
Submitted:
03 February 2025
Posted:
05 February 2025
You are already at the latest version
Abstract
The ability of participants to monitor the correctness of their own decisions by rating their
confidence is a form of metacognition. This introspective act is crucial for many aspects of cognition
including perception, memory, learning, emotion regulation, and social interaction. Researchers
assess the quality of confidence ratings according to bias, sensitivity, and efficiency. To do so, they
deploy such quantities as meta − d′ − d′ , or M− ratio [1,2]. These measures compute the expected
accuracy level of performance in the primary task (Type 1) from the secondary confidence rating task
(Type 2). However, these measures have several limitations. For example, they relay on unwarranted
parametric assumptions, and they fall short of accommodating the granularity of confidence ratings.
Two recent papers by Dayan [3] and Fitousi [4] have proposed information-theoretic measures of
metacognitive efficiency that can ameliorate these problems. Dayan suggested meta − I, and Fitousi
proposed: meta − U, meta − KL, and meta − J . These authors demonstrated the convergence of
their measures on the notion of metacognitive efficiency using simulations, but did not apply their
measures to real empirical data. The present study set to test the convergence of these measures in a
concrete behavioral task using two independent data sets. The present results supported the viability
of these novel indexes of metacognitive efficiency, and provide substantial empirical evidence for
their convergence.
Keywords:
Metacognition
; Confidence
; Metacognitive Efficiency
; Mutual Information
; KL Distance
; 17 Jeffrey’ Distance
1. Introduction
Assessing the validity of our own decisions is a self-reflective act of immense survival value. For example, while learning for a test, we have to constantly monitor the level of our knowledge. If we feel that a satisfactory level of knowledge has been accomplished we can halt our preparation, otherwise we have to continue our learning [4,5]. This self-reflective ability is a form of metacognition [6,7,8,9,10,11,12]. Metacognition plays a central role in various domains, including: learning [13], memory [14,15], self-awareness [16], action [17,18], psychiatric disorders [19], and social interaction [20]. Several neural substrates are involved in metacognitive assessments and monitoring of behavior [22]. These include the right anterior dorsolateral prefrontal cortex and the bilateral parahippocampal cortex [10]. A prominent method of assessing metacognition behaviorally is based on collecting confidence judgments from participants [12]. Measuring the quality of these confidence ratings is consequential for understanding the underlying mechanisms of metacognition. The goals of the present study are threefold: (a) to introduce several recently developed information-theoretic measures of metacognitive efficiency that are based on confidence judgments [3,4], (b) to demonstrate how these measures can be applied to a concrete behavioral task of face-matching [21], and (c) to show that these information-theoretic measures converge on a single theoretical construct in this empirical context [22].
A primary objective of research on metacognition is that of measuring the quality of confidence judgments. Three quantities stand out as crucial aspects of measurement and modeling: bias, sensitivity, and efficiency. To motivate our understanding of these concepts, consider a simple task by which an observer is asked to detect whether a signal is present or absent by emitting one of two possible responses, and then immediately she is asked to rate her confidence in the correctness of her decision. It is often customary to call the first task type 1 task, and the second type 2 task [23,24]. It is also theoretically convenient to separate the actor, who performs in the type 1 task, from the rater, who engages in the type 2 task, although the two entities might be the same person [25]. Sensitivity plays a role in both the actor’s and the rater’s decisions. The actor’s sensitivity is reflected in her ability to separate between noise and noise plus signal. In the language of Signal Detection Theory [SDT, [26,27] this quantity is captured by the parameter . The rater’s sensitivity reflects his ability to distinguish between the actor’s correct and incorrect decisions. A metacognitively sensitive rater tends to provide high confidence ratings for the actor’s correct decisions, and low confidence ratings for the actor’s incorrect decisions. However, the sensitivity of the rater cannot serve as a viable measure of the rater’s quality of decision. Trivially, a rater can be highly sensitive if the actor is giving correct decisions most of the time. In other words, the rater’s job becomes much easier as the actor becomes more sensitive. Thus, a genuine measure of metacognitive efficiency should correct the rater’s sensitivity for the actor’s performance. Moreover, metacognitive efficiency can be affected by bias. An overconfident rater, one who gives high confidence ratings even when the actor’s decisions are incorrect, is effectively both insensitive and inefficient.
Model-free [28] and model-based [1,2,24,25,29] approaches have been developed to quantify metacognitive bias, sensitivity and efficiency. One of the most influential model-based frameworks in the field is called the model [1,2]. This model (see Figure 1) relies on principles of SDT [26,27], and as such incorporates parametric assumptions [23,24,30]. The model’s objective is to predict the rater’s hypothetical sensitivity in the type 1 task based on the rater’s performance in the type 2 task. The value of this theoretical quantity is dubbed . Because this quantity and the actor’s type 1 are expressed in the same measurement units [2], they can be directly compared. Metacognitive efficiency can then be assessed in two possible ways: either as an M-ratio () or as a difference (). The rater’s efficiency is optimal when , or when . The rater is hyposensitive when or when . There are situations in which the rater is hypersensitive, namely when , or when [1]. This can occur when the rater has access to additional information accumulated after the actor’s decision. Such a scenario can be modeled, for example, by the second-order model [25]. According to this model, the actor and the rater are sampling evidence from two separate distributions. Hypersensitivity in this model can be modeled by making the noise (i.e.,variance) in the rater’s distribution much lower than the noise (i.e.,variance) in the actor’s distribution.
Several measures emanating from the model [1,2], such as and , have been used extensively by researchers to evaluate the quality of confidence judgments [32]. However, these measures are not without their limitations [3]. First, it is not immediately clear why empirical confidence ratings should necessarily accommodate to a type 1 decision process [3]. Second, strong evidence suggests that these measures carry-over a residual dependency on type 1 performance [33], and on metacognitive bias [34]. Beyond these two reasons, these measures: (a) require distributional assumptions, (b) are not bias-free, (c) are applicable only to ratio-scale variables, (d) do not scale with the number of stimuli, responses, or confidence rating alternatives, (e) do not have definite upper and lower bounds, and (f) are applicable only to experimental designs with two stimuli and two responses. Dayan [3] and Fitousi [4] have recently proposed information-theoretic indexes of metacognitive efficiency that can ameliorate most of these problems, and serve as additional means of assessment.
Dayan [3] has succinctly summarized the utility of an information-theoretic approach to judgments of confidence: ”the problem of confidence is inherently one of information – that the actor has about the true state of the stimulus; and that the rater has about the same quantity and about what the actor used. It therefore seems appropriate to use the methods of information theory to judge the relationship between the stimulus, the actor and the rater” (p.11). Indeed, the information theoretic measures have many desirable characteristics: (a) they are relative measures, (b) accommodate to type 1 performance, (c) bias- free (e.g., do not depend on criterion shifts), (d) do not require any parametric assumptions, (e) scale with the number of confidence rating points, (f) do not require the assumption of ratio or order of confidence ratings, and (g) relatively easy to compute. Both Dayan [3] and Fitousi [4] performed simulation with canonical Bayesian models to support the validity of the information-theoretic measures they developed. Both authors demonstrated convergence of their information-theoretic measures based on those SDT and related Bayesian models. However, neither of them computed the measures in real empirical data sets, nor did they examine the convergence validity of those measures is such cases. The present study sought to accomplish these objectives.
2. An information-Theoretic Approach to Metacognitive Efficiency
Recent years have seen a renewed interest [35] in information-theoretic approaches to perception and cognition [36,37,38,39,40,41,42,43,44]. Many researchers have began to realize the potential strength of information theory [45,46] in providing powerful tools for addressing the uncertainty that characterizes brain and behavior [47,48]. In two recent studies, Dayan [3] and Fitousi [4] have developed complementary information-theoretic approaches to metacognition that build on the idea of confidence judgments as a communication system. An illustration of such a system is presented in Figure 2. The communication model consists of three entities: Stimuli which are set by the Experimenter, Actor who responds to the stimuli, and Rater who provides confidence judgments of the Actor’s response to the Stimuli.
2.1. Dayan’s
Dayan [3] outlined an information-theoretic measure of metacognitive efficiency he called . Consider an actor who performs in a two-choice signal detection task with consequences of a =1, or a = -1. The actor’s response is r, and she is correct when and incorrect when . The confidence-accuracy discrete distributions can be used to assess the metacognitive efficiency of the rater as a difference between two entropies.
where
and
where
is the entropy of a Bernoulli random variable. The first entropy is the overall uncertainty about the actor’s accuracy. In the SDT model it is determined by the value of the parameter . When the actor is perfectly accurate and or when the actor is perfectly wrong, this entropy amounts to 0 ; when the actor is completely uncorrelated with , which occurs when , this entropy amounts to 1 . The second entropy is the weighted average uncertainty about the residual accuracy after observing the confidence rating c where the weights arrive from the probability of observing that rating c.
The measure has many desirable characteristics: (a) it is a relative measure, (b) accommodates to type 1 performance, (c) does not require any parametric assumptions, (d) is bias-free, (e) scales with the number of confidence rating points, (f) does not require the assumption of ratio or order of confidence ratings, and (g) has definite bounds from above and from below.
The is an ingenious measure on its right. But it can be modified to become a more general index of metacognitive efficiency. Note that the measure is contingent on accuracy (i.e.,it depends on a specific partition, r = a, a), while there is strong evidence that participants do not necessarily rate confidence based on the accuracy of response [49]. For example, Koriat [52,53] has demonstrated the operation of a consensuality principle in judgments of confidence, whereby participants give the highest confidence rating to the most popular option, not necessarily to the one that is objectively correct. Moreover, was originally developed to assess metacognitive efficiency in the two-choice SDT task (i.e., it assumes two mutual choices, a = 1 or a=-1). However, does not apply to tasks of multi-alternative choice [49]. For example, assume an experimental design with four stimuli that are categorized into four responses, and are then rated on a 1-4 confidence scale. In that case, is not readily applicable. Thus, a more general version of , I call , is needed. This version is not contingent on accuracy, and makes no assumptions about the structure of the experimental design (i.e., number of stimuli or/and responses). The new proposed here meets these requirements. It is computed as the mutual information between response and the joint confidence-stimuli variable:
This quantity amounts to 0 bits when the actor shares no information with the stimuli and rater; it is maximal when the actor shares all the information with the stimuli and the rater. An upper-bound on is determined by the variable with the lowest number of alternatives. For example, if the stimuli variable has the lowest number of alternatives, say four, then the upper bound is 2 bits. In the case of a two-choice SDT task, the upper bound is 1 bit. Decomposition of into its entropy terms can provide more insights. According to one possible decomposition, it reflects the degree to which uncertainty in the actor’s response to the stimuli is reduced after observing the rater’s confidence judgments . According to another decomposition, reflects the reduction in the combined uncertainty in the actor’s response and the confidence-stimuli variables after removing the uncertainty in the joint stimuli-response-confidence variable . In its new form, can be applied to complex experimental designs, with several stimuli and responses, and without the need to define the correctness of the response.
2.2. Fitousi’s , , and
Fitousi [4] has recently developed three complementary information-theoretic measures of meatcognitive efficiency he called: , , and . The first measure bears close affinity with Dayan’s , and its generalized form . The measure quantifies metacognitive efficiency as the mutual information exchanged between the rater’s confidence judgments and the stimuli-response variable:
The index expresses the amount of information gained about confidence from knowing the actor’s response, after knowing the stimuli. When the rater’s metacognitive efficiency is null, amounts to zero bit, setting a lower bound on efficiency. An upper-bound on is placed by the variable with the lowest number of alternatives in the communication system. Decomposition of into entropy terms can explicate the logic of this measure. In the first decomposition, reflects the degree to which the conditional uncertainty of confidence after knowing the stimulus is reduced after observing the actor’s response. In the second decomposition, we note that gauges the degree to which uncertainty in the confidence and stimulus-response variables is reduced after observing the actor’s response . This measure corrects for type 1 performance by taking the difference between type 1 uncertainty and the type 1 and type 2 uncertainty , in a similar way to .
Importantly, it can be shown that equals due to the symmetry of mutual information:
In the case of a two-choice SDT task, and are equal to Dayan’s .
The other two measures advanced by Fitousi [4], , and , are based on the Kullback-Leibler (KL) [50] and Jeffrey’s [51] divergences. These divergences are applied to the normalized confidence-accuracy distributions and . It should be noted though that, in principle, these divergence measures can be derived for any required partition of the stimuli-response joint variable, irrespective of accuracy. Accuracy is defined by labels (i.e., ”correct”, ”incorrect”) placed by the experimenter on the actor’s responses. But information-theoretic quantities are agnostic to such labels. A rater can be metacognitively efficient even when she flips the ”correct” and ”incorrect” labels on the actor’s responses.
The new measure proposed by Fitousi, , is based on a KL divergence that measures the degree of separation between correct and incorrect accuracy-confidence distributions:
It amounts to 0 bits when the rater cannot distinguish between correct and incorrect responses of the actor, and increases as the rater becomes more metacognitively efficient. An upper bound is met when the two distributions are at their maximal separability. An analogous expression of gauges the difference between the entropy in the joint correct and incorrect distribution and the entropy in the correct distribution:
Metacognitive efficiency is null when uncertainty in the joint correct-incorrect confidence-accuracy distribution is equal to the uncertainty in the correct confidence-accuracy distribution. Metacognitive efficiency increases as the uncertainty in the correct distribution decreases. It reaches an upper bound when the latter is 0 , namely, the rater eliminates all uncertainty in the actor’s correct (incorrect) responses to the stimuli.
The measure does not satisfy the triangle inequality, and is also not symmetric in the two distributions, since . In this sense, does not qualify as a metric [52]. To address these constraints, Fitousi [4] has also proposed based on the Jeffrey’s divergence [51,53], which offers a symmetric measure of divergence:
This measure functions in a similar way to . It equals 0 bits when the rater cannot distinguish between the correct and incorrect accuracy-confidence distributions, and increases as the rater becomes more efficient. But unlike , it takes into consideration the two possible KL divergences, and between the correct and incorrect confidence-accuracy distributions. Another way of expressing the same measure:
suggests that metacognitive efficiency gauges the degree to which the rater reduces uncertainty in the actor’s response by eliminating uncertainty in the correct accuracy-confidence distribution, and/or in the incorrect accuracy-confidence distribution. The takes into consideration two sources of uncertainty, weighting them as two independent contributions to metacognitive efficiency. This is in contrast to the , which gives all the weight to the uncertainty in the correct accuracy-confidence distribution.
To validate these novel measures, Fitousi [4] has performed simulations with the model [1,31]. He varied the values of and incrementally in small steps, and in an orthogonal fashion and generated the corresponding confidence-accuracy distribution for each pair of values. He then computed the information-theoretic measures , , and for each confidence-accuracy distribution, and plotted those values as a heatmap, with in the abscissa and in the ordinate. Figure 3 presents the results of these simulations. As can be noted, all three heatmaps reveal one of the most important properties of an efficiency measures, namely that the rater’s sensitivity is corrected for type 1 performance. To see why, note that the highest values of metacognitive efficiency are achieved when the actor’s sensitivity () is low and the rater’s sensitivity () is high. In all three heatmaps, as the actor’s sensitivity increases, there is less and less room for the rater to accomplish high metacognitive efficiency. Also notable are the differences between the mutual information measure (), and the divergence measures (, ) with respect to the maximal values they can take, and their overall dynamics.
The information theoretic measures have many valuable characteristics. These are discussed in detail in the papers by Dayan [3] and Fitousi [4]. Here I give a brief summary of the most important features. They are: (a) relative measures, (b) accommodate type 1 performance, (c) bias-free, (d) do not require any parametric assumptions, (e) scale with the number of confidence rating points, (f) do not require the assumption of ratio or order of confidence ratings, (g) easy to compute, and (h) offer definite lower and upper bounds on performance.
One important question that remains to be address is whether these measures of metacognitive efficiency converge on the same psychological construct. Previous efforts by Dayan [3] and Fitousi [4] have emulated various simulations with theoretical models to show that the measures converge. But there is still the need to assess these measures’ convergence with real data sets. If these different indexes capture the same psychological construct, they should correlate in real empirical data. This hypothesis is subjected to scrutiny in the next section.
3. Empirical Validation
3.1. The Face-Matching Task
Here I provide an empirical validation of the information-theoretic measures of metacognitive efficiency. To do so, I take advantage of two data sets collected in a recent face-matching study in my lab. The face-matching task [54,55,56,57,58] has become an important tool in assessing sundry aspects of face recognition. In this task participants are presented with two face images and are asked to decide whether these belong to the same identity, or alternatively to two different identities. The images are taken under various lighting conditions, with different cameras, and at different times. It turns out that with unfamiliar facial identities, this task poses serious challenges for both humans [21,54,55,56,57,58] and machines [59]. This is mainly because under variable ambient conditions, images of the same personal identity can look completely different; whereas images of different identities may appear similar.
Figure 4 presents examples of pairs of face images from the Glasgow Face Matching Task [GFMT [54], and from the Kent Face Matching Task [KFMT 60], two of the most popular standard tests, which were also deployed in the present investigation. Extensive research on the face-matching task [61,62] has greatly enhanced our understanding of the underlying mechanisms that govern this task. A recent paper by Fitousi [21] has introduced an unequal-variance signal detection model, one that can account for many aspects of this task, including type 1 confidence judgments, similarity ratings, and accuracy.
However, despite extensive research on the face-matching task [55,63,64,65], only little is known about the underlying metacognitive capabilities with which participants perform this task. The application of the indexes, along with the novel information-theoretic measures can shed new light on this issue. But most importantly, the joint application of these measures is needed to garner strong evidence for their convergence.
3.2. The Data Sets
The data sets were collected in my lab. In data set 1, seventy participants engaged in a face-matching task with the long version of the GFMT [54]. In data set 2, seventy new participants were tested with the KFMT [60]. There were 168 images in the GFMT and 40 images in the KFMT. More details about these tests can be found here [21]. The general method in both experiments was identical. Participants were sitting in front of a computer screen. On each trial they were presented with a randomly selected face-pair, and were asked to decided as accurately and as speedily as they can, whether the pair constituted a ”match” or a ”mismatch” by pressing one of two computer keys (type 1 task). Immediately after responding, the images were removed from the screen, and a a four-point confidence scale appeared on the screen with 1=”not confident ” and 4 = ”highly confident.” In data set 1 participants completed two blocks, which amounted to a total of 336 trials. In data set 2 participants completed four blocks, which resulted in a total of 160 trials.
3.3. Results
The face-matching task administrated in data set 1 was relatively easier ( = 2.51, sd = 0.65) than the one in data set 2 ( = 1.01, sd = 0.41). However, the results from both data sets converged on the conclusion that, on average, participants did exhibit meta-knowledge about their face-matching performance. The mean of the , measure amounted to 0.86 (sd = 1.31) in data set 1, and 1.09 (sd = 0.97) in data set 2. Recall that for a value greater than zero entails hypersensitivity. Similarly, the mean of the measure was equal to 1.44 (sd = 0.66) in data set 1, and 2.83 (sd = 3.25) in data set 2. Recall that for a value greater than 1 entails hypersensitivity. One-sided student-tests supported these conclusions, with all t-statistics being significant at the level. The novel information-theoretic measures also supported the conclusion that participants in both data sets acquired meta-knowledge about their decisions.The average values were 0.22 bits (sd = 0.17) and 0.37 bits (sd = 0.21) in the two data sets, respectively. Recall that in the two-choice task is quantitatively comparable to Dayan’s [3]. The average values amounted to 1.54 bits (sd = 0.95) and 1.11 bits (sd = 0.74) in the two data sets, respectively. The average values were 4.15 bits (sd = 2.37) and 2.54 bits (sd = 1.74) in the two data sets, respectively.
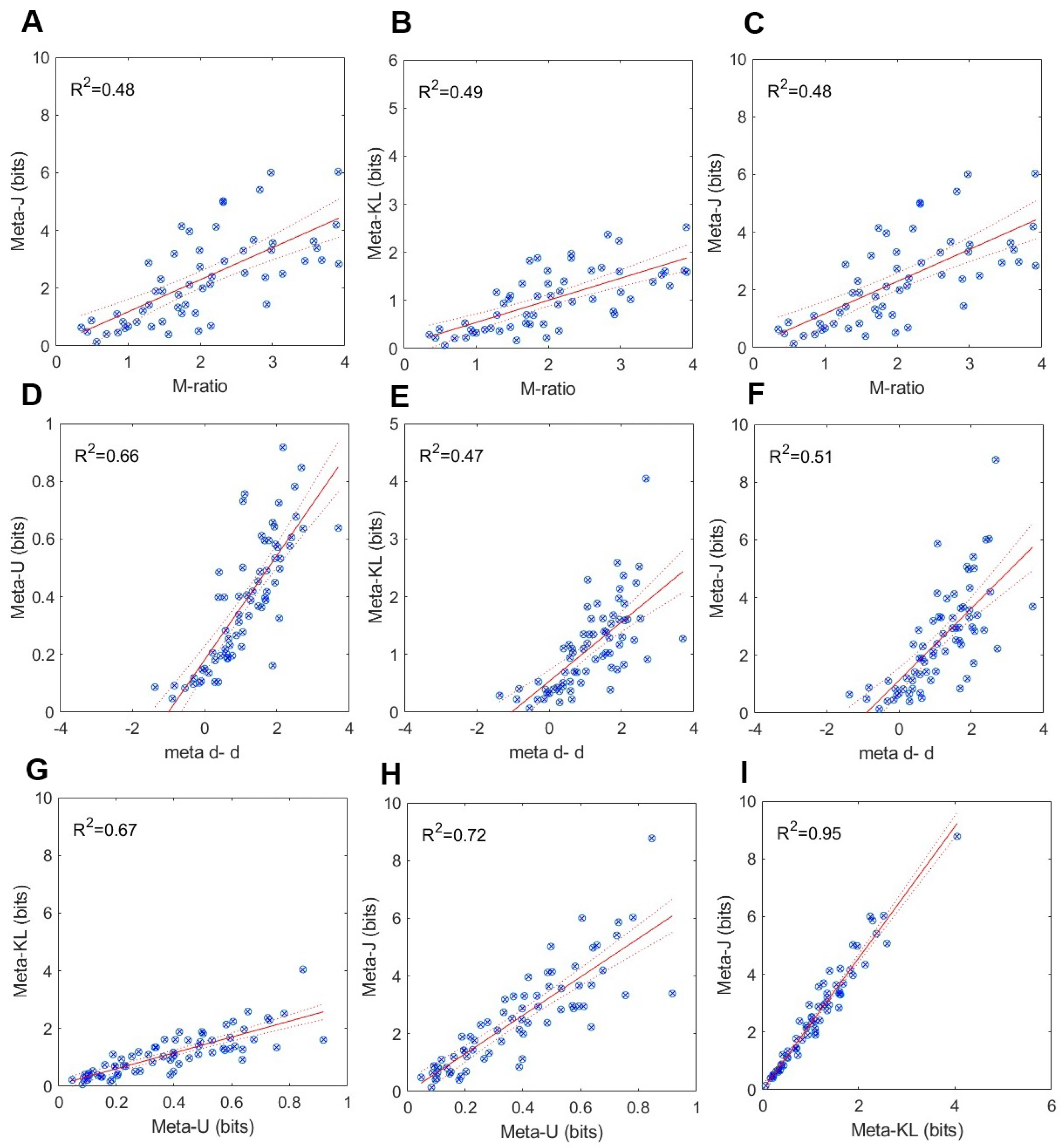
I then computed the SDT and information-theory measures for each participant, and used linear regression on each pair of measures to quantify the coefficient of determination . Figure 5 and Figure 6 present the results of these analyses, respectively, for the GFMT and KFTM data sets.
As can be noted in Figure 5 and Figure 6, significant positive and strong relations ensued between each pair of measures in both data sets. Overall, higher obtained for the KFMT than the GFMT data. In the former, all coefficient of determination values were larger than . In the latter, all those values exceeded . The strongest relations were observed between and . This is quite expected given their mathematical affinity. Taken collectively, these results: (a) support the conclusion that participants do have meta-knowledge about their face-matching performance, and (b) confer validation support in the convergence of the information-theoretic measures on a common psychological structure – metacognitive efficiency.
4. Conclusions
I introduced various information-theoretic measures of metacognitive efficiency recently developed by Dayan [3] and Fitousi [4]. These indexes consist of: the [3], and the , , , and [4]. These measures were originally developed within a common theoretical framework, assuming a communication system with stimuli (experimenter), actor, and rater as encoders/decoders. I provided a succinct account of each measure, along with its possible interpretations. I then applied these information indexes, along with the and indexes, to data sets from the face-matching task [54]. The results strongly supported the convergence of these measures on a single psychological construct.
One source of motivation for developing information-theoretic markers of metacognitive efficiency has to do with the limitations of existing model-based measures, such as and . These indexes are built on the assumption that they should fit exactly to a type 1 decision process. But this assumption is dubious [3]. Moreover, these measures are subjected to decisional bias [1,2], have a remaining dependency on type 1 performance [33], and on metacognitive bias [34]. Information theory measures are free of such limitations.
Another crucial point is that both model-based and model-free measures of metacognitive efficiency [66] do not accommodate changes in the granularity of type 2 confidence ratings, nor do they scale with the number of type 1 stimuli or responses. Information-theoretic measures can be computed relatively easily, without making any parametric assumptions, can be applied to tasks which incorporate multi-alternative choices, are compatible with existent SDT-based measures, and can be applied to data without labeling the responses as correct or incorrect. Moreover, unlike SDT-based measures, they can accommodate the granularity of the confidence judgments (e.g., number of rating points), and can provide definite upper- and lower-bounds on performance. All of these valuable characteristics have been previously demonstrated by Dayan [3] and Fitousi [4].
Another reason for advancing the information-theoretic approach to meatcognition has to do with the suitability of such a theory to characterize capacity limitations, information-bottlenecks, rate-distortions, and other quantities that are not readily available in current approaches (e.g. SDT). Future work on confidence and metacognition should seek to expand our theoretical understanding by building on these powerful notions.
Conflicts of Interest
The author declares no conflict of interest.
References
- Maniscalco, B.; Lau, H. A signal detection theoretic approach for estimating metacognitive sensitivity from confidence ratings. Consciousness and cognition 2012, 21, 422–430. [Google Scholar] [CrossRef] [PubMed]
- Maniscalco, B.; Lau, H. Signal detection theory analysis of type 1 and type 2 data: meta-d, response-specific meta-d, and the unequal variance SDT model. In The Cognitive Neuroscience of Metacognition; Springer, 2014; pp. 25–66. [Google Scholar]
- Dayan, P. Metacognitive information theory. Open Mind 2023, 7, 392–411. [Google Scholar] [CrossRef] [PubMed]
- Schulz, L.; Rollwage, M.; Dolan, R.J.; Fleming, S.M. Dogmatism manifests in lowered information search under uncertainty. Proceedings of the National Academy of Sciences 2020, 117, 31527–31534. [Google Scholar] [CrossRef] [PubMed]
- Schulz, L.; Fleming, S.M.; Dayan, P. Metacognitive computations for information search: Confidence in control. Psychological Review 2023, 130, 604–639. [Google Scholar] [CrossRef]
- Peirce, C.S.; Jastrow, J. On small differences in sensation. Memoirs of the National Academy of Sciences 1884, 3–11. [Google Scholar]
- Henmon, V.A.C. The relation of the time of a judgment to its accuracy. Psychological Review 1911, 18, 186–201. [Google Scholar] [CrossRef]
- Lau, H. In consciousness we trust: The cognitive neuroscience of subjective experience; Oxford University Press, 2022. [Google Scholar]
- Metcalfe, J.; Shimamura, A.P. Metacognition: Knowing about knowing; MIT press, 1994. [Google Scholar]
- Fleming, S.M.; Dolan, R.J. The neural basis of metacognitive ability. Philosophical Transactions of the Royal Society B: Biological Sciences 2012, 367, 1338–1349. [Google Scholar] [CrossRef]
- Fleming, S.M.; Weil, R.S.; Nagy, Z.; Dolan, R.J.; Rees, G. Relating introspective accuracy to individual differences in brain structure. Science 2010, 329, 1541–1543. [Google Scholar] [CrossRef] [PubMed]
- Fleming, S.M. Metacognition and confidence: A review and synthesis. Annual Review of Psychology 2024, 75, 241–268. [Google Scholar] [CrossRef]
- Meyniel, F.; Schlunegger, D.; Dehaene, S. The sense of confidence during probabilistic learning: A normative account. PLoS computational biology 2015, 11, e1004305. [Google Scholar] [CrossRef] [PubMed]
- Koriat, A.; Goldsmith, M. Monitoring and control processes in the strategic regulation of memory accuracy. Psychological Review 1996, 103, 490–517. [Google Scholar] [CrossRef] [PubMed]
- Koriat, A. Monitoring one’s own knowledge during study: A cue-utilization approach to judgments of learning. Journal of Experimental Psychology: General 1997, 126, 349–370. [Google Scholar] [CrossRef]
- Koriat, A. The feeling of knowing: Some metatheoretical implications for consciousness and control. Consciousness and Cognition 2000, 9, 149–171. [Google Scholar] [CrossRef] [PubMed]
- Persaud, N.; McLeod, P.; Cowey, A. Post-decision wagering objectively measures awareness. Nature neuroscience 2007, 10, 257–261. [Google Scholar] [CrossRef] [PubMed]
- Van den Berg, R.; Zylberberg, A.; Kiani, R.; Shadlen, M.N.; Wolpert, D.M. Confidence is the bridge between multi-stage decisions. Current Biology 2016, 26, 3157–3168. [Google Scholar] [CrossRef] [PubMed]
- Hoven, M.; Lebreton, M.; Engelmann, J.B.; Denys, D.; Luigjes, J.; van Holst, R.J. Abnormalities of confidence in psychiatry: an overview and future perspectives. Translational psychiatry 2019, 9, 268. [Google Scholar] [CrossRef] [PubMed]
- Bahrami, B.; Olsen, K.; Latham, P.E.; Roepstorff, A.; Rees, G.; Frith, C.D. Optimally interacting minds. Science 2010, 329, 1081–1085. [Google Scholar] [CrossRef] [PubMed]
- Fitousi, D. A Signal-detection based confidence-similarity model of face-matching. Psychological Review 2024, 131, 625–663. [Google Scholar] [CrossRef]
- Garner, W.R.; Hake, H.W.; Eriksen, C.W. Operationism and the concept of perception. Psychological Review 1956, 63, 149–159. [Google Scholar] [CrossRef]
- Clarke, F.R.; Birdsall, T.G.; Tanner Jr, W.P. Two types of ROC curves and definitions of parameters. The Journal of the Acoustical Society of America 1959, 31, 629–630. [Google Scholar] [CrossRef]
- Galvin, S.J.; Podd, J.V.; Drga, V.; Whitmore, J. Type 2 tasks in the theory of signal detectability: Discrimination between correct and incorrect decisions. Psychonomic Bulletin & Review 2003, 10, 843–876. [Google Scholar]
- Fleming, S.M.; Daw, N.D. Self-evaluation of decision-making: A general Bayesian framework for metacognitive computation. Psychological Review 2017, 124, 91–114. [Google Scholar] [CrossRef]
- Green, D.M.; Swets, J.A. Signal detection theory and psychophysics; Wiley: New York, 1966; Vol. 1. [Google Scholar]
- Macmillan, N.A.; Creelman, C.D. Detection theory: A user’s guide; Psychology press, 2004. [Google Scholar]
- Nelson, T.O. A comparison of current measures of the accuracy of feeling-of-knowing predictions. Psychological Bulletin 1984, 95, 109–133. [Google Scholar] [CrossRef] [PubMed]
- Fleming, S.M. HMeta-d: hierarchical Bayesian estimation of metacognitive efficiency from confidence ratings. Neuroscience of consciousness 2017, 2017, nix007. [Google Scholar] [CrossRef] [PubMed]
- Kunimoto, C.; Miller, J.; Pashler, H. Confidence and accuracy of near-threshold discrimination responses. Consciousness and cognition 2001, 10, 294–340. [Google Scholar] [CrossRef]
- Maniscalco, B.; Peters, M.A.; Lau, H. Heuristic use of perceptual evidence leads to dissociation between performance and metacognitive sensitivity. Attention, Perception, & Psychophysics 2016, 78, 923–937. [Google Scholar]
- Shekhar, M.; Rahnev, D. Sources of metacognitive inefficiency. Trends in Cognitive Sciences 2021, 25, 12–23. [Google Scholar] [CrossRef] [PubMed]
- Guggenmos, M. Measuring metacognitive performance: type 1 performance dependence and test-retest reliability. Neuroscience of consciousness 2021, 2021, niab040. [Google Scholar] [CrossRef] [PubMed]
- Xue, K.; Shekhar, M.; Rahnev, D. Examining the robustness of the relationship between metacognitive efficiency and metacognitive bias. Consciousness and Cognition 2021, 95, 103196. [Google Scholar] [CrossRef]
- Luce, R.D. Whatever happened to information theory in psychology? Review of general psychology 2003, 7, 183–188. [Google Scholar] [CrossRef]
- Knill, D.C.; Pouget, A. The Bayesian brain: the role of uncertainty in neural coding and computation. TRENDS in Neurosciences 2004, 27, 712–719. [Google Scholar] [CrossRef] [PubMed]
- Feldman, J. Information-theoretic signal detection theory. Psychological Review 2021, 128, 976–987. [Google Scholar] [CrossRef]
- Killeen, P.; Taylor, T. Bits of the ROC: Signal detection as information transmission. Unpublished manuscript 2001. [Google Scholar]
- Fitousi, D. Mutual information, perceptual independence, and holistic face perception. Attention, Perception, & Psychophysics 2013, 75, 983–1000. [Google Scholar]
- Fitousi, D.; Algom, D. The quest for psychological symmetry through figural goodness, randomness, and complexity: A selective review. i-Perception 2024, 15, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Fitousi, D. Quantifying Entropy in Response Times (RT) Distributions Using the Cumulative Residual Entropy (CRE) Function. Entropy 2023, 25, 1239. [Google Scholar] [CrossRef] [PubMed]
- Friston, K. The free-energy principle: a unified brain theory? Nature reviews neuroscience 2010, 11, 127–138. [Google Scholar] [CrossRef]
- Norwich, K.H. Information, sensation, and perception; Academic Press: San Diego, 1993. [Google Scholar]
- Hirsh, J.B.; Mar, R.A.; Peterson, J.B. Psychological entropy: A framework for understanding uncertainty-related anxiety. Psychological Review 2012, 119, 304–320. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C. A mathematical theory of communication. The Bell system technical journal 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Shannon, C.; Weaver, W. The Mathematical Theory of Communication,(first published in 1949). Urbana University of Illinois Press 1949. [Google Scholar]
- Friston, K. The free-energy principle: a rough guide to the brain? Trends in cognitive sciences 2009, 13, 293–301. [Google Scholar] [CrossRef] [PubMed]
- Pouget, A.; Drugowitsch, J.; Kepecs, A. Confidence and certainty: distinct probabilistic quantities for different goals. Nature neuroscience 2016, 19, 366–374. [Google Scholar] [CrossRef] [PubMed]
- Li, H.H.; Ma, W.J. Confidence reports in decision-making with multiple alternatives violate the Bayesian confidence hypothesis. Nature communications 2020, 11, 2004. [Google Scholar] [CrossRef]
- Kullback, S. Information theory and statistics; Courier Corporation, 1959. [Google Scholar]
- Jeffrey, R.C. Probability and the Art of Judgment; Cambridge University Press, 1992. [Google Scholar]
- Cover, T.; Thomas, J. Elements of information theory; John Wiley & Sons, 1991. [Google Scholar]
- Pearl, J. Jeffrey’s rule, passage of experience, and neo-Bayesianism. In Knowledge representation and defeasible reasoning; Springer, 1990; pp. 245–265. [Google Scholar]
- Burton, A.M.; White, D.; McNeill, A. The Glasgow face matching test. Behavior research methods 2010, 42, 286–291. [Google Scholar] [CrossRef]
- White, D.; Towler, A.; Kemp, R. Understanding professional expertise in unfamiliar face matching. In Forensic face matching: Research and practice; 2021; pp. 62–88. [Google Scholar]
- Megreya, A.M.; Burton, A.M. Unfamiliar faces are not faces: Evidence from a matching task. Memory & Cognition 2006, 34, 865–876. [Google Scholar]
- Megreya, A.M.; Burton, A.M. Hits and false positives in face matching: A familiarity-based dissociation. Perception & Psychophysics 2007, 69, 1175–1184. [Google Scholar]
- Kemp, R.; Towell, N.; Pike, G. When seeing should not be believing: Photographs, credit cards and fraud. Applied Cognitive Psychology: The Official Journal of the Society for Applied Research in Memory and Cognition 1997, 11, 211–222. [Google Scholar] [CrossRef]
- O’Toole, A.J.; An, X.; Dunlop, J.; Natu, V.; Phillips, P.J. Comparing face recognition algorithms to humans on challenging tasks. ACM Transactions on Applied Perception (TAP) 2012, 9, 1–13. [Google Scholar] [CrossRef]
- Fysh, M.C.; Bindemann, M. The Kent face matching test. British Journal of Psychology 2018, 109, 219–231. [Google Scholar] [CrossRef]
- Bate, S.; Mestry, N.; Portch, E. Individual differences between observers in face matching. In Forensic Face Matching: Research and Practice; 2021; pp. 117–145. [Google Scholar]
- Towler, A.; White, D.; Kemp, R.I. Evaluating training methods for facial image comparison: The face shape strategy does not work. Perception 2014, 43, 214–218. [Google Scholar] [CrossRef]
- Jenkins, R.; White, D.; Van Montfort, X.; Burton, A.M. Variability in photos of the same face. Cognition 2011, 121, 313–323. [Google Scholar] [CrossRef]
- Bindemann, M.; Attard, J.; Leach, A.; Johnston, R.A. The effect of image pixelation on unfamiliar-face matching. Applied Cognitive Psychology 2013, 27, 707–717. [Google Scholar] [CrossRef]
- Megreya, A.M.; Bindemann, M. Feature instructions improve face-matching accuracy. PloS one 2018, 13, e0193455. [Google Scholar] [CrossRef]
- Shekhar, M.; Rahnev, D. The nature of metacognitive inefficiency in perceptual decision making. Psychological Review 2021, 128, 45–70. [Google Scholar] [CrossRef]
Figure 1.
The meta - d’ model [1]. (A) A signal detection theory (SDT) representation of the actor’s decisions in the type 1 task. (B) An SDT representation of the rater’s decisions in the type 2 task. (C) Empirical confidence-rating distributions conditional on type 1 correct and incorrect responses. A rater with high metacognitive sensitivity provides high confidence ratings when the actor is correct, and low confidence ratings when the actor is incorrect. A rater with low metacognitive sensitivity does not distinguish between the actor’s correct and incorrect responses. (D) A theoretical ROC curve of the type 2 task is generated by assuming a hypothetical equal-variance SDT model of confidence. The meta-d’ model [1,29,31] expresses the type 2 hit rates and false alarms in terms of the divergence units of the type 1 d’, and then looks for the type 1 d’ that best fits the empirical confidence data. The resulting parameter is called .
Figure 1.
The meta - d’ model [1]. (A) A signal detection theory (SDT) representation of the actor’s decisions in the type 1 task. (B) An SDT representation of the rater’s decisions in the type 2 task. (C) Empirical confidence-rating distributions conditional on type 1 correct and incorrect responses. A rater with high metacognitive sensitivity provides high confidence ratings when the actor is correct, and low confidence ratings when the actor is incorrect. A rater with low metacognitive sensitivity does not distinguish between the actor’s correct and incorrect responses. (D) A theoretical ROC curve of the type 2 task is generated by assuming a hypothetical equal-variance SDT model of confidence. The meta-d’ model [1,29,31] expresses the type 2 hit rates and false alarms in terms of the divergence units of the type 1 d’, and then looks for the type 1 d’ that best fits the empirical confidence data. The resulting parameter is called .
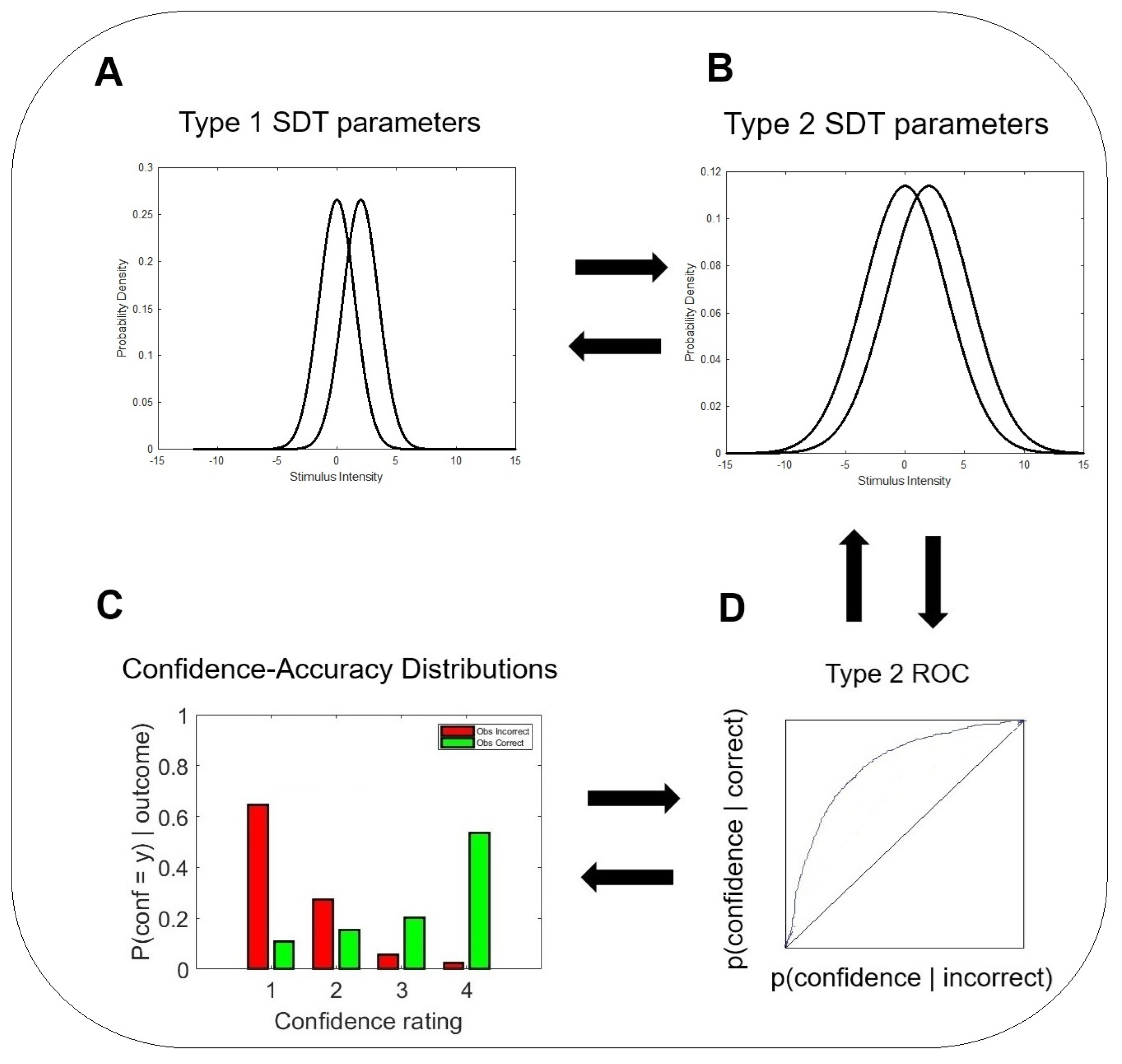
Figure 2.
A Venn diagram illustrating a communication system between stimuli, actor and rater. Uncertainty in Stimuli is depicted by a pink circle, uncertainty in Actor’s response is illustrated by a blue circle, and uncertainty in Rater’s confidence ratings is represented by a green circle. In this example, there are two stimuli. The actor responds by emitting one of two possible responses, and the rater expresses their confidence in the actor’s response by sending one of four confidence-rating levels.
Figure 2.
A Venn diagram illustrating a communication system between stimuli, actor and rater. Uncertainty in Stimuli is depicted by a pink circle, uncertainty in Actor’s response is illustrated by a blue circle, and uncertainty in Rater’s confidence ratings is represented by a green circle. In this example, there are two stimuli. The actor responds by emitting one of two possible responses, and the rater expresses their confidence in the actor’s response by sending one of four confidence-rating levels.
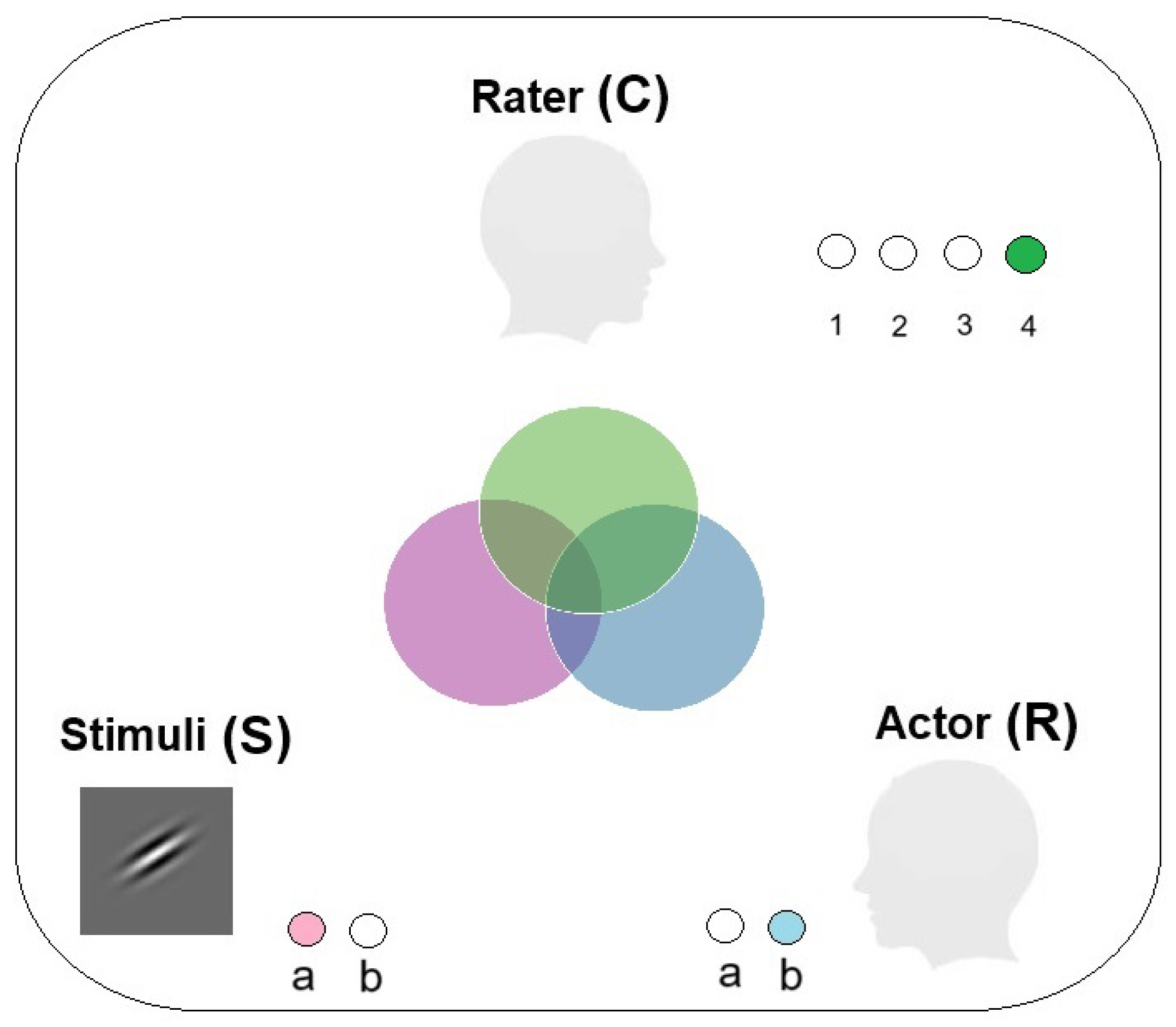
Figure 3.
Theoretical validation of the information measures of metacognitive efficiency using the model [1,31]. Data are generated by increasing incrementally and in an orthogonal fashion the values of parameters and , and then computing the corresponding values of , , and . The resulting values are presented in a heatmap against the values of and . (A) . (B) . (C) .
Figure 3.
Theoretical validation of the information measures of metacognitive efficiency using the model [1,31]. Data are generated by increasing incrementally and in an orthogonal fashion the values of parameters and , and then computing the corresponding values of , , and . The resulting values are presented in a heatmap against the values of and . (A) . (B) . (C) .
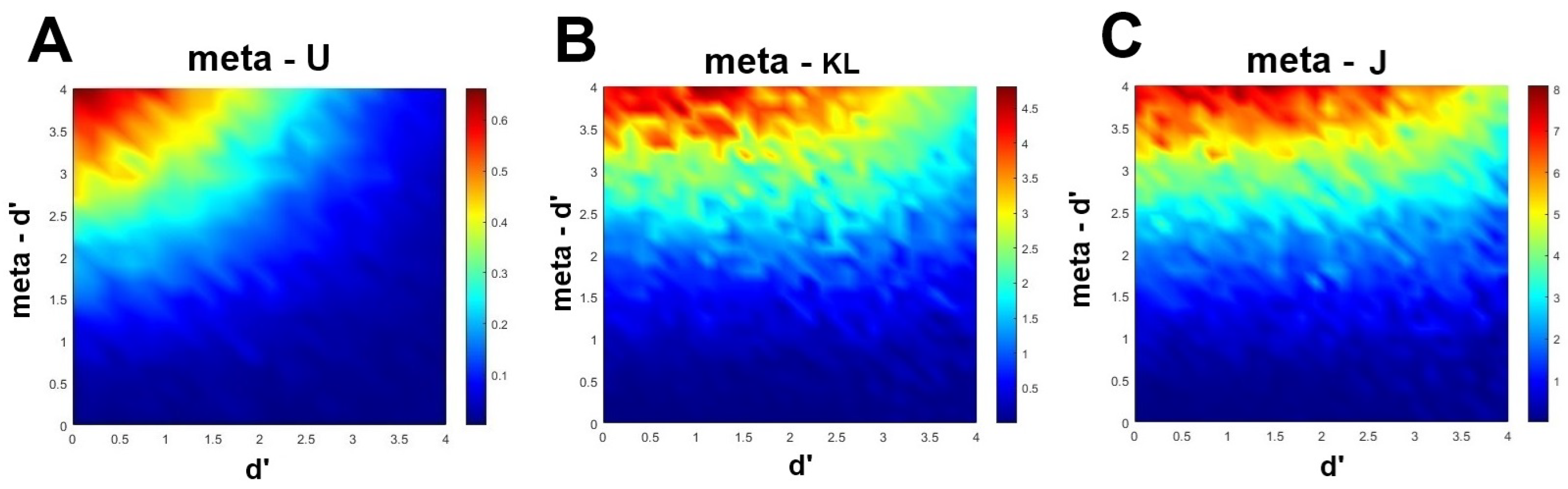
Figure 4.
Examples of face-pairs from the Glasgow Face Matching Task (GFMT, panels A-B) and from the Kent Face Matching Task (KFMT, panels C-D). Panels A and C depict the same identity (i.e., ”match” ), whereas panels B and D depict different identities (i.e., ”mismatch” ).
Figure 4.
Examples of face-pairs from the Glasgow Face Matching Task (GFMT, panels A-B) and from the Kent Face Matching Task (KFMT, panels C-D). Panels A and C depict the same identity (i.e., ”match” ), whereas panels B and D depict different identities (i.e., ”mismatch” ).

Figure 5.
Results from the GFMT (Glasgow Face Matching Task): Relations between SDT and information theoretic measures of metacognitive efficiency. (A)-(C) M-ratio as a function of meta-U, meta-KL and meta - J. (D)-(F) meta d’ - d’ as a function of meta-U, meta-KL and meta - J. (G)-(I) relations between meta-U, meta-KL and meta - J.
Figure 5.
Results from the GFMT (Glasgow Face Matching Task): Relations between SDT and information theoretic measures of metacognitive efficiency. (A)-(C) M-ratio as a function of meta-U, meta-KL and meta - J. (D)-(F) meta d’ - d’ as a function of meta-U, meta-KL and meta - J. (G)-(I) relations between meta-U, meta-KL and meta - J.
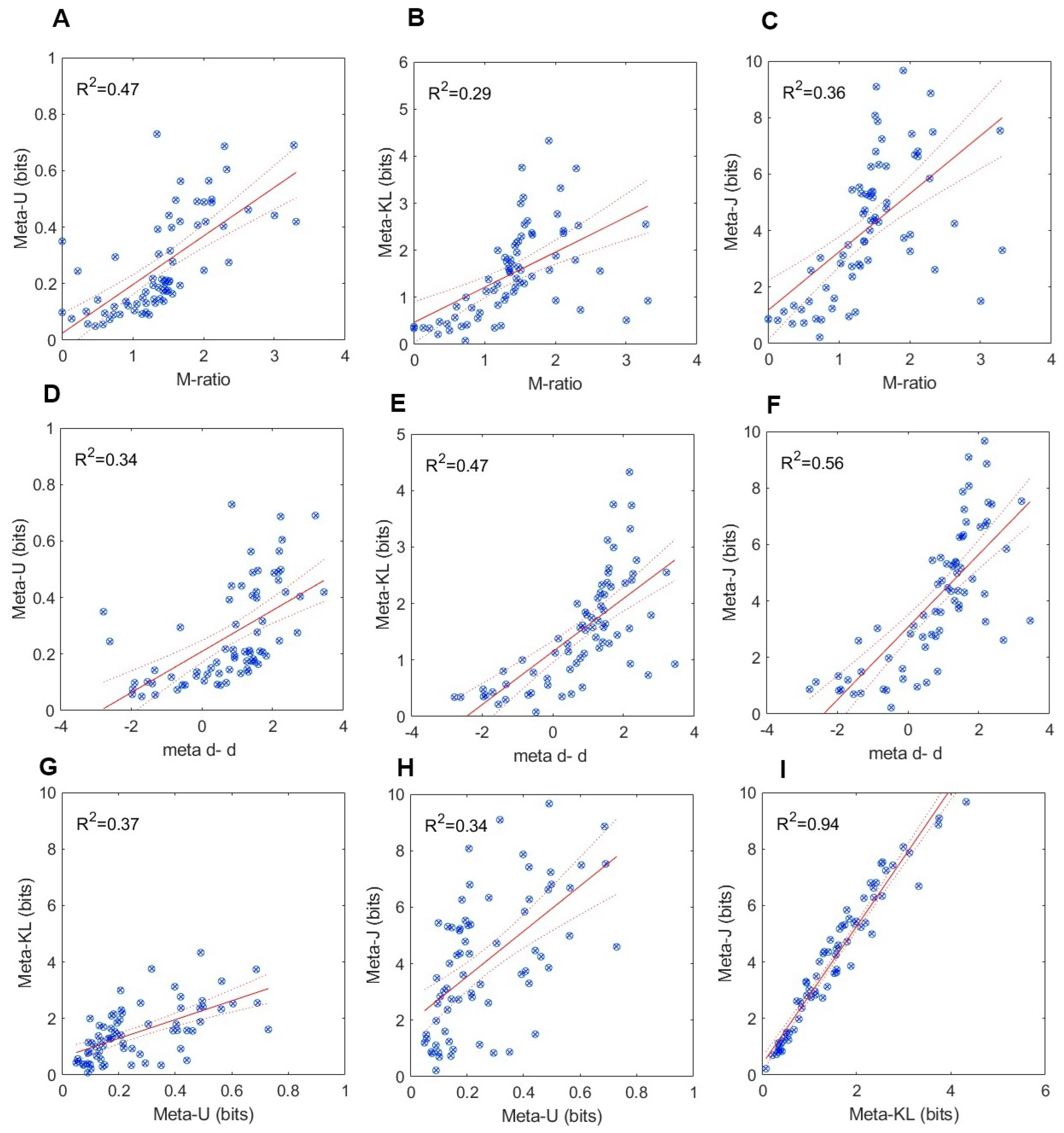
Figure 6.
Results from the KFMT (Kent Face Matching Task): Relations between SDT and information theoretic measures of metacognitive efficiency. (A)-(C) M-ratio as a function of meta-U, meta-KL and meta - J. (D)-(F) meta d’ - d’ as a function of meta-U, meta-KL and meta - J. (G)-(I) relations between meta-U, meta-KL and meta - J.
Figure 6.
Results from the KFMT (Kent Face Matching Task): Relations between SDT and information theoretic measures of metacognitive efficiency. (A)-(C) M-ratio as a function of meta-U, meta-KL and meta - J. (D)-(F) meta d’ - d’ as a function of meta-U, meta-KL and meta - J. (G)-(I) relations between meta-U, meta-KL and meta - J.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



