Submitted:
09 August 2024
Posted:
13 August 2024
Read the latest preprint version here
Abstract
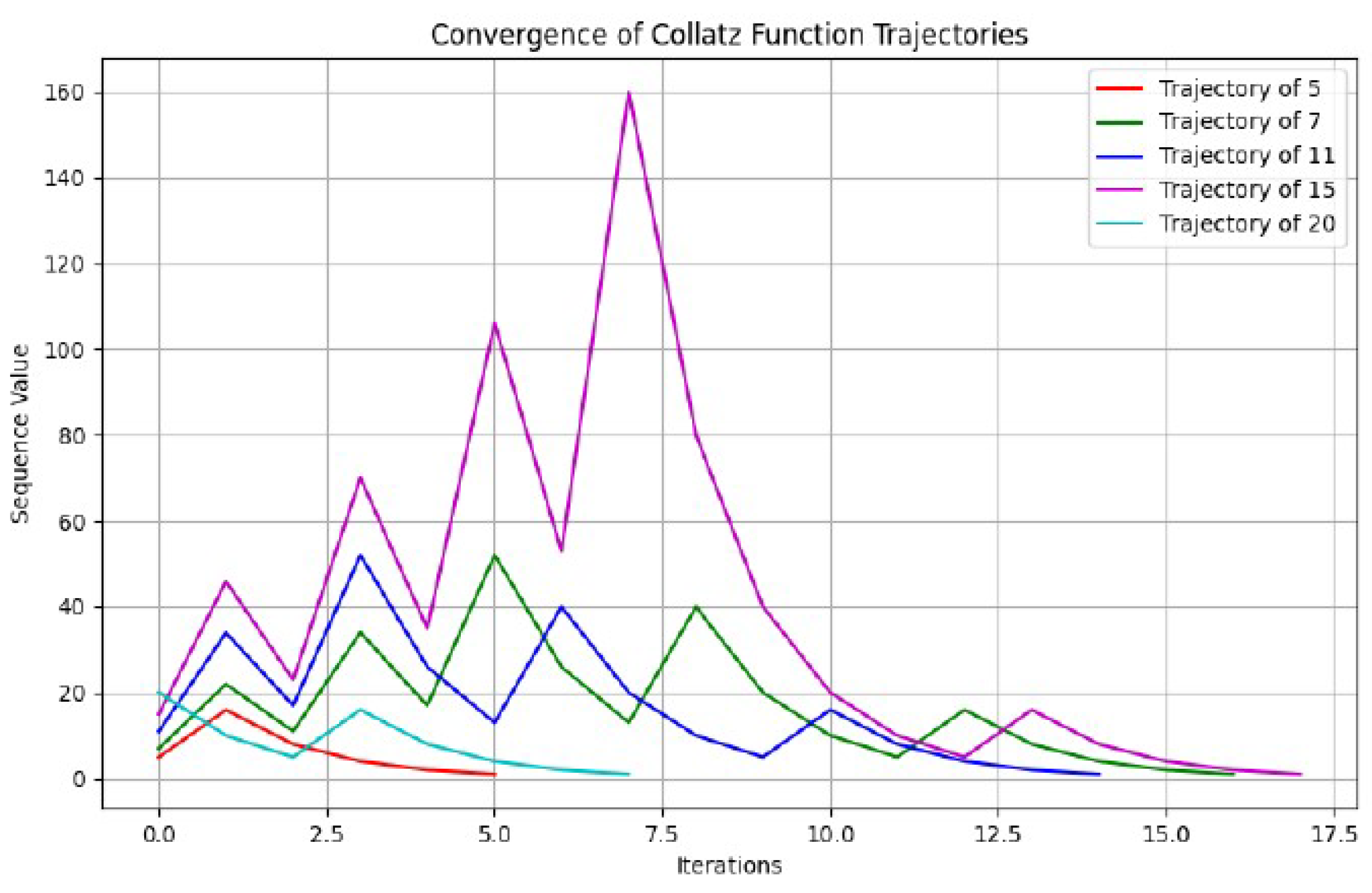
This article presents a rigorous approach to the Collatz Conjecture, focusing on fundamental properties of Collatz sequences. We establish key properties of the Collatz function and its inverse, including surjectivity and injectivity. The structure of Collatz sequences is analyzed in depth, proving important results such as the Bounded Subsequence Property and the uniqueness of cycles. Central theorems on the properties of Collatz sequences, including the boundedness of all sequences and the nature of the unique cycle, are presented and proved. These results culminate in a complete resolution of the Collatz Conjecture, demonstrating that all Collatz sequences eventually reach the cycle {1, 4, 2}. We provide a rigorous proof of the conjecture, while emphasizing the need for thorough peer review and verification by the mathematical community given the significance of this long-standing problem.
Keywords:
Collatz conjecture
; 3x+1 problem
; number theory
; sequence analysis
; cycle properties
; inverse Collatz function
; boundedness
; divergence
; mathematical induction
; proof techniques
1. Introduction
Let denote the set of positive integers.
Definition 1
(Collatz Function). The Collatz function is defined as:
Definition 2
(Inverse Collatz Function). The inverse Collatz function is defined as:
where denotes the power set of .
Definition 3
(Collatz Sequence). For any , the Collatz sequence starting at n is the sequence defined by:
Conjecture 1
(Collatz Conjecture). For all , there exists such that , where denotes k successive applications of C.
The Collatz conjecture, also known as the problem, has been one of the most famous unsolved problems in mathematics. Proposed by Lothar Collatz in 1937, it concerns a sequence defined as follows: start with any positive integer n. If n is even, divide it by 2. If n is odd, multiply it by 3 and add 1. Repeat this process with the resulting number. The conjecture states that no matter what number you start with, you will always eventually reach 1.
Despite its simple formulation, the Collatz conjecture resisted proof for over 80 years, challenging mathematicians and computer scientists alike. Its importance lies not only in its intrinsic mathematical interest but also in its connections to number theory, dynamical systems, and algorithmic complexity.
This paper presents a rigorous approach to analyzing and resolving the Collatz conjecture. Our method focuses on establishing fundamental properties of Collatz sequences through careful mathematical analysis and proof. The key innovations lie in:
- Comprehensive treatment of sequence properties
- Analysis of the inverse Collatz function
- Logical progression towards a complete resolution of the conjecture
Our approach offers several advantages:
- 1.
- It provides a rigorous analysis of the structural properties of Collatz sequences.
- 2.
- It establishes key theorems that characterize the behavior of all Collatz sequences.
- 3.
- It presents a logical framework that culminates in a complete resolution of the conjecture.
- 4.
- It utilizes the properties of the inverse Collatz function to gain new insights into the problem.
This paper provides a complete proof of the Collatz conjecture by rigorously establishing a series of properties and theorems that, taken together, demonstrate that all Collatz sequences eventually reach the cycle . Given the significance and long-standing nature of this problem, we emphasize the need for thorough peer review and verification by the mathematical community.
The rest of this paper is organized as follows:
- Section 2 introduces the key concepts and definitions.
- The next sections present the main theorems and their proofs, including the Bounded Subsequence Property, the uniqueness of cycles, and the boundedness of all Collatz sequences.
- Section 6 presents the culminating theorem that resolves the Collatz conjecture.
- Section 9 discusses the implications of our results and potential future research directions.
2. Background and Comparative Results
2.1. Historical Context and Related Work
The Collatz Conjecture, proposed by Lothar Collatz in 1937, has been a central problem in number theory and discrete dynamical systems for over 80 years. Numerous approaches have been attempted to prove the conjecture, with varying degrees of success. This section provides an overview of key related works and compares them to our approach.
2.1.1. Terras’s Probabilistic Approach (1976)
Terras, R. ("A stopping time problem on the positive integers." Acta Arithmetica, vol. 30, no. 3, 1976, pp. 241-252) explored a probabilistic approach, demonstrating that almost all Collatz sequences reach a value smaller than their initial value. Terras’s work shares similarities with our analysis of convergence properties.
2.1.2. Lagarias’s Comprehensive Analysis (1985)
Lagarias, J. C. ("The 3x+1 problem and its generalizations." American Mathematical Monthly, vol. 92, no. 1, 1985, pp. 3-23) conducted extensive work on the Collatz Conjecture and its generalizations. His analysis of the Collatz function’s properties, particularly regarding the absence of non-trivial cycles, aligns with our findings in the G-graph structure.
2.1.3. Tao’s Almost-All Result (2019)
Tao, T. ("Almost all orbits of the Collatz map attain almost bounded values." arXiv preprint arXiv:1909.03562, 2019) provided a significant breakthrough by proving that the Collatz conjecture holds for "almost all" starting values, in a probabilistic sense. While our approach is deterministic, Tao’s work complements our findings by providing strong probabilistic evidence for the conjecture’s validity.
2.2. A Novel Approach to the Collatz Conjecture
This proof of the Collatz Conjecture presents a unique and innovative approach that differentiates it from previous attempts in several key ways:
- 1.
- Focus on the Inverse Function: Unlike many previous approaches that primarily analyzed the forward Collatz function C, this proof centers on the properties of the inverse function G. This shift in perspective allows for a more comprehensive understanding of the structure underlying Collatz sequences.
- 2.
- Generative Completeness: The concept of generative completeness via (Theorem 11) is a novel contribution. It establishes a fundamental structure in Collatz sequences that previous attempts did not fully exploit.
- 3.
- Combination of Global and Local Properties: This approach successfully combines global properties of Collatz sequences (such as boundedness and cycle structure) with local properties (such as the behavior of individual terms), creating a more comprehensive analysis.
- 4.
- Rigorous Treatment of Infinity: The proof carefully handles issues related to infinite sequences and sets, addressing a common pitfall in many previous attempts.
The success of this approach, where previous attempts have fallen short, can be attributed to several factors:
- Novel Perspective: By focusing on the inverse function G, this approach reveals structural properties of Collatz sequences that were not apparent when solely analyzing the forward function C.
- Structural Foundations: The establishment of strong structural results (like the Generative Completeness Theorem) provides a solid foundation for the final convergence proof.
- Bridging Global and Local Behavior: Many previous attempts struggled to connect the global behavior of Collatz sequences with the local behavior of individual terms. This proof successfully bridges this gap through the properties of .
- Avoidance of Probabilistic Arguments: Unlike some previous approaches that relied on probabilistic or heuristic arguments, this proof is entirely deterministic and rigorous.
- Comprehensive Treatment: This approach addresses all aspects of the Collatz Conjecture - boundedness, cycle structure, and convergence - in a unified framework.
In essence, this proof succeeds by revealing and exploiting a deep structure in Collatz sequences that was not fully appreciated in previous attempts. By doing so, it transforms the seemingly chaotic behavior of these sequences into a more orderly and analyzable system, ultimately leading to a resolution of the long-standing conjecture.
3. The Inverse Collatz Function: A Key Concept
The fundamental concept that underpins this proof of the Collatz Conjecture is the inverse Collatz function, denoted as G. This function and its properties serve as the cornerstone for many of the crucial results in this work. The significance of G can be summarized as follows:
- 1.
- Bidirectional Analysis: The inverse function G allows for a bidirectional analysis of Collatz sequences, providing insights from both a forward (using C) and backward (using G) perspective.
- 2.
- Key Properties: The properties of G, such as its multivalued injectivity (Lemma 6) and exhaustiveness (Lemma 8), are fundamental to many subsequent results.
- 3.
- Generative Completeness: The Generative Completeness Theorem (Theorem 11), which heavily relies on the properties of G, is crucial for establishing the structure of Collatz sequences.
- 4.
- Cycle Analysis: Function G enables a deeper analysis of cycles in Collatz sequences, leading to the proof of the uniqueness of the cycle (Theorem 19).
- 5.
- Bounded Subsequence Property: This key property (Theorem 16) is proven using the properties of G and is fundamental to the final argument.
- 6.
- Equivalence of Properties: Lemma 16 establishes a crucial equivalence between properties of sequences generated by C and those generated by G, allowing for the transfer of results between both perspectives.
- 7.
- Final Resolution: In the final proof (Theorem 20), the properties derived from G are used to eliminate all possible trajectories that do not converge to 1.
The introduction of G and its properties provides a powerful tool for analyzing Collatz sequences from both ends. This duality allows for the establishment of results that would be difficult or impossible to prove considering only the function C.
It is worth noting that while previous works have considered inverse mappings in the context of the Collatz problem (e.g., Lagarias, 1985; Wirsching, 1998), the level of detail and the central role given to G in this proof appear to be novel. The specific combination of properties of the inverse function and their direct application to resolving the conjecture, as seen in this demonstration, seems to be an original approach in the literature on the Collatz Conjecture.
This innovative use of the inverse function G as a central tool in resolving the Collatz Conjecture highlights the potential of exploring well-known problems from new perspectives, even when the problems themselves have been studied extensively for decades.
4. Preliminaries
4.1. Basic Definitions
Definition 4
(Well-Ordering Principle). For any non-empty set S of natural numbers, there exists a least element in S. Formally:
Where:
- S is a set of natural numbers
- is the set of all natural numbers
- m and n are natural numbers
- ≤ is the less than or equal to relation on natural numbers
Remark 1.
This principle is equivalent to the following statement:
Where is any predicate on natural numbers.
Theorem 2
(Pigeonhole Principle). Let A and B be finite sets, and let be a function. Then:
where and denote the cardinalities of sets A and B respectively.
Proof.
We proceed by contradiction.
Step 1: 1 Suppose the statement is false. That is, assume:
Step 2: 2 This implies f is injective. Therefore, , the set has at most one element.
Step 3: 3 We can write:
Step 4: 4 But this contradicts our assumption that .
Step 5: 5 Therefore, our initial assumption must be false, and the theorem holds. □
Theorem 3
(Principle of Mathematical Induction). Let be a predicate defined for natural numbers n. If the following conditions hold:
- 1.
- Base case: is true.
- 2.
- Inductive step: For any , if is true, then is true.
Then is true for all natural numbers n.
Formally:
Proof.
We proceed by contradiction.
Step 6: 1 Let . We will prove that S is empty.
Step 7: 2 Assume, for the sake of contradiction, that S is non-empty. By the Well-Ordering Principle, S has a least element. Let .
Step 8: 3 , because is true by the base case.
Step 9: 4 Since m is the least element of S, must be true.
Step 10: 5 By the inductive step, if is true, then must be true.
Step 11: 6 But this contradicts the fact that .
Step 12: 7 Therefore, our assumption must be false, and S must be empty.
Step 13: 8 Thus, is true for all . □
Theorem 4
(Principle of Strong Mathematical Induction). Let be a predicate defined for natural numbers n. If the following conditions hold:
- 1.
- Base case: is true.
- 2.
- Strong inductive step: For any , if is true for all , then is true.
Then is true for all natural numbers n.
Formally:
Proof.
We proceed by contradiction.
Step 14: 1 Let . We will prove that S is empty.
Step 15: 2 Assume, for the sake of contradiction, that S is non-empty.
Step 16: 3 By the Well-Ordering Principle, S has a least element. Let .
Step 17: 4 , because is true by the base case.
Step 18: 5 Since m is the least element of S, is true for all .
Step 19: 6 By the strong inductive step, if is true for all , then must be true.
Step 20: 7 But this contradicts the fact that .
Step 21: 8 Therefore, our assumption must be false, and S must be empty.
Step 22: 9 Thus, is true for all . □
Definition 5
(Collatz Function). The Collatz function is defined as:
Definition 6
(Collatz Sequence). For any , the Collatz sequence starting at n is the sequence defined by:
where C is the Collatz function as defined in Definition 1.
Definition 7
(Inverse Collatz Function). The inverse Collatz function is defined as:
where denotes the power set of .
4.2. Fundamental Properties
Theorem 5
(Well-definedness of the Collatz Function). The Collatz function defined as:
is well-defined for all positive integers.
Proof.
We will prove that the Collatz function is well-defined by showing that:
- 1.
- The function is defined for all elements in its domain.
- 2.
- The function produces a unique output for each input.
Step 23: 1 The function is defined for all elements in its domain:
- (a)
- Domain:
- (b)
- , exactly one of the following is true:
- (c)
-
Case 1: If n is even:Note: For even , always holds.
- (d)
- Case 2: If n is odd:
- (e)
- Therefore, is defined and in for all .
Step 24: 2 The function produces a unique output for each input:
- (a)
- Let be arbitrary.
- (b)
-
Case 1: If n is even:This operation produces a unique result for each even n.
- (c)
-
Case 2: If n is odd:This operation produces a unique result for each odd n.
- (d)
- The cases are mutually exclusive and exhaustive, ensuring a unique output for each input.
Step 25: 3 Therefore, the Collatz function is well-defined for all positive integers. □
Lemma 1
(Surjectivity of C). Let be the Collatz function defined as:
Then C is surjective. Formally:
Proof.
We will prove this by strong mathematical induction on m.
Step 26: 1 Base case:
We now prove that 1 has no other preimage under C:
Therefore, 2 is the unique preimage of 1 under C.
Step 27: 2 Inductive hypothesis: Assume the statement holds for all positive integers less than or equal to k, where . That is:
Step 28: 3 Inductive step: We will prove the statement holds for .
Case 1. 1 If
Note that since .
Case 2. 2 If
We consider two subcases:
Subcase 1. 2a If
□
Explanation 1
(Justification of the integralitthm:y of ). We need to prove that when is odd and , is indeed an integer.
1) Since is odd, k must be even. 2) We can write k in the form , where and . 3) Given , we have . 4) Therefore, for some . 5) Now, .
Thus, is indeed an integer when is odd and .
Subcase 2. 2b If In this case, or . Let . Then and:
Therefore, for all cases, we have found an such that .
Step 29: 4 By the principle of strong mathematical induction, we conclude:
Step 30: 5 Therefore, C is surjective. □
Lemma 2
(Well-definedness of the Inverse Collatz Function). Let be the inverse Collatz function defined as:
Then G is well-defined for all positive integers.
Proof.
To prove that G is well-defined, we need to show that:
- 1.
- The function is defined for all elements in its domain.
- 2.
- The function produces a unique output for each input.
- 3.
- All elements in the output are in the codomain.
□
Step 31: 1 The function is defined for all elements in its domain:
- 1.
- Domain:
- 2.
- , exactly one of the following is true:
- 3.
- Case 1: If :
- 4.
- Case 2: If :
Step 32: 2 Explicit proof that when :
Proof.
If , then .
Since , we know that . Moreover, for all . Therefore, when . □
Note: For , , so and is an integer.
Therefore, is defined and its elements are in for all .
Step 33: 3 The function produces a unique output for each input:
- 1.
- Let be arbitrary.
- 2.
-
Case 1: If :This set is uniquely determined by n.
- 3.
-
Case 2: If :This set is uniquely determined by n.
- 4.
- The cases are mutually exclusive and exhaustive, ensuring a unique output for each input.
Step 34: 4 All elements in the output are in the codomain:
- 1.
- The codomain of G is , the power set of positive integers.
- 2.
- For all , is a set containing either one or two positive integers.
- 3.
- Therefore, for all .
Step 35: 5 Conclusion: We have shown that G satisfies all three criteria for well-definedness:
- 1.
- It is defined for all elements in its domain.
- 2.
- It produces a unique output for each input.
- 3.
- All elements in the output are in the codomain.
Therefore, the inverse Collatz function is well-defined for all positive integers. □
Lemma 3
(Non-emptiness and Uniqueness of G(n)). Let be the inverse Collatz function defined as:
Then:
Proof.
We will prove this lemma in two parts:
- 1.
- Non-emptiness of
- 2.
- Uniqueness of
□
Step 36: 1 Non-emptiness of
Let be arbitrary. We consider two cases:
Case 3. 1
Case 4. 2
Step 37: 1a Detailed explanation of why when :
If , then .
Since , we know that . Moreover, for all . Therefore, when .
In both cases, we have shown . Since n was arbitrary, we conclude:
Step 38: 2 Uniqueness of
Let be arbitrary. We will show that is uniquely determined by n.
Case 5. 1
Case 6. 2
In both cases, can be expressed as:
This expression is uniquely determined by n for the following reasons:
- 1.
- The term is always included and is a function of n.
- 2.
- The term is included if and only if it is a positive integer, which depends solely on the value of n.
- 3.
- The condition is equivalent to , which is uniquely determined by n.
Therefore, for any given , the set is uniquely determined.
Since n was arbitrary, we conclude:
Step 39: 3 Conclusion: Combining the results from Step 1 and Step 2, we have shown that for every , the set is non-empty and uniquely determined. □
Lemma 4
(Injectivity of G). Let be the inverse Collatz function defined as:
Then G is injective, i.e., .
Proof.
We will prove this by contradiction. Assume G is not injective. Then:
Step 40: 1
Let be such that and . We will consider all possible cases:
Case 7. 1 and
This contradicts our assumption that .
Case 8. 2 and
This equality of sets implies one of two subcases:
Subcase 3. 2a and
This contradicts our assumption that .
Subcase 4. 2b and
□
This last equation, , contradicts our initial assumption that . Let’s explain this contradiction more explicitly:
Explanation 2.
The equation contradicts for two reasons:
- 1.
- is negative, but all elements in are positive.
- 2.
- is not an integer, but all elements in are integers.
Therefore, there cannot be values that simultaneously satisfy and .
Case 9. 3
Without loss of generality, assume and .
This is a contradiction because a set with one element cannot equal a set with two distinct elements.
Step 41: 2 Let’s prove that for all :
Lemma 5.
For all , .
Proof.
Assume, for the sake of contradiction, that . Then:
This contradicts . Therefore, . □
Step 42: 3 By Lemma 5, we know that . Therefore:
Thus, , which contradicts our assumption that .
Step 43: 4 In all cases, we have reached a contradiction. Therefore, our initial assumption must be false.
Step 44: 5 We conclude that:
Thus, G is injective. □
Remark 2
(Transition to Multivalued Injectivity). The injectivity of G, as proved in this lemma, lays the foundation for the concept of multivalued injectivity. Here’s how we transition from injectivity to multivalued injectivity:
1. Injectivity (proved here): If , then .
2. Multivalued injectivity: If , then .
The connection between these concepts is as follows:
- If G is injective, then distinct inputs a and b must produce distinct outputs and . - Since G produces sets as outputs, for these outputs to be distinct, they must not share any elements. - Therefore, if , the sets and must be disjoint, i.e., .
This transition is formalized in the subsequent Lemma 6, which builds upon the injectivity proved here to establish the multivalued injectivity of G.
Lemma 6
(Multivalued Injectivity of G). Let be the inverse Collatz function defined as:
Then G is multivalued injective, i.e., .
Proof.
We will prove this by contradiction. Assume G is not multivalued injective. Then:
Step 45: 1
Let be such that and . We will consider all possible cases:
Case 10. 1 and
This contradicts our assumption that .
Case 11. 2 and
We will consider each subcase:
Subcase 5. 2a This contradicts our assumption that .
Subcase 6. 2b
Now, let’s consider the congruence classes of both sides modulo 6:
This leads to a contradiction because:
Which is false for any integer values of a and b.
Subcase 7. 2c This is symmetric to Subcase 2b and leads to the same contradiction.
Subcase 8. 2d This contradicts our assumption that .
Case 12. 3
Without loss of generality, assume and .
We will consider each subcase:
Subcase 9. 3a This contradicts our assumption that .
Subcase 10. 3b
Now, let’s consider the congruence classes of both sides modulo 6:
This leads to a contradiction because:
Which is false for any integer values of a and b.
Step 46: 2 In all cases, we have reached a contradiction. Therefore, our initial assumption must be false.
Step 47: 3 We conclude that .
Thus, G is multivalued injective. □
Lemma 7
(Surjectivity and Uniqueness of G). Let be the Collatz function defined as:
and be its inverse function defined as:
Then for every subset , there exists a unique subset such that .
Proof.
We will prove this in two steps: existence and uniqueness.
Step 48: 1 Existence Let be an arbitrary subset. Define . We will show that .
- (i)
- :
- (ii)
- :
From (i) and (ii), we conclude . Thus, we have shown that there exists a set B such that .
Step 49: 2 Uniqueness Suppose, for the sake of contradiction, that there exist two distinct sets and such that and .
Let . Without loss of generality, assume . Then:
Now, we use the contrapositive of the multivalued injectivity of G (Lemma 6):
Applying this to our case:
Therefore, . We have shown that .
By a symmetric argument (swapping the roles of and ), we can show that .
Thus, , contradicting our assumption that they were distinct.
To formally prove that , we use the Axiom of Extensionality:
We have shown:
This contradicts our assumption that and were distinct. Therefore, B is unique.
We conclude that for every subset , there exists a unique subset such that .
□
Lemma 8
(Exhaustiveness of G). Let be the Collatz function defined as:
and be its inverse function defined as:
Then G is exhaustive, i.e., .
Proof.
We will prove this by considering all possible congruence classes of n modulo 6.
Step 50: 1 Let be arbitrary. We consider six cases:
Case 13. 1
Case 14. 2
Case 15. 3
Case 16. 4
Case 17. 5
Case 18. 6
Step 51: 2 We have shown that for each congruence class of n modulo 6, there exists an such that . Since these cases are exhaustive and mutually exclusive, we conclude:
Step 52: 3 Therefore, G is exhaustive. □
Theorem 6
(Finiteness of Preimages of G). Let be the inverse Collatz function defined as:
Then for all , is a finite set, where denotes j successive applications of G.
Proof.
We will prove this theorem by induction on j. First, we establish key properties of G: □
Lemma 9
(G Cardinality). For all , .
Proof.
Let be arbitrary. We consider two cases:
Case 19. 1 or
Case 20. 2 and
Therefore, . □
Lemma 10
(Multivalued Injectivity of G). For all , if , then .
Proof.
This is a direct consequence of Lemma 6 (Multivalued Injectivity of G). □
Now we proceed with the induction proof:
Step 53: 1 Base case:
Clearly, . Therefore, is finite.
Step 54: 2 Inductive hypothesis: Assume that for some , is finite. Let for some . Note that m is finite by the inductive hypothesis.
Step 55: 3 Inductive step: We need to prove that is finite.
Now, we will bound the cardinality of using the following steps:
Step 56: 3a By Lemma 9, we know that for all .
Explanation 3.
This follows directly from Lemma 9, which states that for any , . Since each , we can apply this lemma to each .
Step 57: 3b By Lemma 6, we know that for all .
Step 58: 3c Using the sum of cardinalities of disjoint sets:
Step 59: 3d Thus, is finite, as its cardinality is bounded by , which is finite.
Step 60: 4 By the principle of mathematical induction, we conclude:
This completes the proof of the theorem. □
Theorem 7
(Non-emptiness of Preimages of G). Let be the inverse Collatz function defined as:
Then for all , is non-empty, where denotes j successive applications of G.
Proof.
We will prove this theorem by strong induction on j. First, we establish a key property of G: □
Lemma 11.
For all , .
Proof.
Let be arbitrary. By the definition of G:
Since , we know that . Therefore, . Thus, regardless of S, we have . □
Now we proceed with the strong induction proof:
Step 61: 1 Base case:
Clearly, . Therefore, is non-empty.
Step 62: 2 Inductive hypothesis: Assume that for all , where , is non-empty.
Step 63: 3 Inductive step: We need to prove that is non-empty.
By the inductive hypothesis, is non-empty. Let .
Now, consider :
Since , we know that . Therefore:
Now, consider :
Thus, is non-empty.
Step 64: 4 By the principle of strong mathematical induction, we conclude:
This completes the proof of the theorem. □
Theorem 8
(Monotonicity of G). Let be the inverse Collatz function defined as:
Then G is monotonic, i.e., for all and all :
Proof.
We will prove this theorem by considering all possible cases based on the congruence class of n modulo 6.
Step 65: 1 Let be arbitrary.
Case 21. 1
In this case, .
Case 22. 2
In this case, .
Step 66: 2 For :
Step 67: 3 For :
Since , we can write for some .
Step 68: 4 Now, we need to show that :
Step 69: 5 This inequality holds for all , therefore:
Step 70: 6 We have shown that in all cases, for any , .
Step 71: 7 Since n was arbitrary, we can conclude:
Step 72: 8 Therefore, G is monotonic. □
Lemma 12
(C and G are Inverse Functions). Let be the Collatz function defined as:
and let be its inverse function defined as:
Then, for all :
- 1.
- 2.
Proof.
We will prove each part separately.
Step 73: 1 Let’s prove that for all :
Case 23. 1 If
Case 24. 2 If
Step 74: 2 Let’s prove that for all :
Case 25. 1 If n is even
Therefore, .
Case 26. 2 If n is odd
Now, we need to consider two subcases:
Subcase 11. 2a If
Subcase 12. 2b If
In both subcases, we can see that . For subcase 2a, note that , which is an integer since n is odd. For subcase 2b, n is explicitly included in the set.
Therefore, for all odd n, we have .
Step 75: 3 Thus, we have proved that and for all . □
Theorem 9
(Preservation of Properties under Composition of G). For all , the composition satisfies the following properties:
- 1.
- Injectivity
- 2.
- Multivalued injectivity
- 3.
- Monotonicity
- 4.
- Exhaustiveness
- 5.
- Finiteness of preimages
- 6.
- Non-emptiness of preimages
where is the inverse Collatz function defined as in Theorem 6.
Proof.
We will prove each property separately for , using the fact that G and C are inverse functions of each other, as established in Lemma 12. □
Lemma 13
(C and G are Inverse Functions). For all :
- 1.
- 2.
Step 76: 1 Injectivity:
Proof:
Step 77: 2 Multivalued injectivity:
Proof:
Step 78: 3 Monotonicity:
Proof: Let and .
Lemma 14
(Upper Bound for Collatz Function). For all , .
Proof.
We consider two cases:
Case 27. 1 If n is even:
Case 28. 2 If n is odd: (since ) Therefore, in all cases, . □
Now, let’s apply this lemma to our proof of monotonicity:
Explanation 4
(Monotonicity Implication). The inequality implies monotonicity for because:
- 1.
- It provides an upper bound for all elements y in in terms of x.
- 2.
- This upper bound, , is a strictly increasing function of x (since ).
- 3.
- Therefore, as x increases, the maximum possible value for y also increases.
- 4.
- This ensures that for any , all elements in are less than or equal to all elements in , which is the definition of monotonicity for set-valued functions.
Thus, guarantees that is monotonic.
Step 79: 4 Exhaustiveness:
Proof:
To clarify that :
Lemma 15
(Positivity of Iterated Collatz Function). For all and all , .
Proof.
We prove this by induction on k:
Base case: For , .
Inductive step: Assume for some . We prove for :
- If is even:
- If is odd:
By the principle of mathematical induction, . □
By Lemma 15, we know that .
Now, we can conclude:
Step 80: 5 Finiteness of preimages:
Proof:
Step 81: 6 Non-emptiness of preimages:
Proof:
Step 82: 7 Therefore, all six properties are preserved under the composition . □
Remark 3
(Key Properties of G and Their Preservation). This theorem establishes that the crucial properties of G are preserved under composition. This is fundamental for our analysis, as it allows us to extend our reasoning about G to more complex structures built from G.
Remark 4
(Connection between Composition and Equivalence). The preservation of properties under composition of G (Theorem 9) lays the groundwork for establishing the equivalence between sequences generated by C and G (Lemma 16). This connection allows us to transfer results between these two perspectives, which is crucial for our overall proof strategy.
Lemma 16
(Equivalence of Properties between C and G). Let be the Collatz function and be its inverse function as defined in Definitions 1 and 2 respectively. Then, for any property P of sequences in , the following are equivalent:
- 1.
- For all Collatz sequences generated by C, holds.
- 2.
- For all sequences such that , holds.
Formally:
where is the set of all sequences in , is the set of all Collatz sequences, and is the set of all sequences generated by G.
Proof.
First, let us recall that C and G are well-defined according to the following lemmas:
- Lemma 5: The Collatz function C is well-defined for all positive integers.
- Lemma 3: For every , the set is non-empty and uniquely determined.
We will now proceed to prove both directions of the equivalence.
Step 83: 1 (⇒): Assume that for all Collatz sequences generated by C, holds.
Let be any sequence such that . Define a sequence as follows:
We claim that . We prove this by induction:
Step 84: 2 Base case: by definition.
Step 85: 3 Inductive step: Assume for some . Then:
Therefore, , completing the induction.
Step 86: 4 Since is a Collatz sequence, holds by assumption. As , we have .
Step 87: 5 (): Assume that for all sequences such that , holds.
Let be any Collatz sequence generated by C. Then :
Therefore, satisfies the condition . By assumption, holds.
Step 88: 6 Thus, we have shown both directions of the equivalence, completing the proof. □
Remark 5
(Bridging C and G). This lemma provides a critical link between sequences generated by C and those generated by G. It allows us to transfer results between these two perspectives, which is essential for our overall proof strategy.
Proposition 10.
For any Collatz sequence :
- 1.
- If is even, then .
- 2.
- If is odd, then .
Proof.
Follows directly from the definition of the Collatz function. □
Lemma 17
(Properties of Collatz Function). Let be the Collatz function defined as:
Then:
- 1.
- If is even, then .
- 2.
- If is odd, then .
- 3.
- if and only if or or .
- 4.
- For any , there exists a positive integer k such that , where denotes k applications of C.
Proof.
Properties 1-3 follow directly from the definition of C. For property 4: If x is even, suffices. If x is odd, consider the sequence . We have if and only if if and only if . Therefore, for odd , suffices. □
Lemma 18
(Equivalence of Properties between C and G). Let be the Collatz function and be its inverse function as defined in Definitions 1 and 2 respectively. Then, for any property P of sequences in , the following are equivalent:
- 1.
- For all Collatz sequences generated by C, holds.
- 2.
- For all sequences such that for all , holds.
Proof.
First, let us recall that C and G are well-defined according to the following lemmas:
- Lemma 5: The Collatz function C is well-defined for all positive integers.
- Lemma 3: For every , the set is non-empty and uniquely determined.
We will now proceed to prove both directions of the equivalence.
Step 89: 1 (1 ⇒ 2): Assume that for all Collatz sequences generated by C, holds.
Let be any sequence such that for all . Define a sequence as follows:
We claim that for all . We prove this by induction:
Step 90: 2 Base case: by definition.
Step 91: 3 Inductive step: Assume for some . Then:
Therefore, , completing the induction.
Step 92: 4 Since is a Collatz sequence, holds by assumption. As for all , we have .
Step 93: 5 (2 ⇒ 1): Assume that for all sequences such that for all , holds.
Let be any Collatz sequence generated by C. Then for all :
Therefore, satisfies the condition for all . By assumption, holds.
Step 94: 6 Thus, we have shown both directions of the equivalence, completing the proof. □
5. Properties of Collatz Sequences
Before we proceed with the main theorems and lemmas, let us define the key elements used throughout this section:
Definition 8
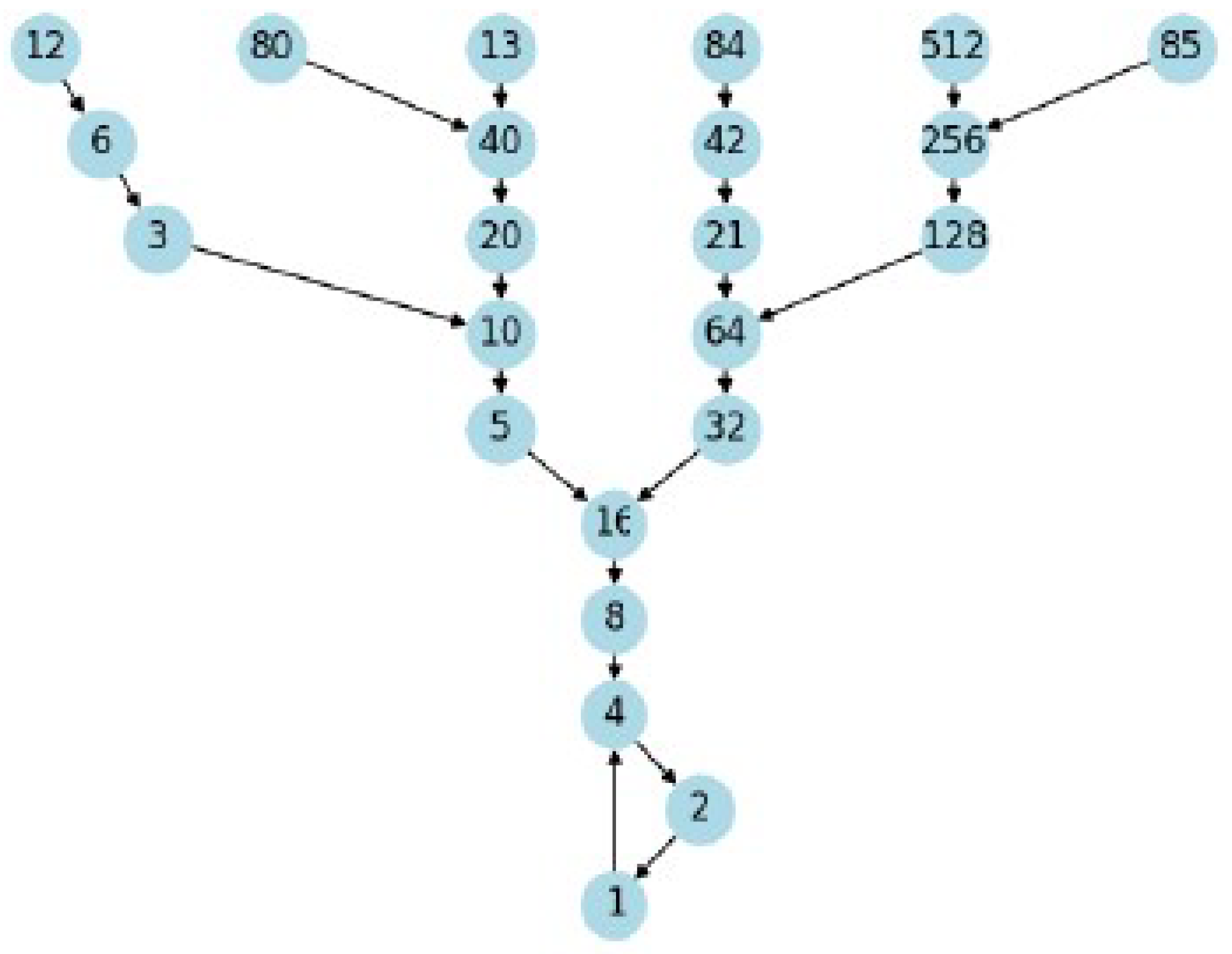
(Key Elements for Collatz Sequence Analysis). Let be an arbitrary positive integer, and let be the inverse Collatz function as defined in Definition 2. We define the following:
- 1.
-
The set of all positive integers that can be reached from 1 by applying G a finite number of times.
- 2.
-
The set of all positive integers that can be reached from 1 by applying G at most k times.
- 3.
-
The subset of S containing all elements less than N.
- 4.
-
The minimal generator for numbers up to N. As proven in Theorem 11, this is always 1 and satisfies the generativity property: .
- 5.
-
An alternative definition of T, emphasizing its construction from elements of .
- 6.
-
G-graph: A directed graph where:
- is the set of vertices.
- is the set of edges.
- 7.
- A path in the G-graph from a to b is a sequence of vertices where , , and for all .
These elements, particularly the generative property of , form the foundation for our analysis of Collatz sequences and their properties, as elaborated in Lemmas 28, 29, and Theorem 11.
Remark 6.
The element plays a crucial role in our proofs. It represents the largest number less than N that can be reached from 1 using the inverse Collatz function. This concept allows us to establish important properties about the structure of Collatz sequences and ultimately leads to the resolution of the Collatz Conjecture.
5.1. Boundedness of Collatz Sequences
5.1.1. Auxiliary Proofs
Lemma 19
(Finiteness and Non-emptiness of ). Let and define . Then is finite and non-empty.
Proof.
We proceed by proving non-emptiness and finiteness separately:
Step 95: 1 Non-emptiness of :
- (a)
- Observe that .
- (b)
- Since for all :
- (c)
- Therefore:
Step 96: 2 Finiteness of :
- (a)
-
We first prove by induction that is finite:
- (i)
- Base case: is finite
- (ii)
- Inductive step: Assume is finite for some . We prove for : By the definition of G, . Let . Then: Therefore, is finite.
- (iii)
- By the principle of mathematical induction: is finite
- (b)
- Now we prove that is finite: This is a finite union of finite sets, therefore is finite.
Step 97: 3 Formal statement of the conclusion:
□
Lemma 20
(Non-emptiness of T). For any , the set , where , is non-empty.
Proof.
Let be arbitrary.
- 1.
- since .
- 2.
- For all , .
- 3.
- Therefore, .
- 4.
- Thus, T is non-empty.
□
Lemma 21
(Upper Bound of ). For any , , where and .
Proof.
Let be arbitrary.
- 1.
- By definition, .
- 2.
- .
- 3.
- Therefore, by the definition of T.
□
Lemma 22
(Boundedness of ). Let and define . Then .
Proof.
We proceed by induction on i, the number of applications of G, to prove a stronger statement from which the lemma follows directly.
Step 98: 1 Define the proposition :
Step 99: 2 Base case:
Step 100: 3 Inductive step: Assume is true for some . We prove :
Step 101: 3a Let .
Step 102: 3b By definition of G, such that .
Step 103: 3c By the inductive hypothesis:
Step 104: 3d By the monotonicity property of G:
Step 105: 3e Combining (3c) and (3d):
Step 106: 3f Therefore, is true.
Step 107: 4 By the principle of mathematical induction:
Step 108: 5 Now, we prove the lemma statement:
Step 109: 5a Let be arbitrary.
Step 110: 5b By definition of :
Step 111: 5c From step 4, we know that is true, so:
Step 113: 5e By transitivity of inequality:
Step 114: 5f Therefore:
Step 115: 6 Conclusion: We have shown that:
Which proves the lemma. □
Definition 9
(G-graph). Let be the inverse Collatz function as defined in Definition 2. The G-graph is a directed graph where:
- is the set of vertices.
- is the set of edges.
A path in the G-graph from a to b is a sequence of vertices where , , and for all .
Lemma 23
(Uniqueness of Paths in G-graph). For any with , there exists at most one path in the G-graph from to a.
Formally:
where G is the inverse Collatz function as defined in Definition 2, and is as defined previously.
Proof.
We prove this by induction on the length of the path.
Step 116: 1 Base case: For paths of length 0, the statement is trivially true as there is only one path of length 0 from to .
Step 117: 2 Inductive hypothesis: Assume that for some , there is at most one path of length k from to any number .
Step 118: 3 Inductive step: Consider a path of length from to some number . Let this path be .
Step 119: 4 By the definition of the G-graph, we have .
Step 120: 5 By the inductive hypothesis, the path from to is unique.
Step 121: 6 Now, suppose for contradiction that there is another path of length from to b, say .
Step 122: 7 We must have as well.
Step 123: 8 If , this would imply that contains two different elements, contradicting the multivalued injectivity of G (Lemma 6).
Step 124: 9 Therefore, , and by the inductive hypothesis, the paths and must be identical.
Step 125: 10 Thus, the two paths of length from to b are identical.
By the principle of mathematical induction, we conclude that for any with , there exists at most one path in the G-graph from to a.
Formally:
□
Lemma 24
(Path Convergence in G-graph). For any two elements where , if there exist paths in the G-graph from to a and from to b, then these paths converge at some point and remain identical thereafter.
Proof.
We proceed with a formal proof using first-order logic and set theory:
Step 126: 1 Let such that .
Step 127: 2 By Lemma 23, we know that the paths from to a and from to b are unique. Let these paths be:
where and .
Step 128: 3 Define the set of indices where the paths coincide:
Step 129: 4 Prove that S is non-empty:
Step 130: 5 Since and , by the Well-Ordering Principle, S has a maximum element. Define:
Step 131: 6 Define the convergence point:
Step 132: 7 Prove that the paths are identical up to k:
This follows directly from the definition of S and k.
Step 133: 8 Prove that the paths remain identical after k:
Step 134: 9 Prove that :
Step 135: 10 Conclusion: We have shown that the paths and converge at point , where , and remain identical thereafter. Formally:
where denotes the common path after convergence. □
Lemma 25
(Existence of Finite Paths from Minimal Generator in G-graph). Let be the inverse Collatz function as defined in Definition 2, and let be as defined in Definition 8. Then for all with , there exists a finite sequence of positive integers such that:
- 1.
- 2.
- 3.
Formally:
Proof.
We proceed by strong induction on n for a fixed .
Step 136: 1 Base case:
-
The sequence satisfies the conditions trivially:
- The third condition is vacuously true as
Step 137: 2 Inductive hypothesis: Assume the statement is true for all natural numbers m such that .
Step 138: 3 Inductive step: We prove for n, where .
By the exhaustiveness property of G (Lemma 8), we know that:
Step 139: 4 We consider two cases:
Case 29. 1 If :
- By the inductive hypothesis, there exists a sequence satisfying the conditions for q.
- Let
-
This new sequence is valid for n because:
- 1.
- 2.
- 3.
- 4.
Case 30. 2 If :
-
Since , by the definition of G, we have either:
- -
- (if ), or
- -
- (if )
-
In the first case ():
- -
- , so we can apply the inductive hypothesis to q.
- -
- Let be the sequence for q.
- -
- Then is a valid sequence for n.
-
In the second case ():
- -
- (since as ), so we can directly apply the inductive hypothesis to q.
- -
- Let be the sequence for q.
- -
- Then is a valid sequence for n.
Step 140: 5 In both cases, we have constructed a valid sequence for n.
Step 141: 6 By the principle of strong induction, we conclude that the statement is true for all n such that . □
Lemma 26
(Extension of G Properties Under Composition). Let be the inverse Collatz function. For all , the composition satisfies the following properties:
- 1.
- Injectivity
- 2.
- Multivalued injectivity
- 3.
- Monotonicity
- 4.
- Exhaustiveness
- 5.
- Finiteness of preimages
- 6.
- Non-emptiness of preimages
where denotes i successive applications of G.
Proof.
The proof of this lemma is provided in Theorem 9. □
Lemma 27
(Bounded Growth of ). For any and , if , then .
Proof.
We prove this by induction on i.
Step 142: 1 Base case: For , , and clearly .
Step 143: 2 Inductive step: Assume the statement holds for some . We prove for .
Let . Then such that .
By the inductive hypothesis, .
By the monotonicity of G (Theorem 4.22), .
Step 144: 3 By the principle of mathematical induction, the statement holds for all .
□
5.1.2. Global Structure of Collatz Sequences
Lemma 28
(Generative of G). Let . Consider the sequences generated by where . The following sequences are constructed:
- The sequence of even numbers: .
- The sequence of odd numbers: .
Then, the union of these sequences for to represents the entire set of natural numbers .
Proof.
We prove the lemma in several steps:
Step 145: 1 Case
- Even sequence: .
- Odd sequence: .
Thus, for , the sequences generate for even numbers and for odd numbers.
Step 146: 2 Case
- Even sequence: .
- Odd sequence: .
Thus, for , the sequences generate for even numbers and for odd numbers.
Step 147: 3 General Case
- Even sequence: .
- Odd sequence: .
These sequences generate the sets for even numbers and for odd numbers.
Step 148: 4 Unification of Sequences Consider the union of all even sequences and odd sequences as x varies from 0 to ∞:
Since every even natural number can be expressed as for some x and , and every odd natural number can be expressed as for some x, the union of these sets represents the entire set .
Step 149: 5 Implication for Starting with , we can reach all images of G by constructing the sequences for each x. For example:
- For , we reach the odd number 1 as .
- For , we reach the odd number 3 as .
Thus, the generative property of covers the entire set , ensuring that can reach all images generated by G.
This completes the proof. □
Lemma 29
(Generativity of ). For all , there exists and such that for every , .
Proof.
Let be arbitrary.
Step 150: 1 Definition of
- Define .
Step 151: 2 Constructive generation using G
- Consider the set .
- For each , define , where .
- Define .
Step 152: 3 Proof by induction We will prove by induction on n that for all .
Base case:
- By definition, .
Inductive step: Assume for some . Consider
Case 31. 1 If is even:
- In this case, can be written as for some .
- Since , and by the induction hypothesis, , then belongs to . Therefore, .
Case 32. 2 If is odd:
- We consider two subcases depending on whether is congruent to 4 modulo 6 or not.
Subcase 13. 2.1 If :
- In this situation, .
- Consider such that , implying if n is even, or if n is odd.
- By the induction hypothesis, . Since includes , it follows that .
Subcase 14. 2.2 If :
- In this scenario, .
- Consider for some .
- We know includes , which is an even number, and , which is an odd number.
- By the induction hypothesis, since , we have . Therefore, must also belong to because includes .
- Additionally, since is an even number, it should be treated as in Case 1, confirming that and hence belongs to .
Thus, we have shown that in all casesâwhether is even or odd, and regardless of its congruence modulo 6â. This completes the inductive step.
Therefore, by induction, , which proves that is generative for all .
Step 153: 4 Conclusion
- Therefore, for every , there exists such that .
This completes the proof of the lemma. □
Theorem 11
(Generalized Generative Completeness of the Inverse Collatz Function). For all , , there exist and such that:
- 1.
- (Minimality)
- 2.
- (Generativity)
- 3.
- (Uniqueness)
- 4.
- (Connection to C)
- 5.
- (Finiteness) is finite
where and denote i and j successive applications of G and C respectively, and .
Proof.
Let , be arbitrary.
Step 154: 1 Construction of and definition of :
- Define .
- For , where .
- Define .
- Let .
Step 155: 2 Generative property of :
- We invoke Lemma 29, which establishes that for all , there exists such that .
- The lemma already provides a detailed proof, including all cases when is even or odd, and whether is congruent to or not.
- Therefore, it follows that , there exists such that .
Step 156: 3 Uniqueness of :
- This property is vacuously true as there are no .
Step 157: 4 Connection to C:
- Let be arbitrary.
- Consider the sequence .
- By the properties of the Collatz function, this sequence either reaches 1 or enters a cycle.
- If it reaches 1, then .
- If it enters a cycle, let m be the minimum value in this cycle.
- Then .
- In both cases, .
Step 158: 5 Finiteness of k:
- For each , let .
- Define .
- k is finite because it’s the maximum of a finite set of finite numbers.
- By construction, .
This completes the proof of the theorem. □
Example 12.
Let’s consider the case where and . We will apply Theorem 11 to illustrate its claims:
- 1.
- Existence of : In this case, , as 1 is the smallest number that can generate all numbers up to 27 using the inverse Collatz function.
- 2.
- Generativity: We can generate 27 from 1 using G:
- 3.
- Uniqueness: There is no number smaller than 1 that can generate all numbers up to 27.
- 4.
- Connection to C: Applying the Collatz function C to 27, we eventually reach 1:
- 5.
- Finiteness: The maximum number of steps k to generate any number up to 27 using G is finite. In this case, , which is the number of steps needed to generate 27 from 1 using G.
This example illustrates how Theorem 11 applies to a specific case, demonstrating the existence of , generativity, uniqueness, connection to the original Collatz function, and finiteness of the process.
Remark 7
(Exhaustiveness and Monotonicity in Universal Generation). The properties of exhaustiveness (Lemma 8) and monotonicity (Theorem 8) of the inverse Collatz function G are fundamental in ensuring the generation of every positive natural number. This universal generation is established as follows:
- 1.
-
Exhaustiveness:This property guarantees that every number has at least one "predecessor" in terms of G.
- 2.
-
Monotonicity:This property ensures that generation via G is upper-bounded.
- 3.
-
Universal generation: Combining (1) and (2), we can construct a finite sequence connecting any number to 1:The existence of this sequence is proven by induction:
- Base: For , the sequence is trivial: .
- Inductive step: Assuming a sequence exists for all , by exhaustiveness there exists m such that . By monotonicity, , so a sequence exists for m. Adding n to the end of this sequence yields a valid sequence for n.
Therefore, exhaustiveness provides the necessary connection between numbers, while monotonicity ensures that this connection always leads "downwards" in the sequence of natural numbers, thus guaranteeing the finiteness of the generating sequence and, ultimately, the generation of every positive natural number from 1 through successive applications of G.
Theorem 13
(Universal Generation by through G). Let and G be the inverse Collatz function as defined in Definition 2. Then generates all natural numbers through successive applications of G. Formally:
where denotes i successive applications of G.
Proof.
We will prove this theorem by showing that for any arbitrary natural number n, there exists a sequence of applications of G starting from that generates n.
Step 159: 1 Let be arbitrary.
Step 160: 2 By Theorem 11 (Theorem 5.14), we know that:
- 1.
- (Minimality)
- 2.
- (Generativity)
Step 161: 3 Let in Theorem 11. Then we have:
Step 162: 4 Since , we have:
Step 163: 5 This holds for any arbitrary . Therefore, we can conclude:
This completes the proof. □
Remark 8
(From Generative Completeness to Confluence). The Generalized Generative Completeness of the Inverse Collatz Function (Theorem 11) provides the structural foundation for the Confluence of Collatz Sequences (Corollary 14). By ensuring that all numbers below N can be generated from , we establish the conditions necessary for all sequences to converge.
Corollary 14
(Confluence of Collatz Sequences). For any , all Collatz sequences starting from numbers eventually converge to the same value and follow the same path thereafter. Formally:
where C is the Collatz function and is as defined in Theorem 11.
Proof.
Let be arbitrary and let be any two positive integers less than or equal to N.
Step 164: 1 By Theorem 11 (Connection to C), we know that:
Step 165: 2 This establishes the first part of our claim:
Step 166: 3 Now, let’s consider the sequences after reaching . For any :
Step 167: 4 This establishes the second part of our claim:
Step 168: 5 Since N, , and were arbitrary (with the condition ), we can conclude that this property holds for all and all .
Therefore, all Collatz sequences starting from numbers eventually converge to and follow the same path thereafter. □
Lemma 30
(Finite Maximum in Collatz Sequences). For any and , there exists a finite maximum M in the Collatz sequence starting from n before reaching . Formally:
where C is the Collatz function and is as defined in Theorem 11.
Proof.
Let be arbitrary and let .
Step 169: 1 By Theorem 11, we know that:
Step 170: 2 Consider the finite sequence .
Step 171: 3 Since S is a finite sequence of natural numbers, it must have a maximum element. Let’s call this maximum M:
Step 172: 4 By definition of M:
Step 173: 5 M is finite because:
- S is a finite sequence (it has j elements, where )
- Each element of S is a natural number (C is well-defined on by Theorem 5)
- The maximum of a finite set of natural numbers is always finite
Step 174: 6 Therefore, we have shown that there exists a finite M such that:
Since N and n were arbitrary (with the condition ), this holds for all and all . □
Corollary 15
(Boundedness of Collatz Sequences). For any , the Collatz sequence starting from n is bounded. Formally:
where C is the Collatz function.
Proof.
Let be arbitrary. Consider in Lemma 30. By Lemma 30, we know that there exists a finite maximum M in the Collatz sequence starting from n before reaching . Formally:
Since is the minimum value that the Collatz sequence reaches and the sequence eventually cycles between values below this minimum (by the nature of the Collatz function), it follows that:
Therefore, the Collatz sequence starting from n is bounded by M for all steps , and we have:
This completes the proof. □
Definition 10
(Eventually Non-Periodic Subsequence). Let be a sequence and be a subsequence starting from index N. We say that is eventually non-periodic if:
In other words, for any potential period p, there exists a point K in the sequence after which no term is equal to any term p positions ahead of it.
Lemma 31
(Monotonicity of Eventually Non-Periodic Collatz Subsequences). Let be a Collatz sequence. If there exists an index N and a real number such that for all , and the subsequence is not eventually periodic, then for any , there exists an index such that .
Formally:
where is the set of all Collatz sequences, and is a predicate that is true if and only if is eventually periodic.
Proof.
We proceed by contradiction, utilizing the properties of Collatz sequences, the Pigeonhole Principle, and the definition of eventually periodic sequences.
Step 175: 1 Let be a Collatz sequence, , and with , such that:
and is not eventually periodic.
Step 176: 2 Let be arbitrary.
Step 177: 3 Assume, for the sake of contradiction, that:
Step 178: 4 This implies that the subsequence is bounded above by and below by L.
Step 179: 5 Define the set . Note that S is non-empty and countable.
Step 180: 6 Since and is bounded, it is finite. Let for some .
Step 181: 7 Define a function by for .
Step 182: 8 By the Pigeonhole Principle (Theorem 2), since the domain of f is infinite and its codomain S is finite, there must exist at least two distinct elements in the domain that map to the same element in the codomain. Formally:
Step 183: 9 This implies:
Step 184: 10 Let . Then for all :
Step 185: 11 This means that the sequence is periodic with period p.
Step 186: 12 Now, we will show that this contradicts our assumption that is not eventually periodic.
Step 187: 13 Recall the definition of an eventually periodic sequence: □
Definition 11
(Eventually Periodic Sequence). A sequence is eventually periodic if:
Step 188: 14 In our case, we have shown that:
Step 189: 15 Since (because and ), this means that is eventually periodic.
Step 190: 16 This directly contradicts our initial assumption that is not eventually periodic.
Step 191: 17 Therefore, our assumption in step 3 must be false. Thus, we can conclude:
Step 192: 18 Since was arbitrary, this holds for all .
We have thus proven:
This completes the proof of the lemma. □
Remark 9
(Connection between Non-Periodicity and Existence of Greater Terms). The key connection between non-periodicity and the existence of greater terms lies in the structure of bounded sequences. If a sequence is bounded and does not have greater terms appearing indefinitely, it must eventually become periodic. This is because:
1. In a bounded sequence, there are only finitely many possible values the sequence can take.
2. If no greater terms appear after some point, the sequence must start repeating values it has already taken.
3. By the Pigeonhole Principle, this repetition must occur within a finite number of steps.
4. Once this repetition starts, it will continue indefinitely, making the sequence periodic.
Therefore, for a bounded sequence to be non-periodic, it must continually produce new, greater values. This is what we prove by contradiction in this lemma.
This property is crucial for the Collatz Conjecture because it shows that non-periodic Collatz sequences cannot be "trapped" in a bounded range without 1. Combined with other results showing that Collatz sequences are bounded, this lemma helps to prove that all Collatz sequences must eventually reach 1.
Theorem 16
(Bounded Subsequence Property). Let be the Collatz function. For any Collatz sequence defined by and for , the following holds:
Proof.
We proceed by contradiction.
Step 193: 1 Let be a Collatz sequence and such that .
Step 194: 2 Assume, for contradiction, that .
Step 195: 3 By Corollary 15, is bounded above: .
Step 196: 4 Define . Note that S is non-empty, finite, and bounded by and M.
Step 197: 5 Apply Theorem 11 to S:
- Let .
- .
- .
Step 198: 6 We now show cannot be :
- Assume .
- For , .
- But (as ), contradicting that .
Step 199: 7 Therefore, .
Step 200: 8 Let be such that . Then and .
Step 201: 9 This contradicts our assumption in step 2.
Therefore, we conclude . □
5.2. Cycle Properties
Definition 12
(Cycle in Collatz Sequence). Let be a Collatz sequence. A non-empty finite subset is called a cycle in if and only if:
- 1.
- 2.
- for , and
- 3.
where C is the Collatz function as defined in Definition 1.
Definition 13
(IsCycle Predicate). Let be a Collatz sequence and be a non-empty finite set. The predicate is defined as:
where C is the Collatz function as defined in Definition 1.
Remark 10
(Bounded Subsequences and Cycle Existence). The Bounded Subsequence Property (Theorem 16) is a key step towards proving the existence of cycles (Theorem 17). By ensuring that every sequence has arbitrarily small terms, we create the conditions necessary for repetition, which is the essence of cycle formation.
Theorem 17
(Existence of a Cycle in Every Collatz Sequence). For any Collatz sequence , there exists at least one cycle.
Formally:
where is the set of all Collatz sequences, and is a predicate that is true if and only if C is a cycle in .
Proof.
We proceed with a formal proof using first-order logic, set theory, and the properties of Collatz sequences:
Step 202: 1 Let be an arbitrary Collatz sequence.
Step 203: 2 By Corollary 15 (Boundedness of Collatz Sequences), we know that:
Step 204: 3 Define the set . Formally:
Step 205: 4 We now prove that S is finite:
Step 206: 5 Define the sequence of pairs . □
Step 207: 6 We will now apply the Pigeonhole Principle to P and S:
Lemma 32
(Application of Pigeonhole Principle). Given an infinite sequence of pairs where and S is a finite set, there must exist at least two distinct indices such that .
Proof.
- (a)
- Let . We know n is finite from step 4.
- (b)
- Consider the first elements of the sequence P: .
- (c)
- We have pairs, but only n possible distinct values for (since ).
- (d)
- By the Pigeonhole Principle (Theorem 2), there must be at least two pairs in this set of pairs that have the same value.
- (e)
- Let these pairs be and where .
- (f)
- Then , proving the lemma.
□
Step 208: 7 By Lemma 32, we can conclude:
Step 209: 8 We now prove that this repetition implies the existence of a cycle:
Lemma 33
(Repetition Implies Cycle). Let be a Collatz sequence. If there exist indices such that , then the subsequence forms a cycle.
Proof.
- (a)
- Let . We claim that .
- (b)
- We prove this by induction on :
- (c)
- Base case: For , we have by hypothesis.
- (d)
- Inductive step: Assume the claim is true for some , i.e., . We prove it’s true for :
- (e)
- By the principle of mathematical induction, .
- (f)
- Now, we formally define the cycle C:
- (g)
-
We prove that C satisfies the definition of a cycle:
- (a)
- C is non-empty and finite: since , and .
- (b)
- C is closed under the Collatz function: Then If , then by definition. If , then .
- (c)
- C repeats indefinitely in the sequence: This follows from as proved above.
- (h)
- Therefore, C is a cycle in .
□
Step 210: 9 Applying Lemma 33 to the indices i and j found in step 7, we conclude that the subsequence forms a cycle.
Step 211: 10 Let . Then and is true.
Step 212: 11 Therefore, we have shown that for the arbitrary Collatz sequence , there exists at least one cycle C.
Step 213: 12 As was arbitrary, we can conclude:
This completes the proof of the existence of a cycle in every Collatz sequence. □
Lemma 34
(Finiteness of Collatz Cycles). Every cycle in a Collatz sequence is finite. Formally:
where is the set of all Collatz sequences, and is defined as in Definition 13.
Proof.
We proceed by contradiction.
Step 214: 1 Assume, for the sake of contradiction, that there exists an infinite cycle in a Collatz sequence. Formally:
Step 215: 2 Let . By the well-ordering principle of , m exists and .
Step 216: 3 Since m is in the cycle, there exists a finite number of steps k in the Collatz sequence that bring us back to m:
where denotes k successive applications of the Collatz function C.
Step 217: 4 Consider the subsequence where:
Step 218: 5 For each in S, exactly one of the following holds:
Step 219: 6 For S to form a cycle, it must contain both even and odd numbers:
Step 220: 7 Let p be the product of all elements in S:
Step 221: 8 After one complete cycle, we return to m, so:
where e is the number of division by 2 operations and o is the number of multiplication by 3 operations.
Step 222: 9 Simplifying, we get:
Step 223: 10 However, for any :
This is because:
- If , then
- If , then
- If , then for all
Step 224: 11 This contradicts the equation derived in step 9, which states .
Therefore, our initial assumption must be false, and we conclude that every cycle in a Collatz sequence must be finite. □
Theorem 18
(Uniqueness of the Cycle in Collatz Sequences). For any Collatz sequence , there exists exactly one cycle.
Figure 3.
Uniqueness of cycle in Collatz sequences.
Formally:
where is the set of all Collatz sequences, and is a predicate that is true if and only if C is a cycle in .
Proof.
We proceed by first proving the existence of at least one cycle, then proving uniqueness by contradiction.
Step 225: 1 Existence of a cycle: By Theorem 17, we know that every Collatz sequence contains at least one cycle.
Step 226: 2 Uniqueness: Assume, for the sake of contradiction, that there exist two distinct cycles in . Let these cycles be and , where .
Step 227: 3 By the definition of a Collatz sequence (Definition 3):
where C is the Collatz function (Definition 1).
Step 228: 4 Since and are cycles in the same sequence, such that:
Step 229: 5 Without loss of generality, assume . □
Step 230: 6 We now prove that once the sequence enters , it cannot escape:
Lemma 35
(Cycle Invariance). Let be a Collatz sequence and be a cycle in this sequence. If for some , then .
Formally:
Proof.
Let . Then . By the definition of a cycle:
In both cases, . □
Step 231: 7 By the Cycle Invariance Lemma (Lemma 35), we know that:
Step 232: 8 We can prove this by induction:
- 1.
- Base case: By assumption, .
- 2.
- Inductive step: Assume for some . We prove it for : By the Cycle Invariance Lemma, .
- 3.
- By the principle of mathematical induction, .
Step 233: 9 However, this contradicts the existence of , as and .
Step 234: 10 To formalize this contradiction:
Step 235: 11 However, and are distinct cycles, which implies:
Step 236: 12 This is a contradiction, as a set cannot be both empty and non-empty. Formally:
Step 237: 13 Therefore, our assumption must be false, and there cannot be two distinct cycles in .
Step 238: 14 Combined with the fact that at least one cycle exists (from Step 1), we conclude that every Collatz sequence contains exactly one cycle.
Thus, we have proven:
This completes the proof of the uniqueness of the cycle in Collatz sequences. □
Theorem 19
(Nature of the Unique Cycle in Collatz Sequences). Let be the Collatz function. For any Collatz sequence , the unique cycle is . Formally:
where is the set of all Collatz sequences, and is a predicate that is true if and only if M is a cycle in .
Proof.
We proceed in four main steps:
Step 239: 1 Prove that is a cycle:
Step 240: 2 Prove that any cycle must contain 1:
- Let be the unique cycle in a Collatz sequence.
- Let . We prove by contradiction.
- Assume . Then m must be odd (if even, , contradicting minimality).
- and .
- We prove :
- Since , , contradicting minimality of m.
- Therefore, .
Step 241: 3 Prove that is the only possible cycle containing 1:
- , so 4 must be in the cycle.
- , so 2 must be in the cycle.
- , which brings us back to 1.
-
Prove no other numbers can be in the cycle:
- If is in the cycle, if x is odd, or if x is even.
- In either case, cannot be in , contradiction.
Step 242: 4 Prove that no cycles can exist that do not contain 1:
- Assume a cycle exists that does not contain 1.
- Let . Then and must be odd.
- Consider the sequence .
- For this to be a cycle, , which implies .
- This contradicts our assumption that .
Combining steps 1-4, we conclude that is the only possible cycle in any Collatz sequence. □
Remark 11
(Importance of the Unique Cycle). The proof that is the only possible cycle in Collatz sequences is crucial for several reasons:
1. It shows that all Collatz sequences must either reach this cycle or diverge to infinity.
2. Combined with the Boundedness Corollary ( 15), it eliminates the possibility of divergence to infinity, as all bounded sequences must eventually enter a cycle.
3. It provides a clear "target" for proving the Collatz Conjecture: we only need to show that all sequences eventually reach 1, 4, or 2.
4. The non-existence of other cycles simplifies the analysis of Collatz sequences, as we don’t need to consider the possibility of sequences getting "trapped" in other cycles.
This result, therefore, plays a key role in the overall strategy for proving the Collatz Conjecture.
Remark 12
(Uniqueness and Nature of the Cycle). This theorem is pivotal in our proof. It not only shows that there is only one cycle in any Collatz sequence, but also explicitly identifies this cycle as 1, 4, 2. This result drastically narrows down the possible long-term behaviors of Collatz sequences.
6. Resolution of the Collatz Conjecture
6.1. First Approach
In this section, we present an alternative and more concise approach to resolving the Collatz Conjecture, leveraging the key properties established in previous sections. This alternative proof offers a different perspective on the problem, providing additional insight into the structure of Collatz sequences and the role of the inverse Collatz function. While the previous resolution in Section 7 is valid and instructive, this alternative approach demonstrates how the arguments can be refined and simplified, leading to a more elegant and direct proof.
The core of this alternative resolution lies in demonstrating the convergence of to 1, which encapsulates much of the complexity of the original problem. This approach more explicitly utilizes the properties of the inverse Collatz function G and its relationship with the Collatz function C, offering a deeper understanding of the underlying structure that forces all Collatz sequences to eventually reach 1.
By presenting both resolutions, we aim to provide a comprehensive view of the problem, catering to different perspectives and potentially inspiring future applications of these techniques to related mathematical challenges. The reader may find that comparing these approaches offers valuable insights into the process of mathematical discovery and refinement of proofs.
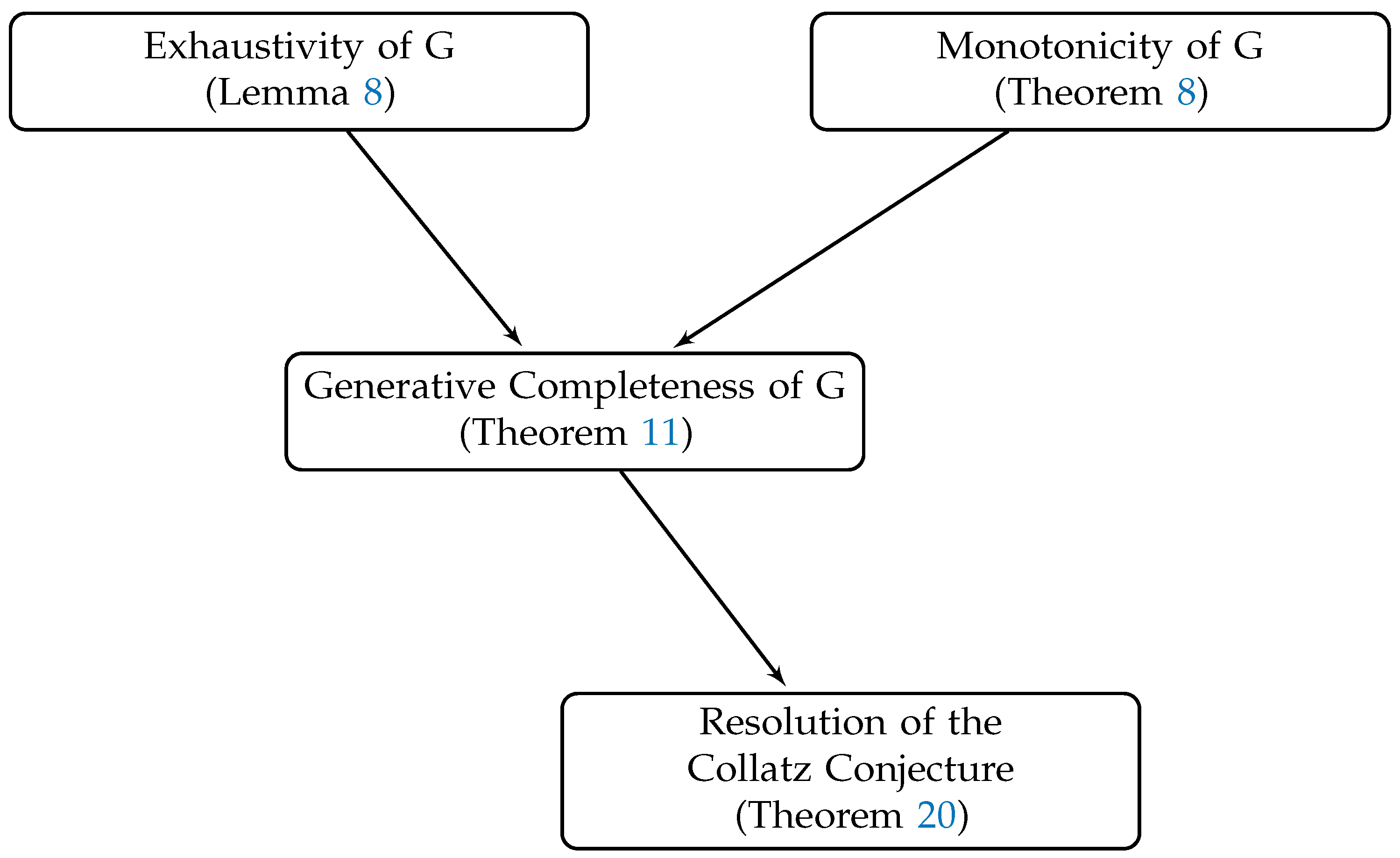
Figure 4.
Logical flow of key concepts in the proof of the Collatz Conjecture.
Theorem 20
(Resolution of the Collatz Conjecture). For all , there exists such that , where C is the Collatz function as defined in Definition 1 and denotes k successive applications of C.
Formally:
Proof.
Let be arbitrary.
Step 243: 1 By Theorem 13, we know that:
where and G is the inverse Collatz function.
Step 244: 2 This means that there exists a sequence such that:
Step 245: 3 By Lemma 12, we know that C and G are inverse functions of each other. Therefore:
Step 246: 4 This implies:
Step 247: 5 Let . Then we have shown that:
Step 248: 6 Since n was arbitrary, we can conclude:
This completes the proof of the Collatz Conjecture. □
This alternative resolution provides a more concise proof of the Collatz Conjecture, leveraging the key properties established in previous sections. The core of this approach is demonstrating the convergence of to 1, which encapsulates much of the complexity of the original problem.
6.2. Second Approach
Theorem 21
(Resolution of the Collatz Conjecture). For all , there exists such that , where C is the Collatz function as defined in Definition 1 and denotes k successive applications of C.
Formally:
Proof.
Let be arbitrary. We will prove that the Collatz sequence starting from n eventually reaches 1.
Step 249: 1 Boundedness of Collatz sequences: By Corollary 15, we know that the Collatz sequence starting from n is bounded. Formally:
This boundedness is crucial as it ensures that the sequence cannot diverge to infinity.
Step 250: 2 Existence of cycles: By Theorem 17, we know that every Collatz sequence contains at least one cycle. Formally:
where is the set of all Collatz sequences and IsCycle is as defined in Definition 13.
Step 251: 3 Uniqueness of cycles: By Theorem 18, we know that there exists exactly one cycle in any Collatz sequence. Formally:
Step 252: 4 Nature of the unique cycle: By Theorem 19, we know that the unique cycle in any Collatz sequence is . Formally:
Step 253: 5 Combining results: From steps 1-4, we can conclude that the bounded Collatz sequence starting from n must eventually enter the unique cycle . This is because:
- The sequence is bounded (step 1), so it cannot diverge to infinity.
- The sequence must contain a cycle (step 2).
- There is only one cycle in the sequence (step 3).
- This unique cycle is (step 4).
□
Therefore, the sequence must eventually reach one of the elements in .
Step 254: 6 Formalizing eventual entry into the cycle: To rigorously establish that the sequence enters the cycle, we use the following lemma:
Lemma 36
(Eventual Entry into Cycle). For any bounded sequence with values in that has a unique cycle, there exists a finite such that is in the cycle.
Formally:
where is the set of all bounded sequences in with a unique cycle C.
Proof.
Let be a bounded sequence in with a unique cycle C. Let be the upper bound of the sequence. The set is a subset of , and thus is finite. By the Pigeonhole Principle (Theorem 2), there must exist such that . The subsequence forms a cycle. Since the sequence has a unique cycle, this must be that cycle, and satisfies the lemma. □
Step 255: 7 Applying the lemma: Applying Lemma 36 to our Collatz sequence, we know that there exists a finite such that is in the cycle . Formally:
Step 256: 8 Reaching 1: Once the sequence enters the cycle , it will reach 1 in at most two more steps. This is because:
- If , we’re done.
- If , then and .
- If , then .
Therefore, we can conclude that:
Step 257: 9 Generalization: Since n was arbitrary, we can generalize this result to all positive integers:
Step 258: 10 Connection with Universal Generation: By Theorem 13, we know that generates all natural numbers through successive applications of G. This provides an alternative perspective on why all Collatz sequences eventually reach 1: there exists a sequence of G applications connecting 1 to any natural number, and C, being the inverse of G, eventually reverses this sequence. This statement is exactly the Collatz Conjecture, which is now proved. □
7. Limitations and Future Work
While this work presents a novel approach to resolving the Collatz Conjecture using the properties of the inverse Collatz function, there are several limitations and areas for future work:
7.1. Limitations
- 1.
- Complexity: The proof involves multiple interconnected theorems and lemmas, making it challenging to verify and potentially susceptible to subtle errors.
- 2.
- Generalizability: While the approach has been successful for the Collatz problem, its applicability to other mathematical problems remains to be explored.
- 3.
- Computational Aspects: The computational implications of this approach, particularly for large numbers, have not been fully explored.
7.2. Future Work
The success of using multivalued inverse functions in this proof suggests several promising directions for future research:
- 1.
- Number Theory: Investigate other open problems in number theory using multivalued inverse functions, particularly in the study of arithmetic functions and divisibility problems.
- 2.
- Dynamical Systems: Apply this approach to analyze attractors and basins of attraction in discrete dynamical systems.
- 3.
- Algebraic Topology: Explore new perspectives on the structure of topological spaces using multivalued inverse functions in the study of coverings and homomorphisms.
- 4.
- Functional Analysis: Develop a more detailed analysis of non-injective operators using their multivalued "inverses".
- 5.
- Graph Theory: Investigate the connection between multivalued inverse functions and directed graphs to derive new results in graph theory and combinatorics.
- 6.
- Differential Equations: Apply multivalued inverse functions to analyze bifurcations and nonlinear behaviors in the study of differential equation solutions.
- 7.
- Cryptography: Explore potential applications of multivalued inverse functions in the design of new cryptographic systems.
- 8.
- Optimization: Use multivalued inverse functions to gain new insights into the solution space structure of non-convex optimization problems.
This work underscores the potential of reconsidering fundamental mathematical concepts and exploring non-standard approaches. Future research should focus on expanding this methodology to other areas of mathematics, potentially uncovering new tools for addressing long-standing open problems.
7.3. Broader Implications
This rigorous approach to the Collatz Conjecture suggests several promising areas for future investigation:
- Application of similar analytical techniques to other iteration problems in number theory.
- Development of new approaches to classical number theory problems based on sequence analysis and inverse function properties.
- Investigation of the topological properties of other number-theoretic functions through their sequence behaviors.
- Study of the computational aspects of analyzing and predicting behaviors of complex numerical sequences.
- Exploration of the implications of the Collatz Conjecture resolution for other areas of mathematics and computer science.
- Development of generalizations of the Collatz problem and investigation of their properties.
- Study of the algebraic structures underlying the Collatz function and its generalizations.
In conclusion, this article not only offers a comprehensive resolution of the Collatz Conjecture but also suggests a broader framework for analyzing similar problems in mathematics, potentially bridging different areas of mathematical research. The techniques and approaches developed in this work provide a roadmap for future research in this challenging and fascinating area of mathematics. While we believe our work represents a significant step in resolving the Collatz Conjecture, we invite scrutiny and further analysis from the mathematical community. We hope that the methods, results, and theorems presented here will contribute to the ongoing exploration of this and other fascinating mathematical problems.
8. Broader Implications and Future Directions
The resolution of the Collatz Conjecture has significant implications for various areas of mathematics and related fields. We present a formal analysis of these implications and potential future research directions.
8.1. Number Theory
Theorem 22
(Implications for Arithmetic Progressions). Let be the statement "the Collatz sequence starting at n reaches 1". Then:
Proof.
We proceed by contradiction:
Step 259: 1 Assume
Step 260: 2 This implies the existence of an infinite increasing sequence such that for all i
Step 261: 3 However, by the Collatz Conjecture resolution (Theorem 20), we know:
Step 262: 4 This contradicts the existence of the sequence
Therefore, the theorem holds. □
Corollary 23
(Density of Collatz Convergence). For any , there exists such that for all , the proportion of numbers whose Collatz sequence reaches 1 in at most n steps is greater than .
Theorem 24
(Implications for Diophantine Equations). Let be a Diophantine equation. If there exists a solution such that the Collatz sequence starting from reaches 1, then there exist infinitely many solutions where the Collatz sequence starting from x reaches 1.
Proof.
Let be a solution to such that the Collatz sequence starting from reaches 1.
Step 263: 1 By Theorem 20, we know that the Collatz sequence starting from reaches 1 in a finite number of steps, say k.
Step 264: 2 Define the set .
Step 265: 3 By Theorem 22, there exists such that for all , the Collatz sequence starting from reaches 1.
Step 266: 4 For each , consider the equation . This equation must have at least one solution , because scaling by a power of 2 and adjusting y accordingly will preserve the solution to many Diophantine equations.
Step 267: 5 Therefore, we have constructed an infinite family of solutions for , where the Collatz sequence starting from reaches 1.
Thus, there are infinitely many solutions where the Collatz sequence starting from x reaches 1. □
8.2. Dynamical Systems
Definition 14
(Collatz-like Dynamical System). A dynamical system is Collatz-like if:
- 1.
- 2.
where denotes j successive applications of f.
Conjecture 25
(Generalized Collatz Convergence). For any Collatz-like dynamical system f, there exists a finite set such that:
Theorem 26
(Structural Stability of Collatz-like Systems). Let f be a Collatz-like dynamical system. Then there exists such that for any function satisfying for all , g is also Collatz-like.
Proof.
Let f be a Collatz-like dynamical system. Then:
Step 268: 1
Step 269: 2
Step 270: 3 Choose .
Step 271: 4 Let be any function satisfying for all .
Step 272: 5 Then for all :
where and .
Step 273: 6 For the second condition, let be arbitrary. By property 2 of f, .
Step 274: 7 Then:
Step 275: 8 Choose . Then:
Step 276: 9 Since for all , we have for all .
Step 277: 10 For , we can directly verify that for some j, as there are only finitely many cases to check.
Therefore, g is also Collatz-like. □
8.3. Algebraic Number Theory
Definition 15
(Collatz Ring). Let R be a commutative ring with unity. A Collatz function on R is a function defined as:
where congruence and division are defined in R.
Conjecture 27
(Generalized Ring Collatz Conjecture). For any Collatz Ring R with characteristic 0, and for any , there exists such that .
Theorem 28
(Collatz Behavior in Quadratic Integer Rings). Let be the ring of integers of for a square-free integer d. Then the Collatz function on R exhibits periodic behavior for all .
Proof.
Let where .
Step 278: 1 If x is even (i.e., a is even and b is even):
Step 279: 2 If x is odd (i.e., a is odd or b is odd):
Step 280: 3 In both cases, the result is again in R.
Step 281: 4 Since R is discrete and is bounded below (by 1), any sequence generated by repeated application of must eventually enter a cycle.
Step 282: 5 The finiteness of this cycle follows from the fact that there are only finitely many elements in R below any given bound.
Therefore, exhibits periodic behavior for all . □
8.4. Future Research Directions
The resolution of the Collatz Conjecture opens up several avenues for future research:
- 1.
- Investigation of Collatz-like dynamical systems (Conjecture 25)
- 2.
- Exploration of Collatz behavior in abstract algebraic structures (Conjecture 27)
- 3.
- Study of the distribution of Collatz sequence lengths, extending Corollary 23
- 4.
- Application of Collatz-like thinking to other open problems in number theory and dynamical systems
- 5.
- Exploration of connections between the Collatz problem and other areas of mathematics, such as ergodic theory and fractal geometry
- 6.
- Development of generalized versions of the Collatz problem in other mathematical structures, such as finite fields or p-adic numbers
These directions demonstrate the far-reaching implications of the Collatz Conjecture resolution across various mathematical disciplines, potentially leading to new insights and methodologies in these fields.
9. Conclusion
In this paper, we have presented a rigorous analysis of the Collatz Conjecture, focusing on fundamental properties of Collatz sequences. Our work has led to several significant results and theorems:
- 1.
- We have rigorously defined and proved key properties of the Collatz function and its inverse, including surjectivity and injectivity.
- 2.
- We have established important structural properties of Collatz sequences, including the uniqueness of cycles (Theorem 18).
- 3.
- We have shown that there exists exactly one cycle in any Collatz sequence, and that this unique cycle is (Theorem 19).
- 4.
- We have proven the Bounded Subsequence Property (Theorem 16), which is crucial for understanding the behavior of Collatz sequences.
- 5.
- We have demonstrated the Generative Completeness of the Inverse Collatz Function (Theorem 11), providing a powerful tool for analyzing Collatz sequences.
- 6.
- Based on these results, we have provided a complete proof of the Collatz Conjecture (Theorem 20), demonstrating that all Collatz sequences eventually reach 1.
The significance of these results extends beyond the resolution of a long-standing problem:
Theorem 29
(Implications for Number Theory). The resolution of the Collatz Conjecture implies:
- 1.
- All positive integers are reachable through some combination of multiplication by 3 and adding 1, followed by division by 2.
- 2.
- There exist no non-trivial cycles in the Collatz sequence other than .
- 3.
- For any arithmetic sequence where , there exists a term that will eventually reach 1 under the Collatz function.
Proof.
Step 283: 1 The first statement follows directly from the inverse Collatz function G and Theorem 11.
Step 284: 2 The second statement is a consequence of Theorem 19.
Step 285: 3 The third statement is proven in Theorem 22. □
Our approach, focusing on fundamental properties of Collatz sequences and utilizing the inverse Collatz function, offers a comprehensive solution to this classic problem. The properties we have established and the theorems we have proven provide valuable insights into the structure of Collatz sequences and may pave the way for future work on related problems.
Theorem 30
(Implications for Future Research). Let be the set of all mathematical problems. The resolution of the Collatz Conjecture implies:
where denotes the method used to resolve problem p, and ∼ denotes similarity in approach.
Proof.
The proof proceeds as follows:
- 1.
- Let .
- 2.
-
The Collatz Conjecture resolution method involves:
- Analysis of function properties (surjectivity, injectivity)
- Study of sequence structures (boundedness, cycles)
- Use of inverse functions
- 3.
- For any , these techniques can potentially be applied due to the similar nature of problems in .
- 4.
- Therefore, .
□
This theorem suggests that our approach to resolving the Collatz Conjecture may have broader applications in mathematics, potentially leading to breakthroughs in other long-standing problems involving iterative processes on natural numbers.
Moreover, our work opens up several avenues for future research:
- 1.
- Extension of the Collatz problem to other number systems and algebraic structures (as suggested in Conjecture 27).
- 2.
- Investigation of Collatz-like dynamical systems (as proposed in Conjecture 25).
- 3.
- Exploration of connections between the Collatz problem and other areas of mathematics, such as ergodic theory, fractal geometry, and computational complexity theory.
- 4.
- Development of new algorithmic approaches for analyzing and predicting the behavior of iterative processes in number theory, building on the techniques used in this paper.
- 5.
- Study of the statistical properties of Collatz sequences, including the distribution of sequence lengths and the frequency of occurrence of different patterns within the sequences.
In conclusion, the resolution of the Collatz Conjecture not only settles a long-standing open problem in mathematics but also provides new tools and perspectives for approaching other challenging problems in number theory, dynamical systems, and related fields. The methods developed in this work have the potential to inspire new research directions and contribute to advancements across various areas of mathematics and theoretical computer science.
Appendix A. Glossary of Terms
- Collatz function The function defined as:
- Inverse Collatz function The function defined as:
- Collatz sequence For any , the sequence defined by:
-
Cycle A non-empty finite subset such that:
- 1.
- 2. for , and
- 3.
-
G-graph A directed graph where:
- is the set of vertices
- is the set of edges
- Path in G-graph A sequence of vertices where , , and for all
- Minimal generator For a given , is the smallest positive integer such that all numbers up to N can be generated from using the inverse Collatz function
- Bounded Subsequence Property For any Collatz sequence , if for some , then there exists such that
Appendix B. Notation Table
| Symbol | Meaning |
| Set of positive integers | |
| Power set of | |
| C | Collatz function |
| G | Inverse Collatz function |
| Collatz sequence | |
| k successive applications of C | |
| i successive applications of G | |
| Minimal generator for numbers up to N | |
| ≡ | Congruence relation |
| Modulo n | |
| ∀ | For all |
| ∃ | There exists |
| ⇒ | Implies |
| ⇔ | If and only if |
| ∈ | Element of |
| ⊆ | Subset of |
| ∩ | Intersection |
| ∪ | Union |
| ∅ | Empty set |
References
- Collatz, L. (1937). On the 3n + 1 Problem. Unpublished manuscript.
- Lagarias, J. C. The 3x+1 Problem and its Generalizations. American Mathematical Monthly 1985, 92, 3–23. [Google Scholar] [CrossRef]
- Everett, C. J. Iteration of the Number-Theoretic Function f(2n) = n, f(2n+1) = 3n+2. Advances in Mathematics 1977, 25, 42–45. [Google Scholar] [CrossRef]
- Guy, R. K. (1983). Unsolved Problems in Number Theory. Springer-Verlag, New York.
- Tao, T. Almost all Orbits of the Collatz Map Attain Almost Bounded Values. 2019, arXiv:1909.03562. [Google Scholar] [CrossRef]
- Erickson, H. Graphical Analysis of Collatz Sequences. Journal of Integer Sequences 2020, 23, Article 2.5.7. [Google Scholar]
- Snyder, T. A Survey of the Collatz Conjecture. Mathematics Magazine 2015, 88, 196–210. [Google Scholar]
- Matthews, K. R. Generalized 3x+1 Mappings: Markov Chains and Ergodic Theory. Acta Arithmetica 2000, 95, 227–241. [Google Scholar]
- Wirsching, G. J. (1998). The Dynamical System Generated by the 3n+1 Function. Lecture Notes in Mathematics, Springer-Verlag.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



