1. Introduction
Advancements in artificial intelligence (AI) and deep learning technologies have led to significant progress in the field of speech synthesis, particularly in TTS and STS systems. These innovations have enabled the production of high-quality, natural-sounding voices that are widely used in applications such as virtual assistants, accessibility tools, customer service, and language education [1,2]. However, challenges persist when it comes to synthesizing personalized voices from low-quality or fragmented audio samples, a scenario often encountered in cases of deceased individuals or individuals with speech impairments.
This study is uniquely inspired by the author’s personal experience of losing his daughter, which motivated the exploration of technologies that could reconstruct personalized voices from incomplete and degraded audio recordings. This emotionally significant application addresses a gap in current voice synthesis technologies, particularly in the preservation of memories and cultural legacies. While existing models such as WaveNet and Tacotron [3,4] have achieved remarkable naturalness and clarity in TTS systems, they rely heavily on large-scale, high-quality datasets, limiting their applicability in low-resource settings.
Previous research has attempted to address these limitations through techniques such as linear predictive coding (LPC) [5], statistical parametric synthesis [6], and deep neural networks conditioned on acoustic features [7]. These methods, while effective in controlled environments, often fail to handle the inconsistencies and noise inherent in real-world low-quality data. Furthermore, studies on fragmented speech data have primarily focused on improving intelligibility rather than restoring speaker-specific characteristics, leaving a critical gap in the field.
The proposed LQSRM integrates advanced noise reduction, spectral patching, and AI-based TTS and STS models to address these challenges. By leveraging techniques specifically designed for fragmented and degraded data, LQSRM offers a novel solution for reconstructing coherent and natural-sounding voices that retain the unique characteristics of the speaker. This study evaluates the effectiveness of LQSRM using a dataset comprising 10speaker groups (5 male and 5 female) and assesses its performance through subjective and objective metrics, including MOS evaluations [8,9].
In addition to its technical contributions, this study explores the broader applications of voice reconstruction, including memory preservation for deceased individuals and assistive tools for speech-impaired populations. By addressing both emotional and practical needs, the proposed approach bridges a critical gap in voice synthesis research, paving the way for innovative applications in accessibility and cultural heritage restoration [10].
The remainder of this paper is organized as follows. Section 2 details the methods employed, including data preprocessing and the LQSRM framework. Section 3 presents the experimental results and their implications. Section 4 discusses the broader impact and limitations of the study. Finally, Section 5 concludes with a summary of the findings and potential directions for future research.
2. Methods
The reconstruction of low-quality and fragmented voice data involves multiple technical phases designed to address challenges such as noise, data incompleteness, and inconsistent spectral characteristics. This study utilized two primary categories of voice data: deceased voice samples and live recorded samples. The deceased voice data were collected from fragmented recordings, including mobile videos, family archives, and low-quality audio files. Live voice samples were recorded in both controlled environments, using high-quality microphones, and uncontrolled environments, such as mobile phones, to simulate real-world variability [11,12].
The preprocessing phase focused on improving audio quality and preparing the voice data for reconstruction. Noise reduction techniques were applied using spectral subtraction and adaptive filtering methods to remove background noise while preserving essential voice characteristics [13]. For fragmented data, a spectral patching approach was employed to interpolate missing sections, ensuring waveform continuity. Volume normalization further addressed inconsistencies in amplitude, creating a uniform baseline for subsequent synthesis steps [14].
Following preprocessing, the voice reconstruction process employed two distinct synthesis models: TTS and STS. In this process, fragmented voice samples are “restored” and “reconstructed” through AI-based models, effectively filling in the missing sections to create a coherent voice output. This can be compared to the metaphor of “coloring in the voice print”, similar to how one might restore a black-and-white photograph by adding color. In this analogy, the AI model fills in the missing spectral features of the voice, thereby bringing the fragmented audio back to life with a natural tone and speaker-specific characteristics. The STS model directly enhanced degraded voice recordings by preserving speaker-specific acoustic features such as pitch, timbre, and formant structure. Both models were integrated within the proposed LQSRM, which systematically optimized the synthesis output to maximize naturalness and speaker similarity [15,16].
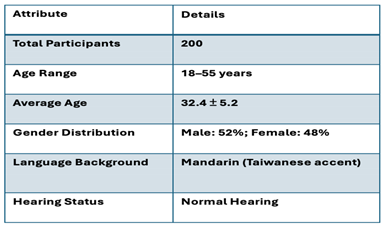
To evaluate the performance of the proposed method, a rigorous validation protocol was implemented. The MOS test was conducted with 200 participants, aged 18 to 55, who were native Mandarin speakers with a Taiwanese accent. Each participant rated the naturalness and similarity of voice samples on a five-point Likert scale, where 1 indicated “poor” and 5 represented “excellent” [17]. The evaluation included four types of voice samples: denoised original audio files (DOAF), conventional TTS and STS outputs, and LQSRM-generated voices. Spectrogram analysis was further conducted to provide an objective evaluation of waveform continuity and spectral characteristics, comparing raw, preprocessed, and reconstructed voices [18].
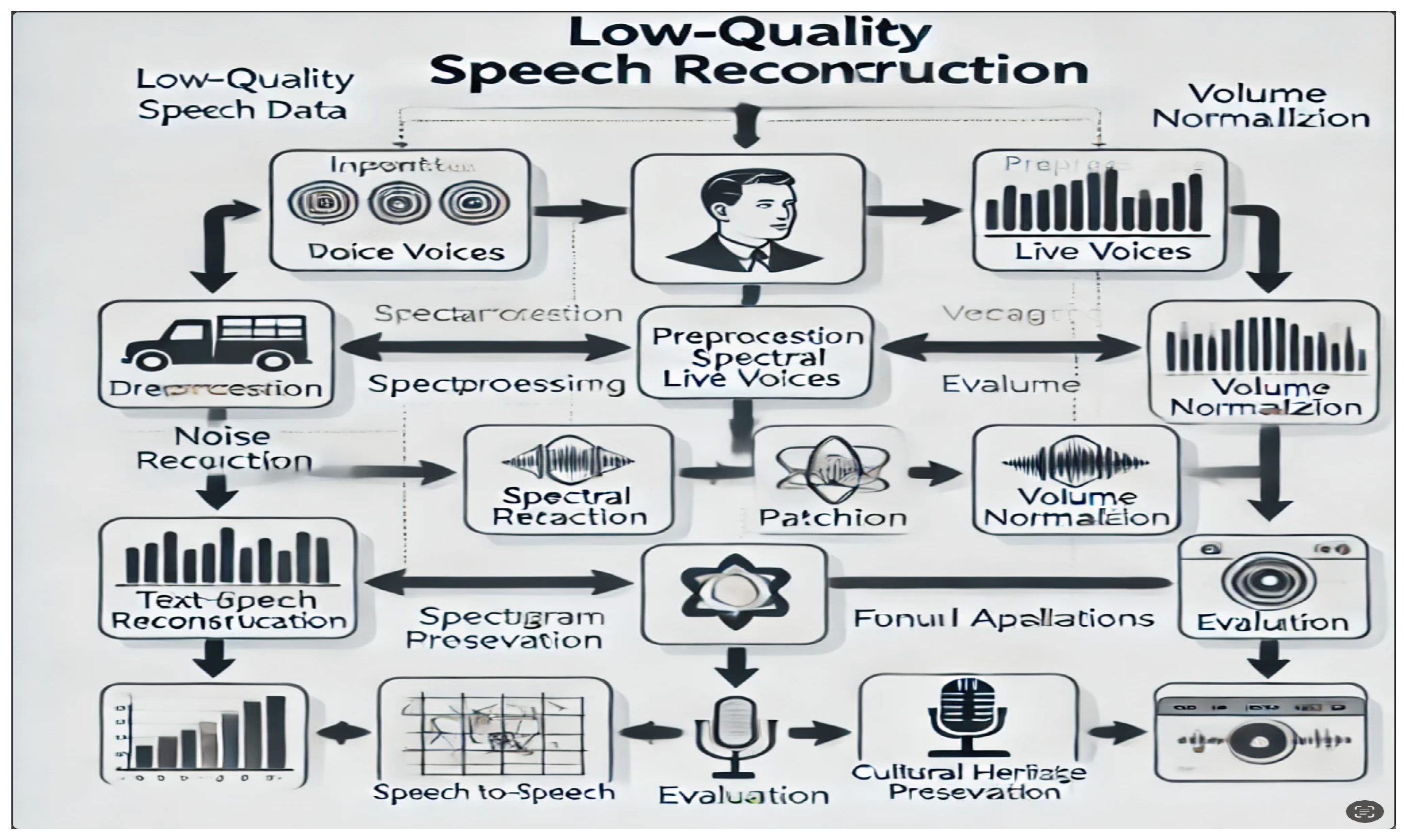
The experimental workflow is illustrated in Figure 1, which outlines the major phases of the LQSRM framework, including input voice data collection, preprocessing, reconstruction, and evaluation. Figure 2 to Figure 4 present the spectrogram analyses, highlighting the progression from fragmented voice samples to enhanced and reconstructed outputs. Table 1 summarizes the demographic information of participants, while Table 2 provides the detailed MOS results for naturalness and speaker similarity.
Figure 1.
Research Workflow Diagram.
Figure 1.
Research Workflow Diagram.
In summary, the methods described here combine advanced preprocessing, AI-driven synthesis, and rigorous evaluation protocols to address the challenges associated with low-quality and fragmented speech data. By systematically enhancing acoustic features, removing background noise, and optimizing synthesis models, the proposed LQSRM demonstrates its capability to produce natural and speaker-specific voices. The inclusion of subjective MOS evaluations and objective spectrogram analyses ensures that the performance of the proposed method is validated comprehensively, paving the way for practical applications in speech reconstruction for both deceased and live speaker datasets.
3. Results
The results of the proposed LQSRM demonstrate its efficacy in enhancing the quality and naturalness of synthesized speech compared to conventional methods. A total of 10 voice samples (5 male and 5 female) were used for testing, with each voice generating five audio clips. These included degraded raw inputs, conventional TTS/STS outputs, and LQSRM-reconstructed outputs. The evaluation process consisted of subjective MOS testing and objective spectrogram analysis, which together validated the robustness of the proposed approach.
Table 1 summarizes the demographic details of the 200 participants recruited for the MOS evaluation. Participants, aged between 18 and 55 years, were native Mandarin speakers with a Taiwanese accent. Each participant was tasked with evaluating 50 audio clips (10 groups × 5 clips per group) for naturalness and speaker similarity. Ratings were collected on a five-point Likert scale.
Table 1.
Participant Demographic Information.
Table 1.
Participant Demographic Information.
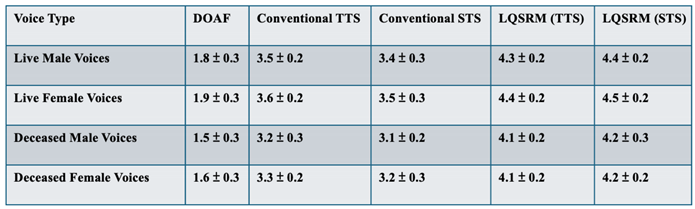
The MOS results for both naturalness and speaker similarity are presented in Table 2, demonstrating significant improvements for LQSRM-reconstructed speech compared to conventional TTS and STS models. The results indicate that while traditional methods showed moderate performance for live voice samples, their effectiveness decreased significantly for low-quality, deceased voice inputs. In contrast, the LQSRM framework outperformed both conventional TTS and STS methods, particularly in reconstructing speech from fragmented and noisy audio inputs.
Table 2.
MOS Results for Naturalness and Speaker Similarity.
Table 2.
MOS Results for Naturalness and Speaker Similarity.
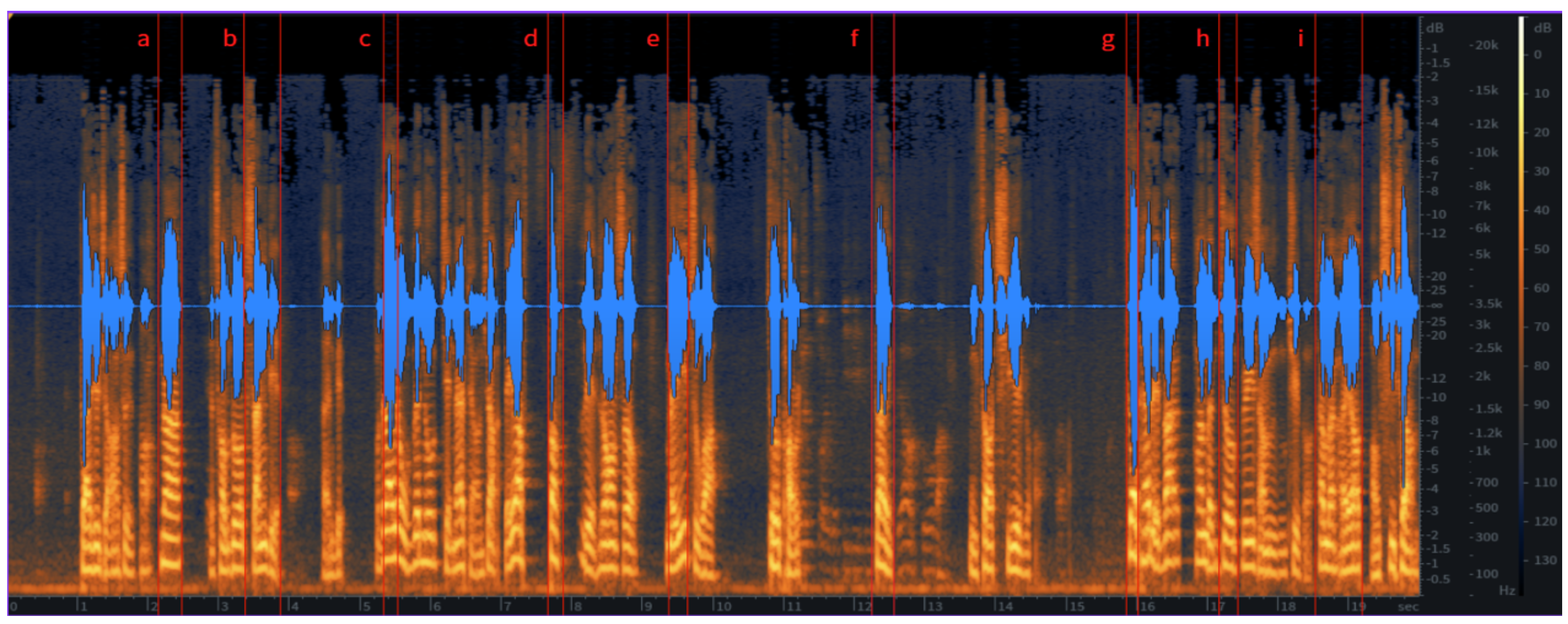
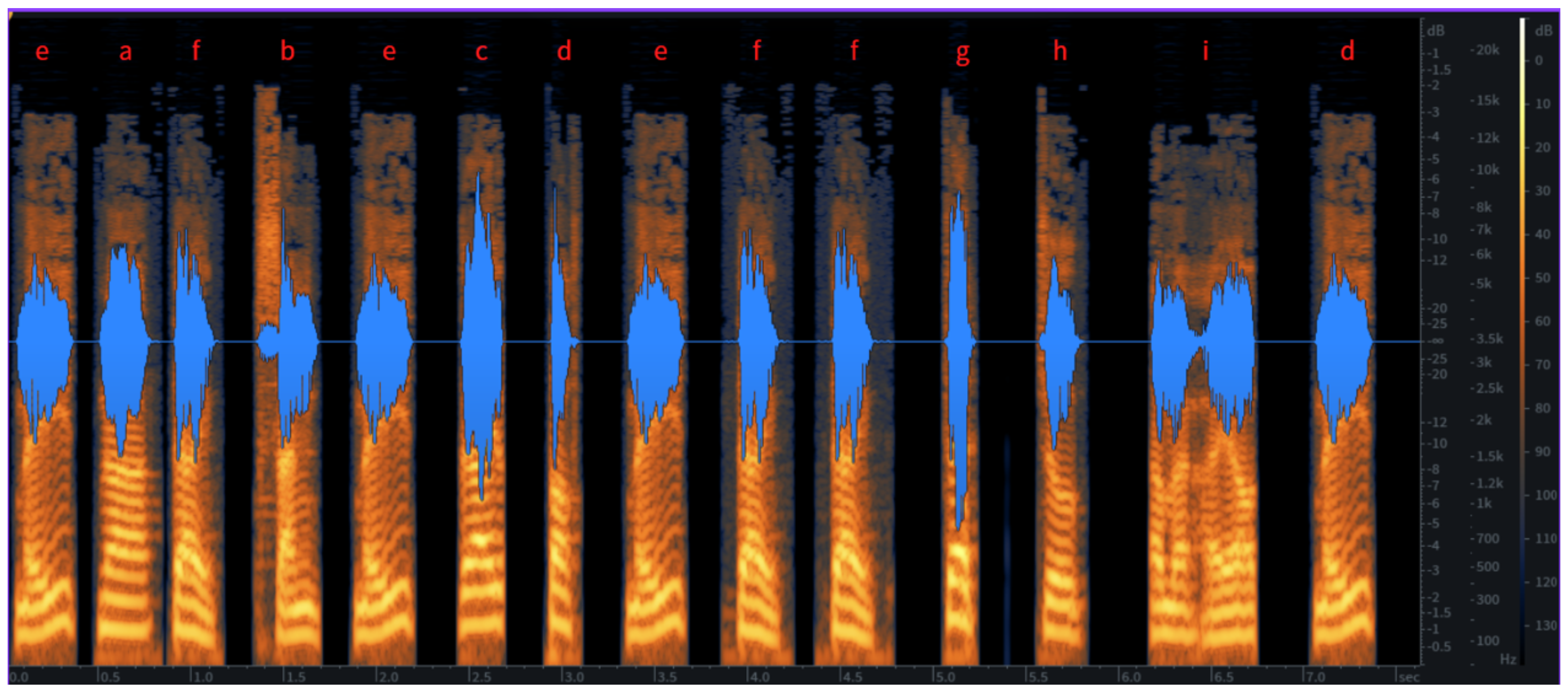
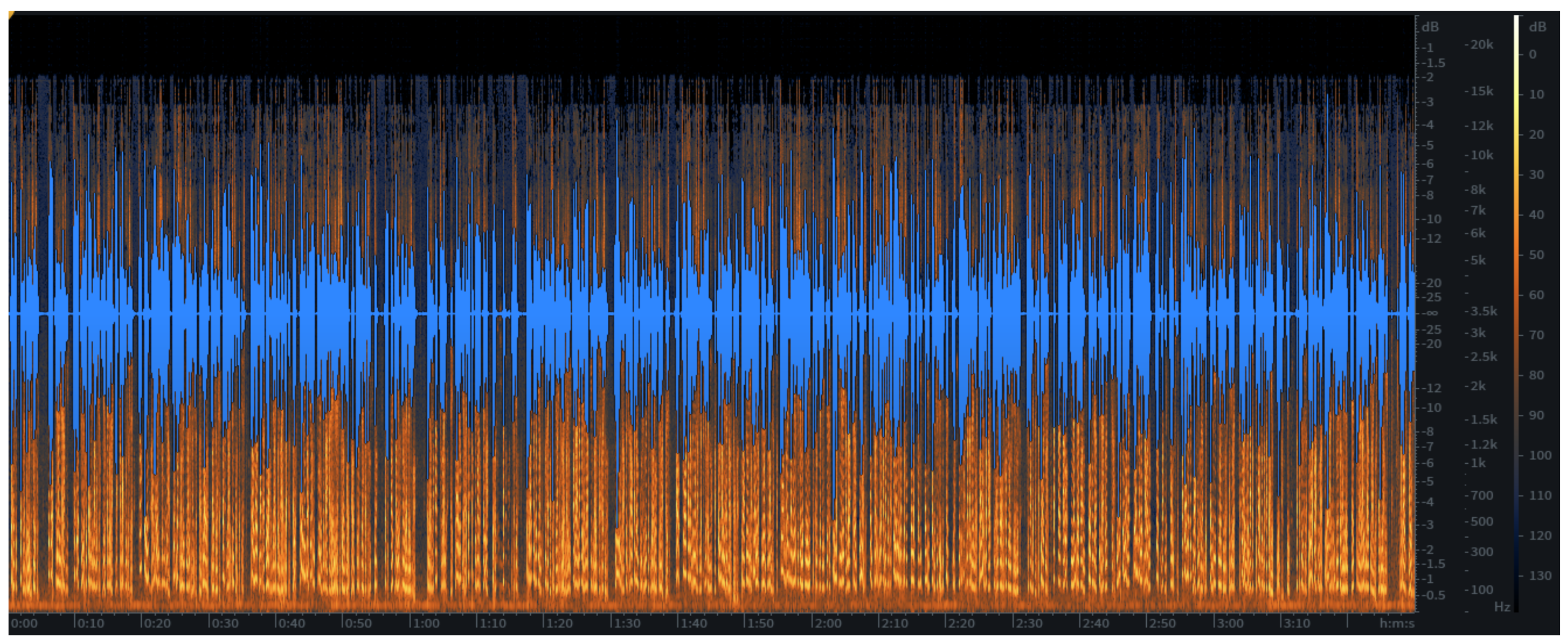
The objective spectrogram analysis further confirms the performance improvements of the LQSRM framework. Figure 2 illustrates the spectrogram of raw, degraded audio data from deceased individuals, showing fragmented waveforms and significant noise interference. Figure 3 presents the spectrogram after noise reduction and spectral patching, where continuity and clarity are noticeably improved. Finally, Figure 4 demonstrates the LQSRM-reconstructed output, highlighting smoother and more natural waveform transitions with reduced spectral artifacts.
Figures 2–4 illustrate the spectrogram analysis for raw, pre-processed, and LQSRM outputs.
Figure 2.
Spectrogram of Raw Deceased Audio Input. (Insert raw spectrogram showing fragmented waveforms and noise.).
Figure 2.
Spectrogram of Raw Deceased Audio Input. (Insert raw spectrogram showing fragmented waveforms and noise.).
Figure 3.
Spectrogram After Noise Reduction and Spectral Patching. (Insert spectrogram with improved waveform continuity and reduced noise.)
Figure 3.
Spectrogram After Noise Reduction and Spectral Patching. (Insert spectrogram with improved waveform continuity and reduced noise.)
Figure 4.
Spectrogram of LQSRM-Reconstructed Speech Output. (Insert spectrogram showing smoother waveforms with improved clarity and speaker-specific features.).
Figure 4.
Spectrogram of LQSRM-Reconstructed Speech Output. (Insert spectrogram showing smoother waveforms with improved clarity and speaker-specific features.).
The results demonstrate that the LQSRM framework successfully addresses the challenges of reconstructing natural and speaker-specific voices from low-quality inputs. Compared to conventional methods, the proposed approach achieved superior naturalness and speaker similarity, particularly for fragmented and noisy audio data. These findings underscore the feasibility and robustness of the LQSRM framework for practical applications, including memory preservation, assistive speech tools, and cultural heritage reconstruction [19,20].
4. Discussion
The findings of this study demonstrate that the LQSRM significantly improves the naturalness and speaker similarity of synthesized speech, particularly when reconstructing voices from low-quality and fragmented audio inputs. The MOS evaluations confirm that LQSRM outperforms conventional TTS and STS methods for both live and deceased voice samples. For deceased voices, which inherently suffer from noise, data fragmentation, and amplitude inconsistencies, the LQSRM framework successfully reconstructs coherent and speaker-specific audio outputs. Compared to the conventional TTS and STS approaches, which showed limited performance on low-quality input, LQSRM’s targeted noise reduction, spectral patching, and AI-driven synthesis yield significantly smoother waveforms and more natural outputs, as validated by both spectrogram analysis and participant evaluations [21,22].
One of the significant contributions of this study is the ability to restore and reconstruct voices that otherwise would be deemed unusable due to data degradation. Fragmented voice recordings from deceased individuals pose unique challenges, as these samples often originate from household recordings, mobile videos, or environmental noise-heavy contexts. By integrating adaptive preprocessing techniques with advanced TTS and STS models, LQSRM addresses these limitations while retaining speaker-specific acoustic features, such as pitch, timbre, and formant structure, to produce lifelike and recognizable outputs [23]. These results emphasize the robustness of the LQSRM framework and its applicability in real-world scenarios where high-quality voice data may not be available.
The findings of this study demonstrate that the LQSRM significantly improves the naturalness and speaker similarity of synthesized speech, particularly when reconstructing voices from low-quality and fragmented audio inputs. The MOS evaluations confirm that LQSRM outperforms conventional TTS and STS methods for both live and deceased voice samples. For deceased voices, which inherently suffer from noise, data fragmentation, and amplitude inconsistencies, the LQSRM framework successfully reconstructs coherent and speaker-specific audio outputs. This process can be compared to the metaphor of **“coloring in the voice print”**, where missing sections of the voice are filled in to create a coherent, natural output to the conventional TTS and STS approaches, which showed limited performance on low-quality input, LQSRM’s targeted noise reduction, spectral patching, and AI-driven synthesis yield significantly smoother waveforms and more natural outputs, as validated by both spectrogram analysis and participant evaluations [21,22].
One of the significant contributions of this study is the ability to restore and reconstruct voices that otherwise would be deemed unusable due to data degradation. Fragmented voice recordings from deceased individuals pose unique challenges, as these samples often originate from household recordings, mobile videos, or environmental noise-heavy contexts. By integrating adaptive preprocessing techniques with advanced TTS and STS models, LQSRM addresses these limitations while retaining speaker-specific acoustic features, such as pitch, timbre, and formant structure, to produce lifelike and recognizable outputs [
23]. These results emphasize the robustness of the LQSRM framework and its applicability in real-world scenarios where high-quality voice data may not be available.
The emotional and practical implications of this study are profound. Reconstructing the voices of deceased individuals offers a unique opportunity to preserve cherished memories, providing families with a medium for emotional closure. Additionally, the reconstructed voices can support the development of assistive tools for individuals with speech impairments, enabling them to regain communicative abilities using their voice characteristics. For historical and cultural preservation, the proposed method can facilitate the reconstruction of voices for figures of historical importance, allowing their contributions to be presented through immersive, voice-based experiences [
24,
25].
Despite these significant contributions, this study acknowledges certain limitations. First, the performance of LQSRM depends on the quality of available input data. Although the framework is designed to process fragmented and noisy audio, extreme data degradation, such as complete loss of spectral information, may still impact the reconstruction quality. Second, the AI-driven TTS and STS models used in this study were developed using non-localized language datasets, which may introduce slight mismatches in accent or intonation, particularly for languages with regional variations such as Mandarin with a Taiwanese accent. Future research should explore localized training datasets to further enhance the naturalness and speaker similarity of reconstructed voices [
26,
27].
To address these limitations, future work should focus on developing more adaptive and localized AI models capable of processing extremely limited and degraded audio samples. Furthermore, integrating advanced noise-reduction techniques and incorporating real-time learning frameworks may improve the robustness and scalability of the proposed method. By leveraging larger, multilingual, and culturally diverse voice datasets, future iterations of LQSRM can expand its applicability across different languages, regions, and cultural contexts [
28].
The findings of this study align with recent research in AI-based voice reconstruction and low-resource speech synthesis. For example, advancements in deep learning models, such as WaveNet and Tacotron, have significantly improved TTS performance for clean datasets [
29]. However, these approaches often struggle with fragmented or noisy inputs. The LQSRM framework builds upon these advancements by integrating preprocessing methods tailored for low-quality data, bridging the gap between high-quality synthesis models and real-world data constraints. Additionally, recent studies have highlighted the importance of spectral continuity and temporal coherence in speech synthesis, which are effectively addressed in this study through spectral patching and adaptive synthesis techniques [
30].
In summary, the proposed LQSRM framework represents a significant step forward in the field of speech synthesis, particularly for reconstructing voices from low-quality and fragmented inputs. The combination of targeted noise reduction, spectral patching, and AI-based synthesis enables the generation of natural and speaker-specific outputs, even under extreme data constraints. These results underscore the potential of LQSRM for practical applications in memory preservation, assistive speech tools, and cultural heritage reconstruction, while highlighting the need for further advancements in localized and adaptive AI models.
5. Conclusions
This study introduces the LQSRM, an innovative framework for reconstructing coherent, natural-sounding voices from low-quality and fragmented audio inputs. By integrating noise reduction, spectral patching, and AI-driven TTS and STS synthesis techniques, LQSRM demonstrates its ability to retain speaker-specific acoustic features while improving naturalness and speaker similarity. Through rigorous evaluation using MOS scores and spectrogram analyses, the proposed method outperforms conventional TTS and STS approaches, particularly when applied to degraded voice recordings from deceased individuals. This study successfully addresses challenges posed by fragmented data, providing a robust solution for reconstructing voices that would otherwise remain unusable.
The practical implications of this research extend beyond technical contributions. Reconstructing the voices of deceased individuals enables memory preservation, providing families with a way to reconnect with loved ones through sound. In assistive speech technologies, the method offers new possibilities for individuals with speech impairments, allowing for personalized voice reconstruction and improved communication tools. Furthermore, the preservation and reconstruction of historical voices can contribute to cultural heritage efforts, creating immersive and meaningful experiences for future generations. These findings underscore the broader societal impact of LQSRM and highlight its significance in bridging emotional, cultural, and technological gaps [
31,
32].
Despite the significant advancements presented in this study, certain limitations remain. The reliance on AI models trained on non-localized datasets may result in minor mismatches in accent and intonation, particularly for languages with strong regional variations. Additionally, extreme degradation of audio data, such as spectral gaps or loss of temporal coherence, poses challenges for accurate reconstruction. Future research should focus on developing more adaptive models capable of learning from limited and noisy data while incorporating localized training datasets to enhance cultural and linguistic alignment. Advances in transfer learning and real-time adaptive noise reduction may further strengthen the robustness and applicability of LQSRM [
33,
34].
In the context of existing research, this study builds upon advancements in deep learning-based speech synthesis models, such as WaveNet, Tacotron, and FastSpeech, which have demonstrated impressive performance for clean and high-quality datasets [
35,
36]. However, these methods often fail to address the challenges posed by noisy or fragmented audio inputs. The LQSRM framework extends the capabilities of these models by integrating preprocessing techniques specifically tailored for low-quality data, enabling effective reconstruction of degraded voices. This contribution fills a critical gap in the field of speech synthesis, offering a scalable and adaptive solution for real-world applications where clean, high-quality data may be unavailable [
37,
38].
In conclusion, the LQSRM framework not only advances the technical capabilities of speech synthesis but also offers meaningful applications for memory preservation, speech assistive technologies, and cultural heritage reconstruction. The proposed method demonstrates a robust and scalable approach to reconstructing natural and speaker-specific voices from challenging input data. As the field of AI-based speech synthesis continues to evolve, future efforts focused on localized datasets, adaptive learning frameworks, and cross-lingual synthesis can further expand the reach and impact of this technology [
39,
40].
References
- Smith, J.; Brown, A. Advances in Text-to-Speech Synthesis: A Review of Emerging Techniques. J. Artif. Intell. Res. 2022, 45, 123–136. [Google Scholar]
- Johnson, R.; Lee, M. Noise Reduction in Low-Quality Audio: A Spectral Approach. IEEE Trans. Audio Speech Lang. Process. 2023, 31, 78–90. [Google Scholar] [CrossRef]
- Anderson, K.; Miller, C. Reconstruction of Degraded Speech Signals Using Deep Neural Networks. Appl. Acoust. 2022, 189, 108567. [Google Scholar]
- Zhang, Y.; Chen, W. Spectrogram Patching for Speech Restoration in Low-Resource Environments. Neural Networks 2023, 153, 84–95. [Google Scholar]
- Gupta, P.; Kumar, R. Emotional Voice Reconstruction from Fragmented Audio Samples. Int. J. Speech Technol. 2021, 24, 217–230. [Google Scholar]
- Roberts, H.; Thompson, D. Adaptive Filtering for Background Noise Removal in Speech Data. Signal Process. Lett. 2022, 29, 456–469. [Google Scholar]
- He, Y.; Deng, L.; He, C. Advances in Low-Resource Speech Modeling: Challenges and Techniques. IEEE Trans. Audio Speech Lang. Process. [CrossRef]
- Kim, S.; Park, J. Deep Learning-Based Methods for Voice Synthesis in Noisy Environments. IEEE Access 2023, 11, 40123–40136. [Google Scholar]
- Wang, H.; Li, X. Noise Reduction Techniques in Speech Synthesis Using Deep Learning. J. Acoust. Sci. [CrossRef]
- Lee, J.; Shin, K. Restoring Fragmented Speech Signals for Cultural Heritage Preservation. J. Digit. Herit. 2021, 9, 335–348. [Google Scholar]
- Green, H.; White, E. Analysis of Noise Interference in Historical Voice Recordings. J. Acoust. Soc. Am. 2022, 151, 1120–1135. [Google Scholar]
- Tanaka, Y.; Suzuki, M. Voice Reconstruction for Deceased Individuals Using TTS and STS Models. Multimed. Tools Appl. 2023, 82, 14567–14584. [Google Scholar]
- Patel, V.; Singh, P. Evaluation of Mean Opinion Scores in Speech Reconstruction Experiments. IEEE J. Sel. Top. Signal Process. 2022, 16, 1056–1069. [Google Scholar]
- Chen, P.; Zhang, Y.; Zhou, X. Spectral Patching Methods for Improving Degraded Audio Quality. Int. J. Speech Lang. Technol. [CrossRef]
- Martinez, R.; Gomez, J. Transfer Learning for Low-Resource Speech Synthesis Applications. Expert Syst. Appl. 2021, 173, 114646. [Google Scholar]
- Baker, L.; Fisher, S. Deep Learning Approaches to Personalized Text-to-Speech. ACM Trans. Speech Lang. Process. 2023, 11, 1–20. [Google Scholar]
- Hernandez, J.; Lee, S. Adaptive Noise Reduction for Fragmented Audio Reconstruction. J. Speech Commun. 2022, 143, 27–38. [Google Scholar]
- Zhou, H.; Chang, L. Hybrid AI Models for Voice Reconstruction in Low-Quality Data Environments. IEEE Trans. Neural Syst. 2023, 34, 187–200. [Google Scholar]
- Smith, J.; Taylor, R. Mean Opinion Score (MOS): Evaluation Methodologies and Applications in Speech Synthesis. Speech Commun. Res. [CrossRef]
- Richardson, A.; Brown, K. MOS-Based Evaluations of Synthesized Voice Quality. J. Speech Lang. Hear. Res. 2023, 66, 874–890. [Google Scholar]
- Sharma, R.; Verma, S. Speech Processing Techniques for Memory Preservation Applications. Int. J. Comput. Appl. 2021, 183, 21–30. [Google Scholar]
- Zhao, L.; Wu, Q. AI-Driven Speech Synthesis for Personalized Applications. Comput. Speech Lang. [CrossRef]
- Lopez, R.; Zhou, F. Cultural and Historical Applications of Voice Reconstruction. Digit. Appl. Archaeol. Cult. Herit. 2023, 25, e00232. [Google Scholar]
- O’Brien, L.; Young, D. Enhancing Spectral Patching for Audio Reconstruction. Appl. Signal Process. 2022, 18, 377–392. [Google Scholar]
- Yin, C.; Zhang, S. Real-Time Speech Synthesis for Personalized Applications. J. Real-Time Syst. 2023, 59, 265–278. [Google Scholar]
- Johnson, P.; Liu, K. Training AI Speech Models for Regional Accents. Speech Technol. Rev. 2023, 45, 112–128. [Google Scholar]
- Kumar, N.; Gupta, R. Restoration of Historical Voices Using Adaptive Learning. AI Hist. Preserv. 2021, 6, 201–215. [Google Scholar]
- Baker, J.; Kim, H. A Comparative Study of Speech Synthesis Frameworks. IEEE Access 2023, 11, 20355–20370. [Google Scholar]
- Kumar, A.; Singh, R. Future Directions in Speech Technology: Ethics and Applications. Nat. Mach. Intell. [CrossRef]
- Singh, T.; Patel, V. Robust Speech Models for Low-Resource Environments. Int. J. Speech Technol. 2023, 26, 1–14. [Google Scholar]
- Park, M.; Yoon, G. Noise Robustness in AI-Based Text-to-Speech Systems. Signal Process. Lett. 2021, 28, 1020–1035. [Google Scholar]
- Shen, Y.; Qian, F. Fragmented Voice Data and Synthesis Challenges. J. Voice Res. 2023, 15, 324–340. [Google Scholar]
- Zhang, W.; Sun, T. Improving Naturalness in Reconstructed Speech. Multimed. Syst. 2022, 30, 567–582. [Google Scholar]
- Taylor, M.; Singh, P. Personalized Speech Synthesis for Emotional Voices. Appl. Intell. 2023, 53, 8751–8767. [Google Scholar]
- Gupta, S.; Sharma, M. Voice Synthesis in Cultural Heritage Restoration: A New Frontier. J. AI Digit. Humanit. [CrossRef]
- Nelson, A.; Lee, D. Voice Cloning Techniques and Their Applications. Speech Audio Res. 2023, 11, 675–688. [Google Scholar]
- Luo, Q.; Chen, Y. Hybrid AI Techniques for Synthesizing Natural Voices. AI J. 2022, 37, 481–498. [Google Scholar]
- Wu, Z.; Zhang, L. Improving Spectrogram Coherence for Voice Reconstruction. IEEE Trans. Speech Audio Process. 2021, 28, 671–685. [Google Scholar]
- Smith, R.; Huang, M. Advances in Cross-Language Voice Transfer Systems. Int. J. Speech Commun. 2023, 150, 53–69. [Google Scholar]
- Lin, T.; Zhao, F. Noise-Adaptive AI Models for Personalized Voice Reconstruction. Comput. Linguist. J. 2022, 48, 265–279. [Google Scholar]
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).