Submitted:
20 February 2025
Posted:
25 February 2025
You are already at the latest version
Abstract
An identical parallel machine offline scheduling problem with rental costs and shared service costs of shared machines is studied. In machine renting, manufacturers with a certain number of identical parallel machines will incur fixed rental costs, unit variable rental costs, and shared service costs when renting the shared machines. The objective is to minimize the sum of the makespan and total sharing costs. To address this problem, an integer linear programming model is established, and several properties of the optimal solution are provided. A heuristic algorithm based on the number of rented machines is designed. Finally, numerical simulation experiments are conducted to compare the proposed heuristic algorithm with a genetic algorithm and the longest processing time (LPT) rule. The results demonstrate the effectiveness of the proposed heuristic algorithm in terms of calculation accuracy and efficiency. Additionally, the experimental findings reveal that the renting and scheduling results of the machines are influenced by various factors, such as the manufacturer’s production conditions, the characteristics of the jobs to be processed, production objectives, rental costs, and shared service costs.
Keywords:
1. Introduction
- (1)
- In the context of shared manufacturing, we incorporate shared machines with rental costs and shared service costs into the classic parallel machine scheduling problem. We investigate how machine sharing influences the production scheduling decisions of enterprises.
- (2)
- We establish an integer programming model, analyze the properties of the problem, and provide the optimal scheduling case without renting machines, the range of the number of machine rentals, and the upper bound of the problem.
- (3)
- We propose a heuristic algorithm based on the number of shared machine rentals to address large-scale instances of the considered problem.
2. Literature Review
2.1. Shared Machine Resource Scheduling Problem
2.2. Scheduling Problem with the Use Cost of Identical Parallel Machines
3. Problem Description
4. Model Formulation
4.1. Notations
4.2. Mathematical Model
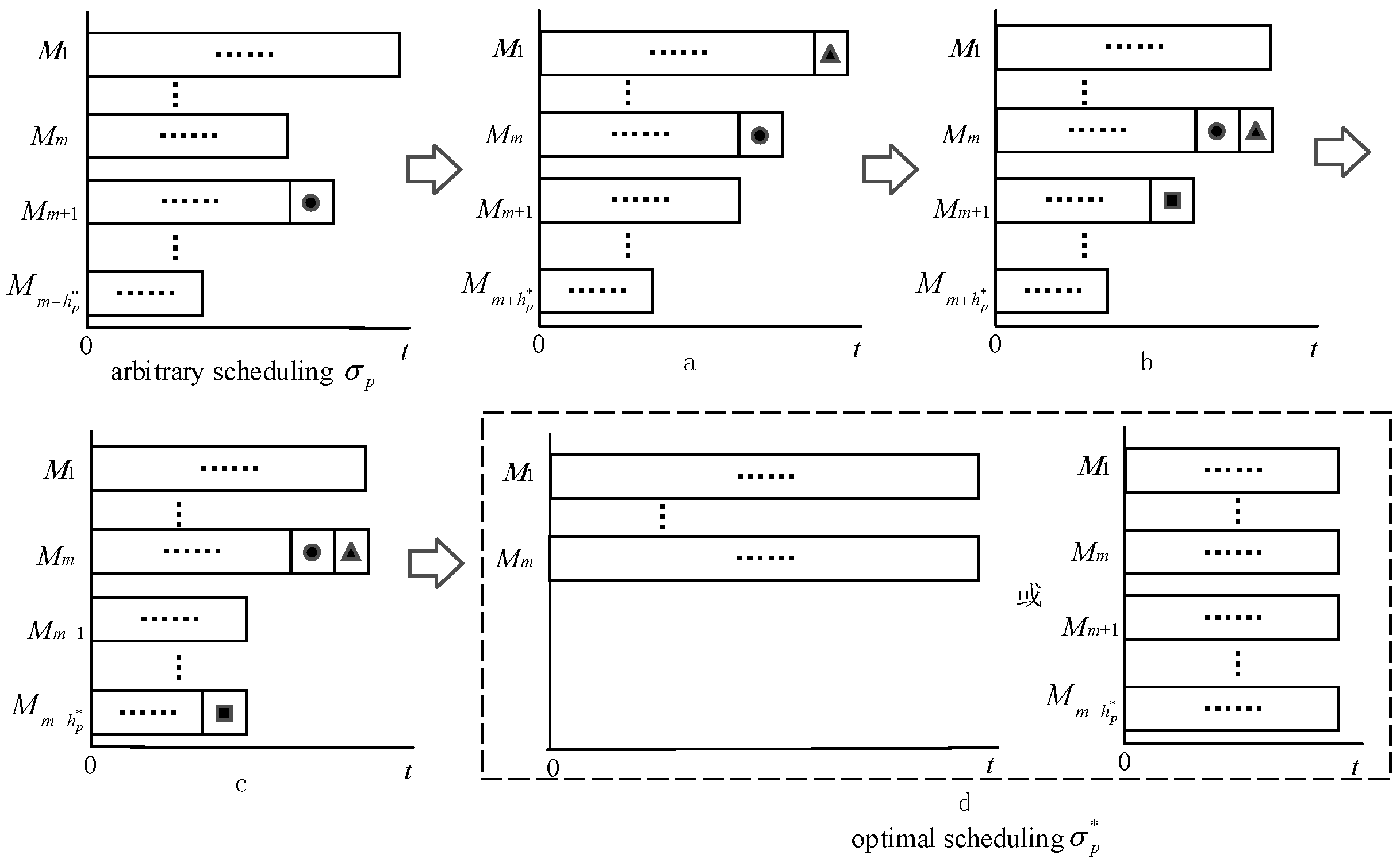
5. Problem property
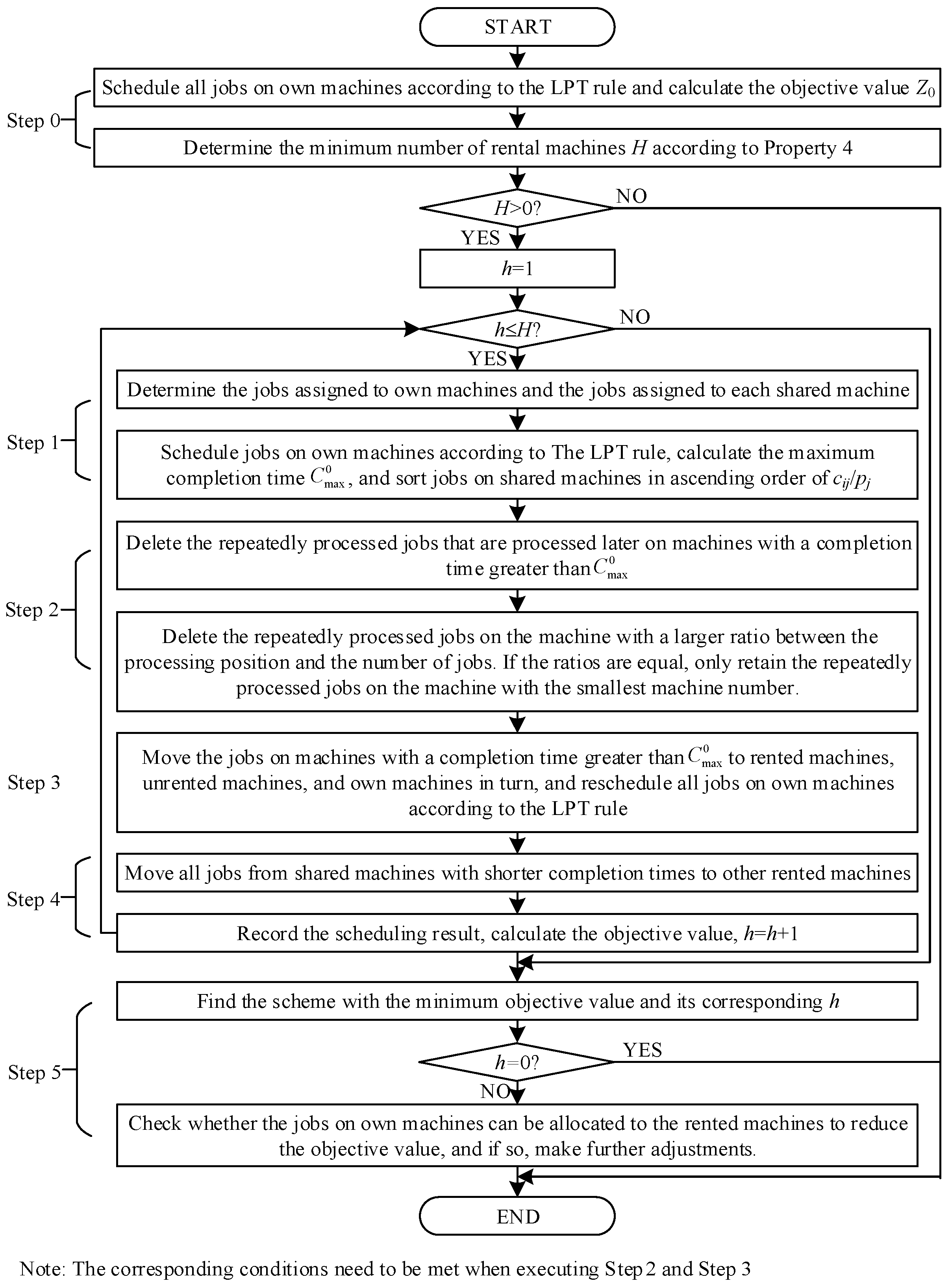
6. Solution Approach
7. Computation Experiments
- (1)
- When the number of jobs and machines is small, CPLEX can accurately solve the problem. However, as the scale of the problem increases, its computation time tends to rise significantly, ranging from 0.65s to 7200s. When the number of jobs and machines is large, CPLEX becomes unstable in terms of computational efficiency. In some cases, CPLEX is unable to provide an accurate solution and corresponding scheduling scheme within two hours. For example, this occurs when there are 200 jobs, 6 own machines, 10 shared machines, and 800 jobs in total.
- (2)
- The NSMD-H algorithm demonstrates a short computation time, even for large-scale cases with 800 jobs, 10 own machines, and 10 shared machines, with a running time of only 2.02 seconds. In terms of computational accuracy, the NSMD-H algorithm performs well. The gap between the objective value obtained by the NSMD-H algorithm and the optimal value obtained by CPLEX ranges from 0.04% to 7.5%. The average gap values for small-scale and large-scale cases are 2.76% and 1.53%, respectively. The difference between the number of rented machines of the NSMD-H algorithm and the number of rented machines of optimal scheduling is not significant. The maximum difference observed is 2 machines. This indicates that the objective value is influenced not only by the number of rented machines but also by the scheduling arrangement of jobs.
- (3)
- The computation time of the GA algorithm gradually increases from 6.43s to 25.15s, indicating relatively high running efficiency. However, compared to the NSMD-H algorithm, the GA algorithm does not significantly improve solution quality. The average gap values of small-scale and large-scale cases are 1.88% and 1.50%, respectively. Additionally, the number of shared machines rented by the GA algorithm is consistent with that of the NSMD-H algorithm. The primary reason for this is that the quality of solutions generated by the GA algorithm through random chromosome initialization differs significantly from that of the NSMD-H algorithm. Consequently, the better solutions obtained during GA iterations are mostly local adjustments to the solutions initially obtained by the NSMD-H algorithm. This results in minimal changes to the objective value. Therefore, the GA algorithm, while increasing computation time, does not significantly enhance the quality of solutions obtained by the NSMD-H algorithm.
- (4)
- The LPT rule, which schedules jobs only on own machines without considering rented machines, has a very low computation time (no more than 0.01 seconds). However, it deviates significantly from optimal scheduling. In some cases, the maximum deviation reaches 95.25%.
- (1)
- When other parameters remain unchanged, an increase in the fixed rental cost a leads to a higher objective value and a gradual decrease in the number of shared machines rented. The same trend is observed for the unit variable rental cost b.
- (2)
- The conclusions drawn from analyzing Tables 2 and 3 are consistent. CPLEX exhibits significant variability in computational efficiency, with computation times ranging from 1.75 seconds to 7200 seconds. The values of parameters a and b have a substantial impact on CPLEX’s computational time, with no discernible pattern.
- (3)
- The NSMD-H and GA algorithms demonstrate high computational efficiency, unaffected by the values of a and b. The average computational times are 0.27 seconds and 10.22 seconds, respectively. Both algorithms achieve higher computational accuracy, with average deviations of 2.84% and 2.12%, respectively.
- (4)
- All jobs are scheduled on own machines using the LPT rule. The objective value is independent of the values of a and b. However, the deviation from the optimal value is significant, particularly in cases where the shared machine rental cost is low and the optimal number of rented machines is high(e.g., the 1st and 10th cases in the table). As previously noted, when parameters n, a, b, and take extreme values, the deviation becomes unbounded.
- (1)
- The rental and scheduling results of machines are influenced by multiple factors. Enterprises should comprehensively consider their own production conditions (such as the number of own machines), the characteristics of jobs to be processed (including the number of jobs and their processing times), the production goals of the enterprise, and the costs associated with shared machines (fixed rental costs, unit variable costs, shared service costs).
- (2)
- Enterprises can utilize the proposed model and algorithm to determine the number of shared machines to be rented and to arrange the order of jobs on their own machines and shared machines. This approach helps reduce the maximum completion time of jobs (i.e., customer waiting time) while optimizing the enterprise’s shared costs. For small-scale problems, the model can be used to obtain exact solutions. For large-scale problems, the proposed algorithm can efficiently generate near-optimal solutions to support decision-making.
8. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Wang, G.; Zhang, G.; Guo, X.; Zhang, Y.F. Digital twin-driven service model and optimal allocation of manufacturing resources in shared manufacturing. J. Manuf. Syst. 2021, 59, 165–179. [Google Scholar] [CrossRef]
- Liu, C.Y.; Liu, P. Dynamic allocation of manufacturing tasks and resources in shared manufacturing. Intell. Autom. Soft. Co. 2023, 36, 3221–3242. [Google Scholar] [CrossRef]
- Liu, P.; Wei, X.L. Three-party evolutionary game of shared manufacturing under the leadership of core manufacturing company. Sustainability 2022, 14, 13682. [Google Scholar] [CrossRef]
- Patterson, S.R.; Kozan, E.; Hyland, P. Energy efficient scheduling of open-pit coal mine trucks. Eur. J. Oper. Res. 2017, 262, 759–770. [Google Scholar] [CrossRef]
- Vélez-Gallego, M.C.; Maya, J.; Montoya-Torres, J.R. A beam search heuristic for scheduling a single machine with release dates and sequence dependent setup times to minimize the makespan. Comput. Oper. Res. 2016, 73, 132–140. [Google Scholar] [CrossRef]
- Zhao, D.Z.; Wang, Z.S. Scheduling optimization of cloud manufacturing platform processing capability sharing. Ops. Res. Manag. Sci. 2016, 28, 1–6. (In Chinese) [Google Scholar]
- Yu, Y.N.; Xu, Z.; Liu, D.N. Distributed multi-project scheduling problem with multi-skilled staff. Sys. Eng. Theor. Pract. 2020, 40, 2921–2933. (In Chinese) [Google Scholar]
- Tang, L.; Han, H.Y.; Tan, Z.; Jing, K. Centralized collaborative production scheduling with evaluation of a practical order-merging strategy. Int. J. Prod. Res. 2023, 61, 282–301. [Google Scholar] [CrossRef]
- Kuroda, M. Integration of product design and manufacturing through real-time due-date estimation and scheduling systems. J. Adv. Mech. Des. Syst. 2016, 10, JAMDSM42. [Google Scholar] [CrossRef]
- Dereniowski, D; Kubiak, W. Shared multi-processor scheduling. Eur. J. Oper. Res. 2017, 261, 503–514. [Google Scholar] [CrossRef]
- Dereniowski, D; Kubiak, W. Shared processor scheduling of multiprocessor jobs. Eur. J. Oper. Res. 2020, 282, 464–477. [Google Scholar] [CrossRef]
- Ji, M.; Ye, X.N.; Qian, F.Y.; Cheng, T.C.E.; Jiang, Y.W. Parallel-machine scheduling in shared manufacturing. J. Ind. Manag. Optim. 2022, 18, 681–691. [Google Scholar] [CrossRef]
- Wei, Q.; Wu, Y. Two-machine hybrid flow-shop problems in shared manufacturing. CMES-Comp. Model. Eng. 2022, 131, 1125–1146. [Google Scholar] [CrossRef]
- Xu, Y.F.; Zhi, R.T.; Zheng, F.F.; Liu, M. Parallel machine scheduling with due date-to-deadline window, order sharing and time value of money. Asia Pac. J. Oper. Res. 2022, 39, 2150024. [Google Scholar] [CrossRef]
- Zheng, F.F.; Jin, K.Y.; Xu, Y.F.; Liu, M. Parallel machine scheduling with order splitting and matching type. Ops. Res. Manag. Sci. 2023, 32, 1–7. (In Chinese) [Google Scholar]
- Fu, Y.P.; Li, H.B.; Huang, M.; Xiao, H. Bi-objective modeling and optimization for stochastic two-stage open shop scheduling problems in the sharing economy. IEEE T. Eng. Manage. 2023, 70, 3395–3409. [Google Scholar] [CrossRef]
- Xu, Y.F.; Zhi, R.T.; Zheng, F.F.; Liu, M. Competitive algorithm for scheduling of sharing machines with rental discount. J. Comb. Optim. 2022, 44, 414–434. [Google Scholar] [CrossRef]
- Xu, Y.F.; Zhi, R.T.; Zheng, F.F.; Liu, M. Online strategy and competitive analysis of production order scheduling problem with rental cost of shared machines. Chinese J. Manage. Sci. 2023, 31, 142–150. (In Chinese) [Google Scholar]
- Ruiz-Torres, A.J.; López, F.J.; Wojciechowski, P.J.; Ho, J.C. Parallel machine scheduling problems considering regular measures of performance and machine cost. J. Oper. Res. Soc. 2010, 61, 849–857. [Google Scholar] [CrossRef]
- Rustogi, K.; Strusevich, V.A. Parallel machine scheduling: impact of adding extra machines. Oper. Res. 2013, 61, 243–257. [Google Scholar] [CrossRef]
- Lee, K.; Leung, J. Y-T.; Jia, Z.H.; Li, W.H.; Pinedo, M.L.; Lin, B.M.T. Fast approximation algorithms for bi-criteria scheduling with machine assignment costs. Eur. J. Oper. Res. 2014, 238, 54–64. [Google Scholar] [CrossRef]
- Li, K.; Zhang, X.; Leung, J. Y-T.; Yang, S.L. Parallel machine scheduling problems in green manufacturing industry. J. manuf. Syst. 2016, 38, 98–106. [Google Scholar] [CrossRef]
- Li, K.; Xu, S.L.; Cheng, B.Y.; Yang, S.L. Parallel machine scheduling problem with machine cost to minimize the maximal lateness. Sys. Eng. Theor. Pract. 2019, 39, 165–173. (In Chinese) [Google Scholar]
- Jiang, Y.W.; Tang, X.L.; Li, K.; Cheng, T.C.E.; Ji, M. Approximation algorithms for bi-objective parallel-machine scheduling in green manufacturing. Comput. Ind. Eng. 2023, 176, 108949. [Google Scholar] [CrossRef]
- Anghinolfi, D.; Paolucci, M.; Ronco, R. A bi-objective heuristic approach for green identical parallel machine scheduling. Eur. J. Oper. Res. 2021, 289, 416–434. [Google Scholar] [CrossRef]
- Jarboui, B.; Masmoudi, M.; Eddaly, M. Epsilon Oscillation Algorithm for the bi-objective green identical parallel machine scheduling problem. Comput. Oper. Res. 2024, 170, 106754. [Google Scholar] [CrossRef]
- Wu, P.; Wang, Y.; Chu, C. Logic-based Benders decomposition for bi-objective parallel machine selection and job scheduling with release dates and resource consumption. Comput. Oper. Res. 2024, 164, 106528. [Google Scholar] [CrossRef]
- Lenstra, J.K.; Rinnooy Kan, A.H.G.; Brucker, P. Complexity of machine scheduling problems. Ann. Discrete Math. 1977, 1, 343–362. [Google Scholar]
- McNaughton, R. Scheduling with deadlines and loss functions. Manage. Sci. 1959, 6, 1–12. [Google Scholar] [CrossRef]
- Graham, R.L. Bounds on multiprocessing time anomalies. SIAM J. Appl. Math. 1969, 17, 416–429. [Google Scholar] [CrossRef]

| Parameter | Value range |
|---|---|
| Number of jobs n | 20, 50, 100, 200, 500, 800 |
| Number of own machines m | 2, 4, 6, 8, 10 |
| Number of shared machines k | 4, 8, 10 |
| Processing time of job | |
| Fixed rental cost of shared machine a | |
| Unit variable rental cost of shared machine b | |
| Shared service cost |
| n | m | k | CPLEX | NSMD-H | GA | LPT | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Z | h | Z | h | Z | |||||||||||
| 20 | 2 | 4 | 109.39 | 2.33 | 3 | 111.34 | 0.14 | 1.78 | 4 | 109.87 | 6.43 | 0.44 | 4 | 133.91 | 22.41 |
| 20 | 2 | 8 | 62.52 | 0.65 | 6 | 63.94 | 0.17 | 2.27 | 6 | 63.35 | 6.65 | 1.33 | 6 | 105.91 | 69.39 |
| 20 | 2 | 10 | 92.05 | 0.67 | 2 | 93.50 | 0.15 | 1.57 | 2 | 92.13 | 7.34 | 0.09 | 2 | 104.58 | 13.61 |
| 20 | 4 | 4 | 44.60 | 3.41 | 1 | 45.28 | 0.16 | 1.52 | 3 | 45.26 | 10.39 | 1.49 | 3 | 46.34 | 3.89 |
| 20 | 4 | 8 | 55.89 | 6.47 | 0 | 56.66 | 0.09 | 1.38 | 0 | 56.38 | 13.99 | 0.88 | 0 | 56.66 | 1.38 |
| 20 | 4 | 10 | 50.89 | 0.78 | 4 | 51.70 | 0.17 | 1.59 | 4 | 51.22 | 11.17 | 0.65 | 4 | 62.80 | 23.40 |
| 50 | 2 | 4 | 144.61 | 3.48 | 4 | 148.22 | 0.49 | 2.50 | 4 | 147.75 | 13.63 | 2.17 | 4 | 267.75 | 85.16 |
| 50 | 2 | 8 | 166.37 | 4.19 | 5 | 178.26 | 0.26 | 7.14 | 6 | 174.16 | 13.20 | 4.68 | 6 | 296.18 | 78.02 |
| 50 | 2 | 10 | 135.39 | 1.40 | 9 | 140.42 | 0.34 | 3.72 | 8 | 140.05 | 11.93 | 3.44 | 8 | 264.36 | 95.25 |
| 50 | 4 | 4 | 106.24 | 2.12 | 3 | 113.33 | 0.23 | 6.67 | 3 | 110.37 | 17.45 | 3.89 | 3 | 125.37 | 18.00 |
| 50 | 4 | 8 | 83.80 | 2.36 | 8 | 86.06 | 0.26 | 2.69 | 8 | 85.81 | 12.03 | 2.40 | 8 | 124.44 | 48.49 |
| 50 | 4 | 10 | 89.83 | 7.36 | 6 | 96.57 | 0.32 | 7.50 | 6 | 93.17 | 12.85 | 3.72 | 6 | 133.80 | 48.94 |
| 100 | 4 | 4 | 275.83 | 2.07 | 0 | 275.94 | 0.15 | 0.04 | 0 | 275.94 | 16.05 | 0.04 | 0 | 275.94 | 0.04 |
| 100 | 4 | 8 | 182.79 | 2.98 | 7 | 185.18 | 0.21 | 1.31 | 7 | 184.95 | 7.80 | 1.18 | 7 | 274.62 | 50.24 |
| 100 | 4 | 10 | 212.26 | 10.95 | 9 | 215.43 | 0.26 | 1.49 | 9 | 215.23 | 8.40 | 1.40 | 9 | 290.05 | 36.65 |
| 100 | 6 | 4 | 166.83 | 27.35 | 4 | 168.24 | 0.18 | 0.85 | 4 | 168.21 | 9.20 | 0.83 | 4 | 270.94 | 62.40 |
| 100 | 6 | 8 | 132.82 | 207.66 | 7 | 138.47 | 0.24 | 4.25 | 6 | 138.25 | 8.60 | 4.09 | 6 | 173.43 | 30.57 |
| 100 | 6 | 10 | 142.97 | 9.69 | 8 | 144.99 | 0.25 | 1.41 | 8 | 144.56 | 8.56 | 1.11 | 8 | 164.35 | 14.95 |
| Average | 125.28 | 16.44 | 4.78 | 128.53 | 0.23 | 2.76 | 4.89 | 127.59 | 10.87 | 1.88 | 4.89 | 176.19 | 39.04 | ||
| n | m | k | CPLEX | NSMD-H | GA | LPT | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Z | h | Z | h | Z | |||||||||||
| 200 | 6 | 4 | 272.07 | 9.35 | 4 | 276.04 | 0.26 | 1.46 | 4 | 276.02 | 11.70 | 1.45 | 4 | 349.87 | 28.60 |
| 200 | 6 | 8 | 292.25 | 24.07 | 8 | 297.24 | 0.35 | 1.71 | 8 | 296.96 | 10.65 | 1.61 | 8 | 355.80 | 21.75 |
| 200 | 6 | 10 | — | — | — | 198.82 | 0.38 | — | 10 | 198.80 | 9.78 | — | 10 | 331.79 | — |
| 200 | 8 | 4 | 230.63 | 1126.93 | 4 | 233.25 | 0.29 | 1.14 | 4 | 233.20 | 11.22 | 1.12 | 4 | 271.50 | 17.72 |
| 200 | 8 | 8 | 241.76 | 6739.49 | 5 | 250.41 | 0.37 | 3.58 | 7 | 250.30 | 11.67 | 3.53 | 7 | 263.22 | 8.88 |
| 200 | 8 | 10 | — | — | — | 194.88 | 0.37 | — | 10 | 194.88 | 10.69 | — | 10 | 259.48 | — |
| 500 | 8 | 4 | 576.97 | 147.11 | 4 | 579.68 | 0.84 | 0.47 | 4 | 579.44 | 18.20 | 0.43 | 4 | 658.87 | 14.20 |
| 500 | 8 | 8 | — | — | — | 667.66 | 0.97 | — | 8 | 667.48 | 18.25 | — | 8 | 670.36 | — |
| 500 | 8 | 10 | 500.11 | 1921.60 | 10 | 505.61 | 0.86 | 1.10 | 10 | 505.54 | 15.91 | 1.09 | 10 | 658.66 | 31.70 |
| 500 | 10 | 4 | — | — | — | 450.83 | 0.89 | — | 4 | 450.83 | 17.87 | — | 4 | 515.71 | — |
| 500 | 10 | 8 | 429.16 | 173.67 | 8 | 434.65 | 0.49 | 1.28 | 8 | 434.56 | 17.37 | 1.26 | 8 | 529.86 | 23.46 |
| 500 | 10 | 10 | — | — | — | 460.50 | 0.99 | — | 10 | 460.38 | 16.88 | — | 10 | 519.11 | — |
| 800 | 10 | 4 | — | — | — | 742.75 | 2.26 | — | 4 | 742.75 | 25.15 | — | 4 | 842.93 | — |
| 800 | 10 | 8 | — | — | — | 662.09 | 1.97 | — | 8 | 662.06 | 21.82 | — | 8 | 801.92 | — |
| 800 | 10 | 10 | — | — | — | 713.75 | 2.02 | — | 10 | 713.24 | 22.67 | — | 10 | 825.33 | — |
| Average | 363.28 | 1448.89 | 6.14 | 444.54 | 0.89 | 1.53 | 7.27 | 444.43 | 15.99 | 1.50 | 7.27 | 523.63 | 20.90 | ||
| n | m | k | a | b | CPLEX | NSMD-H | GA | LPT | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Z | h | Z | h | Z | |||||||||||||
| 50 | 4 | 8 | 0.5 | 0.01 | 71.66 | 2.38 | 8 | 75.56 | 0.19 | 5.45 | 7 | 74.65 | 7.34 | 4.17 | 7 | 129.23 | 80.35 |
| 50 | 4 | 8 | 0.5 | 0.05 | 84.58 | 4.43 | 7 | 86.67 | 0.18 | 2.47 | 7 | 86.13 | 7.58 | 1.83 | 7 | 129.23 | 52.79 |
| 50 | 4 | 8 | 0.5 | 0.1 | 99.68 | 4.24 | 7 | 101.07 | 0.18 | 1.40 | 7 | 100.48 | 8.26 | 0.80 | 7 | 129.23 | 29.64 |
| 50 | 4 | 8 | 2.0 | 0.01 | 82.42 | 2.71 | 7 | 85.03 | 0.19 | 3.17 | 6 | 84.16 | 7.74 | 2.12 | 6 | 129.23 | 56.80 |
| 50 | 4 | 8 | 2.0 | 0.05 | 94.93 | 1.95 | 6 | 96.14 | 0.21 | 1.27 | 6 | 95.47 | 8.18 | 0.57 | 6 | 129.23 | 36.13 |
| 50 | 4 | 8 | 2.0 | 0.1 | 109.39 | 1.75 | 6 | 110.54 | 0.20 | 1.06 | 6 | 109.69 | 7.72 | 0.28 | 6 | 129.23 | 18.14 |
| 50 | 4 | 8 | 5.0 | 0.01 | 99.57 | 5.07 | 5 | 103.03 | 0.17 | 3.48 | 6 | 102.31 | 7.93 | 2.76 | 6 | 129.23 | 29.79 |
| 50 | 4 | 8 | 5.0 | 0.05 | 110.44 | 5.78 | 4 | 114.14 | 0.18 | 3.35 | 6 | 113.58 | 8.97 | 2.84 | 6 | 129.23 | 17.01 |
| 50 | 4 | 8 | 5.0 | 0.1 | 121.55 | 2.09 | 3 | 127.22 | 0.14 | 4.66 | 5 | 125.15 | 9.54 | 2.96 | 5 | 129.23 | 6.32 |
| 200 | 6 | 10 | 0.5 | 0.01 | 186.28 | 2628.48 | 10 | 194.99 | 0.36 | 4.67 | 10 | 193.16 | 10.79 | 3.69 | 10 | 341.28 | 83.21 |
| 200 | 6 | 10 | 0.5 | 0.05 | — | — | — | 242.31 | 0.34 | — | 10 | 240.24 | 11.28 | — | 10 | 341.28 | — |
| 200 | 6 | 10 | 0.5 | 0.1 | 297.03 | 64.29 | 10 | 298.39 | 0.44 | 0.46 | 10 | 297.43 | 11.56 | 0.14 | 10 | 341.28 | 14.90 |
| 200 | 6 | 10 | 2.0 | 0.01 | 201.29 | 141.02 | 10 | 209.99 | 0.37 | 4.32 | 10 | 209.47 | 10.85 | 4.06 | 10 | 341.28 | 69.54 |
| 200 | 6 | 10 | 2.0 | 0.05 | 251.18 | 36.56 | 10 | 257.31 | 0.35 | 2.44 | 10 | 254.53 | 10.65 | 1.33 | 10 | 341.28 | 35.87 |
| 200 | 6 | 10 | 2.0 | 0.1 | 311.01 | 22.40 | 8 | 313.39 | 0.45 | 0.77 | 10 | 312.47 | 11.11 | 0.47 | 10 | 341.28 | 9.73 |
| 200 | 6 | 10 | 5.0 | 0.01 | 230.27 | 357.82 | 9 | 238.25 | 0.36 | 3.47 | 9 | 237.05 | 13.12 | 2.95 | 9 | 341.28 | 48.21 |
| 200 | 6 | 10 | 5.0 | 0.05 | 278.83 | 25.64 | 8 | 285.57 | 0.37 | 2.42 | 9 | 283.71 | 11.17 | 1.75 | 9 | 341.28 | 22.40 |
| 200 | 6 | 10 | 5.0 | 0.1 | 330.15 | 36.87 | 5 | 341.28 | 0.24 | 3.37 | 0 | 341.25 | 20.14 | 3.36 | 0 | 341.28 | 3.37 |
| Average | 174.13 | 196.68 | 7.24 | 182.27 | 0.27 | 2.84 | 7.44 | 181.16 | 10.22 | 2.12 | 7.44 | 235.26 | 36.13 | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



