
Submitted:
15 December 2024
Posted:
18 December 2024
You are already at the latest version
Abstract
Background: Bladder cancer, the most common and heterogeneous malignancy of the urinary tract, presents with diverse types and treatment options, making comprehensive patient education essential. As Large Language Models (LLMs) emerge as a promising resource for disseminating medical information, their accuracy and validity compared to traditional methods remain under-explored. This study aims to evaluate the effectiveness of LLMs in educating the public about bladder cancer. Methods: Frequently asked questions regarding bladder cancer were sourced from reputable educational materials and assessed for accuracy, comprehensiveness, readability, and consistency by two independent board-certified urologists, with a third resolving any discrepancies. The study utilized a 3-point Likert scale for accuracy, a 5-point Likert scale for comprehensiveness, and the Flesch-Kincaid FK Grade Level and Flesch Reading Ease (FRE) scores to gauge readability. Results: ChatGPT-3.5, ChatGPT-4, and Gemini were evaluated on 12 general questions, 6 related to diagnosis, 28 concerning treatment, and 7 focused on prevention. Across all categories, the correct response rate was notably high, with ChatGPT-3.5 and ChatGPT-4 achieving 92.5%, compared to 86.3% for Gemini, with no significant difference in accuracy. However, there was a significant difference in comprehensiveness (p = 0.011) across the models. Overall, a significant difference in performance was observed among the LLMs (p < 0.001), with ChatGPT-4 providing the most college-level responses, though these were the most challenging to read. Conclusion: In conclusion, our study adds value to the applications of AI in bladder cancer education with notable insights on the accuracy, comprehensiveness, and stability of the three LLMs.
Keywords:
1. Introduction
2. Materials and Methods
Statistical Analysis
3. Results
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kirkali Z, Chan T, Manoharan M, Algaba F, Busch C, Cheng L, Kiemeney L, Kriegmair M, Montironi R, Murphy WM, Sesterhenn IA, Tachibana M, Weider J. Bladder cancer: epidemiology, staging and grading, and diagnosis. Urology. 2005 Dec;66(6 Suppl 1):4-34. PMID: 16399414. [CrossRef]
- Alghafees MA, Alqahtani MA, Musalli ZF, Alasker A. Bladder cancer in Saudi Arabia: a registry-based nationwide descriptive epidemiological and survival analysis. Ann Saudi Med. 2022 Jan-Feb;42(1):17-28. Epub 2022 Feb 3. PMID: 35112590; PMCID: PMC8812161. [CrossRef]
- Althubiti MA, Nour Eldein MM. Trends in the incidence and mortality of cancer in Saudi Arabia. Saudi Med J. 2018 Dec;39(12):1259-1262. PMID: 30520511; PMCID: PMC6344657. [CrossRef]
- Lenis AT, Lec PM, Chamie K, Mshs MD. Bladder Cancer: A Review. JAMA. 2020 Nov 17;324(19):1980-1991. PMID: 33201207. [CrossRef]
- Stein JP, Lieskovsky G, Cote R, Groshen S, Feng AC, Boyd S, Skinner E, Bochner B, Thangathurai D, Mikhail M, Raghavan D. Radical cystectomy in the treatment of invasive bladder cancer: long-term results in 1,054 patients. Journal of clinical oncology. 2001 Feb 1;19(3):666-75. [CrossRef]
- Quale DZ, Bangs R, Smith M, Guttman D, Northam T, Winterbottom A, Necchi A, Fiorini E, Demkiw S. Bladder Cancer Patient Advocacy: A Global Perspective. Bladder Cancer. 2015 Oct 26;1(2):117-122. PMID: 27398397; PMCID: PMC4929624. [CrossRef]
- Miner AS, Laranjo L, Kocaballi AB. Chatbots in the fight against the COVID-19 pandemic. NPJ digital medicine. 2020 May 4;3(1):65. [CrossRef]
- Calixte R, Rivera A, Oridota O, Beauchamp W, Camacho-Rivera M. Social and demographic patterns of health-related Internet use among adults in the United States: a secondary data analysis of the health information national trends survey. International Journal of Environmental Research and Public Health. 2020 Sep;17(18):6856. [CrossRef]
- Johnson SB, King AJ, Warner EL, Aneja S, Kann BH, Bylund CL. Using ChatGPT to evaluate cancer myths and misconceptions: artificial intelligence and cancer information. JNCI cancer spectrum. 2023 Apr 1;7(2):pkad015. [CrossRef]
- Corfield JM, Abouassaly R, Lawrentschuk N. Health information quality on the internet for bladder cancer and urinary diversion: a multi-lingual analysis. Minerva urologica e nefrologica= The Italian journal of urology and nephrology. 2017 Jul 12;70(2):137-43. [CrossRef]
- Shahsavar Y, Choudhury A. User Intentions to Use ChatGPT for Self-Diagnosis and Health-Related Purposes: Cross-sectional Survey Study. JMIR Human Factors. 2023 May 17;10(1):e47564. [CrossRef]
- Dave T, Athaluri SA, Singh S. ChatGPT in medicine: an overview of its applications, advantages, limitations, future prospects, and ethical considerations. Frontiers in Artificial Intelligence. 2023 May 4;6:1169595. [CrossRef]
- King MR. Can Bard, Google’s Experimental Chatbot Based on the LaMDA Large Language Model, Help to Analyze the Gender and Racial Diversity of Authors in Your Cited Scientific References?. Cellular and Molecular Bioengineering. 2023 Apr;16(2):175-9. [CrossRef]
- Koski E, Murphy J. AI in Healthcare.
- Ozgor F, Caglar U, Halis A, Cakir H, Aksu UC, Ayranci A, Sarilar O. Urological Cancers and ChatGPT: Assessing the Quality of Information and Possible Risks for Patients. Clin Genitourin Cancer. 2024 Apr;22(2):454-457.e4. Epub 2024 Jan 5. [CrossRef]
- Szczesniewski JJ, Tellez Fouz C, Ramos Alba A, Diaz Goizueta FJ, García Tello A, Llanes González L. ChatGPT and most frequent urological diseases: analysing the quality of information and potential risks for patients. World J Urol. 2023 Nov;41(11):3149-3153. Epub 2023 Aug 26. [CrossRef]
- Musheyev D, Pan A, Loeb S, Kabarriti AE. How Well Do Artificial Intelligence Chatbots Respond to the Top Search Queries About Urological Malignancies? Eur Urol. 2024 Jan;85(1):13-16. Epub 2023 Aug 10. PMID: 37567827. [CrossRef]
- Davis R, Eppler M, Ayo-Ajibola O, Loh-Doyle JC, Nabhani J, Samplaski M, Gill I, Cacciamani GE. Evaluating the Effectiveness of Artificial Intelligence-powered Large Language Models Application in Disseminating Appropriate and Readable Health Information in Urology. J Urol. 2023 Oct;210(4):688-694. Epub 2023 Jul 10. PMID: 37428117. [CrossRef]
- Momenaei B, Wakabayashi T, Shahlaee A, Durrani AF, Pandit SA, Wang K, Mansour HA, Abishek RM, Xu D, Sridhar J, Yonekawa Y, Kuriyan AE. Appropriateness and Readability of ChatGPT-4-Generated Responses for Surgical Treatment of Retinal Diseases. Ophthalmol Retina. 2023 Oct;7(10):862-868. Epub 2023 Jun 3. PMID: 37277096. [CrossRef]
- Robinson MA, Belzberg M, Thakker S, Bibee K, Merkel E, MacFarlane DF, Lim J, Scott JF, Deng M, Lewin J, Soleymani D, Rosenfeld D, Liu R, Liu TYA, Ng E. Assessing the accuracy, usefulness, and readability of artificial-intelligence-generated responses to common dermatologic surgery questions for patient education: A double-blinded comparative study of ChatGPT and Google Bard. J Am Acad Dermatol. 2024 May;90(5):1078-1080. Epub 2024 Feb 1. PMID: 38296195. [CrossRef]
- Hershenhouse JS, Mokhtar D, Eppler MB, Rodler S, Storino Ramacciotti L, Ganjavi C, Hom B, Davis RJ, Tran J, Russo GI, Cocci A, Abreu A, Gill I, Desai M, Cacciamani GE. Accuracy, readability, and understandability of large language models for prostate cancer information to the public. Prostate Cancer Prostatic Dis. 2024 May 14. Epub ahead of print. PMID: 38744934. [CrossRef]
- Zaleski AL, Berkowsky R, Craig KJT, Pescatello LS. Comprehensiveness, Accuracy, and Readability of Exercise Recommendations Provided by an AI-Based Chatbot: Mixed Methods Study. JMIR Med Educ. 2024 Jan 11;10:e51308. PMID: 38206661; PMCID: PMC10811574. [CrossRef]
- Abou-Abdallah M, Dar T, Mahmudzade Y, Michaels J, Talwar R, Tornari C. The quality and readability of patient information provided by ChatGPT: can AI reliably explain common ENT operations? Eur Arch Otorhinolaryngol. 2024 Mar 26. PMID: 38530460. [CrossRef]
- Ömür Arça D, Erdemir İ, Kara F, Shermatov N, Odacioğlu M, İbişoğlu E, Hanci FB, Sağiroğlu G, Hanci V. Assessing the readability, reliability, and quality of artificial intelligence chatbot responses to the 100 most searched queries about cardiopulmonary resuscitation: An observational study. Medicine (Baltimore). 2024 May 31;103(22):e38352. [CrossRef]
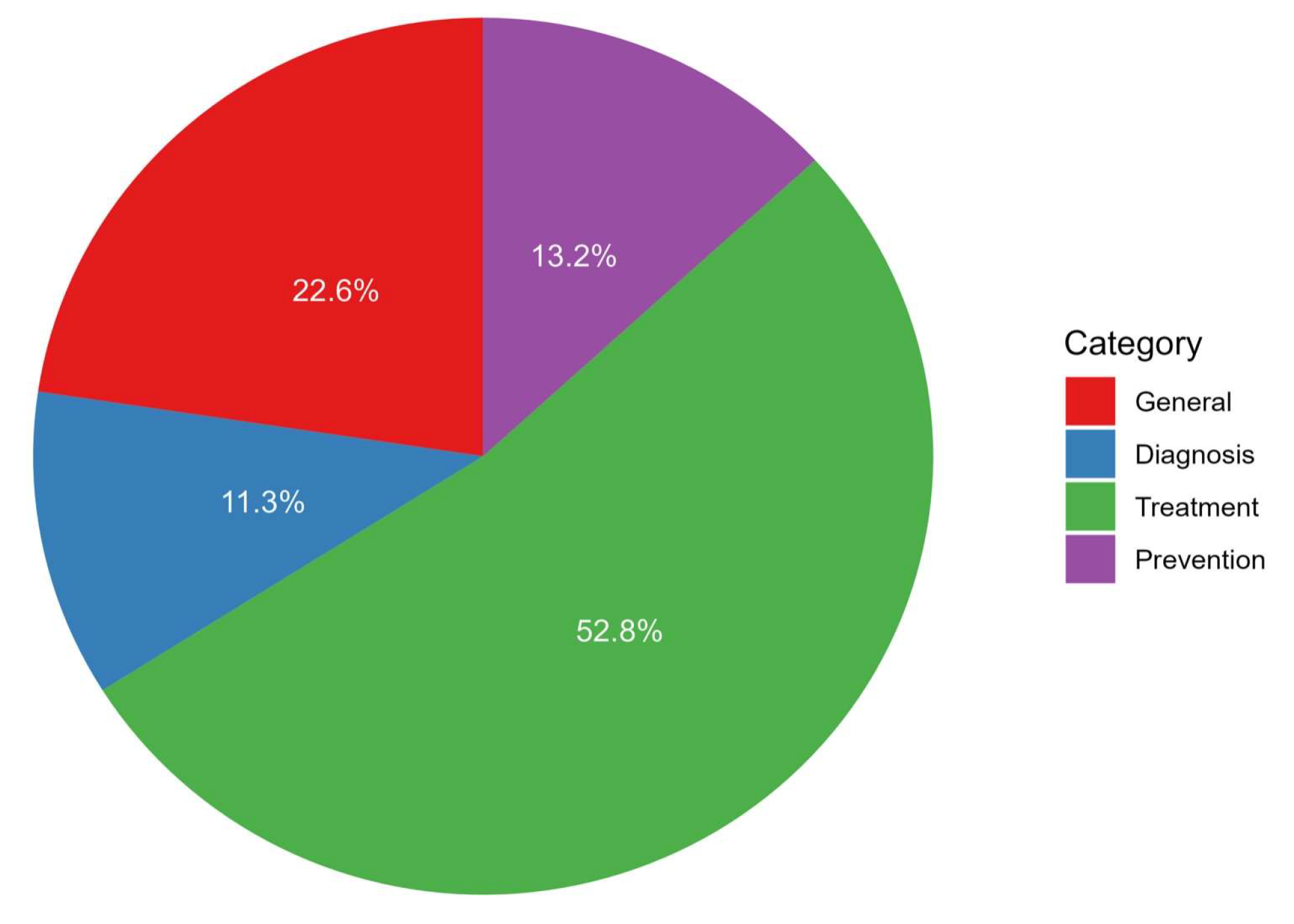

| Characteristic | Missing | ChatGPT | ChatGPT plus | Gemini | p-value |
|---|---|---|---|---|---|
| Overall (n=53) | 2 (1.3%) | 0.655 | |||
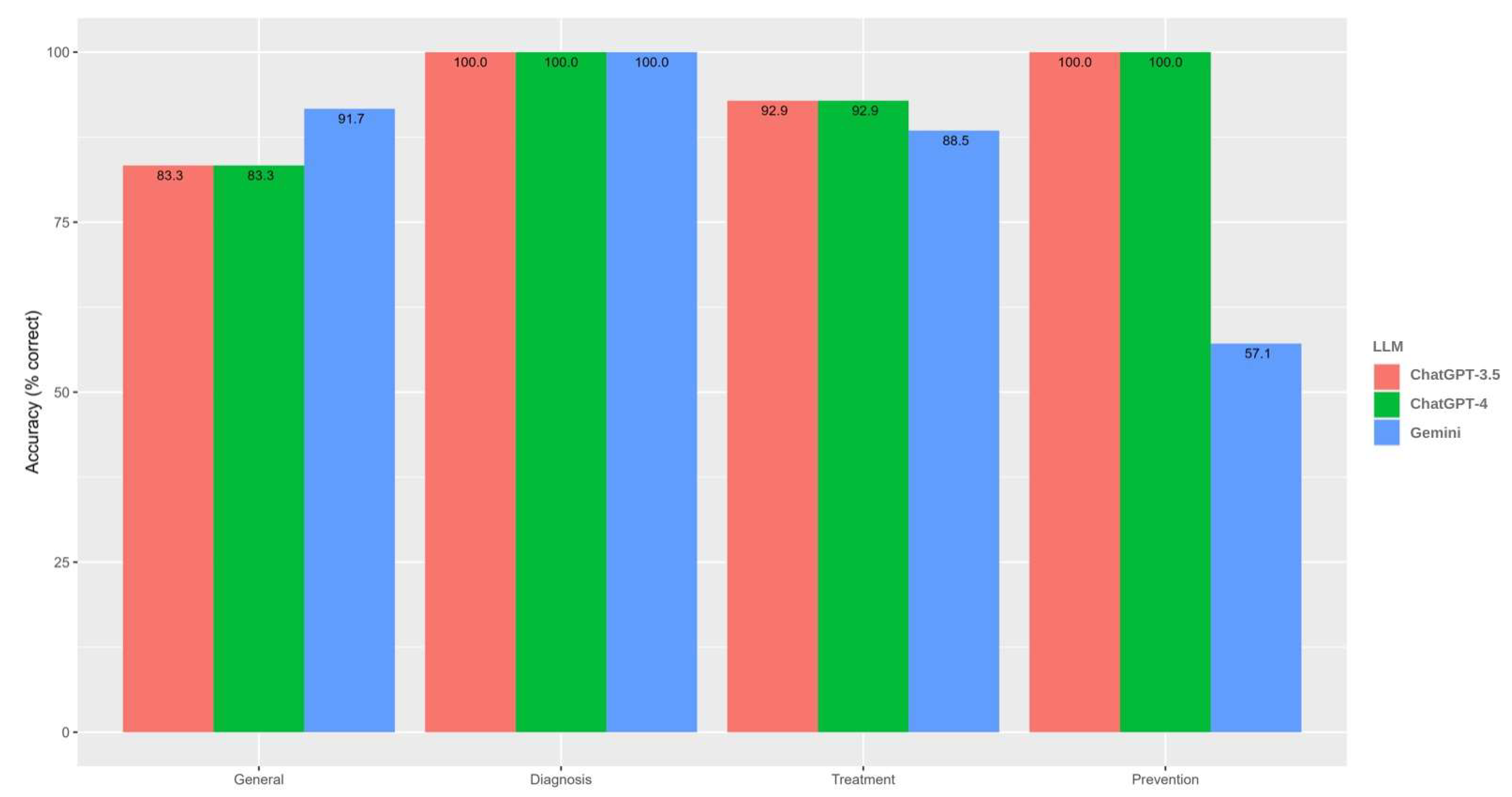
| Correct | 49 (92.5%) | 49 (92.5%) | 44 (86.3%) | ||
| Mixed | 4 (7.5%) | 3 (5.7%) | 6 (11.8%) | ||
| Completely incorrect | 0 (0.0%) | 1 (1.9%) | 1 (2.0%) | ||
| General (n=12) | 0 (0%) | >0.999 | |||
| Correct | 10 (83.3%) | 10 (83.3%) | 11 (91.7%) | ||
| Mixed | 2 (16.7%) | 2 (16.7%) | 1 (8.3%) | ||
| Completely incorrect | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Diagnosis (n=6) | 0 (0%) | >0.999 | |||
| Correct | 6 (100.0%) | 6 (100.0%) | 6 (100.0%) | ||
| Mixed | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Completely incorrect | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Treatment (n=28) | 2 (2.4%) | 0.848 | |||
| Correct | 26 (92.9%) | 26 (92.9%) | 23 (88.5%) | ||
| Mixed | 2 (7.1%) | 1 (3.6%) | 2 (7.7%) | ||
| Completely incorrect | 0 (0.0%) | 1 (3.6%) | 1 (3.8%) | ||
| Prevention (n=7) | 0 (0%) | 0.079 | |||
| Correct | 7 (100.0%) | 7 (100.0%) | 4 (57.1%) | ||
| Mixed | 0 (0.0%) | 0 (0.0%) | 3 (42.9%) | ||
| Completely incorrect | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) |
| Characteristic | Missing | ChatGPT | ChatGPT plus | Gemini | p-value |
|---|---|---|---|---|---|
| Overall (n=53) | 2 (1.3%) | 0.011 | |||
| Very inadequate | 5 (9.4%) | 3 (5.7%) | 5 (9.8%) | ||
| Inadequate | 1 (1.9%) | 1 (1.9%) | 4 (7.8%) | ||
| Neither comprehensive nor inadequate | 7 (13.2%) | 5 (9.4%) | 7 (13.7%) | ||
| Comprehensive | 35 (66.0%) | 22 (41.5%) | 22 (43.1%) | ||
| Very comprehensive | 5 (9.4%) | 22 (41.5%) | 13 (25.5%) | ||
| General (n=12) | 0 (0%) | 0.291 | |||
| Very inadequate | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Inadequate | 1 (8.3%) | 0 (0.0%) | 0 (0.0%) | ||
| Neither comprehensive nor inadequate | 3 (25.0%) | 0 (0.0%) | 2 (16.7%) | ||
| Comprehensive | 7 (58.3%) | 8 (66.7%) | 6 (50.0%) | ||
| Very comprehensive | 1 (8.3%) | 4 (33.3%) | 4 (33.3%) | ||
| Diagnosis (n=6) | 0 (0%) | >0.999 | |||
| Very inadequate | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Inadequate | 0 (0.0%) | 0 (0.0%) | 1 (16.7%) | ||
| Neither comprehensive nor inadequate | 1 (16.7%) | 1 (16.7%) | 1 (16.7%) | ||
| Comprehensive | 2 (33.3%) | 2 (33.3%) | 1 (16.7%) | ||
| Very comprehensive | 3 (50.0%) | 3 (50.0%) | 3 (50.0%) | ||
| Treatment (n=28) | 2 (2.4%) | 0.007 | |||
| Very inadequate | 5 (17.9%) | 3 (10.7%) | 5 (19.2%) | ||
| Inadequate | 0 (0.0%) | 1 (3.6%) | 3 (11.5%) | ||
| Neither comprehensive nor inadequate | 2 (7.1%) | 2 (7.1%) | 3 (11.5%) | ||
| Comprehensive | 20 (71.4%) | 10 (35.7%) | 10 (38.5%) | ||
| Very comprehensive | 1 (3.6%) | 12 (42.9%) | 5 (19.2%) | ||
| Prevention (n=7) | 0 (0%) | 0.205 | |||
| Very inadequate | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Inadequate | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Neither comprehensive nor inadequate | 1 (14.3%) | 2 (28.6%) | 1 (14.3%) | ||
| Comprehensive | 6 (85.7%) | 2 (28.6%) | 5 (71.4%) | ||
| Very comprehensive | 0 (0.0%) | 3 (42.9%) | 1 (14.3%) |
| Characteristic | Missing | ChatGPT | ChatGPT plus | Gemini | p-value |
|---|---|---|---|---|---|
| Overall (n=53) | 0 (0%) | <0.001 | |||
| 6th grade | 0 (0.0%) | 0 (0.0%) | 1 (1.9%) | ||
| 7th grade | 0 (0.0%) | 0 (0.0%) | 4 (7.5%) | ||
| 8th & 9th grade | 2 (3.8%) | 1 (1.9%) | 13 (24.5%) | ||
| 10th to 12th grade | 8 (15.1%) | 4 (7.5%) | 17 (32.1%) | ||
| College | 37 (69.8%) | 40 (75.5%) | 18 (34.0%) | ||
| College graduate | 6 (11.3%) | 7 (13.2%) | 0 (0.0%) | ||
| Professional | 0 (0.0%) | 1 (1.9%) | 0 (0.0%) | ||
| General (n=12) | 0 (0%) | 0.016 | |||
| 6th grade | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| 7th grade | 0 (0.0%) | 0 (0.0%) | 2 (16.7%) | ||
| 8th & 9th grade | 1 (8.3%) | 1 (8.3%) | 3 (25.0%) | ||
| 10th to 12th grade | 3 (25.0%) | 1 (8.3%) | 5 (41.7%) | ||
| College | 8 (66.7%) | 10 (83.3%) | 2 (16.7%) | ||
| College graduate | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Professional | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Diagnosis (n=6) | 0 (0%) | 0.050 | |||
| 6th grade | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| 7th grade | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| 8th & 9th grade | 0 (0.0%) | 0 (0.0%) | 2 (33.3%) | ||
| 10th to 12th grade | 1 (16.7%) | 0 (0.0%) | 3 (50.0%) | ||
| College | 4 (66.7%) | 5 (83.3%) | 1 (16.7%) | ||
| College graduate | 1 (16.7%) | 1 (16.7%) | 0 (0.0%) | ||
| Professional | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Treatment (n=28) | 0 (0%) | <0.001 | |||
| 6th grade | 0 (0.0%) | 0 (0.0%) | 1 (3.6%) | ||
| 7th grade | 0 (0.0%) | 0 (0.0%) | 2 (7.1%) | ||
| 8th & 9th grade | 1 (3.6%) | 0 (0.0%) | 7 (25.0%) | ||
| 10th to 12th grade | 2 (7.1%) | 2 (7.1%) | 7 (25.0%) | ||
| College | 20 (71.4%) | 21 (75.0%) | 11 (39.3%) | ||
| College graduate | 5 (17.9%) | 4 (14.3%) | 0 (0.0%) | ||
| Professional | 0 (0.0%) | 1 (3.6%) | 0 (0.0%) | ||
| Prevention (n=7) | 0 (0%) | 0.561 | |||
| 6th grade | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| 7th grade | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| 8th & 9th grade | 0 (0.0%) | 0 (0.0%) | 1 (14.3%) | ||
| 10th to 12th grade | 2 (28.6%) | 1 (14.3%) | 2 (28.6%) | ||
| College | 5 (71.4%) | 4 (57.1%) | 4 (57.1%) | ||
| College graduate | 0 (0.0%) | 2 (28.6%) | 0 (0.0%) | ||
| Professional | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) |
| Characteristic | Missing | ChatGPT | ChatGPT plus | Gemini | p-value |
|---|---|---|---|---|---|
| Overall (n=53) | 0 (0%) | <0.001 | |||
| Plain English | 2 (3.8%) | 1 (1.9%) | 13 (24.5%) | ||
| Fairly easy to read | 0 (0.0%) | 0 (0.0%) | 4 (7.5%) | ||
| Easy to read | 0 (0.0%) | 0 (0.0%) | 1 (1.9%) | ||
| Difficult to read | 37 (69.8%) | 40 (75.5%) | 18 (34.0%) | ||
| Fairly difficult to read | 8 (15.1%) | 4 (7.5%) | 17 (32.1%) | ||
| Very difficult to read | 6 (11.3%) | 7 (13.2%) | 0 (0.0%) | ||
| Extremely difficult to read | 0 (0.0%) | 1 (1.9%) | 0 (0.0%) | ||
| General (n=12) | 0 (0%) | 0.019 | |||
| Plain English | 1 (8.3%) | 1 (8.3%) | 3 (25.0%) | ||
| Fairly easy to read | 0 (0.0%) | 0 (0.0%) | 2 (16.7%) | ||
| Easy to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Difficult to read | 8 (66.7%) | 10 (83.3%) | 2 (16.7%) | ||
| Fairly difficult to read | 3 (25.0%) | 1 (8.3%) | 5 (41.7%) | ||
| Very difficult to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Extremely difficult to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Diagnosis (n=6) | 0 (0%) | 0.055 | |||
| Plain English | 0 (0.0%) | 0 (0.0%) | 2 (33.3%) | ||
| Fairly easy to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Easy to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Difficult to read | 4 (66.7%) | 5 (83.3%) | 1 (16.7%) | ||
| Fairly difficult to read | 1 (16.7%) | 0 (0.0%) | 3 (50.0%) | ||
| Very difficult to read | 1 (16.7%) | 1 (16.7%) | 0 (0.0%) | ||
| Extremely difficult to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Treatment (n=28) | 0 (0%) | <0.001 | |||
| Plain English | 1 (3.6%) | 0 (0.0%) | 7 (25.0%) | ||
| Fairly easy to read | 0 (0.0%) | 0 (0.0%) | 2 (7.1%) | ||
| Easy to read | 0 (0.0%) | 0 (0.0%) | 1 (3.6%) | ||
| Difficult to read | 20 (71.4%) | 21 (75.0%) | 11 (39.3%) | ||
| Fairly difficult to read | 2 (7.1%) | 2 (7.1%) | 7 (25.0%) | ||
| Very difficult to read | 5 (17.9%) | 4 (14.3%) | 0 (0.0%) | ||
| Extremely difficult to read | 0 (0.0%) | 1 (3.6%) | 0 (0.0%) | ||
| Prevention (n=7) | 0 (0%) | 0.562 | |||
| Plain English | 0 (0.0%) | 0 (0.0%) | 1 (14.3%) | ||
| Fairly easy to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Easy to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) | ||
| Difficult to read | 5 (71.4%) | 4 (57.1%) | 4 (57.1%) | ||
| Fairly difficult to read | 2 (28.6%) | 1 (14.3%) | 2 (28.6%) | ||
| Very difficult to read | 0 (0.0%) | 2 (28.6%) | 0 (0.0%) | ||
| Extremely difficult to read | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) |
| Characteristic | Missing | ChatGPT | ChatGPT plus | Gemini | p-value |
|---|---|---|---|---|---|
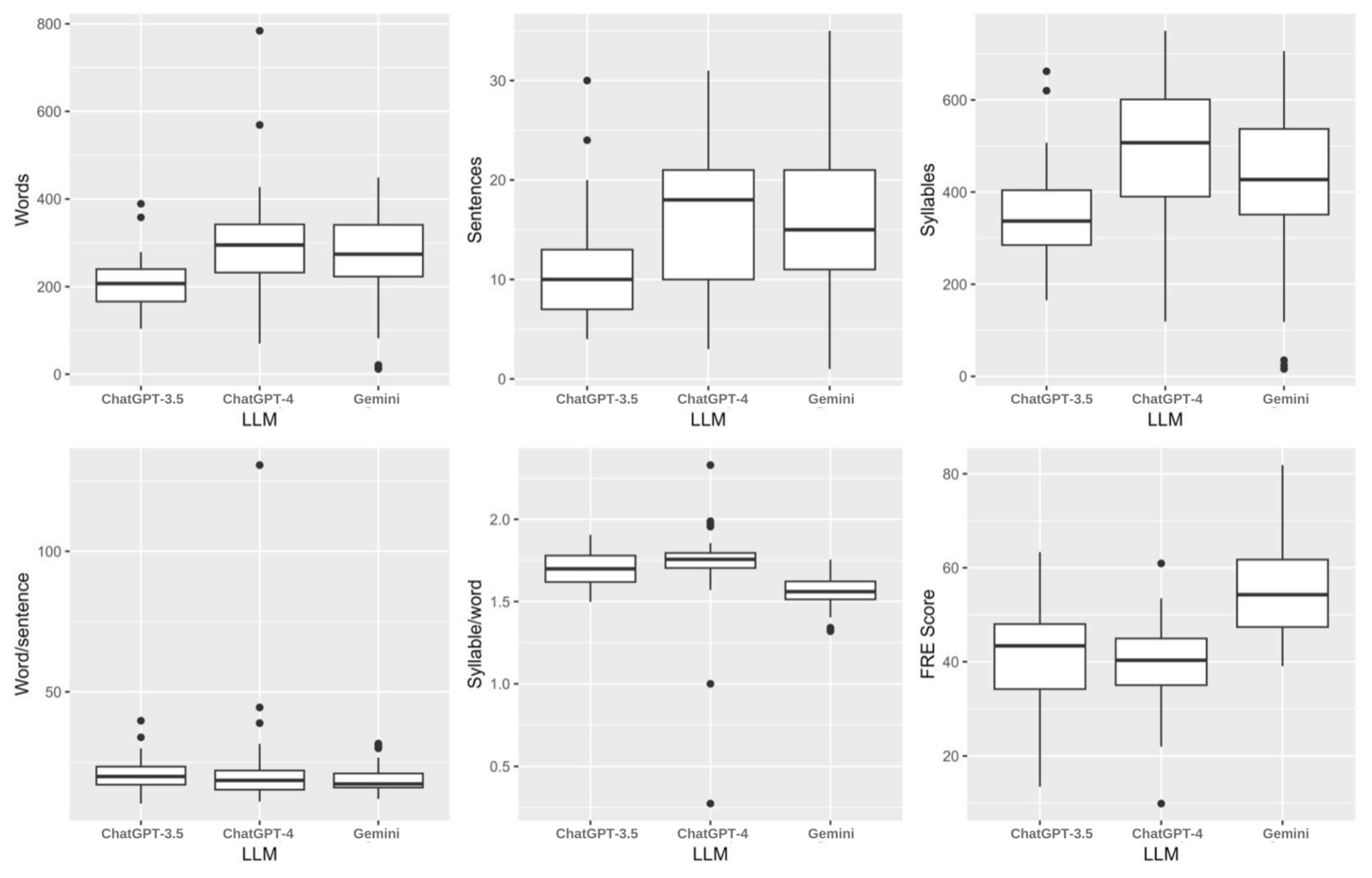
| Words | 0 (0%) | 207.0 (166.0 - 240.0) | 295.0 (232.0 - 342.0) | 274.0 (223.0 - 341.0) | <0.001 |
| Sentences | 0 (0%) | 10.0 (7.0 - 13.0) | 18.0 (10.0 - 21.0) | 15.0 (11.0 - 21.0) | <0.001 |
| Syllables | 0 (0%) | 337.0 (285.0 - 404.0) | 507.0 (390.0 - 601.0) | 427.0 (351.0 - 537.0) | <0.001 |
| Word/sentence | 0 (0%) | 20.0 (17.1 - 23.5) | 18.6 (15.3 - 22.1) | 17.3 (16.1 - 21.1) | 0.099 |
| Syllable/word | 0 (0%) | 1.7 (1.6 - 1.8) | 1.8 (1.7 - 1.8) | 1.6 (1.5 - 1.6) | <0.001 |
| FRE Score | 0 (0%) | 43.4 (34.2 - 48.0) | 40.3 (35.0 - 44.9) | 54.3 (47.4 - 61.7) | <0.001 |
| FK Reading Level | 0 (0%) | 13.6 (11.7 - 15.4) | 12.6 (11.5 - 13.8) | 11.0 (9.4 - 45,116.0) | 0.093 |
| Median (IQR) | |||||
| Kruskal-Wallis rank sum test | |||||
| Characteristic | ChatGPT | ChatGPT plus | Gemini | p-value |
|---|---|---|---|---|
| Overall (n=10) | >0.999 | |||
| Consistent | 9 (90.0%) | 9 (90.0%) | 8 (80.0%) | |
| Inconsistent | 1 (10.0%) | 1 (10.0%) | 2 (20.0%) | |
| Diagnosis (n=3) | 0.671 | |||
| Consistent | 3 (100.0%) | 2 (66.7%) | 1 (33.3%) | |
| Inconsistent | 0 (0.0%) | 1 (33.3%) | 2 (66.7%) | |
| Treatment (n=3) | >0.999 | |||
| Consistent | 2 (66.7%) | 3 (100.0%) | 3 (100.0%) | |
| Inconsistent | 1 (33.3%) | 0 (0.0%) | 0 (0.0%) | |
| Prevention (n=4) | ||||
| Consistent | 4 (100.0%) | 4 (100.0%) | 4 (100.0%) | NA |
| Inconsistent | 0 (0.0%) | 0 (0.0%) | 0 (0.0%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



