
Submitted:
27 December 2025
Posted:
29 December 2025
You are already at the latest version
Abstract
Assembly theory defines structural complexity as the minimum number of steps required to construct an object in an assembly space. We formalize the assembly space as an acyclic digraph of strings. Key results include analytical bounds on the minimum and maximum assembly indices as functions of string length and alphabet size, and relations between the assembly index (ASI), assembly depth, depth index, Shannon entropy, and expected waiting times for strings drawn from uniform distributions. We identify patterns in minimum- and maximum-ASI strings and provide construction methods for the latter. While computing ASI is NP-complete, we develop efficient implementations that enable ASI computation of long strings. We establish a counterintuitive, inverse relationship between a string ASI and its expected waiting time. Geometric visualizations reveal that ordered decimal representations of low ASI bitstrings of even length N naturally cluster on diagonals and oblique lines of the squares with sides equal to 2N/2. Comparison with grammar-based compression (Re-Pair) shows that ASI provides superior compression by exploiting global combinatorial patterns. These findings advance complexity measures with applications in computational biology (where DNA sequences must violate Chargaff's rules to achieve minimum ASI), graph theory, and data compression.
Keywords:
assembly theory
; assembly index
; information theory
; graph theory
; complexity measures
; compression algorithms
; information entropy
; computational biology
1. Introduction
Assembly theory quantifies the minimum number of constructive steps required to generate an object, providing a principled measure of its structural complexity. It is built around two fundamental concepts: an assembly pool (a predefined set of basic items and a set of hitherto assembled subitems) and an assembly step (joining a pair of items taken from the assembly pool in a predefined order and cloning [1] such an assembled subitem to the assembly pool if it is not there), which together define the assembly index (ASI) as the minimal number of steps necessary to construct the object. Since its original formulation in 2017 [2], AT has been generalized to a broad range of theoretical and practical settings. A considerable body of work on AT [3,4,5,6,7,8,9,10,11,12,13,14,13,14] showcased the scale invariance of AT: its implementations, whether based on graphs, building blocks, DNA nucleobases, bounded structures, or more abstract units assembled in various spaces, share the same fundamental characteristics.
Intrinsic purpose-driven mechanics implementing global combinatorics (heuristics) of AT provides a genuinely different perspective from classical notions of algorithmic or statistical complexity, despite the fact that AT appears to share many methodological features with classical dictionary-based [15,16,17] and more particularly grammar-based [18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33] data compression schemes. This resemblance stems from the fact that both AT and compression algorithms seek to capture redundancy, identify reusable substructures, and derive concise generative descriptions of data. However, instead of quantifying randomness or compressibility, AT focuses on causal construction pathways and structural regularities encoded in minimal assembly pathways (i.e., in the ASI). This perspective naturally raises the question of how such regularities can be efficiently detected, represented, and exploited by formal computational methods.
In this study, we focus on the general string version of AT. The paper is organized as follows. Section 2 introduces definitions and basic theorems used in the paper. Section 3 concerns the minimum complexity strings of AT, showing certain relations between the minimum ASI, assembly depth, depth index, and the Shannon entropy. Section 4 concerns the maximum complexity strings of AT, provides certain bounds of the maximum ASI as a function of a string length and the number of basic symbols, as well as certain methods of constructing high ASI strings. Section 5 concerns results common to the minimum and maximum complexity strings of AT, including a correlation between the expected waiting time for a string of outcomes obtainable from a uniform categorical distribution and the ASI of this string. Section 6 discusses the supremacy of ASI compression over all polynomial-time compression algorithms. Finally, Section 7 summarizes the findings of this study. In general, the proofs of theorems and lemmas, methods, and tables are given in Appendices.
2. General Framework
Consider a string (we often write it simply as ) of length N made of b distinct basic symbols (unit-length strings) c. We shall label the symbols c using decimal digits and letters if , where . We can assume that all strings belong to a set C and are vertices of a graph, where certain strings are connected via edges e from a set E. The Definition 2.1 and Lemma 2.1 were already stated in our previous studies [10,12]. We restate them here for clarity.
Definition 2.1
(Assembly Space). An assembly space is an acyclic digraph of strings , where all unit length strings (basic symbol(s)) are source vertices and the remaining strings are 2-in-regular assembly steps vertices, and E is a set of edges.
Definition 2.2
(Assembly Step). An assembly step s is the formation of a new string in an assembly space Ω from two, not necessarily different, strings , by concatenating which establishes the edges and .
Thus, any edge unambiguously resolves to either or . For example, the edge unambiguously resolves to . Even though all the vertices are strings, it is convenient to separate this set into a set of source vertices, and a set of 2-in-regular assembly steps vertices.
Definitions 2.1 and 2.2 are consistent: all vertices are unique (in any standard graph, all vertices should be unique) and all are strings. Since an assembly step always consists of joining two parts only [2], this can be thought of as the left and right fragments of the newly formed string, and those strings that can be the result of the concatenation of two shorter strings are assembly step 2-in-regular vertices. The uniqueness of each vertex is a sufficient criterion to establish the admissibility of an assembly step and to introduce the notion of an assembly pool: vertices (strings) present in the assembly space can not be assembled again as new vertices of , as they would not be unique.
Definition 2.3
(String Assembly Space). An assembly space of a string is the assembly space 2.1 containing the vertex and all the vertices leading to the string .
There can be more than one assembly space for a target string, reflecting different assembly pathways leading to it. However, the ASI of a string is the minimum cardinality of the set of the assembly step vertices of all assembly spaces of the string .
Strings in an assembly space 2.1 can form 2-grams, 3-grams, 4-grams,..., n-grams, in general, wherein the following holds.
Lemma 2.1.
For all b a 4-gram is the shortest string that allows for more than one ASI.
provides available 2-grams with unit ASI. provides available 3-grams with ASI equal to two. Only provides 4-grams that include 4-grams with ASI equal to two, that is b 4-grams and 4-grams , while the ASI of the remaining 4-grams is three. For example, to assemble the 4-gram , we need to assemble the 2-gram and reuse it, while there is nothing available to reuse, in the case of the 4-gram .
Definition 2.4
(Clear/Mixed String). We call a string (an n-gram) containing only one symbol a clear string (a clear n-gram). We call a string (an n-gram) which is not clear a mixed string (a mixed n-gram).
Theorem 2.1.
Each copies of an -gram contained in a string decrease its ASI at least by . That is
where R is the total number of repeated -grams.
For example, due to the presence of three copies of a 5-gram , each with , in a string
its ASI amounts to . The relation (1) provides the upper bound on ASI as it does not describe a situation in which n-gram for is assembled based on a -gram also present in the string , outside of this n-gram. For example, the ASI , while .
Consider the strings and , where is in reverse order. The string can have a distribution of -grams leading to its ASI decrease (1). But the string will have the same distribution of -grams in reverse order. Consequently, the strings and have the same ASI.
Definition 2.5
(AT String Equivalence). We consider two strings and to be AT-equivalent if they have the same ASI because is in reverse order and/or if and differ at most in symbol permutations.
If it is not otherwise clear from the context, in this study, we consider equivalent strings (e.g., ) as one string.
Another measure of a string’s complexity is the assembly depth [34].
Definition 2.6
(Assembly Depth). The assembly depth (ASD)
where , and and are the ASDs of two substrings , of the string that were joined in step s. For , and if there are more assembly pathways with different depths leading to a string, which happens if at least two independent assembly steps are possible, the minimum pathway depth is the ASD of this string. Hence, the ASD captures the notion of an independent assembly step.
Theorem 2.2.
If an assembly space Ω contains strings having the same (non-zero) ASD they were assembled in independent assembly steps.
In other words, if two strings , in have the same ASD, their assembly pathways are unrelated to each other; by the defining equation (3), neither of them could have been used in the assembly pathway of the other.
Corollary 2.1.
If ASI and ASD of a string are equal to each other, an assembly space of this string cannot contain independent assembly steps.
Lemma 2.2.
For all b the maximum length N of any string that can be assembled with the ASD (3) satisfies
Theorem 2.3.
For all b the minimum ASD (minASD) as a function of a string length N, is given by
where denotes the ceiling function.
The ASD need not be a monotonically nondecreasing function of the assembly step. For example
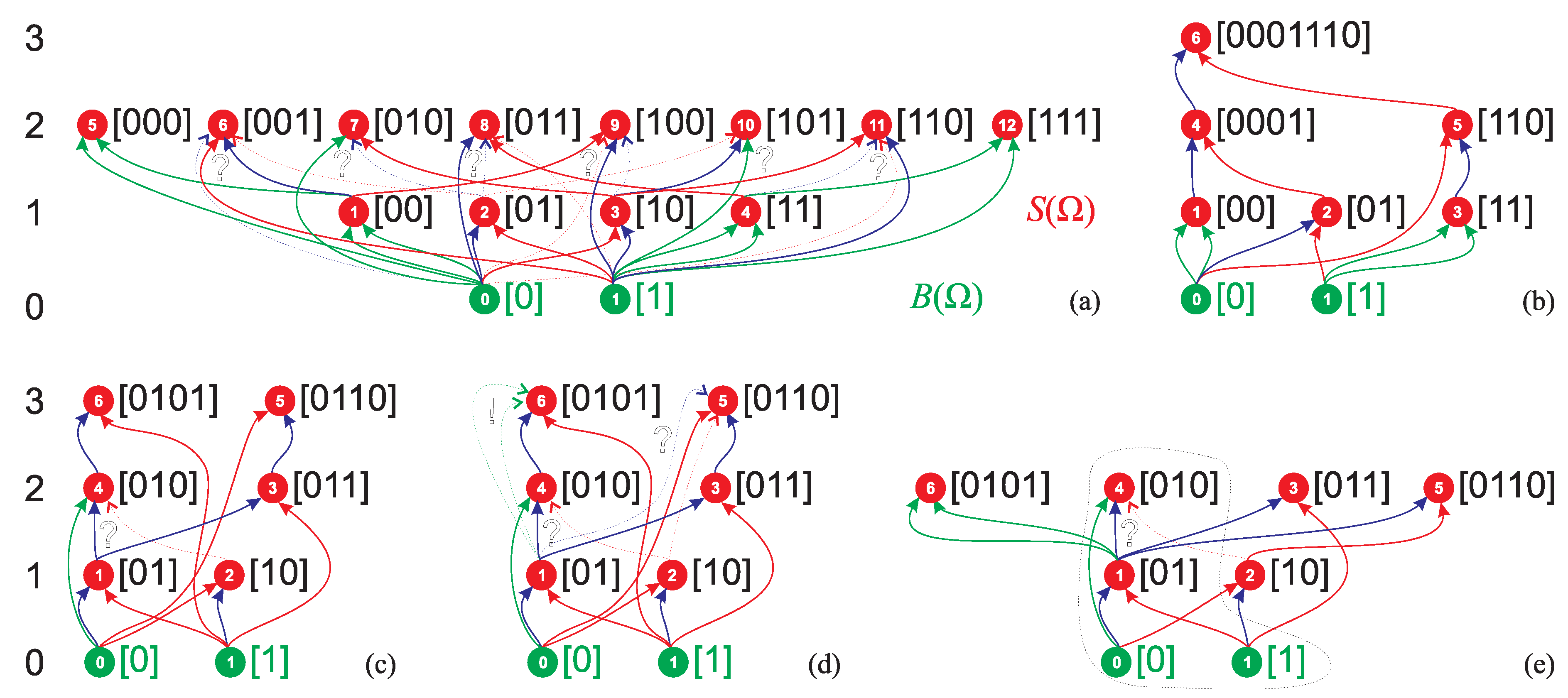
Figure 1.
Assembly spaces of bitstrings (a, c) and (b, d) for (a, b) and (c, d), where the assembly index is a number in a string (final string for (a, c)) and the assembly depth corresponds to the level. For , . In general, for , the assembly depth .
Figure 1.
Assembly spaces of bitstrings (a, c) and (b, d) for (a, b) and (c, d), where the assembly index is a number in a string (final string for (a, c)) and the assembly depth corresponds to the level. For , . In general, for , the assembly depth .
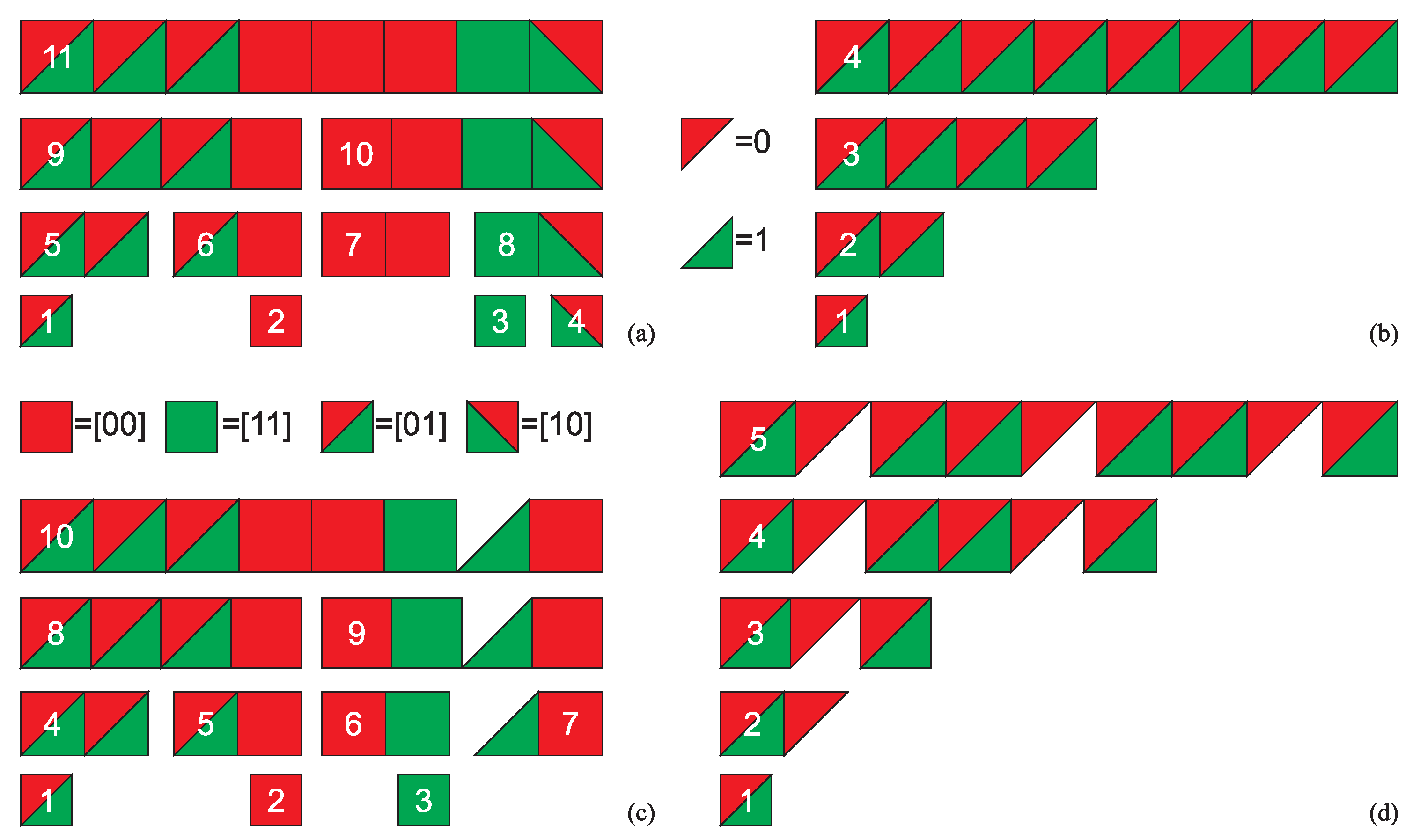
Figure 2.
Assembly space , assembly index, and assembly depth. The assembly space of all eight binary 3-grams with all pathways (a). Blue edge provides the 1st string, red edge provides the 2nd string in the assembly step, and the order is irrelevant for two green edges or green edge provides the 1st or 2nd string in dependence of the color of the complementary edge. Dotted edges and question marks indicate alternative pathways. The assembly space of the bitstring showing that its assembly index (b). The evolution of assembly spaces of strings and (c-e). Strings and are initially assembled from 3-grams and basic symbols, increasing the assembly depth (c). New pathways increasing the number of independent assembly steps are found (d), and the edges of are reconfigured, decreasing the number of assembly steps of the string from three to two steps and the assembly depth of both 4-grams from three to two. Five assembly spaces of the bitstrings , (two alternatives, one encircled), , and (e)
Figure 2.
Assembly space , assembly index, and assembly depth. The assembly space of all eight binary 3-grams with all pathways (a). Blue edge provides the 1st string, red edge provides the 2nd string in the assembly step, and the order is irrelevant for two green edges or green edge provides the 1st or 2nd string in dependence of the color of the complementary edge. Dotted edges and question marks indicate alternative pathways. The assembly space of the bitstring showing that its assembly index (b). The evolution of assembly spaces of strings and (c-e). Strings and are initially assembled from 3-grams and basic symbols, increasing the assembly depth (c). New pathways increasing the number of independent assembly steps are found (d), and the edges of are reconfigured, decreasing the number of assembly steps of the string from three to two steps and the assembly depth of both 4-grams from three to two. Five assembly spaces of the bitstrings , (two alternatives, one encircled), , and (e)
We cannot consider the ASD apart from the ASI. For example, the ASD of a string is even though this string can be assembled in six steps with three larger pathway depths as
Similarly, the ASD of a string is as
However, the non-maximum and non-minimum ASI string has only two 2-grams that can be assembled in independent steps. Hence, its ASD cannot be decreased to
In general, the that contains a -gram having the ASD d can also contain -grams having the ASD d and based on the shorter n-grams of length .
Theorem 2.4.
For all b the ASD of any maximum ASI string , corresponds to the minASD (5) of Theorem 2.3, that is
For example, as shown in Figure 1c,d, the string has the ASI and the ASD , while the string has smaller ASI but larger ASD . On the other hand, the ASD of the maxASI string and the minASI string , shown in Figure 1a,b, is the same.
Here, we introduce the following definition, which — as we shall see — is also related to the independent assembly step.
Definition 2.7
(Depth Index). We call the number of steps to reach 1 starting from and assigning
the depth index (DPI).
The relation (11) yields the same number of steps as the Chandah-sutra method (OEIS A014701) and, unlike the minimum ASI, is an analytical function of N. For example, and .
Applying AT to evolutionary biology, we can assume that initially, a new string of length N is formed in an assembly space based on a basic symbol and a string of length . Subsequently, this string assembly space evolves to reduce the cardinality of the set of the assembly step vertices until it equals the ASI of this string, that is until . Hence, the assembly spaces evolve by reconfiguring the network of edges to decrease the ASD of newly assembled strings, possibly finding shorter pathways for these strings, and if only such a decrease would not result in ASI increase (Length shown in Figure 1d is the shortest length, where ).
The concepts of assembly space, string assembly space, ASI, and ASD, as well as the evolution of assembly spaces, are illustrated in Figure 2. Although the alternative pathways shown in Figure 2a demonstrate that the mixed 2-gram is not required to construct all 3-grams in two steps, this 2-gram is necessary to achieve the ASI of longer strings (Cf. a constrained AT* version shown in list (38) discusses in Section 6.).
3. Minimum Complexity Strings of AT
In this section, we consider factors relevant to the minimum string complexity in the context of AT. The Theorem 3.1 was already stated in our previous study [10]; we restate it here for clarity.
Theorem 3.1.
For all b the minimum ASI (minASI) as a function of N corresponds to the shortest addition chain for N (OEIS A003313).
Any shortest addition chain for n starts with one, not zero, as zero is the neutral element of addition. For the same reason, two is considered the smallest prime, as one is the neutral element of multiplication. Hence, the fundamental theorem of arithmetic can be thought of as the shortest multiplication chain for N. It is conjectured that the largest prime factor must appear in some shortest addition chain for N [35].
Theorem 3.2.
The strings can contain at most two distinct symbols if . Other minASI strings of length can contain at most three distinct symbols if .
Proof.
Minimum ASI strings of length are formed by joining the newly assembled string to itself, where a clear or mixed 2-gram is assembled in the first step. Minimum ASI strings of other lengths admit a 2-gram and a 3-gram containing this 2-gram and an additional basic symbol.
To formally prove the first part, we can also use mathematical induction on the assembly step s. If , then the minASI strings are 2-grams of the form , where . If , the string contains one distinct symbol, and if , the string contains two distinct symbols. In both cases, the string has a form (A13) and the number of distinct symbols does not exceed two. Now assume that for some , all minASI strings contain at most two distinct symbols. We must show that also contains at most two distinct symbols. We construct by joining two identical minASI strings
with each other. By the inductive hypothesis, each contains at most two distinct symbols. Therefore, their concatenation also contains at most two distinct symbols. By induction, for all , the minASI string contains at most two distinct symbols.
We will now show that other minASI strings of length can contain at most three distinct symbols if . We provide the construction of minASI strings with three symbols. In the first step , we assemble a 2-gram where and . Next, we join the existing 2-gram with a new symbol where . This forms a 3-gram , introducing a third distinct symbol and further increasing the ASI by 1. We continue assembling by joining the longest string formed so far with itself or with previously formed strings, maintaining the minimal ASI increase.
Assume a contrario that there exists a minASI string of length that contains four or more distinct symbols. But, incorporating such a fourth symbol is equivalent to assembling a maxASI 4-gram, which contradicts the minimality of (only a 2-gram must be assembled from basic symbols and a 3-gram must be assembled from a basic symbol and a 2-gram). Thus, Theorem 3.2 is proven. □
By Theorem 2.1 the maximum ASI decrease is provided by minASI -grams and amounts to . On the other hand, 1-symbol n-grams are guaranteed to have the minimum ASI for all n. Therefore, the maxASI string will tend to contain only one such long n-gram for each b. We have found, for example, that the sum of the lengths of an -gram of zeros and an -gram of ones should preferably be greater than or equal to of a maxASI string.
The assembly spaces of strings of length are not unique [36]. For example, a string can be assembled in three steps from four assembly spaces with , , , or .
Strings with non-minASI can contain all symbols. For example, the string [37]
has ASI and contains all five basic symbols .
The minASD as a function of the length of a string (5), the ASD of a minASI string (which we call here the minASI ASD), the minASI as a function of the length of a string (OEIS A003313), and DPI (OEIS A014701) define four distinct sets illustrated in Figure 4, wherein . We observed certain salient regularities among them.
Theorem 3.3.
If a minASI string has length , , then the minimum ASD, minASI ASD, minASI, and DPI are equal to s.
Theorem 3.3 can be generalized as follows.
Theorem 3.4.
The minASD, minASI ASD, minASI, and DPI of a minASI string are equal to iff or, in other words
Figure 3.
Lengths of all strings having the property of (a). Lengths , , of certain strings having the property of (b-d). Lengths , of certain strings having the property of (e,f)
Figure 3.
Lengths of all strings having the property of (a). Lengths , , of certain strings having the property of (b-d). Lengths , of certain strings having the property of (e,f)
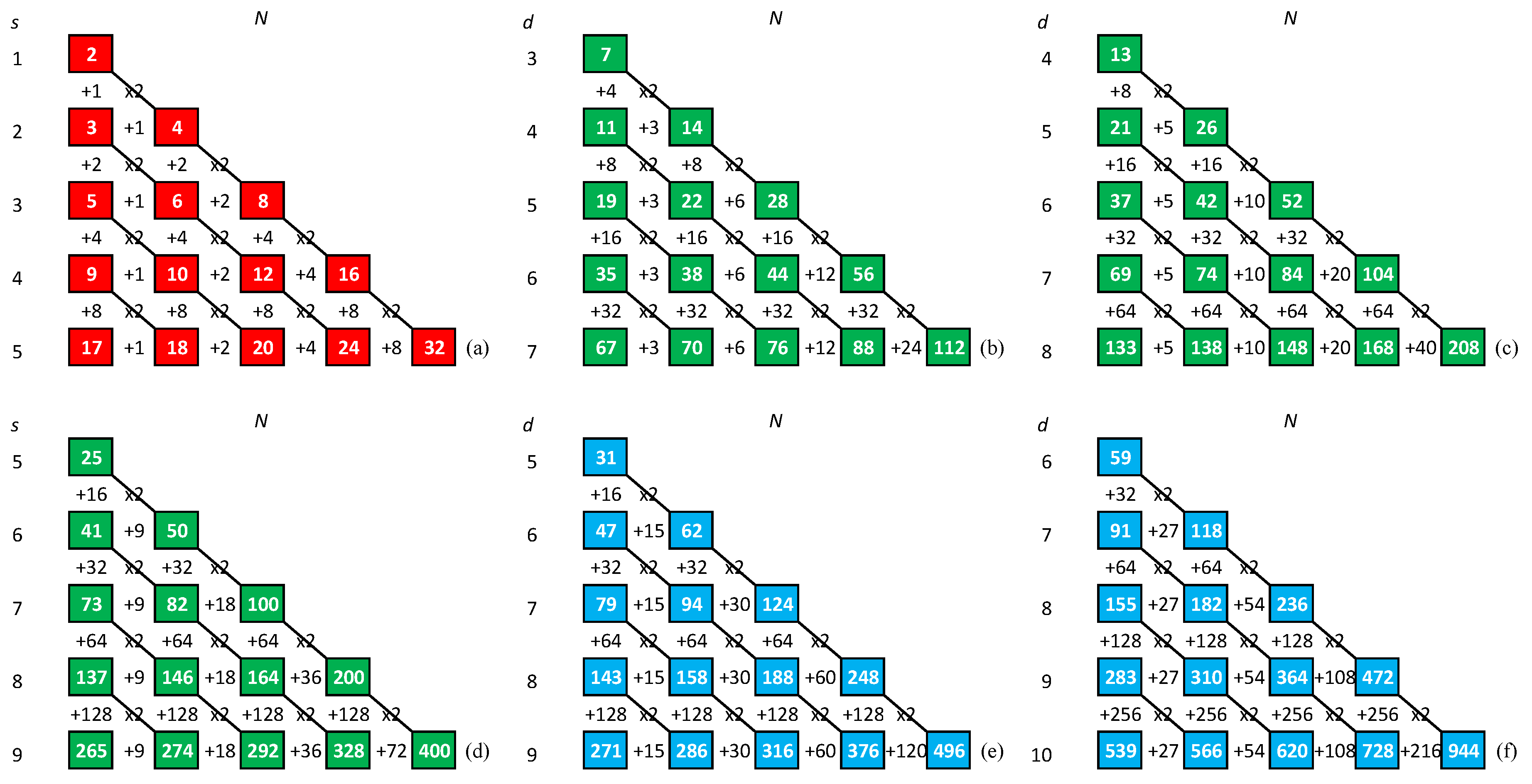
The assembly spaces of other minASI strings can contain independent assembly steps. The first such case occurs for , where, for example, the
results in a string having ma and , since both and were assembled from the 2-gram in two independent assembly steps at the same depth , which is congruent with Theorem 2.2.
Lemma 3.1.
The minASI strings [10] (strings (15)) of lengths
have only one independent assembly step in their assembly spaces, and excluding this step, they are assembled by joining the longest string assembled so far with itself. Therefore, their ASI is one greater than the minASD (5).
Lemma 3.2.
The minASI strings of lengths
have only one independent assembly step in their assembly spaces, and excluding this step, they are assembled by joining the longest string assembled so far with itself. Therefore, their ASI is one greater than the minASD (5).
Lemma 3.3.
The minASI strings of lengths
have only one independent assembly step in their assembly spaces, and excluding this step, they are assembled by joining the longest string assembled so far with itself. Therefore, their ASI is one greater than the minASD (5).
Lemmas 3.1–3.3 allow for the following generalization.
Theorem 3.5.
The minASI strings of lengths
have only one independent assembly step in their assembly spaces, and excluding this step, they are assembled by joining the longest string assembled so far with itself. Therefore, their ASI is one greater than the minASD (5).
Proof.
Theorem 3.6.
The minASI strings [10] of lengths
are assembled by joining the longest string assembled so far with itself. Their ASI and ASD are the same, one greater than the minASD (5) and one smaller than the DPI.
Theorem 3.6 seems to allow for the following generalization, which we have validated numerically based on the sequence OEIS A003313 for . For d, l, and defined by the relation (19), the following holds
The lengths of the strings (21a) and (21b) are listed in rows in Table A1. Furthermore, we have numerically validated the following conjecture. The minASI strings of lengths
have the property of
Figure 4.
The minimum assembly depth (, blue), the assembly depth of the minimum assembly index string (magenta), the minimum assembly index (OEIS A003313, red; , red, dash-dot), depth index (OEIS A014701, green), and , where is the Hamming weight of the binary representation of N (black) for .
Figure 4.
The minimum assembly depth (, blue), the assembly depth of the minimum assembly index string (magenta), the minimum assembly index (OEIS A003313, red; , red, dash-dot), depth index (OEIS A014701, green), and , where is the Hamming weight of the binary representation of N (black) for .
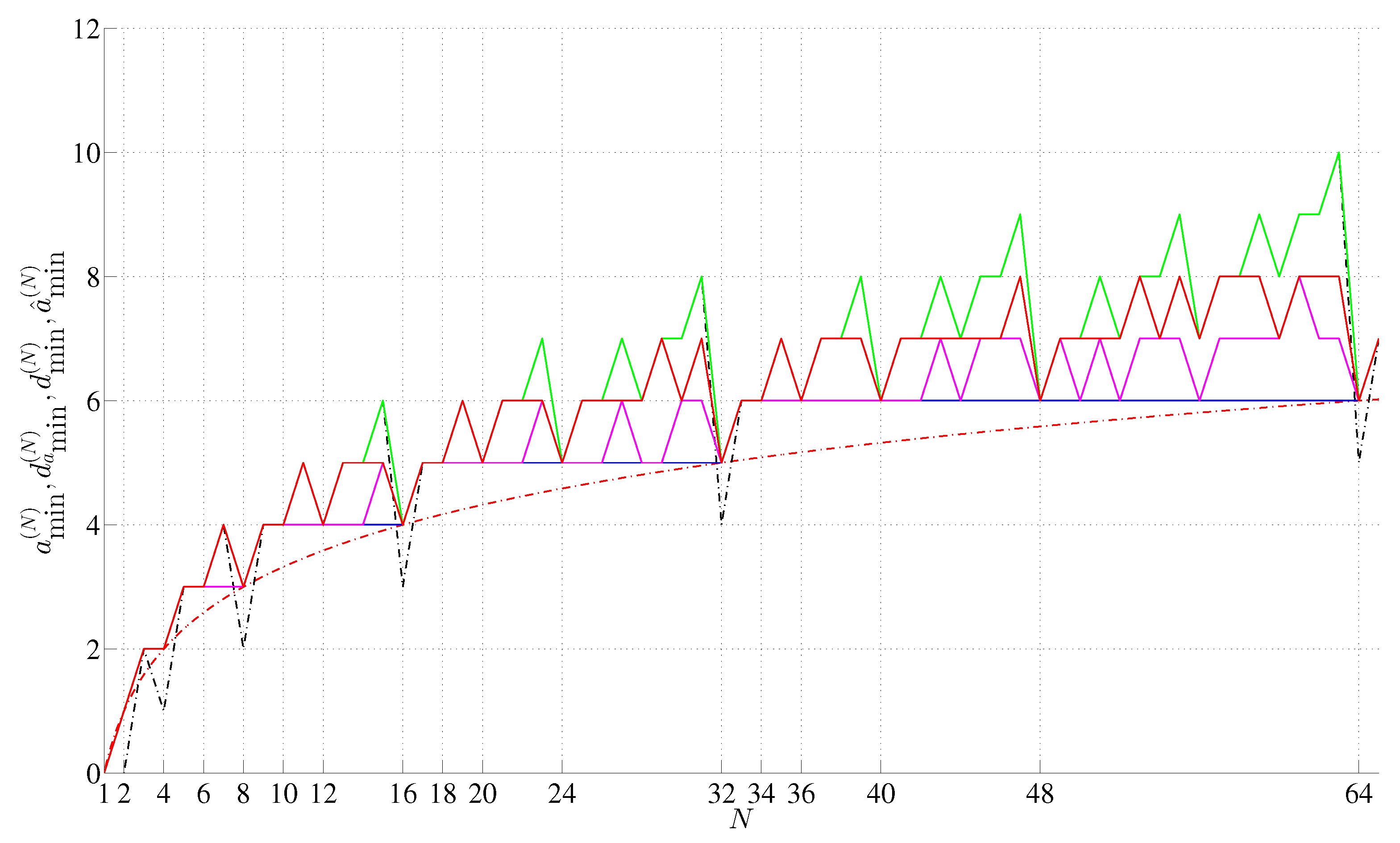
Figure 5.
The Shannon entropy of the most balanced bitstrings having the minimum assembly index for
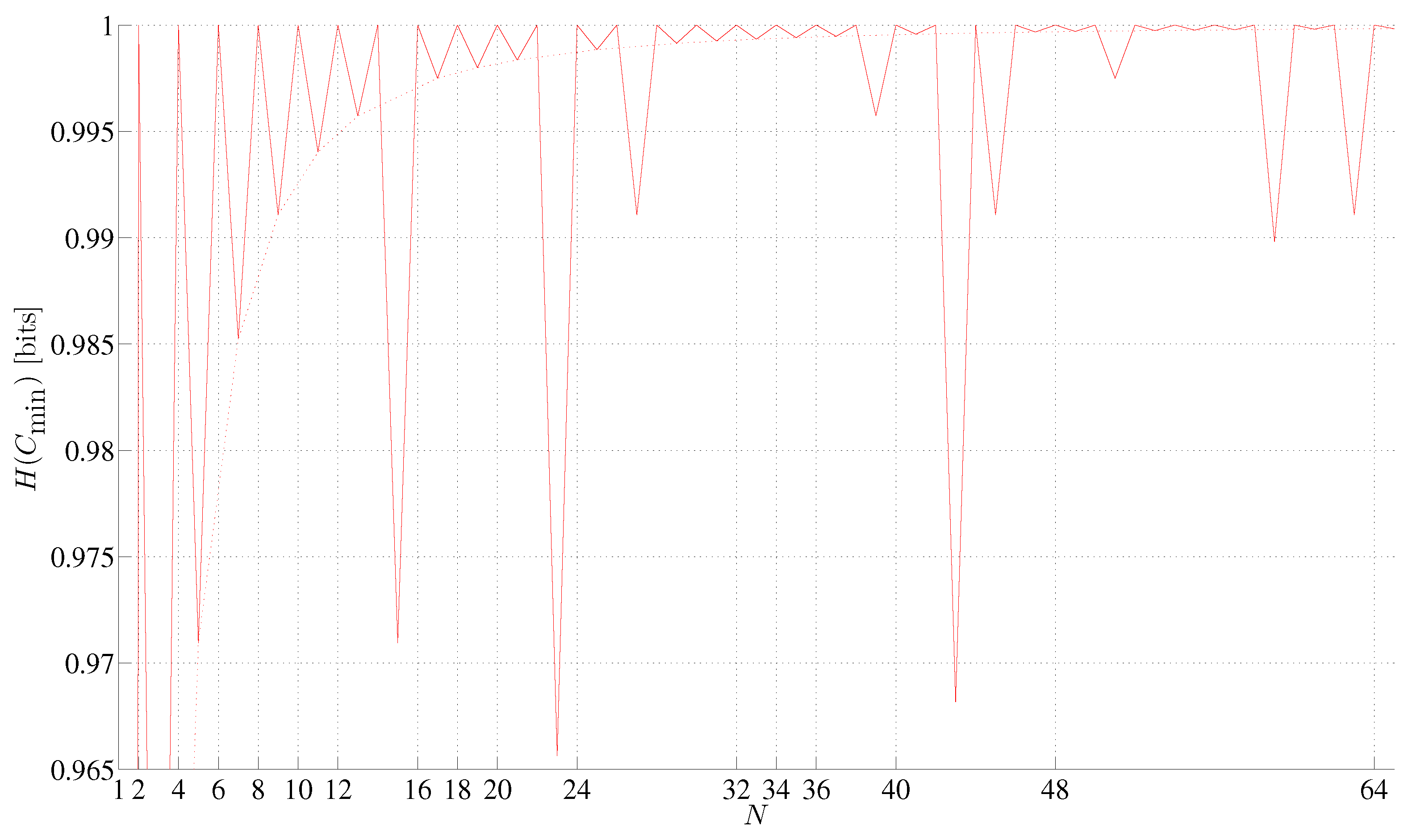
Strings of lengths (14), (16), and (20), revealed in [10] based on the degree of causation, showed that there are certain regularities among the minASI strings. Here, we extended these results to strings of lengths (19), (21), and (22). In general, Theorems 3.4–3.6 (in particular Theorem 3.6) and Conjectures Section 3 and Section 3 show a peculiar interdependence among the minASD (5), minASI ASD, minASI, and DPI, as shown in Figure 4. In particular, they show that
- the of minASI strings having ASI equal to DPI cannot contain strings assembled in independent assembly steps,
- the s of other minASI strings can contain at least two such strings, and therefore
- the assembly space of a maxASI string will tend to maximize the number of strings assembled in independent assembly steps in the , taking into account the saturation of the as it cannot contain more than distinct n-grams, and hence to minimize the possible ASD.
We note that, in general, the difference between the DPI and minASI is larger than 1.
Lemma 3.4.
The minASI bitstrings assembled along the pathway given by the DPI 2.7 and beginning with are balanced bitstrings if N is even or nearly balanced bitstrings () if N is odd.
In other words, the Definition 2.7 removes the imbalance propagation. For example, an imbalanced pathway () becomes a balanced pathway () and . We have also examined the Shannon entropy
of the most balanced minASI bitstrings, where and are fractions of the respective symbols within the string ( is the Hamming weight). Although by Theorem 3.1, the minASI as a function of the length of a string does not depend on b, we have chosen the most balanced bitstrings, as they maximize the Shannon entropy (23). This choice is also supported by physics [38,39,40]. For the same reason, we preferred the pathway (cf. Figure 1d) over , for example, as the string assembled using the former pathway is more balanced () than the one assembled using the latter one (). Similarly, we preferred the pathway that provided a more balanced string over the one that provided independent assembly steps. is the first exception. assembled in five steps along the pathway with the independent assembly steps 3 and 4 has the hamming weight as compared to assembled in five steps along the pathway with no independent assembly steps and the hamming weight . The resulting pathways of the minASI strings maximizing the number of independent assembly steps or the binary Shannon entropy (23) are listed in Table A2 for . As shown in Figure 5, the Shannon entropy (23) of the most balanced minASI bitstrings rapidly converges to one with exceptions for lengths substantially corresponding to lengths at which DPI is larger than the minASI (cf. Figure 4), which highlights the interdependence among the minASI and DPI.
We demonstrated in this section that minimum complexity AT strings cannot be fully derived by any rule-based system. The same is true for the maxASI strings, as we shall show in a subsequent section.
4. Maximum Assembly Index Strings of AT
A seven-bit string is the longest string that can have the maxASI . It contains two clear 3-grams
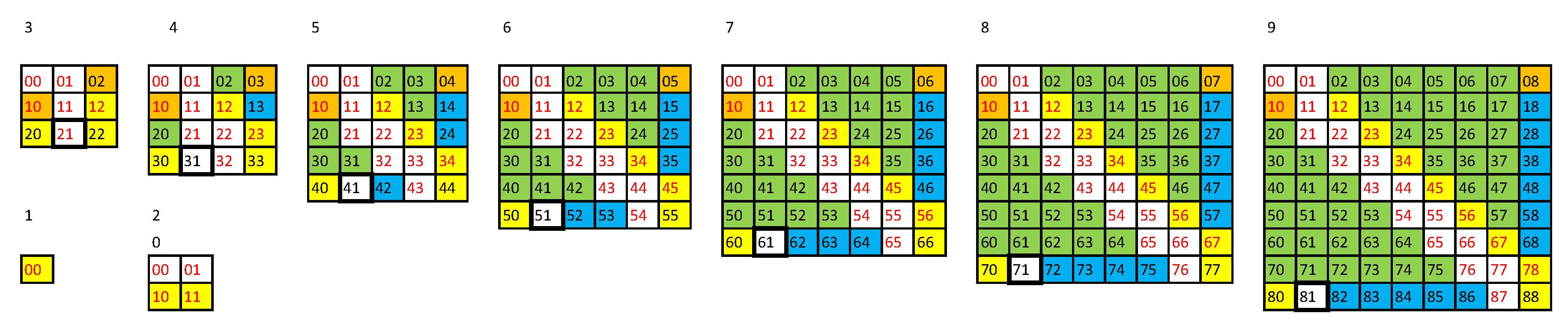
and its length cannot be increased without a repetition of a 2-gram, which keeps the ASI at the same level . This led us to seek a general method to construct the longest possible string having the maxASI , as a function of the radix b. We denote the length of this string by and we call this string a string. We developed two methods of constructing a string of the form
In both methods, we start with an initial balanced string of length containing b clear 3-grams ordered as
The 2-grams that can be inserted into the initial string (26) can be arranged in a matrix
where the crossed out entries on a diagonal cannot be reused, as they would form repetitions in this string. Due to the order of 3-grams in the string (26) we can also cross out the entries in the first superdiagonal of the matrix (27). By construction, the starting string (26) has length and contains only 2-grams and , where and .
In the 1st step of the 1st method, we begin by forming a string containing 2-grams on the first subdiagonal of the matrix (27), starting with 10
and we append it to the string (26). With this step, we also eliminate the 2-grams on the second superdiagonal starting with the 2-gram 02, as well as the 2-gram . In the 2nd step, we form a string containing 2-grams on the third superdiagonal beginning with the 2-gram 03
and append it to the string formed so far. With this step, we also remove the 2-gram and the middle part of the second subdiagonal containing . And so on. Finally, we append 0 if b is even. This process is illustrated in Figure 6 and generates the following strings
We discuss the 2nd method in Appendix A.15.
Figure 6.
2-gram matrices for that illustrate the generation of strings according to a method presented in this section. Coloured 2-grams are appended to the initial string of clear 3-grams in the order indicated by arrows starting from the 1st column or row. Finally, 0 is appended at the end if b is even.
Figure 6.
2-gram matrices for that illustrate the generation of strings according to a method presented in this section. Coloured 2-grams are appended to the initial string of clear 3-grams in the order indicated by arrows starting from the 1st column or row. Finally, 0 is appended at the end if b is even.

The longest length of a string that has the ASI of (a string) is given by
(OEIS A353887), where is the number of occurrences of all but one symbol within the string, so this string has odd length and is nearly balanced. To be the longest, a string must contain all 2-grams from the matrix (27) and all clear 3-grams. A string that contains all k-grams is a linear, minimal de Bruijn string (e.g., for ), which must start and end with the same symbol. Its length is given by , and there are such strings. We consider and have to add b symbols to turn b clear 2-grams of a de Bruijn string into b clear 3-grams, which clearly does not introduce any disjoint occurrences [41]. This leads to the formula (31). For the upper and the lower bound on the ASI are the same, , and this is the only case where the maxASI is not a monotonically non-decreasing function of N. Otherwise, the maxASI must rise. If it were to become constant for , then at some even larger N it would inevitably become lower than the minASI bound of Theorem 3.1, which also rises, and this would be a contradiction.
Subsequently, we considered other strings with the maxASI. A string contains all 2-grams. Hence, inserting any basic symbol into any position inevitably leads to a repetition of a 2-gram. Without loss of generality (w.l.o.g.) we append it at the start of the string, obtaining a string . Another symbol can be introduced to this string without an additional 2-gram repetition, for example, as another prefix leading to the repetition of the 2-gram or but not both of them (here we allow ). Hence, both the length and the ASI of this string increase by one. Finally, 0 can be appended at the start of this string without an additional 2-gram repetition, provided that and . For there are only four1 bitstrings containing only two copies of a 2-gram having the ASI
where the leftmost one is the only unbalanced string within this set (). Each 10-bit string (32) has one clear 4-gram surrounded by the same symbol () and one clear 3-gram (), which can be concatenated () in eight bits or separated () in nine bits. The first three strings (32) correspond to the former case, while the last one to the latter. Each of the strings (32) contains three pairs of mutually exclusive 2-grams, so that only one pair can be reused to decrease the maximum ASI by one.
We developed two methods of constructing generalized strings (32) for . They have clear 4-grams (), one clear 3-gram and of mutually exclusive 2-grams overlapped in patterns surrounding clear 4-gram, so that only one pair from each pattern can be reused in ways to reduce the maxASI to . The 1st method is based on the balanced string (32) and generates the most balanced strings. It starts with a string of length containing all clear 4-grams in the form
to which the missing symbols are appended using the patterns shown in Figure 7 yielding the strings of the form
Figure 7.
2-gram matrices for that illustrate the generation of the most balanced strings (33). Coloured 2-grams are appended to the initial string of clear 4-grams in the order indicated by colours.
Figure 7.
2-gram matrices for that illustrate the generation of the most balanced strings (33). Coloured 2-grams are appended to the initial string of clear 4-grams in the order indicated by colours.
We discuss the 2nd method, generating non-balanced strings, in Appendix A.16.
The mutually exclusive 2-grams of any string comprise adjoining clear 2-grams on the diagonal of the 2-grams matrix (27) and 2-grams on its sub- and super-diagonals, as shown in Figure 7, so that each clear 4-gram is surrounded by the same symbol only one pair from each pattern can be reused. In particular, strings can have forms (A25) or (34) with all clear 4-grams separated by 2-grams and forming 7-gram patterns in the form . However, this is not necessary. For example, the string does not follow this rule. strings are not the maximum length maxASI strings having the property of maxASI incremented by one with every three symbols. For example, the string (34) for can be suffixed with 202, yielding a string with which still is not the maxASI string with this property for (cf. Table A5).
5. Results Common to the Minimum and Maximum Complexity Strings
The minASI and maxASI bounds are illustrated in Figure 8 for . For each b, maxASI initially equals up to the 1st threshold (31). Then it flattens and decreases by one every 3 symbols: once for and times for , as we conjecture based on the results for .
Figure 8.
The minimum assembly index (red; , red, dash-dot) and the maximum assembly index (green) for and .
Figure 8.
The minimum assembly index (red; , red, dash-dot) and the maximum assembly index (green) for and .
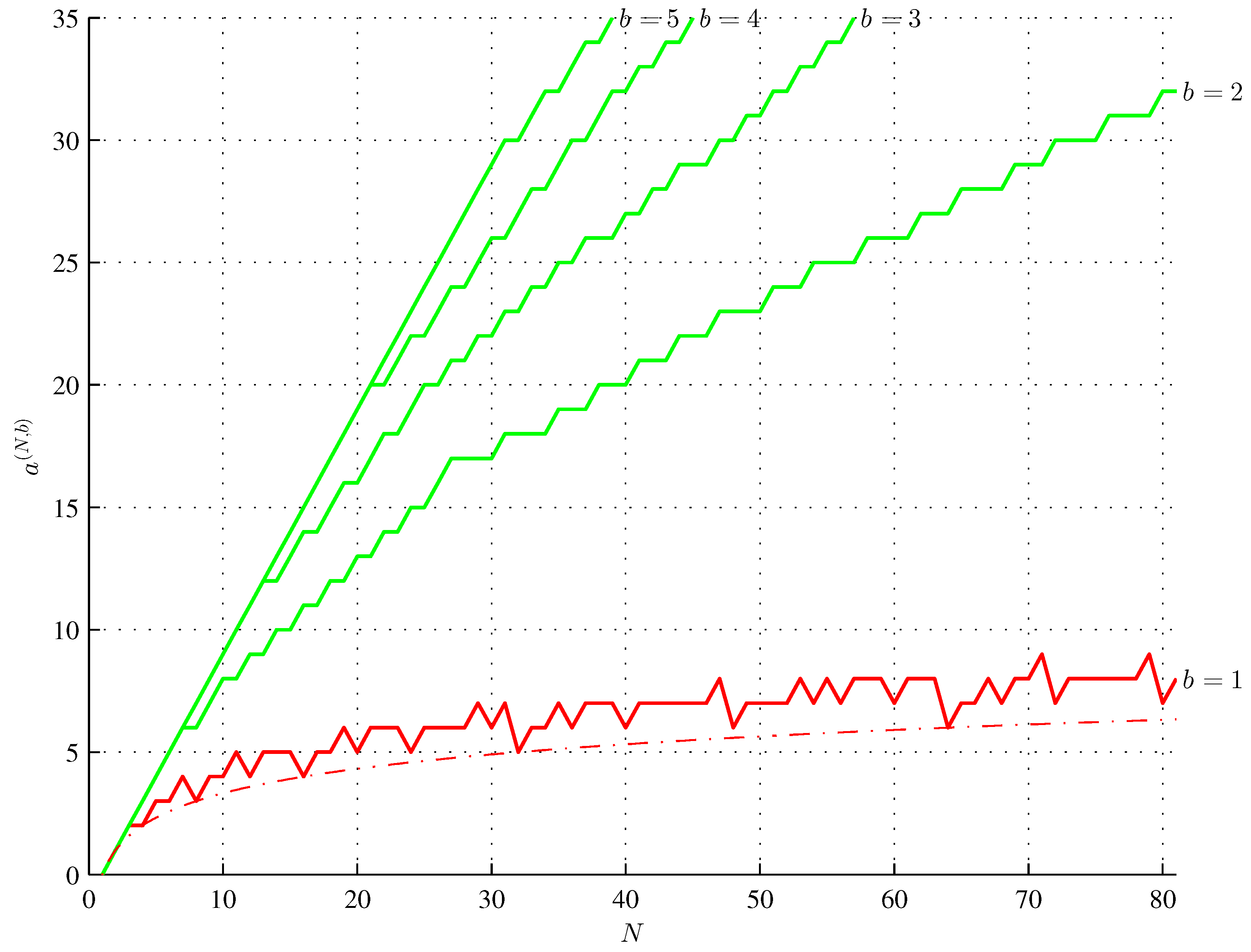
Figure 9.
The ASI of all bitstrings of lengths (a), (b), (c), (d), and (e), as a function of their decimal representations, in squares with sides equal to . Red dots indicate maxASI strings.
Figure 9.
The ASI of all bitstrings of lengths (a), (b), (c), (d), and (e), as a function of their decimal representations, in squares with sides equal to . Red dots indicate maxASI strings.

The ASI of a string is also related to the expected waiting time (EWT) of this string. The EWT is the expected number of trials until a specific string appears in a sequence of independent and identically distributed (i.i.d.) random variables taking values in a finite set of equiprobable outcomes, called a uniform categorical distribution. The general formula for the EWT of a string, which can be determined using Markov chains, is [42]
where is an indicator function that is 1 if the prefix of length k is also the suffix of the string and 0 otherwise. Thus, the EWT is bounded from below and from above as
The upper EWT bound (36) is attained by clear strings, that is, also by the minASI strings, in which case and the formula (35) simplifies to a geometric series which resolves to the upper EWT bound (36). The minASI strings containing two or three symbols do not satisfy this relation and hence have shorter EWT. For example, the minASI alternating strings have the EWT given by if N is even and if N is odd, that is given by (OEIS A026644). The non-alternating minASI bitstrings can have the EWT even closer to the lower bound (36). For example, (cf. Figure 1d) lies firmly at the lower end of the spectrum, being positioned just of the way through the total range. The lower EWT bound (36) is attained by the strings having no prefixes matching suffixes, in which case, for the whole string matches itself. The maxASI strings feature the EWT values equal to or close to this bound.
Applying AT to evolutionary biology, the inverse proportionality between the EWT of a string and its ASI is anticipated but also feels counterintuitive, as common sense would suggest that strings of low complexity should be provided earlier than more complex ones.
We found a correlation between the maxASI and the decimal representation of a string providing an intuitive geometric interpretation of the complexity landscape. For example, Figure 9 shows the ASI of all bitstrings of even lengths distributed in squares of sides equal to , starting from the top-left corner () and ending at the bottom-right corner (). The decimal value of each pixel is given by , where are the row and column indices. The low ASI strings naturally occur on diagonals and oblique lines because of the internal symmetries they exhibit. For example, minASI strings naturally occur on the main diagonal, as for corresponds to a bitstring containing a prefix of length equal to its suffix. Thus, the EWT (35) of a main diagonal bitstring is bounded from below by , and its ASI, taking ito account the relation (1), is bounded by
For example, for , the ASI of all main diagonal strings satisfy , and they include the four minASI strings corresponding to equidistributed decimals 0, 85, 170, and 255. For , the depleted sixteen maxASI strings correspond to decimal values. For , the ten minASI strings are equidistributed on the main square diagonal every 585 and every 1365. Finally, for , the small ASI strings are aligned on diagonals and skewed lines with the four minASI strings again equidistributed on the main square diagonal, while the 506 maxASI strings tend to attain row-like and column-like arrangements.
6. Supremacy of the ASI Compression over Polynomial-Time Compression Algorithms
Calculating the ASI of a string can be contrasted with compression algorithms that run in polynomial time, such as basic dictionary (LZ-type) schemes [43,44,45] or grammar-based algorithms, such as Re-Pair. Indeed, Turing’s universality and algorithmic complexity show that any computable transformation, including the ASI, can be simulated symbolically with no loss of information [43]. This naturally raised doubts regarding the trivial computability of the ASI and its potential equivalence to popular lossless compression algorithms [43].
Yet these doubts proved moot. As the length of a string increases, computing the ASI becomes a hyper-exponentially hard, exhaustive process over all possible combinations and repeated substrings due to the enormous combinatorial space of possible construction pathways and the need to globally evaluate which fragments are most efficient to create early versus later; such a pathway minimization cannot be resolved entirely through local heuristics; there is no local strategy of finding optimal substrings in AT. This ASI problem is widely known in AT literature (cf. [13,46,47,48]). It was conjectured [10] that the ASI problem is NP-complete. A certificate-dependent (assembly-step) proof of this conjecture within predefined assembly spaces [12,47] was found [48] by providing a Karp reduction from the vertex cover problem. A complete, self-contained proofs of NP-completeness of the ASI problem for both decision and optimization variants and for all assembly spaces were found [14] by establishing a correspondence between string assembly spaces and straight-line grammars. Since, for each ASI, there exists a naïve algorithm (exhaustive search of the entire assembly tree), the ASI is computable for all finite objects [7]. Thus, one can say that determining ASI is computable and algorithmically trivial, but it is also computationally non-trivial because the assembly tree grows exponentially with N. One can see this non-triviality by noting that integrating machine-learning–driven methods does not improve ASI computation, even for moderately sized molecules [49]. Interestingly, human intuition can often identify structural patterns or regularities enabling rapid non-algorithmic qualitative estimation of the ASI that remains inaccessible to sequential algorithms.
The computational non-triviality of the ASI raised a second question: whether a worse and slower algorithm [43], such as NP-complete ASI exhaustive search, merits consideration if it provides the same explanatory power and predictive accuracy as known algorithms. Indeed, if additional constraints are imposed on AT, such as restricting assembly steps to substrings of predefined length, allowing/excluding certain assembly steps [12,48], etc., then certain variants of calculating the ASI may yield the same, or even worse results as compared to known compression algorithms, given the large number of the latter.
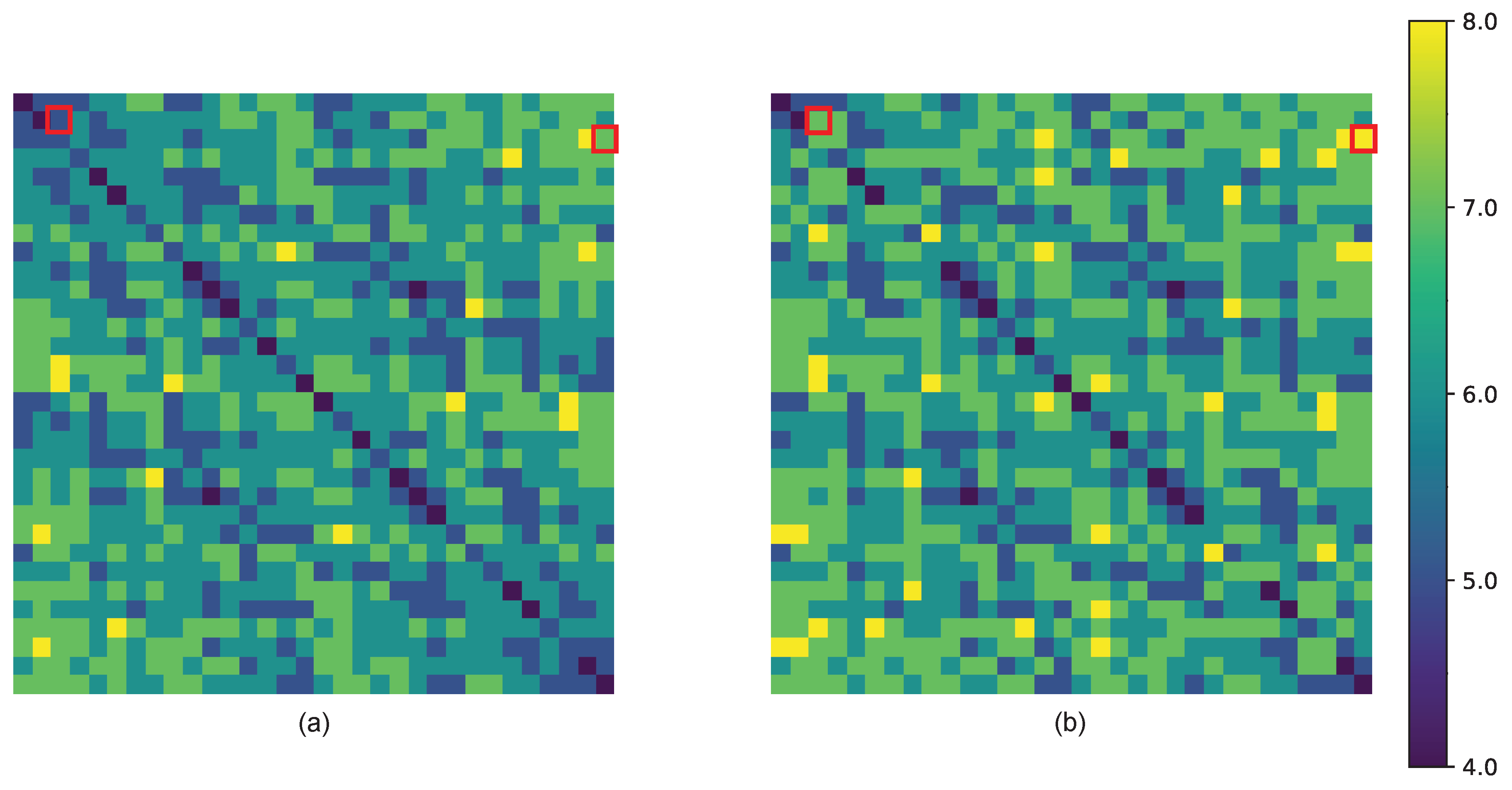
Figure 10.
The ASI (a) and Re-Pair steps (b) of all bitstrings of length , as a function of their decimal representations (), in squares with sides equal to 32 pixels. Visible lack of perfect correlation between the ASI and Re-Pair: the number of Re-Pair steps is higher than ASI for 100 strings (e.g., 7=Re-Pair(34) > ASI(34)=5 for , 8=Re-Pair(95) > ASI(95)=7 for ).
Figure 10.
The ASI (a) and Re-Pair steps (b) of all bitstrings of length , as a function of their decimal representations (), in squares with sides equal to 32 pixels. Visible lack of perfect correlation between the ASI and Re-Pair: the number of Re-Pair steps is higher than ASI for 100 strings (e.g., 7=Re-Pair(34) > ASI(34)=5 for , 8=Re-Pair(95) > ASI(95)=7 for ).
As an example, let us compare AT, a constrained AT* version that prohibits mixed 2-gram in the assembly pool (cf. Figure 2b), and the grammar-based Re-Pair method. The Re-Pair method involves counting all 2-grams in a string, selecting the most frequent 2-gram that occurs at least twice, replacing all its occurrences with a new symbol, and repeating these steps until no 2-gram occurs more than once. This is illustrated in the list (38) for an exemplary maxASI bitstring of length . As shown, the ASI of this string is fifteen, while the ASI* obtained by such a constrained AT* version is sixteen, which corresponds to the number of steps required to compress this string into a Re-Pair compressed version .
However, an unconstrained AT provides different results. The distributions of ASI and Re-Pair steps for all the bitstrings of length illustrated in Figure 10, show that ASI compression is superior to the one provided by the Re-Pair algorithm. We encourage the reader to conduct an independent comparison of the ASI (e.g., for the maxASI strings provided in Table A3–Table A6) with the results produced by well-known compression algorithms.
7. Discussion
The present study provides a general mathematical framework for the general AT string version and demonstrates how this formalization enables efficient computation of assembly indices across various diverse structural sequences. Clarifying the theory’s conceptual structure provides suggestions for its computational implementation. This allowed us to formalize bounding and pruning processes (an approach also proposed in [13,46]) and to develop software capable of effectively computing the ASI of a string, significantly reducing the number of potential configurations to explore. This, in turn, resulted in substantial efficiency gains, allowing us to find the exemplary long maxASI strings (cf. Table A3–Table A6) and determine the maxASI bounds shown in Figure 8, overcoming important limitations exhibited by all the other known implementations of the algorithms to compute the ASI of big objects [50].
Fortunately, the non-triviality of computing the ASI does not close the field but rather delineates a structured landscape for algorithmic exploration. The framework developed here is equally applicable to symbolic representations of various real world patterns within the context of AT, such as detecting biosignatures [6], describing the evolution of music [51], and, as we conjecture, natural language processing (AI-generated text detection, authorship style analysis, plagiarism detection, time series analysis, etc.), financial data changes (distinction between random and predictable behaviour), sensor data anomaly analysis, medical signal analysis, etc.
The implications of our findings extend beyond the formal structure of AT itself. Traditional physics, while offering predictive power from past initial conditions to future states, lacks a functional perspective necessary to differentiate meaningful novelty from random fluctuations. AT may offer a unifying language for describing how information becomes structure. It can do so by showing how biological sequences are governed by foundational mathematical principles, for instance, for understanding the rules underlying the assembly of macromolecules such as proteins and DNA. Evolutionary biology explains the survival and prevalence of certain traits, but it does not address the mechanisms for generating novel phenotypic variants. We have shown, for example, that a DNA strand of length N containing four nucleobases cannot represent a minASI string without violating Chargaff’s rules and Theorem 3.2. Theorem 3.2 establishes that a minASI string can contain at most three distinct symbols (if , as otherwise it can contain at most two), while the first Chargaff’s rule (for double-stranded DNA) states that four nucleobases A, T, and G, C should be pairwise balanced. On the other hand, biological systems tend to deviate from the equilibrium of maximum entropy [10,52] corresponding to balanced strings,
For , the information entropy (23) vanishes, as the bit () is the smallest amount and the quantum of information. Yet AT explains the assembly of such minASI strings, extending beyond the minimal two-valued system necessary to convey any information. Our results clarify that AT is a formal system for describing the generative and causal structure of objects, positioning it as a theoretical extension of information theory, emphasizing not the description of information but the effort required to construct it.
Author Contributions
W.B.: first concept of a general method for constructing the string and it’s implementation (the 1st method); the concept of the 2-gram matrix (27); proposition leading to Theorem 2.1; outline of the Section 1 and Section 7; numerous clarity corrections and improvements; P.M.: outline of the 2nd method (A.15); observation of the relation between Theorems 2.3 and 2.4; crucial observations leading to the proofs of Lemmas 3.2 and 3.4; novel Strings (19); the concept of a Table A1; Conjecture 3.1; numerous clarity corrections and improvements; A.T.: formal proof of Theorem 3.2; proof of the Theorem 3.3; conceptualization of the proof of the Theorem 2.4 and equation (4); numerous clarity corrections and improvements; S.T.: development of an efficient software for computing the ASI of a string generating the strings listed in Table A3–Table A6; hint on the visualisation of the ASI distributions shown in Figure 8; numerous clarity corrections and improvements; S.Ł.: the remaining part of the study.
Funding
This research received no external funding.
Data Availability Statement
Public repository for the code and results of this study is given under the link https://github.com/szluk/AssemblyTheory (accessed on 28 December 2025).
Acknowledgments
Mariola Bala for her motivation, Rafał Bobrowski for assessing the time required to calculate a maxASI of a string as a function of its length, Robert Dobosz for providing valuable hints on earlier research [53] linking information and probability theories, Rafał Winiarski for noting that the relation (1) is inequality, anonymous referee for pointing out the coincidence of the DPI with , shown in Figure 4, and SŁ’s daughter Anna for her support in finding the pattern of strings (34). SŁ thanks his wife, Magdalena Bartocha, for her everlasting support, and his partner and friend, Renata Sobajda, for her prayers.
Conflicts of Interest
Authors Wawrzyniec Bieniawski and Piotr Masierak were employed by the company Łukaszyk Patent Attorneys. The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AT | assembly theory; |
| N | length of a string; |
| b | number of basic symbols ; |
| , | a string; |
| ASI, | assembly index of a string (minASI - minimum, maxASI - maximum); |
| assembly space of a string ; | |
| ASD, | assembly depth of a string (minASD - minimum, minASI ASD - the ASD of a minASI string); |
| DPI | depth index (OEIS A014701); |
| EWT, | expected waiting time; |
OEIS Sequences
The following OEIS sequences are referred to in this manuscript:
| A003313 | Length of shortest addition chain for n (minASI); |
| A014701 | Number of multiplications to compute n-th power by the Chandah-sutra method (DPI); |
| A026644 | Number of moves to solve Chinese rings puzzle; |
| A048645 | Integers with one or two 1-bits in their binary expansion; |
| A173786 | Triangle read by rows: , . |
Appendix A

Table A1.
Certain lengths of minASI strings, which are defined by the ASI and the minASI ASD for .
| s | ... | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 2 | 4 | 3 | 7 | 14 | 28 | 56 | 112 | 224 | ... | |
| 15 | 30 | 60 | 120 | 240 | 480 | ||||||
| 23 | 46 | 92 | 184 | 368 | |||||||
| 3 | 2 | 4 | 8 | 3 | 11 | 22 | 44 | 88 | 176 | ... | |
| 27 | 54 | 108 | 216 | 432 | |||||||
| 43 | 86 | 172 | 344 | ||||||||
| 2 | 4 | 8 | 5 | 13 | 26 | 52 | 104 | 208 | ... | ||
| 45 | 90 | 180 | 360 | ... | |||||||
| 4 | 2 | 4 | 8 | 16 | 3 | 19 | 38 | 76 | 152 | ... | |
| 51 | 102 | 204 | 408 | ||||||||
| 83 | 166 | 332 | |||||||||
| 2 | 4 | 8 | 16 | 5 | 21 | 42 | 84 | 168 | ... | ||
| 85 | 170 | 340 | ... | ||||||||
| 2 | 4 | 8 | 16 | 9 | 25 | 50 | 100 | 200 | ... | ||
| 5 | 2 | 4 | 8 | 16 | 32 | 3 | 35 | 70 | 140 | ... | |
| 99 | 198 | 396 | |||||||||
| 163 | 326 | ||||||||||
| 2 | 4 | 8 | 16 | 32 | 5 | 37 | 74 | 148 | ... | ||
| 165 | 330 | ... | |||||||||
| 2 | 4 | 8 | 16 | 32 | 9 | 41 | 82 | 164 | ... | ||
| 2 | 4 | 8 | 16 | 32 | 17 | 49 | 98 | 196 | ... | ||
| 6 | 2 | 4 | 8 | 16 | 32 | 64 | 3 | 67 | 134 | ... | |
| 195 | 390 | ||||||||||
| 323 | |||||||||||
| 2 | 4 | 8 | 16 | 32 | 64 | 5 | 69 | 138 | 276 | ||
| 325 | 650 | ||||||||||
| 2 | 4 | 8 | 16 | 32 | 64 | 9 | 73 | 146 | ... | ||
| 2 | 4 | 8 | 16 | 32 | 64 | 17 | 81 | 162 | ... | ||
| 2 | 4 | 8 | 16 | 32 | 64 | 33 | 97 | 194 | ... | ||
| 7 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 3 | 131 | ... | |
| 387 | |||||||||||
| 2 | 4 | 8 | 16 | 32 | 64 | 128 | 5 | 133 | 266 | ||
| 645 | |||||||||||
| 2 | 4 | 8 | 16 | 32 | 64 | 128 | 9 | 137 | ... | ||
| 2 | 4 | 8 | 16 | 32 | 64 | 128 | 17 | 145 | ... | ||
| 2 | 4 | 8 | 16 | 32 | 64 | 128 | 33 | 161 | ... | ||
| 2 | 4 | 8 | 16 | 32 | 64 | 128 | 65 | 193 | ... |
Table A2.
Pathways leading to minASI strings (maximizing the number of independent assembly steps - MIA, maximizing the binary Shannon entropy - MBL). for (see Section 3 for details).
Table A2.
Pathways leading to minASI strings (maximizing the number of independent assembly steps - MIA, maximizing the binary Shannon entropy - MBL). for (see Section 3 for details).
| N | MIA pathway | MBL pathway (Hamming weight ) | String | ||||
|---|---|---|---|---|---|---|---|
| 2 | 1 | 1 | 1 | 1 | (1) | ||
| 3 | 2 | 2 | 2 | 2 | (1) | ||
| 4 | 2 | 2 | 2 | 2 | (2) | ||
| 5 | 3 | 3 | 3 | 3 | (2) | ||
| 6 | 3 | 3 | 3 | 3 | (3) | ||
| 7 | 3 | 3 | 4 | 4 | (3) | ||
| 8 | 3 | 3 | 3 | 3 | (4) | ||
| 9 | 4 | 4 | 4 | 4 | (4) | ||
| 10 | 4 | 4 | 4 | 4 | (5) | ||
| 11 | 4 | 4 | 5 | 5 | (5) | ||
| 12 | 4 | 4 | 4 | 4 | (6) | ||
| 13 | 4 | 4 | 5 | 5 | (6) | ||
| 14 | 4 | 4 | 5 | 5 | (7) | ||
| 15 | 4 | 5 | 5 | 6 | (6) | ||
| 16 | 4 | 4 | 4 | 4 | (8) | ||
| 17 | 5 | 5 | 5 | 5 | (8) | ||
| 18 | 5 | 5 | 5 | 5 | (9) | ||
| 19 | 5 | 5 | 6 | 6 | (9) | ||
| 20 | 5 | 5 | 5 | 5 | (10) | ||
| 21 | 5 | 5 | 6 | 6 | (10) | ||
| 22 | 5 | 5 | 6 | 6 | (11) | ||
| 23 | 5 | 6 | 6 | 7 | (9) | ||
| 24 | 5 | 5 | 5 | 5 | (12) | ||
| 25 | 5 | 5 | 6 | 6 | (12) | ||
| 26 | 5 | 5 | 6 | 6 | (13) | ||
| 27 | 5 | 6 | 6 | 7 | (12) | ||
| 28 | 5 | 5 | 6 | 6 | (14) | ||
| 29 | 5 | 6 | 7 | 7 | (14) | ||
| 30 | 5 | 6 | 6 | 7 | (15) | ||
| 31 | 5 | 6 | 7 | 8 | (15) | ||
| 32 | 5 | 5 | 5 | 5 | (16) | ||
| 33 | 6 | 6 | 6 | 6 | (16) | ||
| 34 | 6 | 6 | 6 | 6 | (17) | ||
| 35 | 6 | 6 | 7 | 7 | (17) | ||
| 36 | 6 | 6 | 6 | 6 | (18) | ||
| 37 | 6 | 6 | 7 | 7 | (18) | ||
| 38 | 6 | 6 | 7 | 7 | (19) | ||
| 39 | 6 | 6 | 7 | 8 | |||
| 40 | 6 | 6 | 6 | 6 | |||
| 41 | 6 | 6 | 7 | 7 | |||
| 42 | 6 | 6 | 7 | 7 | |||
| 43 | 6 | 7 | 7 | 8 | (17) | ||
| 44 | 6 | 6 | 7 | 7 | (22) | ||
| 45 | 6 | 7 | 7 | 8 | (20) | ||
| 46 | 6 | 7 | 7 | 8 | (23) | ||
| 47 | 6 | 7 | 8 | 9 | (23) | ||
| 48 | 6 | 6 | 6 | 6 | (24) | ||
| 49 | 6 | 7 | 7 | 7 | (24) | ||
| 50 | 6 | 6 | 7 | 7 | (25) | ||
| 51 | 6 | 7 | 7 | 8 | (24) | ||
| 52 | 6 | 6 | 7 | 7 | (26) | ||
| 53 | 6 | 7 | 8 | 8 | (26) | ||
| 54 | 6 | 7 | 7 | 8 | (27) | ||
| 55 | 6 | 7 | 8 | 9 | (27) | ||
| 56 | 6 | 6 | 7 | 7 | (28) | ||
| 57 | 6 | 7 | 8 | 8 | (28) | ||
| 58 | 6 | 7 | 8 | 8 | (29) | ||
| 59 | 6 | 7 | 8 | 9 | (26) | ||
| 60 | 6 | 7 | 7 | 8 | (30) | ||
| 61 | 6 | 8 | 8 | 9 | (30) | ||
| 62 | 6 | 7 | 8 | 9 | (31) | ||
| 63 | 6 | 7 | 8 | 10 | (28) | ||
| 64 | 6 | 6 | 6 | 6 | (32) | ||
| 65 | 7 | 7 | 7 | 7 | (32) | ||
Table A3.
Exemplary maxASI bitstrings for .
| N | N | ||||
|---|---|---|---|---|---|
| 10 | [1010000111] | 8 | 25 | [0000000101010110011111110] | 15 |
| 11 | [00010111100] | 8 | 26 | [01001100000111111101010110] | 16 |
| 12 | [101010000111] | 9 | 27 | [000000011111110101011001000] | 16 |
| 13 | [1000001110101] | 9 | 28 | [0110101011111110000000110010] | 17 |
| 14 | [10011000010111] | 10 | 29 | [01100000001010100111011111110] | 17 |
| 15 | [000001010111110] | 10 | 30 | [100100000000110010101101111111] | 17 |
| 16 | [1001100001010111] | 11 | 31 | [0101010010000000111111101101100] | 18 |
| 17 | [00000010101111110] | 11 | 32 | [01001100000000101011011111111001] | 18 |
| 18 | [100110100001010111] | 12 | 33 | [100000000010011111111011101101010] | 18 |
| 19 | [0111110110000010100] | 12 | 34 | [1000000000100111111110111011010101] | 18 |
| 20 | [10011010000101011111] | 13 | 35 | [10101000000010110010011111110001101] | 19 |
| 21 | [000000010101100111110] | 13 | 36 | [101010000000101100100111111100011101] | 19 |
| 22 | [0010111111101001100000] | 14 | 37 | [1011010101000000010010001111111001101] | 19 |
| 23 | [00000001010101100111110] | 14 | 38 | [10111010101000000010010001111111001101] | 20 |
| 24 | [011001111111010100000001] | 15 | 39 | [111001100100011010000001010101101101111] | 20 |
Table A4.
Exemplary maxASI bitstrings for .
| N | ||
|---|---|---|
| 40 | [0011001011111110101000000011011000101101] | 20 |
| 41 | [00000111111001110101001011011011000100110] | 21 |
| 42 | [001101111110101010110000000111100100100101] | 21 |
| 43 | [0111100111110110010100000011100011000101101] | 21 |
| 44 | [11101010101011111100100100011000000010110110] | 22 |
| 45 | [111010101010111111001001000110000000111011010] | 22 |
| 46 | [0111100111111010001110000000110010010101001101] | 22 |
| 47 | [01111001111110100011100000001100100101010110110] | 23 |
| 48 | [011110011111101000111000000011001001010101101100] | 23 |
| 49 | [0111100111111010001110000000110010010101011011000] | 23 |
| 50 | [10100111111100010001111010000001011011000011100110] | 23 |
| 51 | [101001111111000100011110100000010110110010011010101] | 24 |
| 52 | [1010011111110001000111101000000101101100100100110101] | 24 |
| 53 | [10100111111100010001111010000001011011001001001101010] | 24 |
| 54 | [101001111111000100011110100000010110110010010011010101] | 25 |
| 55 | [1010011111110001000111101000000101101100100100110101010] | 25 |
| 56 | [10100111111100010001111010000001011011001001001101010101] | 25 |
| 57 | [101001111111000100011110100000010110110010010011010101010] | 25 |
| 58 | [1010011111110001000111101000000101101100100100110101010101] | 26 |
| 59 | [10001011100111001111111011010000001110000011001001001010101] | 26 |
| 60 | [101010111011110011111110100100001100100010001001010110000000] | 26 |
| 61 | [1010101110111100111111101001000011001000100010010101100000001] | 26 |
| 62 | [10101011101111001111111010010000110010001000100101011011000001] | 27 |
| 63 | [101010111011110011111110100100001100100010001001010110110000000] | 27 |
| 64 | [1010101110111100111111101001000011001000100010010101101100000001] | 27 |
| 65 | [10101011101111001111111010010000110010001000100101011011011000001] | 28 |
| 66 | [101010101011001000111110110111110001000000110011001110011010010010] | 28 |
| 67 | [1010101010110010001111101101111100010000001100110011100110100100101] | 28 |
| 68 | [10101010101100100011111011011111000100000011001100111001110001011110] | 28 |
| 69 | [101010101011001000111110110111110001000000110011001110011100010100101] | 29 |
| 70 | [1010101010110010001111101101111100010000001100110011100111000101001001] | 29 |
| 71 | [10101010101100100011111011011111000100000011001100111001110001010010010] | 29 |
| 72 | [101010101011001000111110110111110001000000110011001110011100010100100101] | 30 |
| 73 | [1010101010110010001111101101111100010000001100110011100111000101001001001] | 30 |
| 74 | [10101010101100100011111011011111000100000011001100111001110001010010000001] | 30 |
| 75 | [101010101011001000111110110111110001000000110011001110011100010100100000001] | 30 |
| 76 | [1010101010110010001111101101111100010000001100110011100111000101001000010000] | 31 |
| 77 | [10101010101100100011111011011111000100000011001100111001110001010010000000000] | 31 |
| 78 | [101010101011001000111110110111110001000000110011001110011100010100100000000001] | 31 |
| 79 | [1001011101101011111110100110110010011101010110100101000110011110111100000001011] | 31 |
| 80 | [10010111011010111111101001101100100111010101101001010001100111101111000000010101] | 32 |
| 81 | [100101110110101111111010011011001001110101011010010100011001111011110000000101010] | 32 |
| 82 | [1001011101101011111110100110110010011101010110100101000110011110111100000001010100] | 32 |
| 83 | [10010111011010111111101001101100100111010101101001010001100111101111000000010101000] | 33 |
| 84 | [100101110110101111111010011011001001110101011010010100011001111011110000000101011100] | 33 |
| 85 | [1001011101101011111110100110110010011101010110100101000110011110111100000001010111000] | 33 |
Table A5.
Exemplary maxASI strings for and .
| N | ||
|---|---|---|
| 13 | [0002220111210] | 12 |
| 14 | [00022201112101] | 12 |
| 15 | [000222011121012] | 13 |
| 16 | [0002220111210120] | 14 |
| 17 | [20011121002201021] | 14 |
| 18 | [222111210100001202] | 15 |
| 19 | [0221110100122200021] | 16 |
| 20 | [02211101001222000211] | 16 |
| 21 | [022111010012220002112] | 17 |
| 22 | [0221110100122200002021] | 18 |
| 23 | [02211101001222000211201] | 18 |
| 24 | [022111010012220002011210] | 19 |
| 25 | [0222212112002010001111021] | 20 |
| 26 | [02222121120020100011110210] | 20 |
| 27 | [012221211200201000111102202] | 21 |
| 28 | [0122212112002010001111022010] | 21 |
| 29 | [01222121120020100011110220210] | 22 |
| 30 | [012221211200201000111102202102] | 22 |
| 31 | [0122212112002010001111022021020] | 23 |
| 32 | [01222121120020100011110220210200] | 23 |
| 33 | [012221211200201000111102202102000] | 24 |
| 34 | [0122212112002010001111022021020001] | 24 |
| 35 | [01222121120020100011110220210200000] | 25 |
| 36 | [012221211200201000111102202102000001] | 25 |
| 37 | [0122212112002010001111022021020010101] | 26 |
| 38 | [01222121120020100011110220210200101101] | 26 |
| 39 | [012221211200201000111102202102001011012] | 26 |
| 40 | [0122212112002010001111022021020010110000] | 27 |
| 41 | [01222121120020100011110220210200101100002] | 27 |
| 42 | [012221211200201000111102202102001011000022] | 28 |
| 43 | [0122212112002010001111022021020010110000222] | 28 |
| 44 | [01222121120020100011110220210200101100000110] | 29 |
| 45 | [012221211200201000111102202102001011000001110] | 29 |
| 46 | [2111020110222211012201112212121010020000001202] | 29 |
| 47 | [21110201102222110122011122121210100200000010220] | 30 |
| 48 | [211102011022221101220111221212101002000000120210] | 30 |
| 49 | [2111020110222211012201112212121010020000001202112] | 31 |
| 50 | [21110201102222110122011122121210100200000012021120] | 31 |
| 51 | [211102011022221101220111221212101002000000120212210] | 32 |
| 52 | [2111020110222211012201112212121010020000001202122120] | 32 |
| 53 | [21110201102222110122011122121210100200000012021200220] | 33 |
| 54 | [211102011022221101220111221212101002000000120212002202] | 33 |
Table A6.
Exemplary maxASI strings for and .
| N | ||
|---|---|---|
| 21 | [000111222333102132030] | 20 |
| 22 | [0001112223331021320302] | 20 |
| 23 | [00011122233310213203012] | 21 |
| 24 | [010000111222333102132030] | 22 |
| 25 | [0100001112223331021320302] | 22 |
| 26 | [01000011122233310213203023] | 23 |
| 27 | [010000111222333102132030221] | 24 |
| 28 | [0001102013331121301222230323] | 24 |
| 29 | [00011320133311121022232302030] | 25 |
| 30 | [301000012111123222233310320213] | 26 |
| 31 | [3010000121111232222333103202130] | 26 |
| 32 | [30100001211112322223331032021303] | 27 |
| 33 | [301000012111123222233310320213313] | 28 |
| 34 | [3010000121111232222333203102133130] | 28 |
| 35 | [30100001211112322223332031021331300] | 29 |
| 36 | [301000012111123222233320310213313110] | 30 |
| 37 | [3010000121111232222333203102133131101] | 30 |
| 38 | [30100001211112322223332031021331311011] | 31 |
| 39 | [301000012111123222233320310213313110221] | 32 |
| 40 | [3010000121111232222333203102133131102210] | 32 |
| 41 | [30100001211112322223332031021331311022101] | 33 |
| 42 | [301000012111123222233320310213313110322011] | 33 |
| 43 | [3010000121111232222333203102133131102210103] | 34 |
| 44 | [30100001211112322223332031021331311022101030] | 34 |
| 45 | [301000012111123222233320310213313110221201300] | 35 |
| 46 | [3010000121111232222333203102133131102212013002] | 36 |
| 47 | [30100001211112322223332031021331311022120130023] | 36 |
| 48 | [301000012111123222233320310213313110221201300230] | 37 |
| 49 | [3010000121111232222333203102133131102212013002303] | 38 |
Appendix A.1. Proof of Theorem 2.1
Consider the following two strings of the same length with and the same distributions of other repetitions (if any)
Assembling a 2-gram takes one assembly step. Each appending of a 2-gram to an assembled string counts as another assembly step. Hence, in a general case (i.e., for strings , containing also other symbols), the string requires six additional assembly steps, the same as the string . Thus, a string containing the same three 2-grams has the same ASI as a string containing two pairs of the same 2-grams, provided that both strings have the same distributions of other repetitions and have the same lengths.
Consider the following two strings of the same length with the same distributions of other repetitions
The assembly of a 3-gram takes two steps. Hence, in the general case, the string requires four additional assembly steps, the same as the string . Thus, a string containing the same three 2-grams has the same ASI as a string containing the same two 3-grams, provided that both strings have the same distributions of other repetitions.
Similarly, a string containing the same two 3-grams has the same ASI as a string containing two pairs of the same 2-grams, provided that both strings have the same distributions of other repetitions and have the same lengths.
Consider the following two strings of the same length with the same distributions of other repetitions
The assembly of such a 4-gram takes two steps. Hence, in a general case, the string requires five additional assembly steps, the same as the string . Thus, a string containing the same two 4-grams of the minASI has the same ASI as a string containing the same three 3-grams, provided that both strings have the same distributions of other repetitions and have the same lengths.
Consider the following two strings of the same length with the same distributions of other repetitions
The assembly of such a 4-gram takes three steps. Hence, in a general case, the string requires five additional assembly steps, the same as the string . Thus, a string containing the same two 4-grams of the maxASI has the same ASI as a string containing a 2-gram and the same two 3-grams based on this 2-gram, provided that both strings have the same distributions of other repetitions.
Consider the following two strings of the same length with the same distributions of other repetitions
where . In a general case, the string requires seven additional assembly steps, the same as the string . Thus, a string containing the same two 2-grams and the same two 3-grams not based on this 2-gram has the same ASI as a string containing a 2-gram and the same two 3-grams based on this 2-gram, provided that both strings have the same distributions of other repetitions and have the same lengths.
In general, the above considerations show that
- k copies of a 2-gram in a string decrease the ASI of this string at least by ;
- k copies of a 3-gram in a string decrease the ASI of this string at least by ;
- k copies of a minASI 4-gram in a string decrease the ASI of this string at least by ;
- k copies of a maxASI 4-gram in a string decrease the ASI of this string at least by ;
where, the phrase "at least" is meant to indicate that other repetitions, such as e.g. 2-grams forming multiple 4-grams, etc. can further decrease the ASI of the string. W.l.o.g., consider the following string
containing two copies of an n-gram . The n-gram can be assembled in at least steps and appended to the assembled string in one step. Consider that the ASI of the n-gram is , i.e. the n-gram does not have any repetitions that can be reused and . Then one copy of this n-gram - as expected - does not decrease the ASI of the string , as , while more copies k decrease it by . On the other hand, if then even a single copy of this n-gram will decrease the ASI of .
Appendix A.2. Proof of Theorem 2.2
Without loss of generality (w.l.o.g.) assume a contrario that contains two strings , having the same ASD, i.e., , that were not assembled in independent assembly steps, i.e., that was used in the assembly of along with a basic symbol c in some previous step s. Then
which contradicts our assumption and completes the proof.
Appendix A.3. Proof of Lemma 2.2
Assume a contrario that . Then for the ASD , we have which is a contradiction as all basic symbols c are unit-length strings and . Similarly, for , is also contradiction in the case of 2-grams, and so on. This is a consequence of the ASD Definition (3).
Appendix A.4. Proof of Theorem 2.3
Appendix A.5. Proof of Theorem 2.4
Using the property of the ceiling function valid for , we have
The non-strict inequality (A11) corresponds to the non-strict inequality (4) valid for any N and any ASD. Therefore, we need to prove that the strict inequality holds for all strings. Assume, for contradiction, that there exists a maxASI string such that
But this relation does not hold for the maxASI string .
Appendix A.6. Proof of Theorem 3.1
Strings for which , can be formed in subsequent steps s by joining the longest string assembled so far with itself until is reached. Therefore, if , then . Only strings have such ASI if , including respectively b and strings
and the assembly space of each of the strings (A13) is unique. At each assembly step, its length doubles.
An addition chain for having the shortest length (commonly denoted as ) is defined as a sequence of integers such that , for . Hence, and the first step in forming an addition chain for N is always , which is equivalent to saying that the ASI of any 2-gram is one. The second step in forming an addition chain can be or , which corresponds to assembling a 3-gram based on the previously assembled 2-gram or to assembling a minASI 4-gram (A13) from this 2-gram. The maxASI 4-gram can be assembled in a third step, , which corresponds to joining a basic symbol to a 3-gram. Therefore, four is the smallest number achievable in two ways according to Theorem 2.1.
Thus, finding the shortest addition chain for N corresponds to finding the ASI of a string containing basic symbols and/or 2-grams and/or 3-grams containing these 2-grams if since due to Theorem 2.1 only they provide the same assembly indices with no internal repetitions.
Appendix A.7. Proof of Theorem 3.3
To prove that the minASI ASD equals the minASI, we use mathematical induction on the length N of the string. For the base case (), the string consists of a single basic symbol , where denotes the assembly pool. Hence, its ASI is and its ASD . Therefore, . Assume now that for all strings of length less than N, the ASD equals the minASI, that is
For some integer s, we construct the minASI string as follows. First, we assemble a 2-gram from two basic symbols:
Its ASI is and its ASD is . Then for each we have with the ASI and the ASD and we construct by joining two copies of
The ASI of the string is equal to
and, similarly, its ASD is equal to
Therefore, . At any step, we assemble strings (A13), and no two assembly steps can be independent, which follows from Theorem 3.1. The equation (A10) establishes that is the largest N for which . This proves . Finally, the even part of the definition of the DPI 2.7 is the only defining part of this definition iff . Hence, .
Appendix A.8. Proof of Theorem 3.4
The lengths (14) (OEIS A173786 or OEIS A048645) are the generalization of the strings of length of the Theorem 3.3. For other lengths of the strings (14), the base case for describes the assembly of a 3-gram, by joining a symbol to a 2-gram made in the first step, so that both the ASI and the ASD of this 3-gram increase by one. And so on. For any s we can join a symbol to a string of length assembled in steps or join two such strings, as shown in Figure 3a.
To see that (14) holds for note that there is only one odd part of the definition of the DPI 2.7 that restores. For example, we reach one starting from in five consecutive steps .
Appendix A.9. Proof of Lemma 3.1
We begin at by assembling a using a 4-gram and a 3-gram assembled independently (e.g., using an assembly space (15)) with and . For , the string (16) can be assembled by joining the string assembled in three steps and the 3-gram, while the string by joining two strings made in the previous step. For any d, the shortest string (16) can be assembled by joining the string (A13) assembled in steps and the 3-gram, while the remaining strings - by joining two strings made in a previous step , as shown in Figure 3b.
Appendix A.10. Proof of Lemma 3.2
We begin at by assembling a through with . For any d, the shortest string (17) can be assembled by joining the string (A13) assembled in steps with the 5-gram assembled in the independent assembly step, while the remaining strings - by joining two strings made in a previous step , as shown in Figure 3c.
Appendix A.11. Proof of Lemma 3.3
Appendix A.12. Proof of Theorem 3.6
The equality of ASI and ASD of the strings (20) follows from the proof of Theorem 3.4. Furthermore ,
shows that . Finally, follows from the DPI Definition 2.7: six steps are required to reach one starting from fifteen and additional steps for thirty, sixty, etc., which completes the proof.
Appendix A.13. Support for Conjecture Section 3
The shortest strings of length (22a) can be assembled with the pathways
shown in Figure 3e; the shortest strings of length (22b) can be assembled with the pathways
shown in Figure 3f; and for any d, the shortest strings of length (22c) can be assembled as
The remaining strings of length , , and (Section 3) can be assembled by joining two strings made in a previous step .
Appendix A.14. Proof of Lemma 3.4
By Theorems 3.1 and 3.2, a minASI string of length assembled beginning with is a balanced bitstring. To assemble a longer string of other lengths, we assign or . However, the Definition 2.7 removes the longest string of an odd length from the sequence if it is not the first one in the sequence. Strings longer than this string of length are assembled by joining the longest string assembled so far with itself () or by joining a basic symbol chosen to preserve the balance of the string ().
Appendix A.15. The 2nd Method for Generating C (N-1) Strings
This method is similar to the 1st method discussed in Section 4. We also start with a string of clear 3-grams (26) and the matrix of 2-grams (27) with a crossed diagonal and the first superdiagonal. In the first step, we append the 2-gram (top right 2-gram of the matrix of 2-grams (27)) at the end of the string (26). Next, we generally perform the following pairs of iterations:
- (1)
- we check subsequent subdiagonals until we find one that does not contain a 2-gram present in the string formed so far, we append it at the end of this string and proceed to step 2;
- (2)
- we check subsequent superdiagonals until we find one that does not contain a 2-gram present in the string formed so far, we append it at the end of this string and proceed to step 1.
Finally, we append 0 if b is even. The method is illustrated in Figure A1 and generates the strings in the form
Figure A1.
2-gram matrices for that illustrate the generation of strings according to the 2nd method. Coloured 2-grams are appended to the initial string of clear 3-grams in the order indicated by arrows starting from the 1st column or row. Finally, 0 is appended at the end if b is even.
Figure A1.
2-gram matrices for that illustrate the generation of strings according to the 2nd method. Coloured 2-grams are appended to the initial string of clear 3-grams in the order indicated by arrows starting from the 1st column or row. Finally, 0 is appended at the end if b is even.
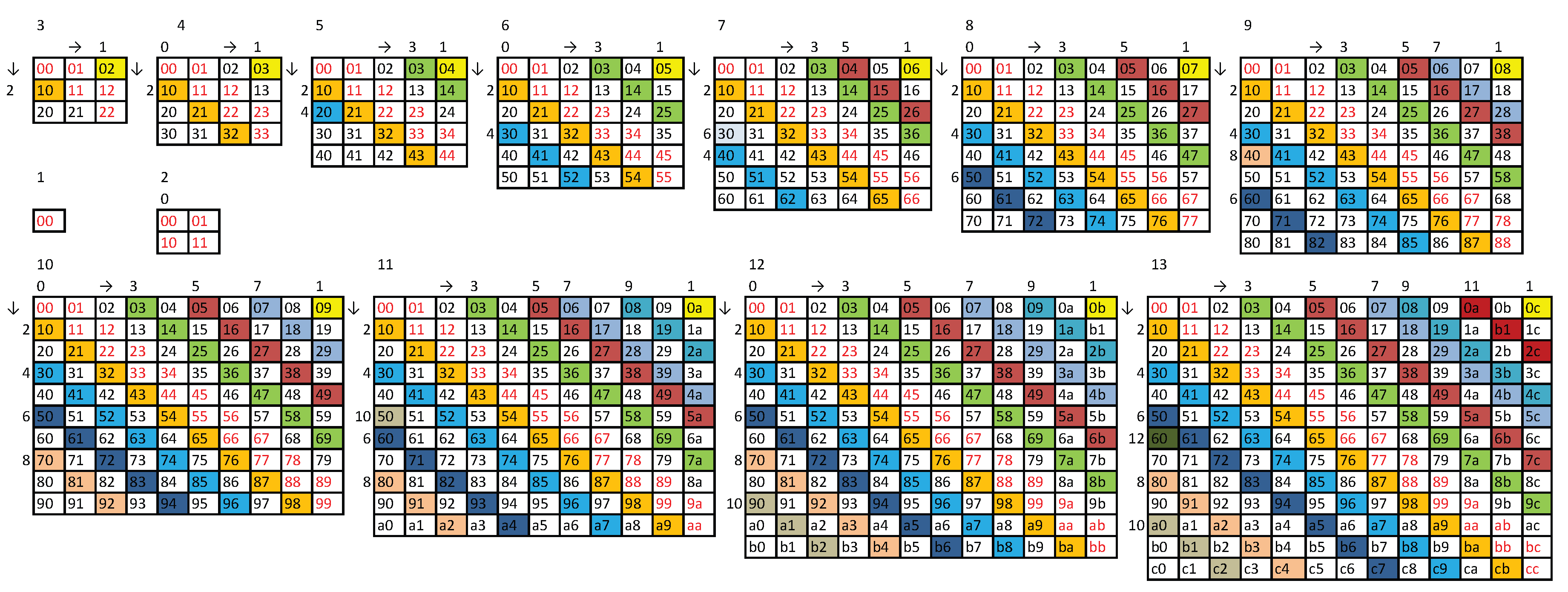
Appendix A.16. Method for Generating Non-Balanced C (N-b) Strings
The strings can also have the following non-balanced (e.g. for ) form
References
- Wootters, WK; Zurek, WH. A single quantum cannot be cloned. Nature 1982, 299(5886), 802–3. Available online: http://www.nature.com/articles/299802a0. [CrossRef]
- Marshall, SM; Murray, ARG; Cronin, L. A probabilistic framework for identifying biosignatures using Pathway Complexity. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences Available from. 2017, 375(2109), 20160342. [Google Scholar] [CrossRef] [PubMed]
- Imari Walker, S; Cronin, L; Drew, A; Domagal-Goldman, S; Fisher, T; Line, M. Probabilistic Biosignature Frameworks. In Planetary Astrobiology; Meadows, V, Arney, G, Schmidt, B, Des Marais, DJ, Eds.; University of Arizona Press, 2019; pp. 1–1. Available online: https://uapress.arizona.edu/book/planetary-astrobiology.
- Planetary astrobiology. In University of Arizona space science series; Meadows, VS, Arney, GN, Schmidt, BE, Des Marais, DJ, Eds.; The University of Arizona Press: Tucson; Lunar and Planetary Institute: Houston, 2020. [Google Scholar]
- Liu, Y; Mathis, C; Bajczyk, MD; Marshall, SM; Wilbraham, L; Cronin, L. Exploring and mapping chemical space with molecular assembly trees. Science Advances Available from. 2021, 7(39), eabj2465. [Google Scholar] [CrossRef] [PubMed]
- Marshall, SM; Mathis, C; Carrick, E; Keenan, G; Cooper, GJT; Graham, H; et al. Identifying molecules as biosignatures with assembly theory and mass spectrometry. Nature Communications 2021, 12(1), 3033. Available online: https://www.nature.com/articles/s41467-021-23258-x. [CrossRef]
- Marshall, SM; Moore, DG; Murray, ARG; Walker, SI; Cronin, L. Formalising the Pathways to Life Using Assembly Spaces. Entropy 2022, 24(7), 884. Available online: https://www.mdpi.com/1099-4300/24/7/884. [CrossRef]
- Sharma, A; Czégel, D; Lachmann, M; Kempes, CP; Walker, SI; Cronin, L. Assembly theory explains and quantifies selection and evolution. Nature 2023, 622(7982), 321–8. Available online: https://www.nature.com/articles/s41586-023-06600-9. [CrossRef]
- Jirasek, M; Sharma, A; Bame, JR; Mehr, SHM; Bell, N; Marshall, SM; et al. Investigating and Quantifying Molecular Complexity Using Assembly Theory and Spectroscopy. ACS Central Science Available from. 2024, 10(5), 1054–64. [Google Scholar] [CrossRef]
- Łukaszyk, S; Bieniawski, W. Assembly Theory of Binary Messages. Mathematics 2024, 12(10), 1600. Available online: https://www.mdpi.com/2227-7390/12/10/1600. [CrossRef]
- Raubitzek, S; Schatten, A; König, P; Marica, E; Eresheim, S; Mallinger, K. Autocatalytic Sets and Assembly Theory: A Toy Model Perspective. Entropy 2024, 26(9), 808. Available online: https://www.mdpi.com/1099-4300/26/9/808. [CrossRef]
- Łukaszyk, S. On the "Assembly Theory and its Relationship with Computational Complexity. 2024. Available online: https://www.preprints.org/manuscript/202412.1492/v1.
- Patarroyo, KY; Sharma, A; Seet, I; Packmore, I; Walker, SI; Cronin, L. Quantifying the Complexity of Materials with Assembly Theory ArXiv:2502.09750. arXiv. 2025. Available online: http://arxiv.org/abs/2502.09750.
- Masierak, P. Computational Complexity of Determining the Assembly Index. Available from. 2025. [CrossRef]
- Ziv, J; Lempel, A. Compression of individual sequences via variable-rate coding. IEEE Transactions on Information Theory 1978, 24(5), 530–6. Available online: https://ieeexplore.ieee.org/document/1055934. [CrossRef]
- Storer, JA; Szymanski, TG. Data compression via textual substitution. Journal of the ACM Available from. 1982, 29(4), 928–51. [Google Scholar] [CrossRef]
- Welch. A Technique for High-Performance Data Compression. Computer 1984, 17(6), 8–19. Available online: https://ieeexplore.ieee.org/document/1659158. [CrossRef]
- Charikar, M; Lehman, E; Liu, D; Panigrahy, R; Prabhakaran, M; Sahai, A; et al. The Smallest Grammar Problem. IEEE Transactions on Information Theory 2005, 51(7), 2554–76. Available online: http://ieeexplore.ieee.org/document/1459058/. [CrossRef]
- Kieffer, JC; Yang, En-Hui. Grammar-based codes: a new class of universal lossless source codes. IEEE Transactions on Information Theory 2000, 46(3), 737–54. Available online: http://ieeexplore.ieee.org/document/841160/. [CrossRef]
- Kieffer, J; Yang, En-hui; Park, T; Yakowitz, S. Complexity of preprocessor in MPM data compression system. Proceedings DCC ’98 Data Compression Conference (Cat. No.98TB100225), 1998; IEEE Comput. Soc: Snowbird, UT, USA; p. 554. Available online: http://ieeexplore.ieee.org/document/672292/.
- Lehman, E. Approximation Algorithms for Grammar-Based Data Compression. Ph.D. Thesis, Massachusetts Institute of Technology (MIT), 2002. Available online: https://compression.ru/download/articles/grammar/lehman_phd_2002_approximation_algorithms.pdf.
- Kieffer, JC; Eh, Yang. Compression and Explanation using Hierarchical Grammars. The Computer Journal 2000, 43(3), 212–22. Available online: https://www.researchgate.net/publication/2826982_1_INTRODUCTION_Compression_and_Explanation_using_Hierarchical_Grammars.
- Kieffer, JC; Yang, En-Hui; Nelson, GJ; Cosman, P. Universal lossless compression via multilevel pattern matching. IEEE Transactions on Information Theory 2000, 46(4), 1227–45. Available online: http://ieeexplore.ieee.org/document/850665/. [CrossRef]
- Kieffer, J; Flajolet, P; Yang, Eh. Universal Lossless Data Compression Via Binary Decision Diagrams. arXiv 2011, 1111.1432. Available online: http://arxiv.org/abs/1111.1432. [CrossRef]
- Nevill-Manning, CG. Compression and Explanation using Hierarchical Grammars. The Computer Journal 1997, 40(2 and 3), 103–16. Available online: https://academic.oup.com/comjnl/article-lookup/doi/10.1093/comjnl/40.2_and_3.103. [CrossRef]
- Larsson, NJ; Moffat, A. Offline dictionary-based compression. Proceedings DCC’99 Data Compression Conference (Cat. No. PR00096), 1999; pp. 296–305. Available online: https://ieeexplore.ieee.org/document/755679, ISSN 1068-0314.
- Larsson, NJ; Moffat, A. Off-line dictionary-based compression. Proceedings of the IEEE 2000, 88(11), 1722–32. Available online: http://ieeexplore.ieee.org/document/892708/. [CrossRef]
- Nevill-Manning, C; Witten, I. Compression and Explanation using Hierarchical Grammars. In The Computer Journal; Source; CiteSeer, 1999; Volume 40, 2. [Google Scholar]
- Nevill-Manning, CG; Witten, IH. Identifying Hierarchical Structure in Sequences: A linear-time algorithm. Journal of Artificial Intelligence Research 1997, 7, 67–82. Available online: https://jair.org/index.php/jair/article/view/10192. [CrossRef]
- Apostolico, A; Lonardi, S. Off-line compression by greedy textual substitution. Proceedings of the IEEE 2000, 88(11), 1733–44. Available online: http://ieeexplore.ieee.org/document/892709/. [CrossRef]
- Apostolico, A; Lonardi, S. Compression of biological sequences by greedy off-line textual substitution. Proceedings DCC 2000. Data Compression Conference, Snowbird, UT, USA, 2000; IEEE Comput. Soc; pp. 143–52. Available online: http://ieeexplore.ieee.org/document/838154/.
- Sakamoto, H; Maruyama, S; Kida, T; Shimozono, S. A Space-Saving Approximation Algorithm for Grammar-Based Compression. IEICE Transactions on Information and Systems 2009, E92-D(2), 158–65. Available online: http://www.jstage.jst.go.jp/article/transinf/E92.D/2/E92.D_2_158/_article. [CrossRef]
- Takabatake, Y; I, T; Sakamoto, H. A Space-Optimal Grammar Compression. LIPIcs, Volume 87, ESA 2017. 2017, 87:67, 1–67:15. Available online: https://drops.dagstuhl.de/entities/document/10.4230/LIPIcs.ESA.2017.67.
- Pagel, S; Sharma, A; Cronin, L. Mapping Evolution of Molecules Across Biochemistry with Assembly Theory. 2024. Available online: https://arxiv.org/abs/2409.05993.
- Knuth, DE. The art of computer programming. In Seminumerical algorithms / Donald E. Knuth (Stanford University). Third edition, forthy-first printing ed; Addison-Wesley: Boston, 2021; Volume 2. [Google Scholar]
- Clift, NM. Calculating optimal addition chains. Computing Available from. 2011, 91(3), 265–84. [Google Scholar] [CrossRef]
- Cronin, L. Exploring assembly index of strings is a good way to show why assembly & entropy are intrinsically different. 2024. Available online: https://x.com/leecronin/status/1850289225935257665.
- Łukaszyk, S. 15. In Black Hole Horizons as Patternless Binary Messages and Markers of Dimensionality; Nova Science Publishers, 2023; pp. 317–74. Available online: https://novapublishers.com/shop/future-relativity-gravitation-cosmology/.
- Łukaszyk, S. Life as the Explanation of the Measurement Problem. Journal of Physics: Conference Series Available from. 2024, 2701(1), 012124. [Google Scholar] [CrossRef]
- Łukaszyk, S. Black hole merger as an event converting two qubits into one. Frontiers in Quantum Science and Technology 2025, 4, 1656200. Available online: https://www.frontiersin.org/articles/10.3389/frqst.2025.1656200/full. [CrossRef]
- Gabric, D; Shallit, J; Zhong, XF. Avoidance of split overlaps. Discrete Mathematics 2021, 344(2), 112176. Available online: https://linkinghub.elsevier.com/retrieve/pii/S0012365X20303629. [CrossRef]
- Guibas, LJ; Odlyzko, AM. String overlaps, pattern matching, and nontransitive games. Journal of Combinatorial Theory, Series A 1981, 30(2), 183–208. Available online: https://linkinghub.elsevier.com/retrieve/pii/0097316581900054. [CrossRef]
- Ozelim, L; Uthamacumaran, A; Abrahão, FS; Hernández-Orozco, S; Kiani, NA; Tegnér, J. Assembly Theory Reduced to Shannon Entropy and Rendered Redundant by Naive Statistical Algorithms. arXiv. 2025. Available online: http://arxiv.org/abs/2408.15108.
- Abrahão, FS; Hernández-Orozco, S; Kiani, NA; Tegnér, J; Zenil, H. Assembly Theory is an approximation to algorithmic complexity based on LZ compression that does not explain selection or evolution. PLOS Complex Systems 2024, 1(1), e0000014. Available online: https://journals.plos.org/complexsystems/article?id=10.1371/journal.pcsy.0000014. [CrossRef]
- Uthamacumaran, A; Abrahão, FS; Kiani, NA; Zenil, H. On the salient limitations of the methods of assembly theory and their classification of molecular biosignatures. npj Systems Biology and Applications 2024, 10(1), 82. Available online: https://www.nature.com/articles/s41540-024-00403-y. [CrossRef]
- Vimal, D; Parzych, G; Smith, OM; Parkar, D; Bergen, S; Daymude, JJ. Open, Reproducible Calculation of Assembly Indices ArXiv:2507.08852 version: 1. arXiv. 2025. Available online: http://arxiv.org/abs/2507.08852.
- Flamm, C; Merkle, D; Stadler, PF. Assembly in Directed Hypergraphs. Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences Available from. 2025, 481(2324), 20250331. [Google Scholar] [CrossRef]
- Kempes, CP; Lachmann, M; Iannaccone, A; MF, G; RC, M; Walker, SI; et al. Assembly theory and its relationship with computational complexity. npj Complexity 2025, 2(1), 27. [Google Scholar] [CrossRef]
- Gebhard, TD; Bell, A; Gong, J; Hastings, JJA; Fricke, GM; Cabrol, N; et al. Inferring molecular complexity from mass spectrometry data using machine learning. Machine Learning and the Physical Sciences workshop, NeurIPS 2022, 2022. [Google Scholar]
- Cronin, L; Parra, JCM; Patarroyo, KY. Assembly Addition Chains. arXiv. 2025. Available online: https://arxiv.org/abs/2512.18030.
- Krzyżanowski, W. Procesy ewolucji kulturowej muzyki w środowisku technologii cyfrowych [Rozprawa doktorska]. Poznań: Uniwersytet im. Adama Mickiewicza w Poznaniu, Wydział Nauk o Sztuce; 2025. Praca doktorska napisana pod kierunkiem prof. UAM dr hab. Piotra Podlipniaka, złożona w 2025 r.
- Vopson, MM. The second law of infodynamics and its implications for the simulated universe hypothesis. AIP Advances 2023, 13(10), 105308. Available online: https://pubs.aip.org/adv/article/13/10/105308/2915332/The-second-law-of-infodynamics-and-its. [CrossRef]
- Mugur-Schachter, M. On a Crucial Problem in Probabilities and Solution. arXiv. 2008. Available online: https://arxiv.org/abs/0801.2654.
| 1 | Sixteen if we relax the Definition 2.5 (cf. Figure 9b). |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



