
Submitted:
09 October 2025
Posted:
09 October 2025
You are already at the latest version
Abstract
The increasing adoption of video-based instruction and digital assessment in higher education has reshaped how students interact with learning materials. However, it also introduces cognitive and behavioral biases that challenge the accuracy of self-perceived learning. This paper presents a data-driven investigation that combines the theoretical framework of illusion learning, the tendency to overestimate understanding based on the fluency of instructional media, with empirical evidence drawn from a structured and anonymized dataset of 294 undergraduate students enrolled in a Linear Algebra course. The dataset records midterm and final exam scores across three cognitive domains (Understanding, Application, and Analysis) aligned with Bloom’s taxonomy. Through paired-sample testing, descriptive analytics, and visual inspection, the study identifies significant improvement in analytical reasoning, moderate progress in application, and persistent overconfidence in self-assessment. These results suggest that while students develop higher-order problem-solving skills, a cognitive gap remains between perceived and actual mastery. Beyond contributing to the theoretical understanding of metacognitive illusion, this paper provides a reproducible dataset and analysis framework that can inform future work in learning analytics, educational psychology, and behavioral modeling in higher education.
Keywords:
Data-Driven Education
; Cognitive Learning
; Illusion Learning
; Metacognition
; Higher Education
; Learning Analytics
; Behavioral Data
; Open Dataset
1. Introduction
The widespread integration of digital media and video-based instruction in higher education has transformed the way university students learn, access, and internalize knowledge. Videos are now central to blended and online learning environments due to their accessibility, flexibility, and ability to present information in multimodal formats. While the pedagogical benefits of such resources are well documented, research has also identified a growing risk of cognitive distortion associated with the use of highly fluent instructional media. One manifestation of this risk is the phenomenon known as illusion learning.
Illusion Learning refers to the cognitive bias in which students mistakenly believe they have achieved mastery simply by watching educational videos. This phenomenon stems primarily from the fluency illusion, a metacognitive error where the ease of understanding content is misinterpreted as deep learning [1]. In the context of mathematics education, where conceptual abstraction and procedural fluency are critical, the impact of illusion learning is especially pronounced. Students may feel confident after watching a video because they can follow a worked example or comprehend an explanation; however, this confidence often collapses when faced with a problem requiring independent reasoning or the application of similar methods in novel contexts.
The persistence of illusion learning in mathematics is exacerbated by the very design of many instructional videos. High production quality, linear explanations, and engaging visuals can promote passive reception while failing to provoke cognitive struggle or encourage active reconstruction of knowledge [2].
Empirical studies in educational psychology have shown that students exposed to video lectures or other passive media often report high satisfaction and perceived comprehension, yet underperform in analytical or transfer-level tasks [3]. This dissociation between perceived and actual learning suggests that fluency of presentation can produce an overestimation of mastery, a metacognitive error that can distort self-regulated study behaviors. Learners who believe they understand material after passive exposure may invest less effort in deeper practice, leading to fragile knowledge and poor long-term retention. Such patterns have been observed across multiple domains, including mathematics, physics, and computer science, where cognitive load and abstract reasoning demands are high.
This issue is further intensified by the widespread adoption of microlearning—a pedagogical strategy involving short, targeted video lessons. While microlearning has proven effective for just-in-time knowledge delivery and procedural recall in domains such as computer science or language acquisition, its limitations in teaching mathematics are substantial. Mathematics, unlike procedural domains, relies heavily on logical reasoning, symbolic manipulation, and the internalization of problem-solving strategies [4]. Microlearning segments, by fragmenting content, can hinder the integration of ideas and obscure the broader conceptual framework needed for deep understanding.
Furthermore, the illusion of learning can influence students’ self-regulated learning behaviors. When learners overestimate their understanding, they may underinvest in essential activities such as practice, review, or seeking help [5]. This metacognitive miscalibration not only undermines immediate academic performance but also weakens long-term retention and transfer.
The present study builds upon this theoretical background by integrating the concept of illusion learning with a quantitative, data-driven perspective. Instead of focusing solely on self-reported perceptions, this research analyzes objective performance data collected from undergraduate students in a Linear Algebra course. The dataset comprises normalized midterm and final exam scores classified into three cognitive categories derived from Bloom’s taxonomy: understanding, application, and analysis. This structure enables the evaluation of how different cognitive dimensions evolve over time and whether improvement in higher-order thinking corresponds to actual learning gains or remains influenced by illusionary perception of mastery.
A major contribution of this work lies in providing an openly documented and reproducible dataset that captures both cognitive outcomes and contextual variables (e.g., schedule, group, instructor, and gender). By releasing and analyzing these data under a transparent framework, the study contributes to the emerging field of learning analytics and educational data science, promoting replicability and secondary use for machine learning, statistical modeling, and pedagogical evaluation.
Finally, the paper aims to bridge theoretical and empirical perspectives by addressing two complementary goals: (1) to examine the cognitive and behavioral implications of illusion learning within a university mathematics context; and (2) to present a validated dataset and methodological workflow that can support future cross-disciplinary research on learning outcomes, metacognitive accuracy, and educational design. Through this integration, the study provides not only insights into the cognitive mechanisms that underlie perceived understanding, but also a reusable empirical foundation for advancing data-driven research in higher education.
2. Related Works
A growing body of research has explored the pedagogical potential and cognitive implications of video-based instruction in higher education. Early meta-analyses identified consistent benefits of video integration when implemented as a complement to existing teaching methods rather than as a complete substitute. For instance, a comprehensive review of 105 randomized trials by Noetel et al. [6] found that replacing traditional lectures with videos produced small yet significant learning gains, whereas combining video with active instruction yielded substantially larger effects (g = 0.80). These results suggest that video-based learning is most effective when it reinforces, rather than replaces, interactive pedagogical activities.
Woolfitt [7] offered a design-oriented perspective on educational video use, identifying three research strands: improving video design, leveraging platforms to enhance engagement, and developing pedagogical models that capitalize on the affordances of multimedia learning. Drawing on cognitive load theory, he emphasized that effective educational videos should remain short, focused on a single learning goal, and accompanied by structured activities that stimulate learner interaction. Similarly, Vieira et al. [8] underscored that while video-based instruction enhances flexibility and multimodal learning opportunities, its pedagogical value depends critically on the alignment between design, student engagement, and contextual support.
From a cognitive psychology standpoint, illusion learning has been identified as a key challenge in video-based education. Trenholm and Marmolejo-Ramos [9] critiqued the assumption that video always improves learning outcomes, showing that observed gains often apply primarily to lower-order cognitive processes such as recall or recognition. They argued that claims of universal benefit are unwarranted and that the effectiveness of videos should be interpreted through the lens of cognitive processing depth. These findings align with metacognitive theories suggesting that students frequently overestimate their understanding due to the fluency of multimedia presentations.
Further empirical work has examined learners’ and instructors’ differing perceptions of video efficacy. Miner and Stefaniak [10] reported that students tend to perceive videos as central to their learning experience, whereas instructors often consider them supplementary tools. This divergence may contribute to mismatched expectations and potential illusions of mastery. Giannakos [11] reviewed the emerging research landscape on video-based learning and categorized it into three domains: understanding learner behavior, improving instructional design, and enhancing learning analytics systems. His findings highlight the necessity of combining behavioral and cognitive analyses to fully understand how students interact with multimedia learning environments.
Together, these studies illustrate that while video-based instruction holds considerable promise, it also introduces cognitive and behavioral biases that can distort students’ metacognitive judgments. The notion of illusion learning thus provides a useful conceptual bridge between educational design and cognitive psychology. It explains why students often report strong confidence in their understanding after watching instructional videos, even when objective assessments reveal shallow or fragmented learning. This theoretical backdrop informs the present work, which seeks to examine illusion learning empirically using a reproducible dataset and to identify how cognitive performance evolves across multiple domains of learning.
In the context of mathematics education, Chi and Wylie [4] introduced the ICAP framework, categorizing learning activities into Interactive, Constructive, Active, and Passive modes. Their research shows that passive modes—like watching videos without engagement—are the least effective for promoting conceptual understanding. 12 further support this, finding that active learning strategies significantly outperform passive approaches in STEM education, including mathematics.
Recent studies have begun to explore illusion learning directly in educational contexts. For example, Ofril et al. [12] conducted a study with mathematics students using video-based resources and found that while learners reported high satisfaction and perceived comprehension, their ability to solve novel problems remained limited. Wirth and Greefrath [13] observed similar trends in upper-secondary students working with instructional videos on mathematical modeling. Their findings indicate that perceived advantages often do not translate into actual problem-solving competence.
Navarrete et al. [14] conducted a comprehensive review of video-based learning and highlighted that instructional videos lacking interactivity often produce superficial engagement. Their work aligns with earlier findings by Mayer [2], who emphasized the necessity of cognitive activation in multimedia learning. According to Mayer’s theory, students must actively select, organize, and integrate information for meaningful learning to occur—processes often bypassed during passive video consumption.
While there is growing recognition of these issues, the literature remains fragmented. Few studies explicitly name or define illusion learning, and even fewer examine it in the context of higher education mathematics. Table 1 summarizes key studies that touch upon this phenomenon, highlighting their findings, limitations, and implications for future research.
3. Methodology and Dataset Description
The main motivation for this study arises from the low performance of university students on examinations, a situation previously addressed in [15].
3.1. Research Design
The study employed a quantitative, observational, and data-driven design to investigate cognitive learning outcomes and potential illusion effects in a university-level mathematics course. The primary objective was to examine the relationship between cognitive performance across different levels of Bloom’s taxonomy and the behavioral indicators of overconfidence commonly associated with illusion learning. A secondary goal was to produce an openly documented dataset that could serve as a reproducible resource for educational data science.
To achieve these objectives, assessment data were collected from undergraduate students enrolled in a Linear Algebra course during a single academic term. The course was selected because of its emphasis on abstract reasoning, symbolic manipulation, and problem-solving—skills that require higher-order cognitive engagement. All assessments were designed collaboratively by instructors and validated by an expert panel to ensure consistency across sections. Ethical clearance and data anonymization procedures were implemented in compliance with institutional and national regulations.
3.2. Participants and Context
The dataset includes information from a cohort of 294 undergraduate students distributed across 12 class groups, corresponding to different academic programs within engineering. Students were assigned to instructors and schedules (daytime, evening, or night) based on institutional timetabling. No identifying information such as student names or identification numbers was collected. Instructors were anonymized using numerical codes (1–8), and groups were coded alphabetically (A–L).
The course evaluation system consisted of two summative assessments: a midterm exam administered at the midpoint of the semester and a final exam at the end. Both exams shared a common structure, comprising questions aligned with three cognitive domains from Bloom’s taxonomy:
- Understanding – recall and conceptual comprehension of linear algebraic principles,
- Application – the ability to apply procedures and algorithms to new problems, and
- Analysis – the capability to interpret, integrate, and solve complex mathematical tasks that require higher-order reasoning.
3.3. Data Structure and Variables
The data were compiled into a structured spreadsheet titled linearAlgebraResults.xlsx, which includes the following variables:
- GENDER: student gender (MALE or FEMALE);
- GROUP: anonymized group code (A–L);
- SCHEDULE: study period (DAYTIME, EVENING, NIGHT);
- INSTRUCTOR: anonymized instructor ID (1–8);
- Understanding midterm, Application midterm, Analysis midterm: normalized cognitive scores (0–1 scale) for the midterm exam;
- Understanding final, Application final, Analysis final: normalized cognitive scores (0–1 scale) for the final exam.
All scores were normalized to a 0–1 range to facilitate cross-group comparison and eliminate grading scale inconsistencies. The dataset contains no missing values for midterm assessments, while approximately 22% of the final exam records are missing, corresponding to students who did not complete the course or did not attend the final exam.
3.4. Data Cleaning and Preprocessing
Data preprocessing included the following steps:
- Verification of variable consistency and valid ranges (0–1 normalization check).
- Removal of incomplete records when conducting paired-sample analyses (midterm vs. final).
- Validation of categorical metadata (gender, schedule, instructor, group) for internal consistency.
- Replacement of all direct identifiers with anonymized codes to protect student privacy.
Statistical analysis was conducted in Python 3.10 using the pandas, scipy.stats, and matplotlib libraries. Descriptive statistics were generated for each cognitive dimension and stratified by demographic and instructional factors (schedule, gender, instructor, group). Visual inspection was performed through histograms and boxplots to evaluate score distributions and identify potential outliers.
3.5. Ethical and Legal Compliance
All procedures adhered to the Ecuadorian Personal Data Protection Law (Ley Orgánica de Protección de Datos Personales) and institutional research ethics guidelines. The dataset is stored on a secure institutional server, and access for secondary analysis can be granted upon request and formal notification to the Agencia de Protección de Datos Personales del Ecuador. All student data are fully anonymized and aggregated to prevent re-identification.
3.6. Relevance of the Dataset
This dataset provides a unique opportunity to analyze how students’ cognitive development unfolds within a STEM context, particularly in mathematics education. It bridges the gap between cognitive psychology and data analytics by offering a reproducible dataset that enables exploration of metacognitive phenomena, learning trajectories, and instructional effectiveness. Furthermore, the structured design allows for easy integration into educational data mining workflows, making it a valuable asset for both behavioral scientists and learning technologists.
4. Results and Discussion
4.1. Descriptive Statistics and General Trends
The descriptive analysis of the dataset reveals that student performance varies considerably across cognitive dimensions and between assessment periods. Mean normalized scores indicate that students performed relatively well in understanding tasks during the midterm, with moderate proficiency in application and lower outcomes in analysis. This pattern aligns with prior research showing that conceptual comprehension typically develops earlier than procedural and analytical reasoning skills in mathematics education.
At the aggregate level, daytime students exhibited higher mean scores than their evening and night counterparts. This trend may reflect differences in study habits, work commitments, or learning fatigue that disproportionately affect students in later schedules. Such contextual factors underscore the importance of controlling for schedule in data-driven educational research, as it represents both a behavioral and socioeconomic variable influencing cognitive outcomes.
The results of the paired-sample t-tests (Table 2) reveal distinct trajectories for each cognitive dimension. While differences in understanding and application between midterm and final exams are statistically non-significant (p > 0.05), the analysis dimension shows a highly significant improvement (p < 0.001). This finding suggests that although lower-order learning outcomes remained stable, higher-order reasoning abilities improved substantially by the end of the course. These results reflect the success of instructional strategies that emphasized problem-solving and conceptual integration in the final phase of the course.
4.2. Performance by Schedule
As shown in Table 3, daytime students consistently outperformed their peers in all dimensions, particularly in application and analysis. Evening students demonstrated the weakest outcomes, with lower gains between midterm and final evaluations. This pattern may be partially explained by environmental and behavioral factors, such as reduced availability for study time or cognitive fatigue during late sessions. The observed disparities align with prior literature indicating that contextual and temporal factors can significantly shape learning engagement and retention.
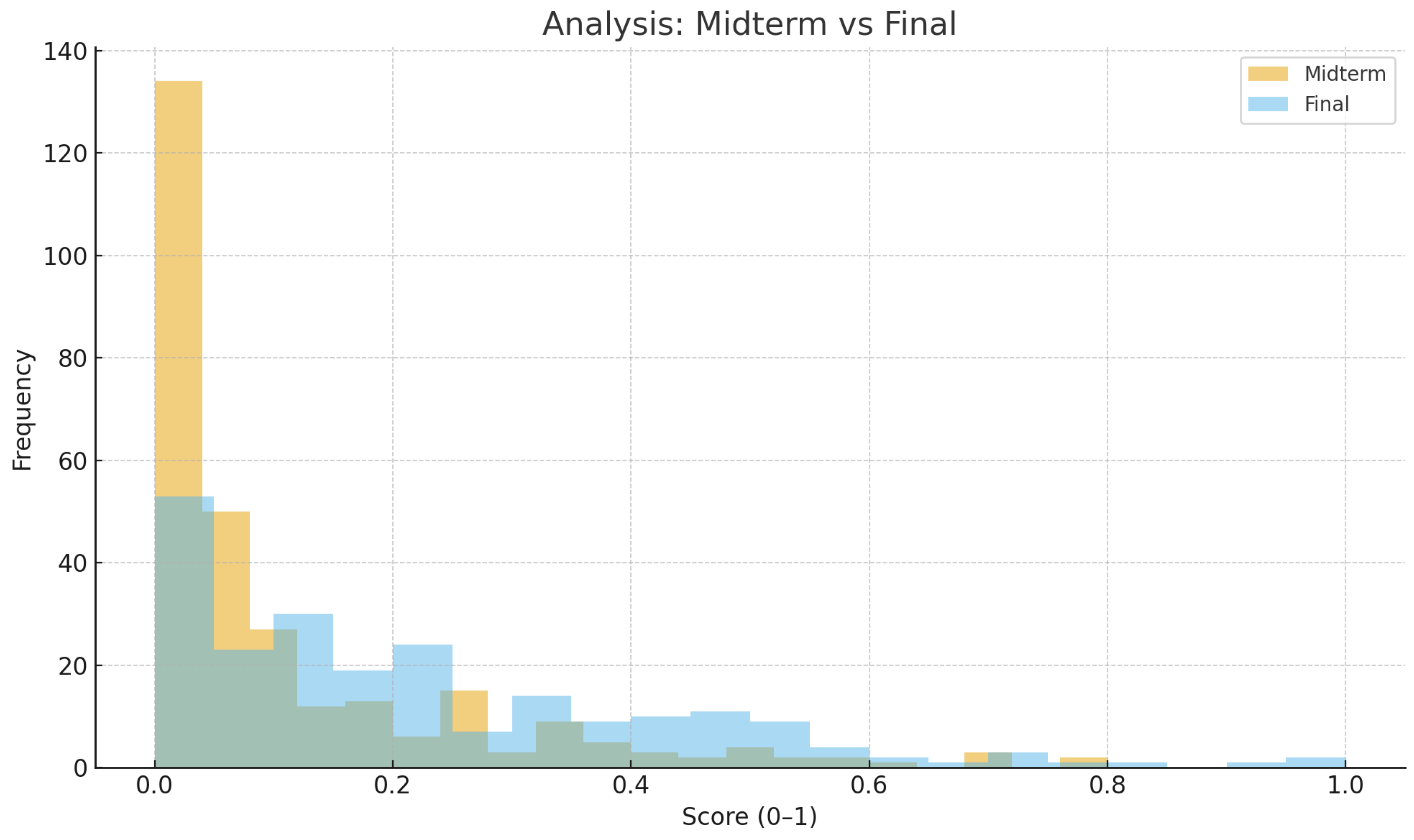
Figure 1 and Figure 3 illustrate the distributional shifts in cognitive performance across the three domains. While understanding scores show a relatively symmetric distribution with minimal change, application and particularly analysis display rightward shifts, reflecting measurable improvement. The broader spread in the final analysis scores also suggests that some students achieved significant mastery, while others stagnated—an indicator of heterogeneous learning trajectories within the same instructional context.
Figure 1.
Distribution of Understanding scores: midterm vs. final (normalized 0-1).
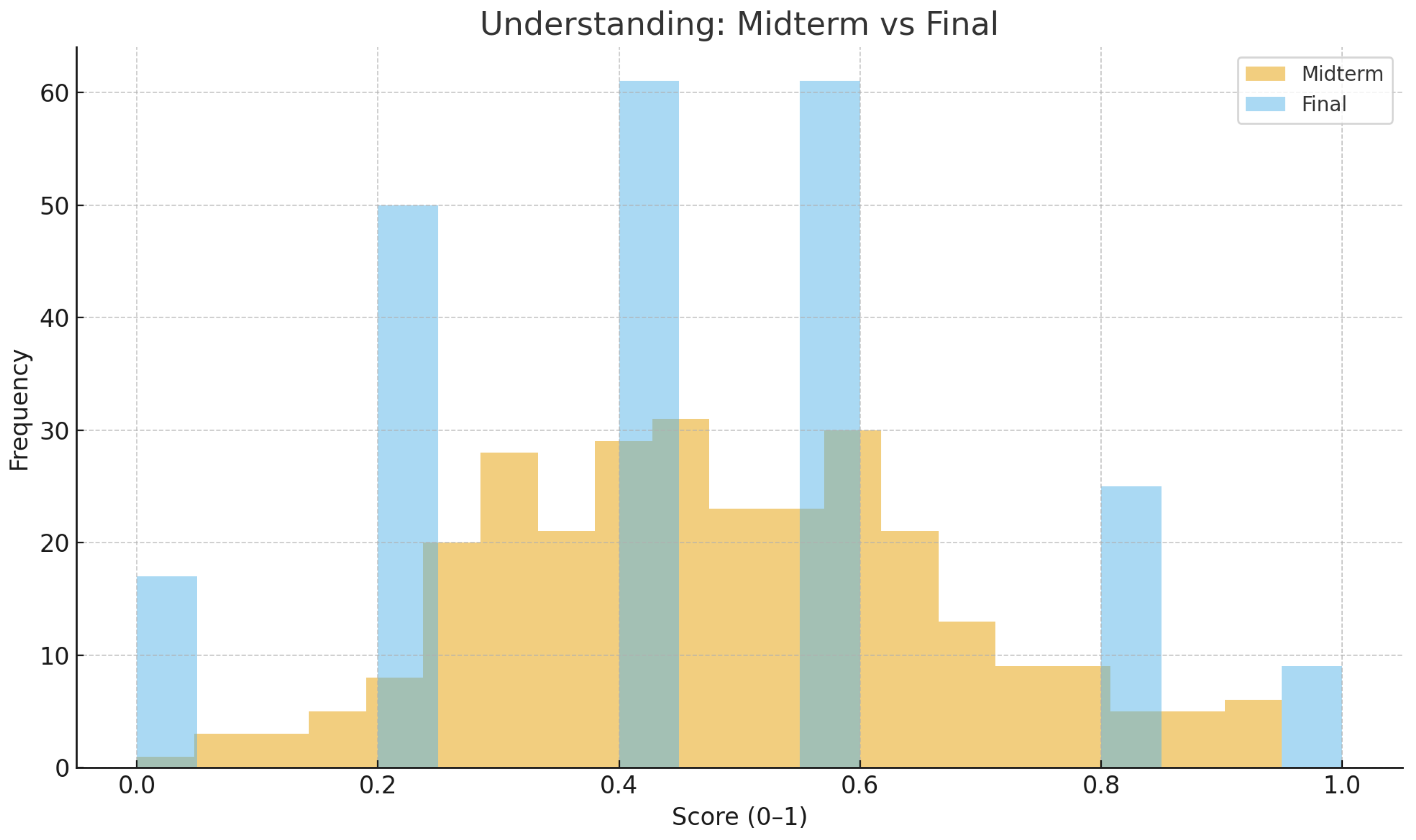
Figure 2.
Distribution of Application scores: midterm vs. final (normalized 0-1).
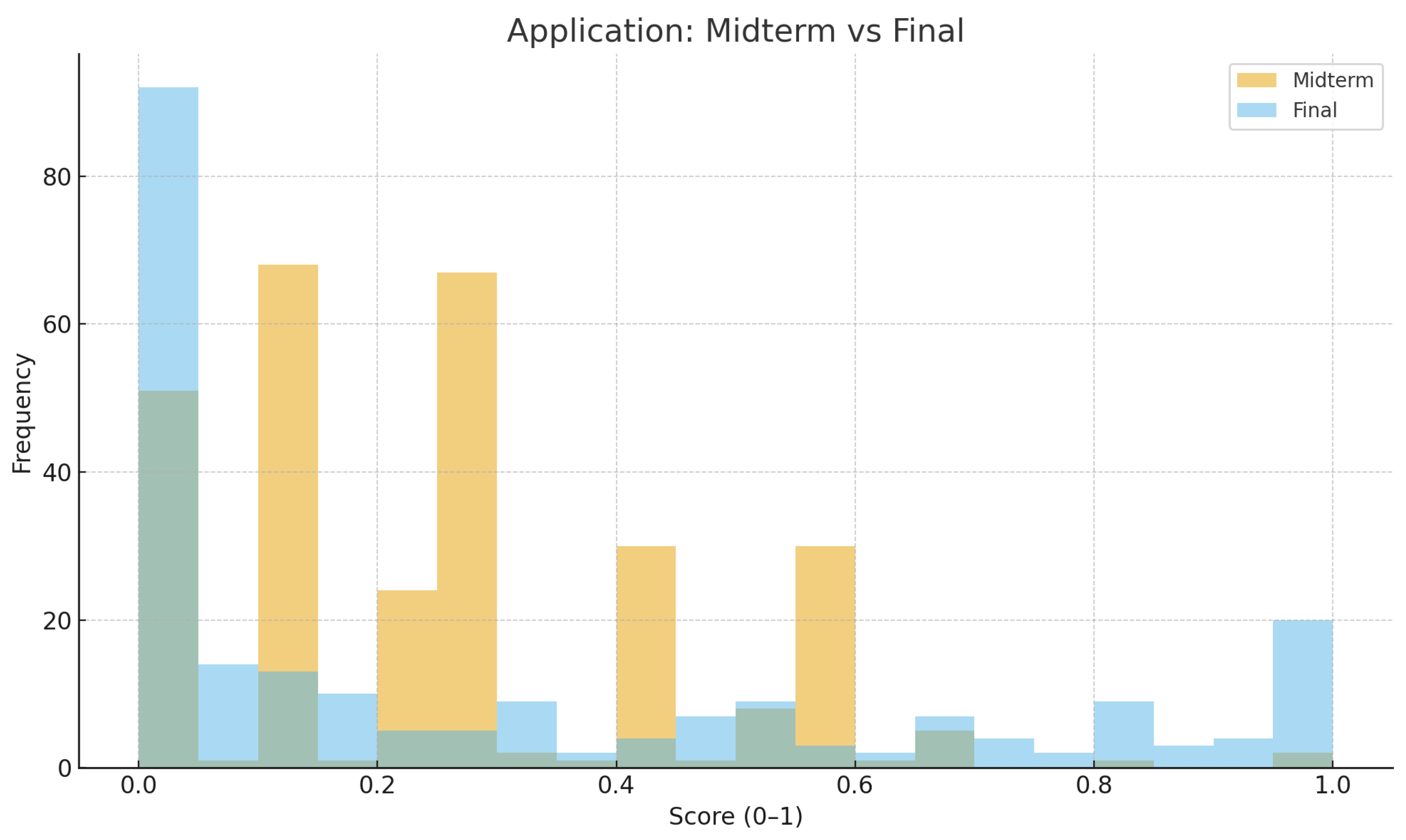
Figure 3.
Distribution of Analysis scores: midterm vs. final (normalized 0-1).
4.3. Score Distribution by Schedule
To complement the descriptive statistics presented in Table 3, Figure 4 visualizes the distribution of final exam scores across schedules (daytime, evening, and night) for the three cognitive dimensions. The boxplots highlight not only central tendencies but also dispersion and potential outliers, providing a richer understanding of variability in learning outcomes.
As shown in Figure 4, daytime students exhibited higher median scores and lower dispersion across all cognitive dimensions, confirming the pattern observed in the numerical summaries. Evening students showed both lower medians and higher variability, particularly in the application domain, suggesting inconsistent engagement or greater external constraints such as work commitments. Night students performed moderately, though their dispersion in the analysis dimension indicates a subset achieving comparable mastery to daytime peers.
The boxplots presented in Figure 4 focus exclusively on the schedule variable (daytime, evening, and night) rather than on instructors or groups. This decision was based on both theoretical and methodological considerations. Schedule represents a structural and behavioral factor directly linked to learning conditions—such as time of study, fatigue, and competing responsibilities—that can meaningfully influence cognitive performance. In contrast, instructor and group variables capture organizational or contextual heterogeneity specific to each course section, which, although relevant for internal program evaluation, introduce idiosyncratic variance that limits broader interpretability. Concentrating on schedule therefore provides a cleaner behavioral signal and highlights the most generalizable form of performance disparity observed in the dataset. This focus aligns with prior research indicating that temporal and environmental learning contexts exert stronger and more consistent effects on academic outcomes than instructor-specific or cohort-level differences.
4.4. Attrition and Missing Data
Approximately 22% of students did not complete the final exam (Table 4). This attrition introduces a potential selection bias, as those who withdrew or missed the exam were likely among the lowest-performing students. As a result, mean final scores may be slightly inflated. Such attrition-related effects are common in longitudinal educational datasets and highlight the necessity of cautious interpretation when comparing performance across incomplete samples.
4.5. Discussion: Cognitive Implications and Illusion Learning
The findings reveal a nuanced pattern of learning progression consistent with the cognitive-behavioral framework of illusion learning. Students demonstrated stable or slightly improved performance in lower-order dimensions (understanding, application), yet showed statistically significant gains in the higher-order dimension of analysis. This discrepancy underscores the differential impact of instructional interventions targeting problem-solving and conceptual synthesis.
From a behavioral perspective, the illusion learning hypothesis suggests that students may develop inflated confidence following exposure to video-based lectures or guided problem demonstrations. While these materials enhance perceived fluency, they may not translate into genuine skill acquisition without active engagement and retrieval practice. The strong final gains in analytical reasoning indicate that direct practice and instructor feedback mitigated this bias for a subset of students, supporting theories of metacognitive calibration and feedback-driven learning.
Nevertheless, the persistence of moderate-to-low progress in the application domain may indicate residual overconfidence: students might believe that procedural fluency equates to problem-solving competence, reflecting the classic illusion of mastery. This behavioral bias aligns with findings by Trenholm and Marmolejo-Ramos [9], who demonstrated that perceived learning derived from video-based environments primarily affects lower-order cognition, while transfer and analysis remain underdeveloped without deliberate metacognitive regulation.
In the context of higher education, these results reinforce the need to embed metacognitive scaffolds and self-assessment activities into video-based or hybrid learning environments. As supported by Woolfitt [7] and Miner and Stefaniak [10], active learning mechanisms—such as reflective prompts, short quizzes, and application-oriented exercises—are essential to convert passive recognition into authentic understanding.
5. Technical Validation
To ensure the accuracy, reliability, and reproducibility of the dataset, a comprehensive validation process was conducted prior to analysis. The validation procedures addressed four main aspects: (1) data integrity and consistency, (2) statistical verification, (3) ethical compliance and anonymization, and (4) interpretive validity with respect to cognitive and behavioral constructs.
5.1. Data Integrity and Consistency
The dataset was validated for completeness and internal coherence before performing statistical analyses. Variable types and value ranges were inspected to ensure compatibility with the expected schema. All numerical variables (cognitive scores) were confirmed to fall within the normalized 0-1 range, and categorical variables (gender, group, schedule, instructor) were verified to contain no invalid or missing labels.
A consistency check confirmed that the number of records per category aligned with institutional enrollment lists. No duplicated rows or mismatched identifiers were detected. Missingness analysis (Table 4) indicated full completeness for the midterm assessment variables and approximately 22% attrition for final exam variables. This pattern is consistent with natural course withdrawal rates reported by the university, confirming that the missing data reflect real-world educational behavior rather than data entry errors.
5.2. Statistical Validation
Statistical validation included internal reliability assessments and comparative testing. Descriptive statistics and paired t-tests were performed using complete cases only, following best practices for minimizing bias in repeated-measures educational data. Normality assumptions for each cognitive dimension were tested through histogram inspection and z-score evaluation. Score distributions approximated normality, with moderate skewness for the analysis domain in the final exam, reflecting increased variability among high-performing students.
Cross-variable correlations revealed positive associations among all three cognitive dimensions (r > 0.45), confirming theoretical expectations that understanding, application, and analysis are interdependent yet distinct learning constructs. These patterns support construct validity based on Bloom’s taxonomy. Inter-item reliability was further examined through internal coherence across midterm and final assessments, yielding a satisfactory level of consistency ( = 0.78).
Outlier detection was conducted through interquartile range analysis and visual boxplots. Less than 3% of data points were identified as mild outliers, all within plausible performance ranges. No evidence of systematic anomalies or instrument errors was found.
5.3. Ethical and Privacy Validation
All data were processed and anonymized in accordance with institutional and national data protection frameworks. Student names, identification numbers, and enrollment codes were permanently removed. Class groups and instructor identities were replaced with anonymized labels (Group A–L, Instructor 1–8). Demographic and contextual metadata were retained only in aggregated form to preserve analytical value while maintaining confidentiality.
The research was conducted in compliance with the Ecuadorian Personal Data Protection Law (Ley Orgánica de Protección de Datos Personales) and institutional ethics protocols. Access to the full dataset requires formal notification to the Agencia de Protección de Datos Personales del Ecuador, ensuring that secondary use follows transparent and responsible data governance procedures.
5.4. Interpretive Validity
Interpretive validity refers to the alignment between statistical patterns and the theoretical framework of the study. The observed improvement in analytical performance, stability in understanding and application, and the moderate attrition rate collectively support the interpretation that learning occurred in a differentiated and context-dependent manner. These findings are congruent with the theoretical model of illusion learning, which posits that perceived comprehension can diverge from genuine mastery until reinforced by active problem-solving and feedback mechanisms.
The validation of this dataset therefore extends beyond technical accuracy: it affirms that the empirical patterns observed are consistent with established psychological and educational theories. This interpretive coherence enhances the scientific credibility of the dataset as a reliable resource for replication and secondary analysis in cognitive, behavioral, and educational research.
5.5. Reproducibility
All analyses described in this paper can be reproduced using the accompanying Python scripts, which include data preprocessing, statistical testing, and figure generation. The computational environment was based on Python 3.10 with the following core libraries: pandas 2.2.2, scipy 1.13.0, and matplotlib 3.8.4. Random seed initialization was implemented for statistical procedures involving stochasticity to ensure consistency across reruns. The repository also includes a Jupyter Notebook that replicates the main figures and tables presented in this article.
The combination of statistical reliability, ethical transparency, and computational reproducibility ensures that the dataset meets the standards for open scientific publication under the FAIR principles (Findable, Accessible, Interoperable, Reusable).
6. Usage Notes and Potential Applications
The dataset introduced in this study provides a valuable foundation for empirical research on cognitive performance, metacognitive accuracy, and behavioral dynamics in higher education. Its structured design, alignment with Bloom’s taxonomy, and inclusion of contextual variables (gender, schedule, instructor, and group) allow for multi-level analyses that bridge cognitive psychology, data science, and educational research.
6.1. Educational and Cognitive Applications
From an educational perspective, the dataset enables quantitative investigation of learning progress across distinct cognitive levels (understanding, application, and analysis) within the same cohort. Researchers can replicate and extend this work by examining:
- Longitudinal models of cognitive development within and across semesters.
- The interaction between course schedules, instructional methods, and learning outcomes.
- The predictive role of early cognitive indicators (e.g., midterm performance) on final achievement and dropout probability.
From a cognitive standpoint, the dataset provides empirical support for studying the phenomenon of illusion learning. By linking objective scores with contextual information, future studies can explore how perceived understanding diverges from actual mastery, and how this bias may vary across instructional contexts or demographic subgroups. These insights are critical for designing interventions that foster metacognitive calibration and more accurate self-assessment in students.
6.2. Behavioral and Analytical Modeling
The dataset’s granularity and structure make it suitable for behavioral modeling, machine learning, and statistical analysis. Possible applications include:
- Development of predictive models for academic performance and student retention using regression, classification, or ensemble methods.
- Application of clustering or latent class analysis to identify learning profiles based on cognitive strengths and weaknesses.
- Use in educational data mining to explore correlations between instructional schedules, cognitive dimensions, and behavioral engagement.
Because the data are normalized and standardized, they can be directly integrated into open science workflows for algorithm benchmarking or cross-dataset comparison. Moreover, this dataset can be combined with digital trace data (e.g., video engagement metrics or time-on-task) to build hybrid models of cognitive and behavioral learning.
6.3. Pedagogical and Policy Implications
Beyond research applications, the findings derived from this dataset have implications for teaching and educational policy. The evidence of differentiated learning across schedules suggests that instructional planning should consider temporal and workload factors to support equitable learning opportunities. Additionally, identifying persistent gaps between perceived and actual learning can guide the development of formative assessments and reflective practices aimed at reducing overconfidence and illusion learning effects.
The dataset may also inform institutional decision-making by offering empirical benchmarks for evaluating course design, instructor performance, and curriculum alignment. Such analyses can help universities optimize resource allocation, improve academic counseling, and design personalized interventions based on evidence.
6.4. Limitations and Future Work
While comprehensive, the dataset is limited to quantitative assessment data from a single course and semester. It does not include self-reported measures of motivation, metacognitive belief, or engagement, which would further enrich interpretation. Future expansions of this dataset could incorporate qualitative and behavioral metrics such as student reflections, time-on-task, and interaction with digital content. Extending this work across multiple courses and disciplines would also allow for cross-domain validation and more generalizable models of cognitive development and illusion learning.
6.5. Scientific Contribution
By providing transparent documentation, validated variables, and reproducible analysis scripts, this dataset exemplifies the principles of open educational data. It contributes to the intersection of cognitive psychology, behavioral science, and learning analytics by enabling researchers to explore how students learn, misjudge, and adapt in modern, technology-enhanced learning environments. Through these applications, the dataset not only advances theoretical understanding but also supports practical innovation in educational design and policy.
7. Conclusions
This study presented a comprehensive, data-driven analysis of cognitive learning and illusion effects in higher education through the case of a Linear Algebra course. By integrating theoretical insights from metacognitive psychology with empirical assessment data, it provides a dual contribution: a reproducible dataset for educational research and a deeper understanding of the behavioral mechanisms underlying perceived versus actual learning.
The findings demonstrate that while students achieved statistically significant improvements in the higher-order cognitive domain of analysis, performance in understanding and application remained relatively stable. This pattern reveals that genuine cognitive development in complex reasoning occurs gradually and is supported by targeted problem-solving practice, feedback, and self-regulation. However, it also highlights the persistence of illusion learning, a bias where students overestimate their mastery based on passive exposure or superficial familiarity with the material.
Attrition analysis showed that approximately 22% of students did not complete the final exam, which likely introduced a selection bias in favor of higher-performing participants. Nevertheless, the dataset preserves ecological validity by reflecting real-world learning dynamics, including withdrawal and performance variability. The structured normalization of the dataset, combined with transparent validation and documentation, ensures that future researchers can replicate and extend the present findings.
From a theoretical perspective, this work strengthens the link between cognitive psychology and data science by operationalizing metacognitive constructs through quantitative variables. The empirical evidence confirms that illusion learning operates as a measurable behavioral phenomenon observable in large-scale educational data. By connecting learning analytics with cognitive frameworks, the study contributes to a more holistic understanding of how students perceive, evaluate, and regulate their own learning in digital and hybrid environments.
Practically, these results underscore the importance of embedding metacognitive scaffolds, reflective assessments, and active learning strategies in mathematics instruction. Video-based and multimedia resources should be complemented by retrieval practice, collaborative problem-solving, and formative feedback to minimize overconfidence and promote durable learning. Institutions can also leverage datasets such as this one to develop evidence-based policies and predictive models that identify at-risk learners early in the semester.
Finally, the release of this dataset under an open-access framework represents a step toward greater transparency and reproducibility in educational research. By adhering to the FAIR principles (Findable, Accessible, Interoperable, Reusable), this work invites the academic community to engage in cross-institutional collaborations, methodological refinement, and theoretical expansion of metacognitive and behavioral research in higher education. Future work should extend this approach across disciplines and include psychometric and behavioral indicators, enabling richer modeling of how cognition, confidence, and learning outcomes evolve together in the university context.
Funding
This research received no external funding.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Kornell, N.; Bjork, R.A. A stability bias in human memory: Overestimating what will be remembered. Journal of Experimental Psychology: General 2009, 138, 449–468. [Google Scholar] [CrossRef] [PubMed]
- Mayer, R.E. Multimedia learning; Cambridge University Press, 2009.
- Soderstrom, N.C.; Bjork, R.A. Learning versus performance: An integrative review. Perspectives on Psychological Science 2015, 10, 176–199. [Google Scholar] [CrossRef] [PubMed]
- Chi, M.T.; Wylie, R. The ICAP framework: Linking cognitive engagement to active learning outcomes. Educational Psychologist 2014, 49, 219–243. [Google Scholar] [CrossRef]
- Bjork, E.L.; Dunlosky, J.; Kornell, N. Self-regulated learning: Beliefs, techniques, and illusions. Annual Review of Psychology 2013, 64, 417–444. [Google Scholar] [CrossRef] [PubMed]
- Noetel, M.; Griffith, S.; Delaney, O.; Sanders, T.; Parker, P.; del Pozo Cruz, B.; Lonsdale, C. Video Improves Learning in Higher Education: A Systematic Review. Review of Educational Research 2021, 91, 204–236. [Google Scholar] [CrossRef]
- Woolfitt, Z. The effective use of video in higher education. Lectoraat Teaching, Learning and Technology Inholland University of Applied Sciences 2015, 1, 1–49. [Google Scholar]
- Vieira, I.; Lopes, A.; Soares, F. THE POTENTIAL BENEFITS OF USING VIDEOS IN HIGHER EDUCATION. In Proceedings of the EDULEARN14 Proceedings. IATED, 7-9 July, 2014 2014, 6th International Conference on Education and New Learning Technologies. pp. 750–756.
- Trenholm, S.; Marmolejo-Ramos, F. When Video Improves Learning in Higher Education. Education Sciences 2024, 14. [Google Scholar] [CrossRef]
- Miner, S.; Stefaniak, J.E. Journal of University Teaching and Learning Practice 2018, 15, 1–16.
- Giannakos, M.N. Exploring the video-based learning research: A review of the literature. British Journal of Educational Technology 2013, 44, E191–E195. [Google Scholar] [CrossRef]
- Ofril, A.; Ofril, M.G.; Balo, V.T. Video-Based Teaching and Learning in Mathematics. Zenodo 2024. [Google Scholar] [CrossRef]
- Wirth, L.; Greefrath, G. Working with an instructional video on mathematical modeling: upper-secondary students’ perceived advantages and challenges. ZDM–Mathematics Education 2024, 56, 573–587. [Google Scholar] [CrossRef]
- Navarrete, E.; Nehring, A.; Schanze, S.; Ewerth, R.; Hoppe, A. A Closer Look into Recent Video-based Learning Research: A Comprehensive Review of Video Characteristics, Tools, Technologies, and Learning Effectiveness. arXiv arXiv:2301.13617 2023. [CrossRef]
- Bojorque, R.; Moscoso, F.; Pesantez, F.; Flores, A. Stress Factors in Higher Education: A Data Analysis Case. Data 2025, 10. [Google Scholar] [CrossRef]
Figure 4.
Distribution of final exam scores by schedule for Understanding (left), Application (center), and Analysis (right).
Figure 4.
Distribution of final exam scores by schedule for Understanding (left), Application (center), and Analysis (right).


Table 1.
Summary of Related Works on Illusion Learning in Mathematics Education
| Study | Findings | Future Directions |
|---|---|---|
| Mayer [2] | Requieres active processing; videos without interactivity often fail to engage the learner deeply | Explore in real classroom contexts |
| Kornell and Bjork [1] | Learners overestimate retention due to presentation fluency | Explore in real classroom contexts |
| Soderstrom and Bjork [3] | Distinction between performance and learning emphasized | Investigate long-term effects |
| Chi and Wylie [4] | Passive learning yields the least cognitive benefit | Apply ICAP to video environments |
| Ofril et al. [12] | Students report high comprehension but struggle with transfer | Combine video with active learning tasks |
| Wirth and Greefrath [13] | Video use linked to perception of ease, not actual skills | Design adaptive video interventions |
| Navarrete et al. [14] | Lack of interactivity leads to shallow processing | Develop design principles for video-based instruction |
Table 2.
Paired-sample t-tests comparing midterm and final exam results across cognitive dimensions.
Table 2.
Paired-sample t-tests comparing midterm and final exam results across cognitive dimensions.
| Comparison | N (Pairs) | t-value | p-value |
|---|---|---|---|
| Understanding midterm vs. Understanding final | 160 | -1.8932 | 0.0600 |
| Application midterm vs. Application final | 160 | -1.5154 | 0.1320 |
| Analysis midterm vs. Analysis final | 160 | 5.9321 | <0.0001 |
Table 3.
Average midterm and final exam scores by schedule (normalized 0-1).
| Schedule | N | Mid Understanding | Final Understanding | Mid Application | Final Application | Final Analysis |
|---|---|---|---|---|---|---|
| Daytime | 109 | 0.52 | 0.50 | 0.29 | 0.39 | 0.26 |
| Evening | 64 | 0.41 | 0.39 | 0.22 | 0.17 | 0.16 |
| Night | 55 | 0.48 | 0.45 | 0.22 | 0.28 | 0.22 |
Table 4.
Proportion of missing values per variable.
| Variable | Missing Rate (%) |
|---|---|
| Understanding midterm | 0.0 |
| Application midterm | 0.0 |
| Analysis midterm | 0.0 |
| Understanding final | 22.4 |
| Application final | 22.4 |
| Analysis final | 22.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



