1. Introduction
In modern, complex information systems, cyber security insider threat detection plays an increasingly important role [
1]. Ransomware attacks and data breaches, often initialized by insiders [
2], cost organizations millions of dollars. Many institutions were forced to shut the businesses down due to the loss of trust or finance. Because of the ever-evolving issues of cybersecurity, administrators and security specialists often struggle to keep up with new developments [
3].
One promising approach, capable of adapting to the changing landscape of security in the digital realm, is the application of artificial intelligence (AI). AI algorithms have ability to discern patterns and effectively learn from observations of data. This allows the application of AI with minimal programming required. Additionally, algorithms learn from new data and are therefore capable of adapting to new developments [
4].
There are several challenges to the proper application of AI in cyber security. The first one is data availability. Companies are often hesitant to make data concerning attacks publicly available and therefore real-world data is scarce. The second challenge is associated with parameter selections. Namely, algorithms are often designed with good general performance in mind, however, to be well suited to a specific task, parameter tuning is required to adjust the algorithm to the available data. This process can often be NP-hard due to the large search spaces when considering options for parameters.
A class of algorithms often selected by researchers to tackle hyperparameter tuning are metaheuristic algorithms [
5]. These algorithms take a randomness-driven approach and often borrow inspiration from search strategies observed in nature to handle and guide optimizations toward an optimal solution. Algorithms could solve NP-hard problems with acceptable results, and within realistic time constraints, however, a true optimal solution is not guaranteed.
This report presents our investigation in the potential of AdaBoost classifier to handle detection of insider threats within an organization. A publicly available simulated cyber security dataset is used, and user login patterns are analyzed to detect malicious actions. Additionally, a modified version of the recently introduced crayfish optimization algorithm (COA) [
6] is introduced specifically for the needs of this study.
1.1. Research Gap, Motivation and Scientific Contributions
There is a significant research gap on insider threat detection, leaving a crucial area of study underexplored. This research seeks to examine the potential of AI in preventing harm caused by insiders, with an emphasis on classifying user behavior. By filling this gap, the study aims to enhance methods for protecting organizations against the dynamic challenges of cybersecurity, particularly those related to insider threats.
Investigation is motivated by the need to address this gap by leveraging AI to develop advanced techniques for identifying and mitigating insider threats. The work specifically aims to propose a new framework based on the AdaBoost algorithm to enhance institutional cybersecurity. Furthermore, it introduces a modified version of the COA to overcome limitations in the original approach and evaluates several contemporary optimization algorithms to determine their effectiveness in optimizing AdaBoost for cybersecurity applications. By addressing these challenges, this research seeks to provide practical and innovative solutions for safeguarding organizations against evolving insider threats.
The main contributions of this work can be outlined as the following:
Proposal for new insider threat detection framework, based on the AdaBoost algorithm to improve institution cyber security;
Introduction of novel, modified version of the COA, designed to overcome some of the observed shortcomings of the original algorithm;
Comparative analysis between several contemporary optimizers was conducted to determine the degree of effectiveness of the proposed approach evaluated on a publicly available dataset;
Feature importance evaluations was also conducted using SHAP, on the best performing model, in order to improve future data collection efforts;
The remining part of this report is structured as following:
Section 2 covers preceding research that inspired and motivated this investigation;
Section 3 presents the new methodology and describes the proposed modified algorithm;
Section 4 and
Section 5 describe experimental configuration and present the attained outcomes. Finally,
Section 6 concludes the report, highlighting limitations, policy implications and potential future research.
2. Related Works
Proper management of cyberspace refers to the application of following principles: responsibility, transparency, rule of law, participation of the entire audience in cyberspace, institutional responsiveness, effectiveness of institutional and individual roles, as well as efficiency in operations. The basic problem in ensuring cyber security is the definition of legal norms and institutions that would monitor the flow of data and actions in cyberspace, as well as ensure the privacy rights of users. U.S. Congress still struggles to establish a system that provides essential privacy protection while retaining investigative capabilities [
7]. Cybersecurity and privacy protection are subjects of intensive research [
8], as well as governments’ considerations around the world. In 2023 Australia has established its 2023-2030 Australian Cyber Security Strategy [
9].
The interconnected nature of cyberspace, "without borders", poses a real problem for the traditional framework of territorial application of laws [
10]. Data and cyber activities are generated on servers that may fall under the jurisdiction of one state, while users or cyber victims may fall under the jurisdiction of another state or legal system [
11].
It is often considered that laws applicable to offline activities should also apply to online activities, but clear characterization of such actions in practice is difficult to achieve. Cybersecurity raises complex legal questions primarily related to the right to privacy and freedom of expression. This complexity is further compounded by public-private collaboration and the related legal issues concerning responsibility and control. The issue of monitoring activities and data flows is complicated due to the diverse nature of actors involved in cyberspace. According to the broadest understanding, national oversight institutions oversee the work of various agencies or functional lines of administration. Consequently, state-level parliamentary committees may oversee the work of intelligence services, armed forces, or judicial bodies. On the other hand, public-private collaboration in the field of cybersecurity goes beyond the boundaries of individual agencies, leading to a collision of expert understandings of cyber activities and surveillance mandates. The consequence of this collision is the existence of many cases where surveillance is either inadequate or nonexistent. Regarding the overlap of responsibilities and control, the procedures of each government agency are linked in a chain of accountability from the first to the last.
In cyberspace, chains of command can be disrupted by the involvement of private actors and the establishment of public-private collaboration mechanisms. In practice, IT companies might be engaged with government agencies and work exclusively for the state. This relationship is often complex and obscured by numerous information asymmetries that reduce transparency and hinder the smooth and successful functioning of surveillance and control mechanisms [
12].
The oversight boards in the government should control government agencies for which they are directly responsible. In this way, there might be an omission of private partners of these agencies from the oversight space, even in cases when they are directly funded or closely collaborate with these agencies. The technical specificity of characterizing cyberspace further complicates the traditional problems, faced by national parliamentarians, tasked with overseeing the security sector, leading to reduced effective accountability. Difficulties in reliably identifying perpetrators of cybercrimes can lead to hindered or even nonexistent accountability of the security sector to civilian authorities, contributing to a culture of impunity for these criminal acts. Thus, the judicial sector may grant special powers to law enforcement and intelligence agencies by issuing search warrants. This is particularly important in the context of communication interception. In practice, judicial oversight is often circumvented or restricted for reasons of national security preservation under emergency conditions.
The National Cyber Security Strategy of Sweden from 2016, which regulates issues from the legal regulation of ICT to the protection of critical infrastructure can be considered as a model of good legislation. However, it seems that there is not just one committee or subcommittee dealing solely with cybersecurity. Unlike most national cybersecurity strategies, the Swedish strategy includes strategic principles and an action plan that helps parliament hold both public and private actors accountable in the process of cyber security control. The principle of the rule of law is interpreted by international courts, such as the European Court of Human Rights (ECHR). This court has developed a rule-of-law test stating that "all restrictions on fundamental rights must be based on clear, precise, accessible, and predictable legal provisions and must pursue legitimate aims in a manner that is necessary and proportionate to the aim in question, and there must be an effective, preferably judicial, remedy". Consequently, authorities in states demand that private companies, who own social media platforms, ensure that their services do not harbor violent extremists and terrorists. To meet these demands, governments [
13], and private companies holding social media, have developed specific terms and codes of conduct to control the content posted on these platforms, and generally, apply legal rules in the digital world. In this way, they have de facto established rules and norms on the Internet. However, these terms and rules are not the same on all platforms, creating ambiguity and legal uncertainties regarding the type of content prohibited on each platform.
Hackers and various agencies routinely engage in eavesdropping on private conversations and intercept them at the "back door". In other words, when it comes to state security, there is no truly established need for the application of the rule of law, although the basic principles that could form the basis of such an important part of the universal fortress of human rights exist. With the increasing partnership between law enforcement agencies and intelligence and security services, this weakening of the rule of law threatens to spread and be transferred to the police and prosecutors. The lack of clear legal frameworks in this area, both domestically and internationally, poses an additional threat to the rule of law on the Internet and in the global digital environment [
14].
Numerous existing approaches attempt to address cyber security, with traditional techniques like firewalls [
15] and block lists proving useful over time [
16]. However, rapid developments and the emergence of zero-day [
17] vulnerabilities make it challenging for administrators to keep up with attackers. To adapt to the fast-paced information age, new techniques are imperative.
IoT networks are frequent targets for Distributed Denial-of-Service (DDoS) and DoS attacks [
18], where relatively simple devices can disrupt operations on a massive scale and compromise information about their environment and users. Additionally, insider actors seeking revenge for perceived unfair treatment pose a significant threat vector [
19].
A noticeable research gap exists in insider threat detection, creating a void in the field. This investigation aims to explore the potential of AI for preventing insiders from causing harm to organizations by focusing on classification of user behavior. By addressing this gap, the research contributes to advancing methods that can better safeguard against evolving cyber security challenges, particularly in the context of insider threats.
2.1. AdaBoost Classifier
AdaBoost [
20] utilized an iterative approach in order to cast an approximation of the Bayes classifier. This is done by combining several weaker classifiers. From a starting point of an unweighted sample used to train the model, this approach builds a group of classifiers. If misclassification occurs, the weights of each classifier are reduced and if correct classification is made weights are incremented. Error of a weak classifier
εt can be determined as given by Equation (1):
where
εt denotes the weighted error of the weak learner in the
t-th iteration. Variable
N represents the number of training instances. Term
ωi,t corresponds to the weight of the
i-th instance in the
t-th iteration. Expression
ht(
xi) signifies the prediction made by the weak learner for the
i-th instance in the
t-th iteration. Variable
yi represents the true label of the
i-th instance. Additionally, function I(
·) is an indicator function that equals 1 if the condition within the parentheses is true, and 0 otherwise.
Further classifiers are built based on the attained weights. Weight adjustment process is repeated. Large groups of classifiers are usually assembled to create accurate classification. A score is given to each of these sub-models, and a linear model is constructed by their combination. Classifier weight in the ensemble can be determined according to Equation (2):
where weight
αt, assigned to each weak learner in the final ensemble, is calculated based on its performance. It depends on the weighted error
εt and is used to determine the contribution of the weak learner to the final combined model. To update weights Equation (3) is used:
where
ωi,t represents the weight of the
i-th instance in the
t-th iteration,
αt denotes the weight of the weak learner in the
t-th iteration,
yi stands for the true label of the
i-th instance, and
ht(
xi) signifies the prediction of the weak learner for the
i-th instance in the
t-th iteration.
AdaBoost algorithm is well suited for binary classification problems. It does struggle with multi-class classification. Since we are dealing with binary classification problems, AdaBoost algorithm is selected for optimization.
2.2. Metaheursitic Optimization
Hyperparameter selection can often be difficult in practice. There is currently no unified approach for selection. Researchers often resort to computationally expensive complete search techniques or a trial-and-error process. When dealing with a mixed set of parameters this challenge can quickly form a mixed NP-hard problem. Therefore, techniques capable of addressing this category of challenge are required.
Taking a heuristic approach is often preferable. Metaheuristic optimizers have demonstrated ability to handle NP-hard problems, often drawing inspiration from natural phenomena. Some notable examples include the genetic algorithm (GA) [
21], particle swarm optimization (PSO) [
22], firefly algorithm (FA) [
23], sine cosine algorithm (SCA) [
24], whale optimization algorithm (WOA) [
25], reptile search algorithm (RSA) [
26] and COLSHADE [
27]. The driving reason for so many algorithms comes from the no free-lunch theorem of optimization (NFL) [
28] that states that no single approach is perfectly suited to all challenges and across all metrics. Therefore, constant experimentation is needed to determine the most suitable optimizer for a given task.
Hybridization of existing algorithms is a popular approach to overcome some of the observed drawbacks of optimizers. Metaheuristics is successfully applied in several fields of optimization, including finance [
29], medicine [
30] [
31], computer security [
32], renewable power generation [
33] and many others [
34].
3. Methods
This section describes the base methods and algorithms that served as inspiration for our work. Following that, the potential for improvements is described alongside the modifications aimed at improving performance. Finally, the algorithm pseudocode is presented.
3.1. Original Crayfish Optimization Algorithm
The Crayfish optimization algorithm (COA) is a metaheuristic algorithm depicting the behavior of crayfish, a form of crustacean, in a natural settings [
6]. These animals belong to the infraorder Astacidea family living in freshwater, such as lakes and rivers. They are omnivores, foraging the floor of the body of water for nutritious meals.
Algorithm emulates crayfish summer resort behavior which entails the crayfish searching for cool caves when the temperatures are high. This behavior acts as the algorithm’s exploration stage. Next, these animals compete for the best shelter. Foraging, which happens when the temperatures allow, is also modeled. Competing and foraging are used as exploitation stages in COA.
As is the norm with swarm intelligence, the population of crayfish
P is initialized in the beginning stage of the algorithm. To manage the stages of exploration and exploitation, temperature is represented by a random constant defined by the Equation (4):
The summer retreat happens when the temperature is higher than 30°C, in which case the crayfish look for a cool shelter from the heat, such as caves. Temperatures between 15°C and 30°C are suitable for crayfish feeding, with 25°C being ideal. Since most reliable foraging behavior happens in the range of 20°C to 30°C, the model’s temperature ranges from 20°C to 35°C. Mathematical representation of the crayfish feeding behavior is given by Equation (5):
In this expression,
µ marks the thriving temperature for crayfish, while
C1 and
σ serve the purpose of controlling the food intake of crayfish at varying temperatures.
When
temp>30, the exploring stage starts. Shelter position that crayfish take from the heat is modeled by Equation (6):
where
XL marks the current colony optimal positioning, while
XG marks the best possible place gained, regarding the number of iterations.
Whether the crayfish competes for the shelter is randomly dictated by the variable
rand value. When this value is less than 0.5, no competition between crayfish for the shelter occurs. Since there is no obstacle, the crayfish will enter the cave without issue, per the Equation (7) and Equation (8):
C2 denotes a decreasing curve,
T marks the topmost number of repetitions, and
t marks live iteration, while
t+1 depicts the repetition number for the next generation.
During the high temperatures, crayfish seeks shelter. Shelter, or cave, is a symbol of the best possible solution. In the summer resort stage, the crayfish heads towards the cave thus nearing the optimal solution. The closer to the cave they are, the better COA‘s potential for exploitation becomes, and the faster the algorithm converges.
When
rand≥0.5, there is competition between crayfish for the shelter. This competition has played the role of the start of the exploitation stage. The conflict is represented by the Equation (9) and Equation (10):
where
z marks the crayfish’s random individual.
In the competition phase, crayfish fight with each other. Crayfish Xi adapts its position in relation to another crayfish’s position Xz. This adaptation of positions expands the search range of COA, thereby boosting the algorithm’s exploration capacity.
The crayfish feed in temperatures below or equal to 30°C. When such conditions are met, the crayfish moves towards the food. Food location,
Xfood and its quantity
Q are defined by Equation (11) and Equation (12), respectively:
In this context, C3 stands for the food factor representing the biggest food source, with a constant value of 3. The fitness variable denotes the fitness value of the i-th crayfish, whereas fitnessfood indicates the fitness value linked to the food’s location.
In the case when the food is too big, and
Q>(
C3+1)
/2, the process of tearing up the food is depicted in Equation (13):
When the food is small enough, Q<(C
3+1)/2, the crayfish will simply eat the food, as given by Equation (14):
During the foraging phase, crayfish employs various feeding tactics depending on the size of their food denoted by Q, where the food location Xfood signifies the ideal solution. They will move closer to the food of readily edible size. Conversely, when Q is excessively large, meaning a substantial disparity between the crayfish and the optimal solution, Xfood will be decreased, thereby drawing it nearer to the meal.
3.2. Hybrid COA
Despite the admirable performance demonstrated by the COA, there is still plenty of room to explore potential improvements. Following that, we have introduced two new mechanisms into the original COA.
The initial modification incorporates quasi-reflective learning (QRL) [
35] in the first
T iterations. Following each iteration, the worst solutions are replaced by new solutions generated based on Equation (15):
where
lb and
ub denote lower and upper bounds of the search space and
rand denotes a random value within the given interval. The newly generated solution is not subjected to objective function evaluation thus the computational complexity of the modified algorithm is kept consistent with the original.
When examining optimization metaheuristics, it becomes crucial to find an equilibrium between exploration and exploitation. In order to enhance exploitation, a supplementary adjustment is incorporated, drawing inspiration from the widely recognized firefly algorithm (FA) [
23]. The FA simulates the courtship behaviors of bioluminescent beetles through mathematical modeling, where individuals emitting brighter light attract those in their vicinity. The brightness of each agent is computed according to a problem-dependent objective function, outlined in Equation (16):
Several environmental factors are also simulated to replicate real-world conditions such as light fading depending on the distance between agents, as well as the characteristics of the medium of propagation. The basic search mechanism of the FA is shown by Equation (17):
Equation (17) is commonly swapped for Equation (18) to improve computational performance, where
β0 represents the attractiveness at
r=0:
where,
Xi(
t) and
Xj(
t) represent current positions of agents
i and
j, respectively, at a specific iteration
t. Paramenter
rij denotes the Cartesian distance between
i and
j agents during the corresponding iteration
t. Parameter
β is termed the agent attraction coefficient, and refers to the intensity of light, while
γ denotes the light absorption coefficient,
α controls the degree of randomness, and
εi(
t) represents a stochastic vector.
Although the introduced search mechanism of the FA does enhance convergence, it is crucial to strike a balance throughout the optimization process. The firefly search mechanism becomes active only in the latter half of the optimization interactions. After each of these iterations, a pseudo-random value is generated within the range [0, 1] and compared to a threshold value ψ. If the generated value surpasses ψ, the firefly search is initiated; otherwise, a normal COA search is employed. The value of ψ is determined empirically to yield optimal results for the given problem, typically set at 0.6.
The described algorithm is dubbed the hybrid COA(HCOA). It is presented by the following Algorithm 1 pseudocode:

In terms of time complexity, metaheuristic algorithms are usually compared based on the number of evaluations conducted during the optimization. As the modified version of the optimized algorithm does not introduce any additional evaluation, complexity is kept consistent with the baseline optimized. In terms of big-O notation, the COA has a complexity of . Time complexity of the QRL approach is . Hence the introduced modifications do not increase computational complexity in comparison to the baseline algorithm.
4. Experimental Configuration
To facilitate experimentation, simulated dataset is utilized, provided by the Carnegie Mellon University CERT Division Software Engineering Institute [
36] and it is publicly available [
37]. While this dataset contains information on several malicious, insider users’ threats, and their activities, our work focuses on logon activities and their relative period.
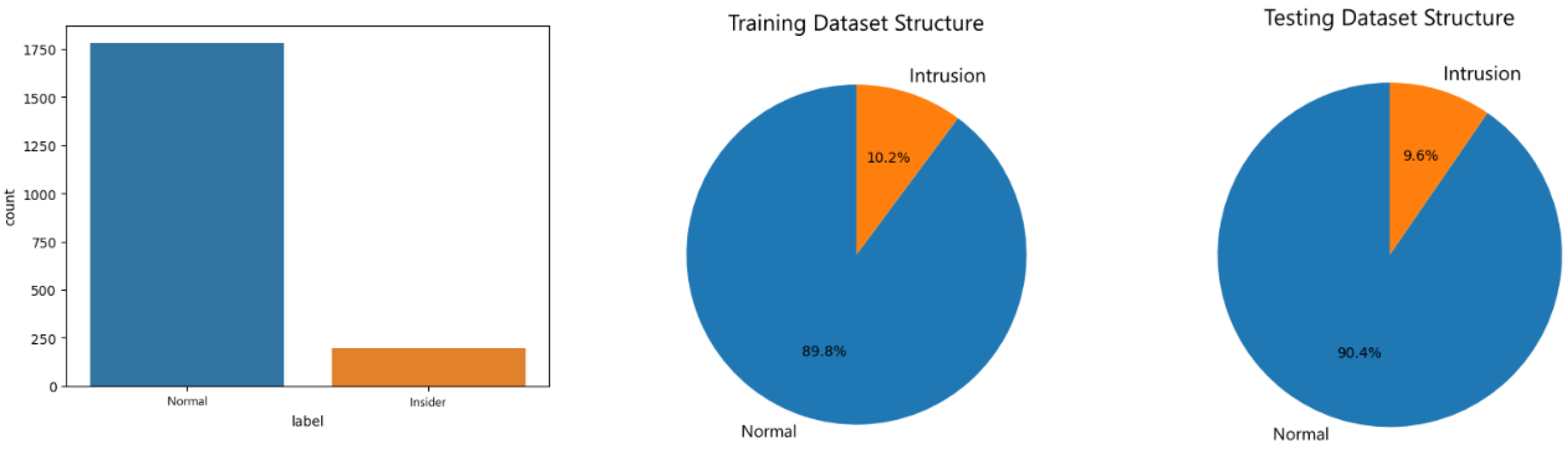
To reflect real-world scenarios dataset is heavily imbalanced with malicious actor activities being a minority. A total of 854661 samples represent normal users, with only 198 samples malicious actors. To facilitate model training, the majority class is downsampled to a 9:1 ratio of normal to malicious activities. During the testing, 1782 samples represented normal user activity and 198 malicious. Datasets are further split into training and testing with 70% allocated to train respective models and 30% withheld for evaluations. Dataset structure, as well as the structure of the training and testing portions, are shown in
Figure 1.
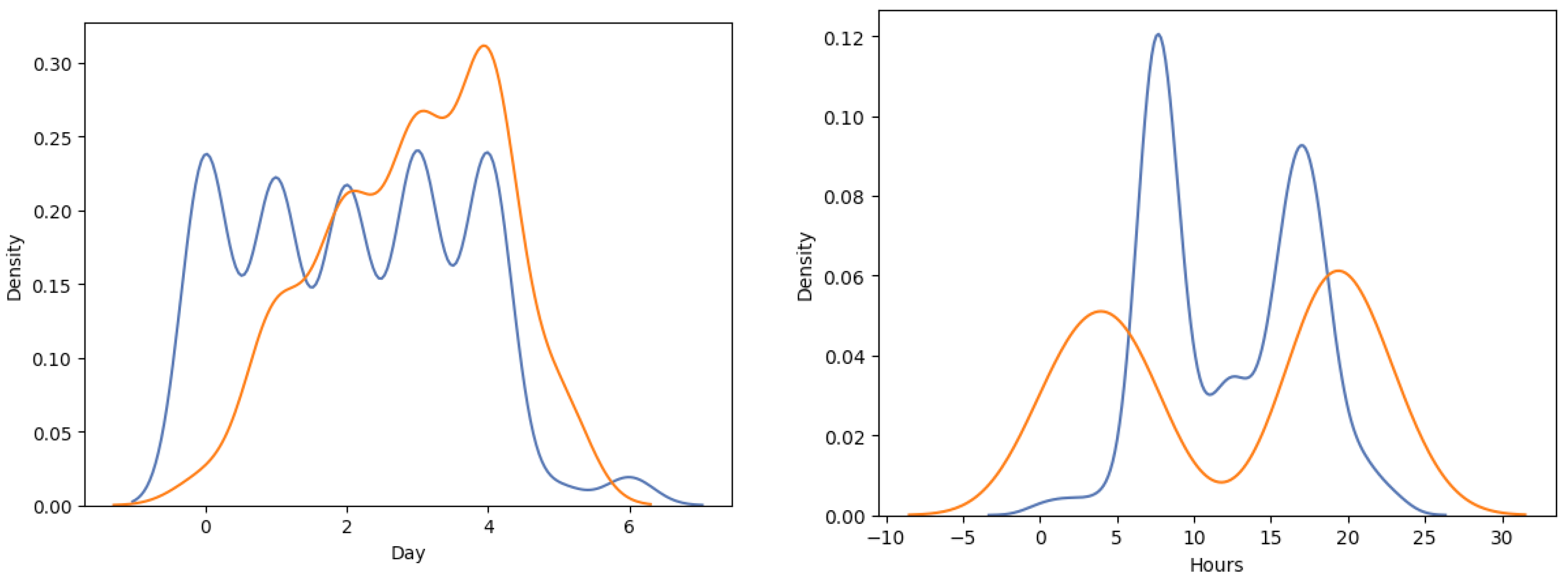
Time of access features are considered, specifically, the day of access and time of the day. Interesting patterns can be observed in the behavior of malicious users when accessing the system. Insider threats often happen outside of the regular working hours. Additionally, insiders prefer accessing machines later in the week. The distribution of normal and malicious user access can be seen in
Figure 2.
Interesting patter differences in terms of days of activity can be observed. Normal users typically log in regularly, during workdays, in a consistent pattern, while users causing insider threat, attempt logins latter in the week, favoring Thursdays and Fridays. In terms of time of the day, insider threat actors seem to prefer to attempt logins prior to normal users (between 00:00 and 5:00) and after normal users in the evening (after 20:00).
Several contemporary optimizers were included in comparative analysis with our novel optimizer. They are: COA [
6], GA [
21], PSO [
22], FA [
23], SCA [
24], WOA [
25], RSA [
26] and COLSHADE [
27]. Algorithms were independently implemented in Python using standard machine-learning libraries provided by Sklearn. Additional supporting libraries utilized include Pandas and Numpy. Optimizers are implemented with parameters set to the values suggested in the original works.
Optimizes are tasked with selecting optimal control parameter values for the AdaBoost algorithms. These parameters and their respective ranges are the number of estimators [10, 50], depth [1, 10] and learning rate [0.1, 2]. A relatively modest number of estimators is used due to the heavy computational demands of the optimization. Each optimizer was allocated a population size of ten and allowed 15 iterations to improve attained solutions. Finally, the experimentation is repeated 30 times in independent executions to account for the randomness inherent in the application of metaheuristics.
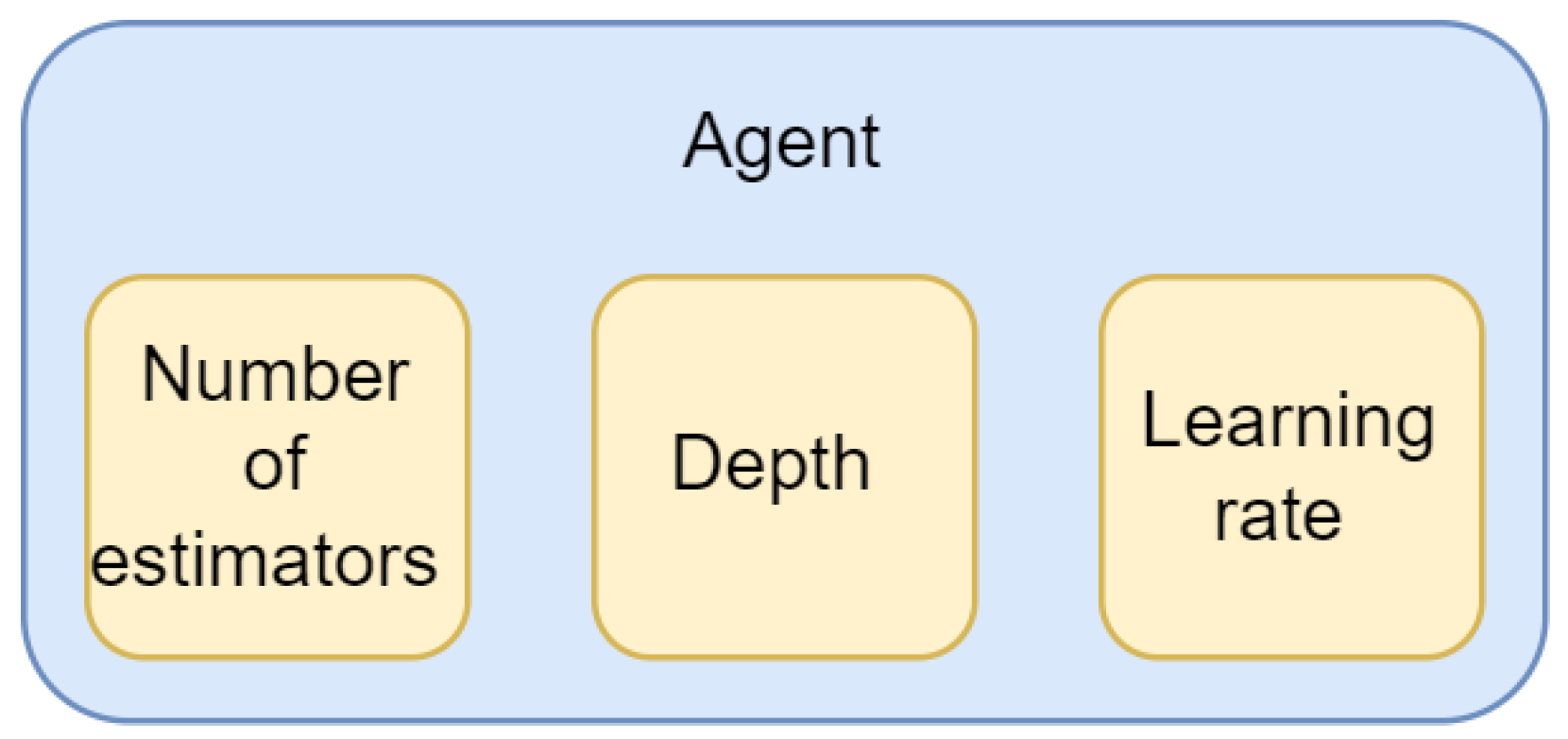
Agent parameters, used in the population of each optimizer, are used to map Adaboost hyperparameters. Each agent consists of three parameters representing the number of estimators, depths and learning rate as shown in
Figure 3.
To guide the optimization Cohen’s kappa metric is utilized due to its ability to evaluate classifications of imbalanced data well. Cohen’s kappa score is determined by Equation (19):
Further metrics are tracked to ensure thorough comparisons. These include a set of standard classification metrics used to get a comprehensive overview of algorithm performances including accuracy shown by Equation (20), precision by Equation (21), recall Equation (22) and f1-score by Equation (23):
Additionally, error rates are recorded for each algorithm determined by Equation (24):
Error rate is the complement of accuracy and represents the proportion of incorrectly classified instances. It is the ratio of the number of misclassifications to the total number of instances. This is a convenient way to represent error rate in terms of more intuitive accuracy metric.
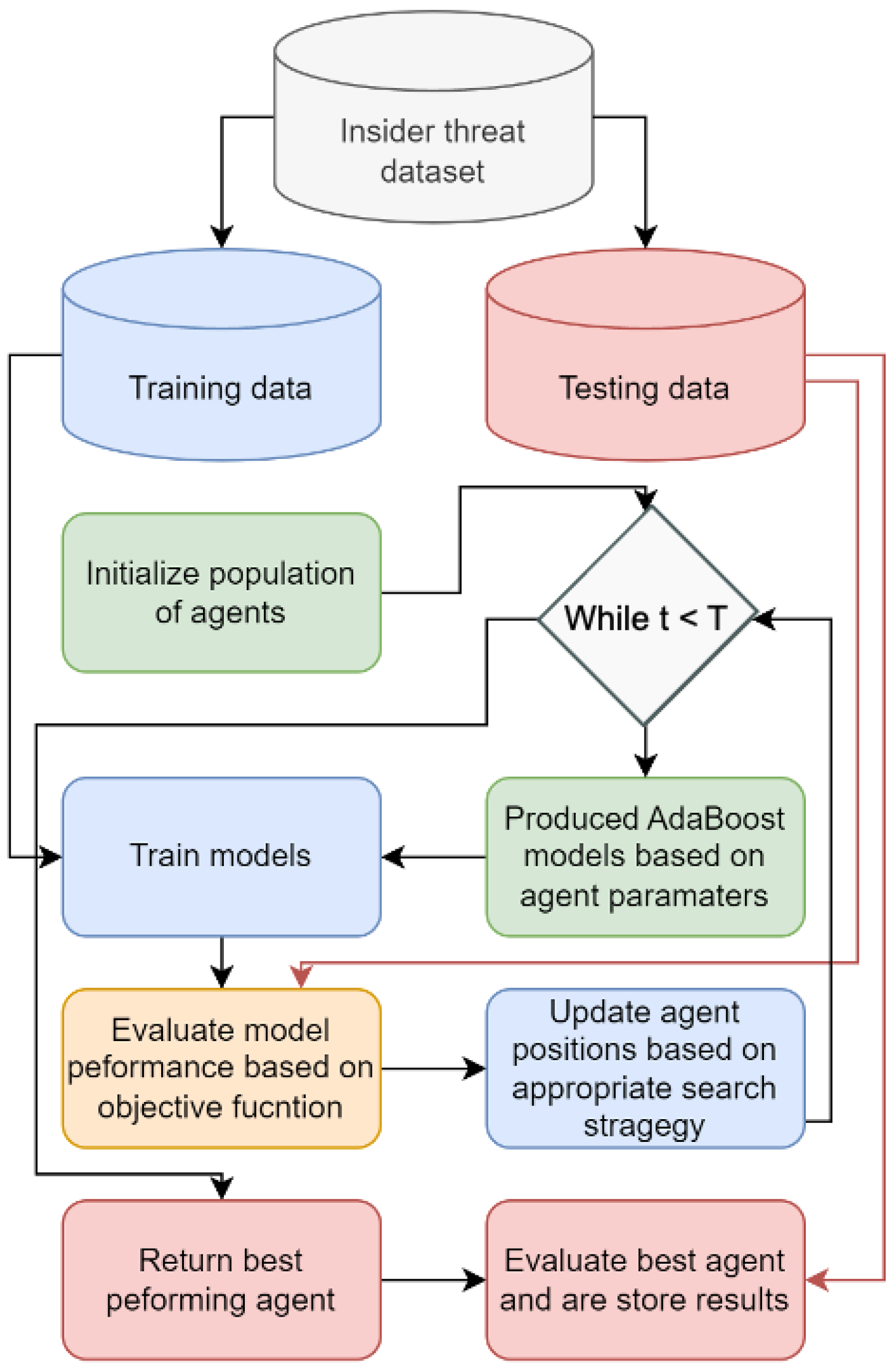
Flowchart of the proposed insider threat detection framework is provided in
Figure 4. It demonstrates the role of optimizers, specifically the modified optimization technique, in improving insider threat detection in real world systems.
5. Simulation Outcomes
Simulation results in terms of objective and indicator functions are provided in
Table 1 and
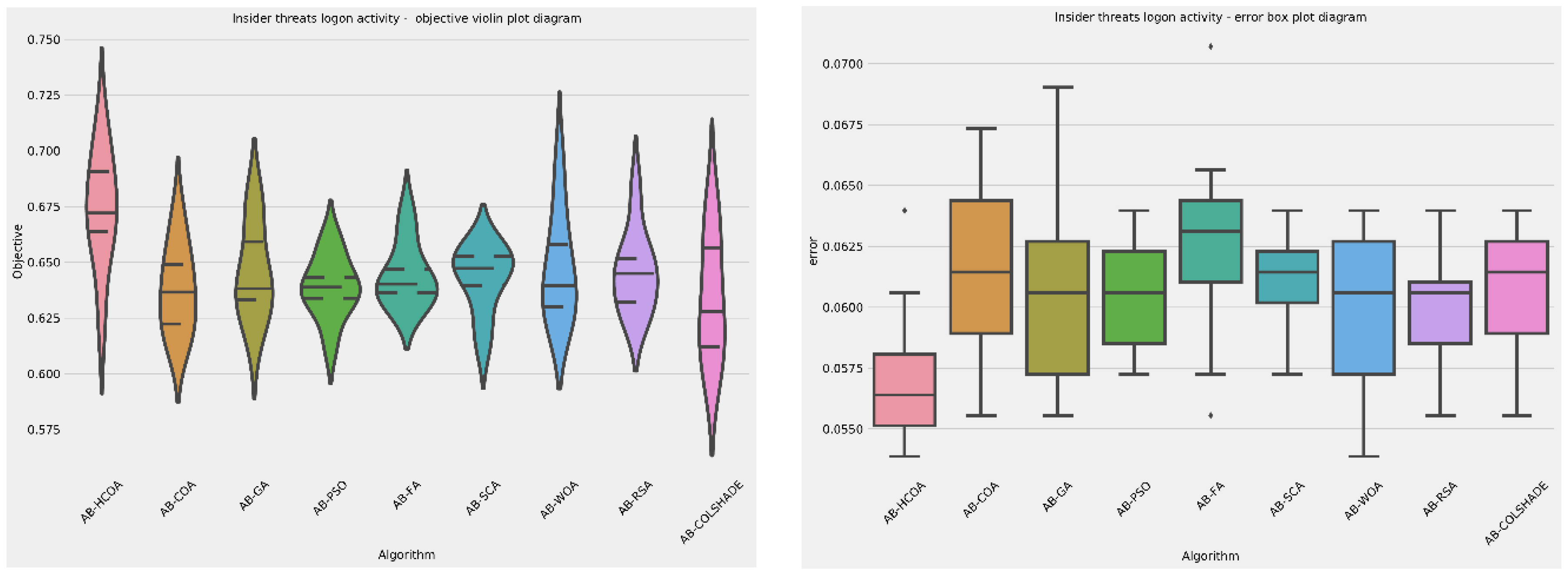
Table 2 respectively. As evident, the introduced optimizer attained the best outcomes with the best scoring of 0.711939, mean scoring of 0.673919, and median executions scoring of 0.672113 in terms of objective function results. The best outcomes in terms of the worst-case performance are demonstrated by the FA attaining an objective function score of 0.630255.
These results are somewhat like the results in terms of an indicator function, with the introduced optimizer matching the best performance of 0.053872, sharing first place with the WOA, and attaining the best outcomes in mean and median executions scoring 0.057239 and 0.056397 respectively. The PSO attained the best results in the worst-case execution scoring 0.062290.
Algorithm stability comparisons can be viewed in
Table 1 and
Table 2, in terms of objective and indicator functions. In terms of stability, the PSO and SCA attained the highest rate of stability in comparison to other tested optimizes. However, they did not demonstrate the best performance. Visual comparisons are provided in
Figure 5. While the introduced optimizer showcases a relatively low stability in terms of objective function it nonetheless demonstrates the best outcomes. Additionally, in terms of indicator function, the introduced optimizers show the highest outcomes, outperforming all other algorithms.
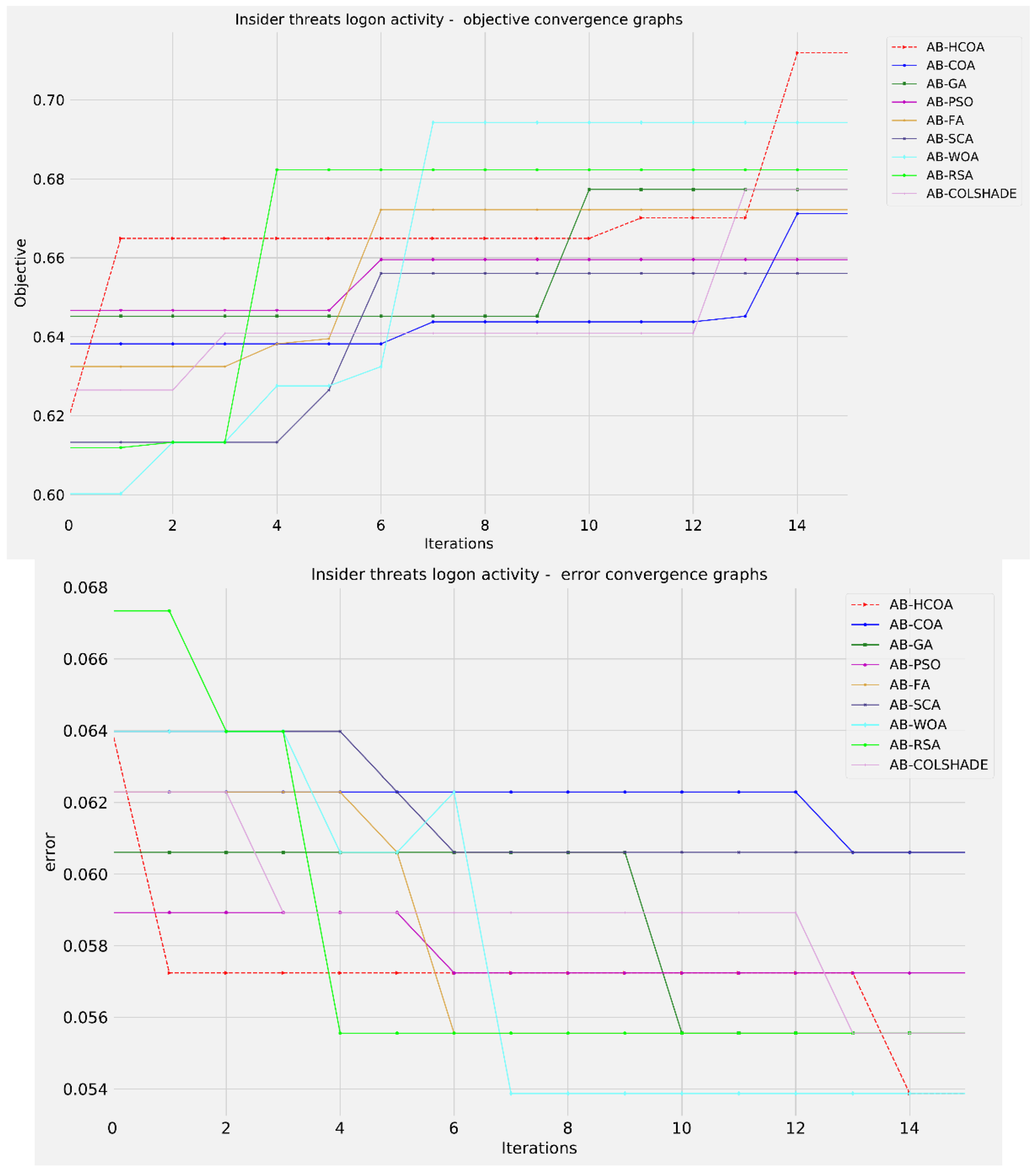
Convergence rate comparisons, in terms of objective, as well as indicator function are shown in the
Table 2. A clear influence of the introduced modifications is evident in the modified version of the algorithm over the baseline.
While many algorithms converge towards a local minimum, modified version locates the best solution towards the final executions, suggesting that the introduced alterations bring improvements.
Figure 6 shows the objective and indicator functions’ outcome convergence plots.
Detail metric comparisons between the best-constructed models are provided in
Table 3. A clear dominance in terms of best outcomes is showcased by the introduced algorithm, with only the FA outperforming the algorithm in terms of precision for insider threat detection. However, this is to be somewhat expected as in accordance with the NFL [
28] no single optimizer is equally suited to all challenges across all metrics.
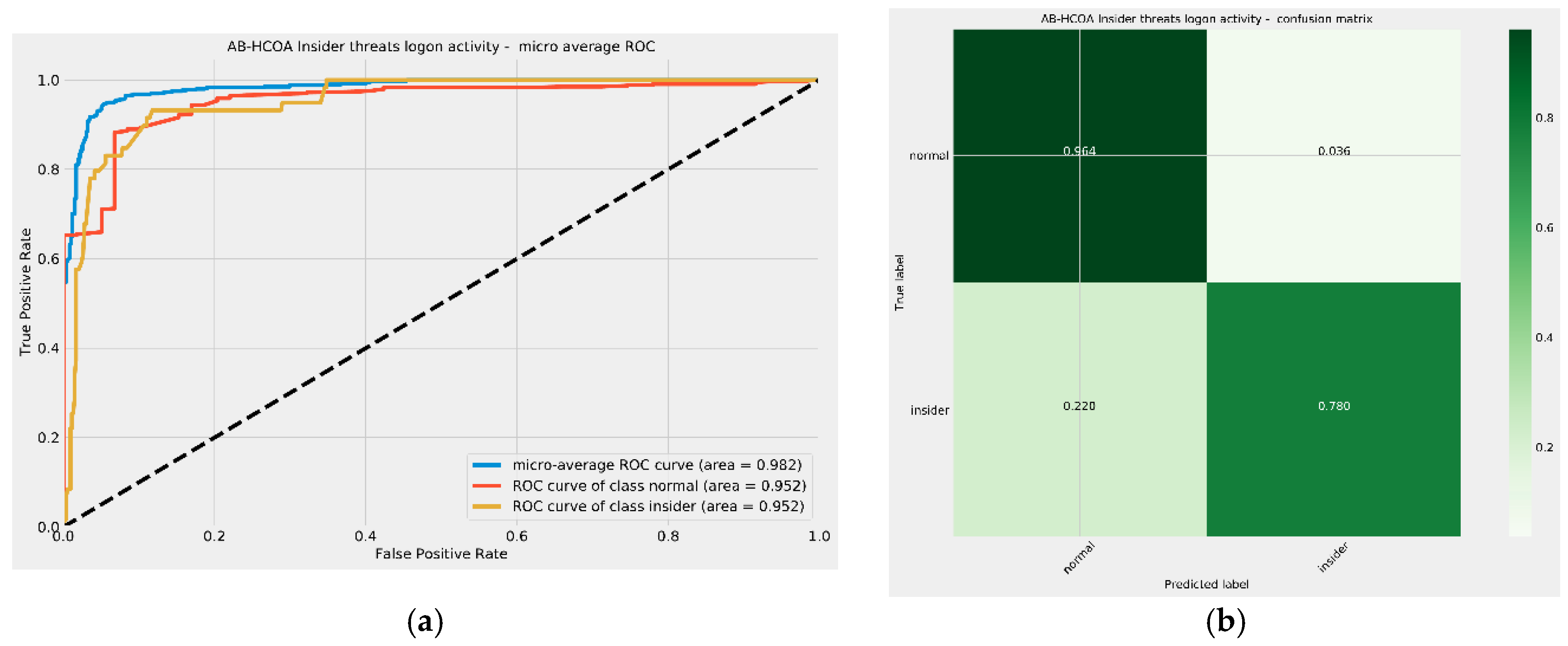
Graphical presentation of the outcomes for the best model in terms of confusion matrix and ROC are provided in
Figure 7.
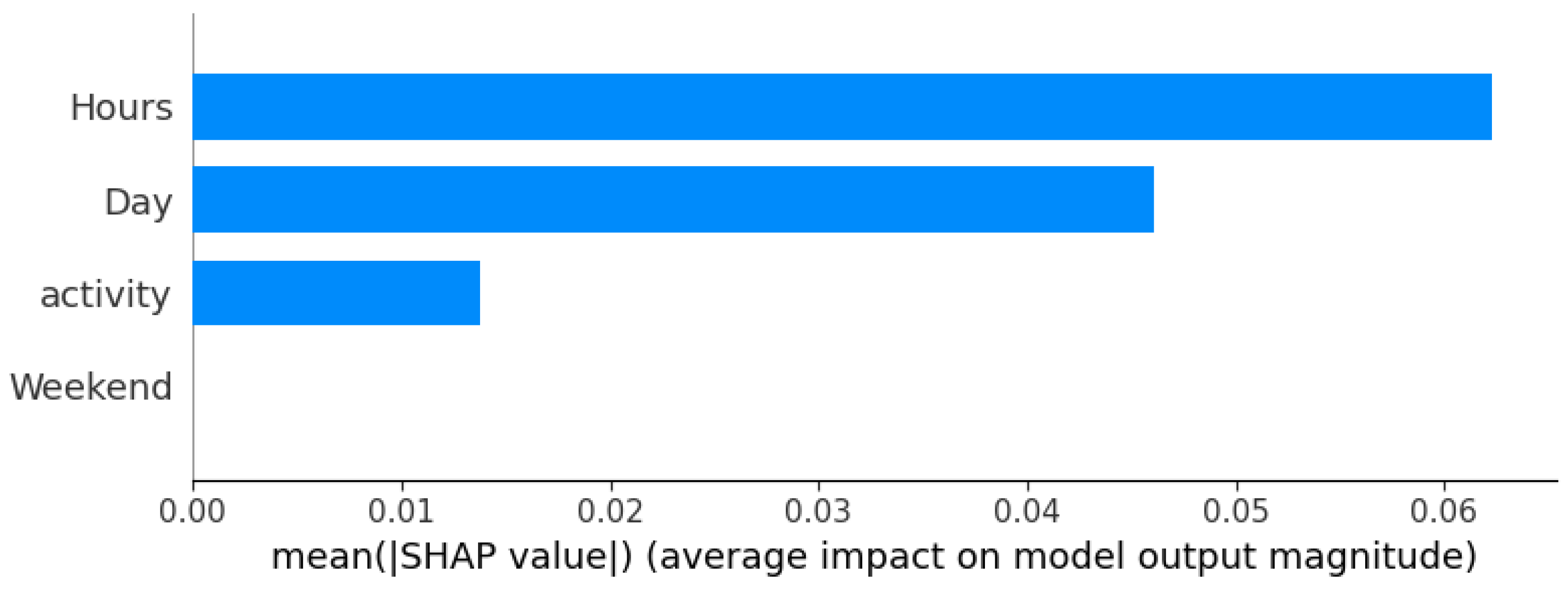
Additional sample additive explanations (SHAP) analysis [
38] is conducted to determine the feature importance for the best models’ decision-making process. The outcomes are presented in
Figure 8. SHAP interpretation suggests that the time of the day, and the day of the week play important roles in user’s activity being classified correctly. Additionally, the type of activity (logon or logoff) is considered. However, if an activity occurs on a weekend that is not considered important for the classification. It is likely due to this information being redundant with the day of the week being available.
Finally, the parameter selections made by each optimizer for the respective best-constructed model are provided in
Table 4.
6. Conclusions
This report presents our solutions for the problem of insider threat detection, based on login activity, within a greater context of cyber security, for the majority of normal users. Improved version of crayfish optimization algorithm is developed and applied to hyperparameter tunning of AdaBoost models to ensure better performances. Comparative analysis is conducted to compare efficiency of new design, with several contemporary optimizers applied on a simulated, publicly available dataset. Our models, optimized by the introduced modified algorithm, attained the best outcomes demonstrating accuracy of 94.6128% and an adaptive convergence rate that overcomes local minima and find the best solution. Additionally, the best-constructed model was subjected to SHAP analysis to determine the key contributing features.
There are few assumptions applied in our investigation. One of the key hypotheses was that the feature set, used for training, remains static and that the characteristics of insider threats do not change significantly over time. In real-world applications, insider behaviour could evolve, necessitating periodic updates to the feature set, and retraining of the model to maintain its effectiveness. Additionally, the study assumes that the labeled data used for training is accurate and true representative of actual insider threats. Mislabelling, or incomplete datasets, could negatively impact model accuracy, which is a common challenge in machine learning. Efforts were made to ensure data quality and coverage, but such challenges remain inherent to the approach. Future research will focus on further expanding the methodology, by incorporating other user actions in the classification. Computational constraint-associated limitations hope to be addressed as more powerful hardware becomes available on daily basis. Finally, other optimization tasks could be improved by the further introduction of novel, modified algorithms.
Author Contributions
Conceptualization, L.J. and N.B.; methodology, N.B.; software, N.B. and L.J.; validation, M.S. and F.M.; formal analysis, Ž.S.; investigation, Ž.S. and F.M.; resources, Ž.S.; data curation, M.S.; writing—original draft preparation, L.J.; writing—review and editing, M.S. and F.M.; visualization, L.J.; supervision, N.B.; project administration, M.S.; funding acquisition, Ž.S. All authors have read and agreed to the published version of the manuscript.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
References
- B. Gupta, B. Gupta, and S. Srinivasagopalan, Handbook of research on intrusion detection systems (Intrusion detection systems). Hershey, Pennsylvania: IGI Global, 2020.
- "Insider threats and Insider Intrusion Detection," International journal of recent technology and engineering, vol. 8, no. 2S5, pp. 158-166, 2019. [CrossRef]
- N. T N and D. Pramod, "Insider Intrusion Detection Techniques: A State-of-the-Art Review," The Journal of computer information systems, vol. ahead-of-print, no. ahead-of-print, pp. 1-18, 2024. [CrossRef]
- M. A. Ferrag, L. Maglaras, S. Moschoyiannis, and H. Janicke, "Deep learning for cyber security intrusion detection: Approaches, datasets, and comparative study," Journal of information security and applications, vol. 50, p. 102419, 2020. [CrossRef]
- I. H. Hassan, A. Mohammed, and M. A. Masama, "Chapter 6 - Metaheuristic algorithms in network intrusion detection," in Comprehensive Metaheuristics, S. Mirjalili and A. H. Gandomi Eds.: Academic Press, 2023, pp. 95-129.
- H. Jia, H. Rao, C. Wen, and S. Mirjalili, "Crayfish optimization algorithm," The Artificial intelligence review, vol. 56, no. Suppl 2, pp. 1919-1979, 2023. [CrossRef]
- J. Kosseff, "Defining Cybersecurity Law," Iowa law review, vol. 103, no. 3, pp. 985-1031, 2018.
- A. Moallem, HCI for Cybersecurity, Privacy and Trust : 6th International Conference, HCI-CPT 2024, Held as Part of the 26th HCI International Conference, HCII 2024, Washington, DC, USA, June 29 – July 4, 2024, Proceedings, Part I, 1st 2024. ed. (Lecture Notes in Computer Science, 14728). Cham: Springer Nature Switzerland, 2024.
- (2023). 2023-2030 Australian Cyber Security Strategy. [Online] Available: https://www.homeaffairs.gov.au/about-us/our-portfolios/cyber-security/strategy/2023-2030-australian-cyber-security-strategy.
- D. J. B. Svantesson and D. Kloza, Trans-Atlantic data privacy relations as a challenge for democracy (European integration and democracy series ; volume 4). Cambridge [England] ;: Intersentia, 2017.
- V. Papakonstantinou, "Cybersecurity as praxis and as a state: The EU law path towards acknowledgement of a new right to cybersecurity?," The computer law and security report, vol. 44, p. 105653, 2022. [CrossRef]
- M. Lukings and A. Habibi Lashkari, Understanding Cybersecurity Law and Digital Privacy : A Common Law Perspective, 1st 2022. ed. (Future of Business and Finance). Cham: Springer International Publishing, 2022.
- A. I. Savin and J. Trzaskowski, Research handbook on EU internet law (Research handbooks in European law series). Northampton: Edward Elgar Publishing, 2023.
- J. H. Pohl, "International Data Transfers and Cybersecurity: Three Regulatory Approaches and Their Implications." United Kingdom: Cambridge University Press, 2023, pp. 134-160.
- J. Ullrich, J. Cropper, P. Frühwirt, and E. Weippl, "The role and security of firewalls in cyber-physical cloud computing," EURASIP Journal on Information Security, vol. 2016, no. 1, p. 1, 2016. [CrossRef]
- S. Thapa and A. M. Dissanayaka, "The Role of Intrusion Detection/Prevention Systems in Modern Computer Networks: A Review," 2020.
- L. Bilge and T. Dumitraş, "Before we knew it: an empirical study of zero-day attacks in the real world," presented at the Proceedings of the 2012 ACM conference on Computer and communications security, Raleigh, North Carolina, USA, 2012. [Online]. Available: . [CrossRef]
- E. Džaferović, A. Sokol, A. A. Almisreb, and S. Mohd Norzeli, "DoS and DDoS vulnerability of IoT: A review," Sustainable Engineering and Innovation, vol. 1, no. 1, pp. 43-48, 2019. [CrossRef]
- M. Kandias, A. Mylonas, N. Virvilis, M. Theoharidou, and D. Gritzalis, "An Insider Threat Prediction Model," Berlin, Heidelberg: Springer Berlin Heidelberg, pp. 26-37. [CrossRef]
- T. J. Hastie, S. Rosset, J. Zhu, and H. Zou, "Multi-class AdaBoost ∗," Statistics and Its Interface, vol. 2, pp. 349-360, 2009.
- J. H. Holland, "Genetic Algorithms," Scientific American, vol. 267, no. 1, pp. 66-73, 1992. [CrossRef]
- J. Kennedy and R. Eberhart, "Particle swarm optimization," 1995, vol. 4: IEEE, pp. 1942-1948 vol.4. [CrossRef]
- Y. Xin-She and X. He, "Firefly Algorithm: Recent Advances and Applications," arXiv.org, 2013. [CrossRef]
- S. Mirjalili, "SCA: A Sine Cosine Algorithm for solving optimization problems," Knowledge-based systems, vol. 96, pp. 120-133, 2016. [CrossRef]
- S. Mirjalili and A. Lewis, "The Whale Optimization Algorithm," Advances in engineering software (1992), vol. 95, pp. 51-67, 2016. [CrossRef]
- L. Abualigah, M. A. Elaziz, P. Sumari, Z. W. Geem, and A. H. Gandomi, "Reptile Search Algorithm (RSA): A nature-inspired meta-heuristic optimizer," Expert Systems with Applications, vol. 191, p. 116158, 2022/04/01/ 2022. [CrossRef]
- J. Gurrola-Ramos, A. Hernàndez-Aguirre, and O. Dalmau-Cedeño, "COLSHADE for Real-World Single-Objective Constrained optimization Problems," in 2020 IEEE Congress on Evolutionary Computation (CEC), 19-24 July 2020 2020, pp. 1-8. [CrossRef]
- D. H. Wolpert and W. G. Macready, "No free lunch theorems for optimization," IEEE Transactions on Evolutionary Computation, vol. 1, no. 1, pp. 67-82, 1997. [CrossRef]
- N. Bacanin, M. Zivkovic, L. Jovanovic, M. Ivanovic, and T. A. Rashid, "Training a Multilayer Perception for Modeling Stock Price Index Predictions Using Modified Whale Optimization Algorithm," in Computational Vision and Bio-Inspired Computing, Singapore, S. Smys, J. M. R. S. Tavares, and V. E. Balas, Eds., 2022// 2022: Springer Singapore, pp. 415-430.
- A. Minic et al., "Applying Recurrent Neural Networks for Anomaly Detection in Electrocardiogram Sensor Data," Sensors, vol. 23, no. 24, p. 9878, 2023. [Online]. Available: https://www.mdpi.com/1424-8220/23/24/9878.
- M. Zivkovic, L. Jovanovic, M. Ivanovic, A. Krdzic, N. Bacanin, and I. Strumberger, "Feature Selection Using Modified Sine Cosine Algorithm with COVID-19 Dataset," in Evolutionary Computing and Mobile Sustainable Networks, Singapore, V. Suma, X. Fernando, K.-L. Du, and H. Wang, Eds., 2022// 2022: Springer Singapore, pp. 15-31.
- N. AlHosni et al., "The XGBoost Model for Network Intrusion Detection Boosted by Enhanced Sine Cosine Algorithm," in Third International Conference on Image Processing and Capsule Networks, Cham, J. I.-Z. Chen, J. M. R. S. Tavares, and F. Shi, Eds., 2022// 2022: Springer International Publishing, pp. 213-228.
- R. Damaševičius et al., "Decomposition aided attention-based recurrent neural networks for multistep ahead time-series forecasting of renewable power generation," (in eng), PeerJ Comput Sci, vol. 10, p. e1795, 2024. [CrossRef]
- S. A. Mirjalili and A. H. Gandomi, Comprehensive metaheuristics : algorithms and applications. London, England ;: Academic Press, 2023.
- W. Luo and X. Yu, "Quasi-reflection based multi-strategy cuckoo search for parameter estimation of photovoltaic solar modules," Solar Energy, vol. 243, pp. 264-278, 2022/09/01/ 2022. [CrossRef]
- J. Glasser and B. Lindauer, "Bridging the Gap: A Pragmatic Approach to Generating Insider Threat Data," in 2013 IEEE Security and Privacy Workshops, 23-24 May 2013 2013, pp. 98-104. [CrossRef]
- B. Lindauer, "Insider Threat Test Dataset," ed: Carnegie Mellon University, 2020.
- L. S. I. Lundberg S M, "A unified approach to interpreting model predictions," Advances in Neural Information Processing Systems, vol. 30, pp. 4765 - 4774, 2017. [CrossRef]
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).