blackwellized Particle Filters (RBPF) to estimate robot trajectories while building a 2D occupancy grid map [33]. The posterior probability of the map m and trajectory given the observations and controls is:
where the first term represents mapping given known poses, and the second term represents localization.
It is widely used for indoor navigation due to its computational efficiency. However, Gmapping suffers from particle degeneracy, where low-weight particles accumulate over time, reducing localization accuracy. Furthermore, it struggles in large-scale environments due to its reliance on odometry, which introduces cumulative errors [27].
Figure 6.
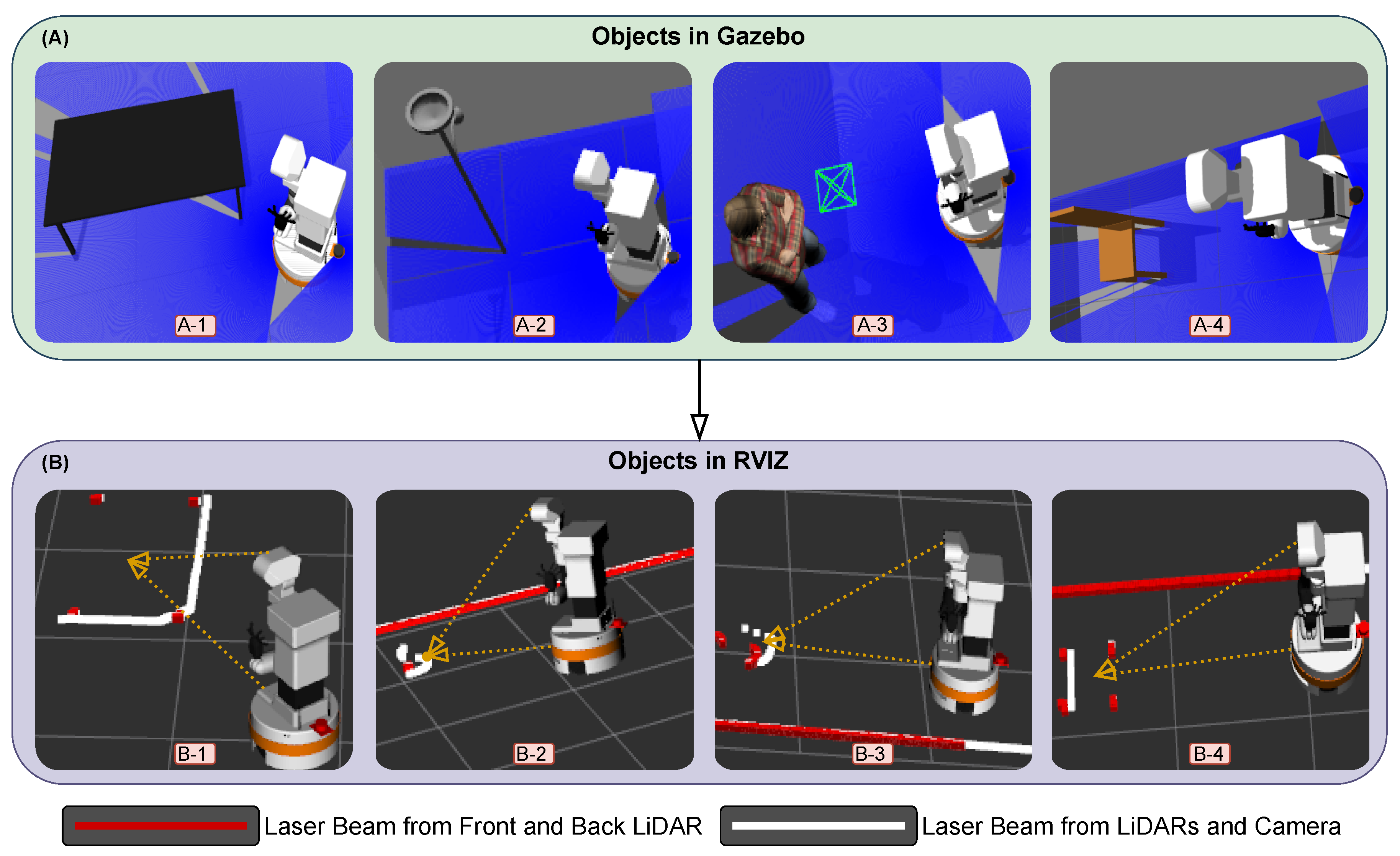
Comparison of object visualization in GAZEBO and RVIZ. (A) Simulation images from GAZEBO. (B) 2D map representations in RVIZ showing data from LiDAR (red lines) and cameras (white lines). The figure illustrates how the robot perceives different objects: (A-1, B-1) The desk boundaries, (A-2, B-2) The lamp holder’s head, (A-3, B-3) The human body, and (A-4, B-4) The chair boundaries.
Figure 6.
Comparison of object visualization in GAZEBO and RVIZ. (A) Simulation images from GAZEBO. (B) 2D map representations in RVIZ showing data from LiDAR (red lines) and cameras (white lines). The figure illustrates how the robot perceives different objects: (A-1, B-1) The desk boundaries, (A-2, B-2) The lamp holder’s head, (A-3, B-3) The human body, and (A-4, B-4) The chair boundaries.
2.2. Direct SLAM Approaches
Unlike feature-based methods, direct SLAM approaches estimate motion by optimizing pixel intensity values directly, eliminating the need for explicit feature extraction. Notable direct methods include LSD-SLAM [15] and DSO (Direct Sparse Odometry) [16].
LSD-SLAM: LSD-SLAM reconstructs semi-dense depth maps using image intensity variations rather than discrete keypoints [15]. It relies on photometric error minimization:
where is the image intensity at pixel i, and represents the estimated camera pose. This makes LSD-SLAM effective in low-texture environments, where feature-based methods typically fail. However, it suffers from high computational costs and is highly sensitive to photometric distortions such as lighting changes.
DSO: Direct Sparse Odometry (DSO) improves upon LSD-SLAM by optimizing a sparse subset of pixels, significantly reducing computational requirements while maintaining accurate motion estimation [16]. However, it does not incorporate loop closure detection, making it prone to drift over long trajectories.
Feature-based SLAM is effective in structured environments but struggles in low-texture areas where keypoints are hard to detect, leading to tracking failures. It also has high computational costs due to real-time feature extraction [39,40]. For example, Gmapping suffers from particle degeneracy, reducing accuracy and increasing computational load, while RTAB-Map requires high memory for loop closure detection [41]. Direct SLAM, on the other hand, performs well in feature-poor environments but has its own challenges. It requires high computational power to process raw pixel intensities in real time [23]. The absence of loop closure detection causes drift and reduces global consistency, while sensitivity to lighting changes and reflections affects accuracy [42].
In conclusion, feature-based SLAM ensures better global consistency but struggles in textureless environments and requires high computational resources [41]. Also, direct SLAM is robust in feature-poor areas but lacks loop closure detection and is sensitive to lighting variations [23]. To address these challenges, researchers have developed a hybrid SLAM, combining feature-based tracking with direct methods to handle feature sparsity [21,43,44]. Multi-sensor fusion, integrating LiDAR, cameras, and IMU, improves robustness by compensating for missing visual features [39,40].
3. Methodology
This section elaborates on the improved Gmapping algorithm, a SLAM framework that fuses data from 2D LiDAR and RGB-D cameras. Figure 2 illustrates the proposed framework, which integrates multi-sensor fusion with Gmapping enhancements, as explained in the following sections.
3.1. Multi Sensor Fusion Framework
The proposed approach combines data from multiple RGB-D cameras and 2D LiDAR sensors to create a unified and comprehensive environmental representation. RGB-D cameras capture both color and depth information, generating 3D point cloud data. These data points are projected onto a 2D plane to simplify processing while preserving critical spatial details. This projection reduces computational complexity while retaining depth information essential for navigation [22,39].
The methodology was adjusted to be able to accept multiple different sensors so that it includes 2D LiDAR sensors and RGB-D cameras to cover all around the robot environment and 360-degree field of view.
3.1.1. RGB-D Cameras and LiDARs Fusion
As shown in Figure 3b, the raw point cloud data generated by the RGB-D cameras is represented as matrices, where each point is defined by its coordinates , corresponding to the horizontal position, depth, and height, respectively. In our simulation case, the point cloud data from the front, back, left, and right cameras are represented as . To simplify the mapping and localization process, the 3D point cloud data is projected onto a laser scan(PC2LS), where the z-coordinate (height) is eliminated, and the points are transformed into coordinates. This transformation enables more efficient processing while maintaining essential depth information for navigation.
The projection process is mathematically represented as:
The resulting 2D representation, denoted as , which contains the spatial coordinates in the plane.
This information will be homogeneous and identical to the data coming from the LiDAR sensor, see Figure 3a.
Figure 7.
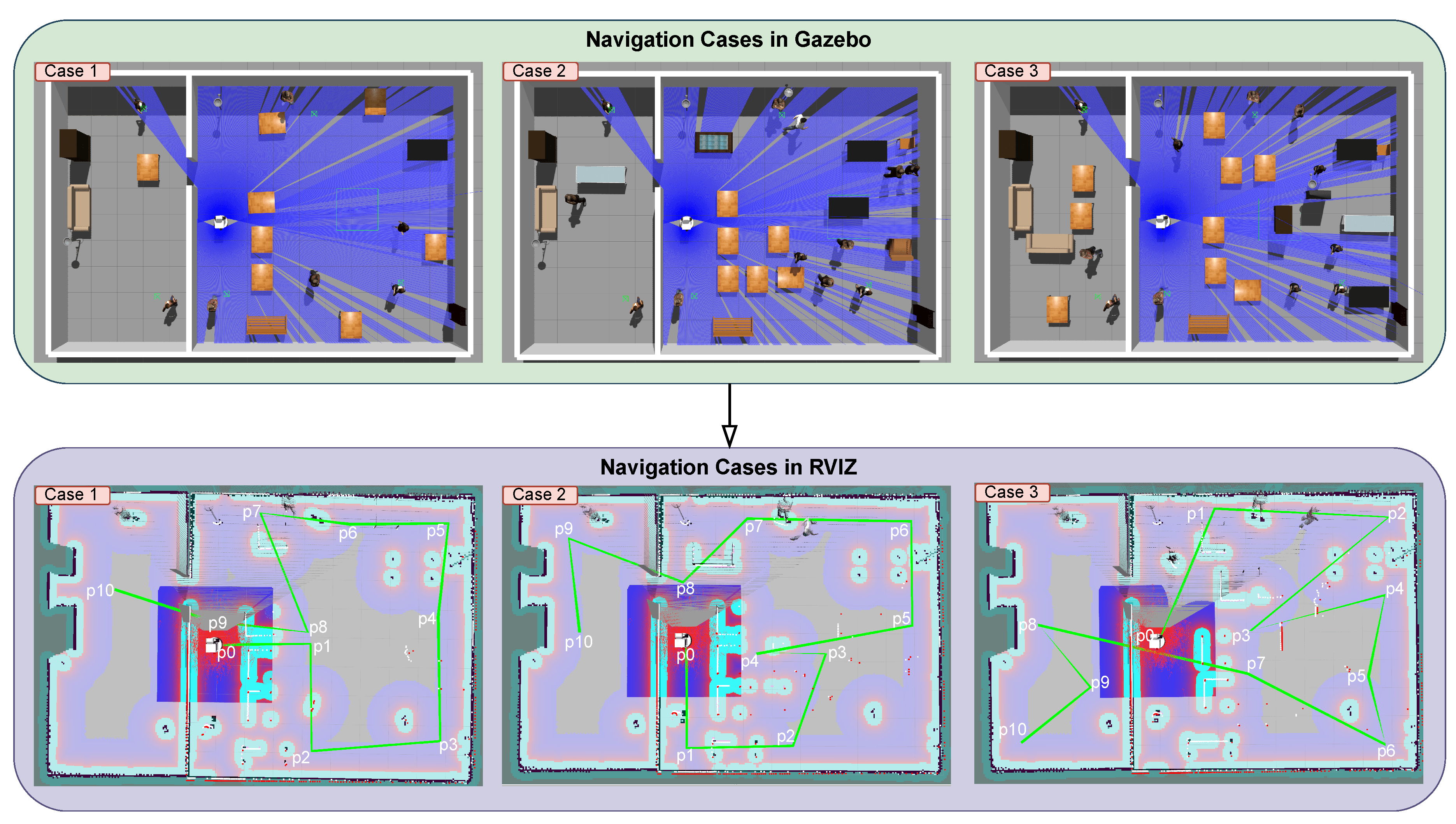
Illustration of three different scenarios simulated in GAZEBO and visualized with RVIZ to compare different navigation variants. Three different levels of navigation difficulty were simulated by adding objects to the environment: Simple, Moderate, and Complex. The most used objects are Desks(d), Participants(p), and keyboards(k). The way-points are marked on the map as through and the sequence in the navigation task is symbolized by the green line.
Figure 7.
Illustration of three different scenarios simulated in GAZEBO and visualized with RVIZ to compare different navigation variants. Three different levels of navigation difficulty were simulated by adding objects to the environment: Simple, Moderate, and Complex. The most used objects are Desks(d), Participants(p), and keyboards(k). The way-points are marked on the map as through and the sequence in the navigation task is symbolized by the green line.
To demonstrate the effectiveness of the projection method, we set up the environment as shown in Figure 5: Rectangle A: Displays the full working environment, including a table, chairs, lamps, and computers, showing how the projection captures the scene. Rectangle B: Shows only the LiDAR data. It detects table legs and parts of the chair but does not capture elevated objects like lamps, illustrating the limitations of LiDAR-only perception. Rectangle C: Combines the LiDAR sensors with RGB-D cameras. Here, the boundaries of the table, the human body, and elevated objects like lamps are detected, demonstrating the enhanced ability to navigate and interact with the environment when both sensor types are used. This comparison highlights how combining LiDAR with RGB-D cameras provides a more covered view, improving the robot’s ability to navigate smoothly in environments and interact with objects at different heights.
3.1.2. Sensors Data Integration
As shown in Figure 3a,b, after obtaining information from LiDAR sensors and RGB-D cameras, a filtration process is applied to extract accurate and clean data necessary for the overall system. The filtering process is performed at an early stage and on each individual sensor separately to improve processing speed and ensure system robustness, meaning the system can continue operating even if one sensor fails.
To smooth the sensor data and reduce noise, we apply the moving average filter, which is computationally simple and effective for real-time applications [45,46]. The moving average filter is defined as follows:
where is the filtered output at index i, M is the window size (number of previous samples used for averaging), and represents the raw sensor measurements.
Figure 8.
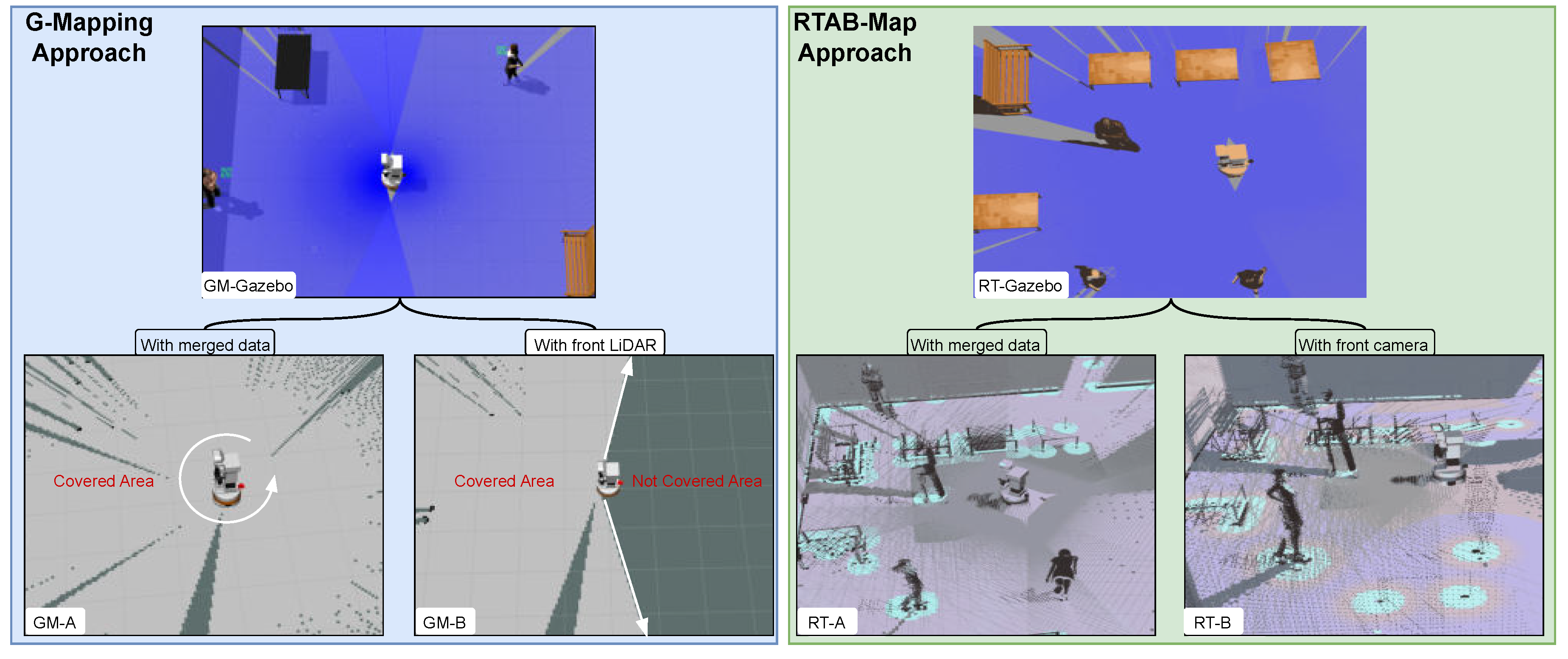
Comparison of mapping coverage in a Gazebo simulation environment with RVIZ visualization, using different sensor setups. The left image (blue box) shows the G-Mapping approach: GM-A covers the entire surroundings using two LiDAR sensors, while GM-B only covers the front area with a single LiDAR. The right image (green box) shows the RTAB-Map approach: RT-A uses all cameras for a full 360-degree view, and RT-B uses just the front camera and LiDAR, giving limited coverage.
Figure 8.
Comparison of mapping coverage in a Gazebo simulation environment with RVIZ visualization, using different sensor setups. The left image (blue box) shows the G-Mapping approach: GM-A covers the entire surroundings using two LiDAR sensors, while GM-B only covers the front area with a single LiDAR. The right image (green box) shows the RTAB-Map approach: RT-A uses all cameras for a full 360-degree view, and RT-B uses just the front camera and LiDAR, giving limited coverage.
After filtering and preparing the sensor data, each sensor publishes its information as a ROS topic with a unique name. To merge the filtered data, we utilize an existing ROS package [47], which combines multiple single-plane laser scans and 2D projections into a unified scan. The result is a 360-degree coverage which is necessary for implementing SLAM methodologies.
The fused data is represented as:
Figure 9.
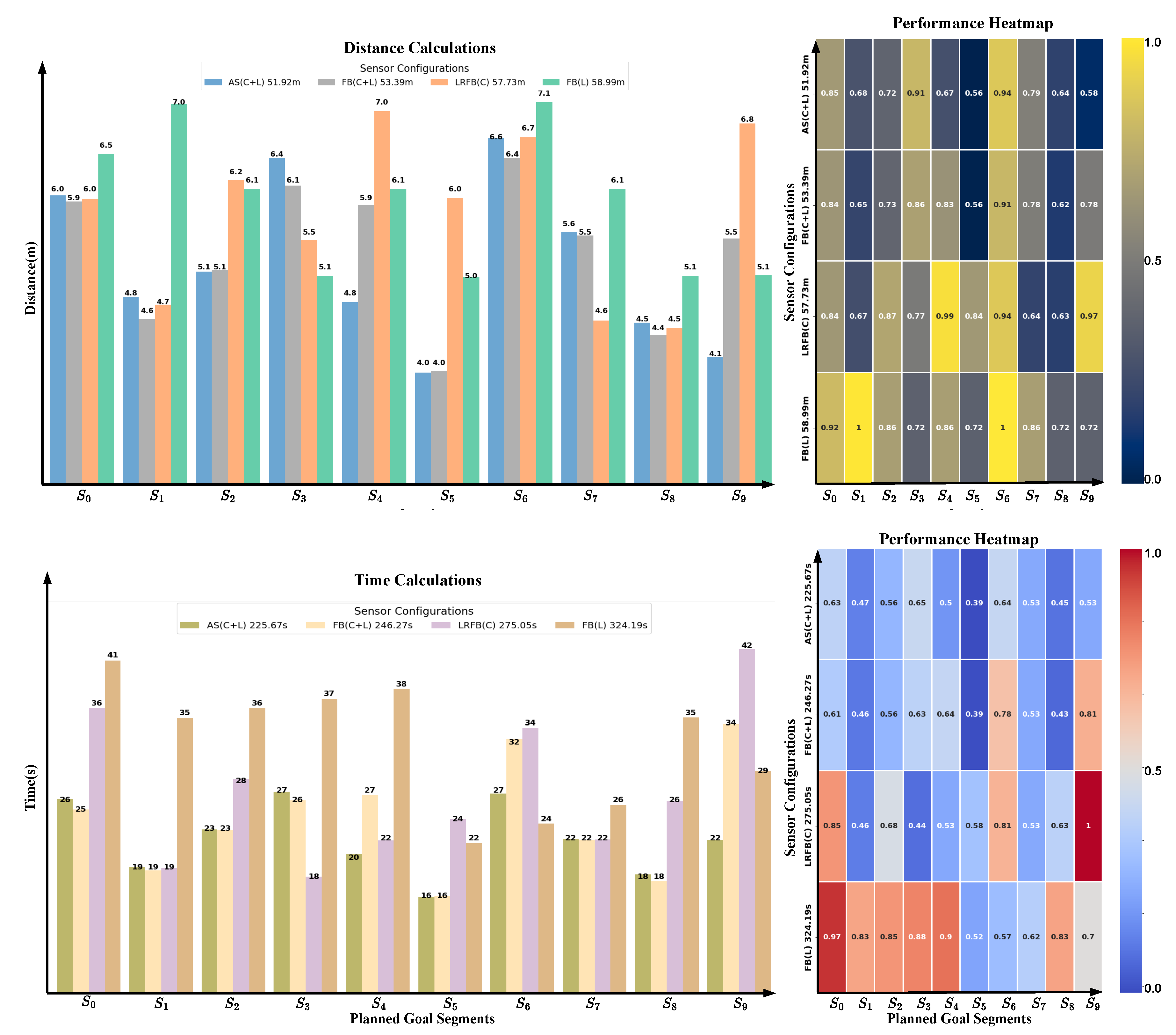
Performance comparison of the robot under different sensor configurations. The configurations include: AS(C+L) (all sensors active: cameras and LiDAR), FB(C+L) (front and back cameras plus LiDAR), LRFB(C) (cameras on all sides), and FB(L) (front and back LiDAR sensors only). The left side presents the measured metrics: Accumulated Distance (in meters) and Accumulated Time (in seconds). The right side displays a heatmap illustrating the impact of combining LiDAR sensors with cameras in improving both travel distance and time efficiency.
Figure 9.
Performance comparison of the robot under different sensor configurations. The configurations include: AS(C+L) (all sensors active: cameras and LiDAR), FB(C+L) (front and back cameras plus LiDAR), LRFB(C) (cameras on all sides), and FB(L) (front and back LiDAR sensors only). The left side presents the measured metrics: Accumulated Distance (in meters) and Accumulated Time (in seconds). The right side displays a heatmap illustrating the impact of combining LiDAR sensors with cameras in improving both travel distance and time efficiency.
Where and represent the 2D projections from the front and back LiDAR sensors, and correspond to the 2D projections from the RGB-D cameras at the front, back, left, and right. This merged data provides a comprehensive environmental map essential for real-time navigation and obstacle avoidance. Once the data is processed and fused, it is converted into a laser scan message, which is broadcast over the ROS firmware, making it accessible for use anywhere. Each point in the 2D matrix corresponds to a detected obstacle, with coordinates indicating the position of the obstacle in the environment.
3.2. Gmapping Enhancements
Gmapping is a widely-used SLAM algorithm based on Rao-Blackwellized Particle Filters (RBPF) [33]. While efficient, traditional Gmapping suffers from issues such as particle degeneracy, fixed grid resolution, and suboptimal scan matching [48,49]. To address these challenges, we propose small improvements; see Figure 10 to increase robustness and efficiency of the method:
3.2.1. Adaptive Resampling
Traditional Gmapping resamples particles at every step, which can lead to particle depletion [27,33]. To mitigate this, we introduce an adaptive resampling strategy based on the Effective Sample Size (ESS), defined as:
where represents the number of effectively independent particles, and is the weight of the i-th particle at time t. Resampling is performed only where is within the threshold . The threshold can be decided based on the size of the environment where the robot is working.
The resampling process is as follows:
1. Compute the cumulative sum of particle weights:
2. Generate N random values from a uniform distribution .
3. Select a particle for each random value based on:
Then, use these candidate particles in preparing the map.
3.2.2. Degeneracy Handling
Particle degeneracy occurs when only a few particles retain significant weights, leading to poor state estimation [49]. To address this, particle weights are normalized as follows:
Additionally, noise injection is applied by perturbing low-weight particles with small random displacements. This approach enhances particle spread, improving robustness against localization errors and preventing particle depletion.
The EGM algorithm integrates the proposed improvements which are shown in the following:
| Algorithm 1 Enhanced Gmapping Algorithm |
|
3.2.3. System Integration
As a final step, we combine all sensor fusion, enhanced Gmapping and already prepared navigation stack. The navigation stack is responsible for path planning, localization, and obstacle avoidance, ensuring smooth robot navigation. As shown in Figure 4, it consists of key components such as the map server, which provides an updated grid map, and AMCL, which estimates the robot’s position using sensor data. The transformation module (/tf) manages coordinate frames, while various sensors, including LiDAR, RGB-D cameras, IMU, and odometry, provide real-time data for accurate navigation. The multi-sensor fusion framework integrates data from these sources and converts it into a laser scan (/m_scan), which is then used by AMCL to improve localization. Additionally, the EGM refines the occupancy grid map (/map) by improving scan matching and particle filtering, ensuring better accuracy in dynamic environments. Together, these components enable the robot to build a precise map, estimate its position reliably, and navigate efficiently in complex surroundings.
4. Experiment Setup
The proposed SLAM system was evaluated using the Tiago Robot. The setup featured front and back LiDAR sensors and cameras at four positions (front, back, left, and right), providing 360-degree coverage. This configuration enabled the robot to detect obstacles, navigate effectively, and interact with its surroundings.
4.1. Experiment Environment Design
The experiments were conducted in three different environments, each with increasing levels of difficulty: simple, moderate, and complex. These environments were designed in Gazebo to closely resemble real-world conditions, including both fixed and moving obstacles such as tables, chairs, and humans. The purpose of these tests was to evaluate how well the robot could navigate, avoid obstacles, and complete its tasks efficiently.
- Simple Environment: This setup has only a few obstacles, such as tables, keyboards, and sofas. The paths are wide and clear, making navigation easy for the robot. It provides a basic test of movement without major challenges.
- Moderate Environment: This setup adds more obstacles, like lamp holders and standing humans, to make navigation harder. The paths are narrower, requiring the robot to move carefully and adjust its route when needed. This helps test how well the robot can handle slightly more difficult spaces.
- Complex Environment: This setup is the most challenging. More obstacles are placed while the robot is moving, and the paths are made even narrower. This forces the robot to make precise movements and smart decisions to avoid collisions. It tests how well the robot adapts to unpredictable situations.
Each environment is shown in Figure 7, which illustrates the planned navigation paths and challenges. The navigation system was implemented using a Python script that processed data from /next_goal and move_base topics. The robot’s movement between waypoints was controlled using the cmd_vel topic. These topics are generally generated in ROS navigation system.
4.2. Comparison Formulas Preparation
For simulation comparison, we assess the path coverage distance, time, battery efficiency, and CPU capabilities of the robot. The robot gathers odometry data from /mobile_base_controller/odom topic. To calculate the time interval between measurements, we subtract the previous timestamp from the current timestamp , resulting in . The linear velocity v is obtained from the absolute value of the x-component of the velocity reported in the odometry data. The incremental distance is then computed as . The total distance is the sum of all incremental distances. The robot’s ability to reach the next goal is assessed by measuring its success in arriving at predetermined positions. The overall journey success rate is calculated based on the accumulated number of successfully reached points.
For battery efficiency, we assume that the battery decreases by 0.01 units per distance step. The drop in battery percentage is calculated as and the drop in voltage is .
4.3. Simulation
We used simulations to test our method and ensure it works well in real-world applications. The simulations were conducted in Gazebo, a robot simulation environment, while Rviz was used for visualization. We tested our method in different scenarios to evaluate its ability to map and locate objects. Additionally, we compared it with another SLAM methods such as RTAB-Map.
4.3.1. Rviz and Gazebo Objects Projection
To show the effectiveness of the fusion of the sensors that we did before which is shown in Figure 3a,b, we demonstrate that affection by using Gazebo and Rviz and by the integration of the python scripts that we prepared. Figure 6 demonstrates some of the fundamentals that we used in our study. Section A represents the objects and environment in Gazebo, section B represents the visualization of the objects and their detection in Rviz. In this demonstration, we aimed to do a comparison between the robot laser beams when it interacts with external objects while creating the map. 1. When the robot just has its front LiDAR sensor which will be represented as the red line, 2. when we integrate the robot back LiDAR sensor which also presented as a red line, 3. when we merge all LiDAR sensors and depth cameras converted scan information which presented as a white line. The robot detects and interacts with various objects, which can be moving, fixed to the ground, or hanging from the ceiling. We selected four objects for our analysis.
Firstly, in images A-1 and B-1, the robot interacts with a table. When using only LiDAR data, the robot detects the table legs, shown by the red points. However, by combining LiDAR and camera data using our approach, all desk boundaries are detected and represented by white dots. For images A-2 and B-2, the robot interacts with a floor lamp that has a head at the top. Using only LiDAR data, the robot detects the vertical column of the lamp, represented by red dots. When camera data is integrated, the boundaries of the lamp head are also detected and projected as white dots, representing the combined sensor data. In images A-3 and B-3, the robot interacts with a human standing in front of it. With only LiDAR data, the robot detects the human legs, shown by red dots. When camera information is added, the robot detects the entire human body, projected as a 2D representation with a white line. Lastly, in images A-4 and B-4, the robot interacts with a chair. Using only LiDAR sensors, the robot detects the chair legs, represented by red dots. By integrating camera information, the boundaries of the chair are also detected, shown by white dots. These results highlight the advantages of fusing cameras with LiDAR sensors, enabling the robot to perceive its environment more effectively and capture finer details for improved navigation and interaction.
4.3.2. Mapping and Localization
Localization and mapping is fundamental for any mobile robot to navigate efficiently and accurately within its environment [19,30]. It involves determining the robot’s position and orientation (pose) relative to a map of its surroundings. In the context of SLAM, mapping, and localization are inherently interdependent; each relies on the other to function effectively [50]. A well-constructed map guides the robot through the environment, aiding in obstacle avoidance and path planning. In this section, we will discuss the methods used for map creation and localization, specifically focusing on three approaches: AMCL, Gmapping, and RTAB-Map. Each method offers unique advantages and is tailored to specific aspects of robot navigation.
A. G-Mapping and AMCL
Gmapping is a widely used ROS package for implementing SLAM. It utilizes scanning data from cameras and/or LiDAR sensors to map the environment where the robot operates. This package creates a 2D occupancy grid map from laser scan data while estimating the robot’s trajectory. The process involves grid mapping, data association, and pose graph optimization [21]. Furthermore, AMCL operates in a 2D space using a particle filter to track the robot’s pose relative to a known map. It publishes a transform between the /map and /odom frames, helping the robot understand its position within the environment. The particle filter estimates the robot’s coordinates. Each particle represents a possible robot pose and has associated coordinates, orientation values, and weight based on the accuracy of its pose prediction. As the robot moves and acquires new sensor data, particles are re-sampled, retaining them with higher weights to refine the pose estimate [51]. Combining Gmapping with AMCL creates a more robust and reliable SLAM system. This combination improves both map creation time and accuracy. As shown in Figure 8 which is represented in blue box, we have the same environment built in GM-Gazebo. By integrating additional sensors, such as back LiDAR and multiple RGB-D cameras as in GM-A, around 360-degree is achieved while the robot is stationary.
However, it takes a longer time to move the robot to cover all places in the environment to create the map, as in GM-B. The setup reduces the time required to generate the map compared to using only front LiDAR and front cameras. The sensor setup accelerates mapping and improves detail, allowing the robot to detect elevated objects and obstacles more effectively. AMCL is better in fast localization compared to RTAB-Map localization as seen in Table 3, and Figure 11.
Finally, by optimizing EGM and AMCL parameters to utilize data from all sensors, we achieve fast and accurate map generation, facilitating reliable localization and efficient navigation. It leverages the strengths of them, combined with sensor coverage, to develop the robot’s operational capabilities [52].
B. RTAB Map
As mentioned before, RTAB-Map performs robot mapping and localization using advanced computer vision algorithms and loop closure detection logic [38]. This approach, while effective, results in high computational demands and longer localization times. During localization, the robot may experience delays in recognizing its position, which in turn affects its ability to reach its goal successfully. Additionally, creating a complete map requires the robot to travel and cover the entire environment, which can be time-consuming.
To address these challenges, we included extra cameras on the robot to speed up data matching and improve localization accuracy. As shown in Figure 8, represented in green box, RT-Gazebo environment consists of three participants and several tables. The RT-A display shows the map created using merged data from multiple cameras, while RT-B) shows the map created using only the front camera sequentially. In the first scenario, RT-A, the three participants and the surrounding environment are detected easily and accurately. In contrast, in the second scenario RT-B, where only one camera is used, only some features are detected initially, requiring the robot to move around the environment to detect the remaining features.
4.3.3. SLAM and Navigation
In our experiment, the navigation setup was configured using the ROS Navigation Stack. First, the environment map was generated using the EGM package, which relies on laser rangefinder data. This map served as the foundation for robot localization. To localize the robot within this map, we used the AMCL package, which performs probabilistic localization using LiDAR data, the map, and initial pose estimates. We employed two mapping methods (G-Mapping and RTAB-Map) and two localization techniques (AMCL and RTAB-Map loop closure detection). This allowed us to test the performance of the navigation stack under different conditions. Three distinct test cases were designed, see Figure 7 with varying environments to assess how the robot navigated under different scenarios.
The simulation was implemented and visualized using Gazebo and Rviz. Python scripts were written to facilitate the simulation process and follow them synchronously. The environments were designed to allow for comparison across different simulation scenarios. Each case involved ten different goals, with the coordinates of each goal stored in TXT files. This was achieved using the /clicked_point topic published from the Rviz interface, allowing automatic storage of goal x and y coordinates for later use. Finally, a Python script published the x and y coordinates from the TXT file and visualized the path by connecting the goals to clearly display the planned trajectory.
4.3.4. Path Planning
After setting up the simulation environment in Gazebo and configuring the /move_base parameters for all scenarios, the next phase of our experiment involved implementing path planning. Once the robot’s position and orientation are localized, a path must be planned to reach the target goal. Path planning is essential for autonomous navigation, ensuring that the robot can move from its current position to the destination while avoiding obstacles [20]. It is generally divided into two types: global path planning and local path planning.
1. Global Path Planning:
It involves finding an optimal or near-optimal path from the starting point to the destination, considering the entire environment. This planning is done without considering the real-time constraints or dynamic obstacles in the environment [53]. Common algorithms used for global path planning include A* (A-star), and Dijkstra’s algorithm. These algorithms consider the entire map or environment, including obstacles, to determine the best path. In our setup, we implemented a global path planning algorithm using the ROS packages /global_planner and navfn. These packages generate a global path based on a static map of the environment. The /move_base package works in tandem with the global planner, handling navigation by sending velocity commands to the robot. This component collaborates with the global planner to manage navigation by sending velocity commands to the robot.
2. Local Path Planning:
Local path planning focuses on the robot’s immediate surroundings. It adjusts the robot’s trajectory in real-time, helping it avoid dynamic obstacles while following the global path. Local path planners respond to changes in the environment, making necessary adjustments to avoid obstacles and maintain the planned trajectory. Techniques like potential fields, reactive methods, and artificial potential fields are commonly employed for this purpose [20]. We implemented local path planning using the /base_local_planner and /dwa_local_planner packages, allowing the robot to make real-time adjustments based on its local environment. However, we observed that the local planner sometimes failed in certain scenarios, especially when limited sensor data was available. This failure could be traced back to the global planner’s initial trajectory calculation. In situations where the robot approached obstacles, such as tables, the empty space between table legs could mislead the robot into thinking a passageway was available, causing collisions.
To ensure a fair comparison and consistent conditions across all three cases, we established ten fixed points on the maps, each with specific positions and orientations, as shown in Figure 7. These points were stored in TXT files using a Python script, ensuring uniformity in the robot’s path planning for each scenario. During the operation of the navigation system, the script continuously logged the positions of clicked points in Rviz to the TXT file by monitoring the /clicked_point topic. This standardization of initial positions, path trajectories, and /move_base parameters was essential for ensuring the repeatability and reproducibility of the experiments.
4.4. Implementation
Due to environmental constraints and the lack of specific sensors, we conducted a small-scale real-world implementation using the Tiago robot with pre-integrated sensors which are 1 RGB-D camera and one 2D LiDAR sensor. The experiment was set up using six independent segments forming a hexagonal path, initializing 1000 particles randomly, see Figure 10. The blue area indicates regions mapped with the original Gmapping technique, whereas the pink area represents our EGM approach, which integrates adaptive resampling and degeneracy handling into classical Gmapping.
This enhancement significantly improved the distribution of particles, shown as red points, making them more concentrated and focused, thus allowing the robot to obtain more precise localization and estimation of its position. The green, black, and blue lines in the visualization represent the planned path, the estimated path using original Gmapping, and the estimated path using our improved method, respectively. The alignment differences between these paths highlight the improvements in robot position estimation.
The quantitative results, summarized in Table 5, illustrate key performance metrics:
- Traveled Distance: Using our EGM, the total traveled distance was 14.95m, compared to 16.10m with the original GM. This reduction demonstrates improved estimation of the robot position based on the distributed particles and in collaboration with obtained sensor fused information.
- Time Required: The journey with EGM was completed in 64.70s, whereas GM required 70.90s.
- Goals Achievement: Both methods successfully reached all goal points (100% success rate), confirming that the EGM and classical GM are scoring the same target for goal achievement.
- Overlap Ratio: The overall overlap ratio with EGM was 68%, while GM had 33.7%. The high overlap ratio in EGM suggests that the particles were more focused, reducing unnecessary dispersion and enhancing robot’s precise positioning.
- Average Error: The cumulative localization error in EGM was 0.85m, while GM had a higher error of 1.56m. This 45.5% reduction in error demonstrates the effectiveness of adaptive resampling in maintaining accurate position estimates.
The overlap ratio was used to evaluate the alignment of estimated positions with the true robot position by considering the fraction of particles within a threshold distance of 0.5 meters. It was computed as follows:
where is the Euclidean distance between particle and the true position . The number of particles satisfying was then used to compute the overlap ratio:
These findings emphasize that integrating adaptive resampling and degeneracy handling in Gmapping enhances particle consistency, leading to more realistic and efficient mapping. The reduction in traveled distance, time, and localization error while maintaining a high goal success rate proves the effectiveness of our approach in real-world implementations.
5. Results and Discussion
This section presents the evaluation and discussion of our proposed method, focusing on multi-sensor integration with optimal fusion strategies and enhanced mapping.
5.1. Evaluation Metrics
To assess the robot’s performance, we considered key metrics that evaluate its efficiency and effectiveness in navigation. Task accomplishment was measured by the robot’s ability to successfully complete assigned tasks. Time and distance efficiency were tracked by recording the time and distance between goals to evaluate navigation performance and compute the total accumulated time and distance. Success rates were analyzed by assessing the percentage of goals successfully reached versus failures due to obstacles, providing insight into the robot’s obstacle avoidance capabilities (see Table 1, Table 3, and Figure 9, Figure 11). Resource consumption, including battery efficiency and CPU usage, was monitored to understand the computational and energy demands during operation. Stability was evaluated by analyzing the robot’s linear and angular velocities to ensure smooth and consistent movement (see Table 2, Table 4). To further analyze time and distance efficiency, we normalized execution times and distances relative to the maximum recorded time and distances. Then, we visualized them using a heatmap. Warmer colors with higher numbers indicate longer execution times and longer distances, while cooler colors with small numbers represent faster performance, allowing for an intuitive comparison of sensor configurations.
For real-world implementation, as described in Section 4.4, we followed the same strategy as in the simulation while additionally incorporating the overlap ratio metric, which quantifies the alignment of the estimated robot position relative to the given position.
5.2. Sensor Configuration Analysis
To evaluate the impact of different sensor configurations on navigation performance, we conducted experiments with four distinct setups using our EGM method:
1. AS(C+L): All sensors, incorporating both cameras and LiDARs.
2. FB(C+L): Front and back cameras and LiDARs.
3. LRFB(C): Left, right, front, and back just cameras.
4. FB(L): Front and back just LiDAR sensors.
As shown in Figure 9 and Table 1, Table 2, all the details and comparisons discussed in this section are provided in these visualizations and tables. Utilizing all available sensors, AS(C+L), which combines all cameras and LiDARs, significantly improved navigation efficiency. This configuration resulted in the shortest travel distance of 51.8 meters and the lowest travel time of 223.7 seconds, outperforming all other setups.
Incorporating only front and back cameras and LiDARs, FB(C+L), enabled the robot to reach all goals successfully. However, it required more time (54.3 seconds) and travel distance (245.5 meters) compared to AS(C+L). When relying solely on cameras, LRFB(C), the robot became stuck at one goal, preventing full completion of the planned journey. In contrast, using only LiDAR sensors, FB(L), resulted in just 40% navigation success, with the robot failing to complete the journey due to obstacles. Moreover, the heatmap indicates that areas with shorter time and distance values are concentrated at the top of the grid. As sensor configurations are reduced, both execution time and distance increase, visually demonstrating the performance decline with fewer sensor incorporation. Battery and voltage consumption was minimized using AS(C+L), with a charge decrease of 5.3% and a voltage drop of 2.6%. CPU usage was also the lowest in this configuration. Stability analysis further demonstrated that AS(C+L) provided more consistent linear and angular velocity, ensuring smoother motion.
In real-time implementation, as shown in Table 5, a slight improvement was observed when comparing EGM with GM in terms of time, distance traveled, overlap ratio between planned and estimated segments, and average error generated. Although environmental constraints limited the scale of our experiments compared to the simulations, the results were still sufficient to demonstrate that incorporating both visual and LiDAR-based data, combined with a well-designed fusion framework and adaptive particle assembly, allows the robot to navigate effectively in complex environments in both simulation and real-world applications.
5.3. Environmental Configuration Analysis
This section evaluates the performance of the proposed EGM method across different environments: simple, moderate, and complex. The goal is to fairly compare the impact of adaptive sampling and degeneracy handling, combined with our sensor fusion technique, against the RTAB-Map approach in varying environmental conditions. The evaluation was conducted using various performance metrics, as shown in Figure 11 and Table 3, Table 4.
In a simple environment, the proposed EGM method completed the task in 230.04 seconds, compared to 327.65 seconds using the RTAB method. The distance covered was 53.04 meters with our approach versus 56.92 meters with RTAB. Additionally, the RTAB-Map approach caused the robot to get stuck at two goals, while our method successfully reached all goals.
In a moderate environment, the proposed method completed the task in 238.83 seconds, compared to 254.93 seconds with the RTAB method. The distance covered was 54.31 meters with our approach versus 58.27 meters with RTAB. Similarly, the RTAB-Map approach caused the robot to get stuck at one goal, whereas our method successfully navigated to all goals.
In a complex environment, the proposed method completed the task in 287.29 seconds, compared to 335.0 seconds with the RTAB method. The distance covered was 66.65 meters with our approach versus 73.37 meters with RTAB. Again, the RTAB-Map approach resulted in the robot getting stuck at two goals, while our method successfully completed the entire task. Additional metrics, including charge and voltage consumption, CPU usage, and motion stability, further highlight the advantages of our approach. While both methods showed increased CPU demand as environmental complexity grew, our approach maintained lower CPU usage in certain cases. In terms of motion stability, both methods demonstrated stable linear and angular velocities, ensuring smoother navigation.
These results demonstrate that the proposed method have slight competitive results against RTAB in terms of time efficiency and distance traveled across various environments. This is primarily due to the localization requirements of RTAB-Map, which involves processing intense features to help the robot localize and move to the next goal.
6. Conclusion
In this work, we developed an improved SLAM system for mobile robot navigation by combining our sensor fusion technique with an enhanced mapping approach. Our fusion method converts RGB-D point clouds into 2D laser scans, allowing seamless integration with LiDAR data, while parallel noise filtering improves sensor reliability. To enhance localization, we introduced Enhanced Gmapping (EGM), which includes adaptive resampling and degeneracy handling to maintain particle diversity and degeneracy handling to prevent mapping errors. These improvements made the system more stable and accurate. Our approach slightly improved traditional methods, achieving 8% less traveled distance, 13% faster processing, and 15% better goal completion in simulations. In real-world tests, EGM further reduced the traveled distance by 3% and execution time by 9%, demonstrating its effectiveness. Despite these improvements, challenges remain, such as difficulty detecting objects with gaps, like table legs, which can cause navigation errors. To address this, we plan to integrate AI-based solutions, including LSTM for better memory of visited locations and CNNs for improved object recognition. Additionally, we will test the system in more complex and dynamic environments beyond controlled simulations to further validate its real-world applicability. These advancements will improve the system’s adaptability and reliability, making it more effective for real-world autonomous navigation.
Author Contributions
Conceptualization, B.A.-L. and A.A.-H; methodology, M.J., A.C., and B.A.-L; software, A.C., and B.A.-L.; validation, A.A.-H, M.J., and B.A.-L; investigation, B.A.-L., A.A.-H, and M.J.; resources, A.A.-H.; writing—original draft preparation, B.A.-L., A.C., and M.J.; writing—review and editing, B.A.-L., A.C., M.J., and A.A.-H.; visualization, B.A.-L., M.J., and A.C..; supervision, A.A.-H.; project administration, B.A.-L. and A.A.-H.; funding acquisition, A.A.-H. All authors have read and agreed to the published version of the manuscript.
Funding
This work is funded and supported by the Federal Ministry of Education and Research of Germany (BMBF) (AutoKoWAT- 3DMAt under grant No. 13N16336), German Research Foundation (DFG- Roboter SEMIAC under grant number No. 502483052) and by the European Regional Development Fund (EFRE-ENABLING under grant No. ZS/2023/12/182056 and EFRE-RoboLab grant No. ZS/2023/12/182065).
Institutional Review Board Statement
The study was conducted according to the guidelines of the Declaration of Helsinki. Ethical approval was done by Ethik Kommision der Otto-von-Guericke Universtiät (IRB00006099, Office for Human Research) 157/20 on 23 October 2020.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, or in the decision to publish the results.
References
- Placed, J.A.; Strader, J.; Carrillo, H.; Atanasov, N.; Indelman, V.; Carlone, L.; Castellanos, J.A. A survey on active simultaneous localization and mapping: State of the art and new frontiers. IEEE 2023, 39, 1686–1705. [Google Scholar] [CrossRef]
- Gu, J.; Stefani, E.; Wu, Q.; Thomason, J.; Wang, X.E. Vision-and-language navigation: A survey of tasks, methods, and future directions. 2022.
- Zhu, J.; Li, H.; Zhang, T. Camera, LiDAR, and IMU based multi-sensor fusion SLAM: A survey. Tsinghua Science and Technology 2023, 29, 415–429. [Google Scholar] [CrossRef]
- Al-Tawil, B.; Hempel, T.; Abdelrahman, A.; Al-Hamadi, A. A review of visual SLAM for robotics: evolution, properties, and future applications. Frontiers in Robotics and AI 2024, 11, 1347985. [Google Scholar] [CrossRef] [PubMed]
- Mokssit, S.; Licea, D.B.; Guermah, B.; Ghogho, M. Deep learning techniques for visual slam: A survey. IEEE Access 2023, 11, 20026–20050. [Google Scholar] [CrossRef]
- Yin, J.; Luo, D.; Yan, F.; Zhuang, Y. A novel lidar-assisted monocular visual SLAM framework for mobile robots in outdoor environments. IEEE Transactions on Instrumentation and Measurement 2022, 71, 1–11. [Google Scholar] [CrossRef]
- Kulkarni, M.; Junare, P.; Deshmukh, M.; Rege, P.P. Visual SLAM combined with object detection for autonomous indoor navigation using kinect V2 and ROS. In Proceedings of the 2021 IEEE 6th international conference on computing, communication and automation (ICCCA). IEEE, 2021, pp. 478–482.
- Peng, G.; Lam, T.L.; Hu, C.; Yao, Y.; Liu, J.; Yang, F. Visual SLAM for Mobile Robot. In Introduction to Intelligent Robot System Design: Application Development with ROS; Springer, 2023; pp. 481–539.
- Hempel, T.; Al-Hamadi, A. Pixel-wise motion segmentation for SLAM in dynamic environments. IEEE Access 2020, 8, 164521–164528. [Google Scholar] [CrossRef]
- Hempel, T.; Al-Hamadi, A. An online semantic mapping system for extending and enhancing visual SLAM. Engineering Applications of Artificial Intelligence 2022, 111, 104830. [Google Scholar] [CrossRef]
- Zhao, L.; Mao, Z.; Huang, S. Feature-based SLAM: Why simultaneous localisation and mapping? Robotics: Science and Systems 2021 2021. [Google Scholar]
- Liang, M.; Leitinger, E.; Meyer, F. Direct Multipath-Based SLAM. arXiv 2024, arXiv:2409.20552. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: a versatile and accurate monocular SLAM system. IEEE transactions on robotics 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Pire, T.; Fischer, T.; Castro, G.; De Cristóforis, P.; Civera, J.; Berlles, J.J. S-PTAM: Stereo parallel tracking and mapping. Robotics and Autonomous Systems 2017, 93, 27–42. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the European conference on computer vision. Springer, 2014, pp. 834–849.
- Wang, R.; Schworer, M.; Cremers, D. Stereo DSO: Large-scale direct sparse visual odometry with stereo cameras. In Proceedings of the Proceedings of the IEEE international conference on computer vision, 2017, pp. 3903–3911.
- Somlyai, L.; Vámossy, Z. Improved RGB-D Camera-based SLAM System for Mobil Robots. Acta Polytechnica Hungarica 2024, 21. [Google Scholar] [CrossRef]
- Hempel, T.; Al-Hamadi, A. Slam-based multistate tracking system for mobile human-robot interaction. In Proceedings of the International Conference on Image Analysis and Recognition. Springer, 2020, pp. 368–376.
- Panigrahi, P.K.; Bisoy, S.K. Localization strategies for autonomous mobile robots: A review. Journal of King Saud University-Computer and Information Sciences 2022, 34, 6019–6039. [Google Scholar] [CrossRef]
- Zhang, X.; Lai, J.; Xu, D.; Li, H.; Fu, M. 2d lidar-based slam and path planning for indoor rescue using mobile robots. Journal of Advanced Transportation 2020, 2020, 1–14. [Google Scholar] [CrossRef]
- Tian, C.; Liu, H.; Liu, Z.; Li, H.; Wang, Y. Research on multi-sensor fusion SLAM algorithm based on improved gmapping. IEEE Access 2023, 11, 13690–13703. [Google Scholar] [CrossRef]
- Sun, C.; Wu, X.; Sun, J.; Sun, C.; Xu, M.; Ge, Q. Saliency-Induced Moving Object Detection for Robust RGB-D Vision Navigation Under Complex Dynamic Environments. IEEE Transactions on Intelligent Transportation Systems 2023. [Google Scholar] [CrossRef]
- Xie, H.; Zhang, D.; Wang, J.; Zhou, M.; Cao, Z.; Hu, X.; Abusorrah, A. Semi-direct multimap SLAM system for real-time sparse 3-D map reconstruction. IEEE Transactions on Instrumentation and Measurement 2023, 72, 1–13. [Google Scholar] [CrossRef]
- Kang, X.; Li, J.; Fan, X.; Wan, W. Real-time rgb-d simultaneous localization and mapping guided by terrestrial lidar point cloud for indoor 3-d reconstruction and camera pose estimation. Applied Sciences 2019, 9, 3264. [Google Scholar] [CrossRef]
- Wang, X.; Li, K.; Chehri, A. Multi-sensor fusion technology for 3D object detection in autonomous driving: A review. IEEE Transactions on Intelligent Transportation Systems 2023. [Google Scholar] [CrossRef]
- Chu, P.M.; Sung, Y.; Cho, K. Generative adversarial network-based method for transforming single RGB image into 3D point cloud. IEEE Access 2018, 7, 1021–1029. [Google Scholar] [CrossRef]
- Ahmed, Z.A.; Raafat, S.M. An Extensive Analysis and Fine-Tuning of Gmapping’s Initialization Parameters. International Journal of Intelligent Engineering & Systems 2023, 16. [Google Scholar]
- Zhou, Y.; Li, B.; Wang, D.; Mu, J. 2D Grid map for navigation based on LCSD-SLAM. In Proceedings of the 2021 11th International Conference on Information Science and Technology (ICIST). IEEE, 2021, pp. 499–504.
- Zhou, Z.; Feng, X.; Di, S.; Zhou, X. A lidar mapping system for robot navigation in dynamic environments. IEEE Transactions on Intelligent Vehicles 2023. [Google Scholar] [CrossRef]
- Meng, J.; Wan, L.; Wang, S.; Jiang, L.; Li, G.; Wu, L.; Xie, Y. Efficient and reliable LiDAR-based global localization of mobile robots using multiscale/resolution maps. IEEE Transactions on Instrumentation and Measurement 2021, 70, 1–15. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM international symposium on mixed and augmented reality. IEEE, 2007, pp. 225–234.
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Transactions on Robotics 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with rao-blackwellized particle filters. IEEE transactions on Robotics 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Yanik, Ö.F.; Ilgin, H.A. A comprehensive computational cost analysis for state-of-the-art visual slam methods for autonomous mapping. Communications Faculty of Sciences University of Ankara Series A2-A3 Physical Sciences and Engineering 2023, 65, 1–15. [Google Scholar] [CrossRef]
- Labbé, M.; Michaud, F. RTAB-Map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation. Journal of field robotics 2019, 36, 416–446. [Google Scholar] [CrossRef]
- Jia, L.; Ma, Z.; Zhao, Y. A Mobile Robot Mapping Method Integrating Lidar and Depth Camera. In Proceedings of the Journal of Physics: Conference Series. IOP Publishing, 2022, Vol. 2402, p. 012031.
- Zhang, T.; Wang, P.; Zha, F.; Guo, W.; Li, M. RGBD Navigation: A 2D navigation framework for visual SLAM with pose compensation. In Proceedings of the 2023 IEEE International Conference on Real-time Computing and Robotics (RCAR). IEEE, 2023, pp. 644–649.
- Muharom, S.; Sardjono, T.A.; Mardiyanto, R. Real-Time 3D Modeling and Visualization Based on RGB-D Camera using RTAB-Map through Loop Closure. In Proceedings of the 2023 International Seminar on Intelligent Technology and Its Applications (ISITIA). IEEE, 2023, pp. 228–233.
- Kim, P.; Chen, J.; Cho, Y.K. SLAM-driven robotic mapping and registration of 3D point clouds. Automation in Construction 2018, 89, 38–48. [Google Scholar] [CrossRef]
- Wei, H.; Jiao, J.; Hu, X.; Yu, J.; Xie, X.; Wu, J.; Zhu, Y.; Liu, Y.; Wang, L.; Liu, M. Fusionportablev2: A unified multi-sensor dataset for generalized slam across diverse platforms and scalable environments. arXiv 2024, arXiv:2404.08563. [Google Scholar] [CrossRef]
- Ali, W.; Liu, P.; Ying, R.; Gong, Z. A feature based laser SLAM using rasterized images of 3D point cloud. IEEE Sensors Journal 2021, 21, 24422–24430. [Google Scholar] [CrossRef]
- Zhang, Y.; Tosi, F.; Mattoccia, S.; Poggi, M. Go-slam: Global optimization for consistent 3d instant reconstruction. In Proceedings of the Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3727–3737.
- Younes, G.; Khalil, D.; Zelek, J.; Asmar, D. H-SLAM: Hybrid direct-indirect visual SLAM. Robotics and Autonomous Systems 2024, 104729. [Google Scholar] [CrossRef]
- Lang, X.; Li, L.; Zhang, H.; Xiong, F.; Xu, M.; Liu, Y.; Zuo, X.; Lv, J. Gaussian-LIC: Photo-realistic LiDAR-Inertial-Camera SLAM with 3D Gaussian Splatting. arXiv 2024, arXiv:2404.06926. [Google Scholar]
- Zhuang, Y.; Chen, L.; Wang, X.S.; Lian, J. A weighted moving average-based approach for cleaning sensor data. In Proceedings of the 27th International Conference on Distributed Computing Systems (ICDCS’07). IEEE, 2007, pp. 38–38.
- Park, J.i.; Jo, S.; Seo, H.T.; Park, J. LiDAR Denoising Methods in Adverse Environments: A Review. IEEE Sensors Journal 2025. [Google Scholar] [CrossRef]
- Ballardini, A.L.; Fontana, S.; Furlan, A.; Sorrenti, D.G. ira_laser_tools: a ROS laserscan manipulation toolbox. arXiv 2014, arXiv:1411.1086. [Google Scholar]
- Tang, M.; Chen, Z.; Yin, F. An improved H-infinity unscented FastSLAM with adaptive genetic resampling. Robotics and Autonomous Systems 2020, 134, 103661. [Google Scholar] [CrossRef]
- Hinduja, A.; Ho, B.J.; Kaess, M. Degeneracy-aware factors with applications to underwater slam. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2019, pp. 1293–1299.
- Ahmed Abdulsaheb, J.; Jasim Kadhim, D. Real-Time SLAM Mobile Robot and Navigation Based on Cloud-Based Implementation. Journal of Robotics 2023, 2023, 9967236. [Google Scholar] [CrossRef]
- Jaenal, A.; Moreno, F.A.; Gonzalez-Jimenez, J. Sequential Monte Carlo localization in topometric appearance maps. The International Journal of Robotics Research 2023, 42, 1117–1132. [Google Scholar] [CrossRef]
- Chung, M.A.; Lin, C.W. An improved localization of mobile robotic system based on AMCL algorithm. IEEE Sensors Journal 2021, 22, 900–908. [Google Scholar] [CrossRef]
- Liu, H.; Shen, Y.; Yu, S.; Gao, Z.; Wu, T. Deep reinforcement learning for mobile robot path planning. arXiv 2024, arXiv:2404.06974. [Google Scholar] [CrossRef]
Short Biography of Authors
 |
Basheer Altawil received his B.Sc. degree in Mechatronics Engineering and M.Sc. degree in Robotics Engineering from İzmir Kâtip Çelebi University, Turkey. Currently, he is pursuing the Ph.D. at Otto-von-Guericke University Magdeburg. His research interests focus on mobile robotic navigation, SLAM, and Human-Robot Interaction. Since 2023, Basheer has served as a Research Assistant with the Neuro-Information Technology research group at Otto-von-Guericke University Magdeburg. |
 |
Adem Candemir received his B.Sc. degree in Mechatronics Engineering and M.Sc. degree in Mechanical Engineering from İzmir Kâtip Çelebi University, Turkey. Currently, he is pursuing the Ph.D. at İzmir Kâtip Çelebi University. His research interests focus on robotics modelling and simulation. |
 |
Magnus Jung received his B.Sc. degree in Systems Engineering and Technical Cybernetics from the Otto-von-Guericke University of Magdeburg, Germany. He received his M.Sc. degree in Technical Cybernetics and Systems Theory from the Technical University, Ilmenau, Germany. He is currently a Ph.D. student at the Otto-von-Guericke University Magdeburg, Germany. His research interests focus on human-robot interaction, computer vision and systems theory. |
 |
Ayoub Al-Hamadi received the Ph.D. degree in technical computer science, in 2001, and the Habilitation degree in artificial intelligence and the Venia Legendi degree in pattern recognition and image processing from Otto-von-Guericke University Magdeburg, Germany, in 2010. He is currently a Professor and the Head of the Neuro-Information Technology Group, Otto-von-Guericke University Magdeburg. He is the author of more than 380 papers in peer-reviewed international journals, conferences, and books. His research interests include computer vision, pattern recognition, and image processing. See www.nit.ovgu.de for more details. |
Figure 10.
Effectiveness of adaptive resampling and degeneracy handling on the particle collection published by the sensors used in the robot. The time steps demonstrate the robot’s movement along the predefined path inside the environment. The figure shows the overlap of the estimated path and the given path in both cases by adding EGM and classical GM.
Figure 10.
Effectiveness of adaptive resampling and degeneracy handling on the particle collection published by the sensors used in the robot. The time steps demonstrate the robot’s movement along the predefined path inside the environment. The figure shows the overlap of the estimated path and the given path in both cases by adding EGM and classical GM.
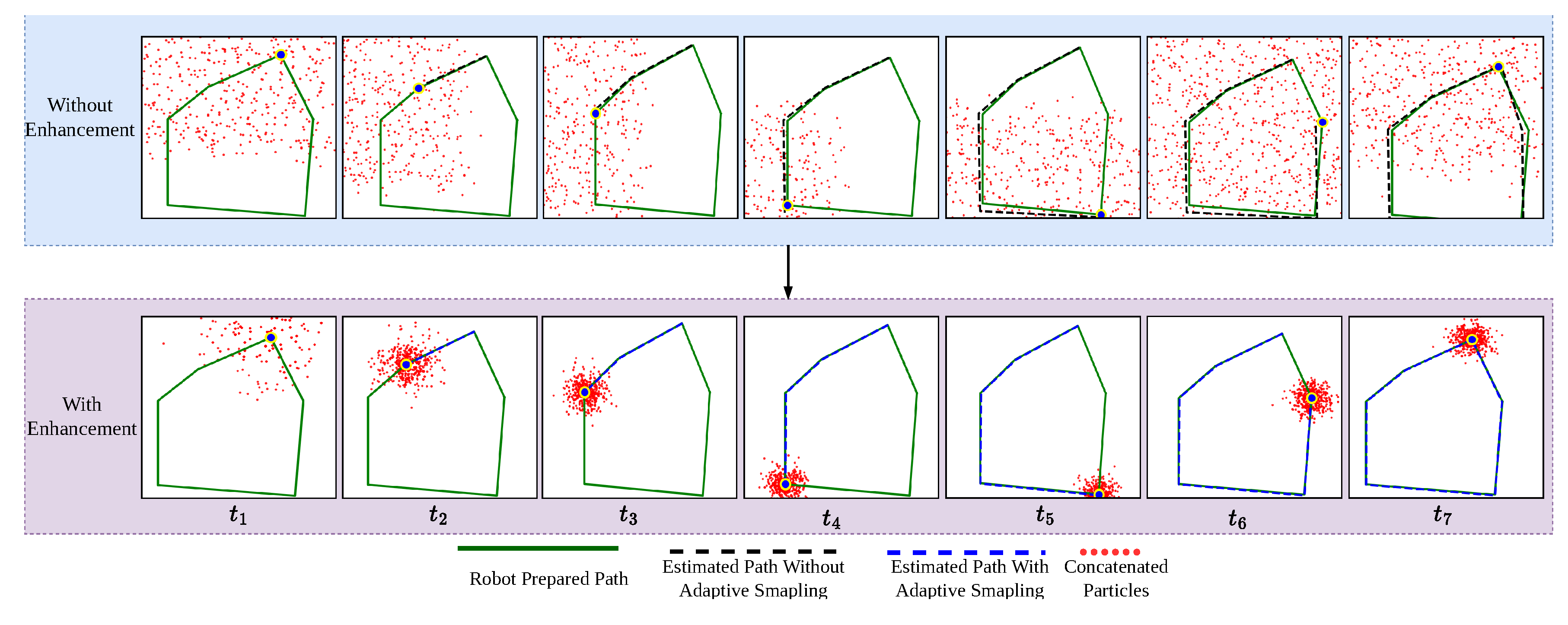
Figure 11.
Showing robot performance parameters across three environments: Simple, Moderate, and Complex. refers to the segment linking points sequentially, starting from the home position and extending up to point nine. The performance is shown between our EGM approach and RTAB-Map. The left column shows the distance calculations between points and their accumulated distance, while the right column shows the time between points and their accumulated time.
Figure 11.
Showing robot performance parameters across three environments: Simple, Moderate, and Complex. refers to the segment linking points sequentially, starting from the home position and extending up to point nine. The performance is shown between our EGM approach and RTAB-Map. The left column shows the distance calculations between points and their accumulated distance, while the right column shows the time between points and their accumulated time.
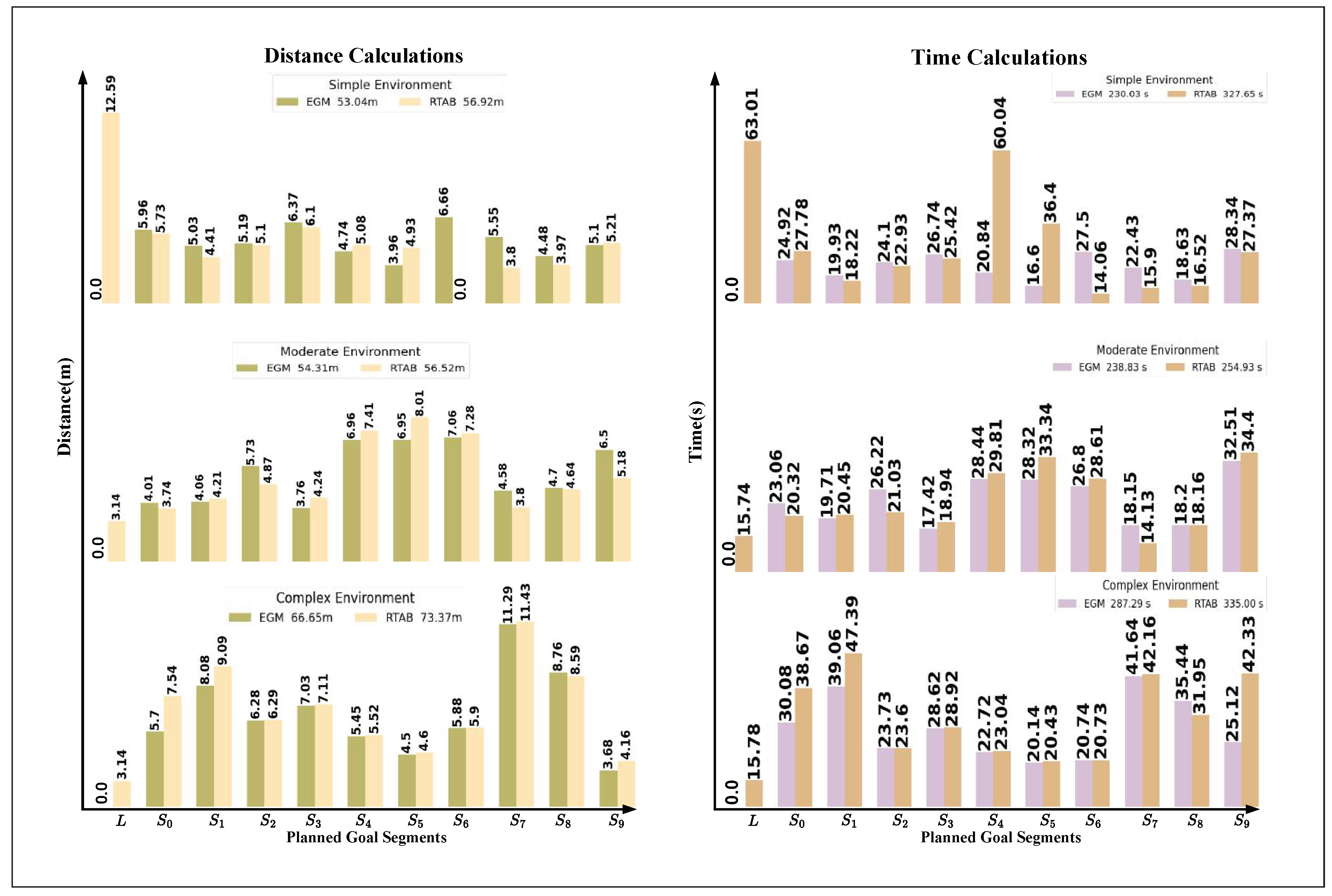

Table 1.
Different Sensors Configurations Goals Achievements.
| Sensor Configurations | AS(C+L) | FB(C+L) | LRFB(C) | FB(L) | ||||||||
| Argument Parameter | D(m) | T(s) | G | D(m) | T(s) | G | D(m) | T(s) | Goal | D(m) | T(s) | G |
| 6.0 | 26.6 | ✓ | 5.9 | 25.5 | ✓ | 5.9 | 36.0 | ✓ | 6.5 | 41.0 | ✓ | |
| 4.8 | 19.6 | ✓ | 4.6 | 19.2 | ✓ | 4.7 | 19.4 | ✓ | 7.0 | 35.2 | ✗ | |
| 5.1 | 23.5 | ✓ | 5.1 | 23.4 | ✓ | 6.2 | 28.7 | ✓ | 6.1 | 36.3 | ✓ | |
| 6.4 | 27.0 | ✓ | 6.1 | 26.5 | ✓ | 5.5 | 18.9 | ✓ | 5.1 | 37.2 | ✗ | |
| 4.8 | 20.3 | ✓ | 5.9 | 27.2 | ✓ | 7.3 | 22.3 | ✓ | 6.1 | 38.1 | ✗ | |
| 4.0 | 16.5 | ✓ | 3.9 | 16.4 | ✓ | 3.9 | 24.3 | ✓ | 5.0 | 22.2 | ✓ | |
| 6.5 | 27.2 | ✓ | 7.4 | 32.2 | ✓ | 6.6 | 34.3 | ✓ | 7.1 | 24.2 | ✗ | |
| 5.6 | 22.3 | ✓ | 5.5 | 22.4 | ✓ | 4.6 | 22.4 | ✓ | 6.1 | 26.3 | ✗ | |
| 4.5 | 18.3 | ✓ | 5.1 | 18.4 | ✓ | 4.5 | 26.4 | ✗ | 5.1 | 35.1 | ✓ | |
| 4.1 | 22.4 | ✓ | 5.5 | 34.3 | ✓ | 6.8 | 42.3 | ✓ | 5.1 | 29.3 | ✗ | |
| Total, Avg | 51.8 | 223.7 | 100 % | 54.3 | 245.5 | 100 % | 56.0 | 275.0 | 90 % | 59.2 | 325.0 | 40 % |
Showing Comparison of navigation results of four different sensor configurations in a sim environment (see Figure 9). AS(C+L) represents all sensors on the robot, FB(C+L) represents front and rear cameras and LiDAR sensors, LRFB(C) represents left, right, rear, and front cameras, and FB(L) represents rear and front LiDAR only. refers to the segment linking points sequentially, starting from the home position and extending up to point nine.
Table 2.
Different Sensors Configurations Work Efficiency.
| Approach | AS(C+L) | FB(C+L) | LRFB(C) | FB(L) | |
| Parameter | |||||
| Charge Decrease % | 5.3 | 5.5 | 4.67 | 6.2 | |
| Voltage Decrease % | 2.6 | 2.8 | 2.3 | 2.2 | |
| CPU Usage % | 0.01 | 0.09 | 0.19 | 0.57 | |
| Average Linear Velocity m/s | 0.15, Stable | 0.15, Stable | 0.15, Not Stable | 0.15, Not Stable | |
| Average Angular Velocity rad/s | 0.5, Stable | 0.5, Stable | 0.5, Not stable | 0.5, Not Stable | |
Showing the robot’s efficiency across four sensor setups: AS(C+L) (all sensors), FB(C+L) (front/back cameras + LiDAR), LRFB(C) (all cameras), and FB(L) (front/back LiDAR). It shows battery and voltage decreases, CPU usage, and stability of movement. AS(C+L) provided stable movement with moderate battery use, while FB(C+L) caused the most battery drain and instability.
Table 3.
Environmental Navigation Goals Achievements.
| Environments | Simple Environment | Moderate Environment | Complex Environment | |||||||||||||||
| Arguments | D(m) | T(s) | Goal.A | D(m) | T(s) | Goal.A | D(m) | T(s) | Goal.A | |||||||||
| EGM | RTAB | EGM | RTAB | EGM | RTAB | EGM | RTAB | EGM | RTAB | EGM | RTAB | EGM | RTAB | EGM | RTAB | EGM | RTAB | |
| Localization(L) | 0.00 | 12.59 | 0.00 | 63.01 | - | - | 0.00 | 3.14 | 0.00 | 15.74 | - | - | 0.00 | 3.14 | 0.00 | 15.78 | - | - |
| 5.96 | 5.73 | 24.92 | 27.78 | ✓ | ✓ | 4.01 | 3.74 | 23.06 | 20.32 | ✓ | ✓ | 5.70 | 7.54 | 30.08 | 38.67 | ✓ | ✓ | |
| 5.03 | 4.41 | 19.93 | 18.22 | ✓ | ✓ | 4.06 | 4.21 | 19.71 | 20.45 | ✓ | ✓ | 8.08 | 9.09 | 39.06 | 47.39 | ✓ | ✓ | |
| 5.19 | 5.10 | 24.10 | 22.93 | ✓ | ✓ | 5.73 | 4.87 | 26.22 | 21.03 | ✓ | ✓ | 6.20 | 6.29 | 23.73 | 23.60 | ✓ | ✓ | |
| 6.37 | 6.10 | 26.74 | 25.42 | ✓ | ✓ | 3.76 | 4.24 | 17.42 | 18.94 | ✓ | ✓ | 7.03 | 7.11 | 28.62 | 28.92 | ✓ | ✓ | |
| 4.74 | 5.08 | 20.84 | 60.04 | ✓ | ✗ | 6.96 | 7.41 | 28.44 | 29.81 | ✓ | ✓ | 5.45 | 5.52 | 22.72 | 23.04 | ✓ | ✗ | |
| 3.96 | 4.93 | 16.60 | 36.40 | ✓ | ✓ | 6.95 | 8.01 | 28.32 | 33.34 | ✓ | ✗ | 4.50 | 4.60 | 20.14 | 20.43 | ✓ | ✓ | |
| 6.66 | 0.00 | 27.50 | 14.06 | ✓ | ✗ | 7.06 | 7.28 | 26.80 | 28.61 | ✓ | ✓ | 5.88 | 5.90 | 20.74 | 20.73 | ✓ | ✓ | |
| 5.55 | 3.80 | 22.43 | 15.90 | ✓ | ✓ | 4.58 | 3.80 | 18.15 | 14.13 | ✓ | ✓ | 11.29 | 11.43 | 41.64 | 42.16 | ✓ | ✓ | |
| 4.48 | 3.97 | 18.63 | 16.52 | ✓ | ✓ | 4.70 | 4.64 | 18.20 | 18.16 | ✓ | ✓ | 8.76 | 8.59 | 35.44 | 31.95 | ✓ | ✗ | |
| 5.10 | 5.21 | 28.34 | 27.37 | ✓ | ✓ | 6.50 | 5.18 | 32.51 | 34.40 | ✓ | ✓ | 3.68 | 4.16 | 25.12 | 42.33 | ✓ | ✓ | |
| Total | 53.04 | 56.92 | 230.04 | 327.65 | 100 % | 80 % | 54.31 | 56.52 | 238.83 | 254.93 | 100 % | 90% | 66.65 | 73.37 | 287.29 | 335.00 | 100 % | 80 % |
Environmental Navigation Goals Achievements: Distance, time, and goal achievement for different environment setups: Simple, Moderate, Complex. refers to the robot’s direction from goal to goal. EGM and RTAB refer to using Enhanced Gmapping and RTAB Map, respectively. D(m) represents the distance in meters, T(s) represents the time in seconds, and Goal.A indicates the goal achievement. For visual details, see Figure 9.
Table 4.
Environmental Configuration Work Efficiency.
| Environments | Simple Environment | Moderate Environment | Complex Environment | |||
| Arguments | EGM | RTAB | EGM | RTAB | EGM | RTAB |
| Charge Decrease % | 5.31 | 4.43 | 5.43 | 5.34 | 6.66 | 7.02 |
| Voltage Decrease % | 2.65 | 2.22 | 2.72 | 2.67 | 3.33 | 3.51 |
| CPU Usage % | 0.04 | 0.14 | 0.4 | 0.84 | 0.55 | 0.92 |
| Average Linear Velocity m/s | 0.15, Stable | 0.15, Stable | 0.15, Stable | 0.15, Stable | 0.15, Stable | 0.15, Not Stable |
| Angular Velocity rad/s | 0.5, Stable | 0.5, Not Stable | 0.5, Stable | 0.5, Stable | 0.5, Stable | 0.5, Stable |
Showing the robot’s efficiency across EGM and RTAB-Map methods. showed slight improvements across most cases, maintaining stable linear and angular velocities and less voltage and battery consumption compared to RTAB-Map.
Table 5.
Real-time implementation table.
| Segments(m) | Traveled Distance (m) | Time(s) | Goals Achievement | Overlap Ratio(%) | Average Error (m) | |||||
| EGM | GM | EGM | GM | EGM | GM | EGM | GM | EGM | GM | |
| , 2.0m | 2.10 | 2.25 | 8.80 | 9.50 | ✓ | ✓ | 48.00 | 35.00 | 0.05 | 0.06 |
| , 2.5m | 2.65 | 2.80 | 11.10 | 12.61 | ✓ | ✓ | 68.00 | 33.00 | 0.15 | 0.30 |
| , 1.0m | 1.10 | 1.25 | 5.20 | 6.5 | ✓ | ✓ | 67.00 | 36.00 | 0.10 | 0.20 |
| , 1.5m | 1.65 | 1.75 | 9.85 | 10.55 | ✓ | ✓ | 71.00 | 32.00 | 0.15 | 0.35 |
| , 3.2m | 3.45 | 3.55 | 14.55 | 15.37 | ✓ | ✓ | 75.00 | 32.00 | 0.25 | 0.37 |
| , 3.8m | 4.00 | 4.50 | 15.20 | 16.37 | ✓ | ✓ | 78.00 | 34.00 | 0.15 | 0.28 |
| Total-Avg, 14.0 | 14.95 | 16.10 | 64.70 | 70.90 | 100% | 100% | 68.00 | 33.70 | 0.85 | 1.56 |
Real-time performance comparison between Enhanced GMapping (EGM) and GMapping (GM) for the robot’s path from goal to , including traveled distance, time, goals achievement, overlap ratio, and average error.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



