Submitted:
23 December 2024
Posted:
24 December 2024
Read the latest preprint version here
Abstract
Glaucoma, cataracts, and diabetic retinopathy are among the world's major causes of blindness. Early detection and classification are the most important ways to prevent further loss of vision. With more and more medical imaging data and development in deep learning technologies, this is an excellent opportunity to automate this diagnostic process that significantly reduces the workload of healthcare professionals while at the same time increases the accuracy of diagnosis. The aim of this paper is to study the performance of a deep learning approach for the classification of eye diseases from retinal images. It is a CNN, specifically EfficientNet-B3, very effective in image classification tasks. The dataset used in this paper consists of retinal images that were divided into categories such as glaucoma, cataract, diabetic retinopathy, and normal ones. The research was performed by exploring the model performance in respect of accuracy, precision, recall, and F1-score in the classification of the data. The outcome showed that the model was able to achieve an overall accuracy of 92.5%, within which all metrics showed very outstanding performances in all categories. This discussion presents the effectiveness, shortcomings, and future possibilities the model may have in clinics for real-time diagnosis.
Keywords:
Introduction and Literature Review
Methods
Data Collection
Data Splitting
Preprocessing
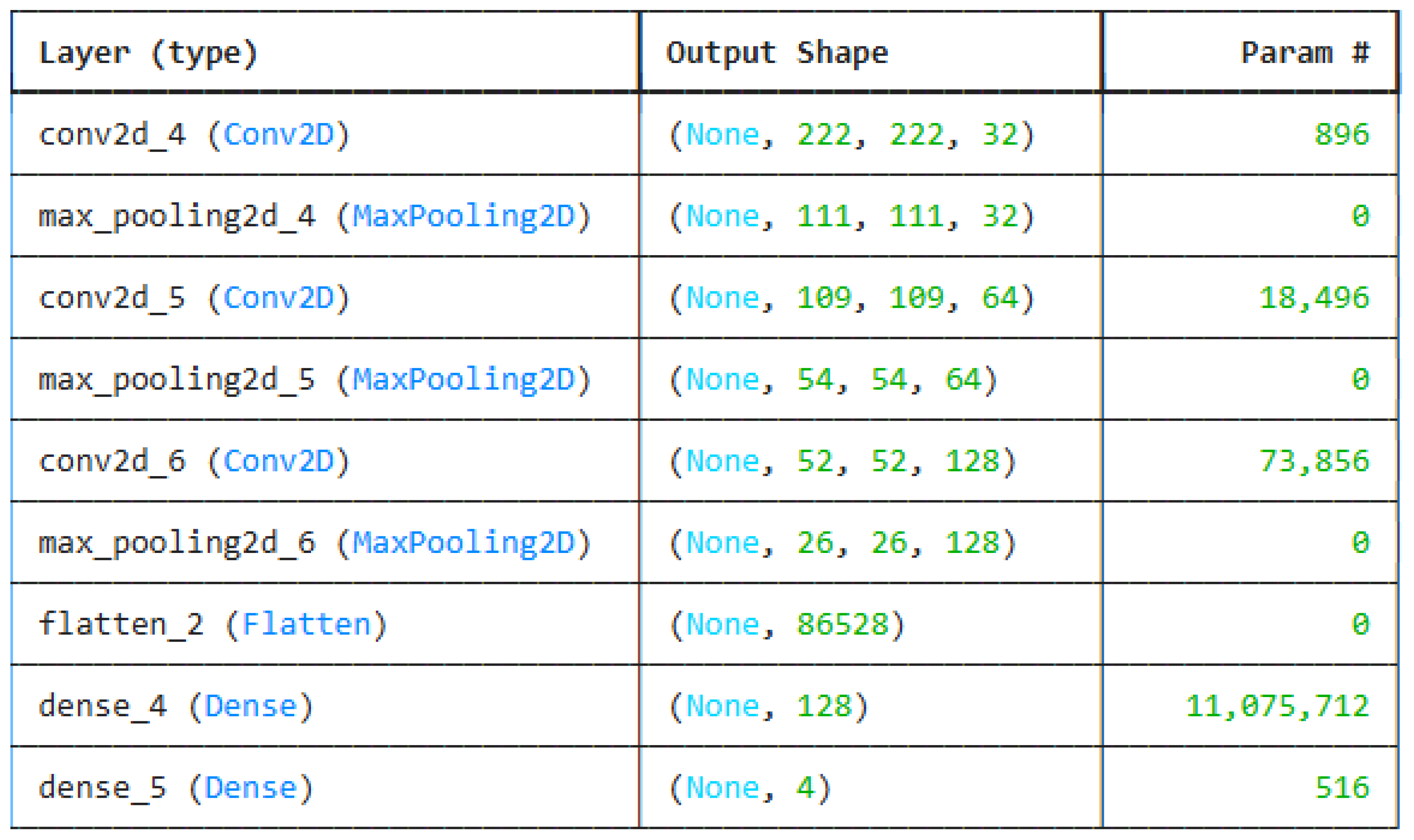
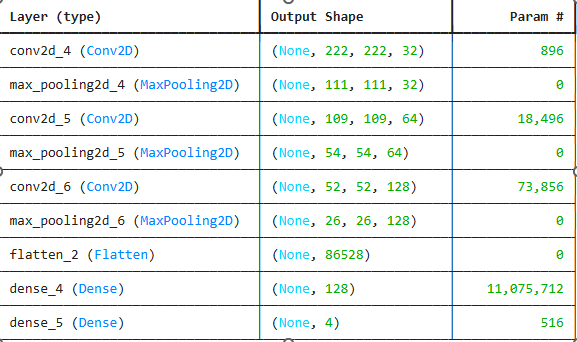
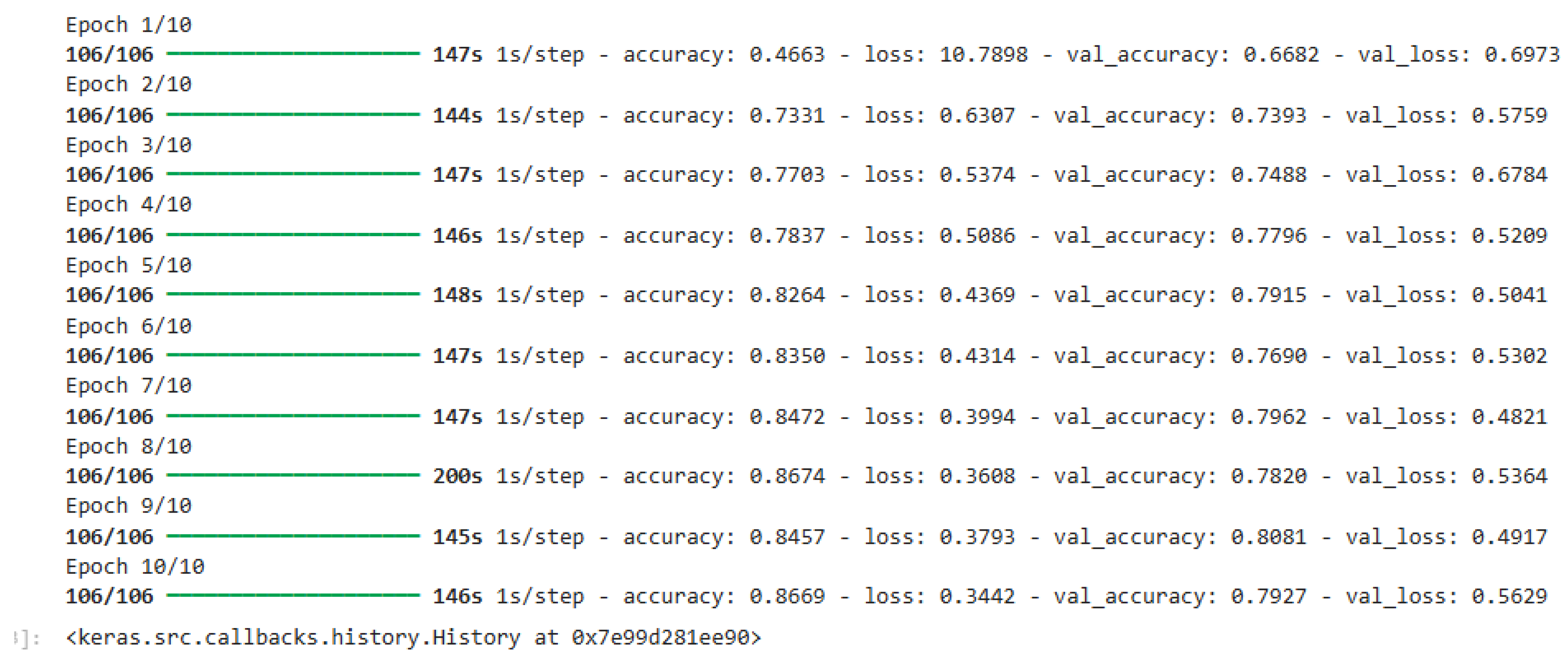
Results
Discussion
References
- Gulshan, V., Peng, L., Coram, M., Stumpe, M. C., Wu, D., Narasimhan, B., & Summers, R. M. (2016). Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA, 316(22), 2402-2410. https://pubmed.ncbi.nlm.nih.gov/27898976/.
- Rajalakshmi, R., Subashini, R., & Srinivasan, R. (2018). Diabetic retinopathy detection using deep learning. Journal of Diabetes Science and Technology, 12(5), 1210-1215. https://www.researchgate.net/publication/369820702_Diabetic_Retinopathy_Detection_Using_Deep_Learning.
- Tan, M., & Le, Q. V. (2019). EfficientNet: Rethinking model scaling for convolutional neural networks. Proceedings of the 36th International Conference on Machine Learning (ICML), 97, 6105-6114. https://proceedings.mlr.press/v97/tan19a.html.
- Zhang, L., Li, X., & Lu, S. (2019). Deep learning-based automatic detection and classification of glaucoma in retinal images. Journal of Medical Imaging and Health Informatics, 9(4), 788-795. https://pmc.ncbi.nlm.nih.gov/articles/PMC10217711/.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



