Submitted:
04 January 2025
Posted:
07 January 2025
You are already at the latest version
Abstract
As the main working part of the combined harvester, the cleaning device affects the cleaning performance of the machine. The simulation of flow field in cleaning chamber has become an important mean of the design. Now post-processing analysis of the flow field simulation still relies on the researchers’ experience, so it is difficult to obtain information from the post-processing automatically. The experience of researchers is difficult to express and spread. This paper studied an intelligent method to analyse the simulation result data, which was based on the object detection algorithm and the reasoning mechanism. YOLOv8, one of the deep learning object detection algorithm, was selected to identify key point data from flow field in the cleaning chamber. First the training data set was constructed by scatter plot drawing, data enhancement, random screening and other technologies. Then the flow field in the cleaning chamber was divided into 6 key areas by identifying the key points of the flow field. And the analysis of the reasonable wind velocity in the areas and the cleaning results of grain were completed by reasoning mechanism based on rules and examples. Finally a system based on the above method was established by Python software. With the help of the method and the system in this paper, the flow field characteristic in the cleaning chamber and the effects of wind upon cleaning effect could be obtained automatically if the physical property of the crop, geometric parameters of the cleaning chamber, working parameters of the machine were given.
Keywords:
1. Introduction
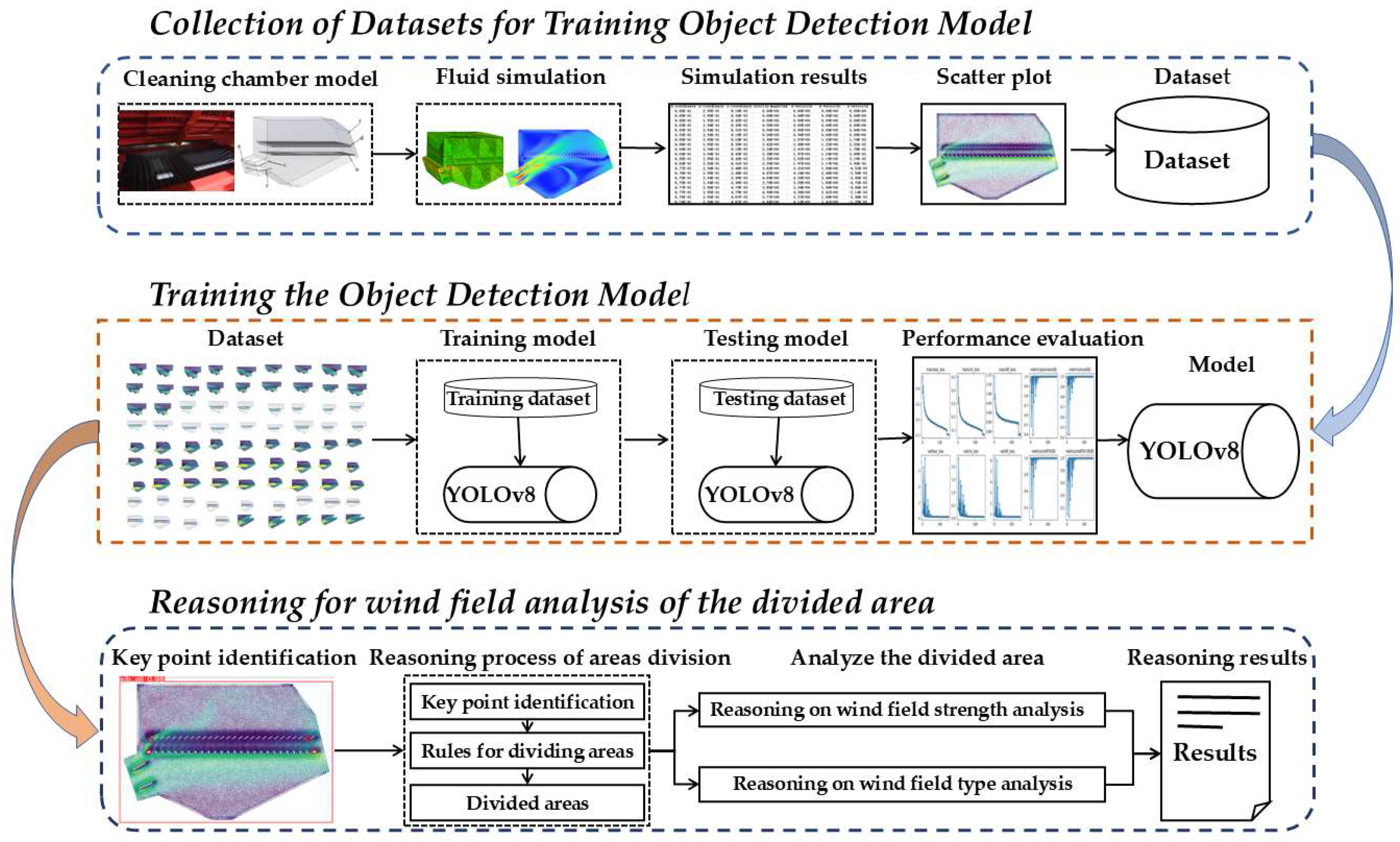
2. Materials and Methods
2.1. Technical Route
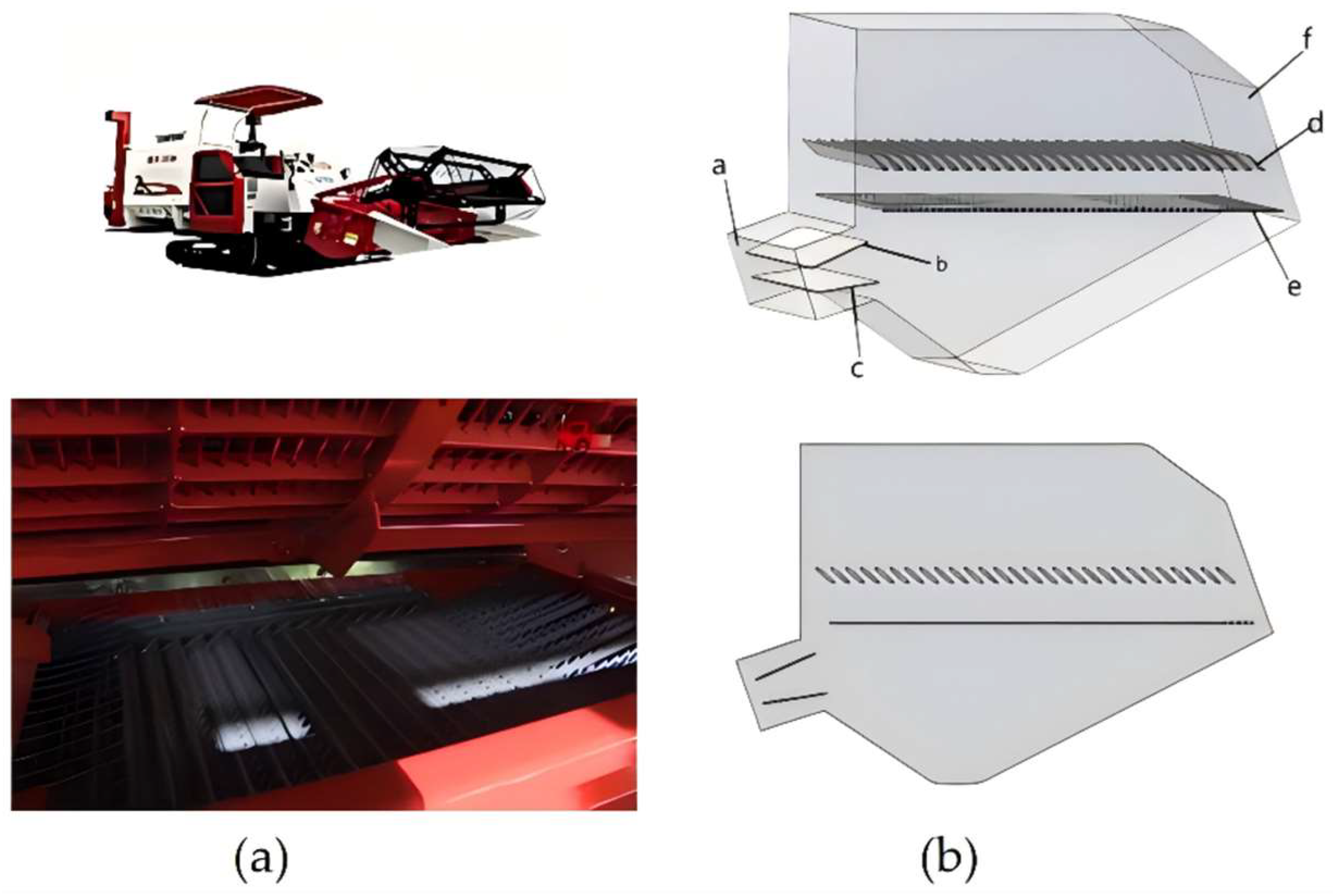
2.2. Cleaning Chamber Model
2.3. Fluid Simulation Based on ANSYS Fluent Software
- Pre-processing of the geometric models
- 2.
- Meshing of the models
- 3.
- Solver settings
2.4. Training Model
2.4.1. Construct the Dataset
2.3.2. YOLOv8 Model
2.4.3. Experimental Environment and Evaluation Criteria
2.5. Construct the Knowledge Base
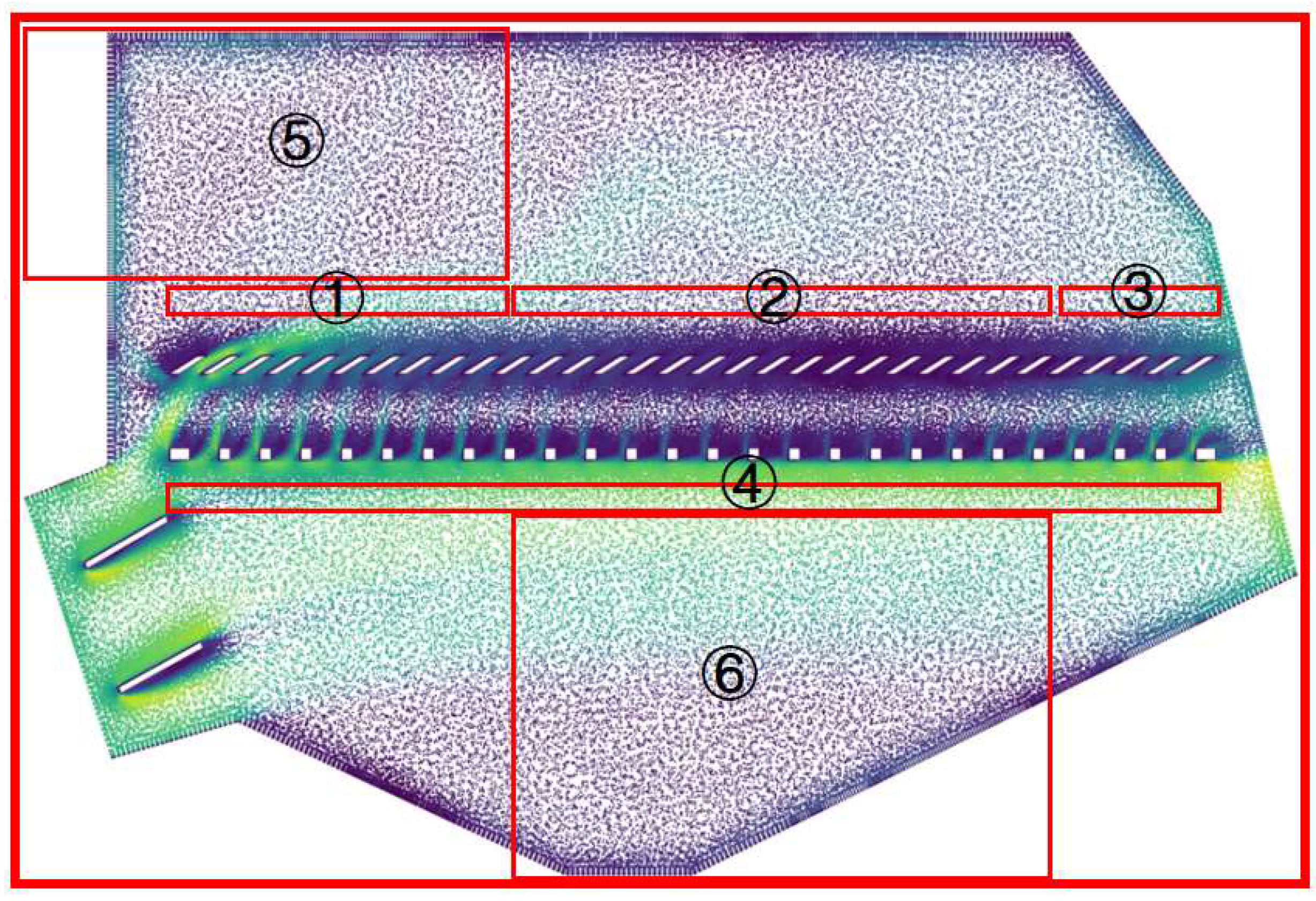
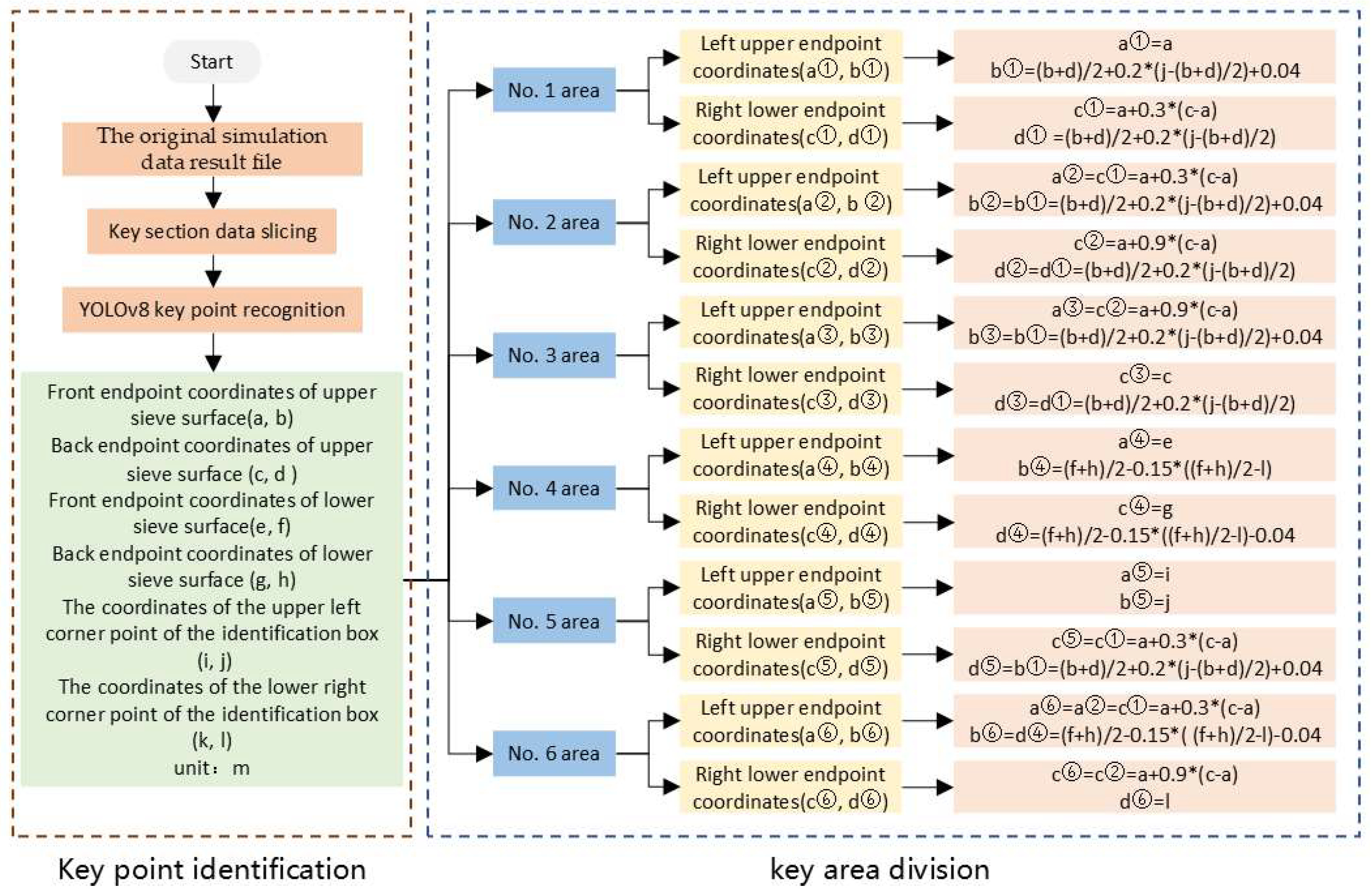
2.6. Post-Processing Reasoning Process of Flow Field Simulation in the Cleaning Chamber
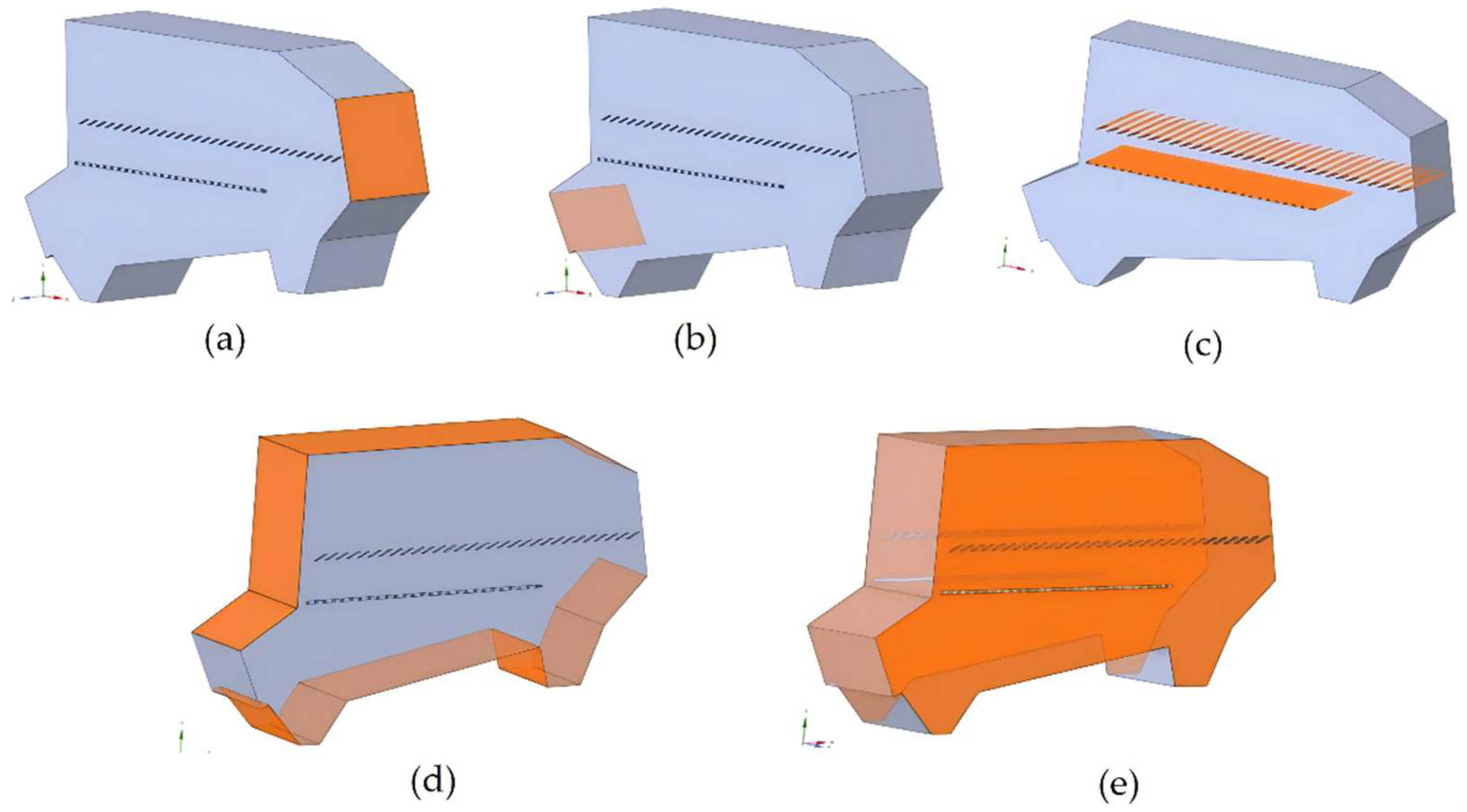
- Reasoning process for key area division of flow field in the cleaning chamber
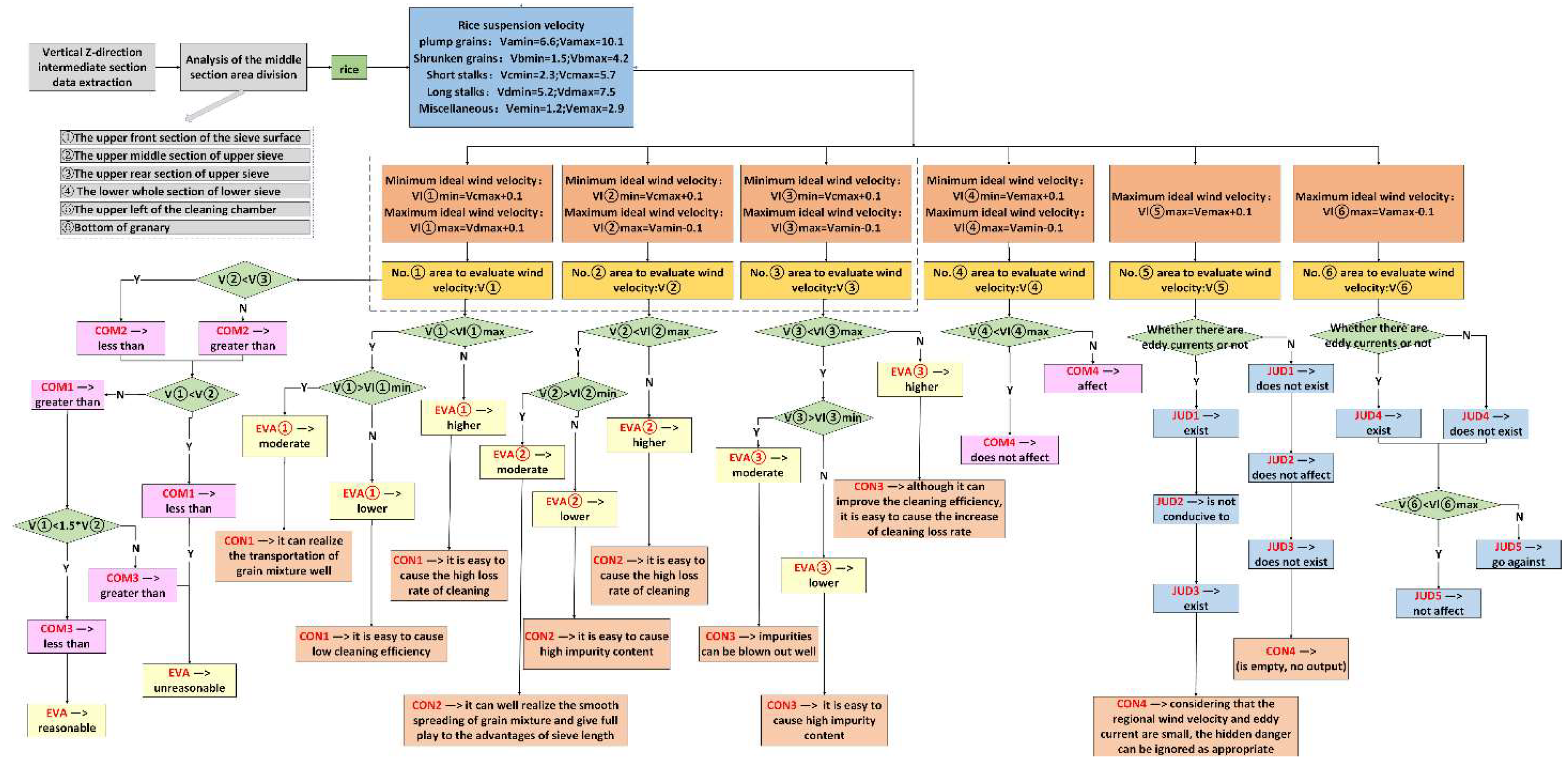
- Reasoning method for airflow analysis above upper sieve surface of the cleaning chamber
- Reasoning method for airflow analysis under lower sieve surface of the cleaning chamber
- Reasoning process for the feed inlet of the cleaning chamber and the grain auger
- Post-processing reasoning method
3. Results and Discussion
3.1. Results of Fluid Simulation
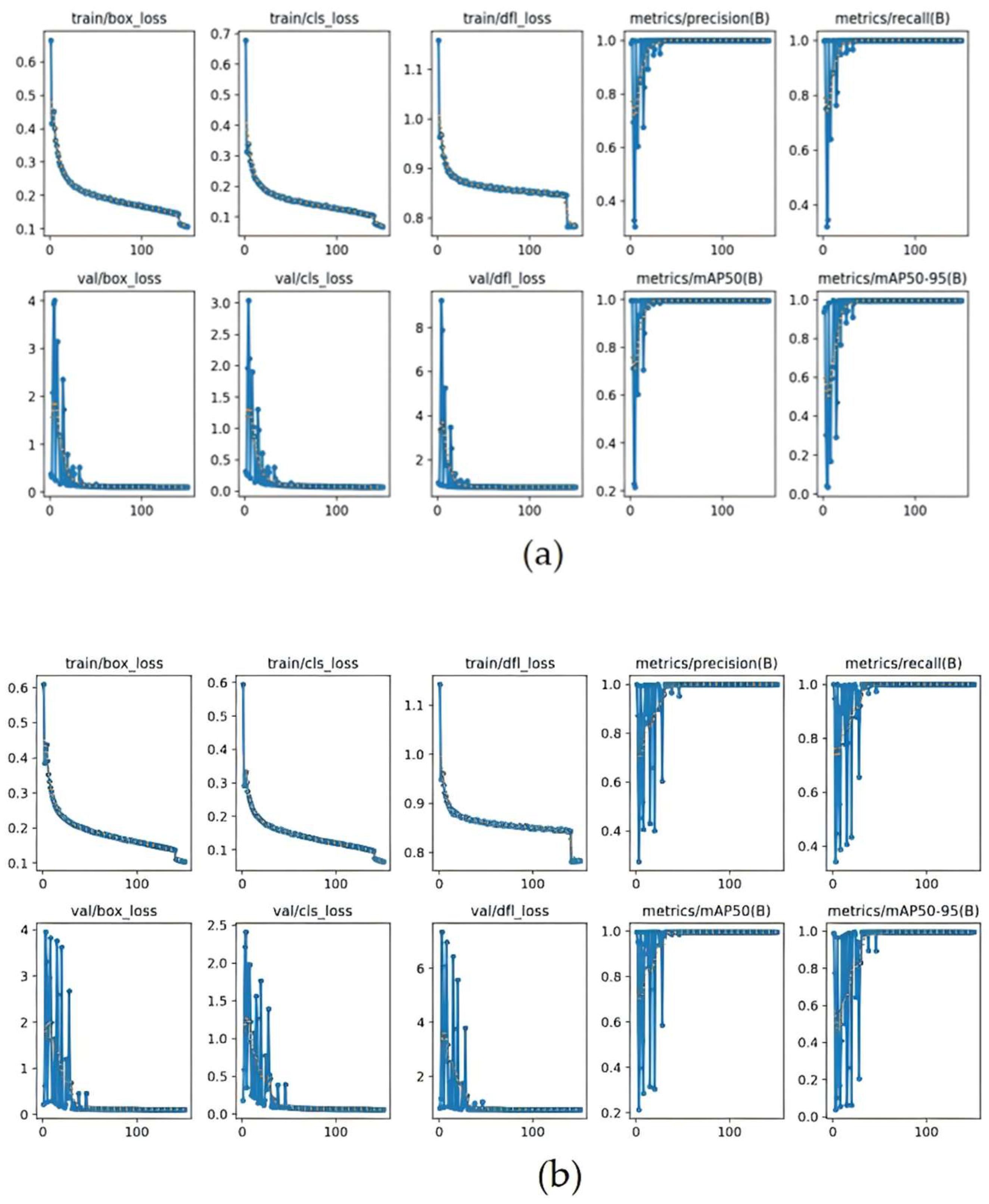
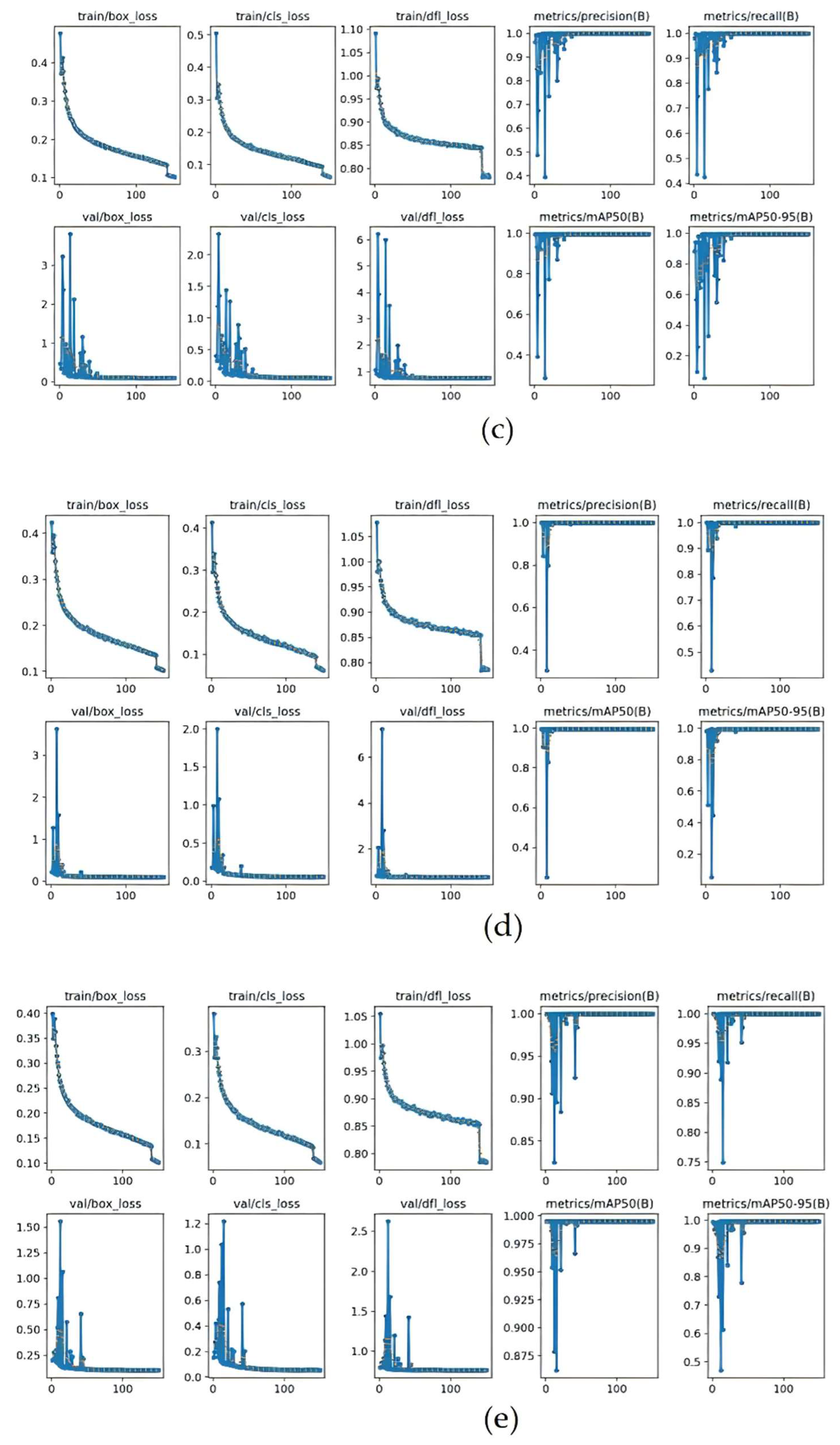
3.2. Performance Evaluation and Training Results of Object Detection Model
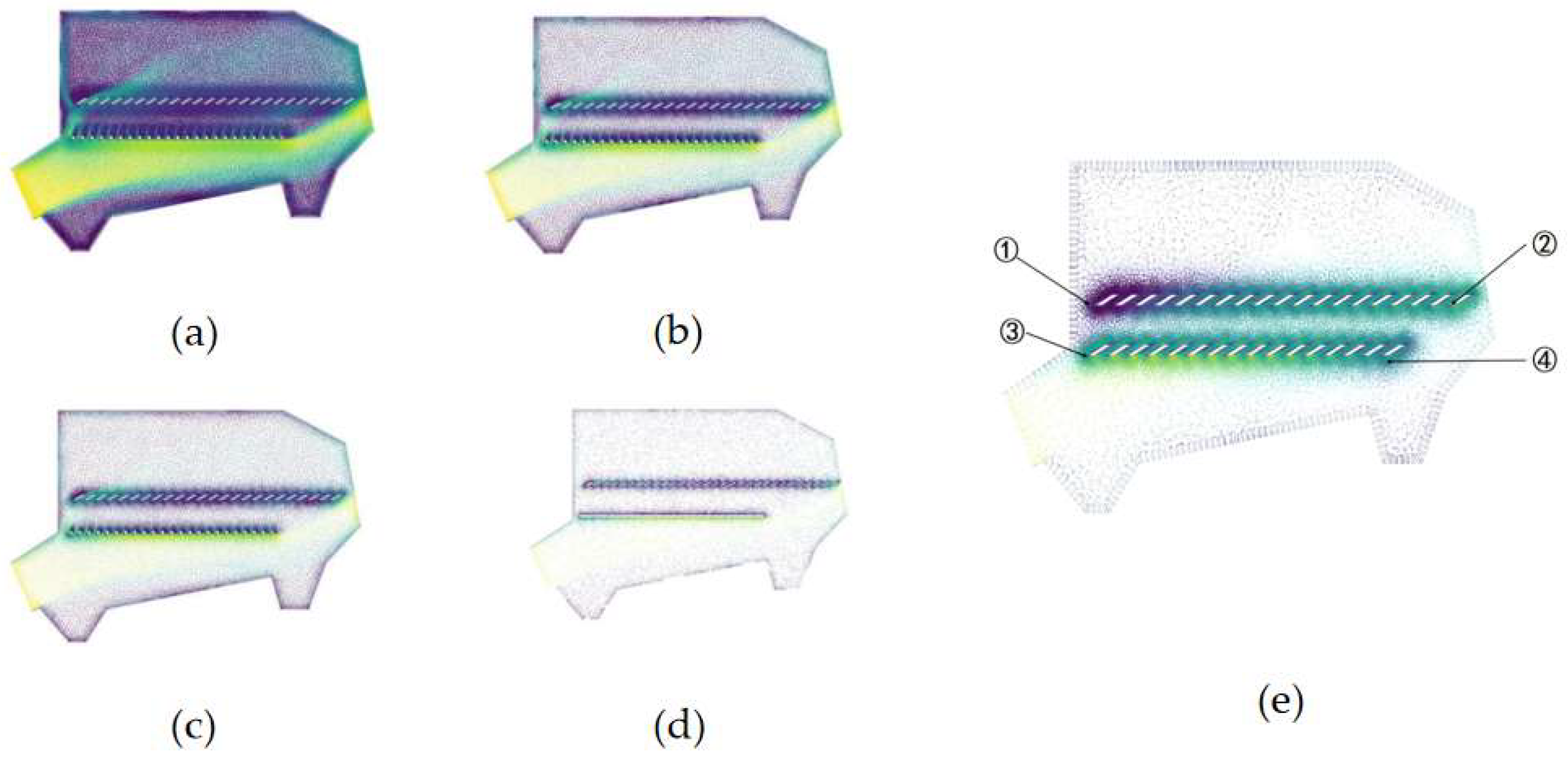
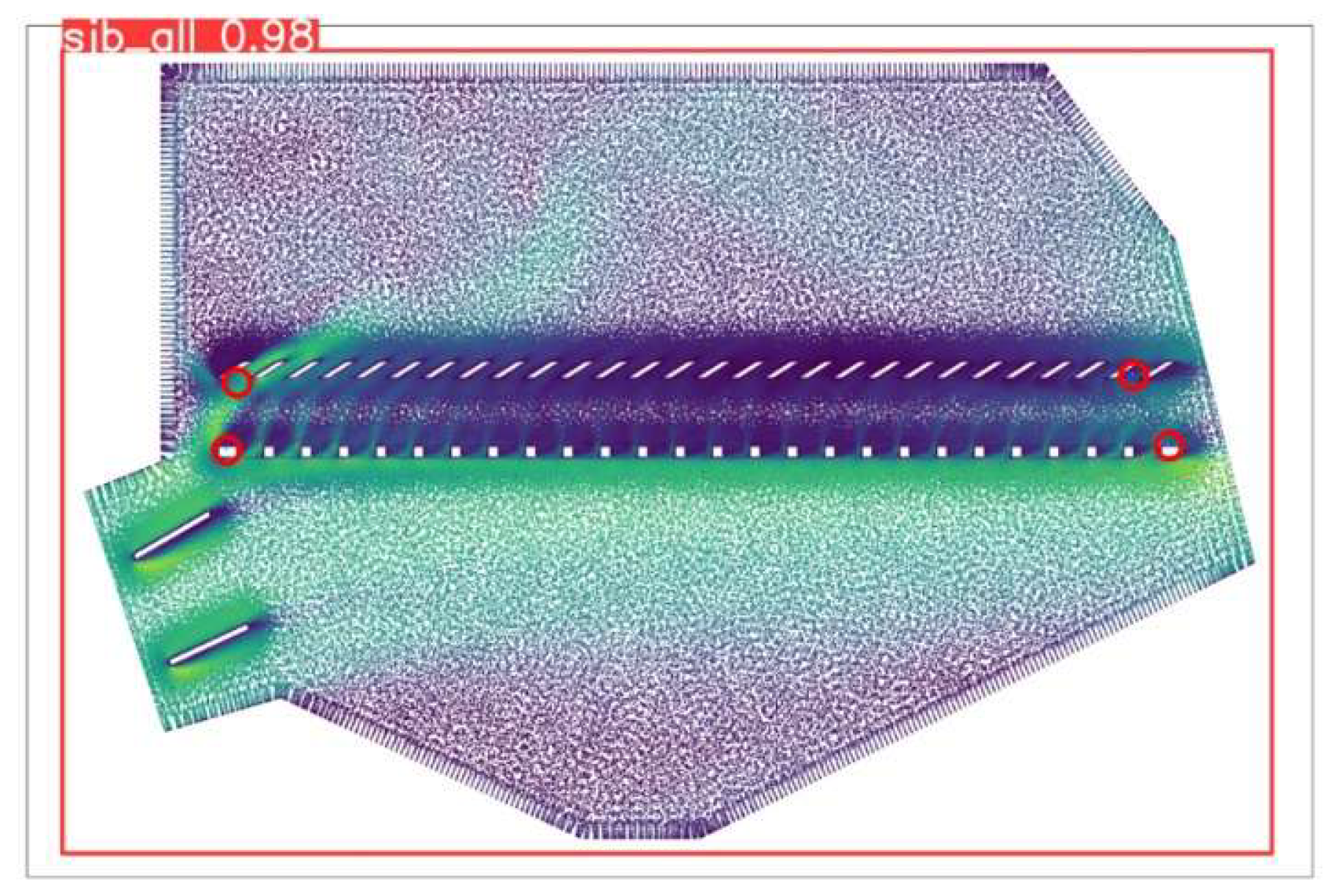
3.3. Testing of Key Point Detection Model
3.4. Reasoning Example of Post-Processing
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Helena, M.; Simon, D. The cultural transmission of tacit knowledge. Journal of the Royal Society Interface, 2022, 19, 20220238.
- Mingjun, C. Developing Simulation System of FEA Based on Visual Studio and Python Language. Master’s Thesis, Qingdao University of Technology, Qingdao, 2015.
- Wenbin, L. Construction of CAE post processing system for key parts of threshing device of combine harvester. Master’s Thesis, Jiangsu University, Zhenjiang, 2021.
- Yuying, S. The Platform Construction of Combine Harvester Cleaning Flow Field CAE PostProcessing and Cleaning Device Optimization. Master’s Thesis, Jiangsu University, Zhenjiang, 2021.
- Ante, T.; Wenbin, S.G. Auto CAE analytical system for the strength and modal analysis on the vehicle’s sub-frame. Journal of Machine Design, 2019, 36, 13-19.
- Che, J.; Zhang, Y.; Yang, Q.; Yuting, H. Research on person re-identification based on posture guidance and feature alignment. Multimedia Systems, 2023, 29, 763-770. [CrossRef]
- Mochen, L.; Zhenyuan, C.; Mingshi, C.; Qinglu, Y.; Jinxing, W.; Huawei, Y. Red Ripe Strawberry Recognition and Stem Detection Based on Improved YOLOv8-Pose. Transactions of the Chinese Society for Agricultural Machinery, 2019, 54, 244-251.
- Zhongfeng, G.; Junchi, L.; Junlin, Y. Weld recognition based on key point detection method. Transactions of the China Welding Institution, 2019, 45, 88-93+134.
- Lu, G.; Xiaodong, L.; Yufeng, W.; Zhen, Z. Control Decision of Equipment Health State based on Big Data Reasoning. Air &Space Defense, 2023, 6, 85-94.
- Yu, Z.; Ziming, K.; Cong, H.; Shaokai, K. Fault diagnosis of belt conveyor drive system based on RBR + CBR dual reasoning. Journal of Mechanical & Electrical Engineering, 2023, 40, 1785-1793.
- Cong, L.; Beibei, F.; Wenwei, Y. Research on Rapid Product Design Based on Reasoning Model. Metrology & Measurement Technology, 2018, 45, 23-26.
- Mengqi, C.; Rong, Q.; Weiguo, F. Case-based reasoning system for fault diagnosis of aero-engines. Expert Systems with Applications, 2022, 202, 117350.
- Lao, S.I.; Choy, K.L.; Ho, G.T.; Richard, C.M.; Tsim, Y.C.; Poon, T.C. Achieving quality assurance functionality in the food industry using a hybrid case-based reasoning and fuzzy logic approach. Expert Systems with Applications, 2012, 39, 5251-5261. [CrossRef]
- Yi, C.; Zhuo, Y.; Zhenxiang, H.; Weihong, S.; Liang, H. A Decision-Making System for Cotton Irrigation Based on Reinforcement Learning Strategy. Agronomy-Basel, 2024, 14, 11.
- Chengang, D.; Guodong, D. An enhanced real-time human pose estimation method based on modified YOLOv8 framework. Scientific Reports, 2024, 14, 8012.
- Jianhua, Z.; Review of commercial CFD software. Journal of Hebei University of Science and Technology, 2005, 26, 160-165.
- Zhenwei, L.; Lizhang, X.; Josse, D.B.; Yaoming, L.; Wouter, S. Optimisation of a multi-duct cleaning device for rice combine harvesters utilising CFD and e02xperiments. Biosystems Engineering, 2020, 190, 25-40.
- Peng, L.; Chengqian, J.; Tengxiang, Y.; Man, C.; Youliang, N.; Xiang, Y. Design and Experiment of Multi Parameter Adjustable and Measurable Cleaning System. Transactions of the Chinese Society for Agricultural Machinery, 2020, 51, 191-201.
- Jaehyeop, C.; Chaehyeon, L.; Donggyu, L.; Heechul, J. SalfMix:A Novel Single Image-Based Data Augmentation Technique Using a Saliency Map. Sensors, 2021, 21, 8444.
- Matheus, F.G.; Igor, R.F.; Rafael, K.; Franklin, C.F. System of Counting Green Oranges Directly from Trees Using Artificial Intelligence. AgriEngineering, 2023, 5, 1813-1831.
- Bochuan, D.; Zhenwei, L.; Yongqi, Q.; Zhikang, Y.; Jiahao, Z. Improving Cleaning Performance of Rice Combine Harvesters by DEM–CFD Coupling Technology. Agriculture-Basel, 2022, 12, 1457.
- Xiaoyu, C.; Lizhang, X.; Yixin, S.; Zhenwei, L.; En, L.; Yaoming, Li. Development of a cleaning fan for a rice combine harvester using computational fluid dynamics and response surface methodology to optimise outlet airflow distribution. Biosystems Engineering, 2020, 192, 232-244.
- Junwei, C.; Zengde, H.; Zirui, Z.; Fuping, H.; Bangxing, G.; Tiansheng, S.; Xiaodong, Q. Experiments and Analysis about Airflow Distribution over Oscillating Sieve of Grain Combine Harvester. Agricultural Engineering, 2015, 5, 1-4+14.
- Fang, C.; Jun, W. Test Study on the Flow Field Above Surface of the Air-and-Screen Cleaning Mechanism. Transactions of the Chinese Society of Agricultural Engineering, 1999, 15, 55-58.
- Guohua, D.; Yi, Y. The Influence of Airstream Distribution Along a Sieve on The Separation of Grain Mixture. Transactions of the Chinese Society for Agricultural Machinery, 1982, No.3, 16-28.
- Lizhang, X.; Yang, L.; Xiaoyu, C.; Guimin, W.; Zhenwei, L.; Yaoming, L.; Baijun, L. Numerical simulation of gase-solid two-phase flow to predict the cleaning performance of rice combine harvesters. Biosystems Engineering, 2020, 19, 11-24.


| Machine Model | Clearing chamber length (m) | Clearing chamber height (m) | Upper sieve length (m) | Lower sieve length (m) | |
|---|---|---|---|---|---|
| 1 | 4LBZ-145 | 0.8755 | 0.5736 | 0.680 | 0.700 |
| 2 | 4LZ-5G | 1.0180 | 0.6065 | 0.800 | 0.800 |
| 3 | 4LZY-1.5 | 1.1109 | 0.8520 | 0.800 | 0.880 |
| 4 | DFQX-3 | 1.1289 | 0.8295 | 0.760 | 0.820 |
| 5 | ZKB-5 | 1.3447 | 1.0226 | 1.018 | 1.018 |
| 6 | 4LZ-7N | 1.1026 | 0.9125 | 0.860 | 0.860 |
| 7 | Fengshou-3.0 | 1.2380 | 0.9270 | 1.000 | 1.000 |
| 8 | 4LZB-105 | 1.0434 | 0.6586 | 0.820 | 0.860 |
| 9 | 4LZ-2.5 | 1.2828 | 0.9289 | 0.800 | 1.000 |
| 10 | 4LZ-1.0 | 0.9872 | 0.6262 | 0.680 | 0.700 |
| 11 | 4LQ-2.5 | 1.0093 | 0.9706 | 0.800 | 1.000 |
| 12 | DF-1.5 | 1.0455 | 0.758 | 0.720 | 0.820 |
| Name | Local size (mm) |
|---|---|
| Little_wall | 2.5 |
| Middle_wall | 5 |
| Out_wall | 5 |
| In_wall | 5 |
| Big_wall | 10 |
| Node number | X-coordinate | Y-coordinate | Z-coordinate | Velocity-magnitude | X-velocity | Y-velocity | Z-velocity |
|---|---|---|---|---|---|---|---|
| 1 | 0.726608 | 0.541836 | 0.028558 | 2.734538 | 2.509488 | 1.084060 | -0.055024 |
| 2 | 0.727234 | 0.542215 | 0.027279 | 2.845202 | 2.604854 | 1.141396 | -0.068198 |
| 3 | 0.726470 | 0.541786 | 0.025921 | 2.741601 | 2.516079 | 1.084341 | -0.082012 |
| 4 | 0.725315 | 0.541097 | 0.026017 | 2.552531 | 2.356438 | 0.975582 | -0.078499 |
| 5 | 0.724714 | 0.540719 | 0.027356 | 2.446941 | 2.264678 | 0.921151 | -0.067528 |
| 6 | 0.725436 | 0.541144 | 0.028614 | 2.552805 | 2.352640 | 0.987235 | -0.056994 |
| 7 | 0.725107 | 0.541634 | 0.028590 | 3.600152 | 3.293722 | 1.452340 | -0.052900 |
| 8 | 0.726143 | 0.542751 | 0.028582 | 3.963142 | 3.616092 | 1.620895 | -0.050203 |
| 9 | 0.725658 | 0.542753 | 0.028570 | 4.131888 | 3.763608 | 1.704038 | -0.049944 |
| 10 | 0.724466 | 0.541147 | 0.027393 | 3.527243 | 3.230571 | 1.414100 | -0.068024 |
| 11 | 0.726772 | 0.543075 | 0.027260 | 3.987315 | 3.638826 | 1.628794 | -0.065586 |
| 12 | 0.726282 | 0.543429 | 0.027800 | 4.351541 | 3.967640 | 1.785891 | -0.060108 |
| 13 | 0.726326 | 0.543033 | 0.026680 | 4.101440 | 3.738727 | 1.684544 | -0.073610 |
| 14 | 0.725576 | 0.543874 | 0.027660 | 4.855009 | 4.404069 | 2.041239 | -0.059116 |
| 15 | 0.726172 | 0.542234 | 0.025922 | 3.594810 | 3.281631 | 1.464883 | -0.081411 |
| 16 | 0.725101 | 0.541493 | 0.026015 | 3.547387 | 3.246728 | 1.426615 | -0.083277 |
| 17 | 0.724560 | 0.541713 | 0.026747 | 3.839289 | 3.501243 | 1.572507 | -0.074493 |
| 18 | 0.759107 | 0.536109 | 0.020085 | 2.331602 | 2.045293 | 1.111270 | -0.012298 |
| 19 | 0.759383 | 0.535617 | 0.020086 | 2.729842 | 2.324775 | 1.429933 | -0.039978 |
| 20 | 0.758751 | 0.535255 | 0.021306 | 2.685071 | 2.298429 | 1.387512 | -0.022273 |
| Model identification coordinates(m) | manual marking coordinates(m) | Error | |
|---|---|---|---|
| 1 | (0.12557, 0.41514) | (0.12673, 0.41875) | (0.92%, 0.86%) |
| 2 | (0.95780, 0.41309) | (0.96078, 0.41875) | (0.31%, 1.35%) |
| 3 | (0.12993, 0.35823) | (0.12988, 0.35041) | (0.04%, 2.23%) |
| 4 | (0.96176, 0.35908) | (0.98225, 0.35041) | (2.08%, 2.47%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



