Submitted:
23 December 2024
Posted:
25 December 2024
You are already at the latest version
Abstract
The study provides an alternative definition of the assembly space as an acyclic, 2-in-regular digraph of strings provided with an edge labeling map that preserves the commutativity of an assembly step but defines the order of concatenation of strings in this step. Remarkably, the uniqueness of each vertex is the sufficient criterion to establish if an assembly step is allowed and to introduce the notion of an assembly pool: unit-length strings cannot be assembled from shorter strings and, hence, are inaccessible, forming the initial assembly pool, and strings present in the assembly space can not be assembled again, possibly using different pathways, as they would not be unique. What is allowed is the evolution of assembly pathways to make them shorter. We also comment on certain results of [10.48550/ARXIV.2406.12176], showing that the Assembly Steps Problem, not the Assembly Index Problem, has been proved in the referenced study to be NP-complete.
Keywords:
assembly theory
; assembly index
; information theory
; complexity measures
; mathematical physics
1. Introduction
A recent study [1] shows that assembly theory offers a distinct approach and answers different questions than computational complexity theory with its focus on minimum descriptions via compressibility and discusses fundamental differences in the ontological basis of assembly theory and the assembly index as a physical observable, which distinguish it from theoretical approaches to formalizing life that are unmoored from measurement. Furthermore, the study [1] claims to contain the proof of the conjecture posed in [2] that the Assembly Index Problem is NP-Complete. In general, it argues to show that any instance of Vertex Cover Problem, which is known to be NP-Hard, can be reformulated as an instance of the Assembly Index Problem. Finally, it leaves open the question of whether the noncommutative concatenation version of string assembly is NP-Complete; its authors see no alternative to reconcile the commutativity of the assembly step with the noncommutativity of the string concatenation (cf. [1], Supplementary Material, footnote 101.).
Here, we show that such a reconciliation is, in fact, possible by providing an alternative definition of the assembly space. We also show that it is the Assembly Steps Problem, not the Assembly Index Problem, which has been shown in [1] to be NP-complete. Hence, finding if a string can be assembled along a given path in a given number of steps is NP-complete. But we do not know if finding the minimal number of assembly steps leading to this string, that is, the assembly index of this string [3], is NP-complete.
2. An Alternative Definition of an Assembly Space
An assembly space is defined in [1] (cf. Definition 8) as an acyclic directed graph , where V is the set of vertices and E is the set of edges together with an edge labeling map . contains a finite and non-empty set of vertices that form the basis of , each reachable only from itself. All remaining vertices of are reachable from a vertex in .
The edge labeling map cleverly defines the assembly step. Namely
allowing to write , , and
However, the commutativity of the relation (2) cannot imply the commutativity of the string concatenation. If all assembly objects in are strings does not imply , as might be expected for string concatenation, but it actually implies also . Therefore, a string assembly space is endowed in [1] with the additional property (cf. [1], Definition 19 and Eq. (10))
and likewise for the 2nd edge .
However, the property (3) makes the terminating string z unresolvable if . Consequently, z cannot be used in subsequent assembly operations. Here, we provide an alternative definition of the assembly space.
Definition 1
(Assembly Space). An assembly space is an acyclic digraph of strings , where all unit length strings (basic symbol(s)) are inaccessible source vertices and the remaining strings are 2-in-regular assembly steps vertices, E is a set of edges, and is an edge labeling map, wherein an assembly step consists of forming a new string from two not necessarily different strings , by concatenating them with each other, establishing edges and , and assigning, strings , to edges , e using ϕ as
where ∘ denotes the string concatenation (strcat) operator.
The definition of edge labeling map (4) is possible if only , i.e., for more than one basic symbol, as in that case we can say that a given inaccessible symbol is the one, another is the one, and so on; we can sort them. Otherwise, the notion of a concatenation direction is pointless for one symbol only. Contrary to the previous definition of the labeling map [1], the relation (4) preserves the commutativity of the assembly step but defines the order of concatenation of the strings, as - in general - for different strings .
The definition 1 is consistent: all vertices are unique (in any standard graph all vertices should be unique), and all are strings. Since an assembly step always consists of joining two parts only [5], this can be thought of as the left and right fragments of the newly formed string [3], and those strings that can be the result of concatenation of two shorter strings are assembly step 2-in-regular vertices, while unit-length strings are inaccessible. Remarkably, the uniqueness of each vertex is the sufficient criterion to establish if an assembly step is allowed (cf. [1], Definition 10) and to introduce the notion of an assembly pool: vertices (strings) present in the assembly space can not be assembled again, possibly using different pathways, as they would not be unique; they can only be used in assembly of other strings. What is allowed is the evolution of assembly pathways to make them shorter, as shown in Figure 1. This evolution seems to be stimulated by the trend to decrease the assembly depth [3,6].
3. The Assembly Steps Problem is NP-Complete
In order to show that any instance of Vertex Cover Problem , where is a graph, is the set of vertices and is the set of edges and k is the cardinality of a set of vertices that includes at least one vertex of every edge of G, which is known to be NP-Hard, can be reformulated in polynomial time as an instance of the Assembly Index Problem, the following procedure is offered (cf. [1], Section 4.2). For a given instance of the Vertex Cover Problem , where , and is the vertex cover number (the size of a minimum vertex cover), an instance of the Assembly Index Problem is constructed, where is a constructed assembly space, and is the target string for which the assembly index is to be determined. It is then claimed that a certificate for the Vertex Cover Problem
containing a subset of vertices of G that includes at least one vertex of every edge of G can be used to produce a certificate for the Assembly Index Problem and vice versa, where is a rooted subspace (cf. [1] Definition 15) of the assembly space containing only a proper subset of the strings of the form . Hence, such an instance of the Assembly Index Problem would be logically equivalent to an instance of the Vertex Cover Problem from which it was constructed.
The construction of (cf. [1], Section 4.2) begins with defining the basis of the assembly space (cf. Eqs. (17), (50)), i.e., the unit-length strings
containing symbols of vertices , and a special symbol that here we call "0" (it is defined as "#" in [1]). Hence, . Then, a set of vertex strings
is assembled (Eq. (18)). Subsequently, a set of edge strings
is assembled (Eq. (19)). The last step of the construction of is a sequence of strings
and strings
defined in [1] by Eqs. (20)-(25), where the target string is defined as the last string of this sequence and
Finally ([1], Section 4.2.3) it is claimed that given is a certificate for the Assembly Index Problem if the set (5) is a vertex cover of G with size k, i.e. a certificate for the Vertex Cover Problem is given, wherein is the assembly index of string and
which depends on k and is minimal if .
By construction, the basic symbols (6), the edge strings (8), and the sequence strings (9a) and (9b) contained in must also be contained in (certificate). However, the vertex strings (7) of the form are the exception, as each of the edge strings (8) can be assembled from strings (7) in one of the two mutually exclusive steps (cf. [1] Eqs. (53), (54))
leaving some of the strings or redundant. It can be seen by comparing the cardinalities of the spaces (10) and (11), which - as expected - leads to . There are strings (7) in and only strings in .
By construction (9a), (9b), the target string has the form
where the is a vertex-specific part of depending solely on and its explicit form is given by the formula (9a), and the is an edge-specific part of , generated by the formula (9b), and depending both on , edge vertex assignments and the order of labeling of the edges of graph G. However, , as the length of each edge string (8) is five and there are such strings in and . Therefore, the length of the target string is
Furthermore, by construction contains two copies of the string of length having the assembly index equal to as it does not contain any repetitions of substrings. We can take advantage of the fact that each m copies of an n-plet contained in a string decrease the assembly index of this string at least by [3], where is the assembly index of this n-plet, to estimate the upper bound for the assembly index of reduced by the presence of these two copies of . Furthermore, excluding the degenerate cases of empty and disjoint graphs G, we can further infer some information about . That is, since any vertex is a part of some edge , contains at least two repetitions of doublets (or ), with as the string also contains such doublets, and each repetition decreases the assembly index by one. Hence, the upper bound must be further decreased by . Finally, each string contains repetitions of a doublet and, hence, the upper bound must be further decreased by . Therefore, the initial upper bound on the assembly index that amounts to [5] if [3] decreases to
which, in contrast to (11), is independent of k.
As an example, consider the trivial graph , shown in Figure 2(b) having two edges connected at one vertex. Hence, its vertex cover number is . In this case, (10) and the target string generated by sequences (9a) and (9b) has the form
As the vertex cover of the graph G is the vertex 2, the subspace (the certificate) is devoid of triplets and , since the edges and share the vertex 2, and the edge strings (8) could be assembled as and . Therefore, the number of steps on the assembly pathway of defined by , given by the relation (11), amounts to , as shown in Figure 3(a) also illustrating the assembly depth [6] () of this string: 7 steps (1-7) for vertex strings (7), 2 steps (8, 9) for edge strings (8), 6 steps (10-15) for sequence strings (9a), and 2 steps (16, 17) for sequence strings (9b)) which corresponds to the vertex cover number , if only the string (16) is assembled using the set of allowed assembly operations defined by the equations Eqs. (38)-(45) of [1].
However, imposing such a set of allowed assembly steps deviates from the principles of assembly theory that assume the possibility of assembling any object from any two objects in the assembly pool. Even if we assume that only some steps are allowed and some are not due to peculiarities of the assembled data structures, this is certainly not the case for strings, considered in [1] in the proof of Lemma 3. All strings are possible and mathematically well defined [7]. What could be the reason for allowing the assembly of a string and disallowing the assembly of a string from a set of basic symbols ? The evolution of information became possible as soon as a first bit, not a first particle or object, became accessible [2,3,8,9].
Therefore, the assembly index of the string (16) is . One of the shortest pathways of the string (16) is shown in Figure 3(c) with . A quadruplet present in two independent copies is assembled in step 5, 5-plet present in two copies is assembled in step 6. Furthermore, contains two independent copies of , , and . A slightly longer pathway leading to the string of length (15) is shown in Figure 3(b).
4. Conclusions
The study [1] shows that the Assembly Steps Problem, that is, a problem of determining if a given string can be assembled in a given number of steps according to principles of assembly theory, can be reformulated as the NP-hard Vertex Cover Problem, that is a problem of determining if a given set of vertices of a graph contains at least one vertex of each edge of this graph, and hence the former problem is also NP-hard. Furthermore, the study [1] shows that, since a proposed solution (certificate) to the Assembly Steps Problem can be checked for correctness in polynomial time, the Assembly Steps Problem becomes NP-complete.
However, based on a few simple graphs, we have here shown that the proposed construction of an assembly space from a graph (a certificate) to map the correspondence between the Minimum Vertex Cover Problem and the Assembly Steps Problem does not reflect the shortest pathway leading to this string and hence does not correspond to the Assembly Index Problem.
In this study, we have also answered in the affirmative the question posed in [1]: using the alternative, novel of the assembly space of strings 1 and the procedure of constructing the Assembly Steps Problem to correspond to the Vertex Cover Problem [1] shows that the noncommutative concatenation version of the Assembly Steps Problem is also NP-Complete.
Unfortunately, we still do not know if the Assembly Index Problem is NP-Complete.
Funding
This research received no external funding.
Acknowledgments
The author thanks Mariola Bala, Wawrzyniec Bieniawski, Piotr Masierak for motivation, critical discussions and numerous clarity, reasoning, and grammar corrections, his wife, Magdalena Bartocha, for her everlasting support, and his partner and friend, Renata Sobajda, for her prayers.
References
- Kempes, C.P.; Lachmann, M.; Iannaccone, A.; Fricke, G.M.; Chowdhury, M.R.; Walker, S.I.; Cronin, L. Assembly Theory and its Relationship with Computational Complexity. arXiv 2024, arXiv:2406.12176. [Google Scholar] [CrossRef]
- Łukaszyk, S.; Bieniawski, W. Assembly Theory of Binary Messages. Mathematics 2024, 12, 1600. [Google Scholar] [CrossRef]
- Bieniawski, W.; Masierak, P.; Tomski, A.; Łukaszyk, S. On the Certain Salient Regularities of Strings of Assembly Theory. 2024. [Google Scholar] [CrossRef]
- Marshall, S.M.; Moore, D.G.; Murray, A.R.G.; Walker, S.I.; Cronin, L. Formalising the Pathways to Life Using Assembly Spaces. Entropy 2022, 24, 884. [Google Scholar] [CrossRef]
- Marshall, S.M.; Murray, A.R.G.; Cronin, L. A probabilistic framework for identifying biosignatures using Pathway Complexity. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 2017, 375, 20160342. [Google Scholar] [CrossRef] [PubMed]
- Pagel, S.; Sharma, A.; Cronin, L. Mapping Evolution of Molecules Across Biochemistry with Assembly Theory. arXiv 2024, arXiv:2409.05993. [Google Scholar] [CrossRef]
- Sharma, A.; Czégel, D.; Lachmann, M.; Kempes, C.P.; Walker, S.I.; Cronin, L. Assembly theory explains and quantifies selection and evolution. Nature 2023, 622, 321–328. [Google Scholar] [CrossRef] [PubMed]
- Łukaszyk, S. Black Hole Horizons as Patternless Binary Messages and Markers of Dimensionality. In Future Relativity, Gravitation, Cosmology; Chapter 15; Nova Science Publishers, 2023; pp. 317–374. [Google Scholar] [CrossRef]
- Łukaszyk, S. Life as the Explanation of the Measurement Problem. Journal of Physics: Conference Series 2024, 2701, 012124. [Google Scholar] [CrossRef]
Figure 1.
The evolution of assembly pathways leading to a string to make them shorter and minimize the assembly depth, also illustrating the definition of the edge labeling map for : (a), ("blue arrow goes first").
Figure 1.
The evolution of assembly pathways leading to a string to make them shorter and minimize the assembly depth, also illustrating the definition of the edge labeling map for : (a), ("blue arrow goes first").
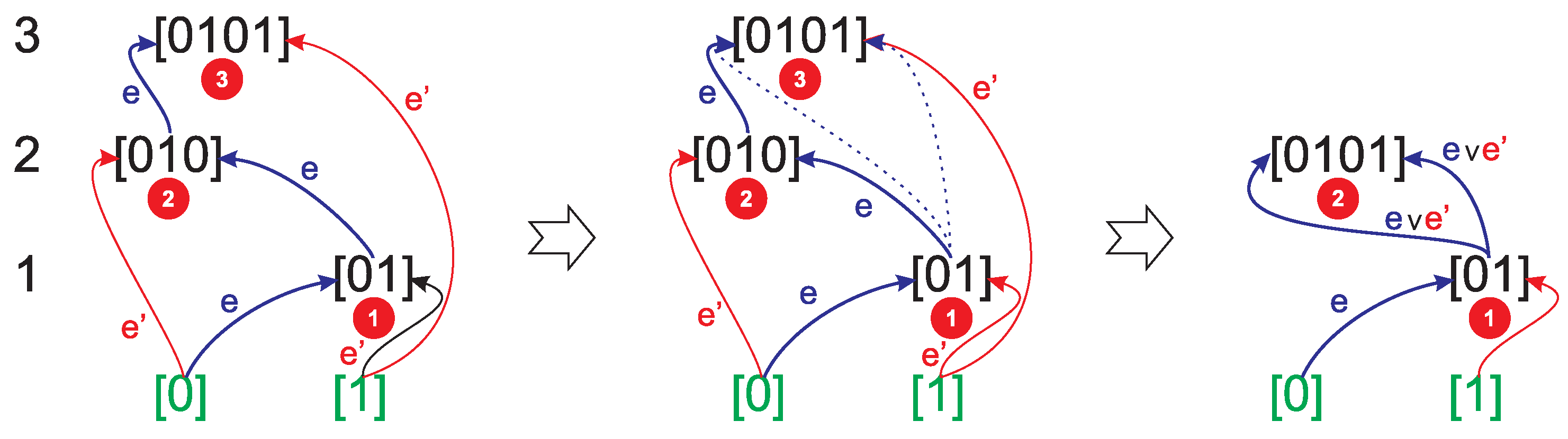
Figure 2.
Simple graphs we examined: one edge (a), two edges (b), three edges (c), square (d), "EM rocket"(e), a complete graph (f). Red circles indicate a minimum vertex cover.
Figure 2.
Simple graphs we examined: one edge (a), two edges (b), three edges (c), square (d), "EM rocket"(e), a complete graph (f). Red circles indicate a minimum vertex cover.

Figure 3.
Three assembly spaces of the same string : the pathway to produce a vertex cover certificate ( steps) (a), the pathway taking into account the general distributions of substrings in all strings ( steps) (b), a shortest, assembly index pathway ( steps) (c).
Figure 3.
Three assembly spaces of the same string : the pathway to produce a vertex cover certificate ( steps) (a), the pathway taking into account the general distributions of substrings in all strings ( steps) (b), a shortest, assembly index pathway ( steps) (c).
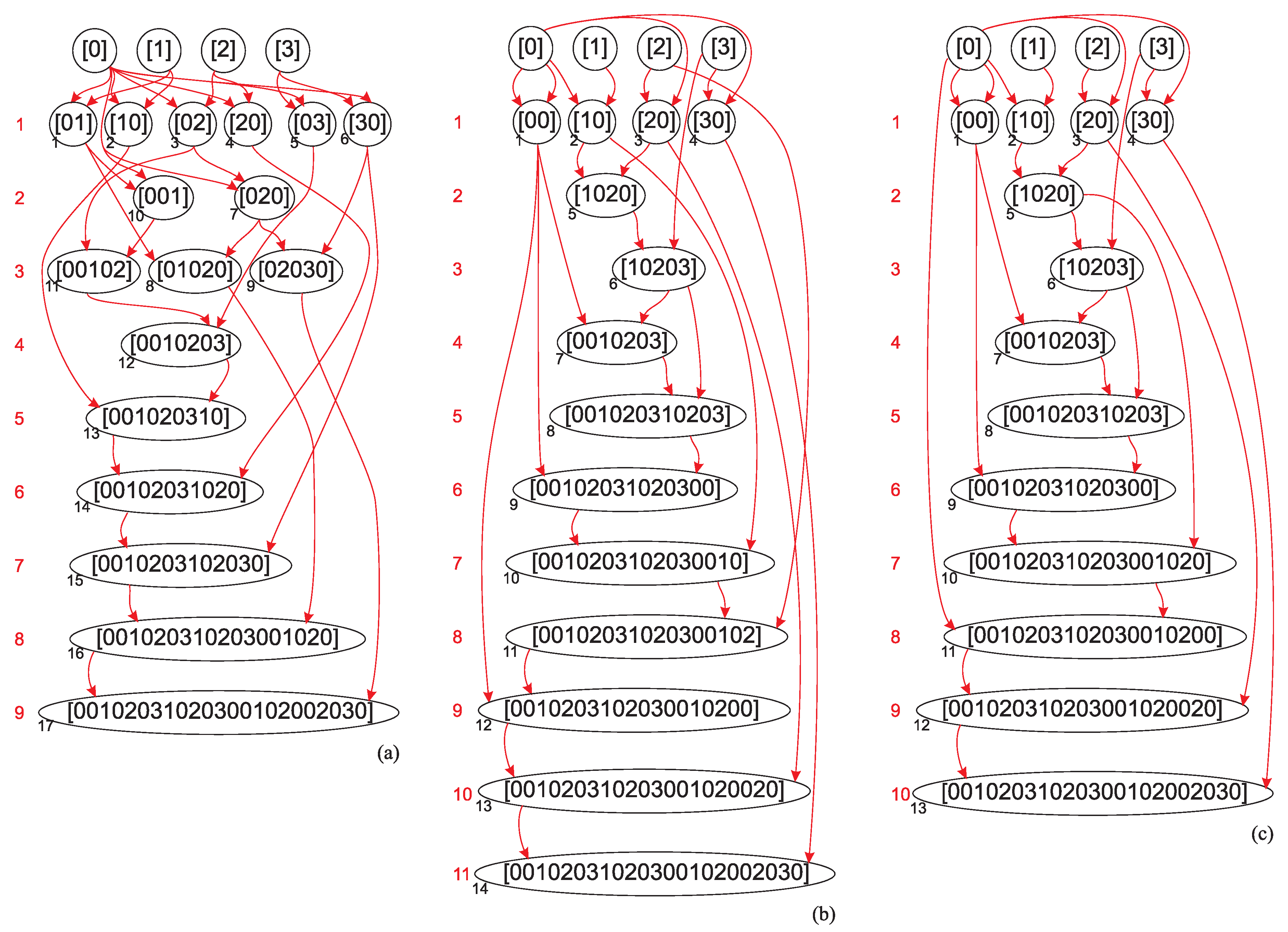

Table 1.
Assembly indices of target strings constructed [1] for the Vertex Cover Problem graphs G; minimum and maximum assembly indices , for ; numbers of steps leading to used in [1] () and derived here (), for examined graphs.
| Graph | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| one edge | 2 | 1 | 1 | 14 | 5 | 8 | 9 | 11 | 12 |
| two edges | 3 | 2 | 1 | 23 | 7 | 13 | 14 | 17 | 21 |
| three edges | 4 | 3 | 1 | 32 | 5 | 18 | 19 | 23 | 30 |
| square | 4 | 4 | 2 | 37 | 7 | 20 | 23 | 26 | 33 |
| "EM rocket" | 6 | 7 | 3 | 60 | 7 | 32 | 37 | 41 | 58 |
| 5 | 10 | 4 | 71 | 9 | 40 | 48 | 44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



