Submitted:
17 December 2024
Posted:
18 December 2024
You are already at the latest version
Abstract
Objectives: To analyze the optimization of unsupervised clustering models in healthcare, identifying applied algorithms, evaluation metrics used, and the main methodological and practical challenges in their implementation. Methodology: A systematic review of articles indexed in Scopus between 2010 and 2024, focused on biomedical applications of clustering, was conducted. Studies employing algorithms such as k-means, hierarchical clustering, hybrid techniques, and advanced methods, with robust validation metrics such as the Silhouette index, principal component analysis (PCA), and data imputation techniques, were selected. Results: The most commonly used algorithms were k-means and fuzzy c-means, along with hybrid approaches integrating artificial intelligence and deep learning. Notable clinical applications included patient segmentation in multimorbidity, oncology, and medical image analysis. Clustering facilitated the identification of complex patterns, clinical subgroups, and risk stratification, improving diagnostics and personalized treatments. Challenges identified included high data dimensionality, clinical heterogeneity, lack of metric standardization, and the need for interpretable results. Conclusions: The optimization of unsupervised clustering models holds high potential in precision medicine and clinical decision-making. Overcoming challenges such as dimensionality reduction, result validation, and integration with advanced techniques is crucial to strengthening their applicability in real-world contexts.

Keywords:
Unsupervised clustering
; k-means
; healthcare
; evaluation metrics
; artificial intelligence
; medical imaging
Introduction
Unsupervised clustering models have emerged as key tools for uncovering hidden patterns in unlabeled data, facilitating patient segmentation and improving diagnostics [1, 2]. Unlike supervised methods, these algorithms do not require prior labels, enabling their application to complex diseases such as multimorbidity and cancer [3, 4].
Among the most commonly used algorithms are k-means and fuzzy c-means, which have proven effective in segmenting subgroups of patients with similar clinical characteristics [5]. For instance, in oncology, clustering has been used to identify molecular subtypes of tumors, optimizing personalized treatments [6]. Similarly, in radiotherapy, spatial stratification techniques have enhanced long-term risk prediction for patients [7]. In liver cirrhosis, robust clustering strategies have allowed for the identification of relevant clinical subgroups [8]. Moreover, advanced techniques such as dimensionality reduction via PCA have facilitated the interpretation of high-complexity data, improving algorithm precision and efficiency [9, 10].
The heterogeneity of clinical data and the presence of missing values remain challenges. The use of robust metrics and cross-validation has been crucial in ensuring the quality of results [11, 12]. Additionally, the visualization and explainability of models are considered essential for achieving effective adoption in clinical practice [13, 14].
Unsupervised clustering models play a significant role in precision medicine. With successful applications in oncology, radiology, and multimorbidity, these techniques enable the identification of clinical patterns and support decision-making, transforming contemporary medical practice [15].
This article aims to analyze the applications of unsupervised clustering models in clinical contexts. Furthermore, it seeks to identify the most commonly used algorithms, the evaluation metrics applied, and the main challenges in their implementation.
Methods
Study Type
A systematic bibliographic review was conducted on the use of unsupervised clustering models in the biomedical field. The search included articles published between 2020 and 2024, written in English, and exclusively indexed in the Scopus database. The search terms used were: “unsupervised clustering”, “biomedical applications”, and “machine learning”. Studies outside the specified time range or unrelated to the application of these models in biomedical contexts were excluded.
Techniques and Instruments
Information was gathered using an observation sheet designed to record the algorithm used, the clinical application area, evaluation metrics, and results.
Literature Search
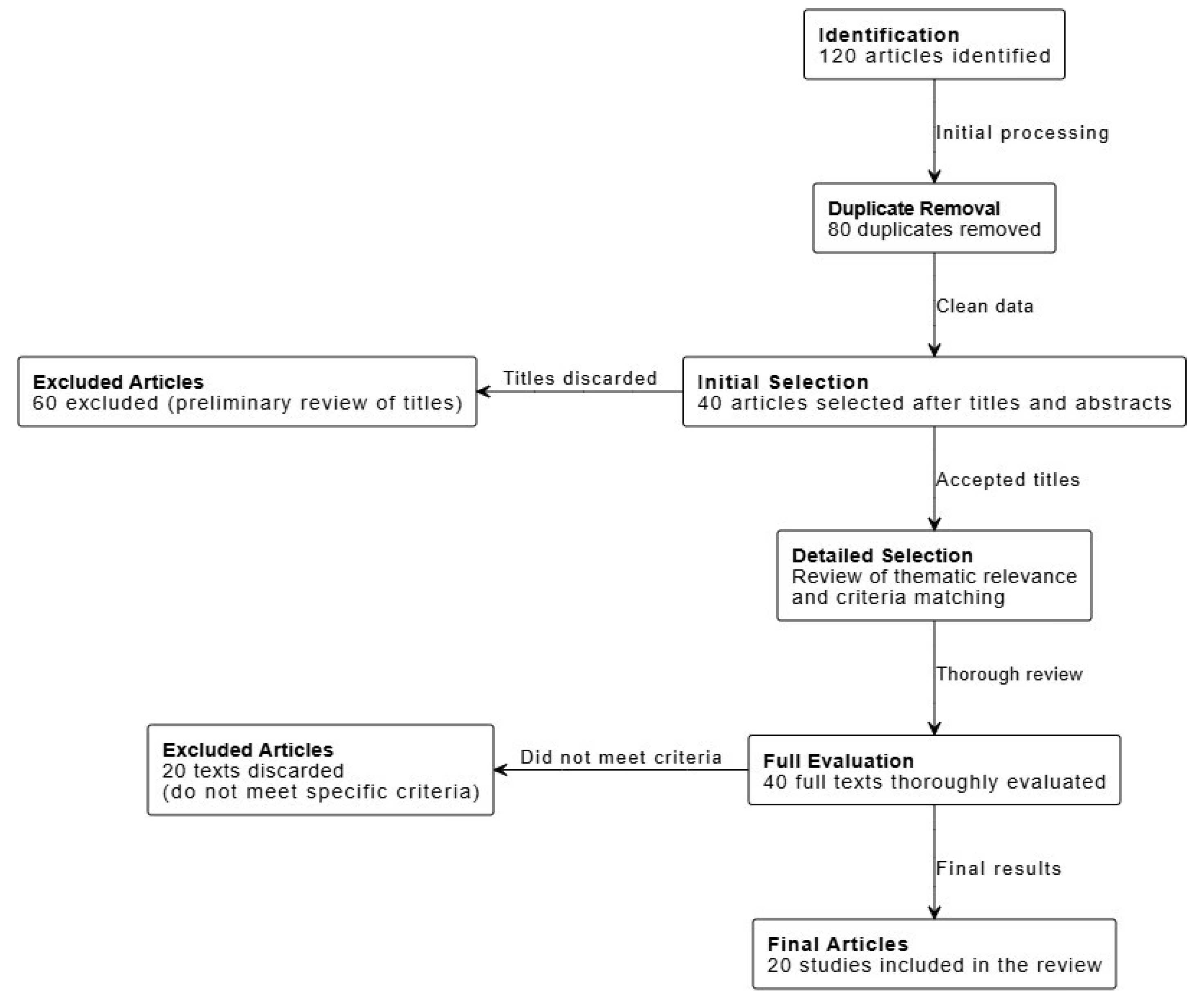
The bibliographic search was conducted between November 22 and 26, 2024, using Scopus as the sole source of information. In the first stage, 120 potential articles were identified using key terms and Boolean combinations. Duplicates were removed, and titles and abstracts were reviewed, reducing the number to 40 articles that met the preliminary inclusion criteria.
In the second stage, the full texts of these articles were reviewed, applying specific inclusion criteria: studies employing unsupervised clustering algorithms such as k-means, hierarchical clustering, or hybrid tools, and presenting clear quantitative results and robust validation metrics. Finally, 20 articles met all methodological and thematic requirements.
Figure 1.
PRISMA Diagram.
Study Analysis
The data from each article were organized and digitized in spreadsheets. This information was then systematized, described in tables, and organized. These indicators allowed for the descriptive quantification of the 20 studies according to clinical context, clustering algorithm used, evaluation metrics applied, and sample size.
Results
The studies conducted between 2021 and 2024 are described in Table 1. A total of 20 studies applying various clustering algorithms in healthcare and related fields were collected. These studies cover multiple clinical contexts and experimental design characteristics.
In general, most studies focused on clustering applications in diverse clinical contexts such as cardiology, multimorbidity, rheumatology, dentistry, oncology, and other specific scenarios. Two studies focused on cardiology, while the remaining contexts reported only one study per area. These results are reflected in Figure 2, where the predominant clinical contexts highlight the breadth of existing research. The sample sizes in the studies varied significantly, ranging from non-reported data (N/A) to large samples exceeding 1,000 patients or images, as shown in Figure 3.
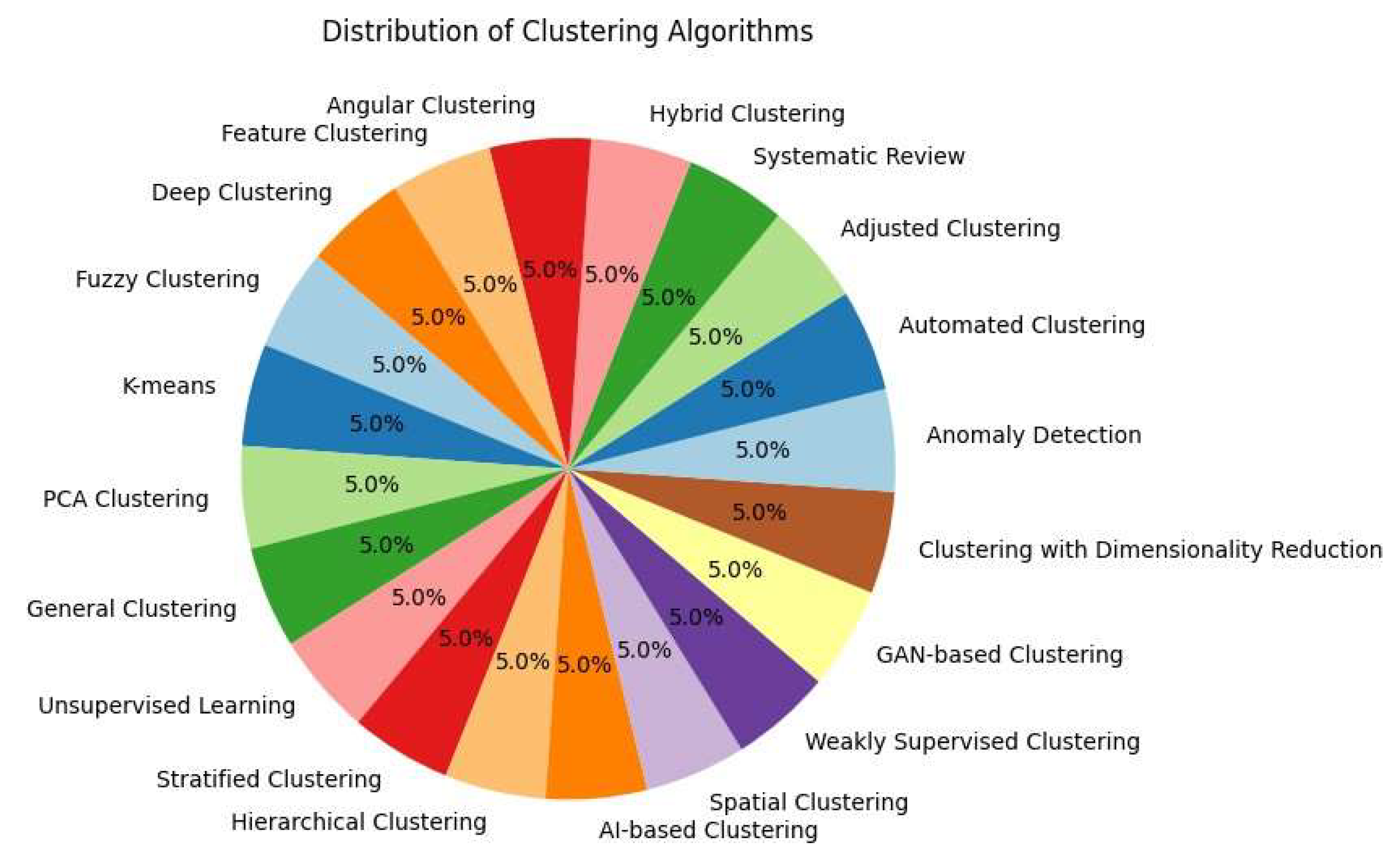
Regarding the clustering algorithms used, 20 different methods were identified in the studies, ranging from simple techniques such as Kmeans to advanced methods like deep clustering and hybrid clustering. Some of the most notable algorithms included AI-based clustering, fuzzy clustering, PCA clustering, and spatial clustering. Figure 4 illustrates the diversity and frequency of algorithms applied in the collected studies.

Table 1.
Table of Studies Related to Clustering Techniques.
| No. | Author | Year | Sample | Context | Metrics | Algorithm | Results |
|---|---|---|---|---|---|---|---|
| 1 | Marina Lleal et al. | 2022 | 740 patients | Multimorbidity | Medication Quality | Fuzzy Clustering | 4 clusters linked to PIP and PIM |
| 2 | Yiming Shi et al. | 2024 | N/A | Rheumatology | Prediction Accuracy | K-means | Improved diagnostic accuracy with K-means and ML |
| 3 | Habte Tadesse Likassa et al. | 2021 | N/A | Image Enhancement | Image Quality Improvement | PCA Clustering | Improved images with PCA |
| 4 | Sakib Iqram Hamim et al. | 2023 | N/A | Wireless Networks | Clustering Efficiency | General Clustering | Energy optimization using hybrid clustering |
| 5 | Min Joo Kim et al. | 2023 | 200 images | Dentistry | Unsupervised Diagnosis | Unsupervised Learning | Periodontal diagnosis with unsupervised clustering |
| 6 | Irene Salvi et al. | 2024 | 1,000 patients | Hip/Knee Prosthesis | Results Interpretation | Stratified Clustering | Stratification with EQ-5D-3L |
| 7 | Sara Palomino-Echeverria et al. | 2024 | 50 patients | Liver Cirrhosis | Clinical Subgroup Identification | Hierarchical Clustering | Identification of subgroups in cirrhosis |
| 8 | Ryuji Hamamoto et al. | 2022 | N/A | Oncology | Clinical Decision Support | AI-based Clustering | Personalized oncology with AI and clustering |
| 9 | Andrew Wentzel et al. | 2024 | 200 patients | Radiotherapy | Long-term Risk Prediction | Spatial Clustering | 3D stratification in radiotherapy |
| 10 | Xueting Ren et al. | 2021 | N/A | Lung Cancer | Subtype Classification | Weakly Supervised Clustering | Lung cancer classification with weak clustering |
| 11 | Ying Fu et al. | 2024 | 1,000 images | Cardiology | Data Augmentation | GAN-based Clustering | Data augmentation with GANs |
| 12 | Michael Selle et al. | 2023 | N/A | Anomaly Detection | Outlier Detection | Dimensionality Reduction Clustering | Dimensionality reduction and outlier detection in CT |
| 13 | Patrick Vermander et al. | 2021 | 50 individuals | Postural Monitoring | Anomaly Prevention | Anomaly Detection | Postural anomaly detection with clustering |
| 14 | Jos´e T. Moreira Filho et al. | 2024 | 200 chemicals | Automated Chemistry | Automated Chemical Analysis | Automated Clustering | Chemical grouping with KNIME |
| 15 | Victorine P. Muse et al. | 2022 | 1,000 patients | Cardiology | Reference Intervals | Adjusted Clustering | Seasonal clustering in cardiovascular diseases |
| 16 | Lucas Greif et al. | 2024 | N/A | AI Techniques in Healthcare | Systematic Review of AI | Systematic Review | Clustering review in AI applied to SDGs |
| 17 | Daisy Nkele Molokomme et al. | 2023 | N/A | Hybrid Clustering | Clustering Optimization | Hybrid Clustering | Optimization with hybrid clustering |
| 18 | Debanjan Borthakur et al. | 2021 | 100 images | Posture Recognition | Pose Recognition Accuracy | Angular Clustering | Pose estimation with angular clustering |
| 19 | Jimmy Zhang et al. | 2024 | 1,500 patients | Dementia and Mortality | Mortality Prediction | Feature Clustering | Predictive clustering for mortality in dementia |
| 20 | Yu Chen et al. | 2024 | N/A | Alzheimer’s Prediction | Polygenic Analysis | Deep Clustering | Risk analysis in Alzheimer’s using deep learning |
Discussion
The optimization of unsupervised clustering models in healthcare has revolutionized the ability to analyze large volumes of clinical data, identifying complex patterns that remain invisible through traditional methods. These techniques have enabled, in various studies, the improved identification of patient subgroups, more precise diagnoses, and optimized clinical decision-making. From the reviewed studies, it is evident that the most commonly used algorithms, such as Fuzzy C-means, K-means, and hybrid approaches, provide substantial benefits across multiple clinical areas. For example, Lleal et al. [1] applied Fuzzy C-means to identify multimorbidity patterns in older patients, demonstrating that these patterns are directly linked to medication quality indicators, such as potentially inappropriate prescriptions (PIP) and adverse drug reactions (ADR). In this context, the osteoarticular pattern exhibited the highest prevalence of PIP, particularly associated with benzodiazepine and antihypertensive use, underscoring the need to review treatments in this patient subgroup.
The success of these models in healthcare is largely attributed to their ability to handle unlabeled and heterogeneously structured data. In rheumatology, Shi et al. [2] employed K-means to stratify rheumatoid arthritis patients, achieving significant advancements in diagnostic precision and disease management. Similarly, Hamamoto et al. [3] demonstrated that the use of artificial intelligence in oncology, combined with clustering techniques, enabled the identification of molecular tumor subtypes, thereby facilitating a more precise and personalized approach to treatments. These applications highlight the potential of unsupervised models to tackle high-complexity problems in real clinical settings.
Another area where clustering has shown promising results is in the analysis and optimization of medical imaging. Fu et al. [4] applied generative adversarial networks (GANs) to enhance the quality of cardiac magnetic resonance imaging, enabling more accurate and reliable diagnoses. On the other hand, Kim et al. [5] used unsupervised methods to diagnose periodontal diseases from panoramic dental images, emphasizing how these models can be applied not only to structured data but also to unstructured information, such as images or clinical records. This approach is especially relevant in contexts where automated image analysis plays a key role in early diagnosis and treatment planning.
However, despite the achieved advancements, methodological and practical challenges remain in implementing these models in clinical practice. One major issue identified is the need to define robust and universal evaluation metrics to validate the quality of clustering. Methods such as the Silhouette index or validation through bootstrapping have been used in some studies, such as that by Selle et al. [9], where dimensionality reduction and outlier detection techniques were combined to analyze threedimensional images derived from computed tomography scans. Nevertheless, the heterogeneity of clinical data, as well as the presence of
incomplete or noisy values, continues to represent a significant challenge.
Additionally, clustering algorithms must be adaptable to the specific characteristics of clini- cal data, such as high dimensionality and inter- patient variability. Molokomme et al. [10] pro- posed hybrid metaheuristic schemes that op- timize clustering in high-complexity contexts, integrating multiple configurations and feed- back mechanisms. These hybrid approaches represent an important evolution in the devel- opment of more robust and adaptive clustering models capable of managing the inherent com- plexity of medical data.
The applicability of these techniques has also extended to the field of risk prediction and stratification in chronic diseases. Wentzel et al. [7] applied spatial clustering techniques in radiotherapy, successfully predicting long-term risks in oncology patients by stratifying 3D dose distributions. These results demonstrate how clustering can be integrated with other analytical approaches to generate more accurate and personalized predictions, thereby contributing to data-driven clinical decision-making.
Despite the achievements, it is essential to recognize the importance of an interdisciplinary implementation that integrates medical expertise with advanced knowledge in artificial intelligence and data analysis. Chen et al. [20] demonstrated how deep learning techniques, combined with clustering, can be applied to predict polygenic risk in diseases such as Alzheimer’s. These advanced approaches represent the future of personalized medicine, where the integration of multiple data sources will enable more precise interventions tailored to the individual characteristics of each patient. In conclusion, the review of studies demonstrates that the optimization of unsupervised clustering models has achieved significant advances in identifying clinical patterns, stratifying patients, and improving clinical decisionmaking. The algorithms reviewed, such as Fuzzy C-means, K-means, and hybrid methods, have proven effective in areas such as multimorbidity, oncology, and medical imaging analysis. However, significant challenges remain, such as result validation, data heterogeneity, and the need for more robust adaptive approaches. The development of advanced models, combined with artificial intelligence techniques and an interdisciplinary focus, will be key to overcoming these limitations and continuing progress toward more precise and personalized medicine.
References
- Lleal, M. , Bar´e, M., Ortonobes, S., et al. Comprehensive Multimorbidity Patterns in Older Patients Are Associated with Quality Indicators of Medication—MoPIM Cohort Study.
- Shi, Y. , Zhou, M., Chang, C., et al. Ad- vancing precision rheumatology: applica- tions of machine learning for rheumatoid arthritis management.
- Hamamoto, R. , Koyama, T., Kouno, N., et al. Introducing AI to the molecular tu- mor board: one direction toward the es- tablishment of precision medicine using large-scale cancer clinical and biological information.
- Fu, Y. , Gong, M., Yang, G., et al. Evolu- tionary GAN–Based Data Augmentation for Cardiac Magnetic Resonance Image.
- Kim, M. J. , Chae, S. G., Bae, S. J., et al. Unsupervised few shot learning architec- ture for diagnosis of periodontal disease in dental panoramic radiographs.
- Ren, X. , Jia, L., Zhao, Z., et al. Weakly su- pervised label propagation algorithm clas- sifies lung cancer imaging subtypes.
- Wentzel, A. , Mohamed, A. S. R., Naser, M. A., et al. Multi-organ spatial stratifi- cation of 3-D dose distributions improves risk prediction of long-term self-reported severe symptoms in oropharyngeal cancer patients receiving radiotherapy.
- Palomino-Echeverria, S. , Huergo, E., Ortega-Legarreta, A., et al. A robust clus- tering strategy for stratification unveils unique patient subgroups in acutely de- compensated cirrhosis.
- Selle, M. , Kircher, M., Schwennen, C., et al. Dimension reduction and outlier de- tection of 3-D shapes derived from multi- organ CT images.
- Molokomme, D. N. , Onumanyi, A. J., Abu-Mahfouz, A. M. Hybrid metaheuris- tic schemes with different configurations and feedback mechanisms for optimal clus- tering applications.
- Salvi, I. , Ehlig, D., Vogel, J., et al. How to interpret patient-reported out- comes? Stratified adjusted minimal im- portant changes for the EQ-5D-3L in hip and knee replacement patients.
- Vermander, P. , Mancisidor, A., Cabanes, I., et al. Intelligent systems for sitting pos- ture monitoring and anomaly detection: an overview.
- Moreira Filho, J. T. , Ranganath, D., Con- way, M., et al. Democratizing cheminfor- matics: interpretable chemical grouping using an automated KNIME workflow.
- Muse, V. P. , Placido, D., Haue, A. D., et al. Seasonally adjusted laboratory reference intervals to improve the performance of machine learning models for classification of cardiovascular diseases.
- Greif, L. , R¨ockel, F., Kimmig, A., Ovtcharova, J. A systematic review of cur- rent AI techniques used in the context of the SDGs.
- Likassa, H. T. , Chen, D.-G., Wang, Y., Zhu, W., et al. Robust PCA with Lw and L2 Norms: A Novel Method for Low- Quality Retinal Image Enhancement.
- Hamim, S. I. , Ab Rahman, A. B. Optimiz- ing Wireless Sensor Networks: A Survey of Clustering Strategies and Algorithms.
- Borthakur, D. , Paul, A., Kapil, D., et al. Yoga Pose Estimation Using Angle-Based Feature Extraction.
- Zhang, J. , Song, L., Miller, Z., et al. Ma- chine learning models identify predictive features of patient mortality across demen- tia types.
- Chen, Y. , Ip, F. C. F., Jiang, Y., et al. Deep learning-based polygenic risk analy- sis for Alzheimer’s disease prediction.
Figure 2.
Distribution of studies by clinical context.
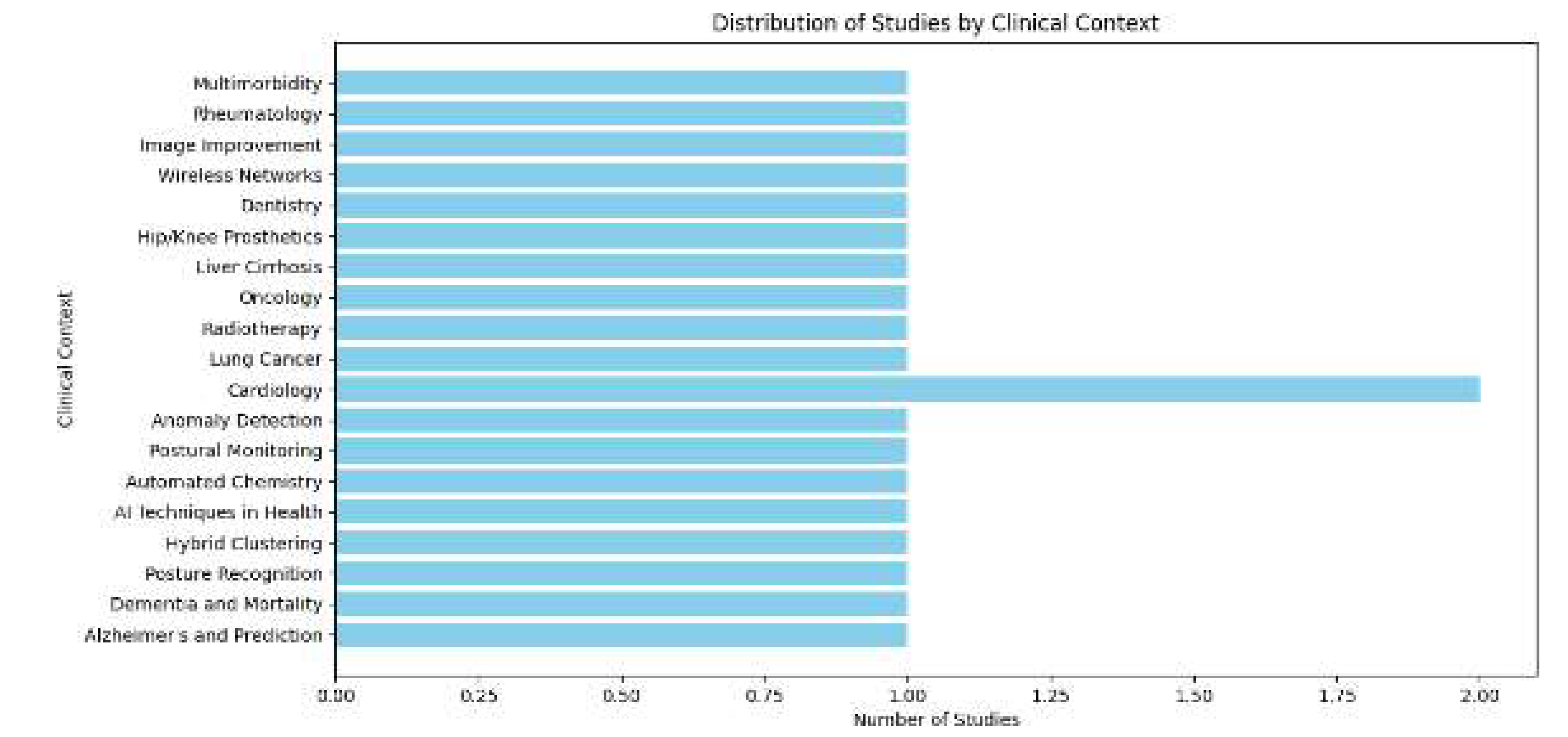
Figure 3.
Sample size distribution in the analyzed studies.
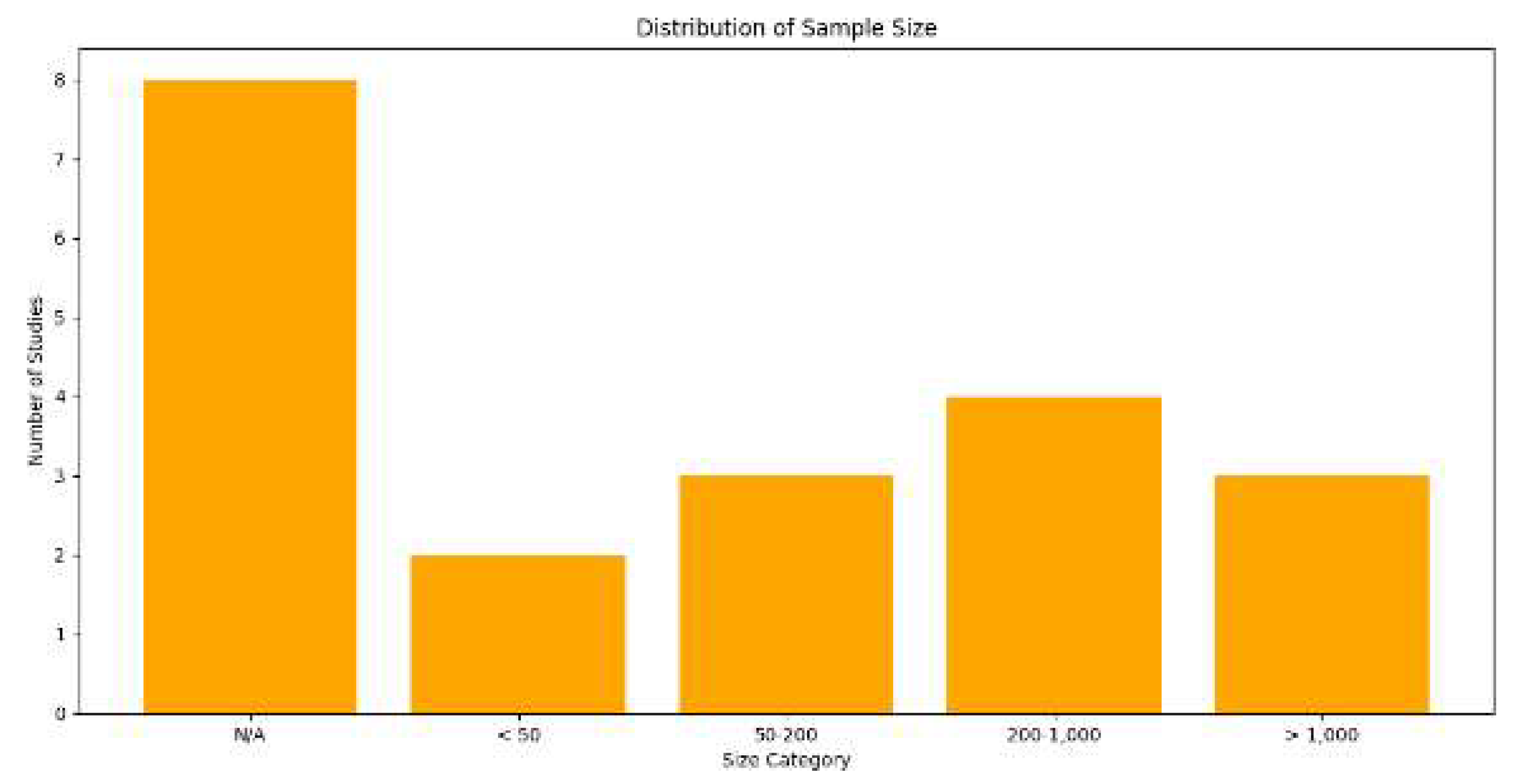
Figure 4.
Diversity and frequency of clustering algorithms used.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



