
Submitted:
19 November 2024
Posted:
20 November 2024
You are already at the latest version
Abstract
One of the most critical components of reinforced concrete structures are the beam-column joint systems, which greatly affect the overall behavior of the structure during a major seismic event. According to modern design codes, if the system fails, it should fail due to flexural yielding of the beam and not due to shear failure of the joint, which occurs suddenly and can lead to collapse, endangering human lives. Thus, a reliable tool is required for the prediction of the failure mode of the joints in a preexisting population of structures. In the present paper, a novel methodology for the derivation of analytical equations for this task is presented. The formulation is based on SHapley Additive exPlanations values, which is commonly employed as an explainability tool in Machine Learning. Instead, in the present paper, they are also utilized as a transformed target variable on which the analytical curves are fitted, which approximate the predictions of an underlying Machine Learning model. A dataset comprised of 478 experimental results is utilized and the eXtreme Gradient Boosting algorithm is initially fitted. This achieved an overall accuracy of ≈84%. The derived analytical equations achieved an accuracy of ≈78%. The corresponding metrics of Precision, Recall, and F1-Score ranged from ≈76% to ≈80% and were close across the two modes, indicating an unbiased model.
Keywords:
reinforced concrete
; beam-column joints
; failure mode prediction
; machine learning
; SHAP
; analytical equations
1. Introduction
One of the most critical aspects that affect the overall behavior of a reinforced concrete (RC) structure during a major seismic event pertains to the mechanical behavior of its beam-column joints [1]. Joints support the adjacent beams and slabs and, thus, their failure can lead to structural destabilization and part of the structure to collapse, potentially endangering human lives [2]. This mechanical behavior is largely described by two distinct and complementary aspects. On the one hand, the total strength of the joint provides a quantification of capacity of the system in terms of shear forces. On the other hand, the qualitative behavior of the joint in terms of its failure mode can be an even more important factor in terms of the overall safety of the system and the amount of seismic energy it can absorb.
Qualitatively, there are two primary failure modes that an RC beam-column joint system can exhibit [3]. In the first one, the longitudinal reinforcement bars in the adjacent beam are the first to reach their yield capacity. However, the system maintains its stability and, furthermore, due to a phenomenon known as hardening [4], the beam can absorb further amounts of seismic energy until either the reinforcement bars or the concrete fail [2]. In the second case, the joint fails due to shear prior to the beam reaching the aforementioned yielding point. This failure mode is fundamentally different than the previous one. Contrary to the ductile, yielding failure mode caused by bending, the joint failure due to shear is sudden, brittle, and leads to destabilization of the system. In addition, no further amounts of energy can be absorbed.
To this end, modern design codes [5,6,7] are often grounded in the so-called principle of ductility, mandating that, if failure is to occur, then the first failure mode is to be preferred. Thus, given the large number of existing RC structures, buildings, the prediction of the failure modes of their joints is crucial. If a structure does not abide by the standards imposed by modern design codes, preventative steps might be required [8,9]. Thus, significant research efforts have been dedicated to this task, both from a theoretical and an experimental perspective [10,11,12,13].
From a different perspective, the proliferation of Machine Learning (ML) methodologies has allowed for the implementation of powerful ML algorithms on many engineering challenges, producing state-of-the-art results [14,15]. Specifically for the task of RC beam-column joint failure mode prediction, several researchers have previously examined the problem from different perspectives.
In particular, Kotsovou et al. [16] utilized Artificial Neural Networks (ANNs) to estimate the total strength of exterior joints and predict their failure mode. Similarly, Suwal and Guner also employed ANN algorithms in their work [17]. However, contrary to [16], they work on a more extensive dataset, which included interior joints as well. Mangathalu and Jeon [18] experimented with various ML algorithms to predict both the strength of the joint as well as its failure mode. This included the implementation of so-called intrinsically explainable models [19], such as LASSO Logistic Regression, which also produce analytical expressions. However, the results presented therein are unbalanced, as the model is greatly skewed in favor of one of the failure modes. Marie et al. [20] employed several algorithms, including Support Vector Machines (SVMs), Ordinary Least Squares (OLS), and non-parametric kernel regression, to estimate the joints’ ultimate bearing capacity Lastly, Gao and Lin [21] utilized models such as k-Nearest Neighbors (k-NN), eXtreme Gradient Boosting (XGBoost), ANNs, and Random Forest, to predict the RC beam-column joint failure mode. They also utilized the SHapley Additive exPlanations (SHAP values) explainability algorithm to quantify the overall significance of each of their considered input features in the model predictions.
The research presented herein exhibits notable novel elements. A novel methodology for the derivation of analytical equations for the predictions of the RC joint failure mode is presented. The methodology is based on a recently developed modeling approach [22] which utilizes SHAP values as a basis to form simplified analytical expressions that approximate the predictions of the underlying ML model. SHAP is a feature attribution algorithm. This means that the predictions of the underlying model are decomposed into terms corresponding to the contribution of each individual feature. Thus, it is often employed to quantify the magnitude of the total effect of each feature in the outcome [21]. In the work presented herein, SHAP values are not only employed to gauge the importance of each feature, i.e., to identify which features should be utilized in a potential analytical expression. Rather, SHAP values themselves form the basis of these analytical expressions.
Therefore, the methodology presented herein offers several distinct advantages in comparison with the currently established literature. Firstly, feature selection is carried out in an informed manner, utilizing SHAP, and components are added in the resulting equations incrementally. Secondly, this allows for the tradeoff between model complexity and accuracy to be tuned, depending on the specific application at hand. Thirdly, the form of the terms corresponding to each individual feature is adjusted independently. In addition, this is not carried out blindly, but rather in an informed manner, guided by the form of the respective SHAP scatter plots, as it is shown in Section 3.2. Finally, the so-called Precision-Recall (P-R) curves are employed to demonstrate how the resulting equations can be further fine-tuned, depending on the requirements of the application at hand.
2. Materials and Methods
2.1. Dataset Overview and Feature Engineering
The dataset that was employed in the present study is comprised of experimental measurements on reinforced concrete beam-column joints. A total of 486 specimens are contained in the dataset, which was originally collected by Suwal and Guner [17] from 153 studies previously published in the literature. The experiments pertain to the cyclic loading of the beam-column joint systems until failure occurs, mimicking their behavior during a significant seismic event. In all cases, the applied load at the moment of failure was measured using appropriately placed sensors. In addition, the failure mode of each specimen was also recorded. Thus, each input vector in the original dataset was described by the following 14 attributes [17]:
- The joint type: This categorical variable, describes whether the joint is “interior”, i.e., beams are attached on two opposing sides, or “exterior”.
- : The compressive strength of the concrete, measured in MPa.
- : The amount of transverse reinforcement, i.e., stirrups, in the joint, expressed as a percentage of its area.
- : The yield strength of the stirrups in the joint, measured in MPa.
- : The amount of longitudinal reinforcement in the beam and column, respectively, expressed as a percentage of the respective cross-sectional areas.
- : The yield strength of the longitudinal reinforcement in the beam and column, respectively, measured in MPa.
- : The height (h) and width (b) of the beam and column, respectively, measured in mm.
- ALF: The Axial Load Factor,i.e., the axial load applied to the column normalized to the respective compressive strength .
- The failure mode: This is the dependent variable in the present study and takes two distinct values. Specifically, the value “Joint Shear” (“JS”) corresponds to cases where the joint failed suddenly in a brittle, shear manner and the beam had not yet reached its yield capacity. Accordingly, the value “Beam Yield-Joint Shear” (“BY-JS”) pertains to specimens wherein the ductile flexural yielding of the beam reinforcement preceded the brittle shear failure of the joint [3].
As was stated in the Introduction, the aim of the present study is to obtain simple, analytical expressions to predict the failure mode of the joints based on the independent variables/features. Thus, the input features are critical to the proposed formulation and to this end a procedure known as feature engineering [23] was performed on the original dataset. It should be highlighted that feature engineering is more general and more involved than preprocessing the dataset. Indeed, preprocessing steps often include appropriate scaling of the features [24], removing outliers, or imputing missing values [25]. On the other hand, feature engineering can also include the generation of new features from the existing ones, which can be more appropriate for the specific modeling purposes.
To this end, in the present study, each reinforcement percentage was multiplied by the respective yield stress . This resulted in three new features, denoted by where for the joint, beam, and column, respectively. Furthermore the heights of the beam and column where combined into a single feature by obtaining the ratio . Thus, the original set of 13 independent variables was reduced to only 7. Finally, in 8 out of 486 instances (1.65%) the compressive strength of the concrete was over 100 MPa. These are considered extreme values for this feature [5] and thus, this small subsample was removed from the dataset.
Figure 1 shows the distribution of the attributes that were included in the final dataset after feature engineering. It can be observed that the approximately 53.35% of specimens belong to the failure mode “JS” and the remaining 46.65% belong to “BY-JS”. A large gap between the two would indicate the presence of what is known as the class imbalance problem [26,27]. This can lead to the degradation of the performance of any ML model and specialized techniques exist in the literature to address it [28,29]. However, in the present study, the distribution of the failure modes is balanced and, thus, the implementation of such techniques was not necessitated.
2.2. Machine Learning Modeling
There are a large number of readily available classification algorithms that can be implemented for the task of the prediction of the failure mode of joints [30,31]. However, as was previously mentioned, the goal of the present study is not to exhaustively search the many available algorithms to identify the best possible Machine Learning model. Rather, the aim is to utilize the predictions of one such model, in conjunction with the SHAP values explainability technique, as a basis to produce simplified, analytical equations for the prediction of the failure mode. As is shown in the sequel, the SHAP values approximate the behavior of the underlying ML model. Given that they are fundamental to the proposed formulation, their reliability must be ensured and thus, it is important for the underlying ML model to obtain a sufficiently high accuracy. To this end, there exist many readily available classification algorithms in the literature.
In the present study, the so-called eXtreme Gradient Boosting (XGBoost) [32] algorithm was employed, which has been successfully utilized in similar studies [2,21]. The fundamental idea of this algorithm is to combine a group of so-called “weak learners” (usually Decision Trees) in a powerful ensemble model via an iterative procedure called boosting [33]. Thus, the final model takes the form of the following Equation (1) [32,33]
where in the above equation, are the base models of the ensemble, are the learned model parameters as well as the respective weights, and is the maximum number of base models in the ensemble and is one of the user-defined hyperparameters. In the present study, a maximum number of trees was employed, each with a maximum depth of 3 and a maximum number of leaves equal to 5. These were selected using a trial-and-error approach in order to obtain sufficiently high accuracy without overfitting.
In addition to XGBoost being a very powerful algorithm, it offers several advantages in comparison with other popular classification algorithms, such as Artificial Neural Networks (ANNs) or Support Vector Machines (SVMs). Firstly, as a tree-based algorithm, XGBoost is not susceptible to features whose ranges have different orders of magnitude, which is why no feature scaling was performed as part of the preprocessing presented in the previous Section. Secondly, the tree-based nature of XGBoost offers significant computational gains. On the one hand, the ML models themselves are faster to train. On the other hand, the computation of the SHAP values, which generally can be a slow process, can be efficiently carried out using the dedicated TreeSHAP algorithm [34].
2.3. Shapley Additive Explanations (SHAP values)
Shapley Additive exPlanations (SHAP values) [35] belongs to the class of the so-called machine learning interpretability methodologies [36], which aim to explain and analyze how complex ML models arrive at their predictions. In addition, SHAP values belong to the subclass of the so-called additive feature attribution methods [35]. Fundamentally, this means that the underlying trained ML model f is locally (at each input vector ) approximated by a linear function g, which is given by the following Equation (2) [35]
where in the above equation, k is the number of input variables, are the corresponding SHAP values, is the average prediction of the model, and is the so-called “simplified input” [35] and shows whether the value of each particular feature was missing or not in the input vector . The above condition is known as local accuracy [35] and ensures that the sum of the SHAP values is close to the predictions of the underlying ML model. Thus, if this model has a sufficiently high accuracy, the sum of the SHAP values will, in turn, will approximate the real target variable in the dataset.
Lundberg and Su-In, which introduced SHAP values in their seminal paper [35], based the computation of these coefficients on the so-called Shapley regression values. These coefficients were introduced by Lloyd Shapley in the framework of cooperative game theory [37]. Intuitively, the aim is to divide the “score” from a “game” fairly amongst the “players”, according to each “player’s” contribution. Formally, and following the original notation in [35], let denote the set of all the independent variables/features in the dataset and let be a subset, called a “coalition” [38]. Then, the coefficients are given by the following equation (3) [35]
Thus, conceptually, the SHAP values are obtained as a result of a weighted averaging over all feature coalitions of the difference between the model predictions with and without the inclusion of feature i.
In a binary classification setting utilizing XGBoost, as is the case in the present study, the SHAP values decompose the so-called log-odds, or logits [34]. Specifically, one of the failure modes is designated as the generic “positive” class, while the other becomes the “negative”. The log-odds are then given by the following Equation [39]
where in the above equation, p denotes the probability that a given input vector belongs to the “positive” class. In the present study, the failure mode “JS” was designated as the positive class and “BY-JS” as the “negative” one.
3. Results
In this Section, the main results and findings of the present study are presented. As was previously mentioned, the ultimate goal of the proposed formulation is to derive simplified, analytical expressions for the prediction of the failure mode. This is carried out by unraveling the predictions of a fully trained ML classifier via the SHAP values explainability methodology, which was presented in the previous section. Subsequently, these SHAP values are used as a basis for the derivation of the final analytical equations.
As was mentioned, the underlying ML classifier needs to exhibit high enough accuracy, in order to ensure the reliability of the SHAP values and, ultimately, of the analytical equations. To this end, the rest of this Section is organized as follows. Firstly, Section 3.1 briefly presents the results of the XGBoost classifier presented in Section 2.2. Similar results have been analyzed in the literature [2,21]. However, they serve as the basis for the subsequent derivation of the analytical equations, which is the main novelty of the present study. This procedure is presented in Section 3.2 along with the corresponding classification metrics from the derived equations.
3.1. Xgboost Classification Results
To measure the performance of the binary classification model, several well-known metrics were employed. Specifically we utilized the so-called Precision, Recall, F1-Score, and Overall Accuracy. In a binary classification framework, these are given by the following equations [40]:
where in the above equations, TP (true positive) denotes the number of input vectors that belongs to the generic “positive” class (in this case, the failure mode “JS”) and are correctly assigned to it by the classifier, TN (true negative) denotes the number of input vectors that belongs to the generic “negative” class (in this case, the failure mode “BY-JS”) and are correctly classified, while FP (false positive) and FN (false negative) denote the input vectors that the model incorrectly assigned to the respective failure modes. It should be highlighted that the first three metrics are defined for each failure mode separately, while Accuracy is an overall metric.
In order to obtain the performance metrics, a so-called k-fold cross-validation scheme was employed [41]. This procedure starts by splitting the dataset into k parts. Subsequently, the algorithm iterates over these partitions and, at each iteration, it utilizes the k-1 parts of the dataset for training, while the remaining part is used to gauge the performance of the trained model on “unseen” data. The final classification metrics are obtained as the averages of the respective metrics of each fold.
This procedure greatly reduces the variance of the obtained classification metrics, which can occur due the randomness of the train/test split. Thus, the reliability and robustness of the obtained results is increased. In the present study, a number of folds was employed. Furthermore, it should be highlighted that the cross-validation scheme was stratified [41]. This means that each train/test subset had approximately the same proportion of exterior/interior nodes and failure modes and these proportions were approximately the same with the original dataset.
Following the above, Figure 2 presents the cross-validated classification metrics obtained from the XGBoost classifier described in Section 2.2. As it can be readily observed, the average classification accuracy on the test dataset is high, approximately 84%. The respective classification metrics of the two failure modes are relatively close to each other, indicating a model that is not skewed towards one of the two modes. This is also supported by the fact that Precision, Recall, and F1-score are all relatively close with each other and with the Overall Accuracy.
3.2. Derivation of the Analytical Equations
In this section, the main results and findings of the present study are presented. These pertain to the derivation of simplified, analytical equations for the rapid and efficient determination of the failure mode of reinforced concrete beam-column joints. These equations are based on the SHAP values, presented in Section 2.3, and they can be constructed by sequentially and incrementally adding more terms, to achieve the desired trade-off between complexity and accuracy [22].
To this end, the first step in the proposed methodology pertains to the computation of the SHAP values for each input vector. These were computed separately for the train and test parts of each fold in the 10-fold cross-validation scheme. This facilitates the training of the analytical equations in a similar manner as the underlying ML model. Subsequently, the SHAP values were aggregated and normalized to produce a single quantifier for the overall effect of each feature on the model’s predictions. Specifically, these aggregated values were obtained as [42]
In the above equation, denotes the SHAP value corresponding to feature j computed for the input vector i, n is the total number of such input vectors in the dataset, and k is the total number of independent variables/features. Due to the above normalization, the extracted coefficients can be interpreted as the percentage of the average influence of each feature on the model’s predictions. The coefficients were computed for each fold in the 10-fold cross validation and their average was computed. The results are shown in Figure 3.
It can be readily observed that the two most important numerical features were found to be , with an average importance of approximately 22.3%, and , with an average importance of approximately 22.9%. The ratio of the height of the beam to the height of the column also had a relatively high importance, while the importance of the Axial Load Factor was found to be relatively small.
As was previously discussed, the fundamental idea of the proposed methodology is to fit simplified, analytical equations to the SHAP values of each feature. These values are additive and, according to the local accuracy condition shown in equation (2), their sum approximates the true predictions of the ML model. Thus, as was discussed in Section 2.3 and equations (3)-(4), they approximate the logit of the probability that a given input vector belongs to the failure mode “JS”.
Figure 4 presents the scatter plots of the SHAP values for the two most important features as identified in Figure 3, namely and . The analytical equations that correspond to the contribution of each feature are derived based on these scatter plots. For example, the SHAP values of could be approximated by a square root function, a logarithm, or a parabola. Similarly, the SHAP values of could be approximated by a function of the form , or an exponential.
In the present study, we experimented with a wide array of possible analytical functions for each features, including polynomials of various degrees, and the aforementioned roots, logarithms, and inverses. For each feature, the form of the analytical equation that resulted in the highest accuracy was selected. The final coefficients in each case were computed by averaging the coefficients that were computed for each fold in the 10-fold cross validation process. Figure 5 shows the scatter plots of the SHAP values of the features that were employed in the final equations, as well as the best fitted curves that resulted from the cross validation process. It also displays the envelope of each fitted curve, i.e., the minimum and maximum across the 10 folds. It can be readily observed that the coefficients of the fitted curves did not exhibit a hug variation across each fold, as the respective bands of the envelopes are not very large. In any case, as was previously mentioned, the 10-fold cross validation procedure reduces the variance of the coefficients that are obtained for each particular dataset.
The curves presented above are in qualitative agreement with the currently established literature with regards to the behavior of reinforced concrete beam-column joints. For example, increasing the compressive strength of the concrete and the amount or strength of the stirrups in the joint decreases the log-odds that the given joint/input vector will exhibit the “JS” failure mode, i.e., that it will belong in the “positive” class. Additionally, increasing the amount of reinforcement in the beam or its strength results in a beam with increased strength compared to the joint, thus increasing the likelihood that the “JS” failure mode will occur. A similar observation holds for increasing the ratio of the height of the beam, compared to the height of the column. It should be noted that there is a correlation between the height of each bar in Figure 3 and the range of the respective SHAP values in the above figure. Furthermore, the variations of these values, as seen for example in the subplot foor , can be further analyzed using SHAP interaction values [34]. However, due to the excellent results achieved herein, this added complexity was not deemed justifiable. Before the final forms of the derived analytical expressions are presented, two additional points should be highlighted.
First, as can be observed from Figure 5, the expression for the contribution of is not valid if , i.e., if the joint has no stirrups. For those cases, the SHAP values of this feature ranged from approximately 0.36 to 0.505. Therefore, its contribution can be adequately captured using a single value, the mean. In this case, the average across the 10-folds was approximately equal to 0.429, with a standard deviation of approximately 0.055. Secondly, as can be seen from equation (2), in order for the condition of local accuracy to be valid, the constant must be added. This corresponds to the mean model prediction. In our case, this had an average value of approximately 0.156 across the 10-folds and a standard deviation of approximately 0.0067. It should be reiterated that these values correspond to the log-odds, as defined in equation (4), that a given input vector/joint belongs to the failure mode “JS”. Thus, if the inverse sigmoid transformation is employed to solve for the actual probability p, we obtain
This means that, on average, the model predicts a 53.89% probability for the “JS” failure mode, which is close to the distribution of the original dataset, as shown in the last subplot of Figure 1. Following the above, the final derived analytical equations for the prediction of the failure mode take the form:
If the above quantity is , then the corresponding probability is . Thus, the joint under consideration is predicted to belong in the “JS” failure mode. Otherwise, it is assigned to “BY-JS”. Table 1 shows the respective average classification metrics obtained via the 10-fold cross-validation procedure. For each fold, the classification metrics derived from the corresponding analytical equation were computed separately on the respective training and test subsets. The respective standards deviations are also presented. Finally, Figure 6 displays the classification metrics of the final model, i.e., wherein the formulae in equations (10a)-(10b) have been employed.
As it can be readily observed from Table 1, the average classification metrics between the training and test datasets were close with each other. This indicates that the fitted analytical equations did not overfit. This can be attributed to the fact that relatively simple terms have been selected for the analytical equation of each feature, as shown in Figure 5. In addition, as was mentioned in Section 2.2, the employed cross-validation scheme was stratified, which means that each train/test subset had approximately the same proportion of exterior/interior nodes and failure modes and these proportions were approximately the same with the original dataset. This meant that the training and test subsets were balanced, which can also contribute in reducing overfitting.
Similarly, from Figure 6, it can be readily observed that the final simplified equations achieved high classification metrics in both failure modes. For the failure mode “JS”, Precision, Recall, and F1-Score were all very close with each other and approximately equal to 80%. This demonstrates the very good ability of the analytical equations to detect this failure mode, which, as was mentioned, is the most severe and potentially damaging one. Similarly, the Precision, Recall, and F1-Score for the “BY-JS” failure mode were also very close with each other, ranging from approximately 76-77%. These metrics were approximately 2.3-4.4% lower than the corresponding ones of the “JS” failure mode. If these differences are large, then the derived model is considered to be biased towards the failure mode with the highest metrics. However, in this case, the respective differences are very small and the derived model is balanced between the two modes. Finally, it should be highlighted that the obtained overall accuracy is also high, approximately equal to 78%. All the aforementioned metrics, including the overall accuracy, are relatively close with the respective metrics obtained by the underlying XGBoost model. Thus, the derived formulae (10a)-(10b) can be employed confidently, without a substantial performance degradation, compared to the underlying fully trained ML model.
The above results pertain to the “balanced” classifier obtained in equations (10a)-(10b). The classification threshold for the “JS” failure mode was set at or, equivalently, . However, it is often the case, especially in engineering applications, that “erring on the side of safety” is preferred. For example, it could be required that a higher Recall is obtained for the “JS” failure mode, the most dangerous and potentially damaging one. This would lead to more “JS” specimens to be identified, although the corresponding Precision index would be lower. This is due to the well-known Precision-Recall tradeoff [43,44]. This tradeoff can be visualized via the so-called Precision-Recall (P-R) curves [45,46]. Similar to ROC curves [47,48], the Area Under the Curve (AUC) of P-R curves gives a quantification of its overall performance. The baseline in this case is the simple “majority classifier”, i.e., a model that constantly assigns the input vectors to the class with the most input vectors in the training dataset.
Following the above, Figure 7 shows the Precision-Recall curve of the “JS” failure mode, computed via the analytical equations (10a)-(10b). The top-right corner corresponds to the “perfect classifier” and the closer the P-R curve is to it, the better its overall performance.
Firstly, it can be readily observed that as the threshold for p decreases, more input vectors are assigned to the “JS” failure mode. Thus, the Recall index of this mode increases, while conversely the Precision index decreases. The threshold is a balanced one, with Precision and Recall very close to each other and close to 80%. We have also identified the p threshold for a Recall of , which is a commonly employed engineering standard. In this case, and Precision is reduced to , while the overall Accuracy of the classifier is reduced from to .
4. Summary and Conclusions
The mechanical behavior of reinforced concrete beam-column joints during a major seismic event is one of the most critical aspects that affect the overall behavior of the structure. Qualitatively, modern design codes dictate that, if failure is to occur, the flexural yielding of the beam, which is a ductile failure mode, should be the first to occur (“BY-JS” failure mode). In turn, this does not lead to the beam-column system to lose stability and it can continue to absorb seismic energy. On the other hand, failure in the joint itself is often caused by shear forces (“JS” failure mode). Contrary to flexural yielding, shear failure is brittle and leads to an abrupt and instantaneous loss of stability. In turn, the joint system loses its ability to absorb further amounts of seismic energy and collapses, either partially or totally, potentially leading to loss of human lives. Thus, the rapid and reliable estimation of the joint failure mode is one of the most crucial engineering problems faced by modern societies.
In this regard, Machine Learning classification algorithms have a demonstrated capability to produce state-of-the-art results in similar engineering challenges. However, they often suffer from a lack of transparency, as their predictions cannot be easily understood. Furthermore, ML algorithms are hard to incorporate into the adopted engineering practice and design codes, which necessitate the existence of simplified analytical formulae in order to make predictions.
Thus, in the framework of the present research effort, a methodology for the derivation of simplified analytical equations for the prediction of the failure mode of reinforced concrete beam-column joints is presented. The proposed formulation aims to create a link between the proven ability of ML algorithms to produce state-of-the-art results and the aforementioned need for simplified analytical expressions.
To this end, an underlying ML model is employed for the classification task, i.e., for the prediction of the probability corresponding to each failure mode. Subsequently, the SHAP values explainability technique is utilized to decompose these predictions into components pertaining to each individual feature. As equation (9) and Figure 3 demonstrate, this allows for a quantification of the overall influence of each feature on the outcome. Guided by this feature importance hierarchy, the most important features’ SHAP values are utilized as a basis for the derivation of the simplified analytical expressions. The proposed methodology offers several distinct advantages.
Firstly, the derived equations are derived in an informed manner, wherein more terms can be added or removed independently to achieve the desired tradeoff between complexity and accuracy, guided by the feature importance hierarchy presented in Figure 3. This is also facilitated by individually adjusting the form of the analytical equation that is fitted to each feature’s SHAP values, guided by the form of the corresponding SHAP scatter plots, as shown in Figure 4.
Secondly, as is shown in equation (2), the SHAP values approximate the behavior of the underlying ML model. Thus, the derived equations can achieve comparable levels of performance, as demonstrated in Figure 2 and Figure 6. Indeed, the XGBoost classification model achieved an overall accuracy of approximately 84%. It corresponding Precision, Recall, and F1-Score for the “JS” failure mode ranged from approximately 83.7-87%. Accordingly, the overall classification accuracy for the derived equations (10a)-(10b) was approximately 78% and the corresponding classification metrics ranged from 79.1-80%.
Finally, it should be noted that the obtained classification metrics of the analytical equations were balanced between the two failure modes. Indeed, as it is shown in Figure 6, the respective differences ranged from approximately 2.3-4.4%. However, as is demonstrated by Figure 7, the derived equations can easily be modified to achieve a different metric balance, for example to obtain a higher Recall index for the “JS” failure mode.
Overall, the results presented herein are promising, as they demonstrate the potential for the derivation of analytical expressions with comparable accuracy to fully trained ML models. Even though the examined application pertained to the prediction of RC joint failure mode, the results presented herein encourage the application of the examined methodology to similar complex and impactful engineering challenges. Finally, even though the derived equations are based on a dataset consisting of 478 RC joint experimental results, they can be continuously updated as more data are incorporated, potentially leading to new insights on the behavior of RC beam-column joints.
Author Contributions
Conceptualization, I.K., M.K., T.R., L.I., and A.K.; methodology, I.K., M.K., T.R., L.I., and A.K.; software, I.K., M.K., T.R., L.I., and A.K.; validation, I.K., M.K., T.R., L.I., and A.K.; formal analysis, I.K., M.K.; investigation, I.K., M.K., T.R., L.I., and A.K.; resources, M.K., T.R., and L.I.; data curation, I.K., M.K., T.R., L.I., and A.K.; writing—original draft preparation, I.K., M.K.; writing—review and editing, T.R., L.I., and A.K; visualization, I.K. and M.K.; supervision T.R., L.I., and A.K.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| RC | Reinforce Concrete |
| ML | Machine Learning |
| ANN | Artifical Neural Network |
| SHAP | SHapley Additive exPlanations |
| k-NN | k-Nearest Neighbors |
| SVM | Support Vector Machine |
| OLS | Ordinary Least Squares |
| XGBoost | eXtreme Gradient Boosting |
| P-R | Precision-Recall |
References
- Najafgholipour, M.; Dehghan, S.; Dooshabi, A.; Niroomandi, A. Finite element analysis of reinforced concrete beam-column connections with governing joint shear failure mode. Latin American Journal of Solids and Structures 2017, 14, 1200–1225. [Google Scholar] [CrossRef]
- Karabini, M.; Karampinis, I.; Rousakis, T.; Iliadis, L.; Karabinis, A. Machine Learning Ensemble Methodologies for the Prediction of the Failure Mode of Reinforced Concrete Beam–Column Joints. Information 2024, 15, 647. [Google Scholar] [CrossRef]
- Kuang, J.; Wong, H. Behaviour of Non-seismically Detailed Beam-column Joints under Simulated Seismic Loading: A Critical Review. fib Symposium on Concrete Structures: the Challenge of Creativity, Avignon, France, 2004.
- Braga, F.; Caprili, S.; Gigliotti, R.; Salvatore, W.; others. Hardening slip model for reinforcing steel bars. Earthquakes and Structures 2015, 9, 503–539. [Google Scholar] [CrossRef]
- Recommendations for Design of Beam-Column Connections in Monolithic Reinforced Concrete Structures (ACI 352R-02). Technical report, American Concrete Institute, Indianapolis, IN, USA, 2002.
- Retrofitting of Concrete Structures by Externally Bonded FRPs with Emphasis on Seismic Applications (FIB-35). Technical report, TheInternational Federation for Structural Concrete, Lausanne, Switzerland, 2002.
- EN 1992 Eurocode 2 Part 1-1: General rules and rules for buildings. Technical report, European Committee for Standardization, Brussels, Belgium, 2004.
- Karayannis, C.G.; Sirkelis, G.M. Strengthening and rehabilitation of RC beam–column joints using carbon-FRP jacketing and epoxy resin injection. Earthquake Engineering & Structural Dynamics 2008, 37, 769–790. [Google Scholar]
- Tsonos, A.; Stylianidis, K. Pre-seismic and post-seismic strengthening of reinforced concrete structural subassemblages using composite materials (FRP). Proc., 13th Hellenic Concrete Conference, 1999, Vol. 1, pp. 455–466.
- Park, R.; Paulay, T. Reinforced concrete structures; John Wiley & Sons: Hoboken, NJ, USA, 1991. [Google Scholar]
- Tsonos, A.G. Cyclic load behaviour of reinforced concrete beam-column subassemblages of modern structures. WIT Transactions on The Built Environment 2005, 81. [Google Scholar]
- Antonopoulos, C.P.; Triantafillou, T.C. Experimental investigation of FRP-strengthened RC beam-column joints. Journal of Composites for Construction 2003, 7, 39–49. [Google Scholar] [CrossRef]
- Nikolić, Ž.; Živaljić, N.; Smoljanović, H.; Balić, I. Numerical modelling of reinforced-concrete structures under seismic loading based on the finite element method with discrete inter-element cracks. Earthquake Engineering & Structural dynamics 2017, 46, 159–178. [Google Scholar]
- Thai, H.T. Machine learning for structural engineering: A state-of-the-art review. Structures. Elsevier, 2022, Vol. 38, pp. 448–491. [CrossRef]
- Kaveh, A. Applications of Artificial Neural Networks and Machine Learning in Civil Engineering. Studies in Computational Intelligence 2024, 1168, 472. [Google Scholar]
- Kotsovou, G.M.; Cotsovos, D.M.; Lagaros, N.D. Assessment of RC exterior beam-column Joints based on artificial neural networks and other methods. Engineering Structures 2017, 144, 1–18. [Google Scholar] [CrossRef]
- Suwal, N.; Guner, S. Plastic hinge modeling of reinforced concrete Beam-Column joints using artificial neural networks. Engineering Structures 2024, 298, 117012. [Google Scholar] [CrossRef]
- Mangalathu, S.; Jeon, J.S. Classification of failure mode and prediction of shear strength for reinforced concrete beam-column joints using machine learning techniques. Engineering Structures 2018, 160, 85–94. [Google Scholar] [CrossRef]
- Oviedo, F.; Ferres, J.L.; Buonassisi, T.; Butler, K.T. Interpretable and explainable machine learning for materials science and chemistry. Accounts of Materials Research 2022, 3, 597–607. [Google Scholar] [CrossRef]
- Marie, H.S.; Abu El-hassan, K.; Almetwally, E.M.; El-Mandouh, M.A. Joint shear strength prediction of beam-column connections using machine learning via experimental results. Case Studies in Construction Materials 2022, 17, e01463. [Google Scholar] [CrossRef]
- Gao, X.; Lin, C. Prediction model of the failure mode of beam-column joints using machine learning methods. Engineering Failure Analysis 2021, 120, 105072. [Google Scholar] [CrossRef]
- Karampinis, I.; Morfidis, K.; Iliadis, L. Derivation of Analytical Equations for the Fundamental Period of Framed Structures Using Machine Learning and SHAP Values. Applied Sciences 2024, 14, 9072. [Google Scholar] [CrossRef]
- Verdonck, T.; Baesens, B.; Óskarsdóttir, M.; vanden Broucke, S. Special issue on feature engineering editorial. Machine learning 2024, 113, 3917–3928. [Google Scholar] [CrossRef]
- Ahsan, M.M.; Mahmud, M.P.; Saha, P.K.; Gupta, K.D.; Siddique, Z. Effect of data scaling methods on machine learning algorithms and model performance. Technologies 2021, 9, 52. [Google Scholar] [CrossRef]
- Lee, H.; Yun, S. Strategies for Imputing Missing Values and Removing Outliers in the Dataset for Machine Learning-Based Construction Cost Prediction. Buildings 2024, 14, 933. [Google Scholar] [CrossRef]
- Ghosh, K.; Bellinger, C.; Corizzo, R.; Branco, P.; Krawczyk, B.; Japkowicz, N. The class imbalance problem in deep learning. Machine Learning 2024, 113, 4845–4901. [Google Scholar] [CrossRef]
- Kumar, P.; Bhatnagar, R.; Gaur, K.; Bhatnagar, A. Classification of imbalanced data: review of methods and applications. IOP conference series: materials science and engineering. IOP Publishing, 2021, Vol. 1099, p. 012077. [CrossRef]
- Wongvorachan, T.; He, S.; Bulut, O. A comparison of undersampling, oversampling, and SMOTE methods for dealing with imbalanced classification in educational data mining. Information 2023, 14, 54. [Google Scholar] [CrossRef]
- Jeong, D.H.; Kim, S.E.; Choi, W.H.; Ahn, S.H. A comparative study on the influence of undersampling and oversampling techniques for the classification of physical activities using an imbalanced accelerometer dataset. Healthcare 2022, 10, 1255. [Google Scholar] [CrossRef]
- Sen, P.C.; Hajra, M.; Ghosh, M. Supervised classification algorithms in machine learning: A survey and review. Emerging Technology in Modelling and Graphics: Proceedings of IEM Graph 2018. Springer, 2020, pp. 99–111. [CrossRef]
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Machine learning: a review of classification and combining techniques. Artificial Intelligence Review 2006, 26, 159–190. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August, 2016, pp. 785–794.
- Friedman, J.H. Greedy function approximation: a gradient boosting machine. Annals of Statistics, 1189. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nature Machine Intelligence 2020, 2, 56–67. [Google Scholar] [CrossRef]
- Lundberg, S.; Su-In, L. A unified approach to interpreting model predictions. arXiv preprint arXiv:1705.07874, arXiv:1705.07874 2017.
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef]
- Shapley, L. Notes on the n-Person Game-II: The Value of an n-Person Game. RAND Corporation, Santa Monica, CA, USA,.
- Aas, K.; Jullum, M.; Løland, A. Explaining individual predictions when features are dependent: More accurate approximations to Shapley values. Artificial Intelligence 2021, 298, 103502. [Google Scholar] [CrossRef]
- Norton, E.C.; Dowd, B.E. Log odds and the interpretation of logit models. Health Services Research 2018, 53, 859–878. [Google Scholar] [CrossRef]
- Raschka, S. An overview of general performance metrics of binary classifier systems. arXiv preprint arXiv:1410.5330, arXiv:1410.5330 2014.
- Allgaier, J.; Pryss, R. Cross-Validation Visualized: A Narrative Guide to Advanced Methods. Machine Learning and Knowledge Extraction 2024, 6, 1378–1388. [Google Scholar] [CrossRef]
- Karampinis, I.; Iliadis, L.; Karabinis, A. Rapid Visual Screening Feature Importance for Seismic Vulnerability Ranking via Machine Learning and SHAP Values. Applied Sciences 2024, 14, 2609. [Google Scholar] [CrossRef]
- Buckland, M.; Gey, F. The relationship between recall and precision. Journal of the American society for Information Science 1994, 45, 12–19. [Google Scholar] [CrossRef]
- Gordon, M.; Kochen, M. Recall-precision trade-off: A derivation. Journal of the American Society for Information Science 1989, 40, 145–151. [Google Scholar] [CrossRef]
- Sofaer, H.R.; Hoeting, J.A.; Jarnevich, C.S. The area under the precision-recall curve as a performance metric for rare binary events. Methods in Ecology and Evolution 2019, 10, 565–577. [Google Scholar] [CrossRef]
- Miao, J.; Zhu, W. Precision-recall curve (PRC) classification trees. Evolutionary intelligence 2022, 15, 1545–1569. [Google Scholar] [CrossRef]
- Fan, J.; Upadhye, S.; Worster, A. Understanding receiver operating characteristic (ROC) curves. Canadian Journal of Emergency Medicine 2006, 8, 19–20. [Google Scholar] [CrossRef]
- Yang, S.; Berdine, G. The receiver operating characteristic (ROC) curve. The Southwest Respiratory and Critical Care Chronicles 2017, 5, 34–36. [Google Scholar] [CrossRef]
Figure 1.
Distribution of the input features and the failure mode in the final dataset, after feature engineering.
Figure 1.
Distribution of the input features and the failure mode in the final dataset, after feature engineering.
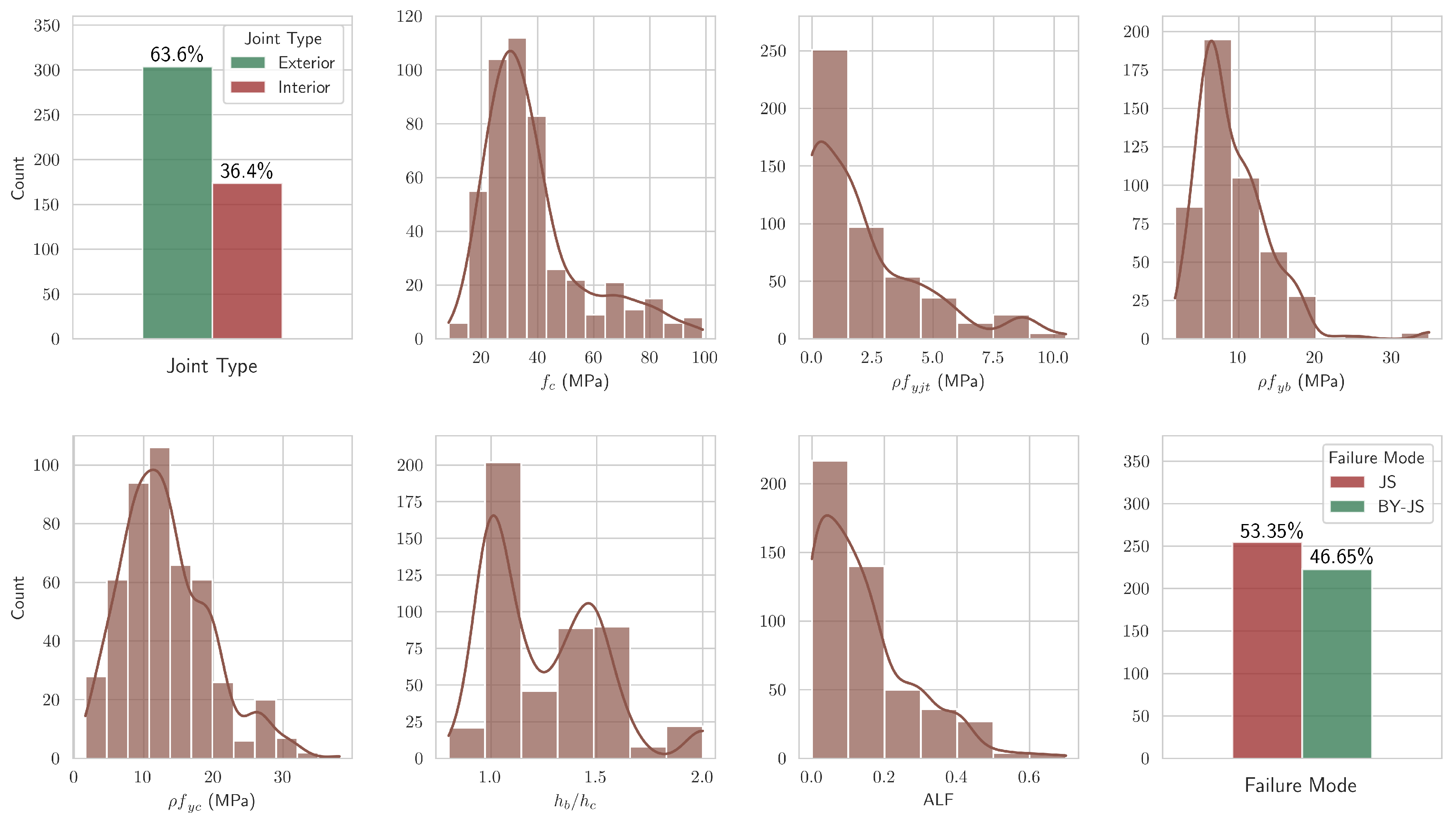
Figure 2.
Classification metrics of the XGBoost classifier obtained via 10-fold cross-validation.
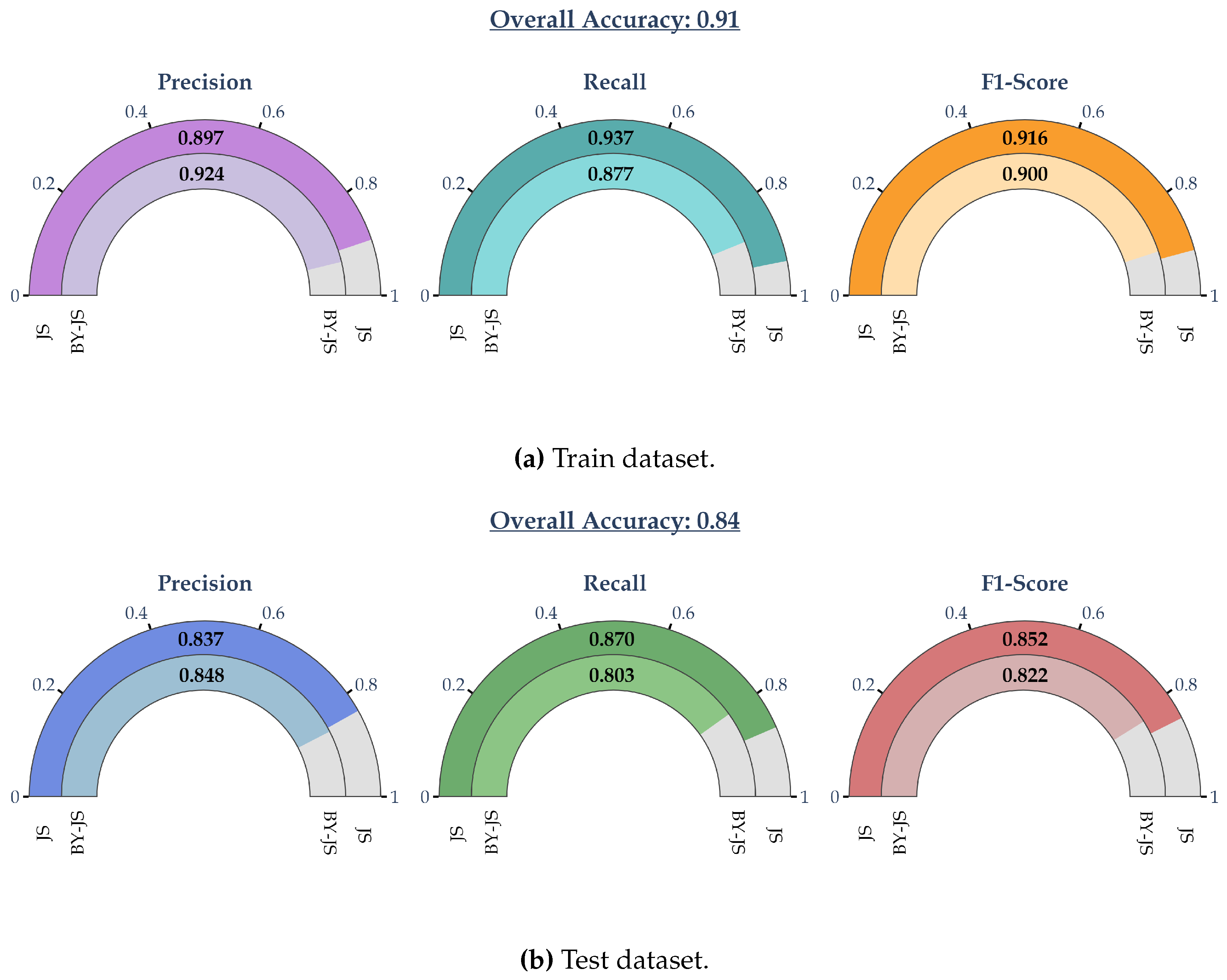
Figure 3.
Cross-validated normalized SHAP values as in Equation (9).
Figure 3.
Cross-validated normalized SHAP values as in Equation (9).
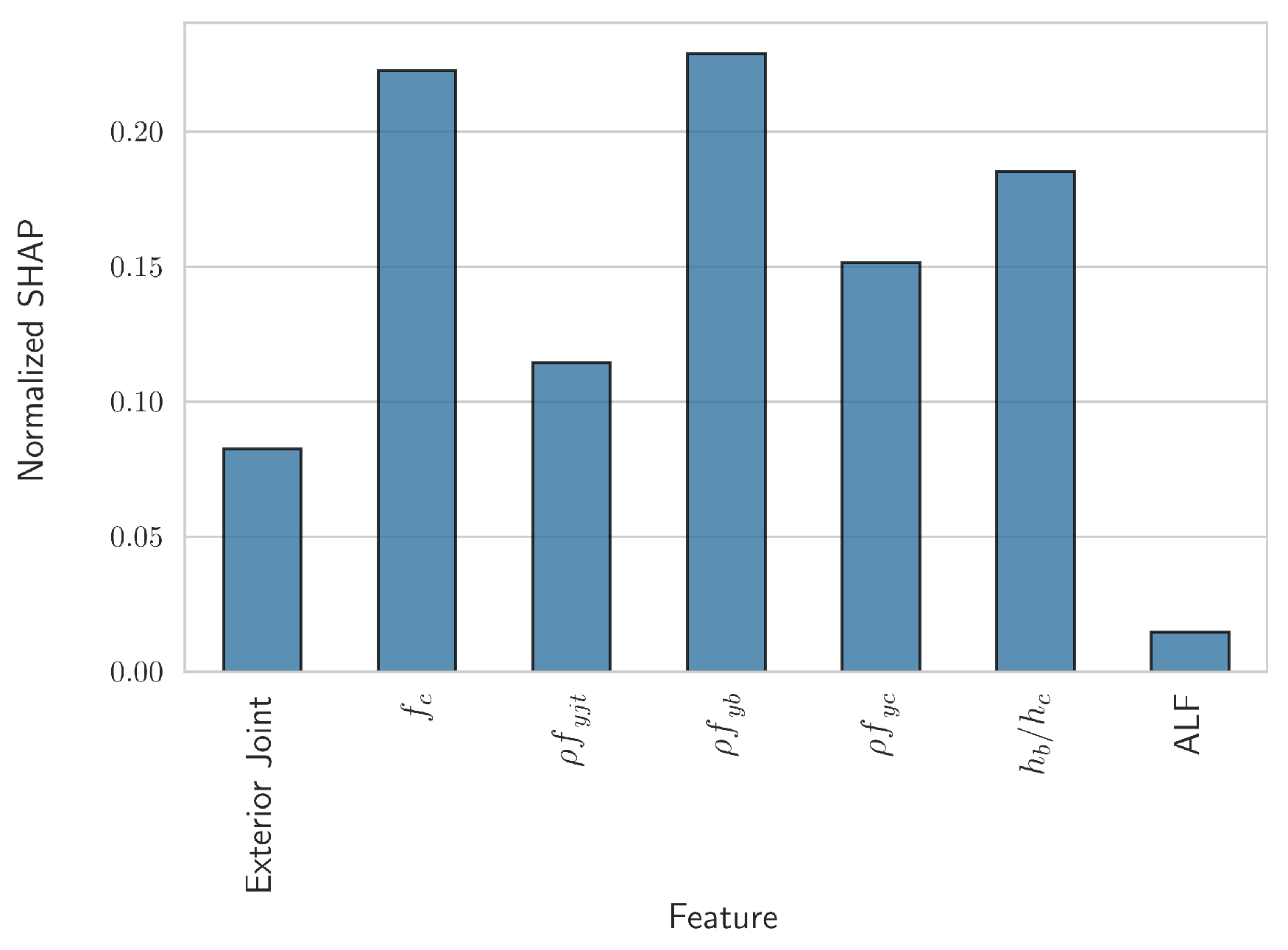
Figure 4.
Scatter plots of the SHAP values of the top two most significant numerical features, namely and .
Figure 4.
Scatter plots of the SHAP values of the top two most significant numerical features, namely and .
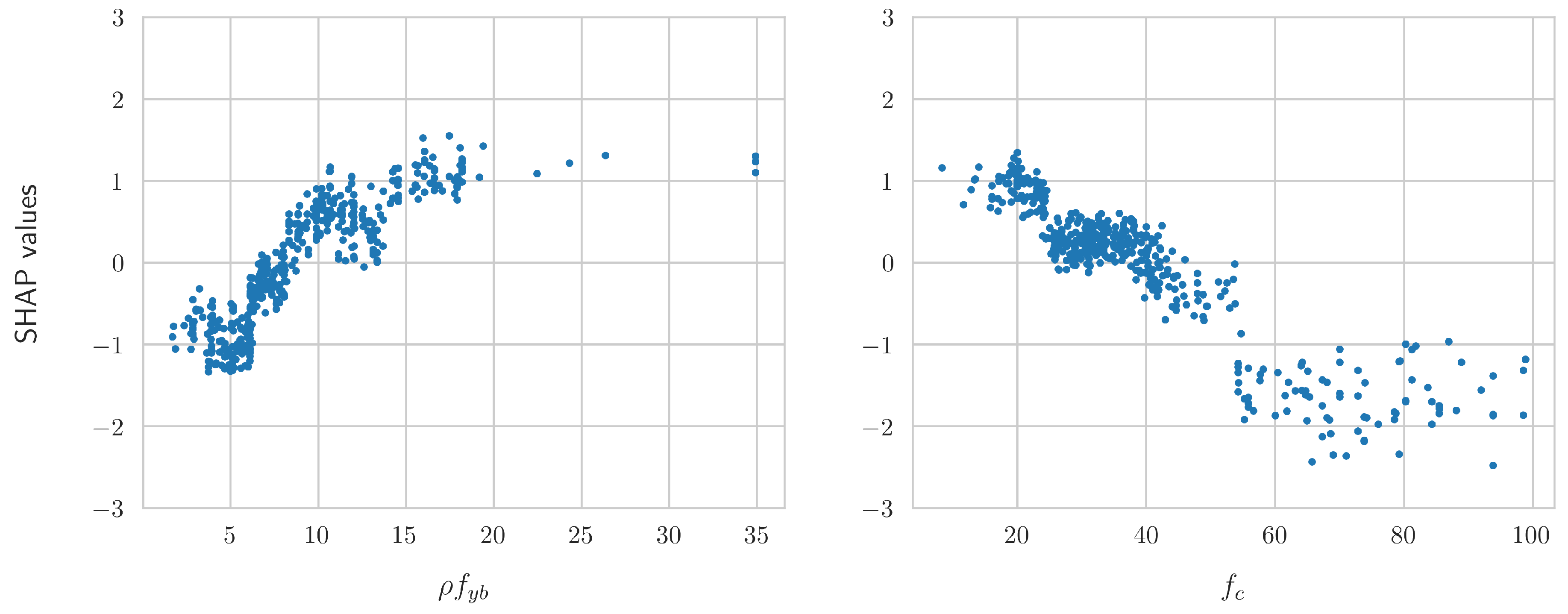
Figure 5.
Scatter plots of the SHAP values of the numerical features that were employed, along with the best fitted cross-validated curve. The envelope corresponds to the minimum and maximum value across the 10 folds.
Figure 5.
Scatter plots of the SHAP values of the numerical features that were employed, along with the best fitted cross-validated curve. The envelope corresponds to the minimum and maximum value across the 10 folds.
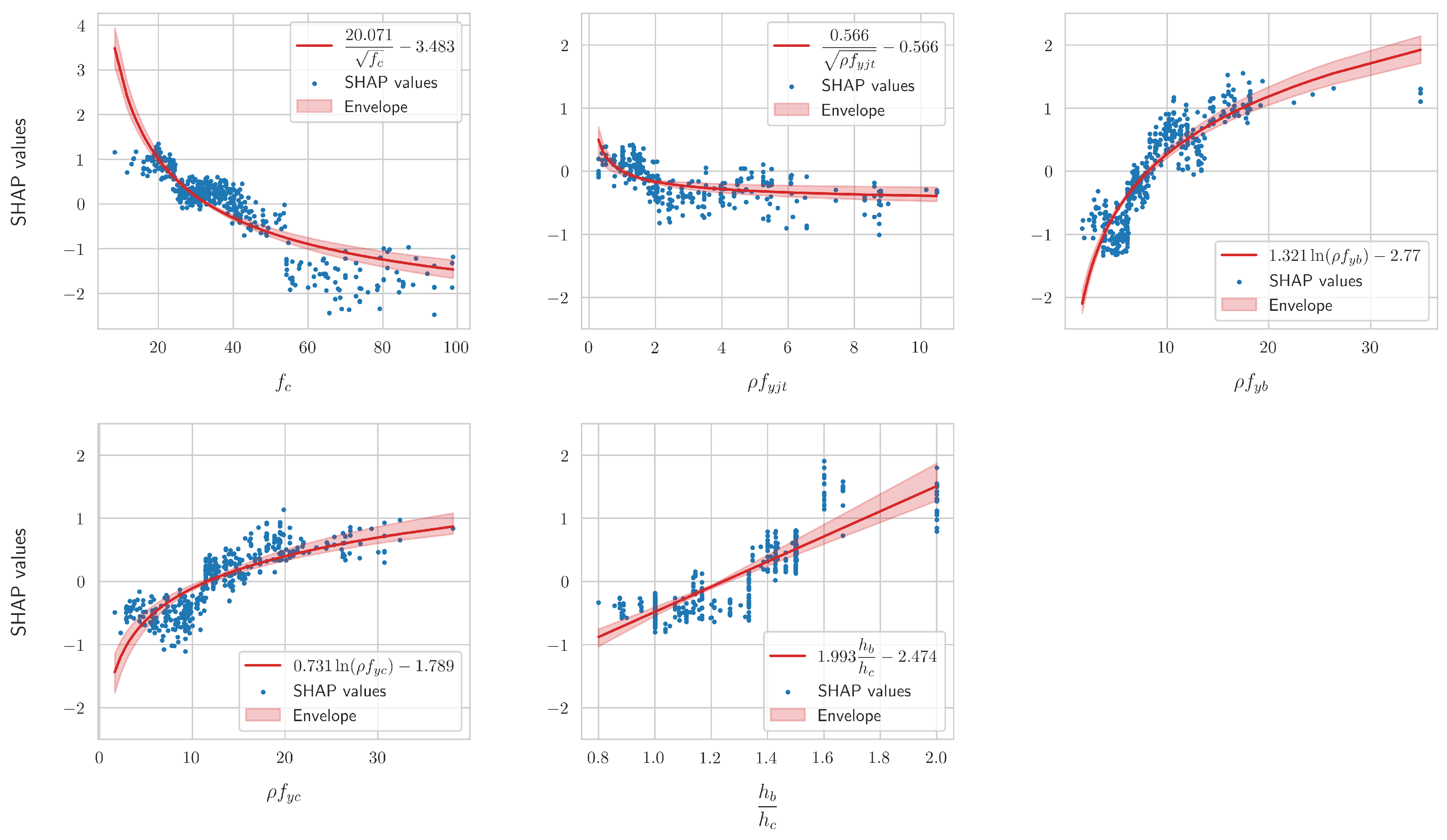
Figure 6.
Classification metrics on the entire dataset of the final fitted equations (10a)-(10b) using the cross-validated coefficients.
Figure 6.
Classification metrics on the entire dataset of the final fitted equations (10a)-(10b) using the cross-validated coefficients.
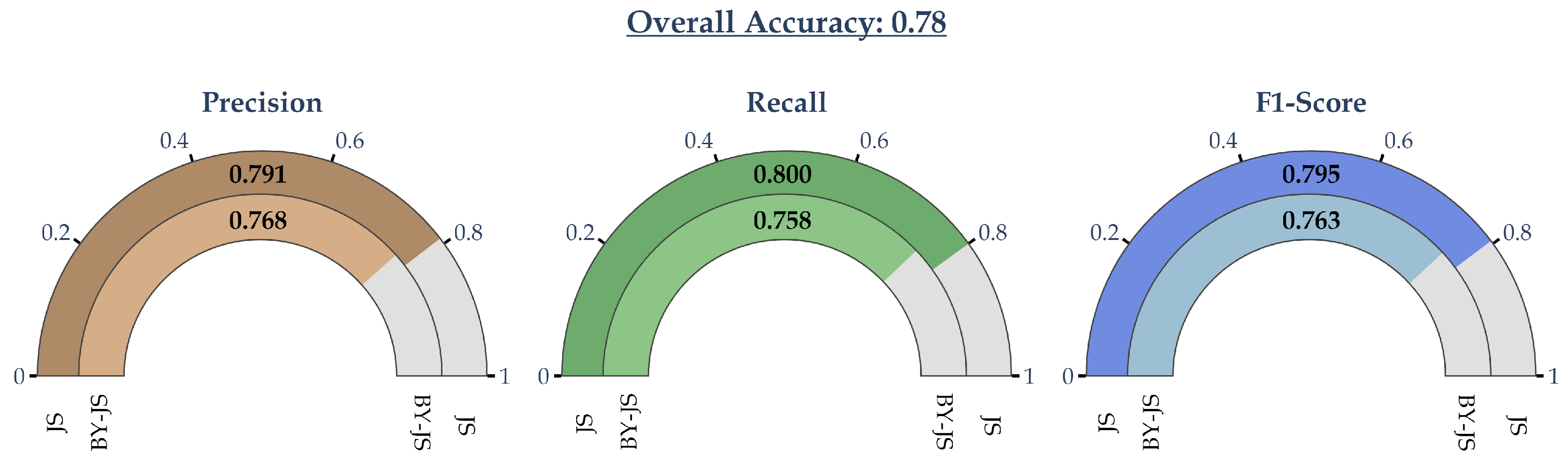
Figure 7.
Classification metrics on the entire dataset of the final fitted equations (10a)-(10b) using the cross-validated coefficients.
Figure 7.
Classification metrics on the entire dataset of the final fitted equations (10a)-(10b) using the cross-validated coefficients.
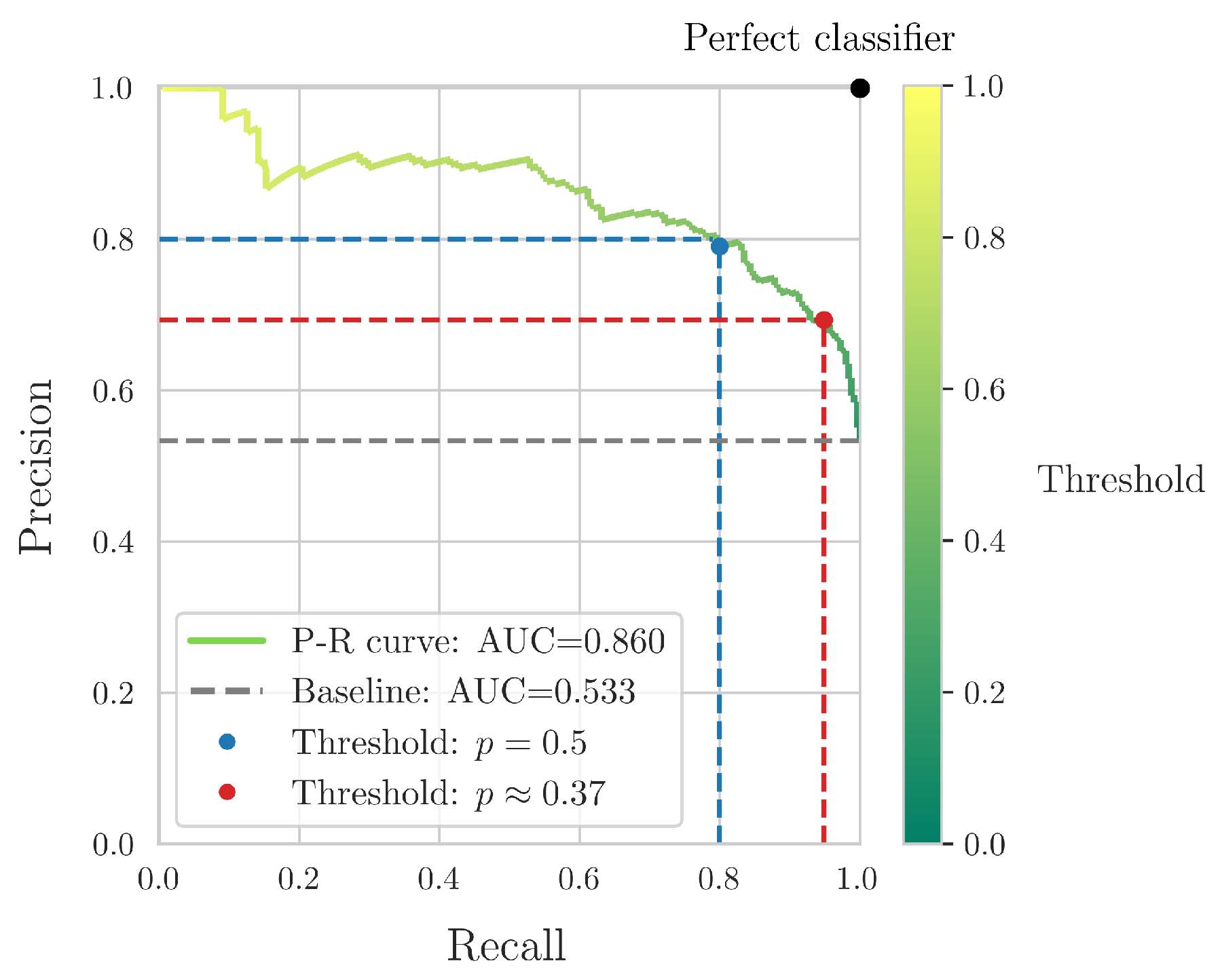

Table 1.
Cross-validated classification metrics of the fitted analytical curves of each fold.
| Training set | Testing set | |||
|---|---|---|---|---|
| BY-JS | JS | BY-JS | JS | |
| Precision | ||||
| Recall | ||||
| F1-Score | ||||
| Accuracy | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



